XPath – это невероятно гибкий, мощный, и вместе с тем сравнительно простой инструмент для навигации по документам XML. Предлагаю перевод руководства по XPath, сделанный на основе руководства консорциума W3C.
Краткий справочник по XPath

XPath используется для навигации по элементам и атрибутам XML-документа. XPath является одним из основных элементов в стандарте XSLT консорциума W3C.
1Что такое XPath
 |
|
Выражения XPath
XPath использует выражения пути для выбора отдельных узлов или набора узлов в документе XML. Эти выражения очень похожи на выражения, которые вы видите, когда работаете с традиционной файловой системой компьютера.
Стандартные функции XPath
XPath включает в себя более 100 встроенных функций. Есть функции для строковых и числовых значений, даты и времени, сравнения узлов и манипулирования QName, управления последовательностями, булевых значений, и многое другое.
XPath используется в XSLT
XPath является одним из основных элементов в стандарте XSLT. Без знания XPath вы не будете иметь возможность создавать XSLT-документы.
XPath является рекомендацией консорциума W3C
XPath стал рекомендацией W3C 16 ноября 1999 года. XPath был разработан для использования в XSLT, XPointer и другом программном обеспечении для разбора (парсинга) документов XML.
2Терминология XPath
Узлы
В XPath существует семь видов узлов: элемент, атрибут, текст, пространство имён, инструкции обработки, комментарии и узлы документа. XML-документы обрабатываются в виде деревьев узлов. Верхний элемент дерева называется корневым элементом. Посмотрите на следующий документ XML:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J. K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
Пример узлов в документе XML выше:
<bookstore> (корневой элемент) <author>J. K. Rowling</author> (узел) lang="en" (атрибут)
Атомарные значения
Атомарные значения являются узлами, не имеющие детей или родителей. Пример атомарных значений:
J. K. Rowling "en"
Элементы
Элементы – это атомарные значения или узлы.
3Отношенияузлов
Родитель
Каждый элемент и атрибут имеет одного родителя. В следующем примере элемент «книга» (book) является родителем элементов «название» (title), «автор» (author), «год» (year) и «цена» (price):
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
Потомки
Узлы элементов могут иметь ноль, один или более потомков. В следующем примере элементы «название», «автор», «год» и «цена» – они все потомки элемента книга:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
Элементы одного уровня
Это узлы, которые имеют одного и того же родителя. В следующем примере элементы «название», «автор», «год» и «цена» все являются элементами одного уровня:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
Предки
Родитель узла, родитель родителя узла и т.д. В следующем примере предки элемента «название» (title) – это элементы «книга» (book) и «книжный магазин» (bookstore):
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
Потомки
Дети узла, дети детей узла и т.д. В следующем примере потомками элемента «книжный магазин» являются элементы «книга», «название», «автор», «год» и «цена»:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
4Синтаксис XPath
XPath использует выражения пути для выбора узлов или множества узлов в документе XML. Узел можно выбрать, следуя пути или по шагам. Мы будем использовать следующий XML-документ в приведённых ниже примерах.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
Выбор узлов
С помощью выражений XPath для выбора узлов в документе XML можно выбрать узел, следуя пути или шагам. Самые полезные выражения пути перечислены ниже:
| Выражение | Описание |
|---|---|
| имя_узла | Выбирает все узлы с именем имя_узла |
| / | Выбирает от корневого узла |
| // | Выбирает узлы в документе от текущего узла, который соответствует выбору, независимо от того, где они находятся |
| . | Выбирает текущий узел |
| .. | Выбирает родителя текущего узла |
| @ | Выбирает атрибуты |
В приведенной ниже таблице перечислены некоторые пути выражения и результат выполнения выражения:
| Выражение XPath | Результат |
|---|---|
| bookstore | Выбирает все узлы с именем «bookstore» |
| /bookstore | Выбирает корневой элемент книжного магазина
Примечание: Если путь начинается с косой черты (/), он всегда представляет собой абсолютный путь к элементу! |
| bookstore/book | Выбирает все элементы «книга» (book), которые являются потомками элемента «книжный магазин» (bookstore) |
| //book | Выбирает все элементы «книга» независимо от того, где они находятся в документе |
| bookstore//book | Выбирает все элементы «книга», которые являются потомком элемента «книжный магазин», независимо от того, где они находятся под элементом «книжный магазин» |
| //@lang | Выбирает все атрибуты, которые называются «lang» |
Предикаты
Предикаты используются для поиска специфического узла или узла, который содержит специфическое значение. Предикаты всегда обрамляются квадратными скобками. В приведённой ниже таблице перечислены некоторые выражения пути с предикатами, и результат выражения:
| Выражения XPath | Результат |
|---|---|
| /bookstore/book[1] | Выбирает первый элемент «книга», который является потомком элемента «книжный магазин».
Примечание: В IE 5,6,7,8,9 первый узел имеет индекс [0], но в соответствии с рекомендациями W3C, это [1]. Для решения этой проблемы в IE, задаётся опция «SelectionLanguage» для XPath: На JavaScript: xml.setProperty(«SelectionLanguage», «XPath»); |
| /bookstore/book[last()] | Выбирает последний элемент «книга» (book), который является дочерним элементом элемента «книжный магазин» (bookstore) |
| /bookstore/book[last()-1] | Выбирает предпоследний элемент «книга», который является дочерним элементом элемента «книжный магазин» |
| /bookstore/book[position()<3] | Выбор первых двух элементов «книга», которые являются потомками элемента «книжный магазин» |
| //title[@lang] | Выбирает все элементы «название» (title), которые имеют атрибут с именем «lang» |
| //title[@lang=’en’] | Выбирает все элементы «название», которые имеют атрибут «язык» со значением «en» |
| /bookstore/book[price>35.00] | Выбирает все элементы «книга» после элемента «книжный магазин», которые имеют элемент «цена» со значением больше, чем 35.00 |
| /bookstore/book[price>35.00]/title | Выбирает все элементы «название» книги элемента «книжный магазин», которые имеют элемент «цена» со значением больше, чем 35.00 |
Выбор неизвестных узлов
Специальные символы XPath могут использоваться для выбора неизвестных XML узлов.
| Wildcard | Описание |
|---|---|
| * | Соответствует любому узлу |
| @* | Соответствует узлу-атрибуту |
| node() | Соответствует любому узлу любого типа |
В приведённой ниже таблице мы перечислили некоторые пути выражения и результаты выражений:
| Выражение пути | Результат |
|---|---|
| /bookstore/* | Выбирает все дочерние узлы элемента «книжный магазин» (bookstore) |
| //* | Выбирает все элементы в документе |
| //title[@*] | Выбирает все элементы «название» (title), которые имеют по крайней мере один атрибут любого вида |
Выбор нескольких путей
С помощью оператора | в выражениях XPath вы можете выбрать несколько путей. В таблице ниже перечислены несколько выражений путей и результаты их применения:
| Выражение пути | Результат |
|---|---|
| //book/title | //book/price | Выбирает все элементы «название» (title) И «цена» (price) всех элементов «книга» (book) |
| //title | //price | Выбирает все элементы «название» (title) И «цена» (price) в документе |
| /bookstore/book/title | //price | Выбирает все элементы «название» элемента «книга» элемента «книжный магазин» И все элементы «цена» в документе |
5ОсиXPath
Мы будем использовать следующий XML документ далее в примере.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
Оси определяют наборы узлов, относительно текущего узла.
| Название оси | Результат |
|---|---|
| ancestor | Выбирает всех предков (родителей, прародителей и т.д.) текущего узла |
| ancestor-or-self | Выбирает всех предков (родителей, прародителей и т.д.) текущего узла и сам текущий узел |
| attribute | Выбирает все атрибуты текущего узла |
| child | Выбирает всех потомков текущего узла |
| descendant | Выбирает всех потомков (детей, внуков и т.д.) текущего узла |
| descendant-or-self | Выбирает всех потомков (детей, внуков и т.д.) текущего узла и сам текущий узел |
| following | Выбирает всё в документе после закрытия тэга текущего узла |
| following-sibling | Выбирает все узлы одного уровня после текущего узла |
| namespace | Выбирает все узлы в данном пространстве имён (namespace) текущего узла |
| parent | Выбирает родителя текущего узла |
| preceding | Выбирает все узлы, которые появляются перед текущим узлом в документе, за исключением предков, узлов атрибутов и узлы пространства имён |
| preceding-sibling | Выбирает всех братьев и сестёр до текущего узла |
| self | Выбирает текущий узел |
6Выраженияпути выборки
Путь определения местоположения может быть абсолютным или относительным. Абсолютный путь расположения начинается с косой черты (/), а относительный – нет. В обоих случаях путь выборки состоит из одного или нескольких шагов, разделённых косой чертой:
Абсолютный путь расположения:
/step/step/...
Относительный путь выборки расположения:
step/step/...
Каждый шаг оценивается по узлам в текущем наборе узлов. Шаг состоит из:
- ось (определяет древовидную связь между выбранными узлами и текущим узлом);
- проверка узла (идентифицирует узел в пределах оси);
- ноль или более предикатов (для дальнейшего уточнения выбранного набор узлов)
Синтаксис шага выборки такой:
axisname::nodetest[predicate] имяОси::проверкаУзла[предиктор]
| Пример | Результат |
|---|---|
| child::book | Выбирает все узлы «книга» (book), которые являются потомками текущего узла |
| attribute::lang | Выбирает атрибут «язык» (lang) текущего узла |
| child::* | Выбирает всех потомков текущего узла |
| attribute::* | Выбирает все атрибуты текущего узла |
| child::text() | Выбирает все текстовые узлы текущего узла |
| child::node() | Выбирает всех ближайших потомков текущего узла |
| descendant::book | Выбирает всех потомков текущего узла |
| ancestor::book | Выбирает всех предков «книга» (books) текущего узла |
| ancestor-or-self::book | Выбирает всех предков «книга» (book) текущего узла – и текущий узел, если он также «книга» (book) |
| child::*/child::price | Выбирает все потомки «цена» (price) через один уровень от текущего узла |
7Операторы XPath
Выражения XPath возвращают как набор узлов, строки, булевы или числовые значения. Ниже представлен список операторов, используемых в выражениях XPath:
| Оператор | Описание | Пример |
|---|---|---|
| | | Вычисляет два набора узлов | //book | //cd |
| + | Сложение | 6 + 4 |
| — | Вычитание | 6 — 4 |
| * | Умножение | 6 * 4 |
| div | Деление | 8 div 4 |
| = | Равенство | price=9.80 |
| != | Неравенство | price!=9.80 |
| < | Меньше, чем | price<9.80 |
| <= | Меньше или равно | price≤9.80 |
| > | Больше, чем | price>9.80 |
| >= | Больше или равно | price≤9.80 |
| or | Или | price=9.80 or price=9.70 |
| and | И | price>9.00 and price<9.90 |
| mod | Остаток от деления | 5 mod 2 |
8Примеры XPath
Давайте рассмотрим базовый синтаксис XPath на нескольких примерах. Мы будем использовать следующий XML документ «books.xml» в примерах ниже:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
Загрузка XML документа
Используйте XMLHttpRequest для загрузки XML документов, который поддерживается большинством современных браузеров:
var xmlhttp=new XMLHttpRequest()
Код для устаревших браузеров Microsoft (IE 5 и 6):
var xmlhttp=new ActiveXObject("Microsoft.XMLHTTP")
Выбор узлов
К сожалению, работа с XPath в Internet Explorer и в других браузерах может отличаться. В наших примерах мы будем использовать код, который должен работать в большинстве браузеров. Internet Explorer использует метод «selectNodes()» для выбора узлов XML документа:
xmlDoc.selectNodes(xpath);
Firefox, Chrome, Opera и Safari используют метод evaluate() для выбора узлов из XML документа:
xmlDoc.evaluate( xpath, xmlDoc, null,
XPathResult.ANY_TYPE, null );
Выбор всех заглавий
Следующий пример выбирает все узлы заголовков:
/bookstore/book/title
Выбор заголовка первой книги
Следующий пример выбирает заголовок первого узла «книга» после элемента «книжный магазин» (bookstore):
/bookstore/book[1]/title
Выбор всех цен
Следующий пример выбирает текст всех узлов «цена» (price):
/bookstore/book/price[text()]
Выбирает узлы с ценой >35
Следующий пример выбирает все узлы с ценами выше 35:
/bookstore/book[price>35]/price
Выбор узлов заголовков с ценой >35
Следующий пример выбирает все узлы заголовков с ценой выше 35:
/bookstore/book[price>35]/title
Для отладки XPath удобно пользоваться специальными инструментами. Например, в IDE Stylus Studio или в Altova XMLSpy имеется генератор и отладчик XPath. Также есть бесплатные онлайн-инструменты для отладки XPath: XPather или CodeBeautify и другие.
Язык разметки XML с самого первого стандарта окружает пользователей компьютеров. Таблицы в Excel, выгрузки из интернет-магазинов, RSS-ленты с новостями — все это основано на XML. Хоть визуальное отображение отличается на устройствах и в программах, но в основе всегда лежит единый формат.
Внутри XML-файла может находиться огромное количество информации, поэтому и встает вопрос о перемещении и выборке внутри документа. Как это сделать быстро? Какие средства применять, чтобы в интернет-магазине найти нужный товар из десятков тысяч других? Для навигации и поиска внутри XML используется язык запросов XPath.
В этой статье разберем:
- для кого может быть полезен XPath
- базовые конструкции языка для поиска информации в XML
- чем XPath отличается от CSS-селекторов при поиске в HTML
- Синтаксис XPath
- Отличия от CSS-селекторов
- Кому нужен Xpath
- Заключение
Синтаксис XPath
Для начала создадим базовый пример XML, с которым и будем работать весь урок. Например, список курсов по верстке на Хекслете в XML будет выглядеть так:
<?xml version="1.0" encoding="UTF-8"?>
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
<course>
<name>Основы современной верстки</name>
<tags>HTML5, CSS, DevTools, верстка</tags>
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
</course>
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
</courses>
Это учебный пример, но для отработки навыков XPath подойдет и любой другой XML. Принципы XPath сохранятся при любой структуре файла, потому что по стандарту XML можно использовать элементы с произвольными тегами.
Для тестирования результата подойдут такие онлайн-сервисы, как:
- Code Beautify
- XPather
Абсолютные пути
Самый простой запрос состоит из обращения к корневому элементу. Для этого достаточно выполнить запрос /courses. Нам вернется XML в почти таком же виде, что и в примере выше. Обратите внимание на строку <?xml version="1.0" encoding="UTF-8"?>. Она отличается, потому что элемент не внутри <courses>:
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
<course>
<name>Основы современной верстки</name>
<tags>HTML5, CSS, DevTools, верстка</tags>
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
</course>
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
</courses>
В качестве результата XPath возвращает узлы XML-документа.
Продолжим цепочку и обратимся к описанию из элемента <description>. Для этого добавим в запрос путь к description: /courses/description. Результатом выполнения станет:
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
Путь, который строится от корневого элемента, называется абсолютным. Используем схему из прошлого запроса и обратимся к любому элементу внутри XML.
Попробуем обратиться к имени курса. В этом случае вернется поле <name> из всех курсов. Запрос /courses/course/name вернет:
<name>Основы современной верстки</name>
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Вот список некоторых базовых запросов и их результат:
| Запрос | Результат |
|---|---|
/courses/course |
Все данные из всех элементов <course></course> |
/courses/course/name |
<name>Основы современной верстки</name><name>Основы верстки контента</name><name>Bootstrap 5: Основы верстки</name> |
/courses/course/duration |
<duration value="9">9 часов</duration><duration value="18">18 часов</duration><duration value="10">10 часов</duration> |
Относительные пути
Прошлые запросы строились с помощью абсолютных путей — то есть мы указывали полный путь до информации. Бывают ситуации, когда полный путь не подходит: например, мы хотим обраться к какому-то уникальному полю или не знаем полный путь. В этом случае можно использовать относительный путь — он произведет поиск по всему XML и вернет узлы, подходящие под запрос.
Чтобы записать относительный путь, нужно использовать конструкцию //. После нее можно написать любое поле и получить результат. Например, //name вернет поля <name> из всего XML:
<name>Основы современной верстки</name>
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Проблема такого подхода — уникальность полей. В документах одни и те же имена полей могут обозначать разные данные в зависимости от расположения. Поэтому используйте относительные пути только там, где уверены в возвращаемых данных. Например, в нашем примере название курса может быть заключено в <title>:
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<!-- ... -->
<course>
<title>Основы современной верстки</title>
<!-- ... -->
</course>
<course>
<title>Основы верстки контента</title>
<!-- ... -->
</course>
<course>
<title>Bootstrap 5: Основы верстки</title>
<!-- ... -->
</course>
</courses>
Запрос //title вернет не только имена курсов, но и узел, который находится в <courses>:
<title>Курсы HTML и CSS (верстка)</title>
<title>Основы современной верстки</title>
<title>Основы верстки контента</title>
<title>Bootstrap 5: Основы верстки</title>
Чтобы сэкономить пару секунд, разработчики опускают корневой элемент и пользуются относительными путями. Например, вместо /courses/course/name они пишут //course/name. Для практики попробуйте прошлые примеры перевести на относительные пути с помощью такого механизма.
Несколько примеров запросов с идентичными ответами, как и в прошлой таблице:
| Запрос | Результат |
|---|---|
//course |
Все данные из всех элементов <course></course> |
//name |
<name>Основы современной верстки</name><name>Основы верстки контента</name><name>Bootstrap 5: Основы верстки</name> |
//course/duration |
<duration value="9">9 часов</duration><duration value="18">18 часов</duration><duration value="10">10 часов</duration> |
Предикаты
В примерах запросов к именам возвращались имена всех найденных курсов. В некоторых ситуациях это может быть избыточно. Что делать, если хочется получить данные только по первому курсу в <courses>? На помощь приходят предикаты — конструкции, с помощью которых можно отфильтровать элементы по заданным условиям.
Выберем ключевые слова первого курса по верстке. Для этого достаточно использовать запрос //course[1]/tags:
<tags>HTML5, CSS, DevTools, верстка</tags>
Обратите внимание на[1]. Это предикат с таким условием: «Взять элемент по индексу 1». Попробуйте сделать запрос ко второму или третьему элементу. Достаточно поменять всего одну цифру!
В XPath индексы элементов начинаются с единицы, а не с нуля, как в принятых стандартах программирования. Если вы уже программируете, это может немного запутать.
Предикаты помогают делать точные выборки. Например, получить ссылки на русскоязычные страницы курсов. Для этого нужно получить элементы <url>, у которых атрибут lang равен ru. Делается это указанием атрибута и значения. Чтобы XPath отличил атрибут от элемента перед атрибутом указывается символ @.
Теперь запрос будет выглядеть так: //course/url[@lang="ru"]
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
Иногда полезно выбрать элементы, которые имеют хоть какой-то атрибут. Для этого можно использовать конструкцию //*[@*]:
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
По примеру выше видно, знак * обозначает «все/любой».
Когда выбраны элементы по атрибутам, можно произвести дополнительную фильтрацию по этим значениям. Например, найдем элементы <duration> со значением атрибута value больше 9. Внутри предикатов используются операторы сравнения, знакомые по языкам программирования:
>— больше<— меньше>=— больше или равно<=— меньше или равно=— равно!=— не равно
Запрос будет выглядеть так: //course/duration[@value > 9]:
<duration value="18">18 часов</duration>
<duration value="10">10 часов</duration>
Мы разобрались, как выбирать одно поле — это интересная, но редкая задача. Чаще разработчики обрабатывают данные по всему файлу или нескольким полям. Попробуем одновременно использовать предикат и обратиться к другим полям. Обратите внимание на два момента:
- Предикат необязательно должен идти в конце запроса
- Внутри предиката могут находиться новые пути, которые нужно проверить
Мы уже знаем, как с помощью предиката отфильтровать данные по полю <duration>. Эту задачу мы выполняли с помощью конструкции duration[@value > 9]. А теперь попробуем сделать эту конструкцию предикатом для <course>. Так мы получим данные о курсах с длительностью больше 9 часов: //course[duration[@value > 9]]:
<course>
<title>Основы верстки контента</title>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<title>Bootstrap 5: Основы верстки</title>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
Можно продолжить этот запрос и получить только имена курсов. Тогда предикат будет в середине запроса, а не в его конце: //course[duration[@value > 9]]/name
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Функции
В прошлых примерах запросы затрагивали теги и атрибуты. Сами данные мы не затрагивали, хотя это огромный пласт информации, по которой можно делать выборки. Для решения этой задачи используются встроенные в XPath функции. Они являются частью предикатов — например, @. Попробуем найти курс с названием «Основы верстки контента».
Для поиска по тексту внутри элемента используется функция text(). Ее задача — получить текстовое значение элемента и сравнить его с условием по необходимости. Вот как будет выглядеть запрос для поиска курса с нужным именем: //course[name[text()="Основы верстки контента"]]
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css:content</url>
<url lang="en">https://hexlet.io/courses/css:content</url>
</course>
Но что, если нам известно только часть названия? Для этого существует функция contains(), которая принимает два аргумента:
- Строка, где будет производиться поиск
- Подстрока, которая будет искаться
Для примера найдем курс, у которого в ключевых словах есть слово «Bootstrap». Функция примет текстовое значение элемента tags и найдет там слово «Bootstrap»: //course[tags[contains(text(), "Bootstrap")]]
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
В стандарте XPath существует еще несколько функций, но цель статьи — показать принципы работы тех или иных механизмов, а не дать исчерпывающую документацию по всему языку.
Отличия от CSS-селекторов
Если вы писали на JavaScript, то знаете, что элементы можно искать с помощью CSS-селекторов, используя методы querySelector() или querySelectorAll(). Почему же разработчики иногда ищут элементы внутри HTML именно с помощью XPath?
Дело в концепции поиска элементов. Используя CSS, можно идти только в глубину без возможности обратиться к родительским элементам. В отличие от CSS, XPath позволяет в любой момент обращаться и к дочерним, и к родительским элементам.
Если вы хотите подробнее изучить поиск по HTML с помощью XPath, рекомендуем обратиться к статье Introduction to using XPath in JavaScript.
С помощью CSS нельзя найти все элементы div, внутри которых есть ссылки — можно найти сами ссылки, но не их родителей. XPath позволяет это сделать простым сочетанием div[a]. Постепенно ситуация меняется: в CSS появился селектор :has(), но он поддерживается еще не всеми новыми версиями браузеров. Со временем это изменится, но пока реальность именно такая.
Другой пример — поиск элементов по тексту внутри них. С этой задачей CSS никогда не справится, так как такой цели у него нет. XPath, как мы изучили, умеет это делать с помощью функции text().
Кому нужен Xpath
Если коротко, Xpath нужен всем, кто работает с XML.
Чтобы разобраться подробнее, изучим несколько примеров:
SEO-специалисты. Специалисты по продвижению часто обрабатывают большие массивы данных и вытаскивают информацию со страниц сайта.
Например, для них критичны мета-теги — дополнительная информация, в которой содержатся иконки сайтов, название страницы, описание и так далее. Эту информацию SEO-специалист может автоматически парсить с помощью запросов в XPath.
Тестировщики. При работе с Front-end тестировщики часто проверяют тот или иной вывод информации на странице — для этого они выбирают отдельные элементы с нужной страницы. Это можно делать через XPath и DevTools, встроенный в браузеры на основе Chromium.
Разработчики. Они часто используют парсеры — это скрипты, которые ищут нужную информацию на страницах одного или нескольких сайтов. Например, мы хотим сравнить стоимость одного и того же товара в разных магазинах. Для такой задачи можно написать скрипт, который пройдется по всем нужным сайтам, сравнит цены и вернет данные. В этом случае для поиска информацию на странице можно использовать XPath.
Это лишь часть сценариев, в которых пригождается язык XPath — на самом деле, их десятки.
Заключение
В этой статье мы рассмотрели, где встречается XML и кому он может пригодиться. Мы научились составлять базовые запросы и изучили часто используемые конструкции XPath:
- Абсолютные и относительные пути
- Предикаты
- Поиск по атрибутам
- Операторы сравнения
- Функции
Также теперь вы знаете, что поиск по HTML с помощью XPath может быть эффективнее поиска с помощью CSS-селекторов.
В этой статье мы постарались дать знания, которые помогут справиться с большинством задач. Но это далеко не все возможности XPath — это более глубокий язык, чем представлено в статье. Как и с другими технологиями, тут важно набить руку. Чем больше вы практикуетесь, тем более точные и полезные запросы пишете.
XPath — Overview
Before learning XPath, we should first understand XSL which stands for Extensible Stylesheet Language. It is similar to XML as CSS is to HTML.
Need for XSL
In case of HTML documents, tags are predefined such as table, div, span, etc. The browser knows how to add style to them and display them using CSS styles. But in case of XML documents, tags are not predefined. In order to understand and style an XML document, World Wide Web Consortium (W3C) developed XSL which can act as an XML-based Stylesheet Language. An XSL document specifies how a browser should render an XML document.
Following are the main parts of XSL −
-
XSLT − used to transform XML documents into various other types of document.
-
XPath − used to navigate XML documents.
-
XSL-FO − used to format XML documents.
What is XPath?
XPath is an official recommendation of the World Wide Web Consortium (W3C). It defines a language to find information in an XML file. It is used to traverse elements and attributes of an XML document. XPath provides various types of expressions which can be used to enquire relevant information from the XML document.
-
Structure Definitions − XPath defines the parts of an XML document like element, attribute, text, namespace, processing-instruction, comment, and document nodes
-
Path Expressions − XPath provides powerful path expressions select nodes or list of nodes in XML documents.
-
Standard Functions − XPath provides a rich library of standard functions for manipulation of string values, numeric values, date and time comparison, node and QName manipulation, sequence manipulation, Boolean values etc.
-
Major part of XSLT − XPath is one of the major elements in XSLT standard and is must have knowledge in order to work with XSLT documents.
-
W3C recommendation − XPath is an official recommendation of World Wide Web Consortium (W3C).
One should keep the following points in mind, while working with XPath −
- XPath is core component of XSLT standard.
- XSLT cannot work without XPath.
- XPath is basis of XQuery and XPointer.
XPath — Expression
An XPath expression generally defines a pattern in order to select a set of nodes. These patterns are used by XSLT to perform transformations or by XPointer for addressing purpose.
XPath specification specifies seven types of nodes which can be the output of execution of the XPath expression.
- Root
- Element
- Text
- Attribute
- Comment
- Processing Instruction
- Namespace
XPath uses a path expression to select node or a list of nodes from an XML document.
Following is the list of useful paths and expression to select any node/ list of nodes from an XML document.
| S.No. | Expression & Description |
|---|---|
| 1 |
node-name Select all nodes with the given name «nodename» |
| 2 |
/ Selection starts from the root node |
| 3 |
// Selection starts from the current node that match the selection |
| 4 |
. Selects the current node |
| 5 |
.. Selects the parent of the current node |
| 6 |
@ Selects attributes |
| 7 |
student Example − Selects all nodes with the name «student» |
| 8 |
class/student Example − Selects all student elements that are children of class |
| 9 |
//student Selects all student elements no matter where they are in the document |
Example
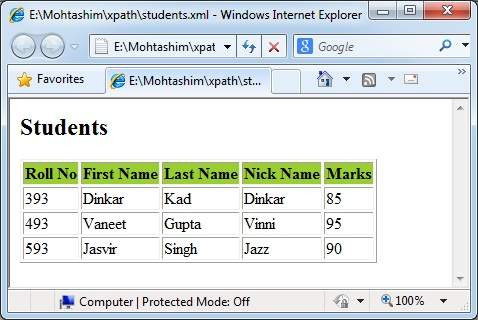
In this example, we’ve created a sample XML document, students.xml and its stylesheet document students.xsl which uses the XPath expressions under select attribute of various XSL tags to get the values of roll no, firstname, lastname, nickname and marks of each student node.
students.xml
<?xml version = "1.0"?>
<?xml-stylesheet type = "text/xsl" href = "students.xsl"?>
<class>
<student rollno = "393">
<firstname>Dinkar</firstname>
<lastname>Kad</lastname>
<nickname>Dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>Vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>Jasvir</firstname>
<lastname>Singh</lastname>
<nickname>Jazz</nickname>
<marks>90</marks>
</student>
</class>
students.xsl
<?xml version = "1.0" encoding = "UTF-8"?>
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/">
<html>
<body>
<h2>Students</h2>
<table border = "1">
<tr bgcolor = "#9acd32">
<th>Roll No</th>
<th>First Name</th>
<th>Last Name</th>
<th>Nick Name</th>
<th>Marks</th>
</tr>
<xsl:for-each select = "class/student">
<tr>
<td> <xsl:value-of select = "@rollno"/></td>
<td><xsl:value-of select = "firstname"/></td>
<td><xsl:value-of select = "lastname"/></td>
<td><xsl:value-of select = "nickname"/></td>
<td><xsl:value-of select = "marks"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Verify the output
XPath — Nodes
In this chapter, we’ll see the XPath expression in details covering common types of Nodes, XPath defines and handles.
| S.No. | Node Type & Description |
|---|---|
| 1 | Root
Root element node of an XML Document. |
| 2 | Element
Element node. |
| 3 | Text
Text of an element node. |
| 4 | Attribute
Attribute of an element node. |
| 5 | Comment
Comment |
XPath — Absolute Path
Location path specifies the location of node in XML document. This path can be absolute or relative. If location path starts with root node or with ‘/’ then it is an absolute path. Following are few of the example locating the elements using absolute path.
/class/student − select student nodes within class root node.
<xsl:for-each select = "/class/student">
/class/student/firstname − select firstname of a student node within class root node.
<p><xsl:value-of select = "/class/student/firstname"/></p>
Example
In this example, we’ve created a sample XML document students.xml and its stylesheet document students.xsl which uses the XPath expressions.
Following is the sample XML used.
students.xml
<?xml version = "1.0"?>
<?xml-stylesheet type = "text/xsl" href = "students.xsl"?>
<class>
<student rollno = "393">
<firstname>Dinkar</firstname>
<lastname>Kad</lastname>
<nickname>Dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>Vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>Jasvir</firstname>
<lastname>Singh</lastname>
<nickname>Jazz</nickname>
<marks>90</marks>
</student>
</class>
students.xsl
<?xml version = "1.0" encoding = "UTF-8"?>
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/" >
<html>
<body>
<h3>Details of each Students. </h3>
<table border = "1">
<tr bgcolor = "#9acd32">
<th>Roll No</th>
<th>First Name</th>
<th>Last Name</th>
<th>Nick Name</th>
<th>Marks</th>
</tr>
<tr>
<td><xsl:value-of select = "/class/student[1]/@rollno"/></td>
<td><xsl:value-of select = "/class/student[1]/firstname"/></td>
<td><xsl:value-of select = "/class/student[1]/lastname"/></td>
<td><xsl:value-of select = "/class/student[1]/nickname"/></td>
<td><xsl:value-of select = "/class/student[1]/marks"/></td>
</tr>
<tr>
<td>
<xsl:value-of select = "/class/student/@rollno"/>
</td>
<td><xsl:value-of select = "/class/student[2]/firstname"/></td>
<td><xsl:value-of select = "/class/student[2]/lastname"/></td>
<td><xsl:value-of select = "/class/student[2]/nickname"/></td>
<td><xsl:value-of select = "/class/student[2]/marks"/></td>
</tr>
<tr>
<td>
<xsl:value-of select = "/class/student[3]/@rollno"/>
</td>
<td><xsl:value-of select = "/class/student[3]/firstname"/></td>
<td><xsl:value-of select = "/class/student[3]/lastname"/></td>
<td><xsl:value-of select = "/class/student[3]/nickname"/></td>
<td><xsl:value-of select = "/class/student[3]/marks"/></td>
</tr>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Verify the output
XPath — Relative Path
Location path specifies the location of node in XML document. This path can be absolute or relative. If location path starts with the node that we’ve selected then it is a relative path.
Following are few examples locating the elements using relative path.
firstname − select firstname related to student nodes.
<p><xsl:value-of select = "firstname"/></p>
Example
In this example, we’ve created a sample XML document students.xml and its stylesheet document students.xsl which uses the XPath expressions.
Following is the sample XML used.
students.xml
<?xml version = "1.0"?>
<?xml-stylesheet type = "text/xsl" href = "students.xsl"?>
<class>
<student rollno = "393">
<firstname>Dinkar</firstname>
<lastname>Kad</lastname>
<nickname>Dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>Vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>Jasvir</firstname>
<lastname>Singh</lastname>
<nickname>Jazz</nickname>
<marks>90</marks>
</student>
</class>
students.xsl
<?xml version = "1.0" encoding = "UTF-8"?>
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/" >
<html>
<body>
<h3>Details of each Students. </h3>
<table border = "1">
<tr bgcolor = "#9acd32">
<th>Roll No</th>
<th>First Name</th>
<th>Last Name</th>
<th>Nick Name</th>
<th>Marks</th>
</tr>
<xsl:for-each select = "/class/student">
<tr>
<td><xsl:value-of select = "@rollno"/></td>
<td><xsl:value-of select = "firstname"/></td>
<td><xsl:value-of select = "lastname"/></td>
<td><xsl:value-of select = "nickname"/></td>
<td><xsl:value-of select = "marks"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Verify the output
XPath — Axes
As location path defines the location of a node using absolute or relative path, axes are used to identify elements by their relationship like parent, child, sibling, etc. Axes are named so because they refer to axis on which elements are lying relative to an element.
Following is the list of various Axis values.
| S.No. | Axis & Description |
|---|---|
| 1 |
ancestor Represents the ancestors of the current node which include the parents up to the root node. |
| 2 |
ancestor-or-self Represents the current node and it’s ancestors. |
| 3 |
attribute Represents the attributes of the current node. |
| 4 |
child Represents the children of the current node. |
| 5 |
descendant Represents the descendants of the current node. Descendants include the node’s children upto the leaf node(no more children). |
| 6 |
descendant-or-self Represents the current node and it’s descendants. |
| 7 |
following Represents all nodes that come after the current node. |
| 8 |
following-sibling Represents the following siblings of the context node. Siblings are at the same level as the current node and share it’s parent. |
| 9 |
namespace Represents the namespace of the current node. |
| 10 |
parent Represents the parent of the current node. |
| 11 |
preceding Represents all nodes that come before the current node (i.e. before it’s opening tag). |
| 12 |
self Represents the current node. |
Following are a few examples on the uses of axes.
firstname − select firstname related to student nodes.
<p><xsl:value-of select = "firstname"/></p> <xsl:value-of select = "/class/student/preceding-sibling::comment()"/>
Example
In this example, we’ve created a sample XML document students.xml and its stylesheet document students.xsl which uses the XPath expressions.
Following is the sample XML used.
students.xml
<?xml version = "1.0"?>
<?xml-stylesheet type = "text/xsl" href = "students.xsl"?>
<class>
<!-- Comment: This is a list of student -->
<student rollno = "393">
<firstname>Dinkar</firstname>
<lastname>Kad</lastname>
<nickname>Dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>Vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>Jasvir</firstname>
<lastname>Singh</lastname>
<nickname>Jazz</nickname>
<marks>90</marks>
</student>
</class>
students.xsl
<?xml version = "1.0" encoding = "UTF-8"?>
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/" >
<html>
<body>
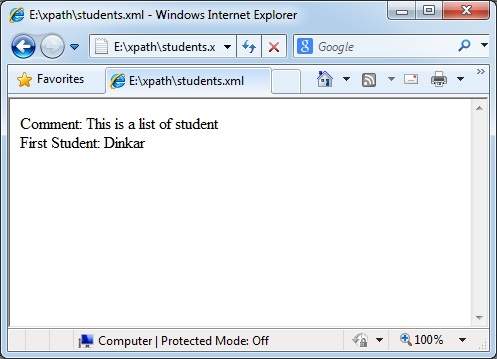
<xsl:value-of select = "/class/student/preceding-sibling::comment()"/>
<br/>
<xsl:text>First Student: </xsl:text>
<xsl:value-of select = "/class/student/child::firstname" />
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Verify the output
XPath — Operators
In this chapter, we’ll see XPath operators and functions in details covering commonly used XPath defines and handles. XPath defines Operators and functions on Nodes, String, Number and Boolean types.
Following is the list we are going to discuss about.
XPath — Wildcard
XPath defines the following wildcards on nodes to be used with the XPath expressions.
| S.No. | WildCard & Description |
|---|---|
| 1 |
* used to match any node. |
| 2 |
. used to match the current node in context. |
| 3 |
@* used to match any attribute |
| 4 |
node() used to match node of any type |
Example
This example creates a table of <student> element with their details, by iterating over each student.
students.xml
<?xml version = "1.0"?>
<?xml-stylesheet type = "text/xsl" href = "students.xsl"?>
<class>
<student rollno = "393">
<firstname>Dinkar</firstname>
<lastname>Kad</lastname>
<nickname>Dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>Vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>Jasvir</firstname>
<lastname>Singh</lastname>
<nickname>Jazz</nickname>
<marks>90</marks>
</student>
</class>
students.xsl
<?xml version = "1.0" encoding = "UTF-8"?>
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/">
<html>
<body>
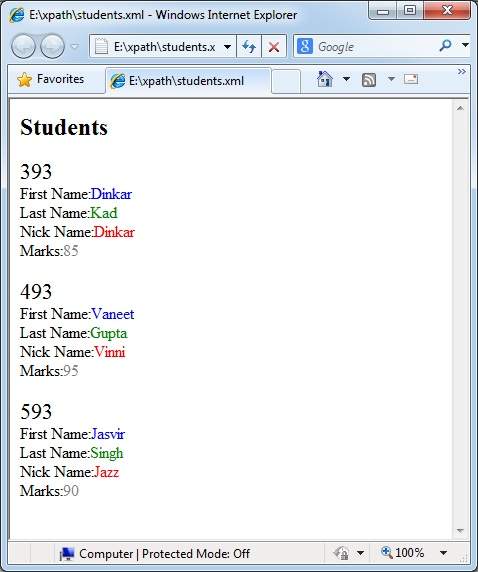
<h2>Students</h2>
<xsl:apply-templates select = "class/*" />
</body>
</html>
</xsl:template>
<xsl:template match = "class/*">
<xsl:apply-templates select = "@rollno" />
<xsl:apply-templates select = "firstname" />
<xsl:apply-templates select = "lastname" />
<xsl:apply-templates select = "nickname" />
<xsl:apply-templates select = "marks" />
<br />
</xsl:template>
<xsl:template match = "@rollno">
<span style = "font-size = 22px;">
<xsl:value-of select = "." />
</span>
<br />
</xsl:template>
<xsl:template match = "firstname">
First Name:<span style = "color:blue;">
<xsl:value-of select = "." />
</span>
<br />
</xsl:template>
<xsl:template match = "lastname">
Last Name:<span style = "color:green;">
<xsl:value-of select = "." />
</span>
<br />
</xsl:template>
<xsl:template match = "nickname">
Nick Name:<span style = "color:red;">
<xsl:value-of select = "." />
</span>
<br />
</xsl:template>
<xsl:template match = "marks">
Marks:<span style = "color:gray;">
<xsl:value-of select = "." />
</span>
<br />
</xsl:template>
</xsl:stylesheet>
Verify the output
XPath — Predicate
Predicate refers to the XPath expression written in square brackets. It refers to restrict the selected nodes in a node set for some condition. For example,
| S.No. | Predicate & Description |
|---|---|
| 1 |
/class/student[1] Select first student element which is child of the class element. |
| 2 |
/class/student[last()] Select last student element which is child of the class element. |
| 3 |
/class/student[@rolllno = 493] Select student element with rollno 493. |
| 4 |
/class/student[marks>85] Select student element with marks > 85. |
Example
This example creates a table of <student> element with their details, by iterating over each student. It calculates the position of the student node and then prints the student(s) details along with serial no.
students.xml
<?xml version = "1.0"?>
<?xml-stylesheet type = "text/xsl" href = "students.xsl"?>
<class>
<student rollno = "393">
<firstname>Dinkar</firstname>
<lastname>Kad</lastname>
<nickname>Dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>Vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>Jasvir</firstname>
<lastname>Singh</lastname>
<nickname>Jazz</nickname>
<marks>90</marks>
</student>
</class>
students.xsl
<?xml version = "1.0" encoding = "UTF-8"?>
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
<xsl:template match = "/">
<html>
<body>
<h2>Students</h2>
<table border = "1">
<tr bgcolor = "#9acd32">
<th>Roll No</th>
<th>First Name</th>
<th>Last Name</th>
<th>Nick Name</th>
<th>Marks</th>
</tr>
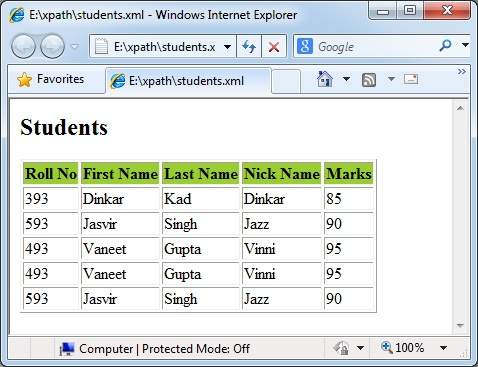
<xsl:for-each select = "/class/student[1]">
<tr>
<td><xsl:value-of select = "@rollno"/></td>
<td><xsl:value-of select = "firstname"/></td>
<td><xsl:value-of select = "lastname"/></td>
<td><xsl:value-of select = "nickname"/></td>
<td><xsl:value-of select = "marks"/></td>
</tr>
</xsl:for-each>
<xsl:for-each select = "/class/student[last()]">
<tr>
<td><xsl:value-of select = "@rollno"/></td>
<td><xsl:value-of select = "firstname"/></td>
<td><xsl:value-of select = "lastname"/></td>
<td><xsl:value-of select = "nickname"/></td>
<td><xsl:value-of select = "marks"/></td>
</tr>
</xsl:for-each>
<xsl:for-each select = "/class/student[@rollno = 493]">
<tr>
<td><xsl:value-of select = "@rollno"/></td>
<td><xsl:value-of select = "firstname"/></td>
<td><xsl:value-of select = "lastname"/></td>
<td><xsl:value-of select = "nickname"/></td>
<td><xsl:value-of select = "marks"/></td>
</tr>
</xsl:for-each>
<xsl:for-each select = "/class/student[marks > 85]">
<tr>
<td><xsl:value-of select = "@rollno"/></td>
<td><xsl:value-of select = "firstname"/></td>
<td><xsl:value-of select = "lastname"/></td>
<td><xsl:value-of select = "nickname"/></td>
<td><xsl:value-of select = "marks"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Verify the output
Kickstart Your Career
Get certified by completing the course
Get Started

Время на прочтение
4 мин
Количество просмотров 512K
Xpath — это язык запросов к элементам xml или xhtml документа. Также как SQL, xpath является декларативным языком запросов. Чтобы получить интересующие данные, необходимо всего лишь создать запрос, описывающий эти данные. Всю «черную» работу за вас выполнит интерпретатор языка xpath.
Очень удобно, не правда ли? Давайте посмотри какие возможности предлагает xpath для доступа к узлам веб-страниц.
Создание запроса к узлам веб-страниц
Предлагаю вашему вниманию небольшую лабораторную работу, в ходе которой я продемонстрирую создание xpath запросов к веб-странице. Вы сможете повторить приведенные мной запросы и, самое главное, попробуете выполнить свои. Я надеюсь, что благодаря этому статья будет одинаково интересна новичкам и программистам знакомым с xpath по xml.
Для лабораторной нам понадобятся:
— веб-страница xhtml;
— браузер Mozilla Firefox с дополнениями;
— firebug;
— firePath;
(вы можете использовать любой другой браузер с визуальной поддержкой xpath)
— немного времени.
В качестве веб-страницы для проведения эксперимента предлагаю главную страницу сайта консорциума всемирной паутины (‘http://w3.org’). Именно эта организация разрабатывает языки xquery(xpath), спецификацию xhtml и многие другие стандарты интернета.
Задача
Получить из xhtml-кода главной страницы w3.org информацию о конференциях консорциума при помощи запросов xpath.
Приступим к написанию xpath запросов.
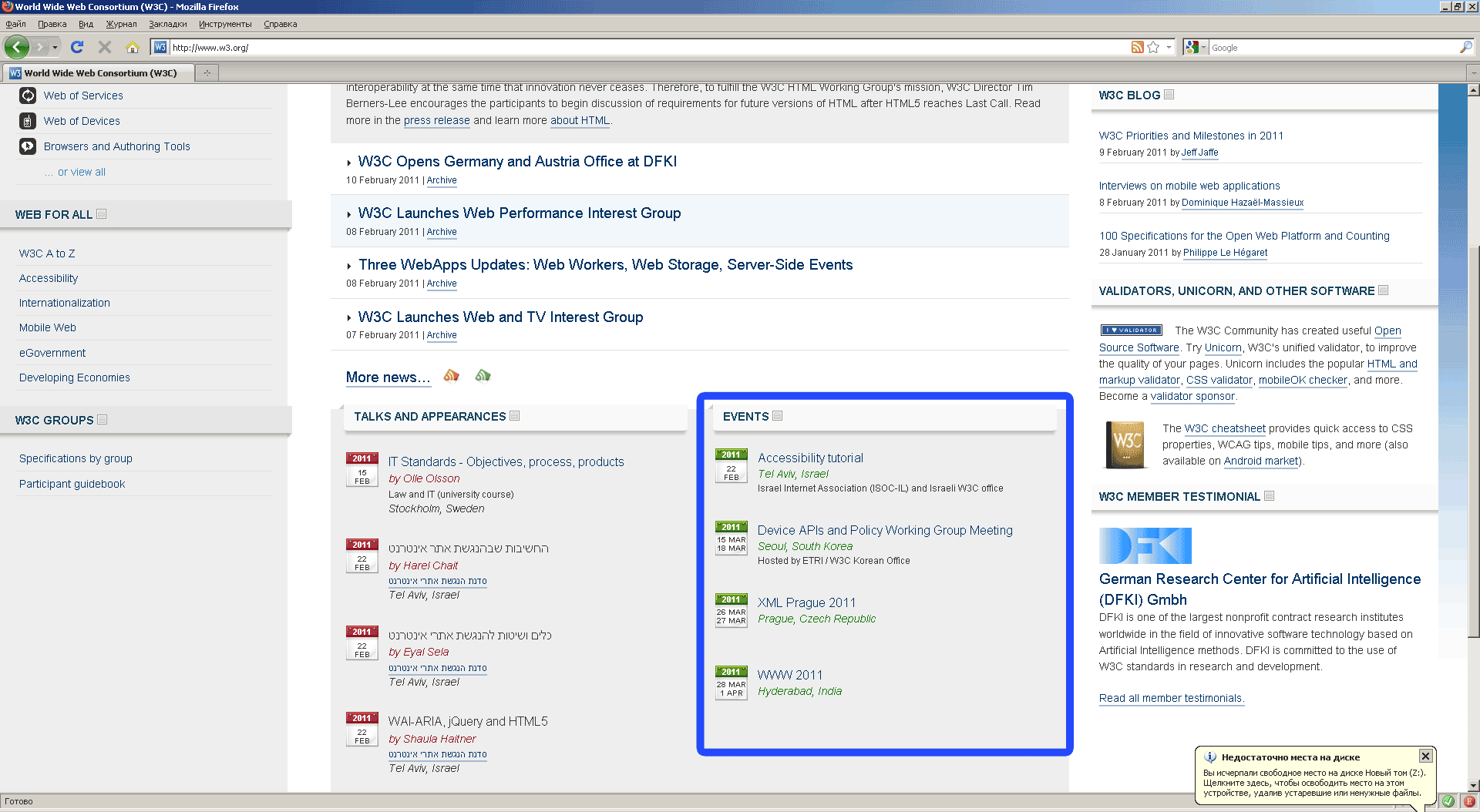
Первый Xpath запрос
Открываем закладку Firepath в FireBug, выделяем с селектором элемент для анализа, нажимаем: Firepath создал xpath запрос к выбранному элементу.
Если вы выделили заголовок первого события, то запрос будет таким:
.//*[@id='w3c_home_upcoming_events']/ul/li[1]/div[2]/p[1]/a
После удаления лишних индексов запрос станет соответствовать всем элементам типа «заголовок».
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p/a
Firepath подсвечивает элементы, которые соответствуют запросу. Вы можете в реальном времени увидеть, какие узлы документа соответствуют запросу.
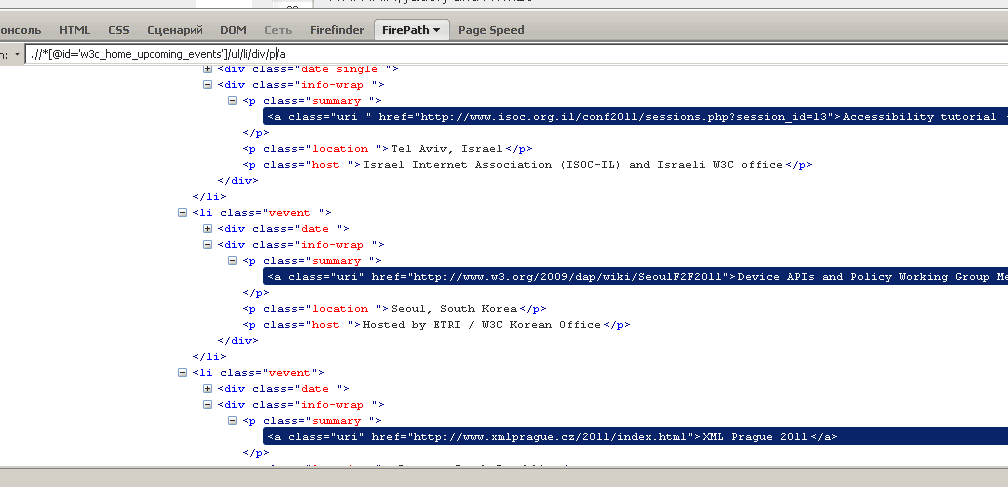
Идем дальше. Создаем запросы для поиска мест проведения конференций и их спонсоров либо с помощью селектора, либо модифицировав первый запрос.
Запрос для получения информации о местах проведения конференций:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]
Так мы получим список спонсоров:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]
Синтаксис xpath
Давайте вернемся к созданным запросам и разберемся в том, как они устроены.
Рассмотрим подробно первый запрос

В этом запросе я выделил три части для демонстрации возможностей xpath. (Деление на части уловное)
Первая часть
.// — рекурсивный спуск на ноль или более уровней иерархии от текущего контекста. В нашем случае текущий контекст это корень документа
Вторая часть
* — любой элемент,
[@id=’w3c_home_upcoming_events’] – предикат, на основе которого осуществляем поиск узла, имеющего атрибут id равным ‘w3c_home_upcoming_events’. Идентификаторы элементов XHTML должны быть уникальны. Поэтому запрос «любой элемент с конкретным ID» должен вернуть единственный искомый нами узел.
Мы можем заменить * на точное имя узла div в этом запросе
div[@id='w3c_home_upcoming_events']
Таким образом, мы спускаемся по дереву документа до нужного нам узла div[@id=’w3c_home_upcoming_events’]. Нас абсолютно не волнует, из каких узлов состоит DOM-дерево и сколько уровней иерархии осталось выше.
Третья часть
/ul/li/div/p/a –xpath-путь до конкретного элемента. Путь состоит из шагов адресации и условия проверки узлов (ul, li и т.д.). Шаги разделяются символом » /»(косая черта).
Коллекции xpath
Не всегда удается получить доступ к интересующему узлу с помощью предиката или шагов адресации. Очень часто на одном уровне иерархии находится насколько узлов одинакового типа и необходимо выбрать «только первые» или «только вторые» узлы. Для таких случаев предусмотрены коллекции.
Коллекции xpath позволяют получить доступ к элементу по его индексу. Индексы соответствуют тому порядку, в котором элементы были представлены в исходном документе. Порядковый номер в коллекциях отсчитывается от единицы.
Исходя из того, что «место проведения» всегда второй параграф после «названия конференции», получаем следующий запрос:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]
Где p[2] – второй элемент в наборе для каждого узла списка /ul/li/div.
Аналогично список спонсоров мы можем получить запросом:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]
Некоторые функции хpath
В хpath существует множество функций для работы с элементами внутри коллекции. Я приведу только некоторые из них.
last():
Возвращает последний элемент коллекции.
Запрос ul/li/div/p[last()] — возвратит последние параграфы для каждого узла списка «ul».
Функция first() не предусмотрена. Для доступа к первому элементу используйте индекс «1».
text():
Возвращает тестовое содержание элемента.
.//a[text() = 'Archive'] – получаем все ссылки с текстом «Archive».
position() и mod:
position() — возвращает позицию элемента в множестве.
mod — остаток от деления.
Комбинацией данных функций можем получить:
— не четные элементы ul/li[position() mod 2 = 1]
— четные элементы: ul/li[position() mod 2 = 0]
Операции сравнения
- < — логическое «меньше»
- > — логическое «больше»
- <= — логическое «меньше либо равно»
- >= — логическое «больше либо равно»
ul/li[position() > 2] , ul/li[position() <= 2] — элементы списка начиная с 3го номера и наоборот.
Полный список функций
Самостоятельно
Попробуйте получить:
— четные URL ссылки из левого меню «Standards»;
— заголовки всех новостей, кроме первой с главной страницы w3c.org.
Xpath в PHP5
$dom = new DomDocument();
$dom->loadHTML( $HTMLCode );
$xpath = new DomXPath( $dom );
$_res = $xpath->query(".//*[@id='w3c_home_upcoming_events']/ul/li/div/p/a");
foreach( $_res => $obj ) {
echo 'URL: '.$obj->getAttribute('href');
echo $obj->nodeValue;
}
В заключение
На простом примере мы увидели возможности xpath для доступа к узлам веб-страниц.
Xpath является отраслевым стандартом для доступа к элементам xml и xhtml, xslt преобразований.
Вы можете применять его для парсинга любой html-страницы. В случае если исходный html-код содержит значительные ошибки в разметке пропустите его через tidy. Ошибки будут исправлены.
Старайтесь отказаться от регулярных выражений при парсинге веб-страниц в пользу xpath.
Это сделает ваш код проще, понятнее. Вы допустите меньше ошибок. Сократиться время отладки.
Ресурсы
Firepath дополнение Mozzilla Firefox
Краткая аннотация языка в википедии
Xороший справочник по xpath. Не обращайте внимание на то, что он для NET Framework. Xpath во всех средах работает одинаково, за исключением пары специфичных функций
Cпецификация xpath 1.0
Cпецификация xpath 1.0 на русском
XQuery 1.0 and XPath 2.0
Tidy
PHP5 tidy::repairFile
- Суть
- Абсолютный и относительный пути
- Синтаксис
- Булевы операторы
- Функции
- Оси XPath
Главное
XPath — один из способов поиска элементов веб-страницы при тестировании. Название означает «XML Path Language», что отражает первичное предназначение: навигацию (поэтому «путь» в названии) по структуре и атрибутам XML-документа. В автоматизации тестирования (особенно в Selenium) XPath применяется для идентификации и проверки веб-элементов. Далее рассмотрим некоторые базовые концепции и синтаксис XPath, а также важнейшие оси.
В практическом рассмотрении XPath представляет собой последовательность шагов, которая описывает, как перейти к какому-то нужному узлу (или группе узлов) в XML-документе. Узлом может считаться элемент страницы, атрибут, текст, комментарий, или любая другая часть страницы, что очень полезно в автоматизации веба, а также и при тестировании мобильных приложений.
Абсолютный и относительный путь

Абсолютный xpath начинается с одного слэша ( / ) и указывает на полный путь из корневого узла (root) к целевому (target). Например, следующее выражение в XPath:
/html/body/div[1]/h1
— означает: «выбрать первый div-элемент под body-элементом под html-элементом, и далее выбрать его вложенный (или дочерний, child) h1-элемент».
Относительный путь начинается с дабл-слэша (двух //) и указывает на путь из любого узла (= нода) который отвечает критериям, к целевому узлу. Например,
//div[@id='main']
— означает «выбрать любой div-элемент, имеющий id-атрибут со значением ‘main’»
Синтаксис XPath
Запись выражений XPath зависит от того какой элемент нужно найти. Базовый синтаксис:
//tagname[@attribute='value']
Это значит «выбрать любой tagname-элемент, обладающий атрибутом со значением ‘value’».

Значения всегда в одинарных кавычках, атрибуты — в квадратных скобках.
К примеру,
//input[@type='text']
— это значит «выбрать любой input-элемент, имеющий атрибут типа со значением ‘text’ ».
//— начать поиск с любого места на страницеinput— HTML-тег, то есть любой тег в HTML (например p, button, span, div …)type— атрибут, любой атрибут в HTML (id, class, link, src, alt …)text— значение атрибута type.
Еще пример:
//a[@href='https://testengineer.ru']
Означает «выбрать любой элемент-якорь с href-атрибутом ‘testengineer.ru’».
Логические операторы
В XPath широко применяются логические операторы типа AND, OR и NOT, для указания нескольких условий поиска и сочетания условий.

Например,
//input[@type='text' AND @name='username']
Означает «выбрать любой input-элемент, имеющий одновременно атрибут типа со значением ‘text’ и атрибут имени со значением ‘username’».
//a[@href='https://testengineer.ru' OR @class='link']
Означает «выбрать любой якорный элемент, имеющий или href-атрибут со значением ’https://testengineer.ru’», или с атрибутом класса со значением ‘link’».
//div[NOT(@id)]
Означает «выбрать любой div-элемент, не имеющий id-атрибута».
Функции
Также в XPath применяются функции типа text(), contains(), starts-with() и ends-with() для проверки точного или частичного совпадения текста (текстовых значений). Примеры:
//h1[text()='Welcome']— это выбрать любой h1-элемент, имеющий текстовое значение ‘Welcome’.//p[contains(text(),'Hello')]— выбрать любой p-элемент, имеющий значение ‘Hello’.//img[starts-with(@src,'logo')]— выбрать любой рисунок с src-атрибутом, который начинается со значения ‘logo’//span[ends-with(@id,'_title')]— выбрать любой span-элемент, который заканчивается значением ‘_title’.
Примечание. Следует учитывать, что функция end-with есть только в версии XPath 2.0, которую большинство современных браузеров не поддерживают. Если нужен такой поиск, для этого лучше использовать CSS-селектор вместо XPath. Например, вместо //span[ends-with(@id,'_title')] можно использовать CSS-селектор span[id$='_title'].
Оси XPath
Оси — это база языка Xpath. Для навигации по узлам применяются оси parent, ancestor, ancestor-or-self, child, descendant, following, following-sibling, preceding и preceding-sibling.

Синтаксис оси XPath:
Axes::tagName[@attribute='value']
Далее на рисунках каждый прямоугольничек представляет собой id каждого элемента с div-тегом.
Parent
Выбирает верхний (родительский) узел (по отношению к текущему узлу). На рисунке:

Пример:
//div[@id='Y2']/parent::* — выбрать любой элемент, являющийся прямым родительским для div-элемента с id ‘Y2’, это B2 в нашем случае.
Ancestor
Выбирает всех предков текущего узла. Иными словами, первый родительский и все старше, то есть «по направлению к корням дерева». На рисунке:

Примеры:
//div[@id='Y2']/ancestor::div[@id='B2'] выбирает div-элемент с id ‘B2’, который является предком div-элемента с id ‘Y2’.
//div[@id='Y2']/ancestor::div[@id='A'] — выбрать div-элемент с id A, являющийся предком div-элемента с id ‘Y2’.
Ancestor-or-self
Вибирает все предковые элементы текущего узла, включая и сам текущий узел.

То есть то же самое что Ancestor, и плюс сам этот узел.
Child
Выбирает непосредственные элементы-потомки (но только первые дочерние) текущего узла:

Примеры:
//div[@id='B2']/child::* — выбрать все элементы, являющиеся прямыми потомками div-элемента с id B2.
//div[@id='B2']/child::div[@id='Y2'] — выбор всех div-элементов с id Y2, прямых потомков div-элемента с id B2.
Descendant
Выбрать всех потомков («во всех коленах») текущего узла.

Примеры:
Выражение //div[@id='B2']/descendant::* выбирает все элементы, которые являются потомками div-элемента с id B2.
//div[@id='B2']/descendant::div[@id='L1'] — выбрать div-элементы-потомки от div-элемента с id L1.
Following
Выбрать все элементы в документе, идущие после закрывающего тега текущего узла. Другими словами, ниже текущего элемента по дереву (на всех уровнях и слоях), но исключая собственных потомков (смотрим рисунок):

Пример:
//div[@id='B2']/following::* — выбрать все div-элементы ниже текущего элемента с id B2.
Following-sibling
Все элементы «братского», то есть того же уровня (= уровня этого узла).

Пример:
//div[@id='B2']/following-sibling::* выбирает все элементы на том же уровне что и div-элемент с id B2, и ниже его в дереве. Иначе говоря, «все братские ниже».
Preceding

Preceding аналогичен Following, но в обратную сторону, то есть все элементы выше указанного.
Пример:
//div[@id='B2']/preceding::* выбирает все элементы идущие перед div-элементом с id B2.
Preceding-sibling

Аналогично Preceding, но выбирает только на том же уровне и перед указанным, иными словами любой элемент с тем же родителем и на том же уровне.
Итак
Этого, может быть, достаточно для ознакомления с XPath. Если тема заинтересовала, и нужно продолжение, пишите в коменты здесь или в коменты в наш ТГ к любому посту (всё читаем).

***
Источники: 1,2,3