XML (Extensible Markup Language) — это язык разметки, используемый для обмена данными между различными программами и платформами. Он позволяет создавать структурированные файлы, содержащие информацию в виде тегов и значений. В данной статье мы рассмотрим пошаговую инструкцию по созданию валидного файла с выбранными организациями в формате XML.
Шаг 1: Определение структуры XML файла
Прежде чем создавать файл, необходимо определить структуру XML, которая будет использоваться для представления данных об организациях. Например, вы можете определить тег organizations как корневой элемент, а каждую организацию представить внутри отдельного тега organization. Далее определите необходимые атрибуты и элементы для каждой организации, такие как name, address, phone и т.д.
<organizations>
<organization>
<name>Название организации</name>
<address>Адрес организации</address>
<phone>Контактный номер телефона</phone>
</organization>
...
</organizations>
Шаг 2: Создание XML файла
Создайте новый текстовый документ и сохраните его с расширением .xml. Название файла может быть любым, например organizations.xml.
Шаг 3: Начало и завершение XML документа
В начале файла необходимо указать начало и завершение XML документа, с помощью тегов <?xml version="1.0" encoding="UTF-8"?> и <root></root>.
<?xml version="1.0" encoding="UTF-8"?>
<organizations>
</organizations>
Шаг 4: Добавление организаций
Внутри корневого элемента organizations добавьте каждую организацию в отдельный тег organization, и заполните необходимые атрибуты и элементы значениями.
<organizations>
<organization>
<name>Название организации 1</name>
<address>Адрес организации 1</address>
<phone>Контактный номер телефона 1</phone>
</organization>
<organization>
<name>Название организации 2</name>
<address>Адрес организации 2</address>
<phone>Контактный номер телефона 2</phone>
</organization>
...
</organizations>
Шаг 5: Сохранение и валидация XML файла
Сохраните внесенные изменения в файле и выполните валидацию XML файла с помощью онлайн-инструментов или специальных программных средств. Валидация XML файла позволит убедиться, что структура и формат файла соответствуют правилам XML.
Поздравляем! Теперь у вас есть валидный файл с выбранными организациями в формате XML. Вы можете использовать его для обмена данными между различными программами или системами.
Примечание: Данная инструкция предоставляет лишь базовое понимание о создании XML файла с выбранными организациями. Структура и элементы могут изменяться в зависимости от ваших потребностей и требований проекта.
Создание товарного фида в формате XML — довольно важная задача для специалиста по контекстной рекламе. Такой фид позволяет запустить несколько рекламных форматов в Яндекс.Директе, динамический ретаргетинг во «ВКонтакте» и myTarget, торговые кампании в Google, а также создать магазин в Яндекс.Маркете и каталог в Facebook.
Есть два способа создать товарный фид:
- автоматически через CMS;
- вручную.
Генерация фида в CMS
Если сайт создан на базе популярной CMS, то можно использовать специальные модули или плагины для генерации прайс-листа. Например, для создания фида в формате YML можно скачать дополнения для таких CMS:
- 1C-Bitrix;
- WordPress (Для Woocommerce);
- Shop-Script 7;
- Insales;
- AdvantShop;
- Opencart 2;
- Opencart 3;
- NetCat;
- PHPShop;
- ReadyScript;
- PrestaShop;
- RetailCRM;
- UMI.CMS;
- Magento 1.7.0.2 — 1.9.4.0;
- Magento 2.1.8 — 2.3.1;
- Simpla;
- OkayCMS;
- Tiu.ru;
- Ecwid;
- Tilda.
Создание XML-файла вручную
Ручной метод можно использовать, когда нет возможности сформировать прайс-лист с CMS, например, если CMS самописная, у сайта неправильная структура или нет разработчика или бюджета на него.
Следует также понимать, что этот способ создания фидов подойдет для тех, у кого обновления товаров происходят редко либо страницы, цены и предложения не меняются вовсе. Обновление собранного вручную фида будет происходить тоже в ручном режиме.
Для работы потребуется Excel и Note Pad++. В инструкции мы будем использовать шаблоны, которые можно скачать с Google Диска. Также в папке есть файлы с меткой ready — это готовые фиды для проверки правильности выполнения инструкции.
Подготовка к созданию XML-фидов
В первую очередь необходимо включить в Excel возможность работы с XML-файлами (панель «Разработчик»), поэтому переходим в параметры программы.
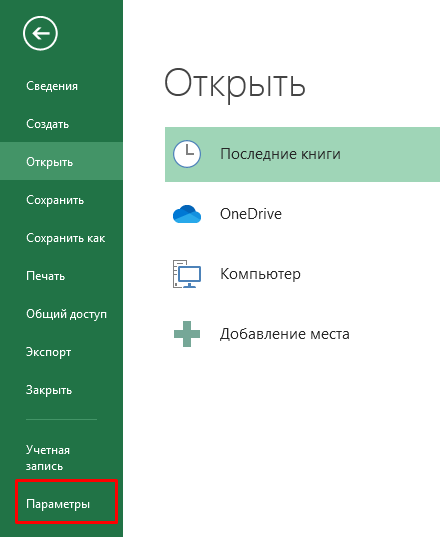
Затем в настройках ленты ставим галочку в пункте «Разработчик» — «XML».
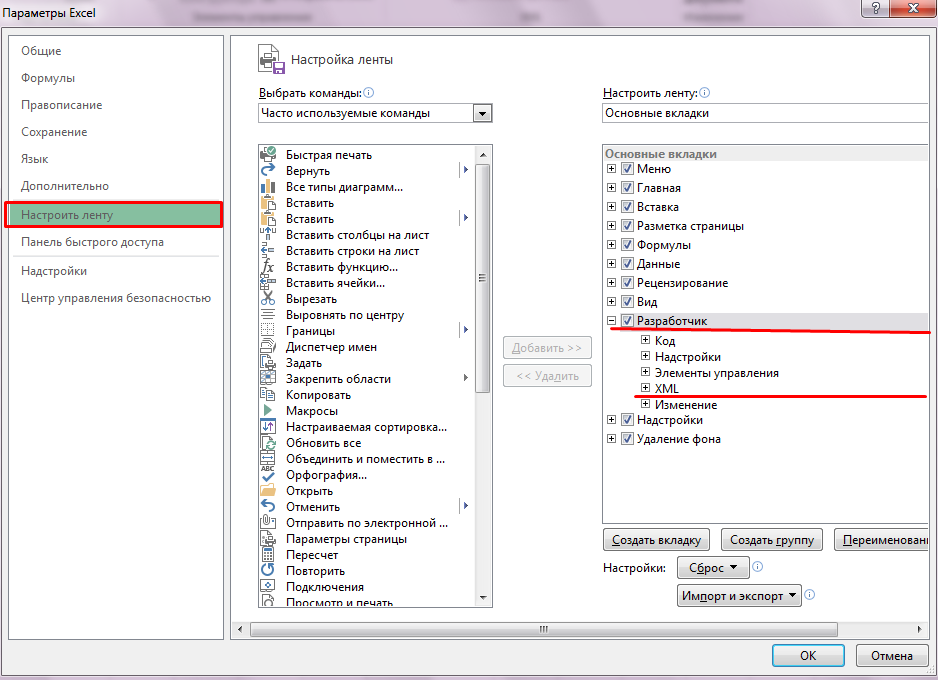
Теперь Excel может открывать файлы в формате XML.
Как работать с XML-фидом в Excel
Чтобы открыть нужный нам XML-фид, достаточно перетащить его в окно Excel и в появившемся окне выбрать «XML-таблица», затем — просто «Ок».
![]()
В Excel откроется таблица со всеми значениями тегов, а если открыть вкладку «Разработчик» и в блоке XML нажать на «Источник», то появится карта с тегами.
Теперь нам осталось заполнить таблицу (например, используя файл полученный из экспорта базы данных или модуля экспорта/импорта), после этого — нажать на «Экспорт», задать название файла и сохранить его.
![]()
Если открыть файл в редакторе NotePad++, то файл будет выглядеть так:
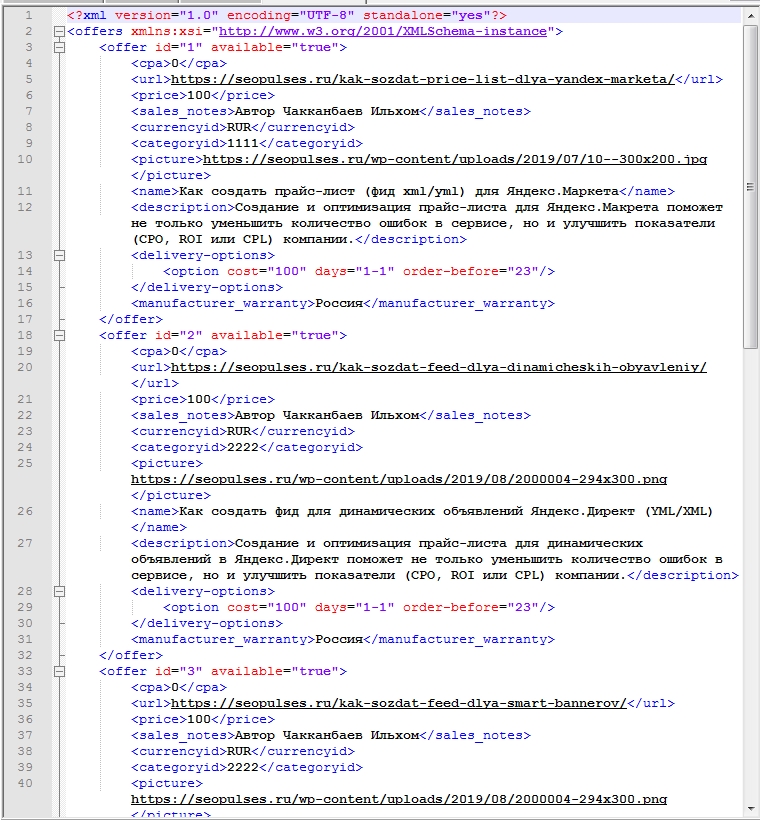
Создаем YML-фид
Чтобы сформировать YML-фид вручную, мы сначала соберем его две отдельные части, которые после соединим. Так, мы разделим его на:
- <categories> — фид с категориями;
- <offers> — фид с товарами.
Для части <offers> выгрузим из базы, модулей экспорта-импорта данные о товарах:
- ID,
- ссылку,
- ссылку на картинку,
- наименование,
- описание,
- цену,
- категорию,
- тип (желательно, но не обязательно).
Затем выгружаем вторую таблицу со значениями для создания части <categories>:
- название категории,
- ID-категории,
- родительская категория (если есть).
После этого для формирования части <offers> в зависимости от полученных данных используем один из представленных прайс-листов:
- упрощенный (файл yml-part-2-name.xml в папке yml) — использует только name (название товара);
- С type (файл xml-part-2-type.xml в папке yml) — передает модель и тип товара.
После того как скачали нужный формат файла, открываем его в Excel, заменяем тестовые значения на свои и сохраняем новый XML. Сделать замену можно, просто заменив столбы в шаблоне на собственные значения из файла экспорта БД или экспорта/импорта.
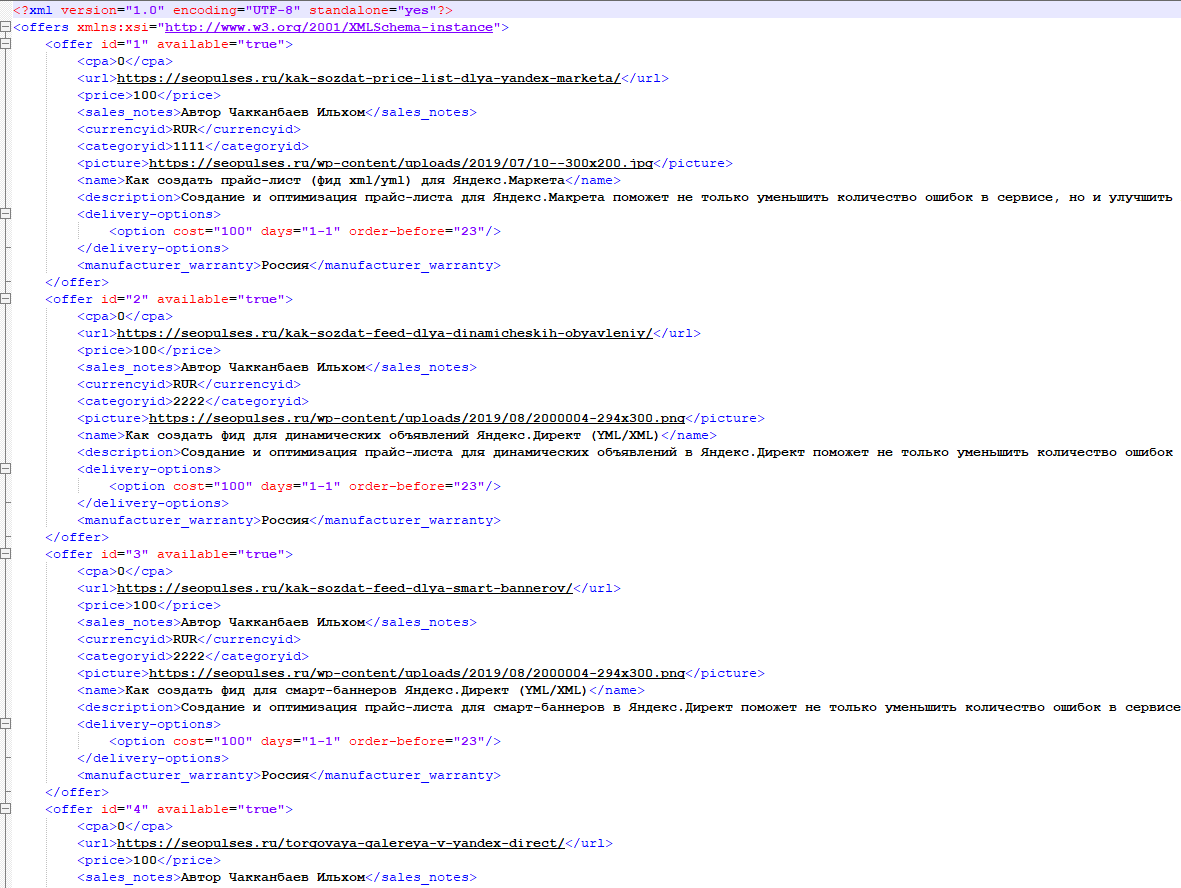
Затем создаем фид с категориями: скачиваем файл yml-part-1.xml, открываем его в Excel и заменяем все значения на собственные из второго выгруженного файла.
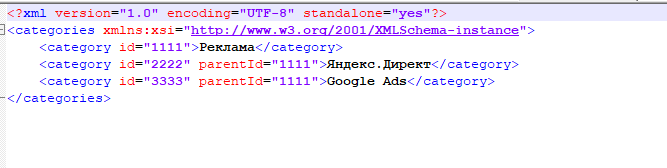
Теперь открываем оба файла в NotePad++ и сохраняем в новом документе формата .xml.
В верхней части документа удаляем сгенерированную часть XML и ставим следующее:
<shop>
<name>SeoPulses</name>
<company> SeoPulses.ru</company>
<url>https://seopulses.ru</url>
<currencies>
<currency id="RUR" rate="1"></currency>
<currency id="USD" rate="70"></currency>
<currency id="EUR" rate="80«></currency>
</currencies>
Где:
- name — название магазина;
- company — название компании;
- url — адрес сайта;
- currencies — список валют (в этом случае они высчитываются по курсу ЦБ).
В конце документа проставляем закрывающие теги:
- </shop>
- </yml_catalog>
Сохраняем документ. Все готово, файл можно загружать на сервер.
Загрузка файла XML на сайт
Чтобы использовать файл в рекламных системах, достаточно загрузить его в корневую папку сайта на вашем сервере.
Открывать файл можно, набрав адрес site.ru/{nazvaniye-dokumenta}.xml. Например, для сайта seopuseses.ru я создал документ yml-feed.xml, ссылка на фид выглядит так: seopuseses.ru/yml-feed.xml.
Вот остальные файлы:
- первый тип YML: https://seopulses.ru/xml-name-ready.xml
- второй тип YML: https://seopulses.ru/xml-type-ready.xml
- для Google Merchant Center и Facebook: https://seopulses.ru/for-merchant-ready.xml
- Sitemap: https://seopulses.ru/for-sitemap.xml
Что делать, если данные с базы или модулей импорта достать не удалось?
В этом случае можно попробовать самостоятельно скачать данные при помощи функции importxml в Google Таблицах (вот пример).
Если же и этот метод не помог, а товаров достаточно много, то лучше обратиться к разработчикам, которые напишут парсер для сайта или смогут выгрузить данные из базы данных.
Создаем фид для Google Merchant Center
Если у вас уже есть созданный YML из CMS, из него можно будет взять все значения нужных нам тегов товаров (названия, цены, ссылки, картинки и другие). Также подойдут те же файлы, которые были сделаны вручную по инструкции выше.
Открываем файл for-merchant из папки merchant в Excel и заполняем все необходимые поля.
После этого между тегами <channel> и <item> добавляем этот фрагмент:
<title>SeoPulses.ru</title>
<link>https://seopulses.ru</link>
<description> Сео Пульс — блог об интернет-маркетинге. Сео-оптимизация, контекстная реклама (ppc), SMM-продвижение (в социальных сетях) и инструменты автоматизации.</description>
<pubDate>Mon, 02 Sep 2019 14:48:44 +0300</pubDate>
<lastBuildDate>Mon, 02 Sep 2019 14:48:44 +0300</lastBuildDate>
<language>ru</language>Где:
- title — название магазина
- link — ссылка на сайт;
- description — описание магазина;
- language — язык;
- lastBuildDate — время генерации.
В конце документа добавляем два закрывающих тега:
- </channel>
- </rss>
Далее в NotePad++ потребуется открыть функцию «Найти и заменить», ввести ggggg и заменить на g:.
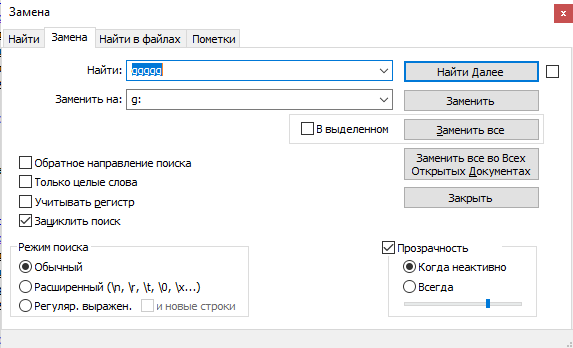
Все готово. Так же, как и файл XML, загружаем его на сервер и отправляем на проверку в Google Merchant Center.
Этот же фид можно будет использовать и для загрузки каталога в Facebook.
Как использовать ХML-фид
С помощью XML-фида можно запустить несколько дополнительных форматов в Яндекс.Директе, спецпредложения в Яндекс.Маркете, а также создать Sitemap для сайта.
Акции в Яндекс.Маркете
При работе с прайс-листом в формате Excel в Яндекс.Маркет нельзя передавать данные об акциях, купонах или подарке. Но если использовать XML-фид и добавить в название файла специальный код (promo), то в Маркет будет выгружаться специальная информация, которая сможет привлечь внимание пользователей и выделиться среди конкурентов.
Ссылка на фид с использованием кода выглядит так: https://seopulses.ru/xml-type-ready-promo.xml.
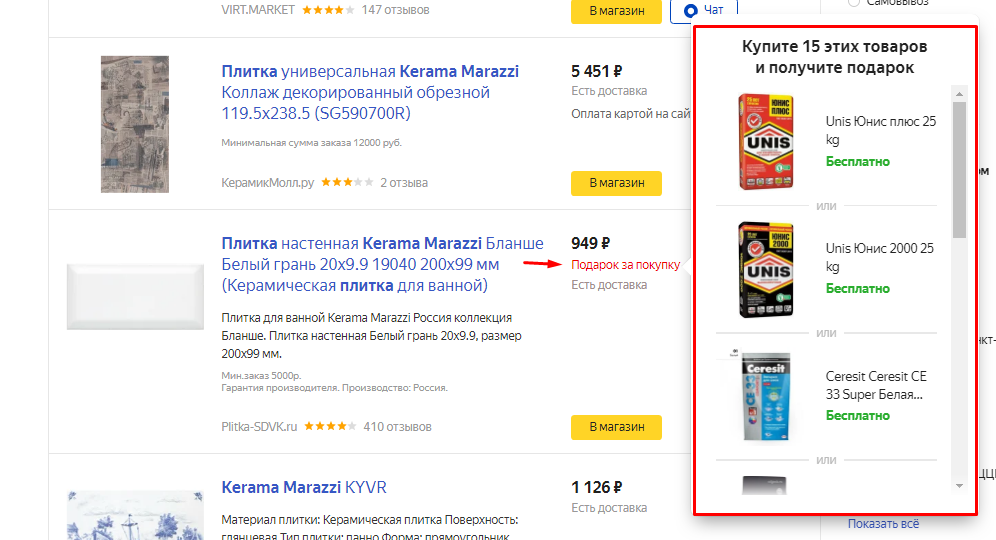
Со спецпредложениями можно попасть в блок Маркета «Скидки и акции», что увеличит количество показов и переходов.
К тому же при загрузке XML-фида отпадает необходимость обновлять файл каждые 30 дней, что удобно для сайтов, ассортимент которых не меняется либо меняется раз в несколько месяцев.
Читайте также:
- Угроза отключения магазина на Яндекс.Маркете: ошибки и способы решения
Динамические объявления Директа
На основе XML-фида можно запустить динамические объявления в Яндекс.Директе. В отличие от таргетинга на индекс сайта, фид дает возможность управлять фильтрами товаров, например, установив более высокие ставки на дорогие продукты или выделяя бренды.
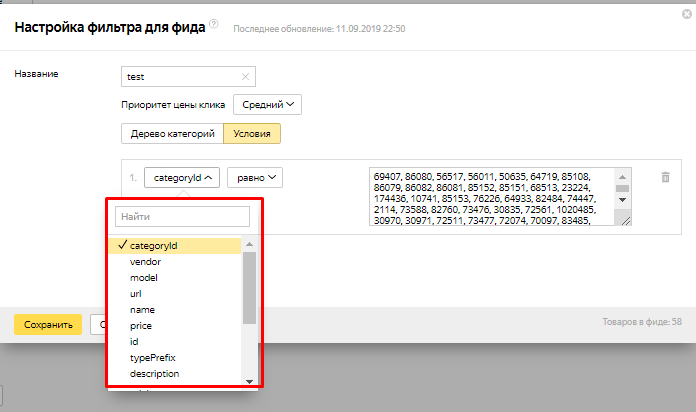
Кроме этого, передавая цену в фиде, вы сможете попасть в товарную галерею Яндекса, которая станет еще одним источником трафика.
Читайте также:
- Динамические объявления Директа: тестируем, разрушаем стереотипы и повышаем продажи
- Динамические объявления в Директе: настройка и способы оптимизации
Смарт-баннеры
Запуск смарт-баннеров возможен только через файл YML. Создав XML-фид, можно легко запустить формат для любого типа бизнеса.

Смарт-баннер для рекламы изготовления и установки антресольных этажей и металлических лестниц

Смарт-баннеры для рекламы проката авто
Смарт-баннеры показывают более высокие результаты по сравнению со стандартными объявлениями в РСЯ, поэтому его обязательно стоит протестировать.
Читайте также:
- Как выжать всё из смарт-баннеров и увеличить выручку — кейс магазина кожаных аксессуаров
- Как создавать эффективные смарт-баннеры в Директе — советы и лайфхаки
- Смарт-баннеры для интернет-магазина: пять рекомендаций по использованию и настройке
Динамический ретаргетинг «ВКонтакте» и динамический ремаркетинг myTarget
Созданный в формате YML файл можно использовать для запуска динамического ретаргетинга во «ВКонтакте» и динамического ремаркетинга в myTarget.
Читайте по теме:
Динамический ретаргетинг «ВКонтакте»: инструкция по настройке
Создание файла Sitemap
Если у сайта нет файла Sitemap, то его можно создать в формате XML. Для этого подойдет файл for-sitemap.xml из папки.
Подключение к Google Merchant Center
Если процесс подключения к Google Merchant Center откладывается из-за отсутствия фида, можно сконвертировать YML-прайс в формат, подходящий для запуска торговых кампаний.
Чтобы сделать это, сначала откроем YML-файл в Excel, сохраним его в Google Sheets по шаблону, после этого загрузим в Merchant Center через Google Таблицы.
Читайте по теме:
- Как начать работу с Google Merchant Center
- Шесть советов по оптимизации фида для торговых кампаний в Google
- Как работать с умными торговыми кампаниями в Google Ads: обзор формата
- На что способны умные торговые кампании от Google? Обзор формата и кейсы
Введение в XML¶
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки,
предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
<?xml version="1.0" encoding="windows-1251"?> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price></price> </book>
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа <book> (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( title, author, year, price). Последняя строка определяет конец корневого элемента </book> (закрывающий тег).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: <author>Erik T. Ray</author>. Т.е. элемент author принимает значение Erik T. Ray. Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег <title lang="en"> имеет атрибут lang, который принимает значение en. Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
<name first="Иван" second="Петрович" />
Структура XML¶
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
<корневой> <потомок> <подпотомок>.....</подпотомок> </потомок> </корневой>
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам.
XML документ отвечающий этим правилам называется валидным (англ.
Valid — правильный) или синтаксически верным. Соответственно, если
документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
- Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег
<Letter>не то же самое, что тег<letter>.
Открывающий и закрывающий теги должны определяться в одном регистре:
<Message>Это неправильно</message> <message>Это правильно</message>
- XML элементы должны соблюдать корректную вложенность:
<b><i>Некорректная вложенность</b></i> <b><i>Корректная вложенность</i></b>
- У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
Примечание
В большинстве XML файлов отчетов для ФНС корневым элементом является
<Файл></Файл>. После закрывающего тега</Файл>больше ничего быть не должно.
- Значения XML атрибутов должны заключаться в кавычки:
<note date="12/11/2007">Корректная запись</note> <note date=12/11/2007>Некорреткная запись</note>
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите,
например, символ < внутри XML элемента, то будет
сгенерирована ошибка, так как парсер интерпретирует его, как начало
нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении "ООО<Мосавтогруз>" атрибута НаимОрг содержатся символы < и >.
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО<Мосавтогруз>"/>
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО"Мосавтогруз""/>
Чтобы ошибки не возникали, нужно заменить символ < на его
сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
< |
< |
меньше, чем |
> |
> |
больше, чем |
& |
& |
амперсанд |
' |
' |
апостроф |
" |
" |
кавычки |
Примечание
Только символы < и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО"Мосавтогруз""/>
или
<НПЮЛ ИННЮЛ="7718962261" КПП="771801001" НаимОрг="ООО«Мосавтогруз»"/>
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам
XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой
элемент (инструкция <?xml version=”1.0”?> к дереву отношения не имеет).
У элемента дерева всегда существуют потомки и предки, кроме корневого
элемента, у которого предков нет, а также тупиковых элементов (листьев
дерева), у которых нет потомков. Каждый элемент дерева находится на
определенном уровне вложенности (далее — «уровень»). У элементов на
одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки
XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример
списка книг:
<?xml version="1.0" encoding="windows-1251"?> <bookstore> <book category="COOKING"> <title lang="it">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
XPath запрос /bookstore/book/price вернет следующий результат:
<price>30.00</price> <price>29.99</price> <price>39.95</price>
Сокращенная форма этого запроса выглядит так: //price.
С помощью XPath запросов можно искать информацию по атрибутам. Например,
можно найти информацию о книге на итальянском языке: //title[@lang="it"] вернет <title lang="it">Everyday Italian</title>.
Чтобы получить больше информации, необходимо модифицировать запрос //book[title[@lang="it"]] вернет:
<book category="COOKING"> <title lang="it">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book>
В приведенной ниже таблице представлены некоторые выражения XPath и
результат их работы:
| Выражение XPath | Результат |
|---|---|
/bookstore/book[1] |
Выбирает первый элемент book, который является потомком элемента bookstore |
/bookstore/book[position()<3] |
Выбирает первые два элемента book, которые являются потомками элемента bookstore |
//title[@lang] |
Выбирает все элементы title с атрибутом lang |
//title[@lang=’en’] |
Выбирает все элементы title с атрибутом lang, который имеет значение en |
/bookstore/book[price>35.00] |
Выбирает все элементы book, которые являются потомками элемента bookstore и которые содержать элемент price со значением больше 35.00 |
/bookstore/book[price>35.00]/title |
Выбирает все элементы title элементов book элементов bookstore, которые содержать элемент price со значением больше 35.00 |
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор
символов.
Самыми распространенными кириллическими кодировками являются Windows-1251 и UTF-8. Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку Windows-1251.
В XML файле кодировка объявляется в декларации:
<?xml version="1.0" encoding="windows-1251"?>
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Примечание
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на Windows-1251 или UTF-8. Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Подробнее об XSD смотрите:
- XML Schema
- XSD — умный XML
2007 г.
| Чиновник по особым порученьям, Который их до места проводил, С заботливым Попова попеченьем Сдал на руки дежурному. А. К. Толстой. Сон Попова |
Аннотация
Установленная в БД XML DB позволяет регистрировать в базе схемы XML, задающие типы документов XML. Зарегистрированная в репозитарии схема может употребляться для данных типа XMLTYPE: как хранимых в обычных таблицах, так и доступных из производных (синтезированных) таблиц типа XMLTYPE. В статье показано на примерах, как это делать.
Введение
Эта статья является продолжением статей «XML DB — новое измерение в организации данных в Oracle» и «Что дает репозитарий XML DB и как с ним работать». Здесь говорится о регистрации в БД пользователя схем XML, что возможно после установки XML DB (об этом рассказывалось ранее). Показано, как выполняется регистрация, и как зарегистрированную схему XML можно использовать при работе с данными типа XMLTYPE.
Как зарегистрировать схему XML
Рассмотрим несложную схему XML, определение которой создадим в файле bookCover.xsd:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="cover" type="coverType"/>
<xsd:complexType name="coverType">
<xsd:sequence>
<xsd:element name="title" type="xsd:string"/>
<xsd:element name="author" type="xsd:string"
maxOccurs="unbounded"/>
<xsd:element name="publisher" type="xsd:string"/>
<xsd:element name="pubdate" type="xsd:string"/>
<xsd:element name="isbn" type="xsd:string"/>
<xsd:element name="pages" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>
Поместим файл bookCover.xsd в репозитарий XML DB в папку /public (любым методом: командной строкой, программно, графическим способом, по WebDAV или же по FTP). Получим ресурс /public/bookCover.xsd репозитария. Зарегистрируем схему, являющуюся содержанием этого ресурса, с помощью пользователя SCOTT.
Для возможности регистрации схемы пользователь БД должен обладать привилегиями
- ALTER SESSION
- CREATE TYPE
- CREATE TABLE
- CREATE PROCEDURE
- CREATE TRIGGER
В версии 10 содержание роли CONNECT было сведено только к привилегии CREATE SESSION, поэтому после версии 9 пользователю SCOTT потребуется так или иначе выдать привилегию ALTER SESSION, например:
CONNECT / AS SYSDBA GRANT ALTER SESSION TO scott; CONNECT scott/tiger
Следующая далее команда не является технологической необходимостью и выдается для возможности дальнейшего анализа произошедшего:
ALTER SESSION SET EVENTS='31098 trace name context forever';
Регистрация:
BEGIN DBMS_XMLSCHEMA.REGISTERSCHEMA ( schemaurl => 'http://localhost:8080/public/bookCover.xsd' , schemadoc => XDBURITYPE ( '/public/bookCover.xsd' ) ); END; /
Описание схемы не обязательно заводить в репозитарии в качестве ресурса. Для регистрации можно воспользоваться и внешним файлом, явно указанным документом XML или же документом, указанным через внешний URL (подтипы URITYPE).
Проверка:
SQL> COLUMN schema_url FORMAT A50 WORD SQL> COLUMN local FORMAT A5 SQL> SELECT schema_url, local FROM user_xml_schemas; SCHEMA_URL LOCAL -------------------------------------------------- ----- http://localhost:8080/public/bookCover.xsd YES
Интерес представляют также другие поля таблицы USER_XML_SCHEMAS, не указанные в этом запросе за экономией места. Например, поле QUAL_SCHEMA_URL указывает на полное (реальное), а не сокращенное имя ресурса, созданного в результате регистрации схемы: в нашем случае /sys/schemas/SCOTT/localhost:8080/public/bookCover.xsd. Если бы регистрируя схему мы объявили ее глобальной (что требует явного указания и наличия прав), полный адрес ресурса был бы иной: /sys/schemas/PUBLIC/localhost:8080/public/bookCover.xsd.
Выдача команды ALTER SESSION выше привела к фиксации в трассировочном файле сеанса некоторых скрытых действий СУБД, например:
CREATE OR REPLACE TYPE "SCOTT"."author342_COLL" AS VARRAY(2147483647) OF VARCHAR2(4000 CHAR)
/
CREATE OR REPLACE TYPE "SCOTT"."coverType341_T" AS OBJECT ("SYS_XDBPD$"
"XDB"."XDB$RAW_LIST_T","title" VARCHAR2(4000 CHAR),"author"
"author342_COLL","publisher" VARCHAR2(4000 CHAR),"pubdate" VARCHAR2(4000 CHAR),"isbn"
VARCHAR2(4000 CHAR),"pages" VARCHAR2(4000 CHAR))NOT FINAL INSTANTIABLE
/
CREATE TABLE "SCOTT"."cover343_TAB" OF SYS.XMLTYPE XMLSCHEMA
"http://localhost:8080/public/bookCover.xsd" ID '6927F846BBDA487F84B9BCCEC191A059'
ELEMENT "cover" ID 2664 TYPE "SCOTT"."coverType341_T"
/
Результат этих действий, а также созданную заодно триггерную процедуру «cover343_TAB$xd» (в нашем случае), можно наблюдать в таблице USER_OBJECTS. (Упражнение. Узнать из таблицы USER_OBJECTS перечень появившихся после регистрации схемы XML объектов). Обратите внимание, что сведения о таблице «cover343_TAB» не отражены в USER_TABLES, хотя представлены в прочих системных таблицах, например, в USER_TAB_COLUMNS и USER_TAB_COLS.
Эти сопутствующие объекты будут технически использоваться для организации хранения данных XMLTYPE, уточненных зарегистрированной схемой. Для возможно повторяющегося элемента author хранение организовано в виде массива VARRAY.
Если мы захотим снять схему с регистрации, да еще удалить эти сопутствующие объекты, нужно при вызове соответствующей процедуры указать особое значение специальному параметру:
BEGIN DBMS_XMLSCHEMA.DELETESCHEMA ( schemaurl => 'http://localhost:8080/public/bookCover.xsd' , delete_option => DBMS_XMLSCHEMA.DELETE_CASCADE ); END; /
Для краткости (но в ущерб ясности кода) можно сразу указать цифровое значение, например в SQL*Plus:
EXECUTE DBMS_XMLSCHEMA -
.DELETESCHEMA ( 'http://localhost:8080/public/bookCover.xsd', 3 )
Использование зарегистрированной схемы
Проверка действия схемы
Метод CREATESCHEMABASEDXML типа XMLTYPE позволяет устроить проверку соответствия документа XML схеме.
Ради краткости записи следующих примеров имя зарегистрированной схемы занесем в переменную SQL*Plus:
VARIABLE bookschema VARCHAR2 ( 100 ) EXECUTE :bookschema := 'http://localhost:8080/public/bookCover.xsd'
Следующие запросы проработают без ошибок:
SELECT XMLTYPE ( '<cover></cover>' ).CREATESCHEMABASEDXML ( :bookschema ) FROM dual ; SELECT XMLTYPE ( '<cover><author>Einstein</author></cover>' ) .CREATESCHEMABASEDXML ( :bookschema ) FROM dual ; SELECT XMLTYPE ( ' <cover> <title>Java Programming with Oracle JDBC</title> <author>Donald Bales</author> <publisher>OReilly and Associates</publisher> <pubdate>December 2001</pubdate> <isbn>0-596-00088-x</isbn> <pages>496</pages> </cover> ' ).CREATESCHEMABASEDXML ( :bookschema ) FROM dual ;
Следующие запросы проработают с ошибками ввиду противоречий документа схеме:
SELECT XMLTYPE ( '<c/>' ).CREATESCHEMABASEDXML ( :bookschema ) FROM dual ; SELECT XMLTYPE ( '<cover><a>Einstein</a></cover>' ) .CREATESCHEMABASEDXML ( :bookschema ) FROM dual ; SELECT XMLTYPE ( '<cover><title>A</title><title>B</title></cover>' ) .CREATESCHEMABASEDXML ( :bookschema ) FROM dual ;
Использование для дополнительной типизации XMLTYPE в базовых таблицах
Просто указанный XMLTYPE требует лишь, чтобы помещаемый в БД документ был правильно оформлен. Зарегистрированная в XML DB схема XML позволяет указать для размещаемых в конкретные поля документов XML-образные ограничения целостности, позволяя хранить только «годные» (valid) из них.
Создадим таблицу объектов XMLTYPE, уточненную ссылкой на зарегистрированную схему:
CREATE TABLE xtbooks OF XMLTYPE XMLSCHEMA "http://localhost:8080/public/bookCover.xsd" ELEMENT "cover" ;
Проверка занесения данных:
INSERT INTO xtbooks VALUES ( XMLTYPE ( '<cover><author>Einstein</author></cover>' ) ); INSERT INTO xtbooks VALUES ( XMLTYPE ( ' <cover> <title>Java Programming with Oracle JDBC</title> <author>Donald Bales</author> <publisher>OReilly and Associates</publisher> <pubdate>December 2001</pubdate> <isbn>0-596-00088-x</isbn> <pages>496</pages> </cover> ' ) ); COMMIT;
Упражнение. Проверьте реакцию СУБД на попытку вставить в таблицу XTBOOKS правильно оформленный документ XML, не соответствующий описанию схемы.
Аналогично накладываются дополнительные ограничения на данные столбца XMLTYPE в обычной таблице:
CREATE TABLE tbooks ( id NUMBER ( 9 ) , description XMLTYPE ) XMLTYPE description STORE AS OBJECT RELATIONAL XMLSCHEMA "http://localhost:8080/public/bookCover.xsd" ELEMENT "cover" ;
В приведенных примерах данные в БД фактически будут храниться «объектно-реляционно», то есть будучи распределены по разным структурам БД, в том числе по спрятанным столбцам таблиц. Однако типизируя таблицу или столбец типа XMLTYPE схемой, можно потребовать фактического хранения документа в виде объекта CLOB, подобно тому, как это происходит при отсутствии типизации схемой.
Пример:
CREATE TABLE xtbooksclob OF XMLTYPE XMLTYPE STORE AS CLOB XMLSCHEMA "http://localhost:8080/public/bookCover.xsd" ELEMENT "cover" ;
Упражнение. Проверить возникновение новых объектов БД и их структуры по результатам заведения таблиц XTBOOKS, TBOOKS и XTBOOKSCLOB. Воспользоваться для этого таблицами USER_OBJECTS, USER_TAB_COLS, USER_TYPES, USER_TRIGGERS, USER_LOBS.
Использование для дополнительной типизации XMLTYPE в производных таблицах (views)
При отсутствии XML DB не заперщено создавать производную таблицу (view), выдающую данные в виде таблицы документов XML (типа XMLTYPE) на основе данных из обычных таблиц. Рассмотрим, как при наличии XML DB можно дополнительно уточнить такую производную таблицу схемой XML.
В этом примере регистрируется схема, не взятая из ресурса репозитария, как ранее, а явно выписанная в виде текста XML:
BEGIN
DBMS_XMLSCHEMA.REGISTERSCHEMA (
schemaurl => 'http://localhost:8080/public/employee.xsd'
, schemadoc =>
'<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="employee">
<xs:complexType>
<xs:sequence>
<xs:element name="ename" type="xs:string"/>
<xs:element name="job" type="xs:string"/>
<xs:element name="sal" type="xs:integer"/>
</xs:sequence>
<xs:attribute name="empno" type="xs:integer"/>
</xs:complexType>
</xs:element>
</xs:schema>
'
);
END;
/
Пример создания производной таблицы:
CREATE OR REPLACE VIEW empxml_schema_view OF XMLTYPE
XMLSCHEMA "http://localhost:8080/public/employee.xsd"
ELEMENT "employee"
WITH OBJECT ID
( EXTRACT ( SYS_NC_ROWINFO$, '/employee/@empno' ).GETNUMBERVAL ( ) )
AS
SELECT
XMLELEMENT (
"employee"
, XMLATTRIBUTES ( e.empno AS "empno" )
, XMLFOREST ( e.ename AS "ename", e.job AS "job", e.sal AS "sal" )
)
FROM emp e
;
Наличие данных, противоречащих схеме, не препятствует извлечению данных результата при обращении к созданой производной таблице. Однако ж имеется метод, способный выполнить проверку соответствия схеме:
SELECT VALUE ( v ).ISSCHEMAVALID ( ) FROM empxml_schema_view v;
Упражнение. Создать производную таблицу EMLXML_VIEW по аналогии с EMLXML_SCHEMA_VIEW, не уточненной схемой (для этого потребуется удалить из определения выше две строки, выделенные жирным шрифтом). Выполнить следующие проверки:
SELECT VALUE ( v ).ISSCHEMAVALID ( ) FROM empxml_view v; SELECT VALUE ( v ) .ISSCHEMAVALID ( 'http://localhost:8080/public/employee.xsd' ) FROM empxml_view v ;
Упражнение. Внести в схему http://localhost:8080/public/employee.xsd пользователя SCOTT изменение (снять с регистрации и зарегистрировать исправленный текст). Заменить в схеме существующее описание зарплаты:
<xs:element name="sal" type="xs:integer"/>
на следующее:
<xs:element name="sal">
<xs:simpleType>
<xs:restriction base="xs:integer">
<xs:maxInclusive value="1500"/>
<xs:minInclusive value="1000"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
Проверить поведение последних трех упоминавшихся выше запросов.
Последний пример показывает использование чуть более сложных ограничений целостности на структуру и данные документов XML (сформулированы минимальное и максимальное значения зарплат).
В статье будет рассказано, что такое XML-файл, его основные характеристики и структура. Будет представлено пошаговое руководство о том, как создать XML-файл с помощью различных инструментов и программ, а также детальное описание способов использования XML для управления данными. Читатели получат полезные советы и инструкции для работы с XML-файлами, что поможет им в управлении информацией с легкостью и эффективностью.
Статья:
XML (Extensible Markup Language) — структурированный язык разметки, широко используемый для хранения, обмена и управления данными в различных сферах. XML-файл состоит из элементов, содержащих информацию, которая может быть организована в иерархическую структуру. В этой статье мы рассмотрим, как создать XML-файл и как его использовать для управления данными.
Шаг 1: Определите структуру данных
Перед тем, как создать XML-файл, необходимо определить его структуру. Размышлите о данных, которые хотите хранить, и представьте их в виде иерархической структуры. Например, если вы создаете XML-файл для хранения информации о клиентах, вы можете определить элементы таким образом: <клиент> <имя>Иван <фамилия>Иванов . Определите необходимые элементы и атрибуты для каждой категории информации.
Шаг 2: Выберите инструмент для создания XML-файла
Существует множество инструментов, позволяющих создавать XML-файлы. Выберите тот, который наиболее удобен и понятен для вас. Например, вы можете использовать программы, такие как Notepad++, Microsoft Visual Studio, XMLSpy или даже Microsoft Excel для создания и редактирования XML-файлов.
Шаг 3: Создайте XML-файл
Откройте выбранный инструмент и создайте новый файл. Введите корневой элемент с помощью угловых скобок и дайте ему имя. Внутри корневого элемента добавьте ваши определенные элементы и атрибуты, используя правильный синтаксис XML. Заполните файл соответствующими данными, сохраните его с расширением .xml и определенным именем.
Шаг 4: Используйте XML-файл для управления данными
После создания XML-файла вы можете использовать его для управления данными. XML обеспечивает простоту и гибкость в обработке и передаче информации. Вы можете использовать синтаксис XML для поиска, фильтрации и изменения данных в файле. При желании вы можете внедрить XML-файл в свое веб-приложение или программу для автоматизации процесса управления данными.
В заключение, XML-файлы предоставляют мощный инструмент для управления данными. Они легко читаются и могут быть использованы на различных платформах и в различных приложениях. Создание XML-файла подразумевает определение структуры данных, выбор инструмента создания, создание файла и его использование для управления данными. Это простой, но важный инструмент, который может значительно упростить процесс управления информацией в различных сферах деятельности.