Процесс управления инцидентами в DevOps и SRE
При подходе DevOps или SRE к управлению инцидентами, команда, которая разрабатывает сервис, также отвечает за его работу и вносит исправления в случае сбоев. Такой подход быстро нашел свою популярность с развитием бесперебойных облачных сервисов, веб-приложений с глобальным доступом, микросервисов и программного обеспечения как услуги.
Все чаще программное обеспечение, которое вы используете в жизни и работе, не находится физически в вашем местоположении. Обычно это веб-приложения, размещенные в центре обработки данных для тысяч и миллионов пользователей по всему миру. Для команд, ответственных за работу подобных служб, гибкость и скорость имеют первостепенное значение. Любой сбой затронет тысячи организаций, а не только одну.
Преимущество подхода «кто разработал, тот и запустил» дает командам, следующим принципам Agile, необходимую гибкость, но при этом размывает границы при распределении ответственности. При менее структурированных процессах разработки команды DevOps работают легче и продуктивнее. Однако для управления инцидентами стоит создать стандартные процессы, чтобы при разрешении критического инцидента ни у кого не возникало вопросов, что делать дальше, а также чтобы отслеживать проблемы и фиксировать способы их решения.
Три принципа управления инцидентами в командах DevOps
- Дежурство по очереди. Обычно команды DevOps не назначают конкретных членов команды на разрешение конфликтов, а создают график дежурств и распределяют его между членами команды.
- Кто разработал, тот лучше всего подходит для внесения исправлений. Основная идея принципа «кто разработал, тот и запускает» заключается в том, что люди, которые больше знакомы с сервисом (разработчики), лучше всего подходят для исправления перебоев в его работе.
- Разрабатывайте быстро, но не забывайте сообщать о прогрессе. Когда разработчики понимают, что они и их команда теряют время при сбое в работе, появляется стимул писать более качественный код.
Такой подход обеспечивает более быстрое реагирование и обратную связь с командами, которым необходимо знать, как разработать более надежный сервис.
В нашем Справочнике по управлению инцидентами мы описываем подход к управлению инцидентами, подходящий именно командам DevOps.
ITIL — библиотека, где собран практический опыт компаний по внедрению процессного подхода к управлению ИТ-услугами.
Фактически, это сборник рекомендаций по воплощению ITSM в отдельно взятой организации.
Один из основных процессов, описанных в этой библиотеке, — управление инцидентами, на котором мы и сконцентрируемся в этой статье.

Управление инцидентами
Любое не планируемое отклонение от нормального положения дел в ИТ-сервисе — будь то прекращение предоставления заявленной услуги или ухудшение ее характеристик, в терминологии ITIL называется «инцидентом».
Грубо говоря, вышла из строя касса — продавать товар мы уже не можем — это инцидент.
Или вместо обещанной скорости доступа к интернету в 100 Мбит/с мы получаем 5 Мбит/с, соответственно, наши задачи решаются гораздо медленнее — тоже инцидент.
Каждое происшествие имеет свои причины и последствия.
Управление инцидентами в контексте ITIL концентрируется на борьбе с последствиями и, что главное, на скорейшем восстановлении сервиса (в наших примерах — на запуске кассы или обеспечении доступа на обещанной скорости в 100 Мбит/с).
Иными словами, работая с инцидентами, мы не пытаемся искать глобальные причины, которые позволят навсегда избавиться от подобных сбоев, а лишь возвращаем клиенту услугу. К примеру, если скорость доступа к интернету упала из-за роутера, его проще и быстрее заменить, а не ковыряться в новой версии прошивки, дабы найти источник сбоя.
Service Desk и роль этой службы в процессе управления инцидентами

«Разгребать» инциденты в соответствии с идеологией сервисного подхода должна выделенная хотя бы логически служба поддержки — Service Desk (или 1-я линия). В задачи поддержки и, соответственно, управления инцидентами входит:
- обработка входящих обращений;
- получение из них информации об инциденте, в частности, выявление инцидентов среди нецелевых обращений и запросов на обслуживание,
- регистрация, классификация и приоритезация;
- контроль за «возвращением» клиентам обещанного уровня сервиса через работу с жизненным циклом инцидента (установка сроков, назначение ответственных, перенаправление задачи и т.п.);
- контроль соблюдения заявленных параметров (в первую очередь SLA).
Стоит отметить, что выполнять эти задачи необходимо по возможности сокращая финансовые и временные затраты, но не в ущерб качеству сервиса — в угоду удешевлению не нужно настаивать на дополнительных «костылях» в сервисе, однако и переписывать все с нуля по каким-либо «канонам» никто не требует. Просто восстанавливаем сервис.
Как внедрить систему управления инцидентами?
Важный момент заключается в том, что service desk не является обособленной «специальной» службой, внедрение которой решит все проблемы и автоматически обеспечит компанию управлением инцидентами в соответствии с ITIL.
Этот отдел должен быть тесно интегрирован с другими подразделениями, должны быть выстроены соответствующие процессы.
Чтобы «система» работала, необходимо:
- позаботиться о распределении нагрузки, чтобы в отделе не было «бутылочных горлышек»;
- учесть компетенции специалистов и их «стоимость». Типичный подход к решению совместно этой и предыдущей задач — выделение линий поддержки, обрабатывающих запросы разной сложности (об этом мы писали ранее). Например, первая линия работает с нецелевыми обращениями и иногда самыми простыми задачами. Вторая — решает вопросы по существу, а на третью отправляются лишь те запросы, что требуют экспертных знаний развернутых ИТ-систем. Внутри каждой линии должно быть продумано распределение задач между сотрудниками, чтобы отсутствие одного человека не сказывалось на общем результате;
- чтобы весь процесс управления инцидентами контролировался рядом метрик — KPI, которые устанавливает сама компания. Это может быть соблюдение предельного времени разрешения проблемы, скорость решения (безотносительно лимитов) или уровень удовлетворенности клиента по его собственной оценке. Часть метрик могут быть упомянуты в SLA, другая же — быть исключительно внутренней инициативой.
Управление инцидентами и клиенты

Интересно, что ITIL очень мало говорит о клиентоориентированности.
Да, там описаны процедуры управления инцидентами, но делать это с улыбкой на лице или дать клиенту ссылку для наблюдения за судьбой своего запроса предписывает лишь внутренняя культура компании.
Внедрение управления инцидентами не поможет напрямую справиться с недовольством клиентов (как с ним справиться мы писали в отдельной статьей).
Однако оно поможет оптимизировать расходы и стабилизировать качество. В дополнение нужно будет лишь поработать над культурой общения.
ITIL включает в себя и другие процессы, в частности, управление проблемами.
В отличие от описанного выше управления инцидентами, этот процесс фокусируется как раз на корневых причинах сбоев в работе сервисов. Еще один «соседствующий» с управлением инцидентами процесс — управление уровнем услуг, в рамках которого как раз и создается упомянутое выше соглашение об уровне сервиса (SLA). Позже мы остановимся подробнее и на этих процессах.
Другие полезные статьи по данной теме:
- ITIL и ITSM. Как использовать в работе?
- Что такое SLA? Как его использовать и каким оно должно быть?
- 13 причин неудачного внедрения Service Desk. Как их избежать?
Сооснователь и директор по развитию Okdesk. Около 10 лет проработал в компании Naumen, где занимался внедрением ITSM и service desk систем в крупнейших российских компаниях: Полюс, Тинькофф, ЛСР и др. Эксперт в области организации и автоматизации процессов техподдержки, сервиса и выездного обслуживания
Уровень сложности
Простой
Время на прочтение
12 мин
Количество просмотров 3.5K


Автор статьи: Рустем Галиев
IBM Senior DevOps Engineer & Integration Architect. Официальный DevOps ментор и коуч в IBM
Привет Хабр! Не так давно общался с SRE в нашей команде и он рассказал мне о базовых принципах процесса управления инцидентами, теперь я поделюсь этим с вами, быть может кому‑то поможет.
Управление инцидентами включает в себя мониторинг, анализ, планирование и выполнение. SRE работают с операционными группами, экспертами по техническим вопросам, разработчиками, инженерами DevOPs, владельцами приложений и другими.
При оценке инцидентов SRE обращают внимание на такие критерии, как импакт и частота повторения — для того, чтобы определить, какие инциденты требуют дальнейшего анализа.
Есть некоторые практики, которых придерживаются в нашей команде:
-
Прежде чем произойдет инцидент, сотрудничайте с другими, настроив уведомления о предупреждениях и информационные панели, чтобы во время события уведомлялись нужные люди и предпринимались правильные действия.
-
Во время инцидента SRE несут ответственность за решение инцидента; выполнение заявок на обслуживание; мониторинг каналов событий и журналов; и анализ информационных панелей, корреляций событий, данных о тикетах и тенденциях.
-
Необходимость меняться. После разрешения инцидента дополнительные действия приводят к управлению изменениями, управлению проблемами и обновлениям управления конфигурацией, чтобы снизить вероятность возникновения подобных инцидентов в будущем.
Автоматизация, связанная с проблемами, постоянно обновляется, чтобы предотвратить повторение инцидента или быстрее решить его, если все же он произойдет снова. Ниже приведена архитектура, которой мы пользуемся (больше как референс).
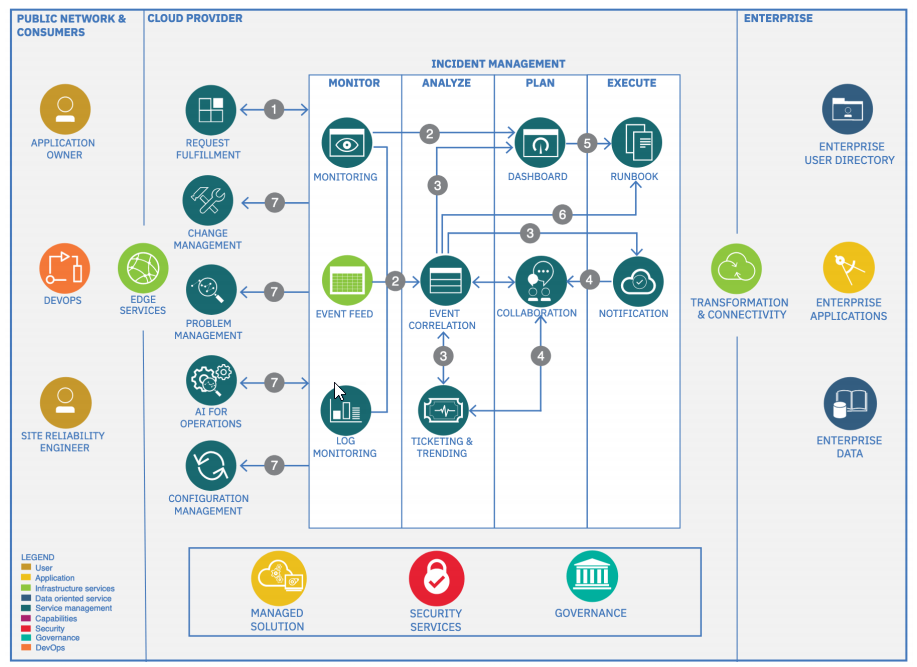
Концепции управления инцидентами
-
Инфраструктура всегда в мониторинге, что выявляет отклонения от нормального поведения, такие как уменьшение времени отклика, и оповещает ops об инцидентах.
Первые респондеры, которые всегда на связи, выявляют неисправный компонент и восстанавливают обслуживание как можно быстрее. Они делают это с помощью автоматизации и runbook (скрипт, который фиксит ту или иную проблему, если совсем уж просто), чтобы устранить зависимость и риски, связанные с ручным выполнением задач.
-
В то время как первые респондеры используют информационные панели, которые обеспечивают обзор приложения, они не смотрят на консоли в ожидании сигналов тревоги. Вместо этого они уведомляются о проблемах через алерты.
Эти алерты объединяются различными системами мониторинга, сопоставляются и дополняются соответствующей информацией, такой как имя приложения, затронутые пользователи и заинтересованные стороны, а также информация о соглашении об уровне обслуживания (SLA). Эти алерты являются и должны быть действенными, в идеале с четким описанием мер по смягчению последствий. Используя call‑rotation и списки on‑call, алерт отправляется правильному первому респонденту, который предпринимает необходимые действия.
-
Оповещения, которые не могут быть быстро определены для смягчения последствий, требуют дополнительного анализа. SME в нескольких доменах сотрудничают, чтобы изолировать инцидент и определить эффективный ответ.
Такие технологии, как ChatOps, помогают в этом сотрудничестве. Инструменты DevOps и управления услугами также интегрируются через бот‑агентов. Командир инцидента (да у нас есть и такие роли) координирует эти задачи и поддерживает прозрачную связь с пострадавшими заинтересованными сторонами.
-
Целью управления инцидентами является восстановление службы. Команда не тратит время на анализ основной причины проблемы. Этот анализ проводится на следующем этапе: управление проблемами.
Подходы к управлению инцидентами включают перезапуск микросервиса, настройку балансировщика нагрузки для игнорирования отказавшего инстанса или откат к предыдущей версии. Типичные принципы DevOps, такие как blue‑green deployment (CD), упрощают реализацию этих подходов.
Инструменты процесса управления инцидентами
Целью мониторинга инцидента является обнаружение простоев, сатурация производительности и т. д. Поскольку неэффективно просто заставлять наших сотрудников постоянно следить за консолями, следующим важным элементом является настройка алертов, чтобы нужный SME уведомлялся, когда что-то идет не так. В этих случаях тулчейн играет важную роль.
SRE часто должны сотрудничать с SME, чтобы изолировать проблему и определить стратегию смягчения последствий. Вместо того, чтобы полагаться на электронную почту и телефоны, SRE используют платформы уведомлений и совместной работы, из такой практики как ChatOps.

В дополнение к мониторингу и активному исследованию служб и API SRE также должны отслеживать файлы журналов служб. Этот мониторинг может помочь выявить проблемы до того, как они повлияют на службу. Это также может ускорить этап идентификации и разрешения инцидента.
По мере увеличения нагрузки и усложнения приложений, первые респондеры начинают получать слишком много предупреждений. Они получают оповещения, связанные с симптомами и причинами. Некоторые предупреждения могут не действовать. События могут не предоставлять достаточный контекст для быстрого реагирования, например соглашение об уровне обслуживания (SLA) или данные об импакте. На этом этапе должен быть “event management” в тулчейне. Управление событиями сопоставляет связанные события, удаляет” шум”, чтобы отображались только предупреждающие действия, и дополняет эти события дополнительным контекстом.
Усовершенствованная цепочка инструментов с управлением событиями будет выглядеть так, как показано здесь.

Чтобы быстро реагировать на проблемы, нужны runbook и средства автоматизации. Runbook могут вызываться автоматически либо для запуска диагностических команд, либо для устранения проблемы. Runbook также может запускаться вручную первым ответчиком и специалистом по разрешению инцидентов. Чтобы избежать ручного входа в систему и риска неправильного набора команд, автоматизированные и полуавтоматические runbook обеспечивают безопасное и согласованное выполнение.
По мере добавления новых инструментов SR-инженерам требуется обзор всего “ландшафта”. Эта видимость не заменяет существующие пользовательские интерфейсы продукта (UI), а вместо этого дополняет их и обеспечивает комбинированное представление среды на панелях управления для конкретных пользователей. В идеале в этих представлениях также отображается дополнительная информация, например действия по развертыванию или информация об уровне обслуживания.
Кроме того, информация об инцидентах постоянно отслеживается в инструментах оформления заявок, которые являются источником достоверной информации для расчета SLA. Предприятиям особенно необходимо вести журнал аудита для всех инцидентов. Отслеживаются начало и конец инцидента, а также любые важные обновления. Интеграция всей цепочки инструментов автоматизирует заполнение этого журнала действий.
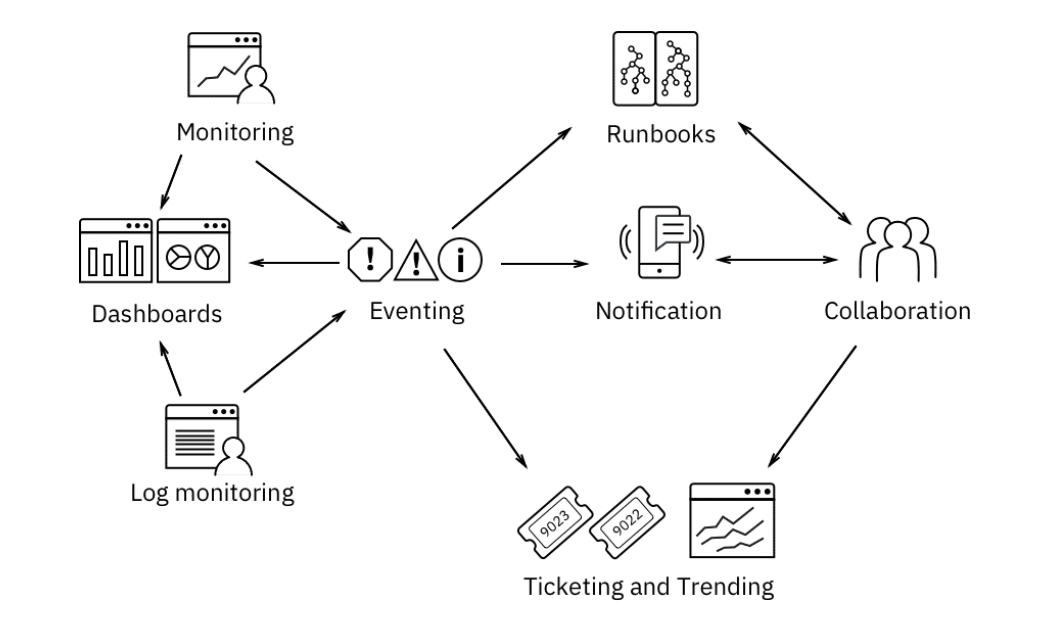
Коммуникация по управлению инцидентами во время простоя
Прозрачность — ключевой аспект завоевания и поддержания доверия пользователей вашего сервиса. Поскольку предприятия полагаются на доступность и качество услуг, они заинтересованы в получении информации о любых проблемах или инцидентах, влияющих на качество этих услуг. В дополнение к незапланированным отключениям любое плановое техническое обслуживание должно следовать той же парадигме. Руководящими принципами любого сообщения о сбоях являются точность, ясность и своевременное предоставление информации.
Можно использовать правило: “How? Who? When?”
How: Поставщики услуг информируют своих пользователей об инцидентах несколькими способами:
-
Веб-страница с информацией о статусе,
-
Информация о статусе через социальные сети, такие как Twitter,
-
Эмейл,
-
Программный API (веб-хук),
-
Инженерный блог компании.
Предоставить нужно информацию об инциденте в сочетании этих каналов. Не будем думать, что пользователи всегда знают, где искать.
Who: При составлении плана передачи информации о состоянии четко определите, кто отвечает за выполнение каждой задачи. Важно определить зоны ответственности, чтобы общение осуществлялось быстро и эффективно.
Типичной ролью, отвечающей за коммуникацию и координацию, является руководитель инцидента.
-
Этот человек олицетворяет культуру прозрачности, честности и подотчетности перед клиентами в качестве руководящих принципов.
-
Сосредоточив общение в одной роли, убедитесь, что общение последовательное и не конфликтное или, что еще хуже, противоречивое.
-
Для своевременного предоставления обновлений этот человек должен иметь возможность предоставлять обновления без трудоемкого процесса утверждения.
-
Использование готовых сценариев или шаблонов постов — хорошая стратегия для заблаговременного завершения проверки и утверждения.
When: Также важно определить, когда общаться. Как только произойдет сбой, подтвердите инцидент и сообщите об этом пользователям. Пользователи в любом случае узнают об инциденте, и если предоставленная поставщиком страница состояния отображает что “все хорошо”, люди будут чувствовать, что им лгут.
После подтверждения сбоя часто обновляйте статус.
-
Найдите баланс между регулярными и содержательными обновлениями. Как только статус изменится или появится значимая информация для обмена, отправьте обновление.
-
Следующее обновление может занять некоторое время, но пользователи хотят видеть, что команда все еще работает над инцидентом.
-
Рекомендуется обновлять информацию по истечении определенного времени, например, каждые 30 минут, даже если новая информация недоступна. Однако будьте осторожны, чтобы не показывать один и тот же ответ для нескольких итераций.
-
После восстановления службы опубликуйте уведомление об окончании сбоя.
Характеристики инцидента
Каким бы надежным ни был сервис, иногда возникают проблемы, которые могут повлиять на качество и доступность. Управление инцидентами — это процесс, посредством которого мы восстанавливаем поврежденный сервис. Работая вместе в команде, мы можем определить характеристики сервиса, чтобы как можно быстрее вернуть сервис в нужное русло.
Некоторые инциденты требуют дальнейшего анализа:
-
Когда проблемы возникают более одного раза (частота),
-
Когда сбой может затронуть многих пользователей (импакт),
-
Когда система не работает так, как задумано.
Каскадный сбой — это сбой, который со временем нарастает в результате положительной обратной связи. Когда одна часть всей системы выходит из строя, возрастает вероятность того, что другие части системы также откажут.Этот шаблон может создать эффект домино или каскада, который отключает все функции службы.
Снижение производительности: падение производительности относится к службам, которые не работают должным образом. Обнаружение и устранение ухудшения производительности может быть затруднено, но SRE несут ответственность за обнаружение и устранение проблем с ухудшением производительности.
Сбой функционала: Иногда команда создает необходимую функцию, и она не работает должным образом.
Воздействие вышестоящих и нижестоящих зависимостейЗачем учитывать восходящие и нисходящие зависимости при обработке инцидента?
Для вас важно учитывать восходящие и нисходящие зависимости, влияющие на микросервис, при обработке инцидента, поскольку они имеют решающее значение для разрешения инцидента в целом.
Примеры восходящих проблем включают в себя:
-
Проблема с сетью,
-
Проблема аутентификации.
Примеры нижестоящих проблем включают:
-
Проблема с облачным объектным хранилищем,
-
Проблема с блочным хранилищем,
-
Сбой в базе данных, на которую повлияла проблема микросервиса.
Зная, какие восходящие и нисходящие зависимости находятся в микросервисе, и как исправить любые проблемы с ними, вы приблизитесь к разрешению общего инцидента.

Распределенная трассировка
Один из методов, который SRE могут использовать для специального изучения зависимостей приложения — это распределенная трассировка. Его можно использовать для идентификации неудачной транзакции и отслеживания потока транзакции через приложение микрослужбы.
Распределенная трассировка — это метод, позволяющий регистрировать информацию в приложениях на основе микрослужб.
-
Уникальный идентификатор транзакции передается через цепочку вызовов каждой транзакции в распределенной топологии.
-
Одним из примеров транзакции является взаимодействие пользователя с веб-сайтом.
-
Уникальный идентификатор генерируется в точке входа транзакции.
-
Затем идентификатор передается каждой службе, используемой для завершения задания, и записывается как часть информации журнала служб.
-
Не менее важно включать временные метки в сообщения журнала вместе с идентификатором.
-
Идентификатор и отметка времени объединяются с действием, которое выполняет служба, и состоянием этого действия.
Создание Runbook для устранения неполадок и смягчения последствий распространенных инцидентов
С помощью инструментов Runbook, интегрированных с уведомлениями о событиях, SRE могут определять автоматические процедуры, которые будут выполняться при возникновении определенного события. Рассмотрим, что происходит, когда система управления событиями получает событие, указывающее на сбой службы. Система может выполнять автоматизированные действия, определенные в runbook. Например, когда система получает событие сбоя службы, сценарий runbook предлагает сделать снимок системы. SRE могут автоматизировать следующие действия:
-
Использование системного имени хоста и учетных данных для входа на сервер,
-
Получение списка процессов, памяти, использования cpu, и другой информации,
-
Извлечение любых связанных журналов и сообщений трассировки.
Результаты действий могут быть немедленно отправлены первому ответчику, как только действие будет завершено. Выявление неполадок с помощью автоматизированных runbook — это низкий барьер, поскольку команды доступны только для чтения и обычно не наносят вреда системам. Со временем команда может писать сценарии для автоматического решения проблем без ручного вмешательства.
Этапы зрелости Runbook
По мере взросления команды и приложения могут развиваться и runbook. Зрелость runbook включает следующие этапы:
Ad hoc: это начальное состояние характеризуется отдельными ручными действиями без документации или согласованности.
Repeatable: стандартные действия задокументированы и согласованы во всей организации. Эти действия по-прежнему выполняются вручную.
Defined: действия принудительно выполняются. Действия становятся доступными, поскольку сценарии и задачи предоставляются оператору в контексте инструментов управления.
Managed: система предлагает правильное действие для события. Используя базовые функции if/then, система автоматически запускает действия.
Optimized: на самом высоком уровне применяется аналитика, чтобы определить, когда и что автоматизировать.
Управление модулями Runbook
Чтобы runbook был оптимальным, SRE должны управлять его содержимым и поддерживать его. Приложение может быть обновлено до версии, требующей других действий. Технологии и инфраструктура могут измениться, что приведет к изменениям в командах runbook. При выборе решения runbook рассмотрите возможность управления отзывами пользователей, управления библиотеками, контролем доступа, API, отчетами и аудитом.
User feedback: Когда инженеры используют runbook, собирайте их отзывы.
Вы можете задать им следующие вопросы:
-
Помог ли runbook решить проблему?
-
Как можно улучшить модуль runbook?
Library management: Некоторые решения Runbook предоставляют библиотеку «строительных блоков» Runbook, которые можно использовать для создания Runbook. В зависимости от инструмента библиотека может быть предоставлена поставщиком или представлять собой набор библиотек, предоставленных другими пользователями.
Например, Red Hat® Ansible поставляется с модулями для выполнения общих задач. Разработчик может использовать модуль для более быстрой разработки Runbook.
Access control: Для средних и крупных организаций решающее значение имеет управление пользователями и ресурсами. Конкретным пользователям или группам пользователей требуется доступ для работы с определенной группой ресурсов. Если необходим аудит, аудитору может потребоваться доступ только для чтения к большей группе ресурсов.
Другой формой управления доступом является имя пользователя и пароль для средства Runbook для выполнения действий с управляемыми ресурсами. Может потребоваться несколько уровней контроля доступа.
Например, чтобы прочитать состояние сервера, используйте обычные учетные данные для входа, но для изменения конфигурации сервера учетная запись должна иметь привилегии root. Runbook могут предоставить средства безопасного делегирования привилегированных команд администраторам.
API: В рамках интеграции Runbook система управления событиями может активировать Runbook. Runbook также можно запускать в результате действия инструмента на панели мониторинга топологии, как действие из системы ChatOps или как задачу в конвейере непрерывной доставки. Решение Runbook должно предоставлять набор API, чтобы другой компонент интеграции мог вызывать правильный Runbook с соответствующими полномочиями.
Report and audit: При рассмотрении решения Runbook обратите внимание на его возможности отчетности и аудита. Полезно знать, какие Runbook выполняются чаще всего или получают самые высокие оценки при решении проблем.. Вашей организации может потребоваться аудит Runbook в рамках деятельности по обеспечению соответствия требованиям.
Информация о выполнении модуля Runbook может быть передана группе SRE из отчета, чтобы расставить приоритеты в отношении необходимых работ по улучшению приложений или инфраструктуры.
Runbook или пофиксить?
В SRE подход к решению повторяющейся проблемы заключается в устранении ее источника. Runbook может быть хорошим краткосрочным тактическим решением, когда исправление требует дополнительного времени и усилий.
SRE может использовать отчет, созданный решением Runbook, и работать с приоритетным списком исправлений. По мере реализации большего количества исправлений требуется запускать меньше Runbook. Помните, что лучше предотвратить проблему до того, как она возникнет, чем решать ее после того, как она возникла. Однако иногда runbook является решением.
Организация может инвестировать в коммерческое программное обеспечение, которое команда SRE не может изменить напрямую, или SRE может использовать решение Runbook для автоматизации повторяющихся задач, выходящих за рамки управления инцидентами.
Методы устранения неполадок и постоянное совершенствование
Устранение неполадок не зависит от удачи. Наша основная теория заключается в том, что SRE могут изучать и обучать эффективным стратегиям. Теория, лежащая в основе эффективного устранения неполадок, заключается в том, что этому можно научиться и чему можно научить.
Процесс устранения неполадок — это способность выдвигать гипотезы о причинах сбоя и тестировать решения.
Помните об этих важных моментах:
-
Не все неудачи одинаково вероятны — при прочих равных условиях наиболее вероятным решением может быть простое или очевидное решение.
-
Корреляция не является причинно-следственной связью.
Шаги в модели устранения неполадок:
-
Получаем сообщение о проблеме, что-то не так с системой.
-
Просмотрим телеметрию и логи, чтобы понять ее текущее состояние.
-
Определим некоторые возможные причины.
-
Активно «лечим» систему — то есть изменяем систему контролируемым образом и наблюдаем за результатами.
-
Повторно тестируем, пока не будет выявлена основная причина.
-
Примем меры для предотвращения повторения.
-
Напишите репорт о решении, задокументируем это.
Так и работаем.
В завершение хочу порекомендовать вам бесплатный вебинар: «Чему могут научить SRE техники? Сравнение SRE и DevOps».
На вебинаре эксперты OTUS разберут как SRE-техники могут помочь вам в построении и обслуживании систем. Вы увидите сравнение SRE с ITSM, DevOps, Platform Engineering. Также будут рассмотрены принципиально новые идеи в каждом фреймворке, какие части фреймворков прошли проверку временем, а какие не работают как ожидается и как оценивать успешность внедрения.
-
Зарегистрироваться на бесплатный урок
3.4. Управление инцидентами
В работе, как и в жизни, не бывает всё гладко. Как бы вы хорошо ни настроили работу своего отдела, всегда что-то происходит, возникают какие-либо препятствия для достижения плана, и под угрозой могут стать взаимоотношения с вашими контрагентами, либо что-то ломается и происходит потеря качества выпускаемой вашим подразделением продукции. Такие события мы будем называть инцидентами.
В литературе по управлению редко говорится об этом аспекте (в основном только в сфере управления IT-службой), хотя у линейных руководителей (да зачастую и на более высоких уровнях руководства) работа с инцидентами съедает огромный временной ресурс. Инциденты – это вторая причина, почему руководитель должен всегда быть на месте (напомним, что первая – это необходимость контроля) и незамедлительно принимать решения по их устранению.
Итак, давайте разберём, какие бывают инциденты. Варианты могут быть самые экзотические, как, например, удар молнии в офисное здание или незапланированная беременность заместителя главного бухгалтера в разгар налоговой проверки. Но наиболее часто встречающиеся инциденты связаны с нарушением технологии и всяческими поломками. Плохой руководитель часто не замечает инциденты. К примеру, если звонит недовольный клиент, то плохой руководитель в лучшем случае постарается его успокоить и облегченно вздохнёт, положив трубку. Хороший же руководитель, кроме этого, разберётся в причинах недовольства и обязательно устранит их.
Принципиально инциденты можно разделить на два типа:
1. Инциденты, связанные с нарушением технологии, правил, процедур (всегда есть конкретный виновник).
2. Инциденты, связанные с плохой постановкой технологии, отсутствием правил и процедур (скорее всего, недоработали вы сами либо вышестоящее начальство).
Суть работы руководителя с инцидентами – минимизировать ущерб от их последствий и сделать так, чтобы они никогда не повторялись. В чём состоит конкретная работа:
1. Определить, что произошло. Иногда, докладывая вам о случившемся, сотрудники показывают лишь вершину айсберга, поэтому надо обязательно докопаться до истины, досконально разобраться, что именно произошло.

Рис. 37. Всё хорошо, прекрасная маркиза!
2. Разработать мероприятия по решению инцидента, по возможности минимизировав ущерб. При этом надо согласовать данные мероприятия со всеми заинтересованными сторонами (контрагентами, начальством, если необходимо, с коллегами и подчинёнными).
3. Определить ущерб. При этом надо определять полный ущерб, не забывая о косвенных и сопутствующих затратах. Это нужно, во-первых, чтобы понять масштаб бедствия, а во-вторых, для разработки мер наказания виновных лиц.
4. Разработать мероприятия по предотвращению повторения инцидента. Это одна из самых главных задач хорошего руководителя. Плохой будет вечно бороться с повторяющимися случаями, проклиная текучку и жалуясь на обстоятельства. Хороший руководитель обязательно произведёт необходимые изменения либо в работающих регламентах, либо создаст новые, обучит по ним своих подчинённых и возложит на них ответственность в случае повторения инцидентов. В основном производимые уточнения регламентов касаются функций организации (технологии, оргструктура, распределение прав и ответственности сотрудников, система мотивации и пр.). Очень часто в качестве меры по предотвращению инцидентов применяется дополнительное обучение сотрудников.
5. Определить и наказать виновника (в основном это касается только инцидентов, связанных с нарушением технологии, правил и процедур). Здесь главное, что наказание должно быть неотвратимым (пусть это будет даже просто устное порицание), соразмерным и справедливым.
В конце месяца хороший руководитель обязательно проанализирует произошедшие инциденты в подразделении, при необходимости проработает их с подчинёнными на отчётном собрании. Для этого хорошо инциденты учитывать. Некоторые руководители отражают всю информацию по инциденту в специально разработанных бланках, некоторым достаточно просто заносить все случаи на страничку своего ежедневника. Умение работать с инцидентами – важнейший показатель в работе любого руководителя.
Приведу один пример работы руководителя с инцидентами:
На заре своей предпринимательской деятельности мне приходилось самому решать вопросы с коммерческими банками. Один из банков возглавлял мой институтский знакомый, с которым мы вместе работали мастерами на крупном оборонном предприятии после окончания вуза.
Я по простоте душевной хотел вломиться к нему в кабинет и решить свою проблему, но не тут-то было. Желая договориться о встрече, я позвонил в приёмную. Секретарь, вежливо поинтересовавшись, по какому я, собственно, вопросу, направила меня к заместителю, который, к моему злорадству, проблему решить не смог, но незамедлительно направил меня к другому специалисту. От своих коллег-предпринимателей я слышал, что в кабинет к моему знакомому попасть практически невозможно, невзирая на любые дружеские отношения – всё должны решать его заместители и другие специалисты банка.
Не вдаваясь в подробности, скажу, что мой случай был неординарный и, по-моему, не попадал ни под один регламент, действующий в банке на тот момент. И я, словно шар, побившись о борта биллиардного стола, наконец, попал в лузу – секретарь, поняв, что проблему может решить только её шеф, спокойно допустила меня к «телу».
Я ожидал, пробившись через очередь в приёмной, увидеть обвешенного телефонными трубками, обложенного бумагами большого начальника, погруженного в свои проблемы.
Ничего подобного. Очереди не было, я встретил своего знакомого спокойным и улыбающимся. Проблему мою он решил секунд за сорок, потом попросил принести нам кофе, а меня подождать, пригласив в приёмную пару своих подчинённых, с которыми быстро и энергично переговорил. Как я понял, одному из них немного досталось, другой что-то быстро записал. Мой случай был разобран, виновный определён и получил устное порицание. Как поступать в подобных случаях, стало ясно всем, включая секретаря. Инцидент был закрыт.
Мы посидели ещё минут десять, вспоминая общих знакомых, и, пожав руки, разошлись. По прошествии времени его перевели в Москву на должность вице-президента этого банка, а ещё через некоторое время я узнал из прессы, что он возглавил один из крупнейших авиационных заводов в России.
Он умел себя ограждать от ненужной текучки, избавляясь от инцидентов один раз, и тратил своё время только на решение важных задач.
Данный текст является ознакомительным фрагментом.
Читайте также
2. Управление инцидентами
2. Управление инцидентами
Инциденты подразделяются на:? Поломка оборудования? Грубое нарушение технологии? Воровство или пропажа материальных ценностей? Претензии клиентов? Другое событие, приведшее к существенным дополнительным затратамНачальник склада при
Управление личным временем как управление фирмой
Управление личным временем как управление фирмой
Жизнь ускоряется, интенсивность информационных потоков возрастает, сохранять контроль над массой дел и работать в свое удовольствие, без стресса, становится все труднее. При этом книги по тайм-менеджменту, как правило,
Демократическое управление
Демократическое управление
Многие руководители считают, что в отношениях с коллективом они – настоящие демократы. Почему им так кажется? Да потому, что за десятки лет «до того» руководители имели только один опыт управления – авторитарный, имели перед собой
6. УПРАВЛЕНИЕ И МЕНЕДЖМЕНТ
6. УПРАВЛЕНИЕ И МЕНЕДЖМЕНТ
Понятия «управление» и «менеджмент» часто используются как синонимы, но между ними есть различия. Управление представляет собой всеобщую человеческую деятельность, а менеджмент – это его специфическая область, включающая деятельность
3.3. Стратегическое управление
3.3. Стратегическое управление
Стратегическое управление заключается в умении моделировать ситуацию; способности выявлять необходимость изменений; разработке самой стратегии; способности воплощать стратегию в жизнь. Исходя из сказанного, можно предложить несколько
Управление
Управление
Управление нередко считают «лидерской» функцией, но в действительности за нее отчасти отвечает каждый менеджер. Слово «управление» может трактоваться по-разному. Менеджер может приказывать своим подчиненным выполнять поставленные задачи, но может также
Управление
Управление
1. Питерс Т., Уотерман Р. В поисках совершенства. Уроки самых успешных компаний Америки. – М., 2004.2. Гербер М. Малый бизнес: от иллюзий к успеху. – М., 2005.3. Макиавелли Н. Государь.4. Сунь Цзы. Искусство войны.5. V., Jr, Jr. Менеджер мафии. – М., 2005.6. Латынина Ю. Стальной