В этой книге приводятся практические решения задач с использованием транзакции LSMW для загрузки данных на основе методов Batch Input, BAPI и Direct Input. Примеры базируются на бизнес-сценарии миграции данных, приведённом чуть далее во вступлении.
Оглавление книги
1. Вступление
2. Массовое обновление материалов методом Batch Input в транзакции LSMW
3. Массовое обновление материалов методом BAPI в транзакции LSMW
4. Загрузка классификации ОЗМ методом Direct Input в транзакции LSMW
5. Загрузка длинных текстов материала методом Direct Input в транзакции LSMW
6. Загрузка остатков ОЗМ методом BAPI в транзакции LSMW
7. Массовое сторно документов материала методом Batch Input транзакции LSMW
8. Полезные возможности транзакции LSMW
9. Загрузка данных из Excel в транзакции LSMW
Благодарности
Эта книга не состоялась бы без поддержки людей, с которыми меня свела судьба, а именно: Светланы Балакиревой, Александра Дублина, Юрия Нечитайлова, Михаила Сковородина.
Транзакция LSMW, как правило, сопровождает проекты внедрения и активной поддержки; и на этих проектах я работал с людьми, которые являлись настоящими профессионалами, и (что важно для меня) помогали мне при решении различных задач. Говорю о: Виталии Сапунове, Владимире Петриеве, Юрии Синко, Андрее Белобродском, Олеге Точенюке, Татьяне Кузьмичёвой, Сергее Смирнове, Анне Трещаловой, Павле Троеве, Александре Шиляеве, Сергее Андриановском.
Благодарю ключевых пользователей и бизнес-экспертов, с которыми были реализованы эффективные решения: Зайцеву Татьяну, Дмитрия Обедзинского, Ирину Петряшову, Дмитрия Леонтьева, Ивана Леонтьева, Людмилу Гусарину, Татьяну Тимохину, Татьяну Скорлыгину, Алексея Смирнова, Эльмиру Рахматбаеву, Juergen Graupner, Alan Green.
Также я благодарен руководителям, которые помогали мне реализовывать идеи и поддерживали в трудных ситуациях: Анне Лобачевской (Юрьевой), Юрию Желтоухову (первое обучение по LSMW было инициировано Юрием, что в дальнейшем явилось прообразом мастер-класса «LSMW: инструкция по применению» и этой книги), Сергею Чумак, Марии Лавровой, Татьяне Типсиной, Марии Лорман, Лебедеву Дмитрию, Шленкину Станиславу.
Спасибо коллегам, которые поддерживали меня: Мясоутовой Ирине, Диковой Алевтине, Свиридову Роману, Спиридоновой Наталье, Алексею Сутягину, Михаилу Абашину, Валерию Фатьянову, Алексею Слободянюк, Роману Байбак, Дмитрию Шулейко, Андрею Налимову, Наталье Смирновой, Вадиму Сухоруких, Денису Желтикову, Алексею Митько.
Огромное спасибо всем слушателям моих мастер-классов за посещение, интересные вопросы и обоснованную критику.
Отдельное спасибо Жанне Максаковой за поддержку, терпение и последовательное применение в своей практике материалов мастер-класса.
Благодарю своих родителей Светлану и Виктора Башкатовых.
Вступление
В этой книге приводятся практические решения задач с использованием транзакции LSMW для загрузки данных на основе методов Batch Input, BAPI и Direct Input. Примеры базируются на бизнес-сценарии миграции данных, приведённом чуть далее во вступлении.
Транзакция LSMW не переведена на русский язык полностью, поэтому в тексте использованы скриншоты в том виде, как они встречаются на практике, а уже в комментариях дополнительно указывается перевод терминов на русский язык.
Данная книга будет интересна всем, кто решает практические задачи, связанные с массовой загрузкой/обновлением данных в системах SAP, включая консультантов, ключевых пользователей и менеджеров проектов.
Транзакция LSMW позволяет сэкономить время на выполнении рутинных задач, высвободив его для решения задач, требующих творческих усилий.
Бизнес-сценарий
Начнём с описания конкретного примера бизнес-сценария. Предприятие в Северо-Западном округе подключает к системе SAP ERP одно из своих подразделений. Одной из задач, требующих решения, является миграция остатков для этого подразделения. Для этого консультантам нужно выполнить следующие действия (рис. А):
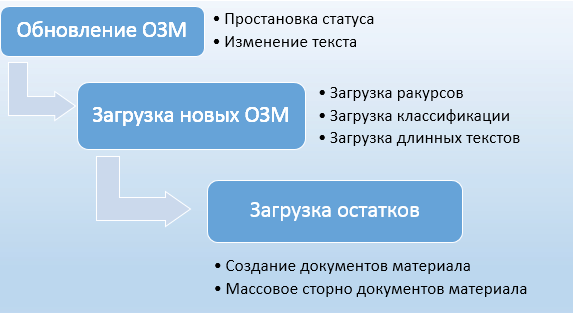
Рис. А. Описание бизнес-сценария
- Обновить существующие основные записи материалов (Material Master Data).
- Создать новые основные записи материалов (ОЗМ).
- Загрузить классификации ОЗМ.
- Загрузить длинные тексты ОЗМ.
- Загрузить остатки (создать документы материалов).
- Создать возможность массового сторно документа материалов.
В последующих главах подробно рассматривается реализация данных действий с использованием транзакции LSMW на основе упомянутых ранее методов. В ходе решения практических задач с использованием данной транзакции будут приведены полезные советы и указаны тонкости, позволяющие ускорить весь этот процесс. Однако ряд тонкостей, связанных с использованием транзакции LSMW, всё же не удастся подчеркнуть на примере реализации действий именно этого бизнес-сценария, поэтому в конце книги приводится отдельная глава, посвящённая ускользнувшим от внимания полезным трюкам по работе с транзакцией LSMW. Помимо этого, в ней описаны некоторые альтернативные инструменты загрузки данных.
Данная книга способствует достаточно полному освоению инструмента загрузки данных.
Массовое обновление материалов методом Batch Input в транзакции LSMW
В рамках задачи миграции данных (рис. 1.1) нам требуется внести изменения в существующие записи материалов, а именно: ограничить их использование, поставив соответствующий статус материала, группу полномочий, а также обновить краткий текст ОЗМ.
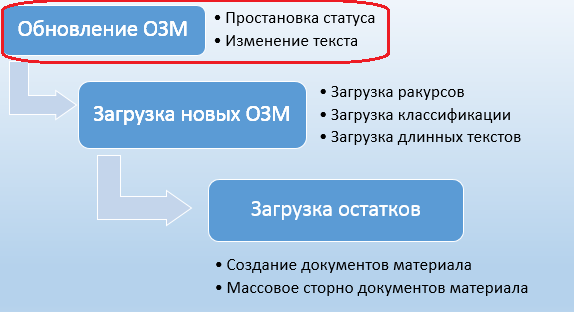
Рис. 1.1. Этап обновления существующих ОЗМ в общей схеме задач миграции
Далее будет показано решение задачи обновления данных методом пакетного ввода. Метод пакетного ввода предполагает предварительное создание записи (recording) на основе ручного указания значений для полей. Система фиксирует поля, которые нужно заполнять. Значения для полей представляют собой переменные данные, которые можно заполнять из внешнего файла.
Помимо этого, мы обсудим следующие важные вопросы:
- использование дополнительного ABAP-кода при обновлении данных;
- решение проблемы внешних нулей при загрузке материалов из внешнего файла;
- работа с Auto-Filled Mapping.
1.1. Практическое решение задачи
Постановка задачи: требуется обновить основные записи материалов, а именно: ракурс Основные данные 1 (Basic Data 1) и Основные данные 2 (Basic Data 2). В таблице 1.1 приведены поля для загрузки.
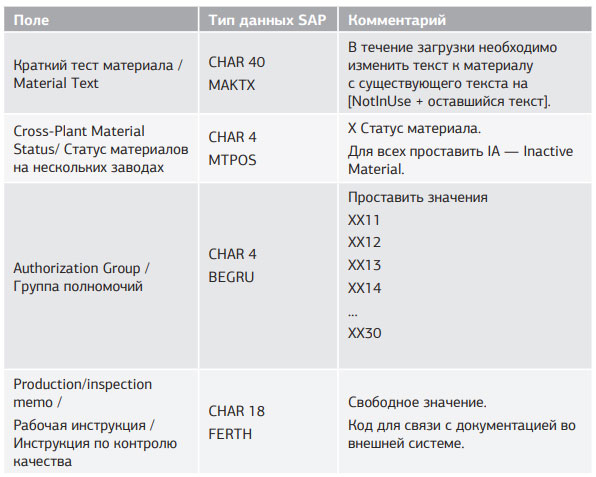
Табл. 1.1. Поля для обновления данных основной записи материала
На предварительном шаге подготовим данные для загрузчика, а именно: пройдёмся вручную по изменяемым полям.
Нам нужно:
- обновить поле «Краткий текст материала»;
- проставить статус Inactive;
- проставить группу полномочий;
- заполнить поле Production/Inspection memo (Рабочая инструкция/Инструкция по контролю качества).
Предварительный шаг
Чтобы сделать загрузчик, пройдемся по пунктам ниже.
- Запустим транзакцию MM02 (рис. 1.2) и укажем материал 403339 ; выделим Basic Data 1 (Основные данные 1) и Basic Data 2 (Основные данные 2) (рис. 1.3).
- К тексту добавим префикс NotInUse (если не помещается, то «отрезаем» текст материала в конце). Ставим статус Inactive, ставим нужную группу полномочий, переходим на ракурс Basic Data 2 (Основные данные 2) (рис. 1.4) и ставим нужное значение в поле Production/Quality Memo; сохраняем материал (рис. 1.5).
Рис. 1.2. Запуск транзакции MM02 для изменения основной записи материала
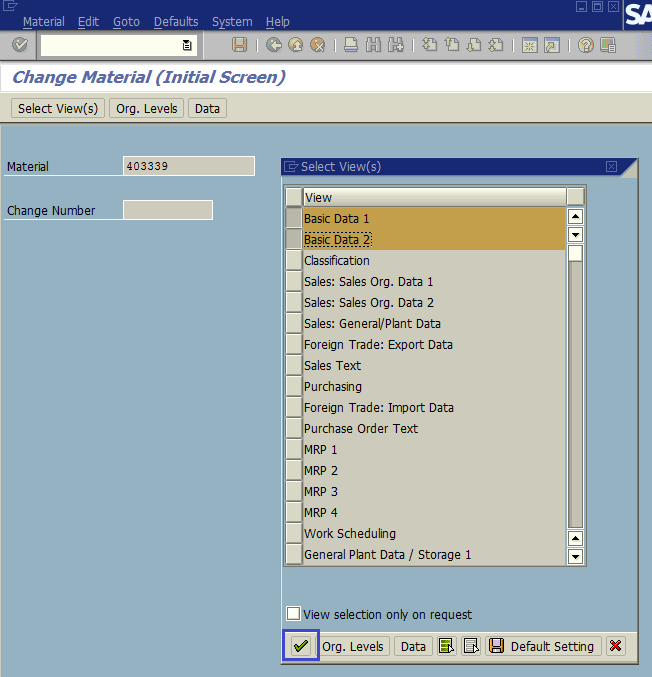
Рис. 1.3. Выделяем ракурсы Основные данные 1 (Basic Data 1) и Основные данные 2 (Basic Data 2)
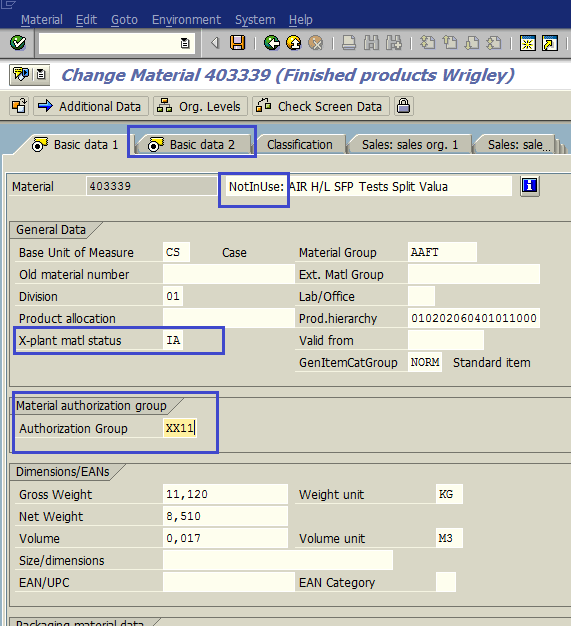
Рис. 1.4. Обновляем данные на ракурсе Основные данные 1 и переходим к ракурсу Основные данные 2
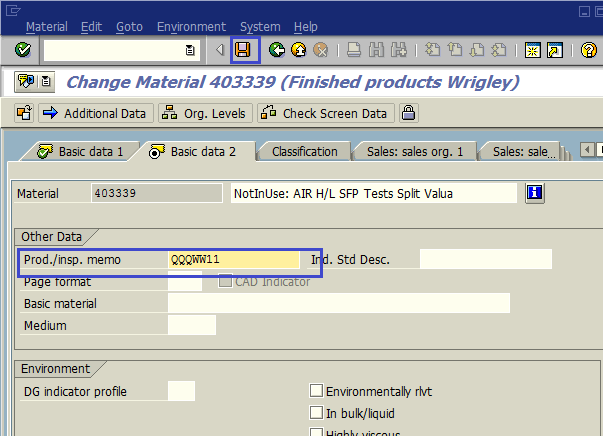
Рис. 1.5. Обновляем Основные данные 2 и можем сохранить изменения
Текущую задачу мы решим с помощью последовательности шагов, выделенных в отдельные последующие параграфы.
Шаги решения
Шаг 1: создание/выбор проекта, подпроекта и объекта
Запустим транзакцию LSMW, заполним данные Project (проект), Subproject (подпроект), Object (объект), нажмем кнопку Создать (если проект уже создан, то нажимаем кнопку Выполнить) (рис. 1.6). Данные для создания проекта приведены в таблице 1.2. Заполнение описания составляющих объекта показано на рис. 1.7.
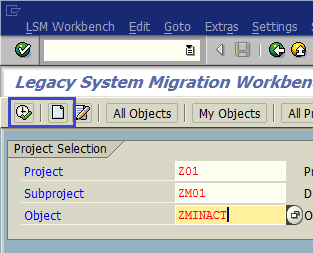
Рис. 1.6. Для создания проекта нажимаем кнопку Создать (если проект существует, нажимаем Выполнить)
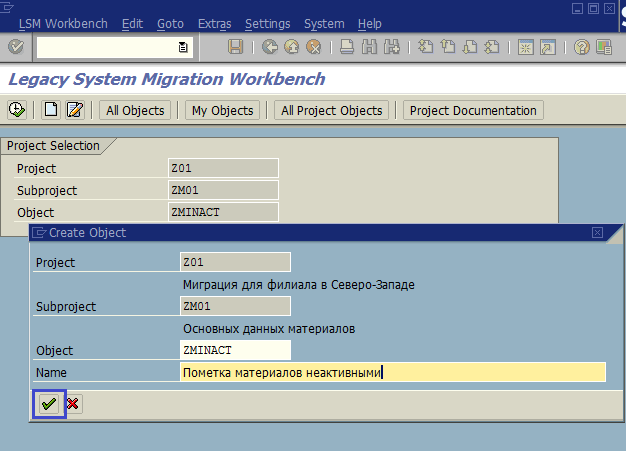
Рис. 1.7. Заполнение описания проекта (Project), подпроекта (Subproject), объекта (Object)

Табл. 1.2. Данные для создания Object (объекта) в транзакции LSMW
После создания и/или запуска проекта система откроет основное меню транзакции LSMW. Пункты меню зависят от метода загрузки и могут настраиваться (подробнее об этом в дальнейших публикациях).
Шаг
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
Зарегистрироваться
У вас уже есть учетная запись?
Войти

Загрузка данных с помощью инструмента LSMW. На примере загрузки Должностей.
1. Создаем текстовой файл с разбиением 2. Набираем транзакцию LSMW 3. создаем проект закачки
4. В появившемся окне выбираем первый пункт Maintain Object Attributes:

5. Выбираем клавишу Display/change выбираем Batch input recording ,жмем на клавишу
Recordings Overview и записываем выполнение своей транзакции,

В появишемся окне создаем Recording:

Далее пишем код транзакции
6. Далее Transaction Code(код транзакции) — PO03, Выбираем объект , нужный нам
период, план, жмем объект- создаем. По окончании жмем ввода записи (1 можно
ввести)

7. Получаем такую структуру . Где находятся поля ,в которые будем закачивать свои
данные ставим курсор на них и нажимаем -default.

8. Выбираем второй пункт в основном меню Maintain Source Structures , нажимаем
изменить, создаем структуру, сохраняем, возвращаемся в основное меню.

9. Выбираем третий пункт Maintain Source Fields, задаем поля входного файла.


Данные по характеристикам поля берем из заполняемой таблицы( например, через тр. Se11 вызываем на просмотр таблицу HRP1000) проваливаясь в ее структуру из тех описании(нажимаем клавишу F1 на нужном поле). Сохраняем 10.

11. Далее, в основном меню выбираем Maintain Structure Relations. Здесь уже
автоматически стоят все привязки структуры для ввода и входного файла

12. Выбираем Maintain Field Mapping and Conversion Rules. Тут мы видим те поля ,ч то
отметили default еще на первых шагах, подставляем поля которые будут подаваться из файла загрузки( те , что специфицировали)
13. Переходим к пункту Specify Files

14. Выбираем Legacy Data, где отмечаем параметры , как на картинке
15. Далее переходим в п.Assign Files ,нажимаем изменить и просто нажимаем
сохранить(ничего не меняем)

16. Нажимаем далее п. Read Data, задаем сколько строк считать из файла , для начала
можно с 1-5.(при этом сам файл загрузки должен быть закрыт)

17. В п.Display Read Data- смотрим правильно ли считывается информация
18. Следующий шаг п. Convert Data- конвертируем данные, в данном пункте можно не
задавать число конвертируемых строк, так как будут обрабатываться те , что указали на предыдущем шаге.
19. Следующий шаг – п. Display Converted Data, смотрим , как конвертировали
информацию:

20. Предпоследний шаг — п.Create Batch Input Session, просто нажимаем выполнить , если
нужно сохранять результаты загрузки на сервере , отметьте галку.
21. Последний, самый долгий шаг – п.Run Batch Input Session. Выбираем наш Batch Input нажимаем Process , выбираем как на картинке

22. Если вся загрузка была задана корректно, то по завершению загрузки выводиться следующее сообщение:

LSMW – инструмент для переноса данных из внешних систем в SAP систему. Данные могут быть введены с помощью следующих технологий: Batch Input, Direct Input, BAPIs или IDocs. Далее инструкция как этим инструментом пользоваться.
Принцип работы LSMW:

Преимущества:
- LSMW – часть SAP системы не зависимая от платформы
- Большое количество возможностей по преобразованию данных
- Поддержка основных технологий ввода: Bath Input, Direct Input, BAPIs, IDocs.
- Удобный путеводитель по миграции данных
- Является бесплатным инструментом для партнеров SAP
Основные функции:
- Импорт данных (данные из файлов, электронных таблиц)
- Преобразование данных в необходимый формат
- Импорт данных в SAP систему.
До того как применять LSMW необходимо убедиться в следующем:
- SAP система окончательно настроена и готова к вводу
- Решите, имеет ли смысл использовать инструмент, его использование оправдано на больших объемах данных. Скорость импорта для режима Direct Input и Bath Input примерно 10000 записей в час, величина может меняться в зависимости от аппаратной части сервера.
- Определитесь с транзакциями в SAP системе, через которые будете выполнять импорт данных. Созданы ли стандартные объекты Direct Input, Batch Input, есть ли необходимые BAPI.
- Протестируйте выбранные транзакции вручную, определите, какие поля являются обязательными к заполнению.
- LSMW не извлекает данные из внешних систем, их необходимо предварительно подготовить. Формат файла должен соответствовать возможностям чтения файлов LSMW. Например: кодировка должна быть либо ASCII или IBM.
- Определитесь с методом импорта данных (BAPI, Direct Input и т.п.).
Предварительная настройка
Убедитесь что у пользователя, под которым будет происходить импорт, достаточные полномочия:
| Уровень авторизации | Профиль | Функции |
| Просмотр | B_LSMW_SHOW | Пользователю разрешается просматривать все проекты LSMW |
| Выполнение | B_LSMW_EXEC | Пользователь может выполнять и редактировать шаги проектов |
| Изменение | B_LSMW_CHG | Пользователь обладает полномочиями на просмотр объекта LSMW, импорт и чтение данных. |
| Администрирование | B_LSMW_ALL | Все полномочия на LSMW |
Внешний вид после запуска инструмента (транзакция LSMW):

Project – имя проекта, например «Логистика»
Subproject – имя подпроекта, например «Закупки»
Object – имя объекта LSMW который включает все операции по переносу данных, например «Заявка».
С помощью кнопок на начальном экране можно:
- Запустить проект на выполнение
- Создать новый проект, объект
- Изменить проект
- Просмотреть все объекты LSMW в системе
- Просмотреть все свои объекты
- Просмотреть все объекты к проекту
- Изменить документацию к проекту
Администрирование
Для копирования, изменения, удаления объектов, проектов и подпроектов необходимо перейти в администрирование: Go to -> Administration.
Импорт данных шаг за шагом
После выбора (создания) проекта, подпроекта и объекта LSMW нажмите ENTER, вы попадете на экран определения шагов для объекта:
ВНИМАНИЕ! При авторизации в SAP GUI на английском языке названия шагов отображаются на английском языке, при авторизации на русском языке, отображаются только номера шагов. Однако при работе на EN русские названия в считываемых файлах отображаются некорректно, поэтому загрузку следует осуществлять ТОЛЬКО с авторизацией на RU(русском) языке в SAP GUI.

С помощью кнопки Personal Menu вы определяете, какие шаги будут использоваться в объекте. Кнопка Object Overview позволяет посмотреть всю информацию по выбранному объекту. Action Log – просмотр истории изменений, запусков. Execute – выполнить выбранный шаг. Для изменения шагов выберите Double Click = Change.
Определение атрибута объекта (Maintain Object Attributes)

- Укажите, как будет происходить импорт данных однократно (once) или с периодичностью (periodic – в статье не рассмотрены). При периодичном импорте необходимо настроить шаг (Frame Program for Periodic Data Transfer).
- Определите, какой тип импорта будете использовать: Standard Bath /Direct Input – заранее подготовленные программы, Batch Input Recording – ранее созданная запись пакетного ввода, (Для записи на начальном экране необходимо выбрать GoTo -> Recordings) BAPI – использование методов бизнес объектов (BAPI), IDoc.
Определение пользовательских структур(Maintain Source Structures)

На данном шаге определяются имена пользовательских структур их описания и иерархия. Одна структура может включать несколько других, которые в свою очередь могут включать другие и т.д. Пользовательская структура заполняется из внешних данных, после чего используется для переноса данных в SAP систему.
Определение полей для структур(Maintain Source Structures)

Этот шаг определяет, из каких полей состоят пользовательские структуры. При создании поля можно определить ее тип, длину, имя, описание. Используя параметр «Selection Parameter for Import/Convert data» мы определяем, будет ли данное поле появляться на экране в шагах чтения, конвертации данных, если да то данные из файла будут считаны в соответствии с введенным значением в эти поля. Структуру можно скопировать из внешнего файла, репозитария, другого объекта. При копировании из внешнего файла с разделением полей табуляцией можно воспользоваться Excel структура файла будет примерно такой:

Определение связей структур (Maintain Structure Relations)

На данном шаге определяется связь между структурами объекта импорта (Поля в структурах BAPI, поля для пакетного ввода и т.п.) и пользовательскими структурами. В приведенном выше примере структуры из пакетного ввода: BGR00, BKN00, BKNA1, BKNB1 будут заполнены из пользовательской структуры CUSTOMER_HEADER, структура BKNVK из CUSTOMER_CONTACTS. Обратите внимание на то, что многие программы пакетного ввода содержат структуры BGR00 и BI000, они должны быть заполнены всегда.
Определение связей и правил преобразования (Maintain Field Mapping and Conversion Rules)

На данном шаге определяется связь между полями пользовательских структур и полями структур назначения (Полями пакетного ввода, BAPI и др.), а так же правила преобразования. Все поля структур назначения, которые были заполнены на предыдущем шаге, будут отображены на этом экране. Поля содержат следующую информацию:
- Описание поля
- Присвоенное поле из структуры назначения
- Правило, по которому присваивается значение полю (Константа, пустое, присвоение и т.п.)
- Код программы преобразования
Некоторые поля являются техническими и заполняются системой автоматически, правило для них присваивается как Default Settings (зеленые записи). Изменение значений данных полей может повлиять на ход выполнения импорта.
Система позволяет автоматически сделать присвоение полей, в случае если их имена совпадают: Extras -> Auto-field Mapping.
Правила присвоения полей:
- Initial: Пустое значение для поля. Когда выбрано данное правило значение поля может принимать следующие значения: для стандартного пакетного ввода – пустое символьное значение ‘’, для записи пакетного ввода ‘/’, для BAPI или IDoc для символьных полей ‘’, для полей числовых ‘0..00’.
- Move: Работает так же, как и ABAP команда MOVE.
- Constant: Значение по умолчанию.
- Fixed value (reusable): Присваивается значение переменной определенной на шаге Maintain Fixed Values, Translations, User-Defined Routine.
- Translation (reusable): Определяется порядок преобразования поля, само преобразование определяется в шаге Maintain Fixed Values, Translations, User-Defined Routine.
- User-written routine (reusable): Определяется имя кодировки для поля, сама кодировка так же определяется на шаге Maintain Fixed Values, Translations, User-Defined Routine.
- Prefix: Задается значение, которое должно быть перед содержимым поля.
- Suffix: Задается значение, которое должно быть после содержимого поля.
- Concatenation: Вы можете задать объединение двух или нескольких исходных полей в одно поле назначения.
- Transfer left-justified: записать содержимое с выравниванием по левому краю.
- ABAP coding: задает кодировку ABAP для преобразования поля. В кодировке можно использовать все поля исходной структуры, глобальные переменные, глобальные функции.
- XField: специальная функция для IDocs и BAPI объектов. Функция заполняет так называемые X-структуры (структуры изменений для BAPI функций). В случае если поле было изменено, соответствующее поле X структуры должно иметь значение «Х». Следующий код генерируется автоматически:
If not <field in the data transfer structure> is initial.
<field in X-structure> = ‘X’.
else.
<field in X-structure> = ‘’.
Endif.
Нажав на кнопку выбора варианта и выбрав последние три галочки, вы можете определить дополнительную кодировку для событий до запуска транзакции, после запуска и т.п.

Например, кодировка __BEGIN_OF_TRANSACTION__: ее выполнение начинается до момента обработки записи, в случае создание объекта в R3 на данном этапе можно проверить его существование в системе, в случае если он уже есть, пропустить текущую запись с помощью глобальной функции — skip_transaction. Таким образом, можно уберечься от падения в дамп сессии пакетного ввода при импорте данных.
Кроме того кодировки позволяют динамически менять транзакции и записи пакетного ввода манипулируя полями bkn00-tcode и TABNAME. Например, в случае если объект присутствует в системе запустить пакетный ввод на его изменение.
На шаге Maintain Fixed Values, Translations, User-Defined Routines с помощью правил преобразования (Translations) можно определить, чем будет заменены значения из исходных структур, определять правила как для конкретных значений, так и для диапазонов. Кроме того на этом шаге определяются константы используемые на предыдущем (Fixed Values) и кодировки которые вызываются не однократно (User-written routine).
Определение файлов(Specify Files)
На данном шаге определяются файлы:
- С вашими данными (Legacy Data)
- Файл с правилами чтения данных …lsmw.read ставится автоматически
- Файл с правилами преобразования данных …lsmw.conv ставится автоматически

При присвоении файла с данными можно выбрать:
- Находится ли в файле содержимое одной структуры, либо файл содержит несколько структур (Data for one source structure или Data for multiple source structures)
- Определить разделители в файле между полями (; tab и др.)
- Содержит ли файл названия полей (Field names at start of file, необходимо чтобы имена совпадали с именами в пользовательской структуре)
- Совпадает ли порядок полей в файле с порядком в пользовательской структуре (Field Order Matches Source Structure Definition)
- Тип файла (Текстовый, бинарный) и кодовая страница по умолчанию (ASCII или IBM).
На данном шаге можно определить шаблон для группы файлов, на рисунке ниже показано как это делается, в данном примере структура HEADER будет заполняться из набора файлов с именами файлов: PO HEADER * .txt, структура POSITION из файлов PO POSITION* .txt. Обратите внимание что файлы с правилами чтения, преобразования так же создаются со значением «*» в имени файла, кроме того необходимо создать 2 набора (wildcards):

Присвоение файлов структурам(Assign Files)
На данном этапе задается из какого файла будет читаться структура. Если структура одна данный шаг можно пропустить.
Генерация программы считывания (Generate Read Program)
На данном этапе генерируется программа чтения данных из файла. Можно пропустить.
Просмотр программы чтения (Generate Read Program)
Просмотр исходника программы чтения файлов. Можно пропустить.
Чтение данных (Read Data)
На данном шаге определяется количество записей, которые необходимо считать (Transaction Number). Если при определении полей структуры было указано что поле должно показываться на экране выбора чтения/конвертации данных, так же его необходимо заполнить. Так же задаются правила для преобразования чисел и дат.

В данном случае при чтении файла проверяется поле CUSTOMERNUMBER.
Просмотр считанных данных (Display Read Data)
На данном шаге отображаются считанные из файлов данные.
Генерация программы преобразования (Generate Conversion Program)
На данном этапе генерируется программа по преобразованию считанных данных. Можно пропустить.
Конвертация данных (Convert Data)
На данном этапе производится преобразование считанных данных в поля объекта LSMW. (BAPI, поля Batch input и т.п.). Если в пользовательской структуре были поля указанные как поля ввода, необходимо их так же ввести.

Просмотр присвоений после конвертации (Display Converted Data)
На данном шаге показываются все присвоения после конвертации данных.
Импорт данных
В зависимости от типа объекта LSMW далее будут отображены следующие шаги:
- Standard batch input or Recordings: Generate batch input session – создание сессии пакетного ввода, Run batch input session – запуск сессии пакетного ввода.
- Standard direct input: start direct input session – запуск сессии direct input.
- BAPI или IDOCs: Start IDoc Creation, Start IDoc Processing, Create IDoc Overview, Start IDoc processing.
После выполнения шагов по импорту данных, если все шаги были правильно определены, данные будут записаны в SAP систему. При запуске в продуктивной системе, если расположение файлов не изменилось, выполнять пункты до определения файлов уже не нужно.
Перенос проектов LSMW.
Для переноса проекта LSMW в систему контроля качества (продуктивную систему) необходимо создать запрос на перенос. На главном экране LSMW Extras -> Generate Change Request. При переносе старый проект удаляется и создается заново.
Экспорт/импорт проектов.
Для экспорта/импорта проектов в главном меню: Extras -> Export (Import).
Запись пакетного ввода (Recordings)
Для создания записи пакетного ввода на начальном экране необходимо перейти по Go to -> Recordings. Обратите внимание, что при создании записи нет режима симуляции, т.е. все изменения которые совершите в системе, сохранятся в ней. Для объекта LSMW можно назначить несколько записей пакетного ввода.

Вы можете назначать полям пакетного ввода значения по умолчанию (столбец слева), поля которым присвоены имена (столбец справа — красные) на шаге «Maintain Field Mapping and Conversion Rules» будет возможно присваивать значения из пользовательской структуры (создавать привязку).
Время на прочтение
6 мин
Количество просмотров 38K
При внедрении ERP-системы SAP одним из наиважнейших вопросов является вопрос загрузки данных исторических систем (тех, что функционировали на предприятии до внедрения SAP) в новую ERP. Для этого существует мощнейший инструмент внутри SAP — Система Переноса данных из Исторических Систем (LSMW). За 8 лет работы с SAP я накоил солидный опыт работы с этой системой, а, поскольку для LSMW нет легкодоступных для понимания мануалов (тем более на русском) и ко мне постоянно обращаются за советами коллеги по цеху, найдя меня на российском форуме САП, смею полагать, что сия статья окажется весьма познавательна как стажёрам, так и опытным консультантам, пока что не имеющих опыта работы с LSWM.
Запускаем транзакцию LSMW и, о чудо, нас уже приветствуют: Welcome to the Legacy System Migration Workbench!
На начальном экране мы видим следующую картинку
Перво-наперво, нужно создать проект (Project). Проектом может быть как, например, верхнеуровневый «проект» (например, с названием «PM» для работы с ним всей группы ТОРО (Техническое обслуживание и ремонт оборудования)), так и более локализованный, например, проект загрузки в систему Технических Объектов (назовём его «Tech Objects»). Я рекомендую не плодить сущности и, вспомнив заповедь дядюшки Окама, в качестве проекта заводить как-раз таки верхний уровень. Это очень удобно всем проектным группам — в LSMW видеть в качестве проекта свои модули.
Становимся курсором в поле Project и жмём белый листок. Создаём проект. В случае с моим примером это будет «PM».
Затем создаём подпроект (Subproject). Это тоже всего лишь структуризация вашего проекта, поэтому в зависимости от принятого решения о выборе проекта соответствующим образом создаём и подпроект. В случае моего примера, подпроектом будет как-раз «Tech Objects».
Ну и объект (Object). Тут уже детализируем, что именно мы собираемся грузить в систему/изменять с помощью LSMW. Например, мне требуется загрузить данные Единиц Оборудования. В таком случае, я создаю объект “PoE Upload”
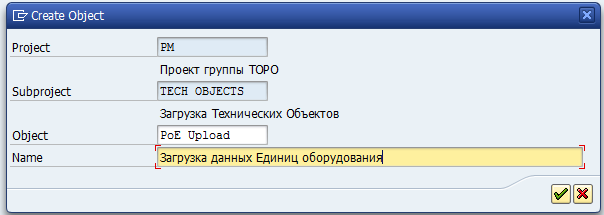
Создали проект, подпроект и объект, запускаем.
Видим экран с двадцатью шагами
(в пункте меню Edit включаем Numering On для того, чтобы напротив каждого шага отображался порядковый номер)
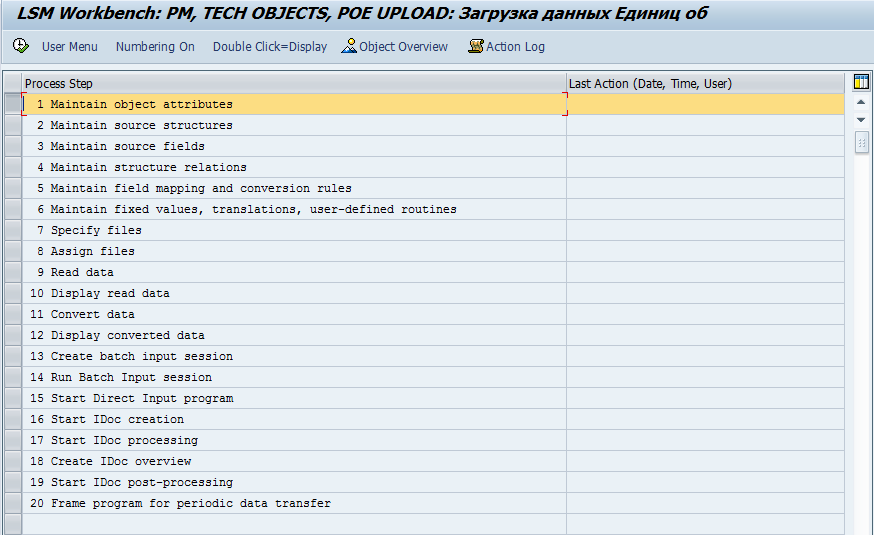
1) Шаг первый — Maintain object attributes
На этом шаге нам необходимо указать, каким образом мы будем производить загрузку данных. Я остановлюсь на двух наиболее часто используемых мною и популярных в принципе методах.
A) Стандартный Объект (Standart Batch/Direct Input)
В LSMW предусмотрен перечень предопределённых объектов, среди оторых с большой долей вероятности есть тот, который нужен вам.
В моём случае это Единица оборудования
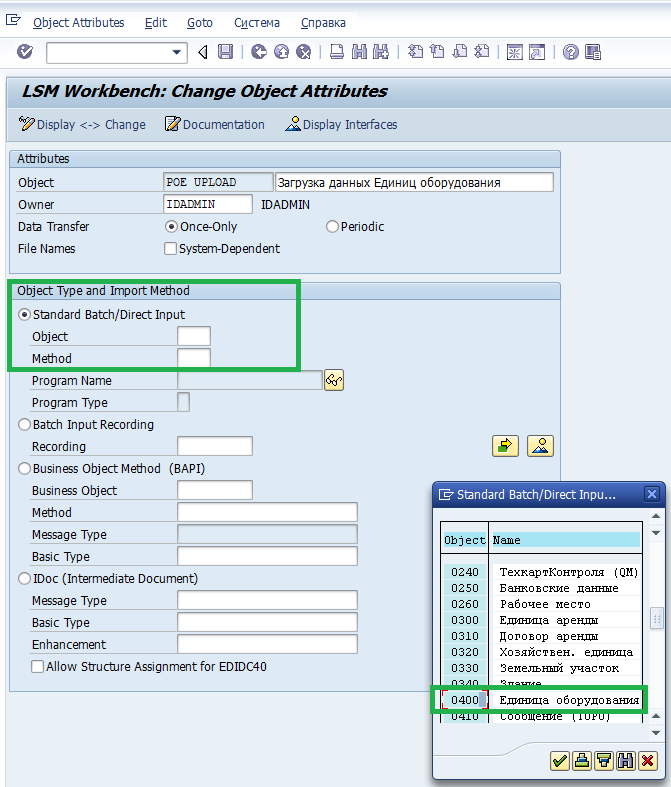
В поле Method выбираем 0001 — Создание ПакВв (то есть «пакетный ввод»).
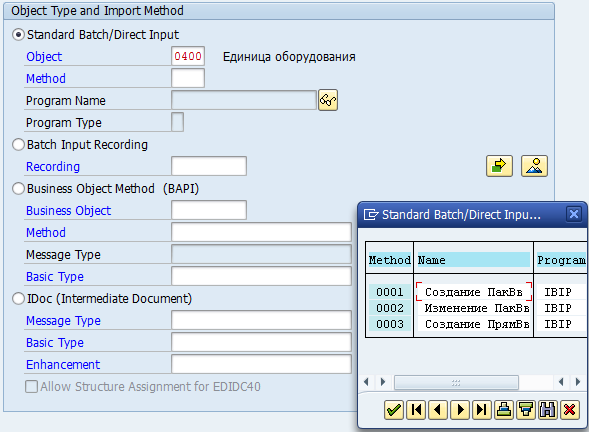
Сохраняем, выходим.
B) Batch Input Recording
Если вам не достаточно стандартного объекта, либо для ваших нужд стандартного объекта нет в принципе, в этом случае вам необходимо записать «макрос» (так я его называю). То есть вы вызовете транзацкию, данные которой вам и необходимо загрузить, и записываете последовательность ваших действий, а потом, на последующих шагах, подстать записанному «макросу» вы создадите структуру для файла-шаблона загрузки.
Метод Batch Input Recording я распишу при наличии времени в отдельном топике (это большая отдельная тема), если топик найдёт своего читателя.
2) Шаг второй — Maintain source structures
На этом шаге нам необходимо определить структуру наших загружаемых данных. В случае с Единицами Оборудования структура будет одноуровневой («плоской»), без подчинённых подструктур. Последние бы пригодились нам, скажем, в случае загрузки Заказов ТОРО, когда для одного заголовка Заказа может быть N операций, к каждй из которых может быть M компонентов. А у единицы оборудования есть номер и набор данных, без вложенности.
Если структура плоская, то этот шаг — формальность. Создаём структуру, например, «Main». Сохраняем, выходим.
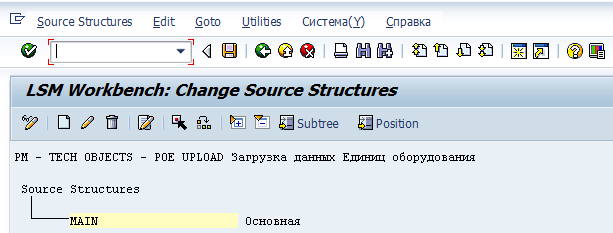
3) Шаг третий — Maintain source fields
На шаге 3 определяем поля, которые мы планируем грузить.Позиционируем курсор на нашу структуру Main, жмём значок «белый лист» и создаём поля.
Поля — это те поля, которые вы собираетесь прогружать для вашего объекта. В моём случае я хочу, скажем, для Единицы Оборудования грузить:
— номер ЕО
— название ЕО
— вид объекта
Это, естественно, пример. Вы можете грузить любые поля. Я же для краткости ограничусь лишь этими тремя.
Чтобы в дальнейшем, на шаге №5 вам не заморачиваться с сопоставлением вами придуманных названий полей с ситемными полями, да и просто для чёткости, предлагаю именовать поля также, как они именуются в системе. Чтобы узнать, как называется то или иное поле, какого они типа и какой разрядности, становимся курсором на это поле и жмём «F1».
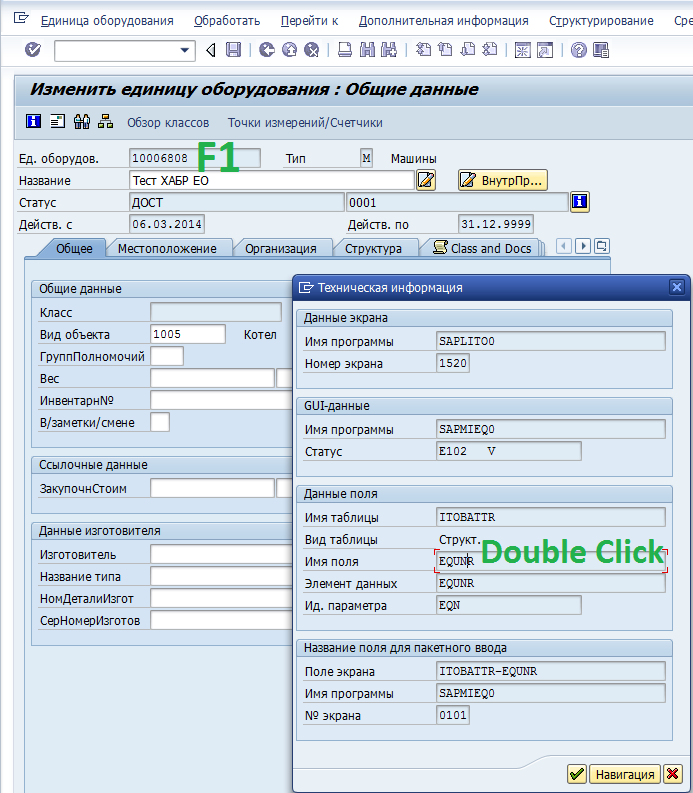
В появившемся окне проваливаемся по двойному клику (drill down) в запись «Имя поля»
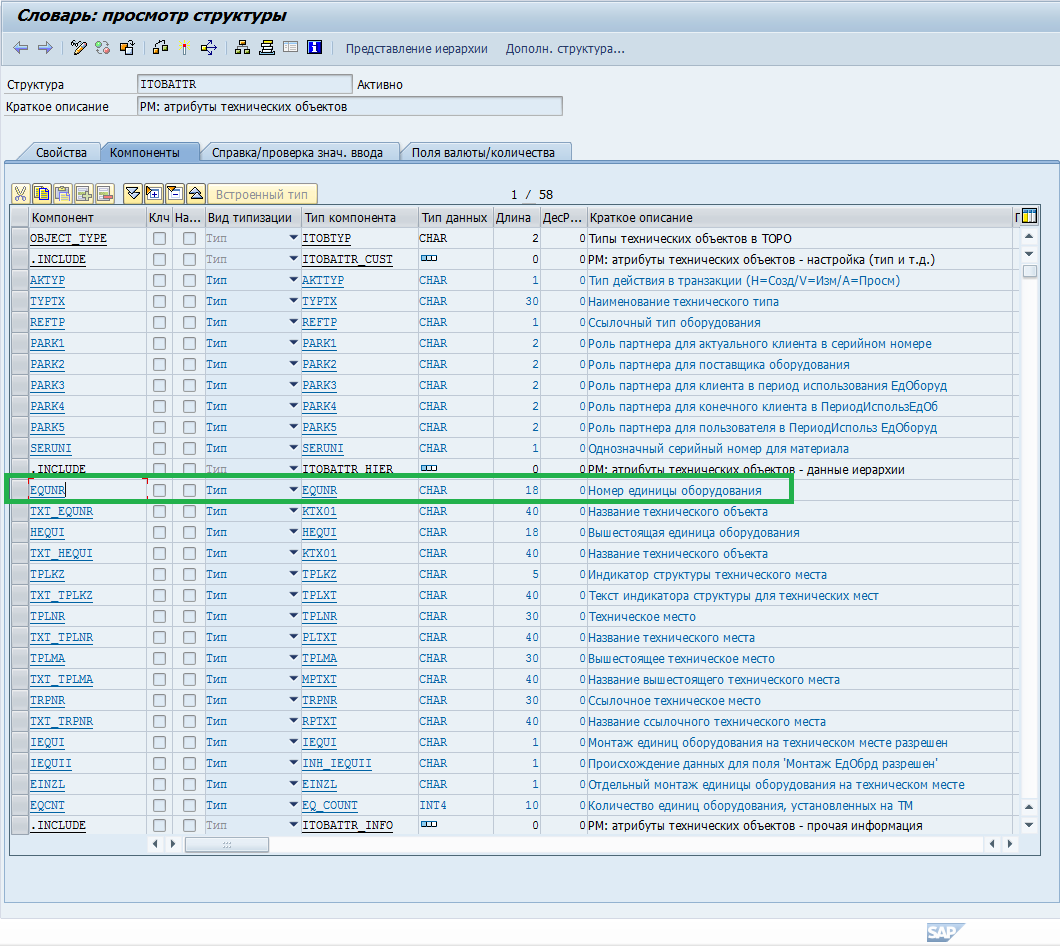
Среди полей находим интересующее нас (в данном случае «Номер единицы оборудования» — это поле EQNR), его тип (CHAR) и длину (18 символов). И, соответственно, эти данные прописываем в создаваемое на третьем шаге поле
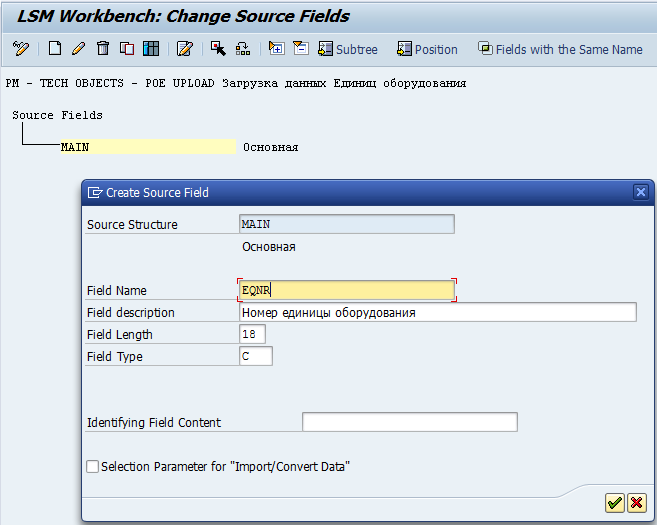
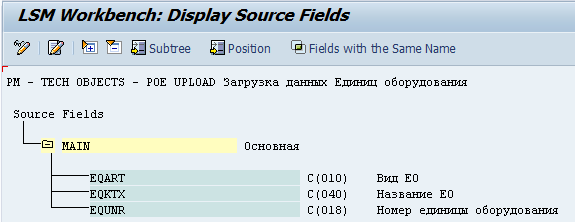
Создали набор интересующих нас в качестве загружаемых полей, сохраняем, выходим.
4) Шаг четвёртый — Maintain structure relations
На этом шаге нам необходимо связать наши структуры с стандартными. В случаес моей простой, плоской структурой всё очень просто: позиционируем курсор на IBIP: Удиница Оборудования, жмём белый листочек. Единственная наша структура Main автоматом подвязывается к стандартной структуре ЕО. Сохраняем, выходим.
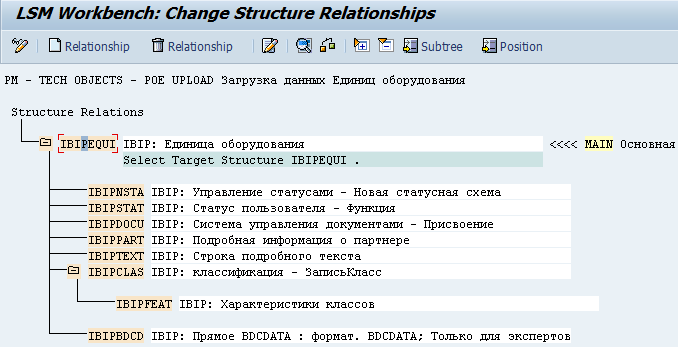
5) Шаг пятый — Maintain field mapping and conversion rules
Здесь нам требуется связать нами созданные поля, предполагаемые к загрузке, с соответствующими полями ЕО, известными системе
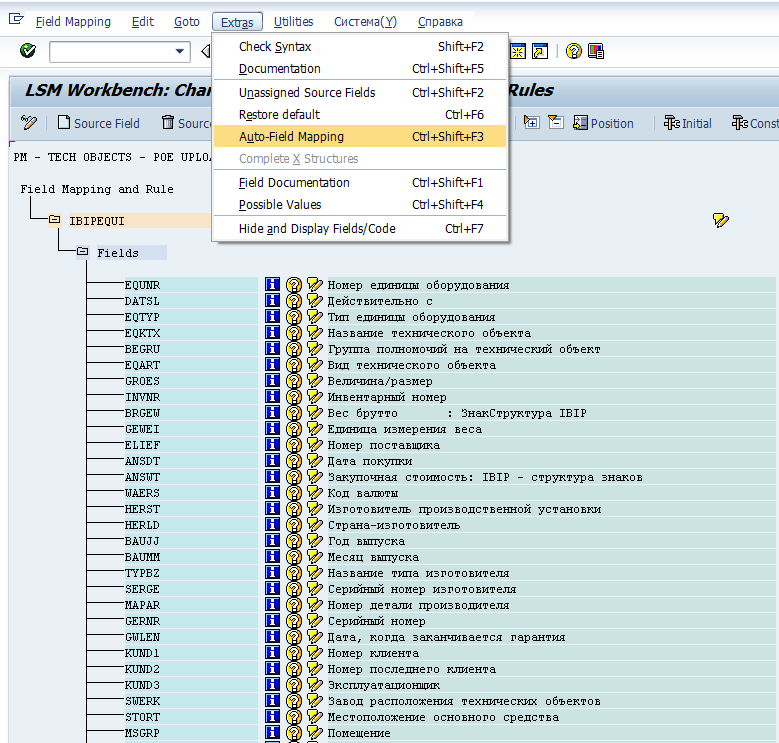
Вот тут-то нам и пригодится тто, что на шаге №3 мы обзывали поля также, как их знает система. Теперь в пункте меню Extras жмякаем на Auto-Field Mapping, после чего система автоматом смэппливает поля. Во всех далее появляющихся окошках необходимо нажимать «ОК» и, если у вас нет ошибок в наименовании вами созданных полей, то система автоматом всё смэппит.
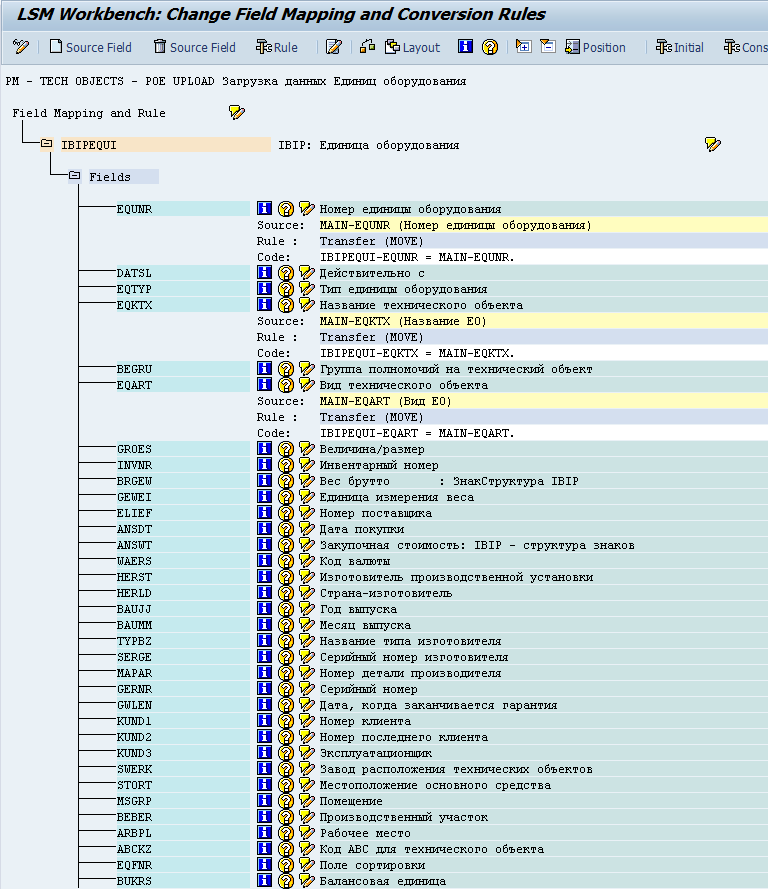
После того, как все поля смэпплены, сохраняем и выходим.
6) Шаг шестой — Maintain fixed values, translations, user-defined routines
Пропускаем, он нам в данном случае не нужен.
7) Шаг седьмой — Specify files
На этом шаге нам необходимо указать файла-шаблона с данными к загрузке.
Тут два варианта:
а) Legacy Data On the PC (Frontend)
б) Legacy Data On the R/3 server (application server)
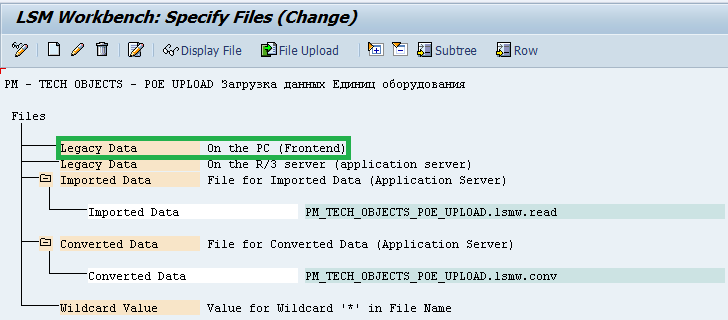
Вариант «а» — это выбор файла-шаблона, располагающего непосредственно на Вашем компьютере, а «б» — на сервере SAP. Со вторым вариантом как-то не сталкивался. Всё время для удобства использую файл, находящийся непосредственно в моей файловой системе. Позиционируемся на Legacy Data (на красную область, жмём листочек «Создать»)
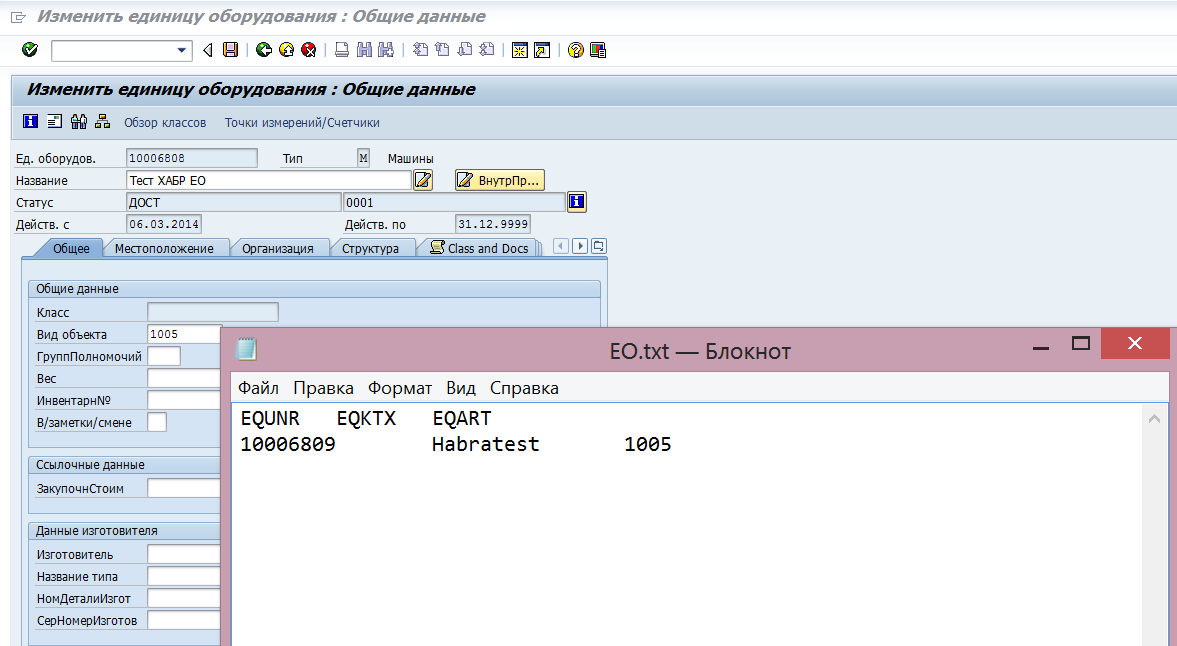
Собственно, создаём текстовый файл на жёстком диске. Вспоминаем, что груим мы три поля:
Номер ЕО
Название ЕО
Вид ЕО
Можно в файле-шаблоне первой строкой через TAB указать системные названия полей для наглядности. Во второй и последующих строчках также через TAB пишем значения для загрузки
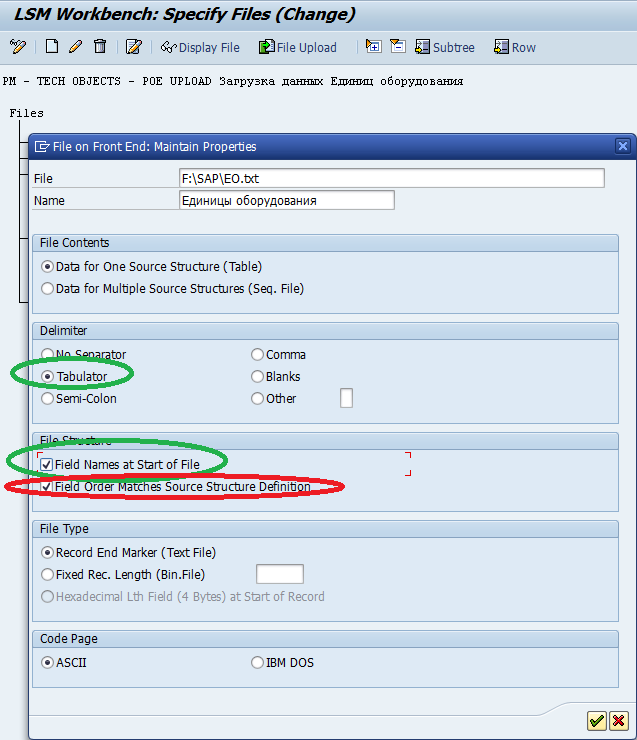
На появившемся экране выбираем месторасположения файла-шаблона на диске Вашего компьютера, устанавливаем радиокнопку “Tabulator” на подэкране Delimiter (разделитель), ставим галку на пункте “Field Names at Start of File” (указываем, что первая строка файла — это технические имена полей).
Если у Вас последовательность полей в файле-шаблоне не соответствует соответствующей последовательности шага три — Maintain source fields, то нужно снять галку с пункта “Fields Order Matches Source Structure Definition”. Остальное на экране не трогаем, закрываем и выходим.
 Шаг восьмой — Assign files
Шаг восьмой — Assign files
Поскольку у нас плоская структура с одним входящим файлом-шаблоном, открываем этот пункт на редактирование, сохраняем и выходим. Единственный файл наш привязывается к единственной структуре. Формальность.
9) Шаг девятый – Read Data
На этом шаге мы читаем наш файл. Выполняем.
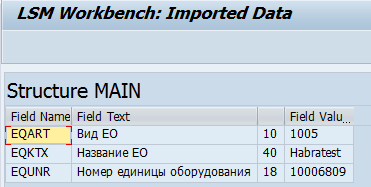
10) Шаг десятый – Display read data
Здесь смотрим на результаты чтения на шаге 10. Если всё нормально, то в правильные поля ложатся правильные данные
11) Шаг одиннадцатый – Convert data
Конвертируем данные во внутренний формат системы
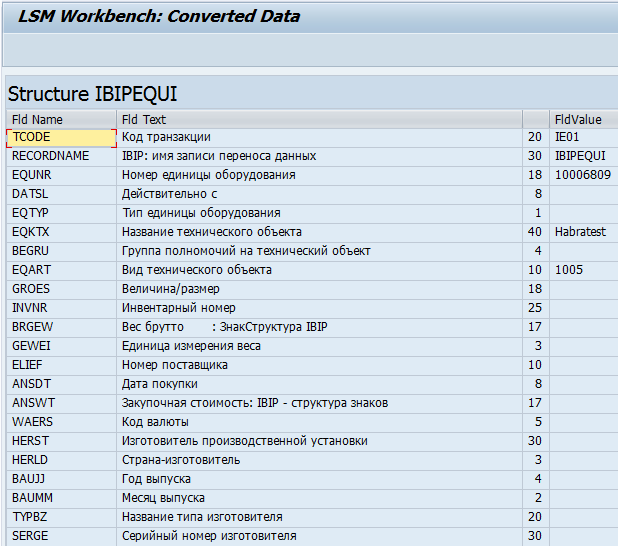
12) Шаг двенадцатый – Display converted data
Собственно, смотрим результаты конвертации
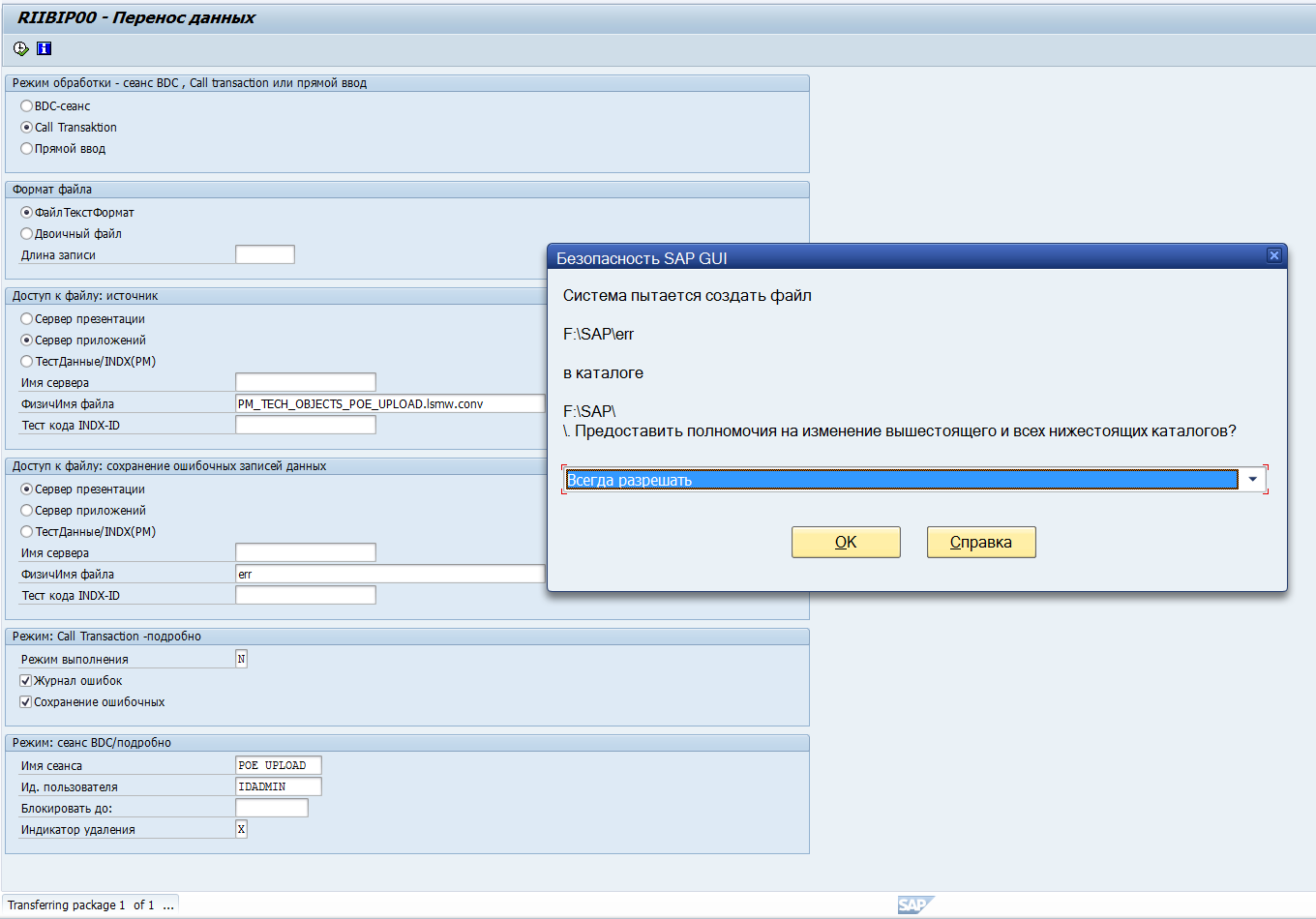
13) Шаг тринадцатый – Create batch input session
Запускаем, галочки выставляем как на принтскрине ниже и разрешаем SAP GUI создавать файл ошибок на локальном жд
14) Шаг четырнадцатый – Run Batch Input session
Запускаем, видим в списке заданий наше. Выделяем строку, жмём «выполнить», открывается окошко. В нём можно выбрать «Выполнить видимо» (тогда каждое заполняемой поле по каждой из N строк из файла-шаблона будет заполняться видимо для Вас и требовать для подтверждения каждой записи нажатия Enter; обычно это используется для теста написанного нами пакетника на одной строчке), либо «Фоновый режим». В фоновом режиме выполнение пакетника будет происходить незримо, а о возникших ошибках или их отсутствии можно будет осведомиться в log-файле.
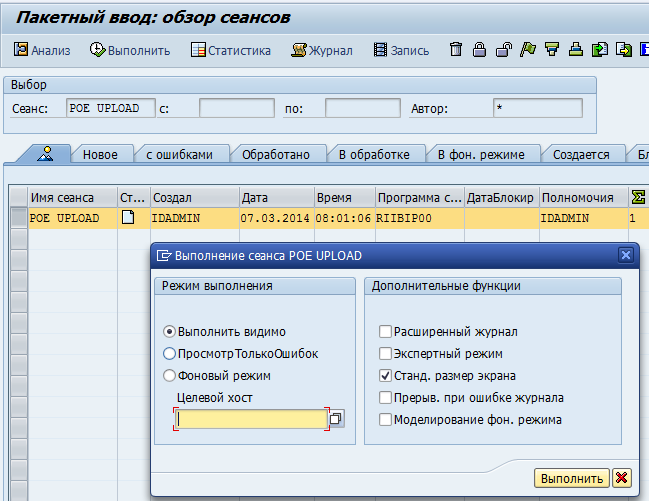
Этот пример я создавал без предварительной репетиции. В частности, на видимом прогоне я понял, что не указал на третьем шаге обязательное при создании ЕО поле «Тип ЕО», а также, поскольку нумерация для ЕО соотв. типа — внутренняя (то есть нарастающий счётчик), то не нужно было указывать в качестве загружаемого поля поле EQUNR. После исправления этих двух ляпов пакетник успешно отработал и автоматизированно создал ЕО. Таким образм и происходит массовая загрузка исторических данных в SAP. По крайней мере, это один из наиудобнейших и простых способов. Удачи в освоении LSMW!
![]()
![]()
saphcmsolutions.com
We’re under construction. Please check back for an update soon.