Время на прочтение
4 мин
Количество просмотров 1M
На Хабре, да и не только, про ботов рассказано уже так много, что даже слишком. Но заинтересовавшись пару недель назад данной темой, найти нормальный материал у меня так и не вышло: все статьи были либо для совсем чайников и ограничивались отправкой сообщения в ответ на сообщение пользователя, либо были неактуальны. Это и подтолкнуло меня на написание статьи, которая бы объяснила такому же новичку, как я, как написать и запустить более-менее осмысленного бота (с возможностью расширения функциональности).
Часть 1: Регистрация бота
Самая простая и описанная часть. Очень коротко: нужно найти бота @BotFather, написать ему /start, или /newbot, заполнить поля, которые он спросит (название бота и его короткое имя), и получить сообщение с токеном бота и ссылкой на документацию. Токен нужно сохранить, желательно надёжно, так как это единственный ключ для авторизации бота и взаимодействия с ним.
Часть 2: Подготовка к написанию кода
Как уже было сказано в заголовке, писать бота мы будем на Python’е. В данной статье будет описана работа с библиотекой PyTelegramBotAPI (Telebot). Если у вас не установлен Python, то сперва нужно сделать это: в терминале Linux нужно ввести
sudo apt-get install python python-pipЕсли же вы пользуетесь Windows, то нужно скачать Python с официального сайта .
После, в терминале Linux, или командной строке Windows вводим
pip install pytelegrambotapiТеперь все готово для написания кода.
Часть 3: Получаем сообщения и говорим «Привет»
Небольшое отступление. Телеграмм умеет сообщать боту о действиях пользователя двумя способами: через ответ на запрос сервера (Long Poll), и через Webhook, когда сервер Телеграмма сам присылает сообщение о том, что кто-то написал боту. Второй способ явно выглядит лучше, но требует выделенного IP-адреса, и установленного SSL на сервере. В этой статье я хочу рассказать о написании бота, а не настройке сервера, поэтому пользоваться мы будем Long Poll’ом.
Открывайте ваш любимый текстовый редактор, и давайте писать код бота!
Первое, что нужно сделать это импортировать нашу библиотеку и подключить токен бота:
import telebot;
bot = telebot.TeleBot('%ваш токен%');Теперь объявим метод для получения текстовых сообщений:
@bot.message_handler(content_types=['text'])
def get_text_messages(message):В этом участке кода мы объявили слушателя для текстовых сообщений и метод их обработки. Поле content_types может принимать разные значения, и не только одно, например
@bot.message_handler(content_types=['text', 'document', 'audio'])Будет реагировать на текстовые сообщения, документы и аудио. Более подробно можно почитать в официальной документации
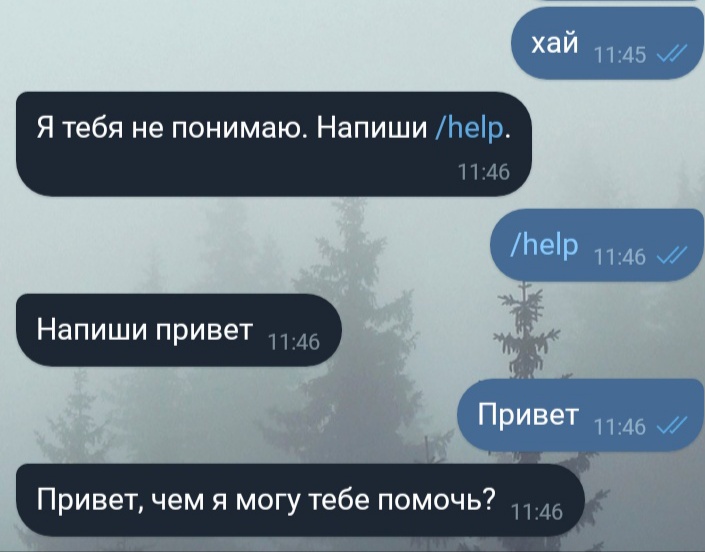
Теперь добавим в наш метод немного функционала: если пользователь напишет нам «Привет», то скажем ему «Привет, чем я могу помочь?», а если нам напишут команду «/help», то скажем пользователю написать «Привет»:
if message.text == "Привет":
bot.send_message(message.from_user.id, "Привет, чем я могу тебе помочь?")
elif message.text == "/help":
bot.send_message(message.from_user.id, "Напиши привет")
else:
bot.send_message(message.from_user.id, "Я тебя не понимаю. Напиши /help.")Данный участок кода не требует комментариев, как мне кажется. Теперь нужно добавить в наш код только одну строчку (вне всех методов).
bot.polling(none_stop=True, interval=0)Теперь наш бот будет постоянно спрашивать у сервера Телеграмма «Мне кто-нибудь написал?», и если мы напишем нашему боту, то Телеграмм передаст ему наше сообщение. Сохраняем весь файл, и пишем в консоли
python bot.pyГде bot.py – имя нашего файла.
Теперь можно написать боту и посмотреть на результат:
Часть 4: Кнопки и ветки сообщений
Отправлять сообщения это несомненно весело, но ещё веселее вести с пользователем диалог: задавать ему вопросы и получать на них ответы. Допустим, теперь наш бот будет спрашивать у пользователя по очереди его имя, фамилию и возраст. Для этого мы будем использовать метод register_next_step_handler бота:
name = '';
surname = '';
age = 0;
@bot.message_handler(content_types=['text'])
def start(message):
if message.text == '/reg':
bot.send_message(message.from_user.id, "Как тебя зовут?");
bot.register_next_step_handler(message, get_name); #следующий шаг – функция get_name
else:
bot.send_message(message.from_user.id, 'Напиши /reg');
def get_name(message): #получаем фамилию
global name;
name = message.text;
bot.send_message(message.from_user.id, 'Какая у тебя фамилия?');
bot.register_next_step_handler(message, get_surnme);
def get_surname(message):
global surname;
surname = message.text;
bot.send_message('Сколько тебе лет?');
bot.register_next_step_handler(message, get_age);
def get_age(message):
global age;
while age == 0: #проверяем что возраст изменился
try:
age = int(message.text) #проверяем, что возраст введен корректно
except Exception:
bot.send_message(message.from_user.id, 'Цифрами, пожалуйста');
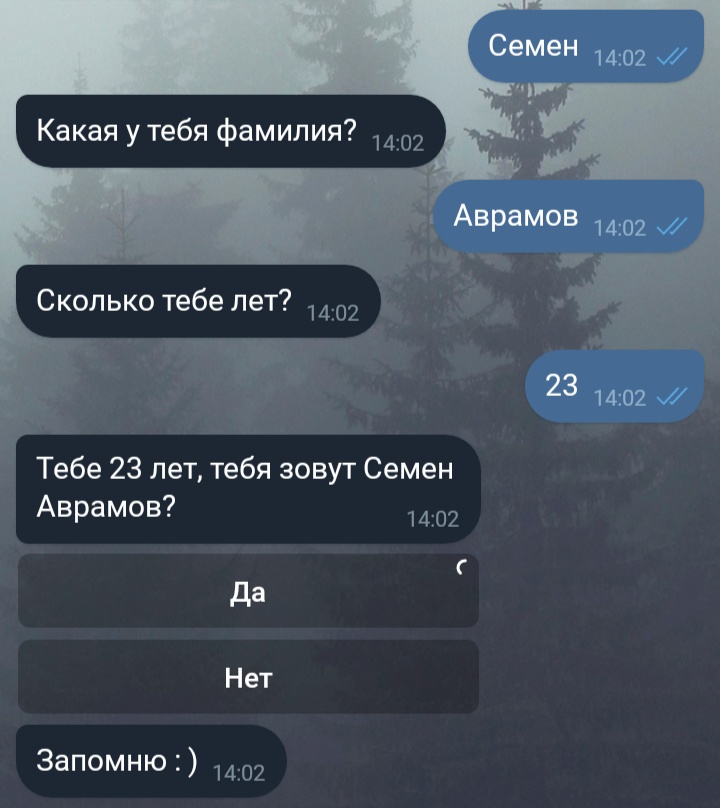
bot.send_message(message.from_user.id, 'Тебе '+str(age)+' лет, тебя зовут '+name+' '+surname+'?')
И так, данные пользователя мы записали. В этом примере показан очень упрощённый пример, по хорошему, хранить промежуточные данные и состояния пользователя нужно в БД, но мы сегодня работаем с ботом, а не с базами данных. Последний штрих – запросим у пользователей подтверждение того, что все введено верно, да не просто так, а с кнопками! Для этого немного отредактируем код метода get_age
def get_age(message):
global age;
while age == 0: #проверяем что возраст изменился
try:
age = int(message.text) #проверяем, что возраст введен корректно
except Exception:
bot.send_message(message.from_user.id, 'Цифрами, пожалуйста');
keyboard = types.InlineKeyboardMarkup(); #наша клавиатура
key_yes = types.InlineKeyboardButton(text='Да', callback_data='yes'); #кнопка «Да»
keyboard.add(key_yes); #добавляем кнопку в клавиатуру
key_no= types.InlineKeyboardButton(text='Нет', callback_data='no');
keyboard.add(key_no);
question = 'Тебе '+str(age)+' лет, тебя зовут '+name+' '+surname+'?';
bot.send_message(message.from_user.id, text=question, reply_markup=keyboard)
И теперь наш бот отправляет клавиатуру, но если на нее нажать, то ничего не произойдёт. Потому что мы не написали метод-обработчик. Давайте напишем:
@bot.callback_query_handler(func=lambda call: True)
def callback_worker(call):
if call.data == "yes": #call.data это callback_data, которую мы указали при объявлении кнопки
.... #код сохранения данных, или их обработки
bot.send_message(call.message.chat.id, 'Запомню : )');
elif call.data == "no":
... #переспрашиваем
Остаётся только дописать в начало файла одну строку:
from telebot import typesВот и всё, сохраняем и запускаем нашего бота:
#Руководства
-

0
Большой гайд по работе с Aiogram на примере эхо‑бота — чат‑бота, который повторяет за пользователем его фразы. Весь код — внутри статьи.
Иллюстрация: Polina Vari для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Компании используют чат-ботов в Telegram для разных задач: рассылают новости о текущих акциях, принимают платежи или даже организуют службы технической поддержки. Обычные пользователи тоже применяют их для своих бытовых нужд — ведут учёт личных финансов или оформляют посты в социальных сетях.
Благодаря этой статье вы научитесь с нуля создавать чат-ботов с помощью Python и библиотеки Aiogram. Мы напишем эхо-бота, который отвечает на сообщения пользователя точно такими же сообщениями. Это первая часть урока по Aiogram — во второй части мы добавим боту кнопки и новые фичи.
Содержание
- Библиотеки для создания бота
- Краткое описание Aiogram
- Создаём эхо-бота
- Шаг 1. Устанавливаем Python
- Шаг 2. Создаём виртуальное окружение
- Шаг 3. Создаём бота
- Шаг 4. Подключаем Aiogram
- Шаг 5. Пишем код для эхо-бота
- Шаг 6. Запускаем бота и проверяем работу
- Что дальше?
Для создания телеграм-ботов на Python существует несколько десятков библиотек. Они различаются популярностью, размером комьюнити и функциональностью. Рассмотрим самые популярные.
Aiogram. Современная библиотека, набирающая популярность: многие чат-боты написаны на ней. В этой и последующих статьях цикла мы будем работать именно с Aiogram. Библиотека реализует асинхронное выполнение кода, что позволяет не останавливать работу бота в ожидании ответа пользователя. Кроме того, у Aiogram есть подробная документация и большое русскоязычное комьюнити.
Python-telegram-bot. Одна из первых библиотек для создания ботов. Отличается от Aiogram синхронным подходом к работе, то есть при ожидании ответа от пользователя выполнение кода останавливается.
TeleBot. Библиотека для создания простых ботов, позволяющая работать с асинхронным и синхронным подходом на выбор. Подходит для небольших проектов. Подробнее можно узнать в документации.
Перед тем как приступить к написанию нашего бота, остановимся подробнее на одной технической особенности Aiogram.
Как уже было сказано ранее, одно из главных достоинств библиотеки — полная асинхронность. Она использует синтаксис async/await, который позволяет программе выполнять несколько задач одновременно и эффективно управлять потоком выполнения.
Вот простой пример функции, использующей механизм async/await:
# Хендлер для команды /start
@dp.message(Command("start"))
async def start(message: types.Message):
await message.answer("Привет, пользователь!")
Функция, которая обрабатывает сообщение пользователя в Telegram, называется хендлером, то есть обработчиком. У каждой команды или группы команд свой обработчик.
В хендлере мы прописываем, что бот должен сделать в ответ на сообщение. А для того, чтобы для каждой команды вызывался нужный обработчик, функция оборачивается в декоратор, которому передаётся имя команды без символа /.
Служебное слово async указывает интерпретатору, что функция будет работать в асинхронном режиме. Это означает, что интерпретатору не нужно ждать, пока выполняется код функции, — он может выполнять следующие инструкции, пока start что-нибудь не вернёт. Это «что-нибудь» следует за служебным словом await («ожидать»), а не return, как в обычном коде.

Другой плюс Aiogram — в большом наборе инструментов и хуков, которые можно использовать для добавления дополнительных функций и настроек бота. Библиотека обеспечивает полный доступ ко всем возможностям Telegram API, включая отправку и получение сообщений, управление клавиатурой, обработку медиафайлов (фотографий, видео, документов) и многое другое.
Вот несколько полезных источников, которые помогут разобраться в библиотеке и следить за её обновлениями:
- официальная документация,
- репозиторий библиотеки на GitHub,
- русскоязычный телеграм-чат, посвящённый Aiogram,
- англоязычный чат, посвящённый Aiogram,
- канал с новостями библиотеки,
- тестовый бот на основе Aiogram.
Переходим к созданию телеграм-бота. Потренируемся на простом примере — создадим эхо-бота, который отвечает на сообщения пользователя его же словами.
Для этого нам необходимо:
- установить Python и настроить виртуальное окружение;
- зарегистрировать бота в специальном телеграм-канале @BotFather;
- установить библиотеку Aiogram;
- написать код эхо-бота, связав его по API с Telegram.
На macOS или Linux. Python установлен в эти операционные системы изначально. Чтобы проверить его наличие, откройте терминал и введите команду:
python --version
Если Python установлен, то терминал покажет его версию:

На Windows требуется установка Python. Сделать это проще всего по нашей инструкции.
После установки и проверки Python требуется установить виртуальное окружение с помощью virtualenv. Это специальный инструмент, который позволяет изолировать друг от друга проекты в разработке, независимо устанавливая для них библиотеки и пакеты. Удобно, когда вы работаете над разными приложениями одновременно.
virtualenv устанавливается через терминал:
sudo pip3 install virtualenv
После этого необходимо создать директорию для проекта, внутри которой будет работать виртуальное окружение:
mkdir telegram_bot
cd telegram_bot
Команда mkdir создаст папку telegram_bot, а команда cd переведёт нас в неё. Теперь в этой директории будут храниться файлы проекта, связанные с нашим ботом.
Развернём виртуальное окружение внутри папки telegram_bot:
virtualenv venv -p python3
Теперь его активируем. Если этого не сделать, то оно не будет работать.
source venv/bin/activate
Виртуальное окружение запущено, и мы готовы перейти к следующему шагу.
Для создания бота необходимо воспользоваться Telegram и ботом @BotFather. Откройте мессенджер и введите название бота в поисковой строке:
Открываем его, жмём кнопку «Запустить» и вводим команду /newbot:
Теперь напишем название и юзернейм для нашего бота. Назовём его echo_skillbox_bot (теперь это имя занято, так что вам надо будет придумать своё). В ответ придёт наш токен, который мы будем использовать для подключения к API Telegram.
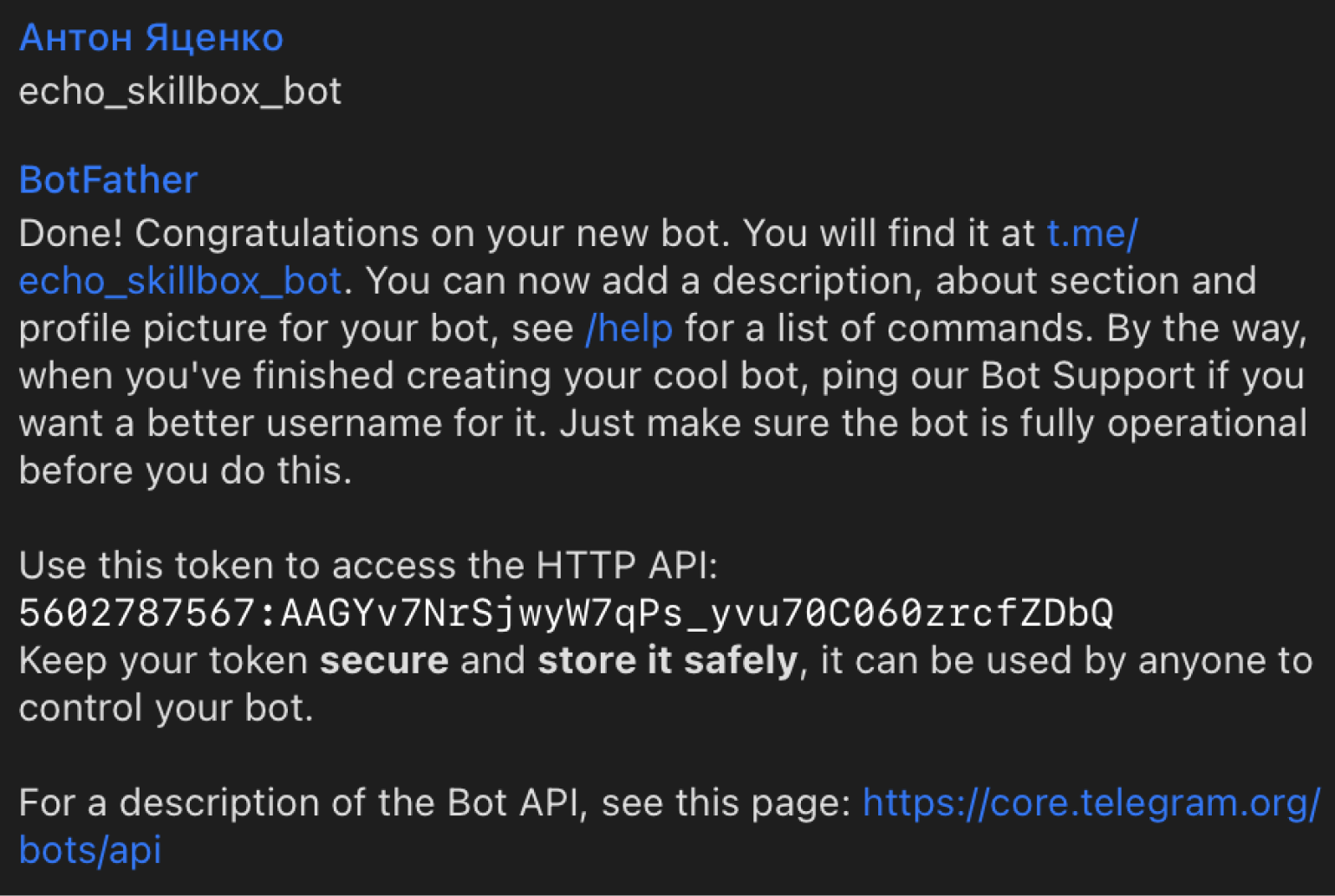
Этот токен мы сохраняем — он потребуется нам в будущем.
Для установки Aiogram воспользуемся менеджером пакетов PIP. Вводим в терминал:
pip install aiogram
Важно! Библиотека устанавливается в созданное ранее виртуальное окружение, связанное с папкой telegram_bot. Если вы решите создать нового бота в другой директории на компьютере, то установку будет необходимо провести заново, иначе Aiogram не будет работать.
Писать код на Python лучше всего в IDE, а не в окне терминала. В проекте ниже мы будем использовать бесплатный редактор Visual Studio Code, но вы можете воспользоваться любым удобным для вас инструментом.
Откроем IDE и создадим файл main.py. Для этого проекта нам потребуется только он. Импортируем из Aiogram нужные классы и модуль:
from aiogram import Bot, Dispatcher, executor, types
Разберёмся, что каждый из них делает. Начнём с классов:
- Bot определяет, на какие команды от пользователя и каким способом отвечать.
- Dispatcher позволяет отслеживать обновления.
- Executor запускает бота и выполняет функции, которые следует выполнить.
Модуль types позволит нам использовать базовые классы для аннотирования, то есть восприятия сообщений. Например, мы будем использовать types.Message, позволяющий работать с приёмом текстовых сообщений пользователя. Подробно об этом можно прочесть в документации.
Импортируем наш токен, который поможет коммуницировать с API Telegram:
API_TOKEN = '5602787567:AAGYv7NrSjwyW7qPs_yvu70C060zrcfZDbQ' #В одинарных кавычках размещаем токен, полученный от @BotFather.
Теперь необходимо инициализировать объекты bot и Dispatcher, передав первому наш токен. Если их не инициализировать, то код не будет работать.
bot = Bot(token=API_TOKEN) dp = Dispatcher(bot)
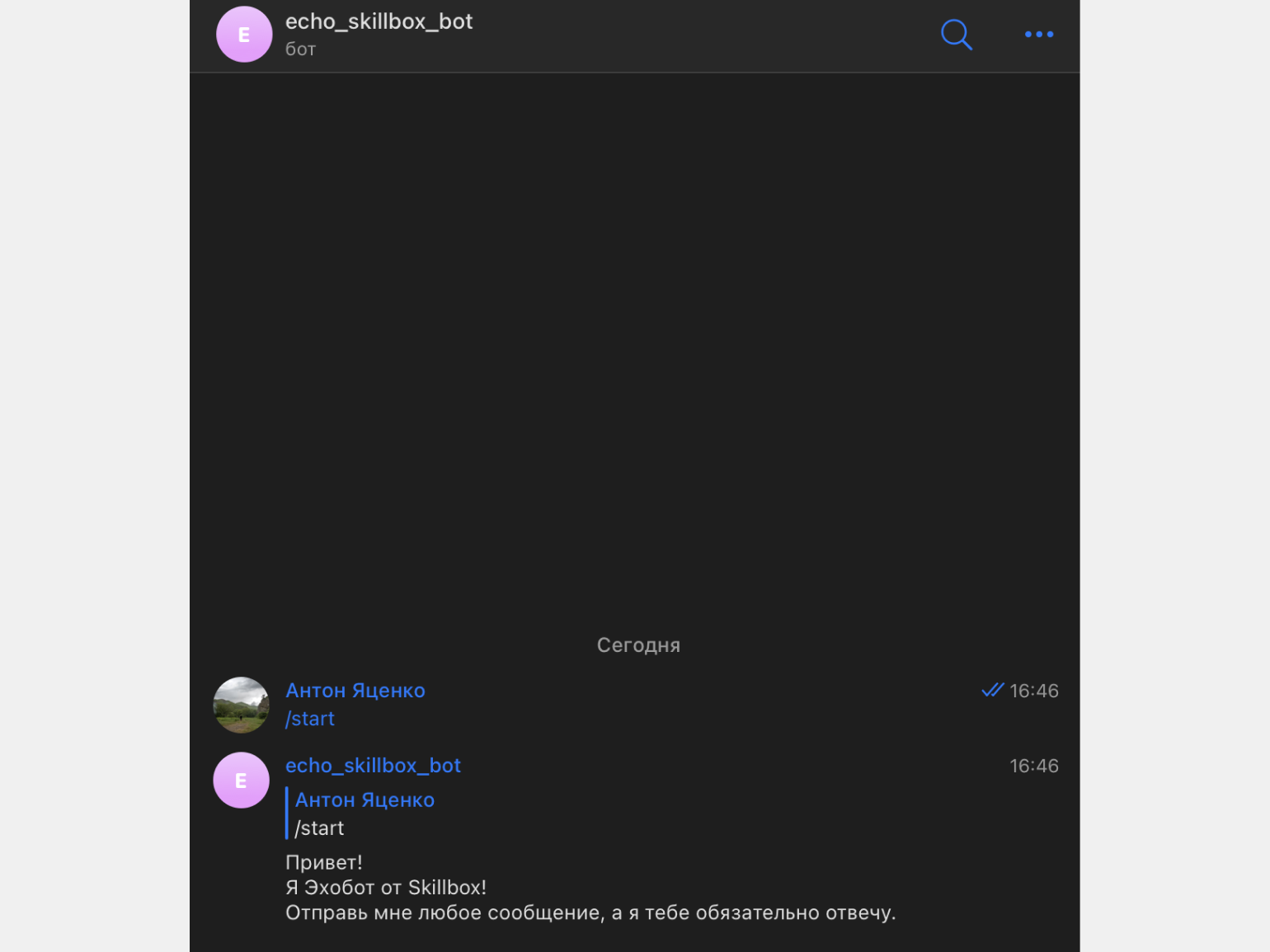
Настроим приветственное окно для нового пользователя, которое будет появляться при нажатии команды /start. Для этого создаём message_handler и прописываем функцию ответа:
@dp.message_handler(commands=['start']) #Явно указываем в декораторе, на какую команду реагируем. async def send_welcome(message: types.Message): await message.reply("Привет!\nЯ Эхо-бот от Skillbox!\nОтправь мне любое сообщение, а я тебе обязательно отвечу.") #Так как код работает асинхронно, то обязательно пишем await.
Теперь при нажатии на кнопку Начать или при вводе команды /start пользователь будет получать от бота приветственное сообщение.
Разберёмся в коде:
- message_handler — это декоратор, который реагирует на входящие сообщения и содержит в себе функцию ответа. Декоратор — это «обёртка» вокруг функций, позволяющая влиять на их работу без изменения кода самих функций. В нашем случае мы управляем функцией, считая команды пользователя.
- commands=[‘start’] — это команда, которая связана с декоратором и запускает вложенную в него функцию.
- async def send_welcome — создаёт асинхронную функцию, которая принимает в себя сообщение пользователя message, определяемое через тип Message. Саму функцию можно назвать любым образом. Мы выбрали send_welcome, чтобы название было понятным и осмысленным.
- await message.reply — определяет ответ пользователя, используя await из-за асинхронности работы библиотеки.
Теперь создадим событие, которое будет обрабатывать введённое пользователем сообщение:
@dp.message_handler() #Создаём новое событие, которое запускается в ответ на любой текст, введённый пользователем. async def echo(message: types.Message): #Создаём функцию с простой задачей — отправить обратно тот же текст, что ввёл пользователь. await message.answer(message.text)
Так как бот должен реагировать на любое текстовое сообщение от пользователя, то скобки в @dp.message_handler мы оставляем пустыми. Параметр message не отличается от использованного в предыдущих шагах.
Для ответа мы также используем метод message, указывая, что возвращаем исходный текст, принятый в message.
Остаётся последний этап — настроить получение сообщений от сервера в Telegram. Если этого не сделать, то мы не получим ответы бота. Реализовать получение новых сообщений можно с помощью поллинга. Он работает очень просто — метод start_polling опрашивает сервер, проверяя на нём обновления. Если они есть, то они приходят в Telegram. Для включения поллинга необходимо добавить две строчки:
if __name__ == '__main__': executor.start_polling(dp, skip_updates=True)
Всё, теперь код нашего бота полностью готов:
from aiogram import Bot, Dispatcher, executor, types API_TOKEN = '5602787567:AAGYv7NrSjwyW7qPs_yvu70C060zrcfZDbQ' bot = Bot(token=API_TOKEN) dp = Dispatcher(bot) @dp.message_handler(commands=['start']) async def send_welcome(message: types.Message): await message.reply("Привет!\nЯ Эхо-бот от Skillbox!\nОтправь мне любое сообщение, а я тебе обязательно отвечу.") @dp.message_handler() async def echo(message: types.Message): await message.answer(message.text) if __name__ == '__main__': executor.start_polling(dp, skip_updates=True)
Сохраняем его в нашей папке telegram_bot под именем main.py.
Для запуска бота нам необходим терминал. Открываем его и переходим в нашу папку telegram_bot. После этого вводим команду:
python3 main.py
В ответ терминал пришлёт сообщение, что обновления успешно пропущены:

Находим нашего бота в Telegram по имени @echo_skillbox_bot и запускаем его, нажав на кнопку Начать. В ответ на это или на команду /start нам придёт приветственное сообщение:
Попробуем написать что-то:
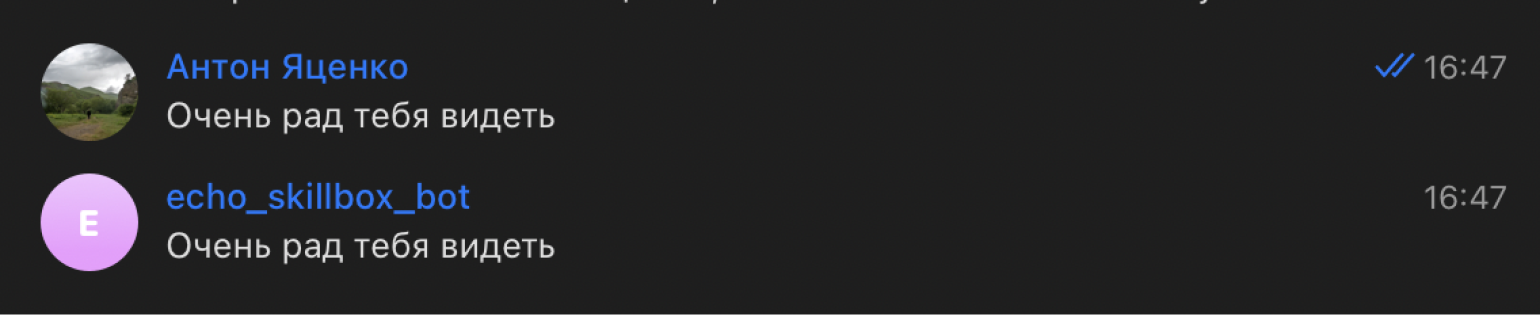
Как мы видим — всё работает. Бот возвращает нам наши сообщения.
Расширять функциональность бота, указывая для разных команд пользователя разные ответы. Например, добавить раздел помощи, который будет появляться по команде /help. Или настроить запуск кода на виртуальном сервере, чтобы бот работал независимо от вашего компьютера.
Во второй части статьи мы добавим к нашему боту кнопки и новые возможности. Так что обязательно заходите и читайте 

Как зарабатывать больше с помощью нейросетей?
Бесплатный вебинар: 15 экспертов, 7 топ-нейросетей. Научитесь использовать ИИ в своей работе и увеличьте доход.
Узнать больше
Добрый день! Сегодня я здесь, чтобы поговорить с вами о создании пользовательских приложений искусственного интеллекта с помощью Python.
Если вы похожи на меня, вам, вероятно, интересно узнать об искусственном интеллекте и о том, как он работает.
Возможно, вы видели искусственный интеллект в действии в популярных фильмах, таких как “Терминатор” или “Из машины”, но на самом деле искусственный интеллект окружает нас повсюду.
Искусственный интеллект становится всё более важным в нашей повседневной жизни — от голосовых помощников, таких как Siri и Alexa, до самоуправляемых автомобилей. Итак, почему бы не научиться создавать своё собственное приложение с искусственным интеллектом?
В этом пошаговом руководстве я покажу вам, как создать чат-бота с искусственным интеллектом с помощью Python.
Не волнуйтесь, если вы ничего не смыслите в программировании — я объясню всё на понятном языке, а фрагменты кода будут очень простыми.
Шаг 1: Установите необходимые библиотеки
Прежде чем мы начнём создавать нашего чат-бота с искусственным интеллектом, нам нужно установить некоторые библиотеки. Библиотека — это набор предварительно написанного кода, который мы можем использовать в нашей программе. В нашем случае мы будем использовать следующие библиотеки:
- tensorflow
- tflearn
- numpy
- nltk
Чтобы установить эти библиотеки, откройте свой терминал или командную строку и введите следующие команды:
pip install tensorflow
pip install tflearn
pip install numpy
pip install nltk
Отсылка к поп-культуре: “Первому игроку приготовиться” — Главный герой использует помощника с искусственным интеллектом по имени “ОАЗИС”, который помогает ему ориентироваться в виртуальном мире.
Шаг 2: Импортируйте библиотеки и загрузите данные
Теперь, когда у нас установлены наши библиотеки, мы можем приступить к написанию нашего кода. Во-первых, нам нужно импортировать библиотеки в нашу программу. Чтобы сделать это, добавьте следующий код в начало вашего файла Python:
import tensorflow as tf
import numpy as np
import tflearn
import nltk
nltk.download(‘punkt’)
Далее нам нужно загрузить данные, которые мы будем использовать для обучения нашего чат-бота с искусственным интеллектом. Для этого примера мы будем использовать набор данных диалогов в фильме.
Набор данных содержит пары предложений, причём одно предложение является вопросом, а другое — ответом.
Чат-бот научится отвечать на вопросы, основываясь на ответах из набора данных.
Чтобы загрузить данные, добавьте следующий код:
import json
with open(‘movie_dialogues.json’) as file:
data = json.load(file)
Отсылка к поп-культуре: “Она” — Главный герой влюбляется в ассистентку искусственного интеллекта по имени “Саманта”, которая использует обработку естественного языка для общения с ним.
Шаг 3: Предварительная обработка данных
Теперь, когда наши данные загружены, нам нужно предварительно обработать их, прежде чем мы сможем использовать их для обучения нашего чат-бота с искусственным интеллектом. Этот процесс включает в себя преобразование текстовых данных в формат, понятный ИИ.
Чтобы предварительно обработать данные, мы выполним следующие шаги:
- Разделим текст на отдельные слова
- Удалим все знаки препинания и специальные символы
- Преобразуем весь текст в нижний регистр
Вот код для этого:
# Tokenize the text
words = []
for dialogue in data:
for sentence in dialogue[‘dialogue’]:
sentence_words = nltk.word_tokenize(sentence)
words.extend(sentence_words)
# Remove any punctuation and special characters
words = [word for word in words if word.isalnum()]
# Convert all the text to lowercase
words = [word.lower() for word in words]
Шаг 4: Создайте обучающие данные
Теперь, когда наши данные предварительно обработаны, мы можем создать обучающие данные, которые будем использовать для обучения нашего чат-бота с искусственным интеллектом.
Мы будем использовать метод под названием bag of words, который преобразует каждое предложение в нашем наборе данных в вектор чисел.
Это облегчает ИИ понимание полученных данных и обучение.
Вот код для создания обучающих данных:
# Create a dictionary of words and their frequencies
word_freq = nltk.FreqDist(words)
# Get the most common words
common_words = word_freq.most_common(1000)
# Create a list of the most common words
word_list = [word[0] for word in common_words]
# Create a dictionary of words and their index in the word list
word_dict = {word: index for index, word in enumerate(word_list)}
# Create the training data
training_data = []
for dialogue in data:
for i in range(len(dialogue[‘dialogue’]) — 1):
input_sentence = dialogue[‘dialogue’][i]
output_sentence = dialogue[‘dialogue’][i+1]
# Tokenize the input and output sentences
input_words = nltk.word_tokenize(input_sentence)
output_words = nltk.word_tokenize(output_sentence)
# Remove any punctuation and special characters
input_words = [word for word in input_words if word.isalnum()]
output_words = [word for word in output_words if word.isalnum()]
# Convert the input and output sentences to vectors of numbers
input_vector = [0] * len(word_list)
for word in input_words:
if word in word_dict:
index = word_dict[word]
input_vector[index] = 1
output_vector = [0] * len(word_list)
for word in output_words:
if word in word_dict:
index = word_dict[word]
output_vector[index] = 1
# Add the input and output vectors to the training data
training_data.append([input_vector, output_vector])
Отсылка к поп-культуре: “Бегущий по лезвию” — Главный герой выслеживает репликантов-изгоев, которые являются искусственно созданными людьми с передовыми возможностями искусственного интеллекта.
Шаг 5: Создайте модель
Теперь, когда у нас есть наши обучающие данные, мы можем построить модель искусственного интеллекта, которая будет обучаться на этих данных и сможет отвечать на вопросы. Мы будем использовать нейронную сеть, которая представляет собой разновидность алгоритма машинного обучения, смоделированного по образцу человеческого мозга.
Вот код для построения модели:
# Build the neural network model
net = tflearn.input_data(shape=[None, len(word_list)])
net = tflearn.fully_connected(net, 
net = tflearn.fully_connected(net, len(word_list), activation=’softmax’)
net = tflearn.regression(net)
# Create the model
model = tflearn.DNN(net)
Ссылка на поп-культуру: “Мир Дикого Запада” — Главные герои — андроиды с продвинутыми возможностями искусственного интеллекта, которые используются для развлечения гостей в футуристическом тематическом парке.
Шаг 6: Обучите модель
Теперь, когда у нас есть наша модель, мы можем обучить её, используя наши обучающие данные. Обучение модели включает в себя ввод обучающих данных в модель и корректировку весовых коэффициентов нейронной сети на основе ошибки между прогнозируемым результатом и фактическим результатом.
Вот код для обучения модели:
# Train the model
model.fit([data[0] for data in training_data], [data[1] for data in training_data], n_epoch=1000, batch_size=8, show_metric=True)
Отсылка к поп-культуре: “Матрица”– Главный герой, Нео, узнаёт, что мир, который он знает, — это смоделированная реальность, созданная искусственным интеллектом.
Шаг 7: Протестируйте модель
Теперь, когда наша модель обучена, мы можем протестировать её, задавая вопросы и наблюдая, как она реагирует. Чтобы сделать это, мы создадим функцию, которая принимает вопрос в качестве входных данных и возвращает ответ.
Вот код для этой функции:
def get_response(question):
# Tokenize the input question
question_words = nltk.word_tokenize(question)
# Remove any punctuation and special characters
question_words = [word for word in question_words if word.isalnum()]
# Convert the question to a vector of numbers
question_vector = [0] * len(word_list)
for word in question_words:
if word in word_dict:
index = word_dict[word]
question_vector[index] = 1
# Use the model to predict the response
prediction = model.predict([question_vector])[0]
response_vector = np.zeros(len(word_list))
response_vector[np.argmax(prediction)] = 1
# Convert the response vector to text
response_words = []
for index, value in enumerate(response_vector):
if value == 1:
response_words.append(word_list[index])
response = ‘ ‘.join(response_words)
return response
Отсылка к поп-культуре: “Я, робот” — Главный герой, детектив Спунер, расследует преступление, совершённое роботом с передовыми возможностями искусственного интеллекта.
Шаг 8: Запустите приложение
Теперь, когда у нас есть наша функция, мы можем запустить наше приложение для чат-бота с искусственным интеллектом и начать задавать ему вопросы. Чтобы сделать это, мы создадим цикл, который постоянно запрашивает пользовательский ввод и печатает ответ от искусственного интеллекта.
Вот код для цикла:
while True:
question = input(«You: «)
response = get_response(question)
print(«AI: » + response)
Отсылка к поп—культуре: “Терминатор 2: Судный день” — За главным героем, Джоном Коннором, охотится продвинутая система искусственного интеллекта, известная как Скайнет.
На этом всё! Мы создали нашего собственного чат-бота с искусственным интеллектом, используя Python!
Хотя фрагменты кода были простыми, возможности того, что вы можете сделать с помощью искусственного интеллекта, безграничны. От обработки естественного языка до компьютерного зрения, искусственный интеллект трансформирует то, как мы взаимодействуем с технологиями
Я надеюсь, что вы нашли это пошаговое руководство полезным и информативным. Если у вас есть какие-либо вопросы или комментарии, не стесняйтесь оставлять их ниже.
И помните — будущее за искусственным интеллектом, так почему бы не научиться создавать свои собственные приложения с искусственным интеллектом?
Статья была взята из этого источника:
Аналитики Gartner утверждают, что к 2020 году 85% взаимодействий клиентов с сервисами сведется к общению с чат-ботами. В 2018 году они уже обрабатывают около 30% операций. В этой статье мы расскажем, как создать своего чат-бота на Python.
Возможно, вы слышали о Duolingo: популярном приложении для изучения иностранных языков, в котором обучение проходит в форме игры. Duolingo популярен благодаря инновационному стилю обучения. Концепция проста: от пяти до десяти минут интерактивного обучения в день достаточно, чтобы выучить язык.
Несмотря на то что Duolingo позволяет изучить новый язык, у пользователей сервиса возникла проблема. Они почувствовали, что не развивают разговорные навыки, так как обучаются самостоятельно. Пользователи неохотно обучались в парах из-за смущения. Эта проблема не осталась незамеченной для разработчиков.
Команда сервиса решила проблему, создав чат-бота в приложении, чтобы помочь пользователям получать разговорные навыки и применять их на практике.
Поскольку боты разрабатывались так, чтобы быть разговорчивыми и дружелюбными, пользователи Duolingo практикуются в общении в удобное им время, выбирая «собеседника» из набора, пока не поборят смущение в достаточной степени, чтобы перейти к общению с другими пользователями. Это решило проблему пользователей и ускорило обучение через приложение.
Итак, что такое чат-бот?
Чат-бот — это программа, которая выясняет потребности пользователей, а затем помогает удовлетворить их (денежная транзакция, бронирование отелей, составление документов). Сегодня почти каждая компания имеет чат-бота для взаимодействия с пользователями. Некоторые способы использования чат-ботов:
- предоставление информации о рейсе;
- предоставление пользователям доступа к информации об их финансах;
- служба поддержки.
Возможности безграничны.
История чат-ботов восходит к 1966 году, когда Джозеф Вейценбаум разработал компьютерную программу ELIZA. Программа подражает манере речи психотерапевта и состоит лишь из 200 строк кода. Пообщаться с Элизой можно до сих пор на сайте.
Читайте также: Нейросети для написания текста на русском языке: подборка онлайн сервисов
Как работает чат-бот?
Существует два типа ботов: работающие по правилам и самообучающиеся.
- Бот первого типа отвечает на вопросы, основываясь на некоторых правилах, которым он обучен. Правила могут быть как простыми, так и очень сложными. Боты могут обрабатывать простые запросы, но не справлятся со сложными.
- Самообучающиеся боты создаются с использованием основанных на машинном обучении методов и определенно более эффективны, чем боты первого типа. Самообучающиеся боты бывают двух типов: поисковые и генеративные.
В поисковых ботах используются эвристические методы для выбора ответа из библиотеки предопределенных реплик. Такие чат-боты используют текст сообщения и контекст диалога для выбора ответа из предопределенного списка. Контекст включает в себя текущее положение в древе диалога, все предыдущие сообщения и сохраненные ранее переменные (например, имя пользователя). Эвристика для выбора ответа может быть спроектирована по-разному: от условной логики «или-или» до машинных классификаторов.
Генеративные боты могут самостоятельно создавать ответы и не всегда отвечают одним из предопределенных вариантов. Это делает их интеллектуальными, так как такие боты изучают каждое слово в запросе и генерируют ответ.
В этой статье мы научимся писать код простых поисковых чат-ботов на основе библиотеки NLTK.
Предполагается, что вы умеете пользоваться библиотеками scikit и NLTK. Однако, если вы новичок в обработке естественного языка (NLP), вы все равно можете прочитать статью, а затем изучить соответствующую литературу.
Обработка естественного языка (NLP)
Обработка естественного языка — это область исследований, в которой изучается взаимодействие между человеческим языком и компьютером. NLP основана на синтезе компьютерных наук, искусственного интеллекта и вычислительной лингвистики. NLP — это способ для компьютеров анализировать, понимать и извлекать смысл из человеческого языка разумным и полезным образом.
Краткое введение в NLKT
NLTK (Natural Language Toolkit) — платформа для создания программ на Python для работы с естественной речью. NLKT предоставляет простые в использовании интерфейсы для более чем 50 корпораций и лингвистических ресурсов, таких как WordNet, а также набор библиотек для обработки текста в целях классификации, токенизации, генерации, тегирования, синтаксического анализа и понимания семантики, создания оболочки библиотек NLP для коммерческого применения.
Книга Natural Language Processing with Python — практическое введение в программирование для обработки языка. Рекомендуем ее прочитать, если вы владеете английским языком.
Загрузка и установка NLTK
- Установите NLTK: запустите pip install nltk.
- Тестовая установка: запустите python, затем введите import nltk.
Инструкции для конкретных платформ смотрите здесь.
Установка пакетов NLTK
Импортируйте NLTK и запустите nltk.download(). Это откроет загрузчик NLTK, где вы сможете выбрать версию кода и модели для загрузки. Вы также можете загрузить все пакеты сразу.
Предварительная обработка текста с помощью NLTK
Основная проблема с данными заключается в том, что они представлены в текстовом формате. Для решения задач алгоритмами машинного обучения требуется некий вектор свойств. Поэтому прежде чем начать создавать проект по NLP, нужно предварительно обработать его. Предварительная обработка текста включает в себя:
- Преобразование букв в заглавные или строчные, чтобы алгоритм не обрабатывал одни и те же слова повторно.
- Токенизация. Токенизация — термин, используемый для описания процесса преобразования обычных текстовых строк в список токенов, то есть слов. Токенизатор предложений используется для составления списка предложений. Токенизатор слов составляет список слов.
Пакет NLTK включает в себя предварительно обученный токенизатор Punkt для английского языка.
- Удаление шума, то есть всего, что не является цифрой или буквой;
- Удаление стоп-слов. Иногда из словаря полностью исключаются некоторые крайне распространенные слова, которые, как считается, не имеют большого значения для формирования ответа на вопрос пользователя. Эти слова называются стоп-словами (междометия, артикли, некоторые вводные слова);
- Cтемминг: приведение слова к коренному значению. Например, если нам нужно провести стемминг слов «стемы», «стемминг», «стемированный» и «стемизация», результатом будет одно слово — «стем».
- Лемматизация. Лемматизация — немного отличающийся от стемминга метод. Основное различие между ними заключается в том, что стемминг часто создает несуществующие слова, тогда как лемма — это реально существующее слово. Таким образом, ваш исходный стем, то есть слово, которое получается после стемминга, не всегда можно найти в словаре, а лемму — можно. Пример лемматизации: «run» — основа для слов «running» или «ran», а «better» и «good» находятся в одной и той же лемме и потому считаются одинаковыми.
Набор слов
После первого этапа предварительной обработки нужно преобразовать текст в вектор (или массив) чисел. «Набор слов» — это представление текста, описывающего наличие слов в тексте. «Набор слов» состоит из:
- словаря известных слов;
- частот, с которыми каждое слово встречается в тексте.
Почему используется слово «набор»? Это связано с тем, что информация о порядке или структуре слов в тексте отбрасывается, и модель учитывает только то, как часто определенные слова встречаются в тексте, но не то, где именно они находятся.
Идея «набора слов» состоит в том, что тексты похожи по содержанию, если включают в себя похожие слова. Кроме того, кое-что узнать о содержании текста можно лишь по набору слов.
Например, если словарь содержит слова {Learning, is, the, not, great} и мы хотим составить вектор предложения “Learning is great”, получится вектор (1, 1, 0, 0, 1).
Метод TF-IDF
Проблема «набора слов» заключается в том, что в тексте могут доминировать часто встречающиеся слова, которые не содержат ценную для нас информацию. Также «набор слов» присваивает большую важность длинным текстам по сравнению с короткими.
Один из подходов к решению этих проблем состоит в том, чтобы вычислять частоту появления слова не в одном тексте, а во всех сразу. За счет этого вклад, например, артиклей «a» и «the» будет нивелирован. Такой подход называется TF-IDF (Term Frequency-Inverse Document Frequency) и состоит из двух этапов:
- TF — вычисление частоты появления слова в одном тексте
TF = (Число раз, когда слово "t" встречается в тексте)/(Количество слов в тексте)
- IDF — вычисление того, на сколько редко слово встречается во всех текстах
IDF = 1+log(N/n), где N - общее количество текстов, n - во скольких текстах встречается "t"
Коэффициент TF-IDF — это вес, часто используемый для обработки информации и интеллектуального анализа текста. Он является статистической мерой, используемой для оценки важности слова для текста в некотором наборе текстов.
Пример
Рассмотрим текст, содержащий 100 слов, в котором слово «телефон» появляется 5 раз. Параметр TF для слова «телефон» равен (5/100) = 0,05.
Теперь предположим, что у нас 10 миллионов документов, и слово телефон появляется в тысяче из них. Коэффициент вычисляется как 1+log(10 000 000/1000) = 4. Таким образом, TD-IDF равен 0,05 * 4 = 0,20.
TF-IDF может быть реализован в scikit так:
from sklearn.feature_extraction.text import TfidfVectorizer
Коэффициент Отиаи
TF-IDF — это преобразование, применяемое к текстам для получения двух вещественных векторов в векторном пространстве. Тогда мы можем получить коэффициент Отиаи любой пары векторов, вычислив их поэлементное произведение и разделив его на произведение их норм. Таким образом, получается косинус угла между векторами. Коэффициент Отиаи является мерой сходства между двумя ненулевыми векторами. Используя эту формулу, можно вычислить схожесть между любыми двумя текстами d1 и d2.
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
Здесь d1, d2 — два ненулевых вектора.
Подробное объяснение и практический пример TF-IDF и коэффициента Отиаи приведены в посте по ссылке.
Пришло время перейти к решению нашей задачи, то есть созданию чат-бота. Назовем его «ROBO».
Обучение чат-бота
В нашем примере мы будем использовать страницу Википедии в качестве текста. Скопируйте содержимое страницы и поместите его в текстовый файл под названием «chatbot.txt». Можете сразу использовать другой текст.
Импорт необходимых библиотек
import nltk import numpy as np import random import string # to process standard python strings
Чтение данных
Выполним чтение файла corpus.txt и преобразуем весь текст в список предложений и список слов для дальнейшей предварительной обработки.
f=open('chatbot.txt','r',errors = 'ignore')
raw=f.read()
raw=raw.lower()# converts to lowercase
nltk.download('punkt') # first-time use only
nltk.download('wordnet') # first-time use only
sent_tokens = nltk.sent_tokenize(raw)# converts to list of sentences word_tokens = nltk.word_tokenize(raw)# converts to list of words
Давайте рассмотрим пример файлов sent_tokens и word_tokens
sent_tokens[:2] ['a chatbot (also known as a talkbot, chatterbot, bot, im bot, interactive agent, or artificial conversational entity) is a computer program or an artificial intelligence which conducts a conversation via auditory or textual methods.', 'such programs are often designed to convincingly simulate how a human would behave as a conversational partner, thereby passing the turing test.']
word_tokens[:2]
['a', 'chatbot', '(', 'also', 'known']
Предварительная обработка исходного текста
Теперь определим функцию LemTokens, которая примет в качестве входных параметров токены и выдаст нормированные токены.
lemmer = nltk.stem.WordNetLemmatizer() #WordNet is a semantically-oriented dictionary of English included in NLTK.
def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
Подбор ключевых слов
Определим реплику-приветствие бота. Если пользователь приветствует бота, бот поздоровается в ответ. В ELIZA используется простое сопоставление ключевых слов для приветствий. Будем использовать ту же идею.
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey",)
GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]
def greeting(sentence):
for word in sentence.split():
if word.lower() in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
Генерация ответа
Чтобы сгенерировать ответ нашего бота для ввода вопросов, будет использоваться концепция схожести текстов. Поэтому мы начинаем с импорта необходимых модулей.
- Импортируйте векторизатор TFidf из библиотеки, чтобы преобразовать набор необработанных текстов в матрицу свойств TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
- Кроме того, импортируйте модуль коэффициента Отиаи из библиотеки scikit
from sklearn.metrics.pairwise import cosine_similarity
Этот модуль будет использоваться для поиска в запросе пользователя ключевых слов. Это самый простой способ создать чат-бота.
Определим функцию отклика, которая возвращает один из нескольких возможных ответов. Если запрос не соответствует ни одному ключевому слову, бот выдает ответ «Извините! Я вас не понимаю».
def response(user_response):
robo_response=''
TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0):
robo_response=robo_response+"I am sorry! I don't understand you"
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_response
Наконец, мы задаем реплики бота в начале и конце переписки, в зависимости от реплик пользователя.
flag=True
print("ROBO: My name is Robo. I will answer your queries about Chatbots. If you want to exit, type Bye!")
while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("ROBO: You are welcome..")
else:
if(greeting(user_response)!=None):
print("ROBO: "+greeting(user_response))
else:
sent_tokens.append(user_response)
word_tokens=word_tokens+nltk.word_tokenize(user_response)
final_words=list(set(word_tokens))
print("ROBO: ",end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("ROBO: Bye! take care..")
Вот и все. Мы написали код нашего первого бота в NLTK. Здесь вы можете найти весь код вместе с текстом. Теперь давайте посмотрим, как он взаимодействует с людьми:

Получилось не так уж плохо. Даже если чат-бот не смог дать удовлетворительного ответа на некоторые вопросы, он хорошо справился с другими.
Заключение
Хотя наш примитивный бот едва ли обладает когнитивными навыками, это был неплохой способ разобраться с NLP и узнать о работе чат-ботов. «ROBO», по крайней мере, отвечает на запросы пользователя. Он, конечно, не обманет ваших друзей, и для коммерческой системы вы захотите рассмотреть одну из существующих бот-платформ или фреймворки, но этот пример поможет вам продумать архитектуру бота.
Интересные статьи:
- Как создать собственную нейронную сеть с нуля на языке Python
- Word2Vec: как работать с векторными представлениями слов
- Как применять теорему Байеса для решения реальных задач
В социальных сетях и мессенджерах огромную популярность набрали так называемые боты. Они пишутся на разных языках программирования, внедряются в ПО и активно применяются на практике.
В данной статье будет рассказано о том, как написать простой бот на Python. А еще – рассмотрены особенности соответствующего ЯП, преимущества и недостатки упомянутого «виджета». Примеры будут приведены на основе Telegram. Здесь bot – это весьма распространенное явление.
Бот – это…
Это специализированный робот-помощник. Он помогает выполнять любые рутинные занятия. Боты способны реализовывать программные коды, которые будут отвечать за активацию разных команд со стороны пользователей.
Переписка с таким ПО осуществляется непосредственно через чат. Клиент дает боту команды, которые он обрабатывает и выполняет в режиме 24/7. Ключевая задача “робота» – дать ответ на вопрос клиента, опираясь на заданную программу. С помощью оных удается экономить не только время, но и остальные ресурсы.
Умения
Бот Телеграмм умеет многое. Сегодня к спектру его навыков относят следующие моменты:
- проведение обучения;
- развлечение публики;
- предложение и запуск «мини-игр»;
- работа с поисковыми системами в пределах Сети;
- скачивание данных – фото, видео, аудио, документов;
- выступать в качестве напоминалки;
- участие в групповых чатах для решения заранее определенного спектра задач (пример – согласование оптимального времени встречи);
- комментирование постов и статей;
- использование функций управления умным домом и другими подобными устройствами.
Bots – это связующее звено между пользователями и интернетом, а также конкретной компанией. Пользоваться ими не очень трудно. Первое, что нужно сделать – это определиться со спектром задач, поручаемых боту. После – написать грамотный код и внедрить его в мессенджер. Это способен сделать даже начинающий разработчик.
Преимущества и недостатки
Как и любое другое ПО, bot – это «виджет», который имеет ряд сильный и слабых сторон. Их предстоит учитывать каждому, кто хочет подключить соответствующего «помощника» в своем чате/диалоге.
Сильные стороны
К преимуществам ботов Телеграм относят:
- круглосуточную помощь – функционирование bots прекратят только в случае аварий на серверах, которые случаются крайне редко;
- удобство и простоту использования – для большинства команд достаточно выбрать из предложенного списка подходящую операцию;
- мгновенное получение ответа;
- отсутствие требований к мощности задействованного устройства – это связано с тем, что для работы ботов используются возможности сторонних серверов;
- высокий уровень безопасности;
- отсутствие необходимости инициализации дополнительного ПО для запуска рассматриваемого вида «помощника».
Ботов применять удобно и интересно. Они упрощают жизнь и владельцу чата/компании, и непосредственным клиентам/участникам диалога.
Слабые стороны
Минусы у такого ПО тоже есть, но они не слишком весомые:
- составлять bot должен программист – тот, кто далек от данной сферы деятельности, будет долго разбираться в принципах коддинга;
- писать бота лучше на одном языке – через Питон;
- нужно заранее хорошо продумать навигационное меню – тем, кто раньше не имел дела с подобным контентом, может потребоваться немало времени для этого.
Бот должен быть полезным, отвечать потребностям ЦА, а также целям владельца чата. Составить его удастся «с нуля» за 15-30 минут. Особенно если придерживаться определенного алгоритма действий.
Почему Питон
Python – универсальный язык программирования с возможностью использования принципов ООП. Он обладает простым и понятным синтаксисом, освоить который еще проще, зная английский.
Бот, написанный на Python, будет отличаться скоростью, безопасностью и стабильностью. Сам ЯП предусматривает следующие преимущества:
- функциональность;
- разделение итоговой кодификации на блоки, что позволяет значительно повысить ее читаемость;
- поддержка длинной арифметики;
- кроссплатформенность;
- огромное количество библиотек, которые смогут выручить в любое время;
- понятный синтаксис.
Это – идеальный вариант для веб-разработки, приложений для мессенджеров и мелких проектов. Крупные и масштабные игры на чистом Python составить не получится. Для этого предстоит подучить Java или C++.
Составление софта
Bot – это просто и удобно. Телеграм позволяет внедрять и искать такие «виджеты» без особого труда. Хорошего бота удастся составить менее чем за час. Главное – придерживаться определенного алгоритма действий.
Принцип
Перед непосредственной разработкой необходимо разобраться в том, как все будет работать. Bot для «Телеги» функционирует по определенным принципам. Пример будет рассмотрен на компьютере и Telegram-клиенте.
Стоит обратить внимание на следующее:
- На компьютере есть интерпретатор Python. Также на устройство необходимо поставить сервер Телеграмма и клиент.
- Внутри интерпретатора будет функционировать программа-бот. Она будет отвечать за весь софт: в оной прописана логика и шаблоны, а также возможные операции.
- Внутри приложения, написанного через Питон, имеется библиотека, отвечающая за связь с сервером Telegram. В нее нужно вшить секретный ключ. Это поможет указать серверу клиента, что программа связана с конкретным ботом.
- Когда клиент с «Телегой» осуществляет запрос гороскопа, bot осуществляет выгрузку на сервер, а сервер – выводит результат на компьютер.
- Запрос будет проходить обработку через утилиту на Python, дает ответ на сервер Телеграмма.
- Сервер передает необходимый результат непосредственному пользователю.
Bot внедряется без особого труда. Описанный принцип действий актуален не только для гороскопов. Он подойдет для bot любого вида в мессенджере.
Краткий план – пошагово
Чтобы bot Телеграм работал, можно представить процедуру его подключения так:
- Провести регистрацию нового бота в мессенджере.
- Установить Питон-библиотеку для работы с Telegram.
- Добавить библиотеку в программу с гороскопом.
- Научить bot реагировать на сообщения в пределах чата.
- Прописать там же кодификацию, которая отвечает за кнопки выбора знака зодиака.
- Сделать так, чтобы при клике по кнопке отображался гороскоп выбранного варианта.
Каждый этап предусматривает собственные нюансы и особенности, о которых должен помнить каждый разраб. Иначе справиться с поставленной задачей не получится.
Регистрация
Для того, чтобы зарегистрировать нового бота в Телеграмме, нужно:
- Открыть соответствующий мессенджер.
- При помощи командной строки найти @BotFather. Он несет ответ за регистрацию нового bot.
- Кликнуть по надписи Start, а также указать команду / newbot.
- Система задаст поочередно вопросы о названии бота и его ника. Имя должно быть уникальным. С первого раза установить его не всегда получается.
На этом первый этап подготовки завершен. Можно двигаться дальше.
Библиотека и ее инициализация
Следующий этап – это установка подходящей библиотеки Python. Работать с «Телегой» можно через telebot. Второй вариант – это инициализация Webhook. Первый вариант проще, поэтому заострим внимание на нем:
- Запустить командную строку от имени администратора на устройстве.
- Набрать команду pip install pytelegrambotapi.
- Подтвердить обработку операции.
- Чтобы приложение понимало бота, в самое начало кода требуется добавить: import telebot;
- Bot = telebot.TeleBot(«токен»);.
- Вместо слова «токен» вставить настоящий токен, выданный @BotFather.
- Открыть программу гороскопа и добавить ее.
Перед тем, как импортировать приложение гороскопа, необходимо его написать. Сделать его требуется на Питоне.
Гороскоп программа
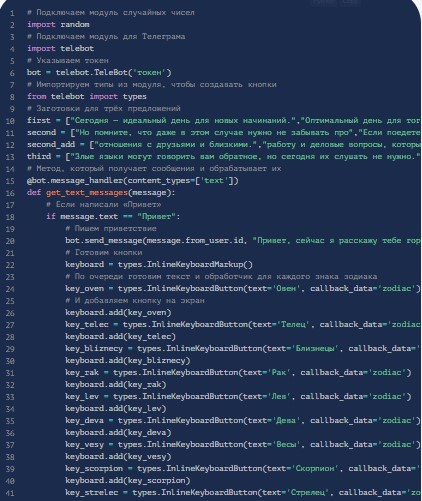
Вот так будет выглядеть код приложения, который отвечает за отображение информации о гороскопах. Создается контент в программной среде Питона:
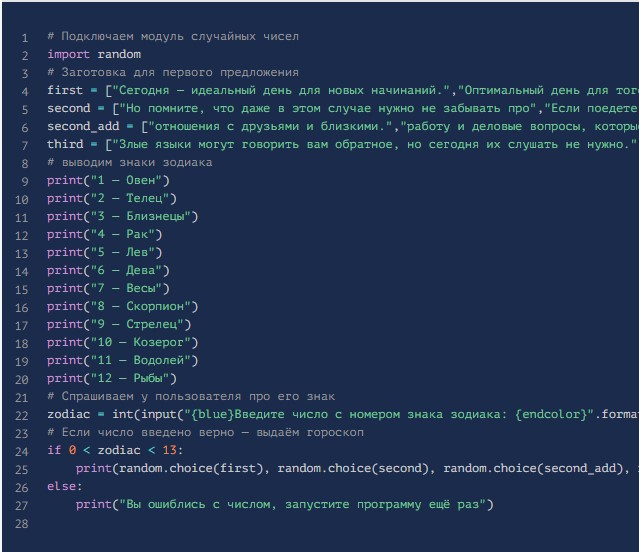
Сразу после формирования ПО можно приступить к следующему этапу настройки.
Реакции
Bot должен реагировать на слово «Привет». После него будет выдана реакция на соответствующую фразу. Чтобы все работало нормально, необходимо добавить после строчек импорта новый метод. Он отвечает за соответствующую операцию:
@bot.message_handler(content_types=['text'])
def get_text_messages(message):
if message.text == "Привет":
bot.send_message(message.from_user.id, "Привет, сейчас я расскажу тебе гороскоп на сегодня.")
elif message.text == "/help":
bot.send_message(message.from_user.id, "Напиши Привет")
else:
bot.send_message(message.from_user.id, "Я тебя не понимаю. Напиши /help.")
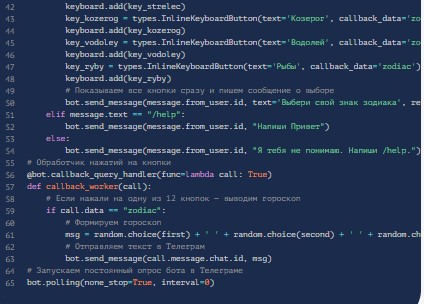
Теперь нужно:
- Добавить после метода строку типа:
bot.polling(none_stop=True, interval=0). - После ее добавления у бота будет постоянно проверяться наличие новых сообщений.
- Прописать код, который предполагает работу с кнопками. Сначала осуществляется вывод всех знаков зодиака. При клике по конкретной – отображается гороскоп оного.
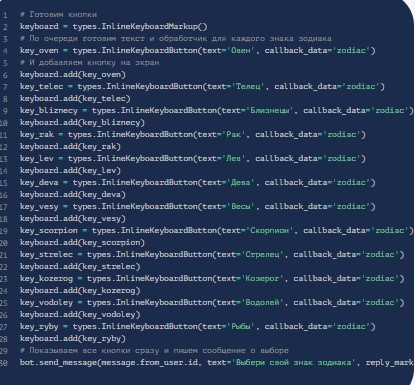
- Добавить обработчик кнопок. Он будет реагировать на слово zodiac. При написании оного в программе отобразится случайный текст:
# Обработчик нажатий на кнопки
@bot.callback_query_handler(func=lambda call: True)
def callback_worker(call):
# Если нажали на одну из 12 кнопок — выводим гороскоп
if call.data == "zodiac":
# Формируем гороскоп
msg = random.choice(first) + ' ' + random.choice(second) + ' ' + random.choice(second_add) + ' ' + random.choice(third)
# Отправляем текст в Телеграм
bot.send_message(call.message.chat.id, msg)- Можно убрать кодификацию, которая ранее отвечала за вывод знаков зодиака в консоли. После очистки получится приложение:
На этом рассматриваемый «помощник» окончен. Теперь все должно нормально работать. Остается запустить его в Телеграме и получить тот или иной результат.
Команды управления
«Помощник» имеет разные функции и команды. Они пишутся через знак «слеш» («/») прямо в сообщении чата. Вот основные операции:
- /start – начать работу помощника;
- /help – вывод помощи на экран;
- /settings – открыть настройки.
Некоторые подобные «дополнения» способны понимать команды на русском языке. Пример – запрос у робота Антона, который «подрабатывает» в Гидрометцентре. Если при общении с ним прописать «Погода Калининград», будет выведен соответствующий результат.
Почему «молчит»
Иногда бывает так, что «помощник» не отвечает. Такое наблюдается при вводе любой команды/выбора подходящего варианта из меню. Данное явление может происходить по нескольким причинам:
- Проблемы и неполадки на сервере. Пример – сбой или полный отказ оного от функционирования.
- Ошибки при написании кодификации. Распространенное явление среди новичков.
- Ввод команды, которую Телеграм бот на Python не понимает. В этом случае можно воспользоваться Google для поиска подходящих операций и их форматов.
Иногда помогает полное отключение и перезапуск «помощника».
Как быстро освоить Python
Питон и его возможности можно выучить в ВУЗе, техникуме или самостоятельно поисках материалы в Сети. Вот видео по боту в «Телеге». Самообразование – один из лучших, но долгих методов обучения.
А чтобы надписи типа examples, def get, main() и другие не доставляли хлопот, стоит пройти дистанционные курсы. Их преимущества:
- Доступность. Обучение можно проводить в любом месте и в любое время, имя под рукой интернет.
- Разнообразие направлений. Есть предложения для новичков и опытных программеров.
- Срок обучения – до 12 месяцев. За это время пользователь сможет освоить даже несколько направлений.
- Хорошо продуманная программа, подпитанная практикой и кураторством опытных разработчиков.
По завершении процесса пользователь получит сертификат, подтверждающий навыки и познания в выбранной области.
