Сегодня мы публикуем ещё один из докладов, прозвучавших на летней встрече об устройстве поиска Яндекса. Выступление руководителя отдела ранжирования Петра Попова получилось в тот день самым доступным для широкой аудитории: минимум формул, максимум общих понятий о поиске. Но интересно было всем, потому что Пётр несколько раз переходил к деталям и в итоге рассказал много такого, о чём Яндекс никогда раньше публично не заявлял.
Кстати, одновременно с публикацией этой расшифровки начинается вторая встреча из серии, посвящённой технологиям Яндекса. Сегодняшнее мероприятие — уже не про поиск, а про инфраструктуру. Вот ссылка на трансляцию.
Ну а под катом — лекция Петра Попова и часть слайдов.
Меня зовут Пётр Попов, я работаю в Яндексе. Здесь я уже примерно семь лет. До этого программировал компьютерные игры, занимался 3D-графикой, знал про видеокарточки, писал на SSE-ассемблере, в общем, такими вещами занимался.
Надо сказать, что, устраиваясь на работу в Яндекс, я достаточно мало знал о предметной области — о том, что здесь люди делают. Знал только, что здесь работают хорошие люди. Поэтому испытывал некоторые сомнения.

Сейчас я расскажу достаточно полно, но не очень глубоко о том, как выглядит наш поиск. Что такое Яндекс? Это поисковик. Мы должны получить запрос пользователя и сформировать десятку результатов. Почему именно десятку? Пользователи чрезвычайно редко переходят на более далёкие страницы. Можно считать, что десять документов — это всё, что мы показываем.
Не знаю, есть ли в зале люди, которые занимаются рекламой Яндекса, потому что они считают, что основной продукт Яндекса — это совсем другое. Как обычно, здесь две точки зрения и обе правильные.
Мы считаем, что основное — это счастье пользователя. И, как ни удивительно, от состава десятки и того, как десятка отранжирована, это счастье зависит. Если мы ухудшаем выдачу, пользователи пользуются Яндексом меньше, уходят в другие поисковики, плохо себя чувствуют.

Какую конструкцию мы соорудили ради решения этой простой задачи — показать десять документов? Конструкция достаточно мощная, снизу, видимо, разработчики на неё взирают.
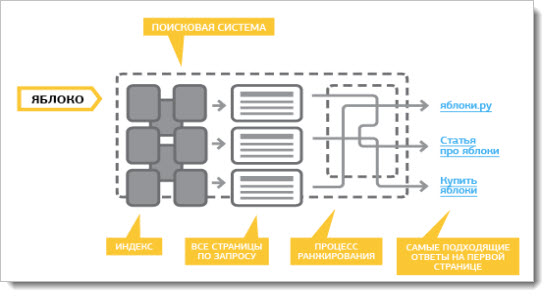
Наша модель работы. Нам нужно сделать всего несколько вещей. Нам нужно обойти интернет, проиндексировать получившиеся документы. Документом мы называем скачанную веб-страницу. Проиндексировать, сложить в поисковый индекс, запустить над этим индексом поисковую программу, ну и ответить пользователю. В общем-то, всё, профит.
Пройдемся по шагам этого конвейера. Что такое интернет и какого он объема? Интернет, считай, бесконечный. Возьмем любой сайт, который продает что-нибудь, какой-нибудь интернет-магазин, сменим там параметры сортировки — появится другая страничка. То есть можно задавать СGI-параметры страницы, и содержание будет совсем другое.
Сколько мы знаем принципиально значащих страниц с точностью до отбрасывания незначащих CGI-параметров? Сейчас — порядка нескольких триллионов. Скачиваем мы странички со скоростью порядка нескольких миллиардов страничек в день. И казалось бы, что нашу работу мы могли бы выполнить за конечное время, там, за два года.
Как мы вообще находим новые странички в интернете? Мы обошли какую-то страничку, вытянули оттуда ссылки. Они — наши потенциальные жертвы для скачивания. Возможно, за два года мы обойдем эти триллионы URL, но появятся новые, и в процессе парсинга документов появятся ссылки на новые странички. Уже тут видно, что наша основная задача — бороться с бесконечностью интернета, имея на руках конечные инженерные ресурсы в виде дата-центров.
Мы скачали все безумные триллионы документов, проиндексировали. Дальше нужно положить их в поисковый индекс. В индекс мы кладем не всё, а только лучшее из того, что скачали.
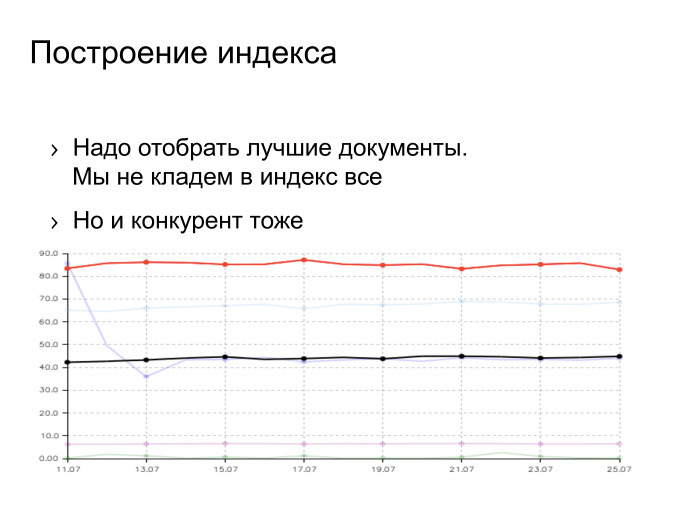
Есть товарищ Ашманов, широко известный в узких кругах специалист по поисковым системам в интернете. Он строит разные графики качества поисковых систем. Это график полноты поисковой базы. Как он строится? Задается запрос из редкого слова, смотрится, какие документы есть во всех поисковиках, это 100%. Каждый поисковик знает про какую-то долю. Сверху красным цветом мы, снизу черным цветом — наш основной конкурент.
Тут можно задаться вопросом: как мы такого достигли? Возможны несколько вариантов ответа. Вариант первый: мы пропарсили страничку с этими тестами, выдрали оттуда все URL, все запросы, которые задает товарищ Ашманов и проиндексировали странички. Нет, мы так не делали. Второй вариант: для нас Россия является основным рынком, а для конкурентов она — что-то маргинальное, где-то на периферии зрения. Этот ответ имеет право на жизнь, но он мне тоже не нравится.
Ответ, который мне нравится, заключается в том, что мы проделали большую инженерную работу, сделали проект, который называется «большая база», под это закупили много железа и сейчас наблюдаем этот результат. Конкурента тоже можно бить, он не железный.
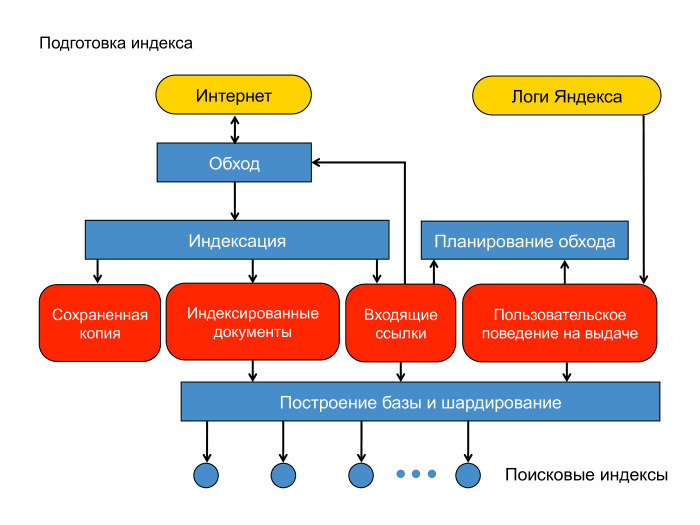
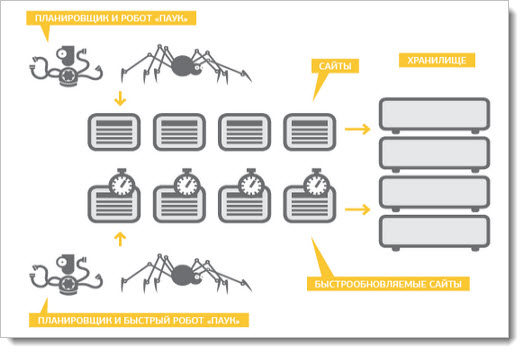
Документы мы скачали. Как мы строим поисковую базу? Вот схема нашей контент-системы. Есть интернет, облачко документов. Есть машины, которые его обходят — спайдеры, пауки. Документ мы скачали. Для начала — положили его в сохраненную копию. Это, фактически, отдельная междатацентровая хеш-таблица, куда можно читать и писать на случай, если мы потом захотим этот документ проиндексировать или показать пользователю как сохраненную копию на выдаче.
Дальше мы документ проиндексировали, определили язык и вытащили оттуда слова, приведенные согласно морфологии языка к основным формам. Ещё мы вытащили оттуда ссылки, ведущие на другие страницы.
Есть еще один источник данных, который мы широко используем при построении индекса и вообще в ранжировании — логи Яндекса. Задал пользователь запрос, получил десятку результатов и как-то там себя ведёт. Ему показались документы, он кликает или не кликает.
Разумно предположить, что если документ показался в выдаче, или, тем более, если пользователь по нему кликнул, провел какое-то взаимодействие, то такой документ нужно оставить в поисковой базе. Кроме того, логично предположить, что ссылки с такого хорошего документа ведут на документы, которые тоже хороши и которые неплохо бы приоритетно скачать. Здесь изображено планирование обхода. Стрелочка от планирования обхода должна вести в обход.
Дальше есть стадия построения поискового индекса. Эти округлые прямоугольнички лежат в MapReduce, нашей собственной реализации MapReduce, которая называется YT, Yandex Table. Тут я немножко лакирую — на самом деле построение базы и шардирование оперируют с индексами как с файлами. Мы это немножко зафиксим. Эти округлые прямоугольнички будут лежать в MapReduce. Суммарный объем данных здесь — порядка 50 ПБ. Тут они превращаются в поисковые индексы, в файлики.
В этой схеме есть проблемы. Основная связана с тем, что MapReduce — сугубо батчевая операция. Чтобы определить приоритетные документы для обхода, например, мы берем весь линковый граф, мёржим его со всем пользовательским поведением и формируем очередь для скачки. Это процесс достаточно латентный, занимающий какое-то время. Ровно так же с построением индекса. Там есть стадии обработки — они батчевые для всей базы. И выкладка так же устроена, мы или дельту выкладываем, или всё.
Важная задача при этих объемах — ускорить процедуру доставки индекса. Надо сказать, что эта задача для нас сложная. Речь идёт о борьбе с батчевым характером построения базы. У нас есть специальный быстрый контур, который качает всякие новости в real time, доносит до пользователя. Это наше направление работы, то, чем мы занимаемся.
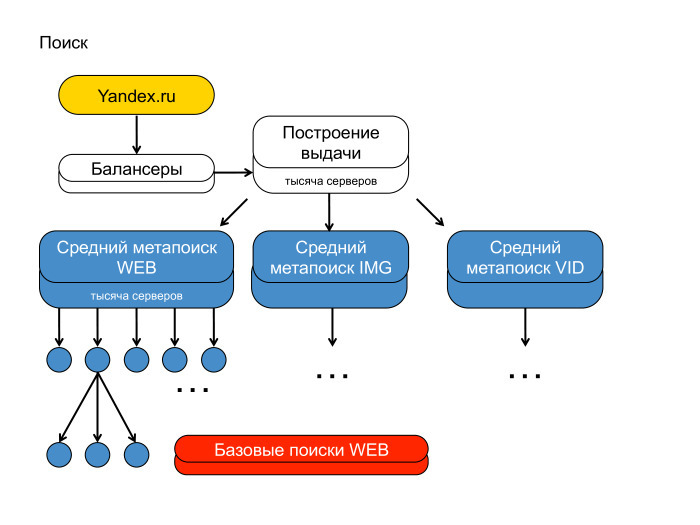
А вот вторая сторона медали. Первая — контент-система, вторая — поиск. Можно понять, почему я рисовал пирамидку — потому что поиск Яндекса действительно похож на пирамиду, такую иерархическую структуру. Сверху стоят балансеры, фронты, которые генерируют выдачу. Чуть пониже — агрегирующие метапоиски, которые агрегируют выдачу с разных вертикалей. Надо сказать, что на выдаче вы наверняка видели веб-документы, видео и картинки. У нас три разных индекса, они опрашиваются независимо.
Каждый ваш поисковый запрос уходит по этой иерархии вниз и спускается до каждого кусочка поисковой базы. Мы весь индекс, который построили, разбили на тысячи кусков. Условно, — на две-три-пять тысяч. Над каждым куском подняли поиск, и этот запрос всюду спустился.

Тут же видно, что поиск Яндекса — большая штука. Почему она большая? Потому что мы в своей памяти храним, как вы видели на предыдущих слайдах, достаточно репрезентативный и мощный кусок интернета. Храним не один раз: в каждом дата-центре от двух до четырёх копий индекса. Запрос наш спускается до каждого поиска, фактически проходится по каждому индексу. Сейчас используемые структуры данных — такие, что мы вынуждены всё это хранить напрямую в оперативке.

Что нужно делать? Вместо дорогой оперативки использовать дешевый SSD, ускорить поиск, допустим, в два раза, и получить профит — десятки или сотни миллионов долларов капитальных расходов. Но тут не нужно говорить: кризис, Яндекс экономит и всё такое. На самом деле всё, что мы сэкономим, мы пустим в полезное дело. Мы увеличим индекс в два раза. Мы будем по нему качественнее искать. И это то, ради чего осуществляется такого рода сложная инженерка. Это реальный проект, правда, достаточно тяжелый и вялотекущий, но мы действительно так делаем, хотим поиск наш улучшить.
Поисковый кластер не только достаточно большой — он ещё и очень сложный. Там реально крутятся миллионы инстансов разных программ. Я вначале написал — сотни тысяч, но товарищи из эксплуатации меня поправили — таки миллионы. На каждой машинке в очень многих экземплярах 10-20 штук точно крутится.
У нас тысячи разных типов сервисов размазаны по кластеру. Надо пояснить: кластер — это такие машинки, хосты, на них запущены программы, все они общаются по TCP/IP. Программы имеют разное потребление CPU, памяти, жесткого диска, сети — короче, всех этих ресурсов. Программы живут на хостах в общежитии. Точнее, если будем сажать одну программу на хост, то утилизация кластера будет никакой. Поэтому мы вынуждены селить программы друг с другом.
Дальше слайд про то, что с этим делать. А здесь — небольшое замечание, что все данные программы, все релизы мы катаем с помощью торрентов, и число раздач на нашем торрент-трекере превышает оное число на Pirate Bay. Мы реально большие.
Что нужно делать со всей этой кластерной конструкцией? Нужно улучшать механизмы виртуализации. Мы реально вкладываемся в разработку ядра Linux, у нас есть собственная система управления контейнерами а-ля Docker, про неё Олег подробнее расскажет.
Нам нужно заранее планировать, на каких хостах какие программы друг с другом селить, это тоже сложная задача. У нас постоянно что-то на кластер едет. Сейчас там наверняка десять релизов катятся.
Нам нужно грамотно селить программы друг с другом, нужно улучшать виртуализацию, нужно-таки объединить два больших кластера — роботный и поисковый. Мы как-то независимо заказывали железо и считали, что есть отдельно машинки с огромным числом дисков и отдельно — тонкие блейды для поиска. Сейчас мы поняли, что лучше заказывать унифицированное железо и запускать MapReduce и поисковые программы в изоляции: одно жрет в основном диски и сеть, второе в основном CPU, но по CPU у них баланс, нужно туда-сюда крутить. Это большие инженерные проекты, которые мы тоже ведем.
Что мы с этого получаем? Пользу в десятки миллионов долларов экономии капитальных расходов. Вы уже знаете, как мы эти деньги потратим — мы потратим их на улучшение нашего поиска.
Здесь я рассказал о конструкции в целом. Какие-то отдельные строительные блоки. Эти блоки люди долбили стамеской, и у них что-то получилось.

Ранжирующая функция Матрикснет. Достаточно простая функция. Можете почитать — там лежат в векторе бинарные признаки документа, а в этом цикле происходит вычисление релевантности. Я уверен, что среди вас есть специалисты, которые умеют на SSE программировать, и они бы живо это ускорили в десять раз. Так оно в какой-то момент и случилось. Тысяча строчек кода нам спасли 10-15% общего потребления CPU на нашем кластере, что опять же составляет десятки миллионов долларов капитальных расходов, которые мы знаем, как потратить. Это тысяча строчек кода, которая стоят очень дорого.
Мы более-менее вычистили из репозитория, соптимизировали, но там ещё есть что поделать.
Имеется у нас платформа для машинного обучения. Индексы с предыдущего слайда нужно подбирать жадным образом, перебирая все возможности. На CPU это делать долго. На GPU — быстро, зато пулы для обучения не лезут в память. Что нужно делать? Или покупать кастомные решения, куда этих железок много-много втыкается, или связывать машинки быстрым, использовать интерконнект какой-то, infiniband, учиться с этим жить. Оно типично глючит, не работает. Это очень забавный инженерный вызов, с которым мы тоже встречаемся. Он, казалось бы, совсем не связа с нашей основной деятельностью, но тем не менее.

Во что мы ещё инвестируем, так это в алгоритмы сжатия данных. Основная задача сжатия выглядит примерно следующим образом: есть последовательность целых чисел, нужно её как-то компрессировать, но не просто компрессировать — нужно ещё иметь случайный доступ к i-тому элементу. Типичный алгоритм — маленькими блоками сжать это, иметь разметку для общего потока данных. Такая задача — совсем другая, нежели контекстное сжатие типа zip или LZ-family. Там совсем другие алгоритмы. Можно сжать Хаффманом, Varlnt, блоками типа PFORX. У нас есть собственный патентованный алгоритм, мы его улучшаем, и это опять же 10-15% экономии оперативной памяти на простенький алгоритм.
У нас есть всякие забавные мелочи, например доработки в CPU, планировщики Linux. Там какая проблема с гипертредными камнями от Intel? То, что на физическом ядре есть два потока. Когда там два треда занимают два потока, то они работают медленно, латенция увеличивается. Нужно правильно раскидывать задачки по физическим процессорам.
Если раскидывать правильно, а не так, как делает стоковый планировщик, можно получить 10-15% латентности нашего запроса, условно. Это то, что видят пользователи. Сэкономленные миллисекунды умножайте на число поисков — вот и сэкономленное время для пользователей.
У нас есть какие-то совсем странные вещи типа собственной реализации malloc, который на самом деле не работает. Он работает в аренах, и каждая локация просто сдвигает указатель внутри этой арены. Ну и ref counter арены поднимает на единичку. Арена жива, пока жива последняя локация. Для всякой смешанной нагрузки, когда у нас есть короткоживущая и долгоживущая локация, это не работает, это выглядит как утечка памяти. Но наши серверные программы устроены не так. Приходит запрос, мы там аллоцируем внутренние структуры, как-то работаем, потом отдаем ответ пользователю, всё сносится. Этот аллокатор идеально работает для наших серверных программ, которые без состояния. За счет того, что все локации локальны, последовательны в арене, оно работает очень быстро. Там нет никаких page fault, cache miss и т. п. Очень быстро — это от 5% до 25% скорости работы наших типичных серверных программ.
Это инженерка, что ещё можно делать? Можно заниматься машинным обучением. Про это вам с любовью расскажет Саша Сафронов.
А сейчас вопросы и ответы.
Я возьму очень понравившийся мне вопрос, который пришел на рассылку и который следовало бы включить в мою презентацию. Товарищ Анатолий Драпков спрашивает: есть знаменитый слайд про то, как быстро росла формула до внедрения Матрикснета. На самом деле и до, и после. Есть ли сейчас проблемы роста?
Проблемы роста у нас стоят в полный рост. Очередной порядок увеличения числа итераций в формуле ранжирования. Сейчас мы там порядка 200 тысяч итераций делаем в функции Матрикснет, чтобы ответить пользователю. Был получен следующим инженерным шагом. Раньше мы ранжировали на базовых. Это значит, что каждый базовый запускает у себя Матрикснет и выдает сто результатов. Мы сказали: давайте мы лучшие сто результатов объединим на среднем и отранжируем ещё раз совсем тяжелой формулой. Да, мы это сделали, на среднем можно вычислять в нескольких потоках функцию Матрикснет, потому что ресурсов нужно в тысячу раз меньше. Это проект, который нам позволил достичь очередного порядка увеличения объемов ранжирующей функции. Что будет ещё — не знаю.
Андрей Стыскин, руководитель управления поисковых продуктов Яндекса:
— Сколько занимала байт первая формула ранжирования Яндекса?
Пётр:
— Десяток, наверное.
Андрей:
— Ну, да, наверное, где-то символов сто. А сколько сейчас занимает формула ранжирования Яндекса?
Пётр:
— Где-то 100 МБ.
Андрей:
— Формула релевантности. Это для наших смотрителей с трансляций, специалистов по SEO. Попробуйте зареверсинженирить наши 100 МБ ранжирования.
Алеся Болгова, Intel:
— По последнему слайду про malloc не могли бы пояснить, как вы выделяете память? Очень интересно.
Пётр:
— Берется обычная страничка, 4 КБ, в начале у нее rev counter, и дальше мы каждую аллокацию… если маленькие аллокации меньше страницы, мы просто двигаемся в этой страничке. В каждом треде, естественно, эта страничка своя. Когда страничку закрыли — всё, про неё забыли. Единственное, у неё rev counter в начале.
Алеся:
— То есть вы страницу выделяете?
Пётр:
— Внутри страницы аллокациями вот так растем. Единственное, страничка живет, пока в ней последняя аллокация живет. Для обычного workload это выглядит как утечка, для нашего — как нормальная работа.
— Как вы определяете качество страницы, стоит её класть в индекс или нет? Тоже машинное обучение?
Пётр:
— Да, конечно. У странички есть множество факторов, от её размера до показов на поиске, до…
Андрей:
— До robot rank. Она находится на каком-то хосте, в какой-то поддиректории хоста, на неё сколько-то входящих ссылок. Те, кто на неё ссылаются, обладают каким-то качеством. Все это берем и пытаемся предсказать, с какой вероятностью, если данную страничку скачать, на ней будет информация, которая попадет по какому-то запросу в выдачу. Это предсказывается, отбирается топ с учетом размера документов — потому что в зависимости от размера документа вероятность, что она хоть по какому-то запросу попадет, повышается. Задача об оптимальном наполнении рюкзака. Отбирается с учетом размера документа и кладется топовая в индекс.
— …
Андрей:
— Давай мы тебя представим сначала.
— Может, не стоит?
Андрей:
— Владимир Гулин, начальник ранжирования поисковика Mail.Ru.
Владимир:
— Первый мой вопрос — про количество поисков вообще. Вы говорили, что вы там драматически увеличили размер базы. Хочется вообще понимать, с какого объема вы стартовали, каков был объем русского индекса, иностранного индекса, сколько документов приходилось на каждый шард, ну и после увеличения…
Пётр:
— Это такие цифры, слишком технические. Может, в кулуарах я бы сказал. Я могу сказать, во сколько раз мы примерно увеличились — на полтора порядка где-то. В 30 раз, условно. За последние три года.
Владимир:
— Я тогда абсолютные цифры в кулуарах уточню.
Пётр:
— Да, за отдельную плату, что называется.
Владимир:
— Ладно. Что касается свежести — какой приблизительно сейчас в Яндексе объем быстрого индекса? И вообще с какой скоростью вы это всё обновляете, смешиваете?
Пётр:
— Индекс реально реалтаймовый, там порядка двух минут латенции на то, чтобы добавить документ в индекс. От момента, как мы его проиндексировали, и дискавери тоже — скачка быстрая.
Владимир:
— Но именно найти документ. Сначала надо узнать, что документ существует.
Пётр:
— Я понимаю, что вопрос такой — непонятно, когда в интернете появилась первая ссылка на данный документ. Когда мы узнали первую ссылку, то дальше это вопрос минут в быстром слое.
Андрей:
— Речь идет о миллионах документов, которые ежедневно находятся в этом быстром индексе. Про них обычно очень много внешней информации: упоминание в Твиттере, сайтмэпы, упоминание новости на сайте Lenta.ru. И так как мы перекачиваем чуть ли не каждую секунду морду Lenta.ru, мы очень быстро обнаруживаем эти документы и в течение единиц минут в худшем случае доставляем их до поиска. Они могут искаться. По сравнению с большим индексом речь идет про драматически маленькое число документов, это миллионы.
Пётр:
— Да, на 3-4 порядка меньше.
Андрей:
— Да, это миллионы документов, которые умеют обновляться real time.
Владимир:
— Миллионы документов в сутки?
Пётр:
— Побольше чуть-чуть, но примерно так, да.
Владимир:
— Теперь вопрос про смешивание свежих результатов и результатов основного поиска.
Пётр:
— У нас два способа смешивания. Один — документ той же формулой ранжируется, что и батчевый обычный документ. А второй — специальное новостное подмешивание, когда мы определяем интент запроса, понимаем, что он реально свежий и что нужно что-то такое показать. Два способа.
Владимир:
— Как вы боретесь с ситуацией, когда у вас по популярным запросам, где дофига кликов, появляются свежие результаты? Как вы определяете, что свежий результат надо показывать выше того результата, который уже накликан? Спросили у вас: «Google». Вы вроде знаете, какие результаты по такому запросу хорошие. Но тем не менее, в новостях ещё что-то, какие-то статьи…
Пётр:
— Это всякие запросные факторы, всякие тренды и всё такое.
Андрей:
— Для всех поясню, в чем сложность задачи и в чем вопрос. Про документ, который долго существует в интернете, мы много чего знаем. Мы много знаем входящих на него ссылок, знаем, сколько на нем люди проводили времени, а про свежие документы этого всего не знаем. Поэтому сложность задачи ранжирования свежих документов и новостей — угадывать, будут ли люди это читать, уметь предсказывать количество ссылок, которые он наберет за какое-то время, чтобы его показывать нормально. И для подмешивания документов по запросу «Google», когда Google что-то хорошее сделал, там существует некая оптимизационная метрика, которая у нас называется профицит. Мы её умеем оптимизировать.
Пётр:
— Мы знаем поток запросов, содержание свежескачанных страниц. Эти две вещи мы можем анализировать и понимать, что реально свежий запрос требует подмешивания.
Андрей:
— А потом, на основе ручной оценки и пользовательского поведения именно в эту секунду в этот день, мы понимаем, что именно сегодня эта новость по запросу важна и у неё есть такие факторы: документ только появился, на него столько-то ретвитов. И поэтому следующую новость, которая будет с таким же распределением признаков, тоже нужно показывать, когда она наберет соответствующие значения.
Пётр:
—А факторы там могут быть такими: число найденного в обычном слое против числа найденного по этому запросу в свежем. Такие, самые наивные, хотя мы его выпиливаем тщательно.
Андрей:
— Для тех, кого пугает слово «факторы», специально будет третий доклад, где мы расскажем базовые принципы — как вообще устроено машинное обучение, ранжирование, что такое факторы, как с помощью этого сделать поисковик, который выдает нормальные хорошие результаты.
Владимир:
— Спасибо, остальное спрошу потом.
Никита Пустовойтов:
— Получается, у вас существует большое количество урлов, про которые вы в принципе знаете, а качать вы можете на несколько порядков меньше. Поскольку за время скачивания будут появляться новые, больше вы никогда не посетите. Для выбора применяется машинное обучение, какие-то эвристики?
Пётр:
—Только машинное обучение. Идея там простая: мы имеем сигнал на какой-то документ, любой, число показов, и его распространяем по ссылочному графу. Всё это агрегируем на странице «цель ссылки», дальше машинным обучением так же обучаем шанс показаться, исходя из этих данных.
Никита:
— Второй вопрос — инженерный. Вы говорили, что у вас много CPU-затратных задач. Рассматривали ли вы вариант использования процессора Xeon Phi от Intel? Он вроде гораздо быстрее работает с оперативной памятью, чем GPU.
Пётр:
— Мы его рассматривали для задач обучения именно нашего Матрикснета, нашей формулы, и там он феерично плохо себя показал. А так вообще у нас профиль очень плоский, у нас топовая функция где-то 1,5%. Мы всё, что можно, руками соптимизировали, а так у нас портянки С++-кода, который туда не ложится.
— Насколько я знаю, Яндекс был первым поисковиком, который начал работать с русской морфологией. Скажите, на данный момент это всё ещё является каким-либо преимуществом или все поисковики одинаково хорошо работают с русской морфологией?
Пётр:
— Сейчас в области морфологии наука не стоит на месте. Саша Сафронов расскажет о том, чего мы сейчас достигаем, там реально есть новые подходы и новые способы решения проблем. Например, определение запросов, похожих на этот, по пользовательскому поведению. Не расширение отдельных слов, а расширение запросов запросами.
Андрей:
— То есть это не совсем морфология. Морфологию действительно, наверное, все поисковики более-менее освоили, но это базовая вещь. А вот лингвистика, нахождение, чем и какие слова запроса можно расширить, какие ещё вещи стоит поискать в документе, чтобы найти кандидатов, которые будут более релевантные — про это будет третий доклад. Там наше ноу-хау, мы расскажем.
Пётр:
— По крайней мере, намекнем.
Андрей (зритель):
— Спасибо за краткий экскурс в столь сложную технологию, как поиск Яндекса. Использует ли Яндекс deep learning и алгоритмы обучения с подкреплением в построении быстрого индекса или кеша? Вообще если используете где-то, то как?
Пётр:
— Deep learning используем для того, чтобы факторы ранжирования обучать. Безотносительно к быстрому или медленному индексу. Он используется для картинок, веба и всего такого.
Андрей Стыскин:
— Летом запустили версию ранжирования, которая дала 0,5% прироста качества, где мы правильно сварили deep learning на словах. Приезжали наши бывшие коллеги из-за границы и рассказывали, что там такое не работает, а мы научились.
Пётр:
— А может, это потому, что мы для топ-100 документов это делаем. Речь идёт об очень затратной задаче. Наш способ построения пайплайна поиска позволяет для сотни документов это делать.
Андрей Стыскин:
— Невозможно посчитать deep learning для всех кандидатов, которых сотни миллионов на запросы, но для топа документов можно провернуть, и у нас эта схема поиска ровно так работает — позволяет такие очень сложные наукоемкие алгоритмы внедрять.
Игорь:
— Про будущее поисковика в целом. Интернет сейчас растет очень быстро, объем, наверное, растет экспоненциально. Уверены ли вы, что через 10 лет вы будете успевать за ростом интернета, и уверены ли, что будете охватывать его в таком же объеме? Повторите ещё раз, в каком объеме сейчас интернет охвачен по вашей оценке, и что будет через 10 лет?
Пётр:
— К сожалению, можно только процентно по отношению с кем-то степень охвата определять. Потому что он реально бесконечный.
Андрей:
— Это красивый философский вопрос. Пока мы в нашем коллективе за законом Мура успеваем, каждый год кратно увеличиваем наш размер базы. Но это правда сложно, правда интересно, и, конечно же, нам даже не хватает рук, чтобы это делать, но мы хотим и знаем, как это увеличивать в ближайшие несколько лет некоторыми сериями улучшений.
Пётр:
— 10 лет — слишком далеко, но ближайшие годы да, осилим.
Андрей (зритель):
— Сколько весит реплика интернета, как она разносится между ДЦ, и как осуществляется синхронизация реплик?
Пётр:
— Полный объем роботных данных — порядка 50 ПБ, реплика меньше, индекс меньше. Можете умножить на коэффициент, который вам кажется разумным. Вы же инженер, прикиньте.
Андрей:
— А как разносится?
Пётр:
— Разносится банально — через torrent, torrent share. Потом качаем этот файлик.
Андрей:
— То есть в какой-то момент времени они не консистентны?
Пётр:
— Нет, там потом консистентные переключения. Бывает, что переключаем по ДЦ, когда ночью оно вдруг не консистентно.
Андрей:
— То есть можно через F5 — если нажимаем, один документ имеем…
Пётр:
— Мы боремся с этой проблемой, знаем о ней, ее решение стоит в наших планах.
Иван:
— Как вы боретесь с различными бот-системами и за что можно отправиться в бан?
Пётр:
— У нас есть специальные люди, которые знают ответ на этот вопрос, но они не скажут.
Андрей Стыскин:
— На сегодняшнем мероприятии мы хотели поговорить про технические детали.
Пётр:
— Про роботоловилку мы можем ответить. Нас действительно регулярно ддосят, поэтому у нас прямо на балансере, на первом слое, когда запрос попадает, есть детекция, что запрос из какой-то сети пришел негодной. Это быстро обновляется, мы быстро реджектим, оно не валит наш кластер.
Андрей:
— И это тоже устроено методом машинного обучения. Показывается капча, и в зависимости от того, как ты её разгадываешь, мы получаем положительные и отрицательные примеры. На каких-то факторах — типа айпишника подсетки, какого-то поведения, времени между действиями — обучаем и баним или не баним такие запросы. DDoS не пройдет.
Андрей Аксёнов, Sphinx Search:
— У меня технические вопросы. Проходной вопрос — почему память? Неужели даже децл подисковать на SSD не получается, чтобы индекс чуть-чуть не влезал, изредка упирался в SSD?
Пётр
— Там получается так, что футпринт одного запроса порядка 50-100 МБ, он прямо жесткий. С такой скоростью ты не сможешь сервить тысячу запросов в секунду, как мы хотим. Мы работаем над тем, чтобы этот футпринт уменьшить. Проблема, что данные про документ рассыпаны по всему диску. Мы хотим их собрать в одно место, и тогда наша общая мечта осуществится.
Андрей Аксёнов:
— Упирается в bandwidth или latency?
Пётр:
— В оба. Мы и последовательно пейджфолдимся, и объемы большие.
Андрей Аксёнов:
— То есть невероятно, но факт: даже если чуть-чуть…
Пётр:
— Да, даже если чуть-чуть отожрешь — всё.
Андрей Аксёнов:
— Экспоненциальное падение во много раз?
Пётр:
— Да-да.
Андрей Аксёнов:
— Теперь важнейший вопрос для промышленного хозяйства: сколько классов строка и классов векторов в базе?
Пётр:
— А вот всё меньше и меньше.
Андрей Аксёнов:
— Ну конкретнее.
Пётр:
— У нас пришли правильные люди, они насаждают правильные порядки. Сейчас это число уменьшается.
Андрей Аксёнов:
— Векторов-то сколько и строк?
Пётр:
— Сейчас векторов, наверное, даже один-два максимум.
Андрей Аксёнов:
— Один не бывает, два хоть…
Пётр:
— Ну вот видишь.
Андрей Аксёнов:
— А строк?
Пётр:
— Ну должен же быть корпоративный какой-то дух Яндекса.
Андрей Аксёнов:
— Скажи, не томи, ну.
Пётр:
— Строк две минимум. Ну три, может.
Андрей Аксёнов:
— Не пять?
Пётр:
— Не пять.
Андрей Аксёнов:
— Налицо прогресс, спасибо.
Фёдор:
— Про вашу схему с метапоисками. У вас очень высокий каскад. Какие тайминги на каждом уровне, можете озвучить?
Пётр Попов:
— Прямо сейчас вставляем ещё один слой, не хватает. Времена ответов… Средний метапоиск делает три раунда хождений туда-сюда, у него порядка 250 мс, 95-я квантиль. Дальше построение выдачи не очень быстрое, но вся конструкция где-то за 700 мс отрабатывает.
Андрей Стыскин:
— Да, там выше JavaScript, так что это 250 мс, а там 700.
Пётр:
— То, что снизу, оно делает кучу раундов. У нас тоже специалисты заняты прямо сейчас решением этой проблемы.
Фёдор:
— У вас нарисовано три группы вертикалей. Но у вас есть ещё Афиша, Новости и так далее. Где вы их замешиваете в итоге?
Пётр:
— В построении выдачи у нас есть такой блендер, который объединяет все эти вертикали, по пользовательскому поведению решает, кого показать. Это как раз построение выдачи.
Андрей:
— Вертикалей порядка сотни, это слой, который называется верхним метапоиском. В нём сливаются результаты средних метапоисков из вертикали веба, Картинок, Видео и ряда других, а также из маленьких базовых источников типа Афиши, Расписаний, ТВ и Электричек.
Пётр:
— Это к вопросу о том, почему у нас тысячи разных типов программ. Там очень много всяких источников, оно набегает.
Фёдор:
— Раз у вас так много вертикалей, есть ли среди них сторонние, которые не вы считаете?
Пётр:
— Особо нет. Реклама наша тоже вертикальная, отдельно от поиска, но стороннего особо нет.
Артём:
— У вашего основного конкурента выдача всегда была real time, он дельта-индексами докидывал. А у Яндекс был up выдачи. Складывалось впечатление, что темной ночью раз в семь дней человек нажимает рычаг и раскатывает индексы.
Пётр:
— К сожалению, так и происходит.
Артём:
— Правильно понимаю, что быстрый индекс был сделан для того, чтобы актуализировать выдачу real time?
Пётр:
— Да, но решение общее. Многие так реально делают, в том числе и наш основной конкурент.
Артём:
— Стремитесь ли вы к тому, чтобы тоже дельта-индексами подкидывать, просто отказаться от быстрого индекса?
Пётр:
— Естественно, стремимся. Ещё бы знать, как.
Артём:
— Когда это можно ожидать?
Пётр:
— Хороший вопрос. На тех же графиках Ашманова видно, как мы обновляем индекс. Сейчас это видно меньше, и мы делаем так, чтобы это проходило совсем быстро и незаметно. Такова одна из наших задач.
Артём:
— Вы каждый раз обрабатываете запрос пользователя? Приходит запрос, вы отсылаете его на бэкенд, рассчитывается формула и результат?
Пётр:
— Есть кеши, но они работают в 50% случаев. 40-50% запросов пользователей — уникальные и никогда больше не будут заданы. Очень много по-настоящему уникальных запросов пользователей вообще за всю жизнь Яндекса. Кешируем 50-60%. Для кеширования тоже своя система.
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Интернет — просто охренеть какая огромная штука. И в нем есть все. Общение с друзьями? Вот, пожалуйста — Facebook. Фотоальбом — в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть поисковики, которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск.
Помните Гермиону из саги о Гарри Поттере? Как вы думаете: почему она была такой сверхэрудированной всезнайкой? Правильно, потому что постоянно ходила где-то читала про всякие зелья, изучала разные заклинания, допытывалась до учителей по всем непонятным моментам. В общем, делала все, чтобы расширить свою базу знаний. Точно так же работает Яндекс поисковик. Еще до того, как вы задали ему вопрос, он уже кое-что узнал про вашу тему и сохранил себе в копилочку.
Как формируется поисковая база Яндекса
Пауки всемирной паутины
Поисковик Яндекс знает несколько триллионов урлов. И каждый день он изучает по паре миллиардов из них. Делают это специальные роботы—пауки, краулеры. Они заходят на страницу, анализируют содержимое, делают копию и отправляют на сервер. А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Если произвести нехитрые математические расчеты, то можно выявить, что пауки Яндекса обойдут все известные страницы приблизительно за 2 года. Но это будет неверно, так как количество урлов постоянно увеличивается
=> работа по созданию поисковой базы бесконечна.
Индексикация
Определение индекса сайта — это процесс добавления всей важной информации о странице в базу поисковика. То есть определяется язык, формируются данные об отдельных словах и вытаскиваются все ссылки исходящие на другие страницы. Кроме того у Yandex есть специальный инструмент, который называется логи Яндекса. Он изучает, как пользователь ведет себя в выдаче: на что кликает, а на что не кликает. Опираясь на все полученные параметры и задается поисковый индекс сайта.
Логи Яндекса широко применяются не только при индексикации, но и при ранжировании.
Составление поисковой базы
Поисковые индексы, полученные в ходе предыдущего этапа, отправляются в поисковую базу. У Яндекс поиска она функционирует на программной платформе мапредьюс YT. Здесь данные превращаются файлы и «остаются жить».
Суммарный объем данных YT приблизительно 50 петабайт = 51 200ТБ.
У поисковой базы данных есть еженедельное обновление — апдейт. Это тот момент, когда поисковый робот Яндекса, накачав определенное количество файлов и рассчитав для них все необходимые характеристики, принимает решение, что можно добавить эту информацию в поиск.
Согласно статистическим данным Игоря Ашманова — специалиста по поисковым системам в интернете, полнота поисковой базы у Яндекса (красные на графике) в несколько раз выше, чем у их ближайшего конкурента Google (черные).
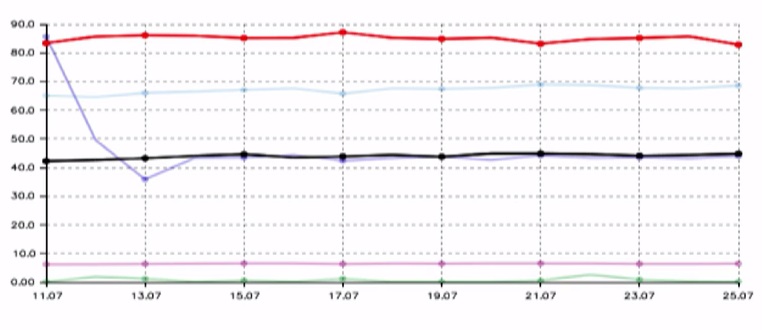
Пока индекс — времязатратный и протекает комплексно сразу для большого количества данных. Поэтому у Яндекса есть специальный быстрый контур, который может добавлять и доносить до пользователя отдельные, срочные файлы. Ну, например, новости в реальном времени.
Как работает сам Яндекс поиск
Любой запрос в поисковой системе Яндекс проходит по следующей схеме.
Балансеры — это машины, которые агрегируют выдачу.
Построение выдачи формируется из результатов трех средних метапоисков. Поясню, что это значит. В выдаче вы видите результаты запроса по страницам, картинкам и видео. Происходит это потому, что ваш запрос проходит по трем разным индексам. И по ним он спускается в самую—самую глубь поисковой базы, разделенную на несколько тысяч кусков. Этот процесс обозначается, как поисковая кластеризация.
Работа поискового кластера состоит из функционирования более миллиона экземпляров различных программ. Они выполняют всяческого рода задачи, у них разные системные требования и всем им нужно где—то «жить». Поэтому поисковая кластеризация занимает еще и огроменное количество компьютерного железного хостинга.
Для хранения и передачи всех программ и данных к ним Яндекс использует внутренний торрент—трекер. Число раздач на нем больше, чем на крупнейшем в мире пиратском трекере The Pirate Bay.
Вернемся к результатам выдачи.
В поисковую выдачу попадают наиболее релевантные, соответствующие поисковому запросу документы. Дальше происходит ранжирование — упорядочивание результатов поиска. Проходит оно с помощью специальной формулы. Чтобы порядок результатов каждый раз был качественным, актуальным и максимально релевантным разработчики Яндекса придумали одну очень крутую штуку.
Матрикснет — метод машинного обучения, с помощью которого строится формула ранжирования Яндекс. Он постоянно модернизирует эту схему: выстраивает комбинации, добавляет и убирает факторы, выставляет коэффициенты. Другая важная характеристика этого метода — возможность индивидуальной настройки формулы ранжирования для узкопрофильных категорий запросов. То есть для отдельных запросов, например, про кино или компьютерные игры, можно улучшить качество поиска. При этом ранжирование по остальным классам запросов не ухудшится.
Первая формула ранжирования Яндекса составляла примерно 10 байт. На сегодняшний момент — около 100 мегабайт.
Задача поисковика не просто находить иголки в сеновалах, но и определять самые острые из них. И самое удивительное то, как работает Яндекс поиск. Результат выдается за доли секунд. Десять первых наиболее релевантных запросов — как правило, это все, что нужно пользователю. Если в этих запросах мы не находим то, что искали, то мы пробуем или другой запрос, или меняем поисковик. Но рано или поздно: «Найдется все!»
Скриншоты взяты из лекции Петра Попова.
icon by Arthur Shlain
Привет дорогие друзья! В этой статье мы продолжим рассматривать поисковую систему Яндекс, и как вы помните, в прошлых статьях был рассмотрена история создания этой великой компании, которая занимает первое место среди конкурентов в России и не только.
Все это хорошо, но новичков и бывалых сайтостроителей интересует самый главный вопрос, конечно же, связанный с тем, как выводить свои проекты на первые места ТОП выдачи.
Поэтому давайте рассмотрим, как работает поисковая система Яндекс, чтобы понять на какие грабли можно наступить, да и чего вообще стоит ждать от русской поисковой машины.
В прошлой статье мы с тобой обсуждали историю развития Яндекса. Тема оказалась достаточно интересной и полезной. Поэтому я решил её дополнить, углубить так сказать.
Итак, наверное, с вопросом «Зачем поисковик индексирует документы» я погорячился – это и ежу понятно. Осталось выяснить вопрос «как».
Алгоритмы ранжирования сайтов
Для начала давай познакомимся с некоторыми алгоритмами, которые являются основополагающими для любой поисковой системы:
— Алгоритм прямого поиска.
Что это такое – вы помните, что читали замечательную историю в одной из книг. И вы начинаете по очереди искать. Взяли одну книгу – полистали – не нашли, взяли другую… Принцип понятен, но этот способ чрезвычайно долгий. Это тоже понятно.
— Алгоритм обратного поиска.
Для этого алгоритма создается из каждой страницы твоего блога – создается текстовый файл. В этом файле перечисляются в алфавитном порядке ВСЕ слова, которые ты использовал. Даже позиция этого слова в тексте указывается (координаты в тексте).
Это достаточно быстрый способ, но уже поиск происходит с какой-то погрешностью.
Здесь главное понимать, что алгоритм этот ищет не в интернете, не поиском по блогу. А в отдельно взятом текстовом файле, который создан был когда-то давно. Когда робот заходил к тебе. И эти файлы (обратные индексы) хранятся на серверах Яндекса.
Так, это были базовые алгоритмы поиска. Т.е. как Яндекс просто находит нужные документы. С этим вроде бы проблем не должно быть.
Но ведь документов Яндекс знает не один и даже не 100, а по последним данным из моих источников – Яндекс знает порядка 11 млрд. документов ( 10 727 736 489 страниц ) .
И среди всего этого количества нужно выбрать документы, подходящие под запрос. И что еще важнее – нужно как-то ранжировать их. Т.е. выстроить по степени важности, а точнее по степени полезности для читателя.
Математические модели поиска
Для решения этого вопроса на помощь приходят математические модели. Вот о простейших моделях мы сейчас и поговорим.

Булевская мат.модель – Если слово встречается в документе – документ считается найденным. Просто на совпадение и ничего сложного.
Но тут есть проблемы. Например, если ты как пользователь введешь какое-то популярное слово, а еще лучше предлог «в», который является самым распространенным словом в русском языке и встречается в КАЖДОМ документе – то тебе выдаст такое количество результатов, что ты даже не осознаешь такую цифру, сколько тебе документов нашлось. Поэтому появилась следующая мат модель.
Векторная мат.модель – эта модель определяет «вес» документа. Уже не только совпадение встречается, но и это слово должно встречаться несколько раз. Причем чем больше слово встречается – тем выше релевантность (соответствие).
Именно векторную модель используют ВСЕ поисковики.
Вероятностная модель – более сложная. Принцип такой: поисковик нашел сам эталон страницы. Например, вы ищете информацию об истории Яндекса. У Яндекса хранится какой-то эталон, допустим это будет моя предыдущая статья о Яндексе.
И все остальные документы он будет сравнивать с этой статьёй. И логика здесь такая: чем более страница твоего блога похож на мою статью – тем ВЕРОЯТНЕЕ тот факт, что твоя страница блога тоже будет полезна читателю и тоже рассказывает об истории Яндекса.
Чтобы сократить количество документов, которые нужно показывать пользователю – было введено понятие релевантности, т.е. соответствия.
Насколько страница твоего блога действительно соответствует теме. Это важная тема, которая касается качества поиска.
Асессоры — кто это и за что отвечают
Нужна эта релевантность еще и для оценки качества работы алгоритмов.
Для этого есть штаб спецназа – их называют Асессоры. Это специальные люди, которые руками просматривают поисковую выдачу.
У них есть инструкция, как проверять сайты, как оценивать и т.п. И они руками определяют по порядку подходят твои страницы поисковым запросам или не подходит.
И вот от мнения асессоров зависит качество поисковых алгоритмов. Если все асессоры скажут, что поисковая выдача не соответствует запросам – значит неправильный алгоритм ранжирования и здесь вина только Яндекса.

Если асессоры говорят о том, что только один сайт не соответствует запросу – значит, сайт улетает куда-то далеко и понижается в выдаче. Точнее не весь сайт, а только одна статья, но это «не суть».
Конечно, асессоры не могут руками и глазами просмотреть и оценить ВСЕ статьи. Это ж понятно.
И на помощь приходят другие параметры, по которым проходит ранжирование страниц.
Их очень много, ну например:
- вес страницы (вИЦ, PageRank, пузомерки в общем);
- авторитетность домена;
- релевантность текста запросу;
- релевантность текстов внешних ссылок запросу;
- а также множество других факторов ранжирования.
Асессоры вносят замечания, а люди, которые отвечают за за настройку математической модели ранжирования уже, в свою очередь, редактируют формулу, в результате чего поисковик работает более качественно.
Основные критерии оценки работы формулы:
1. Точность выдачи поисковой системы — процент документов, соответствующих запросу (релевантных). Т.е. чем меньше страниц, не соответствующих запросу присутствует — тем лучше.
2. Полнота выдачи поисковой системы — это отношение релевантных веб-страниц по данному запросу к общему количеству релевантных документов, находящихся в коллекции (совокупности страниц, находящихся в поисковой системе).
Например, если во всей коллекции релевантных страниц больше, чем в поисковой выдаче, то это означает неполноту выдачи. Это произошло из-за того, что некоторая часть релевантных веб-страниц попала под фильтр.
3. Актуальность выдачи поисковой системы — это соответствие веб-страницы тому, что написано в сниппете. Например, документ может сильно отличаться или вовсе не существовать, но в выдаче присутствовать.
Актуальность выдачи напрямую зависит от того, как часто сканирует поисковый робот документы из своей коллекции.
Сбор коллекции (индексация страниц сайта) осуществляется специальной программой — поисковым роботом.
Поисковый робот получает список адресов для индексации, копирует их, далее содержимое скопированных веб-страниц отдаёт на обработку алгоритму, который преобразует их в обратные индексы.
Ну, вот «в двух словах», если можно так сказать, мы обсудили принципы работы поисковика.
Давай подытожим:
- Поисковой робот приходит к тебе на блог.
- Поисковой робот сохраняет у себя обратный индекс страницы для последующего поиска.
- С помощью математической модели документ обрабатывается и выдается в поисковой выдаче по формулам и с учетом мнения асессора.
Это если очень-очень упрощенно. Просто, чтобы сложилось базовое понимание работы поисковой системы Яндекс.
Я сейчас написал так много текста, и, возможно столько всего не понятно. Поэтому я предлагаю тебе вернуться на эту статью чуть позже и просмотреть вот это видео.
Это отличное руководство, по которому в своё время и я учился.
Надеюсь данная информации поможет лучше понять, почему какой-то из ваших сайтов занимает соответствующие позиции в поиске и сделать все, чтобы их улучшить.
На этом я с вами прощаюсь, если есть вопросы, я всегда рад ответить на них в комментариях. А может вы хотите дополнить статью?
В любом случае высказывайте свое мнение. ") До скорой встречи на seoslim.ru!
До скорой встречи на seoslim.ru!
Поисковый инструментарий
В отличие от конкурента, «Яндекс» дает воспользоваться инструментарием не с главной страницы – yandex.ru, – а уже после того, как была осуществлена попытка поиска:

Нажмите на иконку настроек справа от поля запроса и сможете произвести базовую настройку поиска:
- в каком регионе вы хотите искать информацию;
- выбрать период времени размещения – сутки, 2 недели или месяц;
- задать язык, на котором вы хотите найти данные.
Также обратите внимание на иконку с микрофоном – в «Яндексе» вы можете задавать поисковые запросы голосом.
Вы также можете искать картинки (здесь инструментарий вообще очень богат), видео, товары, новости, вопросы, услуги, музыку и т. д. – все эти данные предоставляют различные сервисы того же «Яндекса».
Продвинем ваш бизнес
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Подробнее

Поиск без рекламы
Если вас раздражает переполненная рекламой и отвлекающими блоками основная страница «Яндекса», то воспользуйтесь специальным «шорткатом» ya.ru, представляющим собой страницу с одним только поисковым полем:

Один минус – после ввода поискового запроса вы попадете на стандартную главную страницу с рекламой и прочими сервисами.
Уточнение слова
«Яндекс» точнее, чем Google, ищет фразы на русском языке. Но если вы хотите найти только заданное вами слово, его лучше уточнить с помощью оператора «!»:

В таком виде поиск должен находить все документы с упоминанием отмеченного вами слова в заданной форме. При этом игнорируется склонение, падеж, но учитывается множественное или единственное число.
Качество работы оператора вам предлагается проверить самостоятельно, поскольку даже в примере выше первая найденная статья не содержит уточненного нами слова в сниппете (описании). Остается надеяться, что оно будет присутствовать при переходе на страницу.

Оператор может быть использован несколько раз для включения всех нужных вам слов в выдачу.
Поиск по точной фразе
Чтобы найти точную фразу или цитату, заключите ее в любые кавычки:

Такой способ должен найти указанное вами сочетание слов в точном виде, при этом вы можете оставить за пределами кавычек прочие слова, которые могут входить в цитату в различном виде или составе.
Способ работает частично, выше вы можете видеть, что в сниппете второй позиции выдачи указанная нами фраза отсутствует. Зато присутствует в точном указании в двух других.
Нахождение отсутствующих слов
Если вы знаете точную фразу, содержание которой необходимо найти, но забыли точное слово или часть из нее, то можете обозначить это оператором «*»:

Оператор работает только в сочетании с фразой в кавычках. А сам способ хорошо подходит в том случае, если вы задаете длинный набор слов, но под ним подразумевается много значений, разброс которых в выдаче слишком велик.
Уточняем присутствие обязательных слов
Допустим, ваш запрос должен содержать несколько слов, относящихся к определенной тематике, но найденная информация по ней может быть любой. Задайте обязательные слова с помощью оператора(ов) «+», а тематику укажите без операторов:

Тему вы можете задать и через кавычки, чтобы гарантированно получить фразы с указанными словами именно по ней.
Исключение слов из запроса
В случае, когда вам нужно найти информацию без упоминания определенных слов или тематик, то добавьте слова в поисковый запрос с оператором «-», который можно использовать сколько угодно раз прежде чем выдача полностью очистится от ненужного:

По данным «Яндекса», по общему количеству запросов в поиске всегда лидируют три темы: школа, кино и порно (последние две темы – вечером и ночью). Первым делом с утра люди спрашивают про погоду, включают радио и выясняют значение своих снов.
Около четверти всех запросов касаются развлекательного контента: люди хотят смотреть, слушать и играть.
Выбор из нескольких вариантов в поиске
Когда вам необходимо найти информацию по нескольким направлениям, но не важно, какое из них будет представлено в выдаче, разделяйте их оператором «|». Одно из слов, разделенных оператором, обязательно будет включено в выдачу, но не обязательно вместе с другим:

Для обязательного включения нескольких слов в запрос используйте операторы-кавычки или восклицательный знак.
Поиск по определенному URL
Чтобы найти текст, размещенный на выбранной вами странице, ее нужно сообщить через оператор «url:». Сначала нужно ввести нужное слово или фразу, затем указать страницу через оператор, причем лучше заключить ее в кавычки. Надо отметить, что способ не самый удобный и не очень работоспособный. Лучше воспользоваться его расширением: через оператор «*» отметить все страницы, размещенные в заданном разделе сайта, например, так:

«Звездочка» заменяет в поиске любые символы или даже фразы.

Новый поиск «Яндекса»: «серому» SEO будет совсем плохо от Y1
Поиск на заданном сайте
Чтобы не указывать конкретные страницы, добавьте к нужным вам словам URL всего сайта, заданный через оператор «site:». Так «Яндекс» будет искать информацию исключительно на указанном сайте, включая все его страницы.

Ищем информацию на определенном домене
Чаще всего домен обозначает принадлежность сайта определенной стране, поэтому вы можете найти необходимую информацию, указав нужный домен через «domain:»

Поиск файлов для скачивания
В том случае, когда вам нужен не сайт, а сразу файл с необходимой информацией, вы можете производить поиск по формату этого файла. Укажите его через оператор «mime:» и добавьте искомый текст:

Как и в Google, здесь невозможно указать сразу несколько типов файлов, чтобы искать данные сразу в нескольких типах исполнения.
Совмещайте оператор с другими, например, с «site:», чтобы искать нужные файлы на определенном сайте.
Поиск на заданном языке
Если вам необходимо найти контент на определенном языке, то выберите его обозначение по стандарту ISO 639-1 и укажите через оператор «lang:»
Например:
- английский – en;
- испанский – es;
- итальянский – it;
- португальский – pt;
- русский – ru.


Самое длинное название России (25 знаков!) и еще гора удивительных фактов в новом отчете «Яндекс.Карты»
Информация по дате изменения страницы
Чтобы найти данные с указанием даты их выкладки или последнего изменения, используйте оператор «date:» следующим образом:
- date:ГГГГММДД – для указания точной даты размещения;
- date:<ГГГГММДД (>) – информация раньше или позже указанной даты;
- date:ГГГГММДД..ГГГГММДД – в указанном интервале;
- date:ГГГГММ* – в указанном месяце года;
- date:ГГГГ* – в указанном году.

Поиск только по заголовкам
Если вам нужно найти слова или фразы исключительно в заголовке страниц сайта, то используйте оператор «title:»

Переводчик в поисковой строке
Чтобы сразу перевести текст (по умолчанию с русского на английский или с определенного системой языка на русский), наберите «перевод:слово»:

«Яндекс.Калькулятор»
Просто наберите в поисковой строке слово «калькулятор»:

Кроме того, вы можете написать выражение в поисковую строку, и «Яндекс.Калькулятор» сразу его посчитает:

«Яндекс.Конвертер»
Вы можете переводить одни единицы в другие, просто начав вводить их название:

Если вам необходимо посчитать конкретное значение одних единиц в других, то введите выражение и получите ответ прямо в браузере.
Спасибо!
Ваша заявка принята.
Мы свяжемся с вами в ближайшее время.
Быстрый прогноз погоды
Чтобы не ходить по сайтам с погодой, вы можете набрать слово «погода» и указать ваш город, после чего увидите краткую сводку гидрометцентра:

Если вы не укажете город, то «Яндекс» покажет погоду в месте, определенном по вашим координатам.
Дополнительные настройки поиска в «Яндексе»
Для персонализации поиска вы можете воспользоваться настройками, ссылка на которые располагается в нижней части страницы поисковой выдачи:

До этого вы можете включить семейный поиск, чтобы избавить выдачу от непристойных результатов и спорного контента.
Содержание самих настроек поиска:

- Чтобы не забыть какие запросы вы вводили, используйте историю поиска. Ее вы можете очистить в настройках или отключить, сняв галочку.
- Часто используемые сайты могут помочь, если вы используете некоторые ресурсы постоянно – так они всегда будут под рукой. Но и их можно отключить в настройках.
- Время посещения сайтов позволяет вам легче вспоминать, с чем и когда вы работали. Эта возможность также отключается здесь.
- Выделяйте меткой персонализированные результаты в выдаче либо отключите и эту возможность.
- Кроме семейного поиска, можно использовать два типа фильтрации контента – без ограничений и с умеренным фильтром. По умолчанию включен именно он, так что имейте в виду.
Надеемся, что эти лайфхаки помогут вам быстро находить нужную информацию.
Вместе с тем, сам поиск «Яндекса» тоже все время становится умнее. Например, он может найти верный фильм по запросам вроде «мужик полетел в космос и застрял между шкафами» («Интерстеллар»), «фильм где дерево живое и енот живой» («Стражи галактики») и даже «фильм Стивена Кинга, где Николсон бухает, печатает книгу и ломает дверь» («Сияние»).
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Интернет — просто охренеть какая огромная штука. И в нем есть все. Общение с друзьями? Вот, пожалуйста — Facebook. Фотоальбом — в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть поисковики, которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск.
Помните Гермиону из саги о Гарри Поттере? Как вы думаете: почему она была такой сверхэрудированной всезнайкой? Правильно, потому что постоянно ходила где-то читала про всякие зелья, изучала разные заклинания, допытывалась до учителей по всем непонятным моментам. В общем, делала все, чтобы расширить свою базу знаний. Точно так же работает Яндекс поисковик. Еще до того, как вы задали ему вопрос, он уже кое-что узнал про вашу тему и сохранил себе в копилочку.
Как формируется поисковая база Яндекса
Пауки всемирной паутины
Поисковик Яндекс знает несколько триллионов урлов. И каждый день он изучает по паре миллиардов из них. Делают это специальные роботы—пауки, краулеры. Они заходят на страницу, анализируют содержимое, делают копию и отправляют на сервер. А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Если произвести нехитрые математические расчеты, то можно выявить, что пауки Яндекса обойдут все известные страницы приблизительно за 2 года. Но это будет неверно, так как количество урлов постоянно увеличивается
=> работа по созданию поисковой базы бесконечна.
Индексикация
Определение индекса сайта — это процесс добавления всей важной информации о странице в базу поисковика. То есть определяется язык, формируются данные об отдельных словах и вытаскиваются все ссылки исходящие на другие страницы. Кроме того у Yandex есть специальный инструмент, который называется логи Яндекса. Он изучает, как пользователь ведет себя в выдаче: на что кликает, а на что не кликает. Опираясь на все полученные параметры и задается поисковый индекс сайта.
Логи Яндекса широко применяются не только при индексикации, но и при ранжировании.
Составление поисковой базы
Поисковые индексы, полученные в ходе предыдущего этапа, отправляются в поисковую базу. У Яндекс поиска она функционирует на программной платформе мапредьюс YT. Здесь данные превращаются файлы и «остаются жить».
Суммарный объем данных YT приблизительно 50 петабайт = 51 200ТБ.
У поисковой базы данных есть еженедельное обновление — апдейт. Это тот момент, когда поисковый робот Яндекса, накачав определенное количество файлов и рассчитав для них все необходимые характеристики, принимает решение, что можно добавить эту информацию в поиск.
Согласно статистическим данным Игоря Ашманова — специалиста по поисковым системам в интернете, полнота поисковой базы у Яндекса (красные на графике) в несколько раз выше, чем у их ближайшего конкурента Google (черные).
Пока индекс — времязатратный и протекает комплексно сразу для большого количества данных. Поэтому у Яндекса есть специальный быстрый контур, который может добавлять и доносить до пользователя отдельные, срочные файлы. Ну, например, новости в реальном времени.
Как работает сам Яндекс поиск
Любой запрос в поисковой системе Яндекс проходит по следующей схеме.
Балансеры — это машины, которые агрегируют выдачу.
Построение выдачи формируется из результатов трех средних метапоисков. Поясню, что это значит. В выдаче вы видите результаты запроса по страницам, картинкам и видео. Происходит это потому, что ваш запрос проходит по трем разным индексам. И по ним он спускается в самую—самую глубь поисковой базы, разделенную на несколько тысяч кусков. Этот процесс обозначается, как поисковая кластеризация.
Работа поискового кластера состоит из функционирования более миллиона экземпляров различных программ. Они выполняют всяческого рода задачи, у них разные системные требования и всем им нужно где—то «жить». Поэтому поисковая кластеризация занимает еще и огроменное количество компьютерного железного хостинга.
Для хранения и передачи всех программ и данных к ним Яндекс использует внутренний торрент—трекер. Число раздач на нем больше, чем на крупнейшем в мире пиратском трекере The Pirate Bay.
Вернемся к результатам выдачи.
В поисковую выдачу попадают наиболее релевантные, соответствующие поисковому запросу документы. Дальше происходит ранжирование — упорядочивание результатов поиска. Проходит оно с помощью специальной формулы. Чтобы порядок результатов каждый раз был качественным, актуальным и максимально релевантным разработчики Яндекса придумали одну очень крутую штуку.
Матрикснет — метод машинного обучения, с помощью которого строится формула ранжирования Яндекс. Он постоянно модернизирует эту схему: выстраивает комбинации, добавляет и убирает факторы, выставляет коэффициенты. Другая важная характеристика этого метода — возможность индивидуальной настройки формулы ранжирования для узкопрофильных категорий запросов. То есть для отдельных запросов, например, про кино или компьютерные игры, можно улучшить качество поиска. При этом ранжирование по остальным классам запросов не ухудшится.
Первая формула ранжирования Яндекса составляла примерно 10 байт. На сегодняшний момент — около 100 мегабайт.
Задача поисковика не просто находить иголки в сеновалах, но и определять самые острые из них. И самое удивительное то, как работает Яндекс поиск. Результат выдается за доли секунд. Десять первых наиболее релевантных запросов — как правило, это все, что нужно пользователю. Если в этих запросах мы не находим то, что искали, то мы пробуем или другой запрос, или меняем поисковик. Но рано или поздно: «Найдется все!»
Скриншоты взяты из лекции Петра Попова.
icon by Arthur Shlain
Ежедневно «Яндекс» обрабатывает 1,5, а Google 3,5–4 млрд запросов. С каждым годом алгоритмы поисковиков все точнее формируют набор ответов на пользовательские запросы, поэтому большинство людей не используют дополнительные инструменты, помогающие добиться от алгоритма более релевантной выдачи. Но пользователи, чья деятельность связана с обработкой большого объема информации, охотно применяют специальный язык поисковых запросов: «Яндекс» и Google предлагают для этого свои наборы инструментов.
Поисковые операторы «Яндекса» и Google: от базовых до продвинутых
Чтобы быстрее находить нужную информацию и получать более точные ответы, научитесь влиять на формирование запросов в поисковых системах с помощью специальных команд. Операторы поисковых запросов — это символы или слова, которые дополнительно вводятся вместе с ключевой фразой. Наличие такой команды — это сигнал для алгоритма, что конкретно он должен искать в своей огромной базе данных.
У «Яндекса» и Google есть базовые операторы, которые известны большинству пользователей, например, кавычки-лапки, которые помогают найти текст по точной цитате, а есть продвинутые символы, о которых знает узкий круг специалистов.
В любом случае, освоив команды, уточняющие поисковые запросы, вы будете быстрее добывать релевантную информацию.
Язык Яндекса: отличия от других поисковых систем и различия внутри сервисов

У разных поисковых систем языки запросов различаются — у каждого свой набор спецсимволов. Конечно это не слишком удобно, но обычно среднестатистический пользователь является приверженцем какого-то одного поисковика, поэтому заучивать несколько наборов у большинства нет необходимости.
У «Яндекса» операторы для уточнения и фильтрации запросов не только отличаются от гугловских, но и различаются внутри экосистемы самого «Яндекса»: в поиске, «Директе» и «Вордстате» не все спецсимволы работают одинаково. В этой статье мы разберем команды для работы с поиском. Про спецсимволы «Вордстата» читайте здесь: «Яндекс Вордстат» ― руководство по подбору ключевых слов.
Что учитывается в запросе по умолчанию
Алгоритмы «Яндекса» учитывают несколько факторов:
- часть речи: существительное, прилагательное, глагол;
- морфологические признаки: падеж, род, число, склонение;
- синонимы.
Это значит, что поисковик выдает все найденные словоформы, образованные от ключевого слова и близкие по смыслу синонимы. При этом однокоренные слова не считаются похожими запросами. Например, «обогреватель» и «обогреть» попадут в одну выдачу, а «грелка» или «нагревать» — нет.
Также алгоритм исправит опечатки, грамматические ошибки и предложит изменить нетипичные слова, которые кажутся ему ошибочными в контексте запроса.
Правила работы «Яндекса»

Составление точного поискового запроса требует соблюдения правил. Чтобы задать алгоритму жесткие рамки, используются специальные команды. Так вы можете исключить из выдачи результаты с синонимами или потребовать у поисковика сохранить порядок слов.
Как составить поисковый запрос в «Яндексе»? Сформулируйте фразу и дополните ее нужной командой:
- В начале фразы вводим ключи.
- Через пробел вводятся нужные команды в виде операторов.
- Если в запросе используется несколько операторов, то каждый вводится через пробел.
ключ оператор№1:значение оператор№2:значение
Любые команды можно комбинировать, чтобы задать более точные условия для фильтрации данных.
Поисковые операторы «Яндекса»
Итак, операторы — это специальные символы и команды, регулирующие параметры поискового запроса. Они помогают очистить результат выдачи от неточных и нерелевантных результатов, конкретизировать поиск.
Виды операторов
Операторы имеют разную форму и делятся на 3 вида:
- Логические — символы и знаки препинания, ставятся рядом со словом, на которое должен распространяться фильтр.
- Документные — команды в виде вспомогательных слов для расширенного поиска, помогают отфильтровать нужные документы по типу, домену или URL-адресу.
- Недокументированные — редкие команды, которые не упоминаются в официальных рекомендациях «Яндекса». Могут работать нестабильно.
Обзор поисковых операторов «Яндекса»
Логические спецзнаки:
- + (плюс)

Маркирует ключ, который должен учитываться алгоритмом. Результаты без отмеченного слова не будут пропущены в выдачу.
Плюс ставится перед ключом без пробела: спряжение +причастий.
- — (минус)
Маркер стоп-слов, которые требуется исключить из поиска. Использование оператора минус в поисковом запросе означает, что в выдаче останутся только результаты без отмеченного слова.
Минус ставится перед словом без пробела: купить смартфон -Samsung.
Если необходимо исключить цифры, то их заключают в кавычки, иначе алгоритм воспримет запись как обозначение отрицательного числа.
- “” (кавычки-лапки)

Кавычки фиксируют фразу, которую необходимо найти. Алгоритм учтет количество слов в запросе, но может проигнорировать словоформы. Поисковый запрос в кавычках полезен для определения текста-первоисточника по цитате.
«мы живем под собою не чуя страны»
Если необходимо найти фразу в точном вхождении, перед каждым словом внутри кавычек поставьте восклицательный знак.
- ! (восклицательный знак)
Фиксирует слово в существующей грамматической форме. Алгоритм будет выкидывать из выдачи словоформы в другом падеже, числе и т.д. Используется для поиска фразы в ее точном вхождении. Например: ремонт !на !дому — поисковик не покажет нерелевантные результаты по близкой фразе ремонт дома.
- * (звездочка)

Замена пропущенного слова в цитате. Оператор используется только в комбинации с кавычками. Алгоритм сам подставляет слово вместо звездочки. Такой инструмент полезен при поиске текста по цитате, которую не удалось вспомнить точно: “шумел камыш * гнулись”.
- | (вертикальная черта)
Аналог союза «или». Используется при перечислении нескольких ключей, когда надо найти хотя бы один из списка: работа в типографии резчик | размотчик | оператор.
- [ ] (квадратные скобки)
Фиксируется фраза с учетом порядка слов и всех словоформ: [рок-концерты в спб].
Документные операторы:
- site:
Ограничивает поиск доменом и поддоменами одного сайта. Оператор также позволяет навскидку оценить количество проиндексированных страниц web-ресурса.
Например, запрос «правила составления поисковых запросов в яндексе site:web-dius.ru» поможет найти нужную информацию по теме на нашем сайте.
- host:
Аналог команды «site:», но поиск ограничивается хостом, без учета поддоменов.
- rhost:

Работает по принципу оператора «host:», но адрес записывается в обратном порядке: например, ключевые фразы rhost:ru.web-dius.www.
- url:
Ограничивает поиск определенной страницей или категорией сайта. С помощью этой команды можно также проверить, проиндексирована ли страница.
Например, по запросу «автоподсказки url:https://www.web-dius.ru/blog/poiskovye_podskazki_yandeks/» в поисковике «Яндекс» найдет ключ «автоподсказки» на указанной странице.
- inurl:
Поиск страниц с требуемым ключом в URL. Например: семантика inurl:dius
- domain:
Ограничивает поиск указанной доменной зоной. Удобно, когда нужна информация по конкретному региону. Например: кризис власти domain:kz.
- title:
Поиск страниц, title которых содержит указанное ключевое слово. Например: title:мандариновый сок.
- mime:

Отфильтровывает документы указанного формата. Оператор понимает расширения doc, ppt, pdf, xls, odp, swf, ods, odt, odg, rtf.
Например, по запросу seo mime:pdf поисковик выдаст все pdf-файлы, где встречается ключ «seo».
- lang:
Ограничивает поиск информацией на указанном языке. Чтобы определить язык, после двоеточия нужно указать двухбуквенный код: русский — ru, белорусский — be, турецкий — tr, татарский — tt, казахский — kk, английский — en, немецкий — de, французский — fr.
- date:
Помогает найти новости за указанный период или найти страницы, которые были обновлены в определенное время. Формулы для ввода периодов или конкретных дат:
- date:ГГГГММДД – конкретная дата;
- date:ГГГГММ* – месяц;
- date:ГГГГ* – год;
- date:ГГГГММДД..ГГГГММДД – период;
- date:>ГГГГММДД – после (или до) указанной даты ( > после, < перед).
Недокументированные операторы:
- intext:
Фильтрует тематические страницы с обязательным вхождением в текст указанного после оператора слова. Например: типографии спб intext:офсетная печать
- image:
Поиск изображений, в названии которых есть указанный ключ.
image: слоненок в яме
Устаревшие знаки в поисковике «Яндекса»

С 2017 года перестали работать следующие типы операторов:
- & — объединение ключей, употребленных в одном предложении;
- && и << — маркировали слова, употребленные в пределах одного документа;
- ~ — разделял два ключа, которые не должны были употребляться в одном предложении;
- () — объединяли в группу несколько ключей в запросе;
- !! — фиксировал начальную форму слова.
Сводная таблица действующих операторов «Яндекса»
| Оператор | Предназначение | Синтаксис |
| Логические операторы | ||
| + | Страницы только с маркированным словом | спряжение +причастий |
| — | Удаление из поисковой выдачи страниц с маркированным словом | купить смартфон -Samsung |
| “” | Отбор страниц с совпадением слов во фразе без учета словоформ | «мы живем под собою не чуя страны» |
| ! | Ограничение поиска точной словоформой маркированного ключевика | ремонт !на !дому |
| * | Подстановка пропущенных в ключевой фразе слов. Используется только в комбинации с кавычками | “шумел камыш * гнулись” |
| | | Смысловой аналог союза «или». Используется, когда надо найти хотя бы один ключ из списка | работа в типографии резчик | размотчик | оператор |
| [ ] | Поиск фразы с точным порядком слов | [рок-концерты в спб] |
| Документные операторы | ||
| site: | Поиск в пределах указанного сайта | правила составления поисковых запросов в яндексе site:web-dius.ru |
| host: | Ограничивает поиск зеркалом сайта без поддоменов | ключевые фразы host:www.web-dius.ru |
| rhost: | Выводит в выдачу страницы указанного хоста. Адрес записывается в обратном порядке | ключевые фразы rhost:ru.web-dius.www |
| url: | Ограничение поиска страницей с указанным URL-адресом | автоподсказки url:https://www.web-dius.ru/blog/poiskovye_podskazki_yandeks/ |
| inurl: | Фильтр страниц с указанным словом в URL | семантика inurl:dius |
| domain: | Поиск в указанной доменной зоне | кризис власти domain:kz |
| title: | Фильтр сайтов с ключевым словом в тайтле | title:мандариновый сок |
| mime: | Фильтр документов указанного формата | seo mime:pdf |
| lang: | Поиск документов на указанном языке | Ilon Mask lang:fr |
| date: | Фильтр поиска по дате | рождаемость в России date:2022* |
| Недокументированные операторы | ||
| intext: | Фильтр страниц с обязательным вхождением указанного слова | типографии спб intext:офсетная печать |
| image: | Поиск изображений по ключевому слову в названии | image: слоненок в яме |
Фильтры расширенного поиска
Пользователям не обязательно заучивать все операторы перед тем, как сделать поисковый запрос в «Яндексе» с настройками фильтров. Справа от строки ввода есть специальный инструмент для расширенного поиска. Открыть его можно, нажав на иконку в виде двух горизонтальных ползунков.
Здесь можно настроить фильтры по региону, дате публикации и языку страницы.
Как узнать дату первой индексации страницы в «Яндексе»

Чтобы проверить, когда интересующая вас страница впервые была проиндексирована в поисковике, можно воспользоваться сервисом XML.Яндекс, в котором у вас должны быть лимиты.
- Заходим на https://xml.yandex.ru/test/.
- Вводим URL страницы в поле query.
- Ищем дату первой индексации под тегом >modtime<.
Поисковые операторы Google
Общие команды обоих сервисов
Язык интернет-запросов поисковых систем частично совпадает. В Google и «Яндексе» одинаково используются логические операторы плюс (+), минус (-), кавычки (“”), звездочка (*), вертикальный слеш (|) и документный оператор «site:».
Базовые операторы Google
- $ или €
Используется для поиска цен в заданной валюте (доллары или евро). Если после оператора поставить цифру, Google будет искать товары по этой цене: смартфон Samsung $ 25.
- OR
Оператор, идентичный вертикальному слешу. Его удобнее использовать, потому что проще найти на клавиатуре. Вводится только в верхнем регистре (прописными буквами): купить лещ OR линь OR щука.
- AND
Объединяет слова и словосочетания в запросе. В выдачу попадут результаты с объединенными ключами. Оператор вводится только в верхнем регистре: купить лещ AND линь.
- in
Оператор для быстрой конвертации валют или мер измерения: 15 м/с in км/час.
Расширенные

- cache:
Выводит последнюю копию указанной страницы из кеша Google. Используется для проверки, проиндексированы ли изменения на странице: cache:https://www.web-dius.ru/seo-prodvizhenie/google/
- source:
Находит новости и упоминания указанного источника в Google News. Для корректной работы оператора важно переключиться на вкладку «Новости».
картон кама source:rbk
- map:
Фильтр по запросам в картографическом сервисе Google Maps.
map:леннеберга
- movie:
Поиск видео по ключевому слову.
movie:леннеберга
- weather:
Прогноз погоды на несколько дней для указанного в запросе места.
weather:леннеберга
- stocks:
Оператор позволяет узнать стоимость акций, ставки и другую информацию по торгам на биржах.
stocks:газпром
- define:
Толковый словарь Google. Находит значение указанного слова по проверенным источникам.
define:каландр
- filetype:
Аналог оператора «Яндекса» mime:. Находит документы с указанным расширением: pdf, doc, xls, ppt, txt, svf, avi, mov. Умеет искать архивы rar, zip и др.
технология офсетной печати filetype:pdf
Комбинация операторов site: и filetype: выявит документы одного формата на указанном сайте.
site:web-dius.ru filetype:pdf
- AROUND(X)

Поиск вокруг указанного слова. В выдачу попадают страницы, где два ключа находятся на расстоянии (X) слов друг от друга. Например, фразы «как писать» и «поисковые запросы» должны находится на расстоянии не более двух слов друг от друга.
“как писать” AROUND(2) “поисковые запросы”
- allintext:
Ищет страницы со словами из указанной фразы.
allintext:сбор семантического ядра
- allintitle:
Поиск страниц с указанным ключом в заголовке Title, допускается нарушение порядка слов. Оператор полезен для анализа сайтов конкурентов.
allintitle:сбор семантического ядра
- allinurl:
Поиск страниц с указанным ключом в URL-адресе, аналог оператора «Яндекс» «inurl:».
allinurl:услуги офсетной печати
Работающие частично
Google регулярно удаляет полезные операторы, причем эти изменения не анонсируются, и пользователи порой узнают о них случайно. Некоторые команды работают некорректно, показывая нестабильный результат.
-
related:
Поиск похожих страниц. Используется для поиска конкурентов.
-
#..#
Поиск диапазона чисел.
-
location:
Поиск новостей через Google News в указанной локации.
-
loc:
Поиск по локации, указанной после двоеточия.
-
inanchor:
Поиск страниц с анкорами, в которых встречаются указанные ключи.
Сводная таблица поисковых операторов Google
| Оператор | Предназначение | Синтаксис |
| Базовые операторы | ||
| $/€ | Цены в указанной валюте | Смартфон Samsung $ 25 |
| OR | Поиск одного или нескольких ключей из списка | купить лещ OR линь OR щука |
| AND | Объединение ключей в запросе | купить лещ AND линь |
| in | Конвертация величин измерений и валют | 15 м/с in км/час |
| Расширенные | ||
| cache: | Проверка обновления страницы в кэше | cache:https://www.web-dius.ru/seo-prodvizhenie/google/ |
| source: | Новости в Google News по указанной теме и источнику | картон кама source:rbk |
| map: | Поиск по Google Maps | map:леннеберга |
| movie: | Видео по указанной теме | movie:леннеберга |
| weather: | Прогноз погоды в указанной локации | weather:леннеберга |
| stocks: | Информация по торгам на биржах | stocks:газпром |
| define: | Значение слова по авторитетным источникам | define:каландр |
| filetype: | Фильтр для выявления документов указанного формата | технология офсетной печати filetype:pdf |
| AROUND(X) | Поиск текстов с ключами, расположенными друг от друга через указанное количество слов | “как писать” AROUND(2) “поисковые запросы” |
| allintext: | Поиск текстов с указанной фразой | allintext:сбор семантического ядра |
| allintitle: | Поиск заголовков с указанными ключами | allintitle:сбор семантического ядра |
| allinurl: | Поиск страниц с указанными ключами в URL | allinurl:услуги офсетной печати |
Выводы
В этой статье мы подробно разобрали правила и примеры оформления поисковых запросов в «Яндексе» и Google. Специальные команды и символы помогают конкретизировать запрос и добиться от поисковика более точных результатов в выдаче.

SEO-оптимизатор диджитал-агентства WebIT
Язык поисковых запросов представляет собой набор специально разработанных операторов и правил для них, помогающих максимально точно сформулировать запрос, а также сузить или наоборот расширить диапазон поиска.
Поисковый язык Яндекса отличается не только от языка других поисковых систем, например, Google, но и внутри собственных сервисов, таких как Директ, Вордстат и т.д.
Виды поиска в Яндексе
Можно выделить 6 видов поиска:
1. Простой – с ним знаком каждый пользователь, который хоть раз сталкивался с необходимостью поиска информации в Яндексе.

2. Расширенный – позволяет указать дополнительные параметры поиска. Вызвать панель выбора можно, кликнув по соответствующему значку справа от строки поиска.

3. Персональный поиск предоставляет результаты для пользователей, авторизованных в почте. Яндекс собирает данные о предпочтениях конкретного пользователя и его «любимых» сайтах и формирует на этой основе выдачу.
4. Поисковые подсказки – предлагаемые варианты выбора поисковых фраз во время ввода запроса.
5. Семейный поиск – ограничение отображения результатов «для взрослых».
6. Поиск людей – поиск информации о человеке, который Яндекс осуществляет по соцсетям.
Операторы поиска
Можно выделить две основные группы операторов поиска, которые позволяют уточнить запрос и быстро найти необходимую информацию:
1. Простые – состоят из знаков препинания и спецсимволов, например, «!».
2. Документальные, их еще называют сложными – поддерживают дополнительные слова, с помощью которых можно уточнить результаты.
Важно! Все нижеприведенные операторы задаются без пробелов перед и после словом или фразой, допускается компоновка в рамках одного поискового запроса.
Простые операторы поиска
1. + (плюс) – применим в случаях, когда необходим поиск по страницам, обязательно содержащим то или иное слово или предлог. Допускается неоднократное применение в рамках одного запроса.

2. – (минус) – в противоположность предыдущему варианту применим, если нужно исключить слово или предлог из запроса.

3. ! (восклицательный знак) – используется в случае поиска по точной словоформе, то есть без изменения числа, падежа и т. д.

4. «» (кавычки) – оператор применяется не к отдельным словам запроса, а к фразе целиком, и позволяет искать среди документов, содержащих указанный запрос в точном соответствии.

5. [] (квадратные скобки) – оператор позволяет сохранить точный порядок слов в запросе, при этом словоформы могут изменяться.

6. * (звездочка) – используется в качестве замены пропущенного слова или целой фразы в запросе, например, в цитате или тексте песни.

7. | (прямая вертикальная черта) – является заменой союза «или». Оператор применим, когда нужно найти совпадения в документах хотя бы по одному слову из тех, что есть в запросе.

Документальная группа поисковых операторов
1. URL – применяйте его для поиска в рамках указанной страницы или раздела. Для указания изменяемой части можно использовать *. Таким образом, мы сужаем Яндексу зону поиска.

2. Inurl – поиск запроса по документам, включающим в свои URL указанное после оператора значение.

3. Site – данный оператор помогает в поиске не в рамках раздела или документа, а внутри всего указанного сайта. В зону поиска попадут также все поддомены. Например, можно грубо оценить количество проиндексированных поисковой системой страниц.

4. Domain – поиск будет осуществлен в рамках указанной доменной зоны, например, .ru, .com и т.д.

5. host (rhost) – помогает в поиске по хосту, результат идентичен оператору «url:», если было задано имя хоста.

6. mime – ищет документы заданного формата (.doc, .pdf и т.д.).

7. lang – нужен для поиска документов на указанном языке. Например, lange:en осуществит поиск документов на английском языке.

8. date – оператор, ограничивающий поиск по заданной дате или диапазону дат.
Формат использования:
- точная дата – date:ГГГГММДД;
- интервал – date:ГГГГММДД..ГГГГММДД;
- до даты, не включая ее – date:<ГГГГММДД;
- до даты, включая ее – date:<=ГГГГММДД;
- после даты, не включая ее – date:>ГГГГММДД;
- после даты, включая ее – date:>=ГГГГММДД;
- неполная дата – date:ГГГГММ*.

9. title – ищет страницы, содержащие в своих заголовках указанный запрос или фразу.

10. image – незаменим в поиске страниц по названию содержащихся на них изображений.

Таким образом, язык поисковых запросов – полезный инструмент, который при правильном использовании может значительно сэкономить время на поиски необходимой информации.
Яндекс – это одна из самых известный поисковых систем, которая пользуется популярностью у миллиона пользователей. Связано это с тем, что в Яндекс можно найти огромное количество разнообразного контента, который тем или иным образом будет связан с тем, что ищет пользователей.
Несмотря на то, что опытные маркетологи и разработчики каждый раз добавляют интересные функции в свой браузер, пользователь мог заметить, что и в утилите есть определенные правила поиска, которым необходимо следовать для более четкого и правильного поиска в сети. На самом деле, это действительно так. Искать в Яндексе необходимо по определенным правилам, более подробно о которых стоит упомянуть далее.
1. Как расширить поисковую строку в Яндексе
Прежде чем приступать к поиску, необходимо посмотреть на поисковую строку. Опытные маркетологи уменьшили её, дабы поставить больше рекламы, а именно «Яндекс. Плюс». Из-за этого ни один пользователь не может нормально набрать необходимый ему текст, посмотреть свой запрос.
Эта проблема решается очень просто. Для её решения необходимо следующее:
- Пользователь придется скачать расширение, которое позволяет поставить определенный пользовательский стиль. Человек может выбрать свое собственное расширение, но, как правило, многие применяют обычное и самое популярное – Google Chrome Stylus;

- После этого идем в Яндекс и скачиваем через сам браузер необходимое расширение;
- Чтобы применить, необходимо кликнуть на кнопку Stylus;
- Откроется окошко, в котором нужно вбить слова Яндекса и поиска.

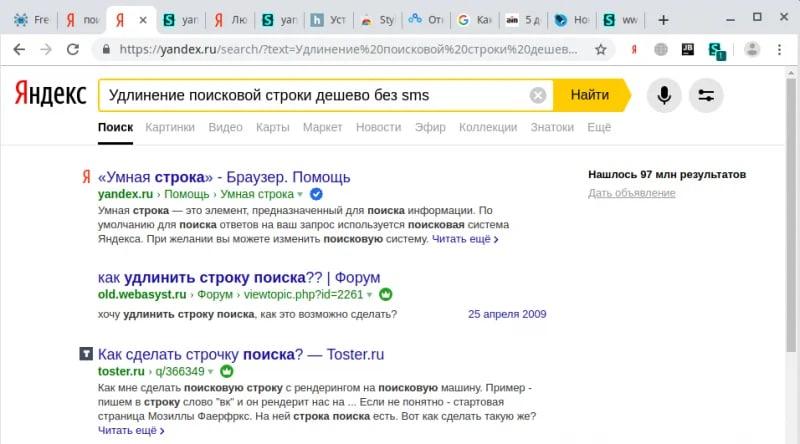
После этих манипуляций пользователь с легкостью увеличит собственную поисковую строку. Это достаточно легкий процесс, с которым справится любой человек. После этого пользователь уберет автоматические кнопки системы, а также ту почту, которой в целом пользователь редко распоряжается.
Более подробно о том, как искать в Яндексе, стоит посмотреть в этом видео
2. Синтаксис поиска Яндекс
Все знают, что Яндекс выдает свои запросы не просто так. Как правило, все, что находит система, имеет не только прямое, но и косвенное значение, то есть программка начинает выдавать синонимы, которые мешают нормальной работе.
Таким образом построены алгоритмы поисковой системы, от которых пользователю никуда не деться. Однако, он может обмануть и обхитрить систему несколькими командами. Для более точного поискового запроса можно использовать определенные символы и правила:
- Для начала необходимо выписать основной текст запроса, то есть те ключевые слова, благодаря которым в дальнейшем пользователь планирует найти определенную информацию;
- После этого стоит через пробел выписать несколько операторов или же определенных фильтров.

Если пользователь хочет найти прям точный поисковой запрос, то ему необходимо использовать только кавычки и восклицательные знаки. Таким образом: «используемые !слова !запроса».
Только при помощи этого оператора пользователь сможет найти самое оптимальное значение.
Обратите внимание! Существуют и другие операторы, более подробно о которых можно найти в морфологии Яндекса. Они помогают найти определенные значения. К таким знакам относят и звездочки, и вертикальные черты, и кавычки, и многое другое.
3. Как искать информацию в своем регионе или городе
Может возникнуть такая ситуация, что необходимо найти информацию в определенном городе или же регионе, потому что при фразе «столовая» может выпасть столовая не только в Липецке, но и в других городах.
Чтобы обмануть систему Яндекса, тем самым найти самое точное положение, необходимо всего лишь задать код региона. Все коды городов и регионов можно найти в специальном «Яндекс. Каталог». В нем собрано более 100 регионов.
Но это еще не все! Необходимо правильно прописать команду:
- Для начала стоит вбить свой запрос;
- После этого поставить cat:;
- Далее необходимо вбить код нужно региона.
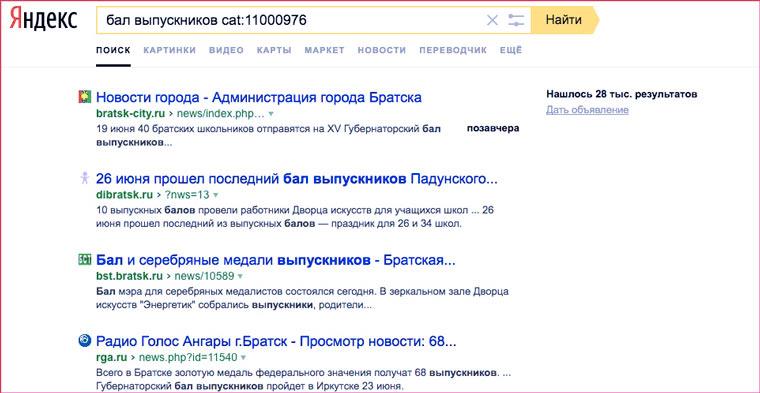
Таким образом для стран СНГ будет характерен код 166, а для Чернигова или же Москвы уже отличные друг от друга значения. Это облегчает поиск, если необходимо найти определенную информацию на местности.
4. Как изменить свое местоположение в Яндексе
Иногда пользователю действительно нужно «обмануть» систему, при этом изменить свое местоположение. Это можно сделать, если знать определенные сервисы, которые занимаются такой сменой информации.
Например, расширение для Хрома под названием Manual Geolocation позволяет это сделать. Все, что требуется от пользователя, так это обозначить определенную точку на карте в приложении, а после Яндекс будет думать о том, что пользователь находится в том месте, где он отметил себя, при этом находясь совершенно в другой стороне.
Таким образом можно, например, искать объекты, которые расположены рядом с Кировом, при этом находится в Москве. Это удобно, если пользователь собирается и планирует съездить именно в этот город, потому что Яндекс выдает информацию в зависимости от положения пользователя.
Обратите внимание! Это относится не только к Яндексу, но и ко всем сайтам, которыми пользуется человек. Очень удобно таким образом подменивать местоположение.
Более подробно об этом расширении стоит посмотреть в этом видео: https://www.youtube.com/watch?v=o-JHE_hc7tA
5. Как искать страницы на конкретном сайте
Может возникнуть необходимость в нахождении информации на определенном сайте. Это также легко сделать, если знать определенные команды, а также необходимый сайт. Для начала пользователю необходимо узнать ссылку сайта, который ему нужен. После этого ему стоит вбить определенный код, который состоит из:
- Самого ключевого слова;
- Site:;
- И названия сайта.
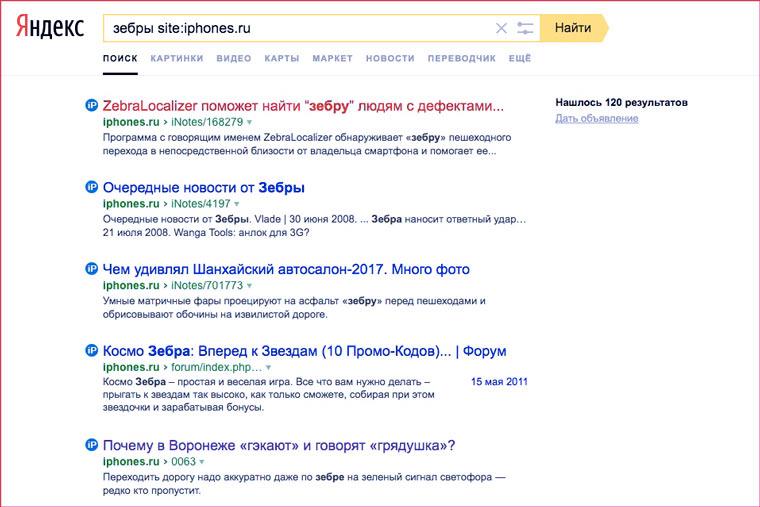
В итоге должно получится слово, которое можно найти только на одном сайте. Это удобная функция, которая позволит найти нужно информацию только на одной страничке, при этом эта информация не заденет другие.
6. Как искать страницы на определенном языке
Каждый сайт имеет свой язык. Например, на каких-то сайтах это русский, а на каких-то украинский. Если пользователю необходимо найти страничку на определённом языке, то он может также воспользоваться определенным правилом поиска.
Для начала необходимо посмотреть краткое обозначение того языка, который необходим. Это может сделать, если вбить в поисковой строке коды языков. Например, для русского языка – это ru. Достаточно просто, ведь практически все сайты в Яндексе на русском.
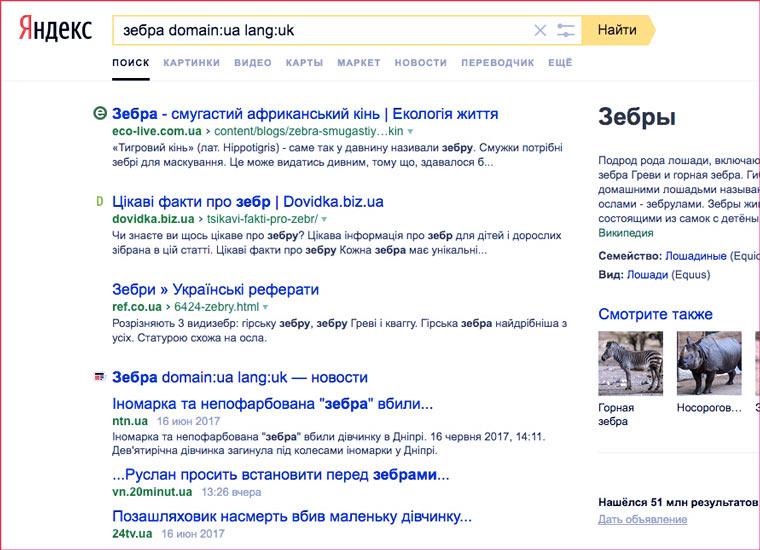
Для того, чтобы отфильтровать информацию на определенном языке и определенные ключевые фразу, необходимо вбить сначала запрос, а потом поставить «domain:ru land:uk». Если пользователь вобьет такое обозначение, то ему автоматически выйдут все статьи на определенном языке.
Обратите внимание! Необходимо смотреть краткий код страны на официальной страничке, чтобы в дальнейшем не возникло вопросов о том, почему не находится запрос и статьи на определенном языке.
7. Как искать в Яндексе ссылки на определенную страницу
И для действия со ссылками на определённую страничку есть свои операторы. Для такого поиска необходимо сделать запрос внутри ссылок. Например, если пользователю нужно найти определенную страничку, нужно сначала вбить «inlink:», а после в кавычках вбить название ссылки.
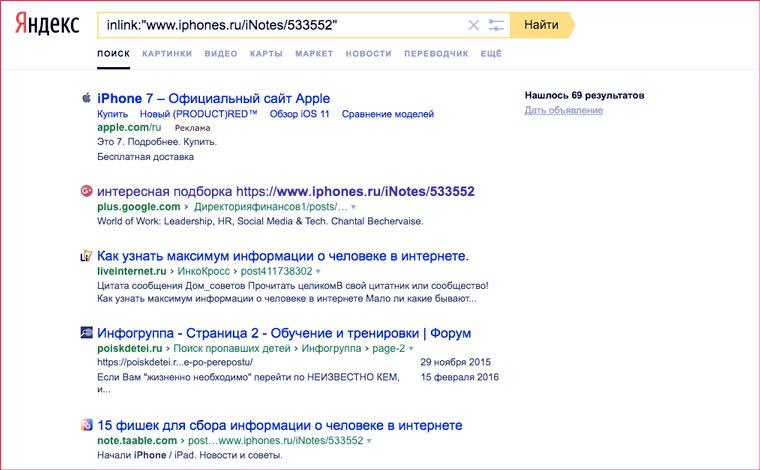
К сожалению, таким способом система может найти не все сайты. Однако, этот способ все равно отлично работает и является неплохой альтернативой другим способам.
8. Как искать страницы по дате
Если пользователю необходимо найти статью, которая сделана в определенную дату, то он также может воспользоваться специальным оператором в Яндекс браузере. Это оператор даты, с помощью которого можно найти определённый запрос, причем страничка будет создана именно в то время, которое укажет пользователь.
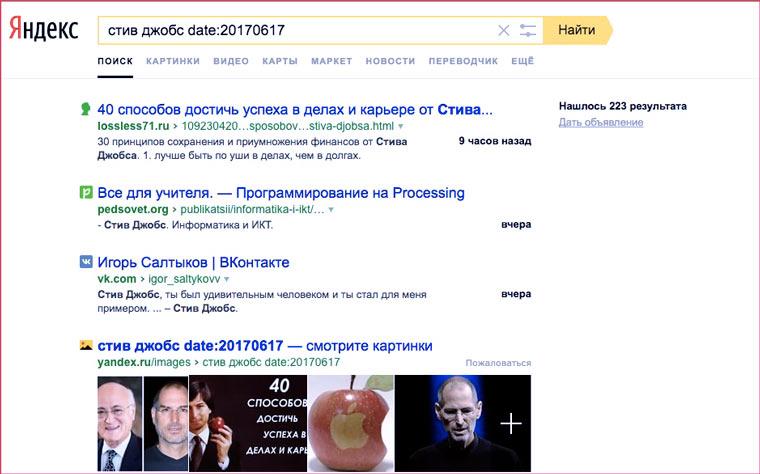
Для того, чтобы применить этого оператора, необходимо вбить запрос, а после написать оператора «date». Теперь стоит поставить двоеточие и вбить определенную дату без пробелов и точек, начиная с года. Если же необходим промежуток, то стоит поставить троеточие. Таким образом можно достаточно быстро и легко найти статьи в определённое время.
9. Как искать определенные файлы
Может возникнуть такая потребность, что необходимо отыскать определенный файл. Это может быть как и pdf формат, так и все другие. Таким образом можно даже найти документы Ворд или же видео.
Существует оператор под названием «mime», причем сам вопрос состоит из следующих пунктов:
- Прописываем сам запрос;
- Делаем пробел;
- Ставим оператора;
- Двоеточие;
- Ставим необходим формат.
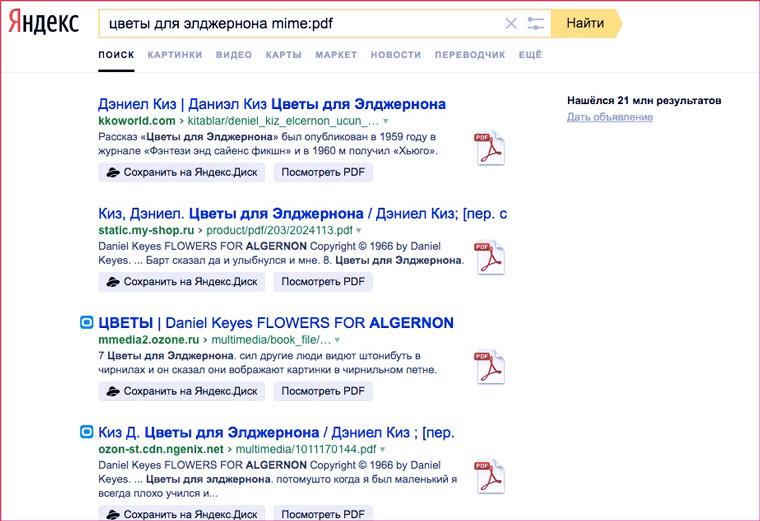
После пользователю выпадут все сайты с нужным форматом.
10. Как искать информацию только в названии страницы
Любая статья имеет свое название. Такая же схема работает и с сайтами. При поиске браузер выдает не только запросы по заглавию, но и по самому содержанию статьи. Чтобы исключить это и искать информацию только по определенному названию, стоит применить оператора «title».
После прописи оператора ставим двоеточие и без пробела прописываем ключевое слово. После этого система выдаст все те сайты, которые содержат этого оператора. Удобно, если нужно найти статью по названию.
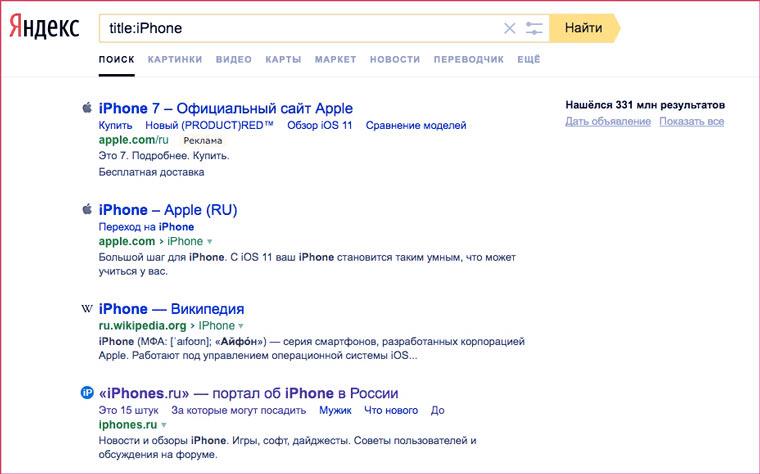
11. Как искать по имени изображения
Пользователь мог сохранить фотографию из интернета, но при этом не вспомнить, откуда он её скачал, то есть не помнит первоначального источника. Необходимо использовать оператора по следующему принципу:
- Ставим оператора «image»;
- Ставим двоеточие;
- Без пробела прописываем название файла.
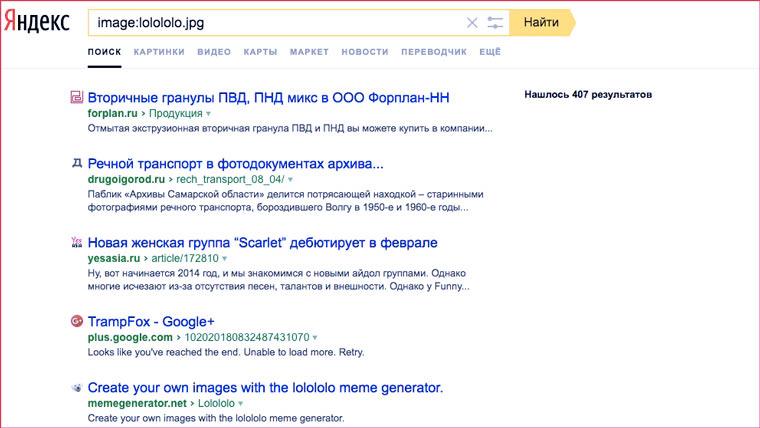
Обратите внимание! Система считывает файлы только с компьютера.
12. Как исключить слово из поиска в Яндексе
Если пользователю необходимо найти определённый товар или же услугу, просто поисковой запрос, но ему не нужно, чтобы были точные словосочетания или же слова в ответах, то можно использовать знак тире. Его необходимо поставить перед теми словами, которые стоит исключить.
Таким образом можно искать различные обозначения. Как видно, в Яндексе есть огромное количество правил и операторов, которые при правильном использовании могут как и упростить, так и усложнить работу.

Вячеслав
Несколько лет работал в салонах сотовой связи двух крупных операторов. Хорошо разбираюсь в тарифах и вижу все подводные камни. Люблю гаджеты, особенно на Android.
Задать вопрос
Нужно ли такие операторы простому пользователю?
Человек может запомнить базовые операторы, чтобы в дальнейшем применять их в своем поиске.
Зачем нужны операторы?
Чтобы пользователь упростил свой поиск различной информации.
Важен ли пробел?
Если человек прописывает точную команду, то даже пробел может сыграть роль. Из-за него может выпасть ошибка.
Поисковый инструментарий
В отличие от конкурента, «Яндекс» дает воспользоваться инструментарием не с главной страницы – yandex.ru, – а уже после того, как была осуществлена попытка поиска:
Нажмите на иконку настроек справа от поля запроса и сможете произвести базовую настройку поиска:
- в каком регионе вы хотите искать информацию;
- выбрать период времени размещения – сутки, 2 недели или месяц;
- задать язык, на котором вы хотите найти данные.
Также обратите внимание на иконку с микрофоном – в «Яндексе» вы можете задавать поисковые запросы голосом.
Вы также можете искать картинки (здесь инструментарий вообще очень богат), видео, товары, новости, вопросы, услуги, музыку и т. д. – все эти данные предоставляют различные сервисы того же «Яндекса».
Продвинем ваш бизнес
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Подробнее
Поиск без рекламы
Если вас раздражает переполненная рекламой и отвлекающими блоками основная страница «Яндекса», то воспользуйтесь специальным «шорткатом» ya.ru, представляющим собой страницу с одним только поисковым полем:
Один минус – после ввода поискового запроса вы попадете на стандартную главную страницу с рекламой и прочими сервисами.
Уточнение слова
«Яндекс» точнее, чем Google, ищет фразы на русском языке. Но если вы хотите найти только заданное вами слово, его лучше уточнить с помощью оператора «!»:
В таком виде поиск должен находить все документы с упоминанием отмеченного вами слова в заданной форме. При этом игнорируется склонение, падеж, но учитывается множественное или единственное число.
Качество работы оператора вам предлагается проверить самостоятельно, поскольку даже в примере выше первая найденная статья не содержит уточненного нами слова в сниппете (описании). Остается надеяться, что оно будет присутствовать при переходе на страницу.
Оператор может быть использован несколько раз для включения всех нужных вам слов в выдачу.
Поиск по точной фразе
Чтобы найти точную фразу или цитату, заключите ее в любые кавычки:
Такой способ должен найти указанное вами сочетание слов в точном виде, при этом вы можете оставить за пределами кавычек прочие слова, которые могут входить в цитату в различном виде или составе.
Способ работает частично, выше вы можете видеть, что в сниппете второй позиции выдачи указанная нами фраза отсутствует. Зато присутствует в точном указании в двух других.
Нахождение отсутствующих слов
Если вы знаете точную фразу, содержание которой необходимо найти, но забыли точное слово или часть из нее, то можете обозначить это оператором «*»:
Оператор работает только в сочетании с фразой в кавычках. А сам способ хорошо подходит в том случае, если вы задаете длинный набор слов, но под ним подразумевается много значений, разброс которых в выдаче слишком велик.
Уточняем присутствие обязательных слов
Допустим, ваш запрос должен содержать несколько слов, относящихся к определенной тематике, но найденная информация по ней может быть любой. Задайте обязательные слова с помощью оператора(ов) «+», а тематику укажите без операторов:
Тему вы можете задать и через кавычки, чтобы гарантированно получить фразы с указанными словами именно по ней.
Исключение слов из запроса
В случае, когда вам нужно найти информацию без упоминания определенных слов или тематик, то добавьте слова в поисковый запрос с оператором «-», который можно использовать сколько угодно раз прежде чем выдача полностью очистится от ненужного:
По данным «Яндекса», по общему количеству запросов в поиске всегда лидируют три темы: школа, кино и порно (последние две темы – вечером и ночью). Первым делом с утра люди спрашивают про погоду, включают радио и выясняют значение своих снов.
Около четверти всех запросов касаются развлекательного контента: люди хотят смотреть, слушать и играть.
Выбор из нескольких вариантов в поиске
Когда вам необходимо найти информацию по нескольким направлениям, но не важно, какое из них будет представлено в выдаче, разделяйте их оператором «|». Одно из слов, разделенных оператором, обязательно будет включено в выдачу, но не обязательно вместе с другим:
Для обязательного включения нескольких слов в запрос используйте операторы-кавычки или восклицательный знак.
Поиск по определенному URL
Чтобы найти текст, размещенный на выбранной вами странице, ее нужно сообщить через оператор «url:». Сначала нужно ввести нужное слово или фразу, затем указать страницу через оператор, причем лучше заключить ее в кавычки. Надо отметить, что способ не самый удобный и не очень работоспособный. Лучше воспользоваться его расширением: через оператор «*» отметить все страницы, размещенные в заданном разделе сайта, например, так:
«Звездочка» заменяет в поиске любые символы или даже фразы.
Новый поиск «Яндекса»: «серому» SEO будет совсем плохо от Y1
Поиск на заданном сайте
Чтобы не указывать конкретные страницы, добавьте к нужным вам словам URL всего сайта, заданный через оператор «site:». Так «Яндекс» будет искать информацию исключительно на указанном сайте, включая все его страницы.
Ищем информацию на определенном домене
Чаще всего домен обозначает принадлежность сайта определенной стране, поэтому вы можете найти необходимую информацию, указав нужный домен через «domain:»
Поиск файлов для скачивания
В том случае, когда вам нужен не сайт, а сразу файл с необходимой информацией, вы можете производить поиск по формату этого файла. Укажите его через оператор «mime:» и добавьте искомый текст:
Как и в Google, здесь невозможно указать сразу несколько типов файлов, чтобы искать данные сразу в нескольких типах исполнения.
Совмещайте оператор с другими, например, с «site:», чтобы искать нужные файлы на определенном сайте.
Поиск на заданном языке
Если вам необходимо найти контент на определенном языке, то выберите его обозначение по стандарту ISO 639-1 и укажите через оператор «lang:»
Например:
- английский – en;
- испанский – es;
- итальянский – it;
- португальский – pt;
- русский – ru.
Самое длинное название России (25 знаков!) и еще гора удивительных фактов в новом отчете «Яндекс.Карты»
Информация по дате изменения страницы
Чтобы найти данные с указанием даты их выкладки или последнего изменения, используйте оператор «date:» следующим образом:
- date:ГГГГММДД – для указания точной даты размещения;
- date:<ГГГГММДД (>) – информация раньше или позже указанной даты;
- date:ГГГГММДД..ГГГГММДД – в указанном интервале;
- date:ГГГГММ* – в указанном месяце года;
- date:ГГГГ* – в указанном году.
Поиск только по заголовкам
Если вам нужно найти слова или фразы исключительно в заголовке страниц сайта, то используйте оператор «title:»
Переводчик в поисковой строке
Чтобы сразу перевести текст (по умолчанию с русского на английский или с определенного системой языка на русский), наберите «перевод:слово»:
«Яндекс.Калькулятор»
Просто наберите в поисковой строке слово «калькулятор»:
Кроме того, вы можете написать выражение в поисковую строку, и «Яндекс.Калькулятор» сразу его посчитает:
«Яндекс.Конвертер»
Вы можете переводить одни единицы в другие, просто начав вводить их название:
Если вам необходимо посчитать конкретное значение одних единиц в других, то введите выражение и получите ответ прямо в браузере.
Спасибо!
Ваша заявка принята.
Мы свяжемся с вами в ближайшее время.
Быстрый прогноз погоды
Чтобы не ходить по сайтам с погодой, вы можете набрать слово «погода» и указать ваш город, после чего увидите краткую сводку гидрометцентра:
Если вы не укажете город, то «Яндекс» покажет погоду в месте, определенном по вашим координатам.
Дополнительные настройки поиска в «Яндексе»
Для персонализации поиска вы можете воспользоваться настройками, ссылка на которые располагается в нижней части страницы поисковой выдачи:
До этого вы можете включить семейный поиск, чтобы избавить выдачу от непристойных результатов и спорного контента.
Содержание самих настроек поиска:
- Чтобы не забыть какие запросы вы вводили, используйте историю поиска. Ее вы можете очистить в настройках или отключить, сняв галочку.
- Часто используемые сайты могут помочь, если вы используете некоторые ресурсы постоянно – так они всегда будут под рукой. Но и их можно отключить в настройках.
- Время посещения сайтов позволяет вам легче вспоминать, с чем и когда вы работали. Эта возможность также отключается здесь.
- Выделяйте меткой персонализированные результаты в выдаче либо отключите и эту возможность.
- Кроме семейного поиска, можно использовать два типа фильтрации контента – без ограничений и с умеренным фильтром. По умолчанию включен именно он, так что имейте в виду.
Надеемся, что эти лайфхаки помогут вам быстро находить нужную информацию.
Вместе с тем, сам поиск «Яндекса» тоже все время становится умнее. Например, он может найти верный фильм по запросам вроде «мужик полетел в космос и застрял между шкафами» («Интерстеллар»), «фильм где дерево живое и енот живой» («Стражи галактики») и даже «фильм Стивена Кинга, где Николсон бухает, печатает книгу и ломает дверь» («Сияние»).
Привет дорогие друзья! В этой статье мы продолжим рассматривать поисковую систему Яндекс, и как вы помните, в прошлых статьях был рассмотрена история создания этой великой компании, которая занимает первое место среди конкурентов в России и не только.
Все это хорошо, но новичков и бывалых сайтостроителей интересует самый главный вопрос, конечно же, связанный с тем, как выводить свои проекты на первые места ТОП выдачи.
Поэтому давайте рассмотрим, как работает поисковая система Яндекс, чтобы понять на какие грабли можно наступить, да и чего вообще стоит ждать от русской поисковой машины.
В прошлой статье мы с тобой обсуждали историю развития Яндекса. Тема оказалась достаточно интересной и полезной. Поэтому я решил её дополнить, углубить так сказать.
Итак, наверное, с вопросом «Зачем поисковик индексирует документы» я погорячился – это и ежу понятно. Осталось выяснить вопрос «как».
Алгоритмы ранжирования сайтов
Для начала давай познакомимся с некоторыми алгоритмами, которые являются основополагающими для любой поисковой системы:
— Алгоритм прямого поиска.
Что это такое – вы помните, что читали замечательную историю в одной из книг. И вы начинаете по очереди искать. Взяли одну книгу – полистали – не нашли, взяли другую… Принцип понятен, но этот способ чрезвычайно долгий. Это тоже понятно.
— Алгоритм обратного поиска.
Для этого алгоритма создается из каждой страницы твоего блога – создается текстовый файл. В этом файле перечисляются в алфавитном порядке ВСЕ слова, которые ты использовал. Даже позиция этого слова в тексте указывается (координаты в тексте).
Это достаточно быстрый способ, но уже поиск происходит с какой-то погрешностью.
Здесь главное понимать, что алгоритм этот ищет не в интернете, не поиском по блогу. А в отдельно взятом текстовом файле, который создан был когда-то давно. Когда робот заходил к тебе. И эти файлы (обратные индексы) хранятся на серверах Яндекса.
Так, это были базовые алгоритмы поиска. Т.е. как Яндекс просто находит нужные документы. С этим вроде бы проблем не должно быть.
Но ведь документов Яндекс знает не один и даже не 100, а по последним данным из моих источников – Яндекс знает порядка 11 млрд. документов ( 10 727 736 489 страниц ) .
И среди всего этого количества нужно выбрать документы, подходящие под запрос. И что еще важнее – нужно как-то ранжировать их. Т.е. выстроить по степени важности, а точнее по степени полезности для читателя.
Математические модели поиска
Для решения этого вопроса на помощь приходят математические модели. Вот о простейших моделях мы сейчас и поговорим.
Булевская мат.модель – Если слово встречается в документе – документ считается найденным. Просто на совпадение и ничего сложного.
Но тут есть проблемы. Например, если ты как пользователь введешь какое-то популярное слово, а еще лучше предлог «в», который является самым распространенным словом в русском языке и встречается в КАЖДОМ документе – то тебе выдаст такое количество результатов, что ты даже не осознаешь такую цифру, сколько тебе документов нашлось. Поэтому появилась следующая мат модель.
Векторная мат.модель – эта модель определяет «вес» документа. Уже не только совпадение встречается, но и это слово должно встречаться несколько раз. Причем чем больше слово встречается – тем выше релевантность (соответствие).
Именно векторную модель используют ВСЕ поисковики.
Вероятностная модель – более сложная. Принцип такой: поисковик нашел сам эталон страницы. Например, вы ищете информацию об истории Яндекса. У Яндекса хранится какой-то эталон, допустим это будет моя предыдущая статья о Яндексе.
И все остальные документы он будет сравнивать с этой статьёй. И логика здесь такая: чем более страница твоего блога похож на мою статью – тем ВЕРОЯТНЕЕ тот факт, что твоя страница блога тоже будет полезна читателю и тоже рассказывает об истории Яндекса.
Чтобы сократить количество документов, которые нужно показывать пользователю – было введено понятие релевантности, т.е. соответствия.
Насколько страница твоего блога действительно соответствует теме. Это важная тема, которая касается качества поиска.
Асессоры — кто это и за что отвечают
Нужна эта релевантность еще и для оценки качества работы алгоритмов.
Для этого есть штаб спецназа – их называют Асессоры. Это специальные люди, которые руками просматривают поисковую выдачу.
У них есть инструкция, как проверять сайты, как оценивать и т.п. И они руками определяют по порядку подходят твои страницы поисковым запросам или не подходит.
И вот от мнения асессоров зависит качество поисковых алгоритмов. Если все асессоры скажут, что поисковая выдача не соответствует запросам – значит неправильный алгоритм ранжирования и здесь вина только Яндекса.
Если асессоры говорят о том, что только один сайт не соответствует запросу – значит, сайт улетает куда-то далеко и понижается в выдаче. Точнее не весь сайт, а только одна статья, но это «не суть».
Конечно, асессоры не могут руками и глазами просмотреть и оценить ВСЕ статьи. Это ж понятно.
И на помощь приходят другие параметры, по которым проходит ранжирование страниц.
Их очень много, ну например:
- вес страницы (вИЦ, PageRank, пузомерки в общем);
- авторитетность домена;
- релевантность текста запросу;
- релевантность текстов внешних ссылок запросу;
- а также множество других факторов ранжирования.
Асессоры вносят замечания, а люди, которые отвечают за за настройку математической модели ранжирования уже, в свою очередь, редактируют формулу, в результате чего поисковик работает более качественно.
Основные критерии оценки работы формулы:
1. Точность выдачи поисковой системы — процент документов, соответствующих запросу (релевантных). Т.е. чем меньше страниц, не соответствующих запросу присутствует — тем лучше.
2. Полнота выдачи поисковой системы — это отношение релевантных веб-страниц по данному запросу к общему количеству релевантных документов, находящихся в коллекции (совокупности страниц, находящихся в поисковой системе).
Например, если во всей коллекции релевантных страниц больше, чем в поисковой выдаче, то это означает неполноту выдачи. Это произошло из-за того, что некоторая часть релевантных веб-страниц попала под фильтр.
3. Актуальность выдачи поисковой системы — это соответствие веб-страницы тому, что написано в сниппете. Например, документ может сильно отличаться или вовсе не существовать, но в выдаче присутствовать.
Актуальность выдачи напрямую зависит от того, как часто сканирует поисковый робот документы из своей коллекции.
Сбор коллекции (индексация страниц сайта) осуществляется специальной программой — поисковым роботом.
Поисковый робот получает список адресов для индексации, копирует их, далее содержимое скопированных веб-страниц отдаёт на обработку алгоритму, который преобразует их в обратные индексы.
Ну, вот «в двух словах», если можно так сказать, мы обсудили принципы работы поисковика.
Давай подытожим:
- Поисковой робот приходит к тебе на блог.
- Поисковой робот сохраняет у себя обратный индекс страницы для последующего поиска.
- С помощью математической модели документ обрабатывается и выдается в поисковой выдаче по формулам и с учетом мнения асессора.
Это если очень-очень упрощенно. Просто, чтобы сложилось базовое понимание работы поисковой системы Яндекс.
Я сейчас написал так много текста, и, возможно столько всего не понятно. Поэтому я предлагаю тебе вернуться на эту статью чуть позже и просмотреть вот это видео.
Это отличное руководство, по которому в своё время и я учился.
Надеюсь данная информации поможет лучше понять, почему какой-то из ваших сайтов занимает соответствующие позиции в поиске и сделать все, чтобы их улучшить.
На этом я с вами прощаюсь, если есть вопросы, я всегда рад ответить на них в комментариях. А может вы хотите дополнить статью?
В любом случае высказывайте свое мнение. До скорой встречи на seoslim.ru!
Поиск находит информацию практически моментально, но что в это время происходит внутри него? Как он понимает, какой ответ подойдет пользователю лучше всего? Руководитель Поиска Яндекса Максим Загребин рассказывает, как алгоритмы обрабатывают запросы и почему ссылка на сайт — не всегда лучший ответ.
Как устроен поиск?
Поиск в интернете состоит из двух частей:
- Поисковик обходит интернет, создавая его образ на своих серверах
- Выбрать из этих образов самую полезную информацию по запросу
Ежедневно Яндекс обрабатывает запросов больше, чем живет людей в России. Примерно половина из них никогда раньше не задавалась. Понятно, что отслеживать все эти показатели руками – невозможно. Невозможно написать для поисковой системы такую программу, в которой предусмотрен каждый запрос и для каждого запроса известен лучший ответ.
Сначала поиск выбирает из миллиардов ответов, потом из миллионов, и через какое-то количество этапов остаются те 10 сайтов на первой странице, которые лучше всего решают задачу пользователя. А для человека это все происходит моментально.
Люди не приходят в поиск, чтобы убить время, человек спрашивает что-то в Яндексе, когда у него есть какая-то конкретная задача. Например, найти какой-то фильм, который он помнит по описанию, но не помнит, как называется. Поэтому задача поиска – не просто найти и показать какую-то информацию, а помочь решить задачу пользователя. И страницу выдачи Яндекс формирует так, чтобы она лучше всего делала именно это – решала ту задачу, которую пользователь сформулировал в строке запроса.
При этом важно, чтобы поиск делал это быстро и удобно. Чтобы человеку не нужно было собирать всю информацию по крупицам с разных сайтов и не приходилось перепроверять ее, если сайт какой-то подозрительный. Например, если пользователь ищет ресторан или кафе, чтобы была сразу понятная шкала с проверенными отзывами: вот в этом ресторане чаще хвалят кухню, а здесь лучше интерьер и атмосфера.
Обычно пользователю нужно обойти несколько отзовиков или сайтов, чтобы собрать эту информацию самому. Почему бы не показать это сразу на странице выдачи?
Как понять, что поиск справился?
В Яндексе работают инженеры, поэтому во всем они ориентируются на цифры и показатели. В данном случае показатели бывают двух типов.
Например, на запрос и на ответ на него может посмотреть человек, или сразу много разных людей – они называются асессорами – и оценить, насколько этот результат полезен и помогает решить задачу. Понятно, чт не всегда человек может оценить это, это довольно субъективно. Поэтом важно также смотреть на то, как пользователи ведут себя на странице результатов.
Если человек на запрос [как научить собаку ходить на поводке] чаще выбирает сайт с курсами дрессировки, который находится ниже, чем страница с общей инструкцией, то поисковая машина поднимает сайт с курсами выше в выдаче, потому что понимает, что он лучше решает задачу по этому запросу. Это называется принципом или показателем профицита*.
Профицит – это метрика, которая определяет полезность объекта в поиске по кликам пользователя.
Раньше просто оценивались переходы, Яндекс считал, что если человек перешел на какой-то сайт и провел там продолжительное время, это значит, что он для него уже оказался полезным. Но понятно, что это не всегда так. Поэтому Яндекс начал смотреть на то, решил ли человек свою конечную задачу на этом сайте.
Например, если он искал кофеварку, положил ли он ее в корзину, после перехода на сайт, оплатил ли заказ. Чтобы поиск мог это понять, сайты сами передают эту информацию через Яндекс.Метрику. Теперь Яндекс может показывать выше в выдаче те результаты, которые лучше решают задачу уже на самом сайте.
Как поиск этому научился?
Поиск Яндекса использует машинное обучение. Именно потому, что невозможно каждый раз оценивать профицит того или иного сайта. Точно также, как инженеры поиска смотрят на все эти показатели – на оценки асессоров и на поведение пользователя на странице – алгоритм учится их оценивать и находить такие результаты, которые эти показатели улучшают.
Поисковая система должна уметь принимать решения самостоятельно и очень быстро, то есть выбирать из сотен миллиардов документов тот, который лучше всего отвечает пользователю. Алгоритмам машинного обучения демонстрируются примеры, огромное количество примеров, что вот тут человек решил свою задачу, а вот тут – нет. И дальше машинно-обученный алгоритм создает для себя такое правило и подбирает результаты.
Откуда берутся короткие ответы?
Иногда поиск понимает, что человеку нужно получить ответ на свой вопрос быстро, но емко. Например, если пользователь задает запрос [почему море соленое], он не хочет читать подробную статью о морской воде, а хочет получить ответ сразу. Тогда пользователь показывает ему быстрый ответ на вопрос. А если человек хочет найти обувную мастерскую, то гораздо лучше решит его задачу карта, на которой будут все обувные мастерские его района, а не просто куча ссылок для них.
Такие ответы появляются по тем запросам, где поиск точно видит, что они полезнее, чем набор ссылок – то есть их профицит намного выше.
А если человек хочет почитать подробнее про состав морской воды, или про конкретную обувную мастерскую, он переходит на сайт. На самом деле поиск уже уходит от того, чтобы искать просто сайты: технологии идут к тому, чтобы поиск стал универсальным и искал сразу по контенту.
Например, пользователь ищет фильм «Семнадцать мгновений весны», поиск должен понять смысл того, что тот ищет, и найти этот фильм на 5 онлайн-кинотеатрах. А дальше пользователь уже сам выберет, где именно этот фильм посмотреть.