
Система распознавания лиц — очень распространенная система на сегодняшний день. Она широко используется в различных областях, таких как безопасность, развлечения, социальные сети и т.д. Данная технология развивается каждый год с невероятными темпами. В этой статье будет по полочкам разложено то, как работает система распознавания лиц, очень простыми словами.
Оглавление
-
Что вообще такое распознавание лиц?
-
Легенда про черно-белые изображения
-
Обнаружение лица
-
Получение геометрий лица
-
Сам процесс распознавания
-
Как устроен FaceID?
-
Как работает TrueDeph?
Введение
Как я и обещал в своей первой статье я выпускаю новую статью. На Хабре уже есть две статьи на данную тему — тык, тык, которые тоже неплохо оценивают данную статью, но они используют много формул научных терминов и т.д. В своей статье я хотел рассказать про систему распознавания лиц от лица обычного разработчика в наипростой для рядового человека форме, отсюда и название. Но не пугайтесь названия, тут будут описываться не такие уж и простые вещи. Да я и не думаю, что чайники будут интересоваться такими темами 😁. Само название было вдохновлено названием книги Стефана Дэвиса: C++ для чайников.

Так как данная тема слишком большая, она будет разделена на 3 части.
-
Основа систем распознавания лиц и как устроен FaceID.
-
Роль нейросетей в системах распознавания лиц.
-
Проблемы и перспективы развития систем распознавания лиц.
Для чего же вообще нужно распознавание лиц?
Конечно же, перед объяснением всего стоит понять, а зачем оно нам надо?
Распознавание лиц нужно для того, чтобы узнать, кто перед нами. Это может быть полезно в разных ситуациях, например:
-
Когда мы хотим наложить какую-нибудь маску на себя в Snapchat или Instagram.
-
Когда мы хотим открыть свой телефон или компьютер с помощью лица, а не пароля.
-
Когда мы хотим найти своих друзей или знаменитостей на фотографиях или видео.
-
Когда мы хотим проверить, что человек, который показывает нам свой паспорт или водительское удостоверение, действительно тот, за кого себя выдаёт.
-
Когда мы хотим следить за безопасностью и преступностью, определяя лица подозреваемых или преступников.
И ещё во многих других специфических областях и нуждах.
Что вообще такое распознавание лиц?

Представьте рутинную ситуацию: вы идете на работу, школу или универ и видите перед собой сотни разных лиц. И вдруг среди незнакомых лиц вы узнали вашего знакомого, но как так получается, что вы можете узнать одного или нескольких людей среди сотен других? На самом деле наш мозг автоматически за доли секунды анализирует каждое лицо, а именно его цвет глаз, форму носа, прическу и другие детали. Далее мозг сравнивает их с теми особенностями лицами которые он помнит.
Исходя из этого, мы можем сказать, что распознавание лиц — это способность узнавать и отличать друг от друга лица разных людей по определенным особенностям лица.
Как компьютер распознает лица?
Мы знаем, как наш мозг распознаёт лица людей, но как же куску металла понять, кто стоит перед ним: его жертва хозяин Иван или Степа с соседнего села? На самом деле тут не надо придумывать велосипед а просто своровать воспользоваться теми способами что изобрела матушка природа.
Легенда про черно-белые изображения
Давным-давно, когда люди еще не умели распознавать лица, они жили в мире, где все было цветным. Они любили разные цвета и украшали себя и свои дома ими. Но они не могли отличать друг друга по лицам, потому что цвета их сбивали с толку. Они часто путали своих друзей и родственников, а иногда даже своих врагов. Это приводило к множеству недоразумений и конфликтов.
Мораль сей басни такова: быть эмо всегда переводите свои изображения в черно-белый цвет перед распознаванием.
Конечно, назревает вопрос: зачем?
И ответ на данный вопрос до боли простой. Изображения делают черно-белыми перед распознаванием, чтобы было компьютеру было проще и быстрее их просматривать. Черно-белое изображение имеет меньше деталей, чем цветное, поэтому его легче смотреть. Также черно-белое изображение показывает только форму и светлоту объектов, а не цвет, который может быть лишним или путать при распознавании. Например, если вы хотите распознать слова на изображении, то цвет слов и фона не так важен, как их отличие и ясность. То же самое работает и с лицами.

Обнаружения лица
В первую очередь мы, конечно же, должны понять, где тут лицо, а не стена или книга. После того, как мы получили поток с веб-камеры или фотографию и перевели его в черно-белый цвет, мы можем начинать процесс обнаружения лица. Для этого мы можем воспользоваться разными способами.
Хаар-признаки — были разработаны в 2001 году Полом Виолой. Эти признаки помогают узнать, как выглядит лицо, по его частям, например, по глазам, носу, рту и т.д. Они делают это с помощью прямоугольников разных цветов, которые кладут на картинку с лицом. С помощью этих признаков можно понять, как светло или темно внутри этих прямоугольников и сравнивают их между собой. Так они могут понять, где на лице есть переходы от светлого к темному или наоборот. Хаар-признаки бывают разных видов, в зависимости от количества и расположения прямоугольных областей. Самые простые — это 2-прямоугольные признаки, которые состоят из двух общих областей. Также есть 3-прямоугольные и 4-прямоугольные признаки, которые состоят из трех или четырех областей соответственно. Кроме того, есть наклонные признаки Хаара, которые имеют угол 45 градусов. Это позволяет увеличить покрытость пространства признаков и улучшить качество распознавания. Эти признаки имеют ряд преимуществ, таких как высокая скорость вычисления, низкая чувствительность к изменению освещения и возможность определения объектов разных масштабов. Однако они также имеют недостатки, такие как низкая точность при повороте или деформации объектов, сложность выбора оптимального набора признаков и необходимость большого объема данных для обучения.


Данные признаки хранятся в файлах, как правило это haar-cascade.xml файлы, в которых описана геометрия лица.
Пример haar-cascade.xml файла
<?xml version="1.0"?>
<opencv_storage>
<cascade type_id="opencv-cascade-classifier"><stageType>BOOST</stageType>
<featureType>HAAR</featureType>
<height>20</height>
<width>20</width>
<stageParams>
<maxWeakCount>93</maxWeakCount></stageParams>
<featureParams>
<maxCatCount>0</maxCatCount></featureParams>
<stageNum>24</stageNum>
<stages>
<_>
<maxWeakCount>6</maxWeakCount>
<stageThreshold>-1.4562760591506958e+00</stageThreshold>
<weakClassifiers>
<_>
<internalNodes>
0 -1 0 1.2963959574699402e-01</internalNodes>
<leafValues>
-7.7304208278656006e-01 6.8350148200988770e-01</leafValues></_>
<_>
<internalNodes>
0 -1 1 -4.6326808631420135e-02</internalNodes>
<leafValues>
5.7352751493453979e-01 -4.9097689986228943e-01</leafValues></_>
<_>
<internalNodes>
0 -1 2 -1.6173090785741806e-02</internalNodes>
<leafValues>
6.0254341363906860e-01 -3.1610709428787231e-01</leafValues></_>
<_>
<internalNodes>
0 -1 3 -4.5828841626644135e-02</internalNodes>
<leafValues>
6.4177548885345459e-01 -1.5545040369033813e-01</leafValues></_>
<_>
<internalNodes>
0 -1 4 -5.3759619593620300e-02</internalNodes>
<leafValues>
5.4219317436218262e-01 -2.0480829477310181e-01</leafValues></_>
<_>
<internalNodes>
0 -1 5 3.4171190112829208e-02</internalNodes>
<leafValues>
-2.3388190567493439e-01 4.8410901427268982e-01</leafValues></_></weakClassifiers></_>
<_>
</stages>Тут только малая часть данных. Сами файлы очень большие и состоят приблизительно из 12-100 тысяч строк.
Так же стоит отметить что Хаар-признаки не единственный способ распознования лица, но очень распространенный. Он все еще используются, но по моему личному мнению, данный алгоритм не очень эффективен в нынешних реалиях.
Вариант по лучше — это нейросети, но про них мы подробно будем говорить во второй части статьи.
Получение геометрий лица
Так, мы поняли где находится изображение, теперь нам нужно взять оттуда нужные данные, а именно: расстояние между глазами, форма скул, контуры губ и другие черты, которые отличают данное лицо от других.

На данной картинке мы видим точки интереса(Interest points) слева и линии опоры(Landmarks) справа.
Поговорим про них подробно:
Точки интереса(Interest points) — это части лица, которые легко увидеть и запомнить, например, уголки глаз, кончик носа, края губ и т.д. Для каждого лица можно выбрать от 68 до 194 таких точек. Эти точки помогают сделать уникальный код (вектор признаков) для каждого лица, который, условно говоря, служит его паспортом в системе распознавания лиц.
Линии опоры(Landmarks) — это линии на лице, которые связывают точки и показывают его форму и расположение. Они могут быть, например, уголками глаз, носа, рта и т.д. Landmarks помогают измерять лицо, то есть сколько сантиметров от одной части лица до другой. Линии опоры также помогают повернуть и увеличить лицо, чтобы оно было в одинаковом положении и размере. Линии опоры можно находить разными способами, например, с помощью нейросетей или алгоритмов (например, Хаар-признаки).
Вектор признаков(Vector feature) — это координаты векторов, которые описывают, как выглядит лицо. Данные координаты могут описывать разные части лица, например, глаза, уши, нос, рот и т.д. Координаты помогают узнать при сравнении, какие лица похожи или разные.

Сохранение полученных данных
После того, как мы нашли лицо, распознали его и получили вектор признаков, мы должы, конечно же, сохранить полученные данные. Вы можете сохранять как изображения в формате (PNG, JPG, JPEG) так и векторы признаков в JSON либо других файлов, в зависимости от логики вашего кода.
Пример сохранения векторов признаков в JSON
{
"faces": [
{
"name": "Alice",
"vector": [-0.096, 0.123, 0.045, ..., 0.067]
},
{
"name": "Bob",
"vector": [0.087, -0.134, -0.056, ..., -0.078]
},
{
"name": "Charlie",
"vector": [-0.034, 0.098, 0.012, ..., 0.055]
}
]
}Сам процесс распознавания
Итак, наконец, после того, как мы перевели картинку в черно-белый цвет, определили, где находится лицо на изображении, получили саму геометрию лица, сохранили нужные нам лица, мы можем начинать сам процесс распознавания. Когда мы «сканируем» новое лицо, получаем его геометрию, мы сравниваем полученную геометрию с тем, что имеем мы. Сам процесс сравнения зависит уже от вашего алгоритма и логики приложения.

Поздравляю, мы только что прошлись по самым базовым, но фундаментальным вещам в системах распознавания лиц.
Как устроен FaceID?
Конечно же при упоминании распознавании лиц многие упомянут FaceID. И вправду, яблочная компания хорошо постаралась делая свою систему распознавания лиц. Но как же все таки работает FaceID. Заранее хотелось бы сказать, что вся дальнейшая информация является всего лишь предположениями, так как исходный код самого FaceID закрыт и мы можем лишь предполагать как он работает. Но как бы то ни было, нам стоит разобраться в нем по подробнее, как хороший пример распознавания лиц.
Face ID использует инфракрасную камеру TrueDeph, которая видит лицо в трехмерном виде и сравнивает его с тем, что он регистрировал ранее. Face ID работает даже в темноте, потому что камера использует инфракрасный свет. Face ID может распознавать лицо, даже если оно меняется со временем, например, растет борода или меняется прическа
Как работает TrueDeph?
Камера TrueDepth работает так: она посылает на лицо маленькие светящиеся точки, которые отражаются от кожи и возвращаются к камере. Камера считывает эти точки и составляет из них картинку лица, как пазл. Эта картинка помогает узнать, кто перед камерой


В данном случае используется нейросеть Apple для обучения и распознавания лиц, и все данные лица хранятся в защищенном модуле Secure Enclave внутри процессора iPhone.
Заключение
Статья получилась достаточно большой, но даже так в ней подробно не описаны методы обучения, использование ложных изображений для обучения, datasets и многое другое, что будет описано во 2-ой части статьи.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Была ли данная статья полезна?
Проголосовали 33 пользователя.
Воздержались 5 пользователей.

Распознавание лица — последний тренд в авторизации пользователя. Apple использует Face ID, OnePlus — технологию Face Unlock. Baidu использует распознавание лица вместо ID-карт для обеспечения доступа в офис, а при повторном пересечении границы в ОАЭ вам нужно только посмотреть в камеру.
В статье разбираемся, как сделать простейшую сеть распознавания лиц самостоятельно с помощью FaceNet.
Ссылка на Гитхаб, кому нужен только код
Немного о FaceNet
FaceNet — нейронная сеть, которая учится преобразовывать изображения лица в компактное евклидово пространство, где дистанция соответствует мере схожести лиц. Проще говоря, чем более похожи лица, тем они ближе.
Триплет потерь
FaceNet использует особую функцию потерь называемую TripletLoss. Она минимизирует дистанцию между якорем и изображениями, которые содержат похожую внешность, и максимизирует дистанцую между разными.
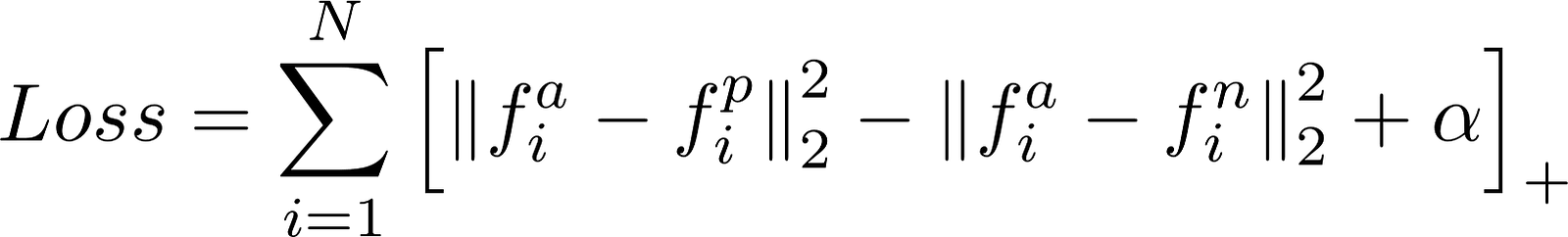
- f(a) это энкодинг якоря
- f(p) это энкодинг похожих лиц (positive)
- f(n) это энкодинг непохожих лиц (negative)
- Альфа — это константа, которая позволяет быть уверенным, что сеть не будет пытаться оптимизировать напрямую f(a) — f(p) = f(a) — f(n) = 0
- […]+ экиввалентено max(0, sum)
Сиамские сети
FaceNet — сиамская сеть. Сиамская сеть — тип архитектуры нейросети, который обучается диффиренцированию входных данных. То есть, позволяет научиться понимать какие изображения похожи, а какие нет.
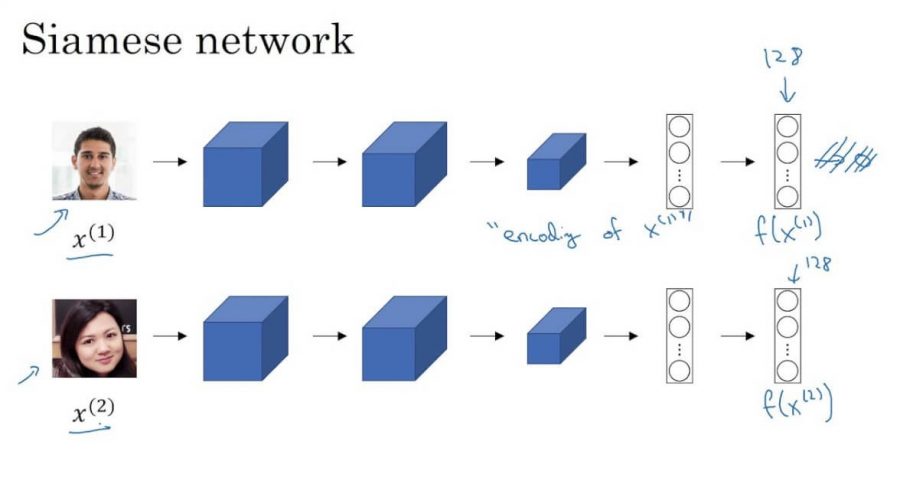
Сиамские сети состоят из двух идентичных нейронных сетей, каждая из которых имеет одинаковые точные веса. Во-первых, каждая сеть принимает одно из двух входных изображений в качестве входных данных. Затем выходы последних слоев каждой сети отправляются в функцию, которая определяет, содержат ли изображения одинаковые идентификаторы.
В FaceNet это делается путем вычисления расстояния между двумя выходами.
Реализация
Переходим к практике.
В реализации мы будем использовать Keras и Tensorflow. Кроме того, мы используем два файла утилиты из репозитория deeplayning.ai, чтобы абстрагироваться от взаимодействий с сетью FaceNet.
- fr_utils.py содержит функции для подачи изображений в сеть и получения кодирования изображений;
- inception_blocks_v2.py содержит функции для подготовки и компиляции сети FaceNet.
Компиляция сети FaceNet
Первое, что нам нужно сделать, это собрать сеть FaceNet для нашей системы распознавания лиц.
import os import glob import numpy as np import cv2 import tensorflow as tf from fr_utils import * from inception_blocks_v2 import * from keras import backend as K
K.set_image_data_format('channels_first') FRmodel = faceRecoModel(input_shape=(3, 96, 96)) def triplet_loss(y_true, y_pred, alpha = 0.3): anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2] pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, positive)), axis=-1) neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, negative)), axis=-1) basic_loss = tf.add(tf.subtract(pos_dist, neg_dist), alpha) loss = tf.reduce_sum(tf.maximum(basic_loss, 0.0)) return loss FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
load_weights_from_FaceNet(FRmodel)
Мы начнем инициализпцию нашей сети со входа размерности (3, 96, 96). Это означает, что картинка передается в виде трех каналов RGB и размерности 96×96 пикселей.
Теперь давайте определим Triplet Loss функцию. Функция в сниппете кода выше удовлетворяет уравнению Triplet Loss, которое мы определили в предыдущей секции.
Если вы не знакомы с фреймворком TensorFlow, ознакомьтесь с документацией.
Сразу после того, как мы определили функцию потерь, мы можем скомпилировать нашу систему распознавания лиц с помощью Keras. Мы будем использовать Adam optimizer для минимизации потерь, подсчитанных с помощью функции Triplet Loss.
Подготовка базы данных
Теперь когда мы скомпилировали FaceNet, нужно подготовить базу данных личностей, которых сеть будет распознавать. Мы будем использовать все изображения, которые лежат в директории images.
Замечание: мы будем использовать по одному изображения на человека в нашей реализации. FaceNet достаточно мощна, чтобы распознать человека по одной фотографии.
def prepare_database():
database = {}
for file in glob.glob("images/*"):
identity = os.path.splitext(os.path.basename(file))[0]
database[identity] = img_path_to_encoding(file, FRmodel)
return database
Для каждого изображения мы преобразуем данные изображения в 128 float чисел. Этим занимается функция img_path_to_encoding. Функция принимает на вход путь до изображения и «скармливает» изображение нашей распознающей сети, после чего возвращают результаты работы сети.
Как только мы получили закодированное изображения в базе данных, сеть наконец готова приступить к распознаванию!
Распознавание лиц
Как уже обсуждалось ранее, FaceNet пытается минимизировать расстояние между схожими изображениями и максимизировать между разными. Наша реализация использует данную информацию для того, чтобы определить, кем является человек на новой картинке.
def who_is_it(image, database, model):
encoding = img_to_encoding(image, model)
min_dist = 100
identity = None
# Loop over the database dictionary's names and encodings.
for (name, db_enc) in database.items():
dist = np.linalg.norm(db_enc - encoding)
print('distance for %s is %s' %(name, dist))
if dist < min_dist:
min_dist = dist
identity = name
if min_dist > 0.52:
return None
else:
return identity
Загружаем новое изображение в функцию img_to_encoding. Функция обрабатывает изображения, используя FaceNet и возвращает закодированное изображение. Теперь мы можем сделать предположение о наиболее вероятной личности этого человека.
Для этого подсчитываем расстояние между полученным новым изображением и каждым человеком в нашей базе данных. Наименьшая дистанция укажет на наиболее вероятную личность человека.
Наконец, мы должны определить действительно ли совпадают личности на картинке и в базе. Следующий кусок кода как раз для этого:
if min_dist > 0.52:
return None
else:
return identity
Магическое число 0.52 получено методом проб и ошибок. Для вас это число может отличатся, в зависимости от реализации и данных. Попробуйте настроить самостоятельно.
На GitHub есть демо работы полученной сети, с входом от простой вебкамеры.
Заключение
Теперь вы знаете, как работают технологии распознавания лиц и можете сделать собственную упрощенную сеть распознавания, используя предварительно подготовленную версию алгоритма FaceNet на python.
Интересные статьи:
- Как создать чат-бота с нуля на Python: подробная инструкция
- Обучение с подкреплением на Python с библиотекой Keras
- Как создать собственную нейронную сеть с нуля на языке Python
The current technology amazes people with amazing innovations that not only make life simple but also bearable. Face recognition has over time proven to be the least intrusive and fastest form of biometric verification. The software uses deep learning algorithms to compare a live captured image to the stored face print to verify one’s identity. Image processing and machine learning are the backbones of this technology. Face recognition has received substantial attention from researchers due to human activities found in various applications of security like airports, criminal detection, face tracking, forensics, etc. Compared to other biometric traits like palm print, iris, fingerprint, etc., face biometrics can be non-intrusive.
They can be taken even without the user’s knowledge and further can be used for security-based applications like criminal detection, face tracking, airport security, and forensic surveillance systems. Face recognition involves capturing face images from a video or a surveillance camera. They are compared with the stored database. Face recognition involves training known images, classifying them with known classes, and then they are stored in the database. When a test image is given to the system it is classified and compared with the stored database.
Face recognition
Face recognition using Artificial Intelligence(AI) is a computer vision technology that is used to identify a person or object from an image or video. It uses a combination of techniques including deep learning, computer vision algorithms, and Image processing. These technologies are used to enable a system to detect, recognize, and verify faces in digital images or videos.
The technology has become increasingly popular in a wide variety of applications such as unlocking a smartphone, unlocking doors, passport authentication, security systems, medical applications, and so on. There are even models that can detect emotions from facial expressions.
Difference between Face recognition & Face detection
Face recognition is the process of identifying a person from an image or video feed and face detection is the process of detecting a face in an image or video feed. In the case of Face recognition, someone’s face is recognized and differentiated based on their facial features. It involves more advanced processing techniques to identify a person’s identity based on feature point extraction, and comparison algorithms. and can be used for applications such as automated attendance systems or security checks. While Face detection is a much simpler process and can be used for applications such as image tagging or altering the angle of a photo based on the face detected. it is the initial step in the face recognition process and is a simpler process that simply identifies a face in an image or video feed.
Image Processing and Machine learning
Image processing by computers involves the process of Computer Vision. It deals with a high-level understanding of digital images or videos. The requirement is to automate tasks that the human visual systems can do. So, a computer should be able to recognize objects such as the face of a human being or a lamppost, or even a statue.
Image reading:
The computer reads any image in a range of values between 0 and 255. For any color image, there are 3 primary colors – Red, green, and blue. A matrix is formed for every primary color and later these matrices combine to provide a Pixel value for the individual R, G, and B colors. Each element of the matrices provide data about the intensity of the brightness of the pixel.
OpenCV is a Python library that is designed to solve computer vision problems. OpenCV was originally developed in 1999 by Intel but later supported by Willow Garage.
Machine learning
Every Machine Learning algorithm takes a dataset as input and learns from the data it basically means to learn the algorithm from the provided input and output as data. It identifies the patterns in the data and provides the desired algorithm. For instance, to identify whose face is present in a given image, multiple things can be looked at as a pattern:
- Height/width of the face.
- Height and width may not be reliable since the image could be rescaled to a smaller face or grid. However, even after rescaling, what remains unchanged are the ratios – the ratio of the height of the face to the width of the face won’t change.
- Color of the face.
- Width of other parts of the face like lips, nose, etc.
There is a pattern involved – different faces have different dimensions like the ones above. Similar faces have similar dimensions. Machine Learning algorithms only understand numbers so it is quite challenging. This numerical representation of a “face” (or an element in the training set) is termed as a feature vector. A feature vector comprises of various numbers in a specific order.
As a simple example, we can map a “face” into a feature vector which can comprise various features like:
- Height of face (cm)
- Width of the face (cm)
- Average color of face (R, G, B)
- Width of lips (cm)
- Height of nose (cm)
Essentially, given an image, we can convert them into a feature vector like:
Height of face (cm) Width of the face (cm) Average color of face (RGB) Width of lips (cm) Height of nose (cm)
23.1 15.8 (255, 224, 189) 5.2 4.4
So, the image is now a vector that could be represented as (23.1, 15.8, 255, 224, 189, 5.2, 4.4). There could be countless other features that could be derived from the image,, for instance, hair color, facial hair, spectacles, etc.
Machine Learning does two major functions in face recognition technology. These are given below:
- Deriving the feature vector: it is difficult to manually list down all of the features because there are just so many. A Machine Learning algorithm can intelligently label out many of such features. For instance, a complex feature could be the ratio of the height of the nose and the width of the forehead.
- Matching algorithms: Once the feature vectors have been obtained, a Machine Learning algorithm needs to match a new image with the set of feature vectors present in the corpus.
- Face Recognition Operations
Face Recognition Operations
The technology system may vary when it comes to facial recognition. Different software applies different methods and means to achieve face recognition. The stepwise method is as follows:
- Face Detection: To begin with, the camera will detect and recognize a face. The face can be best detected when the person is looking directly at the camera as it makes it easy for facial recognition. With the advancements in technology, this is improved where the face can be detected with slight variation in their posture of face facing the camera.
- Face Analysis: Then the photo of the face is captured and analyzed. Most facial recognition relies on 2D images rather than 3D because it is more convenient to match to the database. Facial recognition software will analyze the distance between your eyes or the shape of your cheekbones.
- Image to Data Conversion: Now it is converted to a mathematical formula and these facial features become numbers. This numerical code is known as a face print. The way every person has a unique fingerprint, in the same way, they have unique face prints.
- Match Finding: Then the code is compared against a database of other face prints. This database has photos with identification that can be compared. The technology then identifies a match for your exact features in the provided database. It returns with the match and attached information such as name and address or it depends on the information saved in the database of an individual.
Implementations
Steps:
- Import the necessary packages
- Load the known face images and make the face embedding of known image
- Launch the live camera
- Record the images from the live camera frame by frame
- Make the face detection using the face_recognization face_location command
- Make the rectangle around the faces
- Make the face encoding for the faces captured by the camera
- if the faces are matched then plot the person image else continue
Python3
import cv2 as cv
import face_recognition
import matplotlib.pyplot as plt
known_image = face_recognition.load_image_file("pawankrgunjan.jpeg")
known_faces = face_recognition.face_encodings(face_image = known_image,
num_jitters=50,
model='large')[0]
cam = cv.VideoCapture(0)
if not cam.isOpened():
print("Camera not working")
exit()
while True:
ret, frame = cam.read()
if not ret:
print("Can't receive the frame")
break
face_locations = face_recognition.face_locations(frame)
for face_location in face_locations:
top, right, bottom, left = face_location
frame = cv.rectangle(frame, (right,top), (left,bottom), color = (0,0, 255), thickness=2)
try:
Live_face_encoding = face_recognition.face_encodings(face_image = frame,
num_jitters=23,
model='large')[0]
results = face_recognition.compare_faces([known_faces], Live_face_encoding)
if results:
img = cv.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = cv.putText(img, 'PawanKrgunjan', (30, 55), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255,0,0), 2, cv2.LINE_AA)
print('Pawan Kumar Gunjan Enter....')
plt.imshow(img)
plt.show()
break
except:
img = cv.putText(frame, 'Not PawanKrgunjan', (30, 55), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255,0,0), 2, cv2.LINE_AA)
cv.imshow('frame', img)
if cv.waitKey(1) == ord('q'):
break
cam.release()
cv.destroyAllWindows()
Output:
Pawan Kumar Gunjan Enter....
.png)
Face Recognization
The model accuracy further can be improved using deep learning and and other methods.
Face Recognition Softwares
Many renowned companies are constantly innovating and improvising to develop face recognition software that is foolproof and dependable. Some prominent software is being discussed below:
a. Deep Vision AI
Deep Vision AI is a front-runner company excelling in facial recognition software. The company owns the proprietorship of advanced computer vision technology that can understand images and videos automatically. It then turns the visual content into real-time analytics and provides very valuable insights.
Deep Vision AI provides a plug and plays platform to its users worldwide. The users are given real-time alerts and faster responses based upon the analysis of camera streams through various AI-based modules. The product offers a highly accurate rate of identification of individuals on a watch list by continuous monitoring of target zones. The software is highly flexible that it can be connected to any existing camera system or can be deployed through the cloud.
At present, Deep Vision AI offers the best performance solution in the market supporting real-time processing at +15 streams per GPU.
Business intelligence gathering is helped by providing real-time data on customers, their frequency of visits, or enhancement of security and safety. Further, the output from the software can provide attributes like count, age, gender, etc that can enhance the understanding of consumer behavior, changing preferences, shifts with time, and conditions that can guide future marketing efforts and strategies. The users also combine the face recognition capabilities with other AI-based features of Deep Vision AI like vehicle recognition to get more correlated data of the consumers.
The company complies with international data protection laws and applies significant measures for a transparent and secure process of the data generated by its customers. Data privacy and ethics are taken care of.
The potential markets include cities, public venues, public transportation, educational institutes, large retailers, etc. Deep Vision AI is a certified partner for NVIDIA’s Metropolis, Dell Digital Cities, Amazon AWS, Microsoft, Red Hat, and others.
b. SenseTime
- SenseTime is a leading platform developer that has dedicated efforts to create solutions using the innovations in AI and big data analysis. The technology offered by SenseTime is multifunctional. The aspects of this technology are expanding and include the capabilities of facial recognition, image recognition, intelligent video analytics, autonomous driving, and medical image recognition. SenseTime software includes different subparts namely, SensePortrait-S, SensePortrait-D, and SenseFace.
- SensePortrait-S is a Static Face Recognition Server. It includes the functionality of face detection from an image source, extraction of features, extraction, and analysis of attributes, and target retrieval from a vast facial image database
- SensePortrait D is a Dynamic Face Recognition Server. The capabilities included are face detection, tracking of a face, extraction of features, and comparison and analysis of data from data in multiple surveillance video streams.
- SenseFace is a Face Recognition Surveillance Platform. This utility is a Face Recognition technology that uses a deep learning algorithm. SenseFace is very efficient in integrated solutions to intelligent video analysis. It can be extensively used for target surveillance, analysis of the trajectory of a person, management of population and the associated data analysis, etc
- SenseTime has provided its services to many companies and government agencies including Honda, Qualcomm, China Mobile, UnionPay, Huawei, Xiaomi, OPPO, Vivo, and Weibo.
c. Amazon Rekognition
Amazon provides a cloud-based software solution Amazon Rekognition is a service computer vision platform. This solution allows an easy method to add image and video analysis to various applications. It uses a highly scalable and proven deep learning technology. The user is not required to have any machine learning expertise to use this software. The platform can be utilized to identify objects, text, people, activities, and scenes in images and videos. It can also detect any inappropriate content. The user gets a highly accurate facial analysis and facial search capabilities. Hence, the software can be easily used for verification, counting of people, and public safety by detection, analysis, and comparison of faces.
Organizations can use Amazon Rekognition Custom Labels to generate data about specific objects and scenes available in images according to their business needs. For example, a model may be easily built to classify specific machine parts on the assembly line or to detect unhealthy plants. The user simply provides the images of objects or scenes he wants to identify, and the service handles the rest.
d. FaceFirst
The FaceFirst software ensures the safety of communities, secure transactions, and great customer experiences. FaceFirst is secure, accurate, private, fast, and scalable software. Plug-and-play solutions are also included for physical security, authentication of identity, access control, and visitor analytics. It can be easily integrated into any system. This computer vision platform has been used for face recognition and automated video analytics by many organizations to prevent crime and improve customer engagement.
As a leading provider of effective facial recognition systems, it benefits to retail, transportation, event security, casinos, and other industry and public spaces. FaceFirst ensures the integration of artificial intelligence with existing surveillance systems to prevent theft, fraud, and violence.
e. Trueface
TrueFace is a leading computer vision model that helps people understand their camera data and convert the data into actionable information. TrueFace is an on-premise computer vision solution that enhances data security and performance speeds. The platform-based solutions are specifically trained as per the requirements of individual deployment and operate effectively in a variety of ecosystems. The software places the utmost priority on the diversity of training data. It ensures equivalent performance for all users irrespective of their widely different requirements.
Trueface has developed a suite consisting of SDKs and a dockerized container solution based on the capabilities of machine learning and artificial intelligence. The suite can convert the camera data into actionable intelligence. It can help organizations to create a safer and smarter environment for their employees, customers, and guests using facial recognition, weapon detection, and age verification technologies.
f. Face++
- Face++ is an open platform enabled by the Chinese company Megvii. It offers computer vision technologies. It allows users to easily integrate deep learning-based image analysis recognition technologies into their applications.
- Face++ uses AI and machine vision in amazing ways to detect and analyze faces, and accurately confirm a person’s identity. Face++ is also developer-friendly being an open platform such that any developer can create apps using its algorithms. This feature has resulted in making Face++ the most extensive facial recognition platform in the world, with 300,000 developers from 150 countries using it.
- The most significant usage of Face++ has been its integration into Alibaba’s City Brain platform. This has allowed the analysis of the CCTV network in cities to optimize traffic flows and direct the attention of medics and police by observing incidents.
g. Kairos
- Kairos is a state-of-the-art and ethical face recognition solution available to developers and businesses across the globe. Kairos can be used for Face Recognition via Kairos cloud API, or the user can host Kairos on their servers. The utility can be used for control of data, security, and privacy. Organizations can ensure a safer and better accessibility experience for their customers.
- Kairos Face Recognition On-Premises has the added advantage of controlling data privacy and security, keeping critical data in-house and safe from any potential third parties/hackers. The speed of face recognition-enabled products is highly enhanced because it does not come across the issue of delay and other risks associated with public cloud deployment.
- Kairos is ultra-scalable architecture such that the search for 10 million faces can be done at approximately the same time as 1 face. It is being accepted by the market with open hands.
h. Cognitec
Cognitec’s FaceVACS Engine enables users to develop new applications for face recognition. The engine is very versatile as it allows a clear and logical API for easy integration in other software programs. Cognitec allows the use of the FaceVACS Engine through customized software development kits. The platform can be easily tailored through a set of functions and modules specific to each use case and computing platform. The capabilities of this software include image quality checks, secure document issuance, and access control by accurate verification.
The distinct features include:
- A very powerful face localization and face tracking
- Efficient algorithms for enrollment, verification, and identification
- Accurate checking of age, gender, age, exposure, pose deviation, glasses, eyes closed, uniform lighting detection, unnatural color, image, and face geometry
- Fulfills the requirements of ePassports by providing ISO 19794-5 full-frontal image type checks and formatting
Utilization of Face Recognition
While facial recognition may seem futuristic, it’s currently being used in a variety of ways. Here are some surprising applications of this technology.
Genetic Disorder Identification:
There are healthcare apps such as Face2Gene and software like Deep Gestalt that uses facial recognition to detect genetic disorders. This face is then analyzed and matched with the existing database of disorders.
Airline Industry:
Some airlines use facial recognition to identify passengers. This face scanner would help save time and to prevent the hassle of keeping track of a ticket.
Hospital Security:
Facial recognition can be used in hospitals to keep a record of the patients which is far better than keeping records and finding their names, and addresses. It would be easy for the staff to use this app and recognize a patient and get its details within seconds. Secondly, can be used for security purposes where it can detect if the person is genuine or not or if is it a patient.
Detection of emotions and sentiments:
Real-time emotion detection is yet another valuable application of face recognition in healthcare. It can be used to detect emotions that patients exhibit during their stay in the hospital and analyze the data to determine how they are feeling. The results of the analysis may help to identify if patients need more attention in case they’re in pain or sad.
Problems and Challenges
Face recognition technology is facing several challenges. The common problems and challenges that a face recognition system can have while detecting and recognizing faces are discussed in the following paragraphs.
- Pose: A Face Recognition System can tolerate cases with small rotation angles, but it becomes difficult to detect if the angle would be large and if the database does not contain all the angles of the face then it can impose a problem.
- Expressions: Because of emotions, human mood varies and results in different expressions. With these facial expressions, the machine could make mistakes to find the correct person’s identity.
- Aging: With time and age face changes it is unique and does not remain rigid due to which it may be difficult to identify a person who is now 60 years old.
- Occlusion: Occlusion means blockage. This is due to the presence of various occluding objects such as glasses, beard, mustache, etc. on the face, and when an image is captured, the face lacks some parts. Such a problem can severely affect the classification process of the recognition system.
- Illumination: Illumination means light variations. Illumination changes can vary the overall magnitude of light intensity reflected from an object, as well as the pattern of shading and shadows visible in an image. The problem of face recognition over changes in illumination is widely recognized to be difficult for humans and algorithms. The difficulties posed by illumination condition is a challenge for automatic face recognition systems.
- Identify similar faces: Different persons may have a similar appearance that sometimes makes it impossible to distinguish.
Disadvantages of Face Recognition
- The danger of automated blanket surveillance
- Lack of clear legal or regulatory framework
- Violation of the principles of necessity and proportionality
- Violation of the right to privacy
- Effect on democratic political culture
В этой статье мы разберемся, что такое распознавание лиц и чем оно отличается от определения лиц на изображении. Мы кратко рассмотрим теорию распознавания лиц, а затем перейдем к написанию кода. В конце этой статьи вы сможете создать свою собственную программу распознавания лиц на изображениях, а также в прямом эфире с веб-камеры.
Содержание
- Обнаружение лиц
- Распознавание лиц
- Что такое OpenCV?
- Распознавание лиц с использованием Python
- Извлечение признаков лица
- Распознавание лиц во время прямой трансляции веб-камеры
- Распознавание лиц на изображениях
Что такое обнаружение лиц?
Одной из основных задач компьютерного зрения является автоматическое обнаружение объекта без вмешательства человека. Например, определение человеческих лиц на изображении.
Лица людей отличаются друг от друга. Но в целом можно сказать, что всем им присущи определенные общие черты.
Существует много алгоритмов обнаружения лиц. Одним из старейших является алгоритм Виолы-Джонса. Он был предложен в 2001 году и применяется по сей день. Чуть позже мы тоже им воспользуемся. После прочтения данной статьи вы можете изучить его более подробно.
Обнаружение лиц обычно является первым шагом для решения более сложных задач, таких как распознавание лиц или верификация пользователя по лицу. Но оно может иметь и другие полезные применения.
Вероятно самым успешным использованием обнаружения лиц является фотосъемка. Когда вы фотографируете своих друзей, встроенный в вашу цифровую камеру алгоритм распознавания лиц определяет, где находятся их лица, и соответствующим образом регулирует фокус.
Что такое распознавание лиц?
Итак, в создании алгоритмов обнаружения лиц мы (люди) преуспели. А можно ли также распознавать, чьи это лица?
Распознавание лиц — это метод идентификации или подтверждения личности человека по его лицу. Существуют различные алгоритмы распознавания лиц, но их точность может различаться. Здесь мы собираемся описать распознавание лиц при помощи глубокого обучения.
Итак, давайте разберемся, как мы распознаем лица при помощи глубокого обучения. Для начала мы производим преобразование, или, иными словами, эмбеддинг (embedding), изображения лица в числовой вектор. Это также называется глубоким метрическим обучением.
Для облегчения понимания давайте разобьем весь процесс на три простых шага:
Обнаружение лиц
Наша первая задача — это обнаружение лиц на изображении или в видеопотоке. Далее, когда мы знаем точное местоположение или координаты лица, мы берем это лицо для дальнейшей обработки.
Извлечение признаков
Вырезав лицо из изображения, мы должны извлечь из него характерные черты. Для этого мы будем использовать процедуру под названием эмбеддинг.
Нейронная сеть принимает на вход изображение, а на выходе возвращает числовой вектор, характеризующий основные признаки данного лица. (Более подробно об этом рассказано, например, в нашей серии статей про сверточные нейронные сети — прим. переводчика). В машинном обучении данный вектор как раз и называется эмбеддингом.
Теперь давайте разберемся, как это помогает в распознавании лиц разных людей.

Во время обучения нейронная сеть учится выдавать близкие векторы для лиц, которые выглядят похожими друг на друга.
Например, если у вас есть несколько изображений вашего лица в разные моменты времени, то естественно, что некоторые черты лица могут меняться, но все же незначительно. Таким образом, векторы этих изображений будут очень близки в векторном пространстве. Чтобы получить общее представление об этом, взгляните на график:
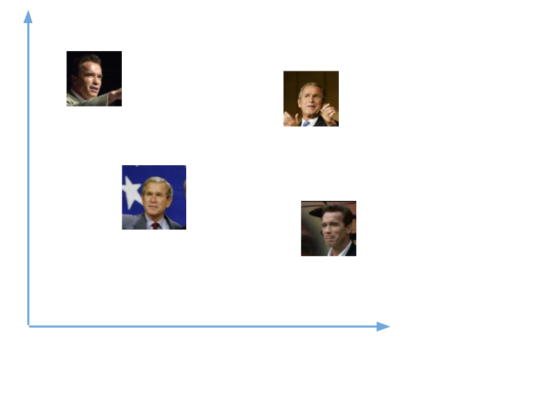
Чтобы определять лица одного и того же человека, сеть будет учиться выводить векторы, находящиеся рядом в векторном пространстве. После обучения эти векторы трансформируются следующим образом:
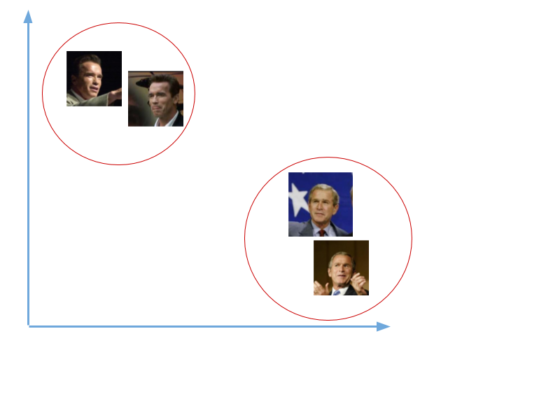
Здесь мы не будем заниматься обучением подобной сети. Это требует значительных вычислительных мощностей и большого объема размеченных данных. Вместо этого мы используем уже предобученную Дэвисом Кингом нейронную сеть. Она обучалась приблизительно на 3000000 изображений. Эта сеть выдает вектор длиной 128 чисел, который и определяет основные черты лица.
Познакомившись с принципами работы подобных сетей, давайте посмотрим, как мы будем использовать такую сеть для наших собственных данных.
Мы передадим все наши изображения в эту предобученную сеть, получим соответствующие вектора (эмбеддинги) и затем сохраним их в файл для следующего шага.
[machinelearning_ad_block]
Сравнение лиц
Теперь, когда у нас есть вектор (эмбеддинг) для каждого лица из нашей базы данных, нам нужно научиться распознавать лица из новых изображений. Таким образом, нам нужно, как и раньше, вычислить вектор для нового лица, а затем сравнить его с уже имеющимися векторами. Мы сможем распознать лицо, если оно похоже на одно из лиц, уже имеющихся в нашей базе данных. Это означает, что их вектора будут расположены вблизи друг от друга, как показано на примере ниже:
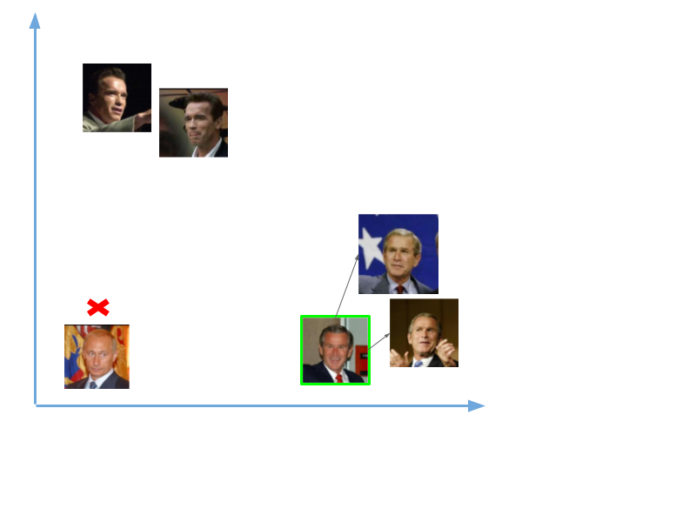
Итак, мы передали в сеть две фотографии, одна Владимира Путина, другая Джорджа Буша. Для изображений Буша у нас были вектора (эмбеддинги), а для Путина ничего не было. Таким образом, когда мы сравнили эмбеддинг нового изображения Буша, он был близок с уже имеющимися векторам,и и мы распознали его. А вот изображений Путина в нашей базе не было, поэтому распознать его не удалось.
В области искусственного интеллекта задачи компьютерного зрения — одни из самых интересных и сложных.
Компьютерное зрение работает как мост между компьютерным программным обеспечением и визуальной картиной вокруг нас. Оно дает ПО возможность понимать и изучать все видимое в окружающей среде.
Например, на основе цвета, размера и формы плода мы определяем разновидность определенного фрукта. Эта задача может быть очень проста для человеческого разума, однако в контексте компьютерного зрения все выглядит иначе.
Сначала мы собираем данные, затем выполняем определенные действия по их обработке, а потом многократно обучаем модель, как ей распознавать сорт фрукта по размеру, форме и цвету его плода.
В настоящее время существуют различные пакеты для выполнения задач машинного обучения, глубокого обучения и компьютерного зрения. И безусловно, модуль, отвечающий за компьютерное зрение, проработан лучше других.
OpenCV — это библиотека с открытым программным кодом. Она поддерживает различные языки программирования, например R и Python. Работать она может на многих платформах, в частности — на Windows, Linux и MacOS.
Основные преимущества OpenCV:
- имеет открытый программный код и абсолютно бесплатна
- написана на C/C++ и в сравнении с другими библиотеками работает быстрее
- не требует много памяти и хорошо работает при небольшом объеме RAM
- поддерживает большинство операционных систем, в том числе Windows, Linux и MacOS.
Установка
Здесь мы будем рассматривать установку OpenCV только для Python. Мы можем установить ее при помощи менеджеров pip или conda (в случае, если у нас установлен пакет Anaconda).
1. При помощи pip
При помощи pip процесс установки может быть выполнен с использованием следующей команды:
pip install opencv-python
2. Anaconda
Если вы используете Anaconda, то выполните следующую команду в окружении Anaconda:
conda install -c conda-forge opencv
Распознавание лиц с использованием Python
В этой части мы реализуем распознавание лиц при помощи Python и OpenCV. Для начала посмотрим, какие библиотеки нам потребуются и как их установить:
- OpenCV
- dlib
- Face_recognition
OpenCV — это библиотека обработки изображений и видео, которая используется для их анализа. Ее применяют для обнаружения лиц, считывания номерных знаков, редактирования фотографий, расширенного роботизированного зрения, оптического распознавания символов и многого другого.
Библиотека dlib, поддерживая Дэвисом Кингом, содержит реализацию глубокого метрического обучения. Мы ее будем использовать для конструирования векторов (эмбеддингов) изображений, играющих ключевую роль в процессе распознавания лиц.
Библиотека face_recognition, созданная Адамом Гейтгеем, включает в себя функции распознавания лиц dlib и является по сути надстройкой над ней. С ней очень легко работать, и мы будем ее использовать в нашем коде. Имейте ввиду, что ее нужно устанавливать после библиотеки dlib.
Для установки OpenCV наберите в командной строке:
pip install opencv-python
Мы перепробовали множество способов установки dlib под WIndows и простейший способ это сделать — при помощи Anaconda. Поэтому для начала установите Anaconda (вот здесь подробно рассказано, как это делается). Затем введите в терминале следующую команду:
conda install -c conda-forge dlib
Далее, для установки библиотеки face_recognition наберите в командной строке следующее:
pip install face_recognition
Теперь, когда все необходимые модули установлены, приступим к написанию кода. Нам нужно будет создать три файла.
Первый файл будет принимать датасет с изображениями и выдавать эмбеддинг для каждого лица. Эти эмбеддинги будут записываться во второй файл. В третьем файле мы будем сравнивать лица с уже существующими изображениями. А затем мы сделаем тоже самое в стриме с веб-камеры.
Извлечение признаков лица
Для начала вам нужно достать датасет с лицами или создать свой собственный. Главное, убедитесь, что все изображения находятся в папках, причем в каждой папке должны быть фотографии одного и того же человека.
Затем разместите датасет в вашей рабочей директории, то есть там, где выбудете создавать собственные файлы.
А вот сам код:
from imutils import paths
import face_recognition
import pickle
import cv2
import os
# в директории Images хранятся папки со всеми изображениями
imagePaths = list(paths.list_images('Images'))
knownEncodings = []
knownNames = []
# перебираем все папки с изображениями
for (i, imagePath) in enumerate(imagePaths):
# извлекаем имя человека из названия папки
name = imagePath.split(os.path.sep)[-2]
# загружаем изображение и конвертируем его из BGR (OpenCV ordering)
# в dlib ordering (RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
#используем библиотеку Face_recognition для обнаружения лиц
boxes = face_recognition.face_locations(rgb,model='hog')
# вычисляем эмбеддинги для каждого лица
encodings = face_recognition.face_encodings(rgb, boxes)
# loop over the encodings
for encoding in encodings:
knownEncodings.append(encoding)
knownNames.append(name)
# сохраним эмбеддинги вместе с их именами в формате словаря
data = {"encodings": knownEncodings, "names": knownNames}
# для сохранения данных в файл используем метод pickle
f = open("face_enc", "wb")
f.write(pickle.dumps(data))
f.close()
Сейчас мы сохранили все эмбеддинги в файл под названием face_enc. Теперь мы можем их использовать для распознавания лиц на изображениях или во время видеострима с веб-камеры.
Распознавание лиц во время прямой трансляции веб-камеры
Вот код для распознавания лиц из прямой трансляции веб-камеры:
import face_recognition
import imutils
import pickle
import time
import cv2
import os
# find path of xml file containing haarcascade file
cascPathface = os.path.dirname(
cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
# load the harcaascade in the cascade classifier
faceCascade = cv2.CascadeClassifier(cascPathface)
# load the known faces and embeddings saved in last file
data = pickle.loads(open('face_enc', "rb").read())
print("Streaming started")
video_capture = cv2.VideoCapture(0)
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60),
flags=cv2.CASCADE_SCALE_IMAGE)
# convert the input frame from BGR to RGB
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# the facial embeddings for face in input
encodings = face_recognition.face_encodings(rgb)
names = []
# loop over the facial embeddings incase
# we have multiple embeddings for multiple fcaes
for encoding in encodings:
# Compare encodings with encodings in data["encodings"]
# Matches contain array with boolean values and True for the embeddings it matches closely
# and False for rest
matches = face_recognition.compare_faces(data["encodings"],
encoding)
# set name =inknown if no encoding matches
name = "Unknown"
# check to see if we have found a match
if True in matches:
#Find positions at which we get True and store them
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
# Check the names at respective indexes we stored in matchedIdxs
name = data["names"][i]
# increase count for the name we got
counts[name] = counts.get(name, 0) + 1
# set name which has highest count
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
# loop over the recognized faces
for ((x, y, w, h), name) in zip(faces, names):
# rescale the face coordinates
# draw the predicted face name on the image
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(frame, name, (x, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
cv2.imshow("Frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
В данном примере для обнаружения лиц использовался метод cv2.CascadeClassifier() из библиотеки OpenCV. Но вы с таким же успехом можете пользоваться и методом face_recognition.face_locations(), как мы уже делали в предыдущем примере.
Распознавание лиц на изображениях
Код для обнаружения и распознавания лиц на изображениях почти аналогичен тому, что вы видели выше. Убедитесь в этом сами:
import face_recognition
import imutils
import pickle
import time
import cv2
import os
# find path of xml file containing haarcascade file
cascPathface = os.path.dirname(
cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
# load the harcaascade in the cascade classifier
faceCascade = cv2.CascadeClassifier(cascPathface)
# load the known faces and embeddings saved in last file
data = pickle.loads(open('face_enc', "rb").read())
# Find path to the image you want to detect face and pass it here
image = cv2.imread(Path-to-img)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# convert image to Greyscale for haarcascade
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60),
flags=cv2.CASCADE_SCALE_IMAGE)
# the facial embeddings for face in input
encodings = face_recognition.face_encodings(rgb)
names = []
# loop over the facial embeddings incase
# we have multiple embeddings for multiple fcaes
for encoding in encodings:
# Compare encodings with encodings in data["encodings"]
# Matches contain array with boolean values and True for the embeddings it matches closely
# and False for rest
matches = face_recognition.compare_faces(data["encodings"],
encoding)
# set name =inknown if no encoding matches
name = "Unknown"
# check to see if we have found a match
if True in matches:
# Find positions at which we get True and store them
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# loop over the matched indexes and maintain a count for
# each recognized face face
for i in matchedIdxs:
# Check the names at respective indexes we stored in matchedIdxs
name = data["names"][i]
# increase count for the name we got
counts[name] = counts.get(name, 0) + 1
# set name which has highest count
name = max(counts, key=counts.get)
# update the list of names
names.append(name)
# loop over the recognized faces
for ((x, y, w, h), name) in zip(faces, names):
# rescale the face coordinates
# draw the predicted face name on the image
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(image, name, (x, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
cv2.imshow("Frame", image)
cv2.waitKey(0)
Результат:
На этом наша статья подошла к концу. Мы надеемся, что вы получили общее представление о задачах распознавания лиц и способах их решения.
Перевод статьи «Face Recognition with Python and OpenCV»
Пошаговое руководство по распознаванию лиц в реальном времени с использованием библиотеки OpenCv

В этом посте я покажу вам, как создать собственный распознаватель лиц с помощью Python. Создание программы, которая обнаруживает и распознает лица, — очень интересный и увлекательный проект для начала работы с компьютерным зрением. В предыдущих постах я показал, как распознавать текст, а также обнаруживать лица на изображении, это отличные проекты для практики Python в компьютерном зрении. Сегодня мы сделаем кое-что более продвинутое, и это будет распознавание лиц.
Как можно понять из названия, мы напишем программу, которая будет распознавать лица на изображении. Когда я говорю «программа», вы можете понимать это как обучение машины тому, что делать и как это делать. Мне нравится использовать обучение вместо программирования, потому что именно этим мы и будем заниматься. Лучший способ обучения — это обучение, поэтому, обучая машину распознавать лица, мы тоже учимся. Прежде чем мы начнем работать над проектом, я хочу поделиться различием между распознаванием лиц и распознаванием лиц. Это полезно знать.
Оглавление:
- Распознавание лиц против распознавания лиц
- Начало работы
- Библиотеки
- Обучение изображений
- Распознавание лиц
- Тестирование распознавателя
Распознавание лиц против распознавания лиц
Эти две вещи могут показаться очень похожими, но на самом деле это не одно и то же. Давайте поймем разницу, чтобы не упустить главное.
Распознавание лиц — это процесс обнаружения лиц по изображению или видео, который не имеет значения. Программа не делает ничего, кроме поиска лиц. Но с другой стороны, распознавание лиц, программа, которая находит лица, а также может определить, какое лицо кому принадлежит. Так что это более информативно, чем просто их обнаружение.
Чтобы написать код, распознающий лица, нужны некоторые обучающие данные, мы должны обучить нашу машину, чтобы она знала лица и кто они. В этом проекте мы преподаем нашу программу. В машинном обучении есть два типа обучения; под присмотром и без присмотра. Я не буду вдаваться в подробности, в этом проекте мы будем использовать контролируемое обучение. Вот хороший пост о методах машинного обучения.
Пример сравнения

Начиная
Мы будем использовать два основных модуля для этого проекта, и они называются Face Recognition и OpenCV. OpenCV — это высокооптимизированная библиотека, ориентированная на приложения реального времени.
OpenCV (Open Source Computer Vision Library) — это библиотека программного обеспечения для компьютерного зрения и машинного обучения с открытым исходным кодом. OpenCV был создан для обеспечения общей инфраструктуры для приложений компьютерного зрения и для ускорения использования машинного восприятия в коммерческих продуктах. OpenCV является продуктом с лицензией BSD и упрощает использование и изменение кода предприятиями.
Источник: https://opencv.org
Библиотеки
Нам нужно установить некоторые библиотеки, чтобы наша программа работала. Вот список библиотек, которые мы установим: cmake, face_recognition, numpy, opencv-python. Cmake — это обязательная библиотека, поэтому установка библиотеки распознавания лиц не выдает ошибок.
Мы можем установить их в одну строку с помощью диспетчера библиотек PIP:
pip install cmake face_recognition numpy opencv-python
После завершения установки давайте импортируем их в наш редактор кода. Некоторые из этих библиотек включены в Python, поэтому мы можем импортировать их, не устанавливая.
import face_recognition import cv2 import numpy as np import os import glob
Большой! Теперь мы переходим к следующему шагу, где мы будем импортировать изображения и использовать их для обучения нашей программы.
Тренировка изображений
Перво-наперво, давайте найдем наши изображения.
Импортировать изображения
Я загрузил изображения некоторых известных людей и добавил их в новую папку под названием «лица». Также, чтобы получить текущий каталог, другими словами, расположение вашей программы, мы можем использовать метод операционной системы, называемый «getcwd ()».
faces_encodings = [] faces_names = [] cur_direc = os.getcwd() path = os.path.join(cur_direc, 'data/faces/') list_of_files = [f for f in glob.glob(path+'*.jpg')] number_files = len(list_of_files) names = list_of_files.copy()
Понимание приведенных выше строк:
- Все изображения находятся в одной папке с названием «лица».
- Имена файлов изображений должны соответствовать имени человека на изображении. (Например: bill-gates.jpg).
- Имена файлов перечислены и присвоены переменной «names».
- Типы файлов должны быть одинаковыми. В этом упражнении я использовал формат «jpg».

Переходим к следующему шагу.
Тренируйте лица
for i in range(number_files):
globals()['image_{}'.format(i)] = face_recognition.load_image_file(list_of_files[i])
globals()['image_encoding_{}'.format(i)] = face_recognition.face_encodings(globals()['image_{}'.format(i)])[0]
faces_encodings.append(globals()['image_encoding_{}'.format(i)])
# Create array of known names
names[i] = names[i].replace(cur_direc, "")
faces_names.append(names[i])
Чтобы дать вам некоторое представление, вот как выглядит мой список «имен».

Большой! Образы обучены. На следующем шаге мы будем использовать веб-камеру устройства, чтобы увидеть, как работает наш код.
Распознавание лица
На этом этапе у нас есть длинные строки кода. Если вы пройдете через это, вы легко поймете, что происходит в каждой строке. Определим переменные, которые потребуются.
face_locations = [] face_encodings = [] face_names = [] process_this_frame = True
А вот и код распознавания лиц. (Возможно, вам придется переформатировать интервал, если вы скопируете следующий код, я рекомендую написать его с нуля, посмотрев на код, а также попытаться понять)
video_capture = cv2.VideoCapture(0)
while True:
ret, frame = video_capture.read()
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
rgb_small_frame = small_frame[:, :, ::-1]
if process_this_frame:
face_locations = face_recognition.face_locations( rgb_small_frame)
face_encodings = face_recognition.face_encodings( rgb_small_frame, face_locations)
face_names = []
for face_encoding in face_encodings:
matches = face_recognition.compare_faces (faces_encodings, face_encoding)
name = "Unknown"
face_distances = face_recognition.face_distance( faces_encodings, face_encoding)
best_match_index = np.argmin(face_distances)
if matches[best_match_index]:
name = faces_names[best_match_index]
face_names.append(name)
process_this_frame = not process_this_frame
# Display the results
for (top, right, bottom, left), name in zip(face_locations, face_names):
top *= 4
right *= 4
bottom *= 4
left *= 4
# Draw a rectangle around the face
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# Input text label with a name below the face
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)
# Display the resulting image
cv2.imshow('Video', frame)
# Hit 'q' on the keyboard to quit!
if cv2.waitKey(1) & 0xFF == ord('q'):
break
Тестирование распознавателя
На первом изображении я использую то же самое изображение, которое использовалось в обучающих данных.

Теперь я попробую это сделать с другим изображением Тейлор Свифт. Работает отлично!

Поздравляю!! Вы создали программу, которая обнаруживает, а также распознает лица на изображении. Теперь у вас есть представление о том, как использовать компьютерное зрение в реальном проекте. Надеемся, что вам понравилось читать это пошаговое руководство. Буду рад, если вы сегодня узнали что-то новое. Работа над проектами практического программирования, подобными этому, — лучший способ отточить свои навыки программирования.
Не стесняйтесь связываться со мной, если у вас возникнут вопросы при внедрении кода.
Я Behic Guven, и мне нравится делиться историями о программировании, образовании и жизни. Подпишитесь на мой контент, чтобы оставаться воодушевленным, и В сторону науки о данных, чтобы оставаться воодушевленным. Спасибо,