Привет, Хабр! На связи СберТех — мы создаём Platform V, цифровую платформу Сбера для разработки бизнес-приложений.
В платформу входит более 60 продуктов на базе собственных сборок open source, доработанных до уровня enterprise по функциональности, безопасности, производительности и отказоустойчивости.
В этой статье расскажем про реализацию паттерна Change Data Capture и межкластерной репликации данных в продукте Platform V DataGrid, распределённой in-memory базе данных для высокопроизводительных вычислений. А также об особенностях внедрения функции и вариантах репликации. Написать материал помог наш коллега Николай Ижиков из команды по развитию баз данных на стеке open source.

Что такое Change Data Capture
Представим, что у вас есть база данных с критичными для бизнеса данными и жёсткими SLA по чтению и записи.
В то же время есть компоненты системы, которым необходимо реагировать на изменения в данных, например на уведомления о поступлении нового заказа, изменение данных пользователя и т. д. Таких компонентов много, и со временем их количество только растёт.
Если база уже нагруженная, навешивать на микросервис, создающий заказ, синхронную обработку или писать хранимую процедуру нерационально — увеличим тайминги по ответам, вероятен риск нарушения SLA.
И тут на помощь приходит паттерн Change Data Capture или CDC.

Когда в базу данных вносятся изменения, для ускорения записи и оптимизации операций она пишет журнал изменений (UNDO, REDO логи). В него база данных последовательно записывает дельту, которую вы изменяете.
CDC — это приложение, которое умеет обрабатывать логи изменений, выделять из них события об изменении данных и уведомлять об этом потребителя изменений, реализующего бизнес-логику.
В результате получаем линейные, упорядоченные по времени события изменений данных: что было, что есть, какая операция, над какой таблицей или кэшем была выполнена. Обработка асинхронная, не триггер и не хранимая процедура. Данные закоммитились, приложение, которое их отправляет, продолжило работать дальше, а потребитель через какое-то время получает уведомление о произошедшем изменении.
Как и когда использовать CDC
• Стриминг изменений в хранилище данных. У вас есть DWH. Обычно в режиме реального времени данные в неё поступать не должны. Для перекладывания данных можно написать процедуры, которые будут раз в час или в сутки определять дельту и отправлять её в хранилище. С помощью CDC эти же данные можно перекладывать с меньшими задержками.
-
Постобработка событий. В системе произошло событие — пользователь зарегистрировался, создал заказ, загрузил новый файл, — и, согласно бизнес-процессу, по новой записи нужно инициировать модерацию или другие действия.
-
Аналитика. По поступающим в CDC событиям можно считать аналитику в режиме, близком к реальному времени.
-
Логическая репликация. В CDC у нас на руках есть ВСЕ изменения, которые происходят в базе. Для реализации репликации нужно всего лишь надёжно исполнить их на реплике.
CDC в open source database
Дизайн
При любой доработке сложной системы, к которой, очевидно, относится распределённая СУБД, всегда есть риск что-то сломать. Лучший выход — делать новую фичу, вообще не трогая существующие.
Поэтому, проектируя CDC на базе Ignite, команда решила, что ignite-cdc должен выступать как отдельный java-процесс, не влияющий на ноду Ignite.
Ignite в persistence-режиме, как и любая классическая СУБД, записывает изменения в WAL (Write-Ahead Log). WAL — бинарный файл, содержащий изменения, дельты, которые мы периодически пишем в основную память (page memory).
Время от времени WAL-сегмент переходит в архив. Ignite-cdc видит, что появился архивный WAL-сегмент, и обрабатывает его.
Обработка — уведомление потребителя об изменениях. Есть public API для потребителя, но можно написать и свой.
Важно, что при этом нет перерасхода места на диске: WAL-архив — это существующая функциональность, которая нужна для восстановления после сбоев. Ignite-cdc обрабатывает ровно те же сегменты, никаких новых данных на диске не появляется.
Следующий важный момент — возможность сохранять состояние чтения. Ignite-cdc — отдельный процесс, который может падать. Нужно реализовать возможность фиксации состояния потребителя каждый раз, когда он решил, что данные обработаны и можно сохраниться. При падении обработка будет продолжена с места последнего commit-а. К счастью, поддерживать это довольно просто: нужно всего лишь сохранять указатель на том месте в сегменте, на котором чтение остановилось.
Из возможности сохранять состояние следует возможность сделать fail-fast-приложение. При любых проблемах Ignite-cdc падает. Предполагается, что поднимать его будут с помощью ОС-механизмов.
На уровне ноды всё выглядит вот так:

Есть небольшая тонкость: WAL-архив не бесконечный, Ignite складывает в архив столько сегментов, сколько было указано в настройках. При архивации n+1 сегмента самый старый удаляется.
Чтобы избежать ситуаций, когда CDC затормозил и не обработал уже удалённый сегмент, архивный сегмент hard-link’ом переносится в папку, с которой работает только Ignite-cdc.
Если удалим данные из архива, файл останется в папке для СDC, и данные будут доступны.
Если Ignite-cdc обработал сегмент, его можно будет сразу же удалить. Данные исчезнут с диска, когда оба hard-link’а будут удалены.
Приложению понадобятся метрики. API уже есть в Ignite, и его нужно переиспользовать.
API и настройки
Для настройки CDC есть три параметра, которые нужно настроить на уровне ноды.
public class DataStorageConfiguration {
long walForceArchiveTimeout;
String cdcWalPath;
}
public class DataRegionConfiguration implements Serializable {
boolean cdcEnabled;
}Здесь:
-
cdcWalPath — путь к папке, где складываются WAL-сегменты для CDC;
-
cdcEnabled — включает CDC для DataRegion’а;
-
walForceArchiveTimeout — таймаут принудительной архивации сегмента: даже если сегмент заполнен не полностью, по таймауту он будет архивирован и станет доступным для CDC.
С walForceArchiveTimeout есть тонкость. WAL-архив работает быстро за счёт того, что он является memory-mapped file. Это позволяет фактически писать не на диск, а в память для того, чтобы операционная система сбросила файл или мы могли сделать это вручную, когда сегмент будет заполнен.
Запись на диск — дорогая операция, в момент которой производительность ноды снижается, поэтому, с одной стороны, запись нужно делать как можно реже. С другой — CDC узнаёт об изменениях после архивации сегмента, поэтому запись нужно делать как можно чаще. Противоречие 
Решить его можно, выбирая таймаут согласно требованиям приложения.
Теперь самое интересное — сonsumer, слушатель, который позволяет узнать и обработать изменения:
public interface CdcConsumer {
public void start(MetricRegistry mreg);
public boolean onEvents(Iterator<CdcEvent> events);
public void onTypes(Iterator<BinaryType> types);
public void onMappings(Iterator<TypeMapping> mappings);
public void stop();
}-
start, stop — для инициализации и остановки;
-
onEvents — callback для обработки изменений: вернули true — состояние коммитнулось;
-
onTypes, onMappings — callback’и для обработки изменений метаинформации о типах.
Что доступно в событии:
public interface CdcEvent extends Serializable {
public Object key();
@Nullable public Object value();
public boolean primary();
public int partition();
public CacheEntryVersion version();
public int cacheId();
}-
key, value — данные: value может быть null, если событие по remove’у;
-
primary — событие произошло на primary или backup;
-
partition — номер партиции, необходим для распределения нагрузки в соответствии с существующими в Ignite партициями;
-
version — версия entry;
-
cacheId — идентификатор кэша.
Таким образом, у нас есть приложение, которое в асинхронном виде получает уведомления обо всех изменениях всех данных внутри кластера Ignite. Теперь на основе этой функциональности мы можем реализовать как необходимые бизнес-функции, так и логическую репликацию.
Логическая репликация с помощью CDC
Под физической репликацией в данной статье я понимаю перенос между экземплярами БД внутреннего представления данных: страниц памяти и т. д.
Под логической — выделение потока изменений из базы-источника и его воспроизведение в базе-приёмнике.
CDC позволяет реализовать именно логическую репликацию.
В Ignite есть поддержка двух схем: Ignite to Ignite и Ignite to Kafka.
Ignite to Ignite

Внутри Ignite-cdc работает IgniteToIgniteCdcStreamer, кстати, доступный из коробки. Это consumer, который внутри себя поднимает клиентскую ноду Ignite, коннектится к кластеру-приёмнику и, получая изменения, отправляет почти обычную операцию put в кластер-приёмник.
Если кластер-источник недоступен, например из-за упавшей ноды, Ignite-cdc будет вечно ждать, пока нода не запустится. Новые данные не поступят, и процесс обработает те, которые были сгенерированы ещё живой нодой.
Если упал Ignite-cdc, то, во-первых, на всех остальных нодах он будет жив. Во-вторых, через некоторое время операционная система его перезапустит, CDC посмотрит, какие изменения он обработал, и продолжит отправлять их в соседний кластер.
Если потерялся соседний кластер или сетевая связность, Ignite-cdc также упадёт, а после перезапуска снова пойдёт в кластер-приёмник. Если кластер недоступен — падение. Если доступен — отлично, CDC начнёт отправлять в него изменения, которые были накоплены в WAL на диске. Диск является буфером изменений, которые будут копиться до тех пор, пока не получится их обработать и отправить в нужную точку.
Ignite to Kafka

Это вариант репликации для ситуаций, когда кластеры Ignite не видят друг друга, нужно использовать Kafka в качестве транспорта, или если есть несколько читателей событий.
Схема практически такая же: для обработки событий используется стример IgniteToKafkaCdcStreamer. Он раскладывает данные по партициям Kafka в соответствии с партициями Ignite.
На стороне приёмника есть приложение kafka-to-ignite — оно читает данные из Kafka и кладёт их в принимающий кластер Ignite.
Conflict resolver
Подошли к самому интересному: что произойдёт, если один ключ будет изменён на обоих кластерах?
Ответ — сработает conflict resolver. Это интерфейс, который определяет, какие именно данные должны попасть в кластер. Он может взять «старое», «новое» значение или выполнить merge.
СDC-extension предоставляет дефолтную имплементацию, но можно реализовать и свою. При этом стоит отметить, что правильного решения при конфликтах изменений не существует. Не зная ничего о данных, невозможно точно определить, какое изменение правильное, а какое нет.
Ключевые свойства дефолтной имплементации:
-
Если изменение произошло на «локальном» кластере, оно выигрывает.
-
Изменения с одного и того же кластера сравниваются по версии. Изменение с большей версией выигрывает.
-
Если указано поле для сравнения, записи сравниваются по нему.
-
Если всё предыдущее не сработало, новая запись отбрасывается. Данные разъезжаются, в логах warning, а вам нужно думать, что делать дальше.
Заключение
Внедрение паттерна CDC позволило добавить востребованную функциональность для реализации событийных подписок и создания реплик без влияния на производительность ядра самой базы данных.
Автор оригинала: Vlad Mihalcea.
Вступление
В этой статье я собираюсь объяснить, что такое CDC (Сбор данных об изменениях) и почему вы должны использовать его для извлечения изменений на уровне строк базы данных.
В системах OLTP (Онлайн-обработка транзакций) доступ к данным и их изменение осуществляются одновременно несколькими транзакциями, и база данных переходит из одного согласованного состояния в другое. Система OLTP всегда показывает последнее состояние наших данных, что облегчает разработку интерфейсных приложений, для которых требуются гарантии согласованности данных почти в реальном времени.
Однако система OLTP не является островом, являясь лишь небольшой частью более крупной системы, которая инкапсулирует все потребности в преобразовании данных, требуемые данным предприятием. При интеграции системы OLTP с кэшем, хранилищем данных или Сеткой данных в памяти нам необходим процесс ETL для сбора списка событий, которые изменили данные системы OLTP за определенный период времени.
В этой статье мы рассмотрим различные методы, используемые для захвата событий и их распространения на другие системы обработки данных.
Традиционно наиболее распространенным методом, используемым для записи событий, было использование триггеров на уровне базы данных или приложений. Причина, по которой эта техника все еще очень широко распространена, заключается в ее простоте и знакомстве.
Журнал аудита представляет собой отдельную структуру, в которой записывается каждое действие вставки, обновления или удаления, выполняемое для каждой строки.
Триггеры базы данных
Каждая СУБД поддерживает триггеры, хотя и с несколько иным синтаксисом и возможностями.
PostgreSQL предлагает специальную страницу для реализации журнала аудита на основе триггеров .
Триггеры на уровне приложений
Существуют фреймворки, такие как Hibernate Envers , которые эмулируют триггеры базы данных на уровне приложения. Преимущество заключается в том, что вам не нужно обращать внимание на синтаксис триггеров, специфичный для базы данных, поскольку события в любом случае фиксируются контекстом сохранения. Недостатком является то, что вы не можете регистрировать события изменения данных, которые не проходят через приложение (например, изменения, поступающие из консоли базы данных или из других систем, использующих одну и ту же СУБД).
CDC на основе журнала транзакций (Сбор данных об изменениях)
Хотя триггеры на уровне базы данных или приложений являются очень распространенным выбором для CDC, есть лучший способ. Журнал аудита-это просто дубликат журнала транзакций базы данных (он же журнал повтора или журнал предварительной записи), в котором уже хранятся изменения на основе строк.
Таким образом, на самом деле вам не нужно создавать новую структуру журнала аудита с использованием триггеров базы данных или уровня приложения, вам просто нужно просмотреть журнал транзакций и извлечь из него события CDC.
Исторически сложилось так, что каждая СУБД использовала свой собственный способ декодирования базового журнала транзакций:
- Предложения Oracle Золотые ворота
- SQL Server предлагает встроенную поддержку CDC
- MySQL, так широко используемый для веб-приложений, позволяет вам фиксировать события CDC с помощью различных сторонних решений, таких как База данных LinkedIn
Но в городе появился новый парень! Debezium -это новый проект с открытым исходным кодом, разработанный Red Hat, который предлагает соединители для Oracle, MySQL, PostgreSQL и даже MongoDB.
Мало того, что вы можете извлекать события CDC , но вы можете распространять их в Apache Kafka , который служит основой для всех сообщений, необходимых для обмена между различными модулями крупной корпоративной системы.
Вывод
Если вы используете приложение OLTP, CDC пригодится, когда дело доходит до интеграции с другими модулями в текущей корпоративной системе. Некоторые могут возразить, что использование источника событий лучше и даже может полностью заменить системы OLTP, поскольку вы регистрируете каждое событие заранее и затем получаете последний снимок.
Хотя источник событий имеет большое значение, существует множество приложений, которые могут извлечь выгоду из модели данных OLTP, поскольку события проверяются перед сохранением, что означает, что аномалии устраняются механизмами управления параллелизмом базы данных.
В противном случае Google, который стал пионером MapReduce для BigData с помощью своего хранилища данных Bigtable , не вложил бы столько усилий в создание глобально распределенной системы баз данных , совместимой с ACID, такой как Spanner , которая была разработана для создания критически важных приложений для обработки онлайн-транзакций (OLTP).
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture.
Паттерны и принципы реализации захвата измененных данных
Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных продолжают стремительно расти, а бизнес-пользователям нужен непрерывный доступ к аналитической информации. Поэтому извлечение всех базовых данных в режиме реального времени становится нецелесообразным из-за долгой передачи большого объема данных по сети. Поэтому вместо полного копирования данных из систем-источников в корпоративное хранилище или озеро более выгодно применять решения идентификации и репликации журнала изменений для поддержки приложений аналитики в режиме, близком к реальному времени.
Технически такая стратегия реализуется с помощью технологии захвата измененных данных (Change Data Capture, CDC) с помощью готовых или самописных решений. Примерами готовых CDC-решений можно назвать Debezium, Oracle Change Data Capture, PowerExchange CDC от Informatica, Hevo Data, IBM Infosphere, Qlik Replicate, Talend, Oracle GoldenGate, StreamSets, а также прочие вендорские и open-source продукты. Пример репликации измененных данных в реальном времени с Apache Kafka и Debezium в Confluent Cloud мы рассматривали здесь.
Впрочем, некоторые дата-инженеры разрабатывают собственные CDC-решения, используя следующие подходы для вычисления измененных данных:
- временные метки, которые отмечают события создания, обновления и истечения срока действия данных в исходных таблицах. Любой процесс, который вставляет, обновляет или удаляет строку, должен также обновлять соответствующий столбец отметки времени, а полные удаления не допускаются. Хотя реализация этого способа проста, очень мало таблиц в типичной базе данных имеет такие временные метки. Также этот шаблон создает тесную связь между исходной таблицей и кодом ETL-процессов, повышая связность между разными компонентами системы, что усложняет ее развитие.
- минус-запрос, когда между исходной и целевой базой данных создается ссылка, и выполняется SQL-запрос c оператором MINUS для расчета журнала изменений. Этот шаблон приводит к тому, что между исходной и целевой базой данных передается большой объем данных, а потому считается антипаттерном. Более того, этот шаблон работает только в том случае, если исходная и целевая базы данных совпадают по типу и другим параметрам, что часто встречается лишь в линейке продуктов одного вендора, например, Oracle и пр.
Оба вышеописанных шаблона CDC вызывают значительную нагрузку на исходную базу данных. Чтобы снизить ее и сократить нагрузку на сеть, инструменты CDC анализируют логи базы данных для расчета журнала изменений. Каждая база данных, поддерживающая транзакции, сперва записывает любые изменения (вставки, обновления и удаления) в лог для обеспечения целостности транзакций от любых сбоев, пока транзакция все еще находится в процессе выполнения.
Логирование переключаются между активным журналом (журналом повторов) и архивными журналами в зависимости от размера файла или событий временного интервала. В зависимости от требований к задержке данных целевой базы CDC-инструмент может получить доступ к активному или архивным журналам для исходной базы. Чтение только логов исходной базы данных не увеличивает нагрузку на нее, т.к. журнал изменений обычно намного меньше, чем сами таблицы.
Коммерческие CDC-инструменты позволяют синхронизировать источники транзакционных данных с аналитическими базами данных практически в реальном времени, сводя к минимуму воздействие на системы-источники, и поэтому лучше всего подходят для приема данных из часто обновляемых реляционных СУБД. Также они имеют высокую отказоустойчивость, поддерживают облегченные преобразования на лету и устраняют сильную связанность между исходной базой и кодом приема данных. Несмотря на эти преимущества, и готовые, и самописные CDC-решения имеют такой недостаток, как дрейф изменений. Что это такое и чем опасно, мы рассмотрим далее.
Проблема дрейфа изменений в CDC-решениях и способы ее решения
Дрейф изменений происходит, когда несколько внесенных изменений не попадают в историю изменений. Это может произойти по множеству причин, от сбоя CDC-инструмента до неправильной записи события. Чтобы избежать ошибок из-за неверного представления текущем состоянии данных, при любом CDC-приеме необходимо обнаружить дрейф, а затем выполнить согласование с источником, чтобы скорректировать реплику. Для этого нужно реализовать следующие шаги:
- определить, до какого момента времени будет производиться сверка, например, по расписанию или по событию, чтобы создать файл моментов времени для сверки данных;
- определить стратегию обнаружения дрейфа. Проще всего сравнить таблицы в исходной и целевой базе, но извлечение полного набора данных часто занимает много времени, а также создает высокую нагрузку на систему-источник и сеть. Быстрее сравнивать какой-то отдельный показатель, например, количество строк или хэшированную сумму значений в каком-то столбце. Этот способ оперативно покажет наличие проблемы, но потребует дополнительных усилий для поиска конкретных несовпадений на уровне отдельных строк. Альтернативой являются построчные проверки значений или хэша строки, если исходная система может его создать.
Обычно коммерческие CDC-инструменты используют наиболее эффективные способы обнаружения изменений в системах-источниках, используя триггеры (особые хранимые процедуры) БД. Возможность работы со множеством систем-источников обеспечивают коннекторы. В случае самописного решения все это необходимо реализовывать самостоятельно. Чтобы выбрать наиболее подходящий CDC-инструмент, важно помнить про следующие особенности и ограничения готовых и самописных решений:
- репликация измененных данных — это не одноразовая задача, а регулярно выполняемая операция, которая не так-то просто реализуется из-за различий между вендорами СУБД, разных форматов записей и сложностям доступа к логам;
- CDC требует регулярного технического обслуживания. Нужно не просто написать сценарий отслеживания и исправления изменений, но и постоянно корректировать его в зависимости от эволюции систем-источников. Это создает дополнительную нагрузку на дата-инженеров и разработчиков, отвлекая их от других проектов.
Читайте в нашей новой статье, как реализовать потоковый CDC-конвейер на Apache NiFi. А практически освоить проектирование и поддержку современных дата-архитектур в проектах аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Аналитика больших данных для руководителей
Источники
- https://hevodata.com/learn/7-best-cdc-tools/
- https://towardsdatascience.com/change-data-capture-cdc-for-data-ingestion-ca81ff5934d2
- https://blog.metamirror.io/cdc-drift-and-reconciliation-6cc524aa8c28
Introduction
In this article, I’m going to explain what CDC (Change Data Capture) is, and why you should use it to extract database row-level changes.
In OLTP (Online Transaction Processing) systems, data is accessed and changed concurrently by multiple transactions, and the database changes from one consistent state to another. An OLTP system always shows the latest state of our data, therefore facilitating the development of front-end applications that require near real-time data consistency guarantees.
However, an OLTP system is no island, being just a small part of a larger system that encapsulates all data transformation needs required by a given enterprise. When integrating an OLTP system with a Cache, a Data Warehouse, or an In-Memory Data Grid, we need an ETL process to collect the list of events that changed the OLTP system data over a given period of time.
In this article, we are going to see various methods used for capturing events and propagating them to other data processing systems.
Trigger-based CDC (Change Data Capture)
Traditionally, the most common technique used for capturing events was to use database or application-level triggers. The reason why this technique is still very widespread is due to its simplicity and familiarity.
The Audit Log is a separate structure that records every insert, update or delete action that happens on a per-row basis.
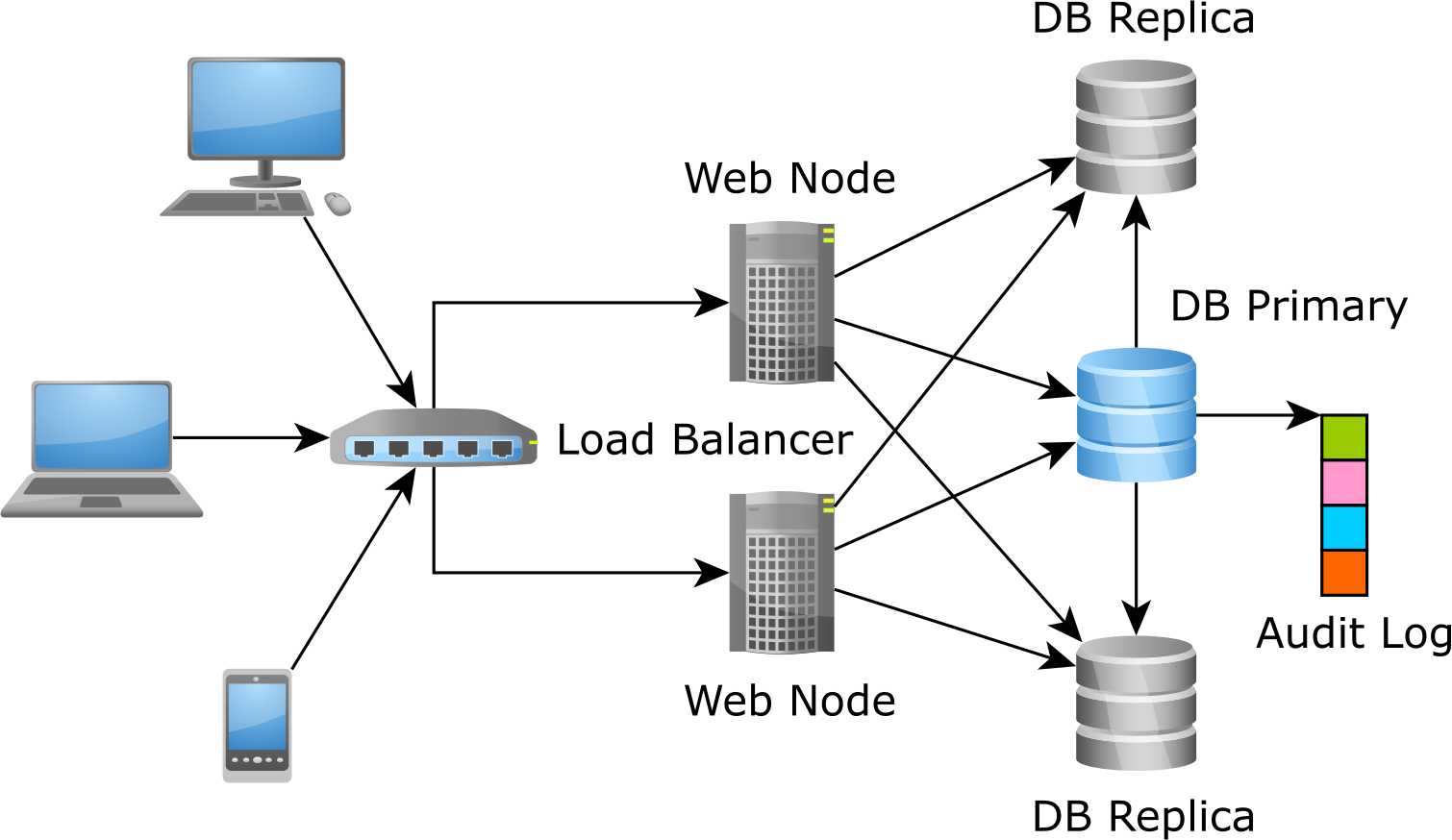
Database triggers
Every RDBMS supports triggers, although with slightly different syntax and capabilities.
PostgreSQL offers a dedicated page for implementing a trigger-based Audit Log.
Application-level triggers
There are frameworks, such as Hibernate Envers, which emulate database triggers at the application level. The advantage is that you don’t need to mind the database-specific syntax for triggers since events are captured anyway by the Persistence Context. The disadvantage is you can’t log data change events that don’t flow through the application (e.g., changes coming from a database console or from other systems that share the same RDBMS).
Transaction log-based CDC (Change Data Capture)
Although the database or application-level triggers are a very common choice for CDC, there is a better way. The Audit Log is just a duplicate of the database transaction log (a.k.a redo log or Write-Ahead Log) which already stores row-based modifications.
Therefore, you don’t really need to create a new Audit Log structure using database or application-level triggers, you just need to scan the transaction log and extract the CDC events from it.
Historically, each RDBMS used its own way of decoding the underlying transaction log:
- Oracle offers GoldenGate
- SQL Server offers built-in support for CDC
- MySQL, being so widely used for web applications, has been allowing you to capture CDC events through various 3rd party solutions, like LinkedIn’s DataBus
But there’s a new guy in town! Debezium is a new open-source project developed by RedHat, which offers connectors for Oracle, MySQL, PostgreSQL, and even MongoDB.
Not only that you can extract CDC events, but you can propagate them to Apache Kafka, which acts as a backbone for all the messages needed to be exchanged between various modules of a large enterprise system.

I’m running an online workshop on the 11th of October about High-Performance SQL.

If you enjoyed this article, I bet you are going to love my Book and Video Courses as well.




Conclusion
If you are using an OLTP application, CDC comes in handy when it comes to integrating with other modules in the current enterprise system. Some might argue that using Event Sourcing is better and can even replace OLTP systems entirely since you log every event upfront and derive the latest snapshot afterward.
While Event Sourcing has a lot of value, there are many applications that can benefit from the OLTP data model because the events are validated prior to being persisted, meaning that anomalies are eliminated by the database concurrency control mechanisms.
Otherwise, Google, who pioneered MapReduce for BigData through its Bigtable data storage, wouldn’t have invested so much effort into building a globally-distributed ACID-compliant database system such as Spanner, which was designed for building mission-critical online transaction processing (OLTP) applications.


