Мы начинаем публиковать перевод книги (как называет ее сам автор) «Руководство хакера по нейронным сетям». Книга состоит из четырех частей, две из которых уже закончены. Мы постараемся разбить текст на логически завершенные части, размер которых позволит не перегружать читателя. Также мы будем следить за обновлением книги и опубликуем перевод новых частей после их появления в блоге автора.
Часть 1:
Введение
Глава 1: Схемы реальных значений
Базовый сценарий: Простой логический элемент в схеме
Цель
Стратегия №1: Произвольный локальный поиск
Всем привет, я аспирант по вычислительной технике в Стэнфорде. Несколько лет, как часть моего исследования, я работал над глубинным обучением, и среди нескольких связанных с ним моих любимых проектов — ConvNetJS – Javascript-библиотека для обучения нейронных сетей. Javascript позволяет хорошо визуализировать то, что происходит, и дает возможность разобраться с различными настройками гиперпараметров, но я все равно регулярно слышу от людей пожелания рассмотреть эту тему более подробно. Эта статья (которую я планирую постепенно расширить до объема нескольких глав) – это моя скромная попытка сделать это. Я размещаю ее в сети, вместо того, чтобы создать в формате PDF, как и следует поступать с книгами, потому что она должна (и я надеюсь, будет) в конечном итоге содержать анимации/демонстрации и пр.
Мой личный опыт работы над нейронными сетями показывает, что все становится намного понятнее, когда я начинаю игнорировать полностраничность, плотные производные уравнений обратного распространения ошибки, и просто начинаю писать код. Поэтому, это руководство будет содержать очень немного математики (мне не кажется, что это необходимо, и это может местами даже усложнить понимание простых концепций). Так как моя специальность – вычислительная техника и физика, я, вместо этого, буду развивать эту тему с точки зрения хакера. Мое изложение будет сосредоточено вокруг кода и физической интуиции, вместо математических производных. В основном я буду пытаться представить алгоритмы таким образом, какой я хотел бы использовать, когда я только начинал.
«… все стало намного понятнее, когда я начал писать код»
Наверняка вы захотите перескочить и сразу начать изучать нейронные сети, как их можно использовать на практике и пр. Но прежде чем мы возьмемся за это, я бы хотел, чтобы мы обо всем этом забыли. Давайте сделаем шаг назад и разберемся, что, по сути, происходит. Давайте сначала поговорим о схемах реальных значений.
Глава 1: Схемы реальных значений
По моему мнению, лучший способ представить себе нейронные сети – это в качестве схем реальных значений, в которых реальные значения (вместо булевых {0,1}) «протекают» вдоль границ и взаимодействуют в логических элементах. Однако, вместо таких логических элементов, как AND, OR,NOT и пр., у нас есть двоичные логические элементы, такие как * (умножить), + (прибавить), max, или унарные логические элементы, такие как exp и пр. Однако, в отличие от обычных булевых схем, у нас в конечном итоге также будут градиенты, протекающие по тем же границам схемы, но в обратном направлении. Но мы забегаем вперед. Давайте сконцентрируемся и начнем с простого.
Базовый сценарий: Простой логический элемент в схеме
Давайте сначала рассмотрим единичную простую схему с одним логическим элементом. Вот пример:

Схема берет два исходных реальных значения x и y и перемножает x * y с помощью логического элемента *.
Javascript-версия этого уравнения будет выглядеть очень просто, например, так:
var forwardMultiplyGate = function(x, y) {
return x * y;
};
forwardMultiplyGate(-2, 3); // returns -6.
А в математическом виде мы можем рассмотреть этот логический элемент в качестве воспроизведения функции с реальными значениями:
f(x,y)=xy
Как и в этом примере, все наши логические элементы будут брать одно или два исходных значения и выдавать одно выходное значение.
Цель
Проблема, изучение которой нас интересует, выглядит следующим образом:
1. Мы вводим в приведенную схему определенные исходные значения (например, x = -2, y = 3)
2. Схема вычисляет выходное значение (например, -6)
3. В результате этого возникает ключевой вопрос: Как нужно незначительно изменить исходящее значение, чтобы увеличить результат?
В данном случае, в какую сторону нам следует изменить x,y, чтобы получить число больше, чем -6? Следует учесть, что, например, x = -1.99 и y = 2.99 дает в результате x * y = -5.95, что уже больше, чем -6.0. Не пугайтесь:-5.95 лучше (выше), чем -6.0. Это улучшение на 0.05, даже несмотря на то, что величина -5.95 (расстояние от нуля) иногда ниже.
Стратегия №1: Произвольный локальный поиск
Хорошо. У нас есть схема, у нас есть несколько исходных значений и нам просто нужно немного их изменить, чтобы увеличить выходное значение? В чем сложность? Мы можем легко «помочь» схеме вычислить результат для любого заданного значения x и y. Разве это не просто? Почему бы не изменить x и y произвольно и не отследить, какое из изменений дает наилучший результат:
// схема, содержащая пока один логический элемент
var forwardMultiplyGate = function(x, y) { return x * y; };
var x = -2, y = 3; // some input values
// пытаемся произвольно изменить x,y на небольшую величину и отследить, что дает наилучший результат
var tweak_amount = 0.01;
var best_out = -Infinity;
var best_x = x, best_y = y;
for(var k = 0; k < 100; k++) {
var x_try = x + tweak_amount * (Math.random() * 2 - 1); // немного изменяем x
var y_try = y + tweak_amount * (Math.random() * 2 - 1); // немного изменяем y
var out = forwardMultiplyGate(x_try, y_try);
if(out > best_out) {
// вот оптимальное улучшение! Следим за изменением x и y
best_out = out;
best_x = x_try, best_y = y_try;
}
}
Когда я это запустил, я получил best_x = -1.9928, best_y = 2.9901, и best_out = -5.9588. Опять же, -5.9588 выше, чем -6.0. Ну, мы закончили, правильно? Не совсем: Это идеальная стратегия для маленьких проблем с небольшим количеством логических элементов, если в вашем распоряжении есть время на вычисление, но это не сработает, если мы захотим разобраться с большими схемами с миллионами исходных значений. Оказывается, мы можем больше, но об этом в следующей части.
Автор: Irina_Ua
Источник
Руководство хакера по нейронным сетям. Схемы реальных значений. Становимся мастером обратного распространения ошибки
Время на прочтение
6 мин
Количество просмотров 28K
Содержание:
Глава 1: Схемы реальных значений
Часть 1:
Введение
Базовый сценарий: Простой логический элемент в схеме
Цель
Стратегия №1: Произвольный локальный поиск
Часть 2:
Стратегия №2: Числовой градиент
Часть 3:
Стратегия №3: Аналитический градиент
Часть 4:
Схемы с несколькими логическими элементами
Обратное распространение ошибки
Часть 5:
Шаблоны в «обратном» потоке
Пример "Один нейрон"
Часть 6:
Становимся мастером обратного распространения ошибки
Глава 2: Машинное обучение
Часть 7:
Бинарная классификация
Часть 8:
Обучение сети на основе метода опорных векторов (SVM)
Часть 9:
Обобщаем SVM до нейронной сети
Часть 10:
Более традиционный подход: Функции потерь
Со временем вы сможете намного эффективнее писать обратные проходы, даже для сложных схем и для всего сразу. Давайте немного попрактикуемся в создании обратного распространения ошибки на нескольких примерах. В дальнейшем мы просто будем использовать такие переменные, как a,b,c,x, а их градиенты назовем da,db,dc,dx соответственно. Опять же, мы представляем переменные в качестве «прямого потока», а их градиенты в качестве «обратного потока» вдоль каждой линии. Нашим первым примером был логический элемент *:
var x = a * b;
// и учитывая градиент по x (dx), мы видим, что при помощи обратного распространения ошибки мы можем рассчитать следующее:
var da = b * dx;
var db = a * dx;
В вышеприведенном коде я допускаю, что нам дана переменная dx, которая приходит откуда-то сверху по схеме, пока мы выполняем обратное распространение ошибки (или в ином случае она по умолчанию равна +1). Я выписываю ее, так как я хочу четко показать, как градиенты связанны между собой. Обратите внимание, что в уравнениях логический элемент * выступает в качестве переключателя в процессе обратного прохода. Он запоминает, какими были его исходные значения, и градиенты по каждому значению будут равны другому в процессе обратного прохода. И тогда, конечно, нам придется умножить его на стоящий выше градиент, что представляет собой цепное правило. Вот так выглядит логический элемент + в сжатой форме:
var x = a + b;
// ->
var da = 1.0 * dx;
var db = 1.0 * dx;
Где 1.0 является локальным градиентом, а умножение представляет собой наше цепное правило. А как же быть с прибавлением трех чисел?:
// давайте вычислим x = a + b + c в два этапа:
var q = a + b; // логический элемент 1
var x = q + c; // логический элемент 2
// обратный проход:
dc = 1.0 * dx; // обратное распространение ошибки первого логического элемента
dq = 1.0 * dx;
da = 1.0 * dq; // обратное распространение ошибки второго логического элемента
db = 1.0 * dq;
Вы же понимаете, что происходит? Если вы помните схему обратного потока, логический элемент + просто берет градиент сверху и направляет его в равной степени на все его исходные значения (так как его локальный градиент всегда равен просто 1 для всех его исходных значений, вне зависимости от их фактических значений). Поэтому мы можем сделать это намного быстрее:
var x = a + b + c;
var da = 1.0 * dx; var db = 1.0 * dx; var dc = 1.0 * dx;
Хорошо, а как насчет комбинирования логических элементов?:
var x = a * b + c;
// учитывая dx, обратное распространение ошибки за один цикл будет выглядеть следующим образом =>
da = b * dx;
db = a * dx;
dc = 1.0 * dx;
Если вы не понимаете, что происходит выше, давайте введем временную переменную q=a*b, после чего вычислим x=q+c, чтобы все проверить. А вот и наш нейрон, поэтому давайте все рассчитаем в два этапа:
// давайте создадим наш нейрон в два этапа:
var q = a*x + b*y + c;
var f = sig(q); // sig – это сигмоидная функция
// а теперь обратный проход, мы получаем df, и:
var dq = (q * (1 - q)) * df;
// а теперь мы связываем его с исходными значениями
var da = x * dq;
var dx = a * dq;
var dy = b * dq;
var db = y * dq;
var dc = 1.0 * dq;
Я надеюсь, тут что-то проясняется. А теперь, как насчет такого:
var x = a * a;
var da = //???
Можно рассмотреть данный пример, как значение a, движущееся в сторону логического элемента *, но линия разделяется и представляет собой оба исходных значения. Это на самом деле просто, так как обратный поток градиентов всегда прибавляется. Другими словами, ничего не меняется:
var da = a * dx; // градиент a из первой ветви
da += a * dx; // и прибавляется к градиенту из второй ветви
// более краткая форма выглядит следующим образом:
var da = 2 * a * dx;
Я надеюсь вы помните, что производная функции f(a) = a^2 равна 2а, что является именно тем значением, которое мы получаем, если представляем его в виде линии, разделяющейся на два исходных значения логического элемента.
Давайте посмотрим на другой пример:
var x = a*a + b*b + c*c;
// мы получаем:
var da = 2*a*dx;
var db = 2*b*dx;
var dc = 2*c*dx;
Хорошо, а теперь давайте немного усложним:
var x = Math.pow(((a * b + c) * d), 2); // pow(x,2) возводит в квадрат исходное значение JS
Когда более сложные случаи попадаются на практике, я люблю разделять выражение на удобные в решении части, которые практически всегда состоят из более простых выражений, после чего я связываю их с помощью цепного правила:
var x1 = a * b + c;
var x2 = x1 * d;
var x = x2 * x2; // это идентично вышеуказанному выражению для x
// а теперь с помощью обратного распространения ошибки идем назад:
var dx2 = 2 * x2 * dx; // обратное распространение ошибки в x2
var dd = x1 * dx2; // обратное распространение ошибки в d
var dx1 = d * dx2; // обратное распространение ошибки в x1
var da = b * dx1;
var db = a * dx1;
var dc = 1.0 * dx1; // готово!
Это было несложно. Это уравнения обратного распространения ошибки для всего выражения, и мы выполнили его по кусочкам, а потом выполнили обратное распространение для всех переменных. Опять же обратите внимание на то, что для каждой переменной в процессе прохода вперед у нас была эквивалентная переменная при обратном проходе, которая содержит градиент по отношению к окончательному результату схемы. Вот еще несколько полезных функций и их локальные градиенты, которые могут пригодиться на практике:
var x = 1.0/a; // деление
var da = -1.0/(a*a);
Так может выглядеть деление на практике:
var x = (a + b)/(c + d);
// давайте разложим его поэтапно:
var x1 = a + b;
var x2 = c + d;
var x3 = 1.0 / x2;
var x = x1 * x3; // эквивалент вышеуказанного значения
// а теперь обратное распространение ошибки, опять в обратном порядке:
var dx1 = x3 * dx;
var dx3 = x1 * dx;
var dx2 = (-1.0/(x2*x2)) * dx3; // локальные градиент, как показано выше, и цепное правило
var da = 1.0 * dx1; // и, наконец, к исходным переменным
var db = 1.0 * dx1;
var dc = 1.0 * dx2;
var db = 1.0 * dx2;
Надеюсь, вы понимаете, что мы разбиваем выражения, выполняем проход вперед, после чего для каждой переменной (например, a) мы ищем производную ее градиента da при движении в обратном направлении, по очереди, применяя простые локальные градиенты и связывая их с верхними градиентами. Вот еще один пример:
var x = Math.max(a, b);
var da = a === x ? 1.0 * dx : 0.0;
var db = b === x ? 1.0 * dx : 0.0;
Здесь очень простое выражение становится трудночитаемым. Функция max передает исходное значение, которое было наибольшим, и игнорирует остальные. При обратном проходе, логический элемент max просто возьмет градиент сверху и направит его к исходному значению, которое фактически протекало через него при проходе вперед. Логический элемент выступает в качестве простого переключателя на основании того, какой исходный элемент имел наибольшее значение при проходе вперед. Прочие исходные значения будут иметь нулевой градиент. Именно это означает ===, так как мы проверяем, какое исходное значение было фактически максимальным, и всего лишь направляем градиент к нему.
Наконец, давайте посмотрим на нелинейность выпрямленного линейного элемента(Rectified Linear Unit или ReLU), о котором вы наверняка слышали. Он используется в нейронных сетях вместо сигмоидной функции. Он просто переступает порог на нуле:
var x = Math.max(a, 0)
// обратное распространение ошибки через данный логический элемент будет иметь следующий вид:
var da = a > 0 ? 1.0 * dx : 0.0;
Другими словами, этот логический элемент просто передает значение, если оно больше 0, или останавливает поток и устанавливает его равным нулю. При обратном проходе логический элемент будет передавать градиент сверху, если он активировался в процессе прохода вперед, или, если оригинальное исходное значение было ниже нуля, он остановит поток градиента.
На этом моменте я остановлюсь. Я надеюсь, вы немного разобрались в том, как можно вычислять целые выражения (которые состоят из множества логических элементов) и как можно вычислять обратное распространение ошибки для каждого из них.
Все, что мы проделали в этой главе, сводится к следующему: Мы поняли, что мы можем ввести какое-либо исходное значение через сложную произвольную схему с реальными значениями, подтолкнуть конец схемы с некоторой силой, а обратное распространение ошибки передаст этот толчок на всю схему обратно до исходных значений. Если исходные значения незначительно реагируют вдоль обратного направления их толчка, схема «подастся» немного в сторону изначального направления натяжения. Возможно, это не так уж и очевидно, но такой алгоритм является мощным молотом для обучения машины.
Введение. Особенно за последние несколько лет нейронные сети (НС) действительно стали практичным и эффективным способом решения проблем, которые не могут быть легко решены с помощью алгоритма, таких как обнаружение лиц, распознавание голоса и медицинская диагностика. Во многом это стало возможным благодаря недавним открытиям в отношении того, как лучше обучать и настраивать сеть, а также увеличению скорости компьютеров. Совсем недавно студент Имперского колледжа Лондона создал сеть сетей под названием Giraffe [http: //www.technologyreview.c
Вступление
Особенно за последние несколько лет нейронные сети (НС) действительно
стали практичным и эффективным способом решения проблем, которые не
могут быть легко решены с помощью алгоритма, таких как обнаружение лиц,
распознавание голоса и медицинская диагностика. Во многом это стало
возможным благодаря недавним открытиям в отношении того, как лучше
обучать и настраивать сеть, а также увеличению скорости компьютеров.
Совсем недавно студент Имперского колледжа Лондона создал НС под
названием
Жираф,
которую можно было обучить всего за 72 часа, чтобы играть в шахматы на
том же уровне, что и международный мастер ФИДЕ. Компьютеры, играющие в
шахматы на этом уровне, на самом деле не новы, но способ создания этой
программы — новый. На создание этих программ обычно уходят годы, и они
настраиваются с помощью настоящего гроссмейстера, в то время как
Giraffe, с другой стороны, был построен просто с использованием глубокой
нейронной сети, некоторого творчества и огромного набора данных о
шахматных партиях. Это еще один пример обещания, которое нейронные сети
демонстрируют в последнее время, и они будут только улучшаться.
Brain.js
Обратной стороной NN и искусственного интеллекта в целом является то,
что эта область очень сложна с математикой, что имеет тенденцию
отпугивать людей еще до того, как они начнутся. Сугубо технический
характер НС и весь сопутствующий ей жаргон затрудняют непосвященным
воспользоваться преимуществом. Здесь на
помощь приходит Brain.js. Brain.js
отлично справляется с задачей упрощения процесса создания и обучения NN,
используя простоту использования JavaScript и ограничивая API
несколькими вызовами методов и опциями.
Не поймите меня неправильно, вам все равно нужно знать некоторые
концепции, лежащие в основе NN, но это упрощение делает его менее
пугающим.
Например, чтобы обучить сеть приближению функции
XOR (которая является одним
из стандартных примеров NN), все, что вам нужно, это:
var brain = require('brain');
var net = new brain.NeuralNetwork();
net.train([{input: [0, 0], output: [0]},
{input: [0, 1], output: [1]},
{input: [1, 0], output: [1]},
{input: [1, 1], output: [0]}]);
var output = net.run([1, 0]); // [0.933]
Этот код просто создает новую сеть ( net ), train сеть, используя
массив примеров, а затем run сеть с вводом [1, 0] , что правильно
приводит к [0.933] (также известному как 1 ).
Хотя в Brain.js нет множества опций, позволяющих настраивать сети, API
принимает достаточно параметров, чтобы сделать его полезным для простых
приложений. Вы можете установить количество и размер ваших скрытых
слоев, порог ошибки, скорость обучения и многое другое:
var net = new brain.NeuralNetwork({
hiddenLayers: [128,64]
});
net.train({
errorThresh: 0.005, // error threshold to reach before completion
iterations: 20000, // maximum training iterations
log: true, // console.log() progress periodically
logPeriod: 10, // number of iterations between logging
learningRate: 0.3 // learning rate
});
См. Полный список опций в документации.
Хотя вы ограничены в типах сетей, которые вы можете построить, это не
значит, что вы не можете сделать ничего значимого. Возьмем, к примеру,
этот
проект.
Автор собрал кучу изображений капчи для своего набора данных,
использовал простую обработку изображений для предварительной обработки
изображений, а затем использовал Brain.js для создания нейронной сети,
которая идентифицирует каждого отдельного символа.
Преимущества
Как я уже упоминал, Brain.js отлично подходит для быстрого создания
простой сетевой сети на языке высокого уровня, где вы можете
воспользоваться преимуществами огромного количества библиотек с открытым
исходным кодом. Имея хороший набор данных и несколько строк кода, вы
можете создать действительно интересную функциональность.
Научные / вычислительные библиотеки, написанные на JavaScript, подобные
этой, как правило, довольно сильно
критикуются
, но лично я думаю, что Brain.js имеет свое место в JS, если у вас есть
правильные ожидания и применение. Например, JS является доминирующим
(единственным?) Языком, работающим на стороне клиента в браузере, так
почему бы не воспользоваться преимуществами этой библиотеки для таких
вещей, как игры в браузере, размещение рекламы (скучно, я знаю) или
распознавание символов?
Недостатки
Хотя мы определенно можем получить некоторую ценность от такой
библиотеки, она не идеальна. Как я уже упоминал, библиотека ограничивает
вашу сетевую архитектуру до такой степени, что вы можете делать только
простые приложения. Возможности для слоев softmax или другой структуры
маловероятны. Было бы неплохо иметь хотя бы возможность дополнительной
настройки архитектуры вместо того, чтобы скрывать все от вас.
Наверное, самая большая моя претензия заключается в том, что библиотека
написана на чистом JavaScript. Обучение NN — это медленный процесс,
который может занять тысячи итераций (то есть миллионы или миллиарды
операций) для обучения миллионам точек данных. JavaScript ни в коем
случае не является быстрым языком и действительно должен иметь
дополнения для подобных вещей,
чтобы ускорить вычисления во время обучения. Взломщик капчи, показанный
выше, занял удивительно небольшое время обучения — 20 минут, но все, что
требуется, — это еще несколько вводов и еще несколько данных, чтобы
увеличить время обучения на несколько часов или даже дней, как вы
увидите в моем примере ниже.
К сожалению, эта библиотека уже заброшена ее автором (к описанию на
Github добавляется «[НЕПОДДЕРЖИВАЕТСЯ]»). Хотя я понимаю, что может
быть трудно удовлетворить требования популярной библиотеки с открытым
исходным кодом, это все еще вызывает разочарование, и мы можем только
надеяться, что кто-то квалифицированный сможет заполнить этот пробел.
Я уверен, что в разработке уже есть хороший форк, но, возможно,
потребуется поискать его.
Пример
Здесь я покажу вам более сложный пример использования Brain. В этом
примере я создал сетевую сеть, которая может распознавать одну
рукописную цифру (0–9). Набор данных, который я использую, — это
популярный набор данных
MNIST , который содержит
более 50 000 образцов рукописных цифр. Этот вид проблемы известен как
оптическое распознавание
символов
(OCR), которое является популярным приложением NN.
Распознавание работает путем получения изображения в оттенках серого
28×28 рукописной цифры и вывода цифры, которую, по мнению сети, она
«видела». Это означает, что у нас будет 784 входа (по одному на каждый
пиксель) со значениями от 0 до 255, и будет 10 выходов (по одному на
каждую цифру). Каждый вывод будет иметь значение 0-1, что по сути
является уровнем уверенности в том, что эта конкретная цифра является
правильным ответом. Тогда наш ответ — это высшая степень достоверности.
К коду:
var brain = require('brain');
var fs = require('fs');
var getMnistData = function(content) {
var lines = content.toString().split('n');
var data = [];
for (var i = 0; i < lines.length; i++) {
var input = lines[i].split(',').map(Number);
var output = Array.apply(null, Array(10)).map(Number.prototype.valueOf, 0);
output[input.shift()] = 1;
data.push({
input: input,
output: output
});
}
return data;
};
fs.readFile(__dirname + '/train.csv', function (err, trainContent) {
if (err) {
console.log('Error:', err);
}
var trainData = getMnistData(trainContent);
console.log('Got ' + trainData.length + ' samples');
var net = new brain.NeuralNetwork({hiddenLayers: [784, 392, 196]});
net.train(trainData, {
errorThresh: 0.025,
log: true,
logPeriod: 1,
learningRate: 0.1
});
});
train.csv — это просто CSV с одним изображением в строке. Первое
значение — это цифра, показанная на изображении, а следующие 784
значения — это данные пикселей.
Количество слоев и узлов, которые я выбрал, было немного произвольным и,
вероятно, излишне большим для этого приложения OCR. Однако, если вы не
можете воспользоваться такими вещами, как softmaxes или пул, возможно,
вам больше повезет, увеличив количество слоев и количество узлов.
Чтобы получить достойные результаты, тренировка заняла больше часа. Хотя
это было ожидаемо, я все же был немного разочарован тем, что пришлось
ждать так долго, чтобы протестировать новую структуру сети или новые
параметры обучения. Такое простое приложение не должно занимать так
много времени, но это цена, которую вы платите за реализацию, полностью
основанную на JavaScript.
Чтобы протестировать сеть, я загрузил другой файл, test.csv , и
использовал его в качестве основы для сравнения сетей. Таким образом, мы
получаем лучшее представление о производительности, поскольку тестируем
входы, на которых сеть еще не обучена.
Вот как я тестировал сеть (я показываю только соответствующие части):
// Require packages...
fs.readFile(__dirname + '/test.csv', function (err, testContent) {
if (err) {
console.log('Error:', err);
}
// Load training data...
// Train network...
// Test it out
var testData = getMnistData(testContent);
var numRight = 0;
console.log('Neural Network tests:');
for (i = 0; i < testData.length; i++) {
var resultArr = net.run(testData[i].input);
var result = resultArr.indexOf(Math.max.apply(Math, resultArr));
var actual = testData[i].output.indexOf(Math.max.apply(Math, testData[i].output));
var str = '(' + i + ') GOT: ' + result + ', ACTUAL: ' + actual;
str += result === actual ? '' : ' -- WRONG!';
numRight += result === actual ? 1 : 0;
console.log(str);
}
console.log('Got', numRight, 'out of 350, or ' + String(100*(numRight/350)) + '%');
});
Заключение
Хотя есть некоторые недостатки, в целом я думаю, что Brain.js может быть
очень полезным и добавить большую ценность приложениям JavaScript /
Node. Его простота использования должна позволить практически любому
начать работу с нейронными сетями.
Если вам нужно что-то более гибкое или вас беспокоит отсутствие
поддержки Brain.js, взгляните на
Synaptic , который позволяет
гораздо больше настраивать вашу сетевую архитектуру. У него не такая
популярность / внимание, как у Brain, но он кажется следующим лучшим
выбором для нейронных сетей в JavaScript.
Какой у вас опыт работы с Brain.js? Вы порекомендуете какие-либо другие
пакеты AI? Дайте нам знать об этом в комментариях!
В этой статье будет показано, как создать и обучить нейронную сеть на JavaScript, используя Synaptic.js. Этот пакет позволяет реализовывать глубокое обучение в Node.js и в браузере. Будет создана простейшая возможная нейронная сеть — та, которой удается выполнить XOR операцию.
Перевод статьи «How to create a Neural Network in JavaScript in only 30 lines of code». Автор — Per Harald Borgen. Ссылка на оригинал — в подвале статьи.
Вы можете видеть созданный мною интерактивный Scrimba туториал:
В Scribma туториале вы можете поиграться с сетью. Но перед тем, как посмотреть на код, давайте вспомним основы нейронных сетей.
Нейроны и синапсы
Самый первый строительный элемент любой нейронной сети — нейрон. Он похож на функцию — берет несколько входных значений и возвращает результат алгебраических действий над ними.
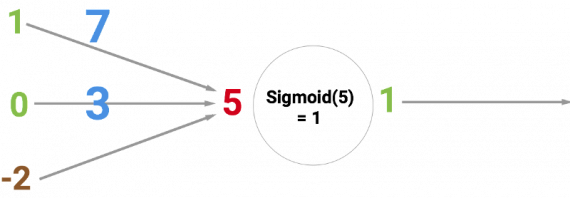
Существует множество типов нейронов. Наша сеть использует нейрон с сигмоидной функцией активации, которая принимает любое число и трансформирует его в значение, лежащее в диапазоне от 0 до 1.
Круг ниже показывает сигмоидный нейрон. На входе — 5, на выходе — 1. Стрелочки называются синапсами, они соединяют нейрон с другими слоями в нейросети.
Почему красное число это 5? Это сумма из трех синапсов, которые соединены с нейроном. Это показано тремя стрелочками слева от нейрона. Поясню сказанное.
Слева можно видеть два плюс одно значения. Зеленые числа — значения 1 и 0. Параметр сдвига -2 — коричневое число. Сначала входные числа умножаются на соответствующие им веса 7 и 3 соответственно. Значения весов представляют синие числа.
Наконец мы добавляем параметр сдвига и получаем итоговой результат 5 — красное число. Это и есть вход для нашего искусственного нейрона.
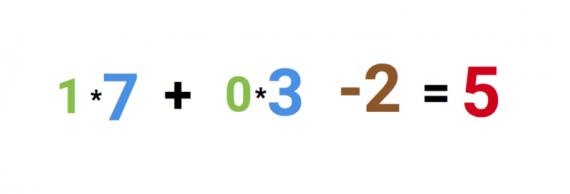
Такак мы работаем с сигмоидным нейроном, который переводит любое входное значение на отрезок от 0 до 1, выход преобразуется в 1.
Если соединить нейроны друг с другом, получится нейронная сеть. Прямое прохождение от входа к выходу осуществляется при помощи соединенных друг с другом через синапсы нейронов. Это выглядит следующим образом.
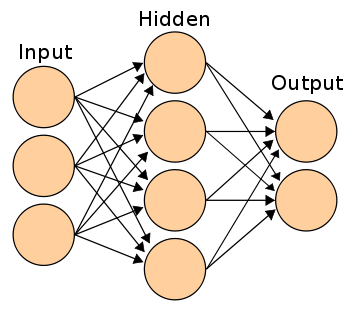
Задача нейронной сети — обучаться находить общие признаки в данных, например, распознавать рукописные символы или спам на электронной почте. Чтобы осуществить эту задачу, требуется точная настройка весов и параметров сдвига во всей сети. Это синие и коричневые числа в примере сверху.
Во время тренировки мы просто показываем сети большое количество примеров — рукописных символов или просто картинок. На основе этого сеть предсказывает ответ.
После каждого предсказания высчитываем, насколько правильным оно оказалось. В соответствии с этим корректируем значения весов и параметров сдвига так, чтобы в следующий раз сеть была более точна. Такая схема называется обратным распространением. Если сделать это тысячи раз, ваша сеть будет обобщать хорошо.
Подробное техническое рассмотрение обратного распространения ошибки.
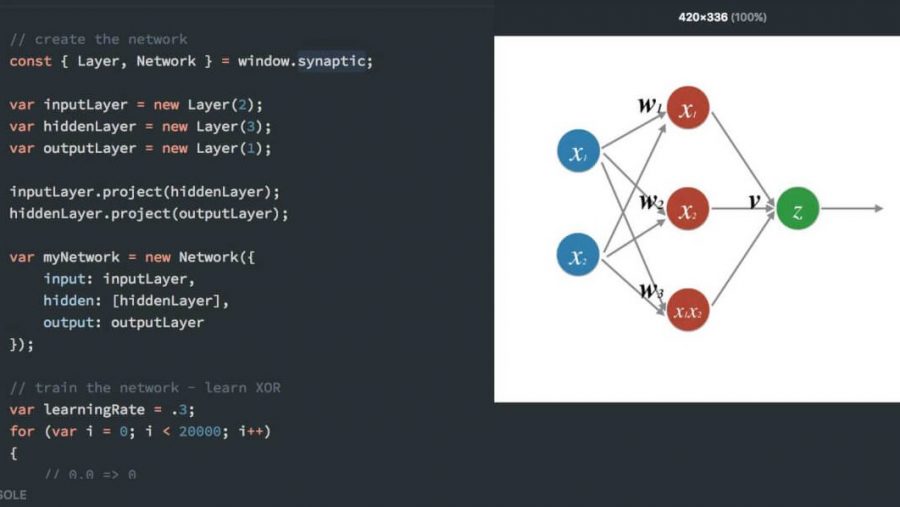
Вы получили базовое представление о нейронных сетях, теперь самое время посмотреть на реализацию. Первое, что необходимо сделать, это создать слои. Это делается при помощи функции new Layer в synaptic. Число в скобках определяет, сколько каждый слой должен содержать нейронов.
Если вам трудно представить, что такое слой, посмотрите еще на скринкаст.
const { Layer, Network } = window.synaptic;
var inputLayer = new Layer(2); var hiddenLayer = new Layer(3); var outputLayer = new Layer(1);
Далее соединяем эти слои вместе и создаем инстанс новой сети, как показано ниже:
inputLayer.project(hiddenLayer); hiddenLayer.project(outputLayer);
var myNetwork = new Network({
input: inputLayer,
hidden: [hiddenLayer],
output: outputLayer
});
У нас получилась сеть с 2-3-1 нейронами в входном, скрытом и выходном слое, соответственно. Архитектура этой сети показана ниже:
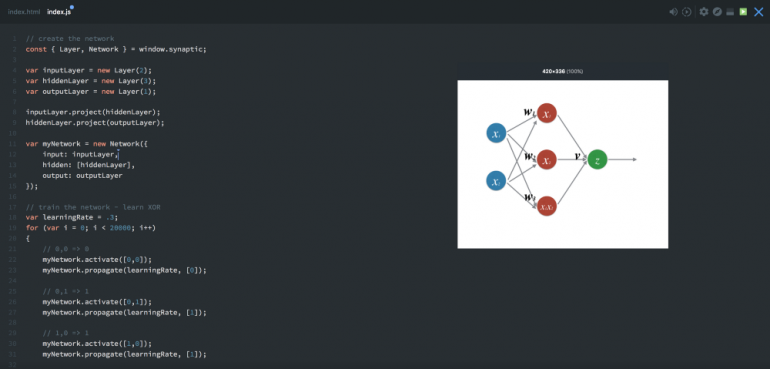
Теперь давайте обучим нашу сеть:
// train the network - learn XOR
var learningRate = .3;
for (var i = 0; i < 20000; i++) {
// 0,0 => 0
myNetwork.activate([0,0]);
myNetwork.propagate(learningRate, [0]);
// 0,1 => 1 myNetwork.activate([0,1]); myNetwork.propagate(learningRate, [1]);
// 1,0 => 1 myNetwork.activate([1,0]); myNetwork.propagate(learningRate, [1]);
// 1,1 => 0 myNetwork.activate([1,1]); myNetwork.propagate(learningRate, [0]); }
Запускаем сеть 20 000 раз. Каждый раз распространяемся в прямом и обратном направлении четыре раза, проходя через четыре возможных входа для этой сети: [0,0], [0,1], [1,0], [1,1].
Начинаем с команды myNetwork.activate([0,0]), где [0,0] — данные, которые посылаются в сеть. Это прямое распространение, которое также называется активизацией сети. После каждого прямого распространения требуется сделать и обратное, тогда сеть обновит свои веса и свдиг.
Обратное распротстранение осуществляется командой myNetwork.propagate(learningRate, [0]). Параметр learningRate — константа, которая говорит сети, насколько каждый раз нужно изменять веса. Второй параметр — 0 представляет корректный ответ для заданного входа [0,0].
Далее сеть сравнивает свое предсказание с правильной меткой. На этом шаге определяется, было ли предсказание сделано правильно.
Сеть использует сравнение в качестве базиса для корректировки значений весов и сдвига. Поэтому в следующий раз предсказание будет немного точнее.
После выполнения 20 000 итераций в цикле for мы можем посмотреть, насколько хорошо обучилась сеть, при помощи активизации сети со всеми четырьмя возможными входами:
console.log(myNetwork.activate([0,0])); -> [0.015020775950893527]
console.log(myNetwork.activate([0,1])); ->[0.9815816381088985]
console.log(myNetwork.activate([1,0])); -> [0.9871822457132193]
console.log(myNetwork.activate([1,1])); -> [0.012950087641929467]
Если округлить эти значения до ближайшего целого числа, получим корректные ответы для XOR операций!
Как-то так. Хотя мы только немного коснулись нейронных сетей, этой статьи должно быть достаточно, чтобы поиграться с Synaptic и начать изучение области самостоятельно. Этот репозиторий содержит много хороших туториалов.
Наконец, когда выучите что-нибудь новое, обязательно поделитесь звоими знаниями с помощью скринкаста Scrimba и написания статьи!
Когда речь идет о задачах, отличных от обработки больших массивов информации, человеческий мозг обладает большим преимуществом по сравнению с компьютером. Человек может распознавать лица, даже если в помещении будет много посторонних объектов и плохое освещение. Мы легко понимаем незнакомцев, даже когда находимся в шумном помещении. Но, несмотря на годы исследований, компьютеры все еще далеки от выполнения подобных задач на высоком уровне.
Искусственные нейронные сети применяются в различных областях науки, начиная с систем распознавания речи и заканчивая системами распознавания вторичной структуры белка, классификации различных видов рака и генной инженерии.
Сегодня нейронные сети популярны как никогда. Свои решения в этой области представляют такие компании, как Google, Microsoft и многие другие. Но существуют и библиотеки с открытым кодом, написанные энтузиастами на самых разных языках. Сегодня tproger расскажет вам об одной из них — это библиотека brain, написанная на JavaScript.
Использование
Самый простой пример применения — обучение на функции XOR:
var net = new brain.NeuralNetwork();
net.train([{input: [0, 0], output: [0]},
{input: [0, 1], output: [1]},
{input: [1, 0], output: [1]},
{input: [1, 1], output: [0]}]);
var output = net.run([1, 0]); // [0.987]А еще есть очень классная визуализация того, как нейронная сеть обучается XOR, OR и другим логическим функциям.
Чтобы установить библиотеку, можно использовать, например, npm:
npm install brain
Можно также скачать последнюю версию brain.js. Тренировать сеть можно даже оффлайн, а затем уже натренированную загрузить на сайт.
Чтобы начать обучать сеть, нужно использовать функцию train(), в которую передаются данные для обучения в виде массива. Сеть будет обучаться всеми данными сразу в одном вызове train(). Чем больше моделей обучения — тем дольше сеть будет обучаться, но и справляться со своей задачей она после этого будет лучше.
Каждая модель для обучения должна иметь параметры input и output, каждый из которых составляет массив или хэш чисел от 0 до 1. Например, для демо с распознаванием контрастности цветов это выглядело так:
var net = new brain.NeuralNetwork();
net.train([{input: { r: 0.03, g: 0.7, b: 0.5 }, output: { black: 1 }},
{input: { r: 0.16, g: 0.09, b: 0.2 }, output: { white: 1 }},
{input: { r: 0.5, g: 0.5, b: 1.0 }, output: { white: 1 }}]);
var output = net.run({ r: 1, g: 0.4, b: 0 }); // { white: 0.99, black: 0.002 }Функция train() умеет принимать в качестве второго аргумента массив нескольких параметров:
net.train(data, {
errorThresh: 0.005, // порог ошибок, которого нужно достичь
iterations: 20000, // максимальное число итераций обучения
log: true, // нужен ли периодический console.log()
logPeriod: 10, // число итераций между логированиями
learningRate: 0.3 // степень обучения
})Обучаться сеть будет до тех пор, пока не будет достигнут заданный порог ошибок (по умолчанию задается 0.005) или не будет совершено заданное число итераций (20000).
По умолчанию вы никак не можете определить, как много времени осталось до конца обучения, но зато можно поставить на true параметр log, чтобы отслеживать ход обучения. Если передать в качестве этого параметра функцию, то она будет вызываться каждый раз через каждое заданное число итераций.
learningRate — параметр, определяющий, как быстро натренируется нейронная сеть. Задается он числом от 0 до 1. Чем меньше параметр, тем дольше сеть будет обучаться. С увеличением числа скорость будет расти, но вместе с этим растет вероятность более плохого качества обучения. По умолчанию это число составляет 0.3.
Результатом обучения будет массив output с информацией о том, как прошло обучение.
{
error: 0.0039139985510105032, // ошибки
iterations: 406 // число итераций
}Если обучение закончилось ошибкой, то параметр error будет близок к порогу ошибки. Причиной этому может стать излишняя «зашумленность» данных, недостаток нейронов или недостаточное число итераций. Если даже после 20000 итераций ошибка составила около 0.4, это может означать, что сеть плохо воспринимает предоставляемые вами данные.
Обученную сеть можно хранить в формате JSON:
var json = net.toJSON();
net.fromJSON(json);Также можно данных сохранить в функцию:
var run = net.toFunction();
var output = run({ r: 1, g: 0.4, b: 0 });
console.log(run.toString()); // это нужно скопировать и вставить в нужное место. Подключать brain.js не требуетсяNeuralNetwork() принимает ассоциативный массив параметров:
var net = new brain.NeuralNetwork({
hiddenLayers: [4],
learningRate: 0.6 // общая степень обученности, полезна при обучении в несколько потоков
});Первый параметр — общее количество скрытых слоев и размер каждого слоя. Например, если нужно два скрытых слоя — один с 3 нодами и второй с 4, то параметр будет таким:
hiddenLayers: [3, 4]
По умолчанию brain использует один слой, пропорциональный размеру входного массива.
Кстати, сеть может использовать WriteStream. Ее можно тренировать, используя pipe(), чтобы отправлять данные в сеть.
Чтобы тренировать сеть в потоке, сначала нужно поток создать вызовом метода net.createTrainStream(), принимающего следующие параметры:
floodCallback()— функция, которая будет вызываться на каждой итерации обучения;doneTrainingCallback(info)— функция, которая выполнится после завершения обучения. Параметр info будет содержать ассоциативный массив информации о том, как прошло обучение:
{
error: 0.0039139985510105032, // ошибки
iterations: 406 // число итераций
}Также можно использовать Transform, чтобы привести данные к корректному формату или чтобы на лету нормализовывать данные.
Источник: GitHub
Build Machine Learning models (especially Deep Neural Networks) that you can easily integrate with existing or new web apps. Think of your ReactJs, Vue, or Angular app enhanced with the power of Machine Learning models.
A hands-on approach to understanding the basics of Machine Learning, build models and deploy real-world solutions using TensorFlow.js with JavaScript. Run your models in the browser or on the server with Node.js.
Solve real-world problems and learn about Computer Vision, Natural Language Processing, Deep Reinforcement Learning by building and training Deep Neural Networks in JavaScript.
A blend of theory, simple explanations, examples, and complete source code serve as a thorough introduction to the beginner, while the experienced professional will enjoy the practical solutions to common problems.

Hacker’s Guide to Neural Networks in JavaScript by Venelin Valkov
English | PDF | 2020 | 163 Pages | ISBN ASIN : B07YLNV2ND | 4.14 MB
Build Machine Learning models (especially Deep Neural Networks) that you can easily integrate with existing or new web apps. Think of your ReactJs, Vue, or Angular app enhanced with the power of Machine Learning models.
A hands-on approach to understanding the basics of Machine Learning, build models and deploy real-world solutions using TensorFlow.js with JavaScript. Run your models in the browser or on the server with Node.js.
Solve real-world problems and learn about Computer Vision, Natural Language Processing, Deep Reinforcement Learning by building and training Deep Neural Networks in JavaScript.
A blend of theory, simple explanations, examples, and complete source code serve as a thorough introduction to the beginner, while the experienced professional will enjoy the practical solutions to common problems.
i will be very grateful when you support me and buy Or Renew Your Premium from my Blog links
i appreciate your support Too much as it will help me to post more and more
Without You And Your Support We Can’t Continue
Thanks For Buying Premium From My Links For Support
Содержание
Часть 1:
Введение
Глава 1: Схемы реальных значений
Базовый сценарий: Простой логический элемент в схеме
Цель
Стратегия №1: Произвольный локальный поиск
Часть 2:
Стратегия №2: Числовой градиент
Часть 3:
Стратегия №3: Аналитический градиент
Часть 4:
Схемы с несколькими логическими элементами
Обратное распространение ошибки
Часть 5:
Шаблоны в «обратном» потоке
Пример "Один нейрон"
Давайте снова посмотрим на наш пример схемы с введенными числами. Первая схема показывает нам «сырые» значения, а вторая – градиенты, которые возвращаются к исходным значениям, как обсуждалось ранее. Обратите внимание, что градиент всегда сводится к +1. Это стандартный толчок для схемы, в которой должно увеличиться значение.

Через какое-то время вы начнете замечать шаблоны в том, как градиенты возвращаются по схеме. Например, логический элемент + всегда поднимает градиент и просто передает его на все исходные значения (обратите внимание, в примере с -4 он был просто передан на оба исходных значения логического элемента +). Это потому, что его собственная производная для исходных значений равна +1, вне зависимости от того, чему равны фактические значения исходных данных, поэтому в цепном правиле градиент сверху просто умножается на 1 и остается таким же.
Тоже самое происходит, например, с логическим элементом max(x,y). Так как градиент элемента max(x,y) по отношению к своим исходным значениям равен +1 для того значения x или y, которое больше, и 0 для второго, этот логический элемент в процессе обратного распределения ошибки эффективно используется только в качестве «переключателя» градиента: он берет градиент сверху и «направляет» его к исходному значению, которое оказывается выше при обратном проходе.
Проверка числового градиента
Прежде чем мы закончим с этим разделом, давайте просто убедимся, что аналитический градиент, который мы вычислили для обратного распространения ошибки, правильный. Давайте вспомним, что мы можем сделать это, просто рассчитав числовой градиент, и убедившись, что получим [-4, -4, 3] для x,y,z. Вот код:
// стартовые условия
var x = -2, y = 5, z = -4;
// проверка числового градиента
var h = 0.0001;
var x_derivative = (forwardCircuit(x+h,y,z) - forwardCircuit(x,y,z)) / h; // -4
var y_derivative = (forwardCircuit(x,y+h,z) - forwardCircuit(x,y,z)) / h; // -4
var z_derivative = (forwardCircuit(x,y,z+h) - forwardCircuit(x,y,z)) / h; // 3
Пример: Один нейрон
В предыдущем разделе вы, наконец, разобрались с понятием обратного распространения ошибки. Давайте теперь рассмотрим более сложный и практический пример. Мы рассмотрим двухмерный нейрон, который вычисляет следующую функцию:

В этом выражении σ представляет собой сигмоидную функцию. Ее можно описать как «сжимающую функцию», так как она берет исходное значение и сжимает его, чтобы оно оказалось между нулем и единицей: Крайне отрицательные значения сжимаются в сторону нуля, а положительные значения сжимаются в сторону единицы. Например, у нас есть выражение sig(-5) = 0.006, sig(0) = 0.5, sig(5) = 0.993. Сигмоидная функция определяется следующим образом:

Градиент по отношению к его единственному исходному значению, как указано в Википедии (или, если вы разбираетесь в методах расчета, можете вычислить его самостоятельно), имеет вид следующего выражения:

Например, если исходным значением сигмоидного логического элемента является x = 3, логический элемент будет вычислять результат уравнения f = 1.0 / (1.0 + Math.exp(-x)) = 0.95, после чего (локальный) градиент по его исходному значению будет иметь следующий вид: dx = (0.95) * (1 — 0.95) = 0.0475.
Это все, что нам нужно, чтобы использовать этот логический элемент: мы знаем, как взять исходное значение и продвинуть его через сигмоидный логический элемент, а также у нас есть выражение для градиента по отношению к его исходному значению, поэтому мы можем также выполнить обратное распределение ошибки с его помощью. Еще один момент, на который стоит обратить внимание – технически сигмоидная функция состоит из целого набора логических элементов, расположенных в ряд, которые вычисляют дополнительные атомические функции: логический элемент возведения в степень, прибавления и деления. Такое отношение работает отлично, но для этого примера я решил сжать все эти логические элементы до одного, который вычисляет сигмоиду за один раз, так как выражение градиента оказалось довольно простым.
Давайте воспользуемся этой возможностью тщательно структурировать связанный код удобным модульным способом. Для начала я бы хотел обратить ваше внимание, что каждая линия в наших графиках имеет две связанные с ней цифры:
1. Значение, которое она имеет при прямом проходе
2. Градиент (т.е. толчок), который проходит обратно по ней при обратном проходе
Давайте создадим простую структуру сегмента (Unit), которая будет сохранять эти два значения по каждой линии. Наши логические элементы не будут работать поверх сегментов: они будут принимать их в качестве исходных значений и создавать их в виде выходных значений.
// каждый сегмент отвечает линии на графиках
var Unit = function(value, grad) {
// значение, рассчитанное при переднем проходе
this.value = value;
// производная результата схемы по отношению к этому сегменту, рассчитанная при обратном проходе
this.grad = grad;
}
Кроме сегментов, нам также нужны три логических элемента: +, * и sig (сигмоида). Давайте начнем с применения логического элемента умножения. Здесь я использую Javascript, который интересно симулирует классы с помощью функций. Если вы не знакомы с Javascript, то, что здесь происходит – это определение класса, у которого есть определенные свойства (доступ к которым получается с помощью ключевого слова this), и некоторые методы (которые в Javascript помещены в прототип функции). Просто запомните их как классовые методы. Также не забывайте, что способ, с помощью которого мы будем их использовать, заключается в том, что мы сначала передадим (forward) все логические элементы по одному, а потом вернем их обратно (backward) в обратном порядке. Вот реализация этого:
var multiplyGate = function(){ };
multiplyGate.prototype = {
forward: function(u0, u1) {
// сохраняем указатели для ввода сегментов u0 и u1 и выходного сегмента utop
this.u0 = u0;
this.u1 = u1;
this.utop = new Unit(u0.value * u1.value, 0.0);
return this.utop;
},
backward: function() {
// берем градиент в выходном сегменте и связываем его с
// локальными градиентами, которые мы дифференцировали для логического элемента умножения заранее
// после этого прописываем эти градиенты в этих сегментах.
this.u0.grad += this.u1.value * this.utop.grad;
this.u1.grad += this.u0.value * this.utop.grad;
}
}
Логический элемент умножения берет два сегмента, каждый из которых содержит значение, и создает сегмент, который сохраняет его результат. Градиенту присваивается в качестве начального значения ноль. Потом, обратите внимание, что при вызове функции backward мы получаем градиент из результата сегмента, который мы создали в процессе переднего прохода (который теперь, надеюсь, будет иметь свой заполненный градиент) и умножаем его на локальный градиент для этого логического элемента (цепное правило!). Этот логический элемент выполняет умножение (u0.value * u1.value) при переднем проходе, поэтому вспоминаем, что градиент по отношению к u0 равен u1.value и по отношению к u1 равен u0.value. Также обратите внимание, что мы используем += для прибавления к градиенту при функции backward. Это, возможно, позволит нам использовать результат одного логического элемента несколько раз (представьте себе это как разветвлении линии), так как оказывается, что градиенты по этим ветвям просто суммируются при расчете окончательного градиента по отношению к результату схемы. Остальные два логических элемента определяются аналогичным образом:
var addGate = function(){ };
addGate.prototype = {
forward: function(u0, u1) {
this.u0 = u0;
this.u1 = u1; // сохраняем указатели для ввода сегментов
this.utop = new Unit(u0.value + u1.value, 0.0);
return this.utop;
},
backward: function() {
// логический элемент сложения. Производная по отношению к обоим результатам равна 1
this.u0.grad += 1 * this.utop.grad;
this.u1.grad += 1 * this.utop.grad;
}
}
var sigmoidGate = function() {
// вспомогательная функция
this.sig = function(x) { return 1 / (1 + Math.exp(-x)); };
};
sigmoidGate.prototype = {
forward: function(u0) {
this.u0 = u0;
this.utop = new Unit(this.sig(this.u0.value), 0.0);
return this.utop;
},
backward: function() {
var s = this.sig(this.u0.value);
this.u0.grad += (s * (1 - s)) * this.utop.grad;
}
}
А теперь давайте рассчитаем градиент: просто повторим все в обратном порядке и вызовем функцию backward! Вспоминаем, что мы сохранили указатели в сегменты, когда выполняли проход вперед, поэтому у логического элемента есть доступ к его исходным значениям, а также к выходному сегменту, который он ранее создал.
s.grad = 1.0;
sg0.backward(); // записывает градиент в axpbypc
addg1.backward(); // записывает градиент в axpby и c
addg0.backward(); // записывает градиент в ax и by
mulg1.backward(); // записывает градиент в b и y
mulg0.backward(); // записывает градиент в a и x
Обратите внимание, что первая строка устанавливает градиент на выходе (самый последний сегмент) в значение 1.0 для запуска цепи градиента. Это можно интерпретировать, как толчок на последний логический элемент с силой равной +1. Другими словами, мы тянет всю схему, заставляя ее прикладывать силы, которые увеличат выходное значение. Если бы мы не задали ему значение 1, все градиенты рассчитывались бы как нулевые ввиду умножения согласно цепному правилу. В конечном итоге, давайте заставим исходные значения реагировать на рассчитанные градиенты и проверим, что функция увеличилась:
var step_size = 0.01;
a.value += step_size * a.grad; // a.grad равно -0.105
b.value += step_size * b.grad; // b.grad равно 0.315
c.value += step_size * c.grad; // c.grad равно 0.105
x.value += step_size * x.grad; // x.grad равно 0.105
y.value += step_size * y.grad; // y.grad равно 0.210
forwardNeuron();
console.log('circuit output after one backprop: ' + s.value); // выводится результат 0.8825
Успех! 0.8825 выше, чем предыдущее значение, 0.8808. Наконец, давайте проверим, что мы правильно выполнили обратное распространение ошибки, проверив числовой градиент:
var forwardCircuitFast = function(a,b,c,x,y) {
return 1/(1 + Math.exp( - (a*x + b*y + c)));
};
var a = 1, b = 2, c = -3, x = -1, y = 3;
var h = 0.0001;
var a_grad = (forwardCircuitFast(a+h,b,c,x,y) - forwardCircuitFast(a,b,c,x,y))/h;
var b_grad = (forwardCircuitFast(a,b+h,c,x,y) - forwardCircuitFast(a,b,c,x,y))/h;
var c_grad = (forwardCircuitFast(a,b,c+h,x,y) - forwardCircuitFast(a,b,c,x,y))/h;
var x_grad = (forwardCircuitFast(a,b,c,x+h,y) - forwardCircuitFast(a,b,c,x,y))/h;
var y_grad = (forwardCircuitFast(a,b,c,x,y+h) - forwardCircuitFast(a,b,c,x,y))/h;
Таким образом, все это дает те же значения, что и градиенты обратного распространения ошибки [-0.105, 0.315, 0.105, 0.105, 0.210]. Отлично!
Я надеюсь, вам понятно, что даже несмотря на то, что мы рассмотрели только пример с одним нейроном, код, который я привел выше, представляет собой довольно простой способ вычисления градиентов произвольных выражений (включая очень глубокие выражения). Все, что вам нужно сделать – это написать небольшие логические элементы, которые будут вычислять локальные простые производные по отношению к их исходным значениям, связать их в график, выполнить проход вперед для вычисления выходного значения, после чего выполнить обратный проход, который свяжет градиент по всему пути к исходному значению.
Автор: Irina_Ua
Источник

Название: Hacker’s Guide to Neural Networks in jаvascript
Автор: Venelin Valkov
Издательство: Amazon
Год: 2020
Формат: PDF
Страниц: 163
Размер: 10 Mb
Язык: English
Build Machine Learning models (especially Deep Neural Networks) that you can easily integrate with existing or new web apps. Think of your ReactJs, Vue, or Angular app enhanced with the power of Machine Learning models. A hands-on approach to understanding the basics of Machine Learning, build models and deploy real-world solutions using TensorFlow.js with jаvascript. Run your models in the browser or on the server with Node.js.
Solve real-world problems and learn about Computer Vision, Natural Language Processing, Deep Reinforcement Learning by building and training Deep Neural Networks in jаvascript.
A blend of theory, simple explanations, examples, and complete source code serve as a thorough introduction to the beginner, while the experienced professional will enjoy the practical solutions to common problems.
