Приветствую! Если вы ищете информацию о SSE2, значит наверняка столкнулись с тем, что на вашем ПК не хочет запускаться какая-нибудь важная программа или игра. И это неудивительно, потому что мало кто задумывается об инструкциях CPU, пока не сталкивается с их недостатком. А далее я расскажу, что это такое и как узнать поддерживает ли процессор SSE2.
Что такое SSE2
В материале об архитектурах ЦП я уже упоминал об этой технологии. Ведь она стала одной из главных инструкций, которую выполняют все современные CPU. Она относится к числу базовых, то есть тех, что заставляют CPU решать основные задачи — вычисления, перенос данных и многое другое.
Есть ещё дополнительные, которые расширяют возможности устройства для решения конкретных задач, например, связанные с обработкой аудио, видео или изображений.
Напомню основное. Инструкции необходимы процессору для работы с программами. Ведь вне зависимости от сложности, каждая программа, даже операционная система, представляет собой набор команд. Если ЦП знает такие же инструкции, какие содержит программа, которую вы пытаетесь запустить, вы сможете рассчитывать на результат. Если же подходящих наборов команд у CPU не найдётся, при запуске ПО вы получите ошибку.
SSE2 расширяет возможности предшественницы, SSE, добавляя к имеющимся 70 командам ещё 144 новых. Так она оптимизирует основные возможности SSE и добавляет новые от устаревшей MMX.
Какие процессоры поддерживают технологию SSE
SSE поддерживают многие процессоры, так как долгое время она была ключевой и на неё опирались производители всей электроники. Поэтому под неё выпущено много всего из того, что ещё отлично работает, а потом пользователи не торопятся «обновляться». Но улучшенная технология встречается всё чаще, уже создав заметный перевес в свою сторону, и только усиливая его с годами.
Поэтому вы можете найти её на всех ЦП, поддерживающих х86-64 и не поддерживающих IA-32. Среди них:
- Все Intel, выпущенные после Pentium 4. То есть, все Intel Core, Xeon, Celeron и другие, вплоть до Intel Atom, в том числе и с разрядностью 32 бита.
- Все AMD начиная с Athlon 64. Например, AMD Sempron 64, Turion 64 и другие, а также линейки AMD FX, Phenom, и, конечно, Ryzen.
Если интересны не только широко распространённые модели, то VIA начиная с C3, а также Transmeta свежее Crusoe, тоже сделаны с поддержкой этой инструкции. И это далеко не весь список, который только увеличивается.
Важна ли поддержка SSE2 процессором
Так как SSE2 — базовая инструкция, без неё центральному процессору будет сложно выполнять все задачи, которые вы перед ним поставите. Всё современное ПО, в том числе и операционные системы, делаются с расчётом на то, что у CPU будет поддержка технологии SSE2. Ведь только так он сможет обработать нужный объём данных и сделать это настолько быстро, насколько нужно пользователю.
Если поддержки этой технологии не будет, вы не сможете установить Windows лучше Windows 8, вам будут не доступны новые версии профессиональных программ, большинство новых игр. Даже браузеры не запустятся, так как эту инструкцию требуют те же Google Chrome, Yandex Browser и другие.
Кстати, многие сталкиваются с ошибками насчёт недостатка каких-то наборов команд именно когда устанавливают современные браузеры, потому что под хорошие игры или профессиональный софт нередко сначала обновляется железо, и все эти проблемы исчезают сами собой.
Как узнать поддерживает ли центральный процессор SSE2
К счастью, узнать, поддерживает ли ваш процессор инструкцию SSE2, очень легко. Вы можете сделать это как с помощью софта, так и просто вручную. Если вам больше нравится искать информацию самостоятельно, отправляйтесь на официальный сайт производителя ЦП. Там должны быть данные обо всех выпущенных моделях, и зная название своей, вы без труда найдёте нужный раздел с характеристиками. Иногда там расписывают все наборы команд.
Если на официальном сайте ничего не найдётся, установите простую утилиту CPU-Z. На её скачивание и установку вы потратите не более 5 минут, а прямо на первой странице будет строчка «Instructions». Там будут написаны все инструкции, так что вы сразу поймёте, каких не хватает, чтобы запустить желаемый софт или игру.
Показать эту информацию могут и другие программы с похожими функциями, просто CPU-Z пользоваться проще всего.
Что делать, если SSE2 не поддерживается
Случается, что у ЦП нет поддержки нужной технологии, а вам очень нужно, чтобы она была. И здесь я могу посоветовать лишь один путь — купить новый процессор. Рад бы предложить более простой и дешёвый метод, но его нет, так как наборы команд для CPU задаются на стадии производства. И их нельзя просто отключать, добавлять и обновлять.
Иногда рекомендуют просто не пользоваться теми программами и играми, что требуют улучшенных технологий, и искать версии, подходящие под возможности вашего ЦП. Но долго с таким подходом не продержишься, всё равно проблема вернётся, так как софт оказывается всё требовательнее. Хотя, если у вас возникли трудности только с браузером, можно действительно попробовать установить что-то попроще, но для этого сначала придётся поискать подходящую версию.
Вы можете подробнее узнать о характеристиках SSE2 и других наборах команд отдельно, ведь тема пусть и непростая, но очень интересная. Я лишь слегка коснулся её в материале об инструкциях процессоров, но вы можете использовать его как отправную точку. И это далеко не всё, о чём я уже рассказывал насчёт CPU. Так что вы можете посмотреть как уже выпущенные статьи, так и подписаться на мои соцсети, чтобы не упустить ничего нового. Увидимся!
С уважением, автор блога Андрей Андреев.
From Wikipedia, the free encyclopedia
In computing, Streaming SIMD Extensions (SSE) is a single instruction, multiple data (SIMD) instruction set extension to the x86 architecture, designed by Intel and introduced in 1999 in their Pentium III series of central processing units (CPUs) shortly after the appearance of Advanced Micro Devices (AMD’s) 3DNow!. SSE contains 70 new instructions (65 unique mnemonics[1] using 70 encodings), most of which work on single precision floating-point data. SIMD instructions can greatly increase performance when exactly the same operations are to be performed on multiple data objects. Typical applications are digital signal processing and graphics processing.
Intel’s first IA-32 SIMD effort was the MMX instruction set. MMX had two main problems: it re-used existing x87 floating-point registers making the CPUs unable to work on both floating-point and SIMD data at the same time, and it only worked on integers. SSE floating-point instructions operate on a new independent register set, the XMM registers, and adds a few integer instructions that work on MMX registers.
SSE was subsequently expanded by Intel to SSE2, SSE3, SSSE3 and SSE4. Because it supports floating-point math, it had wider applications than MMX and became more popular. The addition of integer support in SSE2 made MMX largely redundant, though further performance increases can be attained in some situations[when?] by using MMX in parallel with SSE operations.
SSE was originally called Katmai New Instructions (KNI), Katmai being the code name for the first Pentium III core revision. During the Katmai project Intel sought to distinguish it from their earlier product line, particularly their flagship Pentium II. It was later renamed Internet Streaming SIMD Extensions (ISSE[2]), then SSE. AMD eventually added support for SSE instructions, starting with its Athlon XP and Duron (Morgan core) processors.
Registers[edit]
SSE originally added eight new 128-bit registers known as XMM0 through XMM7. The AMD64 extensions from AMD (originally called x86-64) added a further eight registers XMM8 through XMM15, and this extension is duplicated in the Intel 64 architecture. There is also a new 32-bit control/status register, MXCSR. The registers XMM8 through XMM15 are accessible only in 64-bit operating mode.

SSE used only a single data type for XMM registers:
- four 32-bit single-precision floating-point numbers
SSE2 would later expand the usage of the XMM registers to include:
- two 64-bit double-precision floating-point numbers or
- two 64-bit integers or
- four 32-bit integers or
- eight 16-bit short integers or
- sixteen 8-bit bytes or characters.
Because these 128-bit registers are additional machine states that the operating system must preserve across task switches, they are disabled by default until the operating system explicitly enables them. This means that the OS must know how to use the FXSAVE and FXRSTOR instructions, which is the extended pair of instructions that can save all x86 and SSE register states at once. This support was quickly added to all major IA-32 operating systems.
The first CPU to support SSE, the Pentium III, shared execution resources between SSE and the floating-point unit (FPU).[2] While a compiled application can interleave FPU and SSE instructions side-by-side, the Pentium III will not issue an FPU and an SSE instruction in the same clock cycle. This limitation reduces the effectiveness of pipelining, but the separate XMM registers do allow SIMD and scalar floating-point operations to be mixed without the performance hit from explicit MMX/floating-point mode switching.
SSE instructions[edit]
SSE introduced both scalar and packed floating-point instructions.
Floating-point instructions[edit]
- Memory-to-register/register-to-memory/register-to-register data movement
- Scalar –
MOVSS - Packed –
MOVAPS, MOVUPS, MOVLPS, MOVHPS, MOVLHPS, MOVHLPS, MOVMSKPS
- Scalar –
- Arithmetic
- Scalar –
ADDSS, SUBSS, MULSS, DIVSS, RCPSS, SQRTSS, MAXSS, MINSS, RSQRTSS - Packed –
ADDPS, SUBPS, MULPS, DIVPS, RCPPS, SQRTPS, MAXPS, MINPS, RSQRTPS
- Scalar –
- Compare
- Scalar –
CMPSS, COMISS, UCOMISS - Packed –
CMPPS
- Scalar –
- Data shuffle and unpacking
- Packed –
SHUFPS, UNPCKHPS, UNPCKLPS
- Packed –
- Data-type conversion
- Scalar –
CVTSI2SS, CVTSS2SI, CVTTSS2SI - Packed –
CVTPI2PS, CVTPS2PI, CVTTPS2PI
- Scalar –
- Bitwise logical operations
- Packed –
ANDPS, ORPS, XORPS, ANDNPS
- Packed –
Integer instructions[edit]
- Arithmetic
PMULHUW, PSADBW, PAVGB, PAVGW, PMAXUB, PMINUB, PMAXSW, PMINSW
- Data movement
PEXTRW, PINSRW
- Other
PMOVMSKB, PSHUFW
Other instructions[edit]
MXCSRmanagementLDMXCSR, STMXCSR
- Cache and Memory management
MOVNTQ, MOVNTPS, MASKMOVQ, PREFETCH0, PREFETCH1, PREFETCH2, PREFETCHNTA, SFENCE
Example[edit]
The following simple example demonstrates the advantage of using SSE. Consider an operation like vector addition, which is used very often in computer graphics applications. To add two single precision, four-component vectors together using x86 requires four floating-point addition instructions.
vec_res.x = v1.x + v2.x; vec_res.y = v1.y + v2.y; vec_res.z = v1.z + v2.z; vec_res.w = v1.w + v2.w;
This corresponds to four x86 FADD instructions in the object code. On the other hand, as the following pseudo-code shows, a single 128-bit ‘packed-add’ instruction can replace the four scalar addition instructions.
movaps xmm0, [v1] ;xmm0 = v1.w | v1.z | v1.y | v1.x addps xmm0, [v2] ;xmm0 = v1.w+v2.w | v1.z+v2.z | v1.y+v2.y | v1.x+v2.x movaps [vec_res], xmm0 ;xmm0
Later versions[edit]
- SSE2, Willamette New Instructions (WNI), introduced with the Pentium 4, is a major enhancement to SSE. SSE2 adds two major features: double-precision (64-bit) floating-point for all SSE operations, and MMX integer operations on 128-bit XMM registers. In the original SSE instruction set, conversion to and from integers placed the integer data in the 64-bit MMX registers. SSE2 enables the programmer to perform SIMD math on any data type (from 8-bit integer to 64-bit float) entirely with the XMM vector-register file, without the need to use the legacy MMX or FPU registers. It offers an orthogonal set of instructions for dealing with common data types.
- SSE3, also called Prescott New Instructions (PNI), is an incremental upgrade to SSE2, adding a handful of DSP-oriented mathematics instructions and some process (thread) management instructions. It also allowed addition or multiplication of two numbers that are stored in the same register, which wasn’t possible in SSE2 and earlier. This capability, known as horizontal in Intel terminology, was the major addition to the SSE3 instruction set. AMD’s 3DNow! extension could do the latter too.
- SSSE3, Merom New Instructions (MNI), is an upgrade to SSE3, adding 16 new instructions which include permuting the bytes in a word, multiplying 16-bit fixed-point numbers with correct rounding, and within-word accumulate instructions. SSSE3 is often mistaken for SSE4 as this term was used during the development of the Core microarchitecture.
- SSE4, Penryn New Instructions (PNI), is another major enhancement, adding a dot product instruction, additional integer instructions, a
popcntinstruction (Population count: count number of bits set to 1, used extensively e.g. in cryptography), and more. - XOP, FMA4 and CVT16 are new iterations announced by AMD in August 2007[3][4] and revised in May 2009.[5]
- Advanced Vector Extensions (AVX), Gesher New Instructions (GNI), is an advanced version of SSE announced by Intel featuring a widened data path from 128 bits to 256 bits and 3-operand instructions (up from 2). Intel released processors in early 2011 with AVX support.[6]
- AVX2 is an expansion of the AVX instruction set.
- AVX-512 (3.1 and 3.2) are 512-bit extensions to the 256-bit Advanced Vector Extensions SIMD instructions for x86 instruction set architecture.
Software and hardware issues[edit]
With all x86 instruction set extensions, it is up to the BIOS, operating system and application programmer to test and detect their existence and proper operation.
- Intel and AMD offer applications to detect what extensions a CPU supports.
- The CPUID opcode is a processor supplementary instruction (its name derived from CPU IDentification) for the x86 architecture. It was introduced by Intel in 1993 when it introduced the Pentium and SL-Enhanced 486 processors.
User application uptake of the x86 extensions has been slow with even bare minimum baseline MMX and SSE support (in some cases) being non-existent by applications some 10 years after these extensions became commonly available. Distributed computing has accelerated the use of these extensions in the scientific community—and many scientific applications refuse to run unless the CPU supports SSE2 or SSE3.
The use of multiple revisions of an application to cope with the many different sets of extensions available is the simplest way around the x86 extension optimization problem. Software libraries and some applications have begun to support multiple extension types hinting that full use of available x86 instructions may finally become common some 5 to 15 years after the instructions were initially introduced.
Identifying[edit]
The following programs can be used to determine which, if any, versions of SSE are supported on a system
- Intel Processor Identification Utility[7]
- CPU-Z – CPU, motherboard, and memory identification utility.
- lscpu — provided by the util-linux package in most Linux distributions.
References[edit]
- ^ «Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 1: Basic Architecture». Intel. April 2022. pp. 5-16–5-19. Archived from the original on April 25, 2022. Retrieved May 16, 2022.
- ^ a b Diefendorff, Keith (March 8, 1999). «Pentium III = Pentium II + SSE: Internet SSE Architecture Boosts Multimedia Performance» (PDF). Microprocessor Report. 13 (3). Archived (PDF) from the original on April 17, 2018. Retrieved September 1, 2017.
- ^ Vance, Ashlee (August 3, 2007). «AMD plots single thread boost with x86 extensions». The Register. Archived from the original on April 27, 2011. Retrieved August 24, 2017.
- ^ «AMD64 Technology: 128-Bit SSE5 Instruction Set» (PDF). AMD. August 2007. Archived (PDF) from the original on August 25, 2017. Retrieved August 24, 2017.
- ^ «AMD64 Technology AMD64 Architecture Programmer’s Manual Volume 6: 128-Bit and 256-Bit XOP and FMA4 Instructions» (PDF). AMD. November 2009. Archived (PDF) from the original on January 31, 2017. Retrieved August 24, 2017.
- ^ Girkar, Milind (October 1, 2013). «Intel® Advanced Vector Extensions (Intel® AVX)». Intel. Archived from the original on August 25, 2017. Retrieved August 24, 2017.
- ^ «Download the Intel® Processor Identification Utility». Intel. July 24, 2017. Archived from the original on August 25, 2017. Retrieved August 24, 2017.
External links[edit]
- Intel Intrinsics Guide
![]()
Процессор не поддерживает MMX
Однако такие исключения встречаются редко и в большинстве случав программа, взамен отсутствующих SIMD, будет использовать универсальные (genegic) х86 инструкции. При этом мы не получим никакого повышения быстродействия, но и снижения производительности (по сравнению с обычным кодом) также не будет.
Поскольку каждый производитель процессоров по-своему улучшал архитекутуру, развитие микропроцессоров сопровождалось появлением нескольких вариантов SIMD расширений. Основные из них мы рассмотрим ниже.
MMX-расширение появилось в Pentium MMX (P55, январь 1997) и включало в себя 57 новых команд, предназначенных для обработки звуковых и видеосигналов. Позднее их поддержка появилась в K6 (Little Foot) от AMD и в 6х86MX от Cyrix.
MMX-расширение микропроцессора Pentium предназначено для поддержки приложений, ориентированных на работу с большими массивами данных целого типа, над которыми выполняются одинаковые операции. С данными такого типа обычно работают мультимедийные, графические, коммуникационные программы. По этой причине данное расширение архитектуры микропроцессоров Intel и названо
MultiMedia eXtensions (MMX), что переводится как мультимедиа расширения.
Основа программной компоненты – система команд MMX-расширения (те самые 57 новых команд) и четыре новых типа данных. MMX-команды являются естественным дополнением основной системы команд микропроцессора. Основным принципом их работы является одновременная обработка нескольких единиц однотипных данных одной командой. Основа аппаратной компоненты – 8 MMX регистров, каждый размером в 64 бит = 8 байт. MMX работает только с целыми числами; поддерживаются данные размером в 1, 2, 4 или 8 байт. То есть, один MMX регистр может содержать 8, 4, 2 или 1 операнд соответственно.
![]()
Формат регистра ММХ
На самом деле эти регистры не являются новыми, а MMX-расширение использует регистры сопроцессора (FPU). Как известно, регистры сопроцессора стека имеют размерность 80 бит, что касается MMX регистров, то их разрядность только 64 бита. Поэтому, когда регистры сопроцессора играют роль MMX-регистров, то доступными являются лишь их младшие 64 бита. К тому же, при работе стека сопроцессора в режиме MMX-расширения, он рассматривается не как стек, а как обычный регистровый массив с произвольным доступом. Таким образом, можно сказать, что расширения MMX реализованы в виде дополнительного pежима, в который процессор может переключаться из обычного pежима работы. Регистровый стек сопроцессора не может одновременно использоваться и по своему прямому назначению и как MMX-расширение, поэтому необходимо заботиться о его разделении и корректной работе с ним. Такое совмещение может снизить эффективность работы в случае попеременного использования обычных вычислений с плавающей точкой и работы в режиме MMX.
Данные, содержащиеся в MMX-регистрах, можно покомпонентно складывать, умножать, вычитать, выполнять разнообразные специфические, необходимые для мультимедиа приложений, операции, вроде сложения без переполнения, вычисления среднего арифметического и производить логические операции с битами (побитовый and, or, xor). Делить, правда, нельзя, есть ещё ограничения. Но многие операции можно делать на порядок быстрее, даже больше. Однако, применение MMX в особенности требует специальной ручной оптимизации, никакой компилятор тут существенно не поможет. Под MMX, например, оптимизируются разнообразные кодеки аудио файлов, алгоритмы работы которых хорошо сочетаются с MMX. Причём, не вся программа целиком, а небольшая часть, выполняющая основную работу, и это обстоятельство упрощает оптимизацию.
SSE
Данное расширение появилось в Pentium III (ядро Katmai, сентябрь 1999) и насчитывало 70 новых команд. Позднее в Athlon XP (начиная с Palomino) его стали поддерживать и процессоры AMD. Аббревиатура SSE расшифровывается как
Streaming SIMD Extensions (потоковые SIMD расширения).
SSE интересно прежде всего тем, что оперирует с данными вещественного типа, которые используются в геометрических расчётах, то есть, приложениях трёхмерной графики, компьютерных играх, редакторах вроде 3DStudioMax, и многих других. С тех пор как в компьютерных играх вроде Quake текстурирование треугольников стало производиться при помощи видеоускорителей, большая надобность в целочисленных вычислениях отпала. На первое место вышла скорость операций с плавающей точкой, вроде перемножения вещественного вектора на вещественную матрицу.
При внедрении SSE процессор получил в дополнение к стандартным регистрам архитектуры x87 8 новых больших регистров размером по 128 бит, в каждом из которых содержится 4 32-битных вещественных числа. С четвёрками операндов можно покомпонентно производить следующие операции: сложить две четвёрки чисел, вычесть, перемножить, разделить. Вычислить одновременно 4 (обратных) квадратных корня, точно или приближённо. Ещё можно тасовать содержимое регистров, перекладывать данные из одних частей регистра в другие и производить некоторые другие аналогичные операции. Однако перемещение данных происходит не быстрее их сложения, так что эффективное использование SSE возможно только на подготовленных правильно упакованных данных.
Если посчитать, что SSE-операция заменяет 4 аналогичных обыкновенных, то при оптимизации можно получить прирост производительности в 4 раза. Если быть более точным, то даже несколько больше, за счёт использования новых больших регистров. Однако, далеко не все вычисления можно эффективно оптимизировать под SSE. Как пример «хорошей» задачи следует привести умножение четырёхмерной матрицы на четырёхмерный вектор. Ускорение четырёхкратное без особых затрат.
В первую очередь использование SSE позволяет современным процессорам при выполнении трансформации вершин треугольников, составляющих трёхмерную сцену, успешно соревноваться с видеоускорителями. Другое дело, что у процессора много других задач, и лучше его по возможности разгрузить, чтобы он работал параллельно с видеоускорителем, и каждый выполнял свою задачу.
SSE2
Следующее расширение, являющееся логическим продолжением MMX и SSE появилось в Pentium 4 (начиная с Willamette). В Athlon 64 появилось начиная с Clawhammer.
В данное расширение включены 144 команды SSE2, ориентированные, в первую очередь, на работу с потоковыми данными. Подобно Pentium III, они также оперируют со 128-битными регистрами, но уже не только с четверками чисел одинарной точности, но и с любыми другими типами данных, которые умещаются в 128 бит. Это пары вещественных чисел двойной точности, шестнадцать однобайтовых целых, восьмерки двухбайтовых целых, пары восьмибайтовых целых etc. В результате получился некий симбиоз MMX и SSE.
Теперь те же 8 больших 128-битных регистров уже можно интерпретировать как содержащие не четыре 32-битных вещественных числа, а два 64-битных вещественных числа повышенной точности. Числа с повышенной точностью используются в тех случаях, когда вычисления с обычной точностью приводят к большим погрешностям. Все операции перенеслись с SSE, только работают не с четвёркой пар операндов, а с двойкой пар операндов.
В SSE2 регистры по сравнению с MMX удвоились, то есть, там стало помещаться не, например, 8 чисел, а 16. Поскольку скорость выполнения инструкций не изменилась, при оптимизации под SSE2 программа запросто получала двукратный прирост производительности. Надо отметить ещё следующее обстоятельство. Если программа уже была оптимизирована под MMX, то оптимизация под SSE2 даётся сравнительно легко в силу сходности системы команд.
SSE3
Следующий набор появился в Pentium 4 начиная с Prescott и Athlon 64 начиная с Venice. Это расширение, имевшее поначалу имело рабочее название
Prescott New Instruction, но получившее в итоге не совсем верное с технической точки зрения название SSE3, призвано облегчить оптимизацию программ под SSE и SSE2. Причём, в первую очередь, сделать более легкой полностью автоматическую оптимизацию программ средствами компилятора. То есть, для оптимизации необходимо будет просто перекомпилировать программу.
Некорректность названия SSE3 объясняется тем, что в отличие от других SIMD инструкций, где операции (например сложение) выполняются вертикально, здесь появилась возможность горизонтального выполнения операций.
![]()
Вертикальное сложение
![]()
Горизонтальное сложение
Таким образом в SSE3 появились удобные команды горизонтального последовательного сложения и вычитания операндов, а также другие разнообразные вспомогательные команды, облегчающие работу с данными.
SSE4 *
Данный набор появился в новейших процессорах Intel Core 2. Конкретная информация по этим инструкциям пока отсутствует.
Кстати стоит отметить, что в новых интеловских процессорах появилась технология Intel Advanced Digital Media Boost, суть которой в ускорении выполнения SIMD инструкций. Если раньше каждая инструкция выполнялась за два такта (один такт для обработки старших 64 бит, а второй такт для младших), то теперь выполнение этой инструкции занимает один такт. Налицо двукратное ускорение, что должно сказываться на работе программ, оптимизированных под этот набор инструкций.
*Обновлено: информация о наборе инструкций SSE4 оказалась преждевременной, на самом деле SSE4 появится в процессорах поколения Penryn, которые предположительно должны появиться в четвертом квартале 2007 года.
3DNow!
Различают три поколения этого расширения инструкций: 3DNow!, Enhanced 3DNow! и 3DNow! Professional, однако очень часто их все называют просто 3DNow!
Набор инструкций 3DNow! появился в AMD K6-2 (Chomper). Данный набор, состоящий из 21 команды, был оптимизирован для еще более узкой области, нежели «универсально-мультимедийный» Intel MMX, а именно: для наиболее ресурсоемких расчетов, связанных с 3D-графикой. Даже в самом названии этого набора (3DNow!) отразилась область его применения. Это расширение во многом сходно с SSE, но так же имеет и значительные отличия. Регистров так же 8, но они размером не 128 бит, а 64. Соответственно, в них помещается не 4 числа, а только 2. Имеется аналогичный SSE набор арифметических операций с регистрами. Сложить-умножить-разделить две пары операндов и т.п. Есть и операции нахождения (обратного) квадратного корня, точные и более быстрые приближённые. Однако, есть ещё одно важное отличие расширения 3DNow! Можно складывать между собой содержимое одного регистра. То есть, так же как и в SSE3, производить не только вертикальные операции, но и горизонтальные.
Другое важное обстоятельство, говорящее в пользу 3DNow!, это возможность достаточно эффективной автоматической оптимизации средствами компилятора. SSE слишком громоздко — размеры регистров большие — для автоматической организации данных. На коде, наполненном вычислениями с плавающей точкой, можно было бы бесплатно получить примерно полуторный прирост производительности.
В дальнейшем изменения блока 3DNow! произошли в К7. Он, как и раньше, работал с 64-битными регистрами, в которых находились пары вещественных чисел одинарной точности, зато его набор команд расширился еще на 24 инструкции (Enhanced 3DNow!). Последнее расширение этого набора до 3DNow! Professional появилось в ядре Thoroughbred.
На развитие набора 3DNow! негативно повлияло то, что у AMD первое время отсутствовал оптимизирующий компилятор, к тому же разработчики программ не торопились оптимизировать свои программы под эти инструкции.
Оценка прироста производительности.
Для того, чтобы определить, какой прирост быстродействия дают SIMD-инструкции было решено провести тестирование. Мы должны сравнить быстродействие программы в двух режимах (или двух программ): с оптимизацией под SIMD-инструкции и без нее. Это возможно в двух случаях: при использовании двух версий одной и той же программы (одна версия оптимизирована, а другая нет) или при наличии в программе функции отключения оптимизации. Однако здесь я столкнулся с проблемой – программ, имеющих такую фичу крайне мало
![]() . В случае с различными версиями одной программы, просматривая Changelog было обнаружено, что практически всегда наряду с включением поддержки SIMD-инструкций, в новой версии появлялись какие-либо дополнительные оптимизации. В таком случае сравнение программ разных версий представляется некорректным с точки зрения поставленной цели.
. В случае с различными версиями одной программы, просматривая Changelog было обнаружено, что практически всегда наряду с включением поддержки SIMD-инструкций, в новой версии появлялись какие-либо дополнительные оптимизации. В таком случае сравнение программ разных версий представляется некорректным с точки зрения поставленной цели.
После продолжительного поиска необходимые бенчмарки были найдены. Все они имеют возможность включать/отключать оптимизацию под определнные виды инструкций. Итак, тесты условно были поделены на четыре группы:
1.Видео: кодек XviD 1.1.0, MSU Deblocking Filter v2.2 (фильтр для VirtualDub)
2.Аудио: Lame 3.97 b2.
3.Синтетика: Sandra 2007, CPU RightMark 2003B.
4.Игры: Doom 3 ,Quake 4.
Тестовая конфигурация:
Материнская плата: Gigabyte GA-8I945P-G, BIOS v.F10
Процессор: Intel Pentium 4 630@3.600 MHz
Система охлаждения: TT Big Typhoon
Оперативная память: 512 Mb DDR2–667@638 Samsung Original (5-5-4-14), 512 Mb DDR2–667@638 Hynix (5-5-4-14)
Видеокарта: PCI-E Palit GeForce 6600GT@585/551 MHz
Дисковая подсистема: 160Gb SATA-II SAMSUNG HD160JJ, 40Gb Ultra-ATA/100 Seagate Barracuda ST340014A
Software: Windows XP SP2, ForceWare 91.28
Видео
![]()
XviD 1.1.0
![]()
MSU Deblocking Filter v2.2
Кодеком Xvid кодировался 160 MB файл из формата mpeg2. Перед фильтром MSU Deblocking стояла задача обработки 80 MB файла без последующего сжатия. Оба теста проводились в VirtualDub 1.6.15. Измерялось время выполнения в секундах. Как видно из результатов, использование оптимизации дает более чем двукратный прирост производительности
![]() . Особенно впечатляет ускорение c MMX и SSE. Малый прирост у SSE2 можно списать под плохую оптимизацию кодека.
. Особенно впечатляет ускорение c MMX и SSE. Малый прирост у SSE2 можно списать под плохую оптимизацию кодека.
Аудио
![]()
Lame 3.97 b2
Данный аудиокодек хоть и не обладает графическим интерфейсом, но имеет большое число настраиваемых параметров через командную строку. Для отключения оптимизации используется флаг —noasm xxx (где xxx – отключаемый набор инструкций). В формат mp3 преобразовывался 400 MB wav файл. Прирост не такой большой, как в случае с видео, но все же ускорение в 1,5 раза можно назвать успехом. Особенно сильна ”заточка” под MMX, что не удивительно ведь данное расширение создавалось специально для мультимедиа.
Синтетические тесты
![]()
Sandra 2007, Whetstone
![]()
Sandra 2007, Dhrystone
![]()
CPU RightMark 2003B, Math
![]()
CPU RightMark 2003B, Rendering
C Сандрой все понятно: при прогоне арифметического теста, прирост в тесте с FPU объясняется увеличением объема обрабатываемых данных (за счет увеличенного размера SIMD-регистров), а его отсутствие в тесте АЛУ тем, что SSE2 и SSE3 предназначены для операций с плавающей запятой.
Тест CPU RightMark достаточно редко встречается в обзорах, и я не удивлюсь если о нем слышали немногие (я сам только недавно его ”выловил”). Тест моделирует поведение притягивающихся и отталкивающих шаров в пространстве. Сам он представляет собой, по сути, два теста, объединенных в один. Модуль решателя (solver) рассчитывает физику взаимодействия тел, а модуль рендеринга (render) отображает это взаимодействие на экране. Нагрузку можно изменять и на модуль решателя (увеличивая количество рассчитываемых объектов), и на модуль рендеринга (изменяя количество источников света и качество текстур). В обоих модулях можно настраивать то, какие инструкции будут использованы при решении задачи. Тест больше оптимизирован под SSE/SSE3, поскольку требуется рассчитывать координаты объектов и силы их взаимодействия.
Игры
![]()
Doom3, Low Quality
![]()
Doom 3, Ultra Quality 2xAA, 4xAF
![]()
Quake 4, Low Quality
![]()
Quake 4, Ultra Quality 2xAA, 4xAF
Из игр только последние версии Doom и Quake позволяют отключать оптимизацию под SIMD-инструкции. Делается это в консольной командой com_ForceGenericSimd. Тесты проводились при разрешении 1024*768, при минимальном и максимальном (с 2xAA и 4xAF) качестве. При этом настройки антиалиасинга и анизотропной фильтрации принудительно выставлялись в настройках драйвера видеокарты. Для тестирования Doom 3 использовалось стандартное demo1, для Q4 была записана демка на уровне Air Defence Trenches. Демо прогонялись четыре раза, вычислялось среднее арифметическое последних трех прогонов.
Как и ожидалось прирост от использования SIMD-инструкций в играх мал, и он тем меньше, чем лучше настройки графики.
Заключение
Как видно оптимизация приложений под SIMD-инструкции приносит свои плоды в виде повышения производительности. Прирост состоит от нескольких процентов играх, до полутора-двух раз при обработке видео и звука. Насколько же хороша оптимизация и во сколько секунд/fps/попугаев она выльется зависит и от создателей процессоров, и от производителей программного обеспечения. При их тесном сотрудничестве производительность компьютеров будет повышаться, а это именно то, что нам и надо
![]() .
.
Напоследок хочу привести таблицу десктопных ядер от Intel и AMD с указанием поддерживаемых наборов инструкций.
| Ядро | MMX | SSE | SSE2 | SSE3 | SSE4 | 3DNow! |
|---|---|---|---|---|---|---|
| P54 | — | — | — | — | — | — |
| P55 | + | — | — | — | — | — |
| Covington | + | — | — | — | — | — |
| Mendocino | + | — | — | — | — | — |
| Klamath | + | — | — | — | — | — |
| Deschutes | + | — | — | — | — | — |
| Katmai | + | + | — | — | — | — |
| Coppermine | + | + | — | — | — | — |
| Tualatin | + | + | — | — | — | — |
| Willamette | + | + | + | — | — | — |
| Northwood | + | + | + | — | — | — |
| Prescott | + | + | + | + | — | — |
| Prescott-2M | + | + | + | + | — | — |
| Smithfield | + | + | + | + | — | — |
| Presler | + | + | + | + | — | — |
| Core 2 | + | + | + | + | — | — |
| 5K86 | — | — | — | — | — | — |
| Little Foot | + | — | — | — | — | — |
| Chomper | + | — | — | — | — | + |
| Sharptooth | + | — | — | — | — | + |
| Pluto | + | — | — | — | — | + |
| Orion | + | — | — | — | — | + |
| Spitfire | + | — | — | — | — | + |
| Morgan | + | + | — | — | — | + |
| Thunderbird | + | — | — | — | — | + |
| Palomino | + | + | — | — | — | + |
| Thoroughbred | + | + | — | — | — | + |
| Barton | + | + | — | — | — | + |
| Thorton | + | + | — | — | — | + |
| Applebred | + | + | — | — | — | + |
| Sledgehammer | + | + | + | — | — | + |
| Clawhammer | + | + | + | — | — | + |
| Paris | + | + | + | — | — | + |
| Palermo | + | + | + | + | — | + |
| Newcastle | + | + | + | — | — | + |
| Venice | + | + | + | + | — | + |
| San Diego | + | + | + | + | — | + |
| Winchester | + | + | + | — | — | + |
| Manchester | + | + | + | + | — | + |
| Toledo | + | + | + | + | — | + |
| Manila | + | + | + | + | — | + |
| Orleans | + | + | + | + | — | + |
| Windsor | + | + | + | + | — | + |
При написании статьи использовались материалы с сайтов overclockers.ru, ferra.ru, fcenter.ru, thg.ru, ixbt.com, intel.com, 3dnews.ru.
С уважением, Таболин Юра aka olddanmer
Вопросы и предложения мылить на danmer@udm.ru
В мире компьютерных технологий нет ничего странного в обилии всевозможных аббревиатур: CPU, GPU, RAM, SSD, BIOS, CD-ROM, и многих других. И почти каждый день появляются всё новые и новые сокращения названий каких-то технологий, что является неизбежным следствием бесконечного стремления инженеров улучшить функции и возможности наших вычислительных устройств.
Сегодня речь пойдёт о таких расширениях набора команд процессоров, как MMX, SSE и AVX. Многим знакомы эти сокращения, и мы выясним, действительно ли это какие-то интересные разработки, или же это не более чем бессмысленные маркетинговые уловки.
Ну о-о-очень первые дни
Середина 80-х прошлого столетия. Рынок процессоров был очень похож на сегодняшний. Intel бесспорно преобладала, но столкнулась с жесткой конкуренцией со стороны AMD. Домашние компьютеры, такие как Commodore 64, использовали базовые 8-битные процессоры, тогда как настольные ПК начинали переходить с 16-битных на 32-битные чипы.
Эти числа означают размер значений данных, которые могут быть обработаны математически, при этом чем выше эти значения, тем выше точность и возможности. Они также определяет размер основных регистров в микросхеме: небольших участков памяти, используемых для хранения рабочих данных.
Такие процессоры являются также скалярными и целочисленными. Что это означает? Скаляр – это когда над одним элементом данных выполняется только одна любая математическая операция. Обычно это обозначается как SISD (single instruction, single data, «одиночный поток команд – одиночный поток данных»).
Таким образом, инструкция по сложению двух значений данных просто обрабатывается для этих двух чисел. А если вам, например, нужно прибавить одно и то же значение к группе из 16 чисел, то для этого потребуется выполнить все 16 наборов инструкций – для каждого числа из этой группы по отдельности. По-другому процессоры тех лет складывать ещё не умели.

Intel 80386DX с частотой 16МГц (1985).
Целое (Integer) – в математике, это такое число, которое не имеет дробной части. Например, 8 или -12. Процессоры типа интеловского 80386SX не имели врожденной способности сложить, скажем, 3.80 и 7.26 – такие дробные числа называются числами с плавающей точкой (или запятой, в русском языке это без разницы) – по-английски FP, floating point или просто floats. Чтобы справиться с ними, нужен был другой процессор, например 80387SX, и отдельный набор инструкций – список команд, который сообщает процессору, что делать.
В те времена под инструкциями x86 понимали наборы команд для целочисленных (integer) операций, а под инструкциями x87 – для чисел с плавающей точкой (float). В наши дни все операции умеет выполнять один процессор, поэтому мы используем термин x86 для обозначения набора инструкций обоих типов данных.
Использование отдельных сопроцессоров для обработки разных типов данных было нормой, пока Intel не представила 80486: их первый CPU для персоналок со встроенным математическим сопроцессором для обработки вещественных данных (FPU, Floating Point Unit).

Intel 80486: Жёлтым цветом выделен блок FPU для обработки чисел с плавающей точкой.
Как вы можете видеть, этот блок совсем немного занимает места в процессоре, но рывок в производительности, благодаря этому решению, был огромен.
Но в целом принцип работы оставался скалярным, и таким он перешел и к преемнику 486-го: оригинальному Intel Pentium.
И пройдёт ещё три года после релиза этого первого Пентиума, прежде чем Intel представит миру Pentium MMX. Это произошло в октябре 1996 года.
V – значит «векторный». А MMX что значит?
В мире математики числа можно группировать в наборы различных видов и размеров – одна такая упорядоченная совокупность называется арифметическим вектором. Проще всего представить его себе в виде списка значений, расположенных горизонтально или вертикально. Технология MMX привнесла в мир процессоров возможность выполнять векторные математические вычисления.
Однако она была изначально довольно ограниченной, поскольку оперировала только целыми числами и фактически эксплуатировала для своих целей регистры FPU. Поэтому программисты, желающие использовать какие-то инструкции MMX, вынуждены иметь в виду, что при выполнении таких инструкций любые вычисления с плавающей запятой не могут выполняться одновременно с ними.
Знаменитая реклама технологии Intel MMX (1997).
FPU Pentium имел 64-битные регистры, и в операциях MMX каждый из них мог вместить два 32-битных, четыре 16-битных или восемь 8-битных целых числа. Именно эти группы чисел и являются векторами, и каждая инструкция, предназначенная для них, будет выполняться сразу над всеми значениями в группе.
Такой принцип получил название SIMD (single instruction, multiple data, «одиночный поток команд, множественный поток данных») и знаменует собой большой шаг вперед в развитии возможностей процессоров для персональных компьютеров.
Ну а какие приложения выигрывают от использования такого принципа? Практически все, которым приходится выполнять одинаковые вычисления над группой однородных данных, и в первую очередь это некоторые функции в 3D-моделировании и мультимедийных технологиях, а также в системах обработки стандартных сигналов.
Например, MMX можно применить для ускорения умножения матриц при обработке вершин в 3D, или для смешивания видеопотоков при работе с хромакеем или альфа-композитингом.

Процессор AMD K6-2 – где-то там есть 3DNow!
К сожалению, внедрение MMX продвигалось довольно медленными темпами из-за негативного влияния этой технологии на производительность операций с плавающей точкой. AMD частично решила эту проблему, создав свою собственную версию под названием 3DNow! примерно через два года после появления MMX. Технология от AMD предлагала больше инструкций SIMD и умела обрабатывать числа с плавающей точкой, но также страдала от недостатка понимания программистами.
Ах, да! Как же официально расшифровывается аббревиатура MMX? Согласно Intel – никак!
Проще пареной SSE
Ситуация переломилась в лучшую сторону с приходом в 1999 году процессора Intel Pentium III. Он принёс с собой блестящую реализацию векторной функции под названием SSE (Streaming SIMD Extensions, «потоковые расширения SIMD»). На этот раз это был дополнительный набор из восьми 128-битных регистров, отдельных от регистров в FPU, и стек дополнительных инструкций для обработки чисел с плавающей точкой.
Использование независимых регистров означает, что больше нет такой сильной зависимости от FPU, хотя Pentium III не мог выполнять инструкции SSE одновременно с инструкциями FP. А также, новая функция поддерживает только один тип данных в регистрах: четыре 32-битных FP-числа.
Но переход к использованию FP-инструкций SIMD позволил значительно увеличить производительность в таких приложениях, как кодирование/декодирование видео, обработка изображений и звука, сжатие файлов и многих других.

Pentium IV: желтым цветом выделен блок регистров SSE2.
Усовершенствованная версия SSE2 появилась в 2001 году вместе с Pentium 4, и на этот раз поддержка типов данных была намного лучше: четыре 32-битных или два 64-битных FP-числа, а также шестнадцать 8-битных, восемь 16-битных, четыре 32-битных или два 64-битных целых числа. Регистры MMX остались в процессоре, но все операции MMX и SSE могли выполняться с использованием независимых 128-битных регистров SSE.
Модификация SSE3 появилась на свет в 2003 году, имея больше инструкций и возможность выполнять некоторые математические вычисления между значениями внутри одного регистра.
Ещё через 3 года мы познакомились с архитектурой Intel Core, принёсшей ещё одну ревизию технологии SIMD (SSSE3 – Supplemental SSE, «расширенные SSE»), и чуть позже в том же году – финальную версию, SSE4.

В 2007 году AMD применила собственную версию расширений CPU-инструкций SSE4 в своей архитектуре Barcelona. С названием в AMD париться не стали, и назвали свою версию просто SSE4a.
С линейкой Nehalem Core в 2008 году было выпущено незначительное обновление этой версии, которую Intel обозначила как SSE4.2 (а под SSE4.1 стали понимать исходную версию этого обновления). Обновления не затронули регистры, а лишь добавили больше инструкций в таблицу, расширив диапазон возможных математических и логических операций.
AMD, со своей стороны, сперва предложила новую версию SSE5, но позже решила разделить ее на три отдельных расширения, одно из которых довольно проблемное – подробнее об этом чуть позже.
К концу 2008 года и Intel, и AMD поставляли процессоры, которые уже могли обрабатывать все версии наборов инструкций от MMX до SSE4.2, и многие приложения (в основном игры) начали требовать этих функций для работы.
Время для новых букв
2008 год также был годом, когда Intel объявила о том, что они работают над значительным апгрейдом своей системы SIMD, и в 2011 году выкатила линейку процессоров Sandy Bridge с поддержкой набора инструкций AVX (Advanced Vector Extensions, «продвинутые векторные расширения»).
Всё удвоилось: вдвое больше векторных регистров и вдвое больше их размер.
Шестнадцать 256-битных регистров вмещают только восемь 32-битных или четыре 64-битных вещественных числа, поэтому в плане форматов данных, этот набор инструкций более ограничен в сравнении с SSE, но ведь и SSE никто не отменял. К тому времени программная поддержка векторных операций для CPU была уже хорошо отлажена, начиная с фундаментального мира компиляторов, заканчивая сложными приложениями.

И не даром: Core i7-2600K (или подобный ему), работающий на частоте 3,8ГГц, потенциально может выдавать более 230 GFLOPS (миллиардов операций с плавающей точкой в секунду) при выполнении инструкций AVX – неплохо для дополнения, относительно немного места занимающего на кристалле процессора.
Или могло бы быть неплохо, если бы он действительно работал на частоте 3,8ГГц. Частично проблема AVX заключалась в том, что нагрузка на чип получалась настолько высокой, что Intel пришлось заставить процессор автоматически снижать тактовую частоту в этом режиме примерно на 20%, чтобы уменьшить энергопотребление и не допустить перегрева. К сожалению, такова цена за выполнение любой работы SIMD в современном процессоре.
Еще одно усовершенствование, предлагаемое в AVX – это возможность работать одновременно с тремя значениями. Во всех версиях SSE операции выполнялись между двумя значениями, после чего результат заменял одно из них в регистре. При выполнении инструкций SIMD AVX не трогает исходные значения, сохраняя результирующее значение в отдельный регистр.

AVX2 был выпущен вместе с архитектурой Haswell для процессоров Core 4-го поколения в 2013 году, и представлял собой довольно значительный апгрейд, благодаря добавлению нового расширения: FMA (Fused Multiply-Add, «умножение-сложение с однократным округлением»).
Эта независимая функция в составе AVX2 была крайне востребована для приложений, работающих с векторной и матричной математикой, поскольку давала возможность выполнять две операции с помощью одной инструкции. Функция поддерживала и скалярные операции также.
Проблема оказалась в том, что FMA от Intel отличался от аналогичного расширения AMD настолько, что они были совершенно несовместимы. Причина в том, что Intel FMA представляет собой систему с тремя операндами, то есть работает с тремя отдельными значениями: два слагаемых и сумма, либо три слагаемых и сумма, замещающая одно из слагаемых.
У версии от AMD четыре операнда, поэтому она может вычислить 3 числа и записать ответ в отдельный регистр, не трогая исходные значения. Математически FMA4 лучше, чем FMA3, но его реализация немного сложнее, как с точки зрения программирования, так и с точки зрения интеграции функции в процессор.
AVX-512: а не многовато-ли?
AVX2 ещё только начал появляться на рынке процессоров, а Intel уже плела маниакальные планы относительно его преемника, AVX-512, и общий настрой среди разработчиков был такой: «больше регистров богу регистров!». Мало того, что этих самых регистров снова вдвое больше, и они снова вдвое увеличились в размере, так ещё и появился стек новых инструкций и поддержка устаревших.
Первой партией чипов, на которых поднялся в воздух набор функций AVX-512, стала серия Xeon Phi 7200 – второе поколение громоздких и очень многоядерных процессоров Intel, ориентированных на рынок суперкомпьютеров.

72-ядерный 288-потоковый Knights Landing Xeon Phi.
В отличие от всех предыдущих реализаций, новый набор векторных инструкций состоял из 19-и компонентов: базового – AVX-512F, – необходимого для обеспечения совместимости, и множества весьма специфических. Эти дополнительные наборы охватывают такие области операций, как обратная математика, целочисленные FMA и алгоритмы свёрточной (конволюционной) нейронной сети (CNN-алгоритмы).
Первоначально AVX-512 был только прерогативой крупнейших чипов Intel, предназначенных для рабочих станций и серверов, но теперь их недавние архитектуры Ice Lake и Tiger Lake также поддерживают его. Да, не удивляйтесь: вы можете купить легкий ноутбук с процессором, имеющим 512-битные векторные блоки.
Это может показаться круто. А может и не показаться – в зависимости от вашей точки зрения. Регистры на кристалле CPU обычно группируются в так называемом регистровом файле, как видно на макрофото ниже.
 2-ядерный Intel Skylake
2-ядерный Intel Skylake
Желтым прямоугольником выделен файл векторных регистров, красный прямоугольник – это наиболее вероятное расположение файла целочисленного регистра. Обратите внимание, насколько файл векторного регистра больше integer-регистра. В Skylake используются 256-битные регистры AVX2, следовательно аналогичный векторный регистровый файл AVX-512 занял бы на таком же кристалле в четыре раза больше места: вдвое больше, потому что вдвое больше их размер, и ещё вдвое – потому что самих регистров вдвое больше.
А очень-ли нужно такое количество векторных регистров маленькому чипу, который должен быть максимально мобильным? Хоть речь и не о лишних килограммах в ноутбуке, а лишь о небольшой части площади ядра процессора, каждый квадратный миллиметр имеет значение, когда речь идет о миниатюризации мобильных устройств и наиболее эффективном использовании доступного пространства в них.
И учитывая, что использование AVX в любом виде приводит к автоматическому уменьшению тактовой частоты, использование AVX-512 на таких платформах скорее всего приведет к ещё более сомнительным издержкам по сравнению с любым из своих предшественников, поскольку при работе он потребляет еще больше энергии.

И проблема AVX-512 не только в применении к небольшим мобильным процессорам. Разработчикам, пишущим код для работы на рабочих станциях и серверах, и для которых увеличение возможностей векторных расширений действительно важный вопрос, потребуется создавать несколько версий кода. Это связано с тем, что не все процессоры с AVX-512 работают с одинаковым набором команд.
Например, набор IFMA (Integer Fused Multiply Add, «целочисленное умножение-сложение с однократным округлением») доступен только на процессорах Cannon, Ice и Tiger Lake. В то время как процессоры на архитектуре Cooper и Cascade Lake его не поддерживают, несмотря на то, что они относятся к сегменту процессоров для серверов и рабочих станций.
Стоит отметить, что AMD не предлагает поддержку AVX-512, и не собирается. По их мнению, обработка массивных векторных вычислений – это прерогатива GPU. С AMD полностью солидарна Nvidia, и обе компании уже выпустили продукты специально для таких нужд.
И дальше что?
Много лет назад процессор с возможностью обработки векторной математики ознаменовал собой эпохальный прорыв. Современные процессоры обладают огромными возможностями, предлагая множество наборов инструкций для обработки целочисленных операций и операций с плавающей запятой для скалярных, векторных и матричных данных.
Что касается последних двух типов данных, то CPU теперь напрямую конкурируют с GPU: ведь мир 3D-графики – это как раз всё, что связано с SIMD, векторами, плавающими точками и т.д. И производители GPU не спали – разработка графических ускорителей велась стремительными темпами. В начале 2010-х годов купить видеокарту, процессор которой способен выполнять почти 800 миллиардов инструкций SIMD в секунду, вы уже могли менее чем за 500 долларов.
Это больше, чем то, на что сейчас способны лучшие из десктопных CPU. Но они и не предназначены для рекордов в какой-то конкретной области – их задача обрабатывать очень обобщенный код, который зачастую не повторяется или легко распараллеливается. Поэтому, не стоит думать, что возможности SIMD столь жизненно-важны для CPU, скорее это полезное дополнение к его арсеналу.
 Вас интересует производительность SIMD в чистом виде? Ваш выбор – видеокарта, а не материнка!
Вас интересует производительность SIMD в чистом виде? Ваш выбор – видеокарта, а не материнка!
Стремительное развитие графических процессоров недвусмысленно намекает, что для CPU нет нужды иметь чересчур большие векторные блоки, и почти наверняка именно поэтому AMD даже не пыталась разрабатывать своего собственного преемника для AVX2 (расширение, которое они используют в своих чипах с 2015 года). Давайте также не будем забывать, что процессоры следующего поколения могут больше походить на мобильные однокристальные (SoC, System-on-a-Chip), где под каждый тип задач выделена площадь на кристалле. Intel, в свою очередь, похоже, стремится внедрить AVX-512 в как можно большее количество продуктов.
Ждёт ли нас ещё и AVX-1024? Вряд ли, либо очень нескоро. Скорее всего, Intel займётся расширением AVX-512 с помощью дополнительных компонентов с инструкциями, чтобы повысить гибкость, а чистую SIMD-производительность переложит на плечи своей недавно разработанной линейки графических процессоров Xe.

Библиотеки SSE и AVX теперь являются неотъемлемой частью программного обеспечения: Adobe Photoshop требует, чтобы процессоры поддерживали как минимум SSE4.2; API машинного обучения TensorFlow требует поддержки AVX; Microsoft Teams может выполнять фоновые видеоэффекты, только если доступен AVX2.
Это говорит только об одном: несмотря на то, что в плане обработки SIMD графическим процессорам нет равных, этот функционал ещё долго будет в арсенале CPU. Так что будем ждать нового поколения векторных расширений и надеюсь, реклама нас впечатлит.
Пользователи некоторых старых компьютеров все чаще обнаруживают, что часть новых программ и компьютерных игр больше не работает на их системах. При чем это не зависит от версии или разрядности операционной системы. Ограничения находятся на аппаратном уровне и связаны с поддержкой инструкций SSE 4.1 и SSE 4.2. В данной статье мы расскажем, что это такое и какие процессоры поддерживают SSE 4.1 и SSE 4.2.
Что такое SSE 4.1 и SSE 4.2
SSE 4 – это набор инструкций, который применяется в процессорах Intel и AMD. Впервые о данном наборе инструкций стало известно в конце 2006 года на форуме для разработчиков Intel, а первые процессоры с его поддержкой появились в 2008 году.
Набор SSE 4 включает в себя 54 новых инструкций, 47 из которых относятся SSE 4.1 и еще 7 к SSE 4.2. Данные инструкции включают в себя улучшенные целочисленные операции, операции с плавающей точкой, операции с плавающей точкой одинарной точности, упаковочные операции DWORD и QWORD, быстрые регистровые операции, операции для работы с памятью, а также операции со строками.
Использование данных новых инструкций позволяет значительно повысить производительность программ. Например, такие программы DivX 6.7 и VirtualDub 1.7.2 показывают рост производительности на 49%, а TMPGEncoder Xpress 4.4 на 42%.
В связи с ростом производительности, наборы SSE 4.1 и SSE 4.2 уже давно активно используются разработчиками программ и компьютерных игр. Естественно, если программа требует данного набора инструкций, то без него работать она не будет.
В результате многие современные игры и программы отказываются запускаться на старых компьютерах. Так, наличия SSE 4.1 или 4.2 требуют такие игры как No Man Sky, Dishonored 2, Far Cry 5 или Mafia 3.
Запуск таких программ на компьютере без SSE 4.1 или SSE 4.2 вызывает ошибки, например, может появляться ошибка «Incompatible CPU detected! Missing instruction sets: SSE4.2». В некоторых случаях ошибка указывает на конкретную инструкцию в наборе SSE 4, например, в игре Apex Legends может появляться ошибка «Unsupported CPU. CPU does not have POPCNT».

Иногда эту проблему можно решить с помощью программного эмулятора, но это приводит к значительному снижению производительности.
Процессоры, поддерживающие SSE 4.1 и SSE 4.2
Практически все современные процессоры поддерживают инструкции SSE 4.1 и SSE 4.2. Ниже мы расскажем в каких процессорах Intel и AMD поддержка этих инструкций появилась впервые.
Intel
В настольных процессорах Intel поддержка SSE 4.1 появилась в архитектуре Penryn (процессоры Core 2 Duo, Core 2 Quad), а поддержка SSE 4.2 в архитектуре Nehalem (процессоры Intel Core 1-поколения).
Полная же поддержка инструкций SSE 4.2 (включая POPCNT и LZCNT) доступна начиная с архитектуры Haswell (процессоры Intel Core 4-поколения).
Более подробная информация о поддержке в таблице внизу.
| Микроархитектура Intel | Процессоры | Поддержка инструкций |
| Silvermont
Goldmont Goldmont Plus Tremont |
SSE 4.1 и SSE 4.2 (включая POPCNT) | |
| Penryn | Core 2 Duo Core 2 Quad |
SSE 4.1 |
| Nehalem | Intel Core 1-поколения | SSE 4.1 и SSE 4.2 (включая POPCNT) |
| Haswell и новее | Intel Core 4-поколения и новее | SSE 4.1 и SSE 4.2 (включая POPCNT и LZCNT) |
AMD
В настольных процессорах AMD сначала появилась поддержка собственного набора инструкций SSE4a, который отсутствовал в процессорах Intel.
Но, уже начиная микроархитектуры Bulldozer (FX) была внедрена поддержка SSE 4.1 и SSE 4.2 (включая инструкции POPCNT и LZCNT). Последовавшая в дальнейшем микроархитектура Zen (Ryzen) также в полной мере поддерживает SSE 4.1 и SSE 4.2.
Более подробная информация о поддержке в таблице внизу.
| Микроархитектура AMD | Процессоры | Поддержка инструкций |
| K10
Bobcat Jaguar Puma |
SSE 4a (включая POPCNT и LZCNT) | |
| Bulldozer
Piledriver Steamroller Excavator Zen Zen+ Zen2 и новее |
AMD FX
AMD Ryzen |
SSE 4a, SSE 4.1, SSE 4.2 (включая POPCNT и LZCNT) |
Как узнать, что процессор поддерживает SSE 4.1 и SSE 4.2
Если у вас уже есть готовый компьютер и вы хотите узнать, поддерживает ли его процессор инструкции SSE 4.1 и SSE 4.2, то это можно сделать с помощью программ для просмотра характеристик компьютера.
CPU-Z
Программа CPU-Z предназначена для сбора информации об установленном процессоре. С ее помощью можно узнать название процессора, а также все его основные характеристики. Скачать CPU-Z можно с официального сайта.
Среди прочего, с помощью CPU-Z можно проверить наличие поддержки инструкций SSE 4.1 и SSE 4.2. Для этого нужно просто запустить CPU-Z и изучить строку «Instructions» на вкладке «CPU». Здесь будет доступен список всех инструкций, которые поддерживает данный процессор.

Нужно отметить, что в интернете есть скриншоты CPU-Z практически для любого процессора. Поэтому, вместо установки CPU-Z можно просто поискать в интернете скриншот из этой программы. Для этого нужно ввести поисковый запрос «cpu-z название процессора» и перейти к просмотру картинок.

Таким образом можно найти информацию практически о любом современном процессоре.
Speccy
Speccy — бесплатная программа для получения информации о комплектующих компьютера и их характеристиках. С помощью Speccy можно узнать характеристики процессора, оперативной памяти, материнской платы, видеокарты, жестких дисков и других устройств подключенных к компьютеру. Скачать Speccy можно с официального сайта.
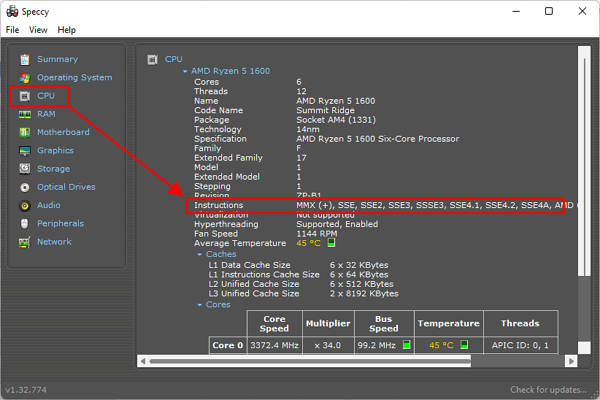
Для того чтобы проверить наличие поддержки инструкций SSE 4.1 и SSE 4.2 нужно запустить программу Speccy и перейти в раздел «CPU». Как и в CPU-Z, здесь в строке «Instructions» будут указаны все поддерживаемые инструкции.
Посмотрите также:
- Что такое процессор
- Сколько термопасты наносить на процессор
- Socket LGA 1150: какие процессоры подходят
- Как часто нужно менять термопасту на процессоре
- Какой процессор лучше для игр