Затеяли мы амбициозный проект — открыть свой электронный научный журнал. Поначалу казалось, что это дело неподъёмное и ничего хорошего не выйдет, тем более, что мы никогда издательским делом не занимались. Однако как и с любым делом тут главное начать. Хотя будущее нашего журнала ещё под вопросом, но я решил описать наш опыт на этом нелёгком пути и, надеюсь, этот рассказ сподвигнет ещё кого-нибудь создать свои хорошие журналы на благо российской науки.
Нам хотелось примерно следующее: создать электронный рецензируемый журнал на английском языке, полностью официальный, который бы воспринимался всерьёз западными учёными, на статьи в котором бы ссылались, чтобы высчитывался импакт-фактор. Программа-минимум — попасть в список журналов ВАК, в идеале — попасть в PubMed (журнал у нас по биоинформатике). Коммерческая выгода не предполагалась.
Софт
Первым делом, конечно, надо установить какое-то веб-приложение для журнала. Теоретически публиковать статьи можно хоть в WordPress, но всё же у журналов своя специфика. Нужна поддержка выпусков, разделов, рецензирования статей и многого другого, что выяснилось по ходу дела. Бесплатного специального софта для ведения журналов на первый взгляд довольно много. Вот, например, список аж из 13 пунктов. Тут приводится некоторый обзор софта. Нам довелось попробовать два варианта.
Ambra project
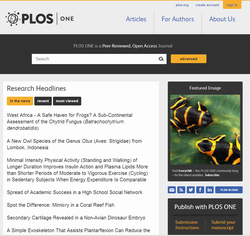 Эта система привлекла нас в первую очередь несколькими вещами. Во-первых, называется на букву A, потому идёт в вышеуказанном списке первой (маркетологи, мотайте на ус!). Во-вторых, она официально используется для всех журналов биологической тематики семейства PLOS, а значит, специфика предметной области может быть лучше учтена в этой системе. Наконец, Ambra написана на Java, под Tomcat, а нам эти технологии привычны.
Эта система привлекла нас в первую очередь несколькими вещами. Во-первых, называется на букву A, потому идёт в вышеуказанном списке первой (маркетологи, мотайте на ус!). Во-вторых, она официально используется для всех журналов биологической тематики семейства PLOS, а значит, специфика предметной области может быть лучше учтена в этой системе. Наконец, Ambra написана на Java, под Tomcat, а нам эти технологии привычны.
К сожалению, тут преимущества закончились. Похоже, PLOS её пишет в основном для себя и хоть и выкладывает исходники, но развернуть и настроить всё посторонним людям — тяжёлое дело. Инсталлятора не прилагается, из полезной документации только Quick-start в вики (который не такой уж и quick), а что делать дальше — неясно. Постоянно создаётся ощущение, что кучи нужных файлов просто не хватает, либо нужно что-то выкачивать из репозитория и куда-то складывать, но непонятно, что и куда. Имеется полумёртвый список рассылки, который не особенно помогает. Помучавшись несколько дней с Ambra, я бросил её и стал искать дальше.
Open Journal Systems (OJS)
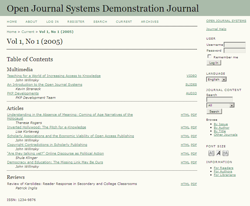 Это PHP-приложение, которое оставило гораздо лучшее впечатление, и в итоге мы на нём и остановились. OJS может похвастаться гораздо более впечатляющим списком использующих её журналов. Установилась легко (главное, не скачайте по ошибке девелоперскую версию, которая почему-то на страничке Download выше стабильной). Система позволяет хостить сразу несколько журналов; поддерживает права доступа, подписки и роли; интегрируется с PayPal для получения денег с подписчиков; позволяет публиковать статью в нескольких форматах (HTML, PDF) и что самое нужное — имеет инструментарий для приведения в порядок списков литературы (к сожалению, в этом компоненте есть несколько неприятных багов). Регулярно обнаруживались новые полезные фичи. Код внятный и структурированный, поэтому, если что-то не нравится, можно легко подправить. Есть вполне живые форум, багтрекер и вики. Из минусов помимо глючноватого библиографического инструментария можно отметить неполную и немного устаревшую официальную документацию.
Это PHP-приложение, которое оставило гораздо лучшее впечатление, и в итоге мы на нём и остановились. OJS может похвастаться гораздо более впечатляющим списком использующих её журналов. Установилась легко (главное, не скачайте по ошибке девелоперскую версию, которая почему-то на страничке Download выше стабильной). Система позволяет хостить сразу несколько журналов; поддерживает права доступа, подписки и роли; интегрируется с PayPal для получения денег с подписчиков; позволяет публиковать статью в нескольких форматах (HTML, PDF) и что самое нужное — имеет инструментарий для приведения в порядок списков литературы (к сожалению, в этом компоненте есть несколько неприятных багов). Регулярно обнаруживались новые полезные фичи. Код внятный и структурированный, поэтому, если что-то не нравится, можно легко подправить. Есть вполне живые форум, багтрекер и вики. Из минусов помимо глючноватого библиографического инструментария можно отметить неполную и немного устаревшую официальную документацию.
Вёрстка и форматы статей
С форматом хранения и представления статей следует определиться сразу. OJS какого-то конкретного формата не навязывает, он предлагает лишь загрузить, к примеру, готовые HTML- и PDF-версии статей. Предполагается, что верстальщик подготовит их сам в сторонних приложениях. Многим придёт в голову LaTeX в качестве внутреннего формата, который легко преобразовать и в HTML, и в PDF. Переводить в LaTeX, впрочем, придётся самому верстальщику: если для математического журнала ещё реально заставить всех авторов присылать статьи в LaTeX, то в биологии это пустой номер. Причём в этом формате тогда придётся работать и рецензентам, и редакторам. Так или иначе, но приходится смириться с фактом, что статьи будут поступать в форматах Microsoft Word.
Впрочем, как оказалось, LaTeX — всё равно не лучший вариант. Для того чтобы попасть в PubMed, надо сперва попасть в PubMedCentral, а для этого требуется, чтобы все статьи были в XML специальной схемы Национальной медицинской библиотеки (NLM Journal Publishing Tag Set), либо в другой широко распространённой схеме. Вполне разумно статьи к этому виду и приводить. Возникает две проблемы: как автоматизировать создание этого XML и как автоматизировать генерацию из него HTML и PDF.
Генерация списка литературы в форматах NLM уже поддерживается в OJS, что очень обрадовало! Для генерации болванки с названием, аннотацией, всеми необходимыми выходными данными и списком литературы я написал специальный шаблон в OJS. Полностью автоматически сконвертировать docx-файл в NLM не удастся. Даже если создать специальный шаблон для MS Word, всё равно авторы не будут готовить статьи строго по нему. Нет-нет, да введут заголовок не стилем, а просто увеличив кегль. Ругаться с авторами дольше, чем исправить это вручную, да и начинающему журналу вообще ругаться с авторами невыгодно. Поэтому надо всё же создать шаблон для MS Word с требованиями, автоматизировать максимум того, что можно, а остальное доделывать вручную.
Мы распаковываем из docx-файла (все же в курсе, что это zip-архив?) document.xml и выполняем самописное XSL-преобразование, которое максимально преобразует его содержимое в то, что надо. Для преобразования используем Saxon. После этого некоторые мелочи допинываем Perl-скриптом, затем вставляем результат в болванку и правим руками.
Для генерации HTML из NLM есть уже готовое XSL-преобразование на сайте NLM. Его, конечно, пришлось немного доработать, чтобы удовлетворить нашим представлениям о стиле, но в целом проблем не было. Сложнее оказалось с генерацией PDF. По той же ссылке есть преобразование к формату XSL-FO, но свободный FO-процессор Apache FOP результат жевать отказывается, ругаясь на использование неподдерживаемых фич. Связываться же с платными FO-процессорами вроде Antenna House Formatter пока неохота. Возникла мысль генерировать PDF из HTML. Из отдельного софта, решающего эту проблему, попробовали wkhtmltopdf, который использует движок WebKit для рендеринга HTML. К сожалению, оказалось, что он не поддерживает формулы в MathML. В итоге на настоящий момент всё свелось к использованию связки Firefox+PDF Creator. В генерируемый HTML добавляются команды window.print() и window.close(); в отдельной инсталляции Firefox разрешена быстрая печать без диалога с параметрами и позволено веб-страницам закрывать своё окно. Для лучшей разбивки PDF на страницы местами используется CSS-свойство page-break-inside:avoid. К сожалению, генерируемый PDF далёк от идеала. Чего особенно не хватает, так это двухколоночной вёрстки с выносом картинок и таблиц из общего потока и приклеиванием их к верхнему и нижнему краям страницы. В общем, тут есть, что улучшать. В других журналах PDF верстают вручную специальные люди, но у нас пока нет ресурсов.
Про формулы следует сказать особо. NLM XML использует MathML для представления формул. В файлах, которые присылают авторы, формулы можно увидеть в виде объектов Microsoft Equation, MathType, в виде родных формул, которые появились в Microsoft Word 2007 или вообще в виде картинок. Ну картинки присылать мы просто запретили, а всё остальное можно преобразовать в MathML с помощью того же MathType. При генерации HTML-версии статьи мы формулы оставляем как есть, только убираем namespace mml. MathML плохо поддерживается браузерами, но использование MathJax спасает. При генерации PDF используется родной MathML-рендерер Firefox.

Регистрация
Чтобы о созданном журнале узнали люди, статьи из него находились в специальных поисковых системах и на него могли нормально ссылаться, надо зарегистрироваться в куче мест. Тут тоже попадаются всякие трудности.
ISSN
 Получить Международный стандартный серийный номер — это, пожалуй, самое первое и самое простое, что надо сделать. Журналы без ISSN в других местах могут и не рассматривать. Получение ISSN бесплатно и для электронных журналов всё можно сделать в онлайне. Заполняете форму, отправляете, ждёте 10 рабочих дней, вам выдают номер. Получить ISSN можно и нужно до публикации первого выпуска журнала (но не ранее, чем за полгода). Вам выдадут номер, который не будет официально зарегистрирован в реестре ISSN. После первого выпуска журнала вы предоставляете ссылку на него, и ваш номер делают официальным.
Получить Международный стандартный серийный номер — это, пожалуй, самое первое и самое простое, что надо сделать. Журналы без ISSN в других местах могут и не рассматривать. Получение ISSN бесплатно и для электронных журналов всё можно сделать в онлайне. Заполняете форму, отправляете, ждёте 10 рабочих дней, вам выдают номер. Получить ISSN можно и нужно до публикации первого выпуска журнала (но не ранее, чем за полгода). Вам выдадут номер, который не будет официально зарегистрирован в реестре ISSN. После первого выпуска журнала вы предоставляете ссылку на него, и ваш номер делают официальным.
DOI
 DOI — идентификатор цифрового объекта; стабильный идентификатор, который присваивается журналам, выпускам, статьям и другим издаваемым в онлайне материалам. Выглядит, например, так: 10.1126/science.338.6114.1558. DOI не меняется даже при переезде журнала в другое издательство, поэтому ссылаясь на статью с использованием DOI, вы можете быть уверены, что ссылка останется живой. Без DOI научному журналу никуда, но за них надо прилично платить. Есть несколько регистраторов DOI, но конкуренция не такая сильная как, к примеру, у регистраторов доменных имён. Собственно, кроме CrossRef других регистраторов трудно рассматривать всерьёз. CrossRef берёт с издателя минимум 275 долларов в год плюс по доллару за каждый новый выделенный DOI для статьи или выпуска журнала. Для регистрации там надо просмотреть часовой вебинар и отправить курьером договор в Штаты. Если всё получится, вам пришлют первый инвойс и после его оплаты выдадут DOI-префикс. Основные требования — публиковать уникальный материал (без копипасты) и в списках литературы в опубликованных статьях указывать DOI-ссылки.
DOI — идентификатор цифрового объекта; стабильный идентификатор, который присваивается журналам, выпускам, статьям и другим издаваемым в онлайне материалам. Выглядит, например, так: 10.1126/science.338.6114.1558. DOI не меняется даже при переезде журнала в другое издательство, поэтому ссылаясь на статью с использованием DOI, вы можете быть уверены, что ссылка останется живой. Без DOI научному журналу никуда, но за них надо прилично платить. Есть несколько регистраторов DOI, но конкуренция не такая сильная как, к примеру, у регистраторов доменных имён. Собственно, кроме CrossRef других регистраторов трудно рассматривать всерьёз. CrossRef берёт с издателя минимум 275 долларов в год плюс по доллару за каждый новый выделенный DOI для статьи или выпуска журнала. Для регистрации там надо просмотреть часовой вебинар и отправить курьером договор в Штаты. Если всё получится, вам пришлют первый инвойс и после его оплаты выдадут DOI-префикс. Основные требования — публиковать уникальный материал (без копипасты) и в списках литературы в опубликованных статьях указывать DOI-ссылки.
OJS неплохо поддерживает DOI: вы можете задать произвольный формат генерации новых идентификаторов, OJS автоматически их присваивает новым статьям и генерирует XML для регистрации новых DOI в CrossRef.
WorldCat
 WorldCat — это объединённый каталог из десятков тысяч библиотек по всему миру. Они поддерживают сервис OAIster, который может индексировать ваши статьи. Регистрироваться там бесплатно и можно до первого выпуска журнала. WorldCat будет самостоятельно выкачивать и индексировать метаинформацию о статьях в формате Open Archives Initiative (OJS этот формат поддерживает).
WorldCat — это объединённый каталог из десятков тысяч библиотек по всему миру. Они поддерживают сервис OAIster, который может индексировать ваши статьи. Регистрироваться там бесплатно и можно до первого выпуска журнала. WorldCat будет самостоятельно выкачивать и индексировать метаинформацию о статьях в формате Open Archives Initiative (OJS этот формат поддерживает).
eLibrary.ru
 Для участия в российском индексе научного цитирования (РИНЦ, это пригодится для попадания в список ВАК) вам потребуется заключить договор с eLibrary.ru. Это бесплатно, но внесло дополнительную сложность: им необходимо предоставлять метаданные (имена авторов, их организации, названия и аннотации статей) на русском и на английском языках, даже если статья публикуется только на английском (или только на русском).
Для участия в российском индексе научного цитирования (РИНЦ, это пригодится для попадания в список ВАК) вам потребуется заключить договор с eLibrary.ru. Это бесплатно, но внесло дополнительную сложность: им необходимо предоставлять метаданные (имена авторов, их организации, названия и аннотации статей) на русском и на английском языках, даже если статья публикуется только на английском (или только на русском).
Импакт-фактор
Несмотря на все недостатки, импакт-фактор остаётся главным критерием качества научного журнала. Чтобы попасть в систему расчёта импакт-фактора, надо зарегистрировать журнал в Web of Science. Тут уже оценивается научная составляющая. Для рассмотрения журнала необходимо предоставить три идущих подряд выпуска, причём надо подавать заявку после выхода первого, а потом повторно после второго и третьего. Если всё пройдёт успешно, через два года вам присвоят импакт-фактор.
PubMedCentral
 PubMedCentral (PMC) — это бесплатный полнотекстовый архив статей по биологии и смежным темам. Практически все западные биологические журналы публикуют свои статьи в PMC. Кроме того, это наиболее прямой путь к PubMed. В целом любому журналу стоит рассмотреть возможность сотрудничества с каким-либо научным архивом (помимо PMC существуют, например, CLOCKSS или Portico). Это гарантирует, что статьи не пропадут для научного мира, даже если ваше издательство прекратит существование.
PubMedCentral (PMC) — это бесплатный полнотекстовый архив статей по биологии и смежным темам. Практически все западные биологические журналы публикуют свои статьи в PMC. Кроме того, это наиболее прямой путь к PubMed. В целом любому журналу стоит рассмотреть возможность сотрудничества с каким-либо научным архивом (помимо PMC существуют, например, CLOCKSS или Portico). Это гарантирует, что статьи не пропадут для научного мира, даже если ваше издательство прекратит существование.
После подачи заявки PMC первым делом оценивает научную составляющую журнала и в случае успеха оценивает техническую сторону. Тут довольно строгие требования. Как я уже сказал выше, статьи должны быть в XML определённой схемы, причём PMC накладывает дополнительные требования. Особые правила существуют и для картинок в статьях. Если всё прошло успешно, то заключается договор на семи страницах, который надо отправить в PMC.
Всё остальное
Если вы преодолели все технические трудности, то остаётся самая малость — найти авторов, рецензентов, редакторов и верстальщиков, которые захотят работать с вашим журналом. Как и где их искать — эти вопросы выходят за рамки моей статьи.
Open Journal Systems (OJS) — открытое программное обеспечение для организации рецензируемых научных изданий.
Содержание
1 Общая информация
- Текущая версия: OJS 3.x.
- Сайт: http://pkp.sfu.ca/ojs
- Загрузка: https://pkp.sfu.ca/ojs/ojs_download/
- Лицензия: GNU General Public License
- Система OJS предназначена для создания рецензируемых электронных журналов с открытым доступом.
- Позволяет не только публиковать статьи в интернете, но и организовывать весь рабочий процесс издательского дела: приём, рецензирование и каталогизирование статей.
2 Установка
2.1 Технические требования
- PHP 7.3 или новее с поддержкой MySQL, MariaDB или PostgreSQL.
- Сервер базы данных: MySQL/MariaDB 4.1 или новее, PostgreSQL 9.5 или новее.
- Рекомендуется UNIX-подобная ОС.
2.2 Дополнительные пакеты
- ADOdb Database Library (http://adodb.sourceforge.net/):
2.3 Установки сервера
2.3.1 SELinux
- Разрешить доступ http-серверу ко всем типам меток
httpd:setsebool -P httpd_unified 1 setsebool httpd_unified 1
2.3.2 Создание базы данных
-
Mysql
-
База данных должна быть создана с использованием кодировки UTF-8 (Unicode) (utf8mb4) и параметров сортировки
utf8mb4_unicode_ciилиutf8mb4_general_ci.- Разница между двумя сопоставлениями связана с тем, насколько быстро они сравнивают символы и сортируют их.
utf8mb4_general_ciнемного быстрее, однакоutf8mb4_unicode_ciболее точен для более широкого диапазона символов.
-
Необходимые значения:
ojs3— имя базы данных;ojs3— имя пользователя базы данных;password— пароль пользователя базы данных.
-
Создайте новую базу данных для вашего сайта (измените
usernameиdatabasename):mysql -u root -p -e "CREATE DATABASE ojs3 CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci" -
Подключитесь к базе данных:
- Создайте пользователя и установите разрешения:
CREATE USER ojs3@localhost IDENTIFIED BY 'password'; GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, INDEX, ALTER, CREATE TEMPORARY TABLES ON `ojs3`.* TO 'ojs3'@'localhost' IDENTIFIED BY 'password'; - Сбросьте привилегии:
- Закройте терминал базы данных, набрав
exit.
- Создайте пользователя и установите разрешения:
-
2.4 Установка OJS
-
Извлеките архив OJS в нужное место на вашем веб-сайте:
mkdir -p /var/www/html/sites/journals.example.com tar xzvf ojs-3.x.y-z.tar.gz --strip-components=1 -C /var/www/html/sites/journals.example.com -
Создайте следующие файлы и каталоги (и их содержимое) доступны для записи:
config.inc.phppubliccacheplugins(для установки плагинов через веб-интерфейс).
-
Для этого установите права доступа:
chown -R apache:apache /var/www/html/sites/journals.example.com -
Создайте каталог для хранения загруженных файлов и сделать этот каталог доступным для записи:
mkdir -p /var/www/data/journals.example.com chown -R apache:apache /var/www/data/journals.example.com chmod 775 /var/www/data/journals.example.com -
Добавьте конфигурацию для web-сервера (
/etc/httpd/conf.d/journals.example.com.conf):<VirtualHost *:80> ServerName journals.example.com ServerAdmin webmaster@example.com DocumentRoot "/var/www/html/sites/journals.example.com" <Directory "/var/www/html/sites/journals.example.com"> Options Indexes FollowSymLinks AllowOverride All Order allow,deny Allow from all </Directory> </VirtualHost> -
Откройте веб-браузер по адресу
http://journals.example.com/и следуйте инструкциям по установке на экране. -
Вместо этого можно использовать установщик командной строки запустив команду
php tools/install.phpиз вашего каталога OJS. -
Рекомендуемые дополнительные действия после установки:
- Просмотрите `config.inc.php` для дополнительных настроек конфигурации.
2.5 После установки
2.5.1 Настройка cron
-
Чтобы включить поддержку использования запланированных задач, отредактируйте файл
config.inc.phpи установите для параметраscheduled_tasksзначениеOn. -
Настройте периодическое выполнение заданий:
0 * * * * php /var/www/html/sites/journals.alternativy.ru/tools/runScheduledTasks.php- Скрипт будет выполняться каждый час.
3 Использование

Дмитрий Сергеевич Кулябов
Профессор кафедры прикладной информатики и теории вероятностей
Мои научные интересы включают физику, администрирование Unix и сетей.
Похожие
- DNS. Bind. DNSSEC
- Domain Name System (DNS)
- DHCP snooping
- Перенос kerberos на другую машину
- Почта. vk.com. Настройка почтового клиента
Файл помощи Open Journal Systems (OJS) создан для того, чтобы помочь пользователям в процессах чтения, отправки статей, редактирования и издания. Кроме того, он может служить руководством по OJS, описывающим возможности этой программы управления журналами. Файл помощи также дает редакционной команде информацию относительно общих методов публикации в журнале. В дополнение к этому файлу помощи пользователи имеют возможность связаться с представителем технической поддержки журнала, который указан в разделе «О журнале».
Поскольку OJS использует понятие ролей в процессе издания (от зеведующего редакцией, управляющего настройками журнала, до автора, который вычитывает гранки), каждая тема, затронутая в файле помощи, обращается к той роли, в которой выступает тот или иной пользователь. На этом принципе основано отображение справки — помощь является контекстной в пределах системы. Пользователи, выступающие в разных ролях, видят разные файлы справки. У пользователей может быть больше чем одна роль в OJS (рецензент также может быть автором, а менеджер журнала также может быть редактором). Соответственно, и один пользователь может видеть разное в зависимости от той роли, в которой он в данный момент выступает. Роль и местоположение на сайте определяют, какие темы помощи отображаются, хотя пользователь всегда может перейти оттуда к связанным разделам, чтобы получить информацию о любом аспекте функционирования системы.
Поиск В правом верхнем углу каждой страницы помощи есть элемент «Поиск». Введите ключевое слово, и вы получите список подходящих пунктов помощи, краткое описание каждого пункта и линки на них.
Содержание Щелкнув на этом пункте, Вы перейдете к полному списку доступных пунктов помощи.
На уровень вверх Щелкнув на этом пункте, Вы перейдете на уровень вверх в иерархической системе помощи.
Помощь по Open Journal Systems
Часто задаваемые вопросы
- Как мне начать пользоваться OJS?
- Как мне получить техническую поддержку? Куда сообщать об ошибках? Куда обращаться с предложениями по улучшению OJS?
- Как мне перевести OJS на другой язык?
- Почему авторы получают сообщение о том, что «в настоящее время рукописи не принимаются»?
- Что следует сделать, чтобы обеспечить доступ к еще не опубликованным рукописям, находящимся на этапе рецензирования или в состоянии препринта?
- Как мне заявить в сети о моем журнале?
- Как получить информацию об истории редакционной команды?
- Как мне разрешить читателям регистрироваться в качестве рецензентов журнала?
- Как мне найти дополнительных рецензентов, не входящих в основной список рецензентов?
- Есть ли другие способы публиковать статьи открытого доступа, предоставляя читателям бесплатный контент?
1. Как мне начать пользоваться OJS??
- Загрузите OJS и установите на веб-сервере, отвечающем техническим требованиям программы, программное обеспечение с помощью инсталляционного скрипта.
- Используйте сгенерированные OJS на этапе установки имя администратора и пароль для входа в систему.
- Создайте новый журнал.
- Администратор сайта автоматически становится менеджером созданного журнала. При необходимости можно создать еще одного или нескольких пользователей с ролью менеджера журнала.
- Затем менеджер журнала должен перейти в меню «Установка» и выполнить пять шагов (не обязательно все сразу), в результате которых сайт становится способен получать рукописи, управлять редакционным процесом и публиковать журнал онлайн.
- Ознакомьтесь с материалом OJS за час для получения дополнительной информации о начале работы с OJS.
2. Как мне получить техническую поддержку? Куда сообщать об ошибках? Куда обращаться с предложениями по улучшению OJS?
Public Knowledge Project создал форум поддержки с тысячами топиков, где можно искать ответы на возникающие вопросы. Например, поиск по сообщению об ошибке может привести к предложенным вариантам решений. В случае неудачи можно отправить вопрос по электронной почте в ящик pkp-support@sfu.ca. Сообщения об ошибках следует отправлять в Bugzilla PKP.
3. Как мне перевести OJS на другой язык?
Инструкции содержатся в файле docs/README, включенном в дистрибутив OJS. Дополнительную информацию общего характера, посвященную переводу, можно найти на форуме поддержки PKP.
4. Почему авторы получают сообщение о том, что «в настоящее время рукописи не принимаются»?
Если менеджер журнала выбрал опцию «Материалы могут отправляться только редакторами и редакторами разделов» для все созданных разделов, в этом случае отправлять могут только редакторы и редакторы разделов. Кроме того, если не существует ни одного раздела, авторы получат такое же сообщение.
5. Что следует сделать, чтобы обеспечить доступ к еще не опубликованным рукописям, находящимся на этапе рецензирования или в состоянии препринта?
У редакторов есть два способа включить «доступ к препринту». Они могут создать раздел «Препринты», в который добавляются статьи, предназначенные в дальнейшие выпуски и еще не готовые для публикации. Препринт-статьи добавляются в содержание текущего выпуска. Как только новый выпуск оказывается готов к публикации, редактор удаляет эти статьи из предыдущего выпуска и переносит их в следующий. Другой способ: редакторы могут использовать URL «Смотреть гранки» статьи на этапе верстки для создания препринт-просмотра. Этот URL предоставляет «превью»-доступ к статье привилегированным пользователям до публикации выпуска. В настоящее время PKP занимается темой препринта и в дальнейшем может появиться формальная процедура для его реализации.
6. Как мне заявить в сети о моем журнале?
Рано или поздно ваш журнал начнет индексироваться Google и другими поисковыми системами, но вы можете предпринять специальные действия. Зарегистрируйте свой журнал в PKP Harvester на третьем шаге раздела «Установка», что приведет к регистрации журнала в индексах Open Archives Initiative, включая PKP Harvester и OAIster. Если ваш журнал находится в открытом доступе, обсудите со своим университетским библиотекарем, можно ли представить журнал в электронных изданиях библиотеки и как связаться с другими библиотеками. Посмотрите, можно ли использовать соответствующие профессиональные сообщества для анонсирования журнала и его отдельных статей. И наконец, в разделе «Установка. 2.7. Безопасность и доступ» менеджер журнала может предоставить возможность пользователям регистрироваться в качестве читателей для автоматического уведомления их о новых выпусках.
7. Как получить информацию об истории редакционной команды?
Менеджер журнала может ввести эту информацию специальным линком в установке журнала, либо создать новую страницу «История редакционной команды» как новый пункт в разделе «О журнале» (раздел «Установка», п. 2.5). На этой странице можно перечислить имена, титулы и годы участия в редакционной команде.
8. Как мне разрешить читателям регистрироваться в качестве рецензентов журнала?
В разделе «Установка. 4.1. Доступ и безопасность» менеджер журнала может предоставить читателям и авторам возможность регистрироваться в качестве рецензентов. После этого они появляются в списке рецензентов, из которого редактор может выбирать рецензентов статей. В разделе «Установка. 5.7» менеджер журнала может добавить примечание «Для читателей» с текстом о заинтересованности журнала в читателях, выступающих в качестве рецензентов. Кроме того, журнал может поощрять пользователей регистрироваться в роли читателей в целях уведомления их о событиях журнала и точного учета числа постоянных читателей.
9. Как мне найти дополнительных рецензентов, не входящих в основной список рецензентов?
Для этого существует ряд способов. Если потенциальный рецензент идентифицируется по имени, его e-mail и адрес могут быть использованы для поиска.
- Используйте библиографический список статьи для поиска подходящих кандидатур, а затем их полные имена в поисковых сайтах для определения контактных данных.
- Используйте булевы выражения в поисковых сайтах, основанные на ключевых словах статьи (например, постколониализм + литература + «Южная Африка») для поиска схожих по тематике онлайн-материалов и людей, работающих в интересующей области.
- На основе того, как автор описывает предмет статьи (см. метаданные в резюме статьи), отправьте запрос коллегам о специалистах в интересующей области.
- Посетите другие онлайн-журналы, публикующие схожие материалы, с целью поиска авторов, которые могли бы выступить в роли рецензентов.
Как открыть научный журнал
Время на прочтение
8 мин
Количество просмотров 73K
Затеяли мы амбициозный проект — открыть свой электронный научный журнал. Поначалу казалось, что это дело неподъёмное и ничего хорошего не выйдет, тем более, что мы никогда издательским делом не занимались. Однако как и с любым делом тут главное начать. Хотя будущее нашего журнала ещё под вопросом, но я решил описать наш опыт на этом нелёгком пути и, надеюсь, этот рассказ сподвигнет ещё кого-нибудь создать свои хорошие журналы на благо российской науки.
Нам хотелось примерно следующее: создать электронный рецензируемый журнал на английском языке, полностью официальный, который бы воспринимался всерьёз западными учёными, на статьи в котором бы ссылались, чтобы высчитывался импакт-фактор. Программа-минимум — попасть в список журналов ВАК, в идеале — попасть в PubMed (журнал у нас по биоинформатике). Коммерческая выгода не предполагалась.
Софт
Первым делом, конечно, надо установить какое-то веб-приложение для журнала. Теоретически публиковать статьи можно хоть в WordPress, но всё же у журналов своя специфика. Нужна поддержка выпусков, разделов, рецензирования статей и многого другого, что выяснилось по ходу дела. Бесплатного специального софта для ведения журналов на первый взгляд довольно много. Вот, например, список аж из 13 пунктов. Тут приводится некоторый обзор софта. Нам довелось попробовать два варианта.
Ambra project
Эта система привлекла нас в первую очередь несколькими вещами. Во-первых, называется на букву A, потому идёт в вышеуказанном списке первой (маркетологи, мотайте на ус!). Во-вторых, она официально используется для всех журналов биологической тематики семейства PLOS, а значит, специфика предметной области может быть лучше учтена в этой системе. Наконец, Ambra написана на Java, под Tomcat, а нам эти технологии привычны.
К сожалению, тут преимущества закончились. Похоже, PLOS её пишет в основном для себя и хоть и выкладывает исходники, но развернуть и настроить всё посторонним людям — тяжёлое дело. Инсталлятора не прилагается, из полезной документации только Quick-start в вики (который не такой уж и quick), а что делать дальше — неясно. Постоянно создаётся ощущение, что кучи нужных файлов просто не хватает, либо нужно что-то выкачивать из репозитория и куда-то складывать, но непонятно, что и куда. Имеется полумёртвый список рассылки, который не особенно помогает. Помучавшись несколько дней с Ambra, я бросил её и стал искать дальше.
Open Journal Systems (OJS)
Это PHP-приложение, которое оставило гораздо лучшее впечатление, и в итоге мы на нём и остановились. OJS может похвастаться гораздо более впечатляющим списком использующих её журналов. Установилась легко (главное, не скачайте по ошибке девелоперскую версию, которая почему-то на страничке Download выше стабильной). Система позволяет хостить сразу несколько журналов; поддерживает права доступа, подписки и роли; интегрируется с PayPal для получения денег с подписчиков; позволяет публиковать статью в нескольких форматах (HTML, PDF) и что самое нужное — имеет инструментарий для приведения в порядок списков литературы (к сожалению, в этом компоненте есть несколько неприятных багов). Регулярно обнаруживались новые полезные фичи. Код внятный и структурированный, поэтому, если что-то не нравится, можно легко подправить. Есть вполне живые форум, багтрекер и вики. Из минусов помимо глючноватого библиографического инструментария можно отметить неполную и немного устаревшую официальную документацию.
Вёрстка и форматы статей
С форматом хранения и представления статей следует определиться сразу. OJS какого-то конкретного формата не навязывает, он предлагает лишь загрузить, к примеру, готовые HTML- и PDF-версии статей. Предполагается, что верстальщик подготовит их сам в сторонних приложениях. Многим придёт в голову LaTeX в качестве внутреннего формата, который легко преобразовать и в HTML, и в PDF. Переводить в LaTeX, впрочем, придётся самому верстальщику: если для математического журнала ещё реально заставить всех авторов присылать статьи в LaTeX, то в биологии это пустой номер. Причём в этом формате тогда придётся работать и рецензентам, и редакторам. Так или иначе, но приходится смириться с фактом, что статьи будут поступать в форматах Microsoft Word.
Впрочем, как оказалось, LaTeX — всё равно не лучший вариант. Для того чтобы попасть в PubMed, надо сперва попасть в PubMedCentral, а для этого требуется, чтобы все статьи были в XML специальной схемы Национальной медицинской библиотеки (NLM Journal Publishing Tag Set), либо в другой широко распространённой схеме. Вполне разумно статьи к этому виду и приводить. Возникает две проблемы: как автоматизировать создание этого XML и как автоматизировать генерацию из него HTML и PDF.
Генерация списка литературы в форматах NLM уже поддерживается в OJS, что очень обрадовало! Для генерации болванки с названием, аннотацией, всеми необходимыми выходными данными и списком литературы я написал специальный шаблон в OJS. Полностью автоматически сконвертировать docx-файл в NLM не удастся. Даже если создать специальный шаблон для MS Word, всё равно авторы не будут готовить статьи строго по нему. Нет-нет, да введут заголовок не стилем, а просто увеличив кегль. Ругаться с авторами дольше, чем исправить это вручную, да и начинающему журналу вообще ругаться с авторами невыгодно. Поэтому надо всё же создать шаблон для MS Word с требованиями, автоматизировать максимум того, что можно, а остальное доделывать вручную.
Мы распаковываем из docx-файла (все же в курсе, что это zip-архив?) document.xml и выполняем самописное XSL-преобразование, которое максимально преобразует его содержимое в то, что надо. Для преобразования используем Saxon. После этого некоторые мелочи допинываем Perl-скриптом, затем вставляем результат в болванку и правим руками.
Для генерации HTML из NLM есть уже готовое XSL-преобразование на сайте NLM. Его, конечно, пришлось немного доработать, чтобы удовлетворить нашим представлениям о стиле, но в целом проблем не было. Сложнее оказалось с генерацией PDF. По той же ссылке есть преобразование к формату XSL-FO, но свободный FO-процессор Apache FOP результат жевать отказывается, ругаясь на использование неподдерживаемых фич. Связываться же с платными FO-процессорами вроде Antenna House Formatter пока неохота. Возникла мысль генерировать PDF из HTML. Из отдельного софта, решающего эту проблему, попробовали wkhtmltopdf, который использует движок WebKit для рендеринга HTML. К сожалению, оказалось, что он не поддерживает формулы в MathML. В итоге на настоящий момент всё свелось к использованию связки Firefox+PDF Creator. В генерируемый HTML добавляются команды window.print() и window.close(); в отдельной инсталляции Firefox разрешена быстрая печать без диалога с параметрами и позволено веб-страницам закрывать своё окно. Для лучшей разбивки PDF на страницы местами используется CSS-свойство page-break-inside:avoid. К сожалению, генерируемый PDF далёк от идеала. Чего особенно не хватает, так это двухколоночной вёрстки с выносом картинок и таблиц из общего потока и приклеиванием их к верхнему и нижнему краям страницы. В общем, тут есть, что улучшать. В других журналах PDF верстают вручную специальные люди, но у нас пока нет ресурсов.
Про формулы следует сказать особо. NLM XML использует MathML для представления формул. В файлах, которые присылают авторы, формулы можно увидеть в виде объектов Microsoft Equation, MathType, в виде родных формул, которые появились в Microsoft Word 2007 или вообще в виде картинок. Ну картинки присылать мы просто запретили, а всё остальное можно преобразовать в MathML с помощью того же MathType. При генерации HTML-версии статьи мы формулы оставляем как есть, только убираем namespace mml. MathML плохо поддерживается браузерами, но использование MathJax спасает. При генерации PDF используется родной MathML-рендерер Firefox.
Регистрация
Чтобы о созданном журнале узнали люди, статьи из него находились в специальных поисковых системах и на него могли нормально ссылаться, надо зарегистрироваться в куче мест. Тут тоже попадаются всякие трудности.
ISSN
Получить Международный стандартный серийный номер — это, пожалуй, самое первое и самое простое, что надо сделать. Журналы без ISSN в других местах могут и не рассматривать. Получение ISSN бесплатно и для электронных журналов всё можно сделать в онлайне. Заполняете форму, отправляете, ждёте 10 рабочих дней, вам выдают номер. Получить ISSN можно и нужно до публикации первого выпуска журнала (но не ранее, чем за полгода). Вам выдадут номер, который не будет официально зарегистрирован в реестре ISSN. После первого выпуска журнала вы предоставляете ссылку на него, и ваш номер делают официальным.
DOI
DOI — идентификатор цифрового объекта; стабильный идентификатор, который присваивается журналам, выпускам, статьям и другим издаваемым в онлайне материалам. Выглядит, например, так: 10.1126/science.338.6114.1558. DOI не меняется даже при переезде журнала в другое издательство, поэтому ссылаясь на статью с использованием DOI, вы можете быть уверены, что ссылка останется живой. Без DOI научному журналу никуда, но за них надо прилично платить. Есть несколько регистраторов DOI, но конкуренция не такая сильная как, к примеру, у регистраторов доменных имён. Собственно, кроме CrossRef других регистраторов трудно рассматривать всерьёз. CrossRef берёт с издателя минимум 275 долларов в год плюс по доллару за каждый новый выделенный DOI для статьи или выпуска журнала. Для регистрации там надо просмотреть часовой вебинар и отправить курьером договор в Штаты. Если всё получится, вам пришлют первый инвойс и после его оплаты выдадут DOI-префикс. Основные требования — публиковать уникальный материал (без копипасты) и в списках литературы в опубликованных статьях указывать DOI-ссылки.
OJS неплохо поддерживает DOI: вы можете задать произвольный формат генерации новых идентификаторов, OJS автоматически их присваивает новым статьям и генерирует XML для регистрации новых DOI в CrossRef.
WorldCat
WorldCat — это объединённый каталог из десятков тысяч библиотек по всему миру. Они поддерживают сервис OAIster, который может индексировать ваши статьи. Регистрироваться там бесплатно и можно до первого выпуска журнала. WorldCat будет самостоятельно выкачивать и индексировать метаинформацию о статьях в формате Open Archives Initiative (OJS этот формат поддерживает).
eLibrary.ru
Для участия в российском индексе научного цитирования (РИНЦ, это пригодится для попадания в список ВАК) вам потребуется заключить договор с eLibrary.ru. Это бесплатно, но внесло дополнительную сложность: им необходимо предоставлять метаданные (имена авторов, их организации, названия и аннотации статей) на русском и на английском языках, даже если статья публикуется только на английском (или только на русском).
Импакт-фактор
Несмотря на все недостатки, импакт-фактор остаётся главным критерием качества научного журнала. Чтобы попасть в систему расчёта импакт-фактора, надо зарегистрировать журнал в Web of Science. Тут уже оценивается научная составляющая. Для рассмотрения журнала необходимо предоставить три идущих подряд выпуска, причём надо подавать заявку после выхода первого, а потом повторно после второго и третьего. Если всё пройдёт успешно, через два года вам присвоят импакт-фактор.
PubMedCentral
PubMedCentral (PMC) — это бесплатный полнотекстовый архив статей по биологии и смежным темам. Практически все западные биологические журналы публикуют свои статьи в PMC. Кроме того, это наиболее прямой путь к PubMed. В целом любому журналу стоит рассмотреть возможность сотрудничества с каким-либо научным архивом (помимо PMC существуют, например, CLOCKSS или Portico). Это гарантирует, что статьи не пропадут для научного мира, даже если ваше издательство прекратит существование.
После подачи заявки PMC первым делом оценивает научную составляющую журнала и в случае успеха оценивает техническую сторону. Тут довольно строгие требования. Как я уже сказал выше, статьи должны быть в XML определённой схемы, причём PMC накладывает дополнительные требования. Особые правила существуют и для картинок в статьях. Если всё прошло успешно, то заключается договор на семи страницах, который надо отправить в PMC.
Всё остальное
Если вы преодолели все технические трудности, то остаётся самая малость — найти авторов, рецензентов, редакторов и верстальщиков, которые захотят работать с вашим журналом. Как и где их искать — эти вопросы выходят за рамки моей статьи.