С++ для начинающих. Урок 1. Компиляция
- Содержание
- Обзор компиляторов C++
- Этапы компиляции
- Препроцессинг
- Ассемблирование
- Компиляция
- Линковка
- Средства сборки проекта
- Простой пример компиляции
Обзор компиляторов
Существует множество компиляторов с языка C++, которые можно использовать для создания исполняемого кода под разные платформы. Проекты компиляторов можно классифицировать по следующим критериям.
- Коммерческие и некоммерческие проекты
- Уровень поддержки современных тенденций и стандартов языка
- Эффективность результирующего кода
Если на использование коммерческих компиляторов нет особых причин, то имеет смысл использовать компилятор с языка C++ из GNU коллекции компиляторов (GNU Compiler Collection). Этот компилятор есть в любом дистрибутиве Linux, и, он, также, доступен для платформы Windows как часть проекта MinGW (Minumum GNU for Windows). Для работы с компилятором удобнее всего использовать какой-нибудь дистрибутив Linux, но если вы твердо решили учиться программировать под Windows, то удобнее всего будет установить некоммерческую версию среды разработки QtCreator вместе с QtSDK ориентированную на MinGW. Обычно, на сайте производителя Qt можно найти инсталлятор под Windows, который сразу включает в себя среду разработки QtCreator и QtSDK. Следует только быть внимательным и выбрать ту версию, которая ориентирована на MinGW. Мы, возможно, за исключением особо оговариваемых случаев, будем использовать компилятор из дистрибутива Linux.
GNU коллекция компиляторов включает в себя несколько языков. Из них, группу языков Си составляет три компилятора.
- g++ — компилятор с языка C++.
- gcc — компилятор с языка C (GNU C Compiler).
- gcc -lobjc — Objective-C — это, фактически, язык C с некоторой макро-магией, которая доступна в объектной библиотеке objc. Ее следует поставить и указать через ключ компиляции -l.
Этапы компиляции
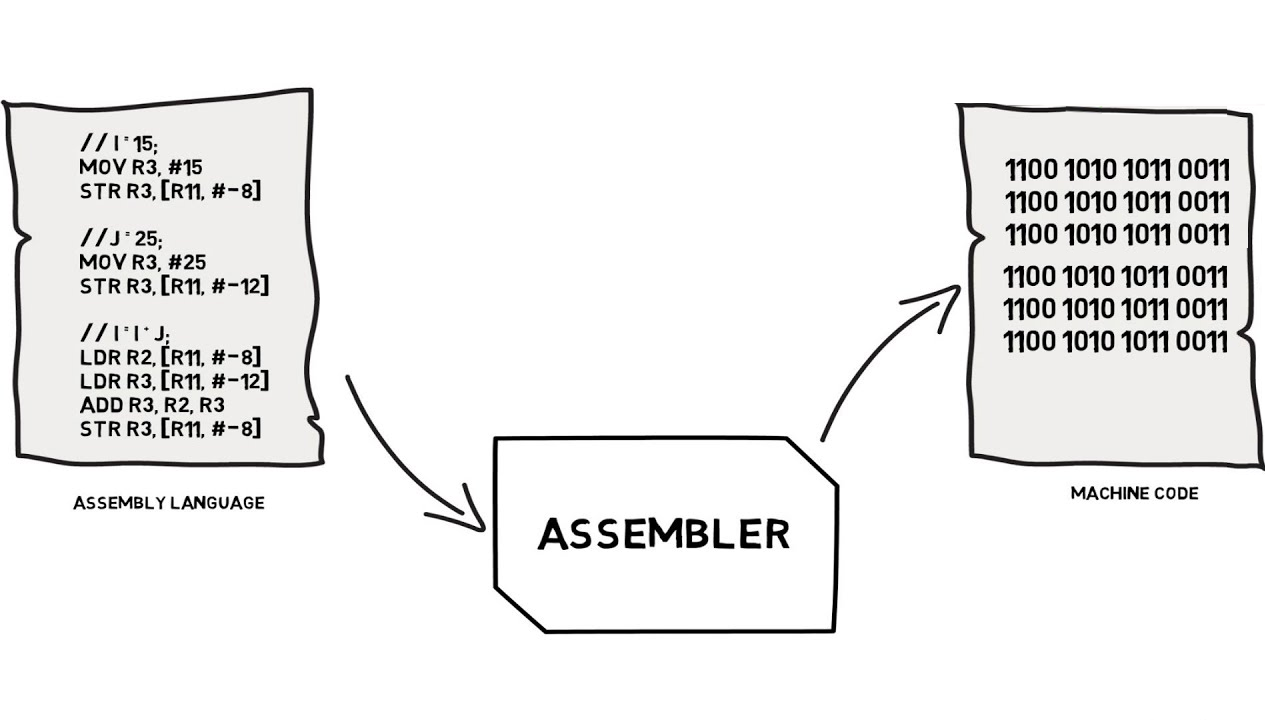
Процесс обработки текстовых файлов с кодом на языке C++, который упрощенно называют «компиляцией», на самом деле, состоит из четырех этапов.
- Препроцессинг — обработка текстовых файлов утилитой препроцессора, который производит замены текстов согласно правилам языка препроцессора C/C++. После препроцессора, тексты компилируемых файлов, обычно, значительно вырастают в размерах, но теперь в них содержится все, что потребуется компилятору для создания объектного файла.
- Ассемблирование — процесс превращения текста на языке C++ в текст на языке Ассемблера. Для компиляторов GNU используется синтаксис ассебмлера AT&T.
- Компилирование — процесс превращения текстов на языке Ассемблера в объектные файлы. Это файлы состоящие из кодов целевого процессора, но в которых еще не проставлены адреса объектов, которые находятся в других объектных файлах или библиотеках.
- Линковка — процесс объединения объектных файлов проекта и используемых библиотек в единую целевую сущность для целевой платформы. Это может быть исполняемая программа или библиотека статического или динамического типа.
Рассмотрим подробнее упомянутые выше стадии обработки текстовых файлов на языке C++.
Препроцессинг
Препроцессинг, это процедура ставшая традиционной для многих обработчиков разного рода описаний, в том числе и текстов с кодами программ. В общем случае, везде, где возникает необходимость в предварительной обработке текстов реализуется некоторый язык препроцессинга элементы которого ищутся препроцессором при обработке файла.
Основными элементами языка препроцессора являются директивы и макросимволы. Директивы вводятся с помощью символа «решетка» (#) в начале строки. Все, что следует за символом решетки и до конца строки считается директивой препроцессора. Директива препроцессора define вводит специальные макросимволы, которые могут быть использованы в следующих выражениях языка препроцессора.
На входе препроцессора мы имеем исходный файл с текстом на языке C++ включающим в себя элементы языка препроцессора.
На выходе препроцессора получаются так называемые компиляционные листы, состоящие исключительно из выражений языка C++, которых должно быть достаточно для создания объектных файлов на следующих этапах обработки. Последнее означает, что на момент использования каких-либо символов языка из других файлов, объявления этих символов должны присутствовать в компиляционном листе выше. Именно такие подстановки и призван осуществлять препроцессор. Часто, на вход препроцессора поступает файл размером в несколько десятков строк, а на выходе получается компиляционный лист из десятков тысяч строк.
Ассемблирование
Процесс ассемблирования с одной стороны достаточно прост для понимания и с другой стороны является наиболее сложным в реализации. По своей сути это процесс трансляции выражений одного языка в другой. Более конкретно, в данном случае, мы имеем на входе утилиты ассемблера файл с текстом на языке C++ (компиляционный лист), а на выходе мы получаем файл с текстом на языке Ассемблера. Язык Ассемблера это низкоуровневый язык который практически напрямую отображается на коды инструкций процессора целевой системы. Отличие только в том, что вместо числовых кодов инструкций используется англоязычная мнемоника и кроме непосредственно кодов инструкций присутствуют еще директивы описания сегментов и низкоуровневых данных, описываемых в терминологии байтов.
Ассемблирование не является обязательным процессом обработки файлов на языке C++. В данном случае, мы наблюдаем лишь общий подход в архитектуре проекта коллекции компиляторов GNU. Чтобы максимально объеденить разные языки в одну коллекцию, для каждого из языков реализуется свой транслятор на язык ассемблера и, при необходимости, препроцессор, а компилятор с языка ассемблера и линковщик делаются общими для всех языков коллекции.
Компиляция
В данном случае, мы имеем компилятор с языка ассемблера. Результатом его работы является объектный файл полученный на основе всего того текста, что был предоставлен в компиляционном листе. Поэтому можно говорить, что каждый объектный файл проекта соответствует одному компиляционному листу проекта.
Объектный файл — это бинарный файл, фактически состоящий из набора функций. Однако в исходном компиляционном листе не все вызываемые функции имели реализацию (или определение — definition). Не путайте с объявлением (declaration). Чтобы компиляционный лист можно было скомпилировать, необходимо, чтобы объявления всех вызываемых функций присутствовали в компиляционном листе до момента их использования. Однако, объявление, это не более чем имя функции и параметры ее вызова, которые позволяют во время компиляции правильно сформировать стек (передать переменные для вызова функции) и отметить, что тут надо вызвать функцию с указанным именем, адрес реализации которой пока не известен. Таким образом, объектные файлы сплошь состоят из таких «дыр» в которые надо прописать адреса из функций, которые реализованы в других объектных файлах или даже во внешних библиотеках.
Вообще, разница между объявлением (declaration) и определением (definition) состоит в том, что объявление (declaration) говорит об имени сущности и описывает ее внешний вид — например, тип объекта или параметры функции, в то время как определение (definition) описывает внутреннее устройство сущности: класс памяти и начальное значение объекта, тело функции и пр.
Исходя из этих определений, в компиляционном листе перед компиляцией должны существовать все объявления (declaration) всех тех сущностей, что используются в этом компиляционном листе. Причем их объявления должны находится до момента использования этих сущностей. Иначе, компилятор не сможет подготовить обращение к соответствующей сущности. Например, не сможет оформить передачу параметров через стек вызова функции и подготовиться к приему возвращаемого функцией значения.
Линковка
На этапе линковки выполняется объединение всех объектных файлов проекта, откомпилированных по соответствующим компиляционным листам проекта в единую сущность. Это может быть приложение, статическая или динамическая библиотека. Разница в бинарных заголовках целевых файлов и несколько различной внутренней организацией. Первичной задачей линковки следует назвать задачу по подстановке адресов вызова внешних объектов, которые были образованы в объектных файлах проекта. Соответствующие реализации сущностей с адресами их размещения должны находится в видимости линковщика. Эти сущности должны быть либо в объектных файлах, тогда они должны быть указаны в списке линковки, либо во внешних библиотеках функций, статических или динамических, тогда они должны быть указаны в списке внешних библиотек.
Средства сборки проекта
Традиционно, программа на языке C++ собирается средствами утилиты make исполняющей сценарий из файла Makefile. Сценарий сборки можно писать самостоятельно,
а можно создавать его автоматически с помощью всевозможных средств организации проекта. Среди наиболее известных средств организации проекта можно указать следующие.
- GNU Toolchain — Старейшая система сборки проектов известная еще по сочетанию команд configure-make-«make install».
- CMake — Кроссплатформенная система сборки, которая позволяет не только создать кроссплатформенный проект но и создать сценарий компиляции под любые известные среды разработки, для которых написаны соответствующие генераторы сценариев.
- QMake — Достаточно простая система сборки, специально реализованная для фреймворка Qt и широко используемая именно для сборки Qt-проектов. Может быть использована и просто для сборки проектов на языке C++. Имеет некоторые проблемы с выявлением сложных зависимостей метакомпиляции, специфической для Qt, поэтому, даже в проектах Qt, рекомендуется использование системы сборки CMake.
Современные версии QtCreator могут работать с проектами, которые используют как систему сборки QMake, так и систему сборки CMake.
Простой пример компиляции
Рассмотрим простейший проект «Hello world» на языке C++. Для его компиляции мы будет использовать консоль, в которой будем писать прямые команды компиляции. Это позволит нам максимально прочувствовать описанные выше этапы компиляции. Создадим файл с именем main.cpp и поместим в него следующий текст программы.
01. #include <iostream>
02.
03. int main(int argc, char *argv[])
04. {
05. std::cout << "Hello world" << std::endl;
06.
07. return 0;
08. }
В представленом примере выполнена нумерация строк, чтобы упростить пояснения по коду. В реальном коде нумерации не должно быть, так как она не входит в синтаксическое описание конструкций языка C++.
В первой строке кода записана директива включения файла с именем iostream в текст проекта. Как уже говорилось, все строки, которые начинаются со знака решетки (#) интерпретируются в языках C/C++ как директивы препроцессора. В данном случае, препроцессор, обнаружив директиву включения файла в текст программы, директиву include, выполнит включение всех строк указанного в директиве файла в то место программы, где стоит инструкция include. В результате этого у нас получится большой компиляционный лист, в котором будут присутствовать множество символов объявленных (declaration) в указанном файле. Включаемые файлы, содержащие объявления (declaration) называют заголовочными файлами. На языке жаргона можно услышать термины «header-файлы» или «хидеры».
Чтобы увидеть результат препроцессинга можно воспользоваться опцией -E компилятора g++. По умолчанию, в этом случае, результат препроцессинга будет выведен в стандартный поток вывода. Чтобы можно было удобно рассмотреть его, следует перенаправить стандартный поток вывода в какой-нибудь текстовый файл. В представленном ниже примере это будет файл main.E.
g++ -E main.cpp > main.E
В третьей строке программы описана функция main(). В контексте операционной системы, каждое приложение должно иметь точку входа. Такой точкой входа в операционных системах *nix является функция main(). Именно с нее начинается исполнение приложения после его загрузки в память вычислительной системы. Так как операционная система Windows имеет корни тесно переплетенные с историей *nix, и, фактически, является далеким проприентарным клоном *nix, то и для нее справедливо данное правило. Поэтому, если вы пишете приложение, то начинается оно всегда с функции main().
При вызове функции main(), операционная система передает в нее два параметра. Первый параметр — это количество параметров запуска приложения, а второй — строковый массив этих параметров. В нашем случае, мы их не используем.
В пятой строке мы обращаемся к предопределенному объекту cout из пространства имен std, который связан с потоком вывода приложения. Используя синтаксис операций, определенных для указанного объекта, мы передаем в него строку «Hello world» и символ возврата каретки и переноса строки.
В седьмой строке мы возвращаем код 0, как код возврата функции main(). В организации процессов в операционной системы, это число будет восприниматься как код возврата приложения.
Следующим шагом проведения эксперимента выполним останов компиляции файла main.cpp после этапа ассемблирования. Для этого воспользуемся ключом -S для компилятора g++. Здесь и далее, знак доллара ($) обозначает стандартное приглашение к вводу команды в консоли *nix. Писать знак доллара не требуется.
$ g++ -S main.cpp
Выполнив остановку компиляции после этапа ассемблирование, возможно будет интересно выполнить остановку компиляции и после этапа, который собственно, и выполняет компиляцию, т.е. превращение ассемблерного кода в объектный файл, который впоследствии надо будет слинковать с библиотеками, в которых будет найдено реализация объекта cout, который используется в нашей программе как некий библиотечный объект.
Для остановки компиляции после, собственно, компиляции следует воспользоваться ключом -c для компилятора g++.
$ g++ -с main.cpp
Наконец, если нас не интересуют эксперименты с остановками компиляции на разных этапах и если мы просто хотим получить из нашего файла на языке C++ исполняемую программу, то следует выполнить следующую команду.
$ g++ main.cpp
В результате исполнения этой команды появится файл a.out который и представляет собой результат компиляции — исполняемый файл программы. Запустим его и посмотрим на результат выполнения. При работе в операционной системе Windows, результатом компиляции будет файл с расширением exe. Возможно, он будет называться main.exe.
$ ./a.out
From Wikipedia, the free encyclopedia
A low-level programming language is a programming language that provides little or no abstraction from a computer’s instruction set architecture—commands or functions in the language map that are structurally similar to processor’s instructions. Generally, this refers to either machine code or assembly language. Because of the low (hence the word) abstraction between the language and machine language, low-level languages are sometimes described as being «close to the hardware». Programs written in low-level languages tend to be relatively non-portable, due to being optimized for a certain type of system architecture.[1]
Low-level languages can convert to machine code without a compiler or interpreter—second-generation programming languages use a simpler processor called an assembler—and the resulting code runs directly on the processor. A program written in a low-level language can be made to run very quickly, with a small memory footprint. An equivalent program in a high-level language can be less efficient and use more memory. Low-level languages are simple, but considered difficult to use, due to numerous technical details that the programmer must remember. By comparison, a high-level programming language isolates execution semantics of a computer architecture from the specification of the program, which simplifies development.[1]
Machine code[edit]

Machine code is the only language a computer can process directly without a previous transformation. Currently, programmers almost never write programs directly in machine code, because it requires attention to numerous details that a high-level language handles automatically.[1] Furthermore, it requires memorizing or looking up numerical codes for every instruction, and is extremely difficult to modify.
True machine code is a stream of raw, usually binary, data. A programmer coding in «machine code» normally codes instructions and data in a more readable form such as decimal, octal, or hexadecimal which is translated to internal format by a program called a loader or toggled into the computer’s memory from a front panel.[1]
Although few programs are written in machine languages, programmers often become adept at reading it through working with core dumps or debugging from the front panel.
Example of a function in hexadecimal representation of 32-bit x86 machine code to calculate the nth Fibonacci number:
8B542408 83FA0077 06B80000 0000C383 FA027706 B8010000 00C353BB 01000000 B9010000 008D0419 83FA0376 078BD989 C14AEBF1 5BC3
Assembly language[edit]
Second-generation languages provide one abstraction level on top of the machine code. In the early days of coding on computers like TX-0 and PDP-1, the first thing MIT hackers did was to write assemblers.[2]
Assembly language has little semantics or formal specification, being only a mapping of human-readable symbols, including symbolic addresses, to opcodes, addresses, numeric constants, strings and so on. Typically, one machine instruction is represented as one line of assembly code. Assemblers produce object files that can link with other object files or be loaded on their own.
Most assemblers provide macros to generate common sequences of instructions.
Example: The same Fibonacci number calculator as above, but in x86-64 assembly language using AT&T syntax:
_fib: movl $1, %eax xorl %ebx, %ebx .fib_loop: cmpl $1, %edi jbe .fib_done movl %eax, %ecx addl %ebx, %eax movl %ecx, %ebx subl $1, %edi jmp .fib_loop .fib_done: ret
In this code example, the registers of the x86-64 processor are named and manipulated directly. The function loads its input from %edi in accordance to the System V ABI and performs its calculation by manipulating values in the EAX, EBX, and ECX registers until it has finished and returns. Note that in this assembly language, there is no concept of returning a value. The result having been stored in the EAX register, the RET command simply moves code processing to the code location stored on the stack (usually the instruction immediately after the one that called this function) and it is up to the author of the calling code to know that this function stores its result in EAX and to retrieve it from there. x86-64 assembly language imposes no standard for returning values from a function (and in fact, has no concept of a function); it is up to the calling code to examine state after the procedure returns if it needs to extract a value.
Compare this with the same function in C:
unsigned int fib(unsigned int n) { if (!n) return 0; else if (n <= 2) return 1; else { unsigned int a, c; for (a = c = 1; ; --n) { c += a; if (n <= 2) return c; a = c - a; } } }
This code is very similar in structure to the assembly language example but there are significant differences in terms of abstraction:
- The input (parameter n) is an abstraction that does not specify any storage location on the hardware. In practice, the C compiler follows one of many possible calling conventions to determine a storage location for the input.
- The assembly language version loads the input parameter from the stack into a register and in each iteration of the loop decrements the value in the register, never altering the value in the memory location on the stack. The C compiler could load the parameter into a register and do the same or could update the value wherever it is stored. Which one it chooses is an implementation decision completely hidden from the code author (and one with no side effects, thanks to C language standards).
- The local variables a, b and c are abstractions that do not specify any specific storage location on the hardware. The C compiler decides how to actually store them for the target architecture.
- The return function specifies the value to return, but does not dictate how it is returned. The C compiler for any specific architecture implements a standard mechanism for returning the value. Compilers for the x86 architecture typically (but not always) use the EAX register to return a value, as in the assembly language example (the author of the assembly language example has chosen to copy the C convention but assembly language does not require this).
These abstractions make the C code compilable without modification on any architecture for which a C compiler has been written. The x86 assembly language code is specific to the x86 architecture.
Low-level programming in high-level languages[edit]
During the late 1960s, high-level languages such as PL/S, BLISS, BCPL, extended ALGOL (for Burroughs large systems) and C included some degree of access to low-level programming functions. One method for this is inline assembly, in which assembly code is embedded in a high-level language that supports this feature. Some of these languages also allow architecture-dependent compiler optimization directives to adjust the way a compiler uses the target processor architecture.
References[edit]
- ^ a b c d «3.1: Structure of low-level programs». Workforce LibreTexts. 2021-03-05. Retrieved 2023-04-03.
- ^ Levy, Stephen (1994). Hackers: Heroes of the Computer Revolution. Penguin Books. p. 32. ISBN 0-14-100051-1.
Про Python, Java, C пишут в блогах онлайн-школ, на хабре и ви-си. Эти языки — лидеры по рейтингу TIOBE, их часто выбирают новички, чтобы изучать как первый язык программирования. Но знания менее популярных языков программирования тоже востребованы. В статье рассматриваем язык ассемблера: о нём расскажет Алексей Каньков, старший backend-разработчик Revizto.
Что такое ассемблер
Язык ассемблера (Assembly, или ASM) — это язык программирования, который используют, чтобы написать программы для аппаратных платформ или архитектур.
В отличие от языков программирования высокого уровня, например Python или Java, язык ассемблера обеспечивает прямое представление инструкций машинного кода. Поэтому язык ассемблера называют языком низкого уровня: он ближе к двоичному коду, который понимает компьютер.
Если больший интерес вызывают языки высокого уровня, приходите на курс Skypro «Java-разработчик». За 11 месяцев научитесь работать с самыми популярными инструментами языка программирования Java и станете востребованным специалистом с дипломом о профессиональной переподготовке. Сможете устроиться на работу уже во время обучения.
Программы на языке ассемблера обычно пишут с комбинациями текстовой мнемоники и числовых кодов, известных как коды операций. Это инструкции: их выполняет процессор. Программы непросто писать и отлаживать из-за их низкоуровневой природы. Зато они дают больший контроль над аппаратным обеспечением компьютера и могут быть более эффективными, чем программы на языках высокого уровня.
Когда и как был создан
Язык программирования ассемблер существует с первых дней вычислительной техники. Его развитие можно проследить до первых электронных компьютеров, построенных в 1940-х и 1950-х.
Один из первых примеров языка ассемблера — язык, используемый для программирования компьютера Manchester Mark 1. Его разработала группа исследователей под руководством Фредерика Уильямса и Тома Килберна из Манчестерского университета в Англии. Manchester Mark 1 был одним из первых компьютеров, использующих архитектуру с хранимой программой. Его язык применяли для написания программ, которые хранились в его памяти.
Компьютерное оборудование развивалось — совершенствовались и языки ассемблера. Добавили новые инструкции и функции для более сложных операций и новых аппаратных возможностей. Сегодня язык ассемблера по-прежнему используют в специализированных областях. Например, в программировании встроенных систем и низкоуровневом системном программировании.
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Получить
программу

Где используют язык ассемблера
Сейчас используют множество различных языков ассемблера, каждый из которых предназначен для конкретной аппаратной платформы или архитектуры. Примеры:
- x86 для ПК на базе Intel;
- ARM для мобильных устройств и встроенных систем;
- MIPS для некоторых встроенных систем и академического использования.
Ассемблер нужен в областях, где требуется низкоуровневое системное программирование или аппаратное управление:
🔸 Разработка операционной системы. Язык ассемблера используют при разработке ОС и драйверов устройств, для которых нужен прямой доступ к аппаратным компонентам.
🔸 Программирование встроенных систем. Ассемблер применяют для разработки микроконтроллеров и других небольших устройств с ограниченной вычислительной мощностью.
🔸 Разработка игр. Язык нужен, чтобы оптимизировать критически важные для производительности участки кода. Примеры игр, в которых использовали ассемблер: TIS-100, RollerCoaster Tycoon, Shenzhen I/O, Human Resource Machine. Правда, эти игры скорее для программистов: в них разрабатывают имитацию кода.
🔸 Обратный инжиниринг. Язык ассемблера часто используют для дизассемблирования и анализа двоичного кода.
🔸 Разработка вредоносных программ. Хакеры создают на ассемблере вирусы.
То есть язык ассемблера используют в тех областях, где критически важны производительность и аппаратный контроль. Там, где другие языки программирования высокого уровня не отвечают конкретным требованиям приложения.
Если хочется работать на них — приходите на курс «Python-разработчик». За 10 месяцев научитесь создавать логику программ, баз данных и разрабатывать приложения. Выполните несколько проектных работ: например, сделаете планировщик задач с авторизацией через соцсети и возможностью управлять карточками. Получите навыки, которые востребованы во многих IT-компаниях.
Как устроен язык ассемблера
💡 Синтаксис
Синтаксис ассемблера может различаться: зависит от конкретной архитектуры или платформы. Одни языки используют двоеточия для меток или целей перехода, у других символы отличаются. Но в целом синтаксис состоит из серии инструкций и операндов, написанных с использованием текстовой мнемоники. Пример:
``` MOV AX, 1 ; move the value 1 into the AX register ADD AX, BX ; add the value in the BX register to the AX register ```
В этом примере MOV и ADD — это мнемоники для инструкций «переместить» и «добавить». AX и BX — это операнды. Они относятся к регистрам, в которых хранятся данные.
Синтаксис языка ассемблера точный и структурированный, потому что предназначен для работы с машинным кодом. Но это затрудняет чтение и написание кода для программистов, привыкших к языкам более высокого уровня.
Если хотите изучать более универсальные и популярные языки, начните с Java и Python. В онлайн-университете Skypro есть такие курсы: учим с нуля, делаем упор на практику. Научитесь разрабатывать приложения, сайты, социальные сети, игры, доски объявлений. В конце — диплом и помощь с работой. Не просто подбираем вакансии, а устраиваем на новую работу — или возвращаем деньги за обучение.
💡 Директивы
В языке ассемблера директивы — это специальные инструкции. Они используются для предоставления дополнительной информации ассемблеру или компоновщику, а не выполняются как часть программы. Директивы обычно обозначают специальным символом, например точкой или решеткой.
📌 `SECTION`: эта директива нужна для определения разделов программы, которые используют для группировки связанного кода и данных вместе.
📌 `ORG`: чтобы установить исходный или начальный адрес программы или раздела.
📌 `EQU`: чтобы определить константы или символы, которые используют во всей программе.
📌 `DB`, `DW`, `DD`: для определения значений данных байтов, слов или двойных слов в памяти.
📌 `ALIGN`: для выравнивания ячейки памяти следующей инструкции или значения данных с указанной границей.
📌 `EXTERN`, `GLOBAL`: чтобы указать, определяется ли символ внешне или глобально. Эту информацию использует компоновщик для разрешения ссылок на символы в разных объектных файлах.
📌 `INCLUDE`: для включения файла кода на языке ассемблера в текущую программу.
Директивы помогают управлять структурой и организацией программы на языке ассемблера, указывать дополнительную информацию для создания конечной исполняемой программы.
💡 Команды
Команды языка ассемблера — основные строительные блоки программ. Эти инструкции используют, чтобы сообщить процессору, какие операции следует выполнять. В одних архитектурах сотни или тысячи различных инструкций, в других может быть всего несколько десятков.
Основные:
📌 Команды перемещения данных. Перемещают данные между регистрами или ячейками памяти: MOV, PUSH и POP.
📌 Арифметические команды. Выполняют арифметические операции с данными в регистрах или ячейках памяти: ADD, SUB и MUL.
📌 Логические команды. Выполняют логические операции с данными в регистрах или ячейках памяти: AND, OR и XOR.
📌 Команды ветвления. Управляют путем перехода к другому разделу кода: JMP, JZ и JE.
📌 Команды стека. Управляют стеком — областью памяти для хранения данных — и управляющей информацией во время вызовов функций и возвратов: PUSH и POP.
📌Системные вызовы. Позволяют программам на ассемблере взаимодействовать с операционной системой или другими системными функциями, такими как INT, которые запускают программное прерывание.
💡 Ассемблерный код
Примеры фрагментов кода ассемблера для архитектуры x86:
Hello World:
``` section .data msg db 'Hello, world!', 0 section .text global _start _start: mov eax, 4 ; System call for write mov ebx, 1 ; File descriptor for stdout mov ecx, msg ; Address of message to print mov edx, 13 ; Length of message int 0x80 ; Call kernel mov eax, 1 ; System call for exit xor ebx, ebx ; Exit code 0 int 0x80 ; Call kernel ```
Эта программа определяет строку сообщения в разделе .data, а затем использует инструкцию mov для настройки параметров системного вызова. Выводит на экран сообщения с помощью системного вызова записи. Затем программа завершается с кодом выхода 0.
Сумма двух чисел:
``` section .data a dw 5 b dw 7 section .text global _start _start: mov ax, [a] ; Load first number into AX add ax, [b] ; Add second number to AX mov cx, ax ; Save result in CX mov eax, 1 ; System call for exit xor ebx, ebx ; Exit code 0 int 0x80 ; Call kernel ```
Эта программа определяет два значения в разделе .data, а потом использует инструкции mov и add для вычисления суммы двух чисел и сохранения результата в регистре cx. Затем программа завершается с кодом выхода 0.
Программа для вычисления последовательности Фибоначчи:
``` section .data n dw 10 section .bss fib resw 10 section .text global _start _start: mov eax, [n] mov ebx, 0 mov ecx, 1 mov edx, 2 mov [fib+ebx], ecx .loop: cmp edx, eax jge .done add ecx, [fib+ebx] mov [fib+edx], ecx mov ebx, edx inc edx jmp .loop .done: mov eax, 1 xor ebx, ebx int 0x80 ```
Эта программа использует цикл для вычисления первых n чисел в последовательности Фибоначчи и сохранения их в массиве, в разделе .bss. Затем программа завершается с кодом выхода 0.
Достоинства и недостатки ассемблера
Преимущества
➕ Эффективность: программы на языке ассемблера можно оптимизировать для конкретной архитектуры — это делает их эффективными и быстрыми.
➕ Низкоуровневый контроль над аппаратными ресурсами: позволяет разработчикам писать программы, адаптированные к конкретным аппаратным требованиям.
➕ Небольшой размер кода: программы на языке ассемблера обычно меньше программ на языках более высокого уровня. Это важно в определенных встроенных системах или других средах с ограниченным объемом памяти.
➕ Переносимость: язык используют для написания кода, который можно скомпилировать для работы на разных платформах с соответствующими модификациями.
➕ Отладка: язык ассемблера полезен для отладки низкоуровневых проблем в программах или оборудовании.
Недостатки
➖ Сложность: язык ассемблера гораздо сложнее написать и понять, чем языки более высокого уровня. Программирование на ассемблере утомительно и занимает много времени: разработчики должны писать код даже для самых простых операций.
Сначала лучше изучать более популярные, универсальные и простые языки. Например, на курсе Skypro «Python-разработчик» изучите Python — его применяют на разных платформах и широко используют в разработке интернет-приложений, программного обеспечения и машинном обучении.
➖ Ограниченная абстракция: в языке нет многих абстракций и высокоуровневых конструкций — это затрудняет написание сложных программ.
➖ Сопровождение: программы на ассемблере трудно поддерживать, потому что изменения в аппаратном или программном обеспечении требуют значительных обновлений кода.
➖ Отладка: это еще и минус, потому что отладка кода на языке ассемблера сложная — проблемы низкого уровня трудно диагностировать и исправить.
Стоит ли изучать язык ассемблера
Это зависит от ваших целей и интересов. Если хотите писать высокопроизводительный код для конкретной аппаратной платформы или устройства, ассемблер полезен. Еще знания пригодятся для отладки низкоуровневых проблем в программах или оборудовании.
Но учитывайте, что язык ассемблера требует глубокого понимания компьютерной архитектуры и наборов инструкций. Учить его сложнее, чем языки более высокого уровня. Особенно если нет опыта в области компьютерных наук, вы еще не знакомы с архитектурой компьютера и концепциями низкоуровневого программирования.
Востребованы ли программисты на ассемблере сегодня
Программирование на языке assembler не так распространено, как раньше. Но всё еще есть отрасли и приложения, где он нужен. Например, встроенные системы, разработка операционных систем и реверс-инжиниринг.
Этот язык программирования используют только для максимально эффективной разработки, потому что команды работают с процессором или контроллером напрямую. То есть код ассемблера будет максимально быстро исполняться и четко работать.
Изучать его стоит, если вы планируете программировать микросхемы или писать эффективные программы для процессоров. Потому что писать программы на ассемблере трудоемко, а разрабатывать приложения с интерфейсами для пользователей бессмысленно.
На 13 марта 2023-го на хедхантере 50 075 вакансий программистов, а вакансий с упоминанием Assembler всего 244 по России — меньше 0,5%. Но с учетом тренда на импортозамещение спрос на таких программистов может вырасти.
Юрий Гизатуллин, руководитель и сооснователь digital-агентства TIQUM, сооснователь RB7.ru




Примеры вакансий на хедхантере с упоминанием ассемблера: зарплаты от 100 000 ₽ до 500 000 ₽
Главное: что такое ассемблер
- Ассемблер — это язык программирования низкого уровня. Он нужен для программирования микроконтроллеров или написания программ, которые работают с процессорами напрямую. Еще его используют для анализа двоичного кода, создания вирусов, оптимизации важных для производительности участков кода при разработке игр.
- Преимущества языка ассемблера: низкоуровневый контроль над аппаратными ресурсами, небольшой размер кода. Код ассемблера можно скомпилировать для работы на разных платформах с соответствующими модификациями. Язык ассемблера полезен для отладки низкоуровневых проблем в программах или оборудовании. Программы на языке ассемблера можно оптимизировать для конкретной архитектуры.
- Недостатки: в языке нет многих абстракций и высокоуровневых конструкций, его сложно изучать, а программы на ассемблере трудно поддерживать.

Оглавление:
Что это
Как работает
Зачем нужен
Кому нужен
Как устроен
Востребован ли в 2023
Подборка обучалок
Язык ассемблера (от англ. assembly language) — это императивный язык низкого уровня, который используется для представления команд CPU. При этом команды процессора остаются читабельными для программиста. Под термином «ассемблер» также может подразумеваться ПО, которое преобразует соответствующий исходный код в машинный код. Обратный процесс (конвертация машинного кода в ассемблер-код) выполняет дизассемблер.
Простыми словами, язык ассемблера — это низкоуровневый язык, позволяющий программисту обращаться непосредственно к процессору машины.
Схема функционирования
Как работает язык ассемблера
Это самый низкоуровневый человекочитаемый язык программирования. Сегодня он используется для точного управления процессором и памятью на «голом» железе. Важно отметить: нет единого языка ассемблера. Существует множество таких языков.
Языки разнятся в зависимости от архитектуры, на которой функционирует машина (например, x86, x32, ARM или PowerPC).
Assembly language позволяет работать с читаемым машинным байт-кодом, который выполняется компьютером напрямую.

Оригинальный assembly language для Motorola MC6800
Процессор и память
Компьютеры состоят из множества аппаратных средств. Самым важным из них является процессор (CPU), который способен выполнять вычисления. Процессор состоит из множества компонентов, например, схем для выполнения основных математических операций (ALU и FPU) и регистров. Регистры можно представить как небольшие ячейки, в которых хранится горстка небольших чисел.

Представление программной модели CPU
Помимо процессора, компьютер имеет и другие компоненты, такие как память (ОЗУ) и устройства ввода-вывода (такие как мышь, клавиатура, монитор и динамики). Для работы с этим оборудованием мы также можем использовать язык ассемблера.

Плашки оперативной памяти DDR4
Проблема в том, что процессор не понимает ассемблер. Слова и буквы типа «mov eax, 5» — ничего не значат для него. CPU понимает только двоичные числа, которые показывают ему то, что он должен делать со своим оборудованием. Это и есть машинный код. И у процессоров разных производителей свой набор таких чисел и команд.
Как это работает
Представьте, что у нас простой компьютер: он считывает три числа за один раз и далее решает, что делать. Первое прочитанное число — может сказать процессору, какую команду нужно выполнить. Например,
- 0 — сложить два числа вместе, используя аппаратное обеспечение ALU.
- 1 — поместить некоторое постоянное число в регистр.
- 2 — выполнить следующую команду, только если определенный регистр имеет определенное значение.
- 3 — заставить динамики воспроизвести звуковой сигнал.
- … и так далее.
Следующие два числа, которые считывает компьютер, могут сообщить ему аргументы команды. Например, когда он видит число 0, которое означает «сложить два числа», следующие два числа могут означать, какие именно два регистра компьютер должен сложить. Помните, регистры — это просто маленькие ячейки, в которых хранятся числа. Например:
0 [команда] 3 [первый аргумент] 1 [второй аргумент] — добавить число в регистре №3 к числу в регистре №1 и поместить ответ в специальный регистр №0
Мы, как создатели компьютера, просто решили, что при сложении — результат попадает в регистр №0 (нам так захотелось).
Запоминание того, какое число что делает — может надоесть, а программа, представляющая собой просто набор чисел — станет очень запутанной. Вместо этого — мы можем создать код на языке ассемблера, который поможет убить всех зайцев сразу. В нашем языке не будут использоваться только нули и единицы, а будут также команды add (добавить) и put (поместить). Например, так:
- add 3 1 = 0 3 1 (сложить регистры 3 и 1).
- put 7 3 = 1 7 3 (поместить число 7 в регистр 3).
- check 4 5 = 2 4 5 (проверить, что регистр 4 равен 5, и только в этом случае запустить следующую строку).
- beep = 3 0 0 — воспроизвести звуковой сигнал. Обратите внимание, что мы не используем вторые два числа: на ассемблере мы можем просто написать «beep». Всё!
Итак, у нас есть слова, соответствующие имеющимся командам. Затем мы используем программу, называемую ассемблером — она читает слова, написанные программистом на языке ассемблера, и преобразует их в числа машинного кода. Позже, программы обязательно станут еще более сложными и захочется писать на еще более читабельном языке. Тут и появится компилятор: он берет более сложный язык программирования и преобразует его в код на языке ассемблера, который затем преобразуется в машинный код ассемблером. Например, так:
- if (3 + 7 == 10) then beep() (код на высокоуровневом языке программирования).
- put 3 1 put 7 3 add 1 3 check 0 10 beep (код на языке ассемблера).
- 1 3 1 1 1 7 3 0 1 3 2 0 10 3 0 0 (машинный код).
Видите, как становится труднее читать код с каждым разом? Да, изначально наш компьютер и сам язык ассемблера были элементарными, но в конечном итоге все языки так усложняются . В них есть сотни команд, каждая из которых использует тот или иной аспект аппаратного обеспечения компьютера. Каждая команда представлена числами, а язык ассемблера — определяет красивый способ записи команд.
Так работает язык ассемблера
Разные производители процессоров по-разному сопоставляют числа с командами и, соответственно, имеют разные машинные коды и язык ассемблера. Эти версии называются различными компьютерными архитектурами.
Шестнадцатеричная система счисления также применяется в этих языках
Зачем нужен язык ассемблера и где он применяется
Этот язык — прямое представление фактического машинного языка, который понимает компьютер. В конечном итоге все, что делает компьютер, сводится к этому машинному языку.
Пример машинного кода программы на языке Java
Обычно разработчики применяют компиляторы или интерпретаторы, чтобы не приходилось осуществлять перевод команд вручную. Но, если вы сами захотите написать компилятор, то без понимания ассемблер-машины, сделать это не удастся.
Если вы работаете с ОС напрямую (либо — напрямую с драйверами устройств), без языка ассемблера не обойтись. Кроме того, переход на язык ассемблера может осуществляться по соображениям скорости / производительности. Сегодняшние компиляторы эффективно справляются с теми задачами для которых они разработаны. Но код во внутреннем цикле непосредственно для процессора, оперативной памяти или другого компонента машины — может быть оптимизирован гораздо эффективнее, чем при использовании компилятора.
Вот еще 5 сценариев, зачем нужен язык ассемблера:
- Доступ к специфическим аппаратным возможностям компьютера, которые являются очень редкими или нестандартными для конкретной платформы, чтобы компилятор выбранного языка мог их использовать или оптимизировать. Такая ситуация может возникать, например, если программирование осуществляется для конкретного оборудования (например, для конкретной модели видеокарты).
- Действительно важна производительность. Трудно превзойти компилятор языка C (например), но когда это необходимо — язык ассемблера действительно может помочь. Кроме того, это как правило единственный способ обогнать компилятор по быстродействию.
- Вы любопытны и хотите узнать, как работает компьютер на самом низком уровне. Assembly language практически напрямую связан с архитектурой аппаратного обеспечения. Поэтому, изучение assembly language — отличный способ узнать о том, как работает компьютер.
- Вы хотите лучше использовать дизассемблирование для отладки скомпилированных языков. Это справедливо для байткода Java и других битовых кодов LLVM.
- Вы самонадеянный новичок и наивно полагаете, что сможете победить хорошо оптимизированную (или даже не очень оптимизированную) программу на C, написав код на языке ассемблера.
Кому нужен язык ассемблера
Если вы заинтересованы в низкоуровневом программировании (в смысле операционных систем и драйверов устройств, а не в смысле «Hello, World»), встроенный ассемблерный код иногда включается в программы на языке C для выполнения тех задач, которые C не смог бы решить самостоятельно.
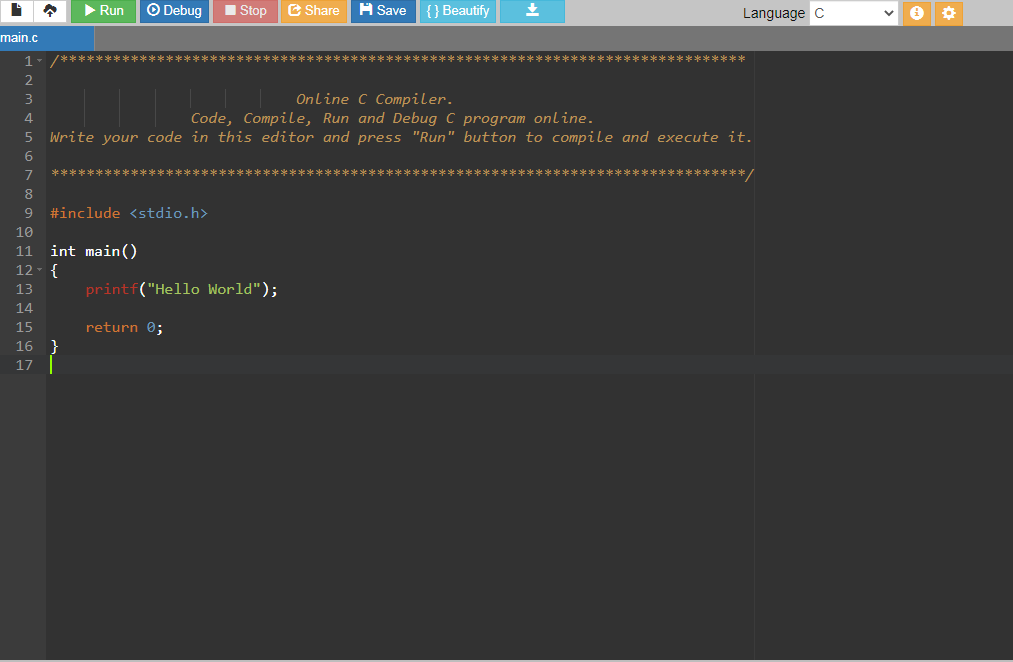
Этот компилятор языка C имеет графический интерфейс
Если вы интересуетесь проектированием микросхем или высокопроизводительными вычислениями, имея некоторое представление об ассемблере, вам будет гораздо легче понять, что происходит на самом деле (даже если вы не используете этот язык непосредственно для выполнения каких-либо действий).
Изучение этих языков — способ привить себе опыт в необходимости программировать очень тщательно, потому что здесь очень мало того, что язык может сделать за вас (в отличие от типичного компилятора).
Как устроен язык ассемблера: команды + пример
В очень упрощенном виде, исполняемый язык во время выполнения может быть приближен к следующему представлению:
[ label ] [ opcode [ operand [ ,operand [ ,operand ] ] ] ] [ ; comment ]Если перевести на русский язык, то получим такое представление:
[ метка ] [ опкод [ операнд [ , операнд [ , операнд ] ] ] ] [ ; комментарий ][ … ] — это необязательная часть строки.
Большинство ассемблеров допускают гораздо более гибкий синтаксис, в котором все или часть необязательных компонентов являются выражениями, оцениваемыми во время сборки, а также — реализуют более или менее сложные директивы, макросы, библиотеки и так далее. Так что синтаксис может быть довольно сложным.
Часто, opcode обозначает какой-либо стандартный оператор (ADD, OR …) в трехадресном наборе инструкций. Например, так:
opcode source 1, source 2, destination stands for или так:
source 1 opcode source 2 => destinationВ зависимости от архитектуры целевого процессора и набора инструкций, опкод может иметь от нуля до трех операндов. Вот примеры:
- NOP ; нет операции, не имеет операндов. Неявным является счетчик программы — он указывает на первую инструкцию после NOP.
- CLeaR operand ; 0 => operand.
- ADD D, S ; Destination <= Destination + Source (Место назначения <= Место назначения + Источник).
- ADD S0, S1, D ; Source0 + Source1 => Destination (Источник0 + Источник1 => Место назначения).
Еще примеры команд:
- ADD A, B — добавить число в ячейке памяти B к числу в ячейке A.
- MOVE B, C — переместить число в ячейке C в ячейку памяти B.
- Команды ADD и MOVE называются кодами команд или мнемониками.
Востребован ли сегодня ассемблер
Мы нашли специализированного программиста, который много лет работает с языками этого типа и задали ему простой вопрос: «Стоит ли изучать эти языки сегодня?». Ответ ниже:
«Нет. Как программист на языке ассемблера, я не думаю, что вам нужно его изучать (если только вы не окажетесь одним из немногих, кому он реально нужен). Или, если ваше интеллектуальное любопытство подтолкнет вас к этому языку, в таком случае — добро пожаловать в клуб. Таким образом, язык ассемблера — такой краеугольный навык, жизненно важный — лишь для единиц, интересный — чуть для большего количества программистов. Ну а для подавляющего большинства — он просто не нужен.
Язык ассемблера всегда будет где-то необходим. Является ли это гарантией того, что вы получите хорошую работу? Нет. Но и пустой тратой времени его изучение точно не будет».
Вот ещё несколько сценариев, когда этот язык точно понадобится:
- Когда вы беретесь за написание компилятора.
- Когда вы изучаете устройство процессора.
- При чтении внутренних частей ядра ОС.
- При изучении производительности компьютера.
- Портирование операционных систем на новые архитектуры
- Проектирование атомарных операций и примитивов синхронизации, блокировки и разблокировки и тому подобное.
- Написание генераторов кода компилятора.
- Написание высокопроизводительных математических библиотек и библиотек времени выполнения.
- Некоторые задачи цифровой обработки сигналов и коммуникаций.
- Программы ядра для использования с крайне низким энергопотреблением (AirPods и тому подобное).
Подборка книг и полезные видео
Напоследок — три книги, которые должен прочитать каждый, кто хочет научиться работать на этих языках:
-
Программирование на ассемблере на платформе x86-64, Руслан Аблязов.

Обложка книги «Программирование на ассемблере на платформе x86-64»
-
Профессиональное программирование на ассемблере x64 с расширениями AVX, AVX2 и AVX-512, Куссвюрм Даниэль.

Обложка книги «Профессиональное программирование на ассемблере x64 с расширениями AVX, AVX2 и AVX-512» -
Программирование на ассемблере х64. От начального уровня до профессионального использования AVX. Йо Ван Гуй.

Обложка книги «Программирование на ассемблере х64. От начального уровня до профессионального использования AVX»



Также обязательно посмотрите эти видео:
Assembly Language in 100 Seconds. Изучите основы Ассемблера с NASM за 100 секунд.
What is assembly language?. Краткое введение в язык ассемблера и то, как он может создавать машинный код.
What Is Assembly Language?. Язык ассемблера является основополагающим для работы компьютеров. Вкратце автор видео рассмотрит очень простой язык ассемблера и покажет, какое место он занимает в системе.
Why should I learn assembly language in 2020? (complete waste of time?). В этом видео вы найдёте ещё несколько важных причин изучать язык в 2023 году.
Is it worth learning assembly language today? | One Dev Question. Нужно ли разработчикам знать язык ассемблера в наше время? Ларри Остерман из Microsoft высказывает свое мнение.
Остались вопросы?
Укажите ваши данные, и мы вам перезвоним
Какой язык программирования называется низкоуровневым
Содержание:
- Низкоуровневый язык программирования — что под этим понимается
- Понятие, характеристики и назначение
-
Примеры таких языков, список популярных
- Ассемблер
- Forth
- С
- Преимущества и недостатки, в чем отличие от языков высокого уровня
- Будущее низкоуровневого программирования
Низкоуровневый язык программирования — что под этим понимается
Программирование – процесс создания компьютерных программ. Программирование представляет собой процесс перевода на компьютерный язык той задачи, которую требуется решить посредством вычислительной техники.
В первую очередь были созданы языки программирования низкого уровня, которые в дальнейшем сыграли роль базисов в процессе развития IT индустрии в целом. Выбор названия связан с непосредственным обращением с помощью команд к микропроцессору компьютера.
Особенностью любого процессора является восприятие определенного набора читаемых только им команд. Таким образом, для каждой модели компьютера были предназначены конкретные языки. Начальные модификации языков отличались минимальным набором команд. По сравнению с высокоуровневыми языками низкоуровневые аналоги не обладали таким большим количеством абстрактных классов и разнообразным синтаксисом.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
В настоящее время большой популярностью пользуются высокоуровневые языки программирования. Однако ранее, на первых этапах развития программирования, лидирующие позиции занимали языки низкого уровня. Сейчас низкоуровневые языки программирования продолжают активно применяться. Благодаря наличию таких инструментов, существуют возможности:
- написания драйверов на компьютерное «железо», периферийные устройства для подключения к компьютеру;
- создания операционных систем и ядер прошивок;
- решения других распространенных задач, управление конкретными устройствами и их параметрами в военной сфере, инженерии, медицине.
Перечень используемых языков никого уровня небольшой. Однако они актуальны в настоящее время и активно применяются для решения важных задач. Теории, на которых базируется низкоуровневое программирование:
- компьютерная архитектура;
- операционные системы.
Вначале был создан машинный код в виде первого языка программирования низкого уровня. Он представлял собой комплекс последовательных команд, передаваемых на процессор нулями и единицами. Нуль означал, что электрический сигнал на устройстве отсутствует. Единица являлась обозначением подачи на устройство какого-то импульса.
В результате с помощью потока сигналов процессор активизировался для решения поставленных задач. Например, первоначальные коды были предназначены для выполнения ЭВМ элементарных операций: таких, как арифметические вычисления, передача простейших данных от одного регистра к другому, сравнение разного числа кодов.
С течением времени задачи, которые могли решать языки программирования, усложнялись. Изменения касались увеличения количества команд и скорости их реализации. Для повышения эффективности и универсальности машинные коды разбивали на микропрограммы.
Понятие, характеристики и назначение
Определение
Низкоуровневым языком программирования называют язык, близкий к программированию непосредственно в машинных кодах эксплуатируемого реального или виртуального процессора.
В данном случае машинные команды обозначают с помощью мнемоники, в форме продуманных сокращений слов человеческого языка (обычно английских), а не в виде ряда из двоичных нулей и единиц. В некоторых случаях одному мнемоническому значению соответствует совокупность машинных команд, предназначенных для выполнения одинакового действия с разными ячейками памяти процессора.
Низкоуровневые языки программирования также могут обладать дополнительными возможностями, в том числе, макроопределения (или макросы). С помощью директив управляют трансляцией машинных кодов с занесением констант и литеральных строк, резервированием памяти для переменных и размещением исполняемого кода по конкретным адресам.
Благодаря этим языкам можно оперировать не конкретными, а переменными ячейками памяти. Работа осуществляется с учетом особенностей конкретного семейства процессоров.
Программы для первых компьютеров писались в двоичных машинных кодах, что представляло собой достаточно трудоемкую и сложную задачу. Упростить процесс позволили низкоуровневые языки программирования. С их помощью машинные команды приобрели более понятный вид. Функцию преобразования их в двоичный код выполняли особые программы (трансляторы) двух видов:
- компиляторы, необходимые для трансформации текста программы в машинный код, сохраняемый и затем используемый уже без компилятора, например файлы с расширением *.ехе;
- интерпретаторы, которые преобразуют частично программу в машинный код, выполняют и далее переходят к следующей части.
Программист, специализирующийся на написании алгоритма для компьютера на низкоуровневом языке, обращается напрямую к компьютерным ресурсам:
- процессору;
- памяти;
- периферийным устройствам.
Такой процесс гарантирует высокую скорость функционирования программ, что объясняется отсутствием скрытых фрагментов кода, добавляющих автоматически компилятор во время трансформации исходного кода в бинарный.
При использовании низкоуровневых языков за все ресурсы внутри компьютера, включая время загрузки процессора и выделяемую память, ответственен программист. В связи с этим языки низкого уровня считают небезопасными, что объясняется большим количеством ошибок в программном коде по сравнению с высокоуровневыми языками.
Низкоуровневое программирование используют для разработки компактного программного обеспечения: такого, как системы реального времени; микроконтроллер; драйверы, управляющие внешними устройствами (включая принтеры, сканеры, камеры).
Примеры таких языков, список популярных
Низкоуровневые языки программирования характеризуются достаточно объемной историей, однако распространение получили лишь некоторые из них. Такой выбор объясняется конкретным назначением каждого языка.
Ассемблер
Данный класс появился после машинных кодов. Его особенность заключается в более широком наборе команд, который может не соответствовать командам конкретной ЭВМ. Данное обстоятельство способствовало открытию новых возможностей. Ассемблер обладает рядом преимуществ по сравнению с машинным кодом:
- написание наиболее компактного кода, что обеспечивает быстродействие машины;
- хранение в оперативной памяти части реализованной задачи и применение ее при необходимости;
- широкий спектр функций при низкой ресурсоемкости.
Указанные достоинства являются основными из списка. Примеры кода рассматриваемого семейства в настоящее время активно применяют в образовании, так как это эффективный способ обучения процессу взаимодействия с микропроцессорами.
Forth
Данный язык из класса низкоуровневых был создан примерно в 70-х годах XX века. Forth характеризуется рядом достоинств, благодаря которым завоевал популярность среди специалистов определенных сфер. В то время машинные языки программирования эксплуатировались все реже, а Форт оценили по достоинству многие.
Программисты, обладающие знаниями архитектуры процессора, с его помощью могли написать ядро для устройства в течение нескольких дней. Опытные специалисты, применяя в работе Forth, получают возможности для реализации самых оригинальных идей.
С
Данный язык является наиболее известным и часто используемым в программировании с 70-х годов XX столетия. Структура данного языка похожа на структуру машинного и ассемблера. В связи с этим, Си активно применяют в процессе создания операционных систем, драйверов, системного программного обеспечения.
Нередко данный тип относят к языкам высокого уровня, однако, согласно определению, он относится к низкоуровневым языкам. Отнесение языка к той или иной группе определяется его назначением. Исходя из набора поддерживаемых команд, Си можно сопоставить с языками низкого уровня.
Преимущества и недостатки, в чем отличие от языков высокого уровня
Низкоуровневые языки обычно применяют для создания системных программ небольшого объема, драйверных устройств, стыковых модулей для нестандартного оборудования, в процессе программирования специальных микропроцессоров. Это оптимальное решение в тех случаях, когда в приоритете такие качества, как компактность, быстродействие, обеспечение прямого доступа к аппаратным ресурсам.
Преимущества языков низкого уровня:
- возможность создания эффективных программ;
- компактность;
- доступ ко всем возможностям процессора.
Недостатки низкоуровневых языков:
- высокие требования к квалификации программиста;
- необходимость в понимании устройства микропроцессорной системы, для которой предполагается написание программы;
- отсутствие возможности для переноса результирующей программы на компьютер или устройство, отличающееся типом процессора;
- на разработку больших и сложных программ необходимо затратить много времени.
Так как программы, созданные на языке низкого уровня, не требуют интерпретации или компиляции, они характеризуются большей скоростью по сравнению с аналогами, написанными на средне- и высокоуровневых языках. В этом случае программы взаимодействуют напрямую с регистрами и памятью. Низкоуровневые языки отличаются от других высокой эффективностью, что можно объяснить потреблением меньшего объема памяти.
С точки зрения работы с языком, низкоуровневые типы характеризуются повышенной сложностью. Программисты нередко испытывают трудности с бинарным кодом и мнемоникой. Языки низкого уровня более технические по сравнению с другими, так как конкретная инструкция пишется под определенную архитектуру компьютера.
В связи с зависимостью от машин, низкоуровневые языки менее портируемые в отличие от средне- и высокоуровневых. Такое понятие, как абстракция, является отношением между языком и аппаратной частью компьютера. В случае с языками низкого уровня данный показатель минимален, либо отсутствует.
Будущее низкоуровневого программирования
Языки низкого уровня характеризуются рядом преимуществ и не лишены недостатков. Однако у низкоуровневого программирования есть предпосылки для дальнейшего развития. К примеру, ассемблер будет востребован до тех пор, пока существуют разнотипные процессоры.
Программисты, обладающие соответствующими знаниями данного языка, могут достаточно просто оптимизировать написанный на нем код. Подобные знания упрощают понимание архитектуры компьютера и функционирования его аппаратной части, что гарантирует грамотное написание программного обеспечения.
Снижение популярности ассемблера объясняется эволюцией в области программирования. Сегодня в приоритете скорость разработки и надежность, что отличает высокоуровневые языки. Такое положение дел не исключает востребованность ассемблера в будущем. Причинами увеличения спроса на него могут послужить достаточно низкая себестоимость и высокое быстродействие, что важно при решении ряда специализированных задач.
Примечание
Не так давно была разработана новая типобезопасная версия языка низкого уровня Форт. Язык Factor создал Слава Пестов и работает над его развитием.
Сам Форт также обладает потенциалом. Это оптимальное решение для создания мультиплатформенных систем, включая операционные системы и системы программирования. Возможно, данный язык займет в будущем какую-либо значимую нишу, благодаря своей уникальной особенности. Она заключается во внутреннем устройстве в виде «шитого кода», который отличается простотой, дешевизной и эффективностью байт-кодов.
Также современная IT индустрия не готова отказаться от языка низкого уровня С. Это простой, портированный на десятки платформ и стандартизированный низкоуровневый язык, который достаточно востребован в настоящее время. В дальнейшем его принципы могут быть использованы для создания новых языков.