Запрос «ЦП» перенаправляется сюда; см. также другие значения.

![]()
Intel Celeron 1100 Socket 370 в корпусе FC-PGA2, вид снизу

![]()
Intel Celeron 1100 Socket 370 в корпусе FC-PGA2, вид сверху
Центра́льный проце́ссор (ЦП; также центральное процессорное устройство — ЦПУ; англ. central processing unit, CPU, дословно — центральное обрабатывающее устройство) — электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (код программ), главная часть аппаратного обеспечения компьютера или программируемого логического контроллера. Иногда называют микропроцессором или просто процессором.
Изначально термин центральное процессорное устройство описывал специализированный класс логических машин, предназначенных для выполнения сложных компьютерных программ. Вследствие довольно точного соответствия этого назначения функциям существовавших в то время компьютерных процессоров, он естественным образом был перенесён на сами компьютеры. Начало применения термина и его аббревиатуры по отношению к компьютерным системам было положено в 1960-е годы. Устройство, архитектура и реализация процессоров с тех пор неоднократно менялись, однако их основные исполняемые функции остались теми же, что и прежде.
Главными характеристиками ЦПУ являются: тактовая частота, производительность, энергопотребление, нормы литографического процесса используемого при производстве (для микропроцессоров) и архитектура.
Ранние ЦП создавались в виде уникальных составных частей для уникальных, и даже единственных в своём роде, компьютерных систем. Позднее от дорогостоящего способа разработки процессоров, предназначенных для выполнения одной единственной или нескольких узкоспециализированных программ, производители компьютеров перешли к серийному изготовлению типовых классов многоцелевых процессорных устройств. Тенденция к стандартизации компьютерных комплектующих зародилась в эпоху бурного развития полупроводниковых элементов, мейнфреймов и миникомпьютеров, а с появлением интегральных схем она стала ещё более популярной. Создание микросхем позволило ещё больше увеличить сложность ЦП с одновременным уменьшением их физических размеров. Стандартизация и миниатюризация процессоров привели к глубокому проникновению основанных на них цифровых устройств в повседневную жизнь человека. Современные процессоры можно найти не только в таких высокотехнологичных устройствах, как компьютеры, но и в автомобилях, калькуляторах, мобильных телефонах и даже в детских игрушках. Чаще всего они представлены микроконтроллерами, где помимо вычислительного устройства на кристалле расположены дополнительные компоненты (память программ и данных, интерфейсы, порты ввода/вывода, таймеры и др.). Современные вычислительные возможности микроконтроллера сравнимы с процессорами персональных ЭВМ десятилетней давности, а чаще даже значительно превосходят их показатели.
Содержание
- 1 История
- 1.1 Перспективы
- 2 Архитектура фон Неймана
- 2.1 Конвейерная архитектура
- 2.2 Суперскалярная архитектура
- 2.3 CISC-процессоры
- 2.4 RISC-процессоры
- 2.5 MISC-процессоры
- 2.6 VLIW-процессоры
- 2.7 Многоядерные процессоры
- 2.8 Кэширование
- 3 Гарвардская архитектура
- 4 Параллельная архитектура
- 4.1 Цифровые сигнальные процессоры
- 5 Процесс изготовления
- 5.1 Энергопотребление процессоров
- 5.2 Тепловыделение процессоров и отвод тепла
- 5.3 Измерение и отображение температуры микропроцессора
- 6 Производители
- 6.1 СССР/Россия
- 6.2 Китай
- 6.3 Япония
- 7 Определение модели
- 8 См. также
- 9 Примечания
- 10 Литература
- 11 Ссылки
История
История развития производства процессоров полностью соответствует истории развития технологии производства прочих электронных компонентов и схем.
Первым этапом, затронувшим период с 1940-х по конец 1950-х годов, было создание процессоров с использованием электромеханических реле, ферритовых сердечников (устройств памяти) и вакуумных ламп. Они устанавливались в специальные разъёмы на модулях, собранных в стойки. Большое количество таких стоек, соединённых проводниками, в сумме представляли процессор. Отличительной особенностью была низкая надёжность, низкое быстродействие и большое тепловыделение.
Вторым этапом, с середины 1950-х до середины 1960-х, стало внедрение транзисторов. Транзисторы монтировались уже на близкие к современным по виду платам, устанавливаемым в стойки. Как и ранее, в среднем процессор состоял из нескольких таких стоек. Возросло быстродействие, повысилась надёжность, уменьшилось энергопотребление.
Третьим этапом, наступившим в середине 1960-х годов, стало использование микросхем. Первоначально использовались микросхемы низкой степени интеграции, содержащие простые транзисторные и резисторные сборки, затем по мере развития технологии стали использоваться микросхемы, реализующие отдельные элементы цифровой схемотехники (сначала элементарные ключи и логические элементы, затем более сложные элементы — элементарные регистры, счётчики, сумматоры), позднее появились микросхемы, содержащие функциональные блоки процессора — микропрограммное устройство, арифметическо-логическое устройство, регистры, устройства работы с шинами данных и команд.
Четвёртым этапом, в начале 1970-х годов, стало создание, благодаря прорыву в технологии создания БИС и СБИС (больших и сверхбольших интегральных схем, соответственно), микропроцессора — микросхемы, на кристалле которой физически были расположены все основные элементы и блоки процессора. Фирма Intel в 1971 году создала первый в мире 4-разрядный микропроцессор 4004, предназначенный для использования в микрокалькуляторах. Постепенно практически все процессоры стали выпускаться в формате микропроцессоров. Исключением долгое время оставались только малосерийные процессоры, аппаратно оптимизированные для решения специальных задач (например, суперкомпьютеры или процессоры для решения ряда военных задач), либо процессоры, к которым предъявлялись особые требования по надёжности, быстродействию или защите от электромагнитных импульсов и ионизирующей радиации. Постепенно, с удешевлением и распространением современных технологий, эти процессоры также начинают изготавливаться в формате микропроцессора.
Сейчас слова микропроцессор и процессор практически стали синонимами, но тогда это было не так, потому что обычные (большие) и микропроцессорные ЭВМ мирно сосуществовали ещё по крайней мере 10-15 лет, и только в начале 1980-х годов микропроцессоры вытеснили своих старших собратьев. Тем не менее, центральные процессорные устройства некоторых суперкомпьютеров даже сегодня представляют собой сложные комплексы, построенные на основе микросхем большой и сверхбольшой степени интеграции.
Переход к микропроцессорам позволил потом создать персональные компьютеры, которые проникли почти в каждый дом.
Первым общедоступным микропроцессором был 4-разрядный Intel 4004, представленный 15 ноября 1971 года корпорацией Intel. Он содержал 2300 транзисторов, работал на тактовой частоте 92,6 кГц[1] и стоил 300 долл.
Далее его сменили 8-разрядный Intel 8080 и 16-разрядный 8086, заложившие основы архитектуры всех современных настольных процессоров. Из-за распространённости 8-разрядных модулей памяти был выпущен дешевый 8088, упрощенная версия 8086, с 8-разрядной шиной памяти.
Затем проследовала его модификация 80186.
В процессоре 80286 появился защищённый режим с 24-битной адресацией, позволявший использовать до 16 Мб памяти.
Процессор Intel 80386 появился в 1985 году и привнёс улучшенный защищённый режим, 32-битную адресацию, позволившую использовать до 4 Гб оперативной памяти и поддержку механизма виртуальной памяти. Эта линейка процессоров построена на регистровой вычислительной модели.
Параллельно развиваются микропроцессоры, взявшие за основу стековую вычислительную модель.
За годы существования микропроцессоров было разработано множество различных их архитектур. Многие из них (в дополненном и усовершенствованном виде) используются и поныне. Например Intel x86, развившаяся вначале в 32-битную IA-32, а позже в 64-битную x86-64 (которая у Intel называется EM64T). Процессоры архитектуры x86 вначале использовались только в персональных компьютерах компании IBM (IBM PC), но в настоящее время всё более активно используются во всех областях компьютерной индустрии, от суперкомпьютеров до встраиваемых решений. Также можно перечислить такие архитектуры как Alpha, POWER, SPARC, PA-RISC, MIPS (RISC-архитектуры) и IA-64 (EPIC-архитектура).
В современных компьютерах процессоры выполнены в виде компактного модуля (размерами около 5×5×0,3 см), вставляющегося в ZIF-сокет (AMD) или на подпруживающую конструкцию — LGA (Intel). Особенностью разъёма LGA является то, что выводы перенесены с корпуса процессора на сам разъём — socket, находящийся на материнской плате. Большая часть современных процессоров реализована в виде одного полупроводникового кристалла, содержащего миллионы, а с недавнего времени даже миллиарды транзисторов.
Перспективы
В ближайшие 10-20 лет, скорее всего, изменится материальная часть процессоров ввиду того, что технологический процесс достигнет физических пределов производства. Возможно, это будут:
- Оптические компьютеры — в которых вместо электрических сигналов обработке подвергаются потоки света (фотоны, а не электроны).
- Квантовые компьютеры, работа которых всецело базируется на квантовых эффектах. В настоящее время ведутся работы над созданием рабочих версий квантовых процессоров.
- Молекулярные компьютеры — вычислительные системы, использующие вычислительные возможности молекул (преимущественно, органических). Молекулярными компьютерами используется идея вычислительных возможностей расположения атомов в пространстве.
Архитектура фон Неймана
Большинство современных процессоров для персональных компьютеров в общем основаны на той или иной версии циклического процесса последовательной обработки данных, изобретённого[источник не указан 507 дней] Джоном фон Нейманом.
Дж. фон Нейман придумал[источник не указан 507 дней] схему постройки компьютера в 1946 году.
Отличительной особенностью архитектуры фон Неймана является то, что инструкции и данные хранятся в одной и той же памяти.
В различных архитектурах и для различных команд могут потребоваться дополнительные этапы. Например, для арифметических команд могут потребоваться дополнительные обращения к памяти, во время которых производится считывание операндов и запись результатов.
Этапы цикла выполнения:
- Процессор выставляет число, хранящееся в регистре счётчика команд, на шину адреса и отдаёт памяти команду чтения.
- Выставленное число является для памяти адресом; память, получив адрес и команду чтения, выставляет содержимое, хранящееся по этому адресу, на шину данных и сообщает о готовности.
- Процессор получает число с шины данных, интерпретирует его как команду (машинную инструкцию) из своей системы команд и исполняет её.
- Если последняя команда не является командой перехода, процессор увеличивает на единицу (в предположении, что длина каждой команды равна единице) число, хранящееся в счётчике команд; в результате там образуется адрес следующей команды.
Данный цикл выполняется неизменно, и именно он называется процессом (откуда и произошло название устройства).
Во время процесса процессор считывает последовательность команд, содержащихся в памяти, и исполняет их. Такая последовательность команд называется программой и представляет алгоритм работы процессора. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода, — тогда адрес следующей команды может оказаться другим. Другим примером изменения процесса может служить случай получения команды остановка или переключение в режим обработки прерывания.
Команды центрального процессора являются самым нижним уровнем управления компьютером, поэтому выполнение каждой команды неизбежно и безусловно. Не производится никакой проверки на допустимость выполняемых действий, в частности, не проверяется возможная потеря ценных данных. Чтобы компьютер выполнял только допустимые действия, команды должны быть соответствующим образом организованы в виде необходимой программы.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора. Частота тактовых импульсов называется тактовой частотой.
Конвейерная архитектура
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифровка команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер микропроцессора с архитектурой MIPS-I содержит четыре стадии:
- получение и декодирование инструкции,
- адресация и выборка операнда из ОЗУ,
- выполнение арифметических операций,
- сохранение результата операции.
После освобождения  -й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в
-й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в  ступеней займёт единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени.
ступеней займёт единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени.
Действительно, при отсутствии конвейера выполнение команды займёт единиц времени (так как для выполнения команды по-прежнему необходимо выполнять выборку, дешифровку и т. д.), и для исполнения  команд понадобится
команд понадобится  единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения команд понадобится всего лишь
единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения команд понадобится всего лишь  единиц времени.
единиц времени.
Факторы, снижающие эффективность конвейера:
- Простой конвейера, когда некоторые ступени не используются (например, адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами).
- Ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд — out-of-order execution).
- Очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что повышает производительность процессора, но, однако, приводит к увеличению длительности простоя (например, в случае ошибки в предсказании условного перехода). Не существует единого мнения по поводу оптимальной длины конвейера: различные программы могут иметь существенно различные требования.
Суперскалярная архитектура
Способность выполнения нескольких машинных инструкций за один такт процессора путем увеличения числа исполнительных устройств. Появление этой технологии привело к существенному увеличению производительности, в то же время существует определенный предел роста числа исполнительных устройств, при превышении которого производительность практически перестает расти, а исполнительные устройства простаивают. Частичным решением этой проблемы являются, например, технология Hyper-threading.
CISC-процессоры
Complex instruction set computer — вычисления со сложным набором команд. Процессорная архитектура, основанная на усложнённом наборе команд. Типичными представителями CISC являются микропроцессоры семейства x86 (хотя уже много лет эти процессоры являются CISC только по внешней системе команд: в начале процесса исполнения сложные команды разбиваются на более простые микрооперации (МОП), исполняемые RISC-ядром).
RISC-процессоры
Reduced instruction set computer — вычисления с упрощённым набором команд (в литературе слово reduced нередко ошибочно переводят как «сокращённый»). Архитектура процессоров, построенная на основе упрощённого набора команд, характеризуется наличием команд фиксированной длины, большого количества регистров, операций типа регистр-регистр, а также отсутствием косвенной адресации. Концепция RISC разработана Джоном Коком из IBM Research, название придумано Дэвидом Паттерсоном (David Patterson).
Упрощение набора команд призвано сократить конвейер, что позволяет избежать задержек на операциях условных и безусловных переходов. Однородный набор регистров упрощает работу компилятора при оптимизации исполняемого программного кода. Кроме того, RISC-процессоры отличаются меньшим энергопотреблением и тепловыделением.
Среди первых реализаций этой архитектуры были процессоры MIPS, PowerPC, SPARC, Alpha, PA-RISC. В мобильных устройствах широко используются ARM-процессоры.
MISC-процессоры
Minimum instruction set computer — вычисления с минимальным набором команд. Дальнейшее развитие идей команды Чака Мура, который полагает, что принцип простоты, изначальный для RISC-процессоров, слишком быстро отошёл на задний план. В пылу борьбы за максимальное быстродействие, RISC догнал и перегнал многие CISC процессоры по сложности. Архитектура MISC строится на стековой вычислительной модели с ограниченным числом команд (примерно 20-30 команд).
VLIW-процессоры
Very long instruction word — сверхдлинное командное слово. Архитектура процессоров с явно выраженным параллелизмом вычислений, заложенным в систему команд процессора. Являются основой для архитектуры EPIC. Ключевым отличием от суперскалярных CISC-процессоров является то, что для них загрузкой исполнительных устройств занимается часть процессора (планировщик), на что отводится достаточно малое время, в то время как загрузкой вычислительных устройств для VLIW-процессора занимается компилятор, на что отводится существенно больше времени (качество загрузки и, соответственно, производительность теоретически должны быть выше). Примером VLIW-процессора является Intel Itanium.
Многоядерные процессоры
|
|
Информация в этой статье или некоторых её разделах устарела.
Вы можете помочь проекту, обновив её и убрав после этого данный шаблон. |
Содержат несколько процессорных ядер в одном корпусе (на одном или нескольких кристаллах).
Процессоры, предназначенные для работы одной копии операционной системы на нескольких ядрах, представляют собой высокоинтегрированную реализацию мультипроцессорности.
Первым многоядерным микропроцессором стал POWER4 от IBM, появившийся в 2001 году и имевший два ядра.
В октябре 2004 года Sun Microsystems выпустила двухъядерный процессор UltraSPARC IV, который состоял из двух модифицированных ядер UltraSPARC III. В начале 2005 был создан двухъядерный UltraSPARC IV+.
14 ноября 2005 года Sun выпустила восьмиядерный UltraSPARC T1, каждое ядро которого выполняло 4 потока.
5 января 2006 года Intel представила первый двухъядерный процессор на одном кристале Core Duo, для мобильной платформы.
В ноябре 2006 года вышел первый четырёхъядерный процессор Intel Core 2 Quad на ядре Kentsfield, представляющий собой сборку из двух кристаллов Conroe в одном корпусе. Потомком этого процессора стал Intel Core 2 Quad на ядре Yorkfield (45 нм), архитектурно схожем с Kentsfield но имеющем больший объём кэша и рабочие частоты.
В октябре 2007 года в продаже появились восьмиядерные UltraSPARC T2, каждое ядро выполняло 8 потоков.
10 сентября 2007 года были выпущены в продажу нативные (в виде одного кристалла) четырёхъядерные процессоры для серверов AMD Opteron, имевшие в процессе разработки кодовое название AMD Opteron Barcelona.[2] 19 ноября 2007 года вышел в продажу четырёхъядерный процессор для домашних компьютеров AMD Phenom.[3] Эти процессоры реализуют новую микроархитектуру K8L (K10).
Компания AMD пошла по собственному пути, изготовляя четырёхъядерные процессоры единым кристаллом (в отличие от Intel, первые четырёхъядерные процессоры которой представляют собой фактически склейку двух двухъядерных кристаллов). Несмотря на всю прогрессивность подобного подхода первый «четырёхъядерник» фирмы, получивший название AMD Phenom X4, получился не слишком удачным. Его отставание от современных ему процессоров конкурента составляло от 5 до 30 и более процентов в зависимости от модели и конкретных задач[источник не указан 1184 дня].
К 1-2 кварталу 2009 года обе компании обновили свои линейки четырёхъядерных процессоров. Intel представила семейство Core i7, состоящее из трёх моделей, работающих на разных частотах. Основными изюминками данного процессора является использование трёхканального контроллера памяти (типа DDR3) и технологии эмулирования восьми ядер (полезно для некоторых специфических задач). Кроме того, благодаря общей оптимизации архитектуры удалось значительно повысить производительность процессора во многих типах задач. Слабой стороной платформы, использующей Core i7, является её чрезмерная стоимость, так как для установки данного процессора необходима дорогая материнская плата на чипсете Intel X58 и трёхканальный набор памяти типа DDR3, также имеющий на данный момент высокую стоимость.
Компания AMD в свою очередь представила линейку процессоров Phenom II X4. При её разработке компания учла свои ошибки: был увеличен объём кэша (по сравнению с первым поколением Phenom), процессоры стали изготавливаться по 45-нм техпроцессу (это, соответственно, позволило снизить тепловыделение и значительно повысить рабочие частоты). В целом, AMD Phenom II X4 по производительности стоит вровень с процессорами Intel предыдущего поколения (ядро Yorkfield) и весьма значительно отстаёт от Intel Core i7[источник не указан 1193 дня]. С выходом 6-ядерного процессора AMD Phenom II X6 Black Thuban 1090T ситуация немного изменилась в пользу AMD.
На данный момент[когда?] массово доступны процессоры с 2, 3, 4 и 6 ядрами, а также 2, 3 и 4-модульные процессоры AMD поколения Bulldozer. В серверном сегменте также доступны 8-ядерные процессоры Xeon и Nehalem (Intel) и 12-ядерные Opteron (AMD).[4]
Кэширование
Кэширование — это использование дополнительной быстродействующей памяти (кэша, англ. cache) для хранения копий блоков информации из основной (оперативной) памяти, вероятность обращения к которым в ближайшее время велика.
Различают кэши 1-, 2- и 3-го уровней (обозначаются L1, L2 и L3 — от Level 1, Level 2 и Level 3). Кэш 1-го уровня имеет наименьшую латентность (время доступа), но малый размер, кроме того, кэши первого уровня часто делаются многопортовыми. Так, процессоры AMD K8 умели производить одновременно 64-битные запись и чтение, либо два 64-битных чтения за такт, AMD K8L может производить два 128-битных чтения или записи в любой комбинации. Процессоры Intel Core 2 могут производить 128-битные запись и чтение за такт. Кэш 2-го уровня обычно имеет значительно большую латентность доступа, но его можно сделать значительно больше по размеру. Кэш 3-го уровня самый большой по объёму и довольно медленный, но всё же он гораздо быстрее, чем оперативная память.
Гарвардская архитектура
Гарвардская архитектура отличается от архитектуры фон Неймана тем, что программный код и данные хранятся в разной памяти. В такой архитектуре невозможны многие методы программирования (например, программа не может во время выполнения менять свой код; невозможно динамически перераспределять память между программным кодом и данными); зато гарвардская архитектура позволяет более эффективно выполнять работу в случае ограниченных ресурсов, поэтому она часто применяется во встраиваемых системах.
Параллельная архитектура
Архитектура фон Неймана обладает тем недостатком, что она последовательная. Какой бы огромный массив данных ни требовалось обработать, каждый его байт должен будет пройти через центральный процессор, даже если над всеми байтами требуется провести одну и ту же операцию. Этот эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и предлагаются архитектуры процессоров, которые называются параллельными. Параллельные процессоры используются в суперкомпьютерах.
Возможными вариантами параллельной архитектуры могут служить (по классификации Флинна):
- SISD — один поток команд, один поток данных;
- SIMD — один поток команд, много потоков данных;
- MISD — много потоков команд, один поток данных;
- MIMD — много потоков команд, много потоков данных.
Цифровые сигнальные процессоры
Для цифровой обработки сигналов, особенно при ограниченном времени обработки, применяют специализированные высокопроизводительные сигнальные микропроцессоры (DSP) с параллельной архитектурой.
Процесс изготовления
Первоначально перед разработчиками ставится техническое задание, исходя из которого принимается решение о том, какова будет архитектура будущего процессора, его внутреннее устройство, технология изготовления. Перед различными группами ставится задача разработки соответствующих функциональных блоков процессора, обеспечения их взаимодействия, электромагнитной совместимости. В связи с тем, что процессор фактически является цифровым автоматом, полностью отвечающим принципам булевой алгебры, с помощью специализированного программного обеспечения, работающего на другом компьютере, строится виртуальная модель будущего процессора. На ней проводится тестирование процессора, исполнение элементарных команд, значительных объёмов кода, отрабатывается взаимодействие различных блоков устройства, ведётся оптимизация, ищутся неизбежные при проекте такого уровня ошибки.
После этого из цифровых базовых матричных кристаллов и микросхем, содержащих элементарные функциональные блоки цифровой электроники, строится физическая модель процессора, на которой проверяются электрические и временные характеристики процессора, тестируется архитектура процессора, продолжается исправление найденных ошибок, уточняются вопросы электромагнитной совместимости (например, при практически рядовой тактовой частоте в 10 ГГц отрезки проводника длиной в 7 мм уже работают как излучающие или принимающие антенны).
Затем начинается этап совместной работы инженеров-схемотехников и инженеров-технологов, которые с помощью специализированного программного обеспечения преобразуют электрическую схему, содержащую архитектуру процессора, в топологию кристалла. Современные системы автоматического проектирования позволяют, в общем случае, из электрической схемы напрямую получить пакет трафаретов для создания масок. На этом этапе технологи пытаются реализовать технические решения, заложенные схемотехниками, с учётом имеющейся технологии. Этот этап является одним из самых долгих и сложных в разработке и иногда требует компромиссов со стороны схемотехников по отказу от некоторых архитектурных решений. Следует отметить, что ряд производителей заказных микросхем (foundry) предлагает разработчикам (дизайн-центру или fabless) компромиссное решение, при котором на этапе конструирования процессора используются представленные ими стандартизованные в соответствии с имеющейся технологией библиотеки элементов и блоков (Standard cell). Это вводит ряд ограничений на архитектурные решения, зато этап технологической подгонки фактически сводится к игре в конструктор «Лего». В общем случае, изготовленные по индивидуальным проектам микропроцессоры являются более быстрыми по сравнению с процессорами, созданными на основании имеющихся библиотек.
Следующим, после этапа проектирования, является создание прототипа кристалла микропроцессора. При изготовлении современных сверхбольших интегральных схем используется метод литографии. При этом, на подложку будущего микропроцессора (тонкий круг из монокристаллического кремния, либо сапфира) через специальные маски, содержащие прорези, поочерёдно наносятся слои проводников, изоляторов и полупроводников. Соответствующие вещества испаряются в вакууме и осаждаются сквозь отверстия маски на кристалле процессора. Иногда используется травление, когда агрессивная жидкость разъедает не защищённые маской участки кристалла. Одновременно на подложке формируется порядка сотни процессорных кристаллов. В результате появляется сложная многослойная структура, содержащая от сотен тысяч до миллиардов транзисторов. В зависимости от подключения транзистор работает в микросхеме как транзистор, резистор, диод или конденсатор. Создание этих элементов на микросхеме отдельно, в общем случае, не выгодно. После окончания процедуры литографии подложка распиливается на элементарные кристаллы. К сформированным на них контактным площадкам (из золота) припаиваются тонкие золотые проводники, являющиеся переходниками к контактным площадкам корпуса микросхемы. Далее, в общем случае, крепится теплоотвод кристалла и крышка микросхемы.
Затем начинается этап тестирования прототипа процессора, когда проверяется его соответствие заданным характеристикам, ищутся оставшиеся незамеченными ошибки. Только после этого микропроцессор запускается в производство. Но даже во время производства идёт постоянная оптимизация процессора, связанная с совершенствованием технологии, новыми конструкторскими решениями, обнаружением ошибок.
Следует отметить, что параллельно с разработкой универсальных микропроцессоров, разрабатываются наборы периферийных схем ЭВМ, которые будут использоваться с микропроцессором и на основе которых создаются материнские платы. Разработка микропроцессорного набора (чипсета, англ. chipset) представляет задачу, не менее сложную, чем создание собственно микросхемы микропроцессора.
В последние несколько лет наметилась тенденция переноса части компонентов чипсета (контроллер памяти, контроллер шины PCI Express) в состав процессора (подробнее см.: Система на кристалле).
Энергопотребление процессоров
С технологией изготовления процессора тесно связано и его энергопотребление.
Первые процессоры архитектуры x86 потребляли мизерное (по современным меркам) количество энергии, составляющее доли ватта. Увеличение количества транзисторов и повышение тактовой частоты процессоров привело к существенному росту данного параметра. Наиболее производительные модели требуют до 130 и более ватт. Несущественный на первых порах фактор энергопотребления, сейчас оказывает серьёзное влияние на эволюцию процессоров:
- совершенствование технологии производства для уменьшения потребления, поиск новых материалов для снижения токов утечки, понижение напряжения питания ядра процессора;
- появление сокетов (разъемов для процессоров) с большим числом контактов (более 1000), большинство которых предназначено для питания процессора. Так у процессоров для популярного сокета LGA775 число контактов основного питания составляет 464 штуки (около 60 % от общего количества);
- изменение компоновки процессоров. Кристалл процессора переместился с внутренней на внешнюю сторону, для лучшего отвода тепла к радиатору системы охлаждения;
- интеграция в кристалл температурных датчиков и системы защиты от перегрева, снижающей частоту процессора или вообще останавливающей его при недопустимом увеличении температуры;
- появление в новейших процессорах интеллектуальных систем, динамически меняющих напряжение питания, частоту отдельных блоков и ядер процессора, и отключающих не используемые блоки и ядра;
- появление энергосберегающих режимов для «засыпания» процессора, при низкой нагрузке.
Тепловыделение процессоров и отвод тепла
Для теплоотвода от микропроцессоров применяются пассивные радиаторы и активные кулеры.
Измерение и отображение температуры микропроцессора
Для измерения температуры микропроцессора, обычно внутри микропроцессора, в области центра крышки микропроцессора устанавливается датчик температуры микропроцессора. В микропроцессорах Intel датчик температуры — термодиод или транзистор с замкнутыми коллектором и базой в качестве термодиода, в микропроцессорах AMD — терморезистор.
Производители
Наиболее популярные процессоры сегодня производят фирмы Intel, AMD и IBM.
Большинство процессоров, используемых в настоящее время, являются Intel-совместимыми, то есть имеют набор инструкций и интерфейсы программирования, сходные с используемыми в процессорах компании Intel.
Среди процессоров от Intel: 8086, i286, i386, i486, Pentium, Pentium II, Pentium III, Celeron (упрощённый вариант Pentium), Pentium 4, Core 2 Quad, Core i3, Core i5, Core i7, Xeon (серия процессоров для серверов), Itanium, Atom (серия процессоров для встраиваемой техники) и др. AMD имеет в своей линейке процессоры архитектуры x86 (аналоги 80386 и 80486, семейство K6 и семейство K7 — Athlon, Duron, Sempron) и x86-64 (Athlon 64, Athlon 64 X2, Phenom, Opteron и др.). Процессоры IBM (POWER6, POWER7, Xenon, PowerPC) используются в суперкомпьютерах, в видеоприставках 7-го поколения, встраиваемой технике; ранее использовались в компьютерах фирмы Apple.
По данным компании IDC, по итогам 2009 г.на рынке микропроцессоров для настольных ПК, ноутбуков и серверов доля корпорации Intel составила 79,7 %, доля AMD — 20,1 %.[5]
Доли по годам:
| Год | Intel | AMD | Другие |
| 2007 | 78,9 % | 13,1 % | 8,0 % |
| 2008 | 80,4 % | 19,3 % | 0,3 % |
| 2009 | 79,7 % | 20,1 % | 0,2 % |
| 2010 | 80,8 % | 18,9 % | 0,3 % |
| 2011[6] | 83,7 % | 10,2 % | 6,1 % |
СССР/Россия
Основная статья: Российские микропроцессоры
В советское время одним из самых востребованных из-за его непосредственной простоты и понятности, стал задействованный в учебных целях МПК КР580 — набор микросхем, копия набора микросхем Intel 82xx. Использовался в отечественных компьютерах, таких как Радио 86РК, ЮТ-88, Микроша и т. д.
Разработкой микропроцессоров в России занимаются ЗАО «МЦСТ», НИИСИ РАН и ЗАО «ПКК Миландр». Также разработку специализированных микропроцессоров, ориентированных на создание нейронных систем и цифровую обработку сигналов, ведут НТЦ «Модуль» и ГУП НПЦ «ЭЛВИС». Ряд серий микропроцессоров также производит ОАО «Ангстрем».
НИИСИ разрабатывает процессоры серии Комдив на основе архитектуры MIPS. Техпроцесс — 0,5 мкм, 0,3 мкм; КНИ.
- КОМДИВ32 (англ.), 1890ВМ1Т, в том числе в варианте КОМДИВ32-С (5890ВЕ1Т), стойком к воздействию факторов космического пространства (ионизирующему излучению)
- КОМДИВ64 (англ.), КОМДИВ64-СМП
- Арифметический сопроцессор КОМДИВ128
ЗАО ПКК Миландр разрабатывает 16-разрядный процессор цифровой обработки сигналов и 2-ядерный процессор:
- 2011 год, 1967ВЦ1Т[7] — 16-разрядный процессор цифровой обработки сигналов, частота 50 МГц, КМОП 0,35 мкм
- 2011 год, 1901ВЦ1Т — 2-ядерный процессор, DSP (100 МГц) и RISC (100 МГц), КМОП 0,18 мкм
НТЦ «Модуль» разработал и предлагает микропроцессоры семейства NeuroMatrix:[8]
- 1998 год, 1879ВМ1 (NM6403) — высокопроизводительный специализированный микропроцессор цифровой обработки сигналов с векторно-конвейерной VLIW/SIMD архитектурой. Технология изготовления — КМОП 0,5 мкм, частота 40 МГц.
- 2007 год, 1879ВМ2 (NM6404) — модификация 1879ВМ1 с увеличенной до 80 МГц тактовой частотой и 2Мбитным ОЗУ, размещённым на кристалле процессора. Технология изготовления — 0,25 мкм КМОП.
- 2009 год, 1879ВМ4 (NM6405) — высокопроизводительный процессор цифровой обработки сигналов с векторно-конвейерной VLIW/SIMD архитектурой на базе запатентованного 64-разрядного процессорного ядра NeuroMatrix. Технология изготовления — 0,25 мкм КМОП, тактовая частота 150 МГц.
- СБИС 1879ВМ3 — программируемый микроконтроллер с ЦАП и АЦП. Частота выборок до 600 МГц (АЦП) и до 300 МГц (ЦАП). Максимальная тактовая частота 150 МГц.[9]
ГУП НПЦ ЭЛВИС разрабатывает и производит микропроцессоры серии «Мультикор»[10], отличительной особенностью которых является несимметричная многоядерность. При этом физически в одной микросхеме содержатся одно CPU RISC-ядро с архитектурой MIPS32, выполняющее функции центрального процессора системы, и одно или более ядер специализированного процессора-акселератора для цифровой обработки сигналов с плавающей/фиксированной точкой ELcore-xx (ELcore = Elvees’s core), основанного на «гарвардской» архитектуре. CPU-ядро является ведущим в конфигурации микросхемы и выполняет основную программу. Для CPU-ядра обеспечен доступ к ресурсам DSP-ядра, являющегося ведомым по отношению к CPU-ядру. CPU микросхемы поддерживает ядро ОС Linux 2.6.19 или ОС жесткого реального времени QNX 6.3 (Neutrino).
- 2004 год, 1892ВМ3Т (MC-12) — однокристальная микропроцессорная система с двумя ядрами. Центральный процессор — MIPS32, сигнальный сопроцессор — SISD ядро ELcore-14. Технология изготовления — КМОП 250 нм, частота 80 МГц. Пиковая производительность 240 MFLOPs (32 бита).
- 2004 год, 1892ВМ2Я (MC-24) — однокристальная микропроцессорная система с двумя ядрами. Центральный процессор — MIPS32, сигнальный сопроцессор — SIMD ядро ELcore-24. Технология изготовления — КМОП 250 нм, частота 80 МГц. Пиковая производительность 480 MFLOPs (32 бита).
- 2006 год, 1892ВМ5Я (MC-0226) — однокристальная микропроцессорная система с тремя ядрами. Центральный процессор — MIPS32, 2 сигнальных сопроцессора — MIMD ядро ELcore-26. Технология изготовления — КМОП 250 нм, частота 100 МГц. Пиковая производительность 1200 MFLOPs (32 бита).
- 2008 год, NVCom-01 («Навиком») — однокристальная микропроцессорная система с тремя ядрами. Центральный процессор — MIPS32, 2 сигнальных сопроцессора — MIMD DSP-кластер DELCore-30 (Dual ELVEES Core). Технология изготовления — КМОП 130 нм, частота 300 МГц. Пиковая производительность 3600 MFLOPs (32 бита). Разработан в качестве телекоммуникационного микропроцессора, содержит встроенную функцию 48-канальной ГЛОНАСС/GPS навигации.
- 2012 год, «Навиком-02T» — однокристальная микропроцессорная система с тремя ядрами. Архитектура микропроцессора — трёхъядерная гетерогенная. Ведущий процессор — MIPS32, сигнальныЙ сопроцессор — MIMD-типа на базе ядер из библиотеки платформы «МУЛЬТИКОР», программируемое ядро сигнального процессора, организованного как двухпроцессорный кластер DSP с плавающей и фиксированной точкой, дополненный многоканальным коррелятором для ГЛОНАСС/GPS-навигации. DSP-кластер следующего поколения имеет ряд новых возможностей, в том числе: набор графических команд; аппаратный ускоритель кодера Хаффмана; возможность отработки DSP внешних прерываний; возможность доступа DSP-ядер к внешнему адресному пространству; гибкая граница программной памяти кластера DSP; прерывания от исключительных ситуаций при операциях с числами с плавающей запятой. Технология изготовления — КМОП 130 нм, частота 250 МГц. Пиковая производительность — 4000 MFLOPs (32 бита) и 24000 MOPs в формате фиксированной точки int8. Имеет пониженную потребляемую мощность.
В качестве перспективного проекта НПЦ ЭЛВИС представлен MC-0428 — процессор MultiForce — однокристальная микропроцессорная система с одним центральным процессором и четырьмя специализированными ядрами. Технология изготовления — КМОП 130 нм, частота — до 340 МГц. Пиковая производительность ожидается не менее 8000 MFLOPs (32 бита).
ОАО «Ангстрем» производит (не разрабатывает) следующие серии микропроцессоров:
- 1839 — 32-разрядный VAX-11/750-совместимый микропроцессорный комплект из 6 микросхем. Технология изготовления — КМОП, тактовая частота 10 МГц.
- 1836ВМ3 — 16-разрядный LSI-11/23-совместимый микропроцессор. Программно совместим с PDP-11 фирмы DEC. Технология изготовления — КМОП, тактовая частота 16 МГц.
- 1806ВМ2 — 16-разрядный LSI/2-совместимый микропроцессор. Программно совместим с LCI-11 фирмы DEC.Технология изготовления — КМОП, тактовая частота 5 МГц.
- Л1876ВМ1 32-разрядный RISC микропроцессор. Технология изготовления — КМОП, тактовая частота 25 МГц.
Из собственных разработок Ангстрема можно отметить однокристальную 8-разрядную RISC микроЭВМ Тесей.
Компанией МЦСТ разработано и внедрено в производство семейство универсальных SPARC-совместимых RISC-микропроцессоров с проектными нормами 90, 130 и 350 нм и частотами от 150 до 1000 МГц (подробнее см. статью о серии — МЦСТ-R и о вычислительных комплексах на их основе Эльбрус-90микро). Также разработан VLIW-процессор Эльбрус с оригинальной архитектурой ELBRUS, используется в комплексах Эльбрус-3М1). Прошел государственные испытания и рекомендован к производству новый процессор Эльбрус-2С+ отличающийся от процессора Эльбрус тем, что содержит два ядра на архитектуре VLIW и четыре ядра DSP (Elcore-09). Основные потребители российских микропроцессоров — предприятия ВПК.
Китай
- Семейство Loongson (Godson)
- Семейство ShenWei (SW)
Япония
- NEC VR (MIPS, 64 bit)
- Hitachi VR (RISC)[11]
Определение модели
В Linux определить модель и параметры установленного процессора, не открывая корпуса, можно прочитав файл /proc/cpuinfo.
В операционных системах Windows узнать модель установленного процессора, тактовую частоту, количество ядер и т. д. можно, например, через программу dxdiag.
См. также
- Сопроцессор
- Криптопроцессор
- Аппаратная платформа компьютера
Примечания
- ↑ 4004 datasheet (в документе говорится, что цикл инструкции длится 10,8 микросекунд, а в рекламных материалах Intel — 108 кГц)
- ↑ AMD Barcelona уже в продаже
- ↑ AMD Phenom: тесты настоящего четырёхъядерного процессора
- ↑ AMD дала зелёный свет 8- и 12-ядерным процессорам серии Opteron 6100 overclockers.ua
- ↑ CNews 2010 AMD «откусила» долю рынка у Intel
- ↑ Intel укрепляет позиции на процессорном рынке — Бизнес — Исследования рынка — Компьюлента
- ↑ 1967ВЦ1Т − Миландр
- ↑ Информация о микропроцессорах производства НТЦ Модуль
- ↑ НТЦ «Модуль»
- ↑ Информация о микропроцессорах производства ГУП НТЦ Элвис
- ↑ Made-in-Japan Microprocessors May 1997
Литература
- Скотт Мюллер. Модернизация и ремонт ПК = Upgrading and Repairing PCs. — 17-е изд. — М.: Вильямс, 2007. — С. 59—241. — ISBN 0-7897-3404-4
Ссылки
- Краткая история процессоров: 31 год из жизни архитектуры х86
- Правительство обнулило пошлины на процессоры 18 сентября 2007
- Крис Касперски. RISC vs. CISC
- Процессор энциклопедия Алфёрова
- Сравнение производительности процессоров (http://www.cpubenchmark.net)
- Сравнение производительности мобильных процессоров (www.notebookcheck-ru.com)
- Исследование эффективности ALU и FPU процессоров разных поколений от TestLabs.kz
|
|
| |
|||||||||
|---|---|---|---|---|---|---|---|---|---|
| Архитектура |
CISC · EDGE · EPIC · MISC · URISC · RISC · VLIW · ZISC · Фон Неймана · Гарвардская 8 бит · 16 бит · 32 бит · 64 бит · 128 бит |
||||||||
| Параллелизм |
|
||||||||
| Реализации | DSP · GPU · SoC · PPU · Векторный процессор · Математический сопроцессор • Микропроцессор · Микроконтроллер | ||||||||
| Компоненты | Barrel shifter · FPU · BSB · MMU · TLB · Регистровый файл · control unit · АЛУ • Демультиплексор · Мультиплексор · Микрокод · Тактовая частота • Корпус • Регистры • Кэш (Кэш процессора) | ||||||||
| Управление питанием | APM · ACPI · Clock gating · Динамическое изменение частоты • Динамическое изменение напряжения |
| |
|
|---|---|
| Системный блок |
Блок питания • Охлаждение • Материнская плата • Процессор • Шины • Видеокарта • Звуковая карта • Сетевая плата |
| Память |
Оперативная память • Запоминающее устройство с произвольным доступом |
| Носители и дисководы |
Жёсткий диск • Твердотельный накопитель (Флеш-память • USB-флеш) • Оптический привод (CD • DVD • BD) • НГМД (Дискета) • Стример • Кардридер |
| Вывод |
Динамик • Монитор • Принтер • Графопостроитель (плоттер) |
| Ввод |
Клавиатура • Мышь • Трекбол • TrackPoint • Тачпад • Сенсорный экран • Цифровая ручка • Световое перо • Графический планшет • Микрофон • Сканер • Веб-камера |
| Игры |
Джойстик • Руль • Штурвал • Педали • Пистолет • Paddle • Геймпад • Дэнспад • Трекер |
| Прочее |
Модем • ТВ-тюнер • Сетевой фильтр • ИБП |
| |
|||||||
|---|---|---|---|---|---|---|---|
| Архитектура |
|
||||||
| Производители | Analog Devices • Atmel • Silabs • Freescale • Fujitsu • Holtek • Hynix • Infineon • Intel • Microchip • Maxim • Parallax • NXP Semiconductors • Renesas • Texas Instruments • Toshiba • Ubicom • Zilog • Cypress | ||||||
| Компоненты | Регистр • Процессор • SRAM • EEPROM • Флеш-память • Кварцевый резонатор • Кварцевый генератор • RC-генератор • Корпус | ||||||
| Периферия | Таймер • АЦП • ЦАП • Компаратор • ШИМ-контроллер • Счётчик • LCD • Датчик температуры • Watchdog Timer | ||||||
| Интерфейсы | CAN • UART • USB • SPI • I²C • Ethernet • 1-Wire | ||||||
| ОС | FreeRTOS • μClinux • BeRTOS • ChibiOS/RT • eCos • RTEMS • Unison • MicroC/OS-II • Nucleus | ||||||
| Программирование | JTAG • C2 • Программатор • Ассемблер • Прерывание • MPLAB • AVR Studio • MCStudio |
Архитектура
ЭВМ (шпаргалка)
1.
Основные
элементы ЭВМ их назначение и взаимодействие
2.
Пример типовой процедуры в ЭВМ.
3.
Числа,
кодирование и арифметическая информация.
4.
Дополнительный код. Арифметика в
дополнительном коде.
5.
Группировки
бит.
6.
Архитектура простой ЭВМ.
7.
Структура
памяти.
8.
Состав
команд МП.
9.
Структура элементарного МП.
10. Функционирование
ЭВМ.
11. Микропроцессор.
12. Использование
регистра адресаданных.
13. Этапы обработки
требования прерывания.
14. указателя стека.
15. Состав команд
арифметических действий.
16. состав команд
логических операций
17. состав команд
операций передачи данных
18. Состав команд
операций ветвление
19. состав команд
операций вызова программ и возврата в основную программу
20. запись программы
21. ветвление программ
22. ЦИКЛЫ
23. ИСПОЛЬЗОВАНИЕ
ПОДПРОГРАММ
Основные элементы ЭВМ
их назначение и взаимодействие
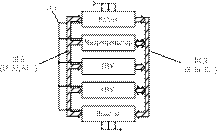
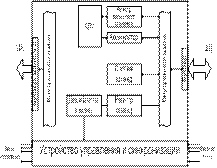
Типовая ЭВМ состоит из пяти основных элементов:
- Устройство ввода – предназначено для ввода
информации или управления ЭВМ от внешних устройств (например, клавиатура,
мышь). - Микропроцессор (МП) – центральный процессор – это
устройство управления всей ЭВМ и выполнения арифметических и логических
операций. - Постоянное запоминающее устройство (ПЗУ). В нашем
случае предназначено для хранения исполненных ЭВМ программ. - Оперативное запоминающее устройство (ОЗУ) –
предназначено для временного хранения данных.
И ПЗУ и ОЗУ представлены в виде множества
локализованных ячеек памяти. Размер ячейки – это количество БИТ информации,
которую можно поместить в ячейку памяти или прочитать из нее.
- Устройство вывода — предназначенного для передачи
данных и управления внешними по отношению к ЭВМ устройствами (экран
монитора, принтеры и т.д.)
Для
организации взаимодействия и управления всеми устройствами ЭВМ в нее включены
три шины:
А)
шина адреса (ША) – выбирает (указывает) ячейку памяти или адрес портов
ввода-вывода. В зависимости от количества ячеек памяти и устройства
ввода-вывода (УВВ) ША бывают 16, 32, 64 и т.д. разрядов.
Б)
линия управления (ЛУ) — представляет из себя шину, состоящую из нескольких
проводов, на каждом из которых формируются управляющие сигналы, обеспечивающие
необходимую временную последовательность работы всех устройств ЭВМ.
В)
шина данных (ШД) – является двунаправленной и служит для передачи данных в МП
или из него.
Пример типовой процедуры
в ЭВМ.
Рассмотрим пример типовой процедуры в ЭВМ:
1.
Нажатие клавиши «А».
2.
Размещение буквы «А» в памяти.
3.
Воспроизведение буквы «А» на
экране дисплея.
Текущими командами в ПЗУ являются:
—
Ввести (INPUT) данные через порт 1
—
Разместить (STORE) данные, поступающие из порта 1 в ячейку памяти с адресом
200.
—
Вывести данные (OUTPUT) через порт 10.
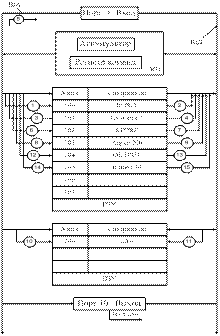
Проследим все этапы выполнения этой программы.
Этап №1: МП выставляет адрес 100 на ША. Линия управления активизирует ввод
считывания из интегральной схемы программной памяти.
Этап №2: Программная память выставляет первую программу (INPUT) на шину данных
(ШД), а МП принимает эту кодированную информацию. Это сообщение помещается в
регистр команд и МП декодирует (интерпретирует) это сообщение. В результате интерпретации
он определяет, что это за команда и что ей нужен операнд.
Этап №3: МП выставляет на ША адрес 101, линией управления активизируется вход
считывания из программной памяти.
Этап №4: Программная
память помещает операнд (Из порта 1) на ШД. Этот операнд находится в ячейке
памяти 101, кодированное сообщение (адрес порта 1) взято на ШД и помещено в
регистр команд. Теперь МП декодирует полную команду (ввести данные, поступающие
из порта 1).
Этап №5: МП побуждает открыть Порт 1 посредством ША и линии управления
устройствами ввода. Кодированная буква «А» из Порта 1 по ШД передается в МП и
размещается в аккумуляторе.
Примечание: МП все время действует в последовательности:.
Этап №6: МП выставляет на ША адрес ячейки памяти 102 и активизирует вход
считывания из программной памяти посредством управляющих линий.
Этап №7: Код команды поместить (STORE) считывается с ШД, принимается МП и
помещается в регистр команд.
Этап №8: МП декодирует эту команду и определяет, что нужен операнд. Он
выставляет на ША следующий адрес 103 и активизирует вход считывания из ПЗУ.
Этап №9: Код операнда в ячейку памяти 200 из памяти помещен на ШД, МП принимает
операнд и помещает его в регистр команд. Команда «поместить данные в ячейку
памяти 200» полностью извлечена и декодирована.
Этап №10: Начинается процесс выполнения: МП выставляет на ША адрес 200 и
активизирует вход записи в ОЗУ.
Этап №11: МП выдает помещенную в аккумулятор информацию (код буквы «А») на ШД.
Этот код записывается в ячейку 200 и таким образом теперь выполнена вторая команда.
Этап №12: МП теперь должен извлечь следующую команду — он адресует ячейку памяти
104 и активизирует вход считывания из памяти.
Этап №13: Команда вывести данные (OUTPUT) помещена на ШД. МП принимает ее,
помещает в регистр команд, декодирует и определяет, что нужен операнд.
Этап №14: МП помещает адрес 105 на ША и активизирует вход считывания из ПЗУ.
Этап №15: Память помещает код операции в порт 10 на ШД. Этот код принимается МП,
который помещает его в регистр команд.
Этап №16: МП декодирует команду «ввести данные в порт 10» полностью, т.е. он
активизирует порт 10 посредством ША и линии управления выводом. Он помещает код
буквы «А» (из аккумулятора) на ШД, по которой передается в порт 10 и далее из
него на монитор.
МП является центром всех операций и полностью ими
управляет. Он следует последовательности: извлечение – декодирование –
выполнение, а выполняемые операции диктуются командами, помещенными в памяти
ПЗУ.
Числа, кодирование и
арифметическая информация.
Так как информационные процессы в цифровых системах
принимают значения только 0 и 1, то и представления данных осуществляется с помощью
двоичных чисел. Сложение и вычитание двоичных чисел, а так
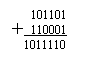 |
 |
||
же
и все остальные арифметические действия выполняются по тем же правилам, что и в
десятичной арифметике.
Сложение двоичных чисел: Вычитание
двоичных чисел:
Умножение двоичных чисел:
 |
Дополнительный
код. Арифметика в дополнительном коде.
Если нужно использовать числа со знаком, в ЭВМ
используется специальный код. Применение его существенно упрощает аппаратные
средства ЭВМ.
Изобразим условно ячейку памяти или регистр ЭВМ.
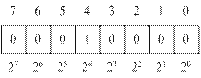
1 – имеет вес 16 (24).
Для представления знака числа принято соглашение о
том, что если старший значащий разряд в числе равен нулю, то число
положительное.
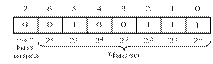
В
остальных ячейках записывается второе параллельное число. Если старший разряд
слова равен 1, то число является отрицательным, а в остальных рядах слова
записано двоичное число в дополнительном коде.
Использование дополнительного кода позволяет операцию
вычитания заменить сложением.
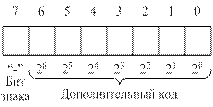
арифметика в дополнительном коде:
Процессоры ЭВМ неприспособленны для выполнения
операций вычитания, поэтому эту операцию заменили операцией сложения, в которой
отрицательные числа представлены в дополнительном коде.
Рассмотрим на примерах все возможные ситуации, при
арифметических действиях с числами:
1. сложение двух положительных чисел: 5+3=8

2.
сложить числа: 7+(-3)=4
00000011
Проинвертируем
это число и и полученному числу прибавим 1:


В
результате получили девятиразрядное число, причем старший разряд является
переполнением восьмиразрядного числа, поэтому им пренебрегаем. Оставшееся число
в старшем разряде имеет 0, поэтому является положительным
3. Сложить 2 отрицательных числа: (-5)+(-7)=-12
00000101
Проинвертируем
это число и и полученному числу прибавим 1:

00000111
Проинвертируем
это число и и полученному числу прибавим 1:


Группировки бит.
Входящий в состав микропроцессора регистр –
аккумулятор является очень важной частью всей вычислительной системы. Все
операции над данными, как правило, выполняются через аккумулятор, в котором
информация записана в виде слова. Обычно длина слова микропроцессора составляет
8 бит (байт) (4,8,16,32,64).
Слово – одна
группа обрабатываемых бит, единое выражение или одна команда. Восьмиразрядный
микропроцессор переносит и помещает все данные группами из 8 бит, которые
передаются восемью параллельными проводниками, составляющими шину данных.
Каждое запоминаемое слово имеет особое значение, когда
оно извлечено и декодировано МП. Содержание любой ячейки памяти может иметь
один из следующих смыслов: двоичное число; двоичное число со знаком;
двоично-десятичное число; буква алфавита; команда; адрес памяти; адрес порта
ввода или вывода.
Рассмотрим ячейку памяти с адресом 01100100 (100) и
содержимым 11011011. Это число может быть интерпретировано как: число 219; число
со знаком (-37); буква алфавита в коде ASCII; команда INPUT; адрес ячейки
памяти – DB и др.
МП включает счетчик команд (счетчик команд –
устройство, содержимым которого является текущий адрес памяти и который
изменяет свое состояние на +1 с каждым тактом выполнения программы). С адреса
100 извлечет, а затем декодирует слово в памяти 11011011, как команду – ввести
данные (INPUT). Затем МП обратится к следующему адресу 101 и найдет там адрес
порта (1), из которого поступают данные. И так далее по тексту программы.
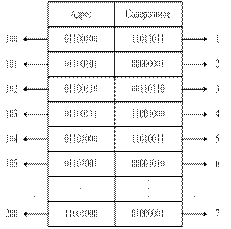
1. Код команды- ввести данные (INPUT);
2. Двоичный адрес Порта 1;
3. Код команды-разместить данные (STORE);
4. Двоичный адрес памяти;
5. Код команды – вывести данные (OUTPUT);
6. Двоичный адрес Порта 10;
7. Код ASCII буквы «А».
Команды программы помещены в 6 верхних ячеек памяти
(100 — 105). Нижняя ячейка памяти (200) является местом размещения данных, т.е.
в эту ячейку помещен код буквы «А».
Важно отметить, что биты информации сгруппированы в
слова внутри ЭВМ. Эти слова в памяти программы интерпретируются МП одно за
другим последовательно.
Программисту важно знать, как ЭВМ располагает и
интерпретирует данные. У каждого типа МП имеется свой состав команд, но у всех
у них доступ к памяти осуществляется одинаково.
Архитектура простой
ЭВМ.
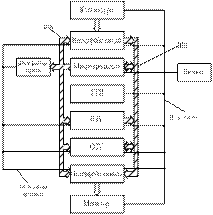
МП является центром всех операций, ему необходимо
питание и тактовые импульсы. ГТИ может быть отдельным устройством или входить в
состав (быть интегрированным) МП. Типовой МП содержит 16 (32, 64…) адресных
линий, которые образуют однонаправленную ША. А так же, обычно, 8 (16, 32…) линий,
которые составляют двунаправленную ШД. В представленной архитектуре имеет места
2 типа памяти: ОЗУ и ПЗУ. ПЗУ представляет собой память, которая содержит
программу – монитор системы, а так же пользовательские программы. ПЗУ имеет
адресные входы, а так же входы активизации только чтения и выбора кристалла.
Тристабильные выходы ПЗУ подключены к ШД. ОЗУ тоже, что и ПЗУ, только предусмотрено
использование полной команды чтение/запись.
Для того, чтобы активизировать (включить в работу)
требуемое устройство, дешифратор адреса считывает данные с ША. Комбинационной
логикой линейной комбинации ША активизируется линия выбора соответствующего
кристалла, включая, таким образом, выбранное устройство.
ГТИ предназначено для формирования базовой задающей
тактовой последовательности импульсов, обеспечивающей временную синхронизацию
работы всей системы.
Структура памяти.
Запись в память или считывание из нее происходит при
наличии доступа в память. Обычно память выполняется с последовательным или произвольным
доступом. Последовательный доступ означает, что к требуемым данным нужно последовательно
пройти всю память, расположенную до размещения искомых данных.
В случае, произвольного доступа данные могут быть
записаны (считаны) в любую ячейку памяти за определенное фиксированное время
называемое временем доступа в памяти.
ОЗУ и ПЗУ ЭВМ являются устройствами с произвольным
доступом к памяти, т.к. они обеспечивают существенно большее быстродействие, по
– сравнению с последовательным доступом.
МП, например, может иметь 16 линий адреса, которые
могут обеспечить 65536 различных комбинаций 0 и 1, т.к. запись не экономична,
то двоичный адрес принято представлять в 16-тиричной системе.
Так как размер ячейки памяти 8 бит (1 байт), а адрес
– 2 байта, то для хранения адреса в памяти необходимо выделять 2 ячейки, в одну
из которых помещают старший байт адреса, а в другую младший байт адреса.
Состав команд МП.
Группа команд, которая может выполнять микропроцессор
(МП) называется его составом команд. В зависимости от типа МП и его назначения
состав команд варьируется от 8 до 200.
Типовой МП представлен следующим составом команд, в
соответствии с нормативами. К ним относятся: арифметические, логические, передачи
данных, ветвление, вызова подпрограмм, возврата из подпрограмм и прочее.
В свою очередь эти группы команд делятся:
А)
Арифметические — сложение, вычитание, инкремент, сравнение и отрицание.
Б) Логические — И, ИЛИ, ИЛИ –
исключающее, НЕ, а так же сдвиг вправо, сдвиг влево (часто встречаются команды
циклического сдвига влево, вправо с переносом, тестированием и т.п.).
В)
Передачи данных — загрузка, размещение, перемещение, ввод и вывод.
Г)
Ветвление — безусловный переход, переход, если ноль, переход, если не ноль,
переход, если равенство, переход, если не равенство, переход, если
положительно, переход, если отрицательно.
Д)
Вызов подпрограмм – это команда, предназначенная для того, чтобы программа
могла перейти к специальной группе команд, которые решают поставленную задачу.
Последней командой в этой группе всегда стоит команда
возврата из подпрограммы. Прочими командами типового МП будут: нет операций,
поместить в стек, выйти из стека, ожидание, остановка.
Структура
элементарного МП.
Центральным устройством вычислительной системы
является МП, который содержит обычно элементы размещения данных называемые регистрами
и устройства счета (арифметическое логическое устройство – АЛУ). МП содержит
так же цепь декодирования команд и секцию управления и синхронизации. МП так же
снабжен необходимыми соединениями с устройствами ввода/вывода.
Основными функциями МП являются:
1.
Извлечение, декодирование и
выполнение команд программы в указанном порядке.
2.
Передача данных из памяти в
память, а так же из устройств ввода/вывода и в устройство ввода/вывода.
3.
Ответы на внешние прерывания.
4.
Установка общей синхронизации и сигнал
управления для всей системы.
АЛУ МП выполняет такие операции, как сложение,
сдвиг/расстановка, сравнение, инкремент, декремент, отрицание, И, ИЛИ, ИЛИ –
исключающее, дополнение, сброс, инициализация.
Рассмотрим, например, операцию сложения (ADD).

Рассмотрим подробнее состав АЛУ.
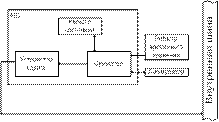
Типовое АЛУ содержит сумматор и устройство сдвига, а
результаты арифметической операции пересылают обратно в аккумулятор, посредством
внутренней шины данных. Регистр состояния слова в АЛУ является чрезвычайно
важным устройством. Этот регистр состоит из группы триггеров, которые могут
быть установлены или сброшены, исходя из результатов последней операции,
выполненной АЛУ. Эти триггера содержат указатели (флаги) нуля, отрицательного
результата, переноса и т.д.
Функционирование ЭВМ.
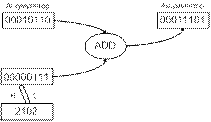
Пусть требуется сложить числа 10+5+18=33. Программа
для выполнения этой задачи может быть записана в следующей последовательности:
1.
загрузить (LOAD) первое число (10)
в МП;
2.
сложить (ADD) второе число (5) с
первым;
3.
сложить (ADD) третье число (18) с
двумя первыми;
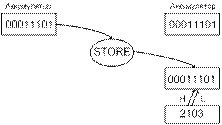
4.
поместить (STORE) сумму (33) в
ячейку памяти с адресом 2ØØØН.
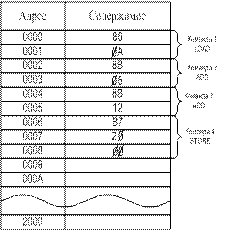
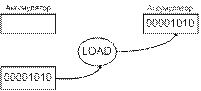
1.
Операция показывает, что содержимым
ячейки памяти 0001 загружено в аккумулятор, который содержит после этого
00001010 (0000А), т.е. первое слагаемое. В результате выполнения операции LOAD
предыдущее содержимое аккумулятора стирается.
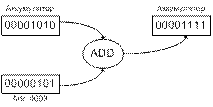
2.
Операция ADD. Содержимое ячейки
памяти 0003 складывается с содержимым аккумулятора, что дает сумму OF
(00001111), помещаемую в аккумулятор.
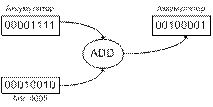
3.
Содержимое аккумулятора —
сложение 00001111 сложена с содержимым ячейки памяти 0005 (00010010), т.е. выполнена
операция.
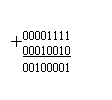
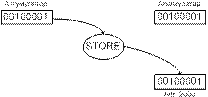
4.
Содержимое аккумулятора 00100001
передано и размещено в ячейку памяти с адресом 2000. Эта ячейка памяти была
индефицирована в тексте программы двумя раздельными байтами (0007 и 0008).
Таким образом, ячейка памяти программы 0006 содержит код операции (КОП) В7 прямой
команды STORE, два следующих байта за ней указывают соответственно на старший и
младший байты адреса.
Микропроцессор.
Типовая документация содержит информацию о структуре
интегральной схемы, схемы выводов и назначения каждого из них. Схематизируется
архитектура МП, описываются его основные свойства. Обычно МП помещается в
корпус интегральной системы с 42 – строчными выводами, эти корпуса бывают
пластмассовыми и керамическими (количество выводов может быть значительно
больше). На корпусе всегда есть метка в виде точки или желобка, непосредственно
после этой отметки, в направлении обратным ходом часовой стрелки, находится
вывод 1 интегральные схемы и далее в том же направлении выхода нумеруются.
INTL 80-80:

Выводы
20,2,11,28 — являются выводами питания.
Выводы
15 и 22 – являются входами внешнего двухфазного генератора тактовых импульсов
(таймер).
Вывода
SYNC, DBIN, WAIT, ![]() , HLDA, INTE – несут сигналы
, HLDA, INTE – несут сигналы
управления и синхронизации всем прочим элементам системы.
Выводы
READY, HOLD, INT, RESET – являются входами управления, они воспринимают информацию
от прочих элементов вычислительной системы.
Типовая
документация содержит так же структурную схему МП, которая содержит внутренние
регистры: аккумулятор; пары регистров ВС, DE и HL; указатель стека SP; регистр
состояния, а так же несколько регистров временного хранения данных. На этой
схеме так же отражены: регистр команд, дешифратор команд и устройство
управления и синхронизации. Используемые программистом регистры B и С, D и Е, H
и L – являются универсальными. Указатель стека, счетчик команд и регистр состояния
являются специальными регистрами.
Важной
особенностью является то, что пара регистров H и L может быть использована в
качестве адресного регистра, при косвенной адресации. Документация содержит
разработанные временные диаграммы, которые показывают соотношение во времени
между тактовыми импульсами на выходе ГТИ и другими внешними сигналами
(синхронизации, записи, ввода/вывода и т.п.).
Использование
регистра адресаданных.
Использование
пары регистров HL (имя регистра) в качестве указателя адреса является важным
свойством типового МП.
Рассмотрим задачу сложение содержимого трех
последовательных ячеек памяти и размещение суммы в следующей ячейке памяти.
Программа загружается в ячейке памяти с 2000Н по 200А, а три слагаемых
(ØС + ØА + Ø7) расположены в ячейке памяти в 2100 по
2102. Программа содержит 7 команд. Так же следует помнить, что текущая сумма
будет всегда помещаться в аккумулятор, который вначале содержит первое
слагаемое ØС.
Команда 1– 3А: приказывает МП загрузить (LOAD) в
аккумулятор содержимое ячейки памяти 2100Н.
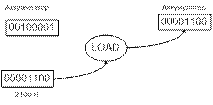
После выполнения команды аккумулятор будет содержать
первое слагаемое ØС.
Команда 2 – 21Н: приказывает МП загрузить (LOAD) число
2101Н в пару регистров HL. Емкость этой пары 16 бит (2 байта). Содержимое 1-ой
ячейки памяти 2004 представляет собой младший байт регистра L, а 2005 старший
байт регистра Н.
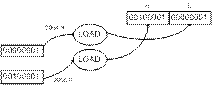
Команда 3 – 86Н: приказывает МП выполнить сложение (ADD)
содержимого аккумулятора (ØС) с содержимым ячейки памяти, адрес которой
содержится в паре регистров HL.

Команда 4 – 23Н: содержимое пары регистров HL
инкрементируется.

Команда 5 – 86Н: сложить содержимое аккумулятора с
содержимым ячейки памяти с адресом 2102, на который указывает пара регистров HL.
Команда 6 – 23Н: инкрементировать пару регистров HL.

Команда 7 – 77Н: поместить (STORE) содержимое
аккумулятора (окончательную сумму) в ячейку памяти, на которую указывает пара
регистров HL, т.е. по адресу 2103.
Этапы обработки
требования прерывания.
Вход требования прерывания INTR отвечает на высокий
уровень сигнала внешнего устройства. Предполагаем, что в устройстве интерфейса
ввода загружается 8 бит параллельных данных готовых для передачи в МП. Тогда,
описание процедуры прерывания имеет следующую последовательность:
1.
Интерфейс ввода выдает сигнал
требования прерывания в направлении МП.
2.
МП завершает выполнение текущей
команды, находящейся в памяти по адресу 2006.
3.
Поскольку, управление должно
обеспечить последующее обращение к команде по адресу 2007, содержимое счетчика
команд (именно 2007) и содержимое большинства регистров МП помещается в
специальную область ОЗУ, называемую стеком. Содержимое стека будет позже извлечено
в определенном порядке в регистры МП и счетчик команд.
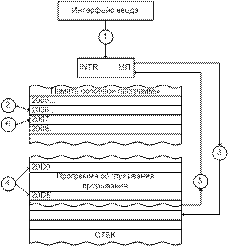
4.
В МП разветвляется в
предопределенный адрес памяти и начинает выполнение программы обслуживания прерывания
(20D0). МП тогда выполняет команды подпрограммы, которые обеспечивает
выполнение операции ввода и размещения. По адресу 20DE МП находит конец этой
подпрограммы и получает приказ вернуться в основную программу.
5.
Перед возвращением в основную
программу данные регистров и счетчик команд, помещенные в стеке, возвращаются в
МП.
6.
Теперь счетчик команд отсылает МП
в память по адресу 2007, т.е. в основную программу и нормальное ее выполнение
продолжается.
Прерывание является нужным способом, позволяющим
периферийным устройствам вмешаться и заставить МП выполнять требуемую операцию
почти сразу.
Многие МП обладают несколькими прерываниями.
Обслуживание и последовательность прерывания обеспечивается соответствующими инструкциями
в тексте некой программы программистом.
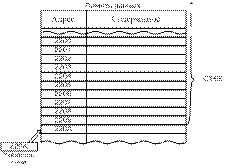
указателя стека.
Типовой МП содержит указатель стека. Указатель стека –
это специализированный 16-тиразрядный регистр – счетчик, содержимым которого
всегда является адрес. Этот адрес принадлежит особой группе ячеек памяти
данных, который называется стеком. Стек, как правило, размещается в ОЗУ или
иногда в физической локализованной на кристалле МП группе ячеек памяти. Стек
типового МП будет находиться в ОЗУ и его положение определяется программистом. Указатель
стека загружается старшим адресом, представляющим собой вершину стека.
В примере указатель стека содержит адрес 220А, что на
единицу старше первой ячейки памяти стека 2209. Данные в стек можно записать, используя
команды поместить (PUSH) и вызвать (CALL). Данные могут быть считаны из стека
по командам извлечь (POP) и возврат (RETERN). Стек функционирует как память с
последовательными доступом по типу: данные, поступившие последними, извлекаются
первыми. Например, команда PUSH приводит к тому, что содержимое пары регистров HL
помещается в стек.
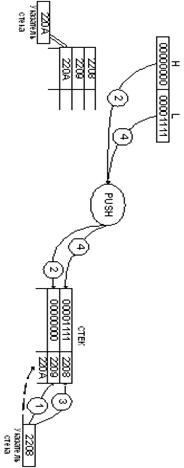
1.
Указатель стека МП
декрементируется от 220А до 2209.
2.
Указатель стека показывает на
ячейку памяти 2209 по адресной шине и старший байт регистра HL помещается в
стек.
3.
Указатель стека снова
декрементируется от 2209 до 2208.
4.
Указатель стека указывает на
ячейку 2208 по адресной шине и младший байт из регистра HL загружается в стек.
Рассмотрим так же операцию загрузки в стек,
содержимого аккумулятора и регистра состояния.

5.
До операции указатель стека
указывает на ячейку памяти 2208, ее называют вершиной
стека, затем указатель стека декрементируется до 2207.
6.
Указатель стека указывает на
ячейку памяти 2207 и содержимое аккумулятора загружается в стек по этому адресу.
7.
Указатель стека декрементируется
до 2206.
8.
Указатель стека указывает на
ячейку памяти 2206 и содержимое регистра состояния (11111111) загружается по
этому адресу.
Стек может продолжать расти, пока длится процесс
загрузки в него, т.е. длина стека формально не имеет ограничений, единственным
ограничением является объем ОЗУ.
Рассмотрим команду POP – аккумулятор и регистр
состояния свободны до операции извлечения из стека.
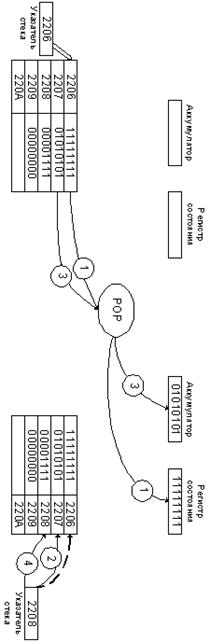
1.
Указатель стека указывает на
вершину, т.е. на адрес 2206, содержимое регистра состояния (11111111) извлечено
из стека и переслано в АЛУ.
2.
Указатель стека инкрементируется с
2206 до 2207.
3.
Указатель стека указывает на адрес
2207, содержимое вершины стека извлекается и пересылается в аккумулятор.
4.
Указатель стека инкрементируется
до 2208 и указывает теперь на следующий адрес извлечения из стека.
Содержимое аккумулятора и регистра состояния было
восстановлено до тех значений, которые были до операции PUSH.
Команды PUSH и POP используются всегда совместно,
однако, между ними располагаются другие команды, которые меняют данные, содержащиеся
в регистрах МП.
Состав команд арифметических
действий.
ADI – C6 – сложить аккумулятор с данными.
ADD L – 85 – сложить содержимое регистра L с
содержимым аккумулятора.
ADD H – 84 – сложить содержимое регистра H с
содержимым аккумулятора.
ADD М – 86 – сложить содержимое аккумулятора с содержимым
ячейки памяти, на которую указывает пара регистров HL.
SUI – Ø6 – вычесть данные из аккумулятора.
SUB L – 95 – вычесть содержимое регистра L из
содержимого аккумулятора.
SUB H – 94 – вычесть из содержимого регистра Н в
аккумулятор.
SUB М – вычесть данные, расположенные по адресу, на
которую указывает пара регистров HL, из аккумулятора.
INR A – 3C – к содержимому аккумулятора +1.
INX H – 23 – инкремент пары регистров HL.
DCR A – 3D – декрементировать (- 1) аккумулятор.
DCX H – 2B – декрементировать пару регистров HL.
CPI – FE – сравнить содержимое аккумулятора с данными
(в следующей ячейке памяти).
CMP L – BD – сравнить содержимое аккумулятора с
содержимым регистра L.
CMP H – сравнить содержимое аккумулятора с содержимым
регистра H.
CMP M – сравнить аккумулятор с ячейкой памяти, на
которую указывает пара регистров HL.
Содержит команды сложить, вычесть, инкрементировать,
декрементировать и сравнить.
Каждая команда точно оговаривает различные источники
другого слагаемого.
Команда ADI – это команда сложить непосредственно, она
является двухбайтовой. Ее формат (код операции С6) содержится в первом байте
команды, а непосредственно за ним, во втором байте, находятся данные для
сложения с содержимым аккумулятора.
Команда ADD L – содержимое аккумулятора (OF)
складывается с содержимым регистра L (01). Полученная в результате выполнения
команды сумма (10) помещается в аккумулятор.
Команда ADD H – выполняется так же.
Команда ADD М – однобайтовая команда – сложить с
косвенным адресом. Адрес второго слагаемого задан в более сложной форме с использованием
так называемого способа косвенной регистровой адресации. При такой адресации
пара регистров HL указывает 16-тиразрядный адрес памяти, где хранится второе
слагаемое.
Команда вычитания SUI.
Эта операция выполняется следующим образом:
осуществляется сложение первого числа и второго, представленного в
дополнительном коде.
Дополнительный код FF второго числа складывается с
первым числом, что дает сумму 100001000. В старшем девятом бите суммы единица
является переполнением и не принадлежит разности 00001000. МП использует это
переполнение для установления индикатора переноса CY в регистре состояния.
Вычитая, МП инвертирует переполнение, и результат становится содержимым
индикатора переноса CY.
 Допустим,
Допустим,
первое слагаемое 5 находится в аккумуляторе, а второе слагаемое находится в регистре
L.
Команда сравнение (СМР) – вычитает содержимое регистра
памяти из содержимого аккумулятора, но при этом не изменяет содержимого ни
того, ни другого. Индикаторы регистра состояния подвержены воздействию команд
сравнения.
Например, сравнить содержимое аккумулятора с
содержимым регистра L.
состав команд
логических операций
Логические команды составляют еще одну
группу команд МП. Состав этих команд следующий: логическое умножение – И,
логическое сложение – ИЛИ, ИЛИ – исключающее, отрицание – НЕ и сдвиг. В этой
группе команд именно аккумулятор составляет ядро большинства операций. Как и
при арифметических операциях, способ адресации и здесь влияет на способ и место
нахождения других данных в системе. Команда ANI выполняет логическое умножение
над содержимым аккумулятора (00010011) и содержимым программной памяти после
команды (00000001). Содержимое аккумулятора подтверждается операции И побитно.
И в соответствии с таблицей истинности для этой операции имеем: 00000001.
Результатом всех операций И будет сброс индикатора переноса. Так же результат
операции И проверяется с целью определения не ноль ли он и если нет, индикатор
нуля Z сбрасывается в ноль.
Пример операции И с косвенной операцией
(ANA M). Содержимое аккумулятора подвергается операции И (бит с битом) с
содержимым ячейки памяти указанной парой регистров HL. Допустим, в аккумуляторе
– 00111100, а в ячейке памяти – 00000001. Результат умножения будет 00000000,
этот результат размещается в аккумуляторе. Индикатор переноса CY сбрасывается в
ноль, кроме того, результат проверяется на ноль и поскольку, ответ да,
индикатор нуля Z устанавливается в единицу.

В обоих примерах второй операнд
(00000001) используется как маска. В первом примере она используется для сброса
в ноль 7 старших бит, а во втором примере, с учетом наличия индикатора нуля,
для тестирования значений ноль или единица в позиции младшего бита
аккумулятора.
Команда ИЛИ
Мнемоника ORA. Выполняется с содержимым
аккумулятора и содержимым какой-либо ячейки памяти или регистра.
Команда ИЛИ –
исключающее
Мнемоника XRA. Этих команд так же
несколько, в зависимости от способа получения данных.
Например. Выполним команду ИЛИ —
исключающее над самим аккумулятором, т.е. Аккумулятор ![]() Аккумулятор.
Аккумулятор.

Выполнение этой операции любого числа с
самим собой всегда даст результат все нули, при этом индикатор нуля Z устанавливается
в единицу, что означает нулевое содержимое аккумулятора.
Команда циклического
сдвига с переносом
Мнемоника RAR.
Например, RAR А (сдвиг вправо с
переносом).
![]()
Например.

Содержимое аккумулятора сдвинуто на одну
позицию вправо и его младший бит (единица) передается в позицию индикатора
переноса CY, тогда как имевшийся там бит (ноль) занимает позицию старшего бита
аккумулятора. После завершения операции CY =1, а Z=0. Используя одну или
несколько команд циклического сдвига, можно тестировать весь заданный состав
бит, а индикатор переноса, может быть, затем проверен командой условного
ветвления.
Команды логических операций
используются, как правило, для манипуляции с переменными по законам алгебры
логики. Они так же могут быть использованы для тестирования и сравнения бит в
слове.
состав команд
операций передачи данных
Эти команды выполняют передачу данных из
регистра в регистр, размещение данных в памяти, размещение извлеченных из
памяти данных в устройство ввода/вывода. Так же эти команды устанавливают
индикатор переноса. Почти все эти команды не влияют на индикаторы регистра состояния.
Каждая команда передачи данных содержит адрес источника и назначения данных.
Способы адресации ориентированны на то, где и как осуществляется поиск данных. К
основным в этой группе команд относятся:
·
MOV R1, R2 –
передача из регистра 2 в регистр 1,
·
MVI, R (M) – загрузить регистр
(или память),
·
LXI R1.2 – загрузить
пару регистров LHL, LDA, STA, SHLD, IN, OUT, STC – команды передачи данных.
Например, команда MOV A, L – следующая
за мнемоникой буква А указывает назначения тогда как последняя буква L
индефицирует источник данных.

Команда SPHL – здесь источником данных
является пара регистров HL, приемником 16-тиразрядный указатель стека SP.

Существует несколько команд
непосредственной загрузки данных. Эти команды часто используются для размещения
начальных значений в регистры МП.
Команда LXI H – пара регистров HL должна
быть загружена данными, следующими непосредственно за кодом операции в
программной памяти. Эта команда является трехбайтовой: 1 байт – код операции
(21); 2-ой байт – содержит младший байт и помещается в регистр L; 3-й байт –
это старший байт, который помещается в регистр H.
Команда загрузки пары регистров HL с
прямой адресацией LHLD. Второй и третий байт являются 16-тиразрядным адресом
памяти данных для загрузки.
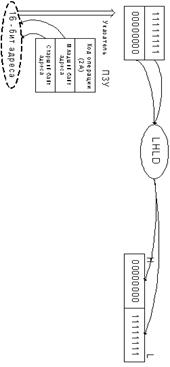
МП преобразует 2 следующих за кодом
операции байта в 16-тиразрядный адрес, который служит указателем адреса памяти
данных (ОЗУ) и загружается в пару регистров HL.
Типовой МП снабжен несколькими командами
размещения. Например, команда STA — загрузка данных с прямой адресацией.
Содержимое аккумулятора помещается в память, на которую указывает
16-тиразрядный адрес, составленный 2 и 3 байтом команды.

Команда ввода (IN) – по сути, идентична
команде загрузки, только здесь источником данных является порт ввода, который
идентифицируется 8-миразрядным числом (адрес устройства ввода/вывода). Назначение
данных из порта всегда аккумулятор.
Данные порта 00001111, на который
указывает второй байт команды, передаются и размещаются в аккумулятор.
Состав команд
операций ветвление
К этим командам относятся:
·
IMP – безусловный переход по
адресу;
·
IZ – перейти, если ноль по адресу;
·
INZ – перейти, если не ноль по
адресу;
·
IC — перейти, если перенос;
·
INC – перейти, если нет переноса
по адресу.
Обычно МП выполняет команды
последовательно, т.е. 16-тиразрядный счетчик команд типового МП содержит всегда
адрес следующий, извлекаемый из памяти команды до ее выполнения. Его содержимое
(счетчик команд) обычно повышается на 1, при каждом счете.
Команды ветвления или перехода являются
средством изменения значения содержимого счетчика команд и следовательно
изменение нормальной последовательности выполнения программы.
Команда IMP – перейти. Она является
трехбайтовой. Используется для изменения специфического адреса в счетчике команд.
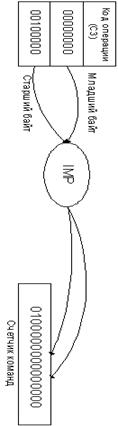
Адрес 2000Н загружен в счетчик команд,
информация об этом адресе следует непосредственно за кодом операции, поэтому
такая адресация называется непосредственной. Младший байт адреса находится во
втором байте памяти сразу за кодом операции. Команду безусловного перехода
можно рассматривать как способ загрузки новой информации об адресе в счетчике команд.
Остальные команды ветвления являются
командами условного перехода. Эти команды повлекут за собой непосредственную
загрузку адреса только, если будет выполнены специальные условия. В противном
случае, счетчик команд будет нормальным способом инкрементирован.
Например, команда IZ – перейти, если
ноль.
В этом случае счетчик команд 2017Н до
операции будет нормально инкрементирован, если только индикатор нуля Z неустановлен
в 1. МП проверяет это и находит 1, значит, результат последней арифметической
или логической операции был ноль. Условие перехода выполнены и МП загружает новый
адрес 2008Н в счетчик команд. Этот новый адрес поступает из ПЗУ. Следующей
выполненной командой программы будет команда размещения данных в памяти по
адресу 2008Н (но не 2018Н).
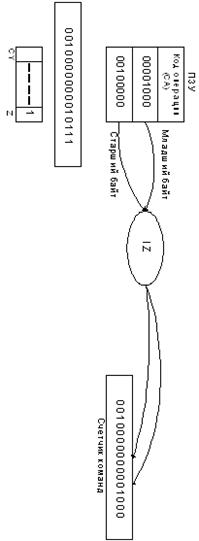
Команды перехода или ветвления
существуют практически во всех программах МП. Они очень эффективны, как
средство принятия решений и удобны для формирования циклов программ.
состав команд
операций вызова программ и возврата в основную программу
Этих команд две: команда вызова CALL и
команда возврата RET. Эти команды всегда используются парами, т.е. если в
тексте программы есть команда CALL, ее всегда сопровождает команда RET.
Трехбайтовая команда CALL используется основной программой для перехода МП к
подпрограмме.
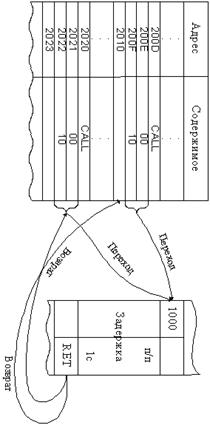
В примере подпрограмма (п/п) является
короткой последовательностью команд, целью которой является создание интервала
времени в течение 1 секунды.
Когда МП передает первую команду CALL по
адресу 1000Н, он находит адрес перехода в двух следующих байтах программы.
Адрес, следующий за CALL команды, отправляется (2010) в стек и МП переходит
тогда в начало подпрограммы по адресу 1000Н. Команды, составляющие эту программу,
выполняются до тех пор, пока МП не встретит команду возврата RET. Сохраняющий в
стеке адрес 2010 помещается в счетчик команд и МП продолжает выполнение
основной программы, принимая ее там, где он ее покинул. Эта программа
выполняется до тех пор, пока МП не встретит другую команду подпрограммы вызова CALL
по адресу 2020. МП сохраняет адрес следующей команды 2023 в стеке и переходит к
подпрограмме, находящейся по адресу 1000Н. После завершения выполнения этой
подпрограммы команда возврата RET извлекает из стека адрес следующей команды
основной программы (2023) и загружает ее в счетчик команд.
Данная подпрограмма может быть
использована много раз в ходе выполнения одной и той же основной программы.
Подпрограммы, как правило, размещены в
ПЗУ МП, но в некоторых случаях для ускорения выполнения программ, подпрограммы
размещают в ОЗУ.
Команда вызова сочетает функции
оператора загрузки в стек и перехода.
Эта команда сначала загружает в стек
содержимое счетчика команд. После этого счетчик команд должен быть загружен
новым адресом для выполнения перехода к подпрограмме.
Нарисуем блок-схему выполнения этой
команды:
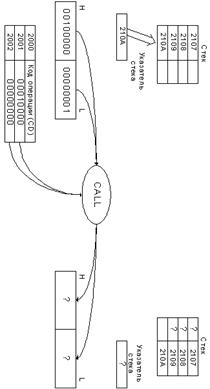
Имеет место следующей последовательности
операции:
1.
Указатель стека декрементирован от
210А до 2109.
2.
Старший байт счетчика команд
загружается в стек по адресу 2109.
3.
Указатель стека декрементируется
до 2108.
4.
Младший байт счетчика команд загружается
в ячейку памяти с адресом 2108.
5.
Младший байт адреса подпрограммы
загружается в младший байт счетчика команд.
6.
Старший байт адреса перехода
загружается в старший байт счетчика команд.
После этого МП ответвляется по адресу,
на который указывает счетчик команд (в примере 1000Н). Этот адрес является
началом подпрограммы. В конце подпрограммы находится команда RETERN. Обнаружив
ее, МП извлекает в известном порядке из стека сначала младший, затем старший
байты и размещает их в счетчике команд (в примере 2010). После этого
продолжается выполнение основной программы до следующей команды CALL.
Имеется ряд других таких команд, как
команды обслуживания стека, отсутствие операции, команда остановок и др. При их
выполнении индикаторы регистра состояния не меняются.
запись программы
Программист
должен:
1. Знать состав команд МП.
2. Быть хорошо знаком с расположением регистров МП.
3. Знать общую архитектуру ЭВМ.
Этапы
развития программы могут быть представлены следующим образом:
·
Определить и проанализировать
задачу.
·
Начертить структурную схему
решения.
·
Записать программу на ассемблере.
·
Записать или генерировать
программу в кодах.
·
Загрузить программу на решение.
·
Документировать программу.
Например.
Сложение
содержимого трех последовательных ячеек памяти и размещение суммы в памяти.
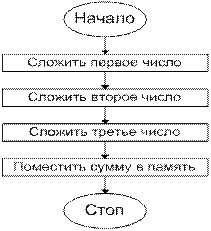
Эта
схема называется функционально-структурной. Она не содержит адекватных деталей,
которые не позволяют перейти ее прямо в сегмент программы на ассемблере или в
машинном коде.
Нарисуем
подробную функциональную схему:
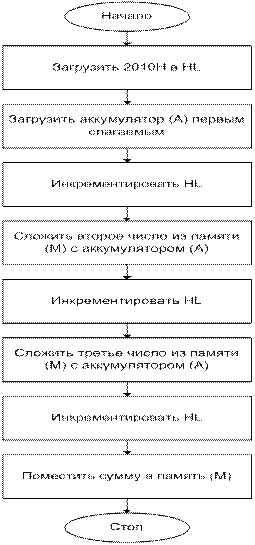
Подробная функциональная
схема организации решения задачи сильно зависит от архитектуры и состава команд
данного МП. В то время, как общая функциональная схема может быть использована
для любой вычислительной системы, т.е. она инвариантна по отношению к системе
команд и архитектуре.
Затем
следует записать версию подробной структурной схемы на ассемблере в 4 типовых
поля: метка, мнемоника, операнд и комментарий.
Метка |
Мнемоника |
Операнд |
Комментарий |
|
LXI |
Н, 2010Н |
Загрузить |
|
|
MOV |
А, |
Поместить |
|
|
INX |
Н |
Инкрементировать |
|
|
ADD |
М |
Сложить |
|
|
INX |
H |
Инкрементировать |
|
|
ADD |
M |
Сложить |
|
|
INX |
Н |
Инкрементировать |
|
|
MOV |
М, |
Поместить |
|
|
HLT |
Остановить |
Записанная
версия должна быть переведена в состав бит из 0 и 1, понимаемых МП и называемых
машинным кодом.
Это
можно сделать с помощью специальных программ или вручную.
Вручную
кодирование выполняется следующим образом:
1.
найти код операции каждой
мнемоники в таблице состава команд.
2.
определить операнды (данные и
адреса), когда это необходимо передать командами из нескольких байт.
3.
установить адреса памяти в
последовательности каждой команды и операнда.
|
Шестнадцатеричная |
Мнемоника |
Операнд |
Комментарий |
|
|
Адрес |
Содержимое |
|||
|
2020 2021 2022 |
21(код операции) 10 (младший байт) 20 (старший байт) |
LXI |
Н, |
Загрузить |
|
2023 |
7Е |
MOV |
А, |
Загрузить |
|
2024 |
23 |
INX |
Н |
Инкрементировать |
|
2025 |
86 |
ADD |
М |
Сложить |
|
2026 |
23 |
INX |
H |
Инкрементировать |
|
2027 |
86 |
ADD |
M |
Сложить |
|
2028 |
23 |
INX |
Н |
Инкрементировать |
|
2029 |
77 |
MOV |
М, |
Поместить |
|
202А |
76 |
HLT |
Остановить |
Затем
нужно проверить программу в том смысле работает ли она. Эта операция
представляет собой процесс отладки программы (поиск и устранение ошибок).
Последним
этапом программирования является документирование. Документировать программу
значит дать ее описание, указывающее в какой последовательности выполняются
операции. Сюда входят: блок-схемы алгоритмов вычислений, списки, данные, адреса
использованных подпрограмм и развернутый комментарий.
ветвление программ
Пример: Найти большее число и поместить его в
определенную ячейку памяти.
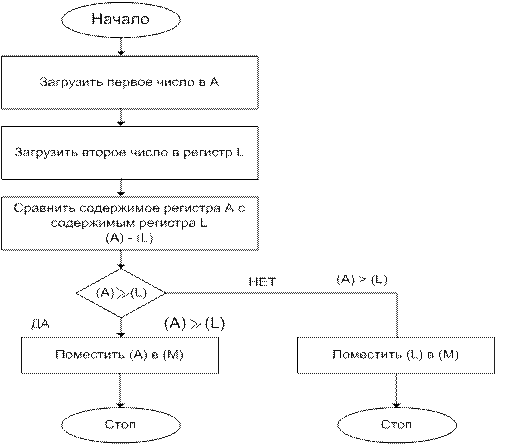
Во-первых, в 2-х кадрах блок-схемы представлены
операции загрузки чисел в регистре A и L. Команда
сравнение, не разрушая содержимого регистров, вычитает из содержимого
Аккумулятора содержимое регистра L. Результат сравнения изменяет состояние индикаторов
(флагов) в регистре состояния. Следующий кадр называется знаком принятия
решений. Он завершает в программе этап решения и содержит поставленный вопрос
[(A) ≥ (L)]? Если да, то программа
продолжается последовательно и содержимое аккумулятора помещается в память,
затем МП останавливается. Если нет, то программа ответвляется и содержимое
регистра L помещается в память, затем МП останавливается.
|
Метка |
Мнемоника |
Операнд |
Комментарий |
|
MVI |
A, ØF |
Загрузить |
|
|
MVI |
L, Ø6 |
Загрузить |
|
|
CPM |
L |
Сравнить |
|
|
JC |
STORE, L |
Перейти |
|
|
STA |
2040H |
Загрузить |
|
|
HLT |
Остановить |
||
|
STORE, |
MOV |
A, L |
Поместить |
|
STA |
2040H |
Загрузить |
|
|
HLT |
Остановить |
В таблице представлена программа на ассемблере,
которая решает задачу нахождения наибольшего числа и размещения его в памяти по
адресу 2040.
Таким образом, рассмотренный на структурной схеме
способ ветвления осуществляется командами перехода, согласно которым
принимаются решения, основанные на состоянии индикаторов в регистре состояния.
ЦИКЛЫ
Вычислительные
машины (системы) особенно эффективны в случае выполнения повторяющихся задач.
Пример.

Структурная
схема размещения ряда чисел (от 0 до последовательно в память с адресами от
2040 до 2048. Два первых кадра соответствуют начальной загрузке пары регистров HL и
аккумулятора значениями 2040 и ØØ соответственно. Третий кадр
соответствует процессу размещения данных в памяти, он будет повторяться 9 раз,
в ходе выполнения этой программы. МП, повторяя свои действия, размещает содержимое
аккумулятора в памяти по адресу, указанному в паре регистров HL.
Четвертый и пятый кадры представляют операции, которые изменяют адрес в паре
регистров HL и числа в аккумуляторе. Кадр сравнение и знак принятия
решения составляют операцию тестирования. Команда сравнение вычитает число
Ø9 из содержимого аккумулятора для установки или сброса индикатора нуля
в регистре состояния.
Если
содержимое аккумулятора меньше 9 индикатор нуля сброшен. Команда сравнения и
условного перехода используются для проверки изменяющегося счета и определения
момента выхода из цикла.
|
Метка |
Мнемоника |
Операнд |
Комментарий |
|
LXI |
H, 2040 |
Загрузить |
|
|
XRA |
A |
Сброс |
|
|
LOOP |
MOV |
M, A |
Поместить |
|
INX |
H |
Инкремент |
|
|
INR |
A |
Инкремент |
|
|
CPI |
Ø9 |
Сравнить |
|
|
JZ |
LOOP |
Перейти |
|
|
HLT |
Остановить |
ИСПОЛЬЗОВАНИЕ
ПОДПРОГРАММ
Существуют
подпрограммы, очень часто используемые одной и той же типовой программой или одним
и тем же программистом в различных программах. Передача управления программой в
подпрограмме выполняется одной командой вызова (CALL). Возврат
или восстановление управления основной программой осуществляется командой
возврата (RET). Кроме того, используются команды размещения в стек
и извлечения из стека – используются как текущие вместе с подпрограммой.
Пример: В задачу МП
входит ввести 2 отобранных числа, образовать их сумму и сохранить ее, затем,
эта сумма должна быть умножена на масштабирующий коэффициент и размещена так же
в памяти. Это связано с тем, что предыдущая сумма должна быть восстановлена в
аккумулятор, затем эта сумма проверяется знаком принятия решения и в этом
случае, если она больше 10Н, программа переводится на сигнализацию.
Нарисуем
блок-схему.
Три первые команды восстанавливают указатель стека
пару регистров HL и аккумулятор соответственно до 20СØ, 2040 и
ØØ.
Четвертая команда складывает содержимое аккумулятора с
содержимым ячейки памяти, на которую указывает пара регистров HL.
Например, содержимое памяти по адресу 2040 – Ø5. После выполнения четвертой
команды, содержимое аккумулятора будет Ø5 (ØØ + Ø5
= Ø5).
Пятая
команда основной программы инкрементирует содержимое пары регистров HL.
Шестая
команда складывает содержимое памяти по адресу 2041 (Ø9) с содержимым аккумулятора.
В результате Ø5 + Ø9= ØЕ.
Следующая
команда PUSH PSW сохраняет содержимое
аккумулятора и индикаторы регистра состояния. Это должно быть выполнено потому,
что следующая команда вызова подпрограммы разрушит содержимое этих регистров,
при выполнении программы умножения.
Операция
вызова помещает адрес команды в последовательность основной программы в стек и
затем переходит к адресу первой команды подпрограммы умножения.
Например,
адрес 2050 (adr. 2050). В примере подпрограммы осуществляется
умножение суммы ØЕ * 2 = 1С и произведение помещается в аккумулятор.
После возврата в основную программу адрес следующей последовательной команды
извлекается из стека и например, равен 200Е.
Т.к.
команды размещения в стек и извлечение из него парные, то содержимое аккумулятора
и регистра состояния восстанавливается командой POP PSW.
Теперь
содержимое аккумулятора является не произведением, а сумма ØЕ. Эта сумма
будет тестируема следующей командой CPI. Две следующие команды
основной программы для тестирования суммы в аккумулятор. Команда сравнить
непосредственно (CPI) выполняет операцию вычитание (ØЕ – 10 = FE).
Результат вычитания будет FE, который представлен в дополнительном коде. Т.е. содержимое
аккумулятора меньше, чем 10. Индикатор CY равен 1 и МП
переходит к символическому адресу START.
Метка |
Мнемоника |
Операнд |
Комментарий |
LXI |
SP, 20CØ |
Поместить |
|
|
LXI |
Н, |
Поместить |
|
|
XRA |
A |
Сброс |
|
|
ADD |
М |
Сложить |
|
|
INX |
H |
Инкрементировать |
|
|
ADD |
M |
Сложить |
|
|
PUSH |
PSW |
Поместить |
|
|
CALL |
MULTIPLAY |
Вызов |
|
|
INX |
H, 2042 |
Инкремент |
|
|
MOV |
M, A |
Разместить |
Тоже самое что и 7
16) Типы файловых систем внешних магнитных дисков
Это тоже самое что и 8
17)Стадии выполнения команды с точки зрения взаимодействия процессора и памяти.
Большинство
современных процессоров для персональных
компьютеров в общем основаны на той или
иной версии циклического процесса
последовательной обработки информации,
изобретённого Джоном
фон Нейманом.
Д. фон Нейман
придумал схему постройки компьютера в
1946 году.
Важнейшие
этапы
этого процесса приведены ниже. В различных
архитектурах и для различных команд
могут потребоваться дополнительные
этапы. Например, для арифметических
команд
могут потребоваться дополнительные
обращения к памяти, во время которых
производится считывание операндов и
запись результатов. Отличительной
особенностью архитектуры фон Неймана
является то, что инструкции и данные
хранятся в одной и той же памяти.
Этапы цикла
выполнения:
-
Процессор
выставляет число, хранящееся в регистре
счётчика
команд,
на шину
адреса,
и отдаёт памяти
команду чтения; -
Выставленное
число является для памяти адресом;
память, получив адрес и команду чтения,
выставляет содержимое, хранящееся по
этому адресу, на шину
данных,
и сообщает о готовности; -
Процессор
получает число с шины данных, интерпретирует
его как команду (машинную
инструкцию)
из своей системы
команд
и исполняет её; -
Если
последняя команда не является командой
перехода,
процессор увеличивает на единицу (в
предположении, что длина каждой команды
равна единице) число, хранящееся в
счётчике команд; в результате там
образуется адрес следующей команды; -
Снова выполняется
п. 1.
Данный
цикл выполняется неизменно, и именно
он называется процессом
(откуда и произошло название устройства).
Во
время процесса процессор считывает
последовательность команд, содержащихся
в памяти, и исполняет их. Такая
последовательность команд называется
программой
и представляет алгоритм
полезной работы процессора. Очерёдность
считывания команд изменяется в случае,
если процессор считывает команду
перехода — тогда адрес следующей
команды может оказаться другим. Другим
примером изменения процесса может
служить случай получения команды
останова
или переключение в режим обработки
аппаратного
прерывания.
Команды центрального
процессора являются самым нижним уровнем
управления компьютером, поэтому
выполнение каждой команды неизбежно и
безусловно. Не производится никакой
проверки на допустимость выполняемых
действий, в частности, не проверяется
возможная потеря ценных данных. Чтобы
компьютер выполнял только допустимые
действия, команды должны быть
соответствующим образом организованы
в виде необходимой программы.
Скорость
перехода от одного этапа цикла к другому
определяется тактовым
генератором.
Тактовый генератор вырабатывает
импульсы, служащие ритмом для центрального
процессора. Частота тактовых импульсов
называется тактовой
частотой.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Процессор
Содержание:
-
История создания процессоров
- Основные функции, для чего нужен
- Характеристики, какие являются главными при выборе
-
Из чего состоит процессор, основные функциональные блоки
- Состав восьмиразрядного процессора
- Состав шестнадцатиразрядного микропроцессора
- Внутреннее устройство процессора
- Перспективы развития процессоров, что их ожидает
История создания процессоров
Определение
Процессор (от англ. «to process» — «обрабатывать») — электронный блок либо интегральная схема, исполняющая машинные инструкции, главная часть аппаратного обеспечения компьютера или программируемого логического контроллера.
Процессоры для персональных компьютеров получили распространение с 70-х годов XX века. В данном направлении работало множество компаний. Каждый представитель индустрии стремился производить оборудование на основе передовых технологий. Лидерами в этом сегменте стали Intel и AMD. Первое упоминание процессоров отмечено в 50-х годах ХХ столетия. Тогда устройства функционировали на механическом реле.
В будущем были разработаны модели, реализованные на электронных лампах и транзисторах. Компьютеры, для которых предназначались такие процессоры, представляли собой сложные крупногабаритные установки и отличались высокой стоимостью. В конце 60-х годов ХХ века компания Busicom работала над созданием нового настольного калькулятора. В процессе реализации проекта было использовано 12 микросхем от Intel. Они были объединены в одну систему. Таким образом, был разработан микропроцессор Intel 4004, скорость функционирования которого составляла 60 тысяч операций в секунду.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
Примечание
Первый компьютер разработал студент из США Джонатан Титус. Он получил название Марк 2.
После 4004 компания Intel представила модель 8008. Ее отличие заключалось в частоте работы процессора, которая составляла от 600 до 800 килогерц. Устройство включало свыше 3 тысяч транзисторов и подходило для эксплуатации на разных вычислительных машинах. Вскоре производитель разработал процессор 8080 с высокой производительностью. Через несколько лет компанией MITS был создан компьютер Altair–8800, функционирующий на процессоре 8800 от Intel.
Примечание
В СССР активно развивалось производство вычислительной техники, особенно в 70-е годы ХХ века. Создание новой концепции на основе разработок IBM связано с указом, датированным 1970 годом, о стандартах совместимости программного обеспечения и машин ЭВМ. В то время инженеры использовали технологию IBM 360. Советский технологии стали неактуальны со временем. Вместо них стали применять импортные разработки. В 80-х годах компьютеры работали на процессорах Zilog или Intel. Отставание России от технологий США измерялось десятилетним периодом.
В середине 70-х годов ХХ столетия компания Motorola разработала собственный процессор MC6800 с высокой производительностью, который работал с 16-битными числами. Стоимость оборудования была соизмерима с ценой Intel 8080. Однако данная модель не завоевала популярность на рынке. В 1975 году бывшие сотрудники Motorola основали компанию MOS Technology. Главным продуктом предприятия стал процессор MOS Technology 6501. Позднее инженеры компании разработали чип 6502, который характеризовался высоким спросом.
Бывшим сотрудникам компании Intel также удалось создать компанию и представить собственную разработку в виде процессора Zilog Z80, который напоминал модель Intel 8080. За счет доступной стоимости и высокой производительности оборудование быстро завоевало популярность среди потребителей. В России данное устройство, как правило, использовалось для оснащения военной техники.
В конце 70-х годов Intel представили новую разработку в виде процессора 8086. Это позволило компании занять лидирующие позиции в области производства чипов. Спустя некоторое время, была презентована более успешная модель Intel 8088, которая включала более 30 тысяч резисторов. Одним из самых мощных в то время стал процессор MC68000 от компании Motorola. Одновременно Zilog выпустили Z8000, который не был востребован среди пользователей.
Эра новых процессоров началась с разработки компанией Intel процессора P5, известный, как Pentium. Менее мощные модели Celeron на ядре процессора Pentium второго поколения предприятие начало выпускать в 1998 году. Конкурентом Intel является компания AMD, которая представила первую собственную модель в 1974 году под названием AMD 9080. После разработки уникальных микросхем для цифрового оборудования AMD презентовали процессор AM 2900. Тогда популярность обрели x86 процессоры. Первая подобная разработка компании называлась AMD K5. После приобретения фирмы NexGen компания запустила в производство чип К6, который составил достойную конкуренцию Intel Pentium 2.
Основные функции, для чего нужен
Процессор представляет собой центральный вычислительный элемент, которым оснащен любой компьютер. Устройство управляет всеми его компонентами. Современные микропроцессоры выпускают в виде прямоугольной пластинки из кристаллического кремния. Маленькая площадь вмещает схемы или транзисторы. Пластина защищена керамическим или пластмассовым корпусом, который соединен с ней с золотыми проводками. Особенности конструкции обеспечивают легкое и надежное подключение процессора к системной плате компьютера. Основные функции процессора:
- обработка информации, согласно заданной программе, с помощью арифметических и логических операций;
- программное управление функционированием устройств компьютера.
Определение
Арифметико-логическое устройство или АЛУ представляет собой ту часть процессора, которая реализует команды.
Устройство управления или УУ является частью процессора, отвечающей за управление его устройствами.
Характеристики, какие являются главными при выборе
Производители процессоров классифицируют выпускаемые компоненты, согласно сериям. Таким образом, существенно упрощается выбор устройств для решения разных задач. Процессор обладает рядом характеристик, наиболее важными из которых являются:
- число ядер;
- тактовая частота;
- архитектура;
- тепловыделение.
При выборе процессора следует обратить внимание на комплекс факторов, определяющих его производительность. Например, количество вычислительных ядер определяет производительность процессора. Многоядерные чипы содержат на одном кристалле или в одном корпусе несколько вычислительных ядер. Устройства для домашних ПК, как правило, обладают 8 ядрами, а процессоры для серверов — 12, как Opteron 6100. Ядра могут отличаться по эффективности, но с увеличением их количества возрастает производительность процессора. Количество потоков может не соответствовать числу ядер процессора. Чем больше потоков, тем эффективнее работа оборудования. За счет технологии Hyper-Threading, 4-ядерный процессор Intel Core i7-3820 работает в 8 потоков и по многим критериям превосходит 6-тиядерные аналоги устройств.
Кеш представляет собой достаточно быструю внутреннюю память процессора, необходимую для реализации функции буфера временного хранения информации, которая обрабатывается в определенный момент времени.
Чем больше кэш, тем лучше работает центральный процессор:
- Кэш-память 1-го уровня отличается высокой скоростью, расположена в ядре ЦП, что объясняет компактные размеры от 8 до 128 Кб.
- Кэш-память 2-го уровня находится в ЦП, но не в ядре. Она превосходит по скорости оперативную память, но уступает кэш-памяти 1-го уровня. Размер составляет от 128 Кбайт до нескольких Мбайт.
- Кэш-память 3-го уровня быстрее оперативной памяти, но медленнее кэш-памяти 2-го уровня.
Частота процессора определяет его производительность. Тактовая частота является частотой работы центрального процессора. В течение 1 такта реализуется несколько операций. Чем выше частота, тем выше быстродействие компьютера. Тактовая частота современных процессоров измеряется в гигагерцах (ГГц): 1 ГГц соответствует 1 миллиарду тактов в секунду.
Скорость шины процессора FSB, HyperTransport или QPI, с помощью которой происходит взаимодействие чипа с материнской платой. Данный показатель измеряют в мегагерцах. Чем больше скорость шины, тем лучше работает компьютер. Разрядность шин кратна 8. Данная характеристика показывает, какой объем данных в байтах можно передать в течение 1 такта. Большое значение имеет пропускная способность шины, которая равна произведению частоты системной шины и количества бит, передаваемых за 1 такт. Например, если при частоте системной шины в 100 Мгц за 1 такт передается 2 бита, то пропускная способность составит 200 Мбит/сек.
Большее количество транзисторов, меньшее энергопотребление и нагревание обеспечивает более тонкий техпроцесс. Данный показатель определяет TDP, то есть потребление и выделение процессором тепла. Величина Termal Design Point измеряется в Ваттах (Вт), зависит от числа ядер, техпроцесса изготовления и частоты, с которой работает процессор. Так называемые, «холодные» процессоры характеризуются TDP до 100 Вт. Путем разгона можно увеличить их производительность от 15% до 25%. При высоком TDP требуется установить эффективную систему охлаждения.
Кроме вычислительных ядер, процессоры нового поколения оснащены графическими ядрами. Они выполняют роль видеокарты. С их помощью можно играть в компьютерные игры, просматривать видео, работать с текстом и решать другие задачи. Выбор в пользу процессора со встроенным графическим ядром поможет сэкономить на покупке отдельного графического адаптера.
Тип и максимальная скорость поддерживаемой оперативной памяти определяет ее совместимость с процессором. Устройства поддерживают работу конкретного типа оперативной памяти:
- DDR;
- DDR2;
- DDR3.
Сокет или разъем вставляется в процессор. Данные устройства не являются универсальными. Кроме того, материнская плата обладает только одним сокетом для процессора, который должен соответствовать его типу. Гнездовой или щелевой разъем, необходим, чтобы интегрировать чип в схему материнской платы. Каждый разъем допускает подключение конкретного типа процессоров:
- PGA (Pin Grid Array) — корпус квадратной или прямоугольной формы, штырьковые контакты.
- BGA (Ball Grid Array) — шарики припоя.
- LGA (Land Grid Array) — контактные площадки.
Из чего состоит процессор, основные функциональные блоки
Выполнение функций обеспечено определенным комплексом аппаратных средств. Функциональные блоки процессора:
- Блок арифметико-логических операций обрабатывает поступающую информацию. Список таких операций зависит от типа процессора. Как правило, это арифметическое сложение и вычитание, логические операции ИЛИ, И, НЕ, исключающее ИЛИ; операции инкремента и декремента; логические и арифметические сдвиги вправо и влево. Блок арифметико-логических операций основан на двоичном сумматоре, включающем схемы ускоренного переноса, регистры для временного хранения операндов и регистры-сдвигатели, комбинационные схемы, формирующие логические условия, схемы десятичной коррекции и другие функциональные компоненты.
- Блок, обрабатывающий команды, принимает и декодирует команды, формирует сигналы управления узлами обработки данных.
- Блок формирования адресов обеспечивает адресацию к внешней памяти и внешним устройствам. Главными компонентами в этом случае являются программный счетчик, указатель стека, инкрементор-декрементор, адресный регистр.
- Блок регистров, реализующих функции сверхоперативной внутренней памяти, временного хранения операндов и другие опции.
- Блок синхронизации и управления координируют функционирование всех узлов, которые содержит в себе процессор.
- Внутренняя шина обеспечивает связь отдельных блоков и узлов процессора. Блок состоит из шин для передачи данных, адресов и управляющих сигналов.
Состав восьмиразрядного процессора
Основные узлы 8-разрядного процессора можно рассмотреть на примере модели 8080 (КР580ВМ80А). Структурная схема изображена на рисунке.
С помощью арифметико-логического устройства АЛУ над восьмиразрядными операндами выполняют такие операции, как:
- арифметическое сложение пары операндов при передаче переноса в старший разряд (и без него) и вычитание с передачей заема в младший разряд (и без него);
- логическое сложение, умножение, которые исключают ИЛИ и сравнение;
- циклические сдвиги четырех видов;
- арифметические операции над десятичными числами.
В процессе суммирования десятичных чисел может понадобиться коррекция результата, за которую отвечает блок десятичной коррекции. При сложении каждый из разрядов десятичного числа (цифра) трансформируется в четырехразрядный двоичный код (полубайт, тетрада), к примеру, код 8421. Полубайт суммируются, согласно правилам двоичной арифметики.
АЛУ связано с пятиразрядным регистром признаков или флагов. В нем записывается итог решения определенных арифметических и логических операций. Триггеры, содержащиеся в регистре:
- Триггер переноса вырабатывает сигнал С = 1 в том случае, когда в процессе сложения и сдвига появляется единица переноса из старшего разряда.
- Триггер дополнительного переноса вырабатывает сигнал V = 1, если при выполнении операции с двоично–десятичными кодами появляется единица из третьего разряда (старшего разряда младшего полубайта).
- Триггер нуля вырабатывает сигнал Z = 1 при нулевом итоге операций.
- Триггер знака вырабатывает сигнал S = 1 в том случае, когда величина старшего разряда операнда (в дополнительном коде) соответствует единице, то есть итог операции является отрицательным числом.
- Триггер четности вырабатывает сигнал Р = 1, если результат операции состоит из четного числа единиц.
Доступ к регистрам, включая счетчик команд и указатель стека, выполняется через мультиплексоры с помощью селектора регистров. Регистры общего назначения РОН используются, как аккумуляторы, в которых хранится обрабатываемая информация, либо указатели с адресами операндов. Регистры В, С, D, Е, Н, L могут играть роль отдельных восьмиразрядных регистров или шестнадцатиразрядных регистровых пар ВС, DE, HL. Регистры W и Z не относятся к программно-доступным и необходимы, чтобы выполнять команды внутри процессора. Они служат местом хранения для второго и третьего байта команд. Микропроцессор и внешние устройства обмениваются данными с помощью двунаправленного буферного регистра. Информационный обмен между памятью и внешними устройствами осуществляется с помощью шестнадцатиразрядного регистра адреса.
Указатель команд или программный счетчик Program Counter — PC указывает адрес нахождения очередного байта команды в памяти. Байты команд, как правило, отбираются по нарастанию их адресов. В связи с этим, выбор каждого очередного байта сопровождается увеличением содержимого программного счетчика на единицу схемой инкремента–декремента.
Указатель стека StackPointer —SP представляет собой шестнадцатиразрядный регистр, задачей которого является оперативная адресация специального вида памяти. Стековая память необходима для обслуживания прерываний и отличается тем, что из нее в первую очередь выбирается информация, которая поступила последней. В стеке фиксируется адрес возврата к прерванной программе на время обработки процессором подпрограммы, состава аккумулятора, регистра признаков.
Первый байт реализуемой команды сохраняется в регистре команд. В дешифраторе команд образуются сигналы, которые способствуют запуску в устройстве управления микропрограммы, что позволяет выполнить необходимую операцию. Микропрограммы операций, определяемых набором команд микропроцессора, «зашиты» в управляющую память.
На входы устройства управления поступают:
- пара последовательности тактовых импульсов (Ф1, Ф2) с периодом Т, которые являются непрерывными;
- сигнал готовности (READY) внешних устройств и памяти к обмену данными с микропроцессором;
- сигнал запроса от внешних устройств на прерывание (INT) осуществления основной программы и переход на выполнение подпрограмм обслуживания прерывания;
- сигнал запроса от внешних устройств на захват шин (HOLD), обычно, для информационного обмена с помощью канала прямого доступа к памяти;
- сигнал сброса (RESET), который обеспечивает начальную установку микропроцессора.
С выхода устройства управления считываются сигналы, что позволяет управлять внутренними компонентами процессора и внешними устройствами. Во втором случае вырабатываются следующие сигналы:
- сигнал синхронизации (SYNC) указывает на начало каждого машинного цикла, то есть временного периода, в течение которого происходит одно обращение процессора к внешним устройствам или памяти;
- сигнал приема (DBIN) указывает, насколько процессор готов принимать информацию;
- сигнал ожидания (WAIT) указывает на то, что процессор пребывает в состоянии ожидания;
- сигнал подтверждения захвата (HLDA) подтверждает высоомное состояние шин, что позволяет внешним устройствам обращаться к памяти напрямую, без участия процессора;
- сигнал разрешения прерывания(INTE) указывает на состояние логической единицы, в котором пребывает триггер разрешения прерывания в блоке управления, что позволяет принимать сигналы запроса;
- сигнал Выдача (WR= 0) указывает на выдачу информации процессором на шину данных, чтобы сохранить ее в памяти или передать во внешние устройства.
Узлы процессора обмениваются информацией с помощью восьмиразрядной внутренней шины данных. Информационный обмен с внешней восьмиразрядной шиной данных осуществляется с помощью буферного регистра. Адресация к памяти и внешним устройствам реализуется по средствам шестнадцатиразрядной шины адреса и регистра адреса.
Состав шестнадцатиразрядного микропроцессора
В качестве примера 16-разрядного процессора можно рассмотреть модель 8086. Структурная схема изображена на рисунке.
Состав микропроцессора:
- арифметико-логическое устройство (АЛУ), которое включает стандартный комплекс операций;
- регистр флагов или регистр слова состояния, необходимый для отражения состояния процессора в результате реализации определенной команды, к примеру, для фиксации нулевого итога операции АЛУ используется флаг Z;
- восемь шестнадцатиразрядных регистров общего назначения (РОН), задачей которых является хранение адресов и информации: АХ (АН, AL), DX ( DН, DL), СХ (СН, CL), ВХ (ВН, BL), BP, SP DI, SI;
- блок формирования адреса и управления шиной, создает адреса с помощью суммирования содержимого конкретного из индексных регистров (DI, SI) с адресом из памяти, выполняет временное мультиплексирование шины данных/адреса (ШД/А), автоматически заполняет буфер очереди команд следующими командами;
- блок формирования адреса и управления шиной включает буферный регистр, сумматор и логику управления шиной;
- регистр команд, необходим, чтобы принимать команды из внешней памяти;
- устройство управления обеспечивает синхронизацию процессора, управление машинными циклами и захватом шины, обслуживание запросов на прерывание от внешних устройств;
- буфер очереди команд позволяет записать максимально шесть байт принимаемой команды;
- четыре шестнадцатиразрядных сегментных регистра (CS, SS, DS, ES) и программный счетчик (Instruction Pointer — IP), которые участвуют в формировании адреса.
Передача управляющих сигналов осуществляется с помощью шины управления. Микропроцессор при этом может функционировать в двух режимах:
- минимальная конфигурация;
- максимальная конфигурация.
Внутреннее устройство процессора
Процессор обладает рядом внутренних ресурсов. Основными из них являются:
- типы данных, распознаваемые и обрабатываемые процессором;
- программно-доступные регистры, в которых хранятся информация и адреса при реализации программы;
- режимы адресации с обозначением Addressing Mode, или способы адресации, которые реализует процессор.
Способ адресации представляет собой метки определения или вычисления адреса, который называют эффективным Effective Address — ЕА, обеспечивающего доступ к операндам или передачу управления. Внутренние ресурсы встроены в чип и записаны в его систему команд. В связи с этим, к задачам внутренних ресурсов относится не только программирование прикладных операций, но и непосредственная реализация программы.
Архитектура процессоров предоставляет максимально часто запрашиваемые типы информации, регистры и режимы адресации. Для любого процессора характерна поддержка несколько типов данных, режимов адресации и содержание конкретного комплекса внутренних регистров. Благодаря разнообразию, доступности и эффективной эксплуатации ресурсов, повышается производительность системы. При недостатке или отсутствии ресурсов допустимо программное моделирование, что сопровождается снижением производительности.
Разработка системной программы основана на жестко связанных с архитектурой процессора системных ресурсах таких, как:
- адреса памяти и ввода/вывода;
- запросы прерываний;
- каналы прямого доступа к памяти.
Примечание
Данные системные ресурсы необходимы для управления виртуальной памятью. С их помощью обеспечивается мультизадачность, реализуются защитные средства. Системные ресурсы формируют основу возможностей режима защиты.
Внутренние компоненты процессора:
- Верхняя крышка из металла защищает чувствительные элементы от механического воздействия, а также отводит тепло.
- Кристалл или камень представляет собой наиболее важную и дорогую деталь микропроцессора. По мере повышения сложности и эффективности «камня», увеличивается производительность компьютера.
- Специальная подложка с контактами на обратной стороне необходима для завершения конструкции процессора. С ее помощью центральный «камень» взаимодействует с внешними устройствами.
Принцип сборки конструкции исключает прямое внешнее влияние на сам кристалл. Строение скрепляют с помощью клея-герметика с особыми свойствами. «Камень» процессора включает следующие функциональные компоненты:
- ядра процессора;
- кэш память;
- контроллер памяти;
- видеопроцессор.
Перспективы развития процессоров, что их ожидает
В будущем технологический прогресс достигнет физических пределов производство, что должно послужить триггером для изменений материальной части процессоров. В данной области выделяют несколько перспективных направлений:
- Оптические компьютеры, обрабатывают вместо электрических сигналов потоки света или фотоны.
- Квантовые компьютеры, в основе функционирования которых квантовые эффекты. Современные инженеры уже работают над созданием функционирующих моделей квантовых процессоров.
- Молекулярные компьютеры, представляют собой вычислительные системы, которые используют при работе вычислительные возможности молекул, как правило, органического происхождения. Молекулярные компьютеры основаны на идее вычислительных возможностей расположения атомов в пространстве.
С развитием технологий и применением инновационных материалов удается сделать процессоры более быстрыми и экономичными. Например, компания Intel в перспективе может отказаться от использования свинца в конструкции микропроцессора. Производители уделяют повышенное внимание внутренней архитектуре и стараются уменьшить габариты транзисторов. Это способствует повышению производительности устройств и удешевлении их производства. Для предотвращения роста токов утечки и повышения энергопотребления требуется использовать новый диэлектрик для более компактных транзисторов.
Увеличение объема кэша должно положительно влиять на параметр скорости работы программного обеспечения. Теоретически, данное нововведение приведет к ускорению работы приложений, основанных на сканировании трактов данных. Благодаря новым техпроцессам, будущие процессоры будут обладать низким тепловыделением и улучшенным температурным режимом работы.
Есть предположение, что усовершенствованные чипы должны стать гетероструктурными. При условии полной гетероструктурности внутреннее строение процессора перемешано, то есть компоненты всех сопроцессоров встроены во внутреннее пространство вычислительных ядер так, что отделить их на плате не представляется возможным. Возможно, потребуются пара особых узлов, которые будут располагаться внутри процессора, и специальная сетка сверху для объединения всех элементов на верхнем уровне.
Важным шагом в будущем производстве процессоров является переход от дискретной логики к непрерывной. Также усовершенствованные модификации чипов, скорее всего, будут обладать 3D-структурой. При этом транзисторы располагаются на конструктивной схеме не планарно, а в объеме, то есть несколькими слоями, связанными друг с другом в вертикальном направлении. Таким образом, структура будущих процессоров будет представлять собой мультиполигональный объект, в котором каждый компонент граничит с десятком других элементов. Возможно, по этой причине сигналы начнут передаваться в нескольких направлениях одновременно.