DeepFake – технология синтеза изображения, основанная на искусственном интеллекте и используемая для замены элементов изображения на желаемые образы. Если вы не слышали о дипфейках, посмотрите приведенный ниже видеоролик. В нём актёр Джим Мескимен читает стихотворение «Пожалейте бедного пародиста» в двадцати лицах знаменитостей.
Название технологии – объединение терминов «глубокое обучение» (англ. Deep Learning) и «подделка» (англ. Fake). В большинстве случаев в основе метода лежат генеративно-состязательные нейросети (GAN). Одна часть алгоритма учится на фотографиях объекта и создает изображение, буквально «состязаясь» со второй частью алгоритма, пока та не начнет путать копию с оригиналом.
В следующем видео показаны процессы, происходящие за кулисами обучения нейросети. Как пишет автор проекта Sham00K, на итоговое видео потрачено более 250 часов работы, использовались 1200 часов съемочных материалов и 300 тыс. изображений. Объем сгенерированных данных составил приблизительно 1 Тб.
Области применения технологии
Уже имеются целые YouTube- и Reddit-каналы c дипфейк-роликами. Технология DeepFake может применяться для самых разных целей.
Кинопроизводство. Производство фильмов сегодня – крайне затратный процесс с арендой камер, студий и оплатой работы актёров. Развитие технологии DeepFake позволит сократить затраты на съемочный процесс, монтаж и спецэффекты.
Локализация рекламы. Достаточно записать один рекламный ролик со знаменитостью, после чего записанное лицо можно переносить в видео с местными актерами, произносящими рекламные слоганы на родном языке. То есть можно добиться эффекта, как будто знаменитость говорит на языке страны дистрибуции продукта.
Виртуальная и дополненная реальности. Технология переноса мимики может применяться для создания цифровых двойников в играх, виртуальной и дополненной реальностях. Источниками лица могут также служить знаменитости или участники игры. Это повышает эмоциональное вовлечение.
Очевидно, что технология должна использоваться с особой осторожностью. Злоумышленниками могут преследоваться цели компрометирования личности или создания фейковых новостей. В начале октября 2019 г. члены Комитета по разведке Сената США призвали крупные технологические компании разработать план для борьбы с дипфейками. Ранее, в сентябре этого года, Google создала специальный датасет дипфейков.
Отметим, что данная публикация подготовлена исключительно в исследовательских целях.
Примечание
Мы обновили гайд в апреле 2021 года, чтобы приблизить описание к текущему состоянию библиотеки DeepFaceLab.
Для синтеза дипфейка мы будем использовать популярную библиотеку DeepFaceLab. Библиотека стремительно развивается, сейчас доступно несколько релизов:
- Windows (magnet-ссылка) – последний релиз, для загрузки требуется торрент-клиент.
- Windows (Mega.nz) – содержит старые и новые релизы. Есть сборки для Nvidia карт размером порядка 3 Гб, а также версия для OpenCl (2020).
- Google Colab (GitHub) – можно использовать удаленные вычислительные мощности.
- DeepFaceLab для Linux (GitHub).
- CentOS Linux (github) – может отставать от основной ветки релизов.
Ниже описан базовый процесс создания дипфейка на примере Windows.
Важно понимать, что на качество результата влияет множество свойств исходных видеофайлов (разрешение и длительность, разнообразность мимики персонажей, освещение и т. д.). За любыми подробностями и деталями настроек перенаправляем к оригинальному репозиторию.
Системные требования для DeepFaceLab
Минимальные системные требования для работы с инструментом:
- ОС Windows 7 или выше (64 бит).
- Процессор с поддержкой SSE-инструкций.
- Оперативная память объемом не менее 2 Гб + файл подкачки.
- OpenCL-совместимая видеокарта (NVIDIA, AMD, Intel HD Graphics).
Рекомендуемые системные требования:
- Процессор с поддержкой AVX-инструкций.
- Оперативная память объемом не менее 8 Гб.
- Видеокарта NVIDIA с объемом видеопамяти не менее 6 Гб.
Алгоритм работы с DeepFaceLab
Предварительно договоримся о терминологии:
src(сокр. от англ. source) – лицо, которое будет использоваться для замены,dst(сокр. от англ. destination) – лицо, которое будет заменяться.
Архив сборки нужно распаковать как можно ближе к корню системного диска. После распаковки в каталоге DeepFaceLab вы найдете множество bat-файлов.
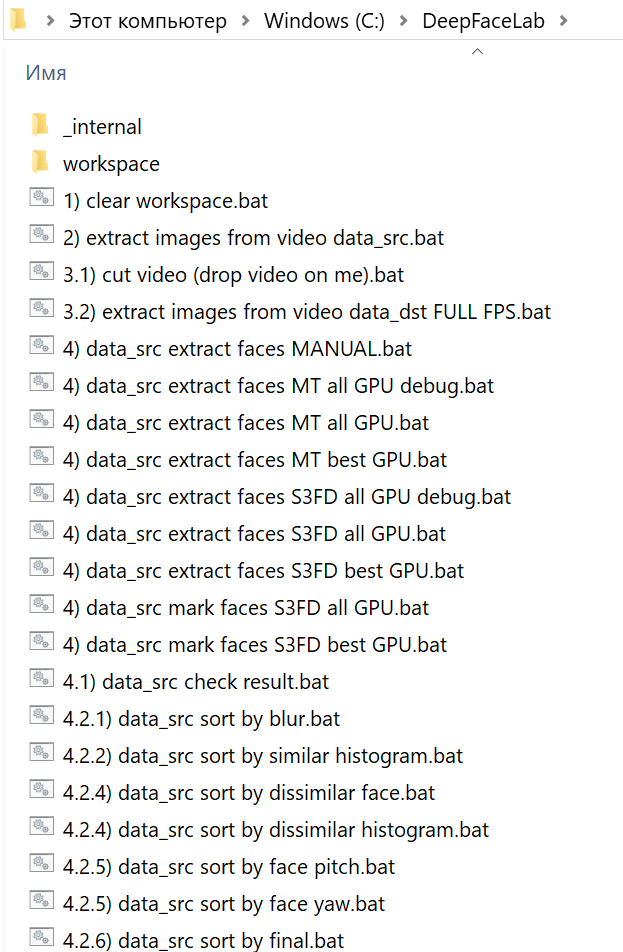
Местом хранения модели служит внутренняя директория workspace. В ней будут содержаться видео, фотографии и файлы самой программы. Вы можете копировать переименовывать каталог для сохранения резервных копий.
Папка _internal используется алгоритмом.
Сразу после распаковки в workspace уже могут содержаться примеры видеороликов для теста. В соответствии с описанной терминологией вы можете заменить их видеофайлами с теми же названиями data_src.mp4 и data_dst.mp4. Максимально поддерживаемое разрешение – 1080p. Приведенные в документации примеры расширений файлов: mp4, avi, mkv.
data_dst – это папка, в которой будут храниться кадры, извлеченные из файла data_dst.mp4 – целевого видео, в котором мы меняем местами лица. Папка также будет содержать две подпапки, которые создаются после запуска «извлечения» лиц:
aligned– изображения лиц (со встроенными данными лицевых ориентиров)align_debug– исходные кадры с наложенными на лица ориентирами, которые используются чтобы идентифицировать корректно или некорректно распознанные лица.
data_src – это папка, в которой будут храниться кадры, извлеченные из файла data_src.mp4, или другие кадры-картинки в формте jpg, на которых изображен хозяин нового лица. Как и в случае с data_dst, после извлечения лиц создаются две подпапки:
aligned– извлеченные изображения лицalign_debugвыполняет ту же функцию, что и дляdst, однако для извлечения набора данных src папка не создается по умолчанию. При желании нужно выбратьyes (y)при запуске извлечения, чтобы её сгенерировать.
Как вы могли заметить, bat-файлы в корне распакованного каталога имеют в начале имени номер. Каждый номер соответствует определенному шагу выполнения алгоритма. Некоторые пункты опциональны. Пройдемся по этой последовательности.
1. Очистка рабочего каталога
На первом шаге запуском 1) clear workspace.bat и нажатием пробела очищаем лишнее содержимое папки workspace. Одновременно создаются необходимые директории.
2. Извлечение кадров из видеофайла источника (data_src.mp4)
На втором шаге извлекаем изображения (кадры) из src-файла (2) extract images from video data_src.bat). Для этого запускаем bat-файл, получаем приглашение для указания кадровой частоты:
Enter FPS ( ?:help skip:fullfps ) :
Пропускаем пункт, нажав Enter, чтобы извлечь все кадры.
Output image format? ( jpg png ?:help skip:png ) : ?
В формат png файлы извлекаются без потерь качества, но на порядок медленнее и с большим объемом, чем в jpg. После задания настроек кадры извлекаются в каталог data_src.
3. Извлечение кадров сцены для переноса лица (опционально)
При необходимости обрезаем видео с помощью 3.1) cut video (drop video on me).bat. Этот пункт удобен, если вы никогда не пользовались программным обеспечением для редактирования видео. Перетаскиваем файл data_dst поверх bat-файла. Указываем временные метки, номер аудиодорожки (если их несколько) и при необходимости битрейт выходного файла. Появляется дополнительный файл с суффиксом _cut.
Запускаем 3.2) extract images from video data_dst FULL FPS.bat для извлечения кадров dst-сцены. Файлы автоматически переносятся в каталог data_dst. Как и для src, есть опция с выбором jpg/png.
4. Составление выборки лиц источника
На этом этапе начинается глубокое обучение. Нам необходимо детектировать лица на src-кадрах. Получаемая выборка будет храниться по адресу workspace\data_src\aligned. Этому пункту соответствует множество bat-файлов, начинающихся с 4) data_src faceset extract. При стандартном подходе используется SF3D-алгоритм детекции лица. Есть следующие опции:
- Выбор зоны, которую мы хотим извлечь: площадь увеличивается от full face (
FF) к whole face (WF) и head (HEAD). - Вариант использования
GPU: ALL(задействовать все видеокарты),Best(использовать лучшую). Выбирайте второй вариант, если у вас есть и внешняя, и встроенная видеокарты, и вам нужно параллельно работать в офисных приложениях. - Записывать или нет результат работы детекторов. Каждый кадр с выделенными контурами лиц записывается по адресу
workspace\data_src\aligned_debug.
Пример вывода программы при запуске на видеокарте NVIDIA GeForce 940MX:
Performing 1st pass...
Running on GeForce 940MX. Recommended to close all programs using this device.
Using TensorFlow backend.
100%|################################################################################| 655/655 [03:32<00:00, 3.08it/s]
Performing 2nd pass...
Running on GeForce 940MX. Recommended to close all programs using this device.
Using TensorFlow backend.
100%|##########################################################################################################################################################| 655/655 [13:28<00:00, 1.23s/it]
Performing 3rd pass...
Running on CPU0.
Running on CPU1.
Running on CPU2.
Running on CPU3.
Running on CPU4.
Running on CPU5.
Running on CPU6.
Running on CPU7.
100%|#########################################################################################################################################################| 655/655 [00:05<00:00, 112.98it/s]
-------------------------
Images found: 655
Faces detected: 654
-------------------------
Done.
Аналогичный bat-файл со словом MANUAL применяется для ручного переизвлечения уже извлеченных лиц в случае ошибок на этапе 4.2) data_src util add landmarks debug images.bat.
4.1. Удаляем большие группы некорректных кадров
Запускаем 4.1) data_src view aligned result.bat. Он запускает обозреватель, в котором можно просмотреть содержимое папки data_src/aligned относительно ложных срабатываний и неправильно определенных лиц, чтобы их можно было удалить.
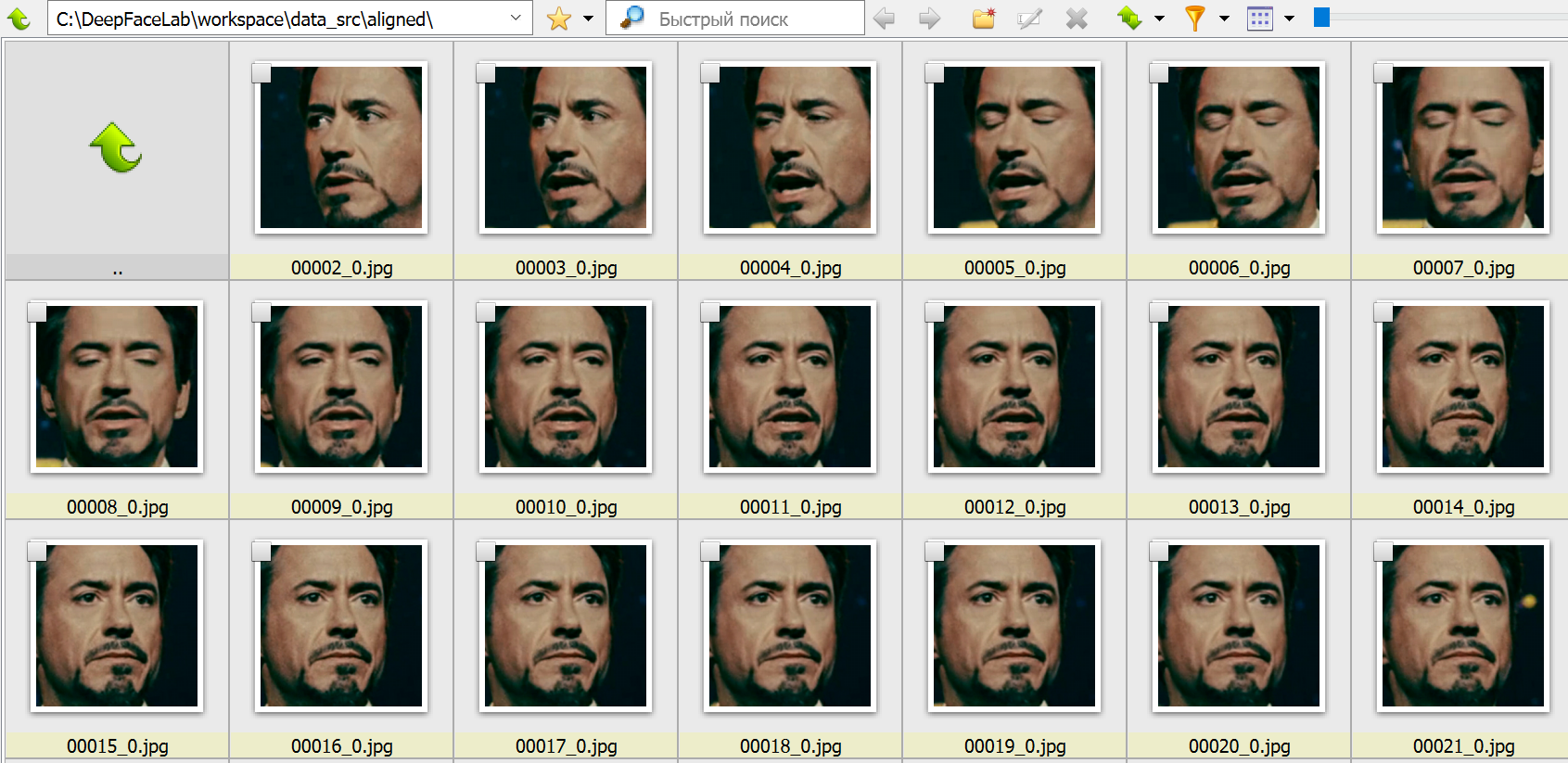
На этом этапе необходимо удалить крупные группы некорректных кадров, чтобы далее не тратить на них вычислительный ресурс. К некорректным кадрам относятся все, что не содержат четко различимого лица. Лицо также не должно быть закрыто предметом, волосами и пр. Не тратьте время на мелкие группы. Мы удалим их на следующем шаге.
4.2. Сортировка и удаление прочих некорректных кадров
Файл 4.2) data_src sort.bat служит для для сортировки и выявления групп некорректных кадров. Не закрывая обозреватель, последовательно запускайте bat-файл с нужной опцией и удаляйте группы некорректных кадров (обычно находятся в конце). Доступные опции:
blur, motion blurсортирует кадры по резкости, удаляем кадры с нечеткими лицами.face yawсортирует лица по взгляду слева направо.face pitch directionсортирует лица так, чтобы в начале списка лицо смотрело вниз, а в конце – вверх.histogram similarityгруппирует кадры по содержанию, позволяет удалять ненужные лица группами.histogram dissimilarityоставляет ближе к концу списка те изображения, у которых больше всего схожих (обычно это лица анфас). По усмотрению можно удалить часть конца списка, чтобы не проводить обучение на идентичных лицах.brightness, hue, amount of black pixelsсоответствуют яркости, насыщенности и количеству черных пикселей. Помогает убрать переходные кадры, где лицо трудно различимо.best faces– помогает выделить наиболее хорошо различимые лица.
4.2) data_src util add landmarks debug images.bat сгенерирует после извлечения лиц папку align_debug.
4.2) data_src util faceset enhance.bat использует специальный алгоритм машинного обучения для масштабирования/«улучшения» качества представления лиц в наборе данных. Полезно, если кадры немного размыты и вы хотите сделать их более резкими.
Файлы 4.2) data_src util faceset metadata restore.bat и 4.2) data_src util faceset metadata save.bat позволяют сохранять и восстанавливать данные об извлеченых наборах лиц/данных, чтобы вы могли редактировать изображения лиц после их извлечения без потери данных о выравнивании. Например, так можно увеличивать резкость, редактировать очки, пятна на коже, делать цветокоррекцию.
4.2) data_src util faceset pack.bat и 4.2) data_src util faceset unpack.bat служат для упаковки (распаковки) лиц из папки aligned в один файл. Используется для подготовки настраиваемого набора данных для предварительного обучения, упрощает совместное использование в виде одного файла и значительно сокращает время загрузки набора данных (секунды вместо минут).
4.2.other) data_src util recover original filename возвращает имена изображений лиц к исходному порядку/именам файлов. Запускать не обязательно – обучение и слияние будут выполняться независимо от имен файлов источника.
5. Составление выборки лиц принимающей сцены (dst)
Следующие операции с некоторыми отличиями идентичны выборке лиц источника. Главным отличием является то, что для принимающей сцены важно определить dst-лица во всех кадрах, содержащих лицо, даже мутных. Иначе в этих кадрах не будет произведено замены на источник.
5) data_dst faceset extract.bat выполняет автоматическое извлечение с использованием алгоритма S3FD.
5) data_dst faceset extract + manual fix.bat позволяет вручную указать контуры лица на кадрах, где лицо не было определено. При этом в конце извлечения файлов открыто окно ручного исправления контуров. Элементы управления описаны вверху окна (вызываются клавишей H).
5) data_dst faceset extract MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.bat используется для ручного переизвлечения из кадров, удаленных из папки align_debug. Подробнее об этом рассказано далее.

Все экстракторы позволяют выбрать между GPU и CPU, а также указать область, выделяемую для извлечения. Аналогично src это FF, WF или HEAD.
5.1. Извлечение лиц вручную (manual extractor)
После запуска 5) data_dst faceset extract MANUAL.bat откроется окно, в котором вы можете вручную найти лица, которые хотите извлечь или переизвлечь:
- Выделите лицо с помощью мыши.
- С помощью колесика мыши можно менять размер области поиска.
- Убедитесь, что все или хотя бы большинство ориентиров находится на важных точках (глазах, рту, носу, бровях) и правильно следуют контурам лица. В некоторых случаях, в зависимости от угла освещения или имеющихся препятствий, может оказаться невозможным точно выровнять все ориентиры, поэтому просто попытайтесь сделать так, чтобы покрывались все видимые части.
- Чтобы изменить режим точности, используйте клавишу
A. Теперь ориентиры не будут так сильно «прилипать» к обнаруженным лицам, но вы сможете более точно позиционировать ориентиры. - Для перемещения вперед и назад используйте клавиши
<и>. Для редактирования нажмитеEnterиликликнителевой клавишей мыши. - Чтобы пропустить оставшиеся грани и выйти из экстрактора, используйте клавишу
q.
Чтобы посмотреть результаты в папке aligned, можно запустить 5.1) data_dst view aligned results.bat.
Чтобы бегло просмотреть содержимое папки align_debug, найти и удалить любые кадры, на которых лицо целевого человека имеет неправильно выровненные ориентиры или ориентиры вообще не были размещены, используйте 5.1) data_dst view aligned_debug results.bat.
5.2. Очистка данных сцены
После того, как мы определили границы data_dst, нужно их очистить аналогично тому, как мы это делали с исходным набором лиц. Однако очистка целевого набора данных отличается от исходного, потому что мы хотим, чтобы все грани были выровнены для всех кадров, в которых они присутствуют, включая проблемные.
Начните с сортировки с помощью 5.2) data_dst sort.bat и используйте сортировку по similarity. Лица будут отсортированы по сходству, цвету, структуре – так будет проще сгруппировать похожие и удалить изображения, содержащие ложные срабатывания, лица других людей и неправильно определенные границы. Послу удаления неверных границ восстановите имена и порядок файлов с помощью утилиты 5.2) data_dst util recover original filename.
Перейдите в папку data_dst/align и используйте следующую, откройте Powershell и с помощью следующей команды удалите суффиксы _0 из имен файлов с размеченными лицами:
get-childitem *.jpg | foreach {rename-item $_ $_.name.replace("_0","")}
Дождитесь завершение процесса – по окончании снова отобразится адрес папки.
Если в сцене есть кроссфейд-переходы или лицо отражается в зеркалах, найдите файлы с суффиксом _1, переместите их в отдельную папку и снова запустите скрипт, но замените в команде _0 на _1. Скопируйте результат обратно в основную папку и убедитесь, что сохранили все файлы.
Создайте копию папки aligned_debug. После этого выделите все файлы в папке aligned, скопируйте их в свежесозданную копию папки align_debug, дождитесь завершения и, пока все только что замененные файлы еще выделены, удалите их. Просмотрите оставшиеся кадры и удалите все, на которых нет лиц, которые вы хотите извлечь вручную. Скопируйте остальные кадры обратно в исходную папку align_debug, замените, дождитесь завершения и, пока все замененные файлы все еще выделены, удалите их.
После таких манипуляций папка align_debug содержит только кадры, из которых были правильно извлечены лица, а также кадры, из которых экстрактор не смог правильно извлечь лица или не извлек. Теперь вы можете запустить 5) data_dst faceset MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.bat для их извлечения вручную Прежде чем вы это сделаете, можно запустить 5.1) data_dst view align_debug results.bat, чтобы быстро просмотреть оставшиеся хорошие и посмотреть, правильно ли выглядят ориентиры.
Если вы хотите еще больше улучшить качество разметки, используйте альтернативную модель разметки XSeg, работа с которой подробно описана в п. 5.3 официального руководства.
6. Обучение
Обучение нейросети – самая времязатратная часть, которая может длиться часы и сутки. Для тренировки необходимо выбрать одну из моделей. Выбор и качество результата определяются объемом памяти видеокарты. В текущей версии программы доступно две модели:
SAEHD (6GB+). Настраиваемая модель для высокопроизводительных графических процессоров.Quick96 (2-4GB). Простой режим, предназначенный для графических процессоров с 2-4 ГБ видеопамяти.
При первом запуске программа попросит указать параметры, применяемые при последующих запусках (при нажатии Enter используются значения по умолчанию). Большинство параметров понятно интуитивно, прочие – описаны в руководстве.
Обратите внимание, что некоторые параметры не могут быть изменены после начала обучения, например:
- разрешение модели (model resolution)
- архитектура модели (model architecture)
- размерность модели (models dimensions)
- тип лица (face type)
Рассмотрим также некоторые другие параметры модели.
Autobackup every N hour: автоматическое резервное копирование вашей модели каждые N часов. По умолчанию отключено.
Target iteration: модель прекратит обучение после достижения заданного количества итераций, например, если вы хотите обучать модель только 100 тыс. итераций, вы должны ввести значение 100000. Если оставить значение равным 0, модель будет работать до тех пор, пока вы не остановите ее вручную.
Flip faces randomly: полезный вариант в случаях, когда в исходном наборе данных нет всех необходимых углов поворота лица.
Batch_size: параметр влияет на количество лиц, сравниваемых друг с другом на каждой итерации. Наименьшее значение — 2, но вы можете увеличить значение, если с этим справится ваш графический процессор. Чем выше разрешение, размеры и больше особенностей у моделей, тем больше потребуется VRAM, поэтому может потребоваться меньший размер пакета. Рекомендуется не использовать значение ниже 4. Для начальной стадии можно установить более низкое значение, чтобы ускорить начальное обучение, а затем повысить его. Оптимальные значения – от 6 до 12.
AE architecture: можно выбрать тип архитектуры модели. Два основных типа: DF и LIAE. Обе модели обеспечивают высокое качество, но DF лучше срабатывает для лиц анфас, а LIAE качественнее справляется с трансформациями. Дополнительные буквы в названии соответствуют повышению сходства (-U) и увеличению разрешения модели (-D).
Прочие настройки подробно описаны в оригинальном руководстве.
На что обратить внимание
Отключите любые программы, использующие видеопамять. Если в процессе тренировки в консоли было выведено много текста, содержащего слова Memory Error, Allocation или OOM, то на вашем GPU модель не запустилась, и ее нужно урезать. Необходимо скорректировать опции моделей.
При корректных условиях параллельно с консолью откроется окно Training preview, в котором будет отображаться процесс обучения и кривая ошибки. Снижение кривой отражает прогресс тренировки. Кнопка p (английская раскладка) обновляет предпросмотр.
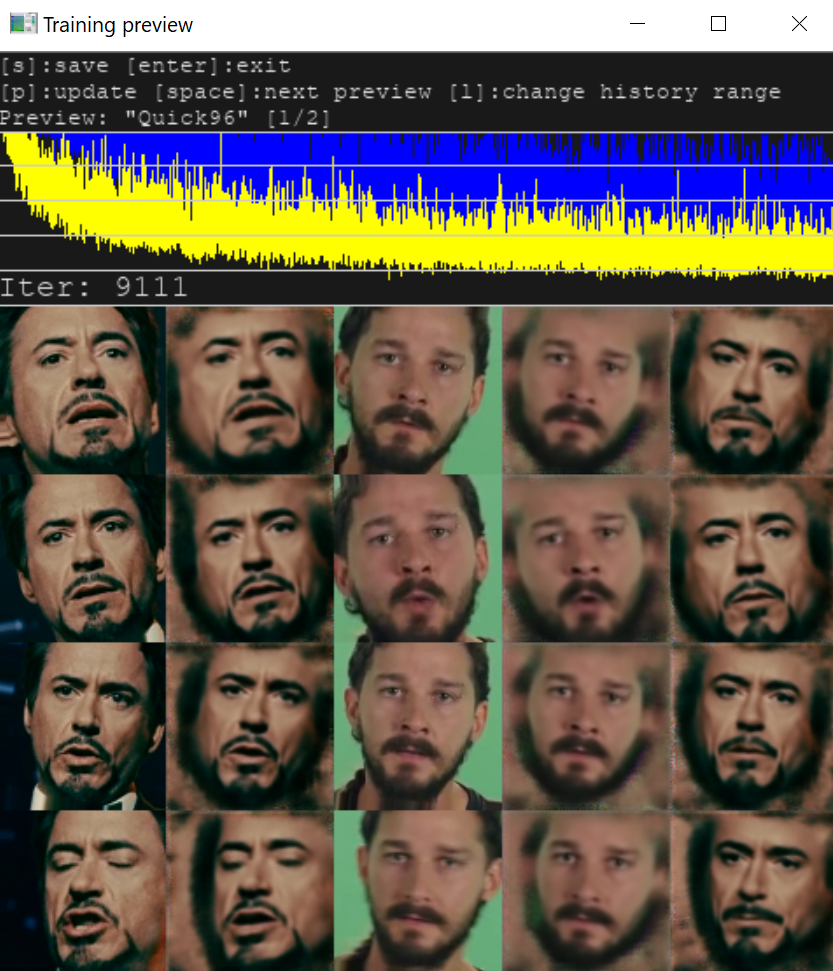
Процесс обучения можно прерывать, нажимая Enter в окне Training preview, и запускать в любое время, модель будет продолжать обучаться с той же точки. Чем дольше длится тренировка, тем лучший результат мы получим.
7. Наложение лиц
Теперь у нас есть результат обучения. Необходимо совместить src-лица и кадры dst-сцены. Из списка bat-файлов выбираем ту модель, на которой происходила тренировка.
В новой версии DeepFaceLab доступно множество режимов наложения с различными масками и дополнительными настройками. В качестве параметров для первой пробы можно использовать параметры по умолчанию (по нажатию Enter) и варьировать их, если вас не устроит результат соединения сцены и нового лица.
8. Склейка кадров в видео
После того, как вы объедините/конвертируете все лица, внутри папки data_dst появится папка с именем merged, содержащая все кадры, а также директория merged_masked, которая содержит кадры масок. Последний шаг – преобразовать их обратно в видео и объединить с исходной звуковой дорожкой из файла data_dst.mp4.
Итоговый файл будет сохранен под именем result. Доступны форматы mp4 и avi. Готово! Ниже представлен пример, полученный для тестовых видео.
Если результат вас не удовлетворил, попробуйте разные опции наложения, либо продолжите тренировку для повышения четкости, используйте другую модель или другие видео с исходным лицом. О неописанных особенностях работы с библиотекой, прочих советах и хитростях читайте в оригинальном руководстве и комментариях к нему.
Планируете протестировать DeepFake? Делитесь результатами 


Эта небольшая заметка не про комплектующие или их разгон, а про первичное знакомство с ПО, которое помогает «утилизировать» мощь наших ПК для создания видео, получивших название DeepFake (и чем они мощнее — тем более качественный фейк мы сможем сделать за более короткое время). Это мой первый опыт написания «статьи», надеюсь блин выйдет не слишком уж большим комом. 
DeepFake, DeepNude, Deep… — всё чаще слова с данным корнем звучат с экранов ТВ или пестрят в заголовках статей и блогов, заманивая сочной провокационной картинкой на обложке. Нейросети всё лучше учатся распознавать или изменять наши лица, тела, голоса. Всё труднее становится заметить эти подделки даже профессионалам. Источник скандалов и дискредитации известных персон, удел мошенников или просто обычное хобби и весёлый досуг? Всё зависит от чистоты помыслов людей, в чьих руках (особенно если прямых) оказывается подобное ПО. Моё внимание к данного рода программам привлекли видео, где Сталлоне остался «Один дома» и был вместо Арнольда в «Терминатор 2». Захотелось попробовать и узнать — насколько реально освоить это ремесло человеку, не обладающему знаниями в этой области, а также и не имеющему особых навыков использования фото- и видеоредакторов?! Попробуем разобраться вместе!
Скачав данный пакет программ (DeepFaceLab) около недели назад, я был несколько ошарашен, ибо перед моим взором предстала следующая картина:
Однако постепенно, шаг за шагом изучая обучающие видео и pdf файл обучения, пробуя что-то с этим всем добром сделать, я понял, что это — большой труд, который проделал автор данного ПО, чтобы облегчить наше бремя создания видеофейков. Сильно глубоко вдаваться в сам процесс создания DeepFake (далее DF) не буду: для этого есть, уже упомянутые выше — видео на ютуб от автора, других умельцев и мануал (или писать отдельную статью). Но некоторые пояснения, которые возможно смогут помочь людям, решившим бросить вызов коварным нейросетям, я, с вашего позволения, попробую сообщить.
1. Про железо, куда же без него родного! Кроме очевидного (конец первого абзаца), тут есть некоторые нюансы: т.к. лимитирующим по времени этапом создания DF является тренировка нейросети (далее ИИ), которое происходит на видеокарте (CUDA предпочтительнее, но можно даже на встройке!), то именно её параметры будут нам важнее, чем CPU. Мощь ядра и большой объём VRAM — ускоряют процесс и позволяют использовать более «тяжёлые» настройки, влияющие как на скорость некоторых операций, так и качество итогового видеоматериала. Автор пакета выставил следующие требования к комплектующим:
Минимальные системные требования: Windows 7 и выше, процессор с поддержкой SSE инструкций, 2Gb ОЗУ с подкачкой, OpenCL-совместимая видеокарта (NVIDIA, AMD, Intel HD Graphics)
Рекомендуемые системные требования: Windows 7 и выше, процессор с поддержкой AVX инструкций, 8Gb ОЗУ, NVIDIA видеокарта 6GB видео памяти.
Из чего можно сделать вывод, что лучше использовать карты уровня GeForce GTX 1060 (и более поздние аналоги) для nVidia или AMD Radeon 470 и выше. Мой конфиг: Ryzen 7 1800X @ 4.0 GHz, GeForce GTX 1080 Ti.
2. Отбор видеоматериала источника лица и видео, из которого делают DF — огромное, если не решающее, влияние на итоговый результат. Лучше использовать FHD исходники, ну или уж хотя бы честный HD. Выбор персонажей для источника лица и под замену — второй кит, на котором держится успешность нашего фейка. Если вы заменяете, например, блондинку с прямыми волосами на брюнетку с пышными — есть не иллюзорный шанс получить плохую узнаваемость героя DF. Худых моделей легче «вписать» в толстых, что наверное логично. Есть конечно исключения — вдруг вы, наоборот, хотите довести фэйк до абсурда и вписываете специально какие-то нелепые соотношения моделей (старика в ребёнка и т.д.). Такой подход тоже вполне имеет право на жизнь! Последний этап «пробоподготовки» — тщательно проверить: какие лица выделил детектор лиц, а он выделяет ВСЮ массовку! И приходится переназначать такие кадры вручную. Тренироваться лучше начинать на простых сценах, где 1 человек, и он более менее статичен: пресс-конференции, монологи и всё в таком духе. По мере увеличения способностей, повышать сложность сцены. Ещё очень важный момент при отборе лиц: SRC — это лицо, которые мы хотим вставить. DST — лицо, заменяемое в нашем фэйке. SRC лицо — нужно очень серьёзно «просеивать»: удалять кадры, где чем-то закрывается лицо, размытые, смазанные и т.д. Оставлять только чёткие! А DST наоборот — нам нужны абсолютно все кадры с данным лицом, а иначе потом будут пропуски кадров, и настоящий герой видео будет возвращаться в фэйк.
3. Тренировка ИИ. Сложный процесс, имеющий кучи, непонятных не только новичку, но и чуть более опытным пользователям, настроек (в продвинутых моделях), поэтому лучше начинать либо с H64 или с DF (в данном случае это название модели для тренировки), т.к. они проще. Хотя можно запускать и более сложные модели, такие как SAE и SAE HD, в режиме «по умолчанию», главное чтобы хватило VRAM, иногда надо снижать некоторые параметры. Тренировать ИИ рекомендуют ОТ одного дня. Но на картах уровня 1080ti и выше, на мой взгляд, это время можно сократить, но исходя из результата, который выводится на экран в процессе тренировки. Пример:
Выложу свой стандартный алгоритм создания DF, который поможет в самостоятельном освоении:
- 2) extract images from video data_src (источники лиц — им заменяют)
- 3.2) extract images from video data_dst FULL FPS (лицо, которое будет заменено)
- 4) data_src extract faces S3FD all GPU (детектирование лиц источника)
- [4.1) data_src check result] (удаляем всех левых персонажей, ошибочные кадры — крупные массивы фото, остальное отсеем позже)
- 4.2.2) data_src sort by similar histogram
- 4.1) data_src check result
- 4.2.1) data_src sort by blur
- 4.1) data_src check result (удалить мутные)
- 4.2.6) data_src sort by best (автоматика сама отбирает лучшие лица и удаляет ненужные, можно сразу использовать только этот пункт и потом вручную проверить, не осталось ли там «неликвида»)
- 5) data_dst extract faces S3FD all GPU (детектирование лица «под замену»)
- [5.1) data_dst check results]
- 5.2) data_dst sort by similar histogram
- 5.1) data_dst check results
- 5.3) data_dst sort by blur (Ручная проверка и удаление кадров, где несколько лиц или не совсем корректно определены контуры нужного лица в папке DeepFaceLab\workspace\data_dst\aligned_debug).
- 5) data_dst extract faces MANUAL RE-EXTRACT DELETED
RESULTS DEBUG (восстановление удалённого и последующая ручная разметка маски лица) - 6) train SAE HD (тренировка модели, можно брать другую использовав соответвующий *.bat файл)
- 7) convert SAE HD (замена dst лица на src, используя натренированную ранее модель)
- converted to mp4 («склеивание» стоп-кадров в видео)
Здесь «2) extract images from video data_src» — это «батник» «2) extract images from video data_src.bat» из папки «DeepFaceLab» и т.д. Эх, наверное сумбур уже пошёл, и я тут чутка перегрузил терминами, которые сложно воспринимать без подробного описания, а писать полную статью с подробным описанием всех действий — я в данный момент не потяну. При просмотре самых вводных видео от автора ПО — многое встанет на свои места. Если не хотите пока забивать голову, можно бегло пробежать по видео ниже, чтобы понять приблизительный уровень DF у человека, который неделю (плотно) пытался разбираться в этом вопросе. И сделать какие-то выводы о дальнейшей целесообразности самостоятельных попыток создания DeepFake видео.
Вывод: за неделю ознакомиться с данным пакетом можно, но получить реально хороший уровень фэйков — тяжело (если конечно вы не гений :)), потому что многие параметры моделей можно подбирать только эмпирическим путём или общаясь с более опытными фэйкерами, например, на рутрекере.
Привожу варианты своих «работ», чтобы вы могли оценить приблизительный уровень и некий прогресс в динамике обучения. Если она вообще имеется конечно. Все видео приводить не буду, можно поглядеть на моём канале. Только основные вехи.
Самое первое видео, его исходники идут в комплекте DeepFaceLab, т.е. и предназначены для первых тренировок (файлы data_dst.mp4 и data_src.mp4 в папке «DeepFaceLab\workspace«, свои видеофайлы вы в дальнейшем должны называть также, чтобы программа их подхватывала и использовала).
Тут особо и комментировать нечего, ляп на ляпе. По сути, я в тот момент просто жал почти везде «Enter» и всё было в режиме «по умолчанию», т.к. я ещё мало что понимал и не умел менять настройки (модели масок, цветовые и почти все прочие). Это делается уже почти в конце, на этапе «7) convert SAE HD» из алгоритма выше. Время тренировки модели — около 3-4 часов.
рекомендации
Ищем PHP-программиста для апгрейда конфы
4070 MSI по старой цене дешевле Palit
13900K в Регарде дешевле чем при курсе 60
Далее пошёл этап набивания шишек (я многие из них уже озвучил ранее): когда наше видео по качеству хуже чем источник — получается, что очень сильно заметны грани заменённого лица. Один раз я не заметил, что детектор не взял некоторые лица, и они потом исчезли в видео. Выбор слишком сложных динамических сцен, совершенно разное освещение SRC и DST лиц — тоже получается слишком «топорная» вставка.
Пример ошибки со вставкой Поклонской в Шурыгину — она довольно тяжело узнаётся из-за совсем разных причёсок и цвета волос:
Тут на миг пропадает лицо Греты (замена на неизвестную широкой общественности журналистку):
Ну и в самом конце, самый последний фэйк, который закончил только сегодня — тренировал 16 часов, личный рекорд пока что. Само обращение очень сочное, хорошего качества, а мой источник лица немного не дотягивает до такого уровня детализации и цветопередачи, возможно если продолжить тренировку модели с некоторыми другими настройками — его качество ещё можно поднять:
Если кого-то заинтересовала данная тема — скачивайте DeepFaceLab, устанавливайте и вперёд! Какие-то моменты могу попробовать подсказать, но в Интернете достаточно подробных рукописных и видеогайдов.
Спасибо за внимание!
Содержание статьи
![]() Listen to this article
Listen to this article
Процесс замены лиц на видео при помощи GAN-нейросетей, именуемый пользователями DeepFake, становится все более популярным в Сети, а его инструменты все более доступными. При этом поддельные ролики уже давно перестали быть простым развлечением и вызвали реакцию со стороны правительств западных стран.
Что такое DeepFake
Сама процедура создания видеофейков высокого уровня реалистичности «DeepFake» базируется на работе алгоритмов машинного обучения типа GAN. Не углубляясь в сложные технические подробности, данный тип алгоритмов можно описать как состязание между двумя нейросетями, одна из которых создает подделку, а другая пытается отличить её от оригинала. Собственно, GAN расшифровывается как «generative adversarial network» или генеративно-состязательные сети, если по-русски.
То есть, реалистичность моделирования достигается следующим образом: на основе исходных данных (в случае с видеоподделками берутся фотографии человека) одна нейросеть начинает генерировать искусственные модели, а вторая — определять и отбраковывать неудачные результаты. Процесс повторяется многократно, при этом первая нейросеть перманентно повышает качество фейка. На видео ниже представлен DeepFake, результат работы GAN-алгоритма, заменившего лица популярных американских телеведущих Джимми Феллона и Джона Оливера.
Для синтеза дипфейка мы будем использовать популярную библиотеку DeepFaceLab. Важно понимать, что на качество результата влияет множество свойств исходных файлов (разрешение и длительность видеофайлов, разнообразность мимики персонажей, освещение и т. д.).
Системные требования для DeepFaceLab
Минимальные системные требования для работы с инструментом:
- ОС Windows 7 или выше (64 бит).
- Процессор с поддержкой SSE-инструкций.
- Оперативная память объемом не менее 2 Гб + файл подкачки.
- OpenCL-совместимая видеокарта (NVIDIA, AMD, Intel HD Graphics).
Рекомендуемые системные требования:
- Процессор с поддержкой AVX-инструкций.
- Оперативная память объемом не менее 8 Гб.
- Видеокарта NVIDIA с объемом видеопамяти не менее 6 Гб.
Установка DeepFaceLab
Имеются три вида прекомпилированных сборок для ОС Windows:
DeepFaceLabCUDA9.2SSE– для видеокарт NVIDIA (вплоть до GTX1080) и любых 64-битных CPU.DeepFaceLabCUDA10.1AVX– для видеокарт NVIDIA (вплоть до RTX) и CPU с поддержкой AVX.DeepFaceLabOpenCLSSE– для видеокарт AMD/IntelHD и любых 64-битных CPU.
Файлы доступны на Google Drive и торрент-трекере (требуется VPN, форум трекера также пригодится в случае трудностей при установке и запуске). Размер сборок – порядка 1 Гб. На Google Drive также хранятся оформленные подборки лиц для теста.
Алгоритм работы с DeepFaceLab
Предварительно договоримся о терминологии:
src(сокр. от англ. source) – лицо, которое будет использоваться для замены,dst(сокр. от англ. destination) – лицо, которое будет заменяться.
Архив сборки нужно распаковать как можно ближе к корню системного диска. После распаковки в каталоге DeepFaceLab вы найдете множество bat-файлов.

Местом хранения модели служит директория workspace. В ней будут содержаться видео, фотографии и файлы самой программы. Вы можете переименовывать каталог для сохранения резервных копий.
Как вы могли заметить, bat-файлы имеют в начале имени номер. Каждый номер соответствует определенному шагу выполнения алгоритма. Некоторые пункты опциональны. Пройдемся по этой последовательности.
1. Очистка рабочего каталога
На первом шаге запуском 1) clear workspace.bat и нажатием пробела очищаем лишнее содержимое папки workspace. Одновременно создаются необходимые директории.
Сразу после распаковки в workspace уже содержатся примеры видеороликов для теста. В соответствии с описанной терминологией вы можете заменить их видеофайлами с теми же названиями data_src и data_dst. Максимально поддерживаемое разрешение – 1080p. Приведенные в документации примеры расширений файлов: mp4, avi, mkv.
2. Извлечение кадров из видеофайла источника
На втором шаге извлекаем изображения из src-файла (2) extract images from video data_src.bat). Для этого запускаем bat-файл, получаем приглашение для указания кадровой частоты:

Пропускаем пункт, нажав Enter, чтобы извлечь все кадры.

В формат png файлы извлекаются без потерь качества, но на порядок медленнее и с большим объемом, чем в jpg. После задания настроек кадры извлекаются в каталог data_src.
3. Извлечение кадров сцены для переноса лица
При необходимости обрезаем видео с помощью 3.1) cut video (drop video on me).bat. Перетаскиваем файл data_dst поверх bat-файла. Указываем временные метки, номер дорожки (если их несколько), битрейт выходного файла. Появляется дополнительный файл с суффиксом _cut.
Запускаем 3.2) extract images from video data_dst FULL FPS.bat для извлечения кадров dst-сцены.
4. Составление выборки лиц источника
Теперь необходимо детектировать лица на src-кадрах. Получаемая выборка будет храниться по адресу workspace\data_src\aligned. Этому пункту соответствует множество bat-файлов, начинающихся с 4) data_src extract faces и имеющих разные дополнения после:
- Тип детектора лица:
MT– чуть более быстрый, но производит больше ложных лиц илиS3FD– рекомендованный, более точный, меньше ложных лиц. - Вариант использования GPU:
ALL(задействовать все видеокарты),Best(использовать лучшую). Выбирайте второй вариант, если у вас есть и внешняя, и встроенная видеокарты, и вам нужно параллельно работать в офисных приложениях. - Запись работы детекторов (
DEBUG). Каждый кадр с выделенными контурами лиц записывается по адресуworkspace\data_src\aligned_debug.
Пример вывода программы при запуске на видеокарте NVIDIA GeForce 940MX:

Bat-файл с параметром MANUAL применяется для ручного переизвлечения уже извлеченных лиц в случае ошибок на этапе 4.2.other) data_src util add landmarks debug images.bat.
4.1. Удаляем большие группы некорректных кадров
Запускаем 4.1) data_src check result.bat, просматриваем результаты в обозревателе XnView MP (при закрытии запускайте этот bat-файл).

На этом этапе необходимо удалить большие группы некорректных кадров, чтобы далее не тратить на них вычислительный ресурс. К некорректным кадрам относятся все те, что не содержат четко различимого лица. Лицо также не должно быть закрыто предметом, волосами и пр. Не тратьте время на мелкие группы. Они будут удалены на следующем шаге.
4.2. Сортировка и удаление прочих некорректных кадров
Файлы с именами, начинающимися с 4.2, служат для сортировки и выявления групп некорректных кадров. Не закрывая обозреватель, последовательно запускайте bat-файлы и удаляйте группы некорректных кадров (обычно находятся в конце).
4.2.1) data_src sort by blur.batсортирует кадры по резкости, удаляем кадры с нечеткими лицами.4.2.2) data_src sort by similar histogram.batгруппирует кадры по содержанию, позволяет удалять ненужные лица группами.4.2.4) data_src sort by dissimilar histogram.batоставляет ближе к концу списка те изображения, у которых больше всего схожих (обычно это лица анфас). По усмотрению можно удалить часть конца списка, чтобы не проводить обучение на идентичных лицах.- Опционально:
4.2.5) data_src sort by face pitch.batсортирует лица так, чтобы в начале списка лицо смотрело вниз, а в конце – вверх. - Опционально:
4.2.5) data_src sort by face yaw.batсортирует лица по взгляду слева направо. - Рекомендованный пункт:
4.2.6) data_src sort by final.batделает финальную выборку целевого количества (по умолчанию 2000). Применяйте только после очистки набора предыдущими инструментами.
Дополнительные сортировочные bat-файлы, названия которых начинаются с 4.2.other, сортируют изображения по количеству черных пикселей, числу лиц в кадре (нужны кадры только с одним лицом) и т. д.
5. Составление выборки лиц принимающей сцены
Следующие операции с некоторыми отличиями идентичны выборке лиц источника. Главным отличием является то, что для принимающей сцены важно определить dst-лица во всех кадрах, содержащих лицо, даже мутные. Иначе в этих кадрах не будет произведено замены на источник.
Опция +manual fix позволяет вручную указать контуры лица на кадрах, где лицо не было определено. При этом в конце извлечения файлов открыто окно ручного исправления контуров. Элементы управления описаны вверху окна (вызываются клавишей H).

Запуск 5.1) data_dst check results debug.bat позволяет посмотреть все dst-кадры c наложенными поверх них предсказанными контурами лица. Удалите лица прочих, неосновных персонажей.
6. Тренировка
Обучение нейросети – самая времязатратная часть, длящаяся часы и сутки. Для тренировки необходимо выбрать одну из моделей. Выбор и качество результата определяются объемом памяти видеокарты:
- ≥ 512 Мб →
SAE. Наиболее гибкая модель с возможностью переносить стиль лица и освещение. - ≥ 2 Гб →
H64. Наименее требовательная модель. - ≥ 3 Гб →
H128. Аналогична моделиH64, но с лучшим разрешением. - ≥ 5 Гб →
DF– умная тренировка лиц, исключающая фон вокруг лица, илиLIAEF128– модель аналогичнаDF, но пытается морфировать исходное лицо в целевое, сохраняя черты исходного лица. - ≥ 6 Гб →
AVATAR– модель для управления чужим лицом, требуются квадратные видеоролики илиSAE HD– для самых последних видеокарт.
В руководстве не описана еще одна модель, присутствующая в наборе (Quick96), но она успешно запустилась при тренировке на видеокарте с 2 Гб памяти.
При первом запуске программа попросит указать параметры, применяемые при последующих запусках (при нажатии Enter используются значения по умолчанию). Большинство параметров понятно интуитивно, прочие – описаны в руководстве.
Отключите любые программы, использующие видеопамять. Если в процессе тренировки в консоли было выведено много текста, содержащего слова Memory Error, Allocation или OOM, то на вашем GPU модель не запустилась, и ее нужно урезать. Необходимо скорректировать опции моделей.
При корректных условиях параллельно с консолью откроется окно Training preview, в котором будет отображаться процесс обучения и кривая ошибки. Снижение кривой отражает прогресс тренировки. Кнопка p (английская раскладка) обновляет предпросмотр.

Процесс тренировки можно прерывать, нажимая Enter в окне Training preview, и запускать в любое время, модель будет продолжать обучаться с той же точки. Чем дольше длится тренировка, тем лучший результат мы получим.
7. Наложение лиц
Теперь у нас есть результат обучения. Необходимо совместить src-лица и кадры dst-сцены. Из списка bat-файлов выбираем ту модель, на которой происходила тренировка. Возможно несколько режимов наложения, по умолчанию используется метод Пуассона. В качестве остальных параметров для первой пробы можно использовать параметры по умолчанию (по нажатию Enter) и варьировать их, если вас не устроит результат наложения.
8. Склейка в видео
Следующие bat-файлы склеивают картинки в видео с той же частотой кадров и звуком, что и data_dst (поэтому файл должен оставаться в папке workspace). Итоговый файл будет сохранен под именем result. Готово! Ниже представлен пример, полученный для тестовых видео.
DeepFakes Robert Downey to Shia Labeouf «Just do it»
Если результат вас не удовлетворил, попробуйте разные опции наложения, либо продолжите тренировку для повышения четкости, используйте другую модель, другое видео с исходным лицом. О неописанных особенностях работы с библиотекой, прочих советах и хитростях читайте в оригинальном руководстве.
Источник: https://teleg.one/joinchat/AAAAAER0WSV-Qy3URO6-xg
Если Вам понравилась статья — поделитесь с друзьями
6 190 просмотров
Отказ от ответственности: Автор или издатель не публиковали эту статью для вредоносных целей. Вся размещенная информация была взята из открытых источников и представлена исключительно в ознакомительных целях а также не несет призыва к действию. Создано лишь в образовательных и развлекательных целях. Вся информация направлена на то, чтобы уберечь читателей от противозаконных действий. Все причиненные возможные убытки посетитель берет на себя. Автор проделывает все действия лишь на собственном оборудовании и в собственной сети. Не повторяйте ничего из прочитанного в реальной жизни. | Так же, если вы являетесь правообладателем размещенного на страницах портала материала, просьба написать нам через контактную форму жалобу на удаление определенной страницы, а также ознакомиться с инструкцией для правообладателей материалов. Спасибо за понимание.
Если вам понравились материалы сайта, вы можете поддержать проект финансово, переведя некоторую сумму с банковской карты, счёта мобильного телефона или из кошелька ЮMoney.

Без сомнения, Deepfake — одна из самых сексуальных технологий нашего времени. Как насчет того, чтобы попробовать это самостоятельно?
ТАК ЧТО ТАКОЕ ГЛУБОКОЕ?
Deepfakes (портмоне слов глубокое обучение и фальшивка [1]) — это синтетические медиа [2], в которых человек на существующем изображении или видео заменяется на чужое подобие. Хотя подделка контента не нова, дипфейки используют мощные методы машинного обучения и искусственного интеллекта для манипулирования или создания визуального и аудиоконтента с высоким потенциалом обмана. [3] Основные используемые методы машинного обучения для создания дипфейков основаны на глубоком обучении и предполагают обучение генеративных нейросетевых архитектур, таких как автокодировщики [3] или генеративные состязательные сети (GAN). [4] [5], говорит Википедия.





У меня для вас шокирующие новости. Вы также можете сделать это на своем домашнем компьютере. Да, звучит интересно, правда? Тогда перейдем к руководству!
ШАГ 1: ЗАГРУЗКА
- Прежде всего, нам нужно попасть на страницу Github этого проекта.
Https://github.com/iperov/DeepFaceLab
- При прокрутке вниз вы увидите раздел «Релизы». Подберите для себя наиболее подходящий вариант. Для загрузки я использовал торрент-клиент.

- Вам не нужно загружать их все. Загрузите только тот, который подходит для ваших видеокарт. У меня RTX 2060, и я скачал NVIDIA-up-to-RTX2080Ti.

- Когда процесс загрузки будет завершен, дважды щелкните и нажмите «Извлечь». Теперь мы готовы творить чудеса!
ШАГ 2: ПЕРЕД НАЧАЛОМ
- Эта страница приветствует вас. К этому лучше привыкнуть, потому что ты будешь проводить здесь все свое время. Вы будете лучшими друзьями! В папке «Рабочая область» вы будете творить чудеса. Все начинается здесь.

- Два видео в формате .mp4 с названиями «data_dst» и «data_src» приветствуют вас при входе в папку «Workspace». Эти два видео являются видео по умолчанию, и вы можете сразу приступить к работе с ними. Я пробовал использовать эти два видео, но потом заменил их новыми, когда работал над новыми проектами. Вот почему эти два видео на фото под этим текстом не являются видео по умолчанию. Я их туда положил.

«Data_src» (источник) — ваше исходное видео.
«Data_dst» (пункт назначения) — это ваше целевое видео.
Наборы лиц из видео data_src будут извлечены, и они будут заменены лицом в видео data_dst.
Требования к исходному и целевому видео
- Высокое разрешение (лучше всего 4K WebM, ниже 1080p не рекомендуется)
- Лица, расположенные не слишком далеко от камеры и беспрепятственные
- Множественные углы, выражения лица
- Ярко и равномерно освещен
- Лица должны несколько совпадать (борода, шляпа, волосы, цвет кожи, форма, очки).
- Требуется как минимум 2 минуты видео хорошего качества. Видео с интервью работают хорошо.
(https://pub.dfblue.com/pub/2019-10-25-deepfacelab-tutorial)
НЕБОЛЬШОЕ ПРИМЕЧАНИЕ ОТ АВТОРА
Вы должны назвать видео, с которыми будете работать, «data_src» и «data_dst». Это очень важный момент. Вы можете создать новую папку и поместить в нее свои старые данные, источник и видео результатов. Мой вам совет: не удаляйте их, потому что их хорошо скомпилировать, и вы можете вернуться и посмотреть свои старые проекты и их материалы.
Кроме того, просто нажмите «Очистить рабочее пространство», когда начнете новый проект. Все будет готово к работе. Единственное, что вам нужно сделать, это затем поместить видео «data_src» и «data_dst» в рабочую область.

ШАГ 3: РЕБЯТА, ПРИСТЯНИТЕ РЕМНИ БЕЗОПАСНОСТИ. МЫ НАЧИНАЕМ!
Что вам нужно сделать:
- 2) извлечь изображения из видео data_src (он извлекает изображения из data_src) (нажмите «Enter» несколько раз, чтобы использовать настройки по умолчанию.)

- 3) извлечь изображения из видео data_dst ПОЛНЫЙ FPS (он извлекает изображения из «data_dst») (нажмите «Enter» несколько раз, чтобы использовать настройки по умолчанию.)
- 4) data_src faceset extract (он извлекает наборы лиц из data_src. Видите? Это не ракетостроители!)

- 4.1) data_src просмотр выровненного результата (Здесь вы можете увидеть свои результаты. Для достижения наилучших результатов удалите ненужные фотографии, которые не соответствуют нашим критериям, перед началом тренировки. Например, неправильно распознанные лица, искаженные изображения, так далее.)

- 5) извлечение набора лиц data_dst (извлекает наборы лиц из data_dst) (аналогично шагу 4)
- 5.1) data_dst просмотреть согласованные результаты ( Вы можете увидеть свои результаты здесь. Для достижения наилучших результатов удалите ненужные фотографии, которые не соответствуют нашим критериям, перед началом сеанса обучения. Например, неправильно распознанные лица, искаженные изображения, и т. д.) (то же, что и в шаге 4.1)

- 5.XSeg) data_dst mask — изменить
Теперь это критический момент. В этой главе мы вручную замаскируем лица. Мы должны тщательно выполнять маскировку. Если вы замаскируете неправильно или небрежно, получите раздражающий результат. Я сделал процесс маскировки немного небрежным и включил волосы человека в нескольких местах. Это дало разочаровывающий результат. Фото поставлю в конец.

- 5.XSeg) data_src mask — изменить
Мы делаем тот же процесс снова для нашего исходного видео. То же, что и на предыдущем шаге.

- 5.XSeg) поезд
Пришло время приступить к обучению нашей модели XSeg. Когда вам будет предложено ввести тип лица, напишите «wf» и начните тренировку, нажав Enter. Начинается захватывающая часть!

Во-первых, давайте договоримся об этом:
БОЛЬШЕ ИТЕРАЦИЙ = ЛУЧШИЙ РЕЗУЛЬТАТ
Я предлагаю вам иметь минимум 10 000 Iters. Конечно, могло быть и больше. Потому что то, что мы только что сказали, БОЛЬШЕ ИТЕРАЦИЙ = ЛУЧШИЙ РЕЗУЛЬТАТ.
Когда вы скажете «ОК», этого достаточно, вы можете нажать «Ввод» и завершить обучение модели. Давай продолжим.
- 5.XSeg) обученная маска data_dst — применить (мы применяем нашу обученную модель)
- 5.XSeg) обученная маска data_src — применить (мы применяем нашу обученную модель)
- 5.XSeg) data_src mask — edit ( Мы проверяем результат, снова маскируем плохие результаты, чтобы получить лучший результат )
- 5.XSeg) data_dst mask — edit ( Мы проверяем результат, снова маскируем плохие результаты, чтобы получить лучший результат )

- 5.XSeg) train (После повторной настройки мы тренируемся еще раз. Если вы не выполняли никаких изменений, вам не нужно переучиваться.)
- 5.XSeg) обученная маска data_dst — применить (мы применяем повторно обученную модель так же, как и на предыдущих шагах.)
- 5.XSeg) обученная маска data_src — применить ( Мы применяем повторно обученную модель так же, как и на предыдущих шагах.)
И МАГИЯ НАЧИНАЕТСЯ!
В качестве последнего шага;
6) поезд SAEHD
Щелкаем и начинаем обучение нашей модели. Убедитесь, что выполнено не менее 100 000 итераций. Чем больше, тем лучше. При желании вы можете сделать 500 000 или 1 000 000 итераций. Но чем больше, тем лучше результат! Когда вы скажете «ОК, хватит», нажмите клавишу «Ввод» и завершите тренировку.

Во время этого процесса вашей системе придется нелегко. Ваш компьютер будет чертовски горячим. Я пошел и купил себе кулер для ноутбука, пока шёл процесс. Я покажу вам это на картинке.


ШАГ 4: К ФИНАЛУ
Мы подошли к концу.
- 7) объединить SAEHD
И вы увидите интерактивный экран.


В этом примере вы видите результаты ложной маскировки. Если бы процесс маскировки был выполнен более детально, я бы на этот раз добился невероятно реалистичного результата. Я сделал эту ошибку специально, чтобы вы не повторяли тех же ошибок.
ШАГ 5: ТОРЖЕСТВЕННЫЙ ФИНАЛ!
 объединено в mp4
объединено в mp4
Щелкните по нему, и вы увидите свой результат. Полученный результат будет ждать вас в папке «Workspace» с именем «result.mp4». Вы можете поделиться своими результатами с друзьями и близкими, в Интернете или со мной!

Надеюсь, этот урок будет вам полезен. Вы можете задать мне вопросы в любое время.
Вы можете связаться со мной по:
LinkedIn: https://www.linkedin.com/in/mehmet-emin-masca-359812207/
Электронная почта: [email protected]
DeepFace Lab Tutorial: How to make a DeepFake
Full DeepFaceLab Tutorial
Table of Contents
1:20 – Software/Hardware Requirements/Recommendations
12:36 – How to Acquire DeepFace Lab Software
16:36 – Extracting DeepFace Lab Software
18:20 – Main Folder Batch Files, “Workspace” Folder Contents
35:25 – Acquiring Source/Destination Video Clips | Exporting and Naming Schemes
42:52 – Extracting Images from “data_src” and “data_dst”
48:05 – Extracting SRC and DST faces | Manual vs Automatic Extraction
1:03:32 – XSEG Editor: Generic vs Manual
1:28:15 – Creating a Faceset.pak file
1:30:42 – Creating the SAEHD Model | Settings Explained + Pretraining
1:30:47 – Default model settings
2:07:50 – Taking note of issues during training
2:10:00 – How to add additional images to your source library
2:21:56 – Adding yet more source images…
2:24:28 – Manually extracting side profiles
2:43:40 – Enabling LRD (Learning Rate Dropoff) | Image Sharpening Begins here
2:50:45 – Disabling RW (Random Warp)
2:59:14 – Enabling GAN
3:07:26 – Enabling Blurout Mask
3:14:17 – SAEHD Interactive Merger
3:49:14 – Enabling Color Transfer Mode
3:50:58 – Final commentary & Edited Deepfake