
Посвящается моему коллеге и наставнику по Informatica Максиму Генцелю, который умер от COVID-19 21.01.2021
Привет! Меня зовут Баранов Владимир, и я уже несколько лет администрирую Informatica в «Альфа-Банк». В статье я поделюсь опытом работы с Informatica PowerCenter. IPC это платформа, которая занимается ETL (Extract, Transformation, Loading). Я сосредоточусь на описании конкретных кейсов и решений, расскажу о некоторых тонкостях и постараюсь дать пищу для ума.
В работе приходится часто сталкиваться с проблемами производительности и стабильности платформы, при этом глубоко во всё вникая, поэтому лично я при работе с Informatica получаю огромное удовольствие. Во-первых, потому, что даже IPC сам по себе не такой уж маленький, а у Informatica целое семейство продуктов. Во-вторых, ETL находится на стыке разных систем, надо знать всего понемногу – базы данных, коннекторы, линукс, скриптовые языки и системы визуализации и мониторинга. В-третьих, это общение с большим количеством разных людей и много интересных задач.
Запуск клиента информатики
Забавно, но даже тут можно наступить на некоторые грабли. Да, прямо на старте и с размахом.
У информатики есть следующие клиенты: Workflow Manager, Workflow Monitor, Repository Manager, Designer и Developer Client. Параметры подключения к репозиториям хранятся в файле domains.infa, который обычно задаётся переменной окружения:
SET INFA_DOMAINS_FILE=C:\Informatica\9.5.1\clients\PowerCenterClient\domains.infa
Но если версий информатики несколько, то файл рано или поздно будет «побит», а клиент информатики будет ругаться при попытке сохранения добавленного репозитория.
Что делать? Создать батники для каждой версии клиента вида:
SET INFA_DOMAINS_FILE=C:\Informatica\9.5.1\clients\PowerCenterClient\domains.infa
cd C:\Informatica\9.5.1\clients\PowerCenterClient\client\bin\
start pmdesign.exe
Последние две строчки попортили мне очень много крови, так как изначально я запускал клиента так:
C:\Informatica\9.5.1\clients\PowerCenterClient\client\bin\pmdesign.exe
И батник прекрасно работал ровно до того момента, пока я не обновился с 9.5.1 до 10.1.1 и не начал пытаться подключаться через клиент информатики к SAP.
Disigner должен был показывать коннекты из файла sapnwrfc.ini, но показывалась пустота, хотя файл лежал в нужном каталоге клиента IPC. Я даже успел немного посидеть с отладчиком над клиентом, но в итоге мне помогла индианка из службы поддержки.
Что ещё можно сказать о файле domains.infa и создании подключений? Вы не сможете единовременно добавить два репозитория с одинаковым именем, даже если они находятся на разных серверах.
Файл domains.infa также используется при использовании консольных команд для подключения к репозиторию* (pmrep), имейте это в виду. Но об этом чуть позже.
*На самом деле не обязательно, смотрите на описание ключей команды.
Настраиваем окружение
Что важного может быть в окружении Informatica? Если вы обратитесь в поддержку Информатики, то первым делом вас попросят показать вывод команд: ulimit –Ha / ulimit –Sa. Soft и hard ограничения пользователя, под которым запущена информатика).
stack size 10240
open files (-n) 500000
Сколько ставить open files? Поддержка Informatica как-то утверждала, что у нас одна из самых высоконагруженных и сложных инсталляций в России – при этом нам хватает 500к open files, с запасом примерно в 150-250к.
На многих серверах стоит по 120-180к, и этого хватает. Со временем (и в случае нашего банка это происходит очень быстро) приходится увеличивать.
Однажды видел, как ведёт себя Oracle, если ему не хватает максимально открытых файлов. Он периодически начинает ощутимо тормозить, клиенты от него отваливаются. Но при этом он оставался работать и не падал.
Если вы не знаете, какое текущее значение у уже запущенного процесса:
cat /proc/pid/limits
max user processes (-u) 4134885
Важный параметр, но ничего особенно интересного про него рассказать не могу.
core file size (blocks, -c)
Потенциально опасный параметр. Дампы памяти от падаюших сервисов или потоков можно проанализировать (иногда помогает поиск по ключевым словам в базе знаний информатики), их также требует поддержка Informatica. По умолчанию они будут падать в $INFA_HOME/server/bin/ и главное — core могут быть очень большими.
Имеет смысл следить за этим каталогом и аккуратно его чистить.
Теперь не такое очевидное:
/etc/systemd/system.conf, /etc/systemd/user.conf
DefaultTasksMax=40000
DefaultLimitNOFILE=500000
Более подробно о TasksMax:
To control the default TasksMax= setting for services and scopes running on the system, use the system.conf setting DefaultTasksMax=. This setting defaults to 512, which means services that are not explicitly configured otherwise will only be able to create 512 processes or threads at maximum.
For thread- or process-heavy services, you may need to set a higher TasksMax value. In such cases, set TasksMax directly in the specific unit files. Either choose a numeric value or even infinity.
Similarly, you can limit the total number of processes or tasks each user can own concurrently. To do so, use the logind.conf setting UserTasksMax (the default is 12288).
Как можно посмотреть текущее значение:
admin@serv:/etc/systemd> systemd-analyze dump|grep -i DefaultLimitNPROC|sort -n -k2
admin@serv:/etc/systemd> systemctl show -p DefaultLimitNOFILE
admin@serv:/proc/38757> systemctl show -p DefaultLimitNPROC
cat /sys/fs/cgroup/pids/user.slice/user-*.slice/pids.max
cat /sys/fs/cgroup/pids/user.slice/user-*.slice/pids.current
Если интересно, что это такое — гуглить «linux cgroup slices»:
Что будет в системных логах, если TaskMax недостаточен:
2020-01-01T03:23:30.674392+03:00 serv kernel: [5145583.466931] cgroup: fork rejected by pids controller in /user.slice/user-*.slice/session-2247619.scope
Кстати
*Вообще, думаю что имеет смысл прочитать требования к окружению при установке разных БД — там очень дельные предложения по окружению. Было немного обидно, когда ровно на следующей день после обнаружения проблемы с TaskMax я прочитал о них в гайде по установке Teradata.
/etc/sysctl.conf
fs.file-max = 6815744
Тут тоже особо не заостряю внимания.
Сеть, sysctl, net.core, net.iipv4
Чтобы что-то тут менять — надо очень хорошо понимать, как работает сеть, ядро, сокеты. Бездумное изменение параметров может сделать только хуже. Не буду здесь приводить конкретных настроек, так как у меня до сих пор фрагментированное понимание этой части sysctl. Хотелось бы, чтобы гайды о сетевой части sysctl сопровождали примерами из netstat -sn и netstat -an.
Кейсы по архитектурным ошибкам
Всё, что я напишу ниже, следует читать осторожно, сознавая что обычный разработчик, который работает с Informatica каждый день, может обладать куда большей экспертизой, чем я.
1. GRID
Информатика может иметь все сервисы на одной машине, а может существовать в виде кластера и балансировать нагрузку между нодами. Даже если вы в ближайшем будущем не планируете использовать кластер, всё же крайне желательно, чтобы разработка велась так, как будто это может произойти в будущем. Вертикальная масштабируемость конечна, сидеть на ней без возможности в любой момент переключиться на горизонтальную — это как сидеть на пороховой бочке.
Я не имел личного опыта работы с гридом, но много людей отзывались о нём негативно. Грид определённо не только решает проблемы, но и добавляет новые. Тем не менее, я знаю организации, у которых всё работает именно на гриде. Надеюсь, у меня будет возможность познакомиться с ним поближе и набить уже своих шишек.
Очень наглядный гайд по созданию грида видел у nutanix.
2. Pushdown
К разработке может быть несколько подходов:
- Всю работу по части ETL выполнять на стороне информатики, постоянно подтягивая в неё данные.
- Всю работу по части ETL выполнять на стороне СУБД приёмника/таргета, использовать дблинки.
Второй вариант и есть так называемый pushdown optimization. Тут сразу уточню, что у информатики есть свои крутые механизмы для pushdown optimization, которые позволяют, например, переносить логику трансформации на source/target — но я говорил не про эти механизмы, а про общие принципы.
Ведь как правило незачем тягать данные на сервер информатики и нагружать его, если source & target находятся в пределах одной БД — лучше сделать процедуру.
На Хабре выходила отличная статья от DIS, где они рассказывали про pushdown на русском, рекомендую к прочтению.
3. Информатика как шедулер
Большинство компаний используют информатику в качестве эдакого шедулера для запуска потоков и не перекладывают на неё вычисления, если это можно сделать на стороне БД. И во всех организациях присутствует дополнительная сущность в виде базы данных, которая используется в качестве управляющего механизма. Это очень удобно для выстраивания логики работы потоков и параметров их запуска (нам же нужно знать, например, какие даты мы уже успешно загрузили, успешно ли отработали потоки и т.д).
В итоге в информатике выстраивается сложная схема, когда один поток запускает десятки других потоков, в это время второй поток дожидается выполнения третьего и пятого потока, а многие-многие сессии запускают sh-файлы, которые взаимодействуют с управляющим механизмом. В некоторых потоках может быть и 1500+ запусков sh-файлов (и до 200-300 запусков одновременно).
На этапе использования sh-файла для обращения к управляющему механизму в некоторых компаниях может закладываться бомба замедленного действия, т.к в одном таком файле может быть до 4 соединений посредством sqlplus (пример работы: проверили, включен ли поток; взяли параметры запуска; записали, что поток отработал и.т.д). И это довольно неплохой способ устроить своеобразную DDoS-атаку штормом коннектов на сервер БД.
Как минимум поэтому сервер БД метаданных информатики и сервер БД управляющего механизма не должны быть в опасной близости друг от друга. И конечно, бест практик не размещать сервер БД, хранящий метаданные информатики, на одной площадке*.
*На самом деле, не так уж это и критично. Но по возможности лучше этого избегать. Я видел примеры с высоконагруженными серверами информатики, где сервера БД были на этом же хосте.
4. «Оптимизация» как угроза
Если какой-нибудь поток выйдет за рамки SLA то у разработчиков и саппорта после доработки хинтами может быть большой соблазн увеличить количество параллелей, т.к это путь наименьшего сопротивления. Пересмотром запросов или архитектуры займутся в последнюю очередь, как наиболее трудозатратное. Возможно стоит мониторить как меняются параллели у потоков.
5. Параметризация
При разработке желательно подумать о том, что вот прямо завтра сервер может переехать на другой хост или в другой каталог. У потока также может сменится репозиторий или интеграционный сервис (с дева на тест, с теста на прод, например). Смену каталога тоже принято делать при обновлении IPC.
Может так сложиться, что вы решите перенести сервис на хост, где будет несколько инстансов информатики.
Посмотрим, нет ли у нас абсолютных путей до информатики в метаданных репозитория:
Предостережение: Даже селекты из метаданных информатики могут быть опасны и у поддержки IPC есть кейсы когда это реально вредило стабильности IPC. Разрешено использовать только view, список которых есть в Repository Guide.
select * from REP_NAME_TST.OPB_TASK_VAL_LIST where pm_value not like '%PMRoot%':
/informatica/pc10/server/bin/pmrep objectexport -f DMQAS_DWH -u
В некоторых запущенных случаях можно обнаружить комбо:
pmcmd startworkflow -sv INT_TT_PROD -d DOMAIN_TT_PROD -u Userlogin -p MyPass -f FLOW_CONTROL_D -wait WF_CTL_
В данном случае поток запускали под пользовательской учёткой, с указанием пароля и инт.сервис+домен не был параметризирован.
С sh-файлами необходимо придерживаться тех же самых правил. Конфиги должны быть отдельно от скриптов, абсолютных путей быть не должно, только относительные. Недопустимо указание инт.сервиса, хостов и других явно зашитых параметров в sh-скрипте.
6. Репозитории, интеграционные сервисы, файловая система и лукапы
Репозитории достаточно просто переносятся с сервера на сервер, я расскажу подробнее в главе «Работа в консоли, девопс». На самом деле сущность репозитория вообще не имеет отражения на уровне файловой системы — репозиторий находится в БД-слое.
А вот интеграционные сервисы, которые привязываются к репозиторию, требуют инфраструктуры каталогов:

По возможности лучше разделять проекты в разные репозитории, чтобы было проще их переносить, масштабировать, актуализировать и понимать, сколько ресурсов они потребляют.
Я бы с самого начала посоветовал сделать как минимум два подкаталога с лукап кэшами. В первом каталоге можно хранить кэши временные, во втором – постоянные (persistent) кэши (не путать с именованными). И ещё, информатика обладает неприятным поведением при падениях – она не чистит за собой старые лукапы.
В «Альфа-Банке», например, раньше часть больших кэшей лежала на медленных дисках, а остальные на быстрых. Кэши в разных каталогах это довольно удобно — в любой момент можно перекинуть часть кэшей на другой массив, оставив симлинк. Это проще, чем когда все кэши находятся в одном месте.
В $PMCacheDir по умолчанию создаются временные кэши, но это не значит, что при создании лукапа нельзя указать, например, $PMRootDir/New_Cache.
Также хочу обратить внимание, что в случае, когда у персистент-лукапов добавляются или меняются поля – эти лукапы будут полностью перестраиваться, создавая в каталоге свою полную копию (*.bak). Это может сыграть злую шутку, если лукап весит 300-500 гб. В целом, грамотное использование лукапа значительно увеличивает производительность.
Обратите внимание на именование лукапов, которые создаёт информатика на уровне ФС:
ls PMLKUP629*
PMLKUP629_21_0_247034L64.dat0
PMLKUP629_21_0_247034L64.dat1
PMLKUP629_21_0_247034L64.idx0
PMLKUP629_21_0_247034L64.idx1
В начале названия файлов идёт префикс (PMLKUP), который означает, что это лукап-кэш. Помимо лукапов в CacheDir создаются джойнеры, сортировка, агрегатор и rank transformation.
Насколько я помню, после префикса идёт session_id — и это даёт возможность получить сессию, которая с ним работает в данный момент.
Определяем, кто работает с файлом кэша (возьму любой из занятых).
admin@server:/informatica/pc10/server/infa_shared/Cache> lsof +D $(pwd)
/informatica_cache/Cache/PMLKUP144968_4_0_74806582L64.idx0
Греп по session_id в процессах:
ps -ef|grep 144968
Отформатирую и порежу вывод, чтобы остановить ваше внимание на самых важных вещах, которые мы можем увидеть, посмотрев pmdtm-процесс.
Смотрим, какие файлы занял процесс:
ls -l /proc/64719/fd/ |grep -i PMLKUP144968
/informatica_cache/Cache/PMLKUP144968_4_0_74806582L64.dat0
И раз уж я начал рассказывать про pmdtm — не могу не поделится крутым параметром для отладки, которые задаётся в Custom-параметрах интеграционного сервера.
DelayDTMStart=<секунды>
Чтобы ещё больше не увеличивать эту статью, просто дам ссылку.
7. Система версионности в информатике
По кейсам в базе знаний сложилось стойкое впечатление, что с ней лучше дел не иметь.
8. Логи сессий и потоков
Подробнее о логах мы говорим позже, но хочется обозначить следующее. Будьте готовы, что в большой инсталляции логи будут занимать десятки гигабайт, и количество логов сессий свободно может перевалить за 1-2 млн в зависимости от выбранной вами стратегии log-rotate.
Я не могу с уверенностью сказать, что большое количество файлов на xfs в одном каталоге влияет на производительность их загрузки, копирования или удаления в случае прямого обращения к ним, без масок. Подозреваю, что на удаление должно уходить больше времени.
При большом количестве файлов с ls могут быть проблемы (Argument list too long), но всегда есть find и exec rm, который работает значительно надёжнее, чем ls.
for i in $(ls *.mp3); do # Неправильно!
some command $i # Неправильно!
done
for i in $(ls) # Неправильно!
for i in `ls` # Неправильно!
for i in $(find . -type f) # Неправильно!
for i in `find . -type f` # Неправильно!
files=($(find . -type f)) # Неправильно!
for i in ${files[@]} # Неправильно!Хотя и к find есть вопросы по использованию памяти — не могу не порекомендовать замечательную и глубокую статью seriyPS.
Поэтому, если вы хотите обеспечить более удобный доступ к логам, лучше хранить их в разных каталогах. Как вариант — создать каталоги по имени папок в репозитории.
Пока писал это всё — появилась идея попробовать зайти на сервер по scp через far, предварительно отключив в фаре сортировку. Интересно, ускорится ли загрузка каталога и попытается ли FAR использовать ls -f (отключение сортировки) для получение списка?
Логи сессий и потоков необходимо периодически чистить.

Внимание вопрос: какая опция наиболее опасна?
В следующей части поговорим о запуске сервера, развернем репозиторий с интеграционным сервисом, изучим немного полезных консольных команд, обсудим бэкапы и узнаем, где лежат логи и как искать ошибки.
Полезные ссылки
- База знаний Informatica
- Хороший блог по Informatica с кучей годных запросов к метаданным
- Канал Informatica Support
- Куча годных видео по PowerCenter
- Пост от Ростелекома «От ежедневных аварий к стабильности» — в этой статье в доступной форме они описали что такое IPC и из каких сервисов она состоит.
The purpose of Informatica ETL is to provide the users, not only a process of extracting data from source systems and bringing it into the data warehouse, but also provide the users with a common platform to integrate their data from various platforms and applications. This has led to an increase in the demand for certified Informatica professional. Before we talk about Informatica ETL, let us first understand why we need ETL.
Why Do We Need ETL?
Every company these days have to process large sets of data from varied sources. This data needs to be processed to give insightful information for making business decisions. But, quite often such data have following challenges:
- Large companies generate lots of data and such huge chunk of data can be in any format. They would be available in multiple databases and many unstructured files.
- This data must be collated, combined, compared, and made to work as a seamless whole. But the different databases don’t communicate well!
- Many organisations have implemented interfaces between these databases, but they faced the following challenges:
- Every pair of databases requires a unique interface.
- If you change one database, many interfaces may have to be upgraded.
Below you can see the various databases of an organisation and their interactions:
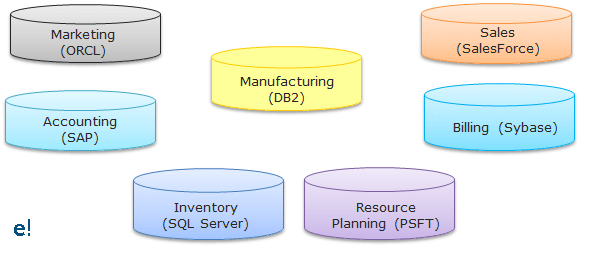
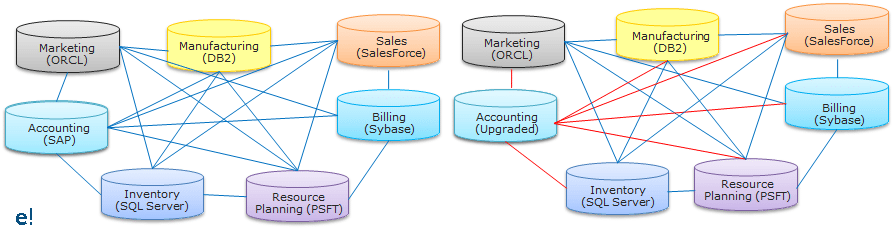
As seen above, an organisation may have various databases in its various departments and the interaction between them becomes hard to implement as various interaction interfaces have to be created for them. To overcome these challenges, the best possible solution is by using the concepts of Data Integration which would allow data from different databases and formats to communicate with each other. The below figure helps us to understand, how the Data Integration tool becomes a common interface for communication between the various databases.
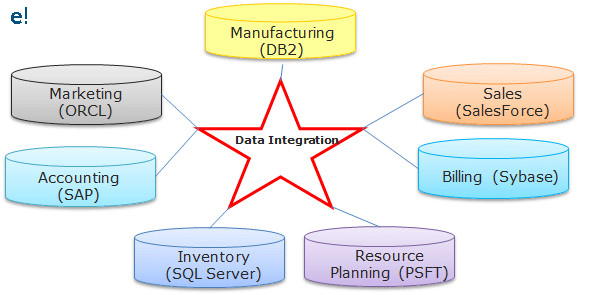
But there are different processes available to perform Data Integration. Among these processes, ETL is the most optimal, efficient and reliable process. Through ETL, the user can not only bring in the data from various sources, but they can perform the various operations on the data before storing this data on to the end target.
Among the various available ETL tools available in the market, Informatica PowerCenter is the market’s leading data integration platform. Having tested on nearly 500,000 combinations of platforms and applications, Informatica PowerCenter inter operates with the broadest possible range of disparate standards, systems, and applications. Let us now understand the steps involved in the Informatica ETL process.
Informatica ETL | Informatica Architecture | Informatica PowerCenter Tutorial | Edureka
This Edureka Informatica tutorial helps you understand the fundamentals of ETL using Informatica Powercenter in detail.
Steps in Informatica ETL Process:
Before we move to the various steps involved in Informatica ETL, Let us have an overview of ETL. In ETL, Extraction is where data is extracted from homogeneous or heterogeneous data sources, Transformation where the data is transformed for storing in the proper format or structure for the purposes of querying and analysis and Loading where the data is loaded into the final target database, operational data store, data mart, or data warehouse. The below image will help you understand how the Informatica ETL process takes place.
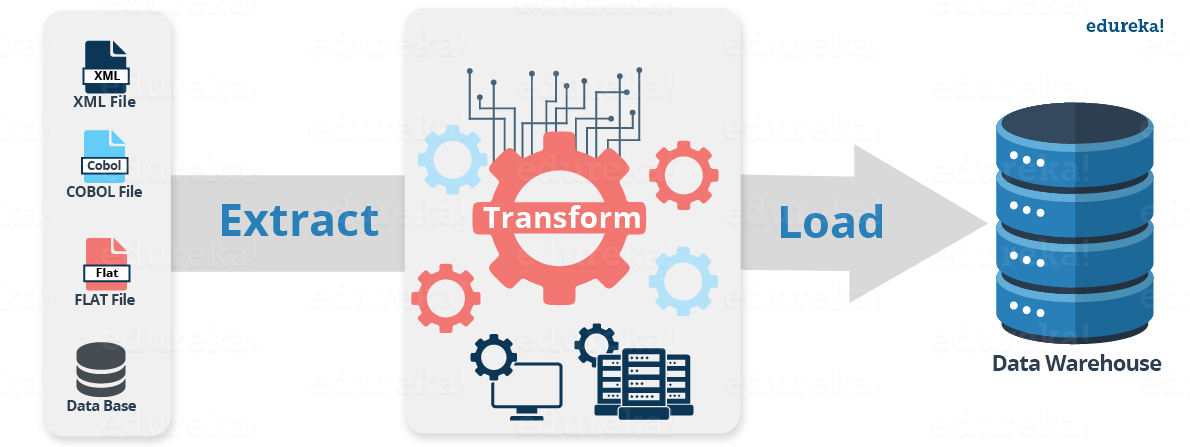
As seen above, Informatica PowerCenter can load data from various sources and store them into a single data warehouse. Now, let us look at the steps involved in the Informatica ETL process.
There are mainly 4 steps in the Informatica ETL process, let us now understand them in depth:
- Extract or Capture
- Scrub or Clean
- Transform
- Load and Index
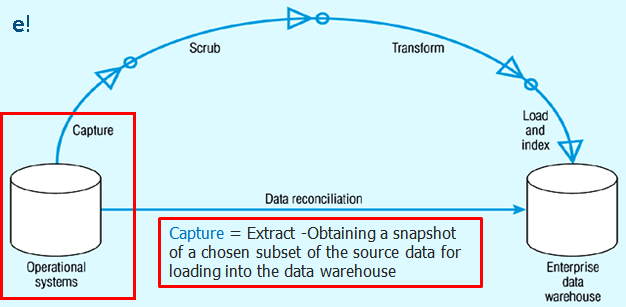
1. Extract or Capture: As seen in the image below, the Capture or Extract is the first step of Informatica ETL process. It is the process of obtaining a snapshot of the chosen subset of data from the source, which has to be loaded into the data warehouse. A snapshot is a read-only static view of the data in the database. The Extract process can be of two types:
- Full extract: The data is extracted completely from the source system and there’s no need to keep track of changes to the data source since the last successful extraction.
- Incremental extract: This will only capture changes that have occurred since the last full extract.
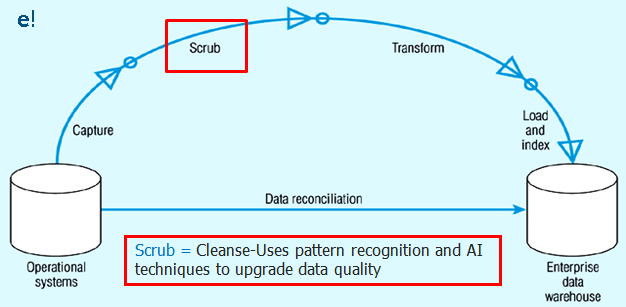
2. Scrub or Clean: This is the process of cleaning the data coming from the source by using various pattern recognition and AI techniques to upgrade the quality of data taken forward. Usually, the errors like misspellings, erroneous dates, incorrect field usage, mismatched addresses, missing data, duplicate data, inconsistencies are highlighted and then corrected or removed in this step. Also, operations like decoding, reformatting, time stamping, conversion, key generation, merging, error detection/logging, locating missing data are done in this step. As seen in the image below, this is the second step of Informatica ETL process.
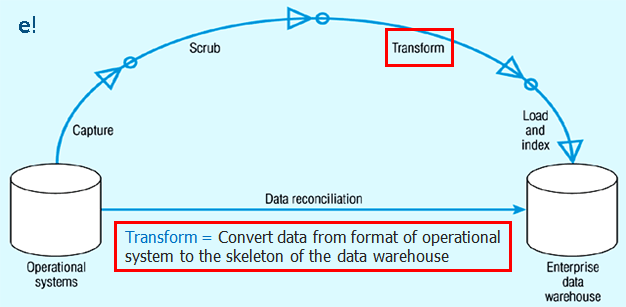
3. Transform: As seen in the image below, this is the third and most essential step of Informatica ETL process. Transformations is the operation of converting data from the format of the source system to the skeleton of Data Warehouse. A Transformation is basically used to represent a set of rules, which define the data flow and how the data is loaded into the targets. To know more about Transformation, check out Transformations in Informatica blog.
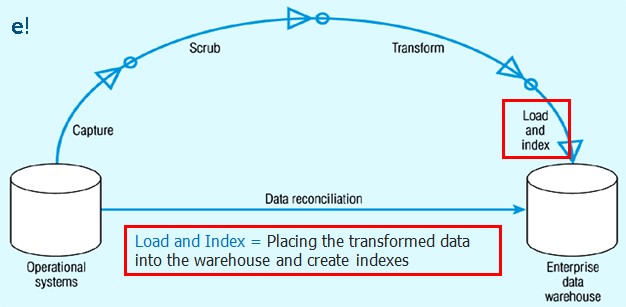
4. Load and Index: This is the final step of Informatica ETL process as seen in the image below. In this stage, we place the transformed data into the warehouse and create indexes for the data. There are two major types of data load available based on the load process.:
- Full Load or Bulk Load: The data loading process when we do it at very first time. The job extracts entire volume of data from a source table and loads into the target data warehouse after applying the required transformations. It will be a one time job run after then changes alone will be captured as part of an incremental extract.
- Incremental load or Refresh load: The modified data alone will be updated in target followed by full load. The changes will be captured by comparing created or modified date against the last run date of the job. The modified data alone extracted from the source and will be updated in the target without impacting the existing data.
If you have understood the Informatica ETL process, we are now in a better position to appreciate why Informatica is the best solution in such cases.
Features of Informatica ETL:
For all the Data integration and ETL operations, Informatica has provided us with Informatica PowerCenter. Let us now see some key features of Informatica ETL:
- Provides facility to specify a large number of transformation rules with a GUI.
- Generate programs to transform data.
- Handle multiple data sources.
- Supports data extraction, cleansing, aggregation, reorganisation, transformation, and load operations.
- Automatically generates programs for data extraction.
- High-speed loading of target data warehouses.
Below are some of the typical scenarios in which Informatica PowerCenter is being used:
- Data Migration:
A company has purchased a new Accounts Payable Application for its accounts department. PowerCenter can move the existing account data to the new application. The figure below will help you understand how you can use Informatica PowerCenter for Data migration. Informatica PowerCenter can easily preserve data lineage for tax, accounting, and other legally mandated purposes during the data migration process.

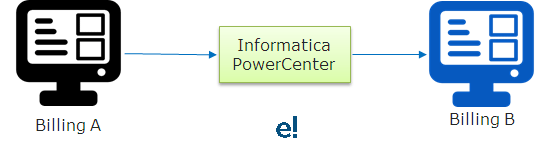
- Application Integration:
Let’s say Company-A purchases Company-B. So, to achieve the benefits of consolidation, the Company-B’s billing system must be integrated into the Company-A’s billing system which can be easily done using Informatica PowerCenter. The figure below will help you understand how you can use Informatica PowerCenter for the integration of applications between the companies.
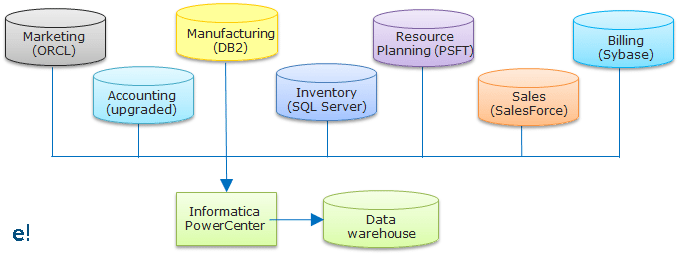
- Data warehousing
Typical actions required in data warehouses are:
- Combining information from many sources together for analysis.
- Moving data from many databases to the Data warehouse.
All the above typical cases can be easily performed using Informatica PowerCenter. Below, you can see Informatica PowerCenter is being used to combine the data from various kinds of databases like Oracle, SalesForce, etc. and bringing it to a common data warehouse created by Informatica PowerCenter.
- Middleware
Let’s say a retail organisation is making use of SAP R3 for its Retail applications and SAP BW as its data warehouse. A direct communication between these two applications is not possible due to the lack of a communication interface. However, Informatica PowerCenter can be used as a Middleware between these two applications. In the image below you can see the architecture of how Informatica PowerCenter is being used as middleware between SAP R/3 and SAP BW. The Applications from SAP R/3 transfer their data to the ABAP framework which then transfers it to the SAP Point of Sale (POS) and SAP Bills of Services (BOS). Informatica PowerCenter helps the transfer of data from these services to the SAP Business Warehouse (BW).
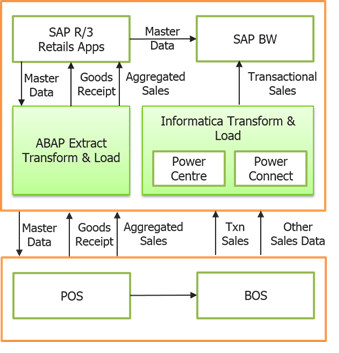
Informatica PowerCenter as Middleware in SAP Retail Architecture
While you have seen a few key features and typical scenarios of Informatica ETL, I hope you understand why Informatica PowerCenter is the best tool for ETL process. Let us now see a use case of Informatica ETL.
Use Case: Joining Two tables to obtain a Single detailed Table
Let’s say you wish to provide department wise transportation to your employees as the departments are located at various locations. To do this, first you need to know which Department each employee belongs to and location of the department. However, the details of employees are stored in different tables and you need to join the details of Department to an existing database with the details of all Employees. To do this, we will be first loading both the tables into Informatica PowerCenter, performing Source Qualifier Transformation on the data and finally loading the details to Target Database. Let us begin:
Step 1: Open PowerCenter Designer.
Below is the Home page of Informatica PowerCenter Designer.
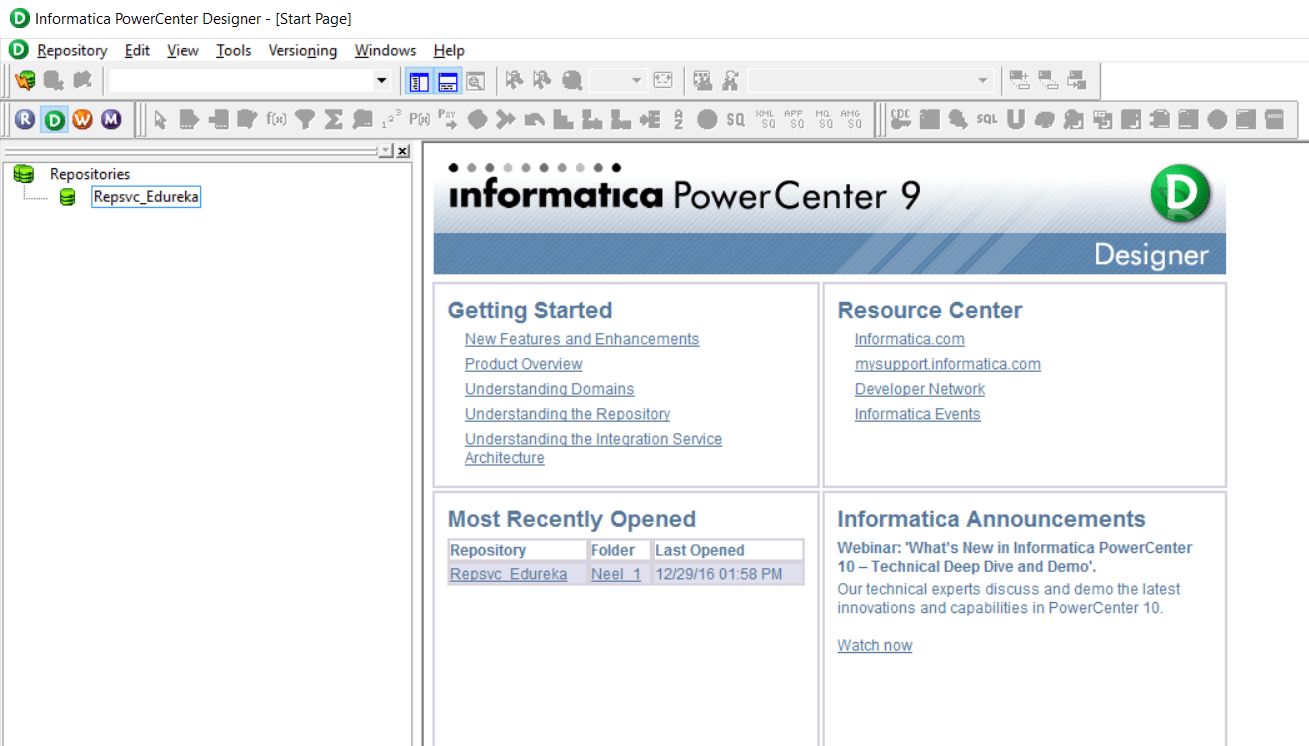
Let us now connect to the repository. In case you haven’t configured your repositories or are facing any issues you can check our Informatica Installation blog.
Step 2: Right click on your repository and select connect option.
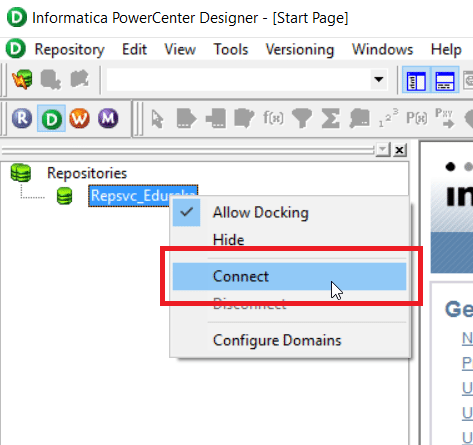
On clicking the connect option, you will be prompted with the below screen, asking for your repository username and password.
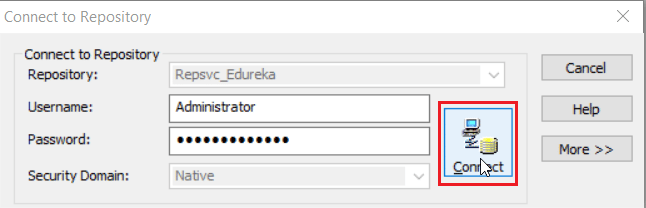
Once you have connected to your repository, you have to open your working folder as seen below:
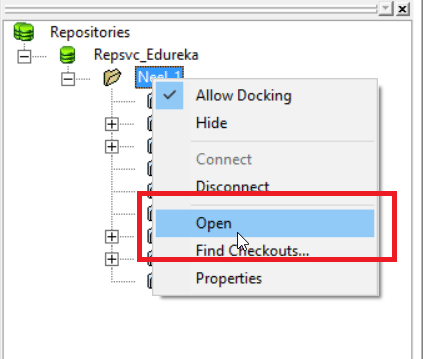
You will be prompted asking the name of your mapping. Specify the name of your mapping and click on OK (I have named it as m-EMPLOYEE).

Step 3: Let us now load the Tables from the Database, Start by connecting to the Database. To do this, select Sources tab and Import from Database option as seen below:
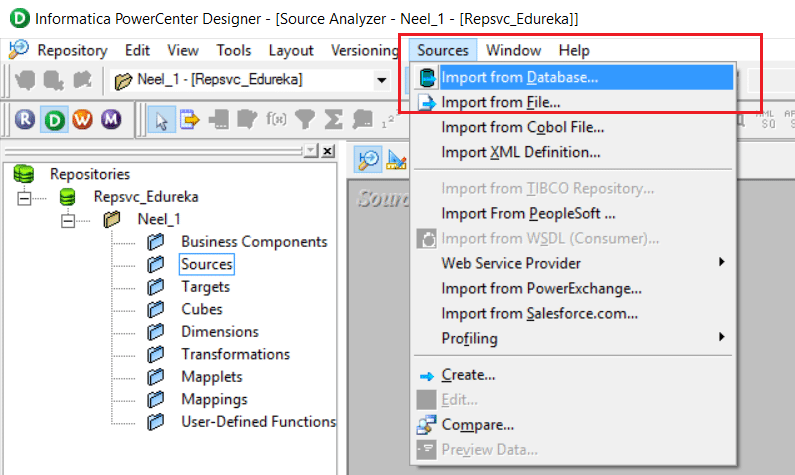
On clicking Import from Database, you will be prompted the screen as below asking the details of your Database and its Username and Password for connection(I am using the oracle database and HR user).
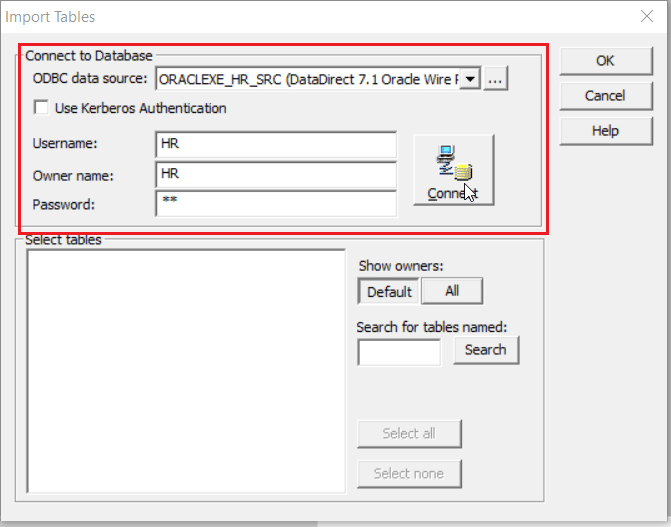
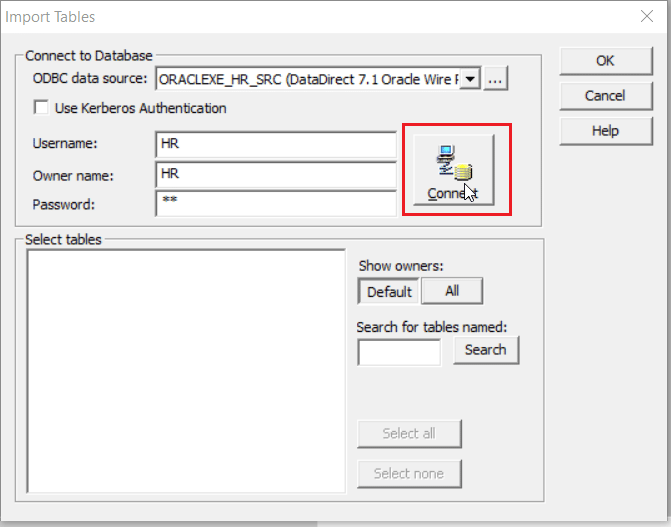
Click on Connect to connect to your database.
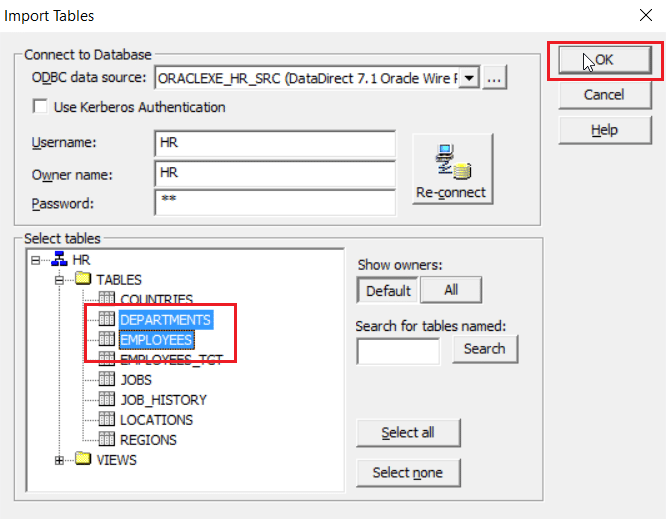
Step 4: As I wish to join the EMPLOYEES and DEPARTMENT tables, I will select them and click on OK.
 The sources will be visible on your mapping designer workspace as seen below.
The sources will be visible on your mapping designer workspace as seen below.
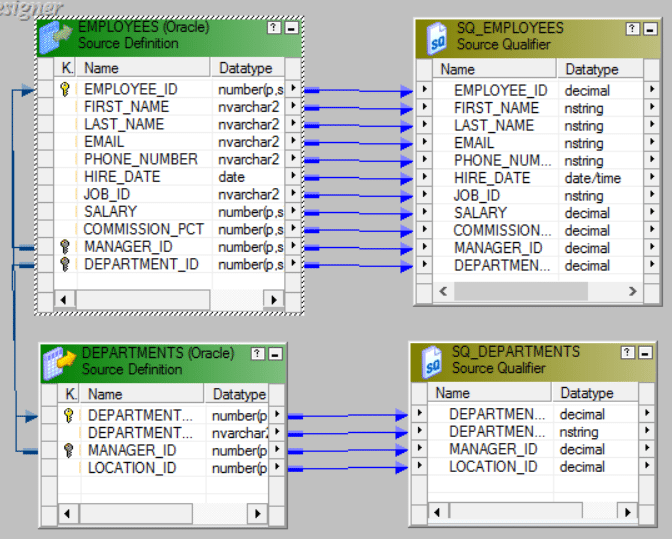
Step 5: Similarly Load the Target Table to the Mapping.
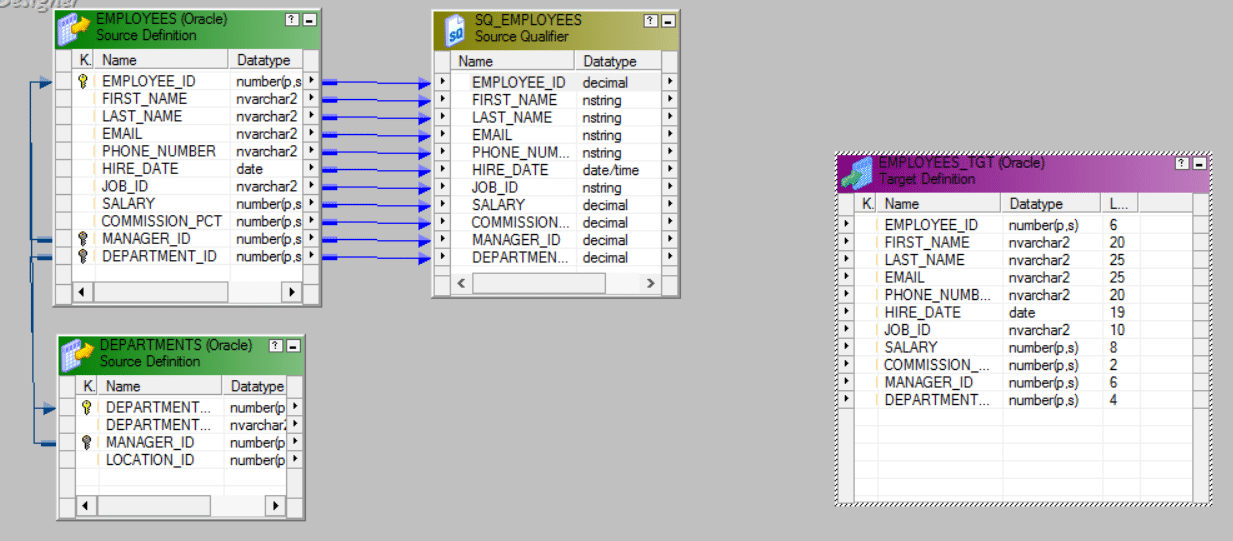
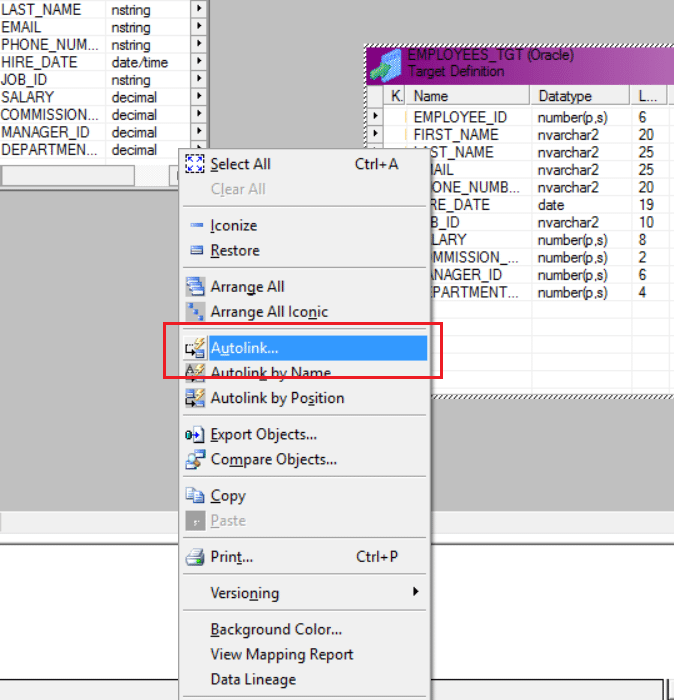
Step 6: Now let us link the Source qualifier and the target table. Right click on any blank spot of the workspace and select Autolink as seen below:
Below is the mapping linked by Autolink.

Step 7: As we need to link both the tables to the Source Qualifier, select the columns of the Department table and drop it in the Source Qualifier as seen below:
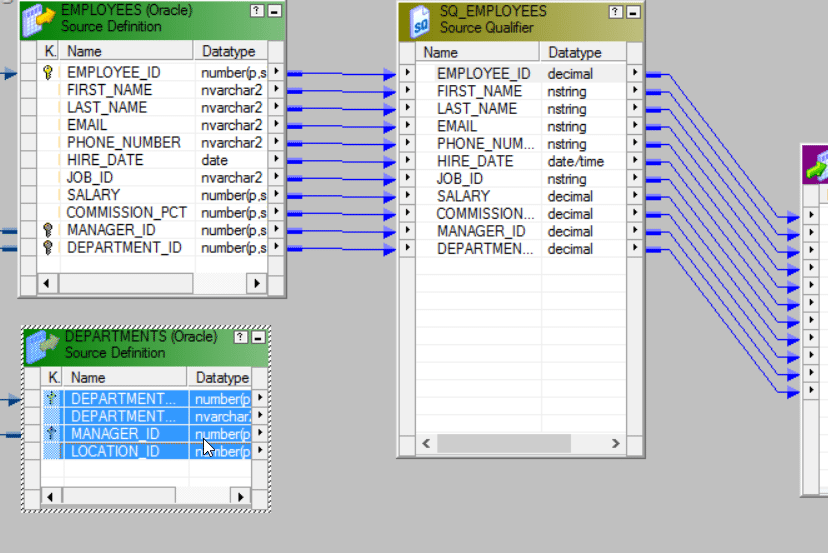
Drop the column values into the Source Qualifier SQ_EMPLOYEES.
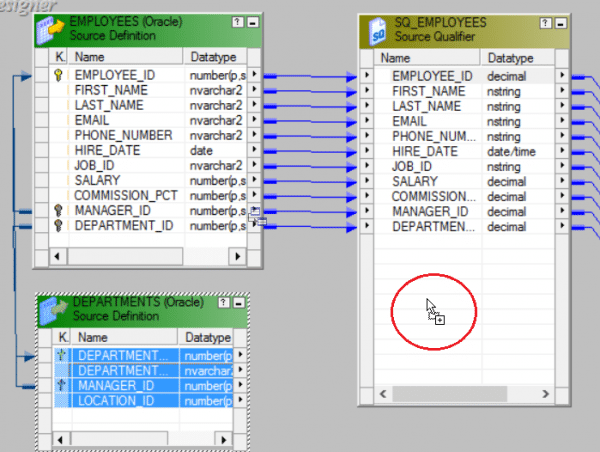
Below is the updated Source Qualifier.

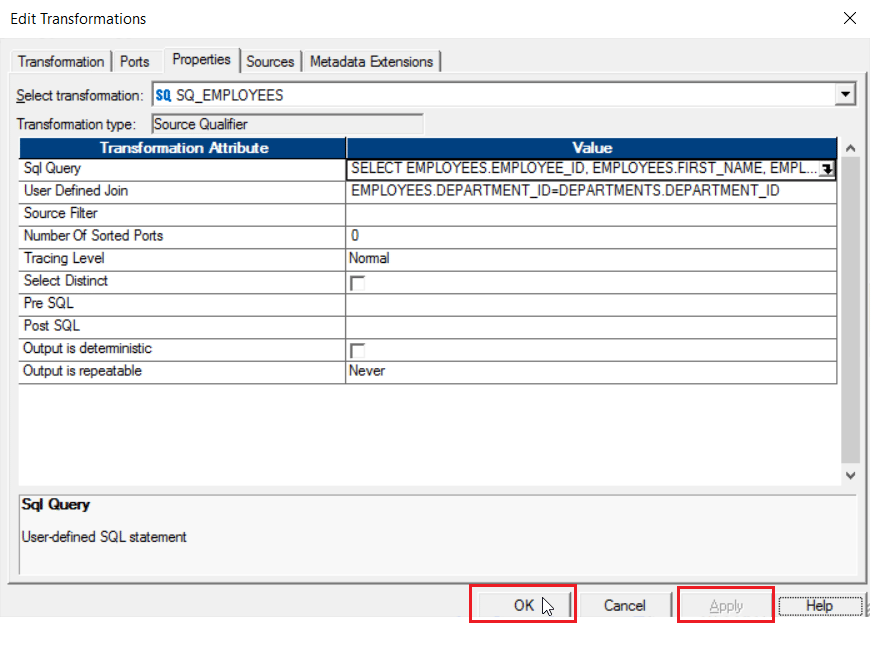
Step 8: Double click on Source Qualifier to edit the transformation.
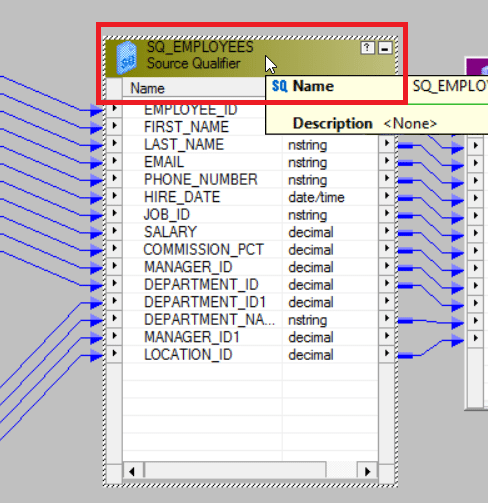
You will get the Edit Transformation pop up as seen below. Click on Properties tab.
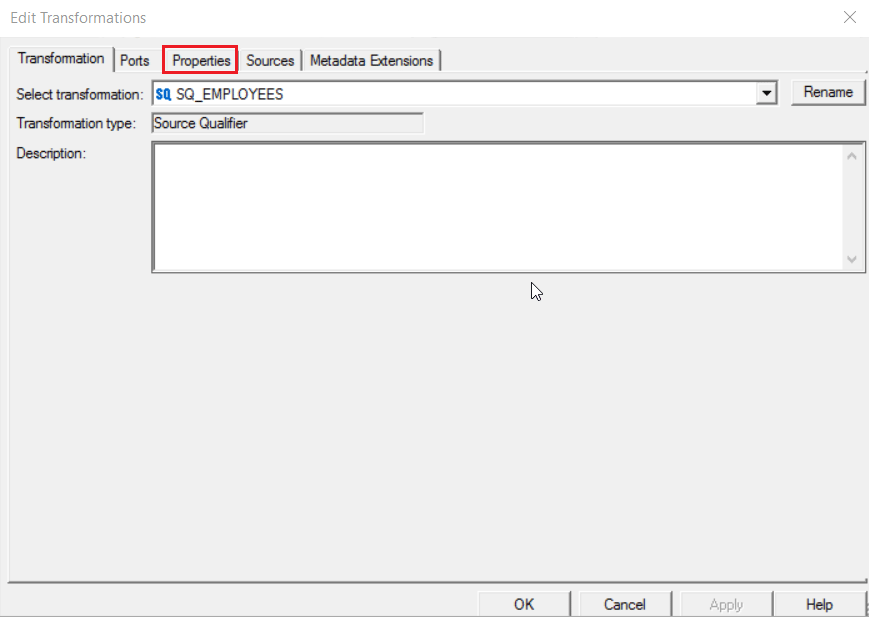
Step 9: Under the Properties tab, Click on Value field of UserDefined Join row.

You will get the following SQL Editor:
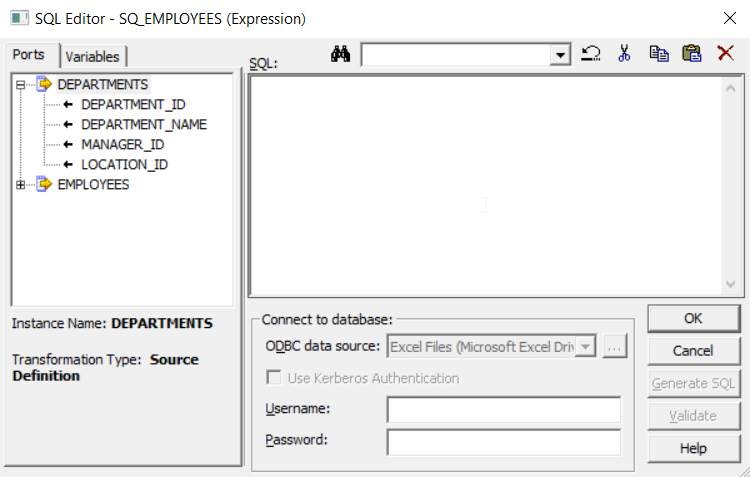
Step 10: Enter EMPLOYEES.DEPARTMENT_ID=DEPARTMENT.DEPARTMENT_ID as the condition to join both the tables in the SQL field and click on OK.
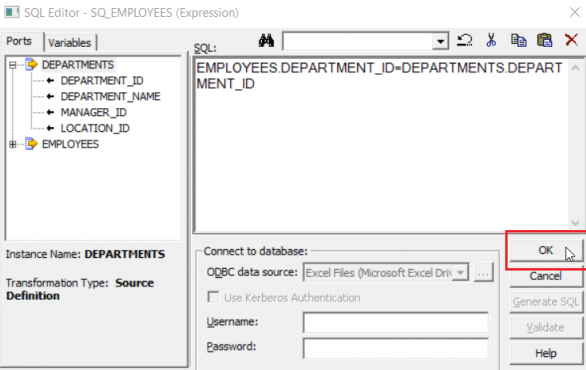
Step 11: Now click on the SQL Query row to generate the SQL for joining as seen below:
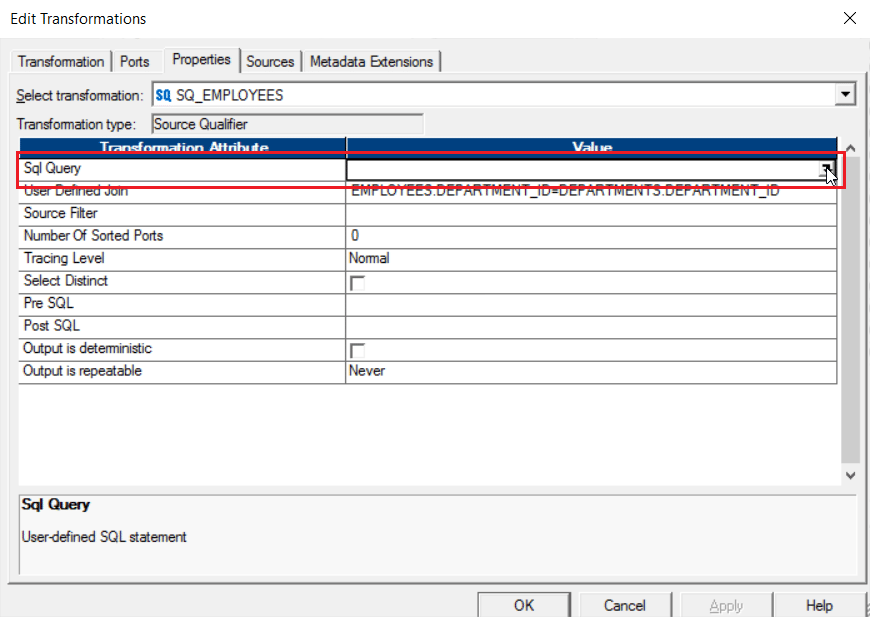
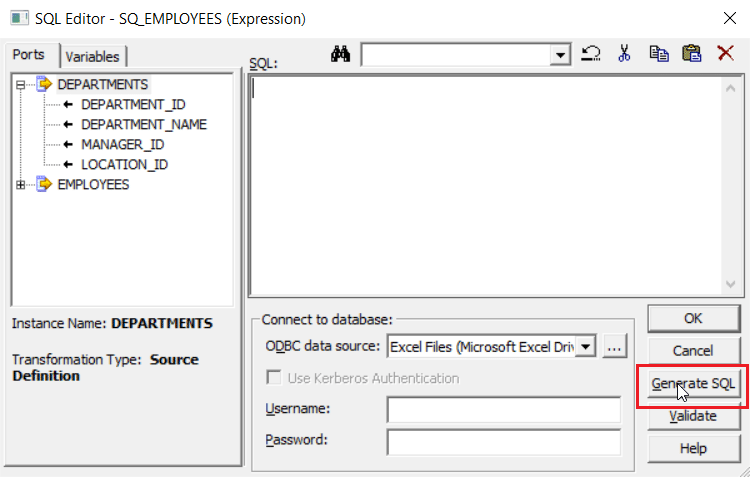
You will get the following SQL Editor, Click on Generate SQL option.
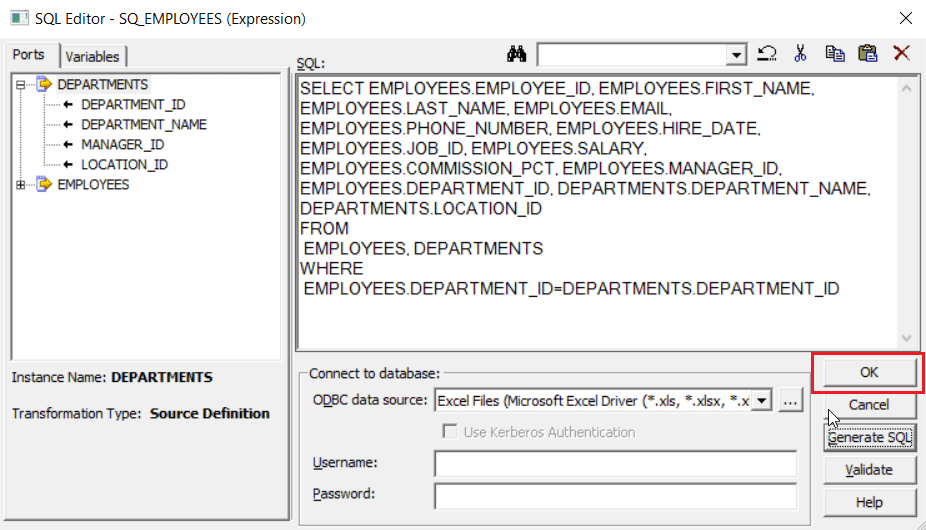
The following SQL will be generated for the condition we had specified in the previous step. Click on OK.
Step 12: Click on Apply and OK.
Below is the completed mapping.
We have completed the designing of the how the data has to be transferred from the source to target. However, the actual transfer of data is still yet to happen and for that we need to use the PowerCenter Workflow Design. The execution of the workflow will lead to the transfer of data from the source to the target. To know more about workflow, check our Informatica Tutorial: Workflow blog
Step 13: Let us now launch the Workflow Manager by Clicking the W icon as seen below:
Below is the workflow designer home page.
Step 14: Let us now create a new Workflow for our mapping. Click on Workflow tab and select Create Option.
You will get the below pop-up. Specify the name of your workflow and click on OK.
Step 15: Once a workflow is created, we get the Start Icon in the Workflow Manager workspace.
Let us now add a new Session to the workspace as seen below by clicking the session icon and clicking on the workspace:
Click on the workspace to place the Session icon.
Step 16: While adding the session you have to select the Mapping you had created and saved in the above steps. (I had saved it as m-EMPLOYEE).
Below is the workspace after adding the session icon.

Step 17: Now that you have created a new Session, we need to link it to the start task. We can do it by clicking on Link Task icon as seen below:
Click on the Start icon first and then on the Session icon to establish a link.
Below is a connected workflow.

Step 18: Now that we have completed the design, let us start the workflow. Click on Workflow tab and select Start Workflow option.

Workflow manager starting Workflow Monitor.
Step 19: Once we start the workflow, the Workflow Manager automatically launches and allows you to monitor the execution of your workflow. Below you can see the Workflow Monitor shows the status of your workflow.
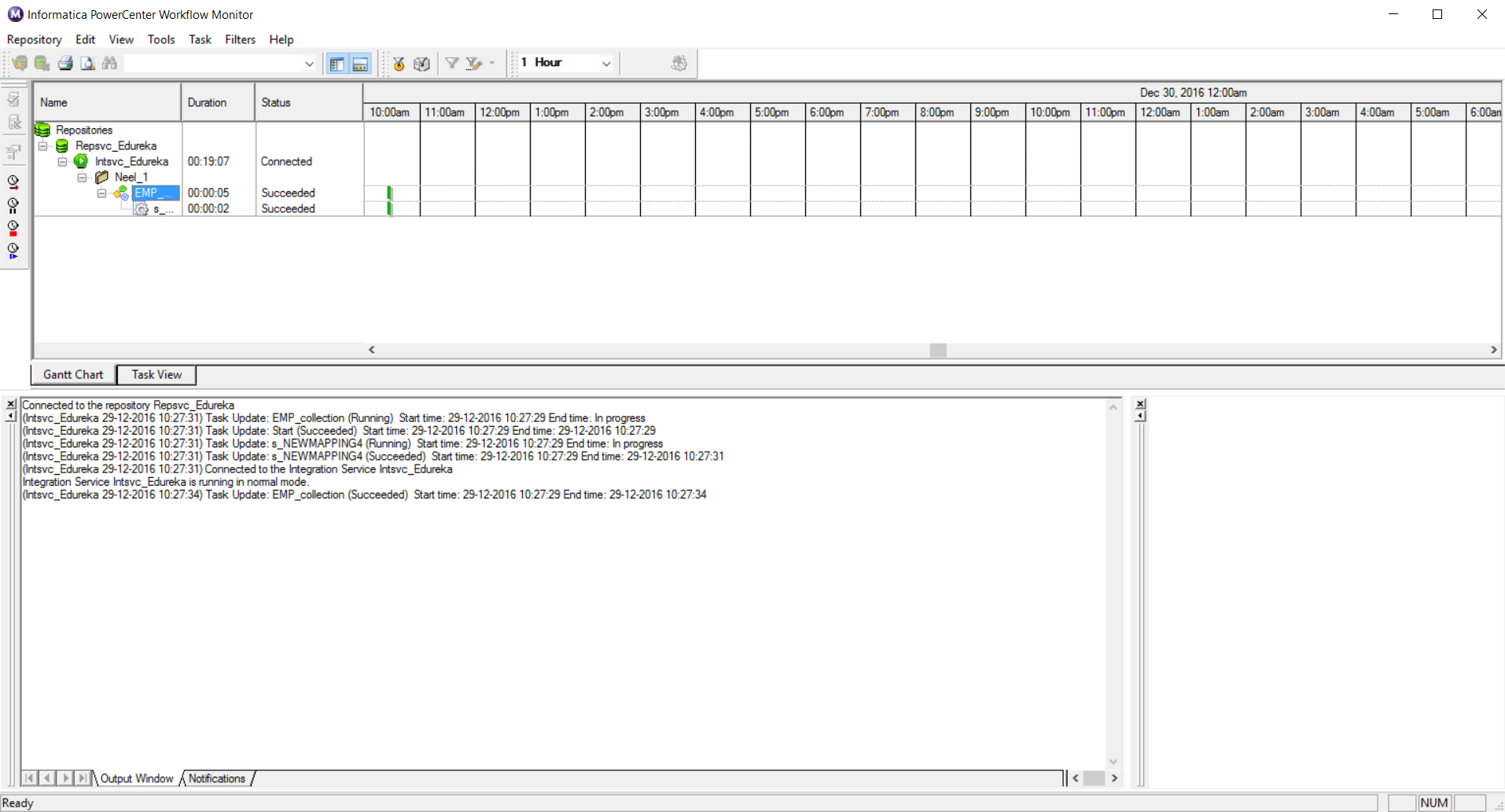
Step 20: To check the status of the workflow, right click on the workflow and select Get Run Properties as seen below:
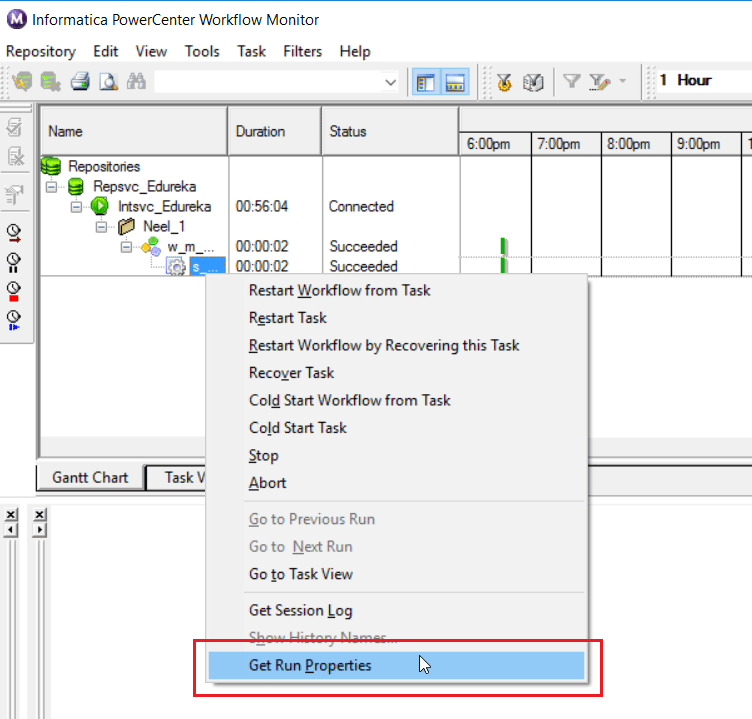
Select the Source/Target Statistics tab.

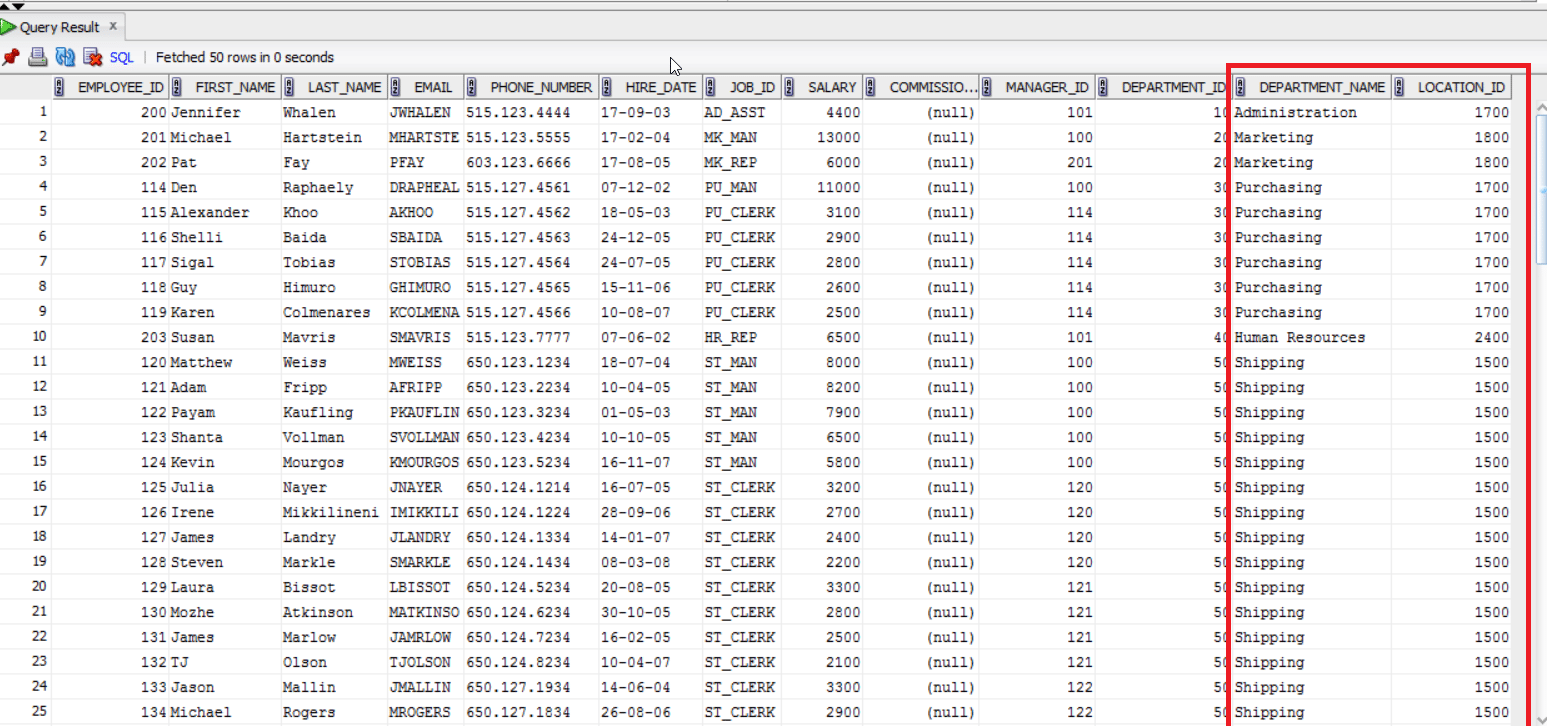
Below you can see the number of rows that have been transferred between the source and target after transformation.

You can also verify your result checking your target table as seen below.
I hope this Informatica ETL blog was helpful to build your understanding on the concepts of ETL using Informatica and has created enough interest for you to learn more about Informatica.
If you found this blog helpful, you can also check out our Informatica Tutorial blog series What is Informatica: A Beginner Tutorial of Informatica PowerCenter, Informatica Tutorial: Understanding Informatica ‘Inside Out’ and Informatica Transformations: The Heart and Soul of Informatica PowerCenter. In case if you are looking for details on Informatica Certification, you can check our blog Informatica Certification: All there is to know.
If you have already decided to take up Informatica as a career, I would recommend you to have a look at our Informatica Training course page. The Informatica Certification training at Edureka will make you an expert in Informatica through live instructor-led sessions and hands-on training using real life use cases.
Краткое содержание обучения
Помимо поддержки нормального процесса ETL / хранилища данных, который имеет дело с большим объемом данных, инструмент Informatica предоставляет комплексное решение для интеграции данных и систему управления данными. В этом учебном пособии вы узнаете, как Informatica выполняет простые действия, такие как очистка данных, профилирование данных, преобразование и планирование рабочих процессов от источника к цели с помощью простых шагов и т. Д.
что я должна знать?
Ничего! Этот курс предполагает, что вы абсолютный новичок в Informatica Powercenter.
Учебная программа
Введение
Advanced Stuff
| Руководство | Анализатор источников и Target Designer в Informatica |
| Руководство | Отображения в Informatica |
| Руководство | Рабочие процессы в Informatica |
| Руководство | Монитор рабочего процесса в Informatica |
| Руководство | Как отладить сопоставления в Informatica |
| Руководство | Объекты сессий в Informatica |
| Руководство | Введение в преобразования в Informatica и преобразование фильтра |
| Руководство | Преобразование квалификатора источника в Informatica |
| Руководство | Преобразователь агрегатора в Informatica |
| Руководство | Преобразование маршрутизатора в Informatica |
| Руководство | Столярная трансформация в Informatica |
| Руководство | Преобразование ранга в Informatica |
| Руководство | Преобразование генератора последовательностей в Informatica |
| Руководство | Трансформация управления транзакциями в Informatica |
| Руководство | Поиск и повторное использование преобразования в Informatica |
| Руководство | Преобразование нормализатора в Informatica |
| Руководство | Настройка производительности для трансформации в Informatica |
Должен знать!
Converting Workflow Parameter Files to Taskflow Parameter Sets
Learn how to convert parameter files from PowerCenter workflows to parameter sets in Cloud Data Integration taskflows when you migrate from PowerCenter to Cloud.
Show More
Show Less
Debugging: PowerCenter + Cloud Data Integration
Learn the differences between PowerCenter’s Debugging tool and Cloud Data Integration’s Mapping Data Preview.
Show More
Show Less
Recovering PowerCenter Workflows and Cloud Data Integration Taskflows
Learn how to configure recovery for PowerCenter workflows and Cloud Data Integration taskflows.
Show More
Show Less
Starting Workflows and Taskflow Jobs with a 3rd-Party Scheduler
Learn how a third-party scheduler can use Informatica’s command line utilities to start a PowerCenter workflow or a Cloud Data Integration taskflow job.
Show More
Show Less
Versioning Objects in PowerCenter and Cloud Data Integration
Learn about the differences in object versioning between PowerCenter and Cloud Data Integration.
Show More
Show Less
Посвящается моему коллеге и наставнику по Informatica Максиму Генцелю, который умер от COVID-19 21.01.2021
Привет! Меня зовут Баранов Владимир, и я уже несколько лет администрирую Informatica в «Альфа-Банк». В статье я поделюсь опытом работы с Informatica PowerCenter. IPC это платформа, которая занимается ETL (Extract, Transformation, Loading). Я сосредоточусь на описании конкретных кейсов и решений, расскажу о некоторых тонкостях и постараюсь дать пищу для ума.
В работе приходится часто сталкиваться с проблемами производительности и стабильности платформы, при этом глубоко во всё вникая, поэтому лично я при работе с Informatica получаю огромное удовольствие. Во-первых, потому, что даже IPC сам по себе не такой уж маленький, а у Informatica целое семейство продуктов. Во-вторых, ETL находится на стыке разных систем, надо знать всего понемногу – базы данных, коннекторы, линукс, скриптовые языки и системы визуализации и мониторинга. В-третьих, это общение с большим количеством разных людей и много интересных задач.
Запуск клиента информатики
Забавно, но даже тут можно наступить на некоторые грабли. Да, прямо на старте и с размахом.
У информатики есть следующие клиенты: Workflow Manager, Workflow Monitor, Repository Manager, Designer и Developer Client. Параметры подключения к репозиториям хранятся в файле domains.infa, который обычно задаётся переменной окружения:
SET INFA_DOMAINS_FILE=C:Informatica9.5.1clientsPowerCenterClientdomains.infa
Но если версий информатики несколько, то файл рано или поздно будет «побит», а клиент информатики будет ругаться при попытке сохранения добавленного репозитория.
Что делать? Создать батники для каждой версии клиента вида:
SET INFA_DOMAINS_FILE=C:Informatica9.5.1clientsPowerCenterClientdomains.infa
cd C:Informatica9.5.1clientsPowerCenterClientclientbin
start pmdesign.exe
Последние две строчки попортили мне очень много крови, так как изначально я запускал клиента так:
C:Informatica9.5.1clientsPowerCenterClientclientbinpmdesign.exe
И батник прекрасно работал ровно до того момента, пока я не обновился с 9.5.1 до 10.1.1 и не начал пытаться подключаться через клиент информатики к SAP.
Disigner должен был показывать коннекты из файла sapnwrfc.ini, но показывалась пустота, хотя файл лежал в нужном каталоге клиента IPC. Я даже успел немного посидеть с отладчиком над клиентом, но в итоге мне помогла индианка из службы поддержки.
Что ещё можно сказать о файле domains.infa и создании подключений? Вы не сможете единовременно добавить два репозитория с одинаковым именем, даже если они находятся на разных серверах.
Файл domains.infa также используется при использовании консольных команд для подключения к репозиторию* (pmrep), имейте это в виду. Но об этом чуть позже.
*На самом деле не обязательно, смотрите на описание ключей команды.
Настраиваем окружение
Что важного может быть в окружении Informatica? Если вы обратитесь в поддержку Информатики, то первым делом вас попросят показать вывод команд: ulimit –Ha / ulimit –Sa. Soft и hard ограничения пользователя, под которым запущена информатика).
stack size 10240
open files (-n) 500000
Сколько ставить open files? Поддержка Informatica как-то утверждала, что у нас одна из самых высоконагруженных и сложных инсталляций в России – при этом нам хватает 500к open files, с запасом примерно в 150-250к.
На многих серверах стоит по 120-180к, и этого хватает. Со временем (и в случае нашего банка это происходит очень быстро) приходится увеличивать.
Однажды видел, как ведёт себя Oracle, если ему не хватает максимально открытых файлов. Он периодически начинает ощутимо тормозить, клиенты от него отваливаются. Но при этом он оставался работать и не падал.
Если вы не знаете, какое текущее значение у уже запущенного процесса:
cat /proc/pid/limits
max user processes (-u) 4134885
Важный параметр, но ничего особенно интересного про него рассказать не могу.
core file size (blocks, -c)
Потенциально опасный параметр. Дампы памяти от падаюших сервисов или потоков можно проанализировать (иногда помогает поиск по ключевым словам в базе знаний информатики), их также требует поддержка Informatica. По умолчанию они будут падать в $INFA_HOME/server/bin/ и главное — core могут быть очень большими.
Имеет смысл следить за этим каталогом и аккуратно его чистить.
Теперь не такое очевидное:
/etc/systemd/system.conf, /etc/systemd/user.conf
DefaultTasksMax=40000
DefaultLimitNOFILE=500000
Более подробно о TasksMax:
To control the default TasksMax= setting for services and scopes running on the system, use the system.conf setting DefaultTasksMax=. This setting defaults to 512, which means services that are not explicitly configured otherwise will only be able to create 512 processes or threads at maximum.
For thread- or process-heavy services, you may need to set a higher TasksMax value. In such cases, set TasksMax directly in the specific unit files. Either choose a numeric value or even infinity.
Similarly, you can limit the total number of processes or tasks each user can own concurrently. To do so, use the logind.conf setting UserTasksMax (the default is 12288).
Как можно посмотреть текущее значение:
admin@serv:/etc/systemd> systemd-analyze dump|grep -i DefaultLimitNPROC|sort -n -k2
admin@serv:/etc/systemd> systemctl show -p DefaultLimitNOFILE
admin@serv:/proc/38757> systemctl show -p DefaultLimitNPROC
cat /sys/fs/cgroup/pids/user.slice/user-*.slice/pids.max
cat /sys/fs/cgroup/pids/user.slice/user-*.slice/pids.current
Если интересно, что это такое — гуглить «linux cgroup slices»:
Что будет в системных логах, если TaskMax недостаточен:
2020-01-01T03:23:30.674392+03:00 serv kernel: [5145583.466931] cgroup: fork rejected by pids controller in /user.slice/user-*.slice/session-2247619.scope
Кстати
*Вообще, думаю что имеет смысл прочитать требования к окружению при установке разных БД — там очень дельные предложения по окружению. Было немного обидно, когда ровно на следующей день после обнаружения проблемы с TaskMax я прочитал о них в гайде по установке Teradata.
/etc/sysctl.conf
fs.file-max = 6815744
Тут тоже особо не заостряю внимания.
Сеть, sysctl, net.core, net.iipv4
Чтобы что-то тут менять — надо очень хорошо понимать, как работает сеть, ядро, сокеты. Бездумное изменение параметров может сделать только хуже. Не буду здесь приводить конкретных настроек, так как у меня до сих пор фрагментированное понимание этой части sysctl. Хотелось бы, чтобы гайды о сетевой части sysctl сопровождали примерами из netstat -sn и netstat -an.
Кейсы по архитектурным ошибкам
Всё, что я напишу ниже, следует читать осторожно, сознавая что обычный разработчик, который работает с Informatica каждый день, может обладать куда большей экспертизой, чем я.
1. GRID
Информатика может иметь все сервисы на одной машине, а может существовать в виде кластера и балансировать нагрузку между нодами. Даже если вы в ближайшем будущем не планируете использовать кластер, всё же крайне желательно, чтобы разработка велась так, как будто это может произойти в будущем. Вертикальная масштабируемость конечна, сидеть на ней без возможности в любой момент переключиться на горизонтальную — это как сидеть на пороховой бочке.
Я не имел личного опыта работы с гридом, но много людей отзывались о нём негативно. Грид определённо не только решает проблемы, но и добавляет новые. Тем не менее, я знаю организации, у которых всё работает именно на гриде. Надеюсь, у меня будет возможность познакомиться с ним поближе и набить уже своих шишек.
Очень наглядный гайд по созданию грида видел у nutanix.
2. Pushdown
К разработке может быть несколько подходов:
- Всю работу по части ETL выполнять на стороне информатики, постоянно подтягивая в неё данные.
- Всю работу по части ETL выполнять на стороне СУБД приёмника/таргета, использовать дблинки.
Второй вариант и есть так называемый pushdown optimization. Тут сразу уточню, что у информатики есть свои крутые механизмы для pushdown optimization, которые позволяют, например, переносить логику трансформации на source/target — но я говорил не про эти механизмы, а про общие принципы.
Ведь как правило незачем тягать данные на сервер информатики и нагружать его, если source & target находятся в пределах одной БД — лучше сделать процедуру.
На Хабре выходила отличная статья от DIS, где они рассказывали про pushdown на русском, рекомендую к прочтению.
3. Информатика как шедулер
Большинство компаний используют информатику в качестве эдакого шедулера для запуска потоков и не перекладывают на неё вычисления, если это можно сделать на стороне БД. И во всех организациях присутствует дополнительная сущность в виде базы данных, которая используется в качестве управляющего механизма. Это очень удобно для выстраивания логики работы потоков и параметров их запуска (нам же нужно знать, например, какие даты мы уже успешно загрузили, успешно ли отработали потоки и т.д).
В итоге в информатике выстраивается сложная схема, когда один поток запускает десятки других потоков, в это время второй поток дожидается выполнения третьего и пятого потока, а многие-многие сессии запускают sh-файлы, которые взаимодействуют с управляющим механизмом. В некоторых потоках может быть и 1500+ запусков sh-файлов (и до 200-300 запусков одновременно).
На этапе использования sh-файла для обращения к управляющему механизму в некоторых компаниях может закладываться бомба замедленного действия, т.к в одном таком файле может быть до 4 соединений посредством sqlplus (пример работы: проверили, включен ли поток; взяли параметры запуска; записали, что поток отработал и.т.д). И это довольно неплохой способ устроить своеобразную DDoS-атаку штормом коннектов на сервер БД.
Как минимум поэтому сервер БД метаданных информатики и сервер БД управляющего механизма не должны быть в опасной близости друг от друга. И конечно, бест практик не размещать сервер БД, хранящий метаданные информатики, на одной площадке*.
*На самом деле, не так уж это и критично. Но по возможности лучше этого избегать. Я видел примеры с высоконагруженными серверами информатики, где сервера БД были на этом же хосте.
4. «Оптимизация» как угроза
Если какой-нибудь поток выйдет за рамки SLA то у разработчиков и саппорта после доработки хинтами может быть большой соблазн увеличить количество параллелей, т.к это путь наименьшего сопротивления. Пересмотром запросов или архитектуры займутся в последнюю очередь, как наиболее трудозатратное. Возможно стоит мониторить как меняются параллели у потоков.
5. Параметризация
При разработке желательно подумать о том, что вот прямо завтра сервер может переехать на другой хост или в другой каталог. У потока также может сменится репозиторий или интеграционный сервис (с дева на тест, с теста на прод, например). Смену каталога тоже принято делать при обновлении IPC.
Может так сложиться, что вы решите перенести сервис на хост, где будет несколько инстансов информатики.
Посмотрим, нет ли у нас абсолютных путей до информатики в метаданных репозитория:
Предостережение: Даже селекты из метаданных информатики могут быть опасны и у поддержки IPC есть кейсы когда это реально вредило стабильности IPC. Разрешено использовать только view, список которых есть в Repository Guide.
select * from REP_NAME_TST.OPB_TASK_VAL_LIST where pm_value not like '%PMRoot%':
/informatica/pc10/server/bin/pmrep objectexport -f DMQAS_DWH -u
В некоторых запущенных случаях можно обнаружить комбо:
pmcmd startworkflow -sv INT_TT_PROD -d DOMAIN_TT_PROD -u Userlogin -p MyPass -f FLOW_CONTROL_D -wait WF_CTL_
В данном случае поток запускали под пользовательской учёткой, с указанием пароля и инт.сервис+домен не был параметризирован.
С sh-файлами необходимо придерживаться тех же самых правил. Конфиги должны быть отдельно от скриптов, абсолютных путей быть не должно, только относительные. Недопустимо указание инт.сервиса, хостов и других явно зашитых параметров в sh-скрипте.
6. Репозитории, интеграционные сервисы, файловая система и лукапы
Репозитории достаточно просто переносятся с сервера на сервер, я расскажу подробнее в главе «Работа в консоли, девопс». На самом деле сущность репозитория вообще не имеет отражения на уровне файловой системы — репозиторий находится в БД-слое.
А вот интеграционные сервисы, которые привязываются к репозиторию, требуют инфраструктуры каталогов:
По возможности лучше разделять проекты в разные репозитории, чтобы было проще их переносить, масштабировать, актуализировать и понимать, сколько ресурсов они потребляют.
Я бы с самого начала посоветовал сделать как минимум два подкаталога с лукап кэшами. В первом каталоге можно хранить кэши временные, во втором – постоянные (persistent) кэши (не путать с именованными). И ещё, информатика обладает неприятным поведением при падениях – она не чистит за собой старые лукапы.
В «Альфа-Банке», например, раньше часть больших кэшей лежала на медленных дисках, а остальные на быстрых. Кэши в разных каталогах это довольно удобно — в любой момент можно перекинуть часть кэшей на другой массив, оставив симлинк. Это проще, чем когда все кэши находятся в одном месте.
В $PMCacheDir по умолчанию создаются временные кэши, но это не значит, что при создании лукапа нельзя указать, например, $PMRootDir/New_Cache.
Также хочу обратить внимание, что в случае, когда у персистент-лукапов добавляются или меняются поля – эти лукапы будут полностью перестраиваться, создавая в каталоге свою полную копию (*.bak). Это может сыграть злую шутку, если лукап весит 300-500 гб. В целом, грамотное использование лукапа значительно увеличивает производительность.
Обратите внимание на именование лукапов, которые создаёт информатика на уровне ФС:
ls PMLKUP629*
PMLKUP629_21_0_247034L64.dat0
PMLKUP629_21_0_247034L64.dat1
PMLKUP629_21_0_247034L64.idx0
PMLKUP629_21_0_247034L64.idx1
В начале названия файлов идёт префикс (PMLKUP), который означает, что это лукап-кэш. Помимо лукапов в CacheDir создаются джойнеры, сортировка, агрегатор и rank transformation.
Насколько я помню, после префикса идёт session_id — и это даёт возможность получить сессию, которая с ним работает в данный момент.
Определяем, кто работает с файлом кэша (возьму любой из занятых).
admin@server:/informatica/pc10/server/infa_shared/Cache> lsof +D $(pwd)
/informatica_cache/Cache/PMLKUP144968_4_0_74806582L64.idx0
Греп по session_id в процессах:
ps -ef|grep 144968
Отформатирую и порежу вывод, чтобы остановить ваше внимание на самых важных вещах, которые мы можем увидеть, посмотрев pmdtm-процесс.
Смотрим, какие файлы занял процесс:
ls -l /proc/64719/fd/ |grep -i PMLKUP144968
/informatica_cache/Cache/PMLKUP144968_4_0_74806582L64.dat0
И раз уж я начал рассказывать про pmdtm — не могу не поделится крутым параметром для отладки, которые задаётся в Custom-параметрах интеграционного сервера.
DelayDTMStart=<секунды>
Чтобы ещё больше не увеличивать эту статью, просто дам ссылку.
7. Система версионности в информатике
По кейсам в базе знаний сложилось стойкое впечатление, что с ней лучше дел не иметь.
8. Логи сессий и потоков
Подробнее о логах мы говорим позже, но хочется обозначить следующее. Будьте готовы, что в большой инсталляции логи будут занимать десятки гигабайт, и количество логов сессий свободно может перевалить за 1-2 млн в зависимости от выбранной вами стратегии log-rotate.
Я не могу с уверенностью сказать, что большое количество файлов на xfs в одном каталоге влияет на производительность их загрузки, копирования или удаления в случае прямого обращения к ним, без масок. Подозреваю, что на удаление должно уходить больше времени.
При большом количестве файлов с ls могут быть проблемы (Argument list too long), но всегда есть find и exec rm, который работает значительно надёжнее, чем ls.
for i in $(ls *.mp3); do # Неправильно!
some command $i # Неправильно!
done
for i in $(ls) # Неправильно!
for i in `ls` # Неправильно!
for i in $(find . -type f) # Неправильно!
for i in `find . -type f` # Неправильно!
files=($(find . -type f)) # Неправильно!
for i in ${files[@]} # Неправильно!Хотя и к find есть вопросы по использованию памяти — не могу не порекомендовать замечательную и глубокую статью seriyPS.
Поэтому, если вы хотите обеспечить более удобный доступ к логам, лучше хранить их в разных каталогах. Как вариант — создать каталоги по имени папок в репозитории.
Пока писал это всё — появилась идея попробовать зайти на сервер по scp через far, предварительно отключив в фаре сортировку. Интересно, ускорится ли загрузка каталога и попытается ли FAR использовать ls -f (отключение сортировки) для получение списка?
Логи сессий и потоков необходимо периодически чистить.
Внимание вопрос: какая опция наиболее опасна?
В следующей части поговорим о запуске сервера, развернем репозиторий с интеграционным сервисом, изучим немного полезных консольных команд, обсудим бэкапы и узнаем, где лежат логи и как искать ошибки.
Полезные ссылки
- База знаний Informatica
- Хороший блог по Informatica с кучей годных запросов к метаданным
- Канал Informatica Support
- Куча годных видео по PowerCenter
- Пост от Ростелекома «От ежедневных аварий к стабильности» — в этой статье в доступной форме они описали что такое IPC и из каких сервисов она состоит.
Краткое содержание обучения
Помимо поддержки нормального процесса ETL / хранилища данных, который имеет дело с большим объемом данных, инструмент Informatica предоставляет комплексное решение для интеграции данных и систему управления данными. В этом учебном пособии вы узнаете, как Informatica выполняет простые действия, такие как очистка данных, профилирование данных, преобразование и планирование рабочих процессов от источника к цели с помощью простых шагов и т. Д.
что я должна знать?
Ничего! Этот курс предполагает, что вы абсолютный новичок в Informatica Powercenter.
Учебная программа
Введение
Advanced Stuff
| Руководство | Анализатор источников и Target Designer в Informatica |
| Руководство | Отображения в Informatica |
| Руководство | Рабочие процессы в Informatica |
| Руководство | Монитор рабочего процесса в Informatica |
| Руководство | Как отладить сопоставления в Informatica |
| Руководство | Объекты сессий в Informatica |
| Руководство | Введение в преобразования в Informatica и преобразование фильтра |
| Руководство | Преобразование квалификатора источника в Informatica |
| Руководство | Преобразователь агрегатора в Informatica |
| Руководство | Преобразование маршрутизатора в Informatica |
| Руководство | Столярная трансформация в Informatica |
| Руководство | Преобразование ранга в Informatica |
| Руководство | Преобразование генератора последовательностей в Informatica |
| Руководство | Трансформация управления транзакциями в Informatica |
| Руководство | Поиск и повторное использование преобразования в Informatica |
| Руководство | Преобразование нормализатора в Informatica |
| Руководство | Настройка производительности для трансформации в Informatica |
Должен знать!
The purpose of Informatica ETL is to provide the users, not only a process of extracting data from source systems and bringing it into the data warehouse, but also provide the users with a common platform to integrate their data from various platforms and applications. This has led to an increase in the demand for certified Informatica professional. Before we talk about Informatica ETL, let us first understand why we need ETL. You can learn more from the Informatica Certification.
Why Do We Need ETL?
Every company these days have to process large sets of data from varied sources. This data needs to be processed to give insightful information for making business decisions. But, quite often such data have following challenges:
- Large companies generate lots of data and such huge chunk of data can be in any format. They would be available in multiple databases and many unstructured files.
- This data must be collated, combined, compared, and made to work as a seamless whole. But the different databases don’t communicate well!
- Many organisations have implemented interfaces between these databases, but they faced the following challenges:
- Every pair of databases requires a unique interface.
- If you change one database, many interfaces may have to be upgraded.
Below you can see the various databases of an organisation and their interactions:
As seen above, an organisation may have various databases in its various departments and the interaction between them becomes hard to implement as various interaction interfaces have to be created for them. To overcome these challenges, the best possible solution is by using the concepts of Data Integration which would allow data from different databases and formats to communicate with each other. The below figure helps us to understand, how the Data Integration tool becomes a common interface for communication between the various databases.
But there are different processes available to perform Data Integration. Among these processes, ETL is the most optimal, efficient and reliable process. Through ETL, the user can not only bring in the data from various sources, but they can perform the various operations on the data before storing this data on to the end target.
Among the various available ETL tools available in the market, Informatica PowerCenter is the market’s leading data integration platform. Having tested on nearly 500,000 combinations of platforms and applications, Informatica PowerCenter inter operates with the broadest possible range of disparate standards, systems, and applications. Let us now understand the steps involved in the Informatica ETL process.
Informatica ETL | Informatica Architecture | Informatica PowerCenter Tutorial | Edureka
This Edureka Informatica tutorial helps you understand the fundamentals of ETL using Informatica Powercenter in detail.
Steps in Informatica ETL Process:
Before we move to the various steps involved in Informatica ETL, Let us have an overview of ETL. In ETL, Extraction is where data is extracted from homogeneous or heterogeneous data sources, Transformation where the data is transformed for storing in the proper format or structure for the purposes of querying and analysis and Loading where the data is loaded into the final target database, operational data store, data mart, or data warehouse. The below image will help you understand how the Informatica ETL process takes place.
As seen above, Informatica PowerCenter can load data from various sources and store them into a single data warehouse. Now, let us look at the steps involved in the Informatica ETL process.
There are mainly 4 steps in the Informatica ETL process, let us now understand them in depth:
- Extract or Capture
- Scrub or Clean
- Transform
- Load and Index
1. Extract or Capture: As seen in the image below, the Capture or Extract is the first step of Informatica ETL process. It is the process of obtaining a snapshot of the chosen subset of data from the source, which has to be loaded into the data warehouse. A snapshot is a read-only static view of the data in the database. The Extract process can be of two types:
- Full extract: The data is extracted completely from the source system and there’s no need to keep track of changes to the data source since the last successful extraction.
- Incremental extract: This will only capture changes that have occurred since the last full extract.
2. Scrub or Clean: This is the process of cleaning the data coming from the source by using various pattern recognition and AI techniques to upgrade the quality of data taken forward. Usually, the errors like misspellings, erroneous dates, incorrect field usage, mismatched addresses, missing data, duplicate data, inconsistencies are highlighted and then corrected or removed in this step. Also, operations like decoding, reformatting, time stamping, conversion, key generation, merging, error detection/logging, locating missing data are done in this step. As seen in the image below, this is the second step of Informatica ETL process.
3. Transform: As seen in the image below, this is the third and most essential step of Informatica ETL process. Transformations is the operation of converting data from the format of the source system to the skeleton of Data Warehouse. A Transformation is basically used to represent a set of rules, which define the data flow and how the data is loaded into the targets. To know more about Transformation, check out Transformations in Informatica blog.
4. Load and Index: This is the final step of Informatica ETL process as seen in the image below. In this stage, we place the transformed data into the warehouse and create indexes for the data. There are two major types of data load available based on the load process.:
- Full Load or Bulk Load: The data loading process when we do it at very first time. The job extracts entire volume of data from a source table and loads into the target data warehouse after applying the required transformations. It will be a one time job run after then changes alone will be captured as part of an incremental extract.
- Incremental load or Refresh load: The modified data alone will be updated in target followed by full load. The changes will be captured by comparing created or modified date against the last run date of the job. The modified data alone extracted from the source and will be updated in the target without impacting the existing data.
If you have understood the Informatica ETL process, we are now in a better position to appreciate why Informatica is the best solution in such cases.
Features of Informatica ETL:
For all the Data integration and ETL operations, Informatica has provided us with Informatica PowerCenter. Let us now see some key features of Informatica ETL:
- Provides facility to specify a large number of transformation rules with a GUI.
- Generate programs to transform data.
- Handle multiple data sources.
- Supports data extraction, cleansing, aggregation, reorganisation, transformation, and load operations.
- Automatically generates programs for data extraction.
- High-speed loading of target data warehouses.
Below are some of the typical scenarios in which Informatica PowerCenter is being used:
- Data Migration:
A company has purchased a new Accounts Payable Application for its accounts department. PowerCenter can move the existing account data to the new application. The figure below will help you understand how you can use Informatica PowerCenter for Data migration. Informatica PowerCenter can easily preserve data lineage for tax, accounting, and other legally mandated purposes during the data migration process.
- Application Integration:
Let’s say Company-A purchases Company-B. So, to achieve the benefits of consolidation, the Company-B’s billing system must be integrated into the Company-A’s billing system which can be easily done using Informatica PowerCenter. The figure below will help you understand how you can use Informatica PowerCenter for the integration of applications between the companies.
- Data warehousing
Typical actions required in data warehouses are:
- Combining information from many sources together for analysis.
- Moving data from many databases to the Data warehouse.
All the above typical cases can be easily performed using Informatica PowerCenter. Below, you can see Informatica PowerCenter is being used to combine the data from various kinds of databases like Oracle, SalesForce, etc. and bringing it to a common data warehouse created by Informatica PowerCenter.
- Middleware
Let’s say a retail organisation is making use of SAP R3 for its Retail applications and SAP BW as its data warehouse. A direct communication between these two applications is not possible due to the lack of a communication interface. However, Informatica PowerCenter can be used as a Middleware between these two applications. In the image below you can see the architecture of how Informatica PowerCenter is being used as middleware between SAP R/3 and SAP BW. The Applications from SAP R/3 transfer their data to the ABAP framework which then transfers it to the SAP Point of Sale (POS) and SAP Bills of Services (BOS). Informatica PowerCenter helps the transfer of data from these services to the SAP Business Warehouse (BW).
Informatica PowerCenter as Middleware in SAP Retail Architecture
While you have seen a few key features and typical scenarios of Informatica ETL, I hope you understand why Informatica PowerCenter is the best tool for ETL process. Let us now see a use case of Informatica ETL.
Use Case: Joining Two tables to obtain a Single detailed Table
Let’s say you wish to provide department wise transportation to your employees as the departments are located at various locations. To do this, first you need to know which Department each employee belongs to and location of the department. However, the details of employees are stored in different tables and you need to join the details of Department to an existing database with the details of all Employees. To do this, we will be first loading both the tables into Informatica PowerCenter, performing Source Qualifier Transformation on the data and finally loading the details to Target Database. Let us begin:
Step 1: Open PowerCenter Designer.
Below is the Home page of Informatica PowerCenter Designer.
Let us now connect to the repository. In case you haven’t configured your repositories or are facing any issues you can check our Informatica Installation blog.
Step 2: Right click on your repository and select connect option.
On clicking the connect option, you will be prompted with the below screen, asking for your repository username and password.
Once you have connected to your repository, you have to open your working folder as seen below:
You will be prompted asking the name of your mapping. Specify the name of your mapping and click on OK (I have named it as m-EMPLOYEE).
Step 3: Let us now load the Tables from the Database, Start by connecting to the Database. To do this, select Sources tab and Import from Database option as seen below:
On clicking Import from Database, you will be prompted the screen as below asking the details of your Database and its Username and Password for connection(I am using the oracle database and HR user).
Click on Connect to connect to your database.
Step 4: As I wish to join the EMPLOYEES and DEPARTMENT tables, I will select them and click on OK.
The sources will be visible on your mapping designer workspace as seen below.
Step 5: Similarly Load the Target Table to the Mapping.
Step 6: Now let us link the Source qualifier and the target table. Right click on any blank spot of the workspace and select Autolink as seen below:
Below is the mapping linked by Autolink.
Step 7: As we need to link both the tables to the Source Qualifier, select the columns of the Department table and drop it in the Source Qualifier as seen below:
Drop the column values into the Source Qualifier SQ_EMPLOYEES.
Below is the updated Source Qualifier.
Step 8: Double click on Source Qualifier to edit the transformation.
You will get the Edit Transformation pop up as seen below. Click on Properties tab.
Step 9: Under the Properties tab, Click on Value field of UserDefined Join row.
You will get the following SQL Editor:
Step 10: Enter EMPLOYEES.DEPARTMENT_ID=DEPARTMENT.DEPARTMENT_ID as the condition to join both the tables in the SQL field and click on OK.
Step 11: Now click on the SQL Query row to generate the SQL for joining as seen below:
You will get the following SQL Editor, Click on Generate SQL option.
The following SQL will be generated for the condition we had specified in the previous step. Click on OK.
Step 12: Click on Apply and OK.
Below is the completed mapping.
We have completed the designing of the how the data has to be transferred from the source to target. However, the actual transfer of data is still yet to happen and for that we need to use the PowerCenter Workflow Design. The execution of the workflow will lead to the transfer of data from the source to the target. To know more about workflow, check our Informatica Tutorial: Workflow blog
Step 13: Let us now launch the Workflow Manager by Clicking the W icon as seen below:
Below is the workflow designer home page.
Step 14: Let us now create a new Workflow for our mapping. Click on Workflow tab and select Create Option.
You will get the below pop-up. Specify the name of your workflow and click on OK.
Step 15: Once a workflow is created, we get the Start Icon in the Workflow Manager workspace.
Let us now add a new Session to the workspace as seen below by clicking the session icon and clicking on the workspace:
Click on the workspace to place the Session icon.
Step 16: While adding the session you have to select the Mapping you had created and saved in the above steps. (I had saved it as m-EMPLOYEE).
Below is the workspace after adding the session icon.
Step 17: Now that you have created a new Session, we need to link it to the start task. We can do it by clicking on Link Task icon as seen below:
Click on the Start icon first and then on the Session icon to establish a link.
Below is a connected workflow.
Step 18: Now that we have completed the design, let us start the workflow. Click on Workflow tab and select Start Workflow option.
Workflow manager starting Workflow Monitor.
Step 19: Once we start the workflow, the Workflow Manager automatically launches and allows you to monitor the execution of your workflow. Below you can see the Workflow Monitor shows the status of your workflow.
Step 20: To check the status of the workflow, right click on the workflow and select Get Run Properties as seen below:
Select the Source/Target Statistics tab.
Below you can see the number of rows that have been transferred between the source and target after transformation.
You can also verify your result checking your target table as seen below.
I hope this Informatica ETL blog was helpful to build your understanding on the concepts of ETL using Informatica and has created enough interest for you to learn more about Informatica.
If you found this blog helpful, you can also check out our Informatica Tutorial blog series What is Informatica: A Beginner Tutorial of Informatica PowerCenter, Informatica Tutorial: Understanding Informatica ‘Inside Out’ and Informatica Transformations: The Heart and Soul of Informatica PowerCenter. In case if you are looking for details on Informatica Certification, you can check our blog Informatica Certification: All there is to know.
If you have already decided to take up Informatica as a career, I would recommend you to have a look at our Informatica training course page. The Informatica Certification training at Edureka will make you an expert in Informatica through live instructor-led sessions and hands-on training using real life use cases.
1. установкаPowercenter 7.12,8.11Клиент, сервер базы знаний иInformaticaСерверное ПО
Необходимо указать регистрационный код;Построить на этой машине для тестированияInformatica Server;
2. 7.12изWindowsТолько один из них может быть установлен на машинеServer, Вам необходимо указать ассоциированную библиотеку при создании; помимо указания регистрационного кода, вам также необходимо указать лицензионный код подключения к базе данных;
4. Используйте менеджер базы знаний (Repository Manager) Добавить существующий сервер базы знаний;
При добавлении базы знаний укажите имя базы знаний и логин пользователя, а также укажите пароль и базу знанийIPИ порт;
5. Используйте платформу управления сервером базы знаний (Repository Server Administration Console) Подключайтесь, управляйте сервером базы знаний и создавайте новые базы знаний и удаляйте базы знаний;
Укажите имя машины, на которой расположен сервер базы знаний при добавлении (илиIP) И порт, а потом вводим пароль при авторизации;
После входа в систему вы можете создать новую базу знаний на текущем сервере базы знаний (в новой базе знаний есть два пользователя по умолчанию и нет папок),
Вы также можете выполнять следующие операции управления с существующей базой знаний: запускать, закрывать базу знаний, создавать резервные копии и восстанавливать, просматривать текущие подключения, текущие блокировки и журналы активности, публиковать сообщения для пользователей и т. Д .;
Вся информация о метаданных Informatica хранится в базе данных метаданных в виде таблиц базы данных. Конечно, собственные инструменты Инфы предоставляют множество гуманизированных функций, так что мы можем легко работать во время разработки, но потребности людей всегда меняются. Если вам нужно легко получить нужную информацию, нам нужно, чтобы база метаданных.
Informatica предоставляет нам всю информацию в виде таблиц и представлений. Здесь мы познакомимся с наиболее распространенными и очень полезными таблицами и представлениями в серии публикаций. На основе этих вещей мы можем узнать, какие данные нам нужны по разным потребностям, а также мы можем разработать некоторые вспомогательные инфа-приложения.
OPB_ATTR:
ИНФОРМАТИКА (Дизайнер, Рабочий процесс и т. Д.) Имена, текущие значения и
Краткое описание элемента атрибута
Например: ATTR_NAME: TracingLevel
ATTR_VALUE:2
ATTR_COMMENT:Amountofdetailinthesessionlog
Цель: используйте эту таблицу, чтобы быстро просмотреть назначение и описание некоторых элементов атрибутов, обнаруженных во время проектирования или настройки.
OPB_ATTR_CATEGORY:
Классификация и описание каждого атрибута ИНФОРМАТИКИ
Например: CATEGORY_NAME: FilesandDirectories
DESCRIPTION:Attributesrelatedtofilenamesanddirectorylocations
Цель: просмотреть несколько категорий и описания элементов атрибутов, упомянутых в таблице выше
OPB_CFG_ATTR:
Данные конфигурации SessionConfiguration в каждой папке в WORKFLOWMANAGER, каждая конфигурация соответствует группе данных с одинаковым Config_Id в таблице, общая группа данных конфигурации составляет 23
Например: ATTR_ID: 221
ATTR_VALUE:$PMBadFileDir
Цель: просматривать все элементы конфигурации и значения SessionConfiguration и легко сравнивать сходства и различия конфигурации между разными папками.
OPB_CNX:
Определение соединений с исходной и целевой базами данных в WORKFLOWMANAGER, включая RelationalConnection, QueueConnection, LoaderConnection и т. Д.
Например: OBJECT_NAME: Orace_Source
USER_NAME:oral
USER_PASSWORD:`?53S{$+*$*[X]
CONNECT_STRING:Oratest
Цель: просмотреть все подключения и данные их конфигурации, настроенные в WorkFlowManager
OPB_CNX_ATTR:
Некоторые связанные значения атрибутов всех подключений к базе данных, записанные в таблице выше, по одному значению атрибута на данные. Например, для подключения класса RelationalConnection есть три дополнительных атрибута, а соответствующая таблица имеет три записи, соответственно записывающие значения атрибутов ее RollbackSegment, EnvironmentSQL и EnableParallelMode, соответствующие ATTR_ID 10, 11, 12
Например: OBJECT_ID: 22
ATTR_ID:10
ATTR_VALUE: 1 (выбран EnableParallelMode)
VERSION_NUMBER:1
Цель: просмотреть связанные значения атрибутов всех настроенных подключений, а также некоторые параметры SQL среды и сегмента отката для упрощения унифицированного просмотра и сравнения
OPB_DBD:
Атрибуты и расположение всех импортированных источников в INFORMATICADESIGNER
Например: DBSID: 37
DBDNAM:DSS_VIEW
ROOTID:37
Цель: просмотреть атрибуты всех источников в ассоциации
OPB_DBDS:
Источник, указанный в INFORMATICAMAPPING, то есть соответствие между Mapping и источником в приведенной выше таблице
Например: MAPPING_ID: 3
DBD_ID:4
VERSION_NUMBER:1
Цель: чтобы увидеть, на какие сопоставления ссылается определенный источник в качестве источника или дать имя сопоставления, в соответствии с ассоциацией таблицы OPB_MAPPING, вы можете увидеть, к каким источникам относится сопоставление
OPB_EXPRESSION:
Все определенные выражения в INFORMATICADESIGNER
Например: WIDGET_ID: 1003
EXPRESSION:DECODE(IIF(TYPE_PLAN!=’05’,1,0),1,QTY_GROSS,0)
Цель: связавшись с таблицей OPB_WIDGET, можно просмотреть определения выражений во всех модулях преобразования выражений во всей базе данных метаданных.
OPB_EXTN_ATTR:
На странице сопоставления EditTasks в WORKFLOWMANAGER, когда выбрано Targets, значение настройки связанных свойств. Одна запись для каждого значения атрибута.
Например: ATTR_ID: 2
ATTR_VALUE:ora_test1.bad
Цель: напрямую просматривать все соответствующие параметры загрузки данных целевой таблицы сеанса посредством ассоциации
OPB_FILE_DESC:
Определение правил импорта для всех текстовых файлов в INFORMATICA, таких как разделители и т. Д.
Например: STR_DELIMITER: 11,
FLD_DELIMITER:9,44,0
CODE_PAGE:936
Цель: просматривать правила для различных текстов в системе. Метаданные Informatica включают все данные, с которыми мы сталкиваемся во время разработки и настройки. Конечно, теоретически мы можем напрямуюмодифицироватьЗначения базы данных для изменения настроек, но цель перечисления этих таблиц — просто простой способ просмотреть информацию. Даже если вы знакомы с базой данных метаданных, настоятельно не рекомендуется напрямуюмодифицироватьЗначение таблицы метаданных следует изменить с помощью инструмента Informatica.
OPB_GROUPS:
Определение всех групп в ИНФОРМАТИКЕ
Например: GROUP_ID: 2
GROUP_NAME:Administrators
Цель: просмотреть все группы, установленные в текущей системе
Метаданные Informatica включают все данные, с которыми мы сталкиваемся во время разработки и настройки. Конечно, теоретически мы можем напрямуюмодифицироватьЗначения базы данных для изменения настроек, но цель перечисления этих таблиц — просто простой способ просмотреть информацию. Даже если вы знакомы с базой данных метаданных, настоятельно не рекомендуется напрямуюмодифицироватьЗначение таблицы метаданных следует изменить с помощью инструмента Informatica.
OPB_GROUPS:
Определение всех групп в ИНФОРМАТИКЕ
Например: GROUP_ID: 2
GROUP_NAME:Administrators
Цель: просмотреть все группы, установленные в текущей системе
OPB_MAPPING:
Хранение всех сопоставлений в INFORMATICA и некоторые атрибуты сопоставления, такие как время последнего хранения, описание и т. Д. Например: MAPPING_NAME: m_PM_COUNT_BILL
MAPPING_ID:1521
LAST_SAVED:03/27/200620:00:24
Цель: цель этой таблицы очень велика. Вы можете запросить данные в этой таблице, чтобы узнать, будут ли через определенное времямодифицироватьпрошлое
Имеется сопоставление, и все сопоставления недействительны, большая роль этой таблицы — связать с другими таблицами и получить
Дополнительная информация о сопоставлении
OPB_MAP_PARMVAR:
Определение всех параметров отображения в INFORMATICA и связанной информации, такой как начальные значения
Например: MAPPING_ID: 1538
PV_NAME:$$DP_ENABLE_RAND_SAMPLING
PV_DEFAULT:0
Цель: для просмотра всей информации о параметрах, заданной системой, связь с OPB_MAPPING может быть основана на заданном
Имя сопоставления для просмотра всей информации о параметрах, заданной в сопоставлении.
OPB_METAEXT_VAL:
Информация о расширении метаданных IINFORMATICA, в которой записана вся информация, связанная с метаданными, расширенная в проекте.
Ниже приводится расширение метаданных сеанса.
Например: METAEXT_NAME: КОММЕНТАРИЙ
OBJECT_TYPE:68(Session)
PM_VALUE:TheLink’sMainTable,DesignbyJack
Цель: просмотреть всю расширенную информацию о метаданных в проекте и просмотреть информацию о расширении метаданных указанного объекта посредством ассоциации.
информация, которая поможет сосредоточиться на просмотре и понимании некоторой информации в процессе проектирования.
OPB_OBJECT_TYPE:
Таблица определения всех объектов в INFORMATICA design
Например: OBJECT_TYPE_ID: 1
OBJECT_TYPE_NAME:SourceDefinition
Цель: вы можете просматривать все объекты, определенные INFOMATICA, и их можно использовать в качестве связанной таблицы измерений других таблиц для просмотра всей соответствующей информации об объекте.
OPB_PARTITION_DEF:
Все определения PARTITION в SESSION
Например: SESSION_ID: 2578
PARTITION_NAME:Partition#1
Цель: посредством ассоциации, в соответствии с именем сеанса, узнать все параметры раздела, содержащиеся в сеансе
OPB_REPOSIT:
Информация, связанная с конфигурацией сервера INFORMATICAREP
Например: DATAVERSION: 5002
PEPOSIT_NAME:hnsever
Цель: просмотреть информацию о конфигурации сервера INFORMATICAREP
OPB_REPOSIT_INFO:
Информация о конфигурации подключения к базе данных INFORMATICAREP
Например: REPOSITORY_NAME: TEST-REP
DB_USER:infa_user
DB_NATIVE_CONNECT:infa_conn
HOSTNAME:hnsever
PORTNUM:5001
Цель: просмотреть информацию о конфигурации подключения к базе данных сервера INFORMATICAREP.
OPB_SCHEDULER:
Вся таблица с информацией о настройках SCHEDULER в WORKFLOW
Например: SCHEDULER_ID: 81
SCHEDULER_NAME:Scheduler_DAY_10
START_TIME:3/13/2005/00/20
Цель: в этой таблице записывается вся информация о ПЛАНИРОВЩИКЕ, а также его различные настройки атрибутов, чтобы упростить общее рассмотрение взаимодействия планирования между каждым ПЛАНИРОВЩИКОМ.
OPB_SERVER_INFO:
Информация о конфигурации сервера INFORMATICASEVER
Например: SERVER_NAME: INFA_SEVER
TIMEOUT:300
HOSTNAME:hnsever
PORT_NO:4001
IP_ADDRESS:196.125.13.1
Цель: просмотреть информацию о конфигурации сервера INFORMATICASEVER
OPB_SESSION:
Все сеансы в WORKFLOW записывают соответствие между сеансом и отображением и связанным с сеансом
Некоторые основные атрибуты
Например: SESSION_ID: 11
MAPPING_ID:3
Цель: просмотреть соответствие между сеансом и сопоставлением и получить соответствие между именем сеанса и именем сопоставления посредством ассоциации
OPB_SESSION:
Все сеансы в WORKFLOW записывают соответствие между сеансом и сопоставлением и связанным с сеансом
Некоторые основные атрибуты
Например: SESSION_ID: 11
MAPPING_ID:3
Цель: просмотреть соответствие между сеансом и сопоставлением и получить соответствие между именем сеанса и именем сопоставления посредством ассоциации
OPB_SESSION_CONFIG:
Запишите информацию о конфигурации конфигурации всех сеансов в WORKFLOW
Например: CONFIG_NAME: default_session_config
COMMENTS:Defaultsessionconfigurationobject
Цель: просмотреть всю настроенную информацию SessionConfig в текущей системе
OPB_SESS_FILE_REF:
Определение корреляции между всеми FlatFile и Session в процессе извлечения INFORMATICA
Например: SESSION_ID: 682
FILE_ID:66
Цель: просмотреть соответствующую ситуацию с источником FlatFile во всей системе
OPB_SESS_FILE_VALS:
Подробная информация обо всех файлах FlatFile в системе, включая имя файла, путь и т. Д.
Например: SESSION_ID: 1560
FILE_NAME:PTM_LU_CHILD.txt
DIR_NAME:$PMSourceFileDirPTM
Цель: посредством ассоциации вы можете просматривать имя плоского файла и путь, относящиеся к сеансу, а также просматривать все связанные плоские файлы и статистику системы.
OPB_SESS_TASK_LOG:
Это информационная запись INFORMATICA для всех журналов запущенного сеанса и записывает ошибочную ситуацию сеанса.
Например: INSTANCE_ID: 6
MAPPING_NAME:m_ASSET_SUB_ACCOUNT
LOG_FILE:C:ProgramFiles……s_ASSET_SUB_ACCOUNT.log
FIRST_ERROR_MSG:Noerrorsencountered.
Цель: это одна из последних таблиц для проверки текущего статуса сеанса. Это самый простой способ узнать, нормально ли работает сеанс, и краткую информацию о первой ошибке, когда это было неправильно, и файл журнала
позиция
OPB_SRC:
Все источники, определенные в INFORMATICADESIGNER
Например: SRC_ID: 12
SUBJ_ID:27
FILE_NAME:AM_EQP_ASSESS
SOURCE_NAME:AM_EQP_ASSESS
Цель: связав Subj_Id, вы можете узнать все источники, определенные в каждой папке
OPB_SRC_FLD:
Определение всех полей исходной таблицы в INFORMATICA
Например: FLDID: 82
SRC_ID:12
SRC_NAME:FLAG_ID
Цель: связать приведенную выше таблицу, чтобы получить все поля исходной таблицы, их определения и связанные значения атрибутов.
OPB_SRV_LOC_VARS:
В конфигурации сервера системы INFORMATICA все системные переменные и текущие значения переменных
Например: VAR_ID: 13
VAR_NAME:$PMRootDir
VAR_VALUE:D:ProgramFilesInformaticaPowerCenter7.1.1Server
Цель: просмотреть все системные переменные текущего сервера и их текущие значения
OPB_SUBJECT:
Все определения тем в INFORMATICA, то есть определения и связанные атрибуты всех папок
Например: SUBJ_NAME: OAM
SUBJ_ID:2
GROUP_ID:3
Цель: идентификатор папки является внешним ключом многих других таблиц, поскольку в связи с другими таблицами вы можете просмотреть всю соответствующую информацию об объекте в папке.
OPB_SWIDGET_INST:
Запишите все объекты и связанные с ними атрибуты, на которые ссылается Mapping, используемое в сеансе, то есть до одной записи для каждого модуля преобразования.
Например: SESSION_ID: 11
MAPPING_ID:3
INSTANCE_NAME:LKP_OTHER_CHECK11
PARTITION_TYPE:1
Цель: просмотреть все объекты, на которые ссылается каждый сеанс, и их текущие значения атрибутов
OPB_SWIDGINST_LOG:
После запуска INFORMATICA текущие журналы связанных исходных и целевых объектов во всех запущенных сеансах, то есть время выполнения, количество успешно извлеченных данных и т. Д.
Например: TASK_INSTANCE_ID: 92
PARTITION_ID:1
PARTITION_NAME:Partition#1
WIDGET_NAME:SQ_SHIFT_CODE
APPLIED_ROWS:723
START_TIME:2004-11-48:48:12
END_TIME:2004-11-48:48:31
Цель: это наиболее подробная запись журнала о работе каждого объекта после запуска INFORMATICA. Она имеет важное эталонное значение для проверки правильности данных и производительности настройки.
OPB_SWIDG_GROUP:
Таблица определения всех групп в модуле Union_Transformation в INFORMATICADESIGNER
Например: SESSION_ID: 1410
GROUP_NAME:PM_GROUP1
Цель: в этой таблице отдельно записываются все группы, заданные в модуле Union_Transformation, и можно узнать все определения UnionGroup в сеансе через ассоциацию.
OPB_TABLE_GROUP:
Таблица определения всех групп в модуле RouterTransformation в INFORMATICADESIGNER.
Например: OBJECT_ID: 3409
ATTR_VALUE:FROM_ID=’xx’
Цель: в этой таблице отдельно записываются все группы, установленные в модуле RouterTransformation, а также условия группировки группы. Вы можете найти маршрутизатор в сопоставлении через корреляцию
Все настройки группировки и условия группировки
OPB_TARG:
Определение всех целевых таблиц в INFORMATICADESIGNER
OPB_TABLE_GROUP:
Таблица определения всех групп в модуле RouterTransformation в INFORMATICADESIGNER.
Например: OBJECT_ID: 3409
ATTR_VALUE:FROM_ID=’xx’
Цель: в этой таблице отдельно записываются все группы, установленные в модуле RouterTransformation, а также условия группировки группы. Вы можете узнать информацию о маршрутизаторе в сопоставлении через корреляцию.
Все настройки группировки и условия группировки
OPB_TARG:
Определение всех целевых таблиц в INFORMATICADESIGNER
Например: TARGET_ID: 3
SUBJ_ID:2
TARGET_NAME:HAM_DEPT
Цель: в этой таблице хранятся все определения целевой таблицы, и все определения целевой таблицы в папке можно найти с помощью ассоциации.
OPB_TARGINDEX:
Индекс может быть определен для целевой таблицы в INFORMATICA. Таблица хранит все определения целевой таблицы Индекс
Например: TARGET_ID: 1626
INDEXNAME:IDX_AUDIT
Цель: узнать обо всех определениях индексов, выполненных в INFORMATICA, и соответствующей информации целевой таблицы
OPB_TARGINDEXFLD:
Все связанные поля, определенные индексом в целевой таблице в INFORMATICA
Например: INDEXID: 6
FLDNAME:AREC_BILL_ID
Цель: сопоставить и найти таблицы и поля, определенные индексом в INFORMATICA
OPB_TARG_FLD:
Информация о полях всех целевых таблиц в INFORMATICA
Например: TARGET_ID: 131
TARGET_NAME:CHECK_PROPERTY
Цель: просмотреть всю информацию о полях целевой таблицы или дать имя поля, найти поле в этих целевых таблицах
OPB_TASK:
Записи всех задач в WORKFLOW, включая Session, Worklet, WorkFlow и т. Д.
Например: TASK_ID: 1717
TASK_NAME:s_OAM_LOG_ARR
Цель: эта таблица является основной таблицей записей задач рабочего процесса. Посредством ассоциации вы можете узнать все рабочие процессы, рабочие процессы, задачи и т. д., содержащиеся в папке, и найти одну
Все задачи рабочего процесса
OPB_TASK_ATTR:
В этой таблице записываются все значения атрибутов Задачи, по одной записи для каждого атрибута.
Например: ATTR_ID: 2
ATTR_VALUE:s_AM_ASSET_TYPE.log
Цель: просмотреть настройки атрибутов связанных задач, найти все задачи с одинаковыми настройками атрибутов в системе
OPB_TASK_INST:
Таблица экземпляров задачи похожа на информацию таблицы OPB_TASK, но в этой таблице в основном подчеркивается связь между рабочим процессом и задачей, а таблица OPB_TASK является базовой таблицей задачи.
Например: WORKFLOW_ID: 9
INSTANCE_NAME:s_USED_KIND
Цель: найти всю информацию о задачах в рабочем процессе
OPB_TASK_INST_RUN:
В этой таблице записывается информация журнала каждого запуска задачи, включая текущее время запуска, имя службы и т. Д.
Например: INSTANCE_NAME: s_ASSET_ACCOUNT
START_TIME:2004-11-315:20:01
END_TIME:2004-11-315:20:08
SERVER_NAME:ETL-SVR
Цель. В этой таблице записывается информация журнала для каждой запущенной задачи. Информация о времени играет чрезвычайно важную роль в настройке производительности. Вы также можете наблюдать за той же задачей в течение определенного периода времени.
Производительность, оценка работы сервера и др.
OPB_TASK_VAL_LIST:
В этой таблице записываются значения атрибутов некоторых задач, например значение команды в CommandTask.
Например: TASK_ID: 2990
PM_VALUE:DEL“D:FILE_LIST.TXT”
VAL_NAME:DELETE
Цель: вы можете просматривать значения атрибутов задачи, установленные в текущей системе, а также все значения команд
OPB_USERS:
В этой таблице записываются все пользователи, установленные в RepManager, и связанные с ними атрибуты.
Например: USER_ID: 5
USER_NAME:DEMO
USER_PASSWD:hG63″4$7.`
USER_PRIVILEGES1:79
Цель: просмотреть всех пользователей и связанные атрибуты, определенные INFORMATICA в системе
OPB_USER_GROUPS:
В этой таблице записаны отношения между пользователями и группами в RepManager.
Например: USER_ID: 2
GROUP_ID:3
Цель: просмотреть, какие пользователи существуют в группе, или связать, к какой группе принадлежит каждый пользователь
OPB_VALIDATE:
В этой таблице записывается вся информация Validate во время проектирования и разработки в Designer или WorkflowManager.
Например: OBJECT_ID: 4
INV_COMMENTS:Replacedsource[V_RCT_CREDIT]duringimport.
Цель: просмотреть тот же объектисторияПодтвердить информацию, просмотреть объектмодифицироватькурс
OPB_VERSION_PROPS:
В этой таблице записана информация о текущей версии различных объектов в системе.модифицироватьвремя. Включая информацию о минимальной текущей версии каждого модуля в каждое отображение.
OPB_VALIDATE:
В этой таблице записывается вся информация Validate во время проектирования и разработки в Designer или WorkflowManager.
Например: OBJECT_ID: 4
INV_COMMENTS:Replacedsource[V_RCT_CREDIT]duringimport.
Цель: просмотреть тот же объектисторияПодтвердить информацию, просмотреть объектмодифицироватькурс
OPB_VERSION_PROPS:
В этой таблице записана информация о текущей версии различных объектов в системе.модифицироватьвремя. Включая информацию о минимальной текущей версии каждого модуля в каждое отображение.
Например: OBJECT_ID: 5
OBJECT_NAME:FLT_CLM_BDL
LAST_SAVED:08/20/200622:52:29
Цель: просмотреть время последней модификации каждого объекта модуля в системе.
OPB_WFLOW_VAR:
В этой таблице записано определение каждой системной переменной в рабочем процессе и является проектной записью всех системных переменных между модулями в процессе проектирования рабочего процесса.
Например: SUBJECT_ID: 2
VAR_NAME:ErrorMsg
VAR_DESC:Errormessageforthistask’sexecution
LAST_SAVED:08/20/200622:38:41
Цель: просмотреть проект соответствующих системных переменных в рабочем процессе
OPB_WIDGET:
Эта таблица представляет собой базовую информационную таблицу всех модулей преобразования во всех отображениях и записывает основную информацию о каждом модуле преобразования.
Например: WIDGET_NAME: AGG_PIM_RES
WIDGET_TYPE:9
IS_REUSABLE:0
Цель: его можно связать с другими таблицами, чтобы узнать, какие модули преобразования требуют различных основ в зависимости от условий.
OPB_WIDGET_ATTR:
Эта таблица является подтаблицей OPB_WIDGET, в которой записываются различные значения атрибутов каждого модуля преобразования. Один атрибут одного модуля занимает одну запись.
Например: WIDGET_ID: 2
WIDGET_TYPE:11
ATTR_VALUE:$PMCacheDir
Цель. В этой таблице записываются все значения атрибутов всех модулей преобразования. Это очень полезная базовая таблица при поиске определенного атрибута. Ее можно получить, связав с другими таблицами. Все готово
Информация о модуле преобразования
OPB_WIDGET_FIELD:
В этой таблице записано определение всех полей в каждом модуле преобразования.
Например: WIDGET_ID: 4
FIELD_NAME:IN_PL_CD
WGT_PREC:10
WGT_DATATYPE:12
Цель: реализовать статистику и поиск определенного имени поля
OPB_WORKFLOW:
Эта таблица является базовой таблицей, определенной Workflow, в которой записана информация о взаимосвязях Workflow.
Например: WORKFLOW_ID: 6
SERVER_ID:0
SCHEDULER_ID:3
Цель: эту таблицу можно в основном использовать в качестве таблицы связи для различных связанных поисков в Workflow.
REP_DB_TYPES:
В этой таблице записан тип базы данных, поддерживаемой INFA.
Например: DATYPE_NUM: 3
DATYPE_NAME:ORACLE
Цель: эта таблица является базовой кодовой таблицей системы, используемой для отображения всех типов баз данных, поддерживаемых INFA.
REP_FLD_DATATYPE:
В этой таблице записываются различные типы данных, поддерживаемые INFA, и типы данных различных баз данных, поддерживаемых INFA.
Например: DTYPE_NUM: 3001
DTYPE_NAME:char
DTYPE_DATABASE:ORACLE
Назначение: эта таблица является базовой кодовой таблицей системы, используемой для отображения всех типов данных, поддерживаемых INFA.
REP_SRC_KEY_TYPES:
В этой таблице записаны все типы значений ключа, установленные INFA в определении источника.
Например: KEYTYPE_NUM: 1
KEYTYPE_NAME:PRIMARYKEY
Цель: эта таблица является базовой кодовой таблицей системы, используемой для отображения всех поддерживаемых типов значений ключа в исходной структуре INFA.
REP_TARG_KEY_TYPES:
В этой таблице записаны все типы значений ключа, установленные INFA в целевом определении.
Например: KEYTYPE_NUM: 2
KEYTYPE_NAME:FOREIGNKEY
Цель: эта таблица является базовой кодовой таблицей системы, используемой для отображения всех поддерживаемых типов значений ключа в целевом дизайне INFA.
REP_TARG_TYPE:
В этой таблице записан тип целевой таблицы INFA.
Например: TARGET_TYPE: 1
TYPE_NAME:DIMENSION
Цель: таблица является базовой кодовой таблицей системы, используемой для отображения всех поддерживаемых типов таблиц назначения в дизайне INFA.
Informatica provides the market’s leading data integration platform. Tested on nearly 500,000 combinations of platforms and applications, the data integration platform interoperates with the broadest possible range of disparate standards, systems, and applications. This unbiased and universal view makes Informatica unique in today’s market as a leader in the data integration platform and Informatica certification one of the most engrossed skills. In this blog, I will help you with Informatica installation and configuration of its services.
Let’s begin by setting up of Oracle database as our primary database on your system. In case you have already installed and configured the Oracle Database and SQL Developer, you can proceed directly to Informatica Installation.
Oracle Database Installation
To commence with the Oracle installation, begin by downloading the setup zip file from the link below.
Step 1: Download Oracle Database Express Edition from the below link (I am installing on a Windows 64 bit OS, so I have selected windows x64):
- www.oracle.com/technetwork/database/database-technologies/express-edition/downloads/index.html
Step 2 : Once the file download is complete, extract the file:
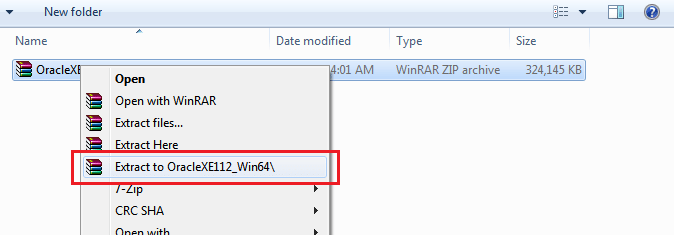
Step 3 : After extracting the file you will get DISK1 folder, Open the folder.
Step 4: Double click on setup to start installation:

Click on Next.
Step 5: Accept the terms and click on Next.
Click on Next.
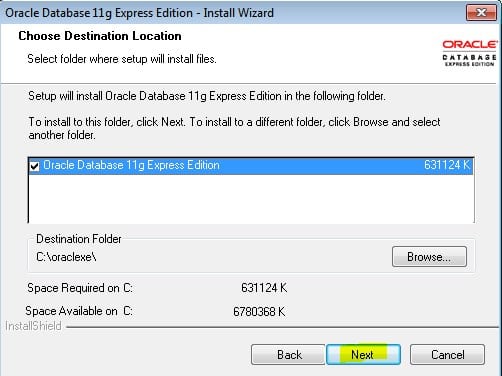
Step 6: Specify the Database Password.
- Enter Password: oracle123
Note: If you are choosing your own password so please make a note, we will need this password again.
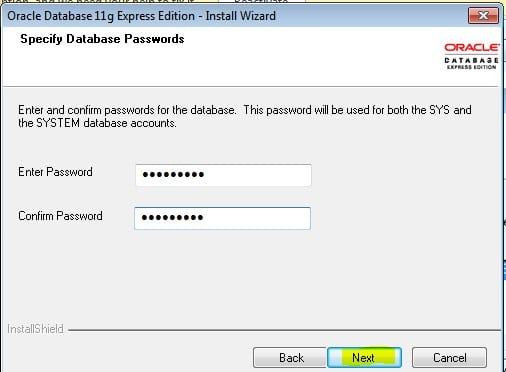
Note: The Default port in which Oracle listens is 1521.
Click on Install.

This may take a while.
Step 7: Click on finish to complete the installation.
Configuration of Oracle SQL Developer
Before beginning the SQL developer installation, make sure you have started the database. If the database isn’t started, the connection between the SQL developer and database will fail.
To start the database: Go to Start -> Oracle Database 11g Express Edition -> Click on Start database.
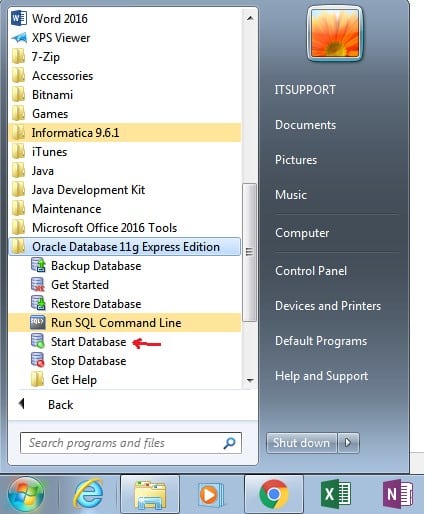
Now we can begin the Configuration of Oracle SQL Developer:
Step 1: Begin by downloading Oracle SQL Developer zip file. I recommend you use SQL Developer 3.2.20 as the later versions require you to install Java 1.8 and manually set the path. You can download the file from the link below:
- http://www.oracle.com/technetwork/developer-tools/sql-developer/downloads/index.html
Step 2: Once the download is complete, extract the downloaded file.
Step 3: After the extraction is complete, you will get sqldeveloper – 3.2.20.09.87 folder. Enter the sqldeveloper – 3.2.20.09.87 folder and double click on click on sqldeveloper to start configuration.
Note: If we go for the version 4.0 or higher of SQL Developer we need to install JDK 1.8 and we have to manually configure the complete path so we will recommend to go with version 3.2 itself.
Step 4: Once the initialization is completed, you will get to the home screen below. Do not select any configure file type association, directly click on cancel.
Step 5: To establish the connection, start by right clicking on connections and Click on New Connections.
Step 6: We will now connect to the Oracle Database. Enter the following details as below :
- Connection Name: ORACLEXE
- Username: sys
- Password: oracle123 (here we have to specify the same password that was set while database installation)
- Role: SYSDBA
Click on Save -> Test -> Connect
Once we will click on connect we can see the Connection is added in the list.
Step 7: Now click on the Plus icon next to ORACLEXE to get the screen below:

Step 8: Now we have to create 2 users.
- INFA_DOM (For Domain)
- INFA_REP (For Repository)
Right click on Other Users to create user.
Click on Create User.
Step 9: We will now be creating the user for domain. Enter the following User details :
- User Name: INFA_DOM
- Password: INFA_DOM
- Default Tablespace: USERS
- Temporary Tablespace: TEMP
Note: After specifying all the details do not click on Apply
Step 10: Click on roles tab to define the roles of the user.
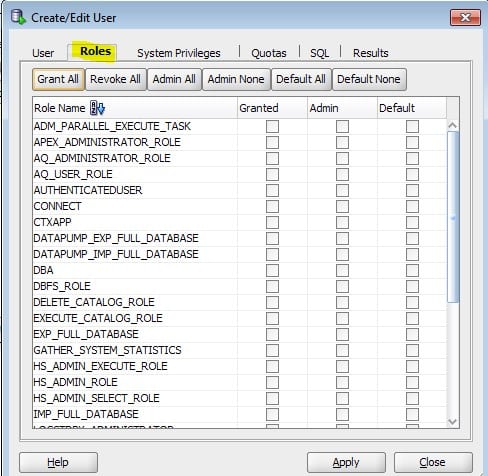
Step 11: We have to assign the Domain user complete permissions for :
- DBA
- CONNECT
- RESOURCE
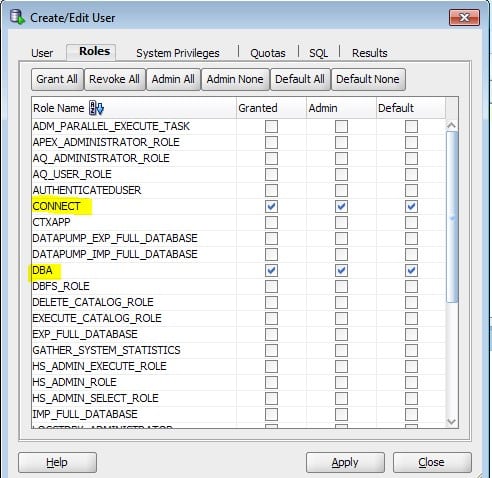
Scroll down for to find resources role :

Step 12: Now Click on Quotas tab to assign tablespace area:
Step 13: Select USERS and assign the unlimited option. Click on Apply
Click on Close.

User INFA_DOM has successfully been created.
Step 14: Now we will click on Connection and New Connection to connect to Domain user.
Step 15: Enter the following user details :
- Connection Name: INFA_DOM
- Username: INFA_DOM
- Password: INFA_DOM
- Connection Type: Basic
- Role: Default
Click on Save -> Test -> Connect
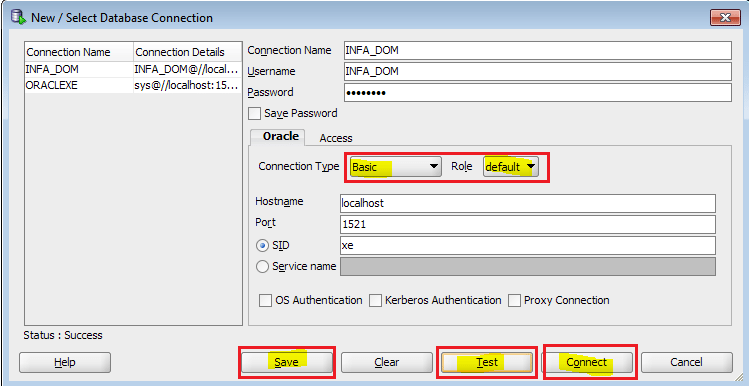
Once we will click on connect we can see the User is added in the list
Step 16: We will now add Repository user in the similar manner. Click on other user and add users under ORACLEXE.

Step 17: Enter the following details for Repository user:
Username: INFA_REP
Password: INFA_REP
Default Tablespace: USERS
Temporary Tablespace: TEMP
Step 18: As in Domain user, provide the Repository user with complete permission for following roles under Roles tab:
- DBA
- CONNECT
- RESOURCE
Step 19: Click on Quotas tab and select unlimited option for Users as seen below:
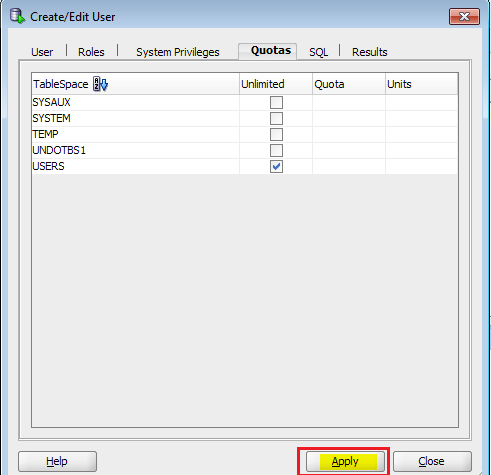
Click on Close.
User INFA_REO has successfully been created.
Step 20: Now we will click on Connection and New Connection to connect to Repository user.
Step 21: Enter the following user details :
- Connection Name: INFA_REP
- Username: INFA_REP
- Password: INFA_REP
- Connection Type: Basic Role: Default
Click on Save -> Test -> Connect
Now you can see New user INFA_REP is created and connected successfully.
Now we are done with the Installation of Oracle and SQL now we have to download the Informatica tool and install them.
The Informatica installation will follow the steps below:
- Downloading the Installation Packs.
- Unpacking the Installation Packages.
- Informatica PowerCenter Pre-Installation check.
- Installing Informatica PowerCenter.
- Domain Configure.
- Configure Repository Service.
- Configure Integration Service.
- Client Installation.
- PowerCenter Designer Configuration.
Lets begin the installation process now :
Step 1: Downloading Installation Packs
To begin with the Informatica installation, we start off by downloading the free version of the Informatica PoweCenter provided by oracle.
Step 1.1: Download Informatica 9.6.1 using below link
- https://edelivery.oracle.com/
Step 1.2: Sign in to your account, If you do not have Oracle account use New User option to create account.
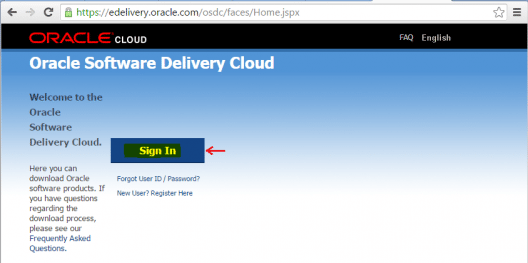
Step 1.3: In search Box type PowerCenter.
Step 1.4: Select Oracle Informatica PowerCenter and PowerConnect Adapters.
Step 1.5: Select Platform (I am installing on a Windows 64 bit OS, so I have selected windows 64 ).
Step 1.6: Click on Continue.
Step 1.7: Accept the Oracle license.
Step 1.8: Now as in below screenshot, you have to select last four files from the list.
Step 1.9: After selecting files click on Download.
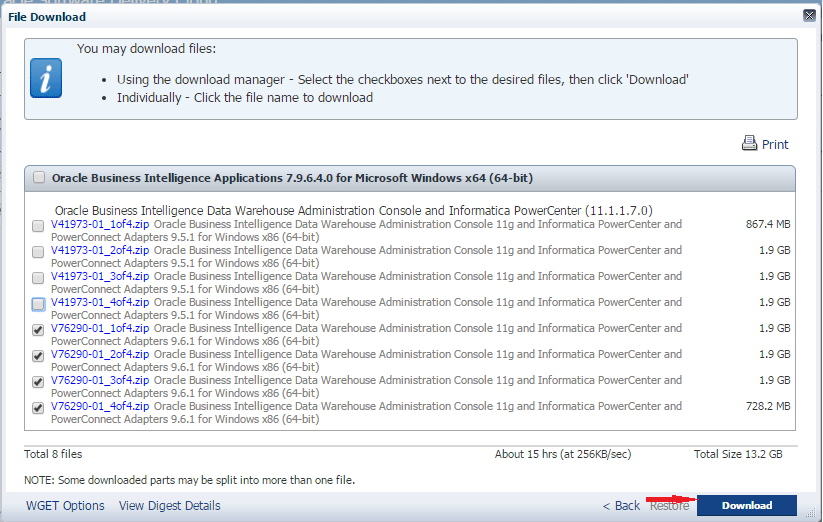
Step 1.10: You will get a pop up asking you to download installer.
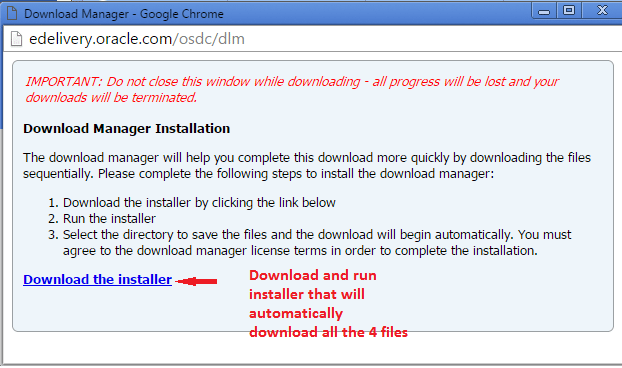
Step 1.11: Download the installer and install it in your system. Once installer is launched it will automatically download all the four files in specified directory.
Since the required files are now downloaded, we will proceed ahead with the Informatica installation by unpacking the downloaded files.
Step 2: Unpacking the Installation Packages
Note : Use WinRAR for extraction of the files as any other file explorer may cause an error while extracting the dac_win_11g_infa_win_64bit_961
Step 2.1: Now extract all the four files one by one.
Step 2.2: Extract it in the same directory using option as suggested in below screenshot.
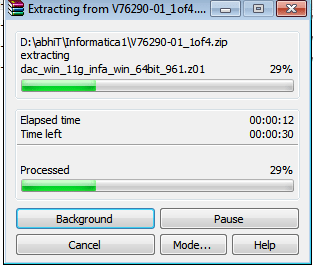
Step 2.3: After extracting, you will get four files :
- V76290-01_1of4.
- V76290-01_2of4.
- V76290-01_3of4.
- V76290-01_4of4.
Step 2.4: Now enter into fourth file V76290-01_4of4, and extract the file named dac_win_11g_infa_win_64bit_961.
Step 2.5: While extracting this file, you have to enter the path of all the 4 extracted files one by one as suggested in below screenshot :

Step 2.6: When you get above window, browse to the location of first extracted file and click OK as suggested below :
Step 2.7: In the same way browse and extract the second, third and fourth file.
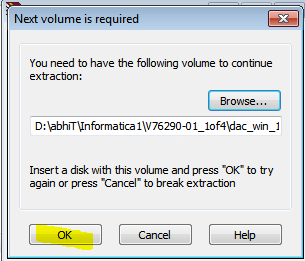
Step 2.8: Now enter into extracted file dac_win_11g_infa_win_64bit_961 and extract server and client installer using option as suggested in below screenshots.

Step 3: Informatica PowerCenter Pre-Installation Check.
From this point onward the Informatica installation process begins, however before we go ahead with the actual process we need to check whether the current system meets with the minimum requirements for Informatica installation.
Step 3.1: Enter into directory 961_Server_Installer_winem-64t and double click on install.bat file to begin the installation.
Step 3.2: Follow below screenshot.
Click on Next.
Step 3.3: Enter the domain configuration as below :
- Host name : EDUREKA23 (this is my machine’s hostname)
- Database Password : INFA_DOM
- Database User ID : INFA_DOM
- Database type : Oracle
To connect to a remote host, you would have to purchase the Licence from Informatica which costs a few thousand USD per year depending on certain parameter like Number of users, Operating System, Number of processors, etc.
- To find the hostname of your machine, go to oracle installation directory and open tnsname.ora file, present in C:oraclexepporacleproduct .2.0server
etworkADMIN path
Step 3.4: Click on Test Connection and Next.
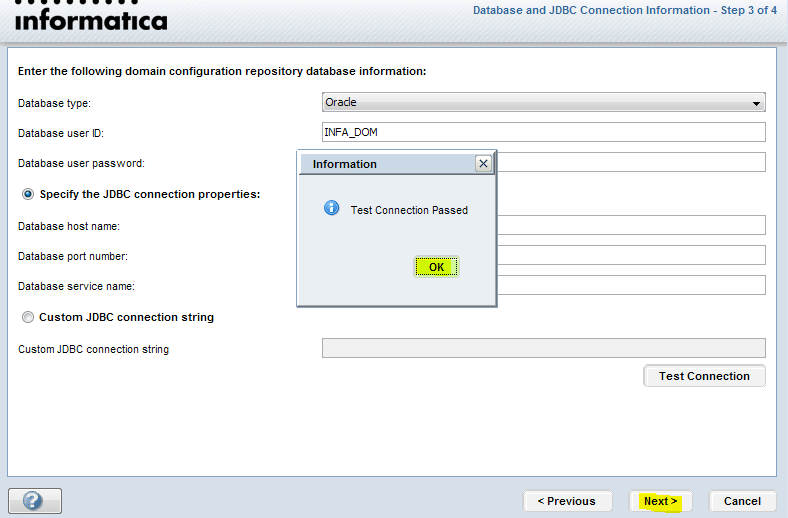
Step 3.5: Click on Done.
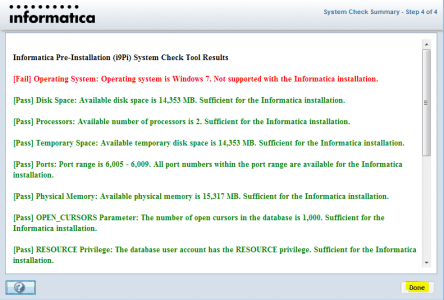
Step 4: Installing Informatica PowerCenter
Now that we have verified that the current system meets the minimum requirements, we will proceed with the actual Informatica installation.
Step 4.1: Now again go to the extracted directory 961_Server_Installer_winem-64t and double click on install.bat file.

Step 4.2: Follow below steps.
Click on Next.

Step 4.3: Now in below window browse for product key Which is present under V76290-01_4of4dac_win_11g_infa_win_64bit_961.

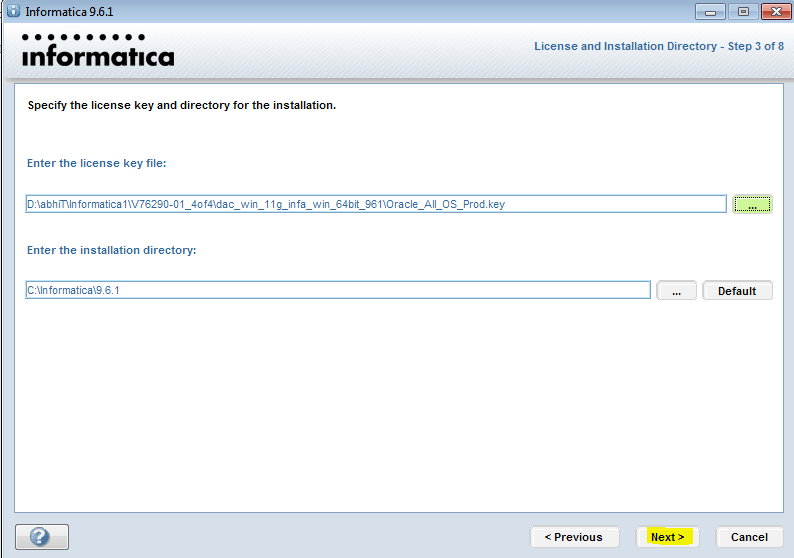
Click on Next.

Click on Install.
- It will take a bit time to install the software.
Step 5: Domain Configuration
Now that we have completed with the Informatica installation, we begin the process of configuration. The first component that needs to be configured is the operational domain.
Step 5.1: Uncheck “Enable HTTPS for Informatica Administrator” and click Next.
Step 5.2: Enter the domain configuration as below :
- Database type : Oracle
- Database User ID : INFA_DOM
- User Password : INFA_DOM
- Rest of the parameter are default.
Step 5.3: Click on Test connection and click Next.
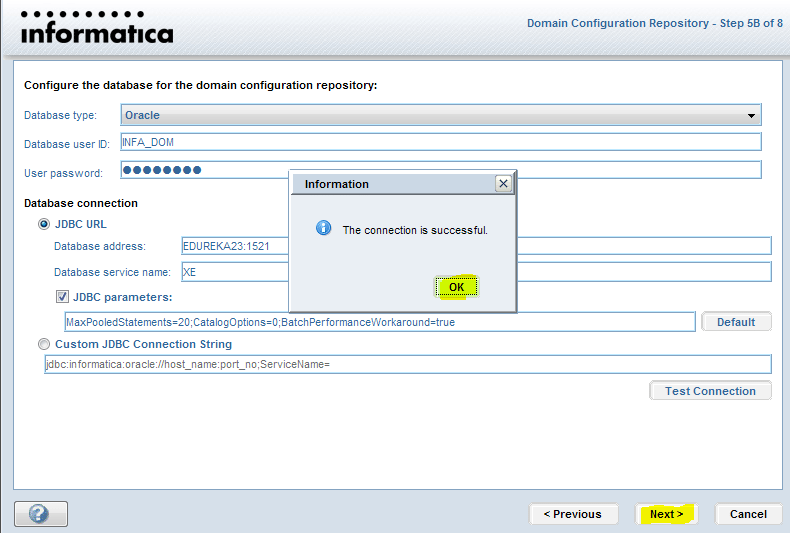
You have successfully tested the domain connection.
Step 5.4: Enter the Encryption key information( I am choosing Edu@1122, you can choose as like):
- Keyword : Edu@1122
Click on Next and OK.
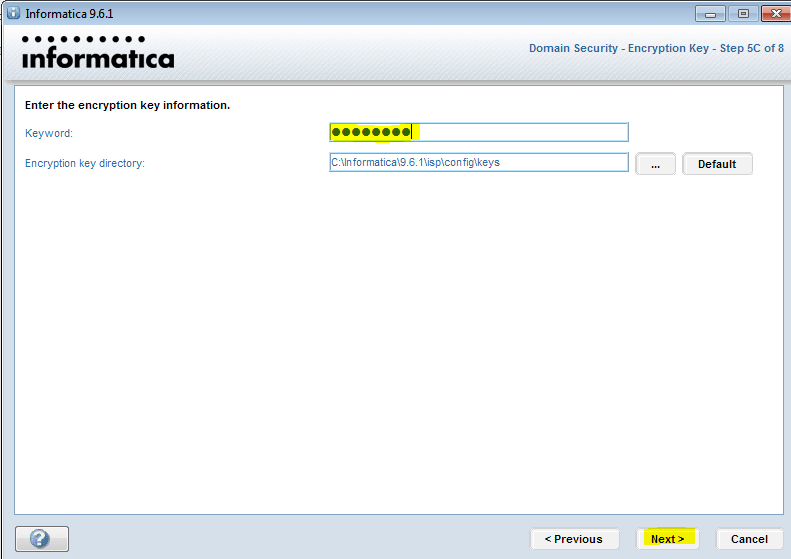
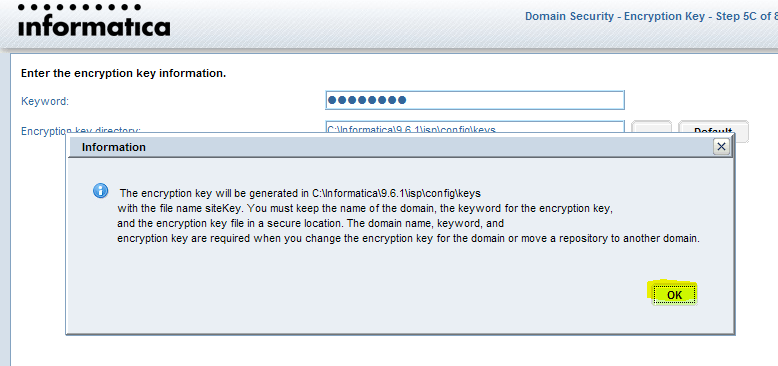
Step 5.5: Enter the following details as below regarding Informatica Domain :
- Domain User Name : Administrator
- Domain Password : Administrator
Mark check on Display advance port configuration page and click on Next.
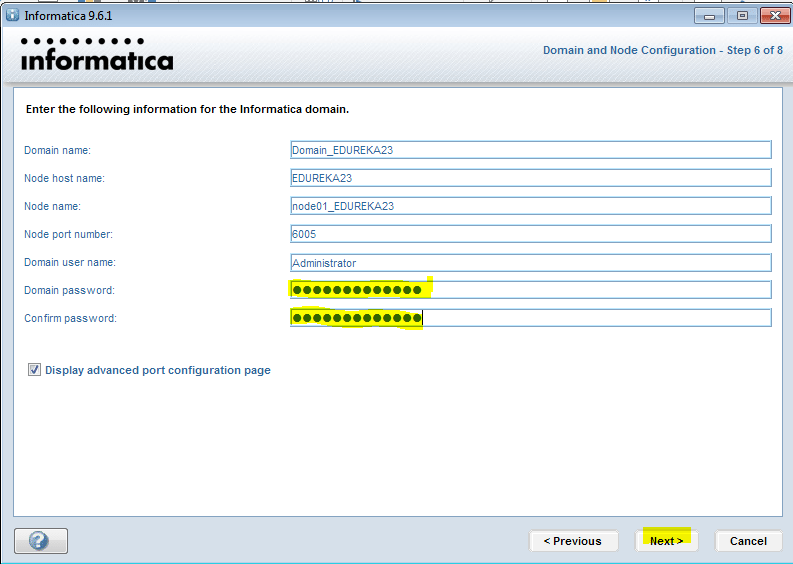
Click on Next.
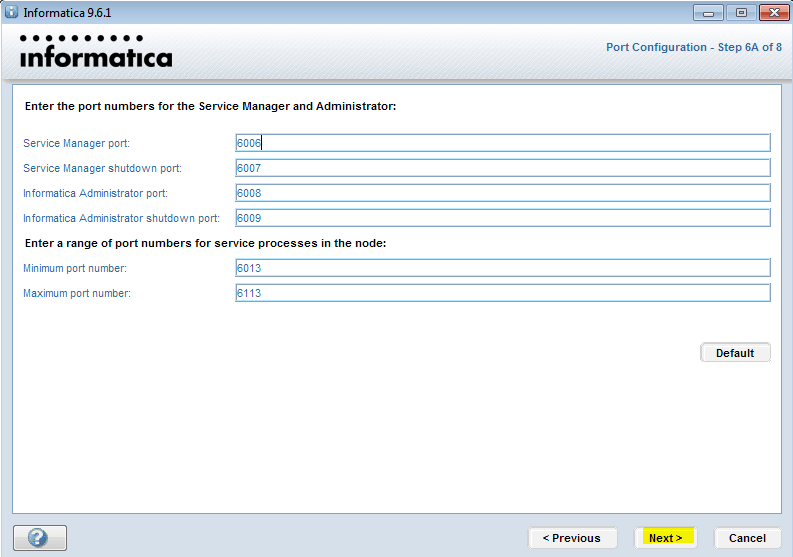
- It will take time to configure settings.
Step 5.6: Uncheck Run Informatica under a different user account and Click on Next.
Step 5.7: Click on Informatica Administrator Home Page link.
Step 6: Configure Repository Service
Once the operational domain is configured, we need to configure the repository services which will connect to the repository from client applications.
Step 6.1: After clicking on above link, Informatica Administrator console will be opened in browser.
- Username : Administrator
- Password : Administrator


Step 6.2: Create Repository services :
- Click on Action -> New -> PowerCenter Repository Service.
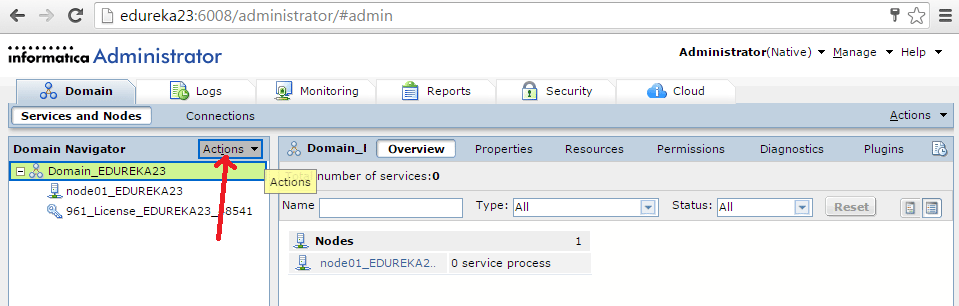
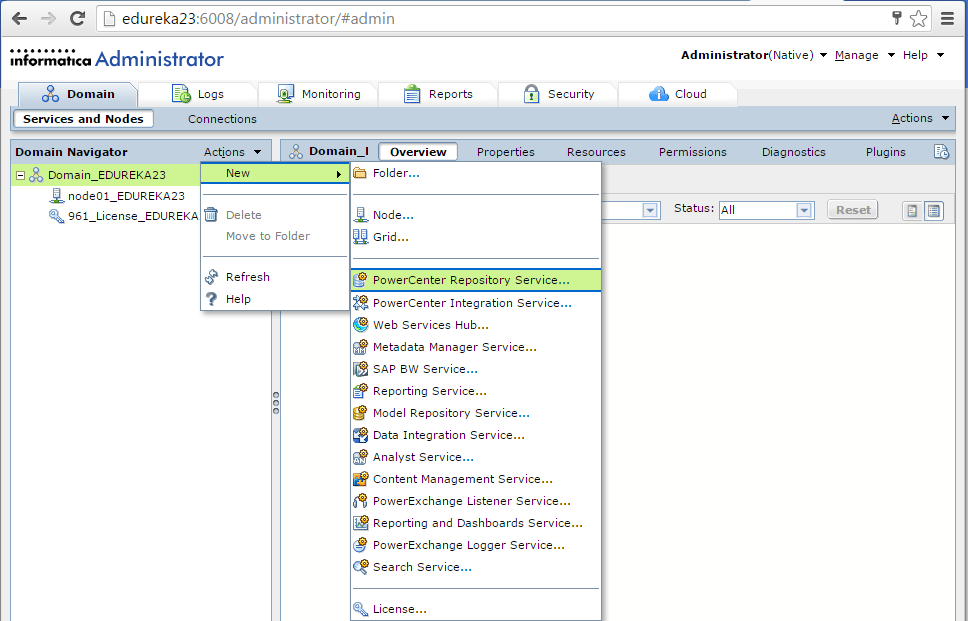
Step 6.3: Enter the following Repository service details :
- Name : Repsvc_Edureka
- From drop down list select License and Node and Click on Next.
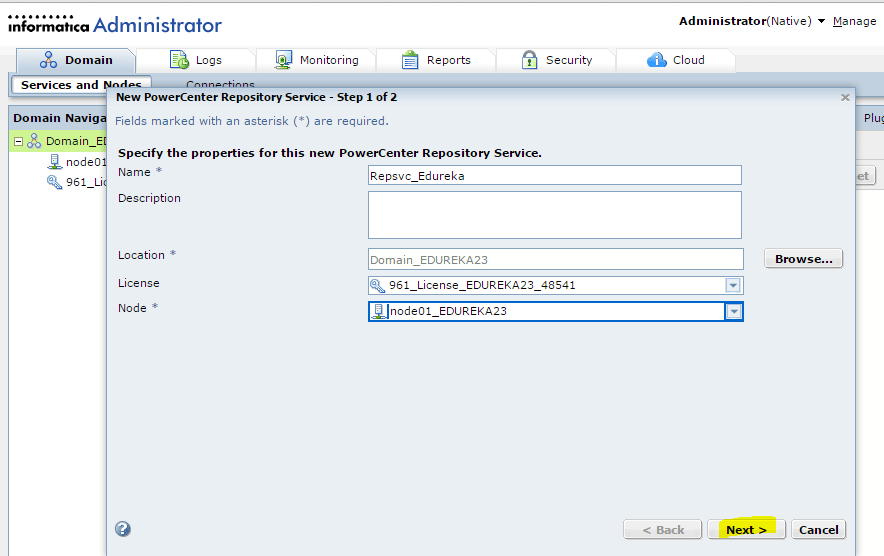
Click Next.
Step 6.4: Enter the following details as below for database properties :
- Database Type : Oracle
- Username : INFA_REP
- Password : INFA_REP
- Connection String : XE

Click on Finish.
Step 6.5: Now change Operating Mode from Exclusive to Normal.

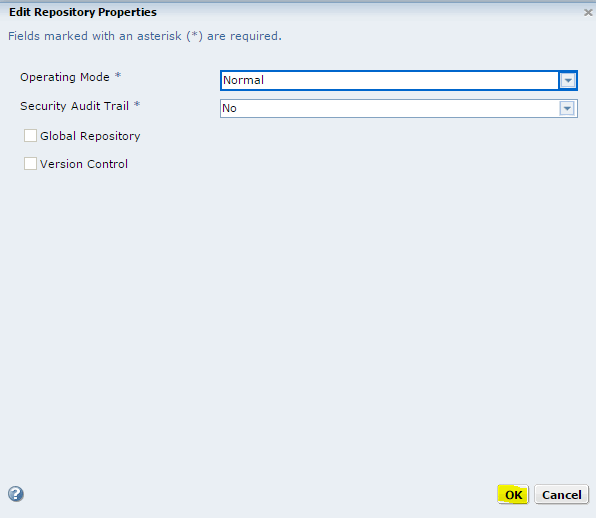
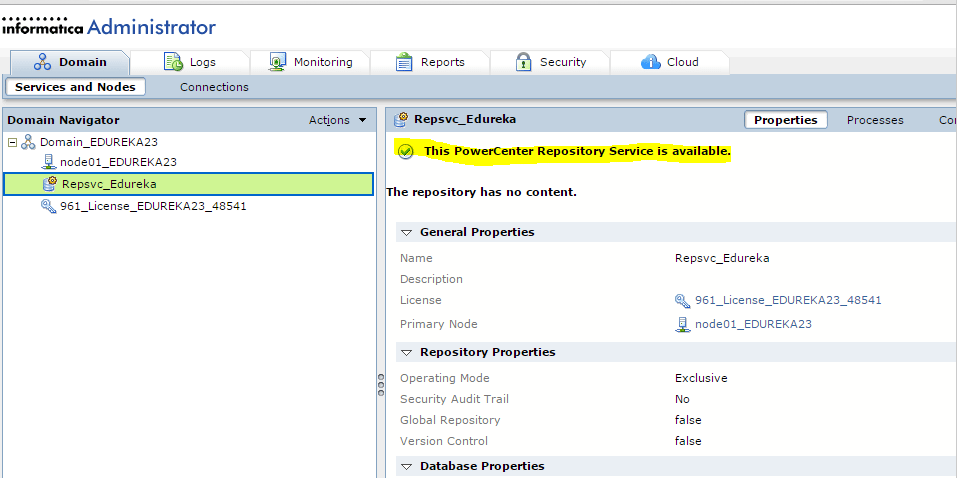
Now we have successfully made the Repository available for further operations.
Step 7: Configure Integration Service
As part of configuration of the repository services, we need to configure the Integration services also which will load the workflows from the repositories and help combine data from different platforms and source types.
Step 7.1: Create Integration services
- Click on Action -> New -> PowerCenter Integration Service
Step 7.2: Enter the following Integration service details
- Name : Intsvc_Edureka
- From drop down list select License and Node and Click on Next
Click on Next
Step 7.3:Enter the following Repository service details
- PowerCenter Repository Service : Repsvc_Edureka
- Username : Administrator
- Password : Administrator


- Now Integration service is created but it is disabled, so we have to enable it.
Step 7.4: Follow the steps below to enable the integration service
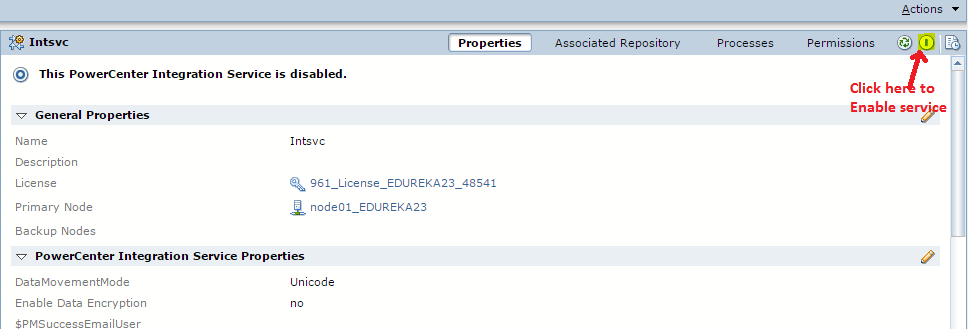
We have now successfully made the Integration Services available for further operations.
Step 8: Client Installation
To proceed ahead with the Informatica installation, we start with the client installation.
Step 8.1: Now Install PowerCenter Client
- Go to the directory 961_Client_Installer_win32-x86 and double click into install.bat .
Click on Next.
Step 8.2: Mark check on PowerCenter Client and click Next.
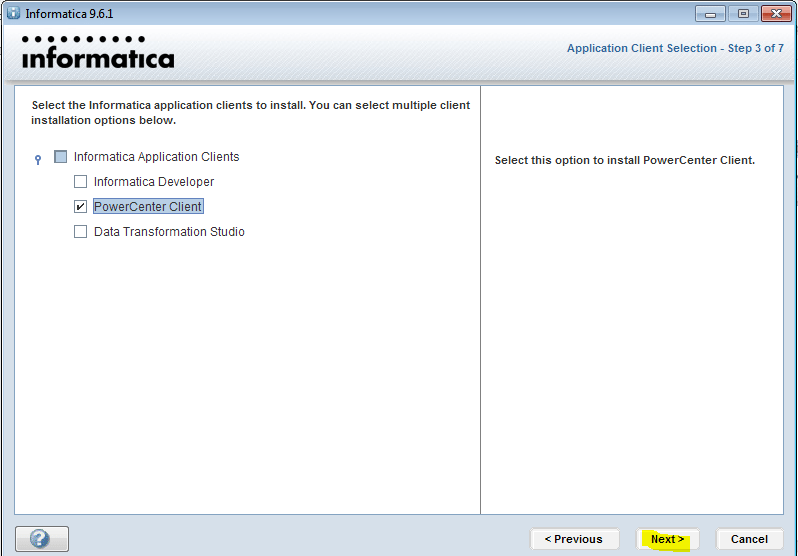
Step 8.3: Click Next and specify installation directory .
Step 8.4: Click Install.
Now this step will take some time to install the software.
Step 8.5: Click on Done
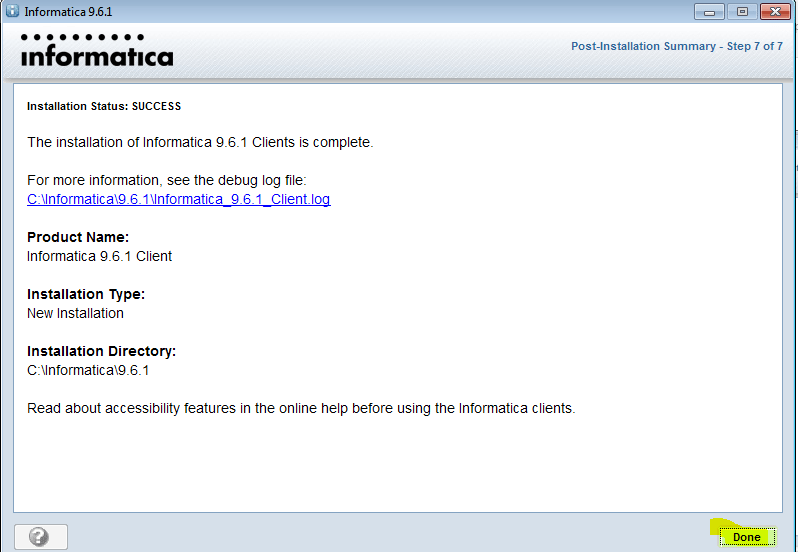
Step 9: Configure PowerCenter Designer
The final step of Informatica installation is the configuration of the PowerCenter Designer to connect to the domain and repositories to load the databases
Step 9.1: Now Click on Windows start button to start PowerCenter Designer.
Step 9.2: Click on Repository -> Configure Domains.
Step 9.3: Click to add domain.
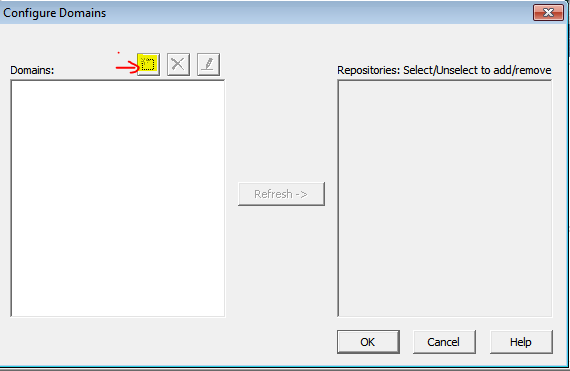
Step 9.4: Enter the following details to add a domain :
- Domain Name : Domain_Edureka23 (here you should type Domain_Host Name Of Your Machine)
- Gateway Host : Edureka23 (your machine’s host name)
- Gateway Port : 6005
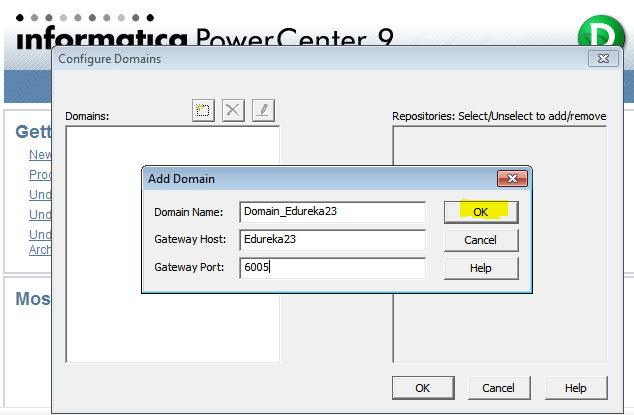
Click OK.
Step 9.5: Select Repsvc_Edureka and click OK.
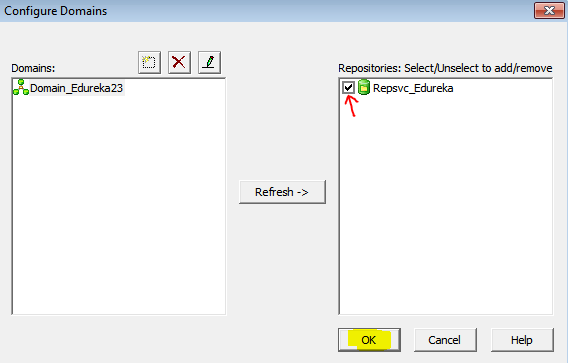
Step 9.6: Select Repsvc_Edureka and connect to the repository as shown below.
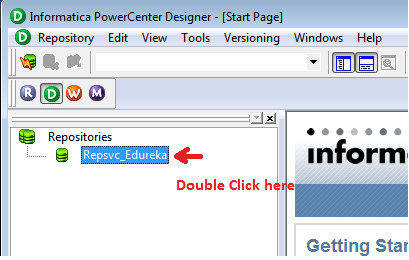
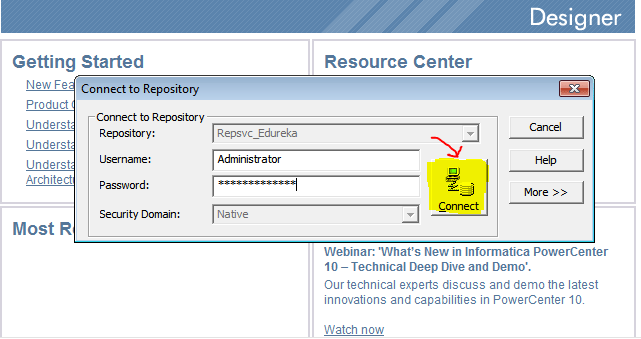
- In below screenshot, you can see that connection is successful.
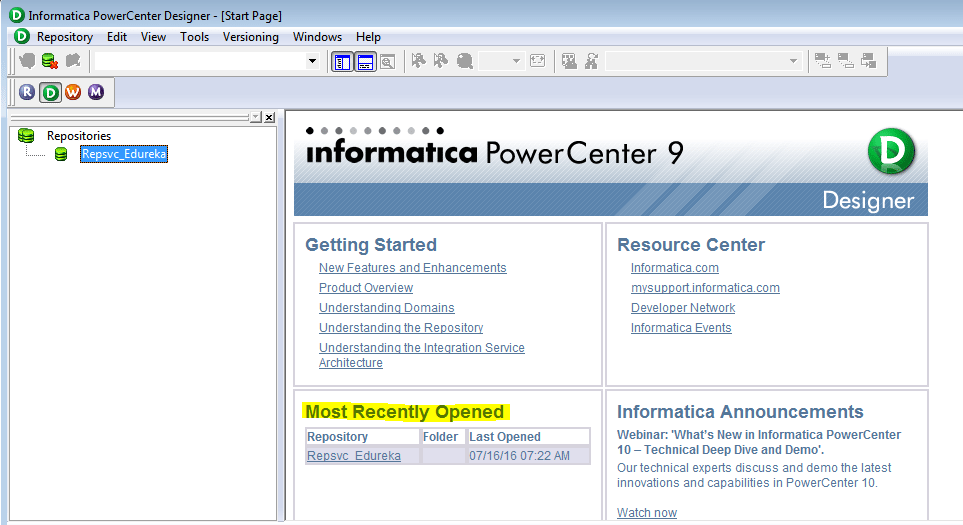
- You can verify the connection in repository service in Informatica administrative console.
- You can see the table listed in Domain Properties.
This completes the Informatica installation, hope this blog has been useful in setting up Informatica PowerCenter in your system.
If you found this blog helpful, you can also check out our Informatica Tutorial blog series What is Informatica: A Beginner Tutorial of Informatica PowerCenter and Informatica Tutorial: Understanding Informatica ‘Inside Out’ . In case if you are looking for details on Informatica Certification, you can check our blog Informatica Certification: All there is to know.
If you have already decided to take up Informatica as a career, I would recommend you why don’t have a look at our Informatica certification training course page. The Informatica Certification training at Edureka will make you an expert in Informatica through live instructor led sessions and hands-on training using real life use cases.
Got a question for us? Please mention it in the comments section and we will get back to you.