10. Факторный анализ
Факторный анализ — представляет собой метод обобщения или сокращения большого количества переменных, объединение их в группы на основе характерных связей. В факторном анализе переменные не делятся
на независимые и зависимые.
В практике маркетинговых исследований с факторный анализ применяется в следующих ситуациях
- для сегментирования рынка и выявления переменных с целью группировки потребителей;
- для определения характеристик торговой марки с целью выявления предпочтений потребителей;
- при разработке рекламной стратегии с целью выявления особенностей восприятия потребителем рекламного продукта
Факторный анализ применяется для выделения из большого массива данных малое число групп, состоящих из переменных, объединенных общими факторами (Рисунок 10.1).
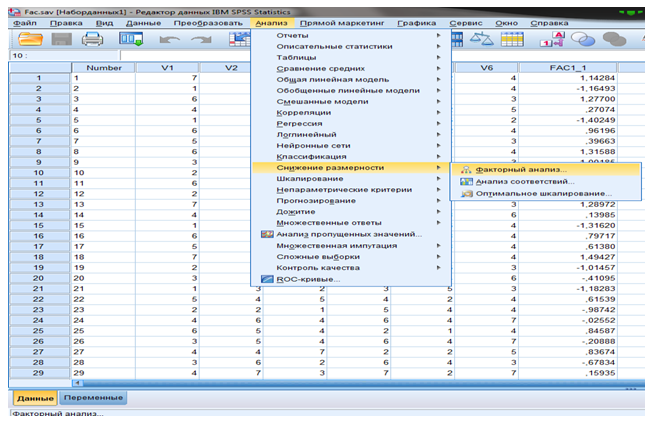
Рисунок 10.1 –Диалоговое окно факторного анализа
В один фактор объединяются переменные, плотно коррелирующие между собой и слабо коррелирующие с переменными, которые объединяются на основе других факторов. Факторный анализ проводится с целью
сокращения числа переменных и упрощение процедуры анализа существующей базы данных.
В процессе проведения факторного анализа рассчитываются и анализируются следующие показатели:
- Критерий сферичности Бартлетта — показатель, с помощью которого проверяют, отличаются ли корреляции от 0. Если г близко к нулю, то выбранная переменная не взаимосвязана с другими.
Значимость меньше 0,05 указывает, на то что проведение факторного анализа приемлемо. - Корреляционная матрица — матрица, включающая в себя все возможные коэффициенты корреляций r между анализируемыми перемнными.
- КМО — мера адекватности выборки Кайзера—Мейера—Олкина — величина, используемая для оценки применимости факторного анализа. Значения от 0,5 до 1 говорят об адекватности факторного анализа,
значения до 0,5 указывают на то, что факторный анализ неприменим к выборке.
Графическое изображение критерия “каменистой осыпи” — график собственных значений факторов, расположенных в порядке убывания, используется для определения достаточного числа факторов.
Процедура факторного анализа включает следующие этапы:
- Формулировка проблемы.
- Проверка возможности проведения, вычисление корреляционной матрицы.
- Выбор метода факторного анализа.
- Извлечение факторов.
- Вращение факторов.
- Определение значений факторов.
- Проведение подгонки выбранной модели.
Пример. Проведем факторный анализ с целью сокращения массива данных, содержащих информацию о мотивах туристов, при выборе места отдыха за городом. Оптимизируем структуру данных, сократив
число переменных.
Основные задачи:
- оценить возможность проведения и адекватность факторного анализа для данной выборки;
- вычислить корреляционную матрицу и выявить взаимосвязи между переменными базы данных;
- выявить и извлечь необходимое количество факторов для создания упрощенной структуры;
- разбить базу данных на группы факторов на основе значений совместной корреляции;
- подобрать названия созданным переменным.
Вверх
Мотивы туристов, при выборе места отдыха за городом:
- близость к городу
- приемлемые цены
- близость водоема, леса
- уровень комфорта
- тишина, уединение
- хорошее питание
- наличие развлечений
- комфорт отдыха с детьми
- возможность лечения, ухода за здоровьем
Пошаговая инструкция
ШАГ 1. Меню “Анализ — Сокращение размерности — Факторный анализ …”. Открывается диалоговое окно “Факторный анализ”.
ШАГ 2. Из этого списка переменных выбрать необходимый массив, и перенести его в поле “Переменные”.
Если есть необходимость провести факторный анализ отдельно для двух переменных, например мужчин и женщин, то в поле “Переменная отбора наблюдений” вносится переменная “пол”. В данном
случае нет необходимости проводить такое деление.
ШАГ 3. Диалоговое окно “Описательные статистики— выбрать “КМО и критерий сферичности Бартлетта” для проведения тестов “КМО” и “Бартлетт”, проверяющих пригодность
данных для проведения факторного анализа.
ШАГ 4. Диалоговое окно “Описательные статистики— “Корреляционная матрица— “Коэффициенты— “Продолжить”.
ШАГ 5. Диалоговое окно “Извлечение— задать условия определения количества факторов. В диалоговом окне “Извлечение— выбрать метод “Главные компоненты. — “Матрица корреляций”
(Рисунок 10.2).
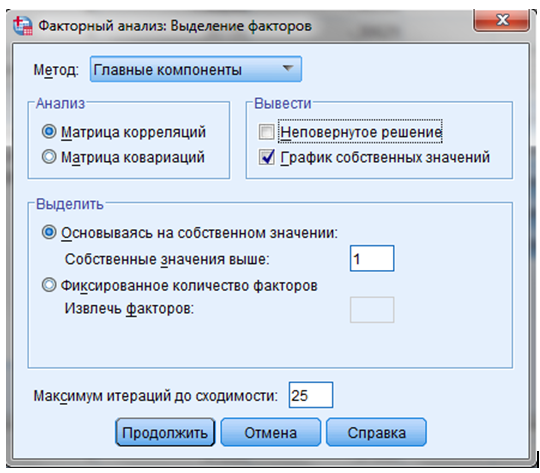
Рисунок 10.2 — Матрица корреляций
ШАГ 6. Задать условие: собственное значение больше “1”. При данном условии программа определит факторы в количестве больше 1.
ШАГ 7. Вывести график собственных значений — “График собственных значений— “Продолжить”.
ШАГ 8. Выбор ротации матрицы коэффициентов: в главном диалоговом окне “Факторный анализ— диалоговое окно “Вращение— метод ротации “Варимакс— “Продолжить”.
ШАГ 9. Создание новых переменных: в диалоговом окне “Факторный анализ— диалоговое окно “Значения факторов— отметить команду “Сохранить как переменные— метод
расчета значений новых переменных “Регрессионная модель”. В итоге создаются новые переменные, которые можно будет использовать в дальнейшем анализе.
ШАГ 10. “ОК”.
Интерпретация результатов
- Величина КМО показывает приемлемую адекватность выборки для факторного анализа КМО = 0,512>0,5. Критерий Бартлетта (p<0,05), что говорит о целесообразности факторного анализа в
силу коррелированности факторов. - Выявление и извлечение необходимого количества факторов для создания упрощенной структуры
Компонента Начальные собственные значения Суммы квадратов нагрузок вращения Всего % дисперсии Кумулятивный % Всего % дисперсии Кумулятивный % 1 2,57 25,7 25,7 2,07 20,76 20,76 2 1,79 17,95 43,66 1,84 18,47 39,23 3 1,4 14,02 57,68 1,56 15,62 54,86 4 1,23 12,29 69,97 1,34 13,42 68,28 5 1,07 10,79 80,77 1,24 12,48 80,77 6 ,87 8,69 89,47 7 ,43 4,31 93,78 8 ,34 3,43 97,21 9 ,27 2,7 99,91 10 ,008 ,08 100,0 Метод выделения: Анализ главных компонент.
Начальные собственные значения должны быть больше 1.
Оптимальное число факторов — 5. Такая модель сохраняет 80,77% исходной информации, при этом число фактор сокращается в два раза.

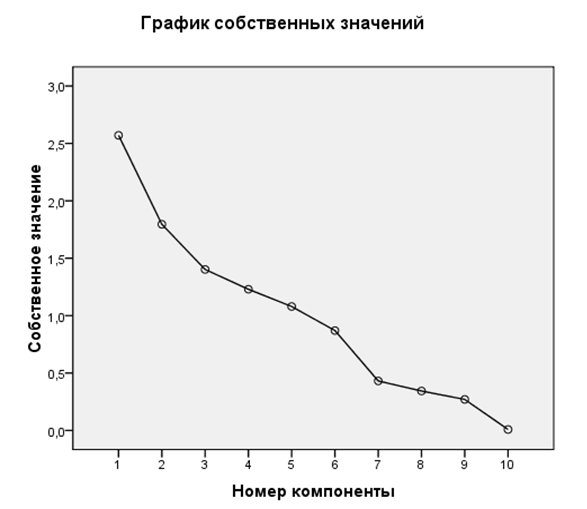
Рисунок 10.1 — График собственных значений
График показывает соответствующие собственные значения в системе координат: с 5 по 6 факторы происходит перелом графика. Это подтверждает, что оптимальное количество факторов 5.
- На основании ротированной матрицы (таблица 10.5) компонентов в одну группу собираются переменные, которые наиболее тесно взаимосвязанные между собой (наиболее высокое значение коэффициента корреляции). В результате программа группирует переменные исходного массива и создает матрицу преобразования компонент (таблица 10.6)
Компонента 1 2 3 4 5 близость к городу -,088 ,852 -,198 -,009 ,147 приемлемые цены ,278 -,190 -,221 -,561 ,622 близость водоема, леса ,074 -,240 -,210 ,664 ,215 уровень комфорта -,062 ,793 ,241 ,093 -,148 тишина, уединение ,988 -,074 ,082 -,040 -9,640E—6 хорошее питание ,059 ,331 ,831 ,158 ,054 наличие развлечений -,075 ,335 -,797 ,261 -,070 комфорт отдыха с детьми -,086 ,078 ,179 ,221 ,874 возможность лечения, ухода за здоровьем ,991 -,071 ,026 -,021 ,006 организация детского отдыха -,084 ,400 ,087 ,659 -,004 Таблица 10.5 — Матрица повернутых компонент
Метод выделения: Анализ методом главных компонент.
Метод вращения: Варимакс с нормализацией Кайзера.Компонента 1 2 3 4 5 1 -,69 ,61 ,023 ,36 -,12 2 ,55 ,48 ,64 ,19 ,03 3 ,45 ,35 ,75 ,32 ,002 4 -,101 -,008 ,000 ,14 ,98 ,020 ,51 -,130 -,83 ,123 Таблица 10.6 — Матрица преобразования компонент
Метод выделения: Анализ методом главных компонент.
Метод вращения: Варимакс с нормализацией Кайзера.Выделяем следующие факторы:
Фактор 1 — тишина и уединение, уход за здоровьем
Фактор 2 — близость к городу, уровень комфорта
Фактор 3 — хорошее питание, наличие развлечений
Фактор 4 — организация детского отдыха, близость водоем
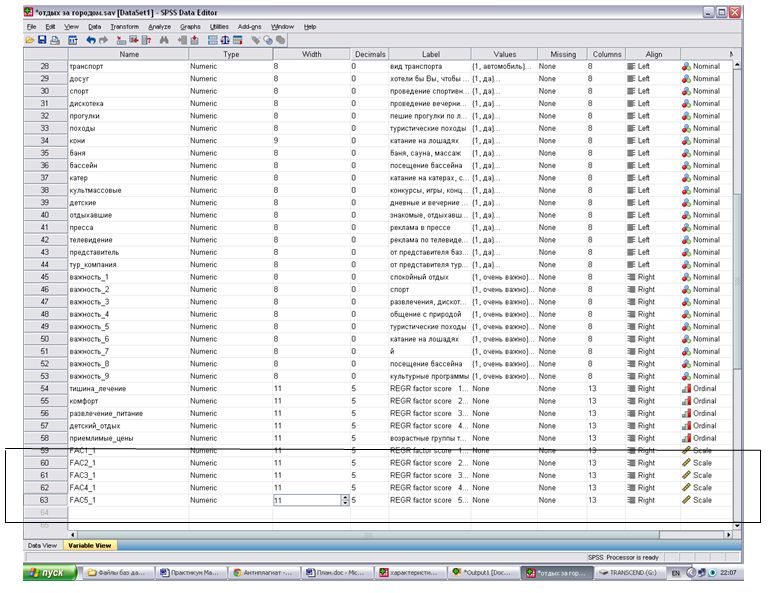
Фактор 5 — комфорт отдыха с детьми, приемлемые цен - В базе данных автоматически переносятся новые переменные построенной факторной модели (Рисунок 10.2). В столбце “Метка” отображается номер компонента факторной модели.
Рисунок 10.2 — Фрагмент вкладки “Переменные”
Названия новых компонент необходимо занести в исходную базу данных в столбец “Метка” таблицы “Переменные”, компьютер автоматически вычисляет значения новых переменных.
Суть новых переменных сводится к следующему: наибольшее отрицательное значение говорит о большей значимости переменной, и наоборот, наибольшее положительное значение говорит о наименьшей значимости переменной.
Созданные переменные в дальнейшем могут использоваться для анализа, например для проведения кластерного анализа.
| Мера адекватности и критерий Бартлетта | ||
|---|---|---|
| Мера выборочной адекватности Кайзера—Мейера—Олкина | ,512 | |
| Критерий сферичности Бартлетта | Приблиз. хи—квадрат | 262,3 |
| ст.св. | 45 | |
| Знч. | ,000 |
Таблица 10.1 — Результаты теста КМО и Бартлетта
| близость к городу | приемлемые цены | близость водоема, леса | уровень комфорта | тишина, уединение | хорошее питание | наличие развлечений | комфорт отдыха с детьми | возможность лечения, ухода за здоровьем | организация детск. отдыха | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Корреляция | близость к городу | 1,000 | -,060 | ,009 | ,519 | -,172 | ,149 | ,322 | ,075 | -,166 | ,241 |
| приемлемые цены | -,060 | 1,000 | -,064 | -,341 | ,270 | -,247 | -,121 | ,232 | ,273 | -,407 | |
| близость водоема, леса | ,009 | -,064 | 1,000 | -,056 | ,017 | -,083 | ,107 | ,114 | ,027 | ,030 | |
| уровень комфорта | ,519 | -,341 | -,056 | 1,000 | -,113 | ,384 | ,070 | ,008 | -,125 | ,256 | |
| тишина, уединение | -,172 | ,270 | ,017 | -,113 | 1,000 | ,084 | -,167 | -,060 | ,989 | -,129 | |
| хорошее питани | ,149 | -,247 | -,083 | ,384 | ,084 | 1,000 | -,422 | ,191 | ,036 | ,237 | |
| наличие развлечений | ,322 | -,121 | ,107 | ,070 | -,167 | -,422 | 1,000 | -,045 | -,116 | ,248 | |
| комфорт отдыха с детьми | ,075 | ,232 | ,114 | ,008 | -,060 | ,191 | -,045 | 1,000 | -,053 | ,202 | |
| возможность лечения, ухода за здоровьем | -,166 | ,273 | ,027 | -,125 | ,989 | ,036 | -,116 | -,053 | 1,000 | -,106 | |
| организация детск. отдыха | ,241 | -,407 | ,030 | ,256 | -,129 | ,237 | ,248 | ,202 | -,106 | 1,000 |
Таблица 10.2 — Корреляционная матрица.
Коэффициенты корреляции характеризуют плотность связи между переменными исходного массива.
Для того, чтобы рассчитать факторный анализ используя статистически пакет SPSS необходимо сделать следующий шаги:
1. Внести значения переменных по которым необходимо рассчитать факторный анализ. Данные вносятся в таблицу Data Editor. (Например 8 переменных var1…var8)
2. Выбираем Analyze -> Data reduction -> Factor…
3. В появившемся окошке под переносим нужные нам переменные из правой части в левую (var1…var8)
4. нажимаем кнопку Extraction…
4.1. В появившемся окне выбираем Principial components.
4.2. Отмечаем галочкой Scree plot
4.3. Нажимаем Continue
5. Затем нажимаем кнопку Rotation.
5.1. В поле Method из выпадающего списка выбираем Varimax
5.2. Нажимаем кнопку Continue
6юНажимаем кнопку Options
6.1. В поле Coefficient display format отмечаем галочкой Suppress absolute values less then 0,1
6.2. Нажимаем кнопку Continue
7. Смотрим результаты
19.1. Порядок выполнения факторного анализа
На первом шаге процедуры факторного анализа происходит стандартизация заданных значений переменных (z-преобразование);
затем при помощи стандартизированных значений рассчитывают корреляционные коэффициенты Пирсона между рассматриваемыми переменными.
Исходным элементом для дальнейших расчётов является корреляционная матрица. Для понимания отдельных шагов этих расчётов потребуются хорошие знания, прежде всего, в области операций над матрицами.
Для построенной корреляционной матрицы определяются, так называемые, собственные значения и соответствующие им собственные векторы, для определения которых используются оценочные значения
диагональных элементов матрицы (так называемые относительные дисперсии простых факторов).
Собственные значения сортируются в порядке убывания, для чего обычно отбирается столько факторов, сколько имеется собственных значений, превосходящих по величине единицу.
Собственные векторы, соответствующие этим собственным значениям, образуют факторы; элементы собственных векторов получили название факторной нагрузки.
Их можно понимать как коэффициенты корреляции между соответствующими переменными и факторами. Для решения такой задачи определения факторов были разработаны многочисленные методы,
наиболее часто употребляемым из которых является метод определения главных факторов (компонентов).
Описанные выше шаги расчёта ещё не дают однозначного решения задачи определения факторов. Основываясь на геометрическом представлении рассматриваемой задачи,
поиск однозначного решения называют задачей вращения факторов. И здесь имеется большое количество методов, наиболее часто употребляемым из которых является
ортогональное вращение по так называемому методу варимакса. Факторные нагрузки повёрнутой матрицы могут рассматриваться как результат выполнения процедуры факторного анализа.
Кроме того на основании значений этих нагрузок необходимо попытаться дать толкование отдельным факторам.
Если факторы найдены и истолкованы, то на последнем шаге факторного анализа, отдельным наблюдениям можно присвоить значения этих факторов, так называемые факторные значения.
Таким образом для каждого наблюдения значения большого количества переменных можно перевести в значения небольшого количества факторов.
Факторный анализ — это статистический инструмент, довольно часто используемый в психологии при создании многофакторных тестов, а также при систематизации и обобщении комплексных наблюдений.
Многочисленные варианты его использования включают конструирование тестов, выявление основных параметров личности и способностей, установление того, сколько отдельных психологических характеристик
(т.е. черт) измеряется набором тестов или заданиями теста.
Термин «факторный анализ» может относиться к двум довольно разным статистическим методикам:
-
Исследовательский факторный анализ (эксплораторный факторный анализ) — более старая и более простая методика.
-
Конфирматорный факторный анализ и его разновидности (известные как «анализ путей», «анализ латентных переменных» или «модели LJSREL») полезны во многих областях
за пределами изучения индивидуальных различий и особенно популярны в социальной психологии. Авторы не всегда четко указывают, какой из видов факторного анализа использовался —
исследовательский или конфирматорный. Если вы увидите термин «факторный анализ» в журнале, следует допустить, что имеется и виду исследовательский факторный анализ.
Часто при создании психологического теста важно, чтобы все задания шкалы измеряли одну (и только одну) психологическую переменную.
Коэффициент альфа Кронбаха может служить показателем надежности шкалы. Эта техника исходит из того,
что все задания в тесте формируют одну шкалу и коэффициент надежности, в сущности, проверяет, насколько это допущение обоснованно.
Однако рассмотрим более простой пример. В интересах науки планируете собрать следующие данные у случайно сформированной выборки, например, у 200 студентов:
• V 1 — вес тела (в кг);
• V 2 — степень невнятности речи (ранжируется по шкале от 1 до 5);
• V 3 — длина ноги (в см);
• V 4 — разговорчивость (ранжируется по шкале от 1 до 5);
• V 5 — длина руки (в см);
• V 6 — степень шатания при попытках пройти по прямой линии (ранжируется по шкале от 1 до 5).
Кажется вероятным, что V1 ,V3 и V5 будут варьировать совместно, поскольку крупные люди будут склонны иметь длинные руки и ноги и больше весить. Все эти три пункта измеряют некоторое
фундаментальное свойство индивидуумов вашей выборки: их размеры. Точно так же вероятно, что V2, V4 и V6 будут варьировать совместно, так как количество употребленного алкоголя,
вероятно, будет связано с четкостью речи, разговорчивостью и с осложнениями при попытках пройти по прямой линии. Таким образом, хотя мы собрали шесть фрагментарных данных,
эти переменные измеряют только 2 конструкта: размеры тела и степень опьянения. В факторном анализе вместо слова «конструкт» обычно используется слово «фактор», и далее мы будем следовать этой традиции.
Исследовательский факторный анализ, по существу, выполняет две функции:
-
Он показывает, сколько отдельных психологических конструктов (факторов) измеряется данным набором переменных. В приведенном выше примере такими двумя факторами являются размеры тела и степень опьянения.
-
Он показывает, какие именно конструкты измеряют использованные переменные. В приведенном выше примере было показано, что VI , V 3 и V 5 измеряют один фактор и V2, V4 и V6 измеряют другой, совершенно отличный фактор.
В некоторых формах факторного анализа дополнительно можно прокоррелировать факторы между собой, и затем вычислить для каждого испытуемого индивидуальную оценку по каждому фактору в целом («факторные оценки»).
Оценки по полным тестам (а не по его отдельным заданиям) также могут подвергаться факторному анализу — на самом деле именно так эта методика и используется. Факторный анализ в этом случае может показать, действительно ли тесты, которые, предположительно, измеряют один и тот же конструкт (например, шесть тестов, которые претендуют на измерение тревожности), продуцируют один фактор, или же в этом случае будут выделены несколько факторов (указывая на то, что тесты на самом деле измеряют несколько разных характеристик). Факторный анализ оценок, полученных на основе полных тестов, может быть чрезвычайно полезен для установления того, что именно измеряется группой тестов, поскольку многозначность языка допускает, что одному и тому же конструкту разными исследователями могут быть даны различные наименования. «Тревога» у одного автора может обозначать то же самое, что «нейротизм» — у другого или «негативный аффект» — у третьего. Число терминов, используемых в психологии индивидуальных различий, потенциально безгранично, и без факторного анализа нет надежного способа установить, действительно ли несколько шкал измеряют один и тот же базисный психологический феномен. Например, если в издательском каталоге указано, что имеются психологические средства измерения «нейротизма», «тревоги», «истерии», «силы Эго», «нервозности», «низкой самоактуализации» и «боязливости», кажется разумным задать вопрос: действительно ли это шесть отдельных понятий или это одна и та же характеристика, которой исследователи, имеющие разные теоретические воззрения, дали различные названия? Факторный анализ может точно ответить на этот вопрос, и поэтому он чрезвычайно полезен для упрощения структуры личности и способностей.
Возможности факторного анализа не ограничиваются анализом заданий или оценок теста. Можно факторизовать, например, показатели времени реакции, взятые из когнитивных тестов различного типа, чтобы определить, какие из них (если такие есть) связаны между собой. Возможен и иной подход. Предположим, что группу школьников, которые не имели специальной спортивной подготовки или спортивной практики, оценивали с точки зрения их успешности в соревнованиях по 30 видам спорта с помощью комплекса оценок, включавшего рейтинги тренеров, регистрацию времени, среднюю длину броска, процент отсутствия очков при игре в крикет, забитые голы и любые другие измерения показателей успешности, наиболее подходящие для каждого вида спорта. Единственное условие состоит в том, что каждый ребенок должен участвовать в каждом виде соревнования. Факторный анализ обнаружит много интересных фактов; например, он покажет, будут ли индивидуумы, успешные в одной игре с мячом, демонстрировать тенденцию к успешности во всех остальных играх, будут ли соревнования по бегу на длинные и короткие дистанции образовывать две различные группы (и какой вид соревнования будет входить в какую группу) и т.д. Таким образом, вместо того чтобы обсуждать происходящее в терминах успешности в 30 различных областях, будет возможно суммировать эту информацию, обсуждая ее в категориях шести основных спортивных способностей (или стольких способностей, сколько выявит факторный анализ).
- What is Factor Analysis?
- Quick Data Check
- Running Factor Analysis in SPSS
- SPSS Factor Analysis Output
- Adding Factor Scores to Our Data
What is Factor Analysis?
Factor analysis examines which underlying factors are measured
by a (large) number of observed variables.
Such “underlying factors” are often variables that are difficult to measure such as IQ, depression or extraversion. For measuring these, we often try to write multiple questions that -at least partially- reflect such factors. The basic idea is illustrated below.
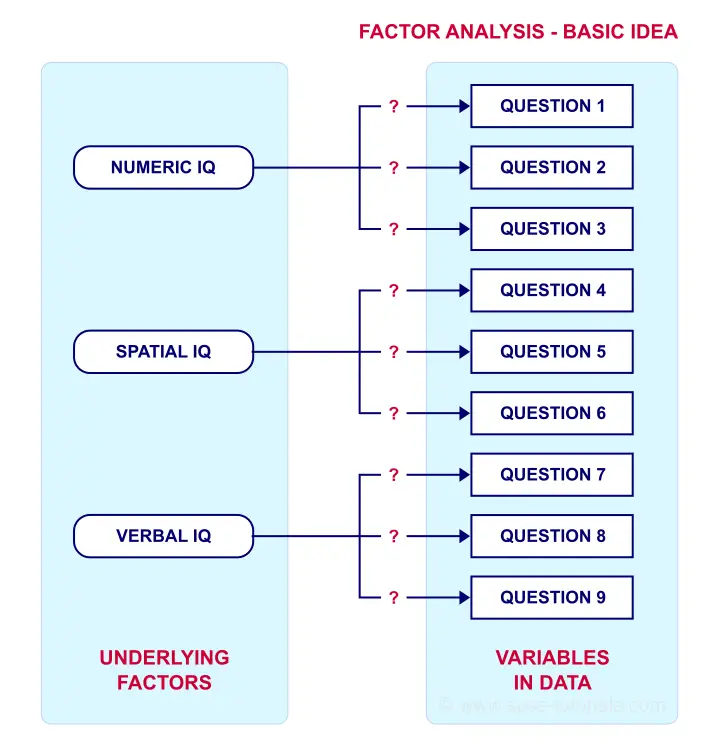
Now, if questions 1, 2 and 3 all measure numeric IQ, then the Pearson correlations among these items should be substantial: respondents with high numeric IQ will typically score high on all 3 questions and reversely.
The same reasoning goes for questions 4, 5 and 6: if they really measure “the same thing” they’ll probably correlate highly.
However, questions 1 and 4 -measuring possibly unrelated traits- will not necessarily correlate. So if my factor model is correct, I could expect the correlations to follow a pattern as shown below.
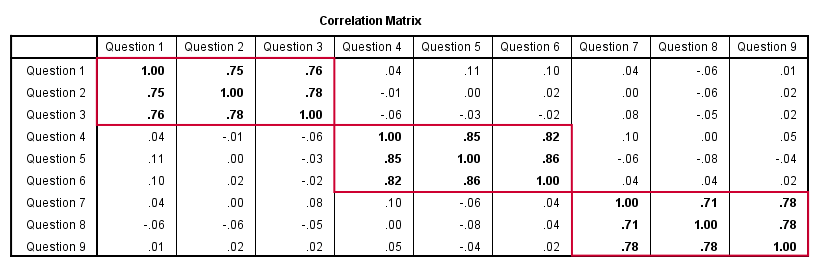
Confirmatory Factor Analysis
Right, so after measuring questions 1 through 9 on a simple random sample of respondents, I computed this correlation matrix. Now I could ask my software if these correlations are likely, given my theoretical factor model. In this case, I’m trying to confirm a model by fitting it to my data. This is known as “confirmatory factor analysis”.
SPSS does not include confirmatory factor analysis but those who are interested could take a look at AMOS.
Exploratory Factor Analysis
But what if I don’t have a clue which -or even how many- factors are represented by my data? Well, in this case, I’ll ask my software to suggest some model given my correlation matrix. That is, I’ll explore the data (hence, “exploratory factor analysis”). The simplest possible explanation of how it works is that
the software tries to find groups of variables
that are highly intercorrelated.
Each such group probably represents an underlying common factor. There’s different mathematical approaches to accomplishing this but the most common one is principal components analysis or PCA. We’ll walk you through with an example.
Research Questions and Data
A survey was held among 388 applicants for unemployment benefits. The data thus collected are in dole-survey.sav, part of which is shown below.
The survey included 16 questions on client satisfaction. We think these measure a smaller number of underlying satisfaction factors but we’ve no clue about a model. So our research questions for this analysis are:
- how many factors are measured by our 16 questions?
- which questions measure similar factors?
- which satisfaction aspects are represented by which factors?
Quick Data Check
Now let’s first make sure we have an idea of what our data basically look like. We’ll inspect the frequency distributions with corresponding bar charts for our 16 variables by running the syntax below.
*Show variable names, values and labels in output tables.
set
tnumbers both /* show values and value labels in output tables */
tvars both /* show variable names but not labels in output tables */
ovars names. /* show variable names but not labels in output outline */
*Basic frequency tables with bar charts.
frequencies v1 to v20
/barchart.
Result
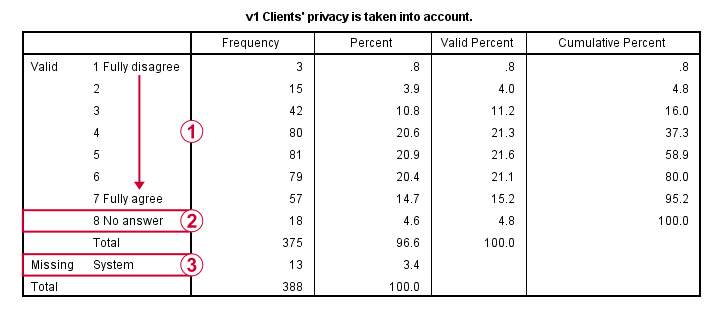
This very minimal data check gives us quite some important insights into our data:
A somewhat annoying flaw here is that we don’t see variable names for our bar charts in the output outline.
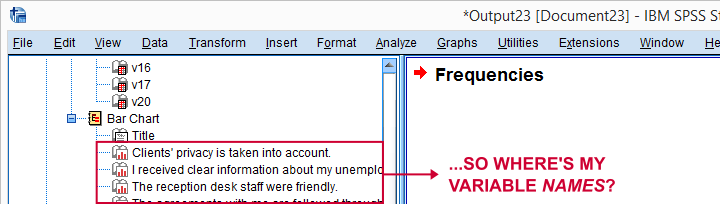
If we see something unusual in a chart, we don’t easily see which variable to address. But in this example -fortunately- our charts all look fine.
So let’s now set our missing values and run some quick descriptive statistics with the syntax below.
*Set 8 (‘No answer’) as user missing value for all variables.
missing values v1 to v20 (8).
*Inspect valid N for each variable.
descriptives v1 to v20.
Result

Note that none of our variables have many -more than some 10%- missing values. However,
only 149 of our 388 respondents have zero missing values
on the entire set of variables. This is very important to be aware of as we’ll see in a minute.
Running Factor Analysis in SPSS
Let’s now navigate to
![]()
![]()
as shown below.
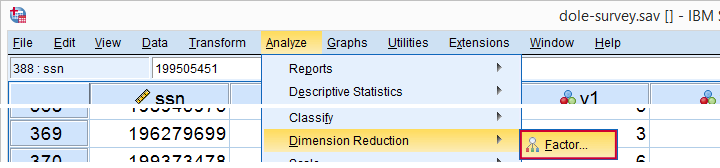
In the dialog that opens, we have a ton of options. For a “standard analysis”, we’ll select the ones shown below. If you don’t want to go through all dialogs, you can also replicate our analysis from the syntax below.
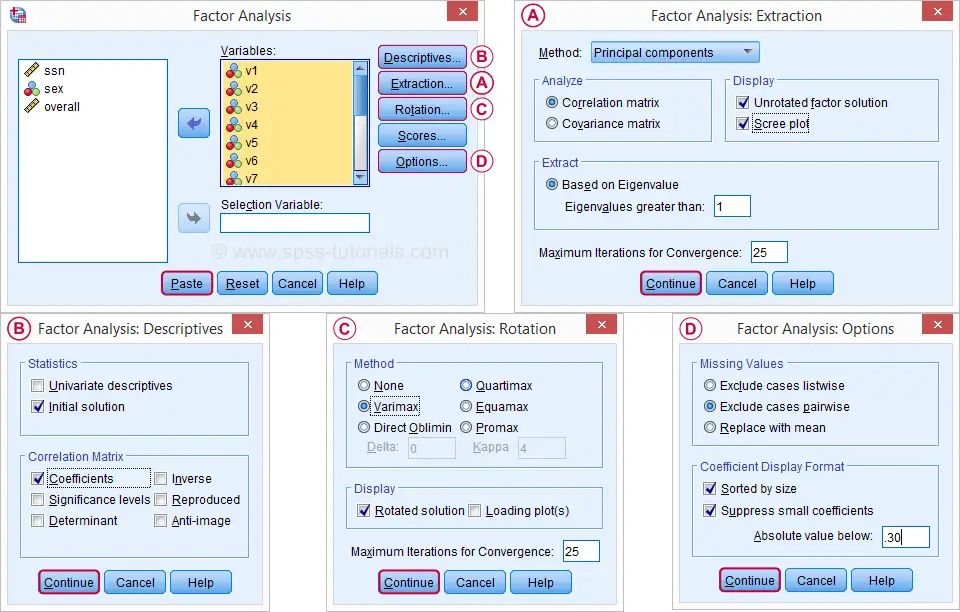
 Avoid “Exclude cases listwise” here as it’ll only include our 149 “complete” respondents in our factor analysis. Clicking Paste results in the syntax below.
Avoid “Exclude cases listwise” here as it’ll only include our 149 “complete” respondents in our factor analysis. Clicking Paste results in the syntax below.
SPSS Factor Analysis Syntax
*Show both variable names and labels in output.
set tvars both.
*Initial factor analysis as pasted from menu.
FACTOR
/VARIABLES v1 v2 v3 v4 v5 v6 v7 v8 v9 v11 v12 v13 v14 v16 v17 v20
/MISSING PAIRWISE /*IMPORTANT!*/
/PRINT INITIAL CORRELATION EXTRACTION ROTATION
/FORMAT SORT BLANK(.30)
/PLOT EIGEN
/CRITERIA MINEIGEN(1) ITERATE(25)
/EXTRACTION PC
/CRITERIA ITERATE(25)
/ROTATION VARIMAX
/METHOD=CORRELATION.
Factor Analysis Output I — Total Variance Explained
Right. Now, with 16 input variables, PCA initially extracts 16 factors (or “components”). Each component has a quality score called an Eigenvalue. Only components with high Eigenvalues are likely to represent real underlying factors.
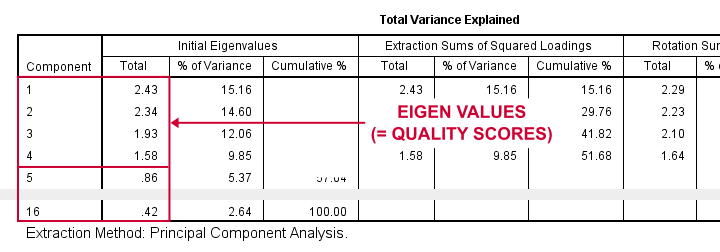
So what’s a high Eigenvalue? A common rule of thumb is to
select components whose Eigenvalues are at least 1.
Applying this simple rule to the previous table answers our first research question:
our 16 variables seem to measure 4 underlying factors.
This is because only our first 4 components have Eigenvalues of at least 1. The other components -having low quality scores- are not assumed to represent real traits underlying our 16 questions. Such components are considered “scree” as shown by the line chart below.
Factor Analysis Output II — Scree Plot
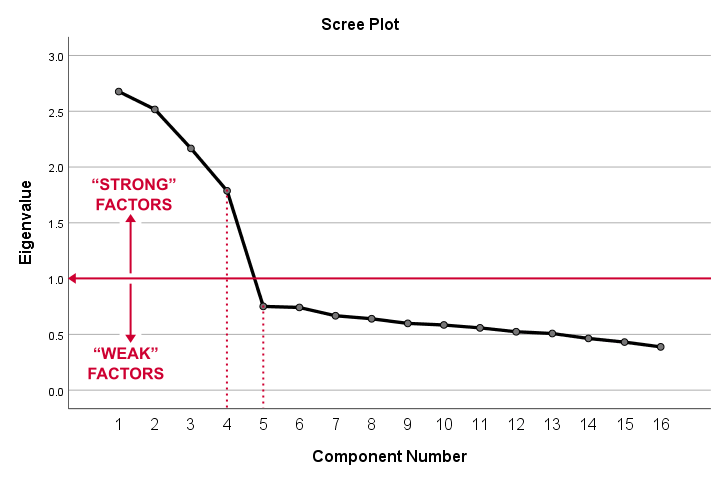
A scree plot visualizes the Eigenvalues (quality scores) we just saw. Again, we see that the first 4 components have Eigenvalues over 1. We consider these “strong factors”. After that -component 5 and onwards- the Eigenvalues drop off dramatically. The sharp drop between components 1-4 and components 5-16 strongly suggests that 4 factors underlie our questions.
Factor Analysis Output III — Communalities
So to what extent do our 4 underlying factors account for the variance of our 16 input variables? This is answered by the r square values which -for some really dumb reason- are called communalities in factor analysis.
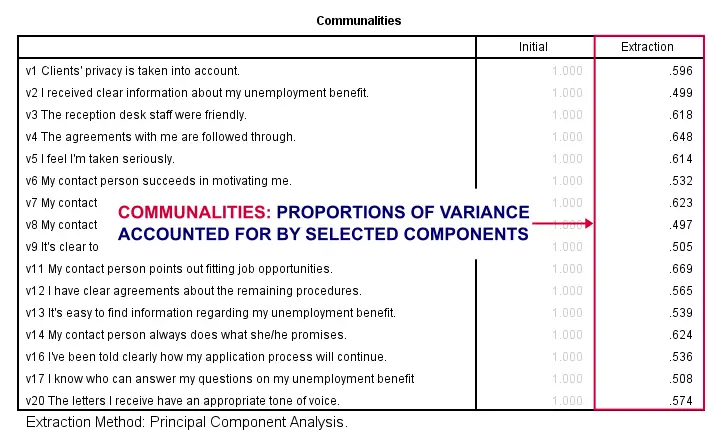
Right. So if we predict v1 from our 4 components by multiple regression, we’ll find r square = 0.596 -which is v1’ s communality. Variables having low communalities -say lower than 0.40- don’t contribute much to measuring the underlying factors.
You could consider removing such variables from the analysis. But keep in mind that doing so changes all results. So you’ll need to rerun the entire analysis with one variable omitted. And then perhaps rerun it again with another variable left out.
If the scree plot justifies it, you could also consider selecting an additional component. But don’t do this if it renders the (rotated) factor loading matrix less interpretable.
Factor Analysis Output IV — Component Matrix
Thus far, we concluded that our 16 variables probably measure 4 underlying factors. But
which items measure which factors?
The component matrix shows the Pearson correlations between the items and the components. For some dumb reason, these correlations are called factor loadings.
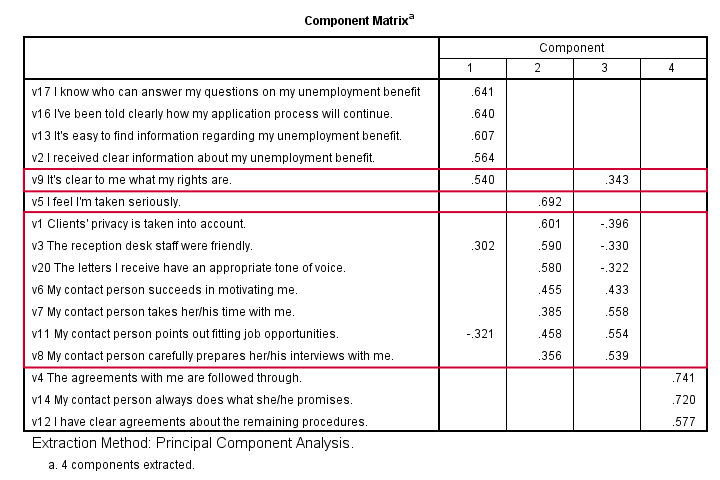
Ideally, we want each input variable to measure precisely one factor. Unfortunately, that’s not the case here. For instance, v9 measures (correlates with) components 1 and 3. Worse even, v3 and v11 even measure components 1, 2 and 3 simultaneously. If a variable has more than 1 substantial factor loading, we call those cross loadings. And we don’t like those. They complicate the interpretation of our factors.
The solution for this is rotation: we’ll redistribute the factor loadings over the factors according to some mathematical rules that we’ll leave to SPSS. This redefines what our factors represent. But that’s ok. We hadn’t looked into that yet anyway.
Now, there’s different rotation methods but the most common one is the varimax rotation, short for “variable maximization. It tries to redistribute the factor loadings such that each variable measures precisely one factor -which is the ideal scenario for understanding our factors. And as we’re about to see, our varimax rotation works perfectly for our data.
Factor Analysis Output V — Rotated Component Matrix
Our rotated component matrix (below) answers our second research question: “which variables measure which factors?”

Our last research question is: “what do our factors represent?” Technically, a factor (or component) represents whatever its variables have in common. Our rotated component matrix (above) shows that our first component is measured by
- v17 — I know who can answer my questions on my unemployment benefit.
- v16 — I’ve been told clearly how my application process will continue.
- v13 — It’s easy to find information regarding my unemployment benefit.
- v2 — I received clear information about my unemployment benefit.
- v9 — It’s clear to me what my rights are.
Note that these variables all relate to the respondent receiving clear information. Therefore, we interpret component 1 as “clarity of information”. This is the underlying trait measured by v17, v16, v13, v2 and v9.
After interpreting all components in a similar fashion, we arrived at the following descriptions:
- Component 1 — “Clarity of information”
- Component 2 — “Decency and appropriateness”
- Component 3 — “Helpfulness contact person”
- Component 4 — “Reliability of agreements”
We’ll set these as variable labels after actually adding the factor scores to our data.
Adding Factor Scores to Our Data
It’s pretty common to add the actual factor scores to your data. They are often used as predictors in regression analysis or drivers in cluster analysis. SPSS FACTOR can add factor scores to your data but this is often a bad idea for 2 reasons:
- factor scores will only be added for cases without missing values on any of the input variables. We saw that this holds for only 149 of our 388 cases;
- factor scores are z-scores: their mean is 0 and their standard deviation is 1. This complicates their interpretation.
In many cases, a better idea is to compute factor scores as means over variables measuring similar factors. Such means tend to correlate almost perfectly with “real” factor scores but they don’t suffer from the aforementioned problems. Note that you should only compute means over variables that have identical measurement scales.
It’s also a good idea to inspect Cronbach’s alpha for each set of variables over which you’ll compute a mean or a sum score. For our example, that would be 4 Cronbach’s alphas for 4 factor scores but we’ll skip that for now.
Computing and Labeling Factor Scores Syntax
*Create factors as means over variables per factor.
compute fac_1 = mean(v16,v13,v17,v2,v9).
compute fac_2 = mean(v3,v1,v5,v20).
compute fac_3 = mean(v11,v7,v6,v8).
compute fac_4 = mean(v4,v14,v12).
*Label factors.
variable labels
fac_1 ‘Clarity of information’
fac_2 ‘Decency and appropriateness’
fac_3 ‘Helpfulness contact person’
fac_4 ‘Reliability of agreements’.
*Quick check.
descriptives fac_1 to fac_4.
Result
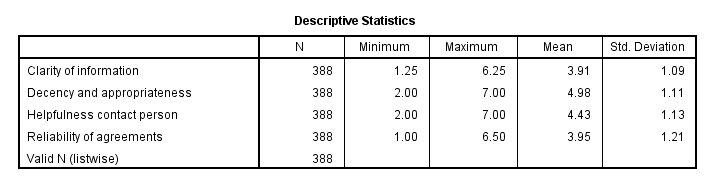
This descriptives table shows how we interpreted our factors. Because we computed them as means, they have the same 1 — 7 scales as our input variables. This allows us to conclude that
- “Decency and appropriateness” is rated best (roughly 5.0 out of 7 points) and
- “Clarity of information” is rated worst (roughly 3.9 out of 7 points).
Thanks for reading!