Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5
. Изучить «Руководство по установке и администрированию DocsVision»; . Электронный документооборот, контроль исполнения . Компания iDoc оказывает услуги по . . Изучить «Руководство по работе с системой расширенных отчетов DocsVision 4.5»;; Изучить «Руководство разработчика на платформе DocsVision . 31 янв 2008 . DocsVision — универсальная система автоматизации . Краткое руководство по разработке бизнес-процессов в среде DocsVision . DOCFLOW: электронный документооборот, СЭД (системы электронного документооборота), ECM (Enterprise . Комплексная автоматизация бизнес-процессов. Оцените наши преимущества![/spoiler]


скачать
Привет всем читающим! Меня зовут Владимир, я — технический писатель в компании Docsvision и я здесь, чтобы опубликовать вторую часть статьи и надрать задницу всем, кто ставил дизлайки к первой части. Статью вы можете найти ниже.
В первой статье я рассказал, как мы выбирали SSG для создания новой документации и как нам пришлось конвертировать DITA сначала в HTML, а потом в AsciiDoc.

В этой статье я расскажу, как я начал работать с SSG Antora, как я настраивал UI и добавлял сквозной поиск по сайту.
С чего начать работу с Antora?
С раздела на сайте документации Antora, который так и называется «с чего начать».
В статье я не буду подробно описывать то, как организовать файлы по папкам, в чём отличие playbook от component version descriptor и т.д. — это всё прекрасно описано в документации Antora. Опишу базовые шаги, необходимые для понимания работы:
-
Сперва нужно установить Antora.
Проверить NODE LTS:
node --versionУстановить Антору:
npm i -g @antora/cli @antora/site-generator-default -
Затем прочитать документацию. Лучше прочитать всю целиком, а не только Quick start guide, чтобы лучше понять Antora в целом.
-
Адрес сайта будет выглядеть следующим образом:
url сайта — например, https://dv-docs.com;
name of component — модуль, например, webclient;
name of version — версия, например, 16 или 17 — указывается в antora.yml;
name of module — тип руководства, например, user, admin, layouts;
name of page — например, intro.
Структурирование файлов
Я прочитал документацию и примерно представил то, как будут организованы наши исходные файлы.
Разные модули ДВ = разные компоненты анторы.
Разные руководства модулей ДВ = разные модули анторы.
Разные компоненты анторы версионируются и отображаются в отдельном меню.
Разные модули анторы отображаются разве что только в адресе сайта, в навигационном меню они никак не выделяются.

Для нас это значит, что руководство пользователя, админа и конструктор разметок будут склеены в единое содержание.
Отсюда у нас два варианта: создавать каждое руководство в качестве отдельного компонента с одним-единственным модулем или смириться с общим содержанием и делать руководства по модулям.
Я остановил выбор на втором варианте.
Сначала мы переводим на новую документацию web-клиент. Следующая релизная версия web-клиента будет под номером 17, пока она в разработке, то есть в ветке develop.
Так и поступим. Исходники я организовал следующим образом:
Я решил сделать для документации каждого модуля ДВ свой репозиторий, а версии хранить в разных ветках.
Ветка Develop — ветка документации для ВК17.
antora.yml — файл, расположенный в корне каждой ветки. Для каждой новой ветки нужно будет создать свой уникальный antora.yml файл, указывающий на версию и её свойства.
> !!! В пути до файла antora.yml не должно быть посторонних символов, кроме латинских букв, цифр, короткого тире (-). Пробелы не разрешаются, решётки (#) тоже. Иначе ничего не будет собираться.
Таким образом обеспечиваются component versions, т.е. разбивка на версии.
В корне репозитория нужно создать папку modules (регистр важен).
В папке modules можно создать сколько угодно подпапок. Каждая папка — отдельный модуль antora. В нашем случае каждый модуль Antora — отдельное руководство пользователя, админа, конструктора разметок.
Для каждого модуля нужно создать свой файл навигации. Файл навигации представляет собой обычный многоуровневый список. Создавать содержание с нуля для больших руководств не очень хочется. К счастью, после конвертации получается файл index.adoc, он отлично подходит в качестве файла навигации. Но есть «но»:
-
Имена папок в структуре Antora отличаются от сконвертированных. В пути до файла нужно убрать
topics/, но оставить всё, что после. -
Ссылки
link:нужно заменить наxref:. -
Расширение
htmlзаменить на.adoc.
Переделки под Антору
По ходу конвертации и подстраивания документации под Антору выяснилось, что нужно переделать ещё многое.
По тексту добавить перекрёстные ссылки на другие модули и компоненты в формате:

Одинаковые страницы в модулях можно добавить в навигацию аналогичным образом: xref:version@component:module:filename.adoc[]. Но лучше делать include всей страницы полностью: include::version@component:module:filename.adoc. Иначе будут ситуации, например, когда пользователь смотрит документацию модуля web-клиент, а потом переходит по ссылке в навигации и внезапно попадает на документацию модуля Платформа. Пользователю потребуется время, чтобы осознать, где он и как вернуться назад.
Ещё одна важная мелочь — заголовки страниц. После конвертации все заголовки страниц второго уровня и дальше. Потребуется вычесть один уровень из каждого заголовка вручную. Есть, конечно, обходной путь — использовать :leveloffset:. :leveloffset: можно даже задать для компонентов, то есть в antora.yml файлах, но лучше всё же делать по-красоте сразу и без костылей.
Есть ещё блоки с исходным кодом. Они выделяются знаками равно после конвертации: ====, такое надо заменить на ----.
Исходный код должен выглядеть так:
[source,yaml]
----
code here
----
Нужно будет ещё исправить путь до изображений — убрать img/ из img/image.png, иначе изображения не будут работать.
Если делать по-красоте, то хорошо бы переделать имена файлов с нижнего подчёркивания на дефис: a_file_name.adoc заменить на a-file-name.adoc.
Добавить kbd:[Ctrl+Shift+N] для клавиш и сочетаний клавиш.
Работы ещё много, но в итоге всё окупится.
Разбивка на версии (antora.yml)
Честно говоря, я боялся, что мне придётся изучать ещё и YAML во всех подробностях, но оказывается, что нет.
Оказывается, файлы antora.yml и playbook.yml сочиняются на YAML, очень просто. Процесс составления antora.yml описан в документации Antora.
Файл уникален для каждой ветки репозитория (main, WC17 и т.д.), лежит в корне репозитория, в каждой ветке.
Содержимое примерно такое:
name: webclient
version: '16'
title: Web Client 16
asciidoc:
attributes:
toclevels: 10
sectids: ''
sectlinks: ''
sectanchors: ''
toc-title: Содержание
figure-caption: Рисунок
appendix-caption: Приложение
wc: WebClient
dv: Docsvision
nav:
- modules/user/nav.adoc
- modules/admin/nav.adoc
start_page: user:Capabilities.adoc
Порядок ключей не имеет значения.

Playbook
Процесс составления описывается в документации Antora. Я ожидал больших сложностей. Но всё оставались вопросы, которые мне были не совсем очевидны. Но сейчас я уверенно могу на них ответить:
-
Куда сохранять книгу?
-
Рекомендуется держать под книгу отдельный репозиторий.
-
-
Как быть с доменом? Его нужно купить, но как посмотреть перед публикацией? Как быть с DNS-записями?
-
Можно запустить сайт на локальном сервере в тестовых целях. Можно просто посмотреть страницы сайта в офлайне. С доменом уже потом разбираться будут специально обученные люди.
-
-
Можно ли подключить аналитику?
-
Да, через ключ yaml в playbook, типа так:
keys: google_analytics: XX-123456
-
-
Как защищённое соединение обеспечивается?
Sв https://-
Специально обученные люди разберутся.
-
-
Где во всём этом процессе стоит сервер?
-
Специально обученные люди разберутся. Нужно уметь разделять обязанности и не взваливать лишнее на себя.
-
-
Ссылка «Edit this page». Как её кастомизировать?
-
В UI, там будет понятно.
-
-
Стили, иконки и прочая мишура
-
Всё делается в UI bundle. Он легко кастомизируется, после чего его надо упаковать и добавить в playbook вот так:
-
ui:
bundle:
url: /home/user/projects/docs-ui/build/ui-bundle.zip
Готовый файл playbook выглядит примерно вот так:
site:
title: Docsvision Docs
url: https://docsvision.github.io/docs-playbook/
start_page: webclient:user:welcome.adoc
robots: allow
content:
sources:
- url: https://github.com/Docsvision/docstest.git
branches: [main, WC*]
ui:
bundle:
url: https://gitlab.com/antora/antora-ui-default/-/jobs/artifacts/master/raw/build/ui-bundle.zip?job=bundle-stable
snapshot: true
asciidoc:
attributes:
toclevels: 10
sectids: ''
sectlinks: ''
sectanchors: ''
toc-title: Содержание
icons: font
figure-caption: Рисунок
appendix-caption: Приложение
wc: WebClient
dv: Docsvision
urls:
html_extension_style: indexify
output:
dir: ./site
runtime:
fetch: true
Порядок ключей не имеет значения. Подробное описание ключей читайте в документации Antora.
Сборка сайта

Перед созданием сайта нужно убедиться, что выполнены следующие требования:
-
Созданы исходники в формате .adoc, включая навигацию (можно и без навигации, но зачем?).
-
Создан файл с описанием версий компонента.
-
Создан playbook.
Убедившись, что все требования выполнены, достаточно просто натравить Антору на файл playbook вот так: antora the-playbook.yml.
После выполнения команды Антора получит информацию из указанных источников:
content:
sources:
- url: https://github.com/Docsvision/docstest.git //где хранятся исходники
branches: [main, WC*] //какие ветки обрабатывать
И опубликует их по адресу, указанному вот тут:
site:
url: https://docsvision.github.io/docs-playbook/
Если есть какие-то ошибки в исходниках, Антора выведет их прямо в консоли. Также нужно помнить, что по умолчанию Антора кэширует UI. Чтобы такого не было, нужно ставить snapshot: true:
ui:
bundle:
url: https://gitlab.com/antora/antora-ui-default/-/jobs/artifacts/master/raw/build/ui-bundle.zip?job=bundle-stable
snapshot: true
А ещё Антора кэширует исходники. Чтобы потом не было так: «Но как же! Я же исправлял эту ошибку! В чём дело? Что ещё нужно исправить?». Делайте вот так:
runtime:
fetch: true
Сайт готов. Остаётся только сделать commit/push.
А также при желании:
-
изменить текст страницы 404
-
изменить текст ссылки «Edit this page»
Об этом чуть ниже, через три небольших пункта.
GitHub Pages
GitHub Pages работают с Jekyll, который удаляет все файлы и папки, начинающиеся с _. Антора в этой папке хранит весь UI. То есть по умолчанию весь UI будет удалён этим самым Jekyll. Решение простое, нужно только добавить в корень репозитория сайта файл .nojekyll.
Я поместил всю документацию в корень репозитория тоже на всякий случай. Иначе у меня сайт не хотел заводиться. Но так даже лучше, потому что адрес вышел короче.
.html to .adoc
При изначальной конвертации из dita в html в adoc остались html артефакты. Например, любая перекрёстная ссылка превращалась в link:ololo.html[trololo]. IntelliJ нормально съедала такие ссылки и не ругалась, нормально делала превью и т.д. Но после создания сайта через Antora все ссылки ломались.
Требовалась замена всех таких ссылок на правильные: xref:ololo.adoc[trololo]. Проблема легко решается заменой всех .html на .adoc, например через ту же IntelliJ.
Из HTML в AsciiDoc подчёркивание конвертируется как +++по дате создания+++. Если очень нужно подчёркивание, то должно быть [.underline]#по дате создания#. Если подчёркивание не нужно, то такие артефакты можно удалить или использовать какой-то другой формат.
Пустая строка перед началом документа
Ещё один нюанс — это пустая строка перед началом документа .adoc. На месте этой строки был какой-то ID, который присваивался всем страницам. То есть однинаковый ID [[ariaid-title1]] для каждой страницы. Asciidoc ругался ещё из IntelliJ плагина, поэтому я удалил этот ID. Образовалась пустая строка в начале каждой страницы. Их можно смело удалять, если вы конвертировали из .html в UTF без BOM.
Настроить UI
Сайт собран, остаётся только настроить UI. Все артефакты, что остались на английском, дополнительные ссылки в разворачивающихся меню, изменить стиль страниц и т.д. Стиль CSS обработан при помощи PostCSS. Чистый CSS, без предпроцессоров, а только с пост-обработкой.
Настройка UI описана в документации Antora. UI настривается очень просто, инструкция очень понятная. Я сам переделал UI на русский за пару часов.
Клонируем репозиторий, лезем в папку srcpartials, а там уже лежат файлы .hbs. Открываем, видим код вперемешку с английским и человекочитаемыми фразами, переводим. Скрипты и стили можно найти выше уровнем, в папках srcjs и srccss соответственно.
Завершили редактирование, собрали UI командой gulp bundle.
Если нужно навертеть ещё что-нибудь, что не предусмотрено стандартным UI, можно нацепить усы и почитать документацию для handlebars
Другое дело — поиск. Его так просто не настроить, к тому же вариантов реализаций уж очень много, и все они выглядят прилично, на мой нубский взгляд.
Настройка поиска Algolia
Самый очевидный вариант — Algolia Docsearch. Это бесплатный поиск, который можно поднять, написав запрос в Algolia вот тут , или развернуть поиск вручную по инструкции.
Чтобы подать заявку на подключение к crawlerscraper от Algolia, чтобы они сами сделали все настройки поиска, нужно отвечать требованиям:
-
иметь админский доступ к сайту,
-
сайт должен быть доступен широкой публике,
-
сайт должен содержать документацию,
-
контент должен быть финальным, то есть не пустым, не плейсхолдером и не быть в стадии разработки.
Если требования не удовлетворяются, то можно попробовать настроить поиск самостоятельно по инструкции. Но сложность в том, что официальная инструкция Algolia написана без учёта развёртывания сайта через Antora, поэтому немного не такая, как надо.
Правильную инструкцию я нашёл случайно на GitLab Antora. Следуя этой инструкции, можно настроить индексирование контента. Однако, если нужен не пробник, а работающий поиск и на своём сайте, необходимо заменить репозиторий на свой, а также отдельно скопировать файл config.json отсюда и изменить его в соответствии со своим сайтом. Главное, грамотно изменять, чтобы json остался целым, иначе ничего не получится. Также потребуется аккаунт Algolia, который просто так даётся только на пробный период. Ну, либо я что-то не догнал.
Я попробовал настроить индексирование контента самостоятельно и вот, что я выяснил:
-
Если настраивать из-под Linux, то проблем не будет совсем.
-
Если настраивать из-под Windows, придётся немного потанцевать с бубном (ну, либо я ничего не умею).
На сайте поиск сам по себе не появится, поэтому его нужно как-то добавить на страницы. Здесь инструкций нет вообще. Единственное, что отдалённо можно назвать инструкцией — вот эта страница в документации Algolia. Один кусок кода нужно встроить перед закрывающим , а вторую часть перед закрывающим . Но есть тонкости:
-
Stylesheet для поиска доступен по ссылке
https://cdn.jsdelivr.net/npm/docsearch.js@{{docSearchJSVersion}}/dist/cdn/docsearch.min.css. Естественно,{{docSearchJSVersion}}нужно заменить на точную версию.Но, во-первых: где узнать эту точную версию? И, во-вторых: что будет, когда версия обновится?
Я нашёл последнюю версию простым подбором, это оказалась версия 2.6. Хотелось бы иметь ссылку на последнюю версию, но я не знаю, как и где её получить. Возможно, я просто что-то упускаю из виду.
-
Во второй части кода нужно не забыть раскомментировать часть
//appId: '', потому что поиск мы запускаем самостоятельно. После этого заполнить всё данными из личного кабинета Algolia, а также добавить CSS Selector. С этим селектором они такие классные — ни слова о том, что это и где искать. Кое-как нашёл информацию на форуме, что на самом деле, блин, всё просто. Но даже там сказано «любой frontend-разработчик знает, что это такое». Ага, но я-то не frontend-разработчик. Не каждый, кто настраивает поиск — разработчик. Впрочем, всё оказалось ещё проще, чем сказано на форуме — CSS селектор — это просто ID или HTML-элемент в позиции по отношению к другим (например,body > header > nav > div.navbar-brand > a). С ID я хорошо знаком, но вот термин «селектор» для меня был новый. Блин. -
Затем самое интересное — вставить поисковую строку в UI сайта. Берём репозиторий Antora UI, находим .hbs-файлы и добавляем в них куски вот с этой страницы. Для удобства я создал два отдельных .hbs-файла, с двумя частями кода. Один файл назвал
search-head.hbs, другойsearch-body.hbs.search-head.hbsя добавил последним в файлhead.hbsиз папкиpartials, аsearch-body.hbsя добавил в файлdefault.hbsв папкеlayouts. Как? По аналогии с другими включениями:{{> search.hbs}} -
После всех операций, нужно построить UI. Он собрался без ошибок с первого раза, что очень порадовало меня. Затем я натравил Антору на playbook — она мне сделала сайт с поиском. Какой я молодец! Теперь можно заняться стилизацией поиска. Если вы настраиваете стили поиска самостоятельно, Algolia даже разрешает вам убрать логотип Algolia из поиска. Какая великая щедрость!
-
На этом месте поиск отвалился. Пробный период закончился и всё сломалось. Такой расклад меня совсем не радует.
Если вы задумываетесь о более глубокой настройке поиска, которая позволяла бы выбирать определённый компонент, версию компонента и т.д., то мы мыслим похоже. Я тоже задумывался об этом, но реализация оказалась не такой простой. Поиск с выбором области поиска используется на сайте docs.couchbase или docs.asciidoctor
И тот, и другой сайт созданы самим создателем AsciiDoc, исходники открыты, подробности можно узнать, например здесь: antora.zulipchat
А что если попробовать Elasticsearch?

В том же чате Antora кто-то говорил, что давно подключил полнотекстовый Elasticsearch к Анторе и пользуется им. Подключали решение Fess Site Search. По их собственным заявлениям Fess Site Search является заменой больше не поддерживаемому Google Site Search.
Я подумал, что, раз я такой успешный и справился с Algolia, то грех не попробовать и Elastic.
Устанавливаем Fess Site Search + Elastic Search
Делюсь алгоритмом действий, если кто-то захочет повторить:
-
Проверяем: установлена ли Java, если нет — ставим.
-
Ставим Elastic, скачав .deb по ссылке: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.2-amd64.deb,
-
Не запускаем, просто ставим.
-
Потом ставим плагины для него:
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install org.codelibs:elasticsearch-analysis-fess:7.13.0
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install org.codelibs:elasticsearch-analysis-extension:7.13.0
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install org.codelibs:elasticsearch-minhash:7.13.0
-
Опять же, ничего не запускаем, не перезагружаем,
-
Ставим elastic-configsync:
Скачиваем по ссылке, выполняем команды:
sudo mkdir -p /usr/share/elasticsearch/modules/configsync
sudo unzip -d /usr/share/elasticsearch/modules/configsync Downloads/elasticsearch-configsync-7.13.0.zip
-
Открываем
/etc/elasticsearch/elasticsearch.yml, добавляем строчку:
configsync.config_path: /var/lib/elasticsearch/config
-
Скачиваем Fess по ссылке,
-
Ставим его.
-
Добавляем Fess и Elastic как сервисы:
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable elasticsearch.service
sudo /bin/systemctl enable fess.service
-
Запускаем:
sudo systemctl start elasticsearch.service
sudo systemctl start fess.service
-
Fess доступен по адресу
http://localhost:8080/, админская панель по адресуhttp://localhost:8080/admin/, по умолчанию данные для входа (логин/пароль):admin/admin. -
Можно переходить к администрированию. Правда перед администрированием лучше назначить для Elastic Search какое-нибудь неприлично больше количество оперативки в зависимости от ваших потребностей.
Вы спросите «но какое же?», а я отвечу: «хрен знает, нигде не сказано». Искал в интернете, обыскался. на нашей виртуалке Ubunbtu процесс Elastic Search перестал отваливаться при 8 гигах оперативки. Когда потребности увеличатся (с увеличением количества пользователей и поисковых запросов), возможно, потребуется больше.
Но как же добавить этот поиск в UI? Для этой цели имеются крупицы информации тут и ещё тут.
Добавляем Fess Site Search в UI сайта
Сначала генерируем скрипт, кастомизируем его внешний вид (при необходимости), добавляем в .hbs с правильным адресом. Добавляем в .hbs туда, где хотим видеть поисковую строку. Например, в шапку сайта — header-content.hbs.
Создаём в playbook страницу поиска способом аналогичным созданию файла .nojekyll.
Придётся написать полный html-код страницы search.html в playbook. На странице указать правильные пути к скрипту и к сайту. Проверить, что в Playbook указан правильно ключ url: с корректным адресом сайта. Также на корректность нужно проверить путь до скрипта. Нужно учитывать, что страница поиска располагается в корне сайта и путь тоже должен быть относительно корня сайта.
Добавить на страницу поиска в удобное место тэг скрипта:
Очень важно указать в URL of FSS JS to src путь до автоматически сгенерированного скрипта на сайте. Например, http://127.0.0.1:5000/_/js/vendor/fess-ss.min.js. В URL of Fess search API to fess-url указать адрес Fess сервера. Именно сервера, а не сайта. Например, если сайт развёрнут на том же сервере, что и fess, это будет выглядеть вот так: http://localhost:8080/json. Указать адрес интерфейса Fess и не забыть в конце /json. Если это будет сервер доступный всем в интернете, настройки понадобится изменить соответственно. Ещё желательно будет настроить https. Вот пускай разработчики и занимаются этим, я мало что понимаю в этом.
И тогда у вас на сайте будет работать поиск Elastic Search, точнее fess Site Search. Ну, вы поняли.
Lunr — ещё один поиск

Можно добавить ещё третий поиск — Lunr. Добавить его проще всего, он уже интегрирован в Антору, но только в другую. Antora with Lunr уже имеет в себе поиск, её нужно только поставить и натравить на playbook.
Из плюсов:
-
Plug and play.
Из минусов:
-
PDF эта Антора делать не умеет, а нам очень нужна эта функция.
С тех пор как я выполнял настройку поиска, прошло несколько месяцев. В Анторе появились расширения, позволяющие подключать различные функции прямо из playbook. Теперь можно одновременно подключить и PDF (об этом ниже), и Lunr.
HTML lang
Ещё один нюанс настройки UI — язык html-страниц сайта. Сначала я думал, что его нельзя менять, но оказалось, что можно сделать это в файле srclayoutsdefault.hbs.
Pagination
Антора позволяет сделать ссылочки на следующую/предыдущую страницу. Но эта фича хитро спрятана! В playbook, component version или на странице надо добавить специальный атрибут page-pagination: '', тогда будет пагинация.
Для пагинации нужна как минимум одна свободная строка в конце документа!
Проблемки
Небольшой упс с breadcrumbs, когда страница становится узкой, а название длинное.

Финальные штрихи и доработки
Ручная доработка AsciiDoc
Есть ещё несколько доработок, которые необходимо выполнить после конвертации. Отличие этих доработок от всех предыдущих в том, что их необходимо выполнять вручную.
По сути — это обычная вычитка документа:
-
Потребуется найти ещё ошибки, например, с блоками-примерами исходного кода. Они конвертируются неправильно.
-
В прошлой части я говорил про вот такое:
[.ph .menucascade]#[.ph .uicontrol]#Документ# > [.ph .uicontrol]#Документ УД# > [.ph .uicontrol]#Акт##И про то, что в идеале это бы надо заменить на
menu:Документ[Документ УД > Акт]. Я решил делать по красоте и переделать все подобные случаи и даже найти новые. -
Переделать примечания, убрав
Прим.:иВажное замечание:.Прим.:можно просто убрать, аВажное замечание:заменить наIMPORTANTвместоNOTE.Если при импорте из DITA в топиках не уделялось внимание такой несущественной мелочи, как язык документа, то работа осложняется ещё тем, что вместо
Прим.:иВажное замечание:могут бытьNote:Important noticeи всякое такое.И вообще, AsciiDoc Предлагает широкую палитру примечаний. Грех — не использовать доступные возможности. Нужно вручную перелопатить все примечания, отредактировать и поменять их тип.

Также потребуется:
-
Избавиться от пустых страниц только со ссылками, заменив их заголовками.
-
Переименовать файлы топиков, чтобы все были через нижнее подчёркивание или все были через тире, или все были через camelCase.
-
Избавиться от
:leveloffset:и лучше его не использовать.
В силах технического писателя подумать над некоторыми из пунктов: подчёркивания, кастомные роли, переделать используемые примечания, добавлять ли новые, лишние страницы, пробелы, содержание, формулировки, [.ph]/[.cmd]. В идеале надо продумать style guide и придерживаться его при написании документации. «То-то будет расчудесно!»
Что ещё?
-
Подумать про мультиязычность.
-
Однажды будет реализована нативными средствами анторы — issue 208, issue 377. Если у нас необходимость возникнет раньше, можно держать как отдельный компонент, например. Или как отдельный сайт.
-
-
Обсудить UI с дизайнером.
-
Обсудить ссылки в шапке сайта с аналитиком.
-
Подумать репозиториями с документацией. Использовать закрытые или открытые? На GitHub или GitLab?
-
В очередной раз подумать о поиске.
Если вас по каким-то причинам не устраивает использовать расширение для создания pdf, можно использовать альтернативные методы:
-
Нативный конвертер AsciiDoctor. Для работы этого метода нужно будет установить дополнительные компоненты, а потом использовать только команду
asciidoctor-pdf basic-example.adoc. Можно генерировать как один исходный файл = один результирующий pdf или много исходных = одно большое руководство. Но сложность в том, что потребуется переделать файл содержания. Буквально из левого файла получить правый:
Левый – это обычный рабочий файл, который создаёт многоуровневое меню страницы. Правый файл собирает каждую строку в один большой документ. Количество звёздочек в правом файле соответствует цифре после
:leveloffset:. Перед следующим уровнем содержания, нужно ещё раз добавить:leveloffset: (закрывающий). Алгоритм логичный и вроде бы несложный, но этот процесс хорошо бы автоматизировать, чтобы каждый раз вручную не переделывать. Нужно, чтобы левый документ конвертировался в правый. По команде или ещё как-то. -
А ещё можно использовать конвертер в Web PDF прямо из IDE. Щадящий PDF конвертер. Но это экспериментальная функция, её нужно включить специально.
-
Ещё один вариант — это использовать Asciidoctor Web PDF. Потребует установки или распаковки, но может быть использован для создания PDF.
-
Четвёртый вариант — кастомная версия Анторы. Использует Asciidoctor PDF. На момент написания — это ещё экспериментальная функция, но она должна стать расширением Анторы версии 3.0, за изменениями в реальном времени можно следить тут.

Доработки UI
-
Поля шире
-
Вместо note, tip, warning должны быть просто иконки, возможно с фирменными цветами.
-
Определиться, что использовать: якоря или полностью ссылка-заголовок.
-
Жирный 700.
-
Курсив более курсивный.
-
Мне не совсем нравится курсив в моноширинном. Возможно, стоит использовать другой шрифт.
-
Fallback font
-
Добавить диаграммы и схемы.
-
Javadoc
-
Кнопка домой при наведении, её бы заCSSить, чтобы лучше работала.
-
div class=title(заголовки списков и изображений) выделить как-то получше? -
Создать красивую стартовую страницу сайта.
-
Переделать стили под корпоративные.
-
Автоматизировать сборку (уже сделано, через TeamCity. Если интересно, ткну нашего DevOps, попрошу поделиться опытом).
-
Окончательно определиться с поиском и доработать его.
-
Избавиться от [.ph], [.cmd], за которыми ничего не следует.
-
Насчёт других кастомных ролей. Гипотетически, их можно использовать, чтобы придать стиль элементам. Но 1) каждый раз их вводить не очень удобно 2) их слишком много. Например, есть keyword, а есть uicontrol и то и то жирное с font weight 700. Какая разница? Или parmname и term — и то и другое курсивом. Зачем тогда два варианта? Мы решили не использовать. Но, если решитесь повторить, вам нужно будет подумать и решить, использовать ли их и, если да, то в каком количестве. И решить, кто будет решать.
-
Убрать убогое
Parent topic:, а вместе с ним иНа уровень выше:. Есть же прекрасная пагинация! -
Найти способ получать ошибки из консоли при автоматической сборке (тоже сделано, тоже могу ткнуть коллегу, если интересно).
-
Добавить трекеры на сайт, чтобы знать, как читают документацию, что вызывает затруднения и прочую статистику.
Заключение

Картинка тюремного заключения в заключении, как ловко придумано, да?
Писать документацию в AsciiDoc гораздо проще и приятнее, чем в DITA. При том, что функциональность этих двух языков сопоставима, многие вещи реализованы в AsciiDoc гораздо более дружелюбно. Чтобы создать ключ в DITA, нужно немного постараться — в AsciiDoc достаточно обозвать его как-нибудь и использовать повсюду, только называется это атрибут.
Конечно, конвертация может быть запарной и сложно отказаться от устоявшейся схемы работы, но результат того стоит. Да, потребуется дорабатывать. Да, потребуется вычитывать. Зато попутно можно отредактировать, перечитать и скорректировать документацию.
Создать статический сайт документации при помощи Анторы оказалось проще, чем я думал. А после создания своего первого сайта и локализации интерфейса вообще можно штамповать новые хоть каждый день.
В общем, я благодарен Docsvision за возможность работать в смелой компании и коллегам за то, что они всегда поддержат. Кстати, мы нанимаем в СПб и Орле. Смотрите также вакансии нашей группы компаний.
Эта статья будет полезной для тех, кто выбирает для своей компании систему электронного документооборота или раздумывает о замене системы, которая сейчас уже используется в организации.
Система управления документами — это программное решение, используемое для отслеживания, управления и архивирования документов, что позволяет значительно сократить объем бумажного документооборота.
После внедрения систем управления компании и органы государственного управления смогли убедиться в том, что сохранение документов в бумажной форме не позволило устранить серьезную неэффективность, связанную с документооборотом и обменом корпоративной информацией.
Содержание
- Краткий обзор
- Функционал
- Базовые задачи
- Создание электронного архива
- Поиск документов
- Делопроизводство
- Договорной документооборот
- Оперативное управление
- Специализированный процесс компании
- Работа с документами
- Работа с заданиями
- Преимущества
- Хороший поиск
- Гибкие настройки профиля пользователя
- Нет ограничений по нагрузке
- Быстрый доступ к данным, поиск и работа с документацией
- Удобная установка и обслуживание
- Легкая интеграция
- Оперативное внедрение
- Простой и мобильный интерфейс
- Не требует обучения
- Позволяет работать с почты
- Разграничение прав доступа
- Недостатки
- Сложная настройка
- Зависимость от специалистов
- Показывает нестабильность в работе с многочисленными структурами
- Выводы
Краткий обзор
DocVision — это облачная платформа анализа документов без кода, которая использует машинное обучение и искусственный интеллект (ИИ) для извлечения данных из документов всех типов.
Платформа позволяет предприятиям организовывать собственные рабочие процессы или обучать модели ИИ для облегчения извлечения данных. DocVision использует новейшие технологии, такие как машинное обучение, искусственный интеллект и обработка естественного языка (NLP), для создания, настройки и реализации пользовательских рабочих процессов извлечения с целью автоматизации сбора информации из различных типов документов.
Благодаря функции перетаскивания пользователи могут указать источник документа, тип документа, желаемое действие, параметры извлечения, место назначения вывода и тип проверки, прежде чем автоматизировать процесс извлечения данных. Источники и адресаты данных могут включать API, электронные письма и сторонние хранилища документов или платформы для совместной работы, такие как SharePoint.
Другие функции платформы DocVision включают инструменты улучшения изображений, обеспечивающие точное извлечение данных, отслеживание проверку извлечения, управление проектами, специальные отчеты и аналитику, а также создание настраиваемых информационных панелей.
Функционал
Компания DocVision — это разработчик системы управления электронными документами, задачами и бизнес-процессами. DocVision — это платформа, на базе которой строятся решения. Сервис содержит ряд инструментов, которые позволяют настраивать систему, дорабатывать своими силами без привлечения программиста и подключать различные модули, которые расширяют ее функциональность.
Верхний уровень занимает готовое бизнес-решение, которое автоматизирует конкретную задачу в вашей компании.
Базовые задачи
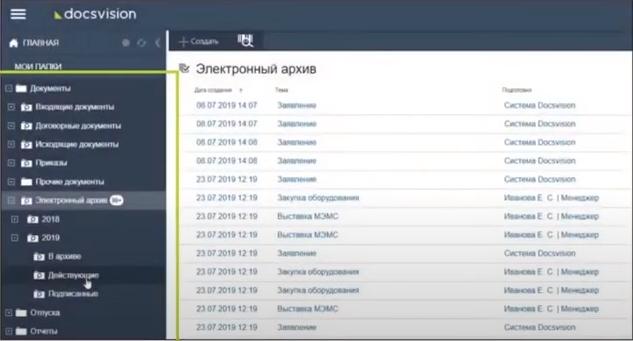
Создание электронного архива
Возможность добавления в архив скан-копий бумажных документов или электронных документов, которые хранятся на компьютерах сотрудников.
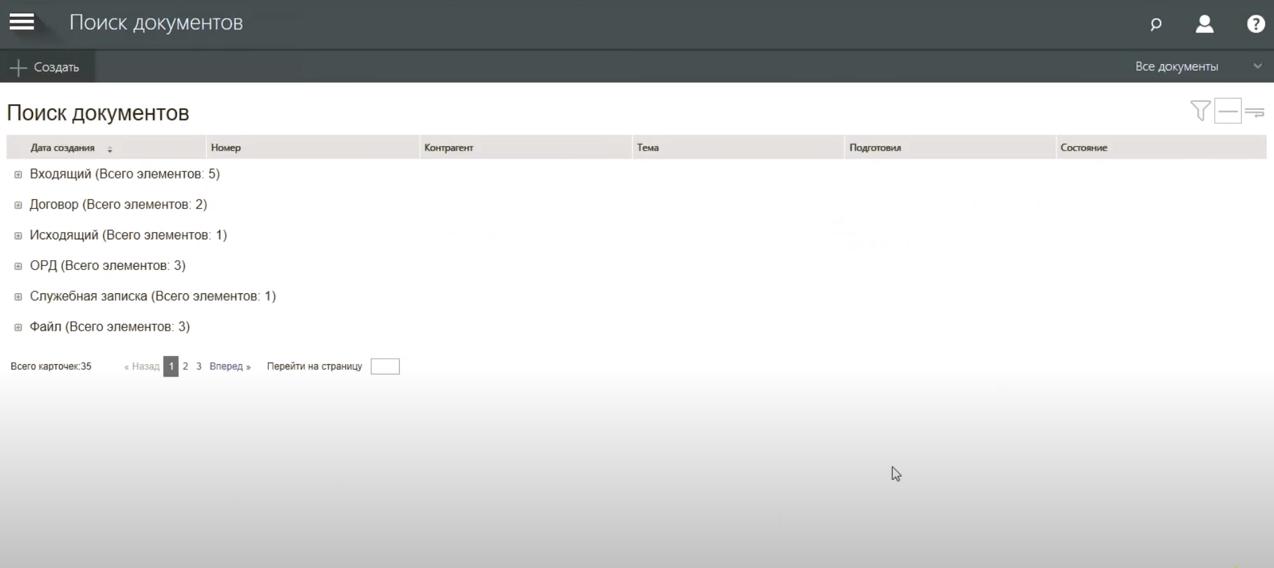
Поиск документов
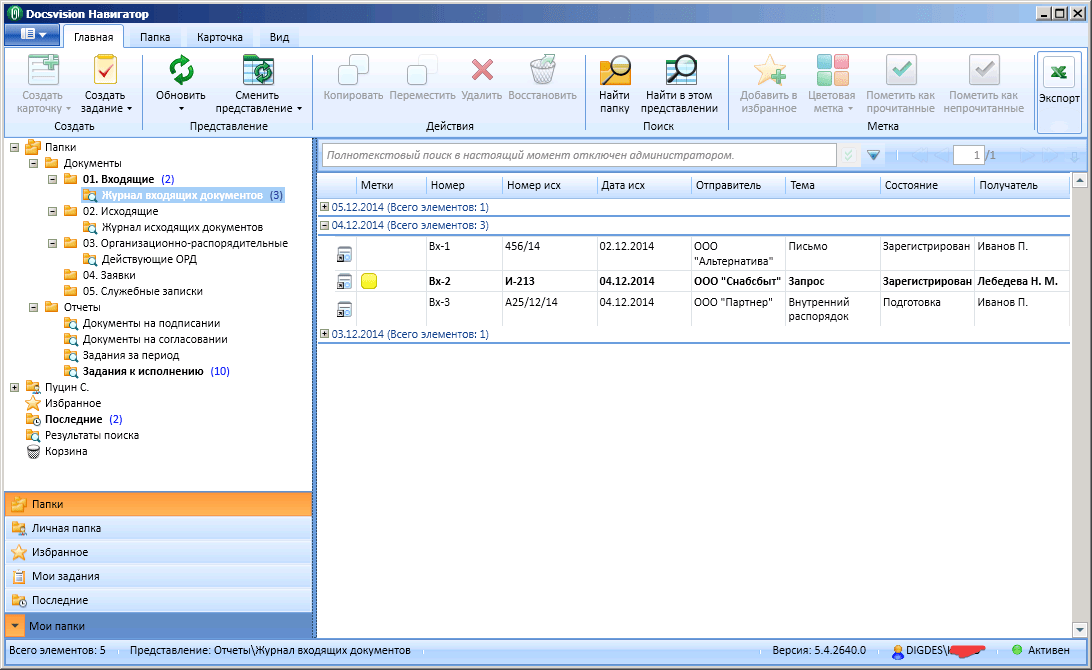
Найти нужные файлы можно по реквизитам или даже по тексту, если те были в формате MS Word или Excel.
Делопроизводство
Делопроизводство есть в каждой российской компании и, переведя его в электронный вид, можно уже не печатать приказы, служебные записки, а все это делать в электронном виде, согласовывать, подписывать без печати на бумаге.
Договорной документооборот
Договорной документооборот есть в каждой компании, и это ключевой процесс для организаций. От того, насколько быстро компания согласует договор, зависит то, когда она получит деньги, как быстро будет оказана услуга или доставлен товар по этому договору. Система документооборота позволяет автоматизировать этот процесс, существенно сократить сроки и повысить прозрачность этого процесса. Вы всегда будете знать, где и у кого находится договор, и сможете его быстро найти.
Оперативное управление
Для любого руководителя важно поставить задачу и иметь возможность ее проконтролировать. В системе DocVision такие возможности есть. Руководитель в любой момент может поставить задачу даже с мобильного телефона и со своего рабочего места проконтролировать ход ее исполнения.
Специализированный процесс компании
В нем есть или документы, или задачи. Автоматизировав его, вы получите полный контроль над этим процессом и существенно сократите срок его выполнения в организации.
Работа с документами
Интерфейс Веб-клиента DocVision позволяет реализовать все нужные опции для работы с электронными документами и бумажными скан-копиями:
- Создание документа с нуля или по готовому шаблону, регистрация.
- Просмотр графических и офисных файлов без необходимости использования сторонней программы.
- Редактирование файлов, создание новых версий без потребности скачивать их на компьютер.
- Связывание документов между собой при помощи ссылок.
- Ознакомление с документами, согласование и исполнение.
- Применение электронной подписи в работе.
- Импорт и экспорт документов с электронной подписью.
- Форматирование реестра с возможностью скачивания базы в MS Excel.
Работа с заданиями
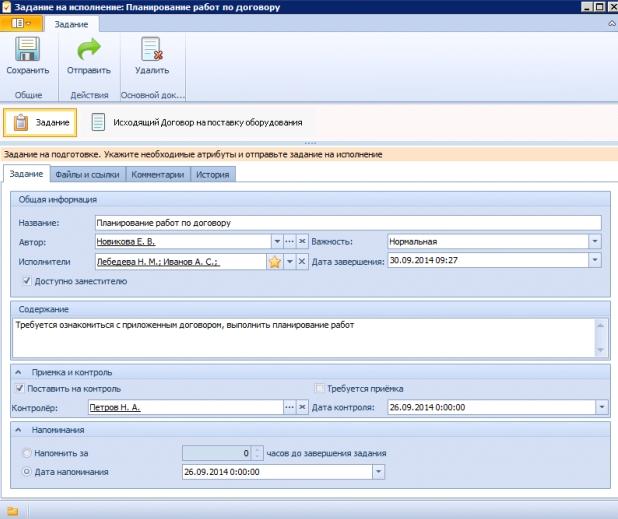
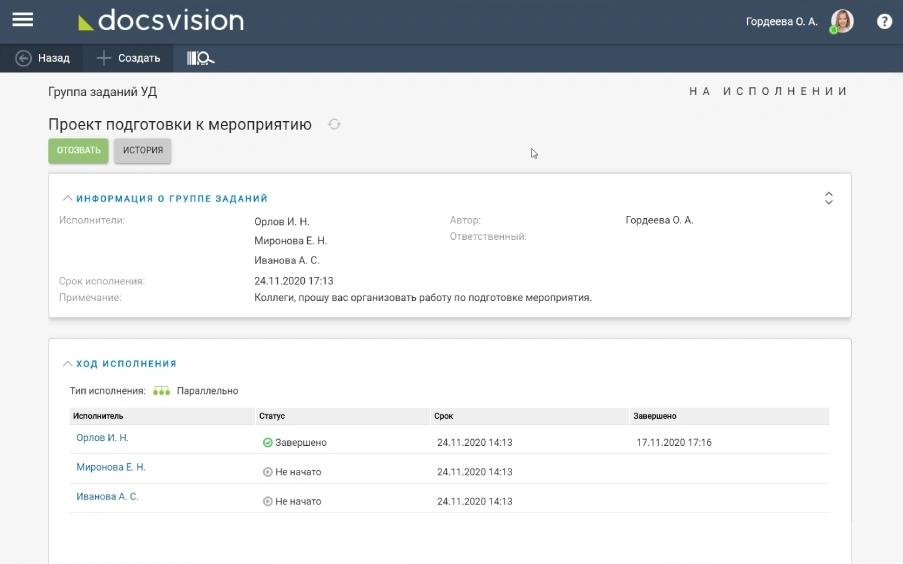
Платформа содержит ряд инструментов для создания заданий и их выполнения, а также для отслеживания их статуса. Эти опции доступны в веб-версии, на ПК и смартфоне:
- Создание инициативных поручений и задач.
- Создание задач на одного или несколько сотрудников.
- Возможность указания в качестве исполнителя имя и фамилию специалиста, роль, или все подразделение.
- Включение опции контроля отслеживания дедлайнов исполнения задач и прием результатов исполнения.
- Делегирование задач другим коллегам.
- Выполнение своих заданий или задач других сотрудников.
- Создание дочерних заданий.
Преимущества
СЭД DocVision обладает большим количеством преимуществ. Перечислим самые главные из них.
Хороший поиск
DocVision предоставляет несколько вариантов поиска, главные среди которых — полнотекстовый (по тексту содержимого файлов) и поиск по атрибутам (реквизитам). В Веб-клиенте вы можете использовать оба вида поиска, а также другие возможности:
- Фильтрация в папке реестра заданий и документов.
- Поиск по коду, присвоенному документу.
Гибкие настройки профиля пользователя
Пользователь может менять настройки непосредственно в браузерной версии:
- Загружать фото аккаунта.
- Указывать причины отсутствия на работу.
- Назначать заместителей для выполнения задач.
- Менять языковые настройки: есть русский, латвийский, английский и казахский языки.
Нет ограничений по нагрузке
Вы можете подсоединять новых пользователей, создавать новые процессы и увеличивать объем хранилища. Не имеет значение количество подключенных пользователей, при 100 и 10 000 пользователях поддерживается стабильная производительность.
Быстрый доступ к данным, поиск и работа с документацией
- Позволяет выполнить типовые операции по работе с реестрами на 40%.
- Платформа использует встроенный поиск Elasticsearch, позаимствованный у Amazon.
- Использует кеш-сервис redis, подходящий под все кластеры баз данных.
Удобная установка и обслуживание
Платформа DocVision имеет модульную архитектуру. Установка и обновление каждого модуля происходит отдельно, что исключает остановку системы.
Легкая интеграция
Готовые пути для подключения к 1С, SAP и прочим корпоративным системам без кодирования. Открытый API для интеграции с любыми IT-системами.
Оперативное внедрение
Более 1500 внедрений платформы подтверждают возможность решения задач автоматизации бизнес-процессов документооборота, используя свои решения.
Простой и мобильный интерфейс
Используя Веб-клиент для доступа к системе, вы ощутите легкость в работе. При необходимости платформа предложит подсказку, подсветит поле ввода, информативно известит вас о прогрессе заданий, обеспечит обработку документа или задания, не открывая его. В Веб-клиент можно зайти с браузера любого устройства.
Не требует обучения
Подавляющая часть пользователей системы считает интерфейс простым и интуитивно-понятным. Его можно настроить по вашему усмотрению.
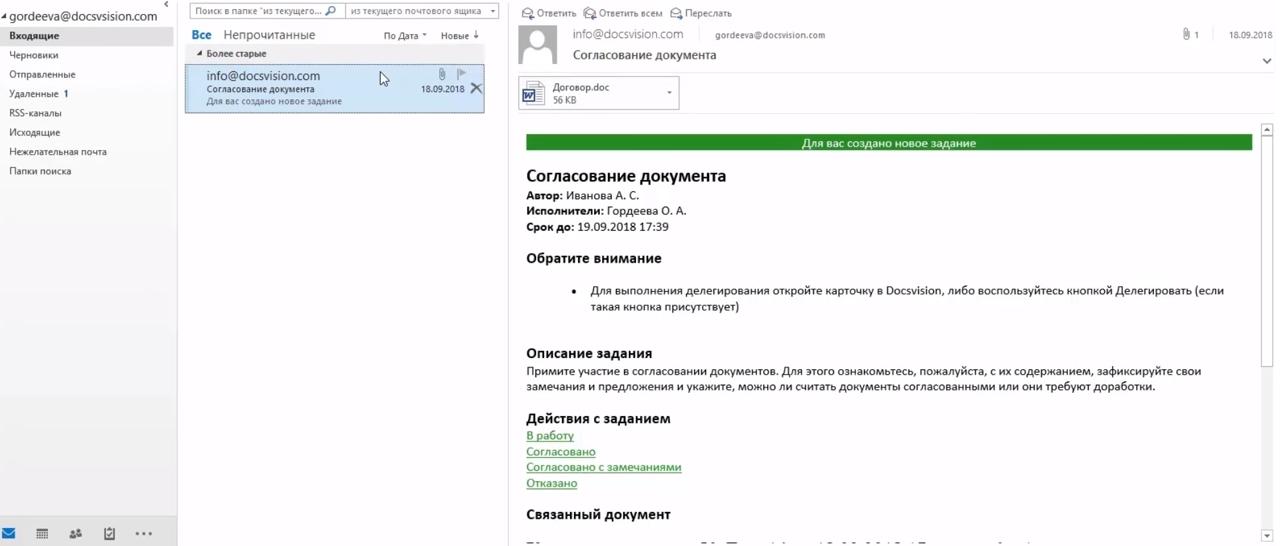
Позволяет работать с почты
Даже не заходя в систему, пользователь может назначать задания, подписывать документы и рассматривать договоры.
Разграничение прав доступа
К документам доступ получат только те сотрудники, кто имеет право их читать и редактировать.
Недостатки
Стоит рассмотреть недостатки, полученные путем анализа постов пользователей на сетевых форумах.
Сложная настройка
На внедрение и настройку системы у одной компании ушло полгода. Это существенный минус сравнительно с заявленными несколькими месяцами от разработчиков. Конечно, многое зависит от конкретного случая.
Зависимость от специалистов
Это недостаток не только данной платформы, но и любой другой СЭД. Вместе с внедрением программного продукта компания становится зависимой от специалистов, занимающимися ее настройкой и обслуживанием.
Показывает нестабильность в работе с многочисленными структурами
Проявляется в зависаниях, иногда для устранения проблем приходится обращаться в службу технической поддержки.
Выводы
Управление документами позволяет оцифровывать процессы, упорядоченно управляя всем жизненным циклом документа и повышая эффективность компаний любого размера.
Интернет и веб-технологии позволяют преодолеть все ограничения на распространение и доступ к информации и документам с явными преимуществами и экономией для государственных и частных организаций.
Внедрение системы управления документами Docvision действительно способно внести большой вклад в повышение производительности любой компании или государственного управления.
Дружелюбное лицо вашего корпоративного друга или немного об интерфейсах.
Сегодня мы разберем с вами, как устроен интерфейс систем электронного документооборота SharePoint Foundation и DocsVision. Как в них происходит работа, и в чем принципиальное различие этих программ. Для удобства прочтения и ознакомления с изображениями мы решили разбить эту статью на 2 части, посвященные DocsVision и SharePoint Foundation соответственно. Данная статья о DocsVision, и именно с этой СЭД будет происходить сравнение в этой статье.
Интерфейс DocsVision
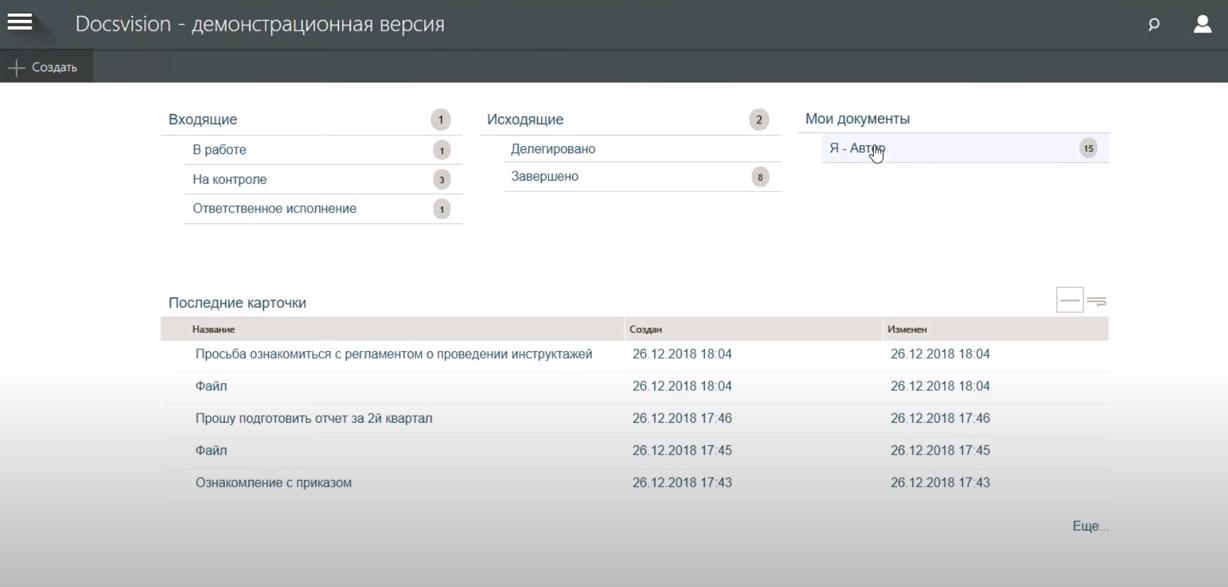
Как вы можете заметить, в этой СЭД, как и в большинстве управленческих и учетных программ, интерфейс разделен на два «окна»: левое с привычной древовидной структурой папок и правое — с выбранной папкой или задачей.

Левое «окно» изначально — абсолютная tabula rasa — чистый лист. Содержимое этого окна и является собственно структурой системы электронного документооборота. Основы этой структуры появляются там на этапе внедрения, в соответствии с техническим заданием. Заполнением структуры может заниматься как сам заказчик самостоятельно, так и подрядчик, выполняющий внедрение системы (например, мы). Правильнее будет отдать формирование структуры СЭД подрядчику, ведь у подрядчика уже есть опыт, и он сформирует систему оптимальным образом. Это не стремление «срубить легких денег», это именно оптимальный вариант, т.к. если структуру изначально сформировать не правильно, то ее переделка в дальнейшем обойдется в бОльшие деньги.
«Веточки» можно вырастить любые, в зависимости от задач, для реализации которых вам нужна система электронного документооборота. Например:
— входящая корреспонденция;
— исходящая корреспонденция;
— договоры;
— счета;
— доверенности;
— приказы;
— коммерческие предложения
И т. д.
Помимо принадлежности к конкретной папке — «веточке» дерева, каждый документ может принадлежать к отдельной упорядоченной структуре данных и участвовать в разных бизнес-процессах. Например, исходящее письмо может относиться к конкретному договору или коммерческому предложению, а протокол совещания – к проекту. Таким образом, на документ можно выйти не только непосредственно, найдя его в папке, но и через связанные документы.
А теперь давайте разберемся что со всем этим можно делать?

В принципе, все, что вы делали прежде, только на совершенно другом уровне – быстрее и качественнее. Документ отправляется все тем же сотрудникам, ответственным за его создание и согласование,
только все это будет не в пример быстрее и прозрачнее. Далее получатель может принять документ в работу, внести коррективы, согласовать либо отклонить. В таком случае документ вернется к своему создателю на доработку. И DocsVision будет автоматически рассылать оповещения о каждом действии всем участникам процесса (или не будет, если вам это не нужно).
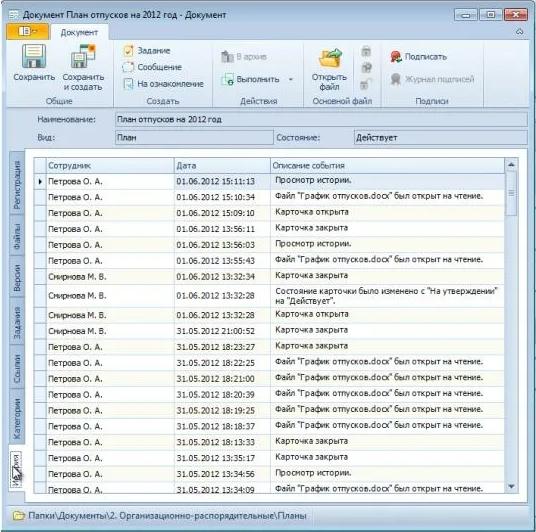
У каждого электронного документа, который хранится в системе DocsVision есть карточка, которую заполняет регистратор,
указывая отправителя, получателя (указывая себя в качестве отправителя или получателя, например), а также тему, дату регистрации, название и краткое содержание документа (собственно, присваивая ему те самые «атрибуты» то есть характерные признаки, по которым этот документ можно будет найти впоследствии. 
Дата регистрации и номер документа формируются автоматически, а счетчик номеров настраивается отдельно под каждый тип документа, например, он может обнуляться каждый год 1 января, таким образом позволяя хранить и осуществлять поиск документов по годам.
Поиск в такой системе происходит, как мы уже упомянули, по какому либо из атрибутов (или по всем, в совокупности), или путем полнотекстового поиска по тексту самого документа (пример карточки поиска ниже)

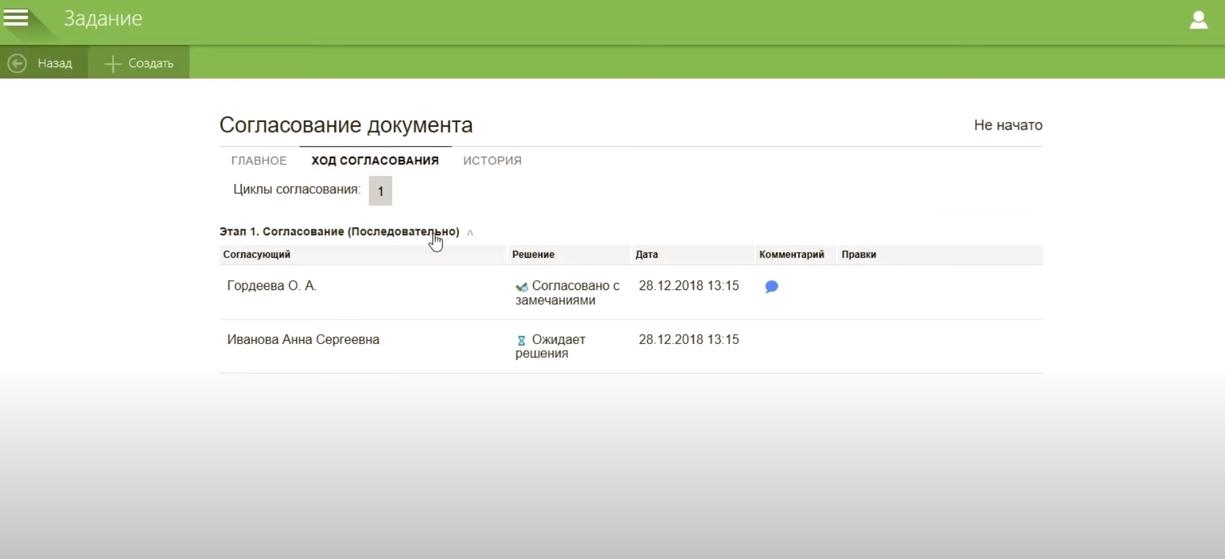
Также обратите, пожалуйста, внимание на один из самых простых бизнес-процессов в системе DocsVision. Бизнес-процесс позволяет настроить алгоритм жизненного цикла документа: что с ним происходит после совершения того или иного действия или принятия того или иного решения (подписать, отклонить, внести коррективы, отправить в архив и т.д.) — всё это настраивается на этапе внедрения, опять же в соответствии с техническим заданием.
А вот пример сложного бизнес-процесса:

Заключение
Как видите, интерфейс системы достаточно прост и приятен в работе. Его наполненность зависит от количества документов, числа отделов, количества сотрудников и выполняемых сотрудниками задач.
Однако поскольку ваши сотрудники уже задействованы в вашем конкретном НЕ электронном документообороте, обучение аналогичной работе, но в ее электронной версии не отнимет много времени и существенно сэкономит его в будущем.
Вы можете посмотреть на программу «в живую», или записаться на бесплатную консультацию к нашим специалистам. Оставляйте свою заявку с именем и контактным номером телефона, и мы свяжемся с вами в ближайшее время!