Документация на программное обеспечение — это документы, сопровождающие некоторое программное обеспечение (ПО) — программу или программный продукт. Эти документы описывают то, как работает программа и/или то, как её использовать.
Документирование — это важная часть в разработке программного обеспечения, но часто ей уделяется недостаточно внимания.
Типы документации
Существует четыре основных типа документации на ПО:
- архитектурная/проектная — обзор программного обеспечения, включающий описание рабочей среды и принципов, которые должны быть использованы при создании ПО
- техническая — документация на код, алгоритмы, интерфейсы, API
- пользовательская — руководства для конечных пользователей, администраторов системы и другого персонала
- маркетинговая
Архитектурная/проектная документация
Проектная документация обычно описывает продукт в общих чертах. Не описывая того, как что-либо будет использоваться, она скорее отвечает на вопрос «почему именно так?» Например, в проектном документе программист может описать обоснование того, почему структуры данных организованы именно таким образом. Описываются причины, почему какой-либо класс сконструирован определённым образом, выделяются паттерны, в некоторых случаях даже даются идеи, как можно будет выполнить улучшения в дальнейшем. Ничего из этого не входит в техническую или пользовательскую документацию, но всё это действительно важно для проекта.
Техническая документация
Это именно то, что подразумевают под термином документация большинство программистов. При создании программы, одного лишь кода, как правило, недостаточно. Должен быть предоставлен некоторый текст, описывающий различные аспекты того, что именно делает код. Такая документация часто включается непосредственно в исходный код или предоставляется вместе с ним.
Подобная документация имеет сильно выраженный технических характер и в основном используется для определения и описания API, структур данных и алгоритмов.
Часто при составлении технической документации используются автоматизированные средства — генераторы документации, такие как Doxygen, javadoc, NDoc и другие. Они получают информацию из специальным образом оформленных комментариев в исходном коде, и создают справочные руководства в каком-либо формате, например, в виде текста или HTML. Использование генераторов документации и документирующих комментариев многими программистами признаётся удобным средством, по различным причинам. В частности, при таком подходе документация является частью исходного кода, и одни и те же инструменты могут использоваться для сборки программы и одновременной сборки документации к ней. Это также упрощает поддержку документации в актуальном состоянии.
Пользовательская документация
В отличие от технической документации, сфокусированной на коде и том, как он работает, пользовательская документация описывает лишь то, как использовать программу.
В случае если продуктом является программная библиотека, пользовательская документация и документация на код становятся очень близкими, почти эквивалентными понятиями. Но в общем случае, это не так.
Обычно, пользовательская документация представляет собой руководство пользователя, которое описывает каждую функцию программы, а также шаги, которые нужно выполнить для использования этой функции. Хорошая пользовательская документация идёт ещё дальше и предоставляет инструкции о том, что делать в случае возникновения проблем. Очень важно, чтобы документация не вводила в заблуждение и была актуальной. Руководство должно иметь чёткую структуру; очень полезно, если имеется сквозной предметный указатель. Логическая связность и простота также имеют большое значение.
Существует три подхода к организации пользовательской документации. Вводное руководство (англ. tutorial), наиболее полезное для новых пользователей, последовательно проводит по ряду шагов, служащих для выполнения каких-либо типичных задач. Тематический подход, при котором каждая глава руководства посвящена какой-то отдельной теме, больше подходит для совершенствующихся пользователей. В последнем, третьем подходе, команды или задачи организованы в виде алфавитного справочника — часто это хорошо воспринимается продвинутыми пользователями, хорошо знающими, что они ищут. Жалобы пользователей обычно относятся к тому, что документация охватывает только один из этих подходов, и поэтому хорошо подходит лишь для одного класса пользователей.
Во многих случаях разработчики программного продукта ограничивают набор пользовательской документации лишь встроенной системой помощи (англ. online help), содержащей справочную информацию о командах или пунктах меню. Работа по обучению новых пользователей и поддержке совершенствующихся пользователей перекладывается на частных издателей, часто оказывающих значительную помощь разработчикам.
Маркетинговая документация
Для многих приложений необходимо располагать рядом рекламных материалов, с тем чтобы заинтересовать людей, обратив их внимание на продукт. Такая форма документации имеет целью:
- подогреть интерес к продукту у потенциальных пользователей
- информировать их о том, что именно делает продукт, с тем чтобы их ожидания совпадали с тем что они получат
- объяснить положение продукта по сравнению с конкурирующими решениями
Одна из хороших маркетинговых практик — предоставление слогана — простой запоминающейся фразы, иллюстрирующей то что мы хотим донести до пользователя, а также характеризующей ощущение, которое создаёт продукт.
Часто бывает так, что коробка продукта и другие маркетинговые материалы дают более ясную картину о возможностях и способах использования программы, чем всё остальное.
Документирование программного обеспечения
Когда программист-разработчик получает в той или иной форме задание на программирование, перед ним, перед руководителем проекта и перед всей проектной группой встают вопросы: что должно быть сделано, кроме собственно программы? что и как должно быть оформлено в виде документации? что передавать пользователям, а что — службе сопровождения? как управлять всем этим процессом? Кроме упомянутых вопросов есть и другие, например, что должно входить в само задание на программирование? Прошло много лет, программирование происходит в среде совершенно новых технологий, многие программисты, работая в стиле drag-and-drop, могут годами не видеть текст своих программ. Это не значит, что исчезла необходимость в их документировании. Более того, вопросы о наличии хоть какой-то системы, регламентирующей эту сторону создания программных средств, продолжают задавать постоянно. Спрашивают и о том, есть ли обязательные для применения стандарты (особенно остро стоит этот вопрос, когда разработка выполняется по заказу государственной организации или предприятия). Интересуются и тем, где можно купить имеющиеся стандарты.
Качество программного обеспечения, наряду с другими факторами, определяется полнотой и качеством пакета документов, сопровождающих ПО. К программным документам относятся документы, содержащие сведения, необходимые для разработки, изготовления, сопровождения программ и эксплуатации.
Техническое задание
Техническое задание. Требование к содержанию и оформлению. Напомним, что техническое задание (ТЗ) содержит совокупность требований к ПС и может использоваться как критерий проверки и приемки разработанной программы.
Поэтому достаточно полно составленное (с учетом возможности внесения дополнительных разделов) и принятое заказчиком и разработчиком, ТЗ является одним из основополагающих документов проекта программного средства.
- Техническое задание на разработку ПО должно включать следующие разделы: введение; основания для разработки;
- назначение разработки;
- требования к программе;
- требования к программной документации;
- технико-экономические показатели;
- стадии и этапы разработки;
- порядок контроля и приемки;
- приложения.
В зависимости от особенностей разрабатываемого ПО стандарт допускает уточнение содержания разделов, введение новых разделов или их объединение.
Руководство пользователя
Под документацией пользователя понимается документация, которая обеспечивает конечного пользователя информацией по установке и эксплуатации программного пакета. Под информацией на упаковке понимают информацию, воспроизводимую на внешней упаковке программного пакета. Ее целью является предоставление потенциальным покупателям первичных сведений о программном пакете.
Пользовательская документация программного средства объясняет пользователям, как они должны действовать, чтобы применить данную программу. Она необходима, если программа предполагает какое-либо взаимодействие с пользователями. К такой документации относятся документы, которыми руководствуется пользователь при установке программы с соответствующей настройкой на среду применения, при применении программы для решения своих задач и при управлении программой (например, когда данное программное средство взаимодействует с другими системами). Эти документы частично затрагивают вопросы сопровождения программного средства, но не касаются вопросов, связанных с модификацией программ.
В связи с этим следует различать две категории пользователей: ординарных пользователей программы и администраторов. Ординарный пользователь программы (end-user) использует программу для решения своих задач (в своей предметной области). Это может быть инженер, проектирующий техническое устройство, или кассир, продающий железнодорожные билеты с помощью данной программы. Он может и не знать многих деталей работы компьютера или принципов программирования. Администратор программы (system administrator) управляет использованием программы ординарными пользователями и осуществляет сопровождение программного средства, не связанное с модификацией программ. Например, он может регулировать права доступа к программе между ординарными пользователями, поддерживать связь с поставщиками программы или выполнять определенные действия, чтобы поддерживать программу в рабочем состоянии, если оно включено как часть в другую систему.
Состав пользовательской документации зависит от аудиторий пользователей, на которые оно ориентировано, и от режима использования документов. Под аудиторией здесь понимается контингент пользователей, у которого есть необходимость в определенной пользовательской документации. Удачный пользовательский документ существенно зависит от точного определения аудитории, для которой он предназначен. Пользовательская документация должна содержать информацию, необходимую для каждой аудитории. Под режимом использования документа понимается способ, определяющий, каким образом используется этот документ. Обычно пользователю достаточно больших программных систем требуются либо документы для изучения программного средства (использование в виде инструкции), либо для уточнения некоторой информации (использование в виде справочника).
Можно считать типичным следующий состав пользовательской документации для достаточно больших программных средств:
- Общее функциональное описание программного средства. Дает краткую характеристику функциональных возможностей программного средства.
- Предназначено для пользователей, которые должны решить, насколько необходимо им данное программного средства.
Руководство по инсталляции программного средства
Предназначено для системных администраторов. Он должен детально предписывать, как устанавливать системы в конкретной среде. Он должен содержать описание машинно-считываемого носителя, на котором поставляется программное средство, файлы, представляющие программное средство, и требования к минимальной конфигурации аппаратуры.
Инструкция по применению программного средства
Предназначена для ординарных пользователей. Содержит необходимую информацию по применению программного средства, организованную в форме удобной для ее изучения.
Справочник по применению программного средства
Предназначен для ординарных пользователей. Содержит необходимую информацию по применению программного средства, организованную в форме удобной для избирательного поиска отдельных деталей.
Руководство по управлению программным средством
Предназначено для системных администраторов. Оно должно описывать сообщения, генерируемые, когда программные средства взаимодействует с другими системами, и как реагировать на эти сообщения. Кроме того, если программное средство использует системную аппаратуру, этот документ может объяснять, как сопровождать эту аппаратуру.
Разработка пользовательской документации начинается сразу после создания внешнего описания. Качество этой документации может существенно определять успех программы. Она должна быть достаточно проста и удобна для пользователя (в противном случае это программное средство, вообще, не стоило создавать). Поэтому, хотя черновые варианты (наброски) пользовательских документов создаются основными разработчиками программного средства, к созданию их окончательных вариантов часто привлекаются профессиональные технические писатели. Кроме того, для обеспечения качества пользовательской документации разработан ряд стандартов, в которых предписывается порядок разработки этой документации, формулируются требования к каждому виду пользовательских документов и определяются их структура и содержание.
Руководство программиста
Документация по сопровождению программного средства (system documentation) описывает программное средство с точки зрения ее разработки.
Эта документация необходима, если программное средство предполагает изучение того, как оно устроена (сконструирована), и модернизацию его программ. Как уже отмечалось, сопровождение — это продолжающаяся разработка. Поэтому в случае необходимости модернизации программного средства к этой работе привлекается специальная команда разработчиков- сопроводителей. Этой команде придется иметь дело с такой же документацией, которая определяла деятельность команды первоначальных (основных) разработчиков программного средства, — с той лишь разницей, что эта документация для команды разработчиков-сопроводителей будет, как правило, чужой (она создавалась другой командой). Команда разработчиков- сопроводителей должна будет изучать эту документацию, чтобы понять строение и процесс разработки модернизируемого программного средства, и внести в эту документацию необходимые изменения, повторяя в значительной степени технологические процессы, с помощью которых создавалось первоначальное программное средство.
Документация по сопровождению программного средства можно разбить на две группы:
1. документация, определяющая строение программ и структур данных ПС и технологию их разработки;
2. документацию, помогающую вносить изменения в программное средство.
Документация первой группы содержит итоговые документы каждого технологического этапа разработки программного средства. Она включает следующие документы:
- Внешнее описание программного средства (Requirements document).
- Описание архитектуры программного средства (description of the system architecture), включая внешнюю спецификацию каждой ее программы.
- Для каждой программы программного средства — описание ее модульной структуры, включая внешнюю спецификацию каждого включенного в нее модуля.
- Для каждого модуля — его спецификация и описание его строения (design description).
- Тексты модулей на выбранном языке программирования (program source code listings).
- Документы установления достоверности программного средства (validation documents), описывающие, как устанавливалась достоверность каждой программы программного средства и как информация об установлении достоверности связывалась с требованиями к программному средству.
Документы установления достоверности включают, прежде всего, документацию по тестированию (схема тестирования и описание комплекта тестов), но могут включать и результаты других видов проверки программного средства, например, доказательства свойств программ.
Документация второй группы содержит
- Руководство по сопровождению программного средства (system maintenance guide), которое описывает известные проблемы вместе с программным средством, описывает, какие части системы являются аппаратно- и программно- зависимыми, и как развитие программного средства принято в расчет в его строении (конструкции).
- Общая проблема сопровождения программного средства — обеспечить, чтобы все его представления шли в ногу (оставались согласованными), когда программное средство изменяется. Чтобы этому помочь, связи и зависимости между документами и их частями должны быть зафиксированы в базе данных управления конфигурацией.
Процесс управления конфигурацией
Процесс управления конфигурацией является процессом применения административных и технических процедур на всем протяжении ЖЦ ПС для определения состояния (базовой линии) программных объектов в системе, управления их изменениями и выпуском.
Данный процесс состоит из шести работ. Общее число задач по данным работам равно 6.
- Подготовка процесса управления конфигурацией — разработка плана управления конфигурацией. Тип выходного результата задачи — план.
- Определение конфигурации — Определение схемы обозначения программных объектов и их версий (объектов программной конфигурации) и документации, в которой фиксируется состояние их конфигурации. Тип выходного результата задачи — описание.
- Контроль конфигурации — Регистрация заявок на внесение изменений; анализ и оценка изменений; принятие или непринятие заявки; реализация, верификация и выпуск измененного программного объекта; обеспечение аудиторских проверок изменений.
- Учет состояний конфигурации — Подготовка протоколов управления конфигурацией и отчетов о состоянии контролируемых программных объектов. Тип выходного результата задачи — протокол, отчет.
- Оценка конфигурации — Определение и обеспечение функциональной законченности и физической завершенности программных объектов. Тип выходного результата задачи — протокол, отчет.
- Управление выпуском и поставка — Контроль выпуска и поставки программных продуктов и документации.
Источник:

Авторы: Дмитрий Лапыгин, Александр Новичков
Оглавление:
- Предисловие к материалу
- Введение в управление конфигурацией программных средств
- История развития дисциплины управления конфигурацией
- Возникновение основных терминов управления конфигурацией
- Базовые концепции и элементы
- Основы управления конфигурацией
- Управление конфигурацией в стандартах
- Виды стандартов
- Управление изменениями как составная часть процесса УК
- Процесс УК в стандарте ГОСТ Р ИСО/МЭК 12207
- Управление конфигурацией с точки зрения Capability Maturity Model
- Требования к процессу УК в СММ
Предисловие к материалу
Рано или поздно любой долгосрочный проект, связанный с разработкой программного обеспечения, разрастается до необъятных размеров, становясь трудно управляемым и трудно прогнозируемым. Руководство больше не в состоянии отслеживать конкретную деятельность подчиненных. Но, пожалуй, самая главная проблема в том, что руководящий состав не имеет четкого представления о качестве выпускаемого изделия. Подчиненные же, в свою очередь, лишены всестороннего осознания поставленных проектных задач, руководствуясь в своей работе не научной базой, а вдохновением и порывами души.
Вполне вероятно, что даже в таком случае определенный контроль над проектом, с той или иной долей успеха, возможен. Правда, трудно определить качественный уровень выходного изделия, как это принято в промышленном производстве.
Вот здесь и возникает потребность перехода на иную качественную ступень. И это обусловлено не только тем, что руководство компании желает из альтруистических побуждений повысить уровень качества изделия — вовсе нет! Улучшение качества — важное условие выживания IT-компаний в современных рыночных условиях.
Одна из дисциплин, которая позволит существенно повысить как качество самого процесса разработки, так и качество выходного продукта — Управление Конфигурациями программных средств. Дисциплина включает в себя управление как версиями ПС (программных средств), так и изменениями.
К сожалению, в российской печати и российском же Интернете практически нет достойных книг и статей, которые детально раскрывали бы Цели и Задачи процесса, описывали бы их (все материалы либо коммерческие либо банальные перепечатки слово в слово стандартов). К тому же имеет место низкая культура разработчиков, считающих УК неким видом тотального контроля над собой (если не насилия). В этом их заблуждение. Любой формализованный процесс — это не насилие, а благо, и мы надеемся это объяснить. К нашей радости, ситуация в России в плане отношения к процессу УК последний год начала резко меняться: начинаются разработки крупных программных продуктов, разработка которых невозможна без данного процесса.
Данный материал — это нарезка из глав книги, которую авторы пишут на протяжении последнего года-полутора. Книги обычно пишутся не быстро, поэтому было решено опубликовать материал в Интернете и собрать отзывы потенциальных читателей.
Статья описывает историю возникновения Управления Конфигурациями и базовые концепции, на которых зиждется данный процесс. Также рассматриваются основные аспекты данного процесса в призме международных стандартов, таких как ISO-12207 и CMM. В материале даются цитаты из требований стандартов с авторскими комментариями.
Полезные ссылки перед прочтением, чтобы войти в курс дела: Проблемы разработки ПО, Осознание необходимости в УК, Что такое RUP)
Приятного чтения.
Введение в управление конфигурацией программных средств
Управление конфигурацией является основополагающей дисциплиной в определении того, каким образом управляются и контролируются рабочие материалы проекта, вносимые в них изменения и информация о состоянии отдельных задач и всего проекта в целом. Успех проекта в большой степени зависит от того, насколько хорошо построен процесс управления конфигурацией, который может как спасти проект, так и похоронить его, если сам процесс УК работает плохо.
История развития дисциплины управления конфигурацией
Первым заметным шагом в развитии управления конфигурациями (сокращенно — УК) было изобретение микрометра в 1636 году (William Gascoigne). Это устройство сыграло важную роль в индустриальной революции и переходе к массовому производству. Этот инструмент позволил использовать взаимозаменяемые части в различных устройствах, что являлось существенной причиной для того, чтобы использовать процедуры управления конфигурацией.
Первые инженерные концепции, которые привели к становлению дисциплины управления конфигурацией, начали формироваться в начале 20-го века и обрели реальную форму в 60-х годах прошлого века.
Изначально создатели концепции управления конфигурацией преследовали цель улучшения способов разработки и сопровождения программных средств (ПС). «Отцы-основатели» управления конфигурацией хотели создать дисциплину, которая обеспечивала бы соответствие разработанного ПС потребностям пользователей, для которых это ПС разрабатывалось. Они изучили успешные проекты и обобщили опыт применения тех технологий, которые хорошо себя проявили. Другой важной целью было обеспечить простоту модификации и сопровождения ПС и (так как «отцы-основатели» в основном работали на правительственные учреждения) возможность для заказчика ПС сменить разработчика без того, чтобы заново проходить весь цикл разработки ПС с нуля.
Кроме того, в качестве дополнительной цели рассматривалось обеспечение оценки состояния проекта на основе отчетности по ключевым показателям. Они сосредоточились на достижении долгосрочных целей и не рассчитывали получить сразу очевидные преимущества от использования разрабатываемых ими технологий. Следует заметить, что преимущества такого сорта трудно выразить количественно, так как при успешном использовании управления конфигурацией в организации просто перестают растрачивать ресурсы на лишнюю работу. Например, на повторное исправление ошибки, которая уже была исправлена ранее, но появилась вновь из-за того, что при сборке ПС правильный код случайно заменили на неправильный.
«Отцы-основатели» осознали, что в первую очередь им требуется контролировать то, какие части входят в готовый продукт (под продуктом может пониматься как ПС, так и оборудование и, в широком смысле, любое изделие, состоящее из различных частей) и каким образом они взаимосвязаны, а также отслеживать изменения в отдельных частях продукта и в их взаимосвязях друг с другом. Они выбрали слово «конфигурация» для обозначения «относительного взаиморасположения частей». Слово «управление» вполне подходило по смыслу, и в итоге получилось «управление конфигурацией».
Возникновение основных терминов управления конфигурацией
Затем было решено, что разрабатываемый конечный продукт будет называться «конфигурационным объектом» (configuration item). Конфигурационные объекты (КО) могут представлять собой стол или самолет, если рассматривать оборудование, или программные средства в виде инсталляционных пакетов, если речь идет о программных средствах.
Но каким образом можно управлять конфигурацией объекта? Это можно сделать, контролируя документы, которые описывают конфигурационный объект, требования к нему, его архитектуру и чертежи (или модель). Создатели дисциплины управления конфигурацией осознали, что такие документы являются самой важной частью процесса разработки и что управлять конфигурацией какого-либо объекта можно, управляя содержанием документов, описывающих эту конфигурацию.
Поэтому вместо того, чтобы предполагать, что такие документы могут быть созданы и могут точно описывать конфигурацию, необходимо было это гарантировать. Было решено, что наиболее важным результатом процесса управления конфигурацией должно быть обеспечение разработки документации, точно описывающей конфигурацию объекта в любой момент времени на протяжении всего проекта. Создатели дисциплины УК основывались на предположении, что если иметь набор точной и актуальной документации, то на ее основе всегда можно создать новую копию продукта.
Затем они занялись определением набора документов, который является критически важным для успешной разработки. Такой набор документов должен содержать, как минимум, требования, спецификации, дизайн, модели (чертежи), перечень компонентов, тестовую документацию, исходные коды и документацию пользователя. Требовалось общее выражение для обозначения любого из этих документов или всех документов, описывающих конфигурационный объект, для проекта любого размера. Так как основное предназначение этих документов было в «идентификации конфигурации» объекта, этот набор документов назвали «конфигурационной идентификацией» (configuration identification). Тогда это казалось разумным, но сейчас мало кто считает, что «конфигурационная идентификация» означает «документы».
Другое важное понятие, определяющее набор документов — «базовая версия» (baseline). Базовая версия представляет собой полный набор документов, составляющих конфигурационную идентификацию, соответствующий определенному моменту времени, т.е. «моментальный снимок» конфигурации. Момент времени, в который создается базовая версия, обычно соответствует какому-либо запланированному событию, например, завершению стадии жизненного цикла продукта или этапа проекта.
Таким образом, было установлено, что точное документирование — наиболее важный момент в управлении конфигурацией. При этом сознательно не перечислялись документы, которые должны создаваться (кроме документов с требованиями).
Базовые процедуры управления конфигурацией
Итак, после определения требований, список остальных документов, составляющих конфигурационную спецификацию, определялся для каждого участниками проекта. Но как удостовериться в том, что эти документы создаются с нужным качеством и с достаточной степенью детализации?
Обычно используется метод декомпозиции требований (или «функциональной декомпозиции») — требования разбиваются на отдельные элементы и детализируются на следующем шаге разработки (дизайн). Затем детализация продолжается на следующем шаге и так далее до тех пор, пока не достигнут требуемый уровень детализации.
Другой способ — сравнение разрабатываемого документа с документами более высокого уровня, которые были утверждены ранее в процессе разработки. Для этой работы было использовано понятие «ревизия» (review) с добавлением слова «конфигурация». «Ревизия конфигурации» (configuration review ) представляет собой сравнение документа низкого уровня с предшествующим ему документом или документом верхнего уровня с тем, чтобы удостовериться, что документ нижнего уровня удовлетворяет всем требованиям, присутствующим в документе верхнего уровня, и нет никаких неожиданных добавлений. Это позволяет постепенно и аккуратно детализировать требования верхнего уровня в документах низкого уровня, уточняя конфигурационную идентификацию по мере разработки конфигурационного объекта.
Ревизия конфигурации используется также для того, чтобы проверить работоспособность продукта на основе документа соответствующего уровня. Например, ревизия исходного кода служит для того, чтобы удостовериться в том, что исходный код написан в соответствии с установленными правилами. Таким образом, ревизия конфигурации служит как для проверки правильности декомпозиции документов всех уровней, так и для проверки этих документов с точки зрения их соответствия правилам, шаблонам и форматам, используемым при создании такого рода документов.
Подобная техника проверки того, что продукт создается по установленным правилам и требованиям, используется при проведении «аудита конфигурации» (configuration audit). Аудит конфигурации подобен процессу ревизии за исключением одной особенности — объектом приложения аудита является конфигурационный объект или конечный продукт, который сравнивается с документацией, составляющей его конфигурационную идентификацию. Объектом приложения ревизии являются отдельные документы.
Еще один способ гарантировать точность конфигурационной спецификации — иметь специальную группу (возможно, состоящую из одного специалиста), которая отслеживала бы все предлагаемые изменения продукта и отвергала или одобряла их. Такая деятельность получила название «контроль конфигурации» (сonfiguration сontrol). Группы, выполняющие функции контроля конфигурации обычно получают название «Группа контроля над изменениями» (Change Control Board) или «Группа контроля конфигурации» (Configuration Control Board, сокращенно CCB). Среди важных функций такой группы — контроль того, что все документы являются актуальными в каждый момент времени и того, что при внесении изменения сначала изменяются документы конфигурационной идентификации, а уже после — сам объект изменений (исходный код, модель и т.п.). Изменение объекта после изменения его описания выгодно еще и тем, что исполнитель, вносящий изменение в объект, будет иметь возможность ознакомиться с описанием этого изменения до начала работы.
Другой областью ответственности управления конфигурацией стала подготовка отчетности о состоянии продукта и состоянии утвержденных изменений на протяжении всего хода работ. Эта деятельность получила название «учет состояния конфигурации» (configuration status accounting)
Базовые концепции и элементы
Нельзя сказать, что никто до этого не использовал таких методов работы. Разработка и раньше велась параллельно с документированием. Ревизии документов проводились и раньше. Тестирование и испытания продукции на предмет соответствия требованиям проводились и до этого. Отчетность использовалась в проектах и раньше. Основатели дисциплины управления конфигурацией сделали другое — они собрали вместе, упорядочили и дали названия всем этим техникам, используемым при разработке, так что в итоге получилась отдельная дисциплина — управление конфигурацией.
Во время формирования дисциплины управления конфигурацией в ней были воплощены следующие важные концепции:
- Документы создаются для описания продукта и являются средством управления конфигурацией продукта.
- Изменения в продукте контролируются посредством контроля изменений в документации.
- Изменения в продукте не производятся до тех пор, пока они не сделаны в документации.
- До того, как быть реализованными в документации и продукте, изменения должны быть формально утверждены.
- Все изменения должны отслеживаться.
- Конфигурационные объекты (продукты), документы и их версии нумеруются и именуются единообразно и недвусмысленно (или уникально).
- Ведется отчетность о состоянии изменений, документов и продуктов.
- Каждый документ периодически сравнивается с соответствующим ему документом верхнего уровня на предмет выявления несоответствий.
- Продукт в целом сравнивается со своим описанием (конфигурационной идентификацией) и должен этому описанию соответствовать.
Используя введенную выше терминологию управления конфигурацией, эти концепции были сгруппированы в следующие четыре элемента управления конфигурацией:
- Конфигурационная идентификация (концепция 1)
- Контроль конфигурации (концепции 2, 3, 4, 5, 6)
- Учет состояния конфигурации (концепция 7)
- Ревизия и аудит конфигурации (концепции 8 и 9)
Такова была первоначальная концепция управления конфигурацией как для программных средств (software), так и для оборудования (hardware). Представленную здесь первоначальную терминологию дисциплины управления конфигурацией можно также найти в стандарте IEEE-STD-610. Далее будут рассмотрены стандарты, определяющие основные положения и терминологию управления конфигурацией.
Недостаточно четкое понимание терминологии управления конфигурацией, происходящее обычно из-за отсутствия формального обучения этой дисциплине, зачастую приводит к смещению концептуальных понятий и путанице в основополагающих принципах УК.
Так, например, основной элемент управления конфигурацией «конфигурационная идентификация» зачастую воспринимается в значении наименования или нумерации документа или продукта, что должно соответствовать понятию «идентификации документа» или «идентификации продукта». В то время как понятие «конфигурация» не относится к документу или продукту. Это понятие относится к содержанию документов, обозначая содержание технической документации, описывающей продукт. Кстати говоря, правила наименования и нумерации документов и продуктов относятся к следующему элементу УК — «контролю конфигурации», и называются «соглашением по наименованию и нумерации».
Основы управления конфигурацией
С момента формального основания дисциплины управления конфигурацией, которое можно условно отсчитывать от даты введения стандарта IEEE-STD-610, она рассматривалась с разных точек зрения и в различных приложениях. Был накоплен богатый опыт использования процедур управления конфигурацией в различных проектах, который обобщался с точки зрения различных стандартов и моделей программной инженерии.
Процесс управления конфигурацией состоит из следующих взаимосвязанных видов деятельности:
- конфигурационная идентификация артефактов (рабочих материалов), используемых или создаваемых в ходе проекта;
- контроль конфигурации, включая информацию о воздействии изменений на организационную и управленческую структуру, текущие приоритеты заданий, ресурсы и состояние проекта;
- учет состояния конфигурации на основе состояния артефактов, используемых в разработке, при выпуске готовых версий ПС или их сопровождении;
- ревизия и аудит конфигурации, в ходе которой оценивается состояние и готовность продукта;
- процедуры управления выпуском продукта (release management), его доставки и мониторинга состояния проекта;
- версионный контроль рабочих материалов проекта, обеспечивающий повторяемость сборки продукта на основании его базовых версий.
К основным элементам процесса управления конфигурацией можно отнести (см. рисунок 1.) следующие четыре элемента:
- Конфигурационная идентификация.
- Контроль конфигурации.
- Учет состояния конфигурации.
- Ревизия и аудит конфигурации.
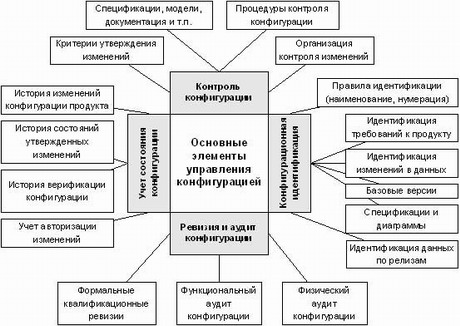
Рисунок 1. Основные элементы процесса управления конфигурацией
Рассмотрим подробнее состав каждого из этих элементов.
Конфигурационная идентификация основывается на следующих составляющих:
- правила идентификации и нумерации — что и каким образом идентифицируется;
- идентификация требований к продукту — каким образом идентифицируются требования к ПС;
- идентификация изменений в данных — каким образом идентифицируются изменения в данных;
- базовые версии — создаются для фиксации стабильных состояний системы и используются как кандидаты на релиз ПС;
- спецификации и диаграммы — документы, описывающие конфигурационную спецификацию ПС и диаграммы, используемые для этих же целей;
- идентификация данных по релизам — методы, позволяющие однозначно сопоставить элементы конфигурации ПС и их версии с определенным релизом ПС.
Контроль конфигурации включает:
- критерии утверждения изменений — определяют формальные критерии, на основании которых принимается решение об утверждении или отклонении предложенного изменения;
- спецификации, модели, документация и т.п. — все эти элементы конфигурации подвержены изменениям и находятся в сфере действия контроля конфигурации;
- процедуры контроля конфигурации — утвержденные процедуры, которым должны следовать участники проекта;
- организация контроля изменений — организационная составляющая процесса, определяющая ответственность участников проекта при выполнении процедур контроля конфигурации.
Учет состояния конфигурации предполагает:
- ведение истории изменений конфигурации продукта — определяет кто, когда и какие изменения делал;
- ведение истории состояний утвержденных изменений — показывает, как менялись состояния утвержденных изменений от момента утверждения и до момента завершения их отработки;
- ведение истории верификации конфигурации — хранит данные о всех проведенных верификациях и их результаты;
- учет авторизации изменений — указывает на то, кто отвечает за сделанные изменения.
Ревизия и аудит конфигурации включает:
- формальные квалификационные ревизии — определяют соответствие элементов конфигурации предъявляемым к ним формальным требованиям, например, соответствие определенному шаблону документа;
- функциональный аудит конфигурации — определяет соответствие конфигурации ПС функциональным требованиям, предъявляемым к продукту;
- физический аудит конфигурации — определяет наличие или отсутствие отдельных элементов в составе конфигурации.
Управление конфигурацией в стандартах
До сих пор мы говорили об управлении конфигурацией в широком смысле как о дисциплине. Это было позволительно, пока не рассматривались стандарты. Теперь же и далее, если не будет явно оговорено что-то другое, мы будем рассматривать процесс управления конфигурацией. Ниже рассматриваются стандарты, определяющие процесс управления конфигурацией, а также рассматривается сам процесс стандартизации с точки зрения применения процедур УК.
Виды стандартов
Для определения основных положений процесса управления конфигурацией представляется разумным воспользоваться существующими стандартами, описывающими процесс УК. При этом следует определить тот стандарт, который будет в наибольшей степени соответствовать потребностям конкретного предприятия.
Все стандарты можно условно разделить на виды, в зависимости от широты их области действия:
- Международные стандарты, действующие без ограничений во всех странах;
- Государственные или отраслевые стандарты, действующие для группы предприятий или организаций, объединяемых некоторыми общими признаками;
- Внутренние стандарты предприятия, действующие для конкретного предприятия и учитывающие специфику этого предприятия.
Некоторые часто используемые международные стандарты приведены ниже (см. таблицу 1). В таблице «SCM» обозначает возможность использования стандарта для УК ПС (software configuration management), а «HCM» — для оборудования (hardware configuration management). В рассматриваемой таблице выделены три наиболее значимые области использования стандартов:
- процесс приобретения, в ходе которого определяется степень совместимости приобретаемого продукта с уже эксплуатирующимися в организации системами и оборудованием;
- процесс поставки/разработки продукта, для которого особенно важным является согласованность действий поставщика/разработчика и заказчика продукта при определении конфигурационной идентификации, ревизий и аудита конфигурации, согласовании изменений, вносимых в продукт;
- данные — эта область действия стандартов достаточно специфическая и касается в первую очередь установления согласованных форматов и правил их изменения при обмене данными между различными подразделениями или организациями.
Таблица 1. Международные стандарты, описывающие процесс УК
|
Стандарты и руководства |
Область действия |
Описание |
|
|---|---|---|---|
|
Процесс приобретения |
Процесс поставки/ разработки |
||
|
IEEE/EIA 12207.0-1996, Industry Implementation of International Standard ISO/IEC 12207:1995 (ISO/IEC12207) Standard for Information Technology — Software Lifecycle Processes |
SCM, SW |
SCM, SW |
Устанавливает общую структуру процессов жизненного цикла (ЖЦ) программных средств. |
|
IEEE/EIA 12207.1-1996, Lifecycle data. |
SCM, SW |
SCM, SW |
Представляет рекомендации о характере данных, которые должны сохраняться при выполнении задач и работ, приведенных в IEEE/EIA 12207.0 |
|
IEEE/EIA 12207.2-1996, Implementation Considerations |
SCM, SW |
SCM, SW |
Представляет рекомендации по реализации требований стандарта IEEE/EIA 12207.0. |
|
ISO 9000-3: Quality Mgmt & Quality Assurance Stds-Part 3: Guidelines for the application of ISO 9001 to the development, supply and maintenance of software |
SCM, SW |
Излагает рекомендации по применению ISO 9001 в организациях, разрабатывающих, поставляющих и сопровождающих программное обеспечение (ПО). |
В качестве примера отраслевого стандарта можно привести MIL-STD-2549 «Configuration Management Data Interface», который детализирует требования для обмена данными между правительственными системами конфигурационного управления.
Международные и отраслевые стандарты не дают возможности напрямую применять описываемый в них процесс на уровне предприятия, так как само описание процесса УК в них приведено недостаточно подробно для прямого использования.
Обычная практика использования таких стандартов состоит в их адаптации для нужд конкретного предприятия. При адаптации стандарта определяется, в какой степени он будет использоваться на предприятии — полностью; за исключением определенных ситуаций; отдельные положения стандарта. Далее положения стандарта детализируются и дополняются с учетом специфики конкретного предприятия.
Для детализации процесса УК при его адаптации можно использовать методологии, разработанные различными международными организациями и фирмами (например, Rational Unified Process). Такие методологии обычно содержат более детальное описание процесса и часто имеют руководства по применению инструментальных средств автоматизации, что существенно упрощает адаптацию методологии. Впрочем, бывают ситуации, когда специфика предприятия настолько отличается от общих правил, предлагаемых методологией, что проще детализировать процесс УК самостоятельно, без привязки к какой-либо методологии.
Итогом такой адаптации обычно является внутренний стандарт предприятия на процесс управления конфигурацией. Таким образом, прослеживается следующая цепочка:
- Международный стандарт — определение общих положений процесса УК;
- Методология, соответствующая выбранным общим положениям — детализация процесса УК на основе проверенных на опыте многих компаний принципов и правил;
- Стандарт предприятия — уточнение процесса и его адаптации к нуждам конкретного предприятия.
Стандарт предприятия требует серьезной проработки своих положений, и работа по вводу его в действие обычно занимает несколько лет. До момента ввода в действие стандарта предприятия в проектах могут действовать отдельные нормативные и организационно-распорядительные документы.
Управление изменениями как составная часть процесса УК
Прежде чем переходить к подробному рассмотрению описания процесса УК в одном из стандартов, необходимо дать некоторые разъяснения, касающиеся современного представления о процессе УК и изменениях, произошедших с момента формирования первоначального представления о дисциплине управления конфигурацией.
Первоначально управление конфигурацией включало в себя и управление требованиями, и управление изменениями, и версионный контроль. Это зафиксировано во всех основных стандартах, касающихся УК. С точки зрения стандартов программной инженерии этот подход действует и сейчас.
С теоретической точки зрения вполне разумно оставить все три взаимосвязанных процесса — управление требованиями, управление изменениями и версионный контроль — в рамках единого процесса управления конфигурацией. Но на практике дело в настоящий момент обстоит иначе.
Трудно сказать, что было первопричиной — реальные потребности пользователей или маркетинговые стратегии фирм-производителей инструментальных средств, но в настоящий момент управление требованиями в подавляющем большинстве проектов рассматривается как отдельный процесс, а управление изменениями в половине проектов рассматривается как отдельный процесс, а в другой половине — как часть процесса управления конфигурацией. И только версионный контроль всегда рассматривается как часть управления конфигурацией.
Далее мы будем рассматривать управление требованиями как отдельный процесс, не являющийся частью процесса управления конфигурацией, хотя и тесно с ним связанный (хотя это и противоречит ряду стандартов, не выделяющих управление требованиями в отдельный процесс).
Разделение управления конфигурацией и управления изменениями на отдельные процессы или рассмотрение единого процесса управления конфигурацией с технологической точки зрения имеет мало отличий. Вопрос о разделении рассматривается главным образом с точки зрения организационной структуры, обеспечивающей выполнение единого процесса или двух взаимосвязанных процессов, и с точки зрения использования инструментальных средств автоматизации процесса управления конфигурацией и управления изменениями. Авторам удавалось одинаково успешно реализовывать проекты и в том, и в другом случае.
Далее, если явно не оговорено противное, управление изменениями всегда будет рассматриваться как часть процесса управления конфигурацией, что соответствует стандартам, используемым при определении процесса УК.
Один из таких стандартов — ГОСТ Р ИСО/МЭК 12207 — рассматривается ниже.
Процесс УК в стандарте ГОСТ Р ИСО/МЭК 12207
Почему при выборе стандарта, определяющего процесс управления конфигурацией, для подробного рассмотрения мы остановились на стандарте ГОСТ Р ИСО/МЭК 12207 «Информационные технологии. Процессы жизненного цикла программных средств»? Для этого есть несколько важных причин:
- Стандарт ГОСТ Р ИСО/МЭК 12207 является российским стандартом, официально введенным в действие на территории Российской Федерации.
- Рассматриваемый стандарт создан на основе одного из наиболее популярных международных стандартов в сфере информационных технологий — ISO/IEC 12207:1995 (ISO/IEC12207) Standard for Information Technology — Software Lifecycle Processes.
- Популярные методологии разработки ПС ( такие как Rational Unified Process) основываются на ISO/IEC 12207:1995 (ISO/IEC12207) Standard for Information Technology — Software Lifecycle Processes.
Прежде чем переходить непосредственно к процессу управления конфигурацией, определяемому в данном стандарте, рассмотрим кратко стандарт в целом.
Российский стандарт ГОСТ Р ИСО/МЭК 12207 рассматривает процессы жизненного цикла (ЖЦ) программных средств (ПС) и подразделяет их на три группы:
- Основные.
- Вспомогательные.
- Организационные.
Стандарт ГОСТ Р ИСО/МЭК 12207 устанавливает общую структуру процессов жизненного цикла (ЖЦ) программных средств (ПС), определяет процессы, работы и задачи, выполняемые в ходе ЖЦ ПС.
Процесс конфигурационного управления определяется как вспомогательный процесс (см. рисунок 2).
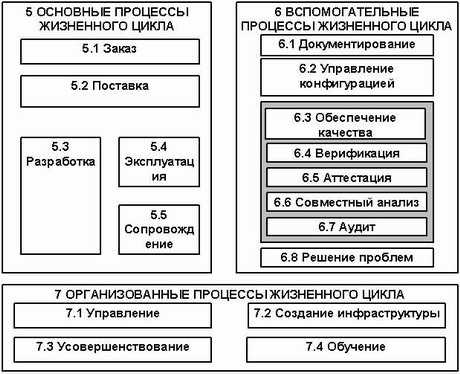
Рисунок 2. Процессы жизненного цикла ПС по ГОСТ Р ИСО/МЭК 12207.
В соответствии с рассматриваемым стандартом, данный процесс состоит из следующих работ:
- подготовка процесса;
- определение конфигурации;
- контроль конфигурации;
- учет состояний конфигурации;
- оценка конфигурации;
- управление выпуском и поставка.
Ниже приведены краткие описания всех работ процесса.
Подготовка процесса
Должен быть разработан план управления конфигурацией. План должен определять: работы по управлению конфигурацией; процедуры и график выполнения данных работ; организацию(и), ответственную(ые) за выполнение данных работ; связь данной организации(й) с другими организациями, например, по разработке и сопровождению программных средств. План должен быть документально оформлен и выполнен (план может быть частью плана управления конфигурацией системы).
Определение конфигурации
Должна быть определена схема обозначения программных объектов и их версий (объектов программной конфигурации), которые контролируются при реализации проекта. Для каждого программного объекта и его версий должны быть определены: документация, в которой фиксируется состояние его конфигурации; эталонные версии и другие элементы обозначения.
Контроль конфигурации
Анализ и оценка изменений; принятие или непринятие заявки; реализация, верификация и выпуск измененного программного объекта. Для каждого изменения должны отслеживаться проводимые аудиторские проверки, посредством которых анализируется каждое изменение, его причина и разрешение на его внесение. Должны быть выполнены контроль и аудиторская проверка всех доступных контролю программных объектов, которые связаны с критическими функциями безопасности или защиты.
Учет состояний конфигурации
Должны быть подготовлены протоколы управления и отчеты о состоянии, которые отражают состояние и хронологию изменения контролируемых программных объектов, включая состояние их конфигурации. Отчеты о состоянии должны включать количество изменений в данном проекте, последние версии программных объектов, обозначения выпущенных версий, количество выпусков и сравнения программных объектов различных выпусков.
Оценка конфигурации
Должны быть определены и обеспечены: функциональная законченность программных объектов с точки зрения реализации установленных к ним требований; физическая завершенность программных объектов с точки зрения реализации в проекте и программах всех внесенных изменений.
Управление выпуском и поставка
Должны официально контролироваться выпуск и поставка программных продуктов вместе с соответствующей документацией. Оригиналы программ и документации должны сопровождаться в жизненном цикле. Программы и документация, связанные с обеспечением критических функций безопасности или защиты, должны обрабатываться, храниться, упаковываться и поставляться в соответствии с установленными правилами.
Управление конфигурацией с точки зрения Capability Maturity Model
CMM (Capability Maturity Model) — модель зрелости процессов создания ПО, или эволюционная модель развития способности компании разрабатывать качественное программное обеспечение.
Изначально CMM разрабатывалась и развивалась как методика, позволяющая крупным правительственным организациям США выбирать наилучших поставщиков ПО. Для этого предполагалось создать исчерпывающее описание способов оценки процессов разработки ПО и методики их дальнейшего усовершенствования. В итоге авторам удалось достичь такой степени подробности и детализации, что стандарт оказался пригодным и для обычных компаний-разработчиков, стремящихся качественно улучшить существующие процессы разработки, привести их к определенным стандартам.
Ключевым понятием стандарта является зрелость организации. Незрелой считается организация, в которой процесс разработки программного обеспечения зависит только от конкретных исполнителей и менеджеров, а решения зачастую просто импровизируются «на ходу» — то, что на современном языке называется творческим подходом, или искусством. В этом случае велика вероятность превышения бюджета или выхода за рамки сроков сдачи проекта, поэтому менеджеры и разработчики вынуждены заниматься только разрешением актуальных проблем, становясь тем самым заложниками собственного программного продукта. К сожалению, на данном этапе развития находится большинство компаний (по градации CMM этот уровень обозначается числом 1).
В зрелой организации, напротив, имеются четко определенные процедуры создания программных продуктов и отработанные механизмы управления проектами. Все процедуры и механизмы по мере необходимости уточняются и совершенствуются в пилотных проектах. Оценки времени и стоимости выполнения работ основываются на накопленном опыте и достаточно точны. Наконец, в компании существуют стандарты на процессы разработки, тестирования и внедрения, а также правила оформления конечного программного кода, компонентов, интерфейсов и т.д. Все это составляет инфраструктуру и корпоративную культуру, поддерживающую процесс разработки программного обеспечения. Технология выпуска будет лишь незначительно меняться от проекта к проекту на основании абсолютно стабильных и проверенных подходов.
CMM определяет пять уровней зрелости организаций. В результате аттестации компании присваивается определенный уровень, который в дальнейшем может повышаться или понижаться. Следует отметить, что каждый следующий уровень включает в себя все ключевые характеристики предыдущих.
(1) Начальный уровень (initial level) — это основной стандарт. К данному уровню, как правило, относится любая компания, которой удалось получить заказ, разработать и передать заказчику программный продукт. Предприятия первого уровня не отличаются стабильностью разработок. Как правило, успех одного проекта не гарантирует успешность следующего. Для компаний данного уровня свойственна неравномерность процесса разработки — наличие авралов в работе. К этой категории можно отнести любую компанию, которая хоть как-то исполняет взятые на себя обязательства.
(2) Повторяемый уровень (repeatable level). Данному уровню соответствуют предприятия, обладающие определенными технологиями управления проектами. Планирование и управление в большинстве случаев основывается на имеющемся опыте. Как правило, в компании данного уровня уже выработаны внутренние стандарты и организованы специальные группы проверки качества.
(3) Определенный уровень (defined level). Уровень характеризуется наличием формального подхода к управлению (то есть описаны все типичные действия, необходимые для многократного повторения: роли участников, форматы документов, производимые действия и пр.). Для создания и поддержания подобного стандарта в актуальном состоянии в организации уже подготовлена специальная группа. Компания постоянно проводит специальные тренинги для повышения профессионального уровня своих сотрудников. Начиная с этого уровня организация перестает зависеть от личностных качеств конкретных разработчиков и не имеет тенденции скатываться на нижестоящие уровни. Абстрагирование от разработчиков обусловлено продуманным механизмом постановки задач и контроля исполнения.
(4) Управляемый уровень (managed level). Уровень, при котором устанавливаются количественные показатели качества.
(5) Оптимизирующий уровень (optimizing level) характеризуется тем, что мероприятия по совершенствованию рассчитаны не только на существующие процессы, но и на оценку эффективности ввода новых технологий. Основной задачей всей организации на этом уровне является постоянное совершенствование существующих процессов, которое в идеале призвано способствовать предупреждению возможных ошибок или дефектов. Применяется механизм повторного использования компонентов от проекта к проекту, например шаблоны отчетов, форматы требований.
Из градации уровней видно, что технологические требования сохраняются только до 3-го уровня, далее же в основном следуют требования к административному управлению. То есть уровни 4 и 5 по большей части управленческие и для их достижения важно не только выпустить программный продукт, но и проанализировать ход проекта, а также построить планы на будущий проект, основываясь на текущих шаблонах. Применение данных подходов должно обеспечить планомерно-плавное улучшение используемых процессов.
Хотя в России знают аббревиатуру СММ, в большинстве организаций не представляют себе, каким образом можно добиться качественного скачка. И дело не только в том, что неизвестно направление этого скачка, а в том, что каждой отдельно взятой компании довольно трудно выстроить свои процессы под требования CMM самостоятельно, без внешнего вмешательства. А зачем изобретать велосипед? Не проще ли взять готовый набор решений (например методологию, IBM Rational Unified Process или аналогичную), внедрить их (здесь уже можно и своими силами обойтись), получив готовый набор решений для качественного построения процесса Управления Конфигурациями, а уж затем приглашать специалистов и аттестоваться на определенный уровень? В России уже есть примеры компаний, которые аттестовались на более высокий уровень СММ именно благодаря внедрению решений на основе IBM Rational Unified Process . Вы можете найти их поиском в Интернет.
На Западе технологии компании IBM Rational сегодня уже широко используют для оптимизации процесса выпуска ПО. Причин тому несколько: во-первых, IBM Rational Software — практически единственная компания, которая четко описала весь производственный цикл по выпуску программного обеспечения (IBM Rational Unified Process), определила все возможные виды документов, сопровождающие проект, строго расписала роли (входные/выходные документы, шаблоны документов и пр.) каждого участника проекта. Во-вторых, компания создала специальное программное обеспечение для качественного исполнения как каждого этапа в отдельности, так и всего проекта в целом. Важно и то, что IBM Rational посредством RUP предлагает перейти от программирования как искусства к программированию как к науке, где все понятно и прозрачно благодаря научному подходу к разработке. По некоторым оценкам западных аналитиков, соотношение возврата капитала до и после внедрения процессов варьируется от 5:1 до 8:1.
Требования к процессу УК в СММ
Конфигурационное управление участвует в идентификации конфигурации выпускаемого ПО (то есть в выборе программного продукта и в его описании) в срок. SCM (Source Configuration Management) обеспечивает систематизированное управление изменениями конфигурации, поддержание их целостности и актуальности на протяжении всего жизненного цикла проекта. Результаты разработки, которые поставляются клиенту, находятся под управлением конфигурационной системы. Также под ее управлением находятся все документы и результаты компиляции (документы требований, отчеты, исходные данные на любом языке программирования).
Библиотеки базовых линий должны быть установлены и содержать работающие версии релизов. Под базовыми версиями здесь и далее понимается набор версий исходных файлов, составляющих конкретную версию откомпилированного релиза. Изменения базовых линий программного продукта, построенных на основе библиотеки базовых линий, должны быть управляемыми посредством контроля изменений и конфигурационного аудита функций в SCM, что полностью обеспечивается продуктом Rational ClearCase (версионное управление).
Все данные из ключевых областей процесса (Key Process Area) охватывают возможные методы исполнения функции конфигурационного управления. В СММ все качественные требования представляются именно как KPA. Каждый из этих методов четко описывает определенный участок с формализованными требованиями, а RUP способен привести этот участок в соответствие означенному требованию.
Механизмы, идентифицирующие определенные единицы конфигурации, содержатся в KPA и описывают развитие и сопровождение каждой единицы конфигурации (исходные тексты, картинки, документация и пр.).
Ниже приведены требования CMM к процессу конфигурационного управления с вольными авторскими комментариями. Это требования 2 и 3 уровней. Хочется отметить, что внедрение УК в соответствии с RUP автоматически дает уровень 3 CMM
Цели процесса УК:
1. Управление конфигурацией происходит на плановой основе
Многие компании при попытке поставить любой процесс (не важно какой, но в данном случае —Управления Конфигурациями ) ограничиваются только инсталляцией программных средств с минимальными затратами в дальнейшей работе. Так был загублен не один проект. Во-первых, всегда должна быть планомерная работа. А во-вторых, сначала внедряется процесс, а потом инсталлируются средства автоматизации (уж никак не наоборот). Соответственно, если есть процесс, то должен быть документ, описывающий его. Таким документом для УК является «План управления конфигурациями», где излагается концепция процесса и имплементация средств автоматизации. В нем же расписываются все роли, и, что особенно важно, деятельности в зависимости от стадии жизненного цикла разработки ПО.
2. Все изменения происходят управляемо
Практически следствие из первого пункта. В проекте не бывает и не может быть неконтролируемых изменений.
Обязательства по выполнению
1. Проект следует документированной организационной политике
1.1. Есть ответственные за выполнение проекта
Мало иметь ответственных. Они должны быть формально утверждены. Должен быть документ (например, приказ) в котором назначаются ответственные за реализацию.
1.2. УК реализуется на протяжении всего жизненного цикла разработки
Недостаточно использовать УК только на этапе разработки. УК реализуется на протяжении всего жизненного цикла: от бизнес-моделирования и постановки требований до ввода в эксплуатацию и сопровождения (если ведется поддержка разработанного программного обеспечения, то УК заканчивается только с окончанием поддержки).
1.3. УК реализуется для конечных продуктов, промежуточных, экспериментальных и перспективных
Очень часто бывает, что разработчикам разрешают промежуточные версии, перспективные макеты и т.д. разрабатывать локально. Логика руководства понятна — пусть он работает — придет время, все, что сделал, впишет в проект. Это неправильно. Нормально поставленный процесс подразумевает, что все изменения делаются в средстве автоматизации процесса УК, так как здесь хранится история изменений и комментарии к ним. Ведь если разработчик уйдет, то в случае такой организации проект пойдет дальше. А если разработка велась локально, то можно и потерять сегменты кода, а значит потерять массу времени на восстановление.
1.4. Все проекты имеют собственный репозиторий
*
*
*
(Примечание: здесь приводятся только основные требования к процессу. В стандарте СММ их существенно больше. Пропуски отмечены символами «*». Более подробную информацию о стандарте можно получить на сайте SEI-CMM)
4. Работы по УК должны быть обеспечены ресурсами
Очень часто внедрение процессов происходит по сценарию: «Витек или Васек все сделают». В итоге ничего не сделано. Процесс должен быть обеспечен ресурсами. Должны быть назначены ответственные, им должны быть вменены дополнительные обязанности. Если это не сделано, то проект рассыплется очень скоро.
4.1. Назначение менеджера УК
Ключевая роль. Этот человек знает процесс разработки. Понимает цели и задачи УК. Все свои знания он излагает в плане УК. Сам управляет процессом УК. Очень часто пытаются либо вообще обойтись без такой роли, либо «спихивают» ее на разработчиков. Естественно, это неправильно, так как разработчик не видит всей картины процесса разработки, может не понимать структурных взаимодействий между отделами… и т.д. Перечень непониманий можно продолжать далее. На первых порах, на порах становления роль менеджера берет на себя человек, который имеет представление о процессе разработки. Такой человек всегда есть в коллективе.
4.2. Назначение администратора УК
Для того, чтобы все работало и проверялось, необходим человек, занимающийся поддержкой процесса. Если менеджер процесса отвечает за его логическую стройность, непротиворечивость и необходимую детальность (все это отражено в плане), то администратор должен имплементировать эту концепцию в дело (превратить в скрипты, настройки). Ведь план — это верхний уровень, а его реализация — нижний. Так вот, администратор и отвечает за реализацию и поддержание процесса. Без него также не обойтись.
4.3. Работы обеспечены инструментальными средствами и оборудованием
5. Участники УК должны пройти обучение целям, процедурам и методам выполнения работ по УК
6. Члены группы разработки ПО должны пройти обучение по своим задачам
Проблема проблем — инструмент поставили, а что делать не сказали. Все участники должны пройти обучение, для понимания того, чего же от них требуется в плане знания инструмента и что же им нужно делать в проекте. Конечно, можно обойтись и без обучения, только риски запороть дело очень высоки, ведь никому в голову не придет сажать за руль автомобиля человека, который не умеет водить, а лишь слышал, как это делается. Кажется, что в деле разработки ПО все не так. Но законы природы одинаковы везде — сначала обучение — потом практика (это общий комментарий к пунктам 5 и 6).
Операции
1. Для каждого проекта готовится план УК
Что хорошо в плане УК, так это то, что он долго пишется всего ОДИН раз. Далее для каждого проекта пишется новый план, на основе существующего, так как способы и методы в новом проекте могут отличаться, то и план описывает все особенности данного проекта. Но план должен относиться к этому проекту, даже если проект ведется точно так же, как все остальные.
1.1. План разрабатывается на ранних стадиях общего планирования проекта
План должен быть подготовлен на самых ранних стадиях, еще до того, как разработчики включили компьютеры.
1.2. План рассматривается всеми участниками процесса и рецензируется ими
План — живой документ. План пишут живые люди, которые могут ошибиться. План — не секретный документ — он должен храниться на видном месте, его должны все читать, так как план описывает процесс разработки, то его ОСОБЕННО должны читать вновь пришедшие разработчики, тестировщики, менеджеры. Чтобы план был живым плодом любви, а не засохшим листком в гербарии — его необходимо читать и корректировать — избавлять от косноязычия и от неправильных формулировок. Такая ошибка, как неправильное понимание процесса, ведет к простоям и частым доработкам продукта.
1.3. План должен быть доступен и управляем в части его изменений
*
*
*
3. Устанавливается библиотечная система УК, служащая репозиторием проекта
Все в третьем пункте относится не столько к процессу, сколько к средству автоматизации. Конечно, можно поставить процесс и без средств автоматизации, только это будет очень неправильно. На рынке есть масса средств, которые при должной настройке смогут поддерживать процесс. Требования к ним приведены ниже.
3.1. Многоуровневая поддержка контроля УК
3.2. Хранение и извлечение элементов конфигурации
3.3. Совместное использование элементов группами разработчиков
3.4. Помощь в применении производственных стандартов УК
3.5. Хранение и извлечение архивных версий
3.6. Обеспечение корректного создания продуктов
3.7. Хранение и обновление записей по УК
3.8. Поддержка создания отчетов
3.9. Поддержка структуры и содержимого библиотеки
4. Идентификация промежуточных программных продуктов, находящихся в системе УК
4.1. Выбор элементов на основании документированных критериев
4.2. Элементам репозитория назначаются уникальные идентификаторы
4.3. Определяются характеристики каждого блока конфигурации
4.4. Определяются базовые линии
4.5. Для каждого блока определена стадия разработки, на которой он помещается в систему УК
4.6. Определен ответственный за каждый элемент
5. Запросы обслуживаются. Отчеты составляются
Здесь важно, чтобы автор каждого запроса был в курсе его текущего статуса, а каждый отчет имел своего читателя.
6. Изменение базовых версий ( baseline ) происходит подконтрольно, в соответствии с документированной процедурой
6.1. Выполнение проверок и регрессионных тестов
6.2. Внесение в библиотеку базовых версий лишь утвержденных блоков конфигурации
6.3. Внесение и извлечение блоков конфигурации не нарушает целостность проекта
7. Создание продуктов на основе библиотек базовых версий и контролирование их выпуска в соответствии с документированной процедурой
7.1. Комиссия контролирует создание продуктов на основе библиотеки базовых версий
7.2. Все элементы создаются только из блоков конфигурации, содержащихся в библиотеке базовых версий
8. Запись статуса элементов конфигурации в соответствии с документированной процедурой
8.1. Запись действий по УК производится с детальностью, достаточной для того, чтобы иметь в наличии статус всех элементов
8.2. Иметь возможность восстановить прежние версии файлов
8.3. Ведение истории изменений
Измерения и анализ
1. Выполнение измерений и использование их результатов для определения состояния работ по УК
Все, с чем мы сталкиваемся в жизни, можно измерить. Процесс УК не исключение — его тоже можно измерить. Мало того, ЕГО НУЖНО измерять. Ведь при активной работе в репозитории (хранилище) скапливается огромное число статистических сведений. Формирование отчетов и аналитических срезов — есть неотъемлемая часть как процесса разработки вообще, так и УК в частности. Ведь только на основе анализа собранной статистики можно принимать решения о дальнейших действиях. СММ оговаривает только самые важные срезы и отчеты.
1.1. Отчеты по количеству запросов за единицу времени
1.2.Отчеты по выполнению этапов работ по УК в сравнении с планом
1.3. Отчеты по объему выполненных работ по УК
1.4. Отчеты по ресурсам
Вместо заключения
Хочется напомнить, что здесь приведены только самые основные ключи СММ. Остальное смотрите в стандарте.
Но перед тем, как вы закроете данную статью — выпишите требования к процессу, выдвигаемые СММ и сравните с тем, как обстоят дела в вашей компании. Мы будем рады, если хотя бы 50% требований у вас совпало!
Если это не так, то вам нужно серьезно задуматься над улучшением процесса УК.
![]()
- Измерители-регуляторы
- Для ГВС, отопления, вентиляции и котельных
- Для пищевых производств
- Счетчики, таймеры, тахометры
- Для управления насосами
- Для электрических сетей
- Архиваторы
- Ручные задатчики сигналов
- Дополнительные устройства
- Программируемые реле
- Программируемые логические контроллеры
- Сенсорные панельные контроллеры
- Панели оператора
- Модули ввода/вывода
- Преобразователи частоты
- Дроссели
- Тормозные резисторы
- Блоки питания
- Устройства коммутации
- Устройства контроля и защиты
- Регуляторы мощности
- Твердотельные реле KIPPRIBOR
- Твердотельные реле Протон-Импульс
- Твердотельные и промежуточные реле MEYERTEC
- Промежуточные реле
- Приборы для индикации и управления задвижками
- Микроклимат для шкафов управления
- Электротехническое оборудование MEYERTEC
- Датчики температуры
- Датчики влажности и температуры воздуха
- Преобразователи давления
- Датчики уровня
- Датчики газа
- Бесконтактные датчики
- Барьеры искрозащиты
- Нормирующие преобразователи
- Аксессуары к датчикам температуры
- Аксессуары к датчикам давления
- Аксессуары к датчикам уровня
- Аксессуары к датчикам влажности
- OwenCloud
- SCADA системы
- OPC-серверы
- Конфигураторы
- Среда программирования CODESYS
- Среда программирования Owen Logic
- Драйверы и библиотеки ОВЕН
- Коммутаторы
- Преобразователи интерфейсов и повторители
- Модемы
- PLC-модемы
- Аксессуары
- Новости
- Мероприятия
- Журнал АиП
- Где купить
- Контакты
- О заводе № 423
- История
- Профиль
- Наши клиенты
- Аттестация на право поверки
- Партнерам
- Работа в компании
- Каталог продукции ОВЕН
- Политика обработки персональных данных
- Материалы для вашего сайта
- Документация и ПО
- Видео
- Прайс-лист
- Новинки
- Полезные материалы
- Каталог проектов
- Сервисный центр
- Проверить статус заказа
- Мастер подбора оборудования
- Учебный центр ОВЕН
- Региональные учебные центры
- Программа сотрудничества с вузами
- Личные данные
- Корзина/оформление
- Оформленные заказы

")
ОВЕН – российский разработчик и производитель средств промышленной автоматизации. На сайте owen.ru представлен полный каталог продукции компании: контрольно-измерительные приборы, программируемые контроллеры, датчики.
Предложения и замечания по работе сайта пишите: internet@owen.ru
© 1991-2023 ОВЕН. Все права защищены.
Тел.: +7 (495) 64-111-56
E-mail: sales@owen.ru
1-я ул. Энтузиастов, д. 15, стр. 1
Общество с ограниченной ответственностью «Производственное Объединение ОВЕН»
ул. 2-я Энтузиастов, д.5, к.5
Москва, 111024
Россия
Конфигурация через Руководство по внедрению
Конфигурация через Руководство по внедрению
Как и в более ранней методологии внедрения SAP, известной как «процедурная модель», в ASAP вся конфигурация осуществляется в среде, называемой «Руководство по внедрению» (Implementation Guide, IMG), которая не сильно отличается от модулей инициализации в традиционных компьютерных системах, хотя и значительно превосходит их по размерам. В SAP предусмотрено более 8000 таблиц конфигурации. Все бизнес-процессы компании могут внедряться в функциональность системы SAP посредством конфигурации параметров в IMG. Во время внедрения любого процесса необходимо идентифицировать параметры, которые нужно будет задать, прежде чем процесс сможет работать в системной среде. Например, при создании счета-фактуры необходимо сначала указать параметры налогообложения и задать их с помощью IMG. Общий процесс идентификации параметров, отвечающих требованиям компании, известен как внесение настроек и также осуществляется с помощью IMG. Впрочем, существенная проблема состоит в том, что в интегрированных системах, сходных с SAP, не существует систематизированного способа быстрой и исчерпывающей идентификации всех параметров, необходимых при внедрении.
Как станет ясно после прочтения раздела, «Руководство по внедрению (IMG)», IMG структурировано таким образом, что отражает последовательность, с которой должны задаваться параметры, но, по большому счету, этого недостаточно для быстрого внесения настроек в SAP. Для стандартной команды проекта SAP идентификация сотен параметров и их последовательности в довольно жестких временных рамках зачастую представляет весьма трудновыполнимую задачу. Это скорее не систематический процесс, а опыт открытий — при том, что количество параметров, которые необходимо идентифицировать и задать, весьма значительно. Во избежание ошибок, команды проектов обычно занимают оборонительную позицию, проверяя и перепроверяя каждый мелкий аспект перед тем, как сделать следующий шаг (хотя и это не гарантирует того, что ничего не будет упущено). Это увеличивает необходимые для завершения проекта затраты времени, попутно теряются все преимущества, которые дает концепция информационных систем как товаров на полках супермаркета (см. соответствующий раздел в главе 1). Очевидное средство преодоления этой проблемы и ускорения внедрения SAP — в решении двух вопросов:
• Сокращение разрыва между требованиями компании и технологией тех процессов компании, которые необходимо внедрить, с одной стороны — и функциональностью SAP и возможными IMG-настройками с другой стороны.
• Быстрая передача профессиональных знаний и опыта, накопленных с помощью множества других проектов, новым командам внедрения SAP.
Как уже упоминалось в этой книге, такие ориентированные на хранилище информации системы, как SAP, продолжают традицию работы со средой автоматизированной разработки программного обеспечения (Computer-aided software engineering, CASE). Похожим образом второй из приведенных выше пунктов относится к среде автоматизированного внедрения программных продуктов (Computer-aided software implementation, CASI), которую мы рассмотрим в следующем разделе.
Читайте также
1. Пошаговое руководство
1. Пошаговое руководство
Это формат информационного продукта, который будет работать всегда. Каждый из нас любит, чтобы все разложили по полочкам – как и что сделать. Нужно выделить 15, 20 или 30 шагов и объяснить, как получить результат. Очень много бестселлеров сделаны по
1.5. Руководство к действию
1.5. Руководство к действию
Рецепт 1. Запустить редактор SCHEMATICS1. Щелкните по кнопке Пуск (Start) на панели задач Windows (рис. 1.1).2. Выберите в основном меню Windows команду Программы?DESIGNLAB EVAL_8?SCHEMATICS (рис. 1.1).3. Щелкните левой клавишей мыши по строке SCHEMATICS. (См. раздел 1.1.)
Внимание!
2.3. Руководство к действию
2.3. Руководство к действию
Рецепт 1. Запустить процесс моделированияПервый способ:1. Откройте меню Analysis.2. Щелкните левой кнопкой мыши по строке Simulate.(См. раздел 2.1 и рис. 2.2.)Второй способ:Щелкните по кнопке
.Рецепт 2. Указать на схеме постоянные напряженияПервый
3.2. Руководство к действию
3.2. Руководство к действию
Рецепт 1. Провести анализ цепи переменного тока (для одной частоты)1. Разместите в требуемых местах схемного чертежа символ(ы) VPRINT и/или IPRINT (см рис. 3.11).2. Установите необходимые атрибуты для символов VPRINT и IPRINT (MAG, PHASE, АС и др.).3. Запустите в окне
4.5. Руководство к действию
4.5. Руководство к действию
Рецепт 1. Провести анализ переходных процессов1. Откройте окно Analysis Setup (см. рис. 4.3), щелкнув по кнопке
.2. В этом окне установите флажок рядом с кнопкой Transient…, чтобы активизировать режим анализа переходных процессов.3. Щелкните по кнопке Transient…,
5.4. Руководство к действию
5.4. Руководство к действию
Рецепт 1. Провести анализ AC Sweep1. Начертите в редакторе SCHEMATICS нужную вам схему. Следите за тем, чтобы выбранный источник напряжения допускал анализ AC Sweep (это может быть источник напряжения VSIN), и не забудьте установить подходящие для анализа AC Sweep
7.6. Руководство к действию
7.6. Руководство к действию
Рецепт 1. Источник постоянного напряжения в качестве изменяемой переменной1. Откройте окно Analysis Setup и установите флажок рядом с кнопкой DC Sweep… (см. рис. 7.2).2. Щелкните по этой кнопке, чтобы открыть окно DC Sweep (см. рис. 7.3).3. В окне выполните следующие
8.6. Руководство к действию
8.6. Руководство к действию
Рецепт 1. Провести параметрический анализ1. Проведите предварительную установку основного анализа. Выберите в качестве изменяемой переменной одну из следующих величин: • для анализа DC Sweep: — источник напряжения; — источник
9.7. Руководство к действию
9.7. Руководство к действию
Рецепт 1. Провести Фурье-анализ процесса1. Выведите на экран PROBE диаграмму процесса (например, напряжения), частотный спектр которого вам необходимо установить с помощью анализа Фурье.2. Убедитесь, что вы смоделировали ровно один период этого
10.3. Руководство к действию
10.3. Руководство к действию
Рецепт 1. Провести статический логический анализ1. Установите на входах источники постоянного напряжения VDC (5 В для сигнала логической единицы, 0 В для сигнала логического нуля).2. Откройте окно Analysis Setup и деактивизируйте все анализы.3. Запустите
7.4.1. Передача данных через параметры и через глобальные объекты
7.4.1. Передача данных через параметры и через глобальные объекты
Различные функции программы могут общаться между собой с помощью двух механизмов. (Под словом “общаться” мы подразумеваем обмен данными.) В одном случае используются глобальные объекты, в другом –
Руководство пользователя PGP.
Руководство пользователя PGP.
Pretty Good Privacy (PGP) выпущено фирмой Phil`s Pretty Good Software и является криптографической системой с высокой степенью секретности для операционных систем MS-DOS, Unix, VAX/VMS и других. PGP позволяет пользователям обмениваться файлами или сообщениями с
Руководство по внедрению
Руководство по внедрению
Implementation Guide (IMG) SAP R/3 играет самую важную роль в настройке системы SAP R/3 под требования конкретной компании. Настройка осуществляется посредством конфигурации программных продуктов SAP в то время, как базовая система SAP остается в
8.2. Подключаться через телефон или через модем?
8.2. Подключаться через телефон или через модем?
Вы можете использовать для подключения к телефону как мобильный телефон, так и EDGE/3G-модем. Какой вариант выбрать? Тут нужно решить, что для вас важнее — экономия или удобство. Ведь сотовый телефон есть у каждого и можно
Особый путь Daimler AG к внедрению в свои машины искусственного интеллекта Михаил Ваннах
Особый путь Daimler AG к внедрению в свои машины искусственного интеллекта
Михаил Ваннах
Опубликовано 17 сентября 2013
Были когда-то автомобили-классики. Не редкой ныне классической схемы (впереди мотор, в середине — кардан, привод на задний мост), а
Мостовая конфигурация (конфигурация hub-and-spoke)
Мостовая конфигурация (конфигурация hub-and-spoke)
В мостовой конфигурации каждый головной УЦ устанавливает отношения кросс-сертификации с единственным центральным УЦ, в чьи функции входит обеспечение таких взаимных связей [101]. Центральный УЦ иногда называют «втулкой» (hub),
Дополнение к документации
Документ содержит описание новых, измененных и исправленных механизмов, а также исправления к книгам документации:
1С:Предприятие 8.0. Конфигурирование и
администрирование. Номер издания 80.002.05
1С:Предприятие 8.0. Руководство пользователя. Номер издания 80.004.05
1С:Предприятие 8.0. Руководство по установке и запуску. Номер издания 80.003.06
1С:Предприятие 8.0. Клиент-сервер. Особенности установки и использования. Номер
издания 80.005.05
Описания содержат только отличия от книг
документации. Описания измененных механизмов представлены в сокращенном виде.
Документ может использоваться только
совместно с документацией.
О
Г Л А В Л Е Н И Е
Книга «1С:Предприятие 8.1.
Конфигурирование и администрирование»
Глава 1. Концепция системы
1С:Предприятие 8.1
Основные понятия системы 1С:Предприятие 8.1
Объект конфигурации
Основные виды объектов конфигурации
Глава 2. Конфигурирование
Окно редактирования объекта
Свойства конфигурации
Категория свойств Основные
Категория свойств Представление
Глава 3. Объекты конфигурации
Модуль сеанса
Ветвь конфигурации «Общие»
Подсистемы
Общие модули
Параметры сеанса
Роли и права доступа
Ограничение доступа к данным
Подписки на события
Регламентные задания
XDTO-пакеты
Импорт схемы XML в глобальную фабрику XDTO
Экспорт схемы XML данных конфигурации
Экспорт схемы XML пакета XDTO
Проверка пакета XDTO
Окно редактирования пакета XDTO
Web-сервисы
Добавление Web-сервиса
Иерархическая структура Web-сервиса
Операции Web-сервиса
Параметр операции
Указание типов, определяемых системой 1С:Предприятие 8.1
Публикация Web-сервисов
WS-ссылки
Отчеты и обработки
Внешние отчеты и обработки
Создание внешней обработки (отчета)
Использование внешних обработок (отчетов)
Редактирование внешней обработки (отчета)
Описание внешней обработки (отчета)
Внешние обработки (отчеты) и объекты конфигурации
Сравнение и объединение внешних обработок (отчетов)
Регистры накопления
Разработка структуры регистра накопления
Свойства измерения (ресурса, реквизита) регистра
накопления
Глава 4. Встроенный язык
Формат исходных текстов программных модулей
Что такое программный модуль?
Виды программных модулей
Модуль сеанса
Операторы и синтаксические конструкции
Особенности режимов запуска 1С:Предприятие
Особенности использования объектов, их свойств и
методов
Глава 5. Работа с запросами
Язык запросов
Использование предопределенных данных конфигурации
Двуязычное представление ключевых слов
Выполнение и работа с запросами во встроенном языке
Работа с временными таблицами
Менеджер временных таблиц
Создание временных таблиц
Использование временных таблиц
Удаление временных таблиц
Глава 6. Работа с данными
Механизм объектных блокировок
Пессимистическая блокировка
Пессимистическая блокировка и транзакции
Оптимистическая блокировка
Механизм транзакций
Использование явного вызова транзакций
Вложенный вызов транзакций
Влияние транзакций на работу программных объектов
Механизм управляемых блокировок
Общие сведения о блокировках
Управляемые блокировки 1С:Предприятия 8.1
Установка режима блокировок в конфигурации
Работа с управляемыми блокировками средствами
встроенного языка
Особенности работы в режиме Автоматический и
управляемый
Модификация конфигураций при переходе к режиму
управляемых блокировок
Определение участков кода, требующих доработки
Выбор режима управляемой блокировки
Примеры доработки конфигурации
Глава 7. Организация бухгалтерского учета
Регистры бухгалтерии
Свойства регистра бухгалтерии
Глава 9. Бизнес-процессы и задачи
Редактирование задачи
Глава 10. Построитель отчета
Схема работы отчета
Язык запросов построителя отчета
Глава 11. Система компоновки данных
Построитель отчета и система компоновки данных
Общие сведения о компоновке данных
Общие объекты системы компоновки данных
Свойство Использование
Поле системы компоновки данных
Параметры системы компоновки данных
Схема компоновки данных
Составные части схемы компоновки данных
Источники данных
Наборы данных
Связи наборов данных
Вычисляемые поля
Поля ресурсов
Параметры
Вложенные схемы
Макеты
Макеты полей
Макеты группировок
Макеты заголовков группировок
Настройки по умолчанию
Работа с несколькими наборами данных
Расширение языка запросов для системы компоновки
данных
Синтаксические элементы расширения языка запросов
системы компоновки данных
Автоматическое заполнение доступных полей
Конструктор схемы компоновки данных
Редактирование наборов данных
Редактирование полей набора данных
Редактирование связей наборов данных.
Редактирование вычисляемых полей
Редактирование ресурсов
Редактирование параметров
Редактирование макетов
Вложенные схемы
Настройки
Настройки компоновки данных
Структура настроек компоновки данных
Свойства настроек компоновки данных
Доступные Объекты
Доступные поля
Компоновщик настроек компоновки данных
Макет компоновки данных
Составные части макета компоновки данных
Язык выражений системы компоновки данных
Макеты областей
Макеты оформления
Генератор областей макетов
Формирование макета компоновки данных
Процессор компоновки данных
Результат компоновки данных
Вывод результата компоновки в табличный документ
Вывод данных в сводную таблицу
Расчет итогов по полям остатка в системе компоновки
данных
Расчет итогов по полям остатка
Расчет итогов по полям бухгалтерских остатков
Компоновка макета
Работа с иерархией в системе компоновки данных
Иерархические группировки
Условие В ИЕРАРХИИ
Использование системы компоновки данных при разработке
прикладных решений
Глава 14. Механизм XDTO
Фабрика XDTO
Типы данных XDTO
Тип значения XDTO
Тип объекта XDTO
Свойство XDTO
Экземпляры данных XDTO
Значение XDTO
Объект XDTO
Последовательность XDTO
Список XDTO
Xpath
XML-сериализация на основе XDTO
Рекомендации по оформлению схем XML
Схема XML не должна содержать анонимных типов.
Для контента сложных типов следует использовать только
модель sequence
Свойства объектов должны представляться в XML только
как элементы.
Не следует использовать модель mixed content
Правила проверки фабрики XDTO
Правила проверки пакета XDTO
Правила проверки типа значения XDTO
Правила ограничения фасетов
Правила проверки типа объекта XDTO
Глава 15. Механизм Web-сервисов
Предоставление функциональности 1С:Предприятия 8.1.
через Web-сервисы
Пример реализации Web-сервиса
Работа с Web-сервисами сторонних поставщиков
Пример использования статической WS-ссылки
Пример использования динамической WS-ссылки
Настройка поддержки WEB-сервисов
Настройка поддержки Web-сервисов для IIS 5.1
Настройка поддержки Web-сервисов для IIS 6.0
Настройка поддержки Web-сервисов для Apache 2.0 под Windows
Настройка поддержки Web-сервисов для Apache 2.0 под Linux
Безопасность WEB-сервисов
Аутентификация
Работа по защищенному каналу
Глава 16. Механизм заданий
Фоновые задания
Регламентные задания
Особенности выполнения фоновых заданий файловом и
клиент-серверном вариантах
Создание метаданных регламентного задания
Примеры
Глава 17. Механизм полнотекстового поиска в
данных
Общие сведения о полнотекстовом индексировании
Выполнение полнотекстового поиска в данных
Использование дополнительных словарей
Глава 18. Инструменты конфигурирования
Конструктор пользовательских интерфейсов
Редактор интерфейсов
Создание нового подменю
Редактор форм
Редактирование формы
Страницы формы
Отладчик и замеры производительности
Использование Отладчика
Настройка приложения для работы в отладочном режиме
Выполнение отладки
Пошаговое выполнение
Отладка внешних обработок
Управление отладкой
Замеры производительности
Результаты замера
Сортировка результатов замера
Особенности замера производительности при работе
клиент-серверной базы
Глава 21. Администрирование
Блокировка установки соединений пользователями
Параметры информационной базы
Журнал регистрации
Настройка журнала регистрации
Технологический журнал
Конфигурационный файл технологического журнала
Структура конфигурационного файла
Элемент <event>
Элемент <property>
Элемент <dump>
Структура технологического журнала
Глава 22. Сервисные возможности
Настройка параметров Конфигуратора
Установка параметров редактирования формы
Запуск 1С:Предприятия
Синтакс‑Помощник
Закладка «Содержание» Синтакс‑Помощника
Поиск в Синтакс‑Помощнике
Формат поисковых выражений
Приложение В.
Формат файла настройки прокси по умолчанию inetcfg.xml
protocols
user
password
bypassOnLocal
bypassOnAddresses
Приложение Г.
Используемые компоненты
Приложение Д. Лицензии
Apache License
Перевод интерфейса выполнен:
Книга
«1С:Предприятие 8.1. Руководство пользователя»
Глава 3. Справочники, планы счетов, планы
видов характеристик, планы видов расчета
Справочники
Редактирование элемента справочника
Редактирование элемента справочника при
многопользовательском режиме
Глава 4. Документы и журналы документов
Поиск документов в журнале и списке
Поиск документа по номеру
Глава 5. Отчеты и обработки
Использование отчета (обработки)
Открытие внешних отчетов и
обработок
Работа с отчетами, использующими систему компоновки
данных
Настройка отчета
Работа с расшифровкой отчета
Язык выражений системы компоновки данных
Глава 9. Общие принципы работы с формами
Управляющие элементы формы
Поле ввода
Реквизит типа «Дата»
Реквизит типа «Строка»
Реквизит типа «Булево»
Реквизиты ссылочных типов
Работа с табличным полем формы
Поиск в списке
Произвольный поиск в списках
Отбор и сортировка списка
Настройка отбора
Настройка списка
Глава 10. Групповое проведение документов и
управление итогами
Проведение документов
Управление итогами
Глава 12. Сервисные возможности
Установка параметров
Настройка показа справки
Системные настройки
Управление полнотекстовым поиском
Работа с буфером обмена
Журнал регистрации
Просмотр журнала регистрации
Установка отбора
Сообщения об ошибках
Глава 13. Получение справочной информации
Встроенная система получения справочной информации
Поиск справочной информации
Поиск по справке
Приложение 2.
Редактор табличных документов
Работа с табличным документом
Сохранение табличного документа
Приложение 6.
Конструктор запроса
Приложение 7.
Расписание регламентные задания
Книга
«1С:Предприятие 8.1. Руководство по установке и запуску»
Введение
Требования к компьютеру и программному обеспечению
Глава 2. Установка и обновление системы
1С:Предприятие 8.1
Установка и обновление 1С:Предприятия 8.1
Начальная установка
Установка с использованием групповых политик домена MS
Windows 2000/2003 Server
Совместное использование 1С:Предприятия 8.1 различных
версий
Обновление 1С:Предприятия 8.1 пользователями Microsoft
Windows без прав администратора
Глава 3. Запуск системы
1С:Предприятие 8.1
Ведение списка информационных баз
Настройка диалога запуска
Списки общих информационных баз
Ярлыки информационных баз
Перезапуск системы 1С:Предприятие 8.1
Глава 6. Особенности защиты системы
1С:Предприятие 8.1 с использованием сетевых ключей
Настройка 1С:Предприятия 8.1 для работы с HASP License Manager
Приложение 2. Формат файла описаний зарегистрированных
информационных баз
Приложение 3. Формат файла, содержащего адрес каталога шаблонов
Книга
«1С:Предприятие 8.1. Клиент-сервер. Особенности установки и использования»
Глава 1. Принципы построения и работы 1C:Предприятия 8.1 с информационными базами в варианте
«клиент-сервер»
Кластер серверов 1С:Предприятия 8.1
Взаимодействие клиентского приложения с кластером
серверов
Анализ статистики загруженности рабочих процессов
Масштабируемость кластера серверов
Увеличение количества рабочих процессов
Увеличение количества рабочих серверов
Варианты конфигурирования кластеров серверов
Несколько кластеров на одном центральном сервере
Смешанное использование рабочих серверов
Безопасность кластера серверов 1С:Предприятия 8.1
Безопасность данных, передаваемых между клиентом и
кластером серверов
Безопасность данных, передаваемых между консолью
кластера серверов и кластером серверов
Безопасность данных, хранящихся в кластере серверов
Безопасность данных, передаваемых внутри кластера
серверов
Администраторы центрального сервера и администраторы
кластера
Особенности работы с сервером баз данных PostgreSQL
Работа под управлением различных операционных систем
Ограничения и особенности Linux
Распределение кластера серверов и сервера баз данных
по компьютерам
Требования к аппаратуре и программному обеспечению
Глава 2. Установка 1C:Предприятия 8.1 для работы с информационными базами в
варианте «клиент-сервер»
Установка клиентского приложения
Установка и запуск кластера серверов
Установка кластера серверов под Windows
Запуск кластера серверов под Windows
Общие сведения о запуске агента сервера
Запуск агента сервера как приложения
Запуск агента сервера как сервиса
Установка кластера серверов под Linux
Запуск кластера серверов под Linux
Запуск агента сервера
Запуск агента сервера в режиме демона
Удаление кластера серверов под Linux
Защита кластера серверов от несанкционированного
использования
Защита кластера серверов под Windows
Защита кластера серверов под Linux
Установка серверов баз данных
Установка MS SQL Server
Установка PostgreSQL
Установка PostgreSQL для Windows
Установка PostgreSQL для Linux
Глава 3. Особенности работы 1C:Предприятия 8.1 с информационными базами в варианте
«клиент-сервер»
Создание информационной базы
Добавление существующей информационной базы
Создание новой информационной базы
Программные средства администрирования кластера
серверов 1С:Предприятия 8.1
Глава 4. Утилита администрирования
кластера серверов
Запуск утилиты администрирования
Работа со списком центральных серверов
Подключение утилиты к центральному серверу
Просмотр и изменение свойств центрального сервера
Отключение утилиты от центрального сервера
Отсоединение утилиты от центрального сервера
Работа со списком администраторов центрального сервера
Добавление администратора центрального сервера
Просмотр и изменение свойств администратора
центрального сервера
Удаление администратора центрального сервера
Аутентификация администратора центрального сервера
Работа со списком кластеров центрального сервера
Добавление кластера
Просмотр и изменение свойств кластера
Удаление кластера
Работа со списком администраторов кластера
Добавление администратора кластера
Просмотр и изменение свойств администратора кластера
Удаление администратора кластера
Аутентификация администратора кластера
Работа со списком рабочих серверов кластера
Добавление рабочего сервера в кластер
Просмотр и изменение свойств сервера кластера
Исключение сервера из кластера
Работа со списком рабочих процессов
Добавление рабочего процесса
Просмотр и изменение свойств рабочего процесса
Остановка/запуск рабочего процесса
Удаление рабочего процесса
Работа со списком информационных баз
Регистрация новой информационной базы
Просмотр свойств информационной базы
Удаление информационной базы
Работа со списком соединений
Виды соединений
Соединения с информационной базой
Служебные соединения
Просмотр свойств соединения
Разрыв соединения
Работа со списком блокировок
Глава 1.
Концепция системы 1С:Предприятие 8.1
Основные понятия системы 1С:Предприятие 8.1
Объект конфигурации
Основные виды объектов конфигурации
Отчеты и обработки
Алгоритм получения отчета может описываться с
использованием встроенного языка или формироваться системой автоматически, в случае
использования системы компоновки данных.
Глава 2.
Конфигурирование
Окно редактирования объекта
На закладке
«Прочее» расположены кнопки открытия справочной информации и модуля объекта, а
также может располагаться кнопка «Предопределенные» для открытия списка предопределенных
элементов объекта (для справочников, планов видов характеристик, планов счетов,
планов видов расчетов). Также на закладке могут располагаться реквизиты
управления блокировкой и настройки использования полнотекстового поиска. Эти
реквизиты присутствуют только для следующих прикладных объектов: справочники,
документы, планы видов характеристик, планы счетов, планы видов расчета,
регистры, бизнес-процессы, задачи.
Свойства
конфигурации
Категория свойств Основные
Дополнительные словари полнотекстового поиска – выбор общих макетов
или констант, которые будут выступать в роли дополнительных словарей для
полнотекстового поиска.
Категория свойств Представление
Заставка — выбор заставки. Выбор осуществляется в стандартном
окне выбора картинки. Для заставки необходимо, чтобы картинка удовлетворяла
следующим требованиям: размер 305×110 пикселей, прозрачный цвет можно задать
при выборе картинки. Тип картинки может быть любым из поддерживаемых системой
1С:Предприятие 8.1.
Авторские права — информация об авторе конфигурации. Отображается в
диалоге «О программе» и в окне справки.
Адрес информации о поставщике — ссылка на информацию о
поставщике конфигурации, указывается в свойстве Авторские права.
Может задаваться как с префиксом схемы («http://»), так и без него. Информация
о поставщике, отображаемая в левой части подвала на страницах справки, имеет
ссылку, определенную в данном свойстве.
Адрес информации о конфигурации — ссылка на информацию о
конфигурации. Может задаваться как с префиксом схемы («http://»), так и без
него. Слева в верхней части страниц справки указывается наименование
конфигурации, определенное в свойстве Краткая информация
(если свойство не задано, то выбирается из значения свойства Синоним, если свойство
Синоним не задано, то выбирается из свойства Имя корневого
объекта конфигурации). Показываемое наименование конфигурации имеет ссылку,
заданную данным свойством.
Глава 3.
Объекты конфигурации
Модуль сеанса
Модулем сеанса называется
модуль, который автоматически выполняется при старте системы 1С:Предприятие 8.1
в момент загрузки конфигурации.
Модуль сеанса предназначен для инициализации параметров
сеанса и отработки действий, связанных с сеансом работы. Модуль сеанса всегда
исполняется в привилегированном режиме в кластере серверов 1С:Предприприятия
8.1.
Важно! Модуль
сеанса может содержать только определения процедур и функций.
Модуль сеанса не содержит экспортируемых процедур и функций
и может использовать процедуры из общих модулей конфигурации.
Установка параметров сеанса выполняется в обработчике
события УстановкаПараметровСеанса().
Исполнение модуля сеанса происходит после начала исполнения
модуля приложения (модуля внешнего соединения), до вызова обработчика события ПередНачаломРаботыСистемы
(ПриНачалеРаботыСистемы,
в случае модуля внешнего соединения).
Ветвь конфигурации «Общие»
На этой ветви описываются такие объекты конфигурации, как Подсистемы,
Общие модули, Параметры сеанса, Роли, Планы обмена, Критерии отбора, Подписки
на события, Регламентные задания, Общие формы, Интерфейсы, Общие макеты, Общие
картинки, XDTO-пакеты,
Web-сервисы, WS-ссылки, Стили, Языки.
Подсистемы
Команда контекстного меню Переместить
подсистему позволяет изменить подчиненность подсистемы в иерархии
подсистем.
Общие
модули
Свойство Глобальный определяет,
являются ли экспортируемые методы общего модуля частью глобального контекста.
Если свойство Глобальный установлено
в значение Истина,
то экспортируемые методы общего модуля доступны как методы глобального
контекста.
Если свойство Глобальный установлено
в значение Ложь,
то в глобальном контексте создается свойство с именем, соответствующим имени
общего модуля в метаданных. Данное свойство доступно только для чтения.
Значением данного свойства является объект ОбщийМодуль. Через данный
объект доступны экспортируемые методы данного общего модуля. Таким образом,
обращение к методам неглобальных общих модулей выглядит как XXXXX.YYYYY, где
XXXXX – это имя свойства, соответствующее контексту общего модуля, а YYYYY –
имя экспортируемого метода общего модуля.
Параметры сеанса
Инициализация параметров сеанса выполняется в модуле
сеанса, в обработчике события УстановкаПараметровСеанса().
Роли
и права доступа
Интерактивное открытие внешних отчетов — разрешено
открытие внешних отчетов.
Вывод — ограничение вывода на печать, сохранения,
работы с буфером обмена.
Ограничение
доступа к данным
Шаблоны текста ограничения доступа
Роль может
содержать список шаблонов ограничения доступа, которые описываются на закладке Шаблоны ограничений
формы роли. Каждый шаблон ограничения доступа имеет имя и текст.
Имя шаблона
подчиняется обычными правилам для имен, принятых в системе 1С:Предприятие 8.1.
Текст шаблона
содержит часть текста на языке запросов, и может содержать параметры, которые
выделяются при помощи символа ‘#’. После символа ‘#’ могут следовать:
· ключевое
слово Параметр, после которого,
в скобках указывается номер параметра в шаблоне;
· ключевое
слово ТекущаяТаблица –
обозначает вставку в текст полного имени таблицы, для которой строится
ограничение;
· символ
‘#’ – обозначает вставку в текст одного символа ‘#’.
Шаблоны
ограничений могут использоваться в тексте ограничений доступа. Для этого в
тексте ограничения указывается имя шаблона, перед которым указывается символ
‘#’. После имени шаблона, в круглых скобках, через запятую, перечисляются
параметры шаблона. Значение каждого параметра заключено в двойные кавычки. При
необходимости указания в тексте параметра символа двойной кавычки, следует
использовать две двойные кавычки.
Для удобства
редактирования текста шаблона на закладке «Шаблоны ограничений» в форме роли
нажмите кнопку «Установить текст шаблона». В открывшемся диалоге введите текст
шаблона и нажмите кнопку «OK».
Система
1С:Предприятие 8.1 выполняет проверку синтаксиса текстов шаблонов, проверку
синтаксиса использования шаблонов и макроподстановку текстов шаблонов
ограничения доступа роли, в текст запроса. Макроподстановка шаблона заключается
в:
· замене
вхождений параметров в тексте шаблона на значения параметров из выражения
использования шаблона в тексте ограничения.
· замене
выражения использования шаблона в тексте запроса на получившийся текст шаблона.
При вызове
конструктора запроса для условия, содержащего шаблоны ограничения доступа,
выдается предупреждение о замене всех шаблонов.
Далее приведены
примеры шаблонов ограничений:
|
Имя |
Шаблон |
|
Тело |
Итого |
|
Использование |
где |
|
Результат |
где |
|
Имя |
Шаблон1 |
|
Тело |
ВидДокумента |
|
Использование |
где |
|
Результат |
где |
|
Имя |
Шаблон2 |
|
Тело |
ВидДокумента |
|
Использование |
где |
|
Результат |
где |
|
Имя |
Шаблон3 |
|
Тело |
ВидДокумента |
|
Использование |
где |
|
Результат |
где |
Групповое редактирование ограничений
прав доступа
Режим группового
редактирования ограничений прав доступа вызывается командной Все ограничения доступа
контекстного меню ветки Роли.
Режим позволяет
просматривать все введенные ограничения доступа в общем списке (по всем ролям,
объектам, правам, комбинациям полей).
Существует
возможность добавлять ограничение доступа сразу для нескольких ролей, объектов,
прав и комбинаций ролей.
Существует
возможность фильтровать список по различным критериям.
Режим группового
редактирования позволяет удалять выделенные в списке ограничения.
Существует
возможность редактировать выделенные ограничения. При этом можно заменять
состав полей и/или ограничение доступа.
Режим группового
редактирования позволяет также копировать выделенные ограничения в другие роли.
Подписки на
события
Подписки на
события позволяют назначать обработчики событий для одного или группы объектов
встроенного языка.
При добавлении
новой подписки на событие, кроме общих свойств объектов конфигурации, следует указать
источник события, само событие, обработчик которого назначается, и процедуру,
являющуюся обработчиком этого события.
Источниками
событий могут являться прикладные объекты и наборы записей регистров,
определенные в конфигурации. Допускается множественный выбор объектов,
являющихся поставщиками событий.
Выбор события
осуществляется из выпадающего списка, причем список содержит те события,
которые присутствуют во всех выбранных объектах. Если таких событий нет –
список будет пуст.
Выбор обработчика
события выполняется в окне, содержащем процедуры, которые могут быть назначены
в качестве обработчика события. Такие процедуры должны удовлетворять следующим
требованиям:
·
процедура должна быть расположена в общем
модуле;
·
у общего модуля, в котором расположена
процедура, должны быть заданы следующие свойства:
флаг Глобальный —
сброшен;
флаг Клиент —
установлен;
флаг Сервер —
установлен;
флаг Внешнее соединение —
установлен;
·
количество параметров процедуры должно быть на
единицу больше, чем количество параметров, которое имеет обработчик выбранного
события (т.к. дополнительно к параметрам, передаваемым в обработчик события,
передается еще и объект-источник данного события).
При наступлении
события указанного события выполняется следующая последовательность действий:
·
сначала отрабатывается событие в самом объекте и
вызывается обработчик события, определенный в модуле объекта или набора
записей;
·
если в процессе выполнения обработчика параметр Отказ установлен
в значение Истина
или вызвано исключение, действие прерывается;
·
затем вызываются в произвольном порядке внешние
обработчики, назначенные для данного события;
·
в качестве источника в назначенный обработчик
передается сам объект (набор записей) вызвавший событие;
·
если в процессе выполнения назначенного обработчика
параметр Отказ
установлен в значение Истина или вызвано исключение, действие прерывается.
Назначенные
обработчики событий вызываются в том же контексте что и действие, вызвавшее
событие. Если выполнение назначенного обработчика нужно перенести в кластер
серверов, следует вызывать в коде обработчика процедуру общего модуля,
исполняемую в кластере.
Назначение
обработчиков событий доступно также и средствами встроенного языка. Для этого
используются операторы ДобавитьОбработчик и УдалитьОбработчик.
У объектов,
которые могут являться источниками событий, есть свойство ДополнительныеСвойства типа Структура,
позволяющее хранить информацию между вызовами событий, например, новый или
старый это объект.
Регламентные
задания
Регламентные
задания являются частью механизма заданий.
Подробно о порядке
работы с регламентными заданиями см. главу 16 «Механизм заданий».
XDTO-пакеты
Механизм XDTO является универсальным способом представления
данных для взаимодействия с различными внешними источниками данных и программными
системами. Подробнее об использовании механизма XDTO.
Импорт схемы XML в
глобальную фабрику XDTO
Для того чтобы импортировать схему XML из файла .xsd в глобальную фабрику XDTO, следует выделить в
дереве конфигурации ветку XDTO и выполнить команду контекстного меню «Импорт
XML-схемы…».
После указания требуемого файла .xsd будет
выполнена проверка существования в дереве конфигурации пакетов XDTO, пространства имен
которых совпадают с импортируемыми из файла. Если такие пакеты существуют, то
будет отображен список этих пакетов и будет предложено указать те пакеты,
которые должны быть обновлены (по умолчанию существующие пакеты не
обновляются).
После этого будет выполнен импорт, в результате которого
новые пакеты XDTO будут
добавлены в дерево конфигурации, а пакеты, отмеченные для обновления, будут
обновлены.
Экспорт схемы XML данных конфигурации
Для того чтобы экспортировать схему XML, соответствующую типам данных
конфигурации (без учета пакетов XDTO,
созданных в дереве конфигурации), в файл .xsd, следует выделить в дереве конфигурации ветку XDTO и выполнить команду
контекстного меню «Экспорт XML-схемы данных конфигурации…».
После выбора каталога и указания имени файла будет выполнен
экспорт схемы XML в
указанный файл.
Экспорт схемы XML пакета XDTO
Для того чтобы экспортировать схему XML, соответствующую существующему
пакету XDTO, в файл .xsd, следует выделить в
дереве конфигурации требуемый пакет XDTO и выполнить команду контекстного
меню «Экспорт XML-схемы …».
После этого будет выполнена проверка выгружаемого пакета XDTO и
в случае, если будут обнаружены ошибки, соответствующие сообщения будут
выведены в окно сообщений, а процедура экспорта будет прервана.
В случае успешной проверки, будет предложено выбрать
каталог и имя файла .xsd,
после чего схема XML
будет экспортирована в указанный файл.
Проверка пакета XDTO
Для того чтобы проверить пакет XDTO следует
выделить в дереве конфигурации требуемый пакет XDTO и выполнить команду контекстного
меню «Проверить пакет».
В результате будет выполнена проверка модели пакета XDTO, правила которой описаны
в разделе «Правила проверки пакета XDTO».
В случае если будут обнаружены ошибки, соответствующие
сообщения будут выведены в окно сообщений.
Окно редактирования пакета XDTO
Редактирование пакета XDTO выполняется в окне редактирования
пакета XDTO.
При добавлении нового пакета XDTO в дерево
конфигурации окно редактирования пакета XDTO открывается автоматически.
Для того чтобы открыть окно редактирования для
существующего пакета XDTO,
следует выделить в дереве конфигурации требуемый пакет XDTO и выполнить команду контекстного
меню «Открыть пакет».
Иерархическая структура пакета XDTO
Окно
редактирования пакета XDTO
содержит иерархическую структуру пакета XDTO, отображенную в виде дерева.
В корне дерева расположен идентификатор пакета XDTO, содержащий URI пространства
имен данного пакета.
На первом уровне иерархии могут располагаться следующие
элементы пакета:
·
Директивы импорта –
перечень директив импорта. Каждая директива импорта представляет собой ссылку
на другой пакет, который содержит типы, на которые, так или иначе, ссылается
данный пакет. При работе с данным пакетом XDTO средствами встроенного языка данный перечень директив
импорта будет доступен в виде объекта КоллекцияПакетовXDTO, содержащегося
в свойстве Зависимости
пакета XDTO;
·
Типы значений – перечень
типов значений XDTO,
которые содержит пакет XDTO;
·
Типы объектов – перечень
типов объектов XDTO,
которые содержит пакет XDTO;
·
Корневые объекты –
перечень корневых объектов пакета XDTO. Представляет собой объявления объектов/значений, которые
могут являться корневыми элементами документов XML, принадлежащих URI
пространства имен данного пакета XDTO.
Каждый тип значения XDTO описывается иерархической структурой и может содержать в
своем составе следующие элементы:
·
Образец – описывает один
фасет XDTO типа Образец;
·
Перечисление – описывает
один фасет XDTO типа Перечисление;
Каждый тип объекта XDTO описывается иерархической структурой,
которая может содержать в своем составе набор свойств объекта.
Свойства пакета XDTO
Редактирование свойств пакета XDTO выполняется
в палитре свойств.
Если палитра свойств открыта для пакета XDTO, выделенного в дереве конфигурации,
то в ней будут содержаться следующие свойства: Имя, Синоним, Комментарий, Подсистемы
и URI пространства имен. Кроме этого, палитра свойств
будет содержать ссылку Пакет, по которой можно перейти в
окно редактирования пакета XDTO.
Если палитра свойств открыта для пакета XDTO, выделенного в окне редактирования
пакета XDTO (корневой
элемент), то она содержит единственное свойство – URI
пространства имен. Это свойство задает URI пространства
имен пакета XDTO, к
которому принадлежат все определенные в этом пакете типы.
Свойства директивы импорта
Редактирование свойств директивы импорта выполняется в
палитре свойств. Для директивы импорта палитра свойств содержит единственное
свойство — Пространство имен. Это свойство задает URI
пространства имен импортируемого пакета.
Свойства типа значения XDTO
Редактирование свойств типа значения XDTO выполняется
в палитре свойств.
Для типа значения XDTO палитра свойств содержит следующие
свойства:
·
Имя – имя типа значения XDTO;
·
Базовый тип — базовый тип
для данного типа значения XDTO.
·
Тип элемента – тип
элемента списка в случае, когда тип значения XDTO определяется списком. При
этом все фасеты и свойство Типы подчиненных должны быть
пустыми;
·
Типы объединения – список
типов, образующих объединение, в случае, когда тип значения XDTO определяется
объединением. Объединяться могут только типы значений XDTO. При этом все фасеты
и свойство Тип элемента должны быть пустыми;
·
Длина – фасет длины;
·
Минимальная длина – фасет
минимальной длины;
·
Максимальная длина –
фасет максимальной длины;
·
Пробельные символы –
фасет пробельного символа;
·
Минимум, включающий границу
– фасет минимума, включающего границу;
·
Минимум, не включающий границу
– фасет минимума, не включающего границу;
·
Максимум, включающий границу
– фасет максимума, включающего границу;
·
Максимум, не включающий границу
– фасет максимума, не включающего границу;
·
Общее количество цифр –
фасет общего количества цифр;
·
Количество цифр дробной части
– фасет количества цифр дробной части.
Подробнее о фасетах можно прочитать в разделе «Тип значения
XDTO».
Свойства типа объекта XDTO
Редактирование свойств типа объекта XDTO выполняется
в палитре свойств.
Для типа объекта XDTO палитра свойств содержит следующие
свойства:
·
Имя – имя типа объекта XDTO;
·
Базовый тип – базовый тип
для данного типа объекта XDTO.
Это может быть только тип объекта XDTO.
·
Открытый – признак,
является ли тип объекта XDTO
открытым. Данное свойство показывает, может ли экземпляр объекта XDTO содержать дополнительные
свойства, не определенные в его типе;
·
Абстрактный – признак,
является ли тип объекта XDTO абстрактным;
·
Смешанный – свойство
показывает, имеет ли соответствующий объект XDTO смешанное содержание. Если значение свойства Смешанный
равно Истина,
то значение Последовательный
обязательно равно Истина,
так как смешанное содержание невозможно смоделировать без применения
последовательности XDTO;
·
Упорядоченный – признак,
является ли порядок следования элементов, представляющих значения свойств,
строго соответствующим порядку следования свойств в типе объекта XDTO. Если свойство Упорядоченный
имеет значение Ложь,
то на входе порядок следования элементов XML не контролируется, а на выходе
определяется порядком следования свойств, если только свойство Последовательный
не имеет значение Истина;
·
Последовательный — это свойство
показывает, содержит ли экземпляр соответствующего объекта XDTO
последовательность XDTO.
Данный признак равен значению Истина
в тех случаях, когда порядок следования вложенных элементов XML не может
однозначно определяться порядком следования свойств в типе или соответствующий
объект XDTO имеет
смешанное содержание. Последовательность XDTO позволяет задать в явном виде порядок следования элементов,
как они будут представлены в документе XML. Для объектов типов, у которых
свойство Последовательный
установлено в значение Ложь,
порядок следования вложенных элементов соответствует порядку следования
свойств;
Свойства свойства типа объекта XDTO
Редактирование свойств свойства типа объекта XDTO выполняется
в палитре свойств.
Для свойства типа объекта XDTO палитра свойств содержит следующие
свойства:
·
Имя – имя свойства. В
пределах одного типа объекта XDTO имена свойств должны быть уникальными;
·
Тип – тип свойства. Может
быть как типом значения XDTO, так и типом объекта XDTO;
·
Минимальное количество –
минимальное количество значений свойства. Минимальное количество значений
свойства может принимать значения >= 0. Естественно, значение Минимальное количество должно быть меньше или равно значению Максимальное количество (если, конечно, Максимальное
количество не равно -1);
·
Максимальное количество –
свойство типа объекта XDTO может быть определено как содержащее одно или
множество значений. Свойство считается содержащим одно значение, если свойство Максимальное количество равно 1. Если же свойство Максимальное количество больше 1, то считается, что свойство
может содержать множество значений. Такое свойство в структуре объекта
моделируется как список. Свойство Максимальное количество
показывает максимальное количество значений свойства. Максимальное
количество > 1 может быть задано только для свойств, представляемых в
виде элемента XML;
·
Возможно пустое –
показывает, может ли свойство принимать неопределенное значение. Свойство Возможно пустое равное Истина может быть
определено только для свойств с формой представления Элемент. В случае если Максимальное количество > 1 неопределенное значение
является допустимым для элемента списка значений свойства;
·
Фиксированное –
указывает, является ли значение свойства фиксированным. Если установлено в
значение Истина,
то само фиксированное значение можно получить через свойство По
умолчанию;
·
По умолчанию – значение
свойства по умолчанию. Тип значения по умолчанию может быть только типом
значения XDTO. При этом данное значение должно быть совместимо по типу с типом
свойства (быть того же типа, что и тип свойства или же унаследованного типа).
При создании объекта XDTO, свойство, если оно допускает единственное значение,
принимает значение по умолчанию. Для свойств с множеством значений, список
значений изначально пуст, независимо от того, определено или нет значение по
умолчанию;
·
Форма – форма
представления свойства в XML. Это может быть Текст, Элемент
или Атрибут.
Если формой представления является Атрибут или
Текст,
то значение свойства Максимальное количество не может
быть больше 1. Если свойство принимает значение Текст,
то значение свойства Минимальное количество также должно
быть равным 1. У одного типа только одно свойство может иметь форму
представления Текст,
при этом остальные свойства должны иметь форму представления Атрибут;
·
Локальное имя – локальное
имя, используемое для представления свойства. Для свойств с формой
представления Текст
– пустая строка;
·
URI пространства имен –
URI пространства имен, используемое для представления свойства. Пустая строка, если
пространство имен отсутствует.
Свойства корневого объекта
Редактирование свойств корневого объекта выполняется в
палитре свойств.
Для корневого объекта палитра свойств содержит следующие
свойства:
·
Имя – имя корневого
объекта. В пределах одного типа объекта XDTO имена корневых объектов должны
быть уникальными;
·
Тип — тип корневого
объекта.
Web-сервисы
Механизм Web-сервисов
позволяет использовать 1С:Предприятие 8.1 как набор сервисов в сложных распределенных
и гетерогенных системах, а также позволяет интегрировать
1С:Предприятие 8.1 с другими промышленными системами использованием
сервисно-ориентированной архитектуры.
Подробнее об использовании механизма Web-сервисов см. Главу 15 «Механизм Web-сервисов».
Добавление Web-сервиса
Для того чтобы добавить Web-сервис в дерево конфигурации следует выделить ветку «Общие | Web-сервисы» и выполнить команду контекстного меню «Добавить».
В результате выполнения команды будет открыто окно
редактирования Web-сервиса
(см. параграф «Окно редактирования объекта»).
На закладке «Прочее» окна редактирования веб-сервиса
следует установить следующие параметры:
·
URI пространства имен –
содержит URI пространства имен веб-сервиса. Каждый Web-сервис может быть однозначно идентифицирован
по своему имени и URI пространству имен, которому он принадлежит;
·
Пакеты XDTO –
перечень пакетов XDTO,
типы которых могут использоваться в качестве типов возвращаемого значения
операций и типов параметров операций Web-сервиса;
·
Имя файла публикации –
имя файла описания Web-сервиса,
который расположен на веб-сервере (о публикации Web-сервисов см. параграф
«Публикация Web-сервисов»).
Кроме этого на этой закладке содержится кнопка Модуль, которая позволяет открыть для редактирования модуль Web-сервиса.
Иерархическая структура Web-сервиса
Каждый Web-сервис, описываемый в дереве
конфигурации, может содержать набор операций. Каждой операции должна
соответствовать экспортная процедура, описанная в модуле Web-сервиса.
В свою очередь каждая операция может содержать набор
параметров, имена которых должны соответствовать именам параметров процедуры,
описывающей данную операцию.
Операции Web-сервиса
На закладке «Операции» выполняется добавление операции Web-сервиса. Редактирование
свойств операции выполняется в палитре свойств:
·
Тип возвращаемого значения
– тип значения, которое возвращает операция Web-сервиса. Может являться типом значения XDTO или типом объекта XDTO;
·
Возможно пустое значение
– показывает, может ли возвращаемое значение принимать неопределенное значение;
·
В транзакции –
показывает, будет ли выполняться код модуля Web-сервиса в транзакции, или нет. Если свойство установлено, то
при вызове Web-сервиса
автоматически будет начата транзакция, а при завершении – транзакция будет либо
зафиксирована, либо произойдет откат транзакции (в зависимости от результатов
выполнения). Если свойство не установлено – при начале исполнения модуля Web-сервиса транзакция не
будет начата;
·
Имя процедуры – имя
процедуры модуля Web-сервиса,
которая будет выполнена при вызове данного свойства.
Параметр операции
На закладке «Операции» для указанной операции осуществите
задание параметров операции Web-сервиса.
Редактирование свойств параметра выполняется в палитре свойств.
Помимо общих свойств объектов конфигурации, параметр
операции Web-сервиса
содержит следующие свойства:
·
Тип значения – тип
значения параметра операции Web-сервиса.
Может являться типом значения XDTO,
или типом объекта XDTO;
·
Возможно пустое значение –
показывает, может ли значение параметра операции принимать неопределенное
значение;
·
Направление передачи –
определяет направление передачи данных с помощью данного параметра. Возможные
значения:
Входной – означает, что параметр используется для передачи
данных Web-сервису;
Выходной – означает, что параметр используется для получения
данных от Web-сервиса;
Входной – Выходной – означает, что параметр может
использоваться как для передачи данных, так и для их получения от Web-сервиса.
Указание типов, определяемых системой
1С:Предприятие 8.1
Чтобы в веб-сервисе воспользоваться типами, определяемыми
системой 1С:Предприятие 8.1 (например в параметрах и возвращаемом значении
операций), нужно в конфигурации определить пакеты XDTO и для каждого пакета
указать в его списке импортируемых пакетов (свойство Директивы
импорта) набор пакетов платформы, в которые эти типы входят. URI
пространства имен для указания типа указано в статье Синтакс-Помощника по
объекту данного типа.
Публикация Web-сервисов
Задача публикации Web-сервисов
сводится к размещению конфигурационных файлов *.1cws Web-сервисов в соответствующем каталоге
веб-сервера с соответствующими настройками для веб-сервера. Для того, чтобы
выполнить публикацию Web-сервисов,
следует выполнить команду меню «Администрирование | Публикация
Web-сервисов».
В результате выполнения этой команды будет открыто окно
публикации Web-сервисов.
Окно публикации Web-сервисов содержит путь к веб-серверу и два списка:
·
«Web-сервисы» – список Web-сервисов конфигурации;
·
«Публикация» – список Web-сервисов, опубликованных
на указанном веб-сервере.
С помощью кнопки «Соединение…»
следует указать веб-сервер, на котором требуется опубликовать Web-сервисы.
Окно выбора пути к веб-серверу позволяет указать путь двумя
способами:
·
на закладке «Файлы» –
этот способ используется в том случае, когда публикация выполняется на том же
компьютере, на котором установлен веб-сервер. В качестве пути указывается
локальный каталог, соответствующий интернет-странице, с которой будет выполняться
вызов публикуемого Web-сервера;
·
на закладке «FTP сайт» –
этот способ используется в том случае, когда требуется опубликовать Web-сервис на удаленном
компьютере. Для выполнения публикации необходимо указать параметры FTP-соединения с удаленным
компьютером и каталог, в котором будет опубликован Web-сервис.
Публикация выбранного Web-сервиса осуществляется с помощью кнопки «Опубликовать»
Для отмены публикации Web-сервиса используется кнопка «Удалить» .
Для обновления списка опубликованных Web-сервисов используется кнопка «Обновить текущий список» —.
WS-ссылки
Система 1С:Предприятие 8.1 может использовать веб-сервисы,
предоставляемые другими поставщиками, с помощью статических ссылок, создаваемых
в дереве конфигурации.
Добавление WS-ссылки
Для того чтобы добавить статическую
ссылку на внешний веб-сервис в дерево конфигурации, следует выделить ветку WS-ссылки и выполнить команду
контекстного меню «Добавить», или соответствующую
команду меню «Действия».
В открывшемся окне следует ввести URL описания
добавляемого веб-сервиса, например: http://www.1c.ru/dem/products.1cws?wsdl.
Иерархическая структура WS-ссылки
Просмотр иерархической структуры WS-ссылки выполняется в окне просмотра WS-ссылки. Значения свойств
элементов ссылки можно просмотреть в палитре свойств.
Для того чтобы открыть окно просмотра WS-ссылки следует выделить в дереве
конфигурации требуемую WS-ссылку
и выполнить команду контекстного меню Свойства. После этого в палитре свойств
воспользоваться ссылкой WS-ссылка,
которая открывает окно просмотра WS-ссылки.
Окно просмотра WS-ссылки содержит иерархическую структуру WS-ссылки, отображенную в виде дерева.
На первом уровне иерархии могут располагаться:
·
Модель данных – содержит
перечень пакетов XDTO, описывающих
структуру типов, используемую веб-сервисами, на которые ссылается данная WS-ссылка;
·
Web-сервисы – перечень Web-сервисов, на которые
ссылается данная ссылка.
Просмотр структуры и свойств модели данных выполняется
аналогично работе с пакетами XDTO («Иерархическая структура пакета XDTO»), за исключением того, что
редактирование свойств пакетов, отображаемых в окне просмотра WS-ссылки, невозможно.
Просмотр структуры Web-сервисов выполняется аналогично работе с Web-сервисами («Иерархическая структура Web-сервиса») за исключением
того, что для каждого Web-сервиса
отображаются поддерживаемые точки подключения Web-сервиса, для которых, в свою
очередь, отображается список операций и параметров каждой операции.
Различные точки подключения Web-сервиса позволяют выполнять
операции, используя различные протоколы.
Отчеты и обработки
Каждый объект этого типа может содержать алгоритм
формирования «бумажного» или «электронного» отчета на внутреннем языке системы
1С:Предприятие 8.1, или схему компоновки данных, на основании которой система
1С:Предприятие 8.1 может автоматически создать выполнить отчет.
Основное отличие отчета от обработки заключается в
возможности использования схемы компоновки данных. В остальном обработка не
отличается от отчета.
Внешние отчеты и обработки
Внешним отчетом в системе
1С:Предприятие 8.1 называется отчет, хранящийся вне конфигурации, в отдельном
файле внешнего отчета. Внешний отчет служит для решения тех же задач, что и
объекты конфигурации типа «Отчет».
Внешней обработкой в системе 1С:Предприятие
8.1 называется обработка, хранящаяся вне конфигурации, в отдельном файле
внешней обработки. Внешняя обработка служит для решения тех же задач, что и
объекты конфигурации типа «Отчет» или «Обработка».
Основным отличием внешних отчетов от внешних обработки
состоит в том, что отчеты могут содержать механизмы системы компоновки данных
(подробнее см. главу 11 «Система компоновки данных»).
Внешние отчеты и обработки хранятся в файлах, имеющих
расширение «.erf» и «.ert», соответственно.
Основное преимущество внешней обработки (отчета) — возможность ее проектирования и
отладки в процессе работы системы 1С:Предприятие 8.1. В этом случае разработка
и отладка обработки (отчета) значительно ускоряются: редактирование и
сохранение внешней обработки (отчета) выполняется в режиме «Конфигуратор», без
сохранения конфигурации в целом, а запуск — в режиме «1С:Предприятие». Для
выполнения внешняя обработка (отчет) загружается при помощи пункта «Файл —
Открыть» и работает так же, как и любая другая обработка (отчет) конфигурации.
Любой объект конфигурации типа «Отчет» или «Обработка»
может быть скопирован в файл внешней обработки (отчета) и наоборот — форма
объекта конфигурации может быть заменена формой внешней обработки (отчетом).
Для внешней обработки (отчета) может быть создано описание,
как и для других объектов конфигурации.
Для обеспечения целостности конфигурации внешние обработки
(отчеты) рекомендуется использовать, в основном, в отладочных целях. После
отладки алгоритма формирования обработки (отчета) необходимо включить внешнюю
обработку в конфигурацию.
Создание внешней обработки (отчета)
Для создания внешней обработки (отчета) необходимо выбрать
пункт «Файл — Новый» и в выданном на экран запросе выбрать строку «Внешняя
обработка» или «Внешний отчет»».
На экран будет вызван редактор форм для разработки внешней
обработки (отчета). Для внешнего отчета окно редактирования будет дополнительно
содержать управляющие элементы для создания, настройки и редактирования системы
компоновки данных.
Так как внешняя обработка (отчет) не является частью
текущей конфигурации (хотя и очень тесно с ней связана), процедура ее
сохранения отличается от процедуры сохранения изменений. Для сохранения внешней
обработки (отчета) необходимо использовать пункт «Файл — Сохранить» или «Файл —
Сохранить как…» или «Файл — Сохранить копию». В стандартном диалоге
сохранения файла выберите тип файла «Внешняя обработка (*.epf)» («Внешний отчет (*.erf)») и введите имя для
сохраняемой внешней обработки (отчета).
Использование внешних обработок (отчетов)
Для использования внешней обработки (отчета) при работе с
системой 1С:Предприятие 8.1 ее необходимо открыть так же, как это делается в
Конфигураторе. Однако следует иметь в виду, что в системе 1С:Предприятие 8.1
внешняя обработка (отчет) открывается только для исполнения: пользователь не
может его редактировать.
Компиляция модуля внешней обработки (отчета) выполняется
при открытии внешней обработки (отчета), поэтому после редактирования внешней
обработки (отчета) в Конфигураторе и ее сохранения необходимо вновь открыть эту
обработку в режиме «1С:Предприятие».
Редактирование внешней обработки (отчета)
Редактирование внешней обработки (отчета) выполняется в
Конфигураторе.
Чтобы открыть существующую внешнюю обработку (отчет),
выберите пункт «Файл — Открыть». В выданном на экран стандартном диалоге
выберите тип файла «Внешняя обработка (*.epf)» («Внешний отчет (*.erf)») и укажите имя открываемого файла.
При открытии внешней обработки (отчета) в Конфигураторе
автоматически открывается окно редактирования объекта. В отличие от других
объектов конфигурации отладка внешней обработки (отчета) может производиться
без перезапуска системы 1С:Предприятие 8.1. Достаточно после сохранения
обработки (отчета) Конфигуратором заново вызвать ее на выполнение в режиме «1С:Предприятие».
Описание
внешней обработки (отчета)
Внешняя обработка (отчет) может быть снабжена
пользовательским описанием.
Для редактирования описания в палитре свойств внешней
обработки щелкните ссылку Открыть свойства Справочная информация.
В режиме «1С:Предприятие» для просмотра описания внешней
обработки (отчета) необходимо нажать клавишу F1.
Чтобы описание упоминалось в содержании общей справки,
нужно установить свойство Включать в содержание справки.
Внешние
обработки (отчеты) и объекты конфигурации
Существующие в конфигурации объекты конфигурации типа
«Отчет» и «Обработка» могут быть преобразованы во внешние отчеты и обработки, и
наоборот, внешние отчеты и обработки могут заменять собой существующий объект
конфигурации типа «Отчет» или «Обработка». Также внешние отчеты и обработки
могут быть добавлены в структуру конфигурации как новые объекты конфигурации
типа «Отчет» или «Обработка».
Копирование отчета или обработки во
внешнюю обработку или отчет. Существующий объект конфигурации типа «Отчет»
или «Обработка» может быть скопирован во внешние обработку или отчет. Для этого
выделите наименование объекта конфигурации в окне «Конфигурация» и в
контекстном меню объекта конфигурации выберите пункт «Сохранить как внешнюю
обработку, отчет». Затем в выданном на экран стандартном диалоге сохранения
файла выберите тип файла «Внешняя обработка (*.epf)» («Внешний отчет (*.erf)») и укажите имя файла
внешней обработки (отчета).
В результате будет создана внешняя обработка (отчет),
которая будет скопирована с выбранного объекта конфигурации, сам объект
конфигурации при этом не изменится.
Выполнение этой операции целесообразно для последующей
отладки создаваемого отчета или обработки. По окончании отладки внешняя
обработка или отчет может быть вставлена в конфигурацию взамен существующего
объекта конфигурации.
Замена отчета или обработки на внешнюю
обработку (отчет). Внешние отчет или обработка могут заменить собой
существующий объект конфигурации типа «Отчет» или «Обработка».
Для замены объекта конфигурации внешней обработкой
(отчетом) необходимо выделить его наименование в окне «Конфигурация» и
использовать пункт «Заменить на внешнюю обработку, отчет» контекстного меню
объекта конфигурации. Затем в выданном на экран стандартном диалоге открытия
файла выберите тип файла «Внешняя обработка (*.epf)» («Внешний отчет (*.erf)») и укажите имя файла
внешней обработки (отчета).
Добавление внешней обработки (отчета) в
структуру конфигурации. Существующая внешняя обработка (отчет) может быть
вставлена в структуру конфигурации как новый объект конфигурации типа «Отчет»
или «Обработка». Для этого необходимо в структуре конфигурации выделить
наименование любого объекта конфигурации типа «Отчет» или «Обработка» и
использовать пункт «Вставить внешнюю обработку, отчет» контекстного меню
объекта конфигурации. В выданном на экран стандартном диалоге открытия файла
необходимо выбрать тип файла «Внешняя обработка (*.epf)» («Внешний отчет (*.erf)») и указать имя файла
внешней обработки (отчета), которую требуется вставить в структуру
конфигурации.
В результате этих действий в дереве конфигурации появится
новая обработка (отчет).
Сравнение и объединение внешних обработок (отчетов)
Внешние обработки (отчеты) можно сравнивать и объединять с
обработками (отчетами), расположенными в конфигурации, а также сравнивать и
объединять с другими внешними обработками (отчетами).
Для сравнения и объединения с отчетом или обработкой
конфигурации в окне «Конфигурация» укажите нужный объект, в контекстном меню
этого объекта выберите пункт «Сравнить, объединить с внешней обработкой,
отчетом…». В стандартном диалоге выбора файла выберите нужную внешнюю обработку
(отчет).
На экран выводится окно «Сравнение и объединение…». Приемы
работы в окне полностью совпадают с приемами работы при объединении
конфигураций.
Для сравнения или объединения внешней обработки (отчета) с
другой внешней обработкой (отчетом) откройте исходную внешнюю обработку (отчет)
и в окне редактирования, нажмите кнопку «Действия» и в выпадающем меню выберите
пункт «Сравнить,
объединить с внешней обработкой, отчетом…». В стандартном
диалоге выбора файла выберите нужную внешнюю обработку (отчет).
Регистры накопления
Разрешить
разделение итогов. Если флаг установлен в значение Истина, то будет
задействован механизм разделителя итогов, который обеспечивает более высокую
параллельность работы при записи в регистр. Система при одновременной записи
движений несколькими сеансами не будет обновлять одни и те же записи итогов, а
будет записывать изменения итогов в отдельные записи. При получении итогов эти
данные складываются. Таким образом, обеспечивается и поддержание в актуальном
состоянии итогов (для быстрого получения отчетов, например) и параллельность
записи движений. Этот режим требует дополнительных расходов ресурсов (например,
увеличивается количество данных в итоговых таблицах). Поэтому есть свойства и в
конфигурации, и в языке для управления этим режимом.
Записи будут
«размножаться» только при параллельно выполняемых транзакциях. Их количество по
каждой комбинации измерений будет зависеть от максимального количества
одновременно выполняемых транзакций. При пересчете итогов накопленные отдельные
записи сворачиваются.
Режим разделения
итогов может быть изменен пользователем в режиме работы «1С:Предприятие» в
диалоге «Управление итогами».
По умолчанию
свойство выключено.
Разработка
структуры регистра накопления
Свойства
измерения (ресурса, реквизита) регистра накопления
Использование в итогах. Если свойство не установлено, измерения исключаются
из хранимых итогов регистра (свойство используется только для измерений
оборотного регистра). Если такое измерение используется в запросе или в условии
виртуальной таблицы, то виртуальная таблица не будет использовать хранимые
итоги, а будет рассчитывать данные только по таблице движений.
Глава 4.
Встроенный язык
Формат
исходных текстов программных модулей
Что такое программный модуль?
Виды программных модулей
Модуль
сеанса
Модулем сеанса называется модуль, который автоматически выполняется
при старте системы 1С:Предприятие 8.1 в момент загрузки конфигурации.
Модуль сеанса предназначен для инициализации параметров
сеанса и отработки действий, связанных с сеансом работы. Модуль сеанса всегда
исполняется в привилегированном режиме в кластере серверов 1С:Предприприятия
8.1.
Установка параметров сеанса выполняется в обработчике
события УстановкаПараметровСеанса().
Исполнение модуля сеанса происходит после начала исполнения
модуля приложения (модуля внешнего соединения), до вызова обработчика события ПередНачаломРаботыСистемы
(ПриНачалеРаботыСистемы,
в случае модуля внешнего соединения).
Модуль сеанса может содержать только определения процедур и
функций.
Модуль сеанса не содержит экспортируемых процедур и функций
и может использовать процедуры из общих модулей конфигурации.
Операторы
и синтаксические конструкции
ДобавитьОбработчик (AddHandler)
Синтаксис:
ДобавитьОбработчик <Событие>,
<ОбработчикСобытия>;
Англоязычный синтаксис:
AddHandler <Событие>, <ОбработчикСобытия>;
Параметры:
<Событие>
Событие, которому добавляется обработчик.
Событие задается в форме
<Выражение>.<Имя_события>, где:
·
<Выражение> — произвольное выражение на
встроенном языке, результатом которого должен быть объект, к событию которого
добавляется обработчик;
·
<Имя_события> — идентификатор (имя)
события .
<ОбработчикСобытия>
Процедура/функция-обработчик события.
Обработчиком события может являться метод объекта
встроенного языка. Тогда <ОбработчикСобытия> задается как
<Выражение>.<Имя_обработчика>, где:
·
<Выражение> — произвольное выражение на
встроенном языке, результатом которого должен быть объект, метод которого
служит обработчиком события;
·
<Имя_обработчика> — имя метода обработчика
события.
Также в качестве обработчика события может быть задана
процедура/функция, находящаяся в области видимости. В этом случае обработчик
события задается как имя процедуры/функции.
Описание:
Добавляет обработчик события.
При добавлении обработчика события производится проверка
соответствия числа параметров события числу параметров метода, назначаемого в
качестве обработчика.
Пример:
Обработка = Обработки.КонтрольДокумента.Создать();
Накладная = Документы.Накладная.СоздатьДокумент();
ДобавитьОбработчик Накладная.ПриЗаписи,
Обработка.ПриЗаписиДокумента;
msword = Новый COMОбъект(«Word.Application»);
ДобавитьОбработчик msword.DocumentChange,
ПриИзмененииДокумента;
Процедура ПриИзмененииДокумента()
Сообщить(«Документ
изменен»);
КонецПроцедуры
УдалитьОбработчик (AddHandler)
Синтаксис:
УдалитьОбработчик <Событие>, <ОбработчикСобытия>;
Англоязычный синтаксис:
RemoveHandler <Событие>, <ОбработчикСобытия>;
Параметры:
<Событие>
Событие, обработчик которого удаляется.
Событие задается в форме
<Выражение>.<Имя_события>, где:
·
<Выражение> — произвольное выражение на встроенном
языке, результатом которого должен быть объект, обработчик события которого
удаляется;
·
<Имя_события> — идентификатор (имя)
события .
<ОбработчикСобытия>
Процедура/функция-обработчик события.
Обработчиком события может являться метод объекта встроенного
языка. Тогда <ОбработчикСобытия> задается как
<Выражение>.<Имя_обработчика>, где:
·
<Выражение> — произвольное выражение на
встроенном языке, результатом которого должен быть объект, метод которого
служит обработчиком события;
·
<Имя_обработчика> — имя метода обработчика
события.
Также в качестве обработчика события может быть задана
процедура/функция, находящаяся в области видимости. В этом случае обработчик
события задается как имя процедуры/функции.
Описание:
Удаляет обработчик события.
При удалении обработчика события производится проверка
соответствия числа параметров события числу параметров метода, назначенного в
качестве обработчика.
Пример:
УдалитьОбработчик Накладная.ПриЗаписи,
Обработка.ПриЗаписиДокумента;
Особенности режимов запуска 1С:Предприятие
Системы 1С:Предприятие 8.1 могут использоваться в файловом
и клиент-серверном вариантах, в сессии СОМ-соединения, а также в виде Web-сервисов (см. Главу 15
«Механизм Web-сервисов»).
Особенности использования объектов, их
свойств и методов
Поддержка отображения в XDTO. Указывает
на то, что данный тип имеет возможность отображения в модель данных XDTO. При
этом указывается квалифицированное имя типа (типов) (указывается URI
пространство имен и имя типа), в который отображается данный тип. Например, для
типа ХранилищеЗначения: {http://v8.1c.ru/8.1/data/core}ValueStorage.
Глава 5.
Работа с запросами
Язык запросов
Использование предопределенных данных конфигурации
Текст запроса может содержать предопределенные данные
конфигурации, такие как:
·
значения перечислений;
·
предопределенные данные:
§
справочников;
§
планов видов характеристик;
§
планов счетов;
§
планов видов расчетов;
·
пустые ссылки;
·
значения точек маршрута бизнес-процессов.
Также текст запроса может содержать значения системных перечислений,
которые могут быть присвоены полям в таблицах базы данных: ВидДвиженияНакопления, ВидСчета
и ВидДвиженияБухгалтерии.
Обращение в запросах к предопределенным данным конфигурации
и значениям системных перечислений осуществляется с помощью литерала
функционального типа:
ЗНАЧЕНИЕ(<ПредставлениеЗначения>)
Для системных перечислений <ПредставлениеЗначения>
имеет вид:
<ИмяСистемногоПеречисления>.<Значение>
Допустимые имена системных перечислений приведены выше, с
перечнем допустимых для каждого из них значений можно ознакомиться в его
описании.
Для предопределенных данных конфигурации
<ПредставлениеЗначения> имеет вид:
<ТипПредопределенногоЗначения>
.<ИмяОбъектаМетаданных>.<Значение>
<ТипПредопределенногоЗначения> может быть:
· Справочник (Catalog);
· ПланВидовХарактеристик (ChartOfCharacteristicTypes);
· ПланСчетов (ChartOfAccounts);
·
ПланВидовРасчета (ChartOfCalculationTypes);
·
Перечисление (Enum).
В качестве <ИмяОбъектаМетаданных> указывается имя
объекта метаданных, как оно задано в конфигураторе.
Для определенных в конфигурации перечислений
<Значение> указывается как имя соответствующего объекта метаданных типа ЗначаниеПеречисления.
Для всех остальных типов предопределенных значений <Значение> указывается
как имя предопределенного элемента данных, как оно указано в конфигураторе, или
ПустаяСсылка (EmptyRef)
для указания пустой ссылки.
Для точек маршрутов бизнес-процессов
<ПредставлениеЗначения> имеет вид:
БизнесПроцесс.<ИмяОбъектаМетаданных>.ТочкаМаршрута.<ИмяТочкиМаршрута>
Ниже приведены несколько фрагментов запросов, поясняющих
использование предопределенных данных в запросах:
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.Москва)
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.ПустаяСсылка)
ГДЕ ТипТовара = ЗНАЧЕНИЕ(Перечисление.ВидыТоваров.Услуга)
ГДЕ ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
ГДЕ ТочкаМаршрута =
ЗНАЧЕНИЕ(БизнесПроцесс.БизнесПроцесс1.ТочкаМаршрута.Действие1)
Двуязычное представление ключевых слов
|
Русское написание |
Английское написание |
|
ЗНАЧЕНИЕ |
VALUE |
|
ИНДЕКСИРОВАТЬ ПО
|
INDEX BY
|
|
ПОМЕСТИТЬ |
INTO |
|
УНИЧТОЖИТЬ
|
DROP
|
Выполнение и работа с запросами во встроенном языке
Работа с временными таблицами
Язык запросов 1С:Предприятия
8.1 позволяет использовать временные таблицы в запросах. Использование временных
таблиц помогает повысить производительность запросов и сделать текст сложных
запросов более легким для восприятия.
Работа с временными таблицами обеспечивается двумя
составляющими:
·
объектом встроенного языка МенеджерВременныхТаблиц,
который хранит в себе данные временных таблиц;
·
синтаксисом языка запросов, позволяющим
создавать новые временные таблицы и использовать существующие временные
таблицы.
Менеджер временных таблиц
Менеджер временных таблиц предназначен для управления
временем жизни временных таблиц, создаваемых в процессе работы прикладного
решения.
В одном прикладном решении может быть создано произвольное
количество экземпляров менеджера временных таблиц, каждый из которых хранит
свой набор временных таблиц. Каждая временная таблица однозначно
идентифицируется своим именем, и в пределах одного менеджера временных таблиц
все временные таблицы должны иметь уникальные имена.
Экземпляр менеджера временных таблиц может быть создан с
помощью конструктора Новый.
Например:
МенеджерВременныхТаблиц = Новый
МенеджерВременныхТаблиц;
Все временные таблицы, созданные в данном экземпляре
менеджера, существуют до тех пор, пока существует сам экземпляр менеджера
временных таблиц. При уничтожении экземпляра менеджера все временные таблицы,
содержащиеся в нем, также удаляются.
Менеджер временных таблиц можно закрыть принудительно при
помощи метода Закрыть().
При этом будут удалены все созданные в нем таблицы. Дальнейшая работа с данным
экземпляром менеджера будет невозможна.
Создание временных таблиц
Создание временных таблиц осуществляется с помощью объекта Запрос
встроенного языка 1С:Предприятия 8.1.
Связь запроса с менеджером временных таблиц осуществляется с
помощью свойства МенеджерВременныхТаблиц
запроса, в котором указывается тот экземпляр менеджера, в котором должны
создаваться временные таблицы. Например:
МенеджерВременныхТаблиц = Новый МенеджерВременныхТаблиц;
Запрос = Новый Запрос;
Запрос.МенеджерВременныхТаблиц =
МенеджерВременныхТаблиц;
Временная таблица может быть создана на основе данных базы
данных или на основе внешнего источника данных (например, таблицы значений).
Для того чтобы создать временную таблицу на основе данных
базы данных, следует установить объекту Запрос менеджер временных
таблиц, а затем выполнить запрос к базе данных, используя ключевое слово ПОМЕСТИТЬ,
после которого указать имя создаваемой временной таблицы. Ключевое слово ПОМЕСТИТЬ
располагается после списка выборки запроса. Например:
ВЫБРАТЬ
Код,
Наименование
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ Справочник.Номенклатура
Результат исполнения такого запроса будет содержать одну
строку с одной колонкой с именем «Количество», в которой будет находиться
количество записей, помещенных в созданную таблицу.
В случае если менеджер временных таблиц не установлен, или
менеджер был закрыт, будет выдана ошибка.
В случае если в установленном менеджере временных таблиц уже
существует таблица с указанным именем, будет выдана ошибка.
При необходимости создания индекса для временной таблицы, следует
в запросе указать ключевое слово ИНДЕКСИРОВАТЬ ПО, после которого перечислить
поля, по которым нужно построить индекс. Например:
ВЫБРАТЬ
Код,
Наименование
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ Справочник.Номенклатура
ИНДЕКСИРОВАТЬ ПО Код
Поля, по которым происходит индексирование должны находиться
в списке выборки.
Для того чтобы создать временную таблицу на основании
внешнего источника, следует в тексте запроса в списке источников указать имя
параметра, в который будет помещен внешний источник. Остальной синтаксис
идентичен обычному созданию временной таблицы. В качестве внешнего источника
могут выступать:
·
таблица значений;
·
табличная часть;
·
результат запроса.
Ниже приведен пример создания временной таблицы на основе
внешнего источника:
ВЫБРАТЬ
Код,
Наименование
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ &ВнешнийИсточник КАК ВнешнийИсточник
В данном примере во временную таблицу «ВременнаяТаблица»
будет помещено содержимое колонок «Код» и «Наименование» из внешнего источника,
например, таблицы значений, переданной в качестве параметра «ВнешнийИсточник».
В случае если временная таблица создается на основании
внешнего источника, в запросе нельзя использовать объединения и соединения.
Использование временных таблиц
Для использования существующих временных таблиц в запросе
следует установить объекту Запрос
менеджер временных таблиц, после чего к временным таблицам, содержащимся в
данном менеджере временных таблиц, можно обращаться по имени, как к обычным
таблицам запроса.
Удаление временных таблиц
Для удаления временной таблицы из менеджера временных таблиц
следует воспользоваться ключевым словом языка запроса УНИЧТОЖИТЬ, после
которого указывается имя уничтожаемой таблицы. Например:
УНИЧТОЖИТЬ ВременнаяТаблица
В случае если уничтожаемой таблицы не существует, будет
выдана ошибка.
Глава 6.
Работа с данными
Механизм объектных блокировок
При работе с объектными данными (справочники, документы,
счета и пр.) система 1С:Предприятие 8.1 обеспечивает два вида объектных блокировок
– пессимистическую и оптимистическую, которые позволяют выполнять целостные
изменения объектов при одновременной работе нескольких пользователей.
Пессимистическая блокировка
Механизм пессимистической блокировки объектов базы данных
предназначен для того, чтобы запретить изменение данных объекта другими
сеансами или данным сеансом до тех пор, пока блокировка не будет снята этим
объектом встроенного языка.
В основном механизм пессимистической блокировки
используется системой 1С:Предприятие 8.1 для блокировки объектов,
редактируемых в форме. В то же время разработчик имеет возможность
задействовать этот механизм, используя средства встроенного языка.
Система 1С:Предприятие 8.1 использует механизм
пессимистической блокировки с помощью расширений форм прикладных объектов. В
тот момент, когда пользователь начинает модификацию объекта в форме, расширение
формы устанавливает пессимистическую блокировку. Если после этого другой
пользователь, например, попытается выполнить редактирование того же объекта, ему
будет выдано сообщение о том, что не удалось заблокировать объект. Когда
пользователь, редактировавший объект, закроет форму объекта, расширение формы
снимет пессимистическую блокировку.
Разработчик, для того, чтобы задействовать пессимистическую
блокировку, может использовать метод объекта Заблокировать(). Этот
метод позволяет установить пессимистическую блокировку объекта. Однако следует
учитывать, что сам по себе факт установки блокировки не препятствует изменению
или удалению объекта в базе данных. Поэтому для того, чтобы обеспечить
невозможность изменения заблокированного объекта, операции изменения объекта в
другом сеансе также должна предшествовать попытка блокировки этого объекта.
Блокировка заблокированного объекта базы данных вызывает исключение, которое
может быть обработано конструкцией Попытка … Исключение … КонецПопытки.
ОбъектЭкземпляр1 =
Справочники.Номенклатура.НайтиПоКоду(1).ПолучитьОбъект();
ОбъектЭкземпляр2 =
Справочники.Номенклатура.НайтиПоКоду(1).ПолучитьОбъект();
ОбъектЭкземпляр1.Заблокировать();
Попытка
ОбъектЭкземпляр2.Заблокировать();
// Изменение данных
объекта
// …
Исключение
Сообщить(«Изменение
объекта невозможно,
|данные объекта
заблокированы»);
КонецПопытки;
Для снятия пессимистической блокировки разработчик может использовать
метод объекта Разблокировать().
Также существует метод объекта Заблокирован(), который
позволяет определить, заблокированы ли данные объекта базы данных этим объектом
встроенного языка.
При работе с механизмом пессимистической блокировки средствами
встроенного языка следует помнить о том, что блокировка устанавливается при
выполнении метода конкретного экземпляра объекта встроенного языка.
Соответственно, снять блокировку можно, только выполнив метод Разблокировать()
этого же экземпляра объекта.
Если необходимо узнать, установлена ли блокировка на данные
объекта, или нет, нужно использовать метод Заблокировать(). В
случае, если блокировка уже установлена каким-либо объектом встроенного языка,
будет вызвано исключение.
Пессимистическая блокировка и транзакции
Операции блокировки объектов влияют только на выполнение
других операций блокировки объектов и не влияют на операции над данными и на
процесс течения транзакций.
Блокировка заблокированного объекта базы данных вызывает
исключение, которое может быть обработано и не приводит к обязательному откату
транзакции. Если в течение транзакции при выполнении метода Заблокировать()
возникло исключение, то оно может быть обработано конструкцией Попытка … Исключение … КонецПопытки
и не требует обязательного отката транзакции.
Блокировки объектов, установленные в течение транзакции,
сохраняются при фиксации транзакции и снимаются при откате транзакции.
Оптимистическая блокировка
Оптимистическая блокировка запрещает запись объекта в базу данных,
если после считывания объекта он был изменен в базе данных.
Строго говоря, оптимистическая блокировка представляет
собой проверку, которая выполняется перед записью объекта в базу данных.
Когда объект встроенного языка считывает данные из базы данных,
в числе прочего считывается и версия объекта, хранящегося в базе данных.
Если до начала редактирования данных пользователем (до
установки пессимистической блокировки) данные объекта в базе данных были
изменены (например, другим пользователем), то номер версии объекта, хранящийся
в базе данных, также изменится. При попытке пользователя записать этот объект,
будет выполнена проверка соответствия версии объекта, находящегося в памяти, и
версии объекта, хранящейся в базе данных. Так как версии отличаются, будет
выдано предупреждение о том, что версия объекта изменилась или он был удален,
то есть сработает оптимистическая блокировка.
Оптимистическая блокировка гарантирует, что если
пользователь изменяет объект, то его изменения не «затрут» изменения, сделанные
другими сеансами или другими программными объектами в этого же сеанса.
Механизм транзакций
Независимо о выбранного варианта работы (файловый или
клиент-серверный), система 1С:Предприятие 8.1 обеспечивает работу с
информацией, хранящейся в базе данных с использованием механизма транзакций.
Транзакция — это неделимая, с точки зрения воздействия на
базу данных, последовательность операций манипулирования данными, выполняющаяся
по принципу «все или ничего», и переводящая базу данных из одного
целостного состояния в другое целостное состояние. Если по каким-либо причинам
одно из действий транзакции невыполнимо или произошло какое-либо нарушение
работы системы, база данных возвращается в то состояние, которое было до начала
транзакции (происходит откат транзакции).
Транзакции могут использоваться как самой системой
1С:Предприятие 8.1, так и разработчиком при написании модулей.
Система 1С:Предприятие 8.1 осуществляет неявный вызов
транзакций при выполнении любых действий, связанных с модификацией информации,
хранящейся в базе данных. Например, все обработчики событий, расположенные в
модулях объектов и наборов записей, связанные с модификацией данных базы
данных, вызываются в транзакции.
Наряду с этим разработчик может использовать работу с
транзакциями в явном виде. Для этого используются процедуры глобального
контекста НачатьТранзакцию(),
ЗафиксироватьТранзакцию()
и ОтменитьТранзакцию().
Использование явного вызова транзакций
Процедура НачатьТранзакцию()
позволяет открыть транзакцию. После этого все изменения информации базы данных,
выполняемые последующими операторами, могут быть либо целиком приняты, либо
целиком отвергнуты.
Для принятия всех выполненных изменений используется
процедура ЗафиксироватьТранзакцию().
Для того чтобы отменить все изменения, выполнявшиеся в
открытой транзакции, используется процедура ОтменитьТранзакцию().
Таким образом, схема работы с транзакцией, в общем виде,
может выглядеть следующим образом:
НачатьТранзакцию();
// Последовательность операторов
…
Попытка
// Последовательность
выполняемых операторов
…
ЗафиксироватьТранзакцию();
Исключение
ОтменитьТранзакцию();
КонецПопытки;
// Последовательность выполняемых операторов
…
При использовании такой схемы следует помнить о том, что не
все ошибки, возникающие при работе с базой данных, обрабатываются системой
одинаково.
В общем случае, все ошибки базы данных можно разделить на
две категории:
·
невосстановимые;
·
восстановимые.
Невосстановимые
ошибки — это ошибки, при возникновении которых нормальное функционирование
системы 1С:Предприятие 8.1 может быть нарушено, например, могут быть
испорчены данные. При возникновении невосстановимой ошибки выполнение системы
1С:Предприятие 8.1 прекращается в любом случае.
Если невосстановимая ошибка произошла в процессе выполнения
транзакции, то все изменения, сделанные в рамках этой транзакции отменяются
системой.
Восстановимые ошибки
— это ошибки, не вызывающие серьезных нарушений в работе системы
1С:Предприятие 8.1. В случае возникновения восстановимой ошибки дальнейшая
работа системы может быть продолжена. При этом, естественно, сама операция,
вызвавшая ошибку, прекращается, и вызывается исключение, которое может быть
перехвачено и обработано конструкцией Попытка … Исключение … КонецПопытки.
Если восстановимая ошибка произошла в процессе выполнения
транзакции, то система автоматически не выполняет отмену транзакции,
предоставляя разработчику возможность самостоятельно обработать сложившуюся
ситуацию.
В зависимости от характера произошедшей ошибки, возможны
различные сценарии обработки этой ситуации.
Если произошедшая ошибка не связана с базой данных, то
возможно продолжение транзакции и дальнейшей работы модуля. Если разработчик
считает это необходимым, он может отменить транзакцию, или наоборот, продолжить
выполнение транзакции, если произошедшая ошибка не нарушает атомарность
транзакции.
Если же исключительная ситуация была вызвана ошибкой базы
данных, то система фиксирует факт возникновения ошибки в этой транзакции и
дальнейшее продолжение транзакции или ее фиксация становятся невозможны.
Единственная операция с базой данных, которую разработчик может произвести в
данной ситуации – это отмена транзакции. После этого он может осуществить
попытку выполнения этой транзакции еще раз.
Например, фрагмент кода, реализующий этот подход при записи
некоторых данных в базу данных, может выглядеть следующим образом:
// Признак окончания попыток выполнения записи
Записано = Ложь;
// Попытки записи выполняются в цикле
Пока Не Записано Цикл
Попытка
НачатьТранзакцию();
Данные.Записать();
ЗафиксироватьТранзакцию();
// В случае
фиксации транзакциии прекратить попытки записи
Записано = Истина;
Исключение
// В случае неудачи
отменить текущую транзакцию, и следующую
// попытку начать с
новой транзакции
ОтменитьТранзакцию();
КонецПопытки;
КонецЦикла;
Вложенный вызов транзакций
В рамках уже выполняемой транзакции можно обращаться к
процедурам НачатьТранзакцию(),
ЗафиксироватьТранзакцию()
и ОтменитьТранзакцию().
Например, может использоваться следующая схема вызовов:
НачатьТранзакцию();
…
// Вложенный вызов
транзакции
НачатьТранзакцию();
…
ЗафиксироватьТранзакцию();
…
// Вложенный вызов
транзакции
НачатьТранзакцию();
…
ЗафиксироватьТранзакцию();
…
ЗафиксироватьТранзакцию();
Однако подобное обращение не означает начала новой
транзакции в рамках уже выполняющейся. Система 1С:Предприятие 8.1 не
поддерживает вложенных транзакций. Это означает, что всегда действует только
транзакция самого верхнего уровня. Все транзакции, вызванные внутри уже
открытой транзакции, фактически относятся к той же транзакции, а не образуют
вложенную транзакцию. Таким образом, отмена изменений, выполняемая во
«вложенной» транзакции, будет приводить, в конечном счете, не к отмене
изменений самой «вложенной» транзакции, а к отмене всех изменений транзакции
верхнего уровня. В то же время фиксация изменений, выполненная во «вложенной»
транзакции, игнорируется.
Влияние транзакций на работу программных объектов
В общем случае программные объекты, используемые системой
1С:Предприятие 8.1, абсолютно «прозрачны» для транзакций базы данных.
Иначе говоря, транзакции базы данных могут вызываться при выполнении различных
методов программных объектов, однако, например, действия, выполняемые базой
данных при откате транзакции, в общем случае никак не влияют на соответствующие
программные объекты.
Из этого следует, что при отмене транзакций базы данных
разработчик (если в этом есть необходимость) должен самостоятельно обеспечивать
адекватное изменение данных соответствующих программных объектов. Это можно
выполнять путем перечитывания всех данных объекта или путем изменения некоторых
реквизитов программного объекта (если, например, это необходимо для отображения
в интерфейсе).
Однако, как в любом правиле, здесь тоже есть исключения. В
силу значительной прикладной специфики программных объектов 1С:Предприятия 8.1
в некоторых случаях откат изменений, выполненных в базе данных, все же может
влиять на значения свойств соответствующих программных объектов. Это происходит
следующих случаях:
·
при отмене транзакции признак проведенности
документа восстанавливает значение, которое было до начала транзакции;
·
если объект был создан и записан в транзакции,
то при откате транзакции очищается значение ссылки;
·
если объект создавался вне транзакции, и при
записи его в транзакции использовался код/номер, сгенерированный автоматически,
то при отмене транзакции код/номер очищается.
Механизм управляемых блокировок
Общие сведения о блокировках
В идеальном случае в
любой СУБД транзакции должны обеспечивать изоляцию изменений, выполняемых в
базе данных. Иными словами, несколько транзакций, выполняющих изменение данных,
не должны мешать друг другу.
Самым простым способом решения этой проблемы является
последовательное выполнение транзакций. Следующая транзакция выполняется после
того, как закончилась предыдущая.
Однако в реальной ситуации, при многопользовательской
работе, такой подход приводит к резкому снижению производительности системы.
Поэтому на практике используются механизмы, позволяющие выполнять несколько
транзакций одновременно.
Для того чтобы одновременное выполнение транзакций стало
возможным, используется несколько уровней изоляции транзакций. На самом низшем
уровне изоляции транзакции могут сильно мешать друг другу. На самом высшем
уровне они полностью изолированы.
Таким образом, за большую изоляцию транзакций приходится
платить большими накладными расходами и замедлением работы системы.
Возможность изоляции одних транзакций от других реализуется
благодаря блокировкам, накладываемым на используемые ими данные. В зависимости
от уровня изоляции, накладываются различные типы блокировок на различные
объекты базы данных на различное время.
С точки зрения 1С:Предприятия 8.1 работа с данными может
выполняться в одном из двух режимов:
·
в
транзакции;
·
вне
транзакции;
Режим работы с данными вне транзакции допускает только
операции чтения данных. Этот режим введен для того, чтобы обеспечить
максимальную скорость и параллельность чтения данных. Поэтому любая операция
чтения данных, выполняемая вне транзакции, считается безответственной. Это
означает, что такая операция чтения может вернуть устаревшие данные или даже
незафиксированные изменения, произведенные другой транзакцией, т.е. чтение
выполняется «не глядя» на блокировки данных, расставленные другими транзакциями.
Режим работы с данными в транзакции допускает любые
операции чтения и модификации данных, при этом должны соблюдаться следующие
правила:
·
чтение
данных должно быть воспроизводимым, т.е. любая последующая операция
чтения данных с тем же условием выборки должна возвращать такой же результат;
·
результат
чтения должен содержать наиболее актуальные данные, что означает, что
никакая другая транзакция не может изменить данные, считанные в данной
транзакции, до тех пор, пока данная транзакция не будет завершена;
·
результат чтения не должен содержать
незафиксированные изменения данных базы данных.
Независимо от того, в транзакции или нет выполняется
обращение к данным в 1С:Предприятии 8.1, на уровне СУБД это обращение к данным
(в том числе и чтение данных) выполняется в транзакции, явной или неявной.
Таким образом, при любых операциях с данными платформа 1С:Предприятия 8.1 будет
указывать СУБД уровень изоляции транзакций, который необходимо использовать для
выполнения данной операции, даже если с точки зрения 1С:Предприятия 8.1 эта
операция выполняется вне транзакции.
Управляемые блокировки 1С:Предприятия 8.1
1С:Предприятие 8.1 позволяет использовать два режима
работы с базой данных: режим автоматических блокировок в транзакции и режим управляемых
блокировок в транзакции.
Принципиальное отличие этих режимов заключается в
следующем. Режим автоматических блокировок не требует от разработчика
каких-либо действий по управлению блокировками в транзакции для того, чтобы
обеспечивались перечисленные выше правила работы с данными в транзакции. Эти
правила обеспечиваются платформой 1С:Предприятия 8.1 за счет использования
определенных уровней изоляции транзакций в той или иной СУБД. Такой режим
работы является наиболее простым для разработчика, однако в некоторых случаях
(например, при интенсивной одновременной работе большого количества
пользователей) используемый уровень изоляции транзакций в СУБД не может
обеспечить достаточной параллельности работы, что проявляется в виде большого
количества конфликтов блокировок при работе пользователей.
При работе в режиме управляемых блокировок система
1С:Предприятие 8.1 использует гораздо более низкий уровень изоляции
транзакций в СУБД, что позволяет значительно повысить параллельность работы
пользователей прикладного решения. Однако, в отличие от режима автоматических
блокировок, данный уровень изоляции транзакций уже не может сам по себе
обеспечить выполнение всех правил работы с данными в транзакции (в частности,
не обеспечивается воспроизводимость чтения данных в транзакции). Поэтому, при
работе в управляемом режиме, от разработчика требуется самостоятельно управлять
блокировками, устанавливаемыми в транзакции.
В сводном виде отличия при работе в режиме автоматических
блокировок и в режиме управляемых блокировок приведены в следующей таблице:
|
Режим блокировки в |
СУБД |
Файловая база данных |
MS |
PostgreSQL |
|
Автоматический |
Вид блокировок |
Таблиц |
Записей |
Таблиц |
|
Уровень изоляции транзакций |
Serializable |
Repeatable или Serializable |
Read |
|
|
Управляемый |
Вид блокировок |
Таблиц |
Записей |
Записей |
|
Уровень изоляции транзакций |
Serializable |
Read |
Read |
Установка режима блокировок в конфигурации
Конфигурация имеет свойство Режим управления блокировкой данных.
Каждый прикладной объект конфигурации также имеет свойство Режим управления блокировкой данных.
Режим управления блокировкой данных для всей конфигурации в
целом может быть установлен в значения Автоматический, Управляемый
и Автоматический
и управляемый. Значения Автоматический и Управляемый
означают, что соответствующий режим блокировки будет использоваться для всех
объектов конфигурации, независимо от значений, установленных для каждого из объектов.
Значение Автоматический
и управляемый означает, что для конкретного объекта конфигурации
будет использован тот режим, который указан в его свойстве Режим управления блокировкой данных:
Автоматический
или Управляемый.
Следует отметить, что режим управления блокировкой данных,
указанный для объекта метаданных, устанавливается для тех транзакций, которые
инициируются системой 1С:Предприятие 8.1 при работе с данными этого
объекта (например, при модификации данных объекта).
Если же, например, операция записи объекта выполняется в
транзакции, инициированной разработчиком (метод НачатьТранзакцию()), то
режим управления блокировкой данных будет определяться значением параметра БлокировкаДанных
метода НачатьТранзакцию(),
а не значением свойства объекта метаданных Режим управления блокировкой данных.
По умолчанию параметр БлокировкаДанных имеет
значение Автоматический,
поэтому для того, чтобы в явной транзакции использовать режим управляемых
блокировок следует указывать значение этого параметра РежимУправленияБлокировкойДанных.Управляемый.
Работа с управляемыми блокировками средствами встроенного языка
Для управления блокировками в транзакции предназначен
объект встроенного языка БлокировкаДанных.
Экземпляр этого объекта может быть создан с помощью конструктора и позволяет
описать необходимые пространства блокировок и режимы блокировок. Для установки
всех созданных блокировок используется метод Заблокировать() объекта БлокировкаДанных.
Если этот метод выполняется в транзакции (явной или неявной), блокировки
устанавливаются, и при окончании транзакции будут сняты автоматически. Если
метод Заблокировать()
выполняется вне транзакции, то блокировки не будут установлены.
Объект БлокировкаДанных
представляет собой коллекцию элементов блокировки данных, каждый из которых
описывает блокировки одного пространства блокировок. Пространства блокировок
определены в платформе 1С:Предприятия 8.1 и соответствуют структуре прикладных
объектов конфигурации. Для каждого пространства блокировок в платформе
определены имена полей, значения которых могут анализироваться при установке
тех или иных блокировок.
Допустимы следующие имена пространств блокировок и имена
полей пространств блокировок:
|
Имя пространства блокировки |
Имя поля пространства блокировки |
Для каждого пространства блокировки может быть задано
произвольное количество условий на поля, по которым будут определяться записи, подлежащие
блокировке. Условия задаются на равенство значения поля указанному значению или
на вхождение значения поля в указанный диапазон.
Условия могут быть заданы двумя способами:
·
с помощью явного указания имени поля и значения
(метод УстановитьЗначение()
объекта ЭлементБлокировкиДанных);
·
с помощью указания источника данных, содержащего
необходимые значения (свойство ИсточникДанных
объекта ЭлементБлокировкиДанных).
При явном указании значения поля в параметры метода УстановитьЗначение()
передается имя поля и значение. Например:
Блокировка = Новый БлокировкаДанных;
ЭлементБлокировки =
Блокировка.Добавить(«РегистрНакопления.ТоварыНаСкладах.Итоги»);
ЭлементБлокировки.УстановитьЗначение(«Качество»,
Справочники.Качество.НайтиПоКоду(«1»));
Следует иметь в виду, что одну и ту же запись регистра
можно заблокировать дважды, первый раз блокируя саму запись, а второй раз
блокируя набор, в который эта запись входит.
В качестве значения может быть передан также объект
встроенного языка Диапазон,
который создается с помощью конструктора и позволяет задать верхнюю и нижнюю
границы диапазона (границы диапазона включаются в диапазон).
При использовании источника данных, устанавливается
значение свойства ИсточникДанных,
а затем с помощью метода ИспользоватьИзИсточникаДанных()
задается соответствие полей области блокировки полям источника данных.
Например:
Блокировка = Новый БлокировкаДанных;
ЭлементБлокировки =
Блокировка.Добавить(«РегистрНакопления.ТоварыНаСкладах.Итоги»);
ЭлементБлокировки.ИсточникДанных =
ДокументОбъект.ВозвратнаяТара;
ЭлементБлокировки.ИспользоватьИзИсточникаДанных(«Номенклатура»,
«Номенклатура»);
ЭлементБлокировки.ИспользоватьИзИсточникаДанных(«Склад»,
«Склад»);
В качестве источника данных могут выступать результат
запроса, табличная часть, набор записей или таблица значений. Соответственно
при установке соответствия полей, именами полей источника будут являться имена
колонок результата запроса, имена реквизитов табличной части, имена измерений
или имена колонок таблицы значений. Объект Диапазон также может
являться значением поля источника данных.
Для каждого элемента блокировки может быть задан один из
двух режимов блокировки:
·
разделяемый;
·
эксклюзивный.
Режим блокировки задается с помощью свойства Режим
объекта ЭлементБлокировкиДанных.
Таблица совместимости управляемых блокировок выглядит
следующим образом:
|
Разделяемая блокировка |
Эксклюзивная блокировка |
|
|
Разделяемая блокировка |
+ |
— |
|
Эксклюзивная блокировка |
— |
— |
Разделяемый режим блокировки подразумевает, что заблокированные
данные не могут быть изменены другой транзакцией до окончания текущей
транзакции.
Эксклюзивный режим блокировки подразумевает, что
заблокированные данные не могут быть изменены другой транзакцией до окончания
текущей транзакции, а также не могут быть прочитаны другой транзакцией,
устанавливающей разделяемую блокировку на эти данные.
Говоря о совместимости действий, выполняемых в транзакции,
следует учитывать, что помимо явных управляемых блокировок, устанавливаемых
пользователем, система 1С:Предприятие 8.1 устанавливает также неявные
управляемые эксклюзивные блокировки при записи данных в транзакции. При чтении
данных объекта из базы данных (получении объекта и обращении к ссылке) не
выполняется транзакционная блокировка объекта. Если блокировка необходима, то
ее нужно устанавливать средствами языка до обращения к объекту.
Таким образом, таблица совместимости действий, выполняемых
в транзакции при использовании режима управляемых блокировок, выглядит
следующим образом:
|
Без блокировки |
Разделяемая блокировка |
Эксклюзивная блокировка |
|||||
|
чтение |
запись |
чтение |
запись |
чтение |
запись |
||
|
Без блокировки |
чтение |
+ |
+ |
+ |
+ |
+ |
+ |
|
запись |
+ |
— |
— |
— |
— |
— |
|
|
Разделяемая блокировка |
чтение |
+ |
— |
+ |
— |
— |
— |
|
запись |
+ |
— |
— |
— |
— |
— |
|
|
Эксклюзивная блокировка |
чтение |
+ |
— |
— |
— |
— |
— |
|
запись |
+ |
— |
— |
— |
— |
— |
Особенности работы в режиме Автоматический и управляемый
Режим управления блокировками
Автоматический и управляемый предназначен для решения проблем, возникающих при
параллельной работе с отдельными объектами конфигурации.
Например,
существует большая конфигурация, которую сложно в один момент перевести в режим
управляемых блокировок в транзакции, однако есть один или два документа,
являющиеся «камнем преткновения» при одновременной работе с ними большого
количества пользователей. В этом случае вся конфигурация может быть переведена
в режим Автоматический и управляемый, а затем сам документ, и затрагиваемые при
его записи объекты конфигурации – в режим Управляемый. Это позволит настроить
работу с данным документом в режиме управляемых блокировок, в то время как
основная часть конфигурации будет продолжать функционировать в автоматическом
режиме управления блокировками.
При работе в
режиме управления блокировками Автоматический и управляемый, следует учитывать
две особенности:
·
независимо
от режима, указанного для данной транзакции, система будет устанавливать
соответствующие управляемые блокировки;
·
режим
управления блокировками определяется транзакцией самого «верхнего» уровня.
Другими словами, если к моменту начала транзакции была начата другая
транзакция, то начинаемая транзакция не может быть выполнена в режиме, отличном
о того, который установлен для уже выполняющейся транзакции.
Рассмотрим
перечисленные особенности более подробно.
Первая особенность
заключается в том, что даже если для транзакции используется автоматический
режим управления блокировками, система установит дополнительно и
соответствующие управляемые блокировки при записи данных в этой транзакции. Из
этого следует, что транзакции, исполняющиеся в режиме управляемых блокировок,
могут конфликтовать с транзакциями, исполняющимися в режиме автоматического
управления блокировками.
Вторая особенность
заключается в том, что режим управления блокировками, указываемый для объекта
метаданных в конфигурации или указываемый при начале транзакции в явном виде
(как параметр метода НачатьТранзакцию()), является лишь «желаемым» режимом.
Фактический режим управления блокировками, в котором будет исполняться
транзакция, зависит от того, является ли данный вызов начала транзакции первым,
или к этому моменту уже начата другая транзакция в данной сессии 1С:Предприятия
8.1.
Например, если
требуется управлять блокировками при записи наборов записей регистра при
проведении документа, то управляемый режим блокировок должен быть установлен
как для самого регистра, так и для документа, поскольку запись наборов записей
регистра будет выполняться в транзакции, открытой при записи документа.
Возможны четыре
различных сочетания режимов управления блокировками в транзакции, которые
представлены в следующей таблице:
|
Режим существующей транзакции |
Режим начинаемой транзакции |
Результат |
|
Автоматический |
Автоматический |
Начинаемая |
|
Управляемый |
Управляемый |
Начинаемая |
|
Автоматический |
Управляемый |
Начинаемая |
|
Управляемый |
Автоматический |
Будет вызвана исключительная ситуация |
Модификация
конфигураций при переходе к режиму управляемых блокировок
При переходе к частичной или полной работе в режиме
управляемых блокировок, прикладное решение требует доработки. Доработка
заключается в том, что необходимо выявить участки кода, которые требуют наличия
управляемых блокировок, и затем в этих участках кода установить требуемый режим
блокировки данных.
Определение участков кода, требующих доработки
Управляемые блокировки необходимо устанавливать в тех
участках кода, которые удовлетворяют одному из следующих условий:
·
считываются
данные, которые в дальнейшем должны быть изменены;
·
считывается
некоторая согласованная совокупность данных (содержащихся в нескольких
объектах) и согласованность считанных данных необходимо поддержать. В этом
случае данные из этой совокупности должны быть заблокированы либо единовременно
перед считыванием, либо по мере считывания отдельных элементов. Если некоторый
элемент данных считывается однократно, не связан логически с другими элементами
данных и при этом не будет изменен в той же транзакции, то его можно не
блокировать.
·
важно
обеспечить неизменность считываемых данных до конца транзакции. Например,
некоторые данные, считываемые в транзакции, могут быть прочитаны еще раз, и
важно обеспечить их неизменность.
Типичным примером таких операций может служить запрос к
остаткам номенклатуры в модуле проведения документа.
Выбор режима управляемой блокировки
Для операций, описанных выше, режим блокировки следует
устанавливать исходя из следующих соображений:
·
эксклюзивный
режим блокировки следует устанавливать для тех данных, которые должны быть
изменены в рамках этой же транзакции. Это позволит предотвратить конфликты
блокировок;
·
разделяемый
режим блокировки следует устанавливать для тех данных, которые только
считываются, и изменять которые не предполагается, но заблокировать все-таки
требуется.
Примеры доработки конфигурации
Далее приведен пример установки управляемых блокировок в
модуле набора записей регистра накопления «ТоварыНаСкладах».
Прежде всего, следует создать управляемую блокировку:
Блокировка = Новый БлокировкаДанных;
Затем следует проанализировать текст запроса, формируемого
в модуле, и создать необходимые блокировки.
Эксклюзивная блокировка на регистр ТоварыНаСкладах.
В ходе выполнения модуля набора записей формируется запрос,
содержащий следующий фрагмент:
// …
ЛЕВОЕ СОЕДИНЕНИЕ
РегистрНакопления.ТоварыНаСкладах.Остатки(,
Номенклатура В (ВЫБРАТЬ РАЗЛИЧНЫЕ
Номенклатура
ИЗ
Документ.РеализацияТоваровУслуг.Товары
ГДЕ
Ссылка
= &ДокументСсылка))
// …
В данном случае следует установить следующие блокировки:
БлокировкаТоварыНаСкладах1 =
Блокировка.Добавить(«РегистрНакопления.ТоварыНаСкладах.Итоги»);
БлокировкаТоварыНаСкладах1.Режим=
РежимБлокировкиДанных.Эксклюзивный;
БлокировкаТоварыНаСкладах1.ИсточникДанных = ДокументОбъект.Товары;
БлокировкаТоварыНаСкладах1.ИспользоватьИзИсточникаДанных(«Номенклатура»,
«Номенклатура»);
БлокировкаТоварыНаСкладах1.ИспользоватьИзИсточникаДанных(«ХарактеристикаНоменклатуры»,
«ХарактеристикаНоменклатуры»);
БлокировкаТоварыНаСкладах1.ИспользоватьИзИсточникаДанных(«Склад»,
«Склад»);
Разделяемая блокировка на регистр ТоварыВРезервеНаСкладах
В ходе выполнения модуля формируется запрос, содержащий
следующий фрагмент:
// …
ЛЕВОЕ СОЕДИНЕНИЕ
РегистрНакопления.ТоварыВРезервеНаСкладах.Остатки(,
Номенклатура В (ВЫБРАТЬ РАЗЛИЧНЫЕ
Номенклатура
ИЗ
Документ.РеализацияТоваровУслуг.Товары
ГДЕ
Ссылка
= &ДокументСсылка))
// …
В данном случае следует установить следующие блокировки:
БлокировкаТоварыВРезервеНаСкладах1 =
Блокировка.Добавить(«РегистрНакопления.ТоварыВРезервеНаСкладах.Итоги»);
БлокировкаТоварыВРезервеНаСкладах1.Режим =
РежимБлокировкиДанных.Разделяемый;
БлокировкаТоварыВРезервеНаСкладах1.ИсточникДанных =
ДокументОбъект.Товары;
БлокировкаТоварыВРезервеНаСкладах1.
ИспользоватьИзИсточникаДанных(«Номенклатура»,
«Номенклатура»);
БлокировкаТоварыВРезервеНаСкладах1.ИспользоватьИзИсточникаДанных(«ХарактеристикаНоменклатуры»,
«ХарактеристикаНоменклатуры»);
БлокировкаТоварыВРезервеНаСкладах1.ИспользоватьИзИсточникаДанных(«Склад»,
«Склад»);
Разделяемая блокировка на регистр ТоварыКПередачеСоСкладов
В ходе выполнения модуля формируется запрос, содержащий
следующий фрагмент:
// …
ЛЕВОЕ СОЕДИНЕНИЕ
РегистрНакопления.ТоварыКПередачеСоСкладов.Остатки(,
Номенклатура В
(ВЫБРАТЬ РАЗЛИЧНЫЕ
Номенклатура
ИЗ
Документ.РеализацияТоваровУслуг.Товары
ГДЕ
Ссылка
= &ДокументСсылка))
// …
В данном случае следует установить следующие блокировки:
БлокировкаТоварыКПередачеСоСкладов1 = Блокировка.
Добавить(«РегистрНакопления.ТоварыКПередачеСоСкладов.Итоги»);
БлокировкаТоварыКПередачеСоСкладов1.Режим =
РежимБлокировкиДанных.Разделяемый;
БлокировкаТоварыКПередачеСоСкладов1.ИсточникДанных =
ДокументОбъект.Товары;
БлокировкаТоварыКПередачеСоСкладов1.ИспользоватьИзИсточникаДанных(«Номенклатура»,
«Номенклатура»);
БлокировкаТоварыКПередачеСоСкладов1.ИспользоватьИзИсточникаДанных(«ХарактеристикаНоменклатуры»,
«ХарактеристикаНоменклатуры»);
БлокировкаТоварыКПередачеСоСкладов1.ИспользоватьИзИсточникаДанных(«Склад»,
«Склад»);
Блокировки по табличной части ВозвратнаяТара. Эксклюзивная блокировка на
регистр ТоварыНаСкладах
В ходе выполнения модуля формируется запрос, содержащий
следующий фрагмент:
// …
ЛЕВОЕ СОЕДИНЕНИЕ
РегистрНакопления.ТоварыНаСкладах.Остатки(,
Номенклатура В (ВЫБРАТЬ РАЗЛИЧНЫЕ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара.Номенклатура
ИЗ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара
ГДЕ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара.Ссылка
= &ДокументСсылка)
И Качество =
&Новый)
// …
В данном случае следует установить следующие блокировки:
БлокировкаТоварыНаСкладах2 =
Блокировка.Добавить(«РегистрНакопления.ТоварыНаСкладах.Итоги»);
БлокировкаТоварыНаСкладах2.Режим= РежимБлокировкиДанных.Эксклюзивный;
БлокировкаТоварыНаСкладах2.ИсточникДанных =
ДокументОбъект.ВозвратнаяТара;
БлокировкаТоварыНаСкладах2.ИспользоватьИзИсточникаДанных(«Номенклатура»,
«Номенклатура»);
БлокировкаТоварыНаСкладах2.ИспользоватьИзИсточникаДанных(«Склад»,
«Склад»);
БлокировкаТоварыНаСкладах2.УстановитьЗначение(«Качество»,
Справочники.Качество.НайтиПоКоду(«1»));
Блокировки по табличной части ВозвратнаяТара. Разделяемая блокировка на
регистр ТоварыВРезервеНаСкладах
В ходе выполнения модуля формируется запрос, содержащий следующий
фрагмент:
// …
ЛЕВОЕ СОЕДИНЕНИЕ
РегистрНакопления.ТоварыВРезервеНаСкладах.Остатки(,
Номенклатура В (ВЫБРАТЬ РАЗЛИЧНЫЕ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара.Номенклатура
ИЗ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара
ГДЕ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара.Ссылка
= &ДокументСсылка)) КАК Резервы
// …
В данном случае следует установить следующие блокировки:
БлокировкаТоварыВРезервеНаСкладах2 =
Блокировка.Добавить(«РегистрНакопления.ТоварыВРезервеНаСкладах.Итоги»);
БлокировкаТоварыВРезервеНаСкладах2.Режим =
РежимБлокировкиДанных.Разделяемый;
БлокировкаТоварыВРезервеНаСкладах2.ИсточникДанных =
ДокументОбъект.ВозвратнаяТара;
БлокировкаТоварыВРезервеНаСкладах2.ИспользоватьИзИсточникаДанных(«Номенклатура»,
«Номенклатура»);
БлокировкаТоварыВРезервеНаСкладах2.ИспользоватьИзИсточникаДанных(«Склад»,
«Склад»);
Блокировки по табличной части ВозвратнаяТара. Разделяемая блокировка на
регистр ТоварыКПередачеСоСкладов
В ходе выполнения модуля формируется запрос, содержащий следующий
фрагмент:
// …
ЛЕВОЕ СОЕДИНЕНИЕ
РегистрНакопления.ТоварыКПередачеСоСкладов.Остатки(,
Номенклатура В (ВЫБРАТЬ РАЗЛИЧНЫЕ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара.Номенклатура
ИЗ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара
ГДЕ
Документ.РеализацияТоваровУслуг.ВозвратнаяТара.Ссылка
= &ДокументСсылка)) КАК ТоварыКПередаче
// …
В данном случае следует установить следующие блокировки:
БлокировкаТоварыКПередачеСоСкладов2 =
Блокировка.Добавить(«РегистрНакопления.ТоварыКПередачеСоСкладов.Итоги»);
БлокировкаТоварыКПередачеСоСкладов2.Режим =
РежимБлокировкиДанных.Разделяемый;
БлокировкаТоварыКПередачеСоСкладов2.ИсточникДанных =
ДокументОбъект.ВозвратнаяТара;
БлокировкаТоварыКПередачеСоСкладов2.ИспользоватьИзИсточникаДанных(«Номенклатура»,
«Номенклатура»);
БлокировкаТоварыКПередачеСоСкладов2.ИспользоватьИзИсточникаДанных(«Склад»,
«Склад»);
После того, как все необходимые блокировки созданы, следует
заблокировать перечисленные данные:
Блокировка.Заблокировать();
// … далее следует прежний текст модуля
Глава 7.
Организация бухгалтерского учета
Регистры
бухгалтерии
Свойства регистра бухгалтерии
Свойство Разрешить разделение итогов
позволяет задействовать механизм разделителя итогов, который обеспечивает более
высокую параллельность работы при записи в регистр.
Глава 9.
Бизнес-процессы и задачи
Редактирование задачи
Авто префикс номера задачи. Может
принимать значения НеИспользовать
и НомерБизнесПроцесса.
Если это свойство установлено в значение НомерБизнесПроцесса, то
при создании новой задачи ее номер автоматически дополняется номером
соответствующего ей бизнес-процесса.
Глава 10.
Построитель отчета
Схема работы отчета
Язык запросов
построителя отчета
Для формирования текста запроса
построителя отчета используется обычный язык запросов (см. раздел «Язык
запросов» раздела «Работа с запросами») с дополнительными синтаксическими
элементами, предназначенными для работы построителя.
Элементы языка
построителя выделяются в фигурные скобки. Эти конструкции игнорируются при
выполнении обычного запроса.
В общем случае
предложение языка запросов построителя запросов имеет синтаксис:
{КЛЮЧЕВОЕ_СЛОВО
<список полей>}
<список
полей> — перечисление полей (через запятую), которые будут доступны в
настройках построителя отчета. В качестве полей могут быть использованы как
поля таблиц исходного запроса, так и их псевдонимы. Для каждого поля
допускается указание псевдонима, используя ключевое слово КАК.
Существуют
следующие ключевые слова:
ВЫБРАТЬ — в этом предложении
описываются поля, которые пользователь сможет выбирать для вывода.
Если поля,
перечисленные в этом предложении, совпадают с полями выборки запроса или с их
псевдонимами, то эти поля также автоматически будут добавлены в выбранные поля
построителя отчета.
ГДЕ — описываются поля, на которые пользователь сможет накладывать ограничения.
Поля будут добавлены только в доступные поля построителя.
УПОРЯДОЧИТЬ ПО — описываются
поля для обозначения порядка.
Если поля,
перечисленные в этом предложении, совпадают с полями, перечисленными в
соответствующем предложении запроса, и предложении построителя отчета для них
не заданы псевдонимы, то эти поля будут автоматически добавлены в порядок
построителя отчета с теми условиями, которые заданы в тексте запроса.
ИТОГИ ПО — описываются поля, по которым будут выводиться итоговые значения.
Если поля,
перечисленные в этом предложении, совпадают с полями, перечисленными в
соответствующем предложении запроса, и предложении построителя отчета для них
не заданы псевдонимы, то эти поля будут автоматически добавлены в измерения
строки построителя отчета.
Предложения языка
запроса могут не содержать ключевых слов. Такой способ используется для
передачи построителю отчета параметров виртуальных таблиц.
В отличии от языка
запросов язык запросов построителя отчета допускает использование повторяющихся
псевдонимов. Повторяющиеся псевдонимы могут быть использованы для того, Чтобы
облегчить пользователю выбор полей, Выводимых в отчет. Если несколько полей
имеют одинаковые псевдонимы, То выбор такого псевдонима будет равносилен выбору
каждого поля, имеющего этот псевдоним.
Глава 11.
Система компоновки данных
Система компоновки данных предназначена для создания
отчетов 1С:Предприятия 8.1 на основе их декларативного описания. Использование
декларативного описания отчетов позволяет реализовать следующие возможности:
·
создание отчета без программирования;
·
использование автоматически генерируемых форм
просмотра и настройки отчета;
·
разбиение исполнения отчета на этапы;
·
исполнение отдельных этапов построения отчета на
различных компьютерах;
·
независимое использование отдельных частей
системы компоновки данных;
·
программное влияние на процесс выполнения
отчета;
·
настройки структуры отчета;
·
совмещение в отчете нескольких таблиц;
·
создание вложенных отчетов;
·
и др.
Построитель отчета и система компоновки данных
И построитель отчета, и система компоновки данных являются
средствами для создания отчетов в системе 1С:Предприятие 8.1. Однако они
обладают существенно разными возможностями, на которых следует остановиться
отдельно.
Задачей построителя отчета является динамическое создание
запроса для получения данных на основании настроек, которые указал
пользователь. Кроме этого построитель отчета выполняет динамическое
формирование макета для вывода отчета и непосредственно вывод отчета в
табличный документ или диаграмму.
Исходя из перечисленного, можно рассматривать построитель
отчета как средство для исполнения отчетов. Несмотря на богатые возможности,
которые предоставляет построитель отчета, он позволяет создать далеко не все
возможные отчеты, которые могут понадобиться в бизнес приложении.
Основной особенностью построителя отчета является
отсутствие целостного описания отчета. Отчет описывается запросом, который не
позволяет управлять всеми возможностями отчета. Например, нельзя указать
оформление для поля, применимость ресурса для измерений, роль поля и т.д.
В отличие от построителя отчета, в механизме компоновки
данных отчет описывается целостно, в схеме компоновки данных.
Другая особенность построителя отчета заключается в
невозможности работы с несколькими наборами данных в одном отчете, в то время
как система компоновки данных позволяет использовать произвольное количество
источников данных.
Также следует заметить, что построитель отчета рассчитан на
вывод в отчет лишь одной таблицы. Тогда как с использованием механизма
компоновки данных, за счет более гибкой структуры настроек, в отчет может быть
выведено несколько таблиц, диаграмм и вложенных отчетов.
Общие сведения о компоновке данных
Система компоновки данных представляет собой совокупность элементов,
каждый из которых соответствует определенному этапу выполнения отчета. Таким
образом, весь процесс выполнения отчета в системе компоновки данных сводится к
последовательному переходу от одного элемента к другому, доходя, в итоге, до
готового отчета.
Каждый элемент системы компоновки данных имеет собственное
декларативное описание, возможность программного доступа и возможность
сериализации в/из XML.
Такой подход позволяет гибко управлять различными этапами выполнения отчета.
Основные элементы системы компоновки данных представлены на
следующей схеме:
·
схема
компоновки данных – описывает суть данных, которые предоставляются отчету
(откуда получать данные и как можно управлять компоновкой данных). Представляет
собой базу, на основе которой могут быть сформированы всевозможные отчеты.
Может содержать:
текст запроса с инструкциями системы компоновки данных;
описание нескольких наборов данных;
описание доступных полей;
описание связей между несколькими наборами данных;
описание параметров получения данных;
описание макетов полей и группировок
и др.
·
настройки
компоновки данных – описывают все, что может настроить разработчик или
пользователь в некоторой установленной схеме компоновки данных. Может
содержать:
отбор;
упорядочивание;
условное оформление;
структуру отчета (составные части будущего отчета);
параметры получения данных;
параметры вывода данных;
и др.
·
макет
компоновки данных – представляет собой уже готовое описание того, как
должен быть сформирован отчет. В нем соединяется схема компоновки и настройки
компоновки. Фактически представляет собой результат применения конкретных
настроек к схеме компоновки и является готовым заданием процессору компоновки
на формирование отчета нужной структуры с учетом конкретных настроек;
·
элемент результата
компоновки данных – результат компоновки данных представляется набором
элементов результата компоновки данных. Как самостоятельная логическая сущность
результат компоновки данных не существует, существуют только его элементы.
Элементы результата компоновки данных можно вывести в табличный документ для
представления их конечному пользователю, или в другие виды документов.
Процесс компоновки данных состоит из нескольких этапов,
которые представлены на следующей схеме:
·
создание
схемы компоновки данных – создание схемы компоновки данных может быть
выполнено:
визуально, при помощи конструктора схемы компоновки
данных;
визуально, при помощи любого редактора, позволяющего
редактировать текст XML;
программно, при помощи объектов встроенного языка
1С:Предприятия 8.1;
·
редактирование
настроек компоновки данных — для редактирования настроек компоновки в
системе предусмотрен ряд объектов, встроенного языка и расширений табличного
поля;
·
подготовка
к исполнению — процесс формирования макета компоновки данных. В данном
процессе формируются запросы, необходимые для получения данных, указанных в
настройках, формируются макеты областей отчета;
·
исполнение
компоновки данных — это процесс получения, агрегации, оформления данных;
·
вывод
результата компоновки данных — полученный результат компоновки может быть
выведен в документ, который будет показан пользователю. Отчет может быть
выведен в различных форматах.
Следующая схема в обобщенном виде представляет объекты
системы компоновки данных, используемые на различных этапах создания отчета:
·
конструктор
схемы компоновки данных – может быть использован
для создания схемы компоновки данных;
·
компоновщик
настроек компоновки данных – может быть использован
для редактирования настроек системы компоновки данных;
· компоновщик макета компоновки данных — используется для подготовки к исполнению;
·
процессор
компоновки данных — осуществляет исполнение
компоновки данных;
·
процессор
вывода результата компоновки данных в табличный документ — выводит элементы
результата компоновки данных в табличный документ.
Отличительной особенностью отчета, получаемого с помощью
системы компоновки данных является то, что он может иметь сложную структуру,
включающую в себя различное сочетание следующих элементов:
·
группировка;
·
таблица;
·
диаграмма;
·
вложенный отчет.
Таким образом отчет, полученный с помощью системы
компоновки данных представляет собой не таблицу, а сложную иерархическую
структуру, в которой участвуют перечисленные элементы.
Общие объекты системы компоновки данных
Свойство Использование
Многие объекты, в основном, подсистемы настроек компоновки
данных, имеют свойство булевого типа Использование.
Это свойство позволяет отключать часть функциональности без ее физического
удаления. Значение этого свойства по-умолчанию – Истина,
кроме, отдельно описанных случаев.
Поле системы компоновки данных
Это объект, представляющий путь к данным поля. Поле
реализовано в виде отдельного типа, с целью устранить неоднозначность в
свойствах некоторых объектов, которые могут принимать значения, как строк, так
и полей. Имеет конструктор с параметром строка; свойств и методов не имеет.
Параметры системы компоновки данных
Механизм параметров был реализован для единообразного
использования и редактирования коллекций некоторых значений, состав которых и
тип элементов которых определен заранее и не может быть изменен. Механизм
параметров состоит из двух частей:
·
доступные параметры, они определяют состав
коллекции и допустимые типы ее элементов. Параметр — является аналогом
поля системы компоновки данных;
·
значения параметров.
Схема компоновки данных
Схема компоновки данных представляется объектом встроенного
языка 1С:Предприятия 8.1 СхемаКомпоновкиДанных и
состоит из множества других вложенных объектов. Схема компоновки данных имеет
представление в виде XML,
таким образом может быть создана любыми средствами, позволяющими генерировать XML, равно как и использована
любыми средствами, которые могут читать XML.
Схема компоновки данных используется для предоставления
информации о доступных настройках а также при формировании макета компоновки
данных, т.е. при исполнении компоновки данных.
Для визуального редактирования схемы компоновки данных
предназначен конструктор схемы компоновки данных.
Загрузку схемы компоновки данных из XML можно осуществить стандартными
средствами встроенного языка.
Пример:
ЧтениеXML = Новый ЧтениеXML;
ЧтениеXML.УстановитьСтроку(ЭлементыФормы.ТекстСхемыКомпоновкиДанных.ПолучитьТекст());
СКД = СериализаторXDTO.ПрочитатьXML(ЧтениеXML,
Тип(«СхемаКомпоновкиДанных»));
Все выражения, описываемые в схеме компоновки данных,
записываются на языке выражений системы компоновки данных.
Составные части схемы компоновки данных
Каждая схема компоновки данных содержит множество объектов,
описывающих ту или иную часть. Рассмотрим эти составные части.
Источники данных
Схема компоновки данных
может содержать несколько источников данных.
Под источником данных подразумевается источник, из которого
будут получаться данные. В качестве источника данных выступает информационная
база 1С:Предприятия 8.1.
Источники данных описываются в свойстве ИсточникиДанных схемы, которое содержит коллекцию
значений, состоящую из элементов ИсточникДанныхСхемыКомпоновкиДанных.
Пример описания источника данных с именем «Main»:
<dataSource>
<name>Main</name>
<dataSourceType>Local</dataSourceType>
</dataSource>
Наборы данных
Наборы данных в схеме
компоновки данных содержат информацию о том, какие поля можно получать из
данного набора, какие поля набора данных можно использовать в отборе и т.п.
В схеме компоновки данных допускается наличие нескольких
наборов данных.
Наборы данных описываются в свойстве НаборыДанных
схемы, которое содержит коллекцию значений, в которую могут входить следующие
элементы:
·
запрос (НаборДанныхЗапросСхемыКомпоновкиДанных) — получение данных
описывается при помощи языка запросов;
·
объект (НаборДанныхОбъектСхемыКомпоновкиДанных) — описывается имя
внешнего набора данных из которого будут получаться данные.
·
объединение (НаборДанныхОбъединениеСхемыКомпоновкиДанных) — описываются наборы
данных – составные части объединения;
Все три набора данных содержат ряд общих свойств:
·
Имя – имя набора
данных, под которым к этому набору данных можно будет обращаться из других объектов
схемы компоновки данных. В рамках одной схемы компоновки данных имена наборов
данных должны быть уникальными;
·
Поля — описания
полей, доступных для набора данных.
Кроме этого наборы данных запрос и объект содержат свойство
ИсточникДанных – имя источника данных, из которого
будут получаться данные. Оно должно содержать имя одного источника данных,
присутствующего в схеме компоновки данных.
Набор данных запрос содержит свойство Запрос
– текст запроса, при помощи которого будут получаться данные из источника
данных. Текст запроса записывается в терминах источника данных. Так для типа
источника данных «Local», текст запроса будет записан в терминах языка запросов
1С:Предприятия 8.1, с применением специального расширения – расширения языка
запросов для системы компоновки данных.
Набор данных объединение содержит свойство Элементы – содержащее перечень наборов данных, входящих в
объединение.
Набор данных – запрос
Пример набора данных – запрос:
<dataSet
xsi:type=»DataSetQuery»>
<dataSource>ИсточникДанных1</dataSource>
<query> ВЫБРАТЬ
ПродажиОбороты.Контрагент,
ПродажиОбороты.Номенклатура,
ПродажиОбороты.КоличествоОборот,
ПродажиОбороты.СуммаОборот
ИЗ
РегистрНакопления.Продажи.Обороты
КАК ПродажиОбороты</query>
</dataSet>
В приведенном примере отсутствует описание полей.
Набор данных – объект
Пример набора данных – объект:
<dataSet
xsi:type=»DataSetObject»>
<name>НаборДанных1</name>
<field
xsi:type=»DataSetFieldField»>
<dataPath>Номенклатура</dataPath>
<field>Номенклатура</field>
<title
xsi:type=»v8:LocalStringType»>
<v8:item>
<v8:lang>ru</v8:lang>
<v8:content>Номенклатура</v8:content>
</v8:item>
</title>
<valueType>
<v8:Type
xmlns:d5p1=»http://v8.1c.ru/8.1/data/enterprise/current-config»>d5p1:CatalogRef.Номенклатура</v8:Type>
</valueType>
</field>
<field
xsi:type=»DataSetFieldField»>
<dataPath>Сумма</dataPath>
<field>Сумма</field>
<title
xsi:type=»v8:LocalStringType»>
<v8:item>
<v8:lang>ru</v8:lang>
<v8:content>Сумма</v8:content>
</v8:item>
</title>
<valueType>
<v8:Type>xsd:decimal</v8:Type>
<v8:NumberQualifiers>
<v8:Digits>10</v8:Digits>
<v8:FractionDigits>2</v8:FractionDigits>
<v8:AllowedSign>Any</v8:AllowedSign>
</v8:NumberQualifiers>
</valueType>
</field>
<dataSource>ИсточникДанных1</dataSource>
<objectName>СуммаНоменклатуры</objectName>
</dataSet>
Как видно из примера, наборы данных – объект содержат
только описания полей и имя объекта из которого получать данные.
Набор данных – объединение
Набор данных – объединение содержит свойство Элементы, описывающее наборы данных, которые необходимо
объединить.
Пример набора данных – объединение:
<dataSet xsi:type=»DataSetUnion»>
<name>Документы</name>
<field
xsi:type=»DataSetFieldField»>
<dataPath>Ссылка</dataPath>
<field>Ссылка</field>
</field>
<field
xsi:type=»DataSetFieldField»>
<dataPath>СуммаДок</dataPath>
<field>СуммаДок</field>
</field>
<field
xsi:type=»DataSetFieldField»>
<dataPath>СуммаПрих</dataPath>
<field> СуммаПриход</field>
</field>
<field
xsi:type=»DataSetFieldField»>
<dataPath>СуммаРасх</dataPath>
<field> СуммаРасход</field>
</field>
<item xsi:type=»DataSetQuery»>
<name>РасходныеНакладные</name>
<field
xsi:type=»DataSetFieldField»>
<dataPath>Ссылка</dataPath>
<field>Ссылка</field>
</field>
<field
xsi:type=»DataSetFieldField»>
<dataPath>СуммаПриход</dataPath>
<field>СуммаДок</field>
</field>
<dataSource>ИсточникДанных1</dataSource>
<query> ВЫБРАТЬ
РасходнаяНакладная.Ссылка,
РасходнаяНакладная.Номер,
РасходнаяНакладная.Дата,
РасходнаяНакладная.СуммаДок
ИЗ
Документ.РасходнаяНакладная
КАК РасходнаяНакладная</query>
</item>
<item xsi:type=»DataSetQuery»>
<name>ПриходныеНакладные</name>
<field xsi:type=»DataSetFieldField»>
<dataPath>Ссылка</dataPath>
<field>Ссылка</field>
</field>
<field
xsi:type=»DataSetFieldField»>
<dataPath>СуммаРасход</dataPath>
<field>СуммаДок</field>
</field>
<dataSource>ИсточникДанных1</dataSource>
<query> ВЫБРАТЬ
ПриходнаяНакладная.Ссылка,
ПриходнаяНакладная.Номер,
ПриходнаяНакладная.Дата,
ПриходнаяНакладная.СуммаДок
ИЗ
Документ.ПриходнаяНакладная
КАК ПриходнаяНакладная</query>
</item>
</dataSet>
Заметим, что значения полей набора данных – объединение
будут получаться из полей вложенных наборов данных по их пути к данным. Так, в
приведенном примере, у внешнего набора данных будет поле «СуммаРасх», данные
для которого будут получаться из вложенных наборов данных, у которых путь к
данным — «СуммаРасход».
Поле набора данных схемы компоновки данных
Набор данных может содержать
описания полей, которые будут доступны для этого набора данных.
Поля набора данных описываются в свойстве Поля наборов данных, которое содержит коллекцию значений,
состоящую из элементов ПолеНабораДанныхСхемыКомпоновкиДанных.
Пример описания поля набора данных с именем «Контрагент».
Это поле имеет путь к данным «Контрагент» и является полем измерения:
<field>
<dataPath>Контрагент</dataPath>
<field>Контрагент</field>
<role>
<dimension>true</dimension>
</role>
</field>
Связи наборов данных
Наборы данных, присутствующие в схеме компоновки данных,
могут быть связаны друг с другом. Связи между наборами данных описываются в
схеме компоновки данных.
Связи наборов данных описываются в свойстве СвязиНаборовДанных схемы компоновки данных, которое
содержит коллекцию значений, состоящую из элементов СвязьНаборовДанныхСхемыКомпоновкиДанных.
Пример описания двух связей наборов данных. В первом случае
связываются наборы данных «Продажи» и «НоменклатураИерархия» по полям
«Номенклатура». При этом связь устанавливается по списку, содержащему набор
ссылок.
Во втором случае набор данных «НоменклатураИерархия»
связывается сам с собой по полям «Родитель» и «Номенклатура». Связь также
устанавливается по списку, содержащему набор ссылок.
<dataSetLink>
<sourceDataSet>Продажи</sourceDataSet>
<destinationDataSet>НоменклатураИерархия</destinationDataSet>
<sourceExpression>Номенклатура</sourceExpression>
<destinationExpression>Номенклатура</destinationExpression>
<parameter>Ссылки</parameter>
<parameterListAllowed>true</parameterListAllowed>
</dataSetLink>
<dataSetLink>
<sourceDataSet>НоменклатураИерархия</sourceDataSet>
<destinationDataSet>НоменклатураИерархия</destinationDataSet>
<sourceExpression>Родитель</sourceExpression>
<destinationExpression>Номенклатура</destinationExpression>
<parameter>Ссылки</parameter>
<parameterListAllowed>true</parameterListAllowed>
</dataSetLink>
Вычисляемые поля
В схеме компоновки данных существует возможность описать
поля, которые будут вычисляться по некоторым выражениям с использованием полей
наборов данных. Данные поля могут быть использованы в настройках точно также,
как поля набора данных.
Вычисляемые поля описываются в свойстве ВычисляемыеПоляСхемыКомпоновкиДанных схемы компоновки
данных, которое содержит коллекцию значений, состоящую из элементов ВычисляемоеПолеСхемыКомпоновкиДанных.
Поля ресурсов
В схеме компоновки данных возможно описание полей –
ресурсов, значения которых будут вычисляться для групповых записей.
Осуществляется это при помощи описания поля итога.
Поля итога описываются в свойстве ПоляИтога
схемы компоновки данных, которое содержит коллекцию значений, состоящую
из элементов ПолеИтогаСхемыКомпоновкиДанных.
Пример описания поля итога, имеющего путь к данным
«КоличествоОборот». Выражение для расчета итога определено для этого поля как
«Сумма(КоличествоОборот)»:
<fieldTotal>
<dataPath>КоличествоОборот</dataPath>
<expression>Сумма(КоличествоОборот)</expression>
</fieldTotal>
Параметры
Схема компоновки данных содержит описание параметров
данных.
Параметры данных описываются в свойстве Параметры схемы компоновки данных, которое содержит
коллекцию значений, состоящую из элементов ПараметрСхемыКомпоновкиДанных.
Пример описания параметра с именем «КонецПериода», имеющего
значение 00:00:00 31.12.2006 типа Дата. Значение
данного параметра может быть изменено пользователем:
<parameter>
<name>КонецПериода</name>
<title>Конец периода</title>
<valueType>
<Type
xmlns=»http://v8.1c.ru/8.1/data/core»>xsd:dateTime</Type>
<DateQualifiers
xmlns=»http://v8.1c.ru/8.1/data/core»>
<DateFractions>DateTime</DateFractions>
</DateQualifiers>
</valueType>
<value xsi:type=»xsd:dateTime»>2006-12-31T00:00:00</value>
<restrictUse>false</restrictUse>
</parameter>
Вложенные схемы
Схема компоновки данных может содержать описания вложенных
схем компоновки данных.
Вложенные схемы компоновки данных описываются в свойстве ВложенныеСхемыКомпоновкиДанных схемы компоновки данных,
которое содержит коллекцию значений, состоящую из элементов ВложеннаяСхемаКомпоновкиДанных.
Пример описания вложенной схемы компоновки данных с именем
«ОстаткиИОбороты»:
<dcssch:nestedScheme>
<dcssch:name>ОстаткиИОбороты</dcssch:name>
<dcssch:title>Остатки и
обороты</dcssch:title>
<dcssch:scheme>
Далее идет описание схемы
</dcssch:scheme>
</dcssch:nestedScheme>
Макеты
В схеме компоновки данных можно описать макеты, которые
будут использоваться для вывода поля или группировки. При указании макета для
поля или группировки указывается имя макета, описанного в данном свойстве.
Макеты описываются в свойстве Макеты схемы
компоновки данных, которое содержит коллекцию значений, состоящую из элементов ОписаниеМакетаСхемыКомпоновкиДанных.
Макеты полей
Для каждого поля в схеме компоновки данных может быть
указано имя макета, используемого для вывода данного поля в результат
компоновки.
Связь поля с макетом описывается с помощью объекта МакетПоляСхемыКомпоновкиДанных. Коллекция этих объектов
содержится в свойстве МакетыПолей объекта СхемаКомпоновкиДанных.
Макеты группировок
Для каждой группировки в схеме компоновки данных можно
указать имя макета, который будет использоваться при выводе данной группировки.
Связь группировки с макетом описывается с помощью объекта МакетГруппировкиСхемыКомпоновкиДанных. Коллекция этих
объектов содержится в свойстве МакетыГруппировок объекта
СхемаКомпоновкиДанных.
Макеты заголовков группировок
Для каждой группировки могут описываться также макеты
заголовков группировок.
Связь заголовка группировки с макетом описывается с помощью
объекта МакетГруппировкиСхемыКомпоновкиДанных (см. предыдущий
раздел). Коллекция этих объектов содержится в
свойстве МакетыЗаголовковГруппировок объекта СхемаКомпоновкиДанных.
Настройки по умолчанию
Схема компоновки данных содержит настройки компоновки
данных по умолчанию, которые могут быть заданы разработчиком. Данные настройки
будут применяться при открытии отчета, а также могут быть использованы для программной
установки настроек по умолчанию.
Работа с несколькими наборами данных
Система компоновки
данных позволяет использовать в одной компоновке несколько наборов данных.
Для того чтобы в одной компоновке использовать несколько
наборов данных, необходимо внести в схему описания наборов данных, которые
предполагается использовать, и указать связи между наборами данных.
Рассмотрим следующий пример:
Запишем три набора данных: «ПрайсЛист», «Остатки» и
«Продажи»:
Набор данных «ПрайсЛист» имеет
следующий вид:
<dataSet>
<name>ПрайсЛист</name>
<dataSource>ИсточникДанных1</dataSource>
<query>ВЫБРАТЬ
Номенклатура.Ссылка
КАК Номенклатура,
Номенклатура.Код,
Номенклатура.Наименование,
Номенклатура.ЗакупочнаяЦена,
Номенклатура.Представление
{ВЫБРАТЬ
Номенклатура.*,
Код,
Наименование,
ЗакупочнаяЦена}
ИЗ
Справочник.Номенклатура
КАК Номенклатура
ГДЕ
Номенклатура.ЭтоГруппа
= ЛОЖЬ
{ГДЕ
Номенклатура.Ссылка.*
КАК Номенклатура,
Номенклатура.Код,
Номенклатура.Наименование,
Номенклатура.ЗакупочнаяЦена}
{УПОРЯДОЧИТЬ ПО
Номенклатура.*,
Код,
Наименование,
ЗакупочнаяЦена}
{ИТОГИ ПО
Номенклатура.*}</query>
</dataSet>
Набор данных «Остатки» имеет
следующий вид:
<dataSet>
<name>Остатки</name>
<dataSource>ИсточникДанных1</dataSource>
<query>ВЫБРАТЬ
УчетНоменклатурыОстатки.Номенклатура,
УчетНоменклатурыОстатки.Склад,
ПРЕДСТАВЛЕНИЕ(УчетНоменклатурыОстатки.Склад),
УчетНоменклатурыОстатки.КоличествоОстаток
{ВЫБРАТЬ
Номенклатура.*,
Склад.*,
КоличествоОстаток}
ИЗ
РегистрНакопления.УчетНоменклатуры.Остатки(,
Номенклатура В (&Номенклатура)
{Склад}) КАК УчетНоменклатурыОстатки
{ГДЕ
УчетНоменклатурыОстатки.Склад.*,
УчетНоменклатурыОстатки.КоличествоОстаток}
{УПОРЯДОЧИТЬ ПО
Склад.*,
КоличествоОстаток}
{ИТОГИ ПО
Склад.*}</query>
<field>
<dataPath>КоличествоОстаток</dataPath>
<field>КоличествоОстаток</field>
<title>Количество остаток</title>
</field>
<field>
<dataPath>Номенклатура</dataPath>
<field>Номенклатура</field>
<title>Номенклатура</title>
<useRestriction>
<field>true</field>
<condition>true</condition>
<group>true</group>
<order>true</order>
</useRestriction>
<attributeUseRestriction>
<field>true</field>
<condition>true</condition>
<group>true</group>
<order>true</order>
</attributeUseRestriction>
</field>
</dataSet>
Набор данных «Продажи» имеет
следующий вид:
<dataSet>
<name>Продажи</name>
<dataSource>ИсточникДанных1</dataSource>
<query>ВЫБРАТЬ
ПродажиОбороты.Контрагент,
ПРЕДСТАВЛЕНИЕ(ПродажиОбороты.Контрагент),
ПродажиОбороты.Номенклатура,
ПродажиОбороты.КоличествоОборот,
ПродажиОбороты.СуммаОборот
{ВЫБРАТЬ
Контрагент.*,
Номенклатура.*,
КоличествоОборот,
СуммаОборот}
ИЗ
РегистрНакопления.Продажи.Обороты(,
, , Номенклатура В (&Номенклатура)
{Контрагент}) КАК ПродажиОбороты
{ГДЕ
ПродажиОбороты.Контрагент.*,
ПродажиОбороты.КоличествоОборот,
ПродажиОбороты.СуммаОборот}
{УПОРЯДОЧИТЬ ПО
Контрагент.*,
КоличествоОборот,
СуммаОборот}
{ИТОГИ ПО
Контрагент.*}</query>
<field>
<dataPath>Номенклатура</dataPath>
<field>Номенклатура</field>
<title>Номенклатура</title>
<useRestriction>
<field>true</field>
<condition>true</condition>
<group>true</group>
<order>true</order>
</useRestriction>
<attributeUseRestriction>
<field>true</field>
<condition>true</condition>
<group>true</group>
<order>true</order>
</attributeUseRestriction>
</field>
</dataSet>
Опишем связи между наборами
данных. Связь от набора данных «Прайс-лист» к набору данных «Остатки» будет
выглядеть следующим образом:
<dataSetLink>
<sourceDataSet>ПрайсЛист</sourceDataSet>
<destinationDataSet>Остатки</destinationDataSet>
<sourceExpression>Номенклатура</sourceExpression>
<destinationExpression>Номенклатура</destinationExpression>
<parameter>Номенклатура</parameter>
<parameterListAllowed>true</parameterListAllowed>
</dataSetLink>
Связь от набора данных «Прайс-лист»
к набору данных «Продажи» будет выглядеть следующим образом:
<dataSetLink>
<sourceDataSet>ПрайсЛист</sourceDataSet>
<destinationDataSet>Продажи</destinationDataSet>
<sourceExpression>Номенклатура</sourceExpression>
<destinationExpression>Номенклатура</destinationExpression>
<parameter>Номенклатура</parameter>
<parameterListAllowed>true</parameterListAllowed>
</dataSetLink>
Дополнительно опишем
поля–итоги:
<fieldTotal>
<dataPath>КоличествоОстаток</dataPath>
<expression>Сумма(КоличествоОстаток)</expression>
</fieldTotal>
<fieldTotal>
<dataPath>КоличествоОборот</dataPath>
<expression>Сумма(КоличествоОборот)</expression>
</fieldTotal>
<fieldTotal>
<dataPath>СуммаОборот</dataPath>
<expression>Сумма(СуммаОборот)</expression>
</fieldTotal>
Если в системе компоновки
данных описывается связь между двумя наборами данных, то набор данных, к
которому идет связь, будет считаться зависимым набором данных. Набор данных, от
которого идет связь, будет считаться родительским по отношению к зависимому от
него набору данных.
В приведенных примерах зависимыми наборами данных будут
наборы данных «Остатки» и «Продажи». А родительским, по отношению к обоим этим
наборам, – «ПрайсЛист».
В схеме компоновки данных нет указания типа связи. Все
связи считаются левыми внешними соединениями. Т.е. запись родительского набора
данных будет использоваться в компоновке даже в случае, если для нее не найдены
записи в зависимом наборе.
В макете компоновки данных возможно указание типа связи. Тип
связи генерируется компоновщиком макета в зависимости от накладываемых
глобальных отборов. В случае если на поле набора данных, являющегося зависимым,
накладывается глобальный отбор, генерируемые связи в макете компоновки данных
от этого набора данных до всех его родительских наборов (вплоть до начала
иерархии наборов данных) будут иметь тип «Внутренняя». Это означает, что записи
родительского набора данных будут участвовать в компоновке только в случае,
если будут найдены записи в зависимых наборах данных.
Например, если пользователь наложит глобальный отбор на
поле «Склад», наборы данных «ПрайсЛист» и «Остатки» будут связаны внутренней
связью.
В случае если набор данных зависит от некоторого набора, и
в связи указана возможность использования списка параметров, данные из
зависимого набора данных будут получаться порциями по 1000 записей. В случае
если использование списка параметров в связи не разрешено, записи будут
получаться по одной.
В случае если и зависимый и родительский набор данных
содержат поле с одинаковым именем, данное поле будет получаться из
родительского набора данных. В приведенных примерах поле «Номенклатура» всегда
будет получаться из набора данных «ПрайсЛист».
Не связанные наборы данных не могут содержать поля с
одинаковыми именами, в случае если у них нет общего родителя, в котором данное
поле также присутствует. Так, наборы данных «Остатки» и «Обороты» могут
содержать поле «Номенклатура», но не могли бы оба содержать поле «Контрагент».
В описании связи, в выражении источника используются поля
из набора данных источника (родительского набора), в выражении связи приемника
используются поля набора данных приемника (зависимого набора данных). Так, при
описании связи между наборами данных «ПрайсЛист» и «Остатки», выражение
«Номенклатура» в свойстве ВыражениеИсточник
использует поле набора данных «ПрайсЛист», а выражение «Номенклатура» в
свойстве ВыражениеПриемник использует поле набора
данных «Остатки».
В одной группировке не могут быть использованы поля из не
связанных друг с другом наборов данных, при этом наборы данных, имеющие общие
родительские наборы данных, связанными не считаются. Исключение сделано для
полей–итогов, которые могут быть использованы в любой группировке. В
приведенном примере мы не сможем в одной группировке задействовать поля «Склад»
и «Контрагент». Однако поля «КоличествоОстаток» и «СуммаОборот» – сможем, т.к.
эти поля являются ресурсами.
Данные зависимого набора данных не могут быть получены без
получения данных родительского набора. Т.е. при получении данных из зависимого
набора, автоматически будут получаться и данные из родительского набора (и всех
родителей родителя). Т.е. при получении набора данных «Остатки» будут
получаться данные и из набора «ПрайсЛист».
В случае если в группировке используются наборы данных из
нескольких наборов данных, при исполнении компоновки будет осуществляться обход
по последнему зависимому набору данных. Так, если в группировке будут
использоваться поля наборов «ПрайсЛист» и «Остатки», обход будет происходить по
набору «Остатки».
В случае если ни одного поля из связанного набора данных в
настройках не задействовано, набор данных не будет включен в макет компоновки
данных.
Расширение языка запросов для системы компоновки данных
Расширение языка запросов
для системы компоновки данных осуществляется при помощи специальных
синтаксических инструкций, заключаемых в фигурные скобки и помещаемых
непосредственно в текст запроса.
Синтаксические элементы расширения языка запросов
системы компоновки данных
ВЫБРАТЬ
В этом предложении описываются поля, которые пользователь
сможет выбирать для вывода. После данного ключевого слова через запятую
перечисляются псевдонимы полей из основного списка выборки запроса, которые
будут доступными для настройки.
Например:
{ВЫБРАТЬ Номенклатура, Склад}
После псевдонима поля может находиться комбинация символов
«.*», что обозначает возможность использования дочерних полей от данного поля.
Например, запись Номенклатура.* обозначает
возможность использования дочерних полей поля «Номенклатура» (например, поля
«Номенклатура.Код»). Элемент ВЫБРАТЬ может присутствовать только в первом
запросе объединения.
ГДЕ
Описываются поля, на которые пользователь сможет
накладывать отбор. В данном предложении используются поля таблиц. Использование
псевдонимов полей списка выборки недопустимо. Каждая часть объединения может
содержать собственный элемент ГДЕ.
Примеры:
{ГДЕ Номенклатура.*, Склад }
{ГДЕ Документ.Дата >= &ДатаНачала, Документ.Дата
<= &ДатаКонца}
Если значения параметров не задано, то предложение ГДЕ в
результирующий запрос не включается.
ХАРАКТЕРИСТИКИ
Для обеспечения работы с характеристиками в расширение
языка запросов для системы компоновки данных введен синтаксис описания
характеристик.
Ниже приведен пример
описания характеристик:
{ХАРАКТЕРИСТИКИ ТИП(Справочник.Номенклатура)
СПИСОК (ВЫБРАТЬ
ВидыДопСвойств.Ссылка,
ВидыДопСвойств.Наименование,
ВидыДопСвойств.ТипЗначения
ИЗ
ПланВидовХарактеристик.ВидыДопСвойств
КАК ВидыДопСвойств)
ИДЕНТИФИКАТОР Ссылка
ИМЯ Наименование
ТИПЗНАЧЕНИЯ ТипЗначения
ЗНАЧЕНИЯ
РегистрСведений.ДопСвойства
ОБЪЕКТ Номенклатура
ХАРАКТЕРИСТИКА
ВидСвойства
ЗНАЧЕНИЕ Свойство
}
В данном примере описываются характеристики для полей типа
ссылка на справочник «Номенклатура».
В характеристиках описываются следующие свойства:
·
ТИП – имя типа, для
которого описываются характеристики;
·
СПИСОК – имя таблицы
или запрос для получения списка характеристик;
·
ИДЕНТИФИКАТОР – имя
поля, содержащего идентификатор характеристики;
·
ИМЯ – имя поля,
содержащего имя характеристики;
·
ТИПЗНАЧЕНИЯ – имя
поля, содержащего тип значения характеристики. Если тип значения не указан,
считается, что характеристика имеет тип Булево;
·
ЗНАЧЕНИЯ – имя
таблицы или запрос для получения значений характеристик;
·
ОБЪЕКТ – имя поля,
содержащего идентификатор объекта (например, ссылка номенклатуры);
·
ХАРАКТЕРИСТИКА – имя
поля, содержащего идентификатор характеристики;
·
ЗНАЧЕНИЕ – имя поля,
содержащего значение характеристики. Если не указано – значение будет равно Истина в том случае, если такая характеристика у объекта
есть, Ложь — в противном случае.
Параметры
Кроме основных элементов, система компоновки данных
принимает элементы, записанные в параметрах виртуальных таблиц. В таких случаях
тип полей зависит от типа параметра, в котором располагаются элементы.
Например:
ВЫБРАТЬ
УчетНоменклатурыОбороты.Номенклатура
КАК Номенклатура,
УчетНоменклатурыОбороты.Склад
КАК Склад,
УчетНоменклатурыОбороты.КоличествоПриход
КАК КоличествоПриход,
УчетНоменклатурыОбороты.КоличествоРасход
КАК КоличествоРасход
ИЗ
РегистрНакопления.УчетНоменклатуры.Обороты({&ДатаНачала},
{&ДатаКонца}, ,{Номенклатура.*, Склад.*}) КАК УчетНоменклатурыОбороты
В этом приме поля «ДатаНачала», «ДатаКонца», «Номенклатура»
и «Склад» станут доступными в отборе, т.е. пользователь сможет применять для
них фильтры.
Автоматическое заполнение доступных полей
При автоматическом заполнении
доступных полей запроса выполняются следующие действия:
·
все поля списка выборки и их дочерние поля
становятся доступными для выбора, упорядочивания, группировки, отбора и др.;
·
параметры виртуальных таблиц становятся
доступными для отбора.
Конструктор схемы компоновки данных
Конструктор схемы компоновки
данных представляет собой объект встроенного языка КонструкторСхемыКомпоновкиДанных,
предназначенный для визуального конструирования схемы компоновки данных. Кроме
того, конструктор схемы компоновки данных используется в конфигураторе при
редактировании схемы компоновки данных.
Пример открытия окна
конструктора схемы компоновки данных и последующей сериализации полученной
схемы компоновки в XML:
Процедура КоманднаяПанельРедактораОтчета (Кнопка)
Конструктор = Новый
КонструкторСхемыКомпоновкиДанных;
Конструктор.УстановитьСхему(ПолучитьСхемуКомпоновкиДанных());
Конструктор.Редактировать(ЭтаФорма);
КонецПроцедуры
Процедура ОбработкаВыбора(ЗначениеВыбора, Источник)
Если ТипЗнч(Источник) =
Тип(«КонструкторСхемыКомпоновкиДанных») Тогда
СхемаКомпоновкиДанных
= Источник.ПолучитьСхему();
ЗаписьXML = Новый
ЗаписьXML;
ЗаписьXML.УстановитьСтроку();
СериализаторXDTO.ЗаписатьXML(
ЗаписьXML,
СхемаКомпоновкиДанных,
«dataCompositionScheme»,
«http://v8.1c.ru/8.1/data-composition-system/scheme»);
ЭлементыФормы.ТекстСхемыКомпоновкиДанных.УстановитьТекст(ЗаписьXML.Закрыть());
КонецЕсли;
КонецПроцедуры
Работа со схемой компоновки данных подразделяется на
следующие этапы:
·
редактирование наборов данных;
·
редактирование полей наборов данных;
·
редактирование связей наборов данных;
·
редактирование вычисляемых полей;
·
редактирование ресурсов;
·
редактирование параметров;
·
редактирование макетов;
·
редактирование вложенных настроек;
·
редактирование настроек системы компоновки
данных.
Редактирование наборов данных
Система компоновки данных поддерживает три вида набора
данных:
·
набор данных — запрос;
·
набор данных — объект;
·
набор данных — объединение;
·
редактирование полей запроса.
При добавлении набора данных, набору данных автоматически
генерируется имя и источник данных (если источника данных не существует).
Редактирование набора данных – запрос
Редактирование набора данных запрос заключается в
составлении запроса к данным. Для этого можно воспользоваться конструктором
запроса, или редактировать текст запроса непосредственно в окне конструктора
схемы компоновки данных.
Если флаг Автозаполнение установлен,
то система компоновки данных автоматически заполняет поля схемы компоновки
данных на основании созданного запроса.
Редактирование набора данных – объект
Редактирование набора данных объект заключается в:
·
добавлении/редактировании имени объекта,
содержащего данные;
·
добавлении/редактировании полей и группировок.
Редактирование набора данных – объединение
Редактирование набора данных объединение заключается в
редактировании объединенных полей из состава полей, подчиненных данному набору
данных.
Редактирование полей набора данных
При редактировании полей существует возможность задать:
·
заголовок поля;
·
ограничение доступности поля;
·
ограничение доступности полей-реквизитов;
·
роль для поля;
·
представление поля;
·
выражения упорядочивания;
·
способ проверки иерархии (набор данных и
параметр);
·
тип значения поля;
·
оформление поля.
Следует заметить, что роль поля, представление, выражение
упорядочивания, параметр, тип значения и оформление поля редактируются только
на верхнем уровне иерархии наборов данных.
Роль поля изначально определяется в запросе, но есть
возможность ее изменения в отдельном диалоге.
Установленный признак Игнорировать
значения Null означает, что в результат не будут включены групповые
записи по данному полю, если оно содержит значение NULL.
Выражения упорядочивания поля, тип значения и оформление
также могут быть отредактированы в отдельном диалоге.
Редактирование связей наборов данных.
При наличии нескольких наборов данных верхнего уровня, существует
возможность настроить связь между ними по одному или нескольким полям.
Источником и приемником связи являются наборы данных.
Выражениями источника и приемника – поля наборов данных.
В данном примере связь настраивается между наборами данных
(Остатки и обороты по регистру накопления и документу), связь осуществляется по
номенклатуре – по полю «Номенклатура» в документе и полю «Номенклатура» в
регистре накопления.
Редактирование вычисляемых полей
Закладка «Вычисляемые поля» позволяет создавать и редактировать
следующие свойства/характеристики вычисляемых полей:
·
путь к данным;
·
выражение;
·
заголовок;
·
ограничение доступности;
·
выражение представления;
·
выражения упорядочивания;
·
оформление;
·
доступные значения.
Выражения упорядочивания редактируются в отдельном диалоге.
Редактирование ресурсов
Вычисление ресурсов возможно по всем полям всех наборов
данных и по вычисляемым полям. В левом табличном поле отображается список
доступных и неиспользованных полей. В правом табличном поле отображаются поля,
по которым будут формироваться итоги и выражения их вычисления. По умолчанию
для числовых полей устанавливается функция «Сумма», для нечисловых полей –
«Количество». Нажатием на кнопку >> можно добавить
в ресурсы все поля типа Число. При этом допускается
ввод нескольких строк для одного ресурса. Компоновщик макета получая выражение
для ресурса, использует информацию о том, для какой группировки оно получается
и выдаст соответствующее выражение.
Если для ресурса было указано, что его можно рассчитывать
только в разрезе некоторой группировки (то есть в колонке «Рассчитывать по…»
было выбрано хотя бы одно поле группировки), то данный ресурс будет выводиться
в результат только для этой группировки и группировок в нее вложенных.
Редактирование параметров
Редактирование параметров включает в себя:
·
редактирование имени параметра;
·
редактирование заголовка;
·
редактирование доступных типов и значений
параметра;
·
определение значения и доступности списка
значений параметра;
·
определение выражения;
·
ограничение доступности;
При неопределенном значении параметра, считается, что
значение – нулевая ссылка на заданный тип. В параметрах могут
использоваться предопределенные данные и перечисления(режим Конфигуратора).
В колонке «Доступные значения» редактируются значения,
которые могут быть выбраны пользователем в качестве параметров схемы компоновки
данных. Если флажок в колонке «Доступен список значений» установлен, то это
означает, что можно будет использовать несколько значений параметра.
Редактирование макетов
Добавление макетов осуществляется нажатием кнопки Добавить макет на командной панели. Предлагается выбрать один
из трех вариантов макетов:
·
макет поля;
·
макет группировки;
·
макет заголовка группировки.
Для макета группировки и заголовка группировки можно задать
типа макета. Колонка табличного поля Область указывает
координаты области макета в табличном документе.
Редактирование областей табличного документа возможно с
помощью панели свойств, вызываемой Alt+Enter.
Редактируется как внешний вид, так и само содержимое ячейки. При задании
параметра или шаблона ячейке табличного документа, параметры добавляются в
макет и отображаются в колонке Имя параметра табличного
поля Параметры макета. Возможно редактирование выражения
параметра макета.
Вложенные схемы
Закладка Вложенные схемы позволяют
создавать и редактировать вложенные схемы компоновки данных. В роли схемы могут
выступать вложенные схемы, редактируемые конструктором схемы компоновки данных.
Настройки
Схема компоновки данных содержит настройки компоновки
данных по умолчанию, которые могут быть заданы разработчиком.
Табличное поле структуры отчета
Содержание отчета формируется на закладке «Настройки»
конструктора схемы компоновки данных в табличном поле структуры отчета. Рядом с
каждым элементом в структуре можно поставить пометку. Если пометка установлена,
элемент выводится в результат отчета.
Для добавления новой группировки используйте команду «Новая
группировка». В открывшемся диалоге следует выбрать
поле группировки и тип группировки (иерархия/элементы). Если поле группировки
не задается, то в ней будут выводиться детальные записи, и она будет называться
«<Детальные записи>».
При добавлении новой группировки, в ее параметрах
автоматически добавляются поля автопорядка и автовыбора. При добавлении новой
диаграммы – автовыбор.
Для группировки выбранных записей по заданному полю в
контекстном меню элемента структуры отчета следует выбрать
команду «Сгруппировать», в диалоге выбрать поле группировки и тип группировки
(возможен выбор иерархической группировки и группировки по элементам). При этом
если группируемый элемент уже содержит поле автопорядка, то оно войдет и в
новую группировку. Если создание группировки потеряло смысл, нажмите «Отмена». Чтобы разгруппировать созданную группировку выберите
команду «Разгруппировать». При этом останутся группировки, которые были вложены
в разгруппировываемую.
Чтобы удалить группировку со всеми вложенными в нее группировками выберите в
контекстном меню команду «Удалить». Получив подтверждение об удалении элемента,
система обновит структуру отчета,
Если по полю проводится иерархическая или только
иерархическая группировка, в структуре отчета после заголовка поля в скобках
отобразится тип иерархии.
Для изменения текущей группировки используйте команду
«Изменить». С помощью этой команды можно выбрать иное
поле группировки и тип группировки для текущей группировки.
Для переключения режима настройки
данных следует использовать команды «Текущий отчет» и «Текущий элемент отчета».
Возможности настройки схемы компоновки данных
В зависимости от вида выбранного элемента структуры отчета
меняется состав параметров настройки. При добавлении отбора, сортировки,
условного оформления и пр. в текущей строке табличного поля структуры отчета
появится соответствующая пиктограмма. В настройках схемы компоновки данных, по
умолчанию, везде, где используются поля, отображаются не заголовки полей, а
пути к данным этих полей.
Режим настройки «Текущий отчет»
В этом режиме доступны закладки: «Параметры данных» (если для
схемы был задан хотя бы один параметр), «Выбранные поля», «Отбор»,
«Сортировка», «Условное оформление», «Пользовательские поля», «Другие
настройки»
Режим настройки «Текущий элемент структуры настроек»
В этом режиме доступны закладки:
·
Для элемента типа «Группировка»:
Поля группировки
Выбранные поля
Отбор
Сортировка
Условное оформление
Другие настройки
·
Для элементов типа «Таблица» и «Диаграмма»:
Выбранные поля
Условное оформление
Другие настройки
Если для настроек <Отчет> на
закладке «Параметры» конструктора схемы компоновки данных были заданы
параметры, то они отобразятся в списке доступных полей в папке «Параметры
Данных». В тех местах, где будут использоваться эти поля, при выполнении отчета
будет подставляться значение соответствующих
параметров. Поля – параметры могут использоваться в любом месте настроек, кроме
отбора и группировки. Если на поле – параметр наложено условное оформление, оно
будет применяться к параметру при выводе его значения в результат компоновки.
В качестве значений параметров могут быть использованы
предопределенные данные и перечисления (в режиме Конфигуратора).
На закладке «Выбранные поля» выбираются поля, которые будут
входить в результат компоновки. Имеется возможность с помощью командной панели
добавить Новое поле, Новую папку полей, Новое автополе. Для поля автовыбора
контекстном меню есть команда «Развернуть».
На закладке «Поля группировки» выбираются поля, по которым
будет проводиться группировка и тип группировки (Без иерархии, Иерархия, Только
иерархия). Имеется возможность с помощью меню или контекстного меню добавить
Новое поле, Новое автополе. Для авто поля группировки есть команда
«Развернуть».
На закладке «Отбор» выбираются поля для фильтрации записей
результата компоновки. С помощью меню или контекстного меню можно добавить
Новый элемент или Новую группу. В колонках этой закладки добавленному элементу
можно установить значение, по которому будет проводиться отбор записей
результата компоновки. Могут использоваться предопределенные данные и
перечисления (в режиме Конфигуратора). С помощью команды контекстного меню созданному
элементу или группе отбора можно задать представление, которое будет обозначать
отбор в списке, если кнопка «Подробно» отжата.
Пользователь же сможет выбирать отбор по представлению.
На закладке «Сортировка» выбираются поля, по которым
результат выполнения отчета будет отсортирован. Возможно добавление как
«элемента порядка», так и «авто элемента порядка». Для авто элемента порядка в
контекстном меню есть команда «Развернуть». При развороте авто элемента, когда
в порядок добавляются элементы, соответствующие полям группировки, система
проверяет наличие реквизитов этих полей в глобальном упорядочивании. Если они
присутствуют, то они добавляются в упорядочивание вместо поля группировки.
На закладках «Поля группировки», «Выбранные поля», «Отбор»,
«Сортировка» из списка доступных полей можно переносить в окно выбора поле или
непрерывную группу полей с помощью стандартного механизма перетаскивания.
Также, используя контекстное меню списка доступных
полей можно выбрать текущее или все поля для того, чтобы поместить
их в соответствующую коллекцию (команда «Выбрать все»).
Доступные поля настройки компоновки данных отображаются в
последовательности: вначале поля — не ресурсы по алфавиту заголовка, после них
поля – ресурсы по алфавиту заголовка, и в конце списка – системные папки.
На закладке «Пользовательские поля» можно задать
пользовательские поля (выбор или выражение), которые выводятся в результат
компоновки. Полю-выбор следует задать Заголовок и выражение отбора, значение и
представление. Полю-выражению можно задать Заголовок и выражения для детальных
и итоговых записей.
Если полю или параметру установлен список доступных
значений, то в настройках компоновки данных для параметра можно будет выбрать
значение из этого списка, а в настройке отбора для поля можно будет выбрать
значение поля из его списка доступных значений. При выводе значения параметра
или поля, имеющих доступные значения, в результат компоновки вместо значения
будет выводиться его представление из списка доступных значений.
На закладке «Условное оформление» можно задавать
специфическое оформление элементам компоновки. В колонке «Представление»
задается обозначение условного оформления области, с которым оно будет показано
в списке Условных оформлений, если кнопка «Подробно» отжата.
На закладке «Другие параметры» в режиме «Текущий отчет»
задаются параметры вывода отчета, в режиме «Текущий элемент…» задаются
специфические параметры вывода элементов отчета.
Команда «Стандартная настройка» сменит все пользовательские
изменения настроек отчета на стандартные.
Примечание 1. При генерации макета
компоновки, система выдаст ошибку, если во вложенном отчете используется поле
верхнего отчета, значение которого невозможно определить. Это происходит в
случаях, когда отчет вложен в группировку по данному полю, либо когда отчет
вложен в детальные записи.
Примечание 2. Для некоторых типов
диаграммы система автоматически использует точки в случаях, если отсутствуют
серии и наоборот. Так, например, для вида диаграммы «Круговая» если не заданы серии,
но заданы точки, то в качестве серий системой будут автоматически
использоваться точки. А при выборе вида диаграммы «График» если не заданы
точки, но заданы серии, то в качестве точек будут использоваться серии.
Конструктор настроек компоновки данных
Конструктор настроек компоновки данных облегчает работу с
параметрами вывода данных в отчете.
Вызов этого конструктора может привести к потере настроек,
установленных вручную, поэтому на экране появится вопрос «Настройки, введенные
вручную, будут утеряны. Продолжить?»
При ответе «Да» запустится конструктор настроек компоновки
данных.
Выберите необходимый вид расположения данных и нажмите
кнопку «Далее>». Если не нужно настраивать
остальные параметры или хотите сделать это вручную, нажмите кнопку «ОК». Чтобы прекратить конфигурирование настроек отчета
нажмите «Отмена».
В открывшемся окне выбора полей, выберите
поля, которые должны отображаться в отчете. Для этого можно использовать как
кнопки, так и перетаскивание мышью. Выбранные поля можно сортировать при помощи
стрелок «вверх», «вниз». Если хотите остановиться на данном этапе, нажмите «ОК». Нажмите «Далее>» для перехода
на следующее окно настроек.
Для типа отчета «Таблица» можно
указать группировки в строках, колонках и таблиц. Для типа отчета «Диаграмма» — в сериях, точках и таблицах.
В открытом окне выберите поля и тип группировки, в качестве
которого могут выступать: «Без иерархии», «Иерархия», «Только иерархия».
После нажатия кнопки «Далее>»
конструктор настроек перейдет в окно выбора поля упорядочивания.
Поля упорядочивания выбираются аналогично полям
группировок. Для каждого поля устанавливается направление сортировки.
Для типов отчета «Список» и «Таблица» на этом конфигурирование параметров в
конструкторе настроек закончено. Для типа отчета «Диаграмма»,
после нажатия кнопки «Далее>», следует тип
диаграммы.
Для сохранения выбранных настроек нажмите «ОК». Для отказа – «Отмена».
По окончании работы с конструктором настроек компоновки
данных сохраненные настройки станут доступными для последующих изменений в окне
конструктора схемы компоновки данных.
Настройки компоновки данных
Настройки схемы
компоновки данных могут быть выполнены с помощью конструктора настроек или
вручную. Подробнее об этом см. книгу «1С:Предприятие 8.1. Руководство
пользователя» главу 6 «Отчеты и обработки» параграф «Работа с отчетами,
использующими систему компоновки данных».
Настройки
компоновки данных представляется объектом встроенного языка
1С:Предприятия 8.1 НастройкиКомпоновкиДанных и состоят
из множества других вложенных объектов.
Для визуального редактирования пользователем настроек
компоновки данных предназначен компоновщик настроек компоновки данных.
Загрузку схемы компоновки данных из XML можно
осуществить стандартными средствами встроенного языка.
Структура настроек компоновки данных
Структура – это некоторый скелет настроек, она определяет
взаимное расположение их основных элементов.
Структура настроек доступна через свойство Структура объекта НастройкиКомпоновкиДанных.
Элементами структуры настроек могут быть:
·
группировки;
·
таблицы (ТаблицаКомпоновкиДанных);
·
диаграммы (ДиаграммаКомпоновкиДанных);
·
вложенные объекты настройки (НастройкиВложенногоОбъектаСистемыКомпоновкиДанных).
Группировка
Для реализации группировки в структуре
настроек реализовано три разных типа данных:
·
группировки (ГруппировкаКомпоновкиДанных);
·
группировки таблиц (ГруппировкаТаблицыКомпоновкиДанных);
·
группировки диаграмм (ГруппировкаДиаграммыКомпоновкиДанных).
Наличие трех типов связано с необходимостью реализовать
ограничения, наложенные на взаимное расположение элементов в дереве структуры:
таблицы и диаграммы не могут включать в себя ничего кроме группировок.
Соответственно, все объекты группировок имеют идентичную объектную модель, они
различаются типом вложенной коллекции значений и составом параметров вывода.
Поля группировки
Набор полей, по которым
осуществляется группировка. Описывается с помощью объекта ПоляГруппировкиСистемыКомпоновкиДанных.
В свойстве Элементы этого объекта содержится коллекция
полей группировки, состоящая из объектов ПолеГруппировкиСистемыКомпоновкиДанных.
Авто поле группировки
Перед использованием авто поле будет преобразовано в набор
полей группировки.
Формирование набора происходит следующим образом: берутся
используемые выбранные поля, которые:
·
доступны для использования в полях группировки;
·
не являются ресурсами;
·
не зависят от других выбранных полей;
·
не зависят от уже существующих полей
группировки.
Если поле уже включено в данные поля группировки, повторно
оно не добавляется.
Таблица
Описание таблицы в структуре настроек выполняется с помощью
объекта ТаблицаСистемыКомпоновкиДанных.
Диаграмма
Описание диаграммы в структуре настроек выполняется с
помощью объекта ДиаграммаСистемыКомпоновкиДанных.
Вложенный объект
Описание вложенного объекта в структуре настроек
выполняется с помощью объекта НастройкиВложенногоОбъектаСистемыКомпоновкиДанных.
Свойства настроек компоновки данных
Выбор
Набор полей, выводимых в
результат компоновки. Описывается с помощью объекта ВыбранныеПоляКомпоновкиДанных.
В свойстве Элементы этого объекта содержится
коллекция выбранных полей, состоящая из объектов ВыбранноеПолеКомпоновкиДанных.
Группа выбранных полей
Используется для группировки полей. Описывается с помощью
объекта ГруппаВыбранныхПолейКомпоновкиДанных.
Авто выбранное поле
Перед использованием авто поле будет преобразовано в набор
выбранных полей. Состав набора полей зависит от того, какому элементу структуры
принадлежит разворачиваемое авто поле. Назовем его «данный элемент структуры». Формирование
набора полей выполняется по следующим правилам:
·
если данный элемент структуры:
группировка;
группировка таблицы;
группировка диаграммы,
берутся все используемые поля
этой группировки, которые доступны для использования в выбранных полях;
·
если данный элемент структуры:
группировка;
группировка таблицы;
группировка диаграммы,
в которой нет полей группировки
(группировка «детальные записи»), — из основных выбранных полей настроек,
которым принадлежит группировка, берутся все используемые поля, кроме полей,
использовавшихся для группировки в вышестоящих группировках и реквизитов этих
полей. Если данный элемент структуры – группировка диаграммы, не берутся
ресурсы;
·
обходятся все родительские элементы структуры
настроек, из выбранных полей этих элементов берутся все используемые ресурсы и
поля группировок, если по данному полю была задана группировка типа «Только
иерархия». В случае, если данный элемент структуры:
группировка;
группировка таблицы;
группировка диаграммы,
берутся все используемые выбранные
поля, которые являются реквизитами ее полей группировки.
Если это авто поле принадлежит диаграмме, то оно
разворачивается иначе, оно заменяется на ресурс – первый из встреченных при
исполнении описанных правил.
Если поле уже включено в данные выбранные поля, повторно
оно не добавляется
Отбор
Используется для фильтрации записей,
попадающих в результат компоновки. Кроме того, может использоваться для отбора
записей, к которым применяется некоторое оформление (условное оформление) и для
создания пользовательских полей – выбор.
Описывается с помощью объекта ОтборКомпоновкиДанных.
В свойстве Элементы этого объекта содержится
коллекция элементов отбора, состоящая из объектов ЭлементОтбораКомпоновкиДанных.
Группа элементов отбора
Используется для группировки элементов отбора, которая
упорядочивает данные результата. Описывается с помощью объекта ГруппаЭлементовОтбораКомпоновкиДанных.
Порядок
Описывает, каким образом нужно
упорядочивать записи, выводимые в результат. Представляет собой объект ПорядокКомпоновкиДанных. В свойстве Элементы
этого объекта содержится коллекция элементов порядка, состоящая из объектов ЭлементПорядкаКомпоновкиДанных.
Авто элемент порядка
Перед использованием автоматический элемент порядка будет
преобразован в набор элементов порядка.
Формирование набора происходит по следующим правилам: если
этот элемент порядка — часть порядка группировки (или группировки
таблицы/диаграммы), берутся все используемые поля группировки, которые доступны
для использования в порядке. Для каждого поля группировки проверяется
присутствие его реквизитов в глобальном упорядочивании настроек, которым
принадлежит группировка: если реквизиты найдены, они используются вместо самого
поля.
Если поле уже включено в данный порядок, повторно оно не
добавляется.
Условное оформление
Описание того, каким образом оформлять различные поля
результата. Представляет собой объект УсловноеОформлениеКомпоновкиДанных.
В свойстве Элементы этого объекта содержится
коллекция элементов порядка, состоящая из объектов ЭлементУсловногоОформленияКомпоновкиДанных.
Оформляемые поля
Поля, к которым применяется
оформление. Описываются с помощью объекта ОформляемыеПоляКомпоновкиДанных.
В свойстве Элементы этого объекта содержится
коллекция оформляемых полей, состоящая из объектов ОформляемоеПолеКомпоновкиДанных.
Если поля не указаны, оформление будет применено ко всей области.
Параметры вывода
Значения параметров вывода
определяют внешний вид соответствующих объектов. Для части параметров
поддерживается наследование, в связи с этим, коллекция параметров вывода для
элемента может содержать параметры, не относящиеся к нему самому, но
используемые в элементах, которые могут быть вставлены в подчиненную часть
структуры настроек.
Параметры данных
Значения параметров данных, как правило, используются в
запросах для фильтрации выборки.
Пользовательские поля
Пользовательские поля позволяют пользователю расширить
множество используемых доступных полей, определяя собственные выражения, либо
наборы вариантов, с условиями использования конкретного варианта.
Пользовательские поля описываются с помощью объекта ПользовательскиеПоляКомпоновкиДанных. В свойстве Элементы этого объекта содержится коллекция
пользовательских полей, состоящая из объектов двух видов:
·
поле-выражение (объект ПользовательскоеПолеВыражениеКомпоновкиДанных);
·
поле-выбор (объект ПользовательскоеПолеВыборКомпоновкиДанных).
Тип поля определяется системой автоматически, на основе его
свойств.
Варианты пользовательского поля
Описание набора альтернатив, определяющих значение поля
выбора. Описываются с помощью объекта ВариантыПользовательскогоПоляВыборКомпоновкиДанных.
В свойстве Элементы этого объекта содержится
коллекция вариантов пользовательского поля-выбор, состоящая из объектов ВариантПользовательскогоПоляВыборКомпоновкиДанных.
Работа с авто полями
В случае, если один элемент структуры настроек содержит АвтоПолеГруппировкиСистемыКомпоновкиДанных, АвтоВыбранноеПолеСистемыКомпоновкиДанных и АвтоЭлементПорядкаСистемыКомпоновкиДанных, они
преобразовываются в след. порядке:
· АвтоПолеГруппировкиСистемыКомпоновкиДанных
· АвтоВыбранноеПолеСистемыКомпоновкиДанных
·
АвтоЭлементПорядкаСистемыКомпоновкиДанных.
Доступные Объекты
Доступные объекты — набор, определяющий объекты,
которые могут быть использованы в компоновке как вложенные. Например, вложенные
отчеты.
Доступные поля
Доступные поля, это множество полей, которые могут быть
использованы при настройке компоновки данных, и будут распознаны и правильно
обработаны на последующих этапах компоновки. Доступные поля различаются по
применению, всего выделено 7 коллекций полей:
·
поля для выбора (свойство ДоступныеПоляВыбора);
·
поля группировок (свойство ДоступныеПоляГруппировок);
·
поля порядка (свойство ДоступныеПоляПорядка);
·
поля параметров данных (свойство ДоступныеПоляПараметровДанных);
·
поля отбора (свойство ДоступныеПоляОтбора);
·
поля отбора элементов структуры (используются во
всех элементах структуры кроме верхнего) (свойство ДоступныеПоляОтбораЭлементовСтруктуры);
·
поля дополнительных отборов (используются в
условном оформлении) (свойство ДоступныеПоляДополнительныхОтборов).
Все перечисленные свойства содержат коллекции значений,
элементами которых являются объекты ДоступноеПолеКомпоновкиДанных.
В конструкторе схемы компоновки данных и в настройках схемы
компоновки данных отчета доступные поля располагаются в следующей
последовательности: вначале поля, не являющиеся ресурсами, в алфавитном порядке
по заголовкам, после них поля-ресурсы в алфавитном порядке по заголовком.
Последними в списке отражаются системные папки.
Доступное поле отбора
Для использования в отборах реализован специальный тип
доступных полей. Он обладает всеми свойствами обычного доступного поля, а так
же предоставляет наборы доступных видов сравнения и доступных значений поля,
необходимых для корректного построения элементов отбора.
Компоновщик настроек компоновки данных
Компоновщик настроек представляется объектом встроенного
языка 1С:Предприятия 8.1 КомпоновщикНастроекКомпоновкиДанных.
Объект предназначен для связи настроек компоновки данных и схемы компоновки
данных. На основе схемы компоновки данных строится источник доступных настроек
для работы конструктора настроек.
Макет компоновки данных
Макет компоновки данных
представляется объектом встроенного языка 1С:Предприятия 8.1 МакетКомпоновкиДанных и состоит из множества других
вложенных объектов. Макет компоновки данных является инструкцией для системы
компоновки данных, каким образом требуется выполнить компоновку данных. Макет
компоновки уже содержит в себе описание макетов областей, тексты исполняемых
запросов, расположение группировок и т.д.
Составные части макета компоновки данных
Каждый макет компоновки данных содержит множество объектов,
описывающих ту или иную часть. Рассмотрим эти составные части.
Источники данных
Макет компоновки данных
может содержать несколько описаний источников данных.
Под источником данных подразумевается источник, из которого
будут получаться данные. В качестве источника данных выступает информационная
база 1С:Предприятия 8.1.
Источники данных описываются в свойстве ИсточникиДанных макета, которое содержит коллекцию
значений, состоящую из элементов ИсточникДанных МакетаКомпоновкиДанных.
Допускается создание нескольких источников данных,
указывающих при помощи строки соединения на одну информационную базу.
Наборы данных
Наборы данных макета
компоновки данных содержат описание того, какие данные необходимо получать в
компоновке данных.
Они описываются в свойстве НаборыДанных
макета компоновки данных.
Допускается наличие нескольких наборов данных.
Поле набора данных макета компоновки данных
Набор данных может
содержать описания полей, которые будут доступны для этого набора данных. Поля,
описания которых в наборе данных отсутствуют, являются недоступными. Если
некоторое поле присутствует в запросе набора данных, но отсутствует в описании
полей набора данных, то поле не будет доступно для использования.
Поля набора данных описываются в свойстве Поля набора данных, которое содержит коллекцию значений,
состоящую из элементов ПолеНабораДанныхМакетаКомпоновкиДанных.
Значения параметров макета компоновки данных
Макет компоновки данных может содержать параметры в любых
выражениях, присутствующих в нем.
Значения параметров описываются в свойстве ЗначенияПараметров макета компоновки данных, которое
содержит коллекцию значений, состоящую из элементов ЗначениеПараметраМакетаКомпоновкиДанных.
Связи наборов данных макета компоновки данных
Наборы данных, присутствующие в макете компоновки данных,
могут быть связаны друг с другом. Связи между наборами данных описываются в
макете компоновки данных.
Связи наборов данных описываются в свойстве СвязиНаборовДанных макета компоновки данных, которое
содержит коллекцию значений, состоящую из элементов СвязьНаборовДанныхМакетаКомпоновкиДанных.
Макеты областей макета компоновки данных
При исполнении компоновки в
результат компоновки будут выводиться макеты областей. Эти макеты областей
также находятся в макете компоновки данных.
Описания макетов содержатся в свойстве Макеты
макета компоновки данных, которое содержит коллекцию значений, состоящую
из элементов ОписаниеМакетаОбластиМакетаКомпоновкиДанных.
Тело макета компоновки данных
Предыдущие составные части макета компоновки данных
содержали информацию о том, откуда получать информацию. Само же указание о том,
как следует скомпоновать данные находится в теле макета компоновки данных. Тело
макета компоновки данных состоит из элементов.
Возможно использование следующих типов элементов:
·
группировка — описывает
выводимую в результат группировку;
·
детальные записи — описывает
выводимые в результат детальные записи набора данных;
·
таблица — описывает
таблицу, выводимую в результат;
·
диаграмма — описывает
диаграмму, выводимую в результат;
·
макет — описывает макеты, используемые при
выводе.
Группировка таблицы
Описывает группировку таблицы и представляется объектом
встроенного языка ГруппировкаТаблицыМакетаКомпоновкиДанных.
Группировка таблицы содержит те же свойства, что и обычная
группировка, со следующими различиями:
·
тело группировки таблицы и иерархическое тело
группировки таблицы может содержать только элементы, которые могут содержаться
в теле таблицы, т.е. только группировки таблицы, детальные записи таблицы,
макеты группировки таблицы. Иерархическое тело может дополнительно содержать
иерархическую группировку таблицы, которая обозначает место, в которое будут
выводиться иерархические записи группировки;
·
в качестве макетов заголовков и подвала
используются макеты группировки таблицы;
·
возможно использование свойств:
МакетОбщихИтогов(OverallsTemplate),
которое указывает макет, используемый при выводе общих итогов по группировке,
типа МакетГруппировкиТаблицыМакетаКомпоновкиДанных.
РасположениеОбщихИтогов (OverallsPlacement) – расположение
общих итогов для группировки, типа РасположениеИтоговКомпоновкиДанных.
Детальные записи таблицы
Описывают детальные записи таблицы и представляются объектом
встроенного языка ЗаписиТаблицыМакетаКомпоновкиДанных.
Макет группировки таблицы
Макет группировки таблицы описывает макеты, используемые
при выводе группировки таблицы, и представляется объектом встроенного языка МакетГруппировкиТаблицыМакетаКомпоновкиДанных.
Группировка диаграммы
Описывает группировку диаграммы и представляется объектом
встроенного языка ТелоГруппировкиДиаграммыМакетаКомпоновкиДанных.
Группировка диаграммы содержит те же свойства, что и
обычная группировка, со следующими различиями:
·
тело группировки диаграммы и иерархическое тело
группировки диаграммы может содержать только макеты группировки диаграммы и
группировки диаграммы. Иерархическое тело может дополнительно содержать
иерархическую группировку диаграммы, которая обозначает место, в которое будут
выводиться иерархические записи группировки;
·
отсутствуют макеты для заголовка и подвала;
Макет группировки диаграммы
Макет группировки диаграммы описывает макеты, используемые
при выводе группировки диаграммы, и представляется объектом встроенного языка МакетГруппировкиДиаграммыМакетаКомпоновкиДанных.
Язык выражений системы компоновки данных
Язык выражений системы
компоновки данных предназначен для записи выражений, используемых в различных
частях системы.
Выражения используются в следующих подсистемах:
·
схема компоновки данных — для описания
вычисляемых полей, полей итогов, выражений связи и т.д.;
·
настройки компоновки данных — для описания
выражений пользовательских полей;
·
макет компоновки данных — для описания
выражений связи наборов данных, описания параметров макета и т.д.
Литералы
В выражении могут присутствовать литералы. Возможны
литералы следующих типов:
·
Строка;
·
Число;
·
Дата;
·
Булево.
Строка
Строковый литерал записывается в символах «”», например:
“Строковой литерал“
При необходимости использования внутри строкового литерала
символа «”», следует использовать два таких символов. Например:
“Литерал ““в кавычках“““
Число
Число записывается без пробелов, в десятичном формате.
Дробная часть отделяется при помощи символа «.». Например:
10.5
200
Дата
Литерал типа дата записывается при помощи ключевого
литерала ДАТАВРЕМЯ (DATETIME). После данного ключевого слова, в скобках, через
запятую перечисляются год, месяц, день, часы, минуты, секунды. Указание времени
не обязательно. Например:
ДАТАВРЕМЯ(1975, 1, 06) – Шестое января 1975 года
ДАТАВРЕМЯ(2006, 12, 2, 23, 56, 57) – Второе декабря
2006 года, 23 часа 56 минут 57 секундода, 23 часа 56 минут 57 секунд
Булево
Булевы значения могут быть записаны при помощи литералов Истина (True), Ложь (False).
Значение
Для указания литералов других типов (системных
перечислений, предопределенных данных) используется ключевое слово Значение, после которого в скобках идет указание имени
литерала.
Значение(ВидСчета. Активный)
Поля
В выражениях могут использоваться поля наборов данных. Поле
идентифицируется путем к данным. Части пути к данным оделяются друг от друга
символом «.». Имя поля не является чувствительным к регистру. Например:
Номенклатура.Артикул
Продажи.СуммаОборот
Параметры
Выражения могут использовать параметры. Для использования в
выражении параметра достаточно написать его имя, которому будет предшествовать
символ &. Например:
&Контрагент
&ДатаНачала
Операции над числами
Унарный –
Данная операция предназначена для изменения знака числа на
обратный. Например:
-Продажи.Количество
Унарный +
Данная операция не выполняет над числом никаких действий.
Например:
+Продажи.Количество
Бинарный —
Данная операция предназначена для вычисления разности двух
чисел. Например:
ОстаткиИОбороты.НачальныйОстаток –
ОстаткиИОбороты.КонечныйОстаток
ОстаткиИОбороты.НачальныйОстаток — 100
400 – 357
Бинарный +
Данная операция предназначена для вычисления суммы двух
чисел. Например:
ОстаткиИОбороты.НачальныйОстаток + ОстаткиИОбороты.Оборот
ОстаткиИОбороты.НачальныйОстаток + 100
400 + 357
Произведение
Данная операция предназначена для вычисления произведения
двух чисел. Например:
Номенклатура.Цена * 1.2
2 * 3.14
Деление
Данная операция предназначена для получения результата
деления одного операнда на другой. Например:
Номенклатура.Цена / 1.2
2 / 3.14
Остаток от деления
Данная операция предназначена для получения остатка от
деления одного операнда на другой. Например:
Номенклатура.Цена % 1.2
2 % 3.14
Операции над строками
Конкатенация (Бинарный +)
Данная операция предназначена для конкатенации двух строк.
Например:
Номенклатура.Артикул + “: ”+ Номенклатура.Наименование
Подобно (LIKE)
Данная операция проверяет соответствие строки переданному
шаблону.
Значением оператора ПОДОБНО
является ИСТИНА, если значение <Выражения>
удовлетворяет шаблону, и ЛОЖЬ в противном случае.
Следующие символы в <Строке_шаблона> имеют смысл,
отличный от просто очередного символа строки:
·
% — процент: последовательность, содержащая ноль
и более произвольных символов;
·
_ — подчеркивание: один произвольный символ;
·
[…] — один или несколько символов в квадратных
скобках: один символ, любой из перечисленных внутри квадратных скобок. В
перечислении могут встречаться диапазоны, например a-z, означающие произвольный
символ, входящий в диапазон, включая концы диапазона;
·
[^…] — в квадратных скобках значок отрицания, за
которым следует один или несколько символов: любой символ, кроме тех, которые
перечислены следом за значком отрицания;
Любой другой символ означает сам себя и не несет никакой
дополнительной нагрузки. Если в качестве самого себя необходимо записать один
из перечисленных символов, то ему должен предшествовать <Спецсимвол>,
указанный после ключевого слова СПЕЦСИМВОЛ (ESCAPE).
Например, шаблон
“%АБВ[0-9][абвг]\_абв%” СПЕЦСИМВОЛ “\”
означает подстроку, состоящую из последовательности
символов: буквы А; буквы Б; буквы В; одной цифры; одной из букв а, б, в или г;
символа подчеркивания; буквы а; буквы б; буквы в. Причем эта последовательность
может располагаться, начиная с произвольной позиции в строке.
Операции сравнения
Равно
Данная операция предназначена для сравнения двух операндов
на равенство. Например:
Продажи.Контрагент =
Продажи.НоменклатураОсновнойПоставщик
Не равно
Данная операция предназначена для сравнения двух операндов
на неравенство. Например:
Продажи.Контрагент <>
Продажи.НоменклатураОсновнойПоставщик
Меньше
Данная операция предназначена для проверки того, что первый
операнд меньше второго. Например:
ПродажиТекщие.Сумма < ПродажиПрошлые.Сумма
Больше
Данная операция предназначена для проверки того, что первый
операнд больше второго. Например:
ПродажиТекщие.Сумма > ПродажиПрошлые.Сумма
Меньше или равно
Данная операция предназначена для проверки того, что первый
операнд меньше либо равен второму. Например:
ПродажиТекщие.Сумма <= ПродажиПрошлые.Сумма
Больше или равно
Данная операция предназначена для проверки того, что первый
операнд больше либо равен второму. Например:
ПродажиТекщие.Сумма >= ПродажиПрошлые.Сумма
Операция В (IN)
Данная операция осуществляет проверку наличия значения в
переданном списке значений. Результатом операции будет Истина,
в случае, если значение найдено, или Ложь — в
противном случае. Например:
Номенклатура В (&Товар1, &Товар2)
Операция проверки наличия значения в наборе данных
Операция осуществляет проверку наличия значения в указанном
наборе данных. Набор данных для проверки должен содержать одно поле. Например:
Продажи.Контрагент В Контрагенты
Операция проверки значения на NULL ЕСТЬ NULL(IS NULL)
Данная операция возвращает значение Истина
в случае, если значение является значением NULL.
Например:
Продажи.Контрагент ЕСТЬ NULL
Операция проверки значения на неравенство NULL ЕСТЬ НЕ NULL(IS NOT NULL)
Данная операция возвращает значение Истина
в случае, если значение не является значением NULL.
Например:
Продажи.Контрагент ЕСТЬ НЕ NULL
Логические операции
Логические операции принимают в качестве операндов
выражения, имеющие тип Булево.
Операция НЕ (NOT)
Операция НЕ возвращает значение Истина в случае, если ее операнд имеет значение Ложь, и значение Ложь в случае,
если ее операнд имеет значение Истина. Например:
НЕ Документ.Грузополучатель = Документ.Грузоотправитель
Операция И (AND)
Операция И возвращает значение Истина в случае, если оба операнда имеют значение Истина, и значение Ложь в случае,
если один из операндов имеет значение Ложь.
Например:
Документ.Грузополучатель = Документ.Грузоотправитель И
Документ.Грузополучатель = &Контрагент
Операция ИЛИ (OR)
Операция ИЛИ возвращает значение
Истина в случае, если один из операндов имеет значение
Истина, и Ложь в случае,
если оба операнда имеют значение Ложь. Например:
Документ.Грузополучатель = Документ.Грузоотправитель
ИЛИ Документ.Грузополучатель = &Контрагент
Агрегатные функции
Агрегатные функции осуществляют некоторое действие над набором
данных.
Сумма (Sum)
Агрегатная функция Сумма
рассчитывает сумму значений выражений, переданных ей в качестве аргумента для
всех детальных записей. Например:
Сумма(Продажи.СуммаОборот)
Количество (Count)
Функция Количество рассчитывает
количество значений отличных от значения NULL.
Например:
Количество(Продажи.Контрагент)
Количество различных (Count(distinct))
Эта функция рассчитывает количество различных значений.
Например:
Количество(Различные Продажи.Контрагент)
Максимум (Max)
Функция получает максимальное значение. Например:
Максимум(Остатки.Количество)
Минимум (Min)
Функция получает минимальное значение. Например:
Минимум(Остатки.Количество)
Среднее (Avg)
Функция получает среднее значение для значений, отличных от
NULL. Например:
Среднее(Остатки.Количество)
Другие операции
Операция ВЫБОР
Операция Выбор предназначена для
осуществления выбора одного из нескольких значений при выполнении некоторых
условий. Например:
Выбрать Когда Сумма > 1000 Тогда Сумма Иначе 0 Конец
Правила сравнения двух значений
Если типы сравниваемых значений отличаются друг от друга,
то отношения между значениями определяются на основании приоритета типов:
·
NULL (самый низший);
· Булево;
· Число;
· Дата;
· Строка;
·
Ссылочные типы
Отношения между различными ссылочными типами определяются на
основе ссылочных номеров таблиц, соответствующих тому или иному типу.
Если типы данных совпадают, то производится сравнение
значений по следующим правилам:
·
у типа Булево
значение ИСТИНА больше значения ЛОЖЬ;
·
у типа Число обычные
правила сравнения для чисел;
·
у типа Дата более
ранние даты меньше более поздних;
·
у типа Строка —
сравнения строк в соответствии с установленными национальными особенностями
базы данных;
·
ссылочные типы сравниваются на основе своих
значений (номера записи и т. п.).
Работа со значением NULL
Любая операция, в которой значение одного из операндов NULL, будет давать результат NULL.
Есть исключения:
·
операция И будут
возвращать NULL только в случае, если ни один из
операндов не имеет значение Ложь;
·
операция ИЛИ будет
возвращать NULL только в случае, если ни один из
операндов не имеет значение Истина.
Приоритеты операций
Операции имеют следующие приоритеты (первая строка имеет
низший приоритет):
· ИЛИ;
· И;
· НЕ;
·
В, ЕСТЬ NULL, ЕСТЬ
НЕ NULL;
·
=, <>, <=, <, >=, >;
·
Бинарный +, Бинарный – ;
·
*, /, %;
·
Унарный +, Унарный -.
Функции
Вычислить (Eval)
Функция Вычислить предназначена
для вычисления выражения в контексте некоторой группировки. Функция имеет
следующие параметры:
·
Выражение – строка,
содержащая вычисляемое выражение;
·
Группировка – строка,
содержащая имя группировки, в контексте которой необходимо вычислить выражение.
В случае если в качестве имени группировки используется пустая строка,
вычисление будет выполнено в контексте текущей группировки. В случае если в
качестве имени группировки будет использована строка ОбщийИтог,
вычисление будет выполнено в контексте общего итога. В остальных случаях
вычисление будет выполняться в контексте родительской группировки с таким
именем. Например:
Сумма(Продажи.СуммаОборот) /
Вычислить(«Сумма(Продажи.СуммаОборот)», «ОбщийИтог»)
В данном примере в результате получится отношение суммы по
полю «Продажи.СуммаОборот» записи группировки к сумме того же поля во всей
компоновке.
Уровень (Level)
Функция предназначена для получения текущего уровня записи.
Пример:
Уровень()
НомерПоПорядку (SerialNumber)
Получить следующий порядковый номер. Пример:
НомерПоПорядку()
НомерПоПорядкуВГруппировке (GroupSerialNumber)
Возвращает следующий порядковый номер в текущей
группировке. Пример:
НомерПоПорядкуВГруппировке()
Формат (Format)
Получить отформатированную строку переданного значения.
Форматная строка задается в соответствии с форматной строкой 1С:Предприятие.
Параметры:
·
Значение;
·
Форматная строка.
Пример:
Формат(РасходныеНакладные.СуммаДок, «ЧДЦ=2»)
НачалоПериода (BeginOfPeriod)
Функция предназначена для выделения определенной даты из
заданной даты. Параметры:
·
Дата;
·
Тип периода – строка, содержащая одно из:
Минута;
Час;
День;
Неделя;
Месяц;
Квартал;
Год;
Декада;
Полугодие.
Пример:
НачалоПериода(ДатаВремя(2002, 10, 12, 10, 15, 34),
«Месяц»)
Результат:
01.10.2002 0:00:00
КонецПериода (EndOfPeriod)
Функция предназначена для выделения определенной даты из
заданной даты. Параметры:
·
Дата;
·
Тип периода – строка, содержащая одно из:
Минута;
Час;
День;
Неделя;
Месяц;
Квартал;
Год;
Декада;
Полугодие.
Пример:
КонецПериода(ДатаВремя(2002, 10, 12, 10, 15, 34),
Неделя)
Результат:
13.10.2002 23:59:59
ДобавитьКДате (DateAdd)
Функция предназначена для прибавления к дате некоторой величины.
Параметры:
·
Выражение — типа Дата;
·
Тип увеличения – строка, содержащая одно из:
Секунда;
Минута;
Час;
День;
Неделя;
Месяц;
Квартал;
Год;
Декада;
Полугодие;
·
Величина – на сколько необходимо увеличить дату.
Тип Число. Дробная часть игнорируется.
Пример:
ДобавитьКДате(ДатаВремя(2002, 10, 12, 10, 15, 34),
«Месяц», 1)
Результат:
12.11.2002 10:15:34
РазностьДат (DateDiff)
Функция предназначена для получения разницы между двумя
датами. Параметры:
·
Выражение типа Дата;
·
Выражение типа Дата;
·
Тип разности – одно из:
Секунда;
Минута;
Час;
День;
Месяц;
Квартал;
Год.
Пример:
РАЗНОСТЬДАТ(ДАТАВРЕМЯ(2002, 10, 12, 10, 15, 34),
ДАТАВРЕМЯ(2002,
10, 14, 9, 18, 06),
«ДЕНЬ»)
Результат:
2
Подстрока (Substring)
Данная функция предназначена для выделения подстроки из
строки. Параметры:
·
выражение, имеющее строковый тип;
·
позиция символа, с которого начинается
выделяемая из строки подстрока;
·
длина выделяемой подстроки.
Пример:
ПОДСТРОКА(Контрагенты.Адрес, 1, 4)
ДлинаСтроки (StringLength)
Функция предназначена для определения длины строки.
Параметр — выражение строкового типа.
Пример:
Строка(Контрагенты.Адрес)
Год (Year)
Данная функция предназначена для выделения года из значения
типа Дата. Единственный параметр – это выражение,
имеющее тип Дата.
ГОД(РасхНакл.Дата)
Квартал (Quarter)
Данная функция предназначена для выделения номера квартала
из значения типа Дата. Номер квартала в норме
находится в диапазоне от 1 до 4. Единственный параметр функции – это выражение,
имеющее тип Дата.
КВАРТАЛ(РасхНакл.Дата)
Месяц (Month)
Данная функция предназначена для выделения номера месяца из
значения типа Дата. Номер месяца в норме находится в
диапазоне от 1 до 12. Единственный параметр функции – это выражение, имеющее
тип Дата.
МЕСЯЦ(РасхНакл.Дата)
ДеньГода (DayOfYear)
Данная функция предназначена для получения дня года из
значения типа Дата. День года в норме находится в
диапазоне от 1 до 365(366). Единственный параметр функции – это выражение,
имеющее тип Дата.
ДЕНЬГОДА(РасхНакл.Дата)
День (Day)
Данная функция предназначена для получения дня месяца из
значения типа Дата. День месяца в норме находится в
диапазоне от 1 до 31. Единственный параметр функции – это выражение, имеющее
тип Дата.
ДЕНЬ(РасхНакл.Дата)
Неделя (Week)
Данная функция предназначена для получения номера недели
года из значения типа Дата. Недели года нумеруются,
начиная с 1. Единственный параметр функции – это выражение, имеющее тип Дата.
НЕДЕЛЯ(РасхНакл.Дата)
ДеньНедели (WeekDay)
Данная функция предназначена для получения дня недели из
значения типа Дата. День недели в норме находится в
диапазоне от 1(понедельник) до 7(воскресенье). Единственный параметр функции –
это выражение, имеющее тип Дата.
ДЕНЬНЕДЕЛИ(РасхНакл.Дата)
Час (Hour)
Данная функция предназначена для получения часа суток из
значения типа Дата. Час суток находится в диапазоне
от 0 до 23. Единственный параметр функции – это выражение, имеющее тип Дата.
ЧАС(РасхНакл.Дата)
Минута (Minute)
Данная функция предназначена для получения минуты часа из
значения типа Дата. Минута часа находится в
диапазоне от 0 до 59. Единственный параметр функции – это выражение, имеющее
тип Дата.
МИНУТА(РасхНакл.Дата)
Секунда (Second)
Данная функция предназначена для получения секунды минуты
из значения типа Дата. Секунда минуты находится в
диапазоне от 0 до 59. Единственный параметр функции – это выражение, имеющее
тип Дата.
СЕКУНДА(РасхНакл.Дата)
Выразить (Cast)
Данная функция предназначена для выделения типа из выражения,
которое может содержать составной тип. В случае, если выражение будет содержать
тип, отличный от требуемого типа, будет возвращено значение NULL. Параметры:
·
Преобразуемое выражение;
·
Тип – строка, содержащая строку типа. Например,
«Число», «Строка» и т.п. Кроме примитивных типов данная строка может содержать
имя таблицы. В таком случае будет осуществлена попытка выразить к ссылке на
указанную таблицу.
Пример:
Выразить(Данные.Реквизит1, «Число(10,3)»)
ЕстьNull (IsNull)
Данная функция возвращает значение второго параметра в
случае, если значение первого параметра NULL. В
противном случае будет возвращено значение первого параметра. Пример:
ЕстьNULL(Сумма(Продажи.СуммаОборот), 0)
Функции общих модулей
Выражение механизма компоновки данных может содержать
вызовы функций глобальных общих модулей конфигурации и неглобальных общих
модулей, с установленным свойством Клиент. Никакого дополнительно
синтаксиса для вызова таких функций не требуется. Пример:
СокращенноеНаименование(Документы.Ссылка, Документы.Дата,
Документы.Номер)
В данном примере будет осуществлен вызов функции
«СокращенноеНаименование» из общего модуля конфигурации.
Отметим, что использование функций общих модулей разрешено
только при указании соответствующего параметра процессора компоновки данных.
Кроме того, функции общих модулей не могут быть
использованы в выражениях пользовательских полей.
Макеты областей
Макет области представляет собой декларативное описание
расположения выводимых данных, а также их визуальное оформление, необходимое для
вывода данных в документы различных форматов.
Существует несколько принципиально различных макетов
областей:
·
собственно макет области;
·
макеты областей диаграммы.
·
во встроенном языке 1С:Предприятия 8.1 макет
области представляется объектом типа МакетОбластиКомпоновкиДанных.
Данный объект является коллекцией объектов СтрокаТаблицыОбластиКомпоновкиДанных.
Структура макета области
Как было сказано выше, макет области представляет собой
коллекцию объектов типа СтрокаТаблицыОбластиКомпоновкиДанных.Строка
таблицы представляет собой коллекцию ячеек, расположенных горизонтально слева
направо. Таким образом, несколько идущих подряд строк таблицы области
компоновки данных образуют прямоугольную таблицу.
Коллекция ячеек таблицы
Данный объект представляет собой коллекцию ячеек строки
таблицы. Описывается объектом встроенного языка ЯчейкиТаблицыОбластиКомпоновкиДанных.
Элементами коллекции являются ячейки таблицы – объекты типа ЯчейкаТаблицыОбластиКомпоновкиДанных.
Ячейка таблицы представляет собой прямоугольную область,
используемую для вывода данных в документы различных форматов. Внутри ячейки
могут содержаться выводимые поля, текст и оформления.
Коллекция элементов макета
Коллекция элементов макета (объект ЭлементыМакетаОбластиКомпоновкиДанных)
представляет собой коллекцию полей (объектов типа ПолеОбластиКомпоновкиДанных).
Данные объекты могут содержаться в коллекции в произвольном порядке. Данные,
содержащиеся в этих объектах, используются при выводе в документы различных
форматов.
Поле
Поле представляет собой поле, выводимое в ячейке таблицы
или в элементе списка. Внутри поля может содержаться произвольное значение и
его оформление. Поле описывается объектом встроенного языка ПолеОбластиКомпоновкиДанных.
Оформление ячейки таблицы
Оформление ячейки таблицы представляет собой коллекцию
объектов, описывающих оформление ячейки таблицы. Описывается объектом
встроенного языка ОформлениеЯчейкиТаблицыОбластиКомпоновкиДанных.
Оформление поля
Оформление поля представляет собой коллекцию, содержащую
всего один объект – элемент оформления Формат.
Описывается объектом встроенного языка ОформлениеПоляОбластиКомпоновкиДанных.
Структура макетов областей диаграммы
Существует 3 типа макетов областей диаграммы:
·
макет диаграммы — объект типа МакетДиаграммыОбластиКомпоновкиДанных;
·
макет ресурса диаграммы — объект типа МакетРесурсаДиаграммыОбластиКомпоновкиДанных;
·
макет группировки диаграммы – объект типа МакетГруппировкиДиаграммыОбластиКомпоновкиДанных.
При создании макетов диаграммы формируется один макет
диаграммы, один макет ресурса диаграммы и несколько макетов группировок
диаграммы. Количество макетов группировок соответствует количеству точек и
серий в диаграмме.
Принцип работы
Макеты областей используется при выводе отчетов в документы
различных форматов. Макет области является составной частью определения макета
компоновки данных – объекта типа ОпределениеМакетаМакетаКомпоновкиДанных.
Для того чтобы в ячейках или элементах списка макета
области выводились значения выводимых полей отчета необходимо свойству Значение
поля области компоновки данных (объект типа ПолеОбластиКомпоновкиДанных)
присвоить значение типа ПараметрСистемыКомпоновкиДанных,
содержащее имя параметра. Сам параметр необходимо добавить к списку параметров
определения макета и в качестве имени присвоить имя параметра, а в качестве
выражения имя выводимого поля или выражение в терминах языка выражений системы
компоновки данных.
Макет диаграммы
Макет диаграммы используется для описания типа диаграммы.
Описывается объектом встроенного языка МакетДиаграммыОбластиКомпоновкиДанных.
Макет ресурса диаграммы
Макет ресурса диаграммы используется для формирования
значений диаграммы и описывается объектом встроенного языка МакетРесурсаДиаграммыОбластиКомпоновкиДанных.
Макет группировки диаграммы
Макет группировки диаграммы используется для формирования
точек и серий диаграммы. Описывается объектом встроенного языка МакетГруппировкиДиаграммыОбластиКомпоновкиДанных.
Макеты оформления
Макет оформления представляет собой декларативное описание
предопределенных областей отчета. Данные описания используются генератором
областей макетов при формировании макетов областей на основании элементов
настройки компоновки данных.
Для интерактивного создания макета оформления необходимо
при создании макета с помощью конструктора макетов указать его тип «Макет
оформления компоновки данных» и нажать кнопку «Готово». На экран выводится окно
макета оформления.
Окно конструктора состоит из списка областей оформления,
таблицы настройки оформления и поля табличного документа «Пример» для показа
результата выбранных настроек.
Последовательность действий для настройки оформления
следующая:
·
Выбирается область оформления;
·
В таблице настроек указываются (устанавливаются
пометки) параметры, оформление которых требуется изменить, и указываются значения
оформления;
·
Результат внесенных изменений контролируется в
поле «Пример».
Если предполагается, что в отчет будет выведено несколько
уровней группировки, то нужно в списке областей для каждой области, в которой
будут уровни, создать подчиненные области по числу уровней группировки. Для
создания уровня области укажите область и нажмите кнопку «Добавить» командной
панели. В список областей добавляется строка, имя которой «УровеньN», где
N — номер уровня группировки. Выбор оформления уровня группировки
выполняется как описано выше.
Замечание: Если было указано несколько уровней, то при
удалении уровня группировки, всегда удаляется самый нижний уровень текущей
области, не зависимо от того, какой уровень в списке был выбран.
Структура макета оформления
Каждый макет оформления состоит из некоторого количества
областей макета оформления. Область макета оформления имеет имя – строку из
перечня областей макетов оформления, указывающую, к какой области применять
данный макет, и коллекцию элементов оформления.
Элемент оформления имеет два свойства:
·
Уровень –
положительное число, причем, если уровень равен 0, то считается, что оформление
применяется по умолчанию ко всем макетам области определенного типа;
·
Оформление –
коллекцию, содержащую имена свойств оформления и их значения.
Во встроенном языке 1С:Предприятия 8.1 макет оформления
представляется объектом типа МакетОформленияКомпоновкиДанных.
Макет оформления компоновки данных
Данный объект представляет собой коллекцию областей макета
оформления. Данная коллекция реализована в виде значений параметров. Именем
параметра является имя области. Имя области является предопределенной строкой
из перечня областей. Значением параметра является объект типа ОбластьМакетаОформленияКомпоновкиДанных.
Область макета оформления компоновки данных
Данный объект представляет собой описание предопределенной
области и является коллекцией элементов области макета оформления (объектов
типа ЭлементОбластиМакетаОформленияКомпоновкиДанных).
Элемент области макета оформления компоновки данных
Данный объект представляет собой описание области макета
для определенного уровня иерархии. Если в качестве номера уровня указан 0, то
считается, что данный макет оформления применяется ко всем областям данного
типа.
Генератор областей макетов
Генератор областей макетов
позволяет динамически формировать макеты областей компоновки данных,
используемых для вывода результата компоновки данных в документы различных
форматов. Под макетом области подразумевается декларативное описание
расположения выводимых данных и их оформление.
При работе генератора областей макетов можно выделить
следующие этапы:
·
формирование общих макетов отчета;
·
формирование макетов группировок;
·
расположение группировок;
·
расположение выводимых полей группировок;
·
применение макета оформления;
·
применение условных оформлений;
·
объединение ячеек.
Рассмотрим каждый этап работы генератора областей макетов.
Формирование общих макетов отчета.
На данном этапе генератором областей макетов на основании
настройки компоновки данных создаются общие макеты. Тип и количество макетов
зависит от типа элемента настройки компоновки данных.
Макет группировки
Для группировки формируется специальный макет – шапка
группировки. Данный макет содержит названия выводимых полей в левой части
макета и названия выводимых ресурсных полей в правой части макета. Например:
Макет таблицы
Для таблицы формируется следующая группа макетов:
·
Макет шапки таблицы. Данный макет содержит
названия выводимых полей строк таблицы. Например:
·
Макет
итогов по строкам. Данный макет содержит специальное слово «Итого» и
названия ресурсных полей, если они выводятся горизонтально. Например:
·
Макет
итогов по колонкам. Данный макет содержит специальное слово «Итого» и
названия ресурсных полей, если они расположены вертикально. Например:
·
Макет общих итогов. Данный макет содержит
ресурсные поля, выводимые в таблице, и необходимые для отображения в таблице общих
итогов. Например:
Расположение данных макетов
внутри таблицы показано ниже:
Расположение макетов итогов по
строкам и колонкам управляются свойствами РасположениеОбщихИтоговПоГоризонтали
и РасположениеОбщихИтоговПоВертикали соответственно.
Возможны следующие варианты расположения общих итогов:
o
Нет – общие итоги не
выводятся.
o
Начало – общие итоги
выводятся в первой колонке или в первой строке таблицы соответственно.
o
Конец – общие итоги
выводятся в последней колонке или в последней строке таблицы соответственно.
o
НачалоИКонец – общие
итоги выводятся в первой
колонке/строка, а также в последней колонке/строке таблицы.
·
Авто – итоги по
колонкам располагаются в последней строке, а итоги по строкам в последней
колонке.
Макет диаграммы
Макет содержит оформление, которое содержит оформительские
свойства диаграммы.
Формирование макетов группировок.
В настройке компоновки данных существует 3 вида
группировок:
·
группировка;
·
группировка таблицы;
·
группировка диаграммы.
Для каждого вида группировок формируется свой набор макетов
областей. Однако расположение группировок друг относительно друга, расположение
выводимых полей внутри областей группировок, и расположение ресурсных полей
делается единообразно. При формировании любого макета области группировки можно
выделить следующие этапы:
·
Определение типа макета группировки. Тип макета
группировки указывает, как располагаются выбранные поля в макете группировки.
Тип макета группировки получается из параметра ТипМакетаГруппировкиКомпоновкиДанных
объекта ЗначенияПараметровВыводаКомпоновкиДанных.
Данное свойство имеет смысл только для простых группировок, т.е. группировок,
не входящих в таблицу и диаграмму. Возможны следующие варианты расположения
выбранных полей:
o
Авто. Автоматическое определение
расположения выбранных полей: если в группировке есть вложенная таблица, диаграмма,
вложенный отчет или группировка с типом макета группировки Вертикальный,
то выбранные поля располагаются вертикально, иначе горизонтально.
o
Горизонтальный. Расположение выбранных полей
горизонтально, друг за другом слева направо:
o
Вертикальный.
Расположение выбранных полей вертикально, друг под другом:
·
Расположение группировок друг относительно друга.
Расположение группировок друг относительно друга управляется параметром РасположениеПолейГруппировки объекта ЗначенияПараметровВыводаКомпоновкиДанных.
Возможны следующие варианты расположения:
o
Вместе. Группировки располагаются друг под другом. Например,
для группировок по контрагенту и номенклатуре:
o
Отдельно. Каждая группировка располагается в отдельной
области. Группировки располагаются друг за другом слева направо. Выводимые поля
группировки выводятся также и во вложенных группировках.
o
ОтдельноИТолькоВИтогах.
Каждая группировка располагается
в отдельной области. Группировки располагаются друг за другом слева направо.
Выводимые поля выводятся только в данной группировке:
·
Расположение выводимых полей. Существуют поля
двух видов: собственно выводимые поля (поля — владельцы и/или их реквизиты) и
ресурсные поля. Вывод данных полей имеет существенные различия:
Вывод полей. Как указано выше существуют поля–владельцы
и поля-реквизиты. Поля-владельцы выводятся в макет области в соответствии с их
порядком следования в настройке компоновки данных. Расположение полей-реквизитов
управляется специальным параметром РасположениеРеквизитов
объекта ЗначенияПараметровВыводаКомпоновкиДанных.
Возможны следующие варианты расположения:
o
Вместе.
Поля реквизитов располагаются вместе в отдельной колонке и при выводе
разделяются запятой:
o
Отдельно.
Каждое поле реквизита располагается в отдельной колонке:
o
ВместеСВладельцем.
Поля реквизитов располагаются в
одной колонке с их полем – владельцем и при выводе разделяются запятой:
o
ВСпециальнойПозиции.
Поля-реквизиты располагаются в
специальной колонке, расположенной правее всех остальных колонок группировки:
Вывод полей, расположенных в папках. Расположение
данных полей управляется свойством Расположение
папки. Возможны следующие варианты расположения:
o
Авто. Поля выводятся в зависимости от типа
группировки. Если группировка простая, то поля выводятся горизонтально, если
группировка табличная, то вертикально:
или для таблицы
o
Горизонтально. Поля выводятся горизонтально слева направо:
o
Вертикально. Поля
выводятся вертикально друг под другом:
o
ВОтдельнойКолонке.
Поля выводятся в отдельной колонке, расположенной правее всех остальных
колонок:
o
Вместе. Поля
выводятся вместе и при выводе разделяются
запятой:
·
Вывод ресурсных полей. Расположение ресурсных
полей управляется специальным параметром РасположениеРесурсов
объекта ПараметрыВывода. Возможны следующие варианты
расположения:
o
Горизонтально. Поля
ресурсов располагаются горизонтально слева направо;
o
Вертикально. Поля
ресурсов располагаются вертикально друг под другом.
Если для папки не установлен заголовок, то место для
заголовка в макете не выделяется. В этом случае поля выводятся в соответствии
со значением свойства Расположение папки.
Применение макета оформления
После расположения группировок и полей к сформированной
области применяется макет оформления. Смысл применения макета оформления
состоит в том, что всем элементам макета области добавляются ранее определенные
свойства оформления, например ЦветФона или ЦветТекста. Стоит отметить, что существует большое
количество макетов оформления областей.
Применение условных оформлений.
После применения макета оформления к макету области
применяются условные оформления. Применение условного оформления заключается в
том, что в макет области добавляются свойства оформления, содержащие логические
выражения. В результате вычисления логического выражения принимается решение,
какое значение оформительского свойства необходимо применить.
Объединение ячеек
После формирования макета области в ней могут оказаться
незаполненные ячейки. Такие ячейки необходимо объединять для более наглядного
представления макета области. Возможны следующие варианты расположения ячеек:
·
Незаполненные ячейки расположены справа от
заполненных ячеек. Ячейки, расположенные справа, объединяются с ячейками слева.
·
Незаполненные ячейки расположены под
заполненными ячейками. Ячейки, расположенные снизу, объединяются с ячейками
вверху.
·
Незаполненные ячейки расположены и справа и под
заполненными ячейками. Ячейки, расположенные справа, объединяются с ячейками
слева. Затем ячейки, расположенные снизу, объединяются с ячейками вверху.
Формирование макета компоновки данных
Формирование макета компоновки
данных осуществляется на основании схемы компоновки данных и настроек. Схема
компоновки данных создается разработчиком отчета, настройки вводятся
пользователем.
Формирование макета компоновки осуществляется при помощи
объекта встроенного языка КомпоновщикМакетаКомпоновкиДанных.
Данный объект не имеет свойств и имеет один метод Выполнить(), в который передается схема компоновки данных,
настройки компоновки данных, переменная, в которую помещается объект ДанныеРасшифровки и макет оформления. Возвращает данный
метод созданный макет компоновки данных.
В процессе работы компоновщик макета:
·
создает макет компоновки;
·
модифицирует запросы наборов данных для
получения нужной пользователю информации и помещает их в макет компоновки;
·
формирует фильтры в тексте запроса или описании
набора данных;
·
при необходимости создает наборы данных для
получения и проверки иерархии;
·
в макете компоновки данных создает нужные
параметры со значениями, установленными пользователем;
·
заполняет элементы тела макета компоновки
данных, в которые помещает группировки, таблицы и т.д., заполняет их параметры;
·
использует генератор областей макета для
генерации областей макетов. В случае если указан макет оформления (четвертый
параметр), данный макет будет использоваться для оформления генерируемого
макета;
·
в случае, если указан третий параметр, создает
объект ДанныеРасшфровки и помещает созданный объект в переданную переменную.
Созданный таким образом объект нужно использовать при работе процессора
компоновки и при отработке расшифровки.
Пример кода:
СхемаКомпоновкиДанных = ПолучитьСхемуКомпоновкиДанных();
ИсполняемыеНастройки = ПолучитьИсполняемыеНастройки();
КомпоновщикМакета = Новый КомпоновщикМакетаКомпоновкиДанных;
МакетКомпоновки =
КомпоновщикМакета.Выполнить(СхемаКомпоновкиДанных, ИсполняемыеНастройки);
Созданный макет компоновки данных может быть использован
для исполнения, т.е. для получения результата.
Процессор компоновки данных
Исполнение компоновки данных
осуществляется при помощи объекта 1С:Предприятия 8.1 ПроцессорКомпоновкиДанных.
На вход процессору компоновки данных передается макет
компоновки данных.
Работа с процессором компоновки данных предельно проста:
после установки процессору компоновки данных макета компоновки данных у данного
объекта можно последовательно получать элементы результата компоновки данных,
которые в дальнейшем можно использовать, например, для вывода в табличный
документ или сохранить для последующего использования.
Ниже приведен пример работы с процессором компоновки
данных:
ЭлементыФормы.ТДРезультатТабличныйДокумент.Очистить();
МакетКомпоновкиДанных = ПолучитьМакетКомпоновки();
ПроцессорКомпоновкиДанных = Новый ПроцессорКомпоновкиДанных;
ПроцессорКомпоновкиДанных.Инициализировать(МакетКомпоновкиДанных);
ПроцессорВывода = Новый
ПроцессорВыводаРезультатаКомпоновкиДанныхВТабличныйДокумент;
ПроцессорВывода.УстановитьДокумент(ЭлементыФормы.ТДРезультатТабличныйДокумент);
ПроцессорВывода.НачатьВывод();
Пока Истина Цикл
ЭлементРезультатаКомпоновкиДанных
= ПроцессорКомпоновкиДанных.Следующий();
Если
ЭлементРезультатаКомпоновкиДанных = Неопределено Тогда
Прервать;
КонецЕсли;
ПроцессорВывода.
ВывестиЭлемент(ЭлементРезультатаКомпоновкиДанных);
КонецЦикла;
ПроцессорВывода.ЗакончитьВывод();
При инициализации процессора компоновки данных можно
дополнительно указать:
·
объект – внешние наборы данных – структуру, у
которой в качестве ключа содержится имя внешнего набора данных, а в качестве
значения – набор данных;
·
данные расшифровки – объект, в который будет
помещаться информация о расшифровке;
·
возможность использования внешних функций – признак,
можно ли при в выражениях использовать функции общих модулей конфигурации.
Результат компоновки данных
Результат компоновки данных
представляется набором элементов результата компоновки данных. Как объект
встроенного языка 1С:Предприятия 8.1 результат компоновки данных не существует,
существует лишь набор элементов результата компоновки данных, которые и
образуют результат.
При необходимости, элементы результата компоновки данных
могут быть помещены в некоторую универсальную коллекцию значений, например, Массив, для того, чтобы манипулировать результатом как
единым целым.
Элементы результата могут быть получены при помощи объекта ПроцессорКомпоновкиДанных, а также могут быть созданы и
заполнены средствами встроенного языка.
Элементы результата компоновки данных можно вывести в
табличный документ при помощи процессора вывода.
Рассмотрим пример элементов данных.
Элемент 1
Элемент 2
Элемент 3
Элемент 4
Элемент 5
Элемент 6
Элемент 7
Элемент 8
Элемент 9
Элемент 10
Результат вывода таких элементов
должен выглядеть следующим образом:
Если бы элемент 2 содержал макеты ЗаголовокТаблицы и ЗаголовокСтроки,
то при выводе элемента 3 использовался бы макет из этого элемента, однако при
выводе элемента 7 использовался бы макет из элемента 1, т.к. элемент 2
завершается элементом 5.
Элементы результата могут быть сохранены в XML стандартными
средствами. Например:
ЗаписьXML = Новый ЗаписьXML;
ЗаписьXML.УстановитьСтроку();
ЗаписьXML.ЗаписатьНачалоЭлемента(«result»);
МакетКомпоновкиДанных = ПолучитьМакетКомпоновки();
ПроцессорКомпоновкиДанных = Новый ПроцессорКомпоновкиДанных;
ПроцессорКомпоновкиДанных.Инициализировать(МакетКомпоновкиДанных);
Пока Истина Цикл
ЭлементРезультатаКомпоновкиДанных
= ПроцессорКомпоновкиДанных.Следующий();
Если
ЭлементРезультатаКомпоновкиДанных = Неопределено Тогда
Прервать;
КонецЕсли;
СериализаторXDTO.ЗаписатьXML(
ЗаписьXML,
ЭлементРезультатаКомпоновкиДанных,
«item»,
«http://v8.1c.ru/8.1/data-composition-system/result»);
КонецЦикла;
ЗаписьXML.ЗаписатьКонецЭлемента();
ЭлементыФормы.РезультатКомпоновкиДанных.УстановитьТекст(ЗаписьXML.Закрыть());
Вывод результата компоновки в табличный документ
Вывод отчета в табличный документ осуществляется при помощи
объекта ПроцессорВыводаРезультатаКомпоновкиДанныхВТабличныйДокумент.
Элементы результата компоновки могут быть получены при
помощи процессора компоновки данных, либо сформированы любыми другими
средствами.
Пример вывода результата
компоновки данных в табличный документ:
ЭлементыФормы.ТДРезультатТабличныйДокумент.Очистить();
МакетКомпоновкиДанных = ПолучитьМакетКомпоновки();
ПроцессорКомпоновкиДанных = Новый ПроцессорКомпоновкиДанных;
ПроцессорКомпоновкиДанных.Инициализировать(МакетКомпоновкиДанных);
ПроцессорВывода = Новый
ПроцессорВыводаРезультатаКомпоновкиДанныхВТабличныйДокумент;
ПроцессорВывода.УстановитьДокумент(ЭлементыФормы.ТДРезультатТабличныйДокумент);
ПроцессорВывода.НачатьВывод();
Пока Истина Цикл
ЭлементРезультатаКомпоновкиДанных
= ПроцессорКомпоновкиДанных.Следующий();
Если
ЭлементРезультатаКомпоновкиДанных = Неопределено Тогда
Прервать;
КонецЕсли;
ПроцессорВывода.ВывестиЭлемент(ЭлементРезультатаКомпоновкиДанных);
КонецЦикла;
ПроцессорВывода.ЗакончитьВывод();
Вывод данных в сводную таблицу
Данные схемы компоновки можно выводить в сводную таблицу.
Текущее состояние сводной таблицы можно сохранять как настройки системы
компоновки. Сводная таблица выведет данные на основе настроек схемы компоновки,
при этом как структуру настроек, так и состав выбранных полей первоначальных
настроек можно изменять.
Для организации взаимодействия схемы компоновки данных со
сводной таблицей в системе предусмотрен объект ИсточникДанныхСводнойТаблицыКомпоновкиДанных.
Устанавливая настройки этого объекта, следует иметь в виду следующие факторы:
·
Глобальные выбранные поля настроек соответствуют
измеримым ресурсам сводной таблицы.
·
На данные сводной таблицы влияют глобальные
отбор, упорядочивание и параметры.
·
Структура группировок строк и столбцов первой
таблицы настроек служит образцом для формирования структуры измерений в строках
и столбцах сводной таблицы соответственно. При этом в расчёт принимаются только
группировки с одним полем группировки. Группировки с единственным полем
группировки, которое уже использовано в одной из ранее рассмотренных
группировок, игнорируются. Выбранные поля найденных группировок соответствуют
атрибутам измерений в сводной таблице. Кроме самой структуры настроек и
выбранных полей на данные в сводной таблице влияют также отборы и
упорядочивания групп, соответствующих измерениям.
Расчет итогов по полям остатка в системе компоновки данных
Полем остатка с
точки зрения макета компоновки данных является поле, у которого в роли
проставлен признак остаток.
Расчет итогов по полям остатка
В случае если в макете компоновки данных в некотором наборе
данных присутствует поле начального остатка, то в наборе данных также должно
присутствовать соответствующее ему поле конечного остатка и наоборот.
Все поля–периоды, описанные в наборе данных, должны иметь
непрерывную нумерацию, начинающуюся с единицы.
Для корректного расчета итогов по полям источника данных
данные должны удовлетворять следующему правилу: в данных должна соблюдаться
уникальность значений полей периодов и полей-измерений, т.е. данные не должны
содержать строк, в которых будут данные с одинаковыми значениями полей-периодов
и полей-измерений.
При расчете итогов по полям остатка используется следующий
алгоритм:
·
если требуется осуществить расчет итога поля
остатка для группировки по полю–периоду:
если по всем полям–периодам уже была осуществлена
группировка
o для каждой комбинации полей измерений, по
которым осуществлялась группировка
§
получается
запись, ближайшая к текущему периоду
§
если
полученная запись была на текущий период, то из данной записи будут получаться
начальные и конечные остатки;
§
иначе,
если полученная запись имеет предыдущий период, то конечный остаток записи
будет использован как начальный и конечный остаток;
§
иначе
начальный остаток полученной записи будет использоваться как начальный и
конечный остаток;
иначе (группировка еще не произведена по всем
полям–периодам)
o для каждой комбинации полей измерений, по
которым осуществлялась группировка
§
получается
первая и последние записи, у которых поля использованных периодов равны
текущему периоду
§
если
записи найдены, то первая запись будет использоваться как начальный, последняя
– как конечный;
§
если
записи не найдены, то получается ближайшая запись и ее остатки используются как
начальные остатки и конченые остатки в зависимости от того, предшествует ли
найденная запись текущему периоду;
·
иначе (не группировка по полю–периоду)
первые по хронологии записи для неиспользованных
полей–измерений будут использоваться в качестве записей начального остатка,
последние – в качестве конечного.
Расчет итогов по полям бухгалтерских остатков
Расчет итогов по полям бухгалтерских остатков выполняется
аналогично расчету итогов по обычным полям-остаткам. Кроме того, при расчете
итогов по таким полям используется информация о поле счета. В случае если итоги
рассчитываются для группировки по полю–счет, или если до группировки, для
которой считаются итоги, была осуществлена группировка по полю–счет, при
расчете итога используется вид счета. В противном случае вид счета считается
активно/пассивным.
В зависимости от вида счета итоговый остаток будет
вычисляться по следующим формулам:
Если
полученный остаток > 0
Если полученный
остаток < 0
Компоновка макета
Для обеспечения расчета корректных итогов компоновщик
макета при генерации макета выполняет дополнительные действия:
·
в случае если используется начальный остаток —
автоматически добавит в запрос и поле конечного остатка, даже если он не используется.
Аналогично и наоборот;
·
если в отчете используется поле-реквизит
измерения – автоматически добавит в запрос само поле измерение, даже если оно
не используется.
Работа с иерархией в системе компоновки данных
В системе компоновки данных
имеются следующие аспекты использования иерархии:
·
иерархические группировки;
·
условие В Иерархии.
Рассмотрим перечисленные аспекты подробнее.
Иерархические группировки
При создании группировки пользователь может указать для
некоторого поля группировки необходимость выполнения иерархической группировки.
Для того чтобы система выполнила иерархическую группировку,
процессору компоновки данных необходимо знать, откуда получать данные для
построения иерархии. Реализуется это путем создания набора данных с указанием
связи набора данных самого к себе.
Рассмотрим пример. Допустим, необходимо построить иерархию
для поля типа «Справочник.Номенклатура».
Набор данных для построения
иерархии будет выглядеть так:
ВЫБРАТЬ
Номенклатура.Ссылка КАК
Ссылка,
Номенклатура.Родитель
КАК Родитель
ИЗ
Справочник.Номенклатура
КАК Номенклатура
ГДЕ
Номенклатура.Ссылка
В(&Ссылки)
Для этого набора данных должна быть определена связь от
поля «Родитель» к полю «Номенклатура» с параметром «Ссылка». Таким образом
набор данных позволит последовательно получить всех родителей элемента.
Набор данных для построения иерархии может быть либо явно
описан в схеме компоновки данных, либо будет автоматически сгенерирован
компоновщиком макета компоновки данных.
В случае указания набора
данных иерархии в схеме компоновки, необходимо добавить, например, запрос
следующего вида:
ВЫБРАТЬ
Номенклатура.Ссылка КАК
Ссылка,
Номенклатура.Родитель
КАК Родитель
{ВЫБРАТЬ
Ссылка.*,
Родитель}
ИЗ
Справочник.Номенклатура
КАК Номенклатура
ГДЕ
Номенклатура.Ссылка
В(&Ссылки)
Этот набор данных необходимо
связать сам с собой, как было описано выше. Кроме того, к набору данных нужно
создать связь, от поля, для которого требуется создать иерархию. Например:
<dataSet>
<name>Продажи</name>
<dataSource>Main</dataSource>
<query> ВЫБРАТЬ
ПродажиОбороты.Контрагент
КАК Контрагент,
ПродажиОбороты.Номенклатура
КАК Номенклатура,
ПродажиОбороты.КоличествоОборот
КАК КоличествоОборот,
ПродажиОбороты.СуммаОборот
КАК СуммаОборот
{ВЫБРАТЬ
Контрагент.*,
Номенклатура,
КоличествоОборот,
СуммаОборот}
ИЗ
РегистрНакопления.Продажи.Обороты
КАК ПродажиОбороты
{ГДЕ
ПродажиОбороты.Контрагент.*,
ПродажиОбороты.Номенклатура,
ПродажиОбороты.КоличествоОборот,
ПродажиОбороты.СуммаОборот}
</query>
</dataSet>
<dataSet>
<name>НоменклатураИерархия</name>
<dataSource>Main</dataSource>
<query> ВЫБРАТЬ
Номенклатура.Ссылка КАК Ссылка,
Номенклатура.Родитель КАК Родитель
{ВЫБРАТЬ
Ссылка.*,
Родитель}
ИЗ
Справочник.Номенклатура
КАК Номенклатура
ГДЕ
Номенклатура.Ссылка
В(&Ссылки)</query>
<field>
<dataPath>Родитель</dataPath>
<field>Родитель</field>
<useRestriction>
<field>true</field>
<condition>true</condition>
<group>true</group>
<order>true</order>
</useRestriction>
</field>
<field>
<dataPath>Номенклатура</dataPath>
<field>Ссылка</field>
<useRestriction>
<field>true</field>
<condition>true</condition>
<group>true</group>
<order>true</order>
</useRestriction>
</field>
</dataSet>
<dataSetLink>
<sourceDataSet>Продажи</sourceDataSet>
<destinationDataSet>НоменклатураИерархия</destinationDataSet>
<sourceExpression>Номенклатура</sourceExpression>
<destinationExpression>Номенклатура</destinationExpression>
<parameter>Ссылки</parameter>
<parameterListAllowed>true</parameterListAllowed>
</dataSetLink>
<dataSetLink>
<sourceDataSet>НоменклатураИерархия</sourceDataSet>
<destinationDataSet>НоменклатураИерархия</destinationDataSet>
<sourceExpression>Родитель</sourceExpression>
<destinationExpression>Номенклатура</destinationExpression>
<parameter>Ссылки</parameter>
<parameterListAllowed>true</parameterListAllowed>
</dataSetLink>
Условие В ИЕРАРХИИ
Пользователь может указать для поля условие В Иерархии. В таком случае пользователю должны выдаться
записи, находящиеся в иерархии указанной ссылки.
В случае если такое условие наложено в глобальном фильтре,
данное условие попадет в текст запроса в виде условия В
ИЕРАРХИИ. В случае если условие используется не в глобальном фильтре,
для того, чтобы отработать условие, процессору компоновки данных необходимо
иметь набор данных, который будет содержать ссылки, которые удовлетворяют
условия.
Такой набор данных может быть либо явно описан в схеме
компоновки данных, либо будет автоматически сгенерирован компоновщиком макета.
Использование системы компоновки данных при разработке
прикладных решений
В процессе разработки прикладных
решений система компоновки данных может быть использована средствами
встроенного языка в соответствии с описанной выше объектной моделью.
Кроме этого система компоновки данных может быть
задействована при визуальном конструировании отчетов. Например, после создания
объекта конфигурации Отчет, можно создать макет этого
отчета, содержащий схему компоновки данных. Для этого следует нажать кнопку
открытия у поля ввода Основная схема компоновки данных:
В результате этих действий будет открыт конструктор макета,
который позволит создать макет, содержащий схему компоновки данных:
После нажатия кнопки Готово будет открыт
конструктор схемы компоновки данных, с помощью которого можно создать схему
компоновки данных или загрузить существующую схему компоновки из документа XML.
После создания схемы компоновки данных отчет готов к работе
и может быть запущен в режиме 1С:Предприятие. Система, при запуске отчета,
автоматически сгенерирует форму отчета и форму настроек.
На закладке Формы кроме основной
формы отчета можно указать основную форму настроек отчета, которая будет
появляться при выполнении команды Настройки
отчета в режиме «1С:Предприятие», и которая используется для изменения
состава элементов, выводимых в отчете, их порядка и оформления.
Нажатие на кнопку Открыть схему
компоновки данных на вкладке Основные откроет
основную схему компоновки данных. Если схемы нет, то создаст новую и назначит
ее основной.
Если существует необходимость модификации формы отчета,
генерируемой по умолчанию, то для этого можно воспользоваться конструктором
формы отчета, который позволяет создавать формы, использующие систему
компоновки данных:
Также следует заметить, что кроме работы с объектом
конфигурации Отчет, существует возможность создания
общих форм, содержащих схему компоновки данных. Такие формы могут быть
использованы при работе с системой компоновки данных средствами встроенного
языка.
Глава 14.
Механизм XDTO
Механизм XDTO является
универсальным способом представления данных для взаимодействия с различными
внешними источниками данных и программными системами.
Аббревиатура
XDTO обозначает XML
Data Transfer Objects.
Механизм XDTO
позволяет создать модель представления данных (модель типов и значений),
которая, с одной стороны, обеспечивает возможность просто и естественно
манипулировать данными в среде 1С:Предприятия 8.1, а с другой стороны, данная
модель хорошо приспособлена для прозрачного преобразования данных в другие
форматы, главным образом XML.
Можно выделить несколько задач, для решения которых
используется механизм XDTO:
·
обмен данными между конфигурациями
1С:Предприятия 8.1 с существенно разными схемами данных;
·
обмен данными на основе схем XML, не привязанных
к той или иной конфигурации (например, обмен с информационными системами,
построенными не на основе 1С:Предприятия 8);
·
организация работы с Web-сервисами. Механизм XDTO позволяет
описывать типы параметров и возвращаемых значений Web-сервисов, а также манипулировать
передаваемыми и возвращаемыми данными.
Механизм XDTO обладает следующими ключевыми свойствами:
·
интероперабельность работы с XML;
·
привычная модель работы с данными.
В настоящее время обмен данными с различными программными
платформами и системами реализуется с использованием XML: XML документы служат для представления
данных, а схема XML
используется для описания форматов и структур данных. Механизм XDTO позволяет создавать
требуемые для обмена схемы XML
и формировать XML документы, удовлетворяющие этим схемам.
В то же время использование механизма XDTO позволяет выполнять эти действия в
привычной для большинства разработчиков 1С:Предприятия 8 манере.
Разработчик имеет дело с типами и объектами данных, объекты
данных содержат свойства, свойствам присваиваются значения и т.д. При
манипулировании данными с помощью XDTO разработчик максимально изолирован от подробностей,
связанных с тем, как эти данные представлены в XML. Конечно, совсем избавиться
от этих подробностей невозможно, но важно, что они проявляются только там, где
это действительно нужно.
Фабрика XDTO
Ключевым понятием механизма XDTO является фабрика XDTO. Фабрика XDTO содержит
описание всех типов, с которыми оперирует некоторая система. В частности, для
любой конфигурации 1С:Предприятия 8.1 существует глобальная фабрика XDTO, которая описывает все
типы, используемые в конфигурации, в терминах XDTO (эта фабрика XDTO доступна через свойство глобального
контекста ФабрикаXDTO).
Все описания типов, которые содержит фабрика XDTO, сгруппированы в один
или несколько пакетов XDTO.
Если проводить аналогию между XDTO и XML
то можно сказать, что пакет XDTO
соответствует схеме XML.
Таким образом фабрика XDTO
может соответствовать нескольким схемам XML.
Фабрика XDTO является полностью самодостаточной. То есть любой из типов,
зарегистрированных в фабрике XDTO,
может ссылаться только на типы из той же самой фабрики XDTO.
В общем случае фабрика XDTO создается единовременно на основании описаний всех типов,
которые должны быть зарегистрированы в фабрике. Для создания фабрики XDTO средствами
встроенного языка используется конструктор объекта ФабрикаXDTO,
которому передается набор схем XML,
содержащийся в объекте НаборСхемXML. Сценарий, при
котором типы XDTO добавляются в фабрику по одному или группами, не
поддерживается.
Ниже приведен пример создания фабрики XDTO на основе схемы XML, содержащейся в файле XML. Так как механизм XDTO представляет собой
абстракцию, построенную «над» XML,
то для получения схемы XML из файла XML
необходимо последовательно «пройти» несколько уровней работы с данными XML: сначала низкоуровневое
чтение/запись файлов XML,
а затем объектную модель XML,
из которой уже может быть получен объект встроенного языка СхемаXML,
содержащий данные схемы XML.
// Создать фабрику XDTO на основе схемы XML содержащейся в файле XML
// Создать объект чтения XML по умолчанию
НовоеЧтениеXML
= Новый ЧтениеXML;
// Открыть файл XML
НовоеЧтениеXML.ОткрытьФайл(«D:/MySсhema.xsd»);
// Создать построитель документа DOM по умолчанию
НовыйПостроительDOM = Новый ПостроительDOM;
// Прочитать файл XML в документ DOM
НовыйДокументDOM
= НовыйПостроительDOM.Прочитать(НовоеЧтениеXML);
// Создать построитель схемы XML по умолчанию
НовыйПостроительСхемыXML = Новый ПостроительСхемXML;
// Получить схему XML из документа DOM
НоваяСхемаXML = НовыйПостроительСхемыXML.СоздатьСхемуXML(НовыйДокументDOM);
// Создать набор схем XML по умолчанию
НовыйНаборСхемXML
= Новый НаборСхемXML;
// Добавить схему XML в набор схем XML
НовыйНаборСхемXML.Добавить(НоваяСхемаXML);
// Создать фабрику XDTO на основе набора схем XML
НоваяФабрикаXDTO = Новый ФабрикаXDTO(НовыйНаборСхемXML);
В приведенном примере сначала создается объект ЧтениеXML и открывается файл XML, расположенный на диске. После этого
с помощью построителя документа DOM,
создается объект ДокументDOM, содержащий данные
файла XML. Затем с
помощью построителя схемы XML
на основе документа DOM
создается новый объект СхемаXML, содержащий данные
схемы XML. В заключении
создается пустой набор схем XML,
в который добавляется имеющаяся схема XML, и на основании этого набора создается фабрика XDTO.
В отличие от произвольной фабрики XDTO, которую может создать разработчик,
глобальная фабрика XDTO создается системой автоматически, при создании новой
информационной базы, и допускает добавление типов XDTO по одному или группами. Для этого
используются средства визуального конструирования, позволяющие добавлять пакеты
XDTO в
ветку дерева метаданных «Общие — XDTO».
Все пакеты, содержащиеся в глобальной фабрике XDTO, можно разделить на три вида:
·
один пакет XDTO, содержащий описание типов платформы. Этот пакет является
одинаковым для всех конфигураций 1С:Предприятия 8.1;
·
один пакет XDTO, содержащий описание типов конфигурации, созданных в
результате редактирования метаданных (создания и изменения свойств
справочников, документов и пр.);
·
один или несколько пакетов XDTO, описанных непосредственно в дереве
конфигурации в ветке «Общие — XDTO».
Пакет XDTO содержит описание некоторого множества типов, принадлежащих
одному пространству имен – пространству имен пакета. Кроме непосредственно
описаний типов пакет XDTO
может содержать ссылки на пакеты, которые используются данным пакетом, а также
список объявлений объектов/значений, которые являются корневыми для данного
пакета.
Ссылки на другие пакеты содержатся в свойстве Зависимости пакета XDTO и представляют собой объект КоллекцияПакетовXDTO.
Пакеты этой коллекции содержат типы, на которые, так или иначе, ссылается
данный пакет.
Список корневых объектов пакета представляет собой
объявления объектов/значений, которые могут являться корневыми элементами
документов XML, принадлежащих URI пространства имен данного пакета.
Типы данных XDTO
Каждый из типов данных XDTO является либо типом значения XDTO, либо типом объекта XDTO. Соответственно для
описания типа значения используется объект ТипЗначенияXDTO,
а для описания типа объекта – ТипОбъектаXDTO.
Объект ТипЗначенияXDTO
используется для описания типов простых неделимых значений, в которых не могут
быть выделены отдельные составляющие. Примерами простых значений являются
разнообразные строки, числа, даты и т. п.
Объект ТипОбъектаXDTO
используется для описания типов экземпляров данных, имеющих некоторое
состояние, представляемое как совокупность значений свойств этого экземпляра
данных. При этом типы свойств этого экземпляра данных могут являться как типами
значений XDTO, так и
типами объектов XDTO.
И ТипЗначенияXDTO, и ТипОбъектаXDTO имеют два одинаковых свойства:
·
Имя —
имя типа;
·
URIПространстваИмен — URI пространства имен, в котором определен
данный тип.
Значения этих свойств совпадают с аналогичными параметрами,
с которыми тип определяется в схеме XML. Имя типа и URI пространства имен образуют уникальный идентификатор типа.
Имя типа должно быть обязательно определено. При этом свойство URIПространстваИмен может содержать пустую строку, хотя
это и нежелательно.
Тип значения XDTO
Тип значения XDTO, в соответствии с правилами для simple type из схемы
XML, может определяться тремя способами:
·
ограничением, когда задается базовый тип
(свойство БазовыйТип) и набор ограничений на
множество возможных значений (свойство Фасеты);
·
объединением, когда тип получается в результате
объединения нескольких типов значений (объединяемые типы перечисляются в
свойстве ТипыЧленовОбъединения);
·
списком, когда значение представляет собой
список значений (тип значения элементов, составляющих список значений, задается
в свойстве ТипЭлементаСписка).
Помимо свойств Имя и URIПространстваИмен
тип значения XDTO
содержит следующие свойства:
·
БазовыйТип — базовый тип для данного типа значения XDTO. Базовые типы могут
наследоваться, но только от других типов значений XDTO. Допустимое множество
значений унаследованного типа представляет собой подмножество возможных
значений базового типа. Верхним уровнем в иерархии простых типов является
предопределенный тип «anySimpleType» из пространства имен
«http://www.w3.org/2001/XMLSchema». Все типы значений прямо или опосредовано
унаследованы от этого типа. Типы, образованные объединением или списком, всегда
непосредственно унаследованы от «anySimpleType»;
·
Фасеты — список фасетов, ограничивающих множество
допустимых значений по отношению к базовому типу. Список фасетов задается
только для типов значений XDTO,
определенных ограничением базового типа. Каждый отдельный фасет представляет
собой пару: имя фасета и значение. Определен список имен допустимых фасетов.
Причем не любой из допустимых фасетов может быть применен к любому типу. Список
фасетов и применимость их к тому или иному типу определяется по правилам XML
Schema (http://www.w3.org/TR/xmlschema-2/);
·
ТипыЧленовОбъединения — список типов, образующих объединение.
Объединяться могут только типы значений XDTO. Если тип образован объединением,
то список ТипыЧленовОбъединения содержит, по крайней
мере, один тип. При этом список Фасеты должен быть
пустым, а свойство ТипЭлементаСписка должно
возвращать неопределенное значение;
·
ТипЭлементаСписка — в случае, когда тип значения XDTO определяется списком, данное свойство
показывает тип элемента списка. При этом список Фасеты
и ТипыЧленовОбъединения должны быть пустыми.
Список имен
допустимых фасетов (определяется системным перечислением ВидФасетаXDTO):
·
Длина — фасет длины. Содержит количество единиц длины, причем
единица длины имеет различный смысл для различных типов. Для типов «string»
и «anyURI» длина содержит количество символов. Для типов «hexBinary»
и «base64Binary» длина содержит количество байт
двоичных данных. Для типов, определяемых списком, длина содержит количество
элементов списка;
·
МаксВключающее — фасет максимума, включающего границу. Ограничивает
пространство значений данного типа максимальным значением. Любое значение
данного типа меньше либо равно указанному значению;
·
МаксДлина — фасет максимальной длины. Содержит максимальное
количество единиц длины, причем единица длины имеет различный смысл для
различных типов. Для типа «string» максимальная длина содержит
максимальное количество символов. Для типов «hexBinary» и «base64Binary»
максимальная длина содержит максимальное количество байт двоичных данных. Для
типов, определяемых списком, максимальная длина содержит максимальное
количество элементов списка;
·
МаксИсключающее — фасет максимума, не включающего границу. Ограничивает
пространство значений данного типа максимальным значением. Любое значение
данного типа меньше указанного значения;
·
МинВключающее — фасет минимума, включающего границу. Ограничивает
пространство значений данного типа минимальным значением. Любое значение
данного типа больше либо равно указанному значению;
·
МинДлина — фасет минимальной длины. Содержит минимальное
количество единиц длины, причем единица длины имеет различный смысл для
различных типов. Для типа «string» минимальная длина содержит
минимальное количество символов. Для типов «hexBinary» и «base64Binary»
минимальная длина содержит минимальное количество байт двоичных данных. Для
типов, определяемых списком, минимальная длина содержит минимальное количество
элементов списка;
·
МинИсключающее — фасет минимума, не включающего границу. Ограничивает
пространство значений данного типа минимальным значением. Любое значение
данного типа больше указанного значения;
·
Образец — фасет образца. Содержит регулярное выражение,
определяющее пространство значений данного типа;
·
Перечисление — фасет перечисления. Определяет набор допустимых
значений данного типа;
· ПробельныеСимволы — фасет
пробельных символов. Может принимать одно из трех значений:
o
Сохранять — строка может содержать любые пробельные символы;
o
Заменять — строка не должна содержать #x9
(табуляция), #xA (перевод строки) and #xD
(возврат каретки). Если они существуют, то они должны быть заменены символом #x20
(пробел);
o Сворачивать — дополнительно к
требованиям, указанным для значения replace, строка не должна содержать парных символов #x20
(пробел), а также лидирующих и завершающих символов #x20
(пробел);
·
ЦифрВсего — фасет общего количества цифр. Содержит общее
количество разрядов числа (целая часть плюс дробная часть);
·
ЦифрДробнойЧасти — фасет количества цифр дробной части. Содержит
количество разрядов дробной части числа;
Инфраструктура XDTO определяет набор предопределенных типов
значений XDTO. Этот набор совпадает с набором примитивных типов, определенных в
XML Schema Part 2: Datatypes. Предопределенные типы образуют иерархию в
соответствии с XML Schema Part 2: Datatypes. Имена типов совпадают с именами
типов XML Schema, и принадлежат URI пространства имен –
«http://www.w3.org/2001/XMLSchema». Предопределенные типы являются автоматически
зарегистрированными в любой фабрике XDTO.
Тип объекта XDTO
Помимо свойств Имя и URIПространстваИмен
тип объекта XDTO
содержит следующие свойства:
·
БазовыйТип — базовый тип для данного типа. Это может быть
только тип объекта XDTO. Базовым в иерархии типов объектов XDTO является
предопределенный тип «anyType» из пространства имен
«http://www.w3.org/2001/XMLSchema». Все типы объектов XDTO прямо или опосредованно
унаследованы от этого типа;
·
Открытый — признак, является ли тип объекта XDTO открытым.
Данное свойство показывает, может ли экземпляр объекта XDTO содержать дополнительные свойства,
не определенные в его типе, то есть реализует модель open content.
Соответствует появлению в XML-схеме для данного типа описаний:
<anyElement>, <anyAttribute>, <any>.
·
Абстрактный — признак, является ли тип объекта XDTO абстрактным.
Соответствует появлению в схеме для данного элемента атрибута abstract=”true”;
·
Упорядоченный — признак, является ли порядок следования
элементов, представляющих значения свойств, строго соответствующим порядку
следования свойств в типе объекта XDTO. Если задана модель контента xsd:all, то порядок следования
элементов XML может быть произвольным. При этом допустимым является порядок,
соответствующий порядку следования свойств в типе. То есть, если свойство Упорядоченный имеет значение Ложь,
то на входе порядок следования элементов XML не контролируется, а на выходе
определяется порядком следования свойств, если только признак Последовательный не имеет значение Истина;
·
Последовательный — это свойство показывает, содержит ли экземпляр
соответствующего объекта XDTO последовательность XDTO. Данный признак равен значению Истина в тех случаях, когда порядок следования вложенных
элементов XML не может однозначно определяться порядком следования свойств в типе
(например, в схеме XML контент задан как <sequence … maxOccurs=10 … >)
или для соответствующего типа XML в схеме определен атрибут mixed=”true”.
Последовательность XDTO
позволяет задать в явном виде порядок следования элементов, как они будут
представлены в документе XML. Для объектов типов, у которых свойство Последовательный установлено в значение Ложь, порядок следования вложенных элементов соответствует
порядку следования свойств;
·
Смешанный — свойство показывает, определен ли в схеме XML
для данного типа mixed content. Если значение свойства Смешанный
равно Истина, то значение Последовательный
обязательно равно Истина, так как mixed content
невозможно смоделировать без применения последовательности XDTO;
·
Свойства — список свойств, определенных для данного типа
объекта XDTO. Каждое из
свойств представляется в виде экземпляра объекта СвойствоXDTO.
Список содержит полный список свойств, в том числе свойства, определенные в
базовом типе.
Существует предопределенный тип объекта XDTO с именем «anyType» и URI
пространства имен «http://www.w3.org/2001/XMLSchema». Данный тип является
базовым для любого типа объекта XDTO.
У данного типа объекта XDTO
нет базового типа. Он является открытым, не абстрактным, подразумевает наличие
последовательности и имеет пустой список свойств.
Данный тип объекта XDTO соответствует типу «anyType», определенному в XML Schema
Part 2: Datatypes.
Свойство XDTO
Отдельно взятое свойство отдельного типа объекта XDTO описывается
с помощью экземпляра объекта СвойствоXDTO. Это
означает, что один и тот же экземпляр объекта СвойствоXDTO
не может быть использован для описания свойств в различных типах объектов XDTO и двух различных свойств
одного типа объекта XDTO.
Объект СвойствоXDTO содержит
следующие свойства:
·
Имя — имя свойства. В пределах одного типа объекта XDTO имена
свойств должны быть уникальными;
·
Тип — тип свойства. Может быть как экземпляром
объекта ТипЗначенияXDTO, так и экземпляром объекта ТипОбъектаXDTO;
·
ВерхняяГраница — свойство типа объекта XDTO может быть определено как
содержащее одно или множество значений. Свойство считается содержащим одно
значение, если свойство ВерхняяГраница равно 1. Если
же свойство ВерхняяГраница больше 1, то считается,
что свойство может содержать множество значений. Такое свойство в структуре
объекта моделируется как список (не путать со списком в описании типа значения XDTO). Свойство ВерхняяГраница показывает максимальное количество значений
свойства. ВерхняяГраница > 1 может быть задан
только для свойств, представляемых в виде элемента XML. Свойство ВерхняяГраница соответствует атрибуту xsd:maxOccurs в XML
Schema. Значение -1 соответствует “unbounded”;
·
НижняяГраница — минимальное количество значений свойства.
Минимальное количество значений свойства может принимать значения >= 0.
Естественно, значение НижняяГраница должно быть
меньше или равно значению ВерхняяГраница (если,
конечно, ВерхняяГраница не равно -1);
·
ВозможноПустое — показывает, может ли свойство принимать
неопределенное значение. Неопределенное значение свойства представляется в XML
в виде элемента следующего вида <elem xsi:nil=”true” />. Таким образом,
свойство ВозможноПустое равное Истина
может быть определено только для свойств с формой представления Элемент. Свойство ВозможноПустое
соответствует атрибуту xsd:nillable в XML Schema. В случае ВерхняяГраница
> 1 неопределенное значение является допустимым для элемента списка значений
свойства;
·
ЗначениеПоУмолчанию — значение свойства по умолчанию. Значением
свойства по умолчанию может быть только ЗначениеXDTO.
При этом данное значение должно быть совместимо по типу с типом свойства (быть
того же типа, что и тип свойства или же унаследованного типа). При создании
объекта XDTO, свойство,
если оно допускает единственное значение, принимает значение по умолчанию
(метод Установлено() объекта XDTO возвращает
значение Ложь для этого свойства). Для свойств с
множеством значений, список значений изначально пуст, независимо от того,
определено или нет значение по умолчанию;
·
Фиксированное — указывает, является ли значение свойства
фиксированным. Если установлено в значение Истина,
то само фиксированное значение можно получить через свойство ЗначениеПоУмолчанию.
·
Форма — форма представления свойства в XML. Это может
быть Текст, Элемент или Атрибут. Если формой представления является Атрибут или Текст, то значение
свойства ВерхняяГраница не может быть больше 1. Если
свойство принимает значение Текст, то значение
свойства НижняяГраница также должно быть равным 1. У
одного типа только одно свойство может иметь форму представления Текст, при этом остальные свойства должны иметь форму
представления Атрибут.
·
ЛокальноеИмя — локальное имя атрибута или элемента,
используемого для представления свойства. Для свойств с формой представления Текст — пустая строка.
·
URIПространстваИмен — URI пространства имен для атрибута или
элемента, используемого для представления свойства. Пустая строка, если
пространство имен отсутствует.
Экземпляры данных XDTO
Экземпляры данных XDTO могут являться значениями XDTO (ЗначениеXDTO)
или объектами XDTO(ОбъектXDTO).
Значение XDTO
Значение XDTO представляет собой простое неделимое значение, в котором не
могут быть выделены отдельные составляющие. Примерами простых значений являются
разнообразные строки, числа, даты и т. п. Экземпляры простых значений являются
немутабельными.
Новое значение XDTO может быть создано с помощью метода Создать()
фабрики XDTO:
·
на основе типа значения XDTO и значения;
·
на основе типа значения XDTO и лексического представления
значения.
Ниже приведены примеры создания значения XDTO:
ГлобальнаяФабрикаXDTO = ФабрикаXDTO;
// Создать значение XDTO из ссылки
СсылкаНаЭлементСправочника =
Справочники.Номенклатура.НайтиПоКоду(«0000001»);
ТипЗначенияXDTOСоздаваемогоЗначения = ГлобальнаяФабрикаXDTO.Тип(«urn:schemas—v8-1c—ru:config—data»,
«CatalogRef.Номенклатура»);
НовоеЗначениеXDTO =
ГлобальнаяФабрикаXDTO.Создать(ТипЗначенияXDTOСоздаваемогоЗначения,
СсылкаНаЭлементСправочника);
// Создать значение XDTO из лексического представления
значения
ТипЗначенияXDTOСоздаваемогоЗначения =
ГлобальнаяФабрикаXDTO.Тип(«http://www.w3.org/2001/XMLSchema», «dateTime»);
НовоеЗначениеXDTO =
ГлобальнаяФабрикаXDTO.Создать(ТипЗначенияXDTOСоздаваемогоЗначения,
«2006-04-20T12:00:30»);
Новое значение XDTO может быть получено, также, путем
чтения файла XML:
ГлобальнаяФабрикаXDTO = ФабрикаXDTO;,
// Прочитать данные значения XDTO из файла XML
НовоеЧтениеXML = Новый ЧтениеXML;
НовоеЧтениеXML.ОткрытьФайл(«D:/Exchange.xml»);
…
НовоеЗначениеXDTO =
ГлобальнаяФабрикаXDTO.ПрочитатьXML(НовоеЧтениеXML);
Значение XDTO может быть записано в файл XML:
ГлобальнаяФабрикаXDTO = ФабрикаXDTO;
// Записать данные значения XDTO в файл XML
НоваяЗаписьXML = Новый ЗаписьXML;
НоваяЗаписьXML.ОткрытьФайл(«D:/Exchange.xml»);
…
ГлобальнаяФабрикаXDTO.ЗаписатьXML(НоваяЗаписьXML, НовоеЗначениеXDTO);
Объект XDTO
В противовес простому значению, состояние объекта XDTO представляется как
совокупность значений его свойств. Экземпляры объекта XDTO являются мутабельными, то есть во
время жизни объекта XDTO
его состояние может быть изменено путем изменения значений отдельных его
свойств. В качестве значений свойств могут фигурировать любые экземпляры данных
XDTO, как значение
XDTO, так и объект XDTO. Когда значением свойства является объект XDTO,
говорят, что значением свойства является ссылка на объект.
Новый объект XDTO может быть создан с помощью метода Создать()
фабрики XDTO, на основе
типа объекта XDTO.
После этого следует присвоить соответствующие значения свойствам объекта XDTO. Ниже приведен пример
создания объекта XDTO и
заполнения его свойств:
ГлобальнаяФабрикаXDTO = ФабрикаXDTO;
// Создать «пустой» объект XDTO
ТипОбъектаXDTOСоздаваемогоОбъекта =
ГлобальнаяФабрикаXDTO.Тип(«http://www.1c.ru/demos/products», «Номенклатура»);
НовыйОбъектХDTO = ГлобальнаяФабрикаXDTO.Создать(ТипОбъектаXDTOСоздаваемогоОбъекта);
// Заполнить значения свойств объекта XDTO
ОбъектСправочника =
СсылкаНаЭлементСправочника.ПолучитьОбъект();
НовыйОбъектХDTO.Наименование = ОбъектСправочника.Наименование;
НовыйОбъектХDTO.ПолноеНаименование =
ОбъектСправочника.ПолноеНаименование;
НовыйОбъектХDTO.ЗакупочнаяЦена =
ОбъектСправочника.ЗакупочнаяЦена;
НовыйОбъектХDTO.ШтрихКод = ОбъектСправочника.ШтрихКод;
Так же, как и значение XDTO, данные объекта XDTO могут быть прочитаны из файла XML, или записаны в файл XML:
ГлобальнаяФабрикаXDTO = ФабрикаXDTO;,
// Прочитать данные объекта XDTO из файла XML
НовоеЧтениеXML = Новый ЧтениеXML;
НовоеЧтениеXML.ОткрытьФайл(«D:/Exchange.xml»);
…
НовыйОбъектXDTO = ГлобальнаяФабрикаXDTO.ПрочитатьXML(НовоеЧтениеXML);
…
// Записать данные объекта XDTO в файл XML
НоваяЗаписьXML = Новый ЗаписьXML;
НоваяЗаписьXML.ОткрытьФайл(«D:/Exchange.xml»);
…
ГлобальнаяФабрикаXDTO.ЗаписатьXML(НоваяЗаписьXML,
НовыйОбъектХDTO);
Объект ОбъектXDTO содержит
следующие методы:
·
Тип() — возвращает тип данного объекта XDTO (ТипОбъектаXDTO);
·
Установить(<Выражение>),
Установить(<Свойство>, <Значение>) —
позволяет установить значение свойства.
Выражение —
выражение на XPath,
указывающее свойство. Свойство — имя свойства, Значение
– устанавливаемое значение свойства. Если Выражение
задано неправильно или Значение не может быть
присвоено свойству (например, тип несовместим с типом свойства), то вызывается
исключение. Если свойству присваивается неопределенное значение, а свойство ВозможноПустое равно Ложь, то
выдается исключение. Если свойству присваивается ссылка на объект XDTO и
ссылка на этот объект XDTO уже является значением какого-либо другого свойства, то
данная ссылка перестает быть значением этого другого свойства. Цепочки ссылок
на объекты XDTO,
содержащиеся в свойствах объектов не могут образовывать циклов. Поэтому при
присваивании ссылки на объект XDTO,
вызывающем образование цикла, вызывается исключение. Если свойство допускает
множество значений, то для него применение метода Установить()
недопустимо и приводит к вызову исключения. При присваивании значения свойству
производится проверка на допустимость присваивания данного типа значения
свойству. Значение может быть присвоено в том случае, если его тип совпадает с
типом свойства, является унаследованным от типа свойства или является одним из
типов, входящих в объединение. При присваивании, если формой представления
значения свойства в XML
является Текст или Атрибут,
производится приведение значения к типу свойства. Если формой представления
является Элемент, значение присваивается как есть;
·
Получить(<Свойство>), Получить(<Выражение>) — получение значения свойства.
Свойство — имя
свойства.
Выражение —
выражение на XPath, указывающее свойство. Для свойств с множеством значений
данный метод возвращает список значений свойства – СписокXDTO.
Все операции модификации значений свойства должны выполняться через этот
список;
·
Сбросить(<Свойство>), Сбросить (<Выражение>) — сброс значения свойства.
Свойство — имя
свойства.
Выражение —
выражение на XPath, указывающее свойство. Действие метода Сбросить()
для различных свойств различно. Для свойств, допускающих множество значений (ВерхняяГраница> 1), выполнение метода Сбросить() приводит к очистке списка значений;
·
Установлено() — проверяет установленность значения свойства.
Непосредственно после создания объекта у всех свойств результатом выполнения
метода Установлено() будет значение Ложь;
·
Последовательность() — возвращает объект-последовательность (ПоследовательностьXDTO), принадлежащий данному объекту
XDTO. С помощью последовательности XDTO также можно модифицировать состояние
объекта. Данный метод возвращает последовательность XDTO только в том случае,
если у типа объекта установлено свойство Последовательный;
·
Проверить() — данный метод позволяет проверить правильность
заполнения значений свойств объекта XDTO. При проверке проверяются также объекты, ссылки на которые
являются значениями свойств. Предметом проверки являются: соответствие
количества значений свойств свойствам НижняяГраница
и ВерхняяГраница, правильность следования значений
свойств в последовательности XDTO, если свойство Упорядоченный
имеет значение Истина. Проверка прекращается при
нахождении первой же ошибки. При этом выдается исключение.
Последовательность XDTO
С помощью объекта ПоследовательностьXDTO
моделируется порядок следования элементов и фрагментов текста как они выглядят
в XML-представлении объекта. Последовательность состоит из пар: «свойство-значение».
В качестве свойств могут выступать только свойства с формой представления Элемент, так как порядок следования атрибутов не важен.
Свойство в паре «свойство-значение» может также иметь неопределенное значение.
В этом случае считается, что данный элемент последовательности представляет
фрагмент текста. Появление элементов последовательности, представляющих
фрагменты текста допустимо только для объектов типов, у которых значение
свойства Смешанный равно Истина.
При формировании содержимого объекта XDTO с помощью
присваивания значений свойствам, порядок присваивания отражается в
последовательности XDTO.
Последовательность XDTO содержит следующие методы:
·
Количество() — возвращает число элементов последовательности;
·
ПолучитьСвойство(<Индекс>) — возвращает свойство, которому соответствует
значение, находящееся по индексу Индекс. Если Индекс находится за границами допустимых значений,
выдается исключение. Метод может вернуть неопределенное значение, если элементу
последовательности соответствует фрагмент текста из смешанного содержания
(текст и элементы);
·
ПолучитьЗначение(<Индекс>) — возвращает значение, находящееся по индексу Индекс. Если Индекс находится
за границами допустимых значений, выдается исключение;
·
УстановитьЗначение(<Индекс>,
<Элемент>) — устанавливает
значение Элемент по индексу Индекс.
Индекс должен иметь значение в диапазоне допустимых
индексов. Элемент должен иметь допустимое значение
для свойства, для которого он устанавливается или для текста;
·
Добавить(<Свойство>,
<Элемент>) — добавляет пару
«свойство-значение» к последовательности. Значение должно быть допустимым для
свойства;
·
Добавить(<Текст>) — добавляет фрагмент текста к
последовательности. Если у типа объекта свойство Смешанный
имеет значение Ложь, то выдается исключение;
·
Вставить(<Индекс>,
<Свойство>, <Элемент>) —
вставляет пару «свойство-значение» в позицию Индекс
последовательности. Индекс должен иметь значение
внутри диапазона индексов. Элемент в позиции Индекс
и все элементы с большими значениями индекса сдвигаются вправо на одну позицию;
·
Вставить(<Индекс>,
<Текст>) — вставляет текст Текст в позицию Индекс
последовательности. Индекс должен иметь значение
внутри диапазона индексов. Элемент в позиции Индекс
и все элементы с большими значениями индекса сдвигаются вправо на одну позицию;
·
Удалить(<Индекс>) — удаляет элемент последовательности в позиции Индекс. Индекс должен иметь
значение внутри диапазона допустимых.
Список XDTO
С помощью объекта СписокXDTO
моделируется список значений для свойств с множественными значениями (ВерхняяГраница > 1). Список представляет собой
упорядоченный набор объектов, которые могут являться как значениями XDTO, так и объектами XDTO. Среди них могут иметь
место неопределенные значения, если свойство ВозможноПустое
свойства XDTO имеет
значение Истина. Но понятие «установленности» для
элемента списка не определено.
Объект СписокXDTO содержит
следующие методы:
·
Количество() — возвращает размер списка;
·
Получить(<Индекс>) — получает значение, находящееся по индексу Индекс. Индекс должен
находиться в диапазоне допустимых. В противном случае выдается исключение;
·
Установить(<Индекс>,
<Элемент>) — устанавливает
значение Элемент в позицию Индекс.
Устанавливаемое значение замещает ранее присутствовавшее значение. Индекс должен находиться в диапазоне допустимых, а Элемент должен быть допустимым для свойства. В противном
случае выдается исключение;
·
Добавить(<Элемент>) — добавляет значение в хвост списка. Элемент должен быть допустимым для свойства. В противном
случае выдается исключение;
·
Вставить(<Индекс>,
<Элемент>) — внесение значения
Элемент в позицию Индекс.
Индекс должен находиться в диапазоне допустимых, а Элемент должен быть допустимым для свойства. В противном
случае выдается исключение. Значение в позиции Индекс
и значения с большими позициями сдвигаются вправо на одну позицию;
·
Удалить(<Индекс>) — удаление значения в позиции Индекс. Индекс должен
находиться в диапазоне допустимых. Значения с большими позициями сдвигаются на
освободившееся место.
Xpath
Для навигации по дереву объектов могут использоваться
выражения на XPath.
Строго говоря, это не совсем XPath,
это несколько модифицированное подмножество XPath.
Основной конструкцией данного языка является путь к
значению, который состоит из отдельных шагов. Шаги в пути отделяются друг от
друга символами / (слэш). В качестве шага пути выступает имя свойства или
предопределенные конструкции . (точка) и .. (две точки). Выражение вида:
ИмяСвойства
обозначает свойство с именем «ИмяСвойства» текущего
объекта, а именно объекта, у которого вызвали метод Получить()
или Установить().
Выражение вида:
ИмяСвойства1/ИмяСвойства2
означает, что у текущего объекта получено значение свойства
«ИмяСвойства1», а у объекта, ссылка на который является значением свойства
«ИмяСвойства1», получено свойство «ИмяСвойства2».
Соответственно, шаг, обозначенный как . (точка), означает
текущий объект, а .. (две точки) – объект-владелец текущего.
Если путь поиска начинается с символа / (слэш), то это
означает поиск от корня дерева объектов.
Если какое-либо свойство в пути не найдено, то это вызывает
исключение. Если в пути встречается свойство с множественным значением, то
результатом является весь список значений данного свойства.
Например, если в пути:
Свойство/Список
свойство «Список» имеет множественное значение, то
результат данного выражения – это список (СписокXDTO)
значений данного свойства. Для того чтобы получить отдельное значение из этого
списка, надо через точку от имени свойства указать 0-базированный индекс
значения в списке как это показано ниже:
Свойство/Список.0
Индекс должен быть задан, как целое число, находящееся в
пределах диапазона допустимых индексов. В противном случае будет вызвано
исключение.
Можно получить отдельное значение из списка с
использованием 1-базированного индекса. Для этого применяется конструкция следующего
вида:
Свойство/Список[1]
Индекс может принимать значения от 1 до числа элементов в
списке.
Имеется также возможность поиска в списке (только для
объектов). Выражение для поиска выглядит следующим образом:
Свойство/Список[ИмяСвойства=’СтрокаПоиска’]
здесь «Список» – это свойство со
множественным значением. Значением списка являются объекты, у которых имеется
свойство с именем «ИмяСвойства». Результатом будет первый объект в списке,
значение свойства «Свойство» которого равно строковому значению ‘СтрокаПоиска’.
Если ни одного объекта не найдено, то результатом является неопределенное
значение. Свойство «ИмяСвойства» также может присутствовать не у всех объектов
в списке. А может и не присутствовать ни у кого. Значение, с которым
сравнивается значение свойства, может быть задано в виде числа, логического
значения (true или false)
или строкового литерала.
Свойство/Список[ИмяСвойства!=’СтрокаПоиска’]
Приведенное выше выражение аналогично предыдущему примеру,
за исключением того, что результатом будет первый объект в списке, значение
свойства «ИмяСвойства» которого неравно строковому значению ‘СтрокаПоиска’.
Ниже приведено определение описываемого подмножества XPath:
<Путь>
[/] <Список шагов>
< Список шагов >
<Шаг> [/<Список шагов>] |
<Шаг>
<Имя свойства> [<Уточнение>] | .. | . |
<Имя свойства>
[<Буква> | _]<Остаток имени>
<Остаток имени>
{<Буква> | <Цифра> | _} <Остаток имени > |
<Уточнение>
.<0-базированный индекс> |
[<Имя свойства>=<Значение>] |
[<Имя свойства>!=<Значение>] |
[<1-базированный
индекс>]
<0-базированный индекс>
<Целое без знака>
<1-базированный Индекс>
<Целое без знака>
<Целое без знака>
<Цифра> <Цифры>
<Цифра>
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<Цифры>
<Цифра> <Цифры> |
<Значение>
<Число> | <Строка> | <Булево>
<Число>
[+|-]<Целое без знака>[.<Целое без знака>]
<Строка>
“<Символы>“ | ’<Символы>’
<Булево>
true | false
Замечание. В строке с ограничителями “ среди символов не
может встречаться “. Аналогично, в строке с разделителями ’ не может
встречаться символ ’.
При сравнении значения свойства со значением, заданным в
виде литерала, значение, заданное в виде литерала приводится к типу свойства по
правилам приведения, после чего производится сравнение.
XML-сериализация
на основе XDTO
Значения типов конфигураций 1С:Предприятия 8.1 могут быть
сериализованы непосредственно в/из файл/а XML на основе XDTO.
Для этого используется объект СериализаторXDTO,
который может быть получен с помощью конструктора на основе существующей
фабрики XDTO. Работа с
объектом СериализаторXDTO аналогична работе с
глобальными процедурами и функциями работы с XML.
Например, сериализация ссылки на справочник «Номенклатура»
в файл XML может быть
выполнена с помощью следующего кода:
// Получить ссылку на элемент справочника Номенклатура
СсылкаНаЭлементСправочника =
Справочники.Номенклатура.НайтиПоКоду(«0000001»);
// Создать сериализатор XDTO для глобальной фабрики XDTO
НовыйСериализаторXDTO = Новый СериализаторXDTO(ФабрикаXDTO);
// Создать объект записи XML и открыть файл
НоваяЗаписьXML = Новый ЗаписьXML;
НоваяЗаписьXML.ОткрытьФайл(«D:/Exchange.xml»);
// …
// Cериализовать ссылку в XML
НовыйСериализаторXDTO.ЗаписатьXML(НоваяЗаписьXML,
СсылкаНаЭлементСправочника, НазначениеТипаXML.Явное);
Ниже приведен пример сериализации ссылки на справочник
«Номенклатура» из файла XML:
// Создать сериализатор XDTO для глобальной фабрики XDTO
НовыйСериализаторXDTO = Новый СериализаторXDTO(ФабрикаXDTO);
// Прочитать данные объекта XDTO из файла XML
НовоеЧтениеXML = Новый ЧтениеXML;
НовоеЧтениеXML.ОткрытьФайл(«D:/Exchange.xml»);
…
// Сериализовать ссылку из XML
НоваяСсылкаНаСправочник =
НовыйСериализаторXDTO.ПрочитатьXML(НовоеЧтениеXML);
Рекомендации по оформлению схем XML
Преобразование НаборСхемXML ->
ФабрикаXDTO -> НаборСхемXML в
общем случае не дает на выходе набор схем XML, эквивалентный исходному. Однако,
следование набору рекомендаций по оформлению схем XML позволит добиться
эквивалентности выходного набора схем исходному, а именно:
·
для преобразования НаборСхемXML
-> ФабрикаXDTO -> НаборСхемXML
будет соблюдаться эквивалентность выходного набора схем исходному;
·
успешная проверка правильности заполнения
свойств объекта ОбъектXDTO (метод Проверить()) гарантирует, что представление объекта в XML
будет соответствовать схеме XML;
·
обеспечивается максимальная гибкость и
отсутствие искажений при использовании полиморфизма.
Схема XML, полученная на основе фабрики XDTO, для типов
которой не переопределялись значения по умолчанию параметров, ответственных за
XML-представление данных, безусловно соответствует приведенным рекомендациям.
В общем, приведенный далее список рекомендаций представляет
собой набор правил, позволяющий добиться наилучших результатов с различных
точек зрения.
Схема XML не должна содержать анонимных типов.
Недопустимы конструкции вида:
<element name=”Person”>
<complexType>
<sequence>
<element name=”FirstName”
type=”string” />
<element name=”FamilyName”
type=”string” />
</sequence>
</complexType>
</element>
Этот фрагмент следует оформить следующим образом:
<element
name=”Person” type=”tns:PersonType”>
<complexType
name=”PersonType”>
<sequence>
<element name=”FirstName” type=”string”
/>
<element name=”FamilyName” type=”string”
/>
</sequence>
</complexType>
Для контента сложных типов следует использовать только модель
sequence
Для моделирования контента у сложных типов (complexType)
следует использовать только единственный блок sequence без переопределения
значений по умолчанию атрибутов minOccurs и maxOccurs.
<complexType
name=”PersonType”>
<sequence>
<element name=”FirstName” type=”string”
/>
<element name=”FamilyName” type=”string”
/>
</sequence>
</complexType>
Модель all не нарушает тождественность исходной и
результирующей схемы при преобразовании НаборСхемXML
-> ФабрикаXDTO -> НаборСхемXML,
однако имеет ряд ограничений. В частности, значение атрибута maxOccurs для
элементов в модели all не может быть больше 1.
Модель choice нарушает эквивалентность исходной и
результирующей схем и не позволяет с помощью метода Проверить()
проверить соответствие заполнения данных объекта схеме XML.
По тем же причинам не следует использовать в рамках одного
сложного типа комбинацию из нескольких моделей контента или же определять для
sequence значения атрибутов minOccurs и maxOccurs, отличные от значений по
умолчанию.
Свойства объектов должны представляться в XML только как
элементы.
Представление свойств как атрибутов XML не влияет на
эквивалентность исходной и результирующей схем. Однако имеется ряд ограничений:
·
в атрибуте не может быть представлено значение
объектного типа, — только типов-значений;
·
в атрибуте не могут быть представлены свойства с
множественными значениями;
·
В случаях полиморфных типов у свойства,
представленного как атрибут XML может происходить искажение типа значения. А
именно, при присваивании значения свойству тип значения приводится точно к типу
свойства, так как только для значения свойства в элементе XML можно указать
атрибут xsi:type, который позволяет точно указать тип значения свойства.
Как следствие, не надо использовать simpleContent для
complexType, так как эта модель подразумевает использование для хранения
значений свойств атрибутов и текста включающего элемента XML.
Не следует использовать модель mixed content
Применение в схеме XML конструкции вида:
<complexType
name=”FormLetter” mixed=”true”>
…
</complexType>
означает, что в элементе XML, соответствующем описываемому
типу, текст может быть перемешан с элементами XML. Для поддержки такого
информационного содержимого у соответствующего объекта ТипОбъектаXDTO
значения свойств Последовательный и Смешанный установлены в значение Истина, а у каждого
экземпляра соответствующего объекта ОбъектXDTO
появляется последовательность XDTO
(объект ПоследовательностьXDTO. Управление
информационным содержимым таких объектов намного сложнее, чем объектов,
состояние которых представлено только набором значений свойств.
К счастью, в подавляющем большинстве случаев в применении
mixed conetnt не возникает необходимости.
Свойство ФормаЭлементовПоУмолчанию
у схемы XML должно иметь значение Квалифицированная.
Данная рекомендация является элементом хорошего стиля и
XDTO придерживается этого стиля.
Правила проверки фабрики XDTO
Общая схема кодирования идентификаторов сообщений об
ошибках проверки фабрики XDTO:
xdto-<область>-<раздел>[-<правило>]:
<описание ошибки>
, где
<область> — область проверки
(фабрика XDTO, пакет XDTO, тип значения XDTO, фасет XDTO, тип объекта XDTO);
<раздел> — номер раздела,
проверка правила которого завершилась неудачей;
<правило> — правило раздела;
<описание ошибки> — описание
ошибки.
При проверке непосредственно фабрики XDTO ошибки кодируются префиксом
«model». При этом общий префикс будет иметь вид:
xdto-model-<раздел>[-<правило>]:
<описание ошибки>
·
пакеты, входящие в модель, должны иметь
уникальные URI пространства имен – дублирование пакетов в рамках модели
запрещено;
·
директива импорта должна определять не пустое
URI пространства имен импортируемого пакета;
·
директивы импорта пакетов должны определять
существующие пакеты типов;
·
определенные в модели пакеты типов, должны
удовлетворять правилам проверки пакетов.
Правила проверки пакета XDTO
При проверке
правильности пакета XDTO,
ошибки кодируются префиксом: «package». При этом общий префикс будет иметь вид:
xdto-package-<раздел>[-<правило>]:
<описание ошибки>
1.
пакет XDTO должен иметь установленное свойство URIПространстваИмен;
2.
типы, определяемые в пакете XDTO могут иметь ссылки только на типы,
указанные в списке импортируемых (свойство Зависимости);
3.
директивы импорта должны удовлетворять следующим
правилам:
o
директивы импорта должны определять пакеты XDTO,
в которых не может содержаться директив импорта, указывающих на данный пакет
XDTO — зацикливание импортируемых директив не допускается;
o
директива импорта должна определять не пустое
свойство URIПространстваИмен импортируемого пакета XDTO.
o
директивы импорта должны определять существующие
пакеты XDTO;
·
4. Свойства
пакета должны удовлетворять следующим правилам:
o
имена свойств пакета должны быть установлены и
не являться пустыми;
o
имена свойств пакета должны быть уникальны в
пределах пакета;
o
тип свойства пакета должен быть установлен или
определен;
o
типы свойств пакета должны быть определены в
пакете или его зависимостях;
o
задание одновременно имени типа корневого
элемента и анонимного определения типа корневого элемента недопустимо;
o
свойство пакета не должно ссылаться на
определение другого свойства пакета;
o
свойство пакета не должно определять границы
количества значений свойства;
o
свойство пакета может иметь форму представления
только Атрибут или Элемент.
Правила проверки типа значения XDTO
При проверке правильности типа значения XDTO, ошибки кодируются префиксом:
«valueType». При этом общий префикс будет иметь вид:
xdto-valueType-<раздел>[-<правило>]:
<описание ошибки>
§
общие правила проверки типа значения XDTO:
·
если тип определен в рамках пакета типов, то
должны выполняться следующие условия:
o
тип
значения XDTO должен иметь
установленное свойство Имя, содержащее непустое имя;
o
имя типа
значения XDTO должно быть уникальным в пределах пакета XDTO (среди всех типов пакета XDTO);
·
если тип определен в рамках другого определения
типа значения или в рамках определения свойства объектного типа, то должны
выполняться следующие условия:
o
свойство
Имя определения
типа не должно быть установлено;
·
тип значения XDTO не может содержать ссылок на
самого себя ни в базовом типе, ни в типе элемента списка, ни в одном из типов
объединения на всю глубину иерархии;
2.
правила проверки базового типа — свойство БазовыйТип:
·
если свойство БазовыйТип не установлено, то
o
Если
свойство Вариант не установлено и свойство ТипыЧленовОбъединения не установлено
или свойство Вариант установлено и имеет значение atomic:
o
Если свойство
ОпределениеТипа содержит единственное значение, то это определение типа
является определением анонимного базового типа.
o
В
противном случае базовым типом считается тип anySimpleType пространства имен
XML схемы (http://www.w3.org/2001/XMLSchema).
·
если свойство БазовыйТип определения типа
установлено, то должны выполняться следующие условия:
o базовый тип должен удовлетворять правилу 2
правил проверки пакета XDTO;
o базовый тип должен являться типом значения XDTO;
o базовый тип не может являться данным типом
значения XDTO;
3.
правила проверки типа элемента списка — свойство
ТипЭлементаСписка:
·
если свойство ТипЭлементаСписка определения типа
установлено, то должны выполняться следующие условия:
o
тип
элемента списка должен удовлетворять правилу 2 правил проверки пакета XDTO;
o
тип
элемента списка должен являться типом значения XDTO;
o
тип
элемента списка не может являться данным типом значения XDTO;
o
тип
значения XDTO, являющийся элементом списка, должен быть либо атомарным, либо
объединением типов значений XDTO, состоящим только из атомарных типов значений
XDTO;
·
Если свойство Вариант не установлено и свойство
БазовыйТип установлено или свойство Вариант установлено и имеет значение list:
o
Если
свойство ОпределениеТипа содержит единственное значение, то это определение
типа является определением анонимного типа элемента списка.
·
в противном случае значение свойства
ТипЭлементаСписка определяется из соответствующего свойства базового типа
значения XDTO;
4.
правила проверки типа объединения — свойство ТипыЧленовОбъединения:
·
если свойство ТипыЧленовОбъединения определения
типа XDTO установлено, то должны выполняться следующие условия:
o тип объединения должен удовлетворять правилу
2 правил проверки пакета XDTO;
o тип объединения должен являться типом
значения XDTO;
o тип объединения не должен являться данным
типом значения XDTO;
o тип значения XDTO , являющийся объединением,
должен быть либо атомарным, либо списком;
·
Если свойство Вариант не установлено и свойство
БазовыйТип установлено или свойство Вариант установлено и имеет значение union:
o
Свойство
ОпределениеТипа содержит значения, являющиеся анонимными определениями типов
объединения.
·
в противном случае значение свойства
ТипыЧленовОбъединения определяется значением свойства ТипыЧленовОбъединения
базового типа значения XDTO;
5.
наследование типов значений XDTO считается
правильным, если выполнятся следующие условия:
·
для атомарных типов значений XDTO (после
выполнения правил проверки типа элемента списка и правил проверки типа объединения
свойства ТипЭлементаСписка и ТипыЧленовОбъединения не установлены) должны
выполняться следующие условия:
o тип значения XDTO, являющийся базовым, должен
быть атомарным, т.е. свойства ТипЭлементаСписка и ТипыЧленовОбъединения базового типа XDTO не должны быть
установлены;
o предком типа значения XDTO должен быть один
из примитивных типов пространства имен схемы XML
(«http://www.w3.org/2001/XMLSchema»);
o состав фасетов, установленных в описании типа
значения XDTO, должен соответствовать списку допустимых фасетов для
примитивного типа, являющегося предком данного типа XDTO;
o значение каждого фасета, установленного в
типе значения XDTO, должно удовлетворять правилам ограничения эффективного
значения аналогичного фасета базового типа XDTO;
·
для типов элемента списка (после выполнения
правил проверки типа элемента списка и правил проверки типа объединения
установлено свойство ТипЭлементаСписка):
o базовый тип XDTO не может являться типом
объединения, т.е. свойство ТипыЧленовОбъединения
базового типа XDTO не должно быть установлено;
o если свойство ТипЭлементаСписка базового типа XDTO установлено, то значение
этого свойства должно определять базовый тип для типа элемента списка,
определенного в свойстве ТипЭлементаСписка
данного типа значения XDTO;
o если базовым типом является тип
«anySimpleType» пространства имен XML схемы
(«http://www.w3.org/2001/XMLSchema»), то среди списка фасетов допускается
только фасет ПробельныеСимволы;
o в противном случае могут быть определены
только фасеты: Образец, Перечисление, Длина, МинДлина, МаксДлина и ПробельныеСимволы;
o значение каждого фасета, установленного в
типе должно удовлетворять правилам ограничения эффективного значения
аналогичного фасета базового типа;
·
для типов объединения (после выполнения правил
проверки типа элемента списка и правил проверки типа объединения установлено
свойство ТипыЧленовОбъединения):
o базовым типом может являться тип
«anySimpleType» пространства имен XML схемы
(«http://www.w3.org/2001/XMLSchema») или тип объединения, т.е. у базового типа
должно быть установлено свойство ТипыЧленовОбъединения;
o если базовым типом является тип объединения,
должны выполняться следующие условия:
§
количество
типов объединения базового типа не должно быть больше количества типов
объединения данного типа;
§
типы
объединения должны быть потомками соответствующих им типов объединения базового
типа в порядке следования в списке типов объединения;
o если базовым типом является тип
«anySimpleType» пространства имен XML схемы
(«http://www.w3.org/2001/XMLSchema»), то определение фасетов не допускается;
o в противном случае могут быть определены
только фасеты Образец и Перечисление;
o значение каждого фасета, установленного в типе, должно удовлетворять правилам ограничения
эффективного значения аналогичного фасета базового типа.
6. Если свойство Вариант (модель содержания) определения типа установлено,
то оно не должно противоречить определению типа:
·
Если свойство имеет значение atomic, то тип
имеет атомарную модель содержания и должен удовлетворять правилам
xdto-valueType-5.1
·
Если свойство имеет значение Список то тип имеет
модель содержания список и должен удовлетворять правилам xdto-valueType-5.2
·
Если свойство имеет значение Объединение то тип имеет модель содержания объединение и
должен удовлетворять правилам xdto-valueType-5.3
Правила ограничения фасетов
При проверке правильности фасета XDTO, ошибки кодируются
префиксом: facet. При этом общий префикс будет иметь вид:
xdto-facet-<раздел>[-<правило>]:
<описание ошибки>
1.
правила для фасета Длина:
·
значение фасета должно совпадать с эффективным
значением фасета базового типа;
·
если установлено значение фасета МинДлина, то оно должно удовлетворять следующим условиям:
o значение фасета МинДлина должно быть меньше или равно значению фасета
Длина;
o в базовом типе не установлено значение фасета
Длина
или значение фасета МинДлина не отличается от эффективного значения
фасета МинДлина
базового типа;
·
если установлено значение фасета МаксДлина, то оно должно удовлетворять следующим условиям:
o значение фасета
МаксДлина
должно быть меньше или равно значению фасета Длина;
o в базовом типе не установлено значение фасета
Длина
или значение фасета МаксДлина не отличается от эффективного значения
фасета МаксДлина базового типа;
2.
правила для фасета МинДлина:
·
значение фасета должно быть больше или равно
эффективному значению фасета в базовом классе;
·
значение фасета должно быть меньше или равно
эффективному значение фасета МаксДлина;
3.
правила для фасета МаксДлина:
·
значение фасета должно быть меньше или равно
эффективному значению фасета в базовом классе;
·
значение фасета должно быть больше или равно
эффективному значение фасета МинДлина;
4.
правила для фасета ПробельныеСимволы:
·
если эффективное значение фасета базового типа
равно collapse, то значение фасета не может принимать другое значение;
·
если эффективное значение фасета базового типа
равно preserve, то значение фасета не может принимать значение replace;
5.
правила для фасета МинВключающее:
·
значение фасета должно быть меньше эффективного
значения фасета МаксИсключающее данного типа;
·
значение фасета должно быть больше или равно
эффективному значению фасета базового типа;
·
если установлено значение фасета МаксВключающее,
то оно должно быть меньше или равно эффективному значению фасета МаксВключающее
базового типа.
·
если установлено значение фасета МинИсключающее,
то оно должно быть больше эффективного значения фасета МинИсключающее базового
типа;
·
если установлено значение фасета
МаксИсключающее, то оно должно быть меньше эффективного значения фасета
МаксИсключающее базового типа;
6.
правила для фасета МинИсключающее:
·
установка значения фасета МинИсключающее и
МинВключающее фасета в определении типа не допускается;
·
если установлено значение фасета МаксВключающее,
то значение фасета МинИсключающее должно быть меньше значения фасета
МаксВключающее данного типа;
·
значение фасета должно быть больше или равно
эффективному значению фасета базового типа;
·
если установлено значение фасета МаксВключающее,
то оно должно быть меньше или равно эффективному значению фасета МаксВключающее
базового типа;
·
если установлено значение фасета МинВключающее,
то оно должно быть больше или равно эффективного значения фасета МинВключающее
базового типа;
·
если установлено значение фасета
МаксИсключающее, то оно должно быть меньше эффективного значения фасета
МинВключающее базового типа;
7.
правила для фасета МаксВключающее:
·
значение фасета должно быть больше или равно
значению фасета МинВключающее данного типа;
·
если установлено значение фасета
МаксИсключающее, то оно должно быть меньше эффективного значения базового типа;
·
если установлено значение фасета МинВключающее,
то оно должно быть больше или равно эффективного значения базового типа;
·
если установлено значение фасета МинИсключающее,
то оно должно быть больше эффективного значения базового типа;
8.
правила для фасета МаксИсключающее:
·
установка значения фасета МаксИсключающее и
МаксВключающее фасета в определении типа не допускается;
·
если установлено значение фасета МинИсключающее,
то значение фасета МаксИсключающее должно быть больше значения фасета
МинИсключающее данного типа;
·
значение фасета должно быть меньше или равно
эффективному значению фасета базового типа;
·
если установлено значение фасета МаксВключающее,
то оно должно быть меньше или равно эффективному значению базового типа;
·
если установлено значение фасета МинИсключающее,
то оно должно быть больше эффективного значению базового типа;
·
если установлено значение фасета МинВключающее,
то оно должно быть больше эффективного значения базового типа;
9.
правила для фасета ЦифрВсего:
·
значение фасета должно быть меньше или равно эффективному
значению фасета базового типа;
10. правила
для фасета ЦифрДробнойЧасти:
·
значение фасета должно быть меньше или равно
эффективного значения фасета ЦифрВсего;
·
значение фасета должно быть меньше или равно
эффективному значению фасета базового типа;
Правила проверки типа объекта XDTO
При проверке правильности типа объекта XDTO, ошибки кодируются префиксом:
objectType. При этом общий префикс будет иметь вид:
xdto-objectType-<раздел>[-<правило>]:
<описание ошибки>
1.
общие правила проверки типа объекта XDTO:
·
Если тип определен в рамках пакета типов, то
должны соблюдаться следующие условия:
o
тип
объекта XDTO должен иметь установленное свойство Имя, содержащее непустое имя;
o
имя типа
объекта XDTO должно быть уникальным в пределах пакета (среди всех типов пакета);
·
Если тип определен в рамках свойства объектного
типа, то должны соблюдаться следующие условия:
o
Свойство
Имя определения типа не должно быть установлено;
2.
правила проверки базового типа – свойство БазовыйТип:
·
если свойство БазовыйТип
не установлено, то базовым типом считается тип «anyType» пространства имен XML
схемы («http://www.w3.org/2001/XMLSchema»);
·
если свойство БазовыйТип
типа объекта XDTO
установлено, то должны выполняться следующие условия:
o базовый тип должен удовлетворять правилу 2 правил
проверки пакета XDTO;
o базовый тип должен являться типом объекта XDTO;
o базовый тип не может являться данным типом
объекта XDTO;
3.
каждое свойство типа объекта XDTO должно
удовлетворять следующим правилам:
·
имя свойства должно быть определено;
o имя свойства не может быть пустым;
o имя свойства должно быть уникальным для типа
объекта XDTO;
·
если свойство Тип
установлено, то должны выполняться следующие условия:
o имя типа должно определять существующий тип
объекта XDTO или тип значения XDTO.
o тип свойства должен удовлетворять правилу 2
правил проверки пакета XDTO;
o свойство не может содержать определение
анонимного типа.
·
если свойство Тип не
установлено, то
o если у свойства имеется определение
анонимного типа, то типом свойства является тип, соответствующий данному
определению;
o в противном случае типом свойства считается
тип «anyType» пространства имен XML схемы («http://www.w3.org/2001/XMLSchema»);
·
если у свойства определено значение по
умолчанию, то должны быть выполнены следующие условия:
o тип свойства ЗначениПоУмолчанию должен быть типом значения XDTO;
o лексическое представление значения по
умолчанию должно соответствовать пространству значений типа свойства XDTO;
·
XML представление свойства XDTO должно удовлетворять следующим
требованиям:
o если свойство ЛокальноеИмя свойства XDTO не установлено, то в качестве локального
имени XML представления свойства XDTO используется
свойство Имя
свойства XDTO.
o если свойство URIПространстваИмен свойства XDTO не установлено, то URI пространства имен XML
представления свойства XDTO
определяется следующим образом:
§
в
случае, если формой XML представления свойства XDTO (свойство Форма) является Элемент, то
используется URI пространства имен типа, которому принадлежит данное свойство;
§
в
противном случае URI пространства имен XML представления свойства XDTO считается отсутствующим;
o свойство XDTO должно быть уникально по XML представлению в
пределах типа объекта XDTO;
o если свойство XDTO имеет форму XML представления Текст, то должны
выполняться следующие правила:
§
имя и URI
пространства имен должны быть неустановленны или быть пустыми;
§
среди
свойств типа объекта XDTO
допускается наличия свойств XDTO с
формой XML представления Атрибут;
o если свойство XDTO имеет форму XML представления Элемент, то
наличие среди свойств типа объекта XDTO свойства XDTO с
формой XML представления Текст запрещено;
·
значение нижней границы количества появления
значений свойства НижняяГраница может принимать
значения неотрицательных целых чисел. Значение нижней границы НижняяГраница должно быть меньше или равно значению
верхней границы количества появления значений свойств ВерхняяГраница,
при условии, что данное значение не равно -1;
·
значение верхней границы количества значений
свойства ВерхняяГраница может принимать значения неотрицательных целых чисел или -1. если
значение верхней границы количества появления значений свойств ВерхняяГраница равно -1 — это означает неограниченное
количество значений свойства;
·
если значение свойства Фиксированное
установлено, то должно быть установлено значение по умолчанию ЗначениеПоУмолчанию, соответствующее пространству значений
типа свойства XDTO;
·
Если установлена ссылка на определение
глобального свойства, то должны выполняться следующие правила:
o
Определение
свойства не может переопределять значения свойств глобального определения.
o
Глобальное
свойство, на определение которого ссылается данное определение свойства, должно
быть определено в рамках данного пакета или пакетов-зависимостей данного.
4.
если среди свойств типа объекта XDTO имеется
свойство XDTO,
совпадающее по имени или XML-представлению, со свойством базового типа, то вид
наследования определяется как наследование ограничением. При таком виде
наследования должны выполняться следующие условия:
·
для каждого свойства XDTO должны выполняться следующие
условия:
o в базовом типе должно быть определено
свойство XDTO с тем же именем –
переопределяемое свойство;
o если базовый тип определяет порядок
следования свойств (свойство Упорядоченный), то позиция переопределяемого свойства
должна быть идентична позиции свойства в типе наследнике;
o форма XML представления переопределяемого
свойства и свойства данного типа должна совпадать;
o локальное имя XML представления
переопределяемого свойства и свойства данного типа должна совпадать;
o URI пространства имен XML представления
переопределяемого свойства и свойства данного типа должна совпадать;
o если переопределяемое свойство определяет
фиксированное значение, то:
§
наличие
фиксированного значения не может быть отменено в типе наследнике;
§
фиксированное
значение в базовом типе и типе наследнике должны совпадать;
o нижняя граница количества значений свойства
должна быть меньше или равна нижней границе количества значений
переопределяемого свойства;
o верхняя граница количества значений свойства
должна быть больше или равна верхней границе количества значений
переопределяемого свойства;
o тип свойства должен являться потомком типу
переопределяемого свойства;
·
если базовый тип не обладает смешанным
содержанием (свойство Смешанный), то смешанная
модель не может быть установлена в типе наследнике;
·
если порядок следования свойств базового типа
фиксирован (свойство Упорядоченный), то порядок не
может быть изменен в типе наследнике;
·
если базовый тип не определяет наличие
последовательности (свойство Последовательный), то
наличие последовательности не может быть установлено в типе наследнике;
·
если базовый тип не определяет открытую модель
содержания (свойство Открытый), то открытая модель
содержания не может быть установлена в типе наследнике;
5.
в противном случае вид наследования определяется
как наследование расширением. Для данного вида наследования должны выполняться
следующие правила:
·
если модель содержания базового типа является
смешанной (свойство Смешанный), то смешанная модель не может быть изменена в
типе наследнике;
·
если порядок следования свойств базового типа не
фиксирован (свойство Упорядоченный), то порядок не может быть изменен в типе
наследнике.
·
если базовый тип определяет наличие
последовательности (свойство Последовательный), то последовательность не может
быть запрещена в типе наследнике;
·
если базовый тип определяет открытую модель
содержания (свойство Открытый), то модель содержания не может быть изменена в
типе наследнике.
6.
при любом виде наследования должны выполняться
следующие условия:
·
если модель содержания является смешанной
(свойство Смешанный), то наличие последовательности (свойство Последовательный)
не может быть запрещено;
·
если модель содержания является открытой
(свойство Открытый), то наличие последовательности (свойство Последовательный)
не может быть запрещено.
Глава 15.
Механизм Web-сервисов
Механизм Web-сервисов
в системе 1С:Предприятие 8.1 является средством поддержки
сервисно-ориентированной архитектуры (Service-Oriented Architecture, SOA).
Сервисно-ориентированная архитектура представляет собой
прикладную архитектуру, в которой все функции определены как независимые
сервисы с вызываемыми интерфейсами. Обращение к этим сервисам в определенной
последовательности позволяет реализовать тот или иной бизнес-процесс
Сервисно-ориентированная архитектура предлагает новый
подход к созданию распределенных информационных систем, в которых программные
ресурсы рассматриваются как сервисы, предоставляемые по сети. Такой подход
позволяет обеспечить быструю консолидацию распределенных компонентов — сервисов
— в единое решение для поддержки определенных бизнес-процессов.
Механизм Web-сервисов
позволяет использовать 1С:Предприятие 8.1 как набор сервисов в сложных
распределенных и гетерогенных системах, а также позволяет интегрировать
1С:Предприятие 8.1 с другими промышленными системами использованием
сервисно-ориентированной архитектуры.
Конфигурация 1С:Предприятия 8.1 может экспортировать свою
функциональность через Web-сервисы.
Определения Web-сервисов
задаются в дереве конфигурации, и становятся доступны произвольным
информационным системам благодаря публикации их на веб-сервере.
Кроме этого 1С:Предприятие 8.1 может обращаться к Web-сервисам сторонних
производителей как через статические ссылки, определенные в дереве
конфигурации, так и используя динамические ссылки, создаваемые средствами
встроенного языка.
В основе сервисной архитектуры 1C:Предприятия 8.1 находится менеджер
сервисов. Менеджер сервисов выполняет следующие функции:
·
управление пулом соединений с информационными
базами;
·
поддержка WSDL описания сервиса;
·
реализация протокола SOAP, сериализация сообщений, вызов
соответствующего сервиса.
Менеджер сервисов выполняется в процессе сервисного хоста,
который выполняет функцию приема/передачи сообщений из/в менеджер сервисов. В
качестве сервисного хоста может использоваться веб-сервер IIS или Apache.
Менеджер сервисов содержит в себе пул соединений, через
которые идет взаимодействие с базами данных 1С:Предприятия 8.1.
Предоставление функциональности 1С:Предприятия 8.1. через Web-сервисы
Для того, чтобы функциональность 1С:Предприятия 8.1 могла
быть доступна внешним потребителям Web-сервисов, следует выполнить следующие действия:
·
настроить поддержку Web-сервисов 1С:Предприятия
8.1;
·
создать в конфигурации необходимое количество
Web-сервисов;
·
опубликовать Web-сервисы.
Настройка поддержки Web-сервисов заключается в настройке используемого веб-сервера на
работку с менеджером сервисов и установке прав доступа к каталогам исполняемых
файлов и базы данных (для файлового варианта работы). Настройка поддержки Web-сервисов подробно она
описана в разделе «Настройка поддержки WEB-сервисов».
Публикация Web-сервисов
заключается в размещении конфигурационных файлов Web-сервисов в соответствующем каталоге
веб-сервера с соответствующими настройками для веб-сервера. Публикация Web-сервисов подробно описана
в разделе «Публикация Web-сервисов».
Создание Web-сервиса
заключается в добавлении в дерево метаданных объекта конфигурации Web-сервис, описании
операций, которые может выполнять данный Web-сервис и описании параметров операций. Объект конфигурации Web-сервис содержит модуль, в
котором создаются процедуры на встроенном языке, выполняемые при вызове тех или
иных операций Web-сервиса.
Типы параметров операций Web-сервиса
описываются с помощью типов XDTO и могут представлять собой либо значения XDTO, либо объекты XDTO.
При вызове Web-сервиса,
определенного в 1С:Предприятии 8.1 происходит исполнение модуля сеанса, а затем
исполняется модуль вызванного сервиса. И тот, и другой модуль всегда
исполняются на сервере в привилегированном режиме.
Модуль сеанса служит для инициализации параметров сеанса и
выполнения некоторого набора команд при вызове любого Web-сервиса 1С:Предприятия 8.1. Модуль сеанса
не содержит экспортируемых процедур и может использовать процедуры из общих
модулей конфигурации.
В модуле сеанса может быть определен обработчик события УстановкаПараметровСеанса,
который предназначен для инициализации параметров сеанса.
Пример реализации Web-сервиса
Например требуется создать
Web-сервис
1С:Предприятия 8.1, который должен по переданному номеру расходной накладной
возвращать состав ее табличной части.
Для описания возвращаемого значения создадим пакет XDTO «ДанныеРасходнойНакладной»
с пространством имен «http://www.MyCompany.ru/shipment», содержащий три типа объектов XDTO:
·
«Номенклатура» – для передачи данных элемента
справочника «Номенклатура». Этот тип объекта XDTO будет содержать следующие свойства:
§
«Наименование» – тип «string» из пространства
имен «http://www.w3.org/2001/XMLSchema»;
§
«Полное наименование» – тип «string» из
пространства имен «http://www.w3.org/2001/XMLSchema»;
§
«ШтрихКод» – тип «string» из пространства имен
«http://www.w3.org/2001/XMLSchema»;
§
«ЗакупочнаяЦена» – тип «int» из пространства
имен «http://www.w3.org/2001/XMLSchema»;
·
«СтрокаРасходнойНакладной» – для передачи данных
одной строки расходной накладной. Этот тип объекта XDTO будет содержать
следующие свойства:
§
«Номенклатура» – тип «Номенклатура» из
пространства имен «http://www.MyCompany.ru/shipment». Представляет собой ссылку
на объект XDTO, который мы определили выше;
§
«Количество» – тип «int» из пространства имен
«http://www.w3.org/2001/XMLSchema»;
§
«Цена» – тип «int» из пространства имен
«http://www.w3.org/2001/XMLSchema»;
§
«Сумма» – тип «int» из пространства имен
«http://www.w3.org/2001/XMLSchema»;
·
«РасходнаяНакладная» – для передачи данных всех
строк расходной накладной. Этот тип объекта XDTO будет содержать единственное
свойство:
§
«Состав» – тип «СтрокаРасходнойНакладной» из
пространства имен «http://www.MyCompany.ru/shipment». Представляет собой ссылку
на объект XDTO, который мы определили выше; Для того, чтобы это свойство могло
содержать неограниченное множество значений, необходимо установить его свойство
«Верхняя граница» в значение -1;
После того, как необходимые типы XDTO созданы следует добавить в
конфигурацию новый Web-сервис
«ДанныеРасходнойНакладной» со следующими значениями свойств:
·
URI Пространства имен –
«http://www.MyCompany.ru/shipment»;
·
Пакеты XDTO – ДанныеРасходнойНакладной;
·
Имя файла публикации –
shipment.1cws.
У созданного Web-сервиса следует определить операцию «Получить», со следующими
значениями свойств:
·
Тип возвращаемого значения
– «РасходнаяНакладная» из пространства имен «http://www.MyCompany.ru/shipment»;
·
Возможно пустое –
установлен;
·
Имя процедуры –
«Получить».
У операции «Получить» следует определить параметр
«НомерДокумента», со следующими значениями свойств:
·
Тип значения – тип «string» из пространства имен «http://www.w3.org/2001/XMLSchema»;
·
Направление передачи
– входной.
После этого следует открыть модуль созданного Web-сервиса и разместить в
нем функцию «Получить», которая будет выполняться при вызове данного Web-сервиса:
Функция Получить(НомерДокумента) Экспорт
// Получить объект
расходной накладной по переданному номеру
ДокументСсылка =
Документы.РасходнаяНакладная.НайтиПоНомеру(НомерДокумента, ТекущаяДата());
Если
ДокументСсылка.Пустая() Тогда
Возврат
Неопределено;
КонецЕсли;
Документ = ДокументСсылка.ПолучитьОбъект();
// Получить типы
объектов XDTO
НоменклатураТип =
ФабрикаXDTO.Тип(«http://www.MyCompany.ru/shipment»,
«Номенклатура»);
РасходнаяНакладнаяТип
= ФабрикаXDTO.Тип(«http://www.MyCompany.ru/shipment»,
«РасходнаяНакладная»);
СтрокаРасходнойНакладнойТип
= ФабрикаXDTO.Тип(«http://www.MyCompany.ru/shipment»,
«СтрокаРасходнойНакладной»);
// Создать объект XDTO
расходной накладной
РасходнаяНакладная =
ФабрикаXDTO.Создать(РасходнаяНакладнаяТип);
Для Каждого
СтрокаДокумента Из Документ.Состав Цикл
// Создать объекты
XDTO строки расходной накладной
// и номенклатуры
СтрокаРасходнойНакладной
= ФабрикаXDTO.Создать(СтрокаРасходнойНакладнойТип);
Номенклатура = ФабрикаXDTO.Создать(НоменклатураТип);
// Заполнить
свойства номенклатуры
Номенклатура.Наименование
= СтрокаДокумента.Номенклатура.Наименование;
Номенклатура.ПолноеНаименование
= СтрокаДокумента.Номенклатура.ПолноеНаименование;
Номенклатура.ШтрихКод
= СтрокаДокумента.Номенклатура.ШтрихКод;
Номенклатура.ЗакупочнаяЦена
= СтрокаДокумента.Номенклатура.ЗакупочнаяЦена;
// Заполнить
свойства строки расходной накладной
СтрокаРасходнойНакладной.Номенклатура
= Номенклатура;
СтрокаРасходнойНакладной.Количество
= СтрокаДокумента.Количество;
СтрокаРасходнойНакладной.Цена
= СтрокаДокумента.Цена;
СтрокаРасходнойНакладной.Сумма
= СтрокаДокумента.Сумма;
// Добавить строку
расходной накладной
РасходнаяНакладная.Состав.Добавить(СтрокаРасходнойНакладной);
КонецЦикла;
// Вернуть расходную
накладную
Возврат
РасходнаяНакладная;
КонецФункции
В заключение следует опубликовать созданный Web-сервис на веб-сервере,
например «http://www.MyCompany.ru»
в каталоге «shipment».
Работа с Web-сервисами сторонних поставщиков
Система 1С:Предприятие 8.1
может использовать веб-сервисы, предоставляемые другими поставщиками, двумя
способами:
·
с помощью статических ссылок, создаваемых в
дереве конфигурации;
·
с помощью динамических ссылок, создаваемых средствами
встроенного языка.
Преимущество использования статических ссылок заключается в
большей скорости работы, т.к. описание веб-сервиса поставщика получается один
раз, при создании ссылки. В дальнейшем, при обращении к данному веб-сервису,
используется существующее описание веб-сервиса.
При использовании динамических ссылок, описание веб-сервиса
поставщика будет получаться системой 1С:Предприятие 8.1 каждый раз, при
вызове веб-сервиса, что, естественно, будет замедлять работу с данным
веб-сервисом. Однако преимуществом такого подхода является возможность
получения актуального описания веб-сервиса поставщика. При использовании же
статических ссылок для получения актуального описания веб-сервиса следует
выполнить повторный импорт WSDL-описания
средствами конфигуратора и сохранение измененной конфигурации.
Пример использования статической WS-ссылки
В качестве примера использования веб-сервисов стороннего
поставщика рассмотрим обращение к Web-сервису, созданному в разделе «Пример реализации
Web-сервиса».
Прежде всего следует добавить в дерево конфигурации новый
объект конфигурации WS-ссылка
с именем «ДанныеРасходнойНакладной», ссылающийся на опубликованный сервис. Для
этого следует выполнить импорт WSDL-описания
опубликованного сервиса и в качестве URL указать «http://www.MyCompany.ru/shipment/Shipment.1cws?wsdl». Подробнее об импорте WSDL-описания можно прочитать в разделе «Добавление WS-ссылки».
После этого, например, в модуле приходной накладной можно создать
следующую процедуру, которая заполняет табличную часть документа данными
расходной накладной поставщика, полученными с помощью веб-сервиса поставщика:
Процедура
ПолучитьДанныеРасходнойНакладной(НомерНакладнойПоставщика)
// Создать WSпрокси на
основании ссылки
// и выполнить
операцию Получить()
Прокси =
WSСсылки.ДанныеРасходнойНакладной.
СоздатьWSПрокси(«http://www.MyCompany.ru/shipment»,
«ДанныеРасходнойНакладной»,
«ДанныеРасходнойНакладнойSoap»);
ДанныеНакладной =
Прокси.Получить();
Если ДанныеНакладной =
Неопределено Тогда
Возврат;
КонецЕсли;
// Заполнить приходную
накладную полученными данными
Для Каждого
СтрокаНакладной Из ДанныеНакладной.Состав Цикл
НоваяСтрока =
ДокументОбъект.Состав.Добавить();
НоваяСтрока.Количество
= СтрокаНакладной.Количество;
НоваяСтрока.Цена =
СтрокаНакладной.Цена;
НоваяСтрока.Сумма =
СтрокаНакладной.Сумма;
// Найти элемент
номенклатуры по переданным данным
// (например, по
штрих-коду)
НоваяСтрока.Номенклатура
= Справочники.Номенклатура.НайтиПоРеквизиту(«ШтрихКод»,
СтрокаНакладной.Номенклатура.ШтрихКод);
КонецЦикла;
КонецПроцедуры
Пример использования динамической WS-ссылки
Использование динамической ссылки отличается от
использования статической ссылки только способом создания WS-прокси и отсутствием необходимости
создавать WS-ссылку в
дереве конфигурации.
Если провести сравнение с примером, представленным в
предыдущем разделе, то, в отличие от создания прокси на основе статической
ссылки:
// Создать Wsпрокси на основании ссылки
// и выполнить
операцию Получить()
Прокси =
WSСсылки.ДанныеРасходнойНакладной.СоздатьWSПрокси(«http://www.MyCompany.ru/shipment»,
«ДанныеРасходнойНакладной»,
«ДанныеРасходнойНакладнойSoap»);
ДанныеНакладной =
Прокси.Получить();
при использовании динамической ссылки WS-прокси создается с помощью
конструктора следующим образом:
// Создать WSпрокси на основании WSопределения
// и выполнить
операцию Получить()
Определение = Новый
WSОпределения(
«http://www.MyCompany.ru/shipment/Shipment.1cws?wsdl«);
Прокси = Новый
WSПрокси(Определение,
«http://www.MyCompany.ru/shipment»,
«ДанныеРасходнойНакладной»,
«ДанныеРасходнойНакладнойSoap»);
ДанныеНакладной =
Прокси.Получить();
Настройка поддержки WEB-сервисов
Настройка поддержки Web-сервисов заключается в настройке
используемого веб-сервера на работу с менеджером сервисов и в установке прав
доступа к каталогам исполняемых файлов и базы данных (для файлового варианта
работы).
Настройка поддержки Web-сервисов для IIS 5.1
·
зарегистрировать менеджер сервисов (wsisapi.dll). Для этого следует запустить
утилиту регистрации wsinst.exe (находящуюся в каталоге «bin» файлов 1С:Предприятия 8.1) с ключом
«-iis»;
·
создать виртуальный каталог, где будут
располагаться файлы веб-сервисов;
·
создать приложение IIS на основе
этого виртуального каталога;
·
дать права чтения пользователю, от лица которого
запускается менеджер сервисов wsisapi.dll (IWAM_XXX), на каталог «bin»
файлов 1C:Предприятия
8.1;
·
дать права на модификацию пользователю, от лица
которого выполняются запросы (IUSR_XXX), на каталог
информационной базы и каталог «bin»
файлов 1C:Предприятия
8.1;
Настройка поддержки Web-сервисов для IIS 6.0
·
выполнить настройку поддержки Web-сервисов для IIS 5.1;
·
добавить MIME типы 1C:Предприятия 8.1 в настройки HTTP заголовков
виртуальной директории веб-сервисов (расширения «.1cws» и «.1crs», Mime тип text/xml);
·
разрешить запуск менеджера сервисов wsisapi.dll на IIS. (в расширениях
веб-сервисов IIS добавить wsisapi.dll как
расширение веб-сервисов и разрешить ему запуск);
·
если путь к wsisapi.dll содержит пробелы и другие разделители, при регистрации
необходимо указывать путь в кавычках.
Настройка поддержки Web-сервисов для Apache 2.0 под Windows
·
создать каталог, где будут располагаться файлы
веб-сервисов;
·
добавить в конфигурационный файл apache (conf/httpd.conf)
регистрацию модуля обработки веб-сервисов 1С:Предприятия:
LoadModule
ws_module <1C:Enterprise
Root>/bin/wsapch2.dll
·
добавить в конфигурационный файл apache регистрацию
виртуальной директории доступа к веб-сервисам, например:
Alias /ws С:/InetPub/WWWRoot
<Location /ws>
DirectorySlash Off
SetHandler ws-process
</Location>
·
дать права пользователю, от лица которого
запускается apache, на
каталог «bin» файлов 1C:Предприятия 8.1 (чтение и
выполнение) и каталог информационной базы (чтение и запись).
Настройка поддержки Web-сервисов для Apache 2.0 под Linux
·
создать каталог, где будут располагаться файлы
веб-сервисов;
·
добавить в конфигурационный файл apache (conf/httpd.conf)
регистрацию модуля обработки веб-сервисов 1С:Предприятия:
LoadModule
ws_module <1C:Enterprise
Root>/bin/wsapch2.so
·
добавить в конфигурационный файл apache регистрацию
виртуальной директории доступа к веб-сервисам, например:
Alias /ws /var/www
<Location /ws>
DirectorySlash Off
SetHandler ws-process
</Location>
·
дать права пользователю, от лица которого
запускается apache, на
каталог «bin» файлов 1C:Предприятия 8.1 (чтение и
выполнение) и каталог информационной базы (чтение и запись).
Безопасность WEB-сервисов
Аутентификация
Платформа 1С:Предприятия 8.1 поддерживает следующие виды
аутентификации при работе с Web-сервисами:
·
HTTP
Basic аутентификацию;
·
анонимную аутентификацию;
·
аутентификацию средствами 1С:Предприятия 8.1;
·
аутентификацию средствами Windows.
При взаимодействии клиента и сервера Web-сервисов
используется стандартная HTTP Basic аутентификация. Она использует
challenge-response протокол обмена данными. Алгоритм HTTP Basic аутентификации
заключается в следующем:
·
клиент посылает запрос серверу Web-сервисов;
·
если Web-сервис требует аутентификации и запрос
клиента не содержит реквизитов пользователя, сервер посылает ошибку
аутентификации;
·
если Web-сервис не требует аутентификации,
запрос обрабатывается стандартным образом;
·
если клиент получил ошибку аутентификации, он
посылает серверу реквизиты пользователя – имя пользователя и пароль;
·
если Web-сервис требует аутентификации и запрос
клиента содержит реквизиты пользователя, сервер выполняет аутентификацию
пользователя;
·
если аутентификация прошла успешно, запрос
обрабатывается стандартным образом;
·
если аутентификация не выполнена, сервер
посылает ошибку аутентификации.
Выполнение аутентификации на сервере может производиться
средствами 1С:Предприятия 8.1 и средствами Windows (только для IIS).
Для того чтобы аутентификация выполнялась средствами
1С:Предприятия 8.1, нужно в настройках Web-сервера установить анонимный доступ
к Web-сервису (в IIS DirectorySecurity/AuthenticationMethods/AnonymousAccess).
Учетные записи пользователей 1С:Предприятия 8.1, под которыми планируется вход
в систему, не должны быть привязаны к учетным записям Windows. При входе в
систему в этом случае нужно задавать имя пользователя и пароль учетной записи
пользователя 1С:Предприятия 8.1.
Для того чтобы аутентификация выполнялась средствами
Windows, нужно в настройках IIS установить HTTP Basic аутентификацию
(DirectorySecurity/AuthenticationMethos/BasicAuthentication). Учетные записи
пользователей 1С:Предприятия 8.1, под которыми планируется вход в систему,
должны быть привязаны к учетным записям Windows. При входе в систему в этом
случае нужно задавать имя пользователя и пароль учетной записи пользователя
Windows.
При аутентификации средствами 1С:Предпрятия 8.1 можно
разрешить анонимный вход в систему. В этом случае, если клиент не задает
реквизиты пользователя, они берутся из дескриптора сервиса.
При конфигурировании IIS стоит обратить внимание на учетные
записи пользователей Windows, под которыми работает Web-сервис. Учетная запись,
под которой стартует процесс Web-сервиса, должна иметь право на запуск бинарных
файлов каталога установки 1С:Предприятия. Учетная запись, под которой
выполняется запрос, должна иметь право на запуск бинарных файлов каталога
установки 1С:Предприятия и права на чтение и изменение данных в каталоге
информационной базы (только для файлового варианта). Учетная запись, под
которой выполняется запрос, в случае анонимной аутентификации IIS задается в
настройках виртуальной директории Web-сервиса, в случае Basic аутентификации –
определяется реквизитами пользователя, выполнившего запрос.
Работа по защищенному каналу
При взаимодействии клиента и сервера Web-сервисов обмен
данными может вестись по защищенному каналу. Защищенный канал работает по
протоколу обмена SSL 3.0/TLS 1.0. Для того чтобы включить возможность работы по
протоколу SSL нужно:
·
получить серверный сертификат для Web-сайта, для
которого планируется использовать SSL. Сертификат выдается Центром Сертификации
и привязывается к этому Web-сайту;
·
корневой сертификат Центра Сертификации должен
быть добавлен в файл cacert.pem из каталога установки 1С:Предприятия на всех
клиентах, которым необходим доступ по защищенному каналу. Сертификат должен
быть в формате PEM (Privacy Enhanced Mail);
·
для виртуальной директории Web-сервиса нужно
включить поддержку SSL (для IIS —
DirectorySecurity/SecureCommunication/RequireSecureChannel).
Глава 16.
Механизм заданий
Механизм заданий предназначен для выполнения
какой-либо прикладной или функциональности по расписанию или асинхронно.
Механизм заданий решает следующие задачи:
·
Возможность определения регламентных процедур на
этапе конфигурирования системы;
·
Выполнение заданных действий по расписанию;
·
Выполнение вызова заданной процедуры или функции
асинхронно, т.е. без ожидания ее завершения;
·
Отслеживание хода выполнения определенного
задания и получение его статуса завершения (значения, указывающего успешность
или не успешность его выполнения);
·
Получение списка текущих заданий;
·
Возможность ожидания завершения одного или
нескольких заданий;
·
Управление заданиями (возможность отмены,
блокировка выполнения и др.).
Механизм заданий состоит из следующих
компонентов:
·
Метаданных регламентных заданий;
·
Регламентных заданий;
·
Фоновых заданий;
·
Планировщика заданий.
Фоновые задания — предназначены для выполнения
прикладных задач асинхронно. Фоновые задания реализуются средствами встроенного
языка.
Регламентные задания —
предназначены для выполнения прикладных задач по расписанию. Регламентные
задания хранятся в информационной базе и создаются на основе метаданных,
определяемых в конфигурации. Метаданные регламентного задания содержат такую
информацию как наименование, метод, использование и т.д.
Регламентное задание имеет расписание,
которое определяет, в какие моменты времени нужно выполнять связанный с
регламентным заданием метод. Расписание, как правило, задается в информационной
базе, но может быть задано и на этапе конфигурирования (например, для
предопределенных регламентных заданий).
Планировщик заданий используется для
планирования выполнения регламентных заданий. Для каждого регламентного задания
планировщик периодически проверяет, соответствует ли текущая дата и время
расписанию регламентного задания. Если соответствует, планировщик назначает
такое задание на выполнение. Для этого по данному регламентному заданию
планировщик создает фоновое задание, которое и выполняет реальную обработку.
Фоновые
задания
Фоновые задания удобно использовать для
выполнения сложных вычислений, когда результат вычисления может быть получен
через продолжительное время. Механизм заданий имеет средства для выполнения
таких вычислений асинхронно.
С фоновым заданием связан метод, который
вызывается при выполнении фонового задания. В качестве метода фонового задания
может выступать любая процедура или функция не глобального общего модуля,
которую можно вызвать на сервере. Параметрами фонового задания могут быть любые
значения, которые разрешено передавать на сервер. Параметры фонового задания
должны в точности соответствовать параметрам той процедуры или функции, которую
оно вызывает. Если методом фонового задания является функция, то ее
возвращаемое значение игнорируется.
Фоновое задание может иметь ключ – любое
прикладное значение. Ключ вводит ограничение на запуск фоновых заданий – в
единицу времени может выполняться только одно фоновое задание с определенным
значением ключа и заданным именем метода фонового задания (имя метода состоит
из имени модуля и имени процедуры или функции). Ключ позволяет группировать
фоновые задания, имеющие одинаковые методы, по определенному прикладному
признаку с тем, чтобы в рамках одной группы выполнялось не более одного
фонового задания.
Создание и управление фоновыми заданиями
выполняется программно из любого соединения. Создавать фоновое задание
разрешено любому пользователю. При этом оно выполняется от имени того
пользователя, который его создал. Получать задания, а также ожидать их
завершения разрешено из любого соединения пользователю с административными
правами, либо пользователю, который создал эти фоновые задания.
Фоновое задание является чисто сеансовым
объектом, но не принадлежит какому-либо пользовательскому сеансу. Для каждого
задания создается специальный системный сеанс, выполняющийся от имени того
пользователя, который выполнил вызов. Фоновые задания не имеют сохраняемого состояния.
Фоновое задание может порождать другие
фоновые задания. В клиент-серверном варианте это позволяет распараллеливать
сложные вычисления по рабочим процессам кластера, что может значительно
ускорить процесс вычисления в целом. Распараллеливание реализуется порождением
нескольких дочерних фоновых заданий с ожиданием завершения каждого из них в
основном фоновом задании.
Завершившиеся успешно или аварийно фоновые
задания хранятся в течение суток, а потом удаляются. Если количество
выполнившихся фоновых заданий превышает 1000, то наиболее старые фоновые
задания также удаляются.
Регламентные
задания
Регламентные задания используются, когда
необходимо выполнить определенные периодические или однократные действия в
соответствии с расписанием.
Регламентные задания хранятся в
информационной базе и создаются на основе метаданных регламентного задания,
определенными в конфигурации. Метаданные задают такие параметры регламентного
задания как: вызываемый метод, наименование, ключ, возможность использования,
признак предопределенности и др. При создании регламентного задания
дополнительно можно указать расписание (может быть указано в метаданных),
значения параметров метода, имя пользователя, от имени которого должно
выполняться регламентное задание, и др.
Создание и управление регламентными
заданиями выполняется программно из любого соединения и разрешено только
пользователям, имеющим административные права.
С регламентным заданием связан метод,
который вызывается при выполнении регламентного задания. В качестве метода регламентного
задания может выступать любая процедура или функция не глобального общего
модуля, которую можно вызвать на сервере. Параметрами регламентного задания
могут быть любые значения, которые разрешено передавать на сервер. Параметры
регламентного задания должны в точности соответствовать параметрам той
процедуры или функции, которую оно вызывает. Если методом регламентного задания
является функция, то ее возвращаемое значение игнорируется.
Регламентное задание может иметь ключ –
любое прикладное значение. Ключ вводит ограничение на запуск регламентных
заданий, т.к. в единицу времени среди регламентных заданий, связанных с одним и
тем же объектом метаданных, может выполняться только одно регламентное задание
с определенным значением ключа. Ключ позволяет группировать регламентные
задания, связанные с одним и тем же объектом метаданных, по определенному
прикладному признаку с тем, чтобы в рамках одной группы выполнялось не более
одного регламентного задания.
При конфигурировании можно определить
предопределенные регламентные задания. Предопределенные регламентные задания
ничем не отличаются от обычных регламентных заданий за исключением того, что их
нельзя явно создавать и удалять. Если в метаданных регламентного задания
установлен признак предопределенного регламентного задания, то при обновлении
конфигурации в информационной базе автоматически будет создано предопределенное
регламентное задание. Если признак предопределенности снят, то при обновлении
конфигурации в информационной базе автоматически будет удалено предопределенное
регламентное задание. Начальные значения свойств предопределенного
регламентного задания (например, расписание) устанавливаются в метаданных. В
дальнейшем, при работе приложения их можно менять. Предопределенные
регламентные задания не имеют параметров.
Расписание регламентного задания определяет,
в какие моменты времени регламентное задание должно быть запущено. Расписание
позволяет задавать: дату и время начала и окончания выполнения задания, период
выполнения, дни недели и месяцы, по которым нужно выполнять регламентное
задание и др. (см. описание встроенного языка).
Примеры расписаний регламентных заданий:
|
Каждый |
ПериодПовтораДней |
|
Каждый |
ПериодПовтораДней |
|
Один |
ПериодПовтораДней |
|
Через |
ПериодПовтораДней |
|
Каждый |
ПериодПовтораДней ПериодПовтораВТечениеДня ВремяНачала ВремяКонца |
|
Каждую |
ПериодПовтораДней ДниНедели ВремяНачала |
|
Каждый |
ПериодПовтораДней ПериодНедель |
|
В |
ВремяНачала |
|
Последнее |
ПериодПовтораДней ДеньВМесяце ВремяНачала |
|
Пятое |
ПериодПовтораДней ДеньВМесяце ВремяНачала |
|
Вторая |
ПериодПовтораДней ДеньНеделиВМесяце ДниНедели ВремяНачала |
Регламентные задания всегда выполняются о
имени определенного пользователя. Если пользователь регламентного задания не
указан, то выполнение происходит от имени пользователя по умолчанию, имеющего
административные права.
Выполнение регламентных заданий происходит с
использованием фоновых заданий. Когда планировщик определяет, что регламентное
задание должно быть запущено, то автоматически на основе данного регламентного
задания создается фоновое задание, которое и выполняет всю дальнейшую
обработку. Если данное регламентное задание уже выполняется, то оно не будет
запущено повторно, вне зависимости от его расписания.
Регламентные задания имеют возможность
перезапуска. Это особенно актуально, когда метод регламентного задания должен
быть гарантированно выполнен. Перезапуск регламентного задания осуществляется в
том случае, когда оно завершено аварийно, либо когда рабочий процесс (в
клиент-серверном варианте) или клиентский процесс (в файловом варианте), на
котором выполнялось регламентное задание, завершен аварийно. В регламентном
задании можно указать, сколько раз нужно его перезапускать, а также интервал
между перезапусками. При реализации метода перезапускаемого регламентного
задания нужно учитывать, что при перезапуске его выполнение будет начато с
начала, а не продолжено с момента аварийного завершения.
Особенности
выполнения фоновых заданий файловом и клиент-серверном вариантах
Механизмы выполнения фоновых заданий в
файловом и клиент-серверном вариантах различаются.
·
В файловом варианте необходимо создать
выделенный клиентский процесс, который будет заниматься выполнением фоновых
заданий. Для этого в клиентском процессе должна периодически вызываться функция
глобального контекста ВыполнитьОбработкуЗаданий.
Только один клиентский процесс на информационную базу должен выполнять
обработку фоновых заданий (и, соответственно, вызывать данную функцию). Если
клиентского процесса для обработки фоновых заданий не создано, то при
программном доступе к механизму заданий будет выдана ошибка «Менеджер заданий
не активен». Не рекомендуется клиентский процесс, выполняющий обработку фоновых
заданий, использовать для других функций.
После того, как клиентский процесс,
выполняющий обработку фоновых заданий, запущен, остальные клиентские процессы
получают возможность программного доступа к механизму фоновых заданий, т.е.
могут запускать и управлять фоновыми заданиями.
В клиент-серверном варианте для выполнения
фоновых заданий используется планировщик заданий, который физически находится в
менеджере кластера. Планировщик для всех поставленных в очередь на выполнение
фоновых заданий получает наименее загруженный рабочий процесс и использует его
для выполнения соответствующего фонового задания. Рабочий процесс выполняет
задание и уведомляет планировщик о результатах выполнения.
В клиент-серверном варианте имеется
возможность блокирования выполнения регламентных заданий. Блокирование
выполнения регламентных заданий происходит в следующих случаях:
·
На информационную базу установлена явная
блокировка регламентных заданий. Блокировка может быть установлена через
консоль кластера;
·
На информационную базу установлена блокировка
соединения. Блокировка может быть установлена через консоль кластера;
·
Из встроенного языка вызван метод УстановитьМонопольныйРежим() с параметром Истина;
·
В некоторых других случаях (например, при
обновлении конфигурации базы данных).
Создание
метаданных регламентного задания
Перед тем, как программно создать
регламентное задание в информационной базе, необходимо создать для него объект
метаданных.
Для создания объекта метаданных
регламентного задания в дереве конфигурации в ветке «Общие» для ветки
«Регламентные задания» выполните команду «Добавить» и в палитре свойств
заполните следующие свойства регламентного задания:
Имя метода —
указывается имя метода регламентного задания.
Ключ —
указывается произвольное строковое значение, которое будет использовано в
качестве ключа регламентного задания.
Расписание —
указывается расписание регламентного задания. Для формирования расписания
щелкните ссылку «Открыть» и в открывшейся форме расписания установите нужные
значения.
На закладке «Общее» указываются дата начала
и завершения задания и режим повтора.
На закладке «Дневное» указывается дневное
расписание задания.
Укажите расписание:
·
время начала и время окончания задания;
·
время завершения задания, после которого оно
будет принудительно завершено;
·
период повтора задания;
·
продолжительность паузы между повторами;
·
продолжительность выполнения.
Допускается указание произвольного сочетания
условий.
На закладке «Недельное» указывается
недельное расписание задания.
Установите флажки по тем дням недели, по
которым задание будет выполняться. Если требуется повторять задание, укажите
интервал повтора в неделях. Например, задание выполняется через 2 недели,
значение повтора – 2.
На закладке «Месячное» указывается месячное
расписание задания.
Установите флажки по тем месяцам, в которых
задание будет выполняться. При необходимости можно указать конкретный день
(месяца или недели) выполнения с начала месяца / недели или конца.
Использование —
если установлено, то задание будет выполняться согласно расписанию.
Предопределенное —
если установлено, то задание является предопределенным заданием.
Количество повторов при
аварийном завершении — указывает количество повторов при аварийном
завершении.
Интервал повтора при
аварийном завершении — указывает интервал повтора при аварийном
завершении.
Примеры
Создание фонового задания «Обновление
индекса полнотекстового поиска»:
ФоновыеЗадания.Выполнить(«ОбновлениеИндексаПолнотекстовогоПоиска»);
Создание регламентного задания
«Восстановление последовательностей»:
Расписание = Новый
РасписаниеРегламентногоЗадания;
Расписание.ПериодПовтораДней = 1;
Расписание.ПериодПовтораВТечениеДня = 0;
Задание =
РегламентныеЗадания.СоздатьРегламентноеЗадание(
«ВосстановлениеПоследовательностей»);
Задание.Расписание = Расписание;
Задание.Записать();
Глава 17.
Механизм полнотекстового поиска в данных
Механизм
полнотекстового поиска в данных системы 1С:Предприятие 8.1 позволяет
осуществлять поиск в базе данных с указанием поисковых операторов (И, ИЛИ, НЕ,
РЯДОМ и др.).
Механизм
полнотекстового поиска основан на использовании двух составляющих:
·
полнотекстового индекса, который создается в
базе данных и затем периодически, по мере необходимости, обновляется;
·
средств выполнения полнотекстового поиска.
Создание и
обновление полнотекстового индекса может быть выполнено интерактивно в режиме
1С:Предприятие 8.1 или программно, средствами встроенного языка. Поиск
данных в базе данных выполняется только средствами встроенного языка.
Для выполнения
интерактивного полнотекстового индексирования используется команда меню «Операции — Управление
полнотекстовым поиском…» в режиме запуска 1С:Предприятие.
Общие сведения о
полнотекстовом индексировании
Объектами
полнотекстового поиска являются данные следующих объектов конфигурации:
·
планы обмена;
·
справочники;
·
документы;
·
планы видов характеристик;
·
планы счетов;
·
планы видов расчета;
·
регистры сведений;
·
регистры накопления;
·
регистры бухгалтерии;
·
регистры расчета;
·
бизнес-процессы;
·
задачи.
Для каждого из
перечисленных объектов конфигурации реализовано свойство Полнотекстовый поиск,
которое позволяет включать или исключать данные объекта в/из полнотекстового
индексирования.
Для фиксации
изменений объектов полнотекстового поиска система 1С:Предприятие 8.1 ведет
журнал регистрации изменений. Запись в этот журнал осуществляется в процессе
записи объектов в базу данных. В файлы регистрации изменений попадают только те
объекты, которые настроены для полнотекстового индексирования. Если в
результате отката транзакции запись объекта в базу данных будет отменена, то
запись в журнале регистрации изменений останется.
Полнотекстовое
индексирование выполняется в привилегированном режиме (в контексте сервера) и
не требует монопольного захвата базы данных. В процессе полнотекстового
индексирования выполняется чтение файлов регистрации изменений и получение
измененных объектов из базы данных, а также транслитерация слов и замещение
букв в словах, введенных латиницей на кириллицу (при этом индекс хранит обе
формы слова). Индексированию подлежат только реквизиты следующих типов:
·
Строка;
·
Дата;
·
Число;
·
ссылочные типы;
·
ХранилищеЗначения;
Для каждого
объекта и реквизита в полнотекстовый индекс добавляется его тип – синоним
объекта метаданных – на всех языках конфигурации. Системные и пользовательские
реквизиты индексируются на всех языках, что позволяет проводить поиск на всех
языках конфигурации (например, русский и английский).
При полнотекстовом
индексировании и поиске слова с «ё» – буквы «ё» заменяются
на «е».
Индексы
полнотекстового поиска хранятся в наборе файлов, который располагается в
кластере серверов (в случае клиент-серверного варианта работы), либо в
каталоге, в котором находится файл информационной базы *.1CD, в случае файлового варианта работы.
В результате
полнотекстового индексирования создается основной индекс, а в ходе последующего
изменения данных базы данных – дополнительный, который содержит информацию по
данным, измененным после последнего обновления основного индекса.
Поиск по основному
индексу выполняется эффективно, в то время как поиск по дополнительному индексу
выполнятся медленнее. Поэтому в процессе индексирования предусмотрена
возможность слияния индексов, которая позволяет добавить результат последних
изменений данных к основному индексу. При этом следует учитывать, что эта
операция может оказаться довольно длительной (если размер основного индекса
большой), поэтому рекомендуется выполнять ее в периоды минимальной нагрузки на
систему (в ночное время ли по выходным).
Полнотекстовый
поиск инициируется пользователем в контексте клиентского приложения, а
выполняется в контексте сервера. Это означает, что в файловом режиме работы
поиск будет выполняться на клиентском компьютере, а в клиент-серверном варианте
работы полнотекстовый поиск будет выполняться в кластере серверов
1С:Предприятия 8.1.
Полнотекстовый
поиск в данных осуществляется в соответствии с правами пользователя (в том
числе и в соответствии с ограничениями прав доступа на уровне записей и полей
базы данных). При этом поиск можно вести и по словам, которые были введены в
базу данных с ошибками: например, если в слове вместо русской «с» стоит
английская «c» или если при наборе слова была
нечаянно сменена раскладка клавиатуры, и в результате слово приняло вид
,например, «системf» вместо «система» — эти
слова все равно попадут в результат поиска.
Результаты поиска
возвращаются частями, размер которых определяется при выполнении команды
полнотекстового поиска.
Ранжирование
полученных результатов осуществляется в порядке следующих приоритетов:
·
«вес» объекта метаданных. Чем больше ссылок на
этот объект в реквизитах других объектов, тем выше его «вес»;
·
дата объекта (более новые объекты будут
находиться в начале);
Выполнение
полнотекстового поиска в данных
Полнотекстовый
поиск в данных осуществляется средствами встроенного языка.
Свойство
глобального контекста ПолнотекстовыйПоиск возвращает менеджер полнотекстового
поиска – объекта типа МенеджерПолнотекстовогоПоиска.
Методы менеджера
полнотекстового поиска позволяют:
·
получить информацию о состоянии полнотекстового
индекса;
·
выполнить полнотекстовое индексирование;
·
инициировать процесс выполнения полнотекстового
поиска в данных.
Для получения
информации о состоянии полнотекстового индекса предназначены следующие методы:
·
ПолучитьРежимПолнотекстовогоПоиска() —
возвращает значение Истина, если использование полнотекстового поиска
разрешено или Ложь — в противном случае;
·
ДатаАктуальности() –
дата последнего момента, когда были проиндексированы все данные, и не было
информации о новых объектах для индексирования;
·
ИндексАктуален() –
возвращает значение Истина, если индекс полнотекстового поиска полностью
соответствует текущему состоянию информационной базы;
·
ОбновлениеИндексаЗавершено() –
возвращает значение Истина, если слияние полнотекстового индекса не требуется.
Для выполнения полнотекстового
индексирования предназначены следующие методы:
·
УстановитьРежимПолнотекстовогоПоиска() –
устанавливает режим полнотекстового поиска (Разрешить или Запретить). Если
поиск был запрещен, то вызов этого метода с параметром Истина
автоматически очищает имеющийся полнотекстовый индекс;
·
ОбновитьИндекс() –
обновляет индекс полнотекстового поиска. Если индексы отсутствовали – выполняет
полную переиндексацию всей базы данных. В параметрах метода передаются условия
индексирования:
o
РазрешитьСлияние —
если передается значение Истина, будет выполнено слияние основного и
дополнительного индексов;
o
Порционное —
значение Истина
указывает, что индексирование будет выполняться порциями, из 10 тысяч объектов.
После индексирования данных одной порции процесс завершается. Время
индексирования одной порции сильно зависит от данных. Например, на типовой
конфигурации «Управлении Производственным Предприятием» занимает 3 — 5 минут.
·
ОчиститьИндекс() –
удаляет все файлы полнотекстового индекса. Этот метод рекомендуется использовать
в тех случаях, когда данные были полностью или почти полностью обновлены
(например, при выполнении загрузки информационной базы). После очистки индекса
нужно выполнить индексирование (если требуется).
Инициирование
процесса полнотекстового поиска в данных выполняется с помощью метода СоздатьСписок().
В метод передаются два параметра:
·
СтрокаПоиска –
строка, содержащая поисковое выражение;
·
РазмерПорции –
число, задающее количество объектов, которые будут возвращены в одной части
полнотекстового поиска.
Поддерживается следующий синтаксис поисковых выражений:
|
Оператор |
Пример выражения |
Пояснение |
|
пробел И AND & |
1С 1С AND Архив 1С & Архив |
Должны быть и слово «1С» и слово «Архив» |
|
ИЛИ |
1С |
Должно быть хотя бы одно из слов «1С» или |
|
НЕ NOT ~ |
1С 1С NOT архив 1С ~ |
Должно быть слово «1С», но не должно быть |
|
РЯДОМ/[±]n |
Пример 1: Пример 2: Пример 3: |
Поиск данных, содержащих в одном реквизите Знак указывает, в каком направлении от Если знак не В примере 1 В примере 2 В примере 3 |
|
РЯДОМ NEAR |
Библиотека |
Краткая форма. Запрос найдет элементы, в |
|
«» |
«администратор |
Поиск точной фразы (эквивалентно |
|
() |
(технология |
Группировка слов (сколько угодно уровней |
|
* |
арх* арх* |
Поиск с wildcard – поддерживается только |
|
# |
#Система |
Нечеткий поиск Запрос Запрос Только для |
|
! |
!красный кафель |
Поиск с учетом |
Метод СоздатьСписок()
возвращает объект СписокПолнотекстовогоПоиска, который позволяет выполнять
полнотекстовый поиск и получать результаты полнотекстового поиска. Этот объект
может быть использован многократно, для выполнения поиска с различными
условиями. Свойства объекта СтрокаПоиска и РазмерПорции позволяют изменять используемое поисковое
выражение и размер порции получаемых данных.
Для выполнения
полнотекстового поиска и получения «первых» результатов используется метод ПерваяЧасть(). Для
получения последующих результатов полнотекстового поиска используются методы СледующаяЧасть()
и ПредыдущаяЧасть(),
которые заполняют список полнотекстового поиска результатами поиска.
Метод НачальнаяПозиция()
указывает на позицию, начиная с которой получена очередная часть элементов.
Метод Количество()
содержит количество элементов в текущей части (для последней части оно будет
меньше либо равно размеру порции), а метод ПолноеКоличество() содержит полное
количество элементов, найденных в результате полнотекстового поиска.
Метод ПерваяЧасть()
заполняет список первыми найденными элементами, количество которых равно
размеру порции. При этом начальная позиция становится равной 0.
Метод СледующаяЧасть()
заполняет список следующими элементами в соответствии со значением размера порции.
При этом текущая позиция увеличивается на количество данных, содержащихся в
полученной части. Если данных для получения очередной порции нет (достигнут
конец данных), будет вызвано исключение, которое может быть обработано
конструкцией Попытка … Исключение … КонецПопытки.
Метод ПредыдущаяЧасть()
заполняет список предыдущими найденными элементами в соответствии с размером
порции. Если данных для получения очередной порции нет (достигнуто начало
данных), будет вызвано исключение, которое может быть обработано конструкцией Попытка … Исключение …
КонецПопытки.
Метод СлишкомМногоРезультатов()
возвращает значение Истина если во время поиска, по соображениям
производительности, было произведено усечение количества результатов, что может
сказаться на точности поиска (не все объекты будут найдены). Анализ значения,
возвращаемого этим методом, имеет смысл выполнять при получении последней
порции найденных данных для того, чтобы информировать пользователя о том, что
получены не все результаты, которые содержатся в базе данных.
Свойство ПолучатьОписание
содержит признак получения описания для результатов поиска. Если он установлен
в значение Истина,
то для каждого из результатов поиска будет заполнено значение Описание,
помогающее понять контекст найденных слов. В то же время установка этого
свойства в значение Ложь ускоряет поиск.
Список
полнотекстового поиска представляет собой коллекцию элементов списка
полнотекстового поиска, которую можно обойти с помощью оператора Для Каждого … Из … Цикл.
Каждый элемент
списка полнотекстового поиска представляется объектом ЭлементСпискаПолнотекстовогоПоиска
и содержит следующие свойства:
·
Значение –
идентифицирует данные (объект или набор записей), в которых найдено поисковое
выражение;
·
Метаданные – объект
метаданных, описывающий те данные, в которых найдено поисковое выражение;
·
Представление –
текстовое представление найденного объекта;
·
Описание – содержит
(с новой строки) пары <реквизит>:<значение>, где:
<реквизит> —
реквизит объекта, в значении которого найдено выражение поиска;
<значение> —
значение этого реквизита.
Результат поиска с помощью метода ПолучитьОтображение() можно
получить в виде объекта ЧтениеXML или в виде строки с текстом в формате HTML, в
котором средствами HTML найденные слова подсвечены (жирный шрифт и цвет фона).
Использование
дополнительных словарей
Дополнительные словари
морфологии и синонимов для полнотекстового поиска расширяют системные словари и
могут содержать в себе особые термины и слова, которые используются при работе
с конфигурацией.
В качестве дополнительных словарей могут
выступать макеты из двоичных данных и текстовые макеты, а также константы
строкового типа и типа хранилище значений. Указание дополнительных словарей
выполняется в свойстве Дополнительные словари корневого объекта метаданных.
При этом они должны
иметь следующее содержание:
<?xml version=»1.0″?>
<Dictionary>
<Words>
<lemma>рунет</lemma><forms>рунета рунете рунетом</forms>
<lemma>Ванесса</lemma><forms>Ванессе Ванессы Ванессу</forms>
</Words>
<Synonyms>
<item>ошибка баг сбой</item>
<item>стрим поток</item>
</Synonyms>
</Dictionary>
Секции <Synonyms> и <Words> могут идти в любом
порядке.
Словари загружаются системой при первом
вызове поиска или индексировании. Если в макете содержатся ошибки, то
заполнение словарей будет остановлено на месте ошибки.
Если содержимое словаря было изменено, нужно
перезапустить клиент, и тогда система будет использовать измененный словарь.
При этом индекс автоматически не обновляется и нужно перестроить индекс вручную
(то есть очистить его и заново обновить при помощи диалога, вызываемого
командой «Операции —Управление полнотекстовым поиском»), хотя при поиске
используются новые словари.
Глава 18.
Инструменты
конфигурирования
Конструктор
пользовательских интерфейсов
Редактор интерфейсов
Создание нового
подменю
На закладке
«Модули» выбирается процедура, расположенная в модуле приложения или общих
модулях, как глобальных, так и не глобальных.
В список процедур
включаются только те процедуры, которые являются внешними (имеют в заголовке
процедуры описание «Экспорт») и не имеющие формальных параметров. Обращение к
процедуре или функции производится через имя общего модуля, например,
УчетНДС.ОпределитьСчетаУчетаКосвенныхРасходов, где УчетНДС – имя неглобального
модуля, а ОпределитьСчетаУчетаКосвенныхРасходов – функция этого модуля.
Редактор форм
Редактирование
формы
Страницы
формы
Режим прокручиваемых страниц
При двойном щелчке
мышью в наименование страницы страница показывается, если до этого она была
свернута, и сворачивается, если была показана.
Отладчик и замеры
производительности
Отладчик — вспомогательный инструмент, облегчающий разработку и
отладку программных модулей системы 1С:Предприятие 8.1. Отладчик
предоставляет следующие возможности:
·
возможность отладки выполнения модулей и WEB-сервисов, как в файловом, так и в клиент-серверном режиме,
фоновых заданий;
·
пошаговое выполнение модуля;
·
расстановка точек останова;
·
прерывание и продолжение выполнения модуля;
·
возможность отладки нескольких модулей
одновременно;
·
вычисление выражений для анализа состояния
переменных;
·
просмотр стека вызовов процедур и функций;
·
возможность остановки по возникновению ошибки;
·
возможность редактирования модуля в процессе
отладки.
Для описания
отладчика используется понятие предмета отладки. Предмет отладки — это контекст встроенного
языка, характеризуемый совокупностью параметров:
·
имя пользователя, от имени которого исполняется
код на встроенном языке;
·
тип предмета отладки;
·
сетевое имя компьютера, на котором исполняется
код на встроенном языке;
·
номер соединения с информационной базой;
·
номер IP-порта, через который Отладчик управляет
работой предмета отладки.
К типам предметов
отладки относятся:
·
клиент — код на
встроенном языке, исполняемый в клиентском приложении;
·
сервер — код на
встроенном языке, исполняемый на сервере;
·
внешнее соединение —
код на встроенном языке, исполняемый через COM-connector;
·
web-сервис — код
на встроенном языке, в котором обрабатываются вызовы методов web-сервисов.
·
фоновое задание —
код на встроенном языке, в котором обрабатываются фоновые задания.
Использование
Отладчика
Чтобы иметь
возможность отлаживать код на встроенном языке, нужно обеспечить запуск
приложения, в котором исполняется код, в отладочном режиме.
Если режим
«1С:Предприятие» не запущен, то для начала отладки выберите пункт
«Отладка — Начать отладку». Конфигуратор запускает режим «1С:Предприятие»
в отладочном режиме.
Если в настройках
Конфигуратора установлен режим разрешения отладки или указано, что отладка
будет начата при запуске (окно настроек открывается с помощью команды
«Сервис — Параметры» закладка «Запуск 1С:Предприятия»), то для начала
отладки также можно использовать режим запуска, выполняемый командой
«Сервис — 1С:Предприятие». Если требуется выполнить отладку кода,
выполняемого определенным пользователем, то в форме настроек на можно указывать
пользователя, от лица которого запускается отладочных режим.
Настройка
приложения для работы в отладочном режиме
Отладка клиентского приложения
Для установки
отладочного режима можно использовать следующие варианты запуска:
·
в режиме «Конфигуратор» в форме настроек
(открыть с помощью «Сервис — Параметры») на закладке «Запуск
1С:Предприятия» установить флажок «Устанавливать режим разрешения отладки»,
далее выполнить подключение предмета отладки; также можно установить флажок
«Начинать отладку при запуске», в этом случае при запуске 1С:Предприятия
подключение будет выполнено автоматически;
·
открыть информационную базу в режиме
«1С:Предприятие» с ключом командной строки /Debug (отладочный режим);
·
если запущено клиентское приложение, то в форме
настроек (открыть с помощью «Сервис — Параметры» закладке «Системные»)
установить отладочный режим (установить флажок «Отладка разрешена»). Следует
иметь в виду, что после применения настроек снять установку флажка нельзя;
·
если режим «1С:Предприятие» уже запущен и
требуется установить возможность отладки только для следующего запуска, следует
в форме настроек (открыть с помощью «Сервис — Параметры») на закладке
«Системные» установить флажок «Устанавливать режим разрешения отладки при
запуске».
Отладка кода на сервере
Для установки
отладочного режима следует запустить сервер 1С:Предприятия с ключом командной
строки /Debug (ragent.exe /debug).
Отладка внешнего соединения и web-сервисов
Для указания
внешнему соединению или web-сервису необходимости запуска в отладочном режиме
используют настройки, размещенные в xml-файлах (comcntrcfg.xml и webservicecfg.xml
соответственно), которые должны располагаться в подкаталоге CONF каталога
исполняемого файла 1С:Предприятия 8.1 (BIN).
Если файл не найден, приложение открывается в обычном режиме.
Пример файла
comcntrcfg.xml:
<config
xmlns=»http://v8.1c.ru/v8/comcntrcfg»>
<debugconfig debug=»true»
debuggerURL=»tcp://localhost:1560″/>
</config>
Атрибут debug=»true»
указывает необходимость запуска в отладочном режиме
Атрибут debuggerURL=»tcp://localhost:1560″
указывает адрес отладчика, к которому нужно автоматически подключиться для
отладки, где «localhost» указывает на поиск на на локальном компьютере,
«1560»
– номер IP-порта. Если порт не указан, то будут проверяться все порты в
диапазоне портов 1560 – 1591; указание «tcp://» эквивалентно «tcp://localhost».
Если адрес отладчика не указан, в процессе исполнения кода на встроенном языке
отладка производиться не будет.
Выполнение
отладки
Чтобы выполнить
отладку модуля нужно, чтобы предмет отладки был подключен для отладки.
Управление подключением предметов
отладки
Для управления
подключением выберите пункт «Отладка — Подключение». На экран выводится окно
для выбора предмета отладки. В списке доступных предметов отладки содержатся
предметы, с которыми допустимо выполнение отладки. В список попадают только те
предметы отладки, которые относятся к отлаживаемой информационной базе и для
которых определена возможность отладки.
Фоновые задания
попадают в список доступных предметов отладки только в тот момент времени,
когда управление выполнением переходит назначенному обработчику. Так как
выполнение может занимать очень незначительное время, для фоновых заданий в
клиент-серверной базе рекомендуется устанавливать автоматическое подключение.
Обычно список
содержит одну строку с указанием на запущенную в режиме «1С:Предприятие»
конфигурацию. Если запущено несколько приложений системы
1С:Предприятие 8.1 с данной конфигурацией, то список может содержать
несколько строк.
Если флажок
«Искать предметы отладки на удаленном компьютере» установлен, то в поле,
расположенном справа от флажка, следует ввести имя компьютера (или его сетевой
адрес) или выбрать имя из ранее вводимых имен. При этом в список доступных
предметов отладки будут добавлены предметы отладки, найденные на удаленном
компьютере. Список подключенных предметов отладки будет содержать те предметы
отладки, которые уже подключены к отладчику.
Нажатие кнопки «Подключить» подключает к отладчику выбранный предмет
отладки. В окне подключения это отображается переносом предмета отладки из
списка доступных в список подключенных предметов отладки.
Для исключения
предмета отладки укажите его в списке подключенных и нажмите кнопку «Отключить». В окне подключения это отображается переносом
предмета отладки из списка подключенных в список доступных предметов и к нему
можно повторно подключиться. При этом точки останова, установленные в
отключенных предметах отладки, не будут «срабатывать» при прохождении через них
выполнения.
Для закрытия
предмета отладки нажмите кнопку «Завершить», для останова в месте
выполнения — кнопку «Остановить».
Для открытия
диалога настройки диапазона следует нажать кнопку «Настройки». Диапазон
определяет границы, в рамках которых Отладчик ищет предметы отладки на текущем
или указанном компьютере.
В поле «Отладчик»
диалога содержатся настройки текущего отладчика, которые можно использовать,
например, в командной строке при запуске клиентского приложения в качестве
параметра ключа командной строки /DebuggerURL
или в xml-файле с настройками отладки для
внешнего соединения или web-сервиса.
Для
автоматического подключения предметов отладки на сервере 1С:Предприятия,
работающего в отладочном режиме, можно воспользоваться диалогом «Автоматическое
подключение» и отметить в нем соответствующие типы предметов отладки.
Пошаговое
выполнение
В режиме
пошагового исполнения предмет отладки, выполнив очередную команду, ждет от
Отладчика инструкций о продолжении работы.
В момент
подключения первого из предметов отладки в меню «Отладка» система добавляет
пункты, с помощью которых осуществляется управление процессом отладки.
На каждом шаге
исполнения модуля существует 5 вариантов продолжения. Для выбора варианта продолжения
используются пункты меню «Отладка»:
|
Команда |
Пояснение |
|
Шагнуть |
В |
|
Шагнуть |
Если |
|
Шагнуть |
Прервать |
|
Идти |
Прервать |
|
Продолжить |
Прервать |
Если
выполняется отладка сразу нескольких предметов отладки, то существует ряд
особенностей пошагового выполнения:
·
если выполнена остановка одного предмета отладки,
останавливаются при начале исполнения кода и другие;
·
выполнение команды «Продолжить» приводит к
продолжению выполнения всех предметов отладки;
·
выполнение команды «Шагнуть через» приводит к
исполнению продвижения на следующую строку во всех предметах отладки;
·
выполнение команды «Шагнуть в» (если выполняемым
оператором модуля является вызов функции или процедуры) приводит к переходу на
первый оператор внутри этого вызова, для других предметов отладки всегда
выполняется команда «Шагнуть через»;
Если производится
отладка клиент-серверного варианта и код последовательно выполняется на клиенте
и на сервере (подключение клиентского и серверного предметов отладки
выполнено), то:
·
выполнение команды «Шагнуть в» (если выполняемым
оператором модуля является вызов функции или процедуры, исполняемой на сервере)
приводит к переходу на первый оператор внутри этого вызова;
·
выполнение команды «Шагнуть из» или команды
«Шагнуть через» для последнего исполняемого оператора (если выполняемым
оператором модуля является код функции или процедуры, исполняемый на сервере, и
которая была вызвана из модуля, выполняемого в клиентском приложении) приводит
к переходу на следующий исполняемый оператор внутри этого вызова;
Для выбора
текущего предмета отладки выводится специальная панель инструментов «Предметы
отладки». Панель состоит из единственного поля выбора, в котором показывается
текущий предмет отладки. Это поле выбора доступно только тогда, когда
управление работой какого-либо из подключенных предметов отладки находится в отладчике
(например, после срабатывания точки останова). При этом в список предметов
отладки попадут только те предметы, управление исполнением которых сейчас также
находится в отладчике, включая текущий предмет отладки.
С помощью табло и
диалога «Выражение» вы можете получить значения интересующих вас выражений.
Стек вызовов позволяет проследить последовательность вызова процедур и функций.
Если выполняется
пошаговый процесс выполнения, то стек вызова, значения переменных (в табло и в
окне «Выражение») показываются для текущего предмета отладки. При смене
предмета отладки стек вызова и значения переменных также меняются.
Важно! Если выполнено подключение клиентского и
серверного предметов отладки и осуществлен переход из клиентской части в
серверную, то на клиентских уровнях стека вызова любые вычисления не
выполняются. Такие уровни выводятся в окне стека вызовов серым цветом.
В случае если
необходимо продолжить выполнение модуля, с помощью команды «Отладка — Продолжить
отладку» разрешите подключенным предметам отладки свободное выполнение модуля
(до следующей точки останова). Если для отладки подключено клиентское
приложение, то оно активизируется автоматически.
В случае если
требуется прервать процесс отладки в целом (кроме фоновых заданий), снимите все
точки останова со всех модулей и выполните команду «Отладка — Продолжить
отладку», если в данный момент сработала точка останова. Если необходимо
прервать отладку и завершить работу подключенных предметов отладки,
воспользуйтесь командой «Отладка — Завершить». В последнем случае не будут
выполнены процедуры ПередЗавершениемРаботыСистемы и ПриЗавершенииРаботыСистемы.
В процессе отладки
допускается редактирование текущей конфигурации и сохранение изменений.
Внимание. Хотя в процессе отладки возможно
редактирование отлаживаемого модуля, Отладчик не производит компилирование
измененного кода — продолжается отладка кода конфигурации базы данных (на
момент запуска Отладчика или подключения). Для отладки изменений, внесенных в
конфигурацию, необходимо выполнить обновление конфигурации базы данных.
Если в режиме
«1С:Предприятие» устанавливается монопольный режим, то сохранение текущей
конфигурации невозможно до тех пор, пока монопольный режим не будет снят.
Таблицу сочетаний
клавиш для работы с Отладчиком см. в Справке при использовании программы.
Отладка внешних
обработок
Для отладки модуля
внешней обработки необходимо открыть файл внешней обработки в Конфигураторе,
воспользовавшись пунктом «Файл — Открыть».
В дальнейшем с
модулем внешней обработки в Отладчике можно работать так же, как и с любым
другим модулем.
Управление
отладкой
Команда
«Отладка — Завершить» прекращает выполнение модуля и заканчивает работу
текущего предмета отладки.
Команда
«Отладка — Остановить» останавливает выполнение модуля на текущем
операторе. Данная команда позволяет начать отладку модуля, начиная со следующей
исполняемой строки. Данная команда полезна при анализе «зацикливания» модуля.
Команда «Отладка — Останавливаться при ошибке»
устанавливает или снимает установку остановки в случае, если в процессе
выполнения возникает ошибка. При этом на экран выводится предупреждение «Ошибка
времени выполнения:» и приводится поясняющий текст о месте и причине
возникновения ошибки. На месте возникновения ошибки устанавливается текущая
точка исполнения текущего предмета отладки, а предмет отладки, в котором
произошла ошибка, становится текущим. Просмотр значений выражений и переменных
позволяет установить причину возникновения ошибки.
Замеры производительности
Замер
производительности позволяет оценить скорость работы всей конфигурации или ее
части, работающей в рамках любого типа предмета отладки. Измеряется частота
использования конкретных участков кода и скорость их выполнения; указывается,
какой код исполнялся на сервере, а какой на клиенте; указываются строки кода,
приведшие к вызову сервера. Если имеется несколько способов решения какой-либо
задачи, можно реализовать их все, после чего выбрать самый быстрый.
При этом
необходимо иметь в виду, что сравнение нужно производить в одинаковых условиях.
Например, если во время выполнения задачи одним из сравниваемых способов
процессор компьютера был загружен еще какой-либо задачей, это может повлиять на
достоверность сравнения. Возможны и другие, менее очевидные причины, по которым
условия измерения окажутся различными. Поэтому при сравнении двух способов
выполнения задачи, имеющих близкую производительность, желательно делать с
каждым из них несколько замеров — для оценки и усреднения случайного разброса.
Для замера
производительности выберите команду «Отладка — Замер производительности».
При повторном выборе команды замер прекратится и откроется окно с его
результатами. Включение и выключение замера производительности действует на все
предметы отладки, которые в настоящий момент подключены к отладчику.
Результаты замера
Результаты замера
— ссылки на конкретные строки модуля, с указанием частоты их выполнения и
длительности — представляются в виде табличного поля, имеющего следующие
колонки:
Модуль содержит
название модуля;
Номер строки номер
строки модуля;
Строка текст
данной строки модуля;
Кол. количество вызовов данной строки
за время замера;
%(Врем.) процент суммарного времени выполнения
данной строки к общему времени замера (общее время замера равно сумме всех
промежутков времени, в которые выполнялся код конфигурации), при этом за
100% принимается время выполнения кода на клиенте;
Клиент пиктограммой отмечаются строки кода,
выполняющиеся на клиенте;
Сервер пиктограммой отмечаются строки кода,
выполняющиеся на сервере;
Обр.
сервер пиктограммами отмечаются строки
кода, приводящие к вызову сервера:
Æ вызов сервера происходил на уровне платформы
или непосредственно вызывались процедуры или функции, исполняемые на сервере;
4 локальный вызов процедуры или функции,
исполняемой на клиенте, внутри которой вызов сервера происходил на уровне
платформы или непосредственно вызывались процедуры или функции, исполняемые на
сервере;
Замечание!
Если в строке кода есть вызов сервера или локальный вызов процедуры или
функции, исполняемой на клиенте, внутри которой есть вызов сервера (например, А =
Функция1(Функция2()), где Функция1
выполняется на клиенте и в ней есть вызов сервера, а Функция2 на
сервере), то в колонке «Обр. сервер» будет показана пиктограмма Æ.
В результатах
замера производительности время выполнения каждой строки складывается из
времени выполнения собственно операторов строки («чистое время») и времени
вызова процедуры (функции), если такие в строке есть. С помощью флажка «Для
вызовов процедур и функций включать время выполнения» можно выбирать, какое
время требуется показывать: полное время (как сумму времени вызова и «чистого
времени») или «чистое время» выполнения.
Если в строке есть
хотя бы один вызов процедуры (функции), то время выполнения включает время
выполнения собственно операторов строки и время вызова процедуры (функции).
Если флажок
установлен, то время вызова процедуры (функции) учитывается в общем времени
выполнения.
Если флажок снят,
в результат замера будет включено только время выполнения строк кода, но не
время работы процедуры (функции), которая вызывается в данной строке. В этом
случае суммарное время выполнения данной строки (в колонке «Врем.») не будет
отражать реального времени, потраченного системой на отработку данной строки.
Необходимо иметь в виду, что выполнение вызванной процедуры (функции) может
занимать, в общем случае, значительное время, которое в данном случае не будет
включено в результат («чистое время»).
По умолчанию
флажок установлен, а его состояние запоминается между сеансами. При смене
состояния изменяются наименования колонок времени.
Если флажок
«Клиент» установлен, то будут показаны результаты замера выполнения кода на
клиенте.
Если флажок
«Сервер» установлен, то будут показаны результаты замера выполнения кода на
сервере.
Если флажок
«Клиент» и флажок «Сервер» установлены, то будут показаны результаты замера
выполнения кода на клиенте и сервере.
Флажки
показываются, если выполняется отладка серверной информационной базы.
Флажки доступны,
если выполняется отладка серверного предмета отладки.
Если открыто
несколько окон с результатами замера производительности, то при подведении
указателя мыши к колонке результатов замера показывается подсказка, содержащая
URL файла, данные которого в этой колонке отображаются.
По двойному щелчку
мыши в колонке с результатами замера производительности в редакторе модуля
осуществляется переход к соответствующей строке файла с результатами замера
производительности.
Кроме
специального окна, результаты замера можно видеть непосредственно в окне с
исходным кодом модуля. Если в Отладчике открыто окно с замером, в окнах модулей
появляется колонка, показывающая количество вызовов данной строки и процент
времени ее работы к общему времени.
Пиктограммами
показывается выполнение кода на клиенте или сервере, а также вызовы сервера.
Двойным щелчком
мыши по строке окна результатов замера можно переключиться на соответствующую
строку в окне модуля.
Если открыто
несколько замеров одновременно, то в окнах с текстами модулей появится соответствующее
количество колонок.
Закрытие окна
результатов замера убирает из модулей колонки с количеством вызовов и процентом
времени работы.
Сортировка
результатов замера
Если выполнялся
замер производительности выполнения кода на клиенте и на сервере, то сортировка
допускается также и по этим колонкам.
Особенности
замера производительности при работе клиент-серверной базы
При замере
производительности результаты замера для кода встроенного языка, выполняемого для
одного и того же номера соединения на клиенте и на сервере, будут объединяться
в один общий замер производительности. При этом указывается, какие строки кода
выполнялись на клиенте, а какие на сервере, из каких строк кода осуществлялся
вызов процедуры или функции, исполняемых на сервере, а также системные вызовы
(самой платформы, например, оператор Выполнить для запроса, оператор записи объекта базы
данных) на сервере.
При просмотре
результатов можно указать, что показывать в замере: замер для клиента, замер
для сервера, замер для клиента и сервера вместе. Выбор режима устраивается с
помощью флажков в правом нижнем углу окна с результатами замера
производительности.
Для серверных
вызовов учитывается время выполнения серверного вызова на самом сервере. Можно
рассматривать происходящее по аналогии со временем исполнения вложенных вызовов
процедур и функций для клиентского приложения.
Глава 21.
Администрирование
Блокировка установки соединений пользователями
Система 1С:Предприятие 8.1 позволяет устанавливать
блокировки соединений пользователей с информационной базой. С его помощью можно
запретить установку соединения пользователей с информационной базой с
отображением сообщения о причине запрета.
Эта возможность полезна, например, когда для выполнения
административных действий требуется, чтобы текущие пользователи завершили свои
сеансы работы, и в то же время новые пользователи не могли подключиться к
информационной базе.
При работе в клиент-серверном варианте работы установка
блокировки может быть выполнена с помощью утилиты администрирования кластера
серверов 1С:Предприятия 8.1.
Кроме этого при работе в любом режиме установка блокировки
может быть выполнена средствами встроенного языка. Для этого используется
объект встроенного языка БлокировкаУстановкиСоединений,
который можно создать с помощью конструктора и установить необходимые свойства
блокировки установки соединений.
Метод глобального контекста УстановитьБлокировкуУстановкиСоединений()
позволяет установить созданную блокировку, а метод ПолучитьБлокировкуУстановкиСоединений()
– получить установленную блокировку.
Предусмотрена возможность соединения с информационной базой
в обход установленной блокировки соединений. Для этого используется параметр
командной строки /UC<код
доступа> и параметр строки соединения UC<код доступа>.
Если при установке блокировки задан непустой код доступа, то для установки
соединения в обход блокировки необходимо в параметре /UC указать этот код
доступа.
Параметры информационной базы
Режим настройки параметров информационной базы позволяет
задавать время ожидания блокировки данных и указывать необходимость
использования ограничений на пароли пользователей.
Для настройки доступны следующие параметры:
Время ожидания блокировки данных (в
секундах). Определяет максимальное время ожидания установки
транзакционной блокировки сервером баз данных. Например, если текущая
транзакция должна установить блокировку на запись, а запись уже заблокирована
другой транзакцией, то текущая транзакция будет ожидать снятия блокировки, но не
дольше, чем значение данного параметра. Аналогичным образом этот параметр
регулирует время ожидания транзакционной блокировки в режиме управляемых
блокировок системы 1С:Предприятие 8.1.
Минимальная длина паролей пользователей.
Указывает минимальную длину пароля пользователя. Если установлен параметр
Проверка сложности паролей пользователей, то минимальная длина пароля
пользователя не может быть менее 7 символов.
Проверка сложности паролей пользователей.
Если данный параметр установлен, пароли пользователей должны удовлетворять
следующим требованиям:
·
длина пароля не должна быть менее значения,
указанного в параметре Минимальная длина паролей пользователей;
·
пароль должен состоять из символов, относящихся
как минимум к трем из перечисленных групп:
§
заглавные буквы;
§
строчные буквы;
§
цифры;
§
специальные символы;
·
пароль не должен совпадать с именем
пользователя;
·
пароль не должен являться последовательностью
символов.
Использование ограничений на пароли пользователей информационной
базы не влияет на существующие пароли. Ограничения будут применены только при
изменении существующего пароля или при добавлении нового пользователя
информационной базы.
Журнал регистрации
Настройка журнала регистрации
С помощью пункта меню «Администрирование — Настройка
журнала регистрации» можно настроить учет событий в журнале регистрации.
В случае сетевой работы выбранную установку можно сохранить
только тогда, когда с конфигурацией кроме администратора никто не работает.
Записи журнала регистрации хранятся в файлах. Каждый файл
содержит записи определенного периода. Размер периода задается в поле
«Разделять хранение журнала регистрации по периодам». Новый файл открывается
при наступлении каждого нового часа, дня, недели, месяца или года, в
зависимости от установленного значения параметра настройки.
При создании новой информационной базы, для журнала
устанавливается режим регистрации событий всех уровней важности и периодичность
разделения на файлы – «день».
Если требуется периодически сокращать
журнал и при этом иметь возможность просматривать уже удаленные события
журнала, то установите флажок «Сохранять разделение хранения журнала по
периодам и объединять с сохраненным ранее журналом». Для сохранения разделения
по периодам при запуске Конфигуратора в командном режиме можно также
использоватькоманду /ReduceEventLogSize KeepSplitting.
Технологический журнал
Система
1С:Предприятие 8.1 обеспечивает возможность ведения технологического журнала, в
который помещается информация от всех приложений, относящихся к 1С:Предприятию
8.1.
Технологический
журнал предназначен для выявления ошибок, возникающих при эксплуатации системы
и диагностики работы системы службой технической поддержки фирмы «1С», а также
для анализа технологических характеристик работы системы.
Состав
и свойства событий технологического журнала могут меняться при выпуске
обновлений платформы.
Наряду
с этим, поскольку технологический журнал представляет собой набор текстовых
файлов, хранящихся в различных каталогах, он может быть использован
разработчиками прикладных решений для анализа различных режимов работы системы
1С:Предприятие 8.1 и прикладных решений.
Технологический
журнал может вестись на любом компьютере, на котором имеется инсталляция
системы 1С:Предприятие 8.1. За ведение технологического журнала отвечает
конфигурационный файл, в котором описываются:
·
каталог, в котором будут располагаться файлы
технологического журнала;
·
состав информации, которая будет помещаться в
технологический журнал;
·
время, в течение которого хранятся файлы
технологического журнала;
·
параметры дампа, создаваемого при аварийном
завершении приложения.
По
умолчанию конфигурационный файл отсутствует. Это означает, что технологический
журнал не ведется. Для того чтобы система 1С:Предприятие 8.1 начала вести
технологический журнал необходимо в каталоге программных файлов 1С:Предприятия
8.1 создать конфигурационный файл, описывающий настройки технологического
журнала.
Система
1С:Предприятие 8.1 автоматически с периодичностью 60 секунд опрашивает
каталог программных файлов на наличие конфигурационного файла и его состав.
Таким образом, изменение параметров технологического журнала может быть
выполнено «на ходу», без перезапуска работающих приложений 1С:Предприятия 8.1.
При
определенных настройках объем технологического журнала может быть достаточно
большим, поэтому в конфигурационном файле желательно указывать время, в течение
которого хранятся файлы журнала. По истечении указанного времени система
1С:Предприятие 8.1 удалит устаревшие файлы журнала. Если после удаления
устаревших файлов каталог, в котором располагались эти файлы, оказывается
пустым, то такой каталог тоже удаляется. Таким образом, все дерево каталогов
технологического журнала не содержит устаревших файлов и папок.
Если
работа системы выполняется в среде Linux, управление выдачей аварийных дампов
(core) выполняется средствами операционной системы. При этом в технологический
журнал помещается информация о факте аварийного завершения процесса и о номере
сигнала, повлекшего за собой это завершение.
Конфигурационный
файл технологического журнала
Для
настройки параметров технологического журнала предназначен конфигурационный
файл. Конфигурационный файл располагается в каталоге загрузочных модулей
1С:Предприятия 8.1. Он называется logcfg.xml и имеет формат XML.
В
простейшем виде конфигурационный файл может иметь, например, следующее
содержимое:
<config xmlns=»http://v8.1c.ru/v8/tech-log»>
<log
location=»c:\v81\logs» history=»1″>
<event> <eq
property=»Name» value=»CONN»/>
</event>
</log>
<dump
location=»c:\v81\dumps» create=»1″ type=»2″/>
</config>
Данный
конфигурационный файл указывает, что:
·
в технологическом журнале регистрируются все
события, установки и разрыва клиентского соединения с сервером;
·
файлы технологического журнала располагаются в
каталоге c:\v81\logs;
·
файлы технологического журнала хранятся в
течение одного часа;
·
файлы дампа помещаются в каталог c:\v81\dumps;
·
файлы дампа содержат всю доступную информацию
(содержимое всей памяти процесса).
При отсутствии конфигурационного файла
используется следующие параметры:
·
дампы минимального размера;
· Каталоги дампов создаются в каталоге C:\Documents and Settings\<ИмяПользователя>\Local Settings\Application Data\1C\1Cv81\.
Имя каждого подкаталога технологического журнала одного
процесса будет иметь вид: <ИмяПроцесса>_<ИдентификаторПроцесса>,
например:
rphost_2488.
Структура конфигурационного файла
Корневым
элементом конфигурационного файла является элемент <config>, который
определяет настройки технологического журнала. Он может содержать несколько
элементов <log> и один элемент <dump>.
<config …>
<log …> … </log>
<log …> … </log>
<log …> … </log>
<dump … />
</config>
Элемент
<log>
определяет каталог технологического журнала. Его атрибуты:
·
location – имя каталога, в котором будет размещаться технологический
журнал;
·
history – количество часов, через которое информация будет удаляться
из технологического журнала.
В элемент <log> могут
быть вложены элементы <event> и <property>, состав которых определяет условие записи
в журнал каждого события и условия записи каждого свойства события.
Если этот элемент
не содержит ни одного элемента <event>, то никакие события в журнал записываться не
будут.
Элемент <dump> определяет каталог для записи дампов аварийного
завершения. Для отключения записи дампов нужно в элементе <dump> установить значение параметра create = «0» или create = «false«. Если элемент <dump> не задан, то для записи
дампов используется каталог %USERPROFILE%\Local Settings\Application
Data\1C\1Cv81\Dumps.
Элемент
<event>
Последовательность элементов <event> определяет условие, при выполнении которого событие будет
помещено в журнал. В журнал помещаются только такие события, которые
удовлетворяют условию. Иначе говоря, если условие, определяемое
последовательностью элементов <event>, принимает значение «Истина», то
событие будет записано в журнал. Событие включается в журнал, если оно
удовлетворяет всем условиям внутри хотя бы одного из элементов <event>.
То есть условия внутри <event> объединяются по «И», а элементы
<event> объединяются по «ИЛИ».
Условия задаются
элементами:
·
eq
– равно;
·
ne
– не равно;
·
gt
– больше;
·
ge
– больше или равно;
·
lt
– меньше;
·
le
– меньше или равно.
Каждый из этих элементов
определяет простое сравнение значения параметра события (имя которого задается
атрибутом property)
со значением атрибута value.
Например:
<event>
<eq
property=»Name» value=»PROC»/>
</event>
В данном случае в
технологическом журнале будут регистрироваться события, относящиеся к группе с
именем PROC. Доступны следующие имена групп событий:
·
PROC — события, относящиеся к процессу целиком,
и влияющие на дальнейшую работоспособность процесса. Например: старт,
завершение, аварийное завершение и т.п.;
·
SCOM — события создания или удаления серверного
контекста, обычно связанного с информационной базой;
·
EXCP — исключительные ситуации, приложений
системы 1С: Предприятие 8.1, которые штатно не обрабатываются и могут
послужить причиной аварийного завершения серверного процесса или
подсоединенного к нему клиентского процесса;
·
SDBL — события, связанные с исполнением запросов
к модели базы данных 1С:Предприятия 8.1;
·
CONN — установка или разрыв клиентского
соединения с сервером;
·
ADMIN — управляющие воздействия администратора
кластера серверов 1С:Предприятия 8.1;
·
DBV8DBEng — исполнение операторов SQL файловой
СУБД;
·
DBMSSQL — исполнение операторов SQL СУБД
Microsoft SQL Server;
·
DBPOSTGRS — исполнение операторов SQL СУБД
PostgreSQL;
·
CALL — удаленный вызов;
·
TLOCK – управление
транзакционными блокировками в Управляемом режиме.
Следует заметить,
что на клиентском компьютере могут возникать только те события, которые
относятся к группам PROC, EXCP, SDBL. Также на клиентском компьютере могут возникать
события из группы DBV8DBEng, если используется файловый вариант работы системы
1С:Предприятие 8.1.
Также следует
заметить, что события из групп PROC, SCOM, EXCP, CONN и ADMIN возникают
относительно редко и содержат небольшое количество информации, в то время как
регистрация событий из групп SDBL, DBV8DBEng и DBMSSQL может приводить к
значительному росту объема технологического журнала.
В каждом элементе <event>
может быть задано несколько условий. В этом случае условия объединяются
логической операцией «И». Если элементов <event> несколько, то если хотя бы один из них
выполняется, то событие попадает в журнал.
Например:
<log location=»c:\logs» history=»1″>
<event> <eq
property=»Name» value=»PROC»/> </event>
<event> <eq
property=»Name» value=»SCOM»/> </event>
<event> <eq
property=»Name» value=»CONN»/>
</event>
<event> <eq
property=»Name» value=»EXCP»/> </event>
<event> <eq
property=»Name» value=»DBMSSQL»/> </event>
</log>
В данном примере
указывается, что в технологическом журнале будут регистрироваться события,
относящиеся к группам PROC, SCOM, CONN, EXCP и DBMSSQL.
Все события имеют
свойство process=<ИмяПриложения>, например,
30:28.9222-1,DBMSSQL,2,process=rphost,p:processName=e00074708,t:clientID=17,t:applicationName=Фоновое задание,t:computerName=,t:connectID=14,Sql=SELECT * FROM DBSchema,Rows=1
Элемент
<property>
Элемент
<property>
определяет условия попадания в журнал значения ключевого свойства события, имя
которого является значением атрибута name, при условии, что само
событие в журнал попадает. Условия задаются вложенными элементами <event> по
таким же правилам, что и для событий.
Если элемент <property>
с определенным именем отсутствует, то соответствующее свойство не пишется. Если
элемент <property>
не содержит вложенных элементов <event>, то определяемое им свойство пишется для
всех событий, попадающих в журнал, в которых оно присутствует. Если элемент <property>
содержит вложенные элементы <event>, то свойство будет записано только для
событий, удовлетворяющих условию (если само событие в журнал записывается, и
событие имеет данное свойство).
Элемент <property
name=”all”> </property> включает записи в журнал всех свойств
событий.
Приведенный
ниже элемент <log> определяет запись в журнал событий: процесса,
серверного контекста, соединения, исключений и исполнение операторов SQL. Причем, текст оператора SQL
будет помещен в журнал только, если он исполнялся более секунды. Журнал
располагается в каталоге c:\logs и хранится 1 час.
<log
location=»c:\logs» history=»1″>
<event> <eq
property=»Name» value=»PROC»/> </event>
<event> <eq property=»Name»
value=»SCOM»/> </event>
<event> <eq property=»Name» value=»CONN»/>
</event>
<event> <eq property=»Name»
value=»EXCP»/> </event>
<event> <eq property=»Name» value=»DBMSSQL»/>
</event>
<property name=»sql»>
<event>
<eq property=»Name» value=»DBMSSQL»/>
<gt property=»Duration» value=»10000”/>
</event>
</property>
</log>
Каждое
событие имеет набор свойств. Каждое свойство имеет имя. Возможно присутствие в
событии нескольких ключевых свойств с одинаковыми именами. Имена свойств могут
использоваться для фильтрации событий и свойств. Большие и малые буквы при
сравнении имен не различаются. Пустое условие в элементе <property>
будет означать, что свойство будет выводиться при любом условии.
Примечание.
Свойство события выводится, только если для него присутствует элемент <property>.
Далее
перечислены основные свойства событий, которые могут потребоваться для
настройки конфигурационного файла или просмотра технологического журнала:
·
Administrator – имя администратора кластера или
центрального сервера;
·
Process — наименование приложения, как его
представляет операционная система (имя файла загрузочного модуля приложения);
·
Calls – количество обращений клиентского
приложения к серверному приложению через TCP;
·
Cluster – номер основного порта кластера
серверов;
·
Connection – номер соединения с информационной
базой;
·
Context
–контекст исполнения;
·
Descr – пояснения к программному исключению;
·
DumpError – описание ошибки, произошедшей в
процессе построения дампа;
·
DumpFile – имя файла с дампом;
·
Duration – длительность события в десятитысячных
долях секунды;
·
Err – консольное сообщение: 0 — информационные,
1 — об ошибке;
·
Exception – наименование программного
исключения;
·
Finish – причина завершения процесса;
·
Func – наименование выполняемого действия:
·
beginTransaction – начало транзакции;
·
commitTransaction – фиксация транзакции;
·
rollbackTransaction – отмена транзакции;
·
setRollbackOnly – установка флага наличия в
транзакции ошибки (ее можно только откатить);
·
getTransactionSplitter – получение разделителя
итогов;
·
quickInsert – быстрая вставка данных в таблицу
базы данных;
·
insertRecords – добавление записи в таблицу базы
данных;
·
suspendIndexing – отмена индексирования таблиц
базы данных;
·
resumeIndexing – восстановление индексирования
таблиц базы данных;
·
holdConnection
– удержание соединения;
·
saveObject — сохранение объекта;
·
restoreObject – восстановление объекта;
·
readFile – чтение файла;
·
createFile – создание файла;
·
deleteFile – удаление файла;
·
searchFile – поиск файла;
·
modifyFile – обновление файла;
·
isProperLocale – проверка национальных настроек,
установленных для базы данных;
·
changeLocale – изменение национальные настройки
базы данных;
·
takeKeyVal – получение значения ключа записи
табличной части;
·
lockRecord – блокировка записи;
·
serializeTable – сохранение данных таблицы в
файл;
·
deserializeTable – восстановление данных таблицы
базы данных из файла;
·
xlockTables – установка исключительной
блокировки на таблицу;
·
xlockTablesShared – установка разделяемой
блокировки на таблицу;
·
copyMoveFile –копирование/ перемещение фрагмента
конфигурации между записями таблиц базы данных;
·
moveFile – перемещение файла;
·
securedInsert –вставка записей с наложением
ограничений доступа к данным;
·
selectFileName – выбор имени файла;
·
setSingleUser – установка монопольного режима;
·
insertIBRegistry – создание кластера;
·
eraseIBRegistry – удаление кластера;
·
setRegMultiProcEnable – установка значения флага
поддержки кластером многих рабочих процессов;
·
setServerProcessCapacity – установка значения
пропускной способности рабочего процесса;
·
agentAuthenticate –аутентификация администратора
центрального сервера;
·
insertAgentUser – добавление администратора
центрального сервера;
·
eraseAgentUser – удаление администратора
центрального сервера;
·
setRegSecLevel – установка уровня
безопасности кластера;
·
setRegDescr – установка описания кластера;
·
setInfoBaseDescr – установка описания
информационной базы;
·
insertServerProcess – добавление рабочего
процесса;
·
eraseServerProcess – удаление рабочего процесса;
·
regAuthenticate – аутентификация администратора
кластера;
·
insertRegUser – добавление администратора
кластера;
·
eraseRegUser – удаление администратора кластера;
·
setServerProcessEnable – установка значения
флага разрешения запуска рабочего процесса;
·
insertRegServer – добавление рабочего сервера;
·
eraseRegServer – удаление рабочего сервера;
·
updateRegServer – изменение параметров рабочего
сервера;
·
authenticateAdmin –аутентификация администратора
информационной базы;
·
createInfoBase – создание информационной базы;
·
dropInfoBase – удаление информационной базы;
·
killClient – разрыв соединения клиента с
кластером серверов 1С:Предприятия;
·
authenticateSrvrUser – аутентификация
администратора кластера в рабочем процессе
·
setInfoBaseConnectingDeny – установка режима
блокировки установки соединений с информационной базой;
·
lookupTmpTable – получение/ создание временной
таблицы базы данных;
·
returnTmpTable – освобождение временной таблицы
базы данных;
·
Host – имя компьютера;
·
Name – имя события;
·
OLEDBException – описание исключения от
Microsoft SQL Server;
·
OSException – описание исключения операционной
системы;
·
p:processName – имя серверного контекста, который
обычно совпадает с именем информационной базы;
·
Port – номер основного IP порта процесса;
·
ProcessName – наименование процесса;
·
Reason – номер исключения;
·
Ref – имя информационной базы;
·
Rows – количество полученных записей базы
данных;
·
RowsAffected – количество измененных записей
базы данных;
·
RunAs – режим запуска процесса (приложение или
сервис);
·
SDBL – текст запроса на встроенном языке модели базы данных;
·
ServerName – имя рабочего сервера;
·
Sql – текст оператора SQL;
·
SyncPort – номер вспомогательного IP порта
процесса;
·
t:applicationName – идентификатор клиентской
программы;
·
t:clientID – идентификатор соединения с клиентом
по TCP;
·
t:computerName – имя клиентского компьютера;
·
t:connectID – идентификатор соединения с
информационной базой;
·
Txt – текст консольного сообщения;
·
V8DBEngException – описание ошибки СУБД для
файловой СУБД;
Val
– значение, смысл зависит от значения параметра Func;
Используя свойства элемента <property>, в технологический журнал можно
записывать контекст исполнения. Контекст исполнения может быть двух видов:
контекст встроенного языка и интерфейсный контекст. Контекст встроенного языка
представляет собой список операторов встроенного языка и содержит в себе:
·
Название модуля;
·
Номер строки модуля;
· Текстовое
представление элемента списка вызова встроенного языка
соответствующей строки модуля.
Интерфейсный контекст включает в себя:
·
Полное имя формы;
·
Тип активного элемента формы;
·
Имя активного элемента формы;
·
Имя кнопки командной панели (если она была
нажата);
Действие,
выполняемое элементом формы;
Например:
Контекст
встроенного языка в файле технологического журнала может иметь вид:
Документ.ПриходнаяНакладная :
23 : Движения.УчетНоменклатуры.Записать();
МодульПриложения : 18 :
ПроверитьПодключениеОбработчикаОжидания(Истина);
МодульПриложения
: 230 : Если нпПолучитьЗначениеПоУмолчанию (глТекущийПользователь,
«ИспользоватьНапоминания»)
·ОбщийМодуль.нпНастройкиПользователей
: 481 : Выборка = Запрос.Выполнить().Выбрать();
Интерфейсный
контекст в файле технологического журнала может иметь такой вид:
{Документ.Документ1.ФормаСписка}/{ТабличноеПоле
:
ДокументСписок}/{ОбновлениеОтображения}
{Документ.Документ1.Форма.ФормаДокумента}/{
КоманднаяПанель :
ОсновныеДействияФормы}/{ОсновныеДействияФормыОК}
{Документ.Документ1.Форма.ФормаДокумента}/{
Кнопка :
Кнопка1}/{Нажатие}
Чтобы
включить запись контекста нужно среди фильтров свойств записать элемент <property name=»context»> или элемент <property name=»all»>. Например:
Если
нужно записывать события SDBL (SDBL-запросы) и DBMSSQL (операторы SQL к СУБД MS
SQL Server) с контекстом исполнения:
<config
xmlns=»http://v8.1c.ru/v8/tech-log»>
<log location=»c:\v81\1logs» history=»1″>
<event>
<eq property=»Name» value=»SDBL»/>
</event>
<event>
<eq property=»Name» value=»DBMSSQL»/>
</event>
<property name=»Context»>
</property>
</log>
</config>
Чтобы
записывать события SDBL (SDBL-запросы) и DBMSSQL (операторы SQL к СУБД MS SQL Server) без контекста исполнения:
<config
xmlns=»http://v8.1c.ru/v8/tech-log»>
<log location=»c:\v81\1logs» history=»1″>
<event>
<eq property=»Name» value=»SDBL»/>
</event>
<event>
<eq property=»Name» value=»DBMSSQL»/>
</event>
</log>
</config>
Чтобы
записывать события SDBL (SDBL-запросы) и DBMSSQL (операторы SQL к СУБД MS SQL Server) без контекста исполнения, но со всеми
другими свойствами:
<config
xmlns=»http://v8.1c.ru/v8/tech-log»>
<log location=»c:\v81\1logs» history=»1″>
<event>
<eq property=»Name» value=»SDBL»/>
</event>
<event>
<eq property=»Name» value=»DBMSSQL»/>
</event>
<property name=»all»>
</property>
<property name=»Context»>
<eq property=»Name» value=»»/>
</property>
</log>
</config>
Для
того, чтобы записывать события SDBL (SDBL-запросы) с контекстом исполнения и DBMSSQL (операторы SQL к СУБД MS SQL Server) без контекста исполнения:
<config
xmlns=»http://v8.1c.ru/v8/tech-log»>
<log location=»c:\v81\1logs» history=»1″>
<event>
<eq property=»Name» value=»SDBL»/>
</event>
<event>
<eq property=»Name» value=»DBMSSQL»/>
</event>
<property name=»Context»>
<event>
<eq
property=»Name» value=»SDBL»/>
</event>
</property>
</log>
</config>
Наличие
элемента <property
name=»Context»> означает, что для записываемых в журнал событий при выполнении условий,
указанных в данном элементе, будет записана информация о контексте. После этого
в каждое событие технологического журнала будет добавлена информация о
контексте исполнения в текущем процессе, а после события будет добавлено
мгновенное событие, несущее информацию о контексте исполнения клиентского
процесса.
В
технологический журнал могут быть записаны сообщения об исключительных
ситуациях, связанных с менеджером блокировок. Для этого файл конфигурации
должен иметь примерно следующий вид:
<config xmlns=»http://v8.1c.ru/v8/tech—log«>
<log
location=»c:\v81\logs» history=»7″>
<event>
<eq
property=»Name» value=»EXCP»/>
</event>
<event>
<eq
property=»Name» value=»TLOCK»/>
<gt
property=»Duration» value=»100000″/>
</event>
<property
name=»all»/>
<property
name=»Context»>
<event>
<eq
property=»Name» value=»»/>
</event>
</property>
</log>
<dump
location=»c:\v81\dumps» create=»1″ type=»2″/>
</config>
В
приведенном случае будут регистрироваться все исключительные ситуации,
связанные с блокировками (в частности DEADLOCK — взаимные блокировки сессий и TIMEOUT — истечение предопределенного времени, при
этом в обоих случаях в текст сообщения об исключительной ситуации
включается номер сессии, которая вызвала эту исключительную ситуацию) и ожидания, превысившие 10 секунд. При
этом будет записана информация по всем свойствам, кроме Context.
Элемент <dump>
Элемент <dump> определяет параметры дампа, создаваемого при аварийном
завершении приложения. Чтобы отключить запись дампов нужно в элементе <dump> установить значение параметра create = «0»
или create =
«false». Если элемент <dump> отсутствует, то для
записи дампов будет использоваться каталог %USERPROFILE%\Local
Settings\Application Data\1C\1Cv81\Dumps.
Его
атрибуты:
·
location — имя каталога, в который будут
помещаться файлы дампов;
·
create — 0 («false«) – не создавать, 1 («true«) – создавать;
·
type – тип дампа, произвольная комбинация
следующих флагов, представленная в десятичной или шестнадцатеричной системе.
Представление в шестнадцатеричной системе должно начинаться с символа ‘x’,
например, x0002. Доступны следующие значения:
0 (x0000) — минимальный;
1 (x0001) — дополнительно сегмент
данных;
2 (x0002) — содержимое всей памяти
процесса;
4 (x0004) — данные хэндлов;
8 (x0008) — оставить в дампе только
информацию, необходимую для восстановления стеков вызовов;
16 (x0010) — если стек содержит ссылки
на память модулей, то добавить флаг 0x0040;
32 (x0020) — включить в дамп память
из-под выгруженных модулей;
64 (0x0040) — включить в дамп память,
на которую есть ссылки;
128 (x0080) — добавить в дамп подробную
информацию о файлах модулей;
256 (0x0100) — добавить в дамп
локальные данные потоков;
512 (0x0200) — включение в дамп памяти
из всего доступного виртуального адресного пространства;
Структура технологического журнала
Технологический
журнал представляет собой каталог, в подкаталогах которого располагаются файлы
с собранными технологическими данными. Каталог журнала имеет следующую
структуру:
<каталог
журнала>
<идентификатор
процесса операционной системы>
<файлы журнала одного процесса>
Каждый файл
журнала содержит события за 1 час и имеет имя yymmddhh.log, где:
·
yy — две последние цифры года;
·
mm
— номер месяца;
·
dd
— номер дня;
·
hh
— номер часа.
Файлы журнала
имеют текстовый формат. В файле сведения о завершении каждого события
записываются с новой строки. Например:
11:33.0312-1,DBV8DBEng,2,Func=selectFileName,FileName=versions.new
11:33.0313-3,DBV8DBEng,1,Func=modifyFile,CatName=ConfigSave,FileName=
versions.new,What=content
Строка окончания
события имеет формат:
mm:ss.tttt-d,
<наименование>, <уровень>, <ключевые свойства>
·
mm — номер минуты в текущем часе;
·
ss — номер секунды в текущей минуте;
·
tttt — номер десятитысячной доли текущей
секунды;
·
d — длительность события в десятитысячных
секунды;
·
<наименование> — наименование события;
·
<уровень> — уровень события в стеке текущего
потока;
·
<ключевые свойства> — <ключевое
свойство>, <ключевое свойство>, …;
·
<Ключевое свойство> — <имя> =
<значение>
<наименование>,
<имя>, <значение> — произвольный текст. Если в нем присутствуют
символы «конец строки» или «запятая», то текст заключается в кавычки или
апострофы в зависимости от того, каких символов в строке меньше, а кавычки или
апострофы в тексте удваиваются.
Глава 22.
Сервисные возможности
Настройка параметров Конфигуратора
Установка
параметров редактирования формы
Запуск 1С:Предприятия
Установить режим разрешения отладки — если флажок установлен, то при запуске в режиме
«1С:Предприятие» возможно выполнение отладки (аналог параметру,
передаваемому через ключ командной строки /DebugMode).
Начинать отладку при запуске — если флажок установлен, то при запуске 1С:Предприятия подключение
будет выполнено автоматически.
Синтакс‑Помощник
Окно
Синтакс‑Помощника разделено на две части. Разделение может быть выполнено
по вертикали или по горизонтали (настройка по умолчанию используется
горизонтальное разделение, которое используется в данном разделе).
В
нижнюю часть выводится описание выбранного раздела встроенного языка.
Содержимое верхней части определяется выбранной закладкой.
Окно
содержит три закладки «Содержание», «Индекс» и «Поиск». На первой размещается
иерархической список элементов встроенного языка системы
1С:Предприятие 8.1: операторов, управляющих конструкций, процедур и
функций, системных констант и др., а вторая и третья предназначены для поиска
по наименованию элемента встроенного языка и произвольного поиска по тексту
описания соответственно.
Закладка
«Содержание» Синтакс‑Помощника
Для удобства все элементы встроенного языка объединены в
тематические разделы, представленные в виде ветвей дерева, которое показывается
в верхнем поле окна Синтакс‑Помощника.
Приемы работы в окне Синтакс‑Помощника стандартны для
иерархических структур данных, представленных в виде дерева. Для быстрого
раскрытия ветви рекомендуем использовать клавиши «+», «-» и «*» цифровой
клавиатуры; «+» раскрывает ветвь на один уровень, «-» — сворачивает, «*» —
раскрывает все подветви данной ветви.
Для получения описания следует в верхней части окна Синтакс‑Помощника
выбрать наименование элемента языка. Описание элемента показывается в нижней
части окна Описание может содержать ссылки на описания упоминаемых элементов
встроенного языка.
В окне расположена панель инструментов, с помощью которой
можно просмотреть историю выбранных ранее описаниям.
Для показа местоположения в структуре элементов встроенного
языка элемента, текущее описание которого в данный момент выведено в нижнюю
часть, в панели инструментов нажмите кнопку «Найти текущий элемент в дереве».
Поиск в Синтакс‑Помощнике
Поиск в Синтакс‑Помощнике может выполняться по наименованию
элемента встроенного языка и по произвольному тексту описания.
На закладке «Индекс» окна Синтакс‑Помощника
выполняется поиск по наименованию элемента встроенного языка. В верхней части
содержится поле для ввода наименования нужного элемента языка и полный список
наименований элементов.
На закладке «Поиск» окна Синтакс‑Помощника
выполняется поиск по произвольному тексту описания. В верхней части содержится
поле для ввода строки поиска и поле списка найденных глав описаний элементов
встроенного языка.
Для начала поиска начинайте вводить текст. В процессе ввода
программа выполняет поиск глав, в которых встречается введенный текст. Регистр
ввода может быть любым, слова текста учитываются целиком (если не использован
оператор «*») и с учетом морфологии. Допускается использование поисковых
операторов (см. параграф «Формат поисковых выражений»).
В процессе ввода программа оперативно выводит список этих
глав. Если введенный текст нигде не встречается, то ниже поля ввода программа
выводит об этом сообщение.
При открытии главы программа покажет описание таким
образом, чтобы было видно первое вхождение указанного текста.
Для просмотра главы выберите ее в списке и
нажмите клавишу Enter.
Описание выбранной главы показывается в нижнем поле.
После того, как глава описания элемента встроенного языка
найдена и окно Синтакс‑Помощника открыто, для поиска положения главы в
дереве описаний используйте кнопку командной панели «Найти текущий элемент в
дереве».
Если в процессе просмотра выбирались несколько страниц, то
с помощью команд «Вперед» и «Назад» можно вернуться к просмотренным страницам.
Формат поисковых выражений
Поиск может
осуществляться по нескольким словам, с использованием поисковых операторов и
поиском по точной фразе.
В строке ввода
допускается использование следующих поисковых операторов:
|
Оператор |
Пример |
Пояснение |
|
И |
запись |
Будут найдены все разделы, содержащие и |
|
ИЛИ |
запись |
Будут найдены все разделы, содержащие хотя |
|
НЕ |
закрытие |
Будут найдены все разделы, содержащие |
|
РЯДОМ/[±]n |
Пример 1: Пример 2: Пример 3: |
Поиск раздела, содержащего указанные слова Знак указывает, в каком направлении от Если знак не В примере 1 В примере 2 В примере 3 будут найдены разделы, в |
|
РЯДОМ NEAR |
Библиотека |
Краткая форма. Запрос в короткой форме |
|
«» |
«проведение документа» |
Поиск точной с учетом морфологии фразы проведение РЯДОМ/+1 документ) |
|
() |
(проведение |
Группировка слов (сколько угодно уровней |
|
* |
доку* |
Поиск с использованием группового символа |
Если не
указано никаких операторов (слова набраны через пробел), то программа
осуществляет поиск всех слов из запроса с использованием оператора И.
Замечание 1. Написание операторов И (AND), ИЛИ (OR), НЕ (NOT), РЯДОМ (NEAR) допускается только в
верхнем регистре.
Замечание 2. Операторы не используются как унарные (в
начале строки поиска). Например, нельзя сделать выбор всех глав, в которых
отсутствует указанный текст.
Замечание 3. Все символы в поле поиска, кроме символов
поисковых операторов, букв и цифр, игнорируются.
Приложение В. Формат файла настройки прокси по умолчанию
inetcfg.xml
Файл inetcfg.xml позволяет задавать настройки прокси по умолчанию и имеет
больший приоритет над настройками прокси по умолчанию в Windows.
Файл располагается
в каталоге CONF каталога
исполняемых файлов системы 1С:Предприятие 8.1 и его наличие не является
обязательным.
Если он
отсутствует, то настройки в Windows берутся из настроек InternetExplorer‘a.
В Linux, если есть необходимость работать через прокси, файл inetcfg.xml должен присутствовать.
Корневой элемент
InternetProxy, задающий настройки прокси по умолчанию имеет следующую структуру
(атрибуты):
protocols
protocols : строка
(необязательное) – задает имя и порт хоста для протоколов. Имеет формат:
ПараметрыПроксиПротокола1
ПараметрыПроксиПротокола2
…
ПараметрыПроксиПротоколаN
ПараметрыПроксиПротокола:=
[Протокол] “=”
хост”:”порт
Список параметров
прокси протоколов разделен пробелами. Каждый параметр состоит из
необязательного имени протокола, знака “равно”, имени хоста и порта прокси
сервера разделенных двоеточием. Если имя протокола не указано, то параметры
прокси используются для всех протоколов, для которых они явно не указаны.
Протоколы могут иметь следующие имена:
·
http;
·
https;
·
ftp.
Регистр является
значимым, другие имена протоколов не поддерживаются.
Пример:
protocols=»http=10.1.0.8:8080
10.1.0.9:8080″
В примере для
протокола http определены параметры прокси: хост – 10.1.0.8, порт – 8080. Для
остальных протоколов (https, ftp): хост — 10.1.0.9, порт – 8080.
user
user : строка (необязательное) – имя пользователя для аутентификации на
прокси сервере. Пример:
user=»proxyUser»
password
password : строка (необязательное) – пароль пользователя для аутентификации на прокси сервере.
Пример:
password=»proxyPassword»
bypassOnLocal
bypassOnLocal : булево (необязательное) – признак того, использовать ли прокси сервер для локальных
адресов:
·
true – не использовать;
·
false – использовать.
Локальность адреса
определяется по наличию точки в DNS имени адреса (т.е. все IP адреса не
являются локальными). Поэтому может получиться так, что фактически локальный
адрес не распознается как локальный.
Например:
<пользовать>.<домен> – является в WindowsXP локальным адресом, но
не распознается как локальный. Для того чтобы запретить использовать прокси для
адресов, которые воспринимаются как локальные, используется следующий параметр:
bypassOnLocal=»true»
Для всех остальных
адресов нужно использовать параметр – bypassOnAddresses.
bypassOnAddresses
bypassOnAddresses : строка (необязательное) – список адресов, для которых прокси не используется. Имеет
формат:
хост1 хост2 … хостN
Имена хостов
разделяются пробелами. Имя хоста может содержать специальные символы маски: * –
любое количество символов, ? – любой символ. Например, чтобы блокировать прокси
для всех хостов домена, нужно использовать: *.<имя домена>. Пример:
bypassOnAddresses=»
127.0.0.1 *.master«
В примере для
адреса 127.0.0.1 (localhost) и для всех адресов домена master прокси не используется.
Общий пример файла
inetcfg.xml:
<InternetProxy
protocols=»http=10.1.0.8:8080
10.1.0.9:8080″
user=»proxyUser»
password=»proxyPassword»
bypassOnLocal=»true»
bypassOnAddresses=»127.0.0.1
*. master»
/>,
Приложение Г. Используемые компоненты
В программном продукте были использованы следующие
компоненты:
·
Словари, используемые в полнотекстовом поиске,
основаны на словарных базах и словарях тезауруса русского, украинского и
английского языков, предоставленных компанией «Информатик»
·
zlib
general purpose compression library version 1.1.3. July 9, 1998
Copyright © 1995-1998 Jean-loup Gailly and Mark Adler
·
Portions
of this software are based in part on the work of the Independent JPEG Group.
·
PNG
reference library.
·
libpng
version 1.0.5 — October 15, 1999
·
Copyright
© 1995, 1996 Guy Eric Schalnat, Group 42, Inc.
·
Copyright
© 1996, 1997 Andreas Dilger
Copyright © 1998, 1999 Glenn Randers-Pehrson
·
TIFF
Software Distribution.
·
Copyright
© 1988-1997 Sam Leffler
·
Copyright
© 1991-1997 Silicon Graphics, Inc.
·
Various
1С products provide read/write capability and/or other LZW capability covered
by Unisys-owned U.S.
patent 4,558,302. Licensing information can be obtained by contacting Unisys at
the following address:
Unisys Corporation
Welch Licensing Dept. — MSC1SW19
Township Line and Union Meeting Roads
P.O. Box 500
Blue Bell,
PA 19424-0001
Fax: (215) 986-3090
·
PROJ
4 release 4.4
·
Copyright
(c) 2000, Frank Warmerdam
·
Copyright
(c) 1990-2004 Info-ZIP. All rights reserved.
·
Dr.
Gladman’s AES library: (A Password Based File Encryption Example with AES and
HMAC-SHA1)
·
Copyright
(c) 2002, Dr Brian Gladman, Worcester,
UK. All rights
reserved.
·
This
product includes software developed by the OpenSSL Project for use in the
OpenSSL Toolkit (http://www.openssl.org/).
This product includes cryptographic software written by Eric Young
(eay@cryptsoft.com).
·
ICU
3.4.1. Copyright © 1997-2006 International Business Machines Corporation and
others. All Rights Reserved
·
Xerces-C++
version 2.6.0. Copyright © 1999-2005 The Apache Software Foundation. All Rights
Reserved.
·
Xalan-C++
version 1.9. Copyright © 1999-2005 The Apache Software Foundation. All Rights
Reserved.
Приложение Д. Лицензии
ICU License — ICU 1.8.1 and later
COPYRIGHT
AND PERMISSION NOTICE
Copyright
(c) 1995-2005 International Business Machines Corporation and others
All rights
reserved.
Permission
is hereby granted, free of charge, to any person obtaining a copy of this
software and associated documentation files (the «Software»), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to
do so, provided that the above copyright notice(s) and this permission notice
appear in all copies of the Software and that both the above copyright
notice(s) and this permission notice appear in supporting documentation.
THE
SOFTWARE IS PROVIDED «AS IS», WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
PARTICULAR PURPOSE AND NONINFRINGEMENT OF THIRD PARTY RIGHTS. IN NO EVENT
SHALL THE COPYRIGHT HOLDER OR HOLDERS INCLUDED IN THIS NOTICE BE LIABLE FOR
ANY CLAIM, OR ANY SPECIAL INDIRECT OR CONSEQUENTIAL DAMAGES, OR ANY
DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN
AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING
OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
Except as
contained in this notice, the name of a copyright holder shall not be
used in advertising or otherwise to promote the sale, use or other
dealings in this Software without prior written authorization of the
copyright holder.
———————————————————————————
All
trademarks and registered trademarks mentioned herein are the property of their
respective owners.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND
CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1.
Definitions.
«License»
shall mean the terms and conditions for use, reproduction, and distribution as
defined by Sections 1 through 9 of this document.
«Licensor»
shall mean the copyright owner or entity authorized by the copyright owner that
is granting the License.
«Legal
Entity» shall mean the union of the acting entity and all other entities
that control, are controlled by, or are under common control with that entity.
For the purposes of this definition, «control» means (i) the power,
direct or indirect, to cause the direction or management of such entity,
whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or
more of the outstanding shares, or (iii) beneficial ownership of such entity.
«You»
(or «Your») shall mean an individual or Legal Entity exercising
permissions granted by this License.
«Source»
form shall mean the preferred form for making modifications, including but not
limited to software source code, documentation source, and configuration files.
«Object»
form shall mean any form resulting from mechanical transformation or
translation of a Source form, including but not limited to compiled object
code, generated documentation, and conversions to other media types.
«Work»
shall mean the work of authorship, whether in Source or Object form, made
available under the License, as indicated by a copyright notice that is
included in or attached to the work (an example is provided in the Appendix
below).
«Derivative
Works» shall mean any work, whether in Source or Object form, that is
based on (or derived from) the Work and for which the editorial revisions,
annotations, elaborations, or other modifications represent, as a whole, an
original work of authorship. For the purposes of this License, Derivative Works
shall not include works that remain separable from, or merely link (or bind by
name) to the interfaces of, the Work and Derivative Works thereof.
«Contribution»
shall mean any work of authorship, including the original version of the Work
and any modifications or additions to that Work or Derivative Works thereof,
that is intentionally submitted to Licensor for inclusion in the Work by the
copyright owner or by an individual or Legal Entity authorized to submit on behalf
of the copyright owner. For the purposes of this definition,
«submitted» means any form of electronic, verbal, or written
communication sent to the Licensor or its representatives, including but not
limited to communication on electronic mailing lists, source code control
systems, and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but excluding
communication that is conspicuously marked or otherwise designated in writing
by the copyright owner as «Not a Contribution.»
«Contributor»
shall mean Licensor and any individual or Legal Entity on behalf of whom a
Contribution has been received by Licensor and subsequently incorporated within
the Work.
2. Grant
of Copyright License. Subject to the terms and conditions of this License, each
Contributor hereby grants to You a perpetual, worldwide, non-exclusive,
no-charge, royalty-free, irrevocable copyright license to reproduce, prepare
Derivative Works of, publicly display, publicly perform, sublicense, and
distribute the Work and such Derivative Works in Source or Object form.
3. Grant
of Patent License. Subject to the terms and conditions of this License, each
Contributor hereby grants to You a perpetual, worldwide, non-exclusive,
no-charge, royalty-free, irrevocable (except as stated in this section) patent
license to make, have made, use, offer to sell, sell, import, and otherwise
transfer the Work, where such license applies only to those patent claims
licensable by such Contributor that are necessarily infringed by their
Contribution(s)
alone or by combination of their Contribution(s) with the Work to which such
Contribution(s) was submitted. If You institute patent litigation against any
entity (including a cross-claim or counterclaim in a lawsuit) alleging that the
Work or a Contribution incorporated within the Work constitutes direct or
contributory patent infringement, then any patent licenses granted to You under
this License for that Work shall terminate as of the date such litigation is
filed.
4.
Redistribution. You may reproduce and distribute copies of the Work or
Derivative Works thereof in any medium, with or without modifications, and in
Source or Object form, provided that You meet the following conditions:
(a) You must give any other recipients of the
Work or Derivative Works a copy of this License; and
(b) You must cause any modified files to carry
prominent notices stating that You changed the files; and
(c) You must retain, in the Source form of any
Derivative Works that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work, excluding those notices
that do not pertain to any part of the Derivative Works; and
(d) If the Work includes a «NOTICE»
text file as part of its distribution, then any Derivative Works that You
distribute must include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not pertain to any
part of the Derivative Works, in at least one of the following places: within a
NOTICE text file distributed as part of the Derivative Works; within the Source
form or documentation, if provided along with the Derivative Works; or, within
a display generated by the Derivative Works, if and wherever such third-party
notices normally appear. The contents of the NOTICE file are for informational
purposes only and do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside or as an
addendum to the NOTICE text from the Work, provided that such additional
attribution notices cannot be construed as modifying the License.
You may
add Your own copyright statement to Your modifications and may provide
additional or different license terms and conditions for use, reproduction, or
distribution of Your modifications, or for any such Derivative Works as a
whole, provided Your use, reproduction, and distribution of the Work otherwise
complies with the conditions stated in this License.
5.
Submission of Contributions. Unless You explicitly state otherwise, any
Contribution intentionally submitted for inclusion in the Work by You to the
Licensor shall be under the terms and conditions of this License, without any
additional terms or conditions. Notwithstanding the above, nothing herein shall
supersede or modify the terms of any separate license agreement you may have
executed with Licensor regarding such Contributions.
6.
Trademarks. This License does not grant permission to use the trade names,
trademarks, service marks, or product names of the Licensor, except as required
for reasonable and customary use in describing the origin of the Work and
reproducing the content of the NOTICE file.
7.
Disclaimer of Warranty. Unless required by applicable law or agreed to in
writing, Licensor provides the Work (and each Contributor provides its
Contributions) on an «AS IS» BASIS, WITHOUT WARRANTIES OR CONDITIONS
OF ANY KIND, either express or implied, including, without limitation, any
warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or
FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining
the appropriateness of using or redistributing the Work and assume any risks
associated with Your exercise of permissions under this License.
8.
Limitation of Liability. In no event and under no legal theory, whether in tort
(including negligence), contract, or otherwise, unless required by applicable
law (such as deliberate and grossly negligent acts) or agreed to in writing,
shall any Contributor be liable to You for damages, including any direct,
indirect, special, incidental, or consequential damages of any character
arising as a result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill, work stoppage,
computer failure or malfunction, or any and all other commercial damages or
losses), even if such Contributor has been advised of the possibility of such
damages.
9.
Accepting Warranty or Additional Liability. While redistributing the Work or
Derivative Works thereof, You may choose to offer, and charge a fee for,
acceptance of support, warranty, indemnity, or other liability obligations
and/or rights consistent with this License. However, in accepting such
obligations, You may act only on Your own behalf and on Your sole
responsibility, not on behalf of any other Contributor, and only if You agree
to indemnify, defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason of your
accepting any such warranty or additional liability.
END OF
TERMS AND CONDITIONS
APPENDIX:
How to apply the Apache License to your work.
To apply
the Apache License to your work, attach the following boilerplate notice, with the
fields enclosed by brackets «[]» replaced with your own identifying
information. (Don’t include the brackets!) The text should be enclosed in the
appropriate comment syntax for the file format. We also recommend that a file
or class name and description of purpose be included on the same «printed
page» as the copyright notice for easier identification within third-party
archives.
Copyright
[yyyy] [name of copyright owner]
Licensed
under the Apache License, Version 2.0 (the «License»);
you may
not use this file except in compliance with the License.
You may
obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless
required by applicable law or agreed to in writing, software distributed under
the License is distributed on an «AS IS» BASIS, WITHOUT WARRANTIES OR
CONDITIONS OF ANY KIND, either express or implied.
See the
License for the specific language governing permissions and
limitations
under the License.
Перевод интерфейса выполнен:
|
Язык |
Компания |
|
Румынский |
«Contabilizare-Prof S.R.L.» |
|
Латышский |
ООО «АНДИ М» |
|
Литовский |
АОЗТ «AVAKOMPAS« |
|
Болгарский |
«DAVID |
|
Казахский |
ООО «Зерде» |
|
Грузинский |
ООО |
|
Вьетнамский |
«1 VS » JSC |
Книга
«1С:Предприятие 8.1. Руководство пользователя»
Глава 3.
Справочники,
планы счетов, планы видов характеристик, планы видов расчета
Справочники
Редактирование элемента справочника
Редактирование элемента справочника при
многопользовательском режиме
Когда в системе работают несколько
пользователей, возможна такая ситуация, что один и тот же объект пытаются
отредактировать несколько человек. В этом случае только первому начавшему
правку удастся завершить редактирование объекта. Всем остальным при попытке
начать редактировать объект система выдаст предупреждение с номером соединения
и именем компьютера, с которого был заблокирован этот объект.
Чтобы внести свои изменения в освобожденный
объект, его следует перечитать из базы данных.
Глава 4.
Документы и журналы документов
Поиск документов в журнале и списке
Поиск документа по
номеру
Если в результате поиска по номеру документа
пользователь попытается позиционироваться на документе, который не
соответствует установленному пользователем отбору, то система сообщит об этом и
предложит ему снять отбор. Если пользователь согласится, то установленный ранее
отбор будет снят и позиционирование на найденном документе будет выполнено,
иначе – текущая позиция в списке документов не изменится.
Глава 5.
Отчеты и обработки
Использование
отчета (обработки)
В системе 1С:Предприятие 8.1 существует
специальный механизм внешних отчетов и
обработок. Внешние отчеты и обработки по назначению и способу
использования ничем не отличаются от обычных отчетов и обработок. Однако в
отличие от хранящихся в конфигурации, внешние хранятся в отдельных файлах.
Внешние отчеты и обработки используются в специальных случаях, когда они не
могут быть помещены в конфигурацию по каким либо причинам. Подробно создание
внешних отчетов и обработок описано в книге «1С:Предприятие 8.1.
Руководство по конфигурированию и администрированию».
Открытие внешних отчетов и
обработок
Для выполнения внешний отчет и обработка
загружаются как любой другой внешний файл и работают так же, как и любая другая
обработка конфигурации.
Для вызова внешнего отчета или обработки
используется пункт «Файл — Открыть». При обращении к этому пункту
вызывается стандартный диалог открытия файлов. В нем следует выбрать требуемый
файл. Файлы внешних отчетов имеют расширение «erf», а обработок — «epf». При повторном открытии файл может быть
выбран из списка ранее использованных файлов в меню «Файл» главного меню
программы.
В конфигурации могут быть реализованы и
специальные способы открытия внешних отчетов и обработок. В этом случае они
будут открываться из различных режимов конфигурации, в которых это
предусмотрено.
При выборе файла внешнего отчета или
обработки их форма открывается так же, как и форма обычного отчета или
обработки.
Программа производит загрузку и компиляцию
модуля и открывает форму, если иного не предусмотрено при ее создании.
Внешний вид формы настройки отчета или
обработки, в общем случае, может быть любым и определяется при создании отчета
или обработки в конфигурации.
В отличие от внешних обработок внешние
отчеты могут использовать систему компоновки данных. Подробнее об этом см.
параграф «Работа с отчетами, использующими систему компоновки данных».
В выданной форме следует установить
необходимые параметры и нажать кнопку «Сформировать»
или подобную.
Работа
с отчетами, использующими систему компоновки данных
Отчеты, построенные с помощью системы
компоновки данных, отличаются от обычных тем, что такой отчет имеет
определенную структуру, в которую могут входить группировки, таблицы,
диаграммы, вложенные схемы в разной последовательности и с различной степенью
вложенности относительно друг друга, и каждый такой элемент отчета может быть
по-своему оформлен, упорядочен и отсортирован. Возможности настройки при этом
значительно расширяются.
Как было сказано в начале главы, отчеты
создаются разработчиком на этапе конфигурирования системы. В процессе создания
отчета разработчик устанавливает некоторые настройки по умолчанию. Чтобы
выполнить отчет с готовыми настройками, нажмите кнопку «Сформировать» в окне
отчета. Также можно запустить конструктор настроек или же отредактировать
настройки по умолчанию, нажав кнопку «Настройки»… Подробнее о работе с
конструктором настроек см. далее. В сформированном отчете полученные данные
можно детализировать и оформить. Подробнее см. раздел. Работа с расшифровкой отчета
Конструктор настроек отчета
Конструктор настроек отчета облегчает
настройку отчета. Он имеет несколько относительно простых вариантов настройки
отчета, которые предлагается выбрать. Он удобен для тех, кому нужно настроить
отчет, не вникая во все «тонкости», так как он позволяет выбрать только
основные настройки для каждого вида элементов отчета.
Вызов этого конструктора может привести к
потере настроек, установленных вручную, поэтому на экране появится вопрос
«Настройки, введенные вручную, будут утеряны. Продолжить?». При ответе «Да» запустится конструктор настроек
компоновки данных.
Выберите необходимый вид расположения данных
и нажмите кнопку «Далее>». Если
не нужно настраивать остальные параметры — кнопку «ОК».
В открывшемся окне выбора полей, выберите
поля, которые должны отображаться в отчете. Для этого можно использовать как
кнопки, так и перетаскивание. Выбранные поля можно сортировать при помощи
стрелок «вверх», «вниз».
Для перехода на следующее окно настроек
следует нажать кнопку «Далее>».
Для типа отчета «Таблица» можно указать группировки в строках, колонках и
таблиц. Для типа отчета «Диаграмма» — в
сериях, точках и таблицах.
В открытом окне выберите поля и тип
группировки, в качестве которого могут выступать:
·
«Без иерархии» — только данные элементов;
·
«Иерархия» — данные как по группам, так и
по элементам;
·
«Только иерархия» — вывод данных по группам.
После нажатия кнопки «Далее>» конструктор настроек перейдет в окно выбора
поля упорядочивания
Поля упорядочивания выбираются аналогично
полям группировок. Для каждого поля устанавливается направление сортировки.
Для типов отчета «Список» и «Таблица» на этом
конфигурирование параметров в конструкторе настроек закончено. Для типа отчета
«Диаграмма», после нажатия кнопки «Далее>», выбирается тип диаграммы.
По окончании работы с конструктором настроек
компоновки данных сохраненные настройки станут доступными для последующих
изменений в окне настроек отчета.
Настройка
отчета
Отчет содержит настройки, которые могут быть
изменены пользователем. В понятие «настройки» в данном случае входят:
·
структура отчета;
·
состав полей, выводимых в отчет;
·
состав полей, входящих в группировки;
·
отборы;
·
сортировки;
·
условные оформления;
·
другие настройки.
Настройки открываются для изменения в
отдельном окне по кнопке «Настройки…» отчета (если она предусмотрена на этапе
конфигурирования).
Форма редактирования настроек состоит из
табличного поля структуры отчета, командной панели выбора настраиваемого
элемента и набора настроек, распределенных по закладкам. Настроить можно, как
отчет целиком, так и каждый его элемент по отдельности, в т.ч. вложенный.
Переключение между режимами настройки осуществляется по кнопкам «Отчет» и «Имя
ЭлементаСтруктуры» (заголовок второй кнопки меняется в зависимости от
выбранного элемента структуры).
Создание
и изменение структуры отчета
Табличное поле содержит структуру отчета в
виде элементов настроек отчета, которые будут выводиться в отчет. Слева у
каждого элемента структуры можно установить флаг, в зависимости от значения
которого элемент будет выведен в отчет (если флаг установлен) или не будет
(если флаг снят). Структура отчета может
включать в себя следующие элементы:
Группировка — представляет собой
список, имеющий одно измерение – поле, по которому проводится группировка.
Таблица — элемент структуры отчета,
строками и колонками которого служат указанные группировки.
Диаграмма — изображение,
представляющее табличные данные в графическом виде.
Добавление, изменение и удаление элементов
структуры отчета осуществляется с помощью меню.
Чтобы добавить новую группировку используйте
команду «Новая группировка» или клавишу Insert. В
открывшемся диалоге следует выбрать поле группировки и тип группировки (Без Иерархии,
Иерархия, Только Иерархия). Если не задавать поле группировки, то в ней будут
выводиться детальные записи из используемых в отчете данных, и она будет
называться «<Детальные записи>».
Для удобства настройки нового элемента,
системой могут быть добавлены авто выбранное поле и авто поле порядка (в
группировку добавляются оба объекта, в диаграмму — только выбранное поле, в таблицу и вложенный
отчет ничего не добавляется). При создании отчета поле автовыбора будет
преобразовано системой в набор выбранных полей, а поле автопорядка будет
преобразовано в список полей порядка.
Если
создание группировки потеряло смысл, нажмите «Отмена». Чтобы разгруппировать
созданную группировку выберите команду «Разгруппировать». При этом в структуре
отчета останутся группировки, вложенные в удаляемую. Чтобы удалить группировку
со всеми вложенными в нее группировками выберите в контекстном меню
команду «Удалить». Получив подтверждение об удалении элемента, система обновит
структуру отчета.
Если по полю проводится иерархическая или
только иерархическая группировка, в структуре отчета после заголовка поля в
скобках отобразится тип иерархии.
Для изменения имеющейся группировки
используйте команду «Изменить». В этом случае можно выбрать другое поле
группировки и другой тип группировки для
текущей группировки.
Для удаления элемента
из структуры отчета, следует выбрать его, нажать Del и подтвердить удаление.
Внимание. Не
каждый элемент настроек отчета может быть вложен один в другой. В зависимости
от текущего элемента отчета системой регулируется доступность соответствующих
команд. Например, добавление встроенного отчета может быть недоступно, если он
не был определен для текущего отчета на этапе конфигурирования.
Параметры настройки схемы компоновки данных
В зависимости от выбранного элемента
структуры отчета меняется состав настроек При добавлении отбора, сортировки,
условного оформления и др. в текущей строке табличного поля структуры отчета
появится соответствующая пиктограмма.
Эти пиктограммы означают, что для элемента
была выполнена какая-либо настройка.
Режим настройки отчета
Режим настройки «Отчет» позволяет выполнить
настройку отчета в целом. Для вызова этого режима следует выбрать Отчет в
структуре отчета. Состав закладок зависит от наличия доступных полей.
Режим настройки элемента
структуры отчета
Настройки элемента структуры отчета
становятся доступны, если выбран элемент структуры и нажата кнопка выбора его
настроек.
В этом режиме доступны закладки:
Для элемента типа «Группировка»: Поля группировки,
Выбранные поля, Отбор, Сортировка, Условное оформление, Другие настройки.
Для элементов типа «Таблица» и «Диаграмма»
доступны: Выбранные поля, Условное оформление, Другие настройки.
Доступные поля
Список доступных полей позволяет просто и
эффективно выбирать доступные поля и переносить их в списки полей группировки,
выбора, отбора, сортировки с помощью стандартного механизма перетаскивания.
Используя контекстное меню списка доступных полей можно выбрать текущее
или все доступные поля для того, чтобы поместить их в соответствующую коллекцию
(команда «Выбрать все» выберет все поля, которые в дереве доступных полей
располагаются на одном уровне с текущей строкой, при этом все папки не
выбираются).
Доступные поля настройки отчета отображаются в следующей последовательности:
·
поля, не являющиеся ресурсами в алфавитном
порядке;
·
поля, являющиеся ресурсами в алфавитном порядке;
·
папка “Системные поля”, содержащая
предопределенные поля, не зависящие от схемы компоновки данных, например, номер
по порядку
·
папка “Отчет владелец” (появляется только в
настройках вложенного отчета) содержит доступные поля отчета владельца, которые
можно использовать при настройке данного отчета
·
папка “Параметры”, (появляется, если
настраиваемый объект имеет параметры данных) содержит поля, соответствующие
параметрам. В тех местах, где будут использоваться эти поля, при исполнении
будет подставляться значение соответствующих параметров. Поля – параметры могут
использоваться в любом месте настроек, за исключением упорядочивания и группировки.
Подробнее о параметрах данных см. в следующем разделе.
·
папка “Пользовательские поля” (появляется, если
данные настройки содержат пользовательские поля). Подробнее о пользовательских
полях см. стр. 199.
Параметры
Если на этапе конфигурирования системы для
отчета были заданы какие-либо параметры, то они отобразятся в списке доступных
полей в папке «Параметры» и также они станут доступны для включения/исключения
из отчета и выбора значения (если параметру задано было несколько значений) на
закладке «Параметры данных». Например, если используются дата начала периода и
дата конца периода, за который выполняется отчет, эти значения должны быть
заданы пользователем.
В тех местах, где будут использоваться эти
поля, при выполнении отчета будет подставляться значения соответствующих
параметров. Параметры могут использоваться в любом месте настроек, кроме отбора
и группировки.
В качестве значений параметров могут быть
использованы данные базы данных и перечисления, а также значения, определенные
разработчиком.
Выбранные поля
На закладке «Выбранные поля» выбираются
поля, которые будут входить в отчет. Если выбранных полей нет, в отчет
выводится пустой элемент. Имеется возможность с помощью меню или контекстного
меню добавить новое поле, новую группу полей, новое автополе. Группе полей
можно дать свое название и также можно управлять их размещением в текущем
элементе отчета.
При развороте авто поля
выбора система преобразует его в набор выбранных полей. Также в настройках
отчета для авто поля выбора доступна команда «Развернуть», которая позволяет
просмотреть, в какой набор полей оно будет преобразовано при выполнении отчета.
Состав набора полей зависит от того, какому элементу структуры принадлежит
разворачиваемое авто поле и в какой части структуры этот элемент располагается.
Для каждого элемента система обходит все родительские элементы структуры отчета
и из выбранных полей этих элементов отбирает ресурсы и поля, которые отбираются
по следующему правилу:
·
Для группировки
и группировки таблицы на место авто поля подставляются все используемые
поля этой группировки, которые доступны для использования в выбранных полях,
поля, которые являются реквизитами ее полей группировки и ресурсы родительских
элементов.
Внимание. Система учитывает при
обходе только те группировки, тип которых «Без иерархии» или «Иерархия».
·
Для группировки
диаграммы ресурсы не выбираются, а обходятся все родительские элементы
структуры настроек, и из выбранных полей этих элементов выбираются поля
группировок, если по данному полю была задана группировка типа «Только
иерархия».
·
Для группировок
типа «Детальные записи» (группировка, группировка таблицы, группировка
диаграммы) из основных выбранных полей настроек, которым принадлежит
группировка, выбираются все используемые поля, кроме полей, участвовавших в
вышестоящих группировках и реквизитов этих полей. Если же такая группировка
имеет тип «Только иерархия»,
то ее поля и реквизиты будут использоваться системой при формирования набора
полей выбора. Для группировки диаграммы ресурсы также не выбираются.
·
Для диаграммы
автополе выбора заменяется ресурсом, первым из встреченных при описанном выше
обходе.
·
Для таблицы
авто поле выбора преобразовывается в набор используемых родительскими
элементами ресурсов.
Если поле уже включено в данные выбранные поля, повторно оно не
добавляется.
При этом поля добавляются в набор в
следующем порядке: вначале поля собственных полей группировки(для группировок),
потом поля из глобальных настроек (для группировок типа «Детальные записи» и
самыми последними ресурсы и поля из родительских элементов).
Поля выбора можно объединять в группы,
которые добавляются, командой «Сгруппировать» (Чтобы команда была доступна, все
выделенные строки табличного поля должны иметь одного родителя) и удаляются, сохраняя
вложенные поля, командой «Разгруппировать». Для группы можно задавать
расположение внутри текущего элемента структуры отчета. Для этого следует
выбрать необходимый вид расположения из списка в колонке «Расположение». На
примере выше группа будет расположена горизонтально.
Поля группировки
На закладке «Поля группировки» выбираются
поля, по которым будет проводиться группировка и тип группировки (Без иерархии,
Иерархия, Только иерархия).
Имеется возможность с помощью меню или
контекстного меню добавить новое поле или новое автополе. Для авто поля
группировки есть команда «Развернуть». При развороте авто поля группировки оно
преобразовывается в набор полей группировки.
Формирование набора происходит следующим
образом: берутся используемые выбранные поля, которые:
·
доступны для использования в полях группировки;
·
не являются ресурсами;
·
не зависят от других выбранных полей;
·
не зависят от уже существующих полей
группировки.
Если поле уже включено в данные поля
группировки, повторно оно не добавляется.
Если допустимые типы поля группировки
включают в себя тип “Дата”, доступна настройка дополнения периода (для вывода в
отчет дат, которые не попали в результат).
Отбор
На закладке «Отбор» выбираются поля для
фильтрации записей результата отчета. С помощью меню или контекстного меню
можно добавить элемент или группу элементов. При переходе на эту закладку,
вначале можно выбрать отбор из заданных разработчиком по представлению, если
оно было задано на этапе конфигурирования.
Если
нажать на кнопку «Подробно» или выбрать соответствующую команду
контекстного меню, то на закладке отобразятся условия отбора вместе с
представлением.
В колонках этой закладки добавленному
элементу можно установить значение, по которому будет проводиться отбор записей
результата отчета. С помощью команды контекстного меню «Представление»
созданному элементу или группе отбора можно задать пользовательское
представление, которое будет представлять элемент отбора в списке, если кнопка
«Подробно» командной панели отжата. Если отбору не было задано представление,
то и при неподробном отображении будет показана вся информация об отборе.
Условия
отборов можно объединять в логические Группы по И или Группы по ИЛИ.
Если отборы находятся в группе по И, это
означает, что в отчет будут выводиться данные, для которых выполняются все
условия, находящиеся в группе.
Если отборы находятся в группе по ИЛИ, то
данные будут выводиться, если выполняется хотя бы одно условие. С помощью
контекстного меню группам можно задавать представления, и если оно есть у
группы, то в кратком режиме вложенные элементы группы показываться не будут.
Сортировка
На
закладке «Сортировка» выбираются поля, по которым результат выполнения отчета
будет отсортирован. Возможно добавление как «элемента порядка», так и «авто
элемента порядка». При выполнении отчета система преобразует (разворачивает)
авто элемент порядка в поля группировки, по которым и проведет сортировку.
Для авто элемента порядка в контекстном меню
есть команда «Развернуть». При развороте авто элемента, когда в порядок
добавляются элементы, соответствующие полям группировки, система проверяет
наличие реквизитов этих полей в глобальном упорядочивании. Если они
присутствуют, то они добавляются в упорядочивание вместо поля группировки.
Условное оформление
На закладке «Условное оформление» можно
оформить различные элементы отчета в зависимости от значений данных, которые
выводятся в отчет. Например, выделить цветом отрицательные значения и т.д.
Таким образом может быть оформлено несколько элементов структуры, при этом для
каждого элемента задаются области, которые будут оформлены. Области выбираются
из списка оформляемых полей, которые в свою очередь выбирают из списка
доступных полей отчета.
Условия отбора полей, к которым будет
применяться заданное оформление, указываются в отдельном окне, идентичном окну
отбора пользовательского поля выбора. Для каждой области может быть несколько
условий отбора и они также могут быть объединены в группы по И или по ИЛИ.
В колонке «Представление» задается
обозначение условного оформления области, с которым оно будет показано в списке
Условных оформлений, если кнопка «Подробно» командной панели отжата.
Параметры условного оформления задаются в
отдельном окне. Можно задать цвета фона, текста, границы ячейки, стиль границ
ячейки, шрифт текста в ячейке и др.
Если на поле–параметр наложено условное
оформление, оно будет применяться к параметру при выводе его значения в
результат отчета.
Пользовательские
поля
На закладке «Пользовательские поля» можно
задать свои поля, которые будут выводиться в отчет. Эти поля могут быть двух
видов: поле-выбор или поле-выражение.
Полю-выбору можно задать несколько значений. Выбрано будет первое значение, для
которого выполнится условие отбора. Также следует задать заголовок и выражение
отбора, значение и представление.
Условия отбора задаются в отдельном окне.
Полю-выражению можно задать заголовок и
выражения для детальных и итоговых записей.
Выражение для итоговых записей должно быть
прописано с помощью агрегатных функций, например: Сумма
(Сумма) * 2. Подробнее о языке выражений компоновки данных см.
раздел «Язык выражений системы компоновки данных».
Другие настройки
На
закладке «Другие настройки»
в режиме «Текущий отчет» задаются параметры вывода отчета, в режиме «Текущий
элемент…» задаются специфические параметры вывода элементов отчета.
Команда «Стандартная настройка» сменит все
пользовательские изменения настроек отчета на стандартные (заданные на этапе
конфигурирования).
Примечание 1. При генерации макета
компоновки, система выдаст ошибку, если во вложенном отчете используется поле
верхнего отчета, значение которого невозможно определить. Это происходит в
случаях, когда отчет вложен в группировку по данному полю, либо когда отчет
вложен в детальные записи.
Примечание 2. При размещении
диаграммы в структуре отчета следует иметь в виду, что при выборе вида
диаграммы «Круговая» если не заданы серии, но заданы точки, то в качестве серий
системой будут автоматически использоваться точки. А при выборе вида диаграммы
«График» если не заданы точки, но заданы серии, то в качестве точек будут
использоваться серии.
Работа с расшифровкой отчета
Когда готовый табличный документ открыт в
режиме «Только просмотр», при помещении указателя мыши над ячейкой, для которой
возможна расшифровка, указатель принимает форму. Теперь, если дважды щелкнуть
левой кнопкой мыши на этой ячейке, будет открыто контекстное меню расшифровки.
Расшифровать — Получить более детальную информацию о
содержимом поля. При этом не будет предлагаться сделать расшифровку по полю, по
которому в отчете уже была группировка выше текущей группировки расшифровки.
Например, расшифруем содержимое по полю «Склад». Для этого в новом окне
следует выбрать поле, по которому нужна расшифровка, и нажать «ОК». Детали расшифровки откроются в новой форме.
При
этом поля, по которым происходила группировка с типом «Только иерархия»
по-прежнему будут доступны. Это действительно и для группировки через
расшифровку.
Открыть «….» ‑ открывает форму
просмотра данных, показанных в ячейке. Например, форму элемента справочника.
Отфильтровать —
отфильтровать текущий элемент структуры отчета либо по значению выбранного
поля, либо установить отбор по значению другого поля, используя команду
«Дополнительно» и задав условие отбора. Результат отображается в новой форме.
Упорядочить —
выполняет упорядочивание содержимого текущего элемента отчета по значению
текущего поля. По команде «Дополнительно» можно задать произвол поле. Например, упорядочить
таблицу в отчете по полю «Номенклатура».
Сгруппировать ‑ выполняет выбор поля и
задание типа группировки в текущем элементе структуры отчета. Например,
сгруппировать номенклатуру по складам:
Оформить — позволяет указать условие
применения оформления и настроить оформление для текущего элемента отчета.
Например, оформить поля, где «Номенклатура=1С:Аспект 7.7».
Язык выражений системы компоновки данных
Язык выражений системы компоновки данных
предназначен для записи выражений, используемых в различных частях системы,
например, в настройках компоновки данных, для описания выражений
пользовательских полей.
Литералы
В выражении могут присутствовать литералы.
Возможны литералы следующих типов:
·
Строка;
·
Число;
·
Дата;
·
Булево.
Строка
Строковый литерал записывается в символах
«”», например:
“Строковой литерал“
При необходимости использования внутри
строкового литерала символа «”», следует использовать два таких символов.
Например:
“Литерал ““в кавычках“““
Число
Число записывается без пробелов, в
десятичном формате. Дробная часть отделяется при помощи символа «.». Например:
10.5
200
Дата
Литерал типа дата записывается при помощи
ключевого литерала ДАТАВРЕМЯ (DATETIME). После данного ключевого слова, в скобках,
через запятую перечисляются год, месяц, день, часы, минуты, секунды. Указание
времени не обязательно. Например:
ДАТАВРЕМЯ(1975, 1, 06) – Шестое января 1975
года
ДАТАВРЕМЯ(2006, 12, 2, 23, 56, 57) – Второе
декабря 2006 года, 23 часа 56 минут 57 секундода, 23 часа 56 минут 57 секунд
Булево
Булевы значения могут быть записаны при
помощи литералов Истина (True), Ложь (False).
Значение
Для указания литералов других типов
(системных перечислений, предопределенных данных) используется ключевое слово Значение, после которого в скобках идет указание имени
литерала.
Значение(ВидСчета. Активный)
Поля
В выражениях могут использоваться поля
наборов данных. Поле идентифицируется путем к данным. Части пути к данным
оделяются друг от друга символом «.». Имя поля не является чувствительным к
регистру. Например:
Номенклатура.Артикул
Продажи.СуммаОборот
Параметры
Выражения могут использовать параметры. Для
использования в выражении параметра достаточно написать его имя, которому будет
предшествовать символ &. Например:
&Контрагент
&ДатаНачала
Операции
над числами
Унарный
–
Данная операция предназначена для изменения
знака числа на обратный. Например:
-Продажи.Количество
Унарный
+
Данная операция не выполняет над числом
никаких действий. Например:
+Продажи.Количество
Бинарный
—
Данная операция предназначена для вычисления
разности двух чисел. Например:
ОстаткиИОбороты.НачальныйОстаток –
ОстаткиИОбороты.КонечныйОстаток
ОстаткиИОбороты.НачальныйОстаток — 100
400 – 357
Бинарный
+
Данная операция предназначена для вычисления
суммы двух чисел. Например:
ОстаткиИОбороты.НачальныйОстаток +
ОстаткиИОбороты.Оборот
ОстаткиИОбороты.НачальныйОстаток + 100
400 + 357
Произведение
Данная операция предназначена для вычисления
произведения двух чисел. Например:
Номенклатура.Цена * 1.2
2 * 3.14
Деление
Данная операция предназначена для получения
результата деления одного операнда на другой. Например:
Номенклатура.Цена / 1.2
2 / 3.14
Остаток
от деления
Данная операция предназначена для получения
остатка от деления одного операнда на другой. Например:
Номенклатура.Цена % 1.2
2 % 3.14
Операции
над строками
Конкатенация
(Бинарный +)
Данная операция предназначена для
конкатенации двух строк. Например:
Номенклатура.Артикул + “: ”+
Номенклатура.Наименование
Подобно
(LIKE)
Данная операция проверяет соответствие
строки переданному шаблону.
Значением оператора ПОДОБНО является ИСТИНА,
если значение <Выражения> удовлетворяет шаблону, и ЛОЖЬ в противном случае.
Следующие символы в <Строке_шаблона>
имеют смысл, отличный от просто очередного символа строки:
·
% — процент: последовательность, содержащая ноль
и более произвольных символов;
·
_ — подчеркивание: один произвольный символ;
·
[…] — один или несколько символов в квадратных
скобках: один символ, любой из перечисленных внутри квадратных скобок. В
перечислении могут встречаться диапазоны, например a-z, означающие произвольный
символ, входящий в диапазон, включая концы диапазона;
·
[^…] — в квадратных скобках значок отрицания, за
которым следует один или несколько символов: любой символ, кроме тех, которые перечислены
следом за значком отрицания;
Любой другой символ означает сам себя и не
несет никакой дополнительной нагрузки. Если в качестве самого себя необходимо
записать один из перечисленных символов, то ему должен предшествовать
<Спецсимвол>, указанный после ключевого слова СПЕЦСИМВОЛ (ESCAPE).
Например, шаблон
“%АБВ[0-9][абвг]\_абв%” СПЕЦСИМВОЛ “\”
означает подстроку, состоящую из
последовательности символов: буквы А; буквы Б; буквы В; одной цифры; одной из
букв а, б, в или г; символа подчеркивания; буквы а; буквы б; буквы в. Причем
эта последовательность может располагаться, начиная с произвольной позиции в
строке.
Операции
сравнения
Равно
Данная операция предназначена для сравнения
двух операндов на равенство. Например:
Продажи.Контрагент = Продажи.НоменклатураОсновнойПоставщик
Не
равно
Данная операция предназначена для сравнения
двух операндов на неравенство. Например:
Продажи.Контрагент <>
Продажи.НоменклатураОсновнойПоставщик
Меньше
Данная операция предназначена для проверки
того, что первый операнд меньше второго. Например:
ПродажиТекщие.Сумма <
ПродажиПрошлые.Сумма
Больше
Данная операция предназначена для проверки
того, что первый операнд больше второго. Например:
ПродажиТекщие.Сумма >
ПродажиПрошлые.Сумма
Меньше
или равно
Данная операция предназначена для проверки
того, что первый операнд меньше либо равен второму. Например:
ПродажиТекщие.Сумма <=
ПродажиПрошлые.Сумма
Больше
или равно
Данная операция предназначена для проверки
того, что первый операнд больше либо равен второму. Например:
ПродажиТекщие.Сумма >=
ПродажиПрошлые.Сумма
Операция
В (IN)
Данная операция осуществляет проверку
наличия значения в переданном списке значений. Результатом операции будет Истина, в случае, если значение найдено, или Ложь — в противном случае. Например:
Номенклатура В (&Товар1, &Товар2)
Операция
проверки наличия значения в наборе данных
Операция осуществляет проверку наличия
значения в указанном наборе данных. Набор данных для проверки должен содержать
одно поле. Например:
Продажи.Контрагент В Контрагенты
Операция
проверки значения на NULL ЕСТЬ NULL(IS NULL)
Данная операция возвращает значение Истина в случае, если значение является значением NULL. Например:
Продажи.Контрагент ЕСТЬ NULL
Операция
проверки значения на неравенство NULL ЕСТЬ НЕ NULL(IS NOT NULL)
Данная операция возвращает значение Истина в случае, если значение не является значением NULL. Например:
Продажи.Контрагент ЕСТЬ НЕ NULL
Логические
операции
Логические операции принимают в качестве
операндов выражения, имеющие тип Булево.
Операция
НЕ (NOT)
Операция НЕ возвращает значение Истина в случае, если ее операнд имеет значение Ложь, и значение Ложь
в случае, если ее операнд имеет значение Истина.
Например:
НЕ Документ.Грузополучатель =
Документ.Грузоотправитель
Операция
И (AND)
Операция И возвращает значение Истина в случае, если оба операнда имеют значение Истина, и значение Ложь
в случае, если один из операндов имеет значение Ложь. Например:
Документ.Грузополучатель =
Документ.Грузоотправитель И Документ.Грузополучатель = &Контрагент
Операция
ИЛИ (OR)
Операция ИЛИ возвращает значение Истина в случае, если один из операндов имеет значение Истина, и Ложь в случае,
если оба операнда имеют значение Ложь. Например:
Документ.Грузополучатель =
Документ.Грузоотправитель ИЛИ Документ.Грузополучатель = &Контрагент
Агрегатные
функции
Агрегатные функции осуществляют некоторое
действие над набором данных.
Сумма
(Sum)
Агрегатная функция Сумма рассчитывает сумму значений выражений, переданных ей
в качестве аргумента для всех детальных записей. Например:
Сумма(Продажи.СуммаОборот)
Количество
(Count)
Функция Количество рассчитывает количество значений отличных от
значения NULL. Например:
Количество(Продажи.Контрагент)
Количество
различных (Count(distinct))
Эта функция рассчитывает количество
различных значений. Например:
Количество(Различные Продажи.Контрагент)
Максимум
(Max)
Функция получает максимальное значение.
Например:
Максимум(Остатки.Количество)
Минимум
(Min)
Функция получает минимальное значение.
Например:
Минимум(Остатки.Количество)
Среднее
(Avg)
Функция получает среднее значение для
значений, отличных от NULL. Например:
Среднее(Остатки.Количество)
Другие
операции
Операция
ВЫБОР
Операция Выбор предназначена для осуществления выбора одного из
нескольких значений при выполнении некоторых условий. Например:
Выбрать Когда Сумма > 1000 Тогда Сумма
Иначе 0 Конец
Правила
сравнения двух значений
Если типы сравниваемых значений отличаются
друг от друга, то отношения между значениями определяются на основании
приоритета типов:
·
NULL (самый низший);
· Булево;
· Число;
· Дата;
· Строка;
·
Ссылочные типы
Отношения между различными ссылочными типами
определяются на основе ссылочных номеров таблиц, соответствующих тому или иному
типу.
Если типы данных совпадают, то производится
сравнение значений по следующим правилам:
·
у типа Булево
значение ИСТИНА больше
значения ЛОЖЬ;
·
у типа Число
обычные правила сравнения для чисел;
·
у типа Дата
более ранние даты меньше более поздних;
·
у типа Строка
— сравнения строк в соответствии с установленными национальными особенностями
базы данных;
·
ссылочные типы сравниваются на основе своих
значений (номера записи и т. п.).
Работа
со значением NULL
Любая операция, в которой значение одного из
операндов NULL, будет
давать результат NULL.
Есть исключения:
·
операция И
будут возвращать NULL только в случае,
если ни один из операндов не имеет значение Ложь;
·
операция ИЛИ
будет возвращать NULL только в
случае, если ни один из операндов не имеет значение Истина.
Приоритеты
операций
Операции имеют следующие приоритеты (первая
строка имеет низший приоритет):
· ИЛИ;
· И;
· НЕ;
·
В, ЕСТЬ NULL, ЕСТЬ НЕ NULL;
·
=, <>, <=, <, >=, >;
·
Бинарный +, Бинарный – ;
·
*, /, %;
·
Унарный +, Унарный -.
Функции
Вычислить (Eval)
Функция Вычислить предназначена для вычисления выражения в
контексте некоторой группировки. Функция имеет следующие параметры:
·
Выражение – строка,
содержащая вычисляемое выражение;
·
Группировка – строка,
содержащая имя группировки, в контексте которой необходимо вычислить выражение.
В случае если в качестве имени группировки используется пустая строка,
вычисление будет выполнено в контексте текущей группировки. В случае если в
качестве имени группировки будет использована строка ОбщийИтог, вычисление будет выполнено в контексте общего
итога. В остальных случаях вычисление будет выполняться в контексте
родительской группировки с таким именем. Например:
Сумма(Продажи.СуммаОборот) /
Вычислить(«Сумма(Продажи.СуммаОборот)», «ОбщийИтог»)
В данном примере в результате получится
отношение суммы по полю «Продажи.СуммаОборот» записи группировки к сумме того
же поля во всей компоновке.
Уровень
(Level)
Функция предназначена для получения текущего
уровня записи. Пример:
Уровень()
НомерПоПорядку
(SerialNumber)
Получить следующий порядковый номер. Пример:
НомерПоПорядку()
НомерПоПорядкуВГруппировке
(GroupSerialNumber)
Возвращает следующий порядковый номер в
текущей группировке. Пример:
НомерПоПорядкуВГруппировке()
Формат
(Format)
Получить отформатированную строку
переданного значения. Форматная строка задается в соответствии с форматной
строкой 1С:Предприятие.
Параметры:
·
Значение;
·
Форматная строка.
Пример:
Формат(РасходныеНакладные.СуммаДок, «ЧДЦ=2»)
НачалоПериода (BeginOfPeriod)
Функция предназначена для выделения
определенной даты из заданной даты. Параметры:
·
Дата;
·
Тип периода – строка, содержащая одно из:
Минута;
Час;
День;
Неделя;
Месяц;
Квартал;
Год;
Декада;
Полугодие.
Пример:
НачалоПериода(ДатаВремя(2002, 10, 12, 10,
15, 34), «Месяц»)
Результат:
01.10.2002 0:00:00
КонецПериода
(EndOfPeriod)
Функция предназначена для выделения
определенной даты из заданной даты. Параметры:
·
Дата;
·
Тип периода – строка, содержащая одно из:
Минута;
Час;
День;
Неделя;
Месяц;
Квартал;
Год;
Декада;
Полугодие.
Пример:
КонецПериода(ДатаВремя(2002, 10, 12, 10, 15,
34), Неделя)
Результат:
13.10.2002 23:59:59
ДобавитьКДате
(DateAdd)
Функция предназначена для прибавления к дате
некоторой величины. Параметры:
·
Выражение — типа Дата;
·
Тип увеличения – строка, содержащая одно из:
Секунда;
Минута;
Час;
День;
Неделя;
Месяц;
Квартал;
Год;
Декада;
Полугодие;
·
Величина – на сколько необходимо увеличить дату.
Тип Число. Дробная
часть игнорируется.
Пример:
ДобавитьКДате(ДатаВремя(2002, 10, 12, 10,
15, 34), «Месяц», 1)
Результат:
12.11.2002 10:15:34
РазностьДат
(DateDiff)
Функция предназначена для получения разницы
между двумя датами. Параметры:
·
Выражение типа Дата;
·
Выражение типа Дата;
·
Тип разности – одно из:
Секунда;
Минута;
Час;
День;
Месяц;
Квартал;
Год.
Пример:
РАЗНОСТЬДАТ(ДАТАВРЕМЯ(2002, 10, 12, 10, 15,
34),
ДАТАВРЕМЯ(2002,
10, 14, 9, 18, 06),
«ДЕНЬ»)
Результат:
2
Подстрока (Substring)
Данная функция предназначена для выделения
подстроки из строки. Параметры:
·
выражение, имеющее строковый тип;
·
позиция символа, с которого начинается
выделяемая из строки подстрока;
·
длина выделяемой подстроки.
Пример:
ПОДСТРОКА(Контрагенты.Адрес, 1, 4)
ДлинаСтроки (StringLength)
Функция предназначена для определения длины
строки. Параметр — выражение строкового типа.
Пример:
Строка(Контрагенты.Адрес)
Год
(Year)
Данная функция предназначена для выделения года
из значения типа Дата.
Единственный параметр – это выражение, имеющее тип Дата.
ГОД(РасхНакл.Дата)
Квартал
(Quarter)
Данная функция предназначена для выделения
номера квартала из значения типа Дата. Номер
квартала в норме находится в диапазоне от 1 до 4. Единственный параметр функции
– это выражение, имеющее тип Дата.
КВАРТАЛ(РасхНакл.Дата)
Месяц
(Month)
Данная функция предназначена для выделения
номера месяца из значения типа Дата. Номер
месяца в норме находится в диапазоне от 1 до 12. Единственный параметр функции
– это выражение, имеющее тип Дата.
МЕСЯЦ(РасхНакл.Дата)
ДеньГода
(DayOfYear)
Данная функция предназначена для получения
дня года из значения типа Дата. День года в
норме находится в диапазоне от 1 до 365(366). Единственный параметр функции –
это выражение, имеющее тип Дата.
ДЕНЬГОДА(РасхНакл.Дата)
День
(Day)
Данная функция предназначена для получения
дня месяца из значения типа Дата. День месяца
в норме находится в диапазоне от 1 до 31. Единственный параметр функции – это выражение,
имеющее тип Дата.
ДЕНЬ(РасхНакл.Дата)
Неделя
(Week)
Данная функция предназначена для получения
номера недели года из значения типа Дата.
Недели года нумеруются, начиная с 1. Единственный параметр функции – это
выражение, имеющее тип Дата.
НЕДЕЛЯ(РасхНакл.Дата)
ДеньНедели
(WeekDay)
Данная функция предназначена для получения
дня недели из значения типа Дата. День недели
в норме находится в диапазоне от 1(понедельник) до 7(воскресенье). Единственный
параметр функции – это выражение, имеющее тип Дата.
ДЕНЬНЕДЕЛИ(РасхНакл.Дата)
Час
(Hour)
Данная функция предназначена для получения
часа суток из значения типа Дата. Час суток
находится в диапазоне от 0 до 23. Единственный параметр функции – это
выражение, имеющее тип Дата.
ЧАС(РасхНакл.Дата)
Минута
(Minute)
Данная функция предназначена для получения
минуты часа из значения типа Дата. Минута часа
находится в диапазоне от 0 до 59. Единственный параметр функции – это
выражение, имеющее тип Дата.
МИНУТА(РасхНакл.Дата)
Секунда
(Second)
Данная функция предназначена для получения
секунды минуты из значения типа Дата. Секунда
минуты находится в диапазоне от 0 до 59. Единственный параметр функции – это
выражение, имеющее тип Дата.
СЕКУНДА(РасхНакл.Дата)
Выразить
(Cast)
Данная функция предназначена для выделения
типа из выражения, которое может содержать составной тип. В случае, если
выражение будет содержать тип, отличный от требуемого типа, будет возвращено
значение NULL. Параметры:
·
Преобразуемое выражение;
·
Тип – строка, содержащая строку типа. Например,
«Число», «Строка» и т.п. Кроме примитивных типов данная строка может содержать
имя таблицы. В таком случае будет осуществлена попытка выразить к ссылке на
указанную таблицу.
Пример:
Выразить(Данные.Реквизит1, «Число(10,3)»)
ЕстьNull
(IsNull)
Данная функция возвращает значение второго
параметра в случае, если значение первого параметра NULL. В противном случае будет возвращено значение первого
параметра. Пример:
ЕстьNULL(Сумма(Продажи.СуммаОборот), 0)
Глава 9.
Общие принципы работы с формами
Управляющие
элементы формы
Поле ввода
Реквизит типа «Дата»
При вставке в поле ввода данных из буфера обмена,
выполняется проверка допустимости размещаемых данных в соответствии с указанным
форматом. Неразрешенные символы при вставке игнорируются.
Реквизит типа «Строка»
При вставке в поле ввода данных из буфера обмена, в случае,
если поле ввода имеет ограниченный размер данных, то при вставке будет взята
такая часть исходного текста, чтобы заполнить остаток места (или выделенный
текст).
Реквизит типа «Булево»
Обычно ввод значения реквизита типа «Булево» осуществляется
с помощью элемента управления «Флажок». Установленный флажок соответствует
значению Истина, снятый — Ложь.
Кроме того, может быть использован элемент «Поле ввода». В
этом случае представление значения может быть настроено при конфигурировании в
соответствии с прикладным смыслом реквизита. Например, для указания первичности
документа форма может содержать поле ввода, в котором представление значения Истина будет определено как «Первичный», а Ложь — как «Корректирующий».
Реквизиты ссылочных типов
Замечание 2. Если выбран объект, помеченный на
удаление, система выдаст об этом предупреждение.
Работа с табличным полем формы
Поиск
в списке
Произвольный поиск в списках
Переключатель «Вперед — Назад — С
начала» позволяет задать направление поиска:
Вперед вниз от текущей строки списка;
Назад вверх от текущей строки списка;
С
начала поиск осуществляется с начала
списка.
Поиск в табличном поле, осуществляемый с
помощью диалога поиска, по умолчанию выполняется с направлением «С начала».
Исключением является случай, когда поиск осуществляется с последней строки
табличного поля. В этом случае поиск выполняется с направлением «Назад».
Отбор и сортировка списка
Настройка отбора
Вид сравнения указывает, как будет применен отбор. Состав возможных
видов сравнения определяется типом данных.
Например, для типа «Булево»
допустимые виды сравнения «Равно» или «Не равно», а для типа «Дата» — их
состав существенно шире. Можно отбирать данные, содержащие даты, большие
заданной, находящиеся в интервале дат, входящих в список или наоборот, не
входящих в список, и т.д.
При изменении отбора в списке для
всех регистров, подчиненных регистратору может выполняться изменение порядка на
порядок, оптимальный для установленного отбора в том случае, когда отбор был
установлен системой при открытии списка. Например, при установке отбора по
регистратору устанавливается порядок по номеру строки, а при отмене отбора по
регистратору — по дате.
Настройка списка
Если
флажок «Не проверять соответствие новых строк отбору снят, то при окончании
ввода новой строки, если она не соответствует установленному отбору, об этом
будет выдано сообщение.
Флажок
«При открытии устанавливать иерархический просмотр» присутствует только при
настройках иерархических списков. Он предназначен для управления иерархическим
просмотром в форме при открытии.
Глава 10.
Групповое проведение документов и управление
итогами
Проведение документов
При перепроведении документов в панель состояния выводится
информация о дате и времени обрабатываемого документа.
Управление итогами
Закладка «Установка режима разделения итогов» позволяет
указать для каждого из регистров необходимость использования режима разделения
итогов.
В список регистров выводятся
регистры накопления и бухгалтерии, для которых при конфигурировании
предусмотрен режим разделения итогов. Пользователь может включить или отключить
установленный режим. Пометка означает, что режим разделения итогов установлен.
Установка режима
разделения влияет только на параллельность работы системы и никак не
сказывается на бизнес-логике решаемых задач. Это механизм, который обеспечивает
более высокий уровень параллельности.
Глава 12.
Сервисные возможности
Установка параметров
Настройка показа справки
На закладке «Справка» размещен переключатель, с помощью
которого настраивается показ справки.
Если выбрано «Выводить в одном окне», то справочная
информация показывается в одном окне:
Если выбрано «Выводить в разных окнах», то справочная
информация показывается в разных окне:
Системные настройки
На закладке
«Системные» размещены элементы управления подключения к отладочному режиму.
Устанавливать переключатели следует только в том случае, если выполняется
отладка работы конфигурации.
Если переключатель
«Отладка разрешена» установлен, то устанавливается отладочный режим и данный
предмет отладки включается в список доступных предметов отладки (режим
«Конфигуратор»). Следует иметь в виду, что после применения настроек снять
установку флажка нельзя.
Если требуется установить
возможность отладки только для следующего запуска, то следует установить
переключатель «Устанавливать режим разрешения отладки при запуске».
Управление
полнотекстовым поиском
Система 1С:Предприятие 8.1 предоставляет возможность
организации полнотекстового поиска по данным. Возможность поиска, формы для
ввода условий поиска проектируются при создании конфигурации. Описание работы с
этими формами смотрите в книге описания конфигурации.
Поиск может выполняться по реквизитам только следующих
типов: Дата, Строка, Число, ХранилищеЗначения (если хранится строка), ссылочные
типы.
Если такой поиск организован, то собственно система
1С:Предприятие 8.1 предоставляет возможность управления процессами,
влияющими на выполнение подготовительных операций поиска (построение индекса и
задание режима его обновления).
Для управления полнотекстовым поиском следует использовать
команду «Операции — Управление полнотекстовым поиском».
По кнопке «Настройка…» вызывается диалог настройки полнотекстового
поиска. Установка флажка «Разрешить полнотекстовое индексирование» в этом
диалоге означает «включение» индексирования данных для организации поиска.
Индекс поиска формируется системой после нажатия кнопки
«Обновить индекс». Для оптимизации процесса формирования индекса используется
основной индекс и дополнительный, который формируется при вводе данных и
содержит информацию по данным, введенным после последнего обновления основного
индекса.
Если флажок «Разрешить слияние индексов» установлен, то
результат индексирования последних изменений добавится к основному индексу.
Этот режим может потребовать достаточно большого времени (если размер основного
индекса большой).
Очистка индексов (запускается нажатием кнопки «Очистить
индекс») нужна для того чтобы удалить индекс, например чтобы места было больше.
После очистки индекса нужно выполнить индексирование (если требуется).
В поле «Дата актуальности индекса» указывается дата начала
последнего выполнения индексирования.
В верхней части диалога указывается необходимость
обновления индекса.
Работа с буфером обмена
Кнопка «М» (можно использовать сочетание клавиш Shift + Num*) работает аналогично стандартному действию запоминания значения в
буфер обмена, но запоминает его как число, то есть только числовые значения.
Следует иметь в
виду, что для формульного калькулятора и табло число сохраняется с
региональными установками информационной базы, но без разделителей групп и
заменой разделителя целой и дробной части на точку. Для всех остальных
потенциальных приемников буфера обмена число сохраняется с региональными
установками операционной системы и также без разделителей групп. Это позволяет
вставлять сохраненное в буфере обмена число как в формульный калькулятор и
табло 1С:Предприятия, так и в системные и офисные программы – Калькулятор Windows, MS Excel и т.д.
Кнопка «М+» (сочетание клавиш Shift + Num+) добавляет текущее значение к значению в буфере обмена, кнопка «М-» (сочетание
клавиш Shift + Num—) вычитает текущее значение
из буфера обмена. Хотя собственно значение в буфере обмена хранится в качестве
строки, все указанные действия выполняются с ним как с числовым значением.
Журнал
регистрации
Просмотр журнала регистрации
Событие может быть либо Транзакционным,
либо Независимым (определяется
программным способом, см. описание метода ЗаписьЖурналаРегистрации). По
умолчанию установлен независимый режим записи событий.
Следует учитывать, что есть набор предопределенных событий,
которые формируются на уровне системы. Для таких событий транзакционность
устанавливается также на уровне системы. Так события изменения данных,
проведения документов являются транзакционными, а начало и завершение сеанса
независимыми. Ниже приведен полный список предопределенных событий:
Независимые:
·
Сеанс
o
Начало
o
Завершение
·
ИнформационнаяБаза
o
ИзменениеКонфигурации
o
ИзменениеКонфигурацииБазыДанных
o
ИзменениеРегиональныхУстановок
o
ИзменениеПараметровЖурналаРегистрации
o
ИзменениеГлавногоУзла
·
Пользователи
o
Добавление
o
Изменение
o
Удаление
·
ОшибкаВыполнения
Транзакционные:
·
Данные
o
Добавление
o
Изменение
o
Удаление
o
Проведение
o
ОтменаПроведения
o
ИзменениеПериодаРассчитанныхИтогов
·
Транзакция
o
Начало
o
Фиксация
o
Отмена
В колонках «Транзакция» и «Статус транзакции» показывается
информация о транзакции. Для транзакционных событий статус транзакции может
принимать одно из следующих значений: Не завершена, Зафиксирована,
Отменена. У независимых
событий статус транзакции отсутствует.
При начале транзакции в журнал регистрации записывается
событие начала транзакции Транзакция.Начало, которому присваивается
идентификатор транзакции (указывается в круглых скобках). В состоянии открытой
транзакции при записи события в журнал полю статуса транзакции присваивается
значение Неопределенный.
По завершении транзакции в случае ее фиксации, в журнал записывается событие Транзакция.Фиксация, статус транзакции записи Транзакция.Начало
обновляется на Зафиксирована. В случае отмены
транзакции, в
журнал записывается событие Транзакция.Отмена, статус
транзакции для записи Транзакция.Начало обновляется на Отменена.
В случае аварийного завершения выполнения, статус транзакции остается Неопределенный.
Записи, соответствующие отмененным транзакциям и
транзакциям с неопределенным статусом выводятся «бледными» вариантами картинок,
обозначающих важность события, а слово «Неопределенный» в колонке статуса
выводится жирным шрифтом.
С помощью команды «Отбор по значению в текущей колонке»
можно легко отобрать события, относящиеся к определенной транзакции.
Установка отбора
На закладке «Данные» указываются данные, по которым будет
производиться отбор событий, информация о которых представлена в колонках
«Метаданные», «Данные» и «Представление данных» журнала регистрации.
В поле «Метаданные» содержится список метаданных,
представленных в конфигурации. Установите флажки для тех метаданных, по которым
требуется произвести отбор.
В поле «Данные» выбирается объект информационной базы, по
которому требуется отобрать события.
В поле «Представление данных» указывается строковое
представление.
На закладке «Прочие» указываются дополнительные параметры
отбора:
·
Статус транзакции — выбираются статусы
транзакции;
·
Транзакция — указывается конкретная транзакция;
·
Соединения — указываются номера соединений
(через запятую);
·
Рабочие серверы — выбираются центральные серверы
кластеров (для клиент-серверного варианта работы);
·
Основные IP-порты — выбираются IP-порты
менеджеров кластера (для клиент-серверного варианта работы);
·
Вспомогательные IP-порты — выбираются
вспомогательные порты менеджеров кластера (для клиент-серверного варианта
работы).
Сообщения об ошибках
В случае возникновения ошибки при выполнении
модуля на экран выводится предупреждение (может содержать разное число кнопок,
назначение кнопок также может быть разным), например следующего вида:
Кнопка
«Подробно…» может отсутствовать. Кнопка появляется если:
o
ошибка является ошибкой языка и содержит
техническую информацию о месте возникновения;
o
ошибка порождена другими ошибками (т.е. имеет
некоторый состав «вложенных» ошибок);
o
ошибка имеет два варианта описания – короткое и
подробное.
Кнопка «Перезапустить» появляется, если
продолжение дальнейшей работы невозможно. Нажатие кнопки приводит к перезапуску
сеанса с текущими параметрами командной строки.
Для получения подробного сообщения об ошибке
нажмите кнопку «Подробно…». На экран выводится окно сообщения об ошибке (также
может содержать различные кнопки):
В окне указывается место возникновения
(модуль и номер строки) и краткое описание ошибки.
Если ошибка порождена другими ошибками, они
показываются все, в обратной последовательности. Описания ошибки связывается с
описанием породившей ее ошибки фразой «по причине».
При нажатии кнопки «Закрыть» окно сообщения
закрывается и завершается выполнение модуля.
При нажатии кнопки «Конфигуратор»
открывается текущая конфигурация в режиме «Конфигуратор» (если до этого она не
была открыта) и показывается модуль, выполнивший ошибку. В окне сообщений будет
продублировано сообщение об ошибке. Если данный пользователь не имеет
административных прав, то перед открытием выводится диалог аутентификации для
выбора пользователя с нужным набором прав (используется в основном для показа
ошибки разработчику). Если ошибка не содержит информацию о месте возникновения
(например, произошла ошибка платформы), кнопка «Конфигуратор» не видна.
При нажатии кнопки «Завершить работу»
система 1С:Предприятие 8.1 завершает работу.
Если в процессе работы система произошла
невосстановимая ошибка, которая не повлияет на работу программы в целом, то на
экран выведется окно сообщения об ошибке:
Глава 13.
Получение справочной информации
Встроенная
система получения справочной информации
Поиск справочной
информации
Поиск по справке
Для поиска глав, в которых встречается указанная строка,
выберите пункт «Справка — Поиск по справке». На экран выводится окно, в
котором выполняется поиск по произвольному тексту описания. В верхней части
содержится поле для ввода строки поиска и поле списка найденных глав описаний.
Для начала поиска начинайте вводить текст. В процессе ввода
программа выполняет поиск глав, в которых встречается введенный текст. Регистр
ввода может быть любым, слова текста учитываются целиком (если не использован
оператор «*») и с учетом морфологии. Допускается использование поисковых
операторов (см. параграф «Формат поисковых выражений»).
В процессе ввода программа оперативно выводит список этих
глав. Если введенный текст нигде не встречается, то ниже поля ввода программа
выводит об этом сообщение.
При открытии главы программа покажет описание таким
образом, чтобы было видно первое вхождение указанного текста.
Для просмотра главы выберите ее в списке и
нажмите клавишу Enter.
Описание выбранной главы показывается в нижнем поле.
Если для введенного текста существует только одна глава, то
она сразу выводится в поле описания.
После того, как глава описания элемента встроенного языка
найдена и окно Синтакс‑Помощника открыто, для поиска положения главы в
дереве описаний используйте кнопку командной панели «Найти текущий элемент в
дереве».
Если в процессе просмотра выбирались несколько страниц, то
с помощью команд «Вперед» и «Назад» можно вернуться к просмотренным страницам.
Формат поисковых выражений
Поиск может осуществляться по нескольким
словам, с использованием поисковых операторов и поиском по точной фразе.
В строке ввода допускается использование
следующих поисковых операторов:
|
Оператор |
Пример |
Пояснение |
|
И |
запись И документ |
Будут |
|
ИЛИ |
запись ИЛИ документ |
Будут |
|
НЕ |
закрытие НЕ месяц |
Будут |
|
РЯДОМ/[±]n |
Пример Пример Пример |
Поиск Знак Если знак не указан, то будет найден В примере 1 будут найдены разделы, в В примере 2 будут найдены разделы, в В |
|
РЯДОМ NEAR |
Библиотека РЯДОМ имени РЯДОМ Достоевского |
Краткая |
|
«» |
«проведение документа» |
Поиск проведение РЯДОМ/+1 |
|
() |
(проведение | выписка) & (счета, документа) |
Группировка |
|
* |
доку* |
Поиск |
Если не указано никаких операторов (слова
набраны через пробел), то программа осуществляет поиск всех слов из запроса с
использованием оператора И.
Замечание 1. Написание операторов
И (AND), ИЛИ (OR), НЕ (NOT), РЯДОМ (NEAR) допускается только в верхнем регистре.
Замечание 2. Операторы не
используются как унарные (в начале строки поиска). Например, нельзя сделать
выбор всех глав, в которых отсутствует указанный текст.
Замечание 3. Все символы в поле
поиска, кроме символов поисковых операторов, букв и цифр, игнорируются.
Приложение 2. Редактор
табличных документов
Работа с табличным документом
Сохранение табличного документа
Обычно табличные документы сохраняются в специальном
формате, используемым системой 1С:Предприятие 8.1 для хранения табличных
документов. Такие файлы имеют расширение *.MXL. Для сохранения табличного
документа в других форматах: «Лист Excel» (расширение *.XLS), «Документ HTML»
(расширение *.HTM), текстовом файле и текстовом файле UNICODE (расширение
*.TXT), табличном документе v7.х
(формата предыдущих версий системы 1С:Предприятие 8.1), «Лист Excel95»
(расширение *.XLS), «Лист Excel97» (расширение *.XLS), используйте пункт
«Файл — Сохранить копию».
При выводе в табличный документ ячейка, содержащая многострочный
текст, обрамляется двойными кавычками, двойные кавычки внутри многострочной
строки заменяются на две двойные кавычки.
Сохранение в формате «Лист Excel» выполняет сохранение в
формате MS Excel, используемым по умолчанию (эквивалентно «Лист Excel97»).
Приложение 6. Конструктор запроса
Конструктор запросов позволяет сформировать текст
запроса и отредактировать имеющийся запрос.
Для вызова
конструктора запросов нажмите кнопку «Конструктор запросов».
На экран выводится
конструктор запроса.
С помощью кнопки
«Упорядочить список», расположенной над списком «База данных» можно упорядочить
список объектов. Повторное нажатие кнопки отменяет упорядочивание.
С помощью кнопок «Далее >»
последовательно пройдите по закладкам и выберите необходимые исходные данные,
укажите группировки и условия, установите нужный порядок и опишите итоговые
данные. В результате работы конструктора будет создана форма и макет, которые
будут располагаться на соответствующих ветвях. По кнопке «Запрос» в любой момент можно открыть окно с текстом
сформированного на основании указанных данных запроса.
Для корректировки
данных используйте кнопку «< Назад».
На закладке
«Таблицы и поля» выберите нужные объекты и перенесите их в раздел «Таблицы» и
«Поля».
Для указания
дополнительных условий можно воспользоваться режимом формирования произвольных
выражений в запросе. Для этого в списке «Поля» в контекстном меню выберите
пункт «Добавить». На экран выводится окно произвольного выражения.
В нижнем поле
формируется текст выражения. Выражение можно набирать с помощью клавиатуры. Для
удобства ввода наименований реквизитов можно перетаскивать мышью нужные поля из
списка полей и выбирать нужные функции языка запросов из списка, также
перетаскивая их мышью в поле ввода выражения.
На закладке
«Группировка», если требуется, выберите реквизиты, по которым будет выполнена
группировка.
На закладке
«Условия», если требуется, укажите условия, по которым будет выполняться отбор
исходных данных.
По каждому
выбранному полю необходимо выбрать вид условия (для произвольного условия в
колонке «Произвольное» установите флажок). Если флажок не установлен, то
следует выбрать вид условия и указать наименование параметра. Если флажок
«Произвольное» установлен, то можно воспользоваться окном формирования
произвольных выражений (см. выше).
На закладке
«Дополнительно» указываются дополнительные условия.
На закладке
«Объединения/Псевдонимы», если требуется, введите псевдонимы полей.
В таблице показано
соответствие выбранных полей и исходных данных. Имена полей и соответствие
можно изменить. Для изменения имени выберите поле и нажмите клавишу Enter, введите новое имя поля. Для изменения соответствия в
колонке «Запрос» выберите нужную строку и нажмите клавишу Enter. В выпадающем списке выберите нужное значение.
Если требуется
выбрать только уникальные значения, то установите флажок в колонке «Без дубл.».
Псевдонимы полей,
которые изменены пользователем или были загружены из текста запроса, или при
генерации псевдонима конструктор определил, что данный псевдоним обязателен,
выделяются жирным шрифтом.
На закладке
«Порядок», если требуется, укажите порядок вывода полученных данных.
Выбран порядок
вывода данных, отсортированных по периоду, а в пределах периода выполняется
сортировка по выручке.
На закладке
«Итоги», если требуется, укажите, по каким полям требуется выводить
промежуточные итоговые данные, а также необходимость формирования общих итогов.
При нажатии кнопки
«>>», расположенной рядом с групповыми полями, то в поля для группировки
будут помещены все ссылочные поля. При нажатии кнопки «>>», расположенной
рядом с суммируемыми полями, то в список суммируемых полей будут помещены все
поля, имеющие числовой тип.
На закладке
«Построитель» выполняется настройка построителя отчетов. Выбираются таблицы и
поля, указываются условия и порядок представления, а также описываются итоговые
данные.
На закладке
«Таблицы» редактируются параметры построителя отчета для виртуальных таблиц, а
также отмечаются необязательные таблицы. Для редактирования параметров
виртуальных таблиц необходимо выделить таблицу, для которой требуется настроить
параметры, вызвать команду «Параметры виртуальной таблицы», после чего, в
появившемся диалоге ввести необходимые параметры таблицы для построителя
отчета. Для того чтобы отметить таблицу как необязательную, необходимо снять
флажок «Обязательная» напротив имени таблицы, которую необходимо пометить.
Кроме того, для необязательных таблиц возможно указание номера группы
необязательных таблиц. Необязательные таблицы, находящиеся рядом в списке
соединений и имеющие одинаковые номера групп, будут объединены в одну
необязательную группу. Необязательные таблицы с различными номерами групп будут
разнесены по различным группам необязательных таблиц.
На закладке «Поля»
выбираются поля, которые будет использовать построитель отчета в качестве
доступных полей для вывода в отчет.
На закладке
«Условия» выбираются поля, которые будет использовать построитель отчета в
качестве доступных полей для отбора.
На закладке
«Порядок» выбираются поля, которые будет использовать построитель отчета в
качестве доступных полей для упорядочивания результата.
На закладке
«Итоги» выбираются поля, которые будет использовать построитель отчета в
качестве доступных полей для группировки отчета.
Приложение 7. Расписание регламентные задания
Для изменения расписания
в форме расписания установите нужные значения.
На закладке
«Общее» указываются дата начала и завершения задания и режим повтора.
На закладке
«Дневное» указывается дневное расписание задания.
Укажите
расписание:
·
астрономическое время начала и время окончания
задания;
·
астрономическое время завершения задания, после
которого выполнение задания не требуется;
·
интервал повторения задания;
·
размер паузы между повторами;
·
продолжительность выполнения.
Допускается
указание произвольного сочетания условий.
На закладке
«Недельное» указывается недельное расписание задания.
Установите флажки
по тем дням недели, в которых задание будет выполняться. Если требуется
повторять задание укажите интервал повтора в неделях. Например, задание
выполняется через 2 недели, значение повтора – 2.
На закладке
«Месячное» указывается месячное расписание задания.
Установите флажки
по тем месяцам, в которых задание будет выполняться. При необходимости можно
указать конкретный день (месяца или недели) выполнения с начала месяца / недели
или конца.
Примеры
расписаний регламентных заданий:
|
Каждый час, только один день |
Повторять каждые (дн.)= 0, |
|
Каждый день один раз в день |
Повторять каждые (дн.)= 1, |
|
Один день, один раз |
Повторять каждые (дн.)= 0 |
|
Через день один раз в день |
Повторять каждые (дн.)= 2 |
|
Каждый час с 01.00 до 07.00 каждый день |
Повторять каждые (дн.)= 1 Повторять через (сек.) = 3600 Время начала = 01:00 Время окончания = 07:00 |
|
Каждую субботу и воскресенье в 09.00 |
Повторять каждые (дн.)= 1 Дни недели = Сб, Вс Время начала = 09:00 |
|
Каждый день одну неделю, неделя пропуска |
Повторять каждые (дн.)= 1 Повторять каждые (нед.) = 2 |
|
В 01.00 один раз |
Время начала = 01:00 |
|
Последнее число каждого месяца в 9:00. |
Повторять каждые (дн.)= 1 Выполнять в (день месяца) = -1 Время начала = 09:00 |
|
Пятое число каждого месяца в 9:00 |
Повторять каждые (дн.) = 1 Выполнять в (день месяца) = 5 Время начала = 09:00 |
|
Вторая среда каждого месяца в 9:00 |
Повторять каждые (дн.)= 1 Выполнять Дни недели = Ср Время начала = 09:00 |
Книга «1С:Предприятие 8.1. Руководство по установке и
запуску»
Введение
Требования к компьютеру и программному обеспечению
Система 1С:Предприятие 8.1 предназначена для работы на
IBM‑совместимых
персональных компьютерах. Компьютер должен иметь:
·
компьютер конечного пользователя:
o
операционную систему:
MS Windows 98/Me, MS Windows 2000/XP/Server 2003
(рекомендуется MS Windows XP/Server 2003);
o
процессор Intel Pentium II 400 МГц и выше
(рекомендуется Intel Pentium III 866 МГц);
o
оперативную память 128 Мбайт и выше
(рекомендуется 256 Мбайт);
o
жесткий диск (при установке используется около
120 Мбайт);
o
устройство чтения компакт‑дисков;
o
USB-порт;
o
SVGA‑дисплей;
·
компьютер, используемый для разработки
конфигураций:
o
операционную систему: MS Windows
2000/XP/Server 2003 (рекомендуется MS Windows XP/Server 2003);
o
процессор Intel Pentium III 866 МГц и выше
(рекомендуется Intel Pentium IV/Celeron 1800 МГц);
o
оперативную память 512 Мбайт и выше
(рекомендуется 1024 Мбайт);
o
жесткий диск (при установке используется около
120 Мбайт);
o
устройство чтения компакт‑дисков;
o
USB-порт;
o
SVGA‑дисплей;
Глава 2.
Установка и обновление системы
1С:Предприятие 8.1
Установка и обновление 1С:Предприятия 8.1
Языки интерфейса программы
установки выбираются автоматически по значению региональных установок
операционной системы пользователя. Для указания иного языка интерфейса следует
использовать ключ командной строки /L<Код языка> в соответствии со
следующей таблицей:
|
Язык |
Код языка |
|
Английский |
1033 |
|
Болгарский |
1026 |
|
Латышский |
1062 |
|
Литовский |
1063 |
|
Немецкий |
1031 |
|
Румынский |
1048 |
|
Русский |
1049 |
|
Украинский |
1058 |
Начальная
установка
При установке на компьютере, на котором установлена
операционная система MS Windows 98/Me, состав компонент не будет
содержать компоненту кластера серверов 1С:Предприятия 8.1 и адаптера
Web-сервисов.
При первоначальной установке системы
1С:Предприятие 8.1 компоненты «Сервер 1С:Предприятия 8.1» и «Адаптер
Web-сервисов 1С:Предприятия 8.1» отмечены как не устанавливаемые. При
обновлении системы флажки компонентов отмечаются в соответствии со списком
установленных компонентов.
Укажите нужные интерфейсы. Файлы,
относящиеся к каждому выбранному интерфейсу, будут установлены в каталог «\Bin» каталога, выбранного на предыдущем шаге. Имена файлов
содержат указание принадлежности к определенному интерфейсу.
Например, файлы
русского интерфейса будут содержать подстроку «ru»
(1cv8_ru.hbk), для украинского — «uk» (1cv8_uk.hbk). Имена файлов
основных ресурсов (английский интерфейс) содержат подстроку «root» (1cv8_root.hbk).
После завершения
работы программы установки в каталоге установки будет создан каталог с именем «CONF», а в нем файл, имеющий расширение «*.RES», имя которого совпадает с кодом языка интерфейса. Содержимое
файла не имеет значения. Если файл с расширением «*.RES» отсутствует, при запуске будет выбираться интерфейс,
соответствующий региональным установкам операционной системы. Указание
неизвестного или несуществующего кода языка интерфейса эквивалентно отсутствию
такого файла.
Установка
с использованием групповых политик домена MS Windows 2000/2003 Server
Инсталляционный
пакет 1CEnterprise 8.1.msi, входящий в
комплект поставки, может использоваться независимо от программы setup.exe (в
этом случае возможно использование только английского интерфейса программы
установки). В частности, пакет 1CEnterprise 8.1.msi может
быть использован для централизованной установки 1С:Предприятия 8.1 через
механизм групповых политик домена MS Windows 2000/2003 Server.
Совместное
использование 1С:Предприятия 8.1 различных версий
Если при установке на компьютер, на котором установлена
более ранняя версия 1С:Предприятия 8.1, предполагается использовать данную
версию совместно с прежней, то для установки новой версии следует перед
установкой скопировать существующий каталог программных файлов (по умолчанию «C:\Program Files\1Cv81»). Для сделанной копии необходимо
создать новые ярлыки или внести исправления в ярлыки, созданные ранее при
установке 1С:Предприятия 8.1. Если существующая установка производилась с
административной установки, то в копии установки необходимо удалить файл
admupd.cfg для отключения механизма автоматического обновления.
Следует иметь в виду, что использование 1С:Предприятия 8.1
в качестве Automation сервера, а также в режиме COM-соединение возможно в
каждый момент времени только для одной из используемых версий.
Обновление 1С:Предприятия 8.1 пользователями Microsoft Windows
без прав администратора
Для разрешения
пользователям Microsoft Windows, не обладающим административными правами в
операционной системе, выполнять обновление 1С:Предприятия 8.1 с административной
установки необходимо установить политику AlwaysInstallElevated для компьютера и
пользователя. Установить политику можно как локально в панели управления
групповых политик (запустив gpedit.msc), так через управление политиками Active
Directory.
Вышеуказанные
действия можно проделать не для конкретных пользователей, а для группы
Authenticated users.
Глава 3.
Запуск системы 1С:Предприятие 8.1
В процессе установки 1С:Предприятия 8.1 в меню
«Пуск —Программы» будет создана группа «1С Предприятие 8.1», в
состав которой будут включены пункты:
|
Пункты |
Назначение |
|
1С Предприятие |
Вызов системы в режиме |
|
Конфигуратор |
Вызов системы в режиме |
|
ReadMe — Дополнительная информация |
Дополнительная информация, |
|
Удаление HASP Device Driver |
Программа удаления |
|
Установка HASP Device Driver |
Программа установки |
|
Конвертор ИБ |
Программа для |
|
Серверы |
Утилита |
|
Запуск сервера |
Запуск сервера 1С:Предприятия 8.1 или Запуск сервера |
|
Остановка сервера |
Присутствует только, |
Ведение списка информационных баз
Настройка диалога запуска
Поле Списки общих информационных баз
предназначено для редактирования состава списков общих информационных баз. При
запуске системы 1С:Предприятие 8.1 информационные базы, указанные в
списках общих информационных баз, будут добавлены к основному списку
информационных баз.
Списки общих информационных баз
Списки общих информационных баз представляют собой файлы с
расширением «v8i», которые содержат ссылки
на общие информационные базы.
С помощью диалога настройки окна запуска системы
1С:Предприятие 8.1 можно указать произвольное количество списков общих
информационных баз, которые должны обрабатываться при запуске системы
1С:Предприятие 8.1. В результате, информационные базы, содержащиеся в
указанных общих списках информационных баз, будут добавлены в основной список
информационных баз и отображены при запуске системы в списке информационных
баз. Ссылки на общие информационные базы можно перемещать в списке, однако
операции редактирования и удаления для них недоступны.
Списки общих информационных баз имеют такой же формат, как
и основной список информационных баз. Для того, чтобы ссылка на общую
информационную базу была добавлена в основной список информационных баз, должны
соблюдаться следующие условия:
·
для общей информационной базы должна быть задана
секция <Connect>;
·
строка соединения, указанная в секции
<Connect> не должна совпадать со строками соединения, содержащимися в
основном списке и других добавляемых списках общих информационных баз;
·
для общей информационной базы должна быть задана
секция [<ID>];
·
значение внутреннего идентификатора, указанного
в секции [<ID>] не должно совпадать с идентификаторами информационных
баз, содержащихся в основном списке и других добавляемых списках общих
информационных баз.
Список общих информационных баз может быть сформирован
вручную, или с использованием возможности сохранения существующих ссылок на
информационные базы в файл. Для этого следует выполнить команду контекстного
меню списка информационных баз Сохранить ссылку в файл.
Список общих информационных баз может быть непосредственно
использован для запуска системы 1С:Предприятие 8.1. При запуске файла с
расширением «v8i», будет запущена система
1С:Предприятие 8.1, и в диалоге запуска будут отображены только те ссылки,
которые содержатся в данном списке общих информационных баз.
Ярлыки информационных баз
Ярлыки информационных баз представляют собой файлы с
расширением «v8l», которые содержат ссылки на
списки общих информационных баз.
Ярлыки предназначены для того, чтобы связать основной
список информационных баз с несколькими списками общих информационных баз.
В частности, в каталоге «\Application Data\1C\1Cv81»
текущего пользователя, рядом с основным списком информационных баз (ibases.v8i)
располагается ярлык ibases.v8l,
который и содержит ссылки на те списки общих информационных баз, которые должны
быть добавлены к основному списку при запуске системы 1С:Предприятие 8.1.
Фактически, при интерактивном добавлении списков общих информационных баз в
диалоге настройки окна запуска системы 1С:Предприятие 8.1, происходит
редактирование этого файла — ibases.v8l.
Ярлыки информационных баз также могут быть непосредственно
использованы для запуска системы 1С:Предприятие 8.1. При запуске файла с
расширением «v8l», будет запущена система
1С:Предприятие 8.1, и в диалоге запуска будут отображены только те ссылки,
которые содержатся в списках общих информационных баз, указанных в данном
ярлыке информационных баз.
Перезапуск системы 1С:Предприятие 8.1
В некоторых
случаях открытие информационной базы невозможно. В этом случае система
уведомляет об этом пользователя и предлагает повторить попытку соединения с
информационной базой через 60 секунд.
К таким случаям
относятся:
·
конфигурация уже открыта в режиме «Конфигуратор»
(при попытки запуска в режиме «Конфигуратор»);
·
для информационной базы установлен монопольный
режим работы;
·
не обнаружен сервер 1С:Предприятия 8;
·
административно установлен запрет соединения с
информационной базой.
В таких случаях на
экран выводится окно, в котором сообщается о причине и предлагается выбрать
дальнейшие действия:
Перезапуск
Конфигуратора также предлагается после выполнения загрузки информационной базы
и в случае динамического обновления информационной базы в клиент-серверном
режиме работы.
При работе в
режиме «1С:Предприятие» в случае возникновения критической ошибки система
предлагает осуществить перезапуск с теми же параметрами текущего пользователя.
При перезапуске системы по умолчанию не выполняется запрос пароля. Если в командной строке указать /SAOnRestart, то пароль будет запрашиваться.
Глава 6.
Особенности защиты системы 1С:Предприятие 8.1
с использованием сетевых ключей
Настройка
1С:Предприятия 8.1 для работы с HASP License Manager
1С:Предприятие 8.1
с HASP License Manager
используется конфигурационный файл NETHASP.INI. При запуске
1С:Предприятие 8.1 осуществляет поиск данного файла в каталоге CONF каталога исполняемого файла 1С:Предприятия 8.1 (BIN).
Приложение 2. Формат
файла описаний зарегистрированных информационных баз
В данном приложении приводится описание формата файла
описаний зарегистрированных информационных баз.
Файл располагается на локальном компьютере в каталоге
«\Application Data\1C\1Cv81» текущего пользователя и имеет имя «ibases.v8i».
Приложение 3. Формат файла, содержащего адрес каталога шаблонов
В данном приложении приводится описание файла, содержащего
адрес каталога шаблонов конфигураций и обновлений.
Файл располагается на локальном компьютере в каталоге
«\Application Data\1C\1Cv81» текущего пользователя и имеет имя «v8cscadr.lst».
Книга
«1С:Предприятие 8.1. Клиент-сервер. Особенности установки и использования»
Глава 1.
Принципы построения и работы 1C:Предприятия 8.1 с
информационными базами в варианте «клиент-сервер»
1С:Предприятие 8.1 позволяет работать с
информационными базами в варианте «клиент-сервер». В случае
1С:Предприятия 8.1 под вариантом «клиент-сервер» понимается архитектура,
подразумевающая наличие 3-х программных уровней:
·
клиентское приложение 1С:Предприятия 8.1;
·
кластер серверов 1С:Предприятия 8.1;
·
сервер баз данных.
Ниже показана схема взаимодействия элементов системы:
Клиентское приложение
1С:Предприятия 8.1. Клиентское приложение
1С:Предприятия 8.1 – это и есть 1С:Предприятие 8.1, с которым
работает конечный пользователь.
Для того, чтобы 1С:Предприятие 8.1 получило
возможность работать с информационными базами в варианте «клиент-сервер»,
обычная установка, позволяющая работать с файловым вариантом информационной
базы, должна быть дополнена специализированными компонентами доступа к кластеру
серверов 1С:Предприятия 8.1.
При этом 1С:Предприятие 8.1, имеющее возможность
работать в варианте «клиент-сервер», не утрачивает возможности работы и в
файловом варианте. Выбор необходимого набора компонент осуществляется при
установке 1С:Предприятия 8.1.
Кластер серверов
1С:Предприятия 8.1. Кластер серверов 1С:Предприятия 8.1
является логическим понятием и представляет собой совокупность одного или
нескольких рабочих процессов, функционирующих на одном или нескольких
компьютерах, и списка информационных баз, с которыми работают данные процессы.
Кластер серверов 1С:Предприятия 8.1 образует
промежуточный программный слой между клиентским приложением и сервером баз
данных. Клиентские приложения не имеют непосредственного доступа к серверу баз
данных. Для доступа к информационной базе клиентское приложение взаимодействует
с кластером серверов 1С:Предприятия 8.1.
При этом, помимо простой передачи данных от клиентского
приложения серверу баз данных, кластер серверов 1С:Предприятия 8.1
выполняет и ряд других задач. В частности, в среде кластера серверов
1С:Предприятия 8.1 может быть организовано выполнение достаточно сложных обработок,
написанных на встроенном языке 1С:Предприятия 8.
Кроме того, на центральных серверах, входящих в кластер
серверов 1С:Предприятия 8.1, хранятся файлы, содержащие журналы
регистрации информационных баз, зарегистрированных на данном сервере 1С:Предприятия 8.1,
и другие служебные файлы. Все эти данные не являются жизненно необходимыми для
работы с информационными базами, и их потеря не приведет к неработоспособности
информационных баз.
Кластер серверов 1С:Предприятия 8.1 представляет собой
совокупность рабочих процессов, исполняющихся на одном или нескольких
компьютерах. Установка кластера серверов 1С:Предприятия 8.1 выполняется
программой установки 1С:Предприятия 8.1. Настройка кластера серверов
выполняется с помощью утилиты администрирования кластера серверов, входящей в
комплект поставки.
Ключ аппаратной защиты кластера серверов
1С:Предприятия 8.1 не является сетевым, поэтому он должен быть подключен к
каждому компьютеру, на котором функционируют рабочие процессы кластера. Это
относится только к рабочим процессам, функционирующим под управлением
операционной системы Windows.
Рабочие процессы, функционирующие под управлением операционной системы Linux, не требуют наличия
ключа аппаратной защиты.
Сервер баз данных. Хранение жизненно
важных данных информационных баз 1С:Предприятия 8 в варианте
«клиент-сервер» обеспечивается сервером баз данных. В качестве сервера баз
данных в 1С:Предприятии 8.1 может использоваться MS SQL Server или PostgreSQL. При этом каждая
информационная база целиком сохраняется в отдельной базе данных используемой
СУБД.
Кластер серверов 1С:Предприятия 8.1
Кластер серверов 1С:Предприятия 8.1 представляет собой
множество рабочих процессов, обслуживающих один и тот же набор информационных
баз.
В простейшем виде кластер серверов 1С:Предприятия 8.1 может
функционировать на одном компьютере.
Элементы, которые задействованы в работе кластера серверов:
·
процессы кластера серверов:
ragent.exe;
rmngr.exe;
rphost.exe;
·
хранилища данных:
список
кластеров;
реестр
кластера.
Функционирование компьютера в составе кластера
обеспечивается процессом ragent.exe, который называется агентом сервера. Соответственно компьютер, на котором
запущен агент сервера, называется рабочим сервером.
Одной из функций агента сервера является ведение списка
кластеров, расположенных на данном рабочем сервере. Список
кластеров представляет собой файл srvribrg.lst, который хранится на
рабочем сервере в каталоге данных приложения 1С, например:
«C:\Documents and Settings\<Пользователь>\Application Data\
1C\1Cv81».
Список кластеров содержит следующую информацию:
·
список кластеров, которые зарегистрированы на
данном рабочем сервере;
·
список администраторов центрального сервера.
Агент сервера и список кластеров не входят в состав
кластера серверов, а лишь обеспечивают работу сервера и кластеров, которые
расположены на нем. Непосредственно кластер серверов включает в себя следующие
элементы:
·
процесс rmngr.exe;
·
реестр кластера;
·
один или несколько процессов rphost.exe.
Процесс rmngr.exe называется менеджером кластера. Этот процесс управляет
функционированием всего кластера. В составе кластера этот процесс всегда
существует в единственном экземпляре. Рабочий сервер, на котором функционирует
менеджер кластера и располагается реестр кластера, называется центральным сервером кластера.
Одной из функций менеджера кластера является ведение
реестра кластера. Реестр кластера представляет собой
файл 1CV8Reg.lst, который хранится на центральном сервере кластера в каталоге
данных кластера, например: «C:\Documents and
Settings\<Пользователь>\Application Data\1C\1Cv81\reg_<номер
порта>».
Реестр кластера содержит следующую информацию:
·
список информационных баз, зарегистрированных в
данном кластере;
·
список рабочих серверов, входящих в кластер;
·
список рабочих процессов, входящих в кластер;
·
список администраторов кластера.
Процесс rphost.exe называется рабочим процессом. Рабочий процесс обслуживает
непосредственно клиентские приложения, взаимодействует с сервером баз данных и
в нем, в частности, могут исполняться процедуры серверных модулей конфигурации.
Взаимодействие клиентского приложения с кластером серверов
Взаимодействие различных процессов кластера серверов
1С:Предприятия 8.1 между собой и с клиентским приложением осуществляется
по протоколу TCP/IP, таким образом, каждый из
процессов кластера адресуется именем рабочего сервера, на котором он запущен, и
номером порта.
По умолчанию, при установке кластера серверов, используются
следующие номера портов:
·
агент сервера – порт 1540;
·
менеджер кластера – порт 1541.
Для рабочего процесса номер порта выделяется динамически из
указанного диапазона, по умолчанию используется диапазон адресов 1560:1591.
При необходимости можно изменить номера и диапазон
используемых портов.
Имя центрального сервера – 1C_Serv. Таким образом, сам центральный сервер адресуется как 1С_Serv:1540. Кластер,
расположенный на этом сервере, адресуется как 1С_Serv:1541, а рабочий процесс — 1С_Serv:1561.
Когда клиентское приложение пытается подключиться к
информационной базе в режиме «клиент-сервер», оно обращается к конкретному
кластеру серверов: 1С_Serv:1541:
Менеджер кластера, на основе анализа статистики
загруженности рабочих процессов, сообщает клиентскому приложению адрес рабочего
процесса, с которым оно будет работать. В данном случае, поскольку рабочий
процесс один, это будет 1С_Serv:1561:
Клиентское приложение связывается с выделенным ему рабочим
процессом, который выполняет аутентификацию пользователя информационной базы и
осуществляет все дальнейшее взаимодействие клиентского приложения с
информационной базой.
Анализ статистики загруженности рабочих процессов
Каждый рабочий
процесс имеет свойство «Производительность», которое может принимать значения
от 1 до 1000. Значение 1 – это минимальная производительность, 1000 –
максимальная. Производительность рабочего процесса может быть задана при его
создании (по умолчанию – 1000) и в дальнейшем изменена при помощи утилиты
администрирования кластера серверов.
Для того, чтобы назначить клиентской сессии некоторый
рабочий процесс, выполняется подсчет текущей загруженности рабочих процессов.
Она определяется как частное от текущего количества клиентских соединений,
обслуживаемых конкретным рабочим процессом, и производительности этого
процесса. Процесс, обладающий наименьшей загруженностью в данный момент,
назначается новой клиентской сессии.
Для каждого рабочего процесса кластер серверов вычисляет
ряд параметров, которые используются для анализа загруженности рабочего
процесса. Все эти параметры вычисляются за период времени равный, примерно,
одним суткам:
·
среднее время реакции кластера серверов;
·
среднее время, затраченное кластером серверов;
·
среднее время, затраченное СУБД;
·
среднее время, затраченное клиентом;
·
среднее время, затраченное менеджером
блокировок;
·
среднее количество клиентских потоков.
Среднее время реакции кластера серверов представляет собой
время, которое кластер серверов затратил на обслуживание одного клиентского
соединения. Это время складывается из четырех составляющих:
·
время, затраченное рабочим процессом,
·
время, затраченное СУБД,
·
время, затраченное самим клиентом (если
управление передавалось обратно на клиента);
·
время, затраченное менеджером блокировок.
Обслуживание каждого клиентского соединения рабочий процесс
выполняет в отдельном потоке. Таким образом, в некоторый момент времени рабочий
процесс может выполнять несколько клиентских потоков, количество которых, как
правило, меньше, чем количество соединений (т.к. не все соединения активны
постоянно). Среднее количество клиентских потоков как раз и показывает среднее
за сутки количество потоков, выполняемых рабочим процессом одновременно.
Масштабируемость кластера серверов
Масштабируемость кластера серверов может осуществляться как
за счет модернизации аппаратных средств, так и за счет возможностей
конфигурирования кластера серверов на имеющихся аппаратных средствах.
Рассмотрим второй вариант более подробно.
Увеличение количества рабочих процессов
На одном рабочем сервере может быть запущено несколько
рабочих процессов.
Использование нескольких рабочих процессов, с одной
стороны, позволяет снизить нагрузку на каждый конкретный рабочий процесс.
Например, если кластер серверов обслуживает одновременно 50 клиентских сессий и
при этом использует только один рабочий процесс, то все 50 сессий будут
обслуживаться этим рабочим процессом. Если в этой же ситуации кластер серверов
будет использовать два рабочих процесса, но каждый из них в среднем будет
обслуживать 25 сессий (при условии, что процессы «одинаковы» для кластера с
точки зрения своей пропускной способности). Очевидно, что во втором случае
нагрузка, создаваемая на отдельный рабочий процесс, будет ниже, а значит, сами
процессы будут работать более стабильно.
Конкретные рекомендации по количеству сессий, обслуживаемых
одним рабочим процессом дать затруднительно, поскольку действия, выполняемые в
разных сессиях, могут значительно отличаться. В качестве приблизительного
ориентира можно использовать цифру 50-100 сессий на один рабочий процесс. Таким образом, если планируется одновременная работа 200 сессий, то рекомендуется использовать 2-4 рабочих процесса.
С другой стороны, запуск нескольких рабочих процессов
позволяет более эффективно использовать аппаратные ресурсы рабочего сервера.
Например, если объем физической памяти сервера более 2 Гб, то имеет смысл
использовать несколько рабочих процессов. Каждый рабочий процесс может занимать
до 2 Гб виртуального адресного пространства, поэтому можно запускать несколько
рабочих процессов из расчета 1,5 – 2 Гб оперативной памяти сервера на один
рабочий процесс.
Кроме этого запуск нескольких рабочих процессов позволяет
повысить надежность сервера, изолировав группы клиентов, работающих с разными
информационными базами.
Важно! Если кластер серверов
используется исключительно для конфигурирования (модификации и отладки
конфигураций), рекомендуется использовать только один рабочий процесс в
кластере. В этом случае запуск приложения в отладочном режиме будет происходить
быстрее, т.к. не будет тратиться дополнительное время на соединение с новым
рабочим процессом.
Увеличение количества рабочих серверов
Кластер серверов может функционировать как на одном, так и
на нескольких рабочих серверах. Разделение кластера серверов по нескольким
компьютерам позволяет повысить производительность кластера в целом посредством
разделения нагрузки между компьютерами.
На центральном сервере кластера функционирует менеджер
кластера и несколько рабочих процессов. Также на центральном сервере кластера
расположен реестр кластера. На каждом из других рабочих серверов функционирует
несколько рабочих процессов, которые обмениваются служебными данными с
менеджером кластера по протоколу TCP/IP.
Помимо рабочих процессов на каждом из рабочих серверов функционирует свой агент
сервера.
Одной из функций, которую обеспечивает агент сервера,
является запуск рабочих процессов и менеджера кластера в соответствии с
информацией, хранящейся в реестре кластера и списке кластеров. Сам агент
сервера может запускаться автоматически при старте операционной системы или
вручную.
Агент сервера читает информацию из списка кластеров и
запускает менеджер кластера, если на данном рабочем сервере создан хотя бы один
кластер. После этого агент центрального сервера обращается к запущенному
менеджеру кластера и получает информацию из реестра кластера о рабочих
процессах, которые должны быть запущены в рамках данного кластера.
Если рабочий процесс должен быть запущен на центральном
сервере, агент центрального сервера выполняет запуск нужного рабочего процесса.
Если рабочий процесс должен быть запущен на другом рабочем сервере, то агент
центрального сервера связывается с требуемым агентом сервера (необходимая
информация хранится в реестре кластера) и передает ему команду на запуск
требуемого рабочего процесса. После этого агент сервера выполняет запуск
указанного рабочего процесса.
После того, как рабочие процессы запущены, они
функционируют в рамках кластера независимо, обслуживая клиентские сессии и
самостоятельно обмениваясь служебными данными с менеджером кластера.
Варианты конфигурирования кластеров серверов
Несколько кластеров серверов могут быть различным образом
размещены на нескольких рабочих серверах. Рассмотрим возможные варианты.
Несколько кластеров на одном центральном сервере
Один рабочий сервер может являться центральным для одного
или нескольких кластеров.
Запуском рабочих процессов и менеджеров кластера управляет
агент центрального сервера на основе информации, содержащейся в списке
кластеров и реестрах кластеров, расположенных на данном рабочем сервере.
Дальнейшее функционирование рабочих процессов происходит независимо и только в
рамках того кластера, к которому они относятся.
Смешанное использование рабочих серверов
Один и тот же рабочий сервер может являться центральным для
одного кластера, и в то же время «обычным» сервером для другого кластера, т.е.
на нем могут функционировать рабочие процессы, относящиеся к другому/другим
кластерам.
На центральном сервере кластера 1 расположен кластер 1 и
несколько его рабочих процессов. Кроме этого на нем функционируют рабочие
процессы кластера 2. На центральном сервере кластера 2 расположен кластер 2 и
несколько его рабочих процессов. На сервере функционируют рабочие процессы,
относящиеся как к кластеру 1, так и к кластеру 2.
Запуском рабочих процессов и менеджеров кластеров управляют
агенты центральных серверов кластера 1 и кластера 2. В частности агент центрального
сервера кластера 2 обратится к агенту центрального сервера кластера 1 для того,
чтобы тот запустил рабочие процессы кластера 2, расположенные на центральном
сервере кластера 1. В то же время «свои» рабочие процессы агент центрального
сервера кластера 1 запустит по «собственной инициативе».
Дальнейшее функционирование рабочих процессов происходит
независимо и только в рамках того кластера, к которому они относятся.
Безопасность кластера серверов
1С:Предприятия 8.1
При работе 1С:Предприятия 8.1 в режиме «клиент-сервер»
задача обеспечения безопасности данных сводится к тому, что доступ к данным
1С:Предприятия 8.1 должен осуществляться только механизмами 1С:Предприятия 8.1.
В связи с этим можно выделить несколько областей обеспечения безопасности:
Все клиентские приложения и внешние соединения используют
данные 1С:Предприятия 8.1 только через кластер серверов 1С:Предприятия 8.1,
выполнив процедуру аутентификации 1С:Предприятия 8.1, заключающуюся в том, что
перед началом работы с кластером серверов приложение должно сообщить ему имя
пользователя 1С:Предприятия 8.1 и его пароль. Дальнейшая работа с кластером
серверов будет возможной только, если пользователь с соответствующим паролем
был зарегистрирован в информационной базе.
Данные, с которыми работает кластер серверов
1С:Предприятия, делятся на информационную базу и служебные данные. Таким
образом, задача кластера серверов заключается в том, чтобы обеспечить
безопасность данных в следующих областях:
·
при обмене между клиентом и кластером серверов
(1);
·
при обмене между консолью кластера серверов и
кластером (2);
·
при хранении служебных данных в кластере
серверов (3);
·
при обмене данными внутри кластера (4).
Информационная база размещается в базе данных и ее
безопасность, а также безопасность при обмене между кластером серверов и
сервером баз данных, обеспечивается средствами используемой СУБД (MS SQL Server или
PostgreSQL).
Поэтому далее будут рассмотрены подробно только первые
четыре области обеспечения безопасности, за которые отвечает непосредственно система
1С:Предприятие 8.
Безопасность данных, передаваемых между клиентом и кластером
серверов
Безопасность данных, передаваемых
между клиентом и кластером серверов, обеспечивается за счет возможности
шифрования этих данных. При этом может быть выбран один из трех уровней
безопасности:
·
Выключено;
·
Установка соединения;
·
Постоянно.
Уровень Выключено
является самым низким, уровень Постоянно – самым высоким. При этом используется
безопасное соединение по протоколу TCP/IP с шифрованием алгоритмами RSA и Triple DES.
Уровень безопасности Постоянно
Использование
уровня безопасности Постоянно позволяет полностью защитить весь поток данных
(как пароли, так и непосредственно данные) между клиентом и кластером серверов.
Однако следует учитывать, что при этом возможно значительное снижение
производительности системы (до 70%).
Протокол
взаимодействия одинаков как для менеджера кластера (rmngr.exe), так и для рабочего
процесса (rphost.exe):
после установки соединения первый обмен данными выполняется с использованием
шифрования по алгоритму RSA, дальнейший обмен данными
выполняется с использованием шифрования по алгоритму Triple DES.
Уровень
безопасности задается при создании информационной базы. Эта информация сохраняется
как на клиенте (в списке информационных баз), так и в кластере серверов (в
реестре сервера). После создания информационной базы, ее параметры, сохраненные
в кластере серверов, изменить уже нельзя. Однако можно изменить уровень
безопасности, указанный для этой информационной базы на клиенте.
Поэтому после
установки соединения клиент генерирует приватный и публичный ключи для
шифрования RSA, и передает в кластер серверов
публичный ключ и уровень безопасности, который указан для данной информационной
базы на клиенте. Это желаемый уровень безопасности.
Кластер серверов
выбирает максимальный уровень безопасности из переданного клиентом и указанного
для этой информационной базы в реестре кластера. Это фактический уровень
безопасности. Кроме этого кластер серверов генерирует сеансовый ключ для
шифрования Triple DES и вместе с фактическим уровнем безопасности передает его
клиенту, предварительно зашифровав эти данные с помощью публичного ключа
клиента.
Дальнейший обмен
данными выполняется в соответствии с фактическим уровнем безопасности, при этом
как клиент, так и сервер шифруют передаваемые данные с использованием
сеансового ключа по алгоритму Triple DES.
Уровень безопасности Установка
соединения
Использование
уровня безопасности Установка соединения позволяет частично защитить поток
данных (только пароли) между клиентом и кластером серверов. Этот уровень
безопасности является компромиссом между безопасностью и производительностью.
С одной стороны,
данные информационной базы передаются в открытом виде. Поскольку эти данные
составляют основную массу всего потока данных, производительность системы
практически не снижается.
С другой стороны,
ключевая информация (пароли) передается только в зашифрованном виде. В
результате, если этот поток данных будет перехвачен, то из него можно будет
получить лишь незначительную часть данных информационной базы. Т.к. пароли
будут недоступны, то злоумышленник не сможет аутентифицироваться в
информационной базе и получить доступ ко всем данным или выполнить произвольные
действия с информационной базой.
После установки
соединения первый обмен данными выполняется с использованием шифрования по
алгоритму RSA, затем обмен данными выполняется с
использованием шифрования по алгоритму Triple DES до окончания процедуры аутентификации. Дальнейший обмен
выполняется нешифрованными данными.
Уровень безопасности Выключено
Уровень
безопасности Выключено является самым низким и самым производительным.
Практически все данные передаются без использования шифрования.
После установки
соединения первый обмен данными выполняется с использованием шифрования по
алгоритму RSA. Дальнейший обмен выполняется
нешифрованными данными.
Безопасность
данных, передаваемых между консолью кластера серверов и кластером серверов
Безопасность данных, передаваемых
между консолью кластера серверов и кластером серверов, обеспечивается также за
счет возможности шифрования передаваемых данных. При этом используются те же
самые три уровня безопасности: Выключено, Установка соединения и Постоянно.
Консоль кластера
серверов взаимодействует с агентом сервера (процесс ragent.exe). Желаемый уровень
безопасности задается при старте агента сервера. Фактический уровень
безопасности будет выбран агентом сервера как максимальный из указанного при старте
и уровней безопасности всех кластеров, расположенных на данном центральном
сервере. Уровень безопасности кластера задается при его создании (программном
или интерактивном).
Безопасность
данных, хранящихся в кластере серверов
Кластер серверов использует ряд служебных
данных, например список кластеров сервера, реестры кластеров и др. Все
служебные данные представляют собой совокупность файлов, которые находятся в
двух каталогах:
·
каталог данных приложения;
·
каталог временных файлов.
Общая идеология
работы со служебными данным заключается в том, что доступ к служебным данным
кластера серверов должны иметь только менеджер кластера (rmngr.exe) и агент сервера (ragent.exe). Рабочие процессы (rphost.exe) использует служебные
данные только через менеджер кластера, поскольку являются потенциально
опасными, т.к. в них могут выполняться фрагменты кода конфигураций.
Безопасность каталога данных
приложения
В каталоге данных
приложения при установке кластера серверов 1С:Предприятия 8.1 создается
специальный каталог, предназначенный только для файлов кластера серверов
1С:Предприятия:
Пользователю
USR1CV81, от имени которого стартует по умолчанию агент сервера, назначаются
полные права на этот каталог. Другим пользователям доступ в этот каталог
запрещается. Запуск менеджера кластера выполняет агент сервера от имени того же
самого пользователя, от которого запущен он сам.
Пользователь
USR1CV81 обладает только одним правом – «Log on as service».
Запуск рабочих
процессов также осуществляет агент сервера. По умолчанию рабочий процесс
запускается от имени того пользователя, от которого запущен агент сервера.
Однако предусмотрена возможность создания дополнительного пользователя
операционной системы, от имени которого стартуют только рабочие процессы. Это
позволяет предотвратить непосредственный доступ программного кода конфигураций
к служебным данным.
Для того, чтобы
рабочий процесс запускался не от имени того же пользователя, что и агент
сервера, в каталоге данных приложений, относящемся к пользователю агента
сервера, может быть размещен файл swpuser.ini следующего формата:
user=<имя
пользователя операционной системы>
password=<пароль
пользователя операционной системы>
Например, файл
swpuser.ini может содержать следующие данные:
user=\\server_comp\uuuu
password=1234567
В этом случае
рабочие процессы, запускаемые на данном рабочем сервере, будут запускаться от
имени заданного пользователя (\\server_comp\uuuu), зарегистрированного в
операционной системе.
Безопасность каталога временных
файлов
Защита данных из
временных файлов выполняется иначе. Поскольку системный каталог временных
файлов является общедоступным, то в нем ограничиваются права доступа к каждому
временному файлу отдельно.
Для этого при
создании временного файла кластером серверов 1С:Предприятия пользователю
USR1CV81 устанавливаются полные права на создаваемый файл. Другим пользователям
доступ к этому файлу запрещается. Таким образом, данные, хранимые во временных
файлах, защищаются от несанкционированного доступа:
Шифрование паролей, хранимых в
служебных данных кластера серверов
Пароли
администраторов кластера серверов и пароли доступа к информационным базам
хранятся на кластере серверов в зашифрованном виде. Для этого используется
шифрование алгоритмами SHA1 и AES128.
SHA1 — это
алгоритм контрольного суммирования. С его помощью хранятся пароли, которые
проверяет система 1С:Предприятие (например, пароль администратора кластера,
администратора центрального сервера). При этом исходный текст хранимых паролей
восстановить нельзя, а можно только проверить совпадение контрольной суммы
введенного пароля с хранимой контрольной суммой.
AES128 – это
алгоритм шифрования. С его помощью хранятся пароли, для которых должен
восстанавливаться исходный текст (например, пароли доступа к СУБД).
Безопасность
данных, передаваемых внутри кластера серверов
Безопасность данных, передаваемых внутри
кластера серверов (например, между рабочими процессами и менеджером кластера)
обеспечивается за счет возможности шифрования передаваемых данных. При этом используются
три уровня безопасности, о которых было сказано выше: Выключено, Установка соединения
и Постоянно.
При взаимодействии
рабочего процесса с менеджером кластера используется уровень безопасности
кластера. При взаимодействии агента сервера с менеджером кластера уровень
безопасности выбирается как максимальный из уровня безопасности, с которым
запущен агент сервера и уровнем безопасности кластера, обслуживаемого данным
менеджером.
Администраторы
центрального сервера и администраторы кластера
Администрирование
кластера серверов 1С:Предприятия 8.1 может выполняться как с
использованием аутентификации администраторов, так и без нее.
Если
аутентификация не используется, то любой пользователь, подключившийся к
центральному серверу кластера, может выполнять все административные действия,
как с центральным сервером, так и с любым кластером, расположенным на данном
сервере. По умолчанию после установки кластера серверов 1С:Предприятия 8.1
аутентификация администраторов не используется.
Для ограничения
круга пользователей, которые могут выполнять административные действия,
создаются списки администраторов центрального сервера и списки администраторов
каждого из кластеров, расположенных на данном сервере. Области действий, на
которые распространяются права администраторов центрального сервера и
администраторов кластеров, не пересекаются.
Аутентификация
администратора центрального сервера позволяет пользователю выполнять
административные действия с центральным сервером, но для того, чтобы выполнить
какие-либо административные действия с конкретным кластером, требуется
аутентификация администратора кластера. В то же время для выполнения
административных действий с кластером пользователь должен аутентифицироваться
как администратор кластера; дополнительная аутентификация в качестве
администратора сервера для этого не требуется.
Механизм
аутентификации администраторов центрального сервера/кластера включается
системой автоматически, как только в списке администраторов центрального
сервера/кластера создается хотя бы один администратор.
При включенном
механизме аутентификации пользователь, не аутентифицировавшийся как
администратор центрального сервера, может только просмотреть и изменить
параметры подключения к центральному серверу в консоли администрирования
кластера серверов.
Пользователь, не
аутентифицировавшийся в качестве администратора кластера, может только
просмотреть свойства кластера. Кроме того, используя средства встроенного
языка, такой пользователь может создавать объекты кластера, информационной базы
и пр., но не имеет возможности регистрировать их в кластере.
Особенности работы с сервером баз данных
PostgreSQL
·
При сортировке по возрастанию поля со значениями
NULL оказываются последними в выборке, а в случае использования других СУБД –
первыми. При сортировке по убыванию поведение различается таким же образом.
·
В автоматическом режиме управления блокировками
PostgreSQL использует табличные блокировки. Это означает, что транзакция,
читающая данные из некоторой таблицы, исключает возможность одновременной
записи в ту же таблицу другой транзакцией. Такую же гранулярность блокировок
(гранула – таблица) использует файловый вариант работы.
·
При выполнении операций, связанных с интенсивным
удалением и добавлением записей в таблицы базы данных (например, перепроведении
документов), может наблюдаться деградация производительности выполняемой
операции. Для восстановления исходной производительности рекомендуется
регулярно выполнять операцию REINDEX (или VACUUM) для интенсивно модифицируемых
таблиц базы данных. Частота выполнения указанных операций зависит от
интенсивности работы с этими таблицами.
·
На производительность PostgreSQL оказывает существенное влияние
производительность дисковой системы, поскольку по умолчанию, параметр fsync включен. Это означает, что при
выполнении операции COMMIT данные
сразу переписываются из кеша операционной системы на диск, тем самым
гарантируется консистентность при возможном аппаратном сбое. Обратной стороной
этого является снижение производительности операций записи на диск, поскольку
при этом не используются возможности отложенной записи данных операционной
системы. Повышение производительности возможно при использовании многодисковых RAID-массивов созданных на основе кэширующих RAID-контроллеров с энергонезависимой кэш-памятью и использования
источников бесперебойного питания(UPS). В этом случае задачу по
обеспечению консистентности данных при аппаратном сбое берут на себя описанные
выше устройства, поэтому появляется возможность отключения параметра fsync и увеличения производительности операций
записи на диск. Следует отметить, что увеличение количества дисков в RAID-массиве и объема кэша RAID-контроллера само по себе
позволяет компенсировать снижение производительности, обусловленное включением
параметра fsync.
·
Имеются некоторые различия в работе функций
даты/времени. Так, в MS SQL select datediff(hour, datetime(2006, 10, 29, 0, 0,
0), datetime(2006, 10, 30, 0, 0, 0)) вернет 24, а в PostgreSQL
25 из-за того, что между этими двумя датами был переход на зимнее время.
Аналогичная ситуация в отношении учета летнего времени имеет место для функции DATEADD
Работа под
управлением различных операционных систем
Различные части системы 1С:Предприятие 8.1 в варианте
работы клиент-сервер могут функционировать как под управлением операционной
системы Windows, так и
под управлением операционной системы Linux.
Клиентское приложение системы 1С:Предприятие 8.1 может
работать только на компьютерах под управлением операционной системы Windows.
Рабочие серверы, входящие в кластер серверов, могут
работать как под управлением операционной системы Windows, так и под управлением
операционной системы Linux.
Все процессы кластера серверов поддерживают работу в этих операционных
системах.
Если используется СУБД MS SQL Server, то сервер баз данных может работать только под
управлением операционной системы Windows. Если же используется СУБД PostgreSQL, то сервер баз данных может
работать как под управлением операционной системы Windows, так и под управлением
операционной системы Linux.
Существует единственное ограничение, которое следует
учитывать при конфигурировании системы 1С:Предприятие 8.1 в варианте
работы «клиент-сервер»: рабочий процесс кластера серверов, функционирующий под
управлением операционной системы Linux, не может взаимодействовать с СУБД MS SQL Server. Поэтому приведенная
ниже схема будет неработоспособна:
В то же время, если в составе кластера есть рабочие
процессы, функционирующие как под управлением Windows, так и под управлением Linux, то такой кластер сможет
работать с MS SQL Server,
но только «через» те рабочие процессы, которые функционируют под управлением Windows:
Ограничения и особенности Linux
При работе кластера серверов 1С:Предприятия 8.1 на
компьютерах под управлением операционной системы Linux, существуют следующие ограничения:
·
рабочий процесс кластера серверов
1С:Предприятия 8.1 не может взаимодействовать с СУБД MS SQL Server. Допускается
компиляция серверных модулей, осуществляющих работу с COM объектами, однако,
при попытке выполнения такого модуля будет выдано сообщение об ошибке;
·
рабочий процесс кластера серверов
1С:Предприятия 8.1 не может взаимодействовать с COM объектами.
·
аутентификация выполняется на основе Kerberos (Windows версия поддерживает протокол
NTLM, который способен, в частности, обеспечить аутентификацию без PDC) и/или
имени и пароля пользователя.
·
недоступна функциональность объекта ИнтернетСоединение.
Распределение кластера серверов и сервера баз данных по
компьютерам
Отдельно следует сказать про распределение составляющих по
компьютерам. Из приведенной выше схемы можно сделать вывод, что каждое
клиентское приложение 1С:Предприятия 8.1, кластер серверов
1С:Предприятия 8.1 и сервер баз данных должны исполняться на отдельных компьютерах.
Это не совсем так.
В реальности клиентские приложения 1С:Предприятия 8.1,
кластер серверов 1С:Предприятия 8.1 и сервер баз данных могут быть
распределены по компьютерам произвольным образом. Все вместе они вполне могут
работать и на одном компьютере.
Однако, в большинстве практических случаев, клиентские
приложения исполняются на отдельных компьютерах конечных пользователей, в то
время как кластер серверов 1С:Предприятия 8.1 и сервер баз данных, в
зависимости от обстоятельств, могут выполняться как на одной, так и на двух
отдельных машинах.
И тот, и другой варианты являются совершенно нормальными в
техническом отношении. При относительно небольшой нагрузке кластер серверов
1С:Предприятия 8.1 и сервер баз данных вполне могут работать на одном
компьютере. И этот вариант является вполне приемлемым для тех случаев, когда
ресурсов одного компьютера хватает для выполнения функций кластера серверов
1С:Предприятия 8.1 и сервера баз данных.
А если один компьютер не справляется с выполнением всех
функций, кластер серверов 1С:Предприятия 8.1 и сервер баз данных могут
быть разнесены на отдельные машины.
Требования к аппаратуре и программному обеспечению
Никаких особенных требований к компьютерам конечных
пользователей для организации работы 1С:Предприятия 8 с информационными
базами в варианте «клиент-сервер» не предъявляется, поэтому требования к
аппаратуре и программному обеспечению не отличаются от требований
1С:Предпрития 8 при работе с файловым вариантом информационной базы.
Требования к рабочим серверам, входящим в состав кластера
серверов 1С:Предприятия 8.1:
·
рабочий сервер кластера серверов
1С:Предприятия 8.1:
o операционные
системы MS Windows 2000/XP/Server 2003 или один из
дистрибутивов Linux (текущий состав поддерживаемых дистрибутивов Linux
публикуется на сайте http:\\www.v8.1c.ru\requirements\);
o
процессор не ниже Pentium III 866
МГц (рекомендуется Intel Pentium IV/Xeon
2,4 ГГц). Допустимо и даже желательно использование многопроцессорных
машин, так как наличие нескольких процессоров благотворно сказывается на пропускной
способности кластера серверов 1С:Предприятия 8.1, особенно в случае
интенсивной работы нескольких пользователей.
o
оперативная память не менее 512 Мбайт
(рекомендуется 1024 Мбайт и выше). И хотя рабочие процессы кластера
серверов 1С:Предприятия 8.1 могут исполняться в достаточно небольших
объемах памяти, при пиковых нагрузках их потребности могут быть весьма
значительными.
o
особых требований к дисковой подсистеме со
стороны кластера серверов 1С:Предприятия 8.1 нет, так как он сам не ведет
интенсивной работы с дисковыми файлами;
o требуется
наличие USB-порта для подключения ключа аппаратной защиты кластера серверов 1С:Предприятия 8.1.
Требования к серверу баз данных
главным образом определяются требованиями MS SQL Server или PostgreSQL. В качестве сервера баз данных может использоваться
любой компьютер, на котором может работать MS SQL Server или PostgreSQL. Формально требования могут
быть сформулированы следующим образом:
·
сервер баз данных:
·
Microsoft
SQL Server 2000 + Service Pack 2 (рекомендуется Service Pack 4);
·
Microsoft
SQL Server 2005;
·
PostgreSQL 8.1;
·
операционная система: в соответствии с
требованиями MS SQL Server
или PostgreSQL;
·
компьютер сервера баз данных:
o технические
характеристики компьютера и операционная система должны соответствовать
требованиям используемой версии сервера баз данных MS SQL Server или PostgreSQL;
В качестве рекомендуемых
параметров можно перечислить следующие:
·
операционные системы MS Windows 2000/XP/Server 2003 или один из
дистрибутивов Linux для x86-64
(список дистрибутивов публикуется на пользовательском сайте http://www.v8.1c.ru);
В случае, если кластер серверов
1С:Предприятия 8.1 и сервер баз данных разнесены на разные компьютеры, то
на производительности всей системы может сильно сказываться пропускная
способность сетевого соединения между компьютерами кластера серверов
1С:Предприятия 8.1 и компьютером сервера баз данных. Вплоть до того, что в
некоторых случаях разнесение функций кластера серверов 1С:Предприятия 8.1
и сервера баз данных на разные машины вместо ожидаемого увеличения
производительности может дать его снижение, за счет потерь при передаче данных
между кластером серверов 1С:Предприятия 8.1 и сервером баз данных. По этой
причине рекомендуется использовать сетевые карты с пропускной способностью 100
Мбит и выше.
Важно! Для нормальной работы 1С:Предприятия 8.1 в режиме клиент-сервер необходимо на клиентских компьютерах отключить использование энергосберегающих режимов Sleep, Standby и Hibernate.
Глава 2.
Установка 1C:Предприятия 8.1 для работы с
информационными базами в варианте «клиент-сервер»
Установка клиентского приложения
Установка клиентского приложения выполняется программой
установки 1С:Предприятия 8.1. Как было указано выше, для того, чтобы
устанавливаемое на компьютере пользователя 1С:Предприятие 8.1 получило
возможность работы с информационными базами в варианте «клиент-сервер», обычная
установка должна быть дополнена специализированными компонентами доступа к
кластеру серверов 1С:Предприятия 8.1.
В диалоге выбора компонентов для установки сервер и
Web-сервисы при первом запуске программы установки отмечены как
неустанавливаемые. При изменений состава компонентов флажки компонентов
отмечаются в соответствии со списком установленных компонентов.
Установка и запуск кластера серверов
Установка кластера серверов под Windows
Установка кластера серверов 1С:Предприятия 8.1 также
выполняется программой установки 1С:Предприятия 8.1. Программа установки копирует
на компьютер необходимые файлы и может настроить запуск агента центрального
сервера как приложения или как сервиса. Сервис выполняется от лица специального
пользователя USR1CV81, который также создается в процессе установки кластера
серверов 1С:Предприятия 8.1 и включается в группу USERS или ее
локализованные аналоги.
Для установки кластера серверов следует выбрать компоненту
«Сервер 1С:Предприятия 8.1», как это показано ниже.
При первоначальной установке системы 1С:Предприятие 8.1
компоненты «Сервер 1С:Предприятия 8.1» и «Адаптер Web-сервисов
1С:Предприятия 8.1» отмечены как не устанавливаемые. При обновлении
системы флажки компонентов отмечаются в соответствии со списком установленных
компонентов.
Далее следует выбрать язык интерфейса по умолчанию, а на
следующем шаге параметры установки сервера.
Если выбрана установка сервера как 1С:Предприятия 8.1 как
сервиса Windows, то
следует выбрать пользователя и ввести пароль для этого пользователя.
Пользователь выбирается из существующих или создается
стандартный локальный USR1CV81 (при существовании такого пользователя он
пересоздается). В последнем случае пользователю USR1CV81 устанавливается
указанный пароль. Пользователь не удаляется при деинсталляции 1С:Предприятия 8.1.
Пользователю назначается право «Вход в систему как сервис».
Пользователь и пароль используются только при создании
сервера 1С:Предприятия 8.1 как сервиса. Пользователю в любом случае даются
необходимые права на каталог файлов сервера.
Запуск кластера серверов под Windows
Общие сведения о запуске агента сервера
Для того, чтобы
выполнить запуск кластера серверов 1С:Предприятия 8.1 следует запустить
агент сервера (ragent.exe). Все дальнейшие действия
будут выполнены системой автоматически. При запуске агент сервера выполняет
поиск списка кластеров, зарегистрированных на данном компьютере.
Если список кластеров обнаружен, то агент сервера запускает
указанные менеджеры кластеров. С их помощью он получает информацию о рабочих
процессах, которые должны быть запущены в каждом из кластеров, и выполняет их
запуск самостоятельно, или с помощью агентов других рабочих серверов кластера.
Если список кластеров не обнаружен, агент сервера создает
кластер по умолчанию. Кластер по умолчанию имеет следующие характеристики:
·
номер порта – 1541;
·
диапазон IP портов – 1560:1591;
·
поддержка многих рабочих процессов – выключена;
·
один рабочий процесс, номер порта
устанавливается из указанного диапазона.
Особенностью запуска агента сервера является то, что список
кластеров сервера хранится в каталоге приложения пользователя: «C:\Documents and Settings\<Пользователь>\Application Data\1C\1Cv81″.
Таким образом, если первый раз агент сервера был запущен от
имени одного пользователя, то будет создан кластер по умолчанию. Если затем
агент сервера будет запущен от имени другого пользователя, то так как в
каталоге другого пользователя список кластеров найден не будет, агент сервера
создаст еще один кластер по умолчанию и данные о нем поместит в каталог другого
пользователя.
В результате на компьютере будут созданы два кластера,
которые управляются различными агентами сервера. Такая ситуация является вполне
нормальной и эти кластеры могут функционировать параллельно. Единственное, о
чем следует позаботиться – это о том, чтобы процессы различных кластеров не
использовали одни и те же IP
адреса.
Когда несколько кластеров создаются под управлением одного
агента сервера, агент сервера обеспечивает отсутствие конфликтов IP адресов. В случае, когда
кластеры создаются под управлением разных агентов сервера – следует вручную
изменить IP адреса
процессов одного из кластеров.
Запуск агента сервера как приложения
Агент сервера может быть запущен как приложение в
операционных системах Windows
и Linux. Для этого
следует выполнить следующую команду:
ragent.exe <набор параметров>
В команде запуска могут использоваться следующие ключи:
-port <порт> — номер главного порта агента кластера. Этот порт используется консолью
кластера для обращения к центральному серверу. Порт агента кластера также
указывается в качестве IP порта рабочего сервера;
-seclev <уровень> —
уровень безопасности процесса агента кластера. Определяет уровень безопасности
соединений, устанавливаемых с процессом ragent.exe. <уровень> может
принимать значения: 0 (по умолчанию) соединения не защищенные, 1 – защищенные
соединения только на время выполнения аутентификации пользователей, 2 –
постоянно защищенные соединения;
-regport <порт> —
номер порта кластера, создаваемого по умолчанию при первом запуске ragent.exe;
-range <диапазоны> —
диапазоны IP портов для динамического выбора. Из них выбираются служебные порты
процессов кластера при невозможности их выбора из настроек соответствующего
рабочего сервера. По умолчанию: 1560-1591. Примеры значений <диапазоны>:
«45:49», «45:67,70:72,77:90»;
—debug — запуск кластера серверов в
режиме отладки конфигураций.
Важно! Название и значение параметра
должно разделяться символом пробел.
Подробнее об уровне безопасности соединения можно прочитать
в разделе «Безопасность данных, передаваемых между консолью кластера серверов и
кластером серверов».
Остановка агента сервера, запущенного как приложение,
выполняется нажатием клавиш Ctrl+C.
Запуск агента сервера как сервиса
Если при установке кластера серверов был выбран вариант
запуска агента центрального сервера как сервиса, то данный сервис будет запущен
автоматически, в процессе установки и также будет запускаться при старте
операционной системы.
Если агент центрального сервера был установлен как
приложение, то существует возможность зарегистрировать сервис вручную и затем
осуществить его запуск.
Регистрация сервиса выполняется следующей командой:
ragent.exe -instsrvc -usr <пользователь>
-pwd <пароль>
-port <порт>
-range <диапазоны>
-seclev <уровень>
-debug
| —rmsrvc
| —start | —stop
-instsrvc – регистрация
агента кластера как сервиса Windows. Если ragent.exe запущен с этим ключом, то
он выполняет регистрацию в списке сервисов Windows и завершается. Не совместим
с ключами -srvc, -rmsrvc;
-usr <имя пользователя>
-pwd <пароль пользователя> – имя и пароль пользователя Windows,
от имени которого должен запускаться ragent.exe как сервис Windows. Могут
использоваться только совместно с ключом -instsrvc при регистрации ragent.exe
как сервиса Windows;
-port <порт> – номер главного порта агента кластера. Этот порт используется консолью
кластера для обращения к центральному серверу. Порт агента кластера также
указывается в качестве IP порта рабочего сервера;
-range <диапазоны>
– диапазоны IP портов для динамического выбора. Из них выбираются служебные
порты процессов кластера при невозможности их выбора из настроек
соответствующего рабочего сервера. По умолчанию: 1560-1591. Примеры значений
<диапазоны>: «45:49», «45:67,70:72,77:90»;
-seclev <уровень>
– уровень безопасности процесса агента кластера. Определяет уровень
безопасности соединений, устанавливаемых с процессом ragent.exe.
<уровень> может принимать значения: 0 (по умолчанию) соединения не
защищенные, 1 – защищенные соединения только на время выполнения аутентификации
пользователей, 2 – постоянно защищенные соединения.;
-rmsrvc – отмена
регистрации агента кластера как сервиса Windows. Если ragent.exe запущен с этим
ключом, то он отменяет свою регистрацию в списке сервисов Windows и
завершается. Не совместим с ключами -srvc, -daemon, -instsrvc.
-start — запустить
ragent.exe, зарегистрированный как сервис Windows. Выполняет запуск ragent.exe,
ранее зарегистрированного как сервис Windows, после чего завершается;
-stop — остановить
ragent.exe, зарегистрированный и запущенный как сервис Windows. Выполняет
остановку ragent.exe, ранее зарегистрированного и запущенного как сервис
Windows, после чего завершается;
—debug — запуск кластера серверов в
режиме отладки конфигураций.
Важно! Название и значение параметра
должно разделяться символом пробел.
Подробнее об уровне безопасности соединения можно прочитать
в разделе «Безопасность данных, передаваемых между консолью кластера серверов и
кластером серверов».
Запуск сервиса по умолчанию осуществляется автоматически
при включении компьютера. Также запуск сервиса можно выполнить средствами Windows: My
computer — Manage — Computer Management — Services and Applications — Services
— 1C:Enterprise 8.1 Server Agent. Остановка сервиса также выполняется
средствами Windows.
Для отмены регистрации сервиса следует выполнить команду ragent.exe
/rmsrvc.
Установка кластера серверов под Linux
Дистрибутив серверной части 1С:Предприятия 8.1 для Linux
представлен в виде трех rpm-пакетов. В общем случае имена файлов rpm-пакетов имеют
вид:
·
1C_Enterprise-common-8.1.<X>-<Y>.i386.rpm
·
1C_Enterprise-common-nls-8.1.<X>-<Y>.i386.rpm
·
1C_Enterprise-server-8.1.<X>-<Y>.i386.rpm
·
1C_Enterprise-server-nls-8.1.<X>-<Y>.i386.rpm
·
1C_Enterprise-ws-8.1.<X>-<Y>.i386.rpm
·
1C_Enterprise-ws-nls-8.1.<X>-<Y>.i386.rpm
где <X> и <Y> — соответствующие позиции в
версии 1С:Предприятия 8.1. Например, для 1С:Предприятия версии 8.1.5.89
упомянутые файлы будут иметь следующие имена:
·
1C_Enterprise-common-8.1.5-89.i386.rpm
·
1C_Enterprise-common-nls-8.1.5-89.i386.rpm
·
1C_Enterprise-server-8.1.5-89.i386.rpm
·
1C_Enterprise-server-nls-8.1.5-89.i386.rpm
·
1C_Enterprise-ws-8.1.5-89.i386.rpm
·
1C_Enterprise-ws-nls-8.1.5-89.i386.rpm
Установка должна выполняться от лица пользователя root. Для
установки каждого отдельного пакета следует выполнить команду:
rpm -i <Имя_файла_rpm>
Пакеты содержат в себе следующие компоненты:
·
1C_Enterprise-common-8.1.<X>-<Y>.i386.rpm
– общие компоненты для серверной части 1С:Предприятия 8.1;
·
1C_Enterprise-server-8.1.<X>-<Y>.i386.rpm
– компоненты сервера 1С:Предприятия 8.1;
·
1C_Enterprise-ws-8.1.<X>-<Y>.i386.rpm
– адаптер для публикации Web-сервисов 1С:Предприятия 8.1 на Web-сервере на
основе Apache HTTP Server 2.0 или Server 2.2;
Независимо от того, какие составляющие серверной части
1С:Предприятия 8.1 должны быть установлены на компьютере, обязательно должен
быть установлен пакет 1C_Enterprise-common-8.1.<X>-<Y>.i386.rpm.
Более того, данный пакет должен быть установлен первым, так как оставшиеся два
пакета зависят от него.
Если предполагается, что компьютер должен использоваться в
качестве сервера 1С:Предприятия, то должен быть установлен пакет 1C_Enterprise-server-8.1.<X>-<Y>.i386.rpm. При
установке данного пакета на компьютер устанавливаются компоненты, необходимые
для работы сервера 1С:Предприятия, сервер 1С:Предприятия 8.1 регистрируется как
сервис операционной системы и производится запуск данного сервиса.
Таким образом, сразу после установки пакета 1C_Enterprise-server-8.1.<X>-<Y>.i386.rpm сервер
1C:Предприятия 8.1 готов к работе. При установке сервера 1С:Предприятия
создается пользователь операционной системы с именем USR1CV81. От лица данного
пользователя будет производиться запуск серверных процессов 1С:Предприятия.
Если предполагается, что компьютер должен использоваться
для публикации Web-сервисов 1С:Предприятия 8.1, то должен быть установлен пакет
1C_Enterprise-ws-8.1.<X>-<Y>.i386.rpm.
Пакеты
1C_Enterprise-server-8.1.<X>-<Y>.i386.rpm и
1C_Enterprise-ws-8.1.<X>-<Y>.i386.rpm
не зависят друг от друга. Соответственно, они могут быть установлены на одном компьютере
как вместе, так и по отдельности.
Для уже упомянутой версии 8.1.4.20 команда будет выглядеть
следующим образом:
rpm -i
1C_Enterprise-8.1.4-20.i386.rpm
Непосредственно после выполнения установки происходит запуск
серверных процессов 1С:Предприятия 8.1, после чего сервер готов к работе.
Запуск кластера серверов под Linux
Программа установки настраивает запуск серверных процессов
так, что они запускаются в режиме демонов, то есть без привязки к управляющему
терминалу. Это позволяет запускать процессы сервера 1С:Предприятия 8.1 при
старте операционной системы без необходимости входа в систему какого-либо
пользователя.
При необходимости агент сервера может быть запущен с
указанием ключей командной строки.
Запуск агента сервера
Для запуска агента сервера используются следующие ключи
командной строки:
./ragent
-port<порт>
-range<диапазоны>
—seclev<уровень>
·
<порт> — необязательный. Номер IP
порта. Число. По умолчанию — 1540;
·
<диапазоны> — необязательный. Диапазоны
портов для динамического распределения рабочих процессов. Число:Число. По
умолчанию — 1560:1591;
·
<уровень> — необязательный. Уровень
безопасности соединения;
0 — выключено (по
умолчанию);
1 — установка соединения;
2 — постоянно.
Подробнее об уровне безопасности соединения можно прочитать
в разделе «Безопасность данных, передаваемых между консолью кластера серверов и
кластером серверов».
Запуск агента сервера в режиме демона
Для запуска агента сервера в режиме демона используются
следующие ключи командной строки:
./ragent
-daemon -port<порт>
-range<диапазоны>
-seclev<уровень>
·
<порт> — необязательный. Номер IP порта. Число. По умолчанию —
1540;
·
<диапазоны> — необязательный. Диапазоны портов
для динамического распределения рабочих процессов. Число:Число. По умолчанию —
1560:1591;
·
<уровень> — необязательный. Уровень
безопасности соединения;
0 — выключено (по
умолчанию);
1 — установка соединения;
2 —
постоянно.
Подробнее об уровне безопасности соединения можно прочитать
в разделе «Безопасность данных, передаваемых между консолью кластера серверов и
кластером серверов».
Удаление кластера серверов под Linux
Для удаления сервера 1С:Предприятия 8.1 с компьютера
следует воспользоваться все той же командой rpm. Как и установка, удаление
должно выполняться от лица пользователя root. Для удаления следует выполнить
команду:
rpm -e <Имя_пакета_rpm>
<Имя_пакета_rpm> в данном случае – это имя
установленного rpm-пакета серверной части 1С:Предприятия 8.1. Имена rpm-пакетов
серверной части 1С:Предприятия 8.1 имеют следующий вид:
·
1C_Enterprise-common-8.1.<X>-<Y>;
·
1C_Enterprise-server-8.1.<X>-<Y>;
·
1C_Enterprise-ws-8.1.<X>-<Y>,
где <X> и <Y> — соответствующие позиции в
версии 1С:Предприятия 8.1. Как можно заметить, имена rpm-пакетов соответствуют
именам файлов .rpm. Для версии 8.1.4.25 rpm-пакеты 1С:Предприятия 8.1 будут
иметь следующие имена:
·
1C_Enterprise-common-8.1.4-25;
·
1C_Enterprise-server-8.1.4-25;
·
1C_Enterprise-ws-8.1.4-25.
Удаление rpm-пакетов должно выполняться в порядке, обратном
установке, чтобы зависимый rpm-пакет удалялся до того rpm-пакета, от которого
он зависит. В применении к 1С:Предприятию 8.1 это означает, что rpm-пакет 1C_Enterprise-common-8.1.<X>-<Y> должен быть
удален в последнюю очередь. Соответственно команда для удаления упомянутой
версии сервера 1С:Предприятия 8.1 будет иметь следующий вид:
rpm -e 1C_Enterprise-8.1.4-20
Защита кластера серверов от несанкционированного использования
Кластер серверов 1С:Предприятия 8.1 защищен от
несанкционированного использования с помощью ключа аппаратной защиты HASP4.
Защита кластера серверов под Windows
Для успешной работы кластера сервера к USB-порту компьютера, используемого в
качестве сервера кластера 1С:Предприятия 8.1, должен быть присоединен ключ
аппаратной защиты сервера. Кроме того, для обеспечения доступа к ключу, на этом
же компьютере должен быть установлен HASP Device Driver. Программа установки HASP Device Driver
(HINSTALL.EXE) входит в комплект
поставки и устанавливается на центральный сервер кластера при установке кластера
серверов 1С:Предприятия 8.1.
Для установки HASP Device Driver выберите строку «Установка HASP Device Driver» в меню «Пуск —
1С Предприятие 8.1».
Можно также установить HASP Device Driver «вручную».
Для этого из командной строки следует запустить программу HINSTALL.EXE, размещенную в каталоге BIN, с ключом —I. Таким образом, командная
строка для установки HASP Device Driver
имеет следующий вид:
HINSTALL
—I
Важно! Рекомендуется сначала
произвести установку HASP Device Driver,
а затем присоединить ключ к USB-порту.
Важно! Отсоединение аппаратного
ключа защиты из USB-порта
во время работы не допускается!
В случае ненадобности, HASP Device Driver может быть удален из системы. Для
удаления HASP Device Driver выберите строку «Удаление HASP Device Driver» в меню «Пуск — 1С Предприятие 8.1».
Для удаления HASP Device Driver можно также
воспользоваться командной строкой вида:
HINSTALL
–R
Защита кластера серверов под Linux
Установка
драйвера ключа защиты HASP должна производиться в
соответствии с инструкциями производителя, входящими в комплект поставки
драйвера ключа защиты HASP для
Linux.
Установка
серверов баз данных
В качестве сервера баз данных 1С:Предприятия 8.1 может
использоваться MS SQL Server
или PostgreSQL.
Установка MS SQL Server
Установка сервера баз данных производится с дистрибутивных
носителей MS SQL Server.
Никаких специальных требований по его установке и настройке со стороны
1С:Предприятия 8.1 не предъявляется. Однако, если выбран Microsoft SQL Server 2000,
то для безошибочной работы 1С:Предприятия 8.1 требуется, чтобы «поверх» Microsoft SQL Server 2000
был установлен Service Pack
2 (рекомендуется Service Pack 4).
Установка PostgreSQL
Установка сервера баз данных производится с дистрибутивных
носителей 1С:Предприятия 8.1. СУБД PostgreSQL может функционировать как под
управлением операционной системы Windows, так и под управлением операционной системы Linux.
Установка PostgreSQL для
Windows
Для совместной работы с 1С:Предприятием 8.1 необходима
модифицированная версия PostgreSQL.
Сначала необходимо установить PostgreSQL,
а затем выполнить модификацию конфигурационных файлов PostgreSQL.
Установка
Дистрибутив PostgreSQL
состоит из двух файлов:
·
postgresql-8.1for1c-int.msi;
·
postgresql-8.1for1c.msi.
Файл postgresql-8.1for1c.msi необходимо запустить.
После запуска исполняемого файла на экран будет выдано
стартовое окно программы установки:
На этом этапе следует согласиться с выбором английского
языка для установки и нажать кнопку «Start>» для
продолжения установки.
Будет открыто окно Welcome to the PostgreSQL Installation Wizard:
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Installation notes:
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Installation Options:
Вызовите контекстное меню, нажав мышью на пиктограмму
жесткого диска в корне дерева, расположенного в прокручивающемся списке. В открывшемся меню выберите пункт «Entire
feature will be installed on local hard drive».
По умолчанию PostgreSQL будет установлен в каталог «C:\Program
Files\PostgreSQL\8.1for1c\». Для того, чтобы изменить каталог установки,
нажмите кнопку «Browse»,
и выберите требуемый каталог установки:
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Service configuration.
В последние два поля («Account password»
и «Verify password») введите пароль (например, postgres):
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Account error:
Нажмите кнопку «Yes» для продолжения установки.
Будет открыто окно Password:
Нажмите кнопку «No» для продолжения
установки.
Будет открыто окно Success:
Нажмите кнопку «OK>» для продолжения
установки.
Будет открыто окно Initialise database cluster:
Установите флаг «Accept connections on all addreses,
not just localhost».
В поле «Locale» выберите страну/язык
«Russian, Russia».
В поле «Encoding» выберите кодировку
«UTF-8».
После этого в полях «Password» и «Password(again)» задайте пароль (например, postgres).
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Remote connections:
Нажмите кнопку «OK>» для продолжения
установки.
Будет открыто окно Enable procedural languages:
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Enable contrib modules:
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Enable PostGIS:
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Ready to install:
Нажмите кнопку «Next>» для
продолжения установки.
Будет открыто окно Installation complete!:
Нажмите кнопку «Finish» для окончания установки.
Установка PostgreSQL для
Linux
Для совместной работы с 1С:Предприятием 8.1 необходима
модифицированная версия PostgreSQL,
которая содержится в комплекте поставки 1С:Предприятия 8.1.
Установка
Дистрибутив модифицированной версии PostgreSQL состоит
из 12 пакетов. Из них необходимо установить пять и сделать это нужно в
следующем порядке
·
postgresql-1c-libs-8.1.<X>-<Y>for1c.i386.rpm
·
postgresql-1c-8.1.<X>-<Y>.i386.rpm
·
postgresql-1c-server-8.1.<X>-<Y>.i386.rpm
·
postgresql-1c-pl-8.1.<X>-<Y>.i386.rpm
·
postgresql-1c-contrib-8.1.<X>-<Y>.i386.rpm
где <X> и <Y> — соответствующие позиции в
версии PostgreSQL.
Установка каждого пакета выполняется командой
rpm –i <имя_пакеты>
После этого в системе появится пользователь postgres, будет создана база,
размещенная в каталоге ~postgres/data, и будет создан скрипт /etc/init.d/postgresql для старта и остановки СУБД.
Далее нужно установить желаемое значение переменной LANG и
запустить /etc/init.d/postgresql для первичного создания базы.
Это может быть выполнено командой:
LANG=ru_RU.utf-8 /etc/init.d/postgresql start
Все вышеперечисленные действия должен выполнять
пользователь, обладающий привилегиями SUPERUSER.
Глава 3.
Особенности работы 1C:Предприятия 8.1 с
информационными базами в варианте «клиент-сервер»
В общем случае, работа 1С:Предприятия 8.1 с
информационной базой в варианте «клиент-сервер» не имеет существенных отличий
от работы с информационной базой в файловом варианте. Самое заметное
отличие – это создание информационной базы.
Создание информационной базы
Информационная база в варианте «клиент-сервер»
идентифицируется двумя параметрами:
·
адресом кластера серверов
1С:Предприятия 8.1;
именем
информационной базы.
Как было отмечено выше, адрес кластера серверов 1С:Предприятия 8.1
состоит из имени центрального сервера и номера порта, через который работает
менеджер кластера (например, Test_Server:1541). Если менеджер
кластера использует порт, назначаемый по умолчанию (1541), то достаточно
указать только имя сервера. Имя информационной базы уникально в пределах
кластера серверов 1С:Предприятия 8.1.
При добавлении новой информационной базы в список
информационных баз необходимо решить, какие действия будут выполняться:
создание новой информационной базы или добавление в список уже существующей
информационной базы.
Добавление существующей информационной базы
При добавлении в список уже существующей информационной
базы на экран выводится окно:
В полях потребуется указать:
·
адрес кластера серверов 1С:Предприятия 8.1;
·
имя информационной базы.
При этом не производится проверка того, существует ли
информационная база с указанными параметрами или нет.
Если при запуске Конфигуратора информационная база с
указанными параметрами не обнаружена, будет выдано соответствующее сообщение и
вопрос о создании новой информационной базы. Если ответ на вопрос будет
положительным, то Конфигуратор выводит на экран следующую форму:
В поля данной формы надо внести параметры, необходимые для
создания новой информационной базы.
Создание новой информационной базы
При создании новой информационной базы помимо вышеуказанных
параметров необходимо задать еще ряд параметров, необходимых для создания
информационной базы в кластере серверов 1С:Предприятия 8.1:
Дополнительно необходимо задать:
·
тип СУБД — MS SQL Server или PostgreSQL;
·
имя сервера баз данных, в котором размещается
база данных SQL Server
или PostgreSQL,
содержащая данные информационной базы;
·
имя базы данных;
·
имя пользователя сервера баз данных, от лица
которого будет осуществляться доступ к базе данных. Если используется база
данных MS SQL Server,
то существенно, чтобы указанный пользователь был либо администратором сервера
баз данных (sa), либо
собственником базы данных (если она уже существует) для того, чтобы в
дальнейшем беспрепятственно модифицировать структуру выбранной базы данных. В
последнем случае этот пользователь должен иметь доступ на чтение к базе данных master и полный доступ к базе
данных tempdb. Если
используется база данных PostgreSQL,
то указанный пользователь должен либо обладать привилегиями CREATEDB или
SUPERUSER, либо быть собственником базы данных (если она уже существует);
·
пароль пользователя сервера баз данных.
·
смещение дат – 0 или 2000. Доступно только если
используется СУБД MS SQL Server.
Данный параметр определяет число лет, которое будет прибавляться к датам при их
сохранении в базе данных MS SQL Server
и вычитаться при их извлечении. Наличие данного параметра определяется
особенностями хранения дат в MS SQL Server.
Тип DATETIME, используемый
в MS SQL Server, позволяет
хранить даты в диапазоне с 1 января 1753 года по 31 декабря 9999 года. И если
при работе с информационной базой может возникнуть необходимость хранения дат
предшествующих нижней границе данного диапазона, то в качестве значения
параметра следует выбрать 2000. Если же такие даты встречаться не будут, то в
качестве смещения дат можно выбрать 0. После создания информационной базы
значение данного параметра не может быть изменено;
·
если установлен флажок «Создать базу данных в случае
ее отсутствия», то в случае, если указанный сервер баз данных не содержит базу
данных с указанным именем, она будет создана. Если же флажок не установлен, то
попыток создания базы данных предприниматься не будет;
·
значение параметра «Язык (Страна)» выбирается из
предложенного списка и определяет набор национальных настроек, которые будут
использованы при работе с информационной базой. В дальнейшем значение данного
параметра можно изменить с помощью Конфигуратора.
Если все параметры указаны корректно, то выполняются
следующие действия:
·
производится попытка установить соединение с
указанной базой данных в указанном сервере баз данных с применением указанных
параметров пользователя;
·
если база данных отсутствует и установлен флажок
«Создать базу данных в случае ее отсутствия», то производится попытка создания
требуемой базы данных;
·
если в указанной базе данных обнаруживается уже
существующая информационная база 1С:Предприятия 8.1, то устанавливается
связь с ней. Если же не обнаруживается, то инициализируется новая
информационная база. Если при указании параметров создания новой информационной
базы был указан шаблон, то данный шаблон будет применен при инициализации;
Внимание!!! Связь с
информационной базой, размещаемой в базе данных сервера баз данных, может быть
установлена только для одного кластера серверов 1С:Предприятия 8.1.
Программные средства администрирования кластера серверов
1С:Предприятия 8.1
Программный
интерфейс администрирования кластера серверов 1С:Предприятия 8.1 описан в
справке в разделе «Средства интеграции и администрирования — COM-соединитель —
Администрирование кластера серверов».
Для администрирования кластера серверов используются два
объекта: Соединение с агентом сервера и Соединение с рабочим процессом.
Соединение с агентом сервера может быть получено при помощи
метода ConnectAgent() объекта СОМ-соединитель:
COMСоединитель = Новый
COMОбъект(«V81.COMConnector»);
СоединениеСАгентомСервера = COMСоединитель.ConnectAgent(«TestSrv«);
Соединение с агентом сервера позволяет выполнять такие
действия как:
·
аутентификация, добавление, удаление, получение
списка администраторов центрального сервера и администраторов кластера;
·
создание, удаление, получение списка кластеров;
·
создание, удаление, получение списка серверов;
·
создание, удаление, получение списка рабочих
процессов кластера;
·
получение списка соединений кластера;
·
получение списка соединений информационной базы;
·
получение списка информационных баз,
зарегистрированных в кластере;
·
получение списка блокировок кластера;
·
получение другой информации.
Соединение с рабочим процессом может быть получено при
помощи метода ConnectServer() объекта СОМ-соединитель:
COMСоединитель = Новый
COMОбъект(«V81.COMConnector»);
СоединениеСРабочимПроцессом = COMСоединитель.
ConnectServer(«TestSrv:1562″);
Соединение с рабочим процессом позволяет выполнять такие
действия как:
·
аутентификация пользователей информационных баз;
·
создание, удаление, получение списка
информационных баз, зарегистрированных в кластере;
·
получение списка соединений информационной базы;
·
разрыв соединения информационной базы;
·
соединение с информационной базой (COM-соединение);
·
получение другой информации.
Глава 4.
Утилита администрирования кластера серверов
Данная утилита представляет собой подключаемый (snap—in) модуль Microsoft management console и может быть
использована на компьютерах, на которых установлено программное обеспечение Microsoft management console. Microsoft management console является стандартным
средством в операционных системах Microsoft Windows 2000/XP/Server 2003. При установке 1С:Предприятия 8.1 для
работы с информационными базами в варианте «клиент-сервер» в этих операционных
системах, соответствующий пункт для запуска утилиты будет внесен в системное
меню «Пуск» в раздел «1С Предприятие 8.1».
Задачи, решаемые с помощью утилиты администрирования
кластера серверов, аналогичны возможностям программного администрирования
кластера серверов, описанным в разделе «Программные средства администрирования
кластера серверов 1С:Предприятия 8.1».
Запуск утилиты администрирования
Утилита может быть запущена только на компьютере, на
котором имеется программное обеспечение Microsoft management console. Запуск утилиты может
быть осуществлен через соответствующий пункт раздела
«1С Предприятие 8.1» системного меню «Пуск».
Есть и альтернативный путь. Для этого следует запустить Microsoft management console. Сделать это можно с
помощью командной строки:
mmc
После того, как Microsoft management console будет запущена,
следует выбрать в меню «File»
(в
MS Windows XP/Server 2003) или меню «Console»
(в
MS Windows 2000) пункт Add/Remove Snap-in.
На экране появится диалог Add/Remove Snap—in. В этом диалоге следует
нажать кнопку «Add».
На экране появится диалог Add Standalone Snap—in. В списке этого диалога следует
выбрать пункт 1С:Enterprise 8.1 Servers, нажать кнопку «Add». и
закрыть диалог с помощью кнопки «Close».
Затем следует в диалоге Add/Remove Snap—in нажать кнопку «ОК». Таким образом, будет
выполнено подключение утилиты администрирования к Microsoft management console.
Работа со списком центральных серверов
При первом запуске утилита администрирования показывает в
дереве центральных серверов только сервер, установленный на компьютере, на
котором запущена сама утилита администрирования (если, конечно, агент сервера
запущен на этом компьютере).
Для отображения списка центральных серверов следует в
дереве центральных серверов выбрать и раскрыть ветку «Центральные серверы
1С:Предприятия 8.1»:
Дерево центральных серверов содержит перечень центральных
серверов, к которым подключена утилита. Каждый центральный сервер
идентифицируется именем компьютера, на котором он запущен. В поле свойств
отображается список центральных серверов, содержащий имя центрального сервера и
его описание.
Подключение утилиты к центральному серверу
Для подключения
утилиты к новому центральному серверу следует выполнить команду контекстного
меню «New — Центральный сервер 1С:Предприятия 8.1»
или аналогичную команду главного меню утилиты:
В результате выполнения команды на экране появится диалог
свойств центрального сервера:
В поля диалога необходимо ввести следующие данные:
·
Протокол – протокол
соединения с центральным сервером. Выбирается из списка. Значение по умолчанию
– tcp. В этом поле
указывается протокол, по которому утилита администрирования будет подключаться
к агенту центрального сервера. Поддерживается единственное значение – tcp;
·
Имя – имя центрального
сервера. Именем является сетевое имя компьютера, на котором запущен агент
сервера;
·
IP порт – номер порта
агента сервера, который запущен на центральном сервере. Значение по умолчанию –
1540. Порт агента сервера указывается при его запуске (см. раздел «Запуск
кластера серверов 1С:Предприятия 8.1»);
·
Описание – произвольное
описание центрального сервера.
Просмотр и изменение свойств центрального сервера
Для того, чтобы просмотреть и изменить свойства
центрального сервера, следует выбрать требуемый сервер в списке центральных
серверов и выполнить команду контекстного меню «Properties»
или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств центрального сервера, описанный в предыдущем разделе.
Отключение утилиты от центрального сервера
Для отключения утилиты от центрального сервера следует
выбрать требуемый сервер в списке центральных серверов и выполнить команду
контекстного меню «Delete» или аналогичную команду главного меню утилиты.
Отсоединение утилиты от центрального сервера
Утилита администрирования кластера серверов
1С:Предприятия 8.1 может быть отсоединена от центрального сервера, при этом
параметры подключения к центральному серверу удалены не будут.
Для отсоединения от центрального сервера следует выбрать
требуемый сервер в списке центральных серверов и выполнить команду контекстного
меню «Отсоединить» или аналогичную команду главного меню
утилиты.
Работа со списком администраторов центрального сервера
Кластер серверов предоставляет возможность создать список
администраторов центрального сервера для того, чтобы ряд административных
действий (например, добавление нового кластера, просмотр списка администраторов
центрального сервера) могли выполнять только аутентифицированные пользователи.
По умолчанию список администраторов центрального сервера
пуст. Это означает, что для выполнения перечисленных действий система не будет
требовать аутентификацию администратора центрального сервера.
Для отображения списка администраторов центрального сервера
следует в дереве центральных серверов выбрать нужный сервер, а затем выбрать и
раскрыть ветку «Администраторы»:
Дерево центральных серверов содержит перечень
администраторов выбранного центрального сервера. Каждый администратор
идентифицируется именем. В поле свойств отображается список администраторов
выбранного центрального сервера, содержащий имя администратора и его описание.
Добавление администратора центрального сервера
Для добавления нового администратора центрального сервера
следует выбрать в дереве центральных серверов требуемый сервер, выбрать ветку
«Администраторы» и выполнить команду контекстного меню «New —
Администратор» или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств администратора центрального сервера:
В поля диалога необходимо ввести следующие данные:
·
Имя – имя администратора
центрального сервера;
Внимание! Имена администраторов
центрального сервера должны быть уникальными в пределах каждого центрального
сервера.
·
Описание – произвольное
описание администратора центрального сервера;
·
Аутентификация паролем –
признак аутентификации паролем. По умолчанию установлен;
·
Пароль – пароль
администратора центрального сервера;
·
Подтверждение пароля – подтверждение пароля;
·
Аутентификация операционной
системы – признак аутентификации средствами
операционной системы;
·
Пользователь — пользователь операционной системы. Может быть задан
в виде: «\\имя домена\имя пользователя». Например: \\domainname\username.
Пользователь может быть установлен как непосредственным вводом соответствующей
строки, так и посредством выбора пользователя операционной системы среди
пользователей, видимых с компьютера, на котором запущена утилита
администрирования информационных баз. Для этого необходимо нажать кнопку «…» и
в открывшемся диалоге выбрать нужного пользователя операционной системы.
Система допускает аутентификацию администратора
центрального сервера двумя способами: с помощью пароля и средствами
операционной системы.
В случае аутентификации с помощью пароля система вызовет
диалог аутентификации администратора центрального сервера, в котором необходимо
ввести имя пользователя и пароль.
В случае аутентификации средствами операционной системы не
требуется каких-либо действий по вводу логина и пароля, диалог аутентификации
не отображается. Система анализирует, от имени какого пользователя операционной
системы выполняется подключение, и на основании этого определяет
соответствующего администратора центрального сервера.
Если для администратора не указан ни один из видов
аутентификации, то такой администратор может выполнять только те действия,
которые не требуют аутентификации.
Просмотр и изменение свойств администратора центрального сервера
Для просмотра и изменения свойств администратора
центрального сервера следует выбрать требуемого администратора в списке
администраторов центрального сервера и выполнить команду контекстного меню «Properties»
или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств администратора центрального сервера:
Все свойства, за исключением имени администратора, будут
доступны для редактирования, значения полей «Пароль» и «Подтверждение пароля» будут скрыты.
Удаление администратора центрального сервера
Для удаления администратора центрального сервера следует
выбрать требуемого администратора в списке администраторов центрального сервера
и выполнить команду контекстного меню «Delete» или аналогичную команду
главного меню утилиты.
Аутентификация администратора центрального сервера
Аутентификация
администратора центрального сервера будет запрошена системой автоматически, при
попытке выполнения действия, требующего аутентификации (если список
администраторов центрального сервера не пуст). При этом на экране появится
диалог аутентификации администратора центрального сервера:
В поля диалога необходимо ввести следующие данные:
·
Имя – имя администратора
центрального сервера;
·
Пароль – пароль
администратора центрального сервера.
Работа со списком кластеров центрального сервера
Для отображения списка кластеров, зарегистрированных на
центральном сервере, следует в дереве центральных серверов выбрать нужный
сервер, а затем выбрать и раскрыть ветку «Кластеры»:
Дерево центральных серверов содержит перечень кластеров
выбранного центрального сервера. Каждый кластер идентифицируется номером порта.
В поле свойств отображается список кластеров выбранного центрального сервера,
содержащий номер порта кластера и описание кластера.
Добавление кластера
Для добавления нового кластера в центральный сервер следует
выбрать в дереве центральных серверов требуемый сервер, выбрать ветку
«Кластеры» и выполнить команду контекстного меню «New —
Кластер» или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств кластера:
В поля диалога необходимо ввести следующие данные:
·
Описание – произвольное
описание кластера;
·
Компьютер – имя
центрального сервера, на котором размещается кластер. Не редактируется;
·
IP Порт – номер порта менеджера
кластера. По умолчанию 1541.
Внимание! Номера портов
менеджеров кластеров должны быть уникальными в пределах каждого центрального
сервера.
·
Много процессов – признак
возможности запуска нескольких рабочих процессов в кластере. По умолчанию не
установлен;
·
Безопасное соединение –
уровень безопасности кластера. Выбирается из списка (возможные значения:
выключено, только соединение, постоянно). Значение по умолчанию – выключено.
Подробнее об использовании уровней безопасности кластера можно прочитать в
разделе «Безопасность данных, передаваемых между консолью кластера серверов и
кластером серверов», и в разделе «Безопасность данных, передаваемых внутри кластера
серверов».
Просмотр и изменение свойств кластера
Для просмотра и изменения свойств кластера следует выбрать
требуемый кластер в списке кластеров центрального сервера и выполнить команду
контекстного меню «Properties» или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств кластера:
Помимо свойств, которые отображаются в диалоге при создании
нового кластера, диалог свойств существующего кластера отображает также
служебный IP порт
менеджера кластера, который назначается системой автоматически при запуске
менеджера кластера и используется для взаимодействия процессов кластера
сервера.
В свойствах существующего кластера доступны для изменения
только три поля: «Описание», «Много
процессов» и «Безопасное соединение».
Удаление кластера
Для удаления кластера следует выбрать требуемый кластер в
списке кластеров центрального сервера и выполнить команду контекстного меню «Delete»
или аналогичную команду главного меню утилиты.
Удаление существующего кластера возможно только в том
случае, если он не содержит ни одного активного соединения и не содержит ни
одного рабочего процесса, ни одного сервера и ни одной зарегистрированной
информационной базы.
В противном случае при попытке удаления кластера будет
выдано сообщение об ошибке:
Работа со списком администраторов кластера
Система предоставляет возможность создать отдельный список
администраторов для каждого кластера, зарегистрированного на центральном
сервере, для того, чтобы административные действия, с кластером могли выполнять
только аутентифицированные пользователи.
По умолчанию список администраторов кластера пуст. Это
означает, что система не будет требовать аутентификацию администратора
кластера.
Для отображения списка администраторов кластера следует в
дереве центральных серверов выбрать нужный сервер, выбрать нужный кластер,
зарегистрированный на этом сервере, а затем выбрать и раскрыть ветку
«Администраторы»:
Дерево центральных серверов содержит перечень
администраторов выбранного кластера. Каждый администратор идентифицируется
именем. В поле свойств отображается список администраторов выбранного кластера,
содержащий имя администратора и его описание.
Добавление администратора кластера
Для добавления нового администратора кластера следует
выбрать в дереве центральных серверов требуемый сервер, выбрать требуемый
кластер, зарегистрированный на этом сервере, выбрать ветку «Администраторы» и
выполнить команду контекстного меню «New — Администратор»
или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств администратора центрального сервера:
В поля диалога необходимо ввести следующие данные:
·
Имя – имя администратора
кластера;
Внимание! Имена администраторов
кластера должны быть уникальными в пределах каждого кластера.
·
Описание – произвольное
описание администратора кластера;
·
Аутентификация паролем –
признак аутентификации паролем. По умолчанию установлен;
·
Пароль – пароль
администратора кластера;
·
Подтверждение пароля – подтверждение пароля;
·
Аутентификация операционной
системы – признак аутентификации средствами
операционной системы;
·
Пользователь — пользователь операционной системы. Может быть задан в виде:
«\\имя домена\имя пользователя». Например: \\domainname\username. Пользователь
может быть установлен как непосредственным вводом соответствующей строки, так и
посредством выбора пользователя операционной системы среди пользователей,
видимых с компьютера, на котором запущена утилита администрирования
информационных баз. Для этого необходимо нажать кнопку «…» и в открывшемся
диалоге выбрать нужного пользователя операционной системы.
Система допускает аутентификацию администратора кластера
двумя способами: с помощью пароля и средствами операционной системы.
В случае аутентификации с помощью пароля система вызовет
диалог аутентификации администратора кластера, в который необходимо ввести имя
пользователя и пароль.
В случае аутентификации средствами операционной системы не
требуется каких-либо действий по вводу имени пользователя и пароля, диалог
аутентификации не отображается. Система анализирует, от имени какого
пользователя операционной системы выполняется подключение, и на основании этого
определяет соответствующего администратора кластера.
Если для администратора не указан ни один из видов
аутентификации, то такой администратор может выполнять только те действия,
которые не требуют аутентификации.
Просмотр и изменение свойств администратора кластера
Для просмотра и изменения свойств администратора кластера
следует выбрать требуемого администратора в списке администраторов кластера и
выполнить команду контекстного меню «Properties» или аналогичную
команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств администратора кластера:
Все свойства, за исключением имени администратора, будут
доступны для редактирования, значения полей «Пароль» и «Подтверждение пароля» будут скрыты.
Удаление администратора кластера
Для удаления администратора кластера следует выбрать требуемого
администратора в списке администраторов кластера и выполнить команду
контекстного меню «Delete» или аналогичную команду главного меню утилиты.
Аутентификация администратора кластера
Аутентификация
администратора кластера будет запрошена системой автоматически, при попытке
выполнения действия, требующего аутентификации (если список администраторов
кластера не пуст). При этом на экране появится диалог аутентификации
администратора кластера.
В поля диалога необходимо ввести следующие данные:
·
Имя – имя администратора
кластера;
·
Пароль – пароль
администратора кластера.
Работа со списком рабочих серверов кластера
Для отображения списка рабочих серверов кластера следует в
дереве центральных серверов выбрать нужный сервер, выбрать нужный кластер,
зарегистрированный на данном сервере, а затем выбрать и раскрыть ветку «Рабочие
серверы»:
Дерево центральных серверов содержит перечень рабочих
серверов кластера. Каждый рабочий сервер идентифицируется сетевым именем. В
поле свойств отображается список рабочих серверов выбранного кластера,
содержащий имя сервера, номер порта агента сервера, запущенного на этом
сервере, и описание сервера.
Добавление рабочего сервера в кластер
Для добавления нового рабочего сервера в кластер следует
выбрать в дереве центральных серверов требуемый центральный сервер, выбрать
требуемый кластер, зарегистрированный на этом сервере, выбрать ветку «Рабочие
серверы» и выполнить команду контекстного меню «New — Рабочий
сервер» или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств рабочего сервера:
В поля диалога необходимо ввести следующие данные:
·
Описание сервера –
произвольное описание сервера кластера;
·
Компьютер – сетевое имя компьютера,
который будет являться рабочим сервером кластера;
Внимание! Для того, чтобы
компьютер можно было добавить в качестве рабочего сервера кластера, на нем
должен быть установлен кластер серверов. Если выбранный компьютер не
предполагается использовать в качестве центрального сервера какого-либо
кластера, то все кластеры, созданные на нем, должны быть удалены.
·
IP порт – номер порта
агента сервера, который запущен на указанном компьютере. По умолчанию 1540;
·
Диапазоны IP портов –
диапазон IP адресов, который
будет использоваться системой для назначения адресов рабочим процессам,
создаваемым на этом сервере. По умолчанию — 1560:1591.
Просмотр и изменение свойств сервера кластера
Для просмотра и изменения свойств сервера кластера следует
выбрать требуемый сервер в списке серверов кластера и выполнить команду
контекстного меню «Properties» или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств рабочего сервера:
Помимо свойств, которые отображаются в диалоге при создании
нового сервера, диалог свойств существующего сервера отображает также служебный
IP порт агента сервера,
который назначается системой автоматически при запуске агента сервера и
используется для взаимодействия процессов кластера сервера.
В свойствах существующего сервера доступен для изменения
только диапазон IP
портов.
Исключение сервера из кластера
Для исключения сервера из состава кластера следует выбрать
требуемый сервер в списке серверов кластера и выполнить команду контекстного
меню «Delete»
или аналогичную команду главного меню утилиты.
Исключение существующего рабочего сервера возможно только в
том случае, если он не содержит ни одного активного соединения и не содержит ни
одного рабочего процесса.
В противном случае при попытке исключения рабочего сервера
из кластера будет выдано сообщение об ошибке:
Работа со списком рабочих процессов
Список рабочих процессов может быть отображен двумя
способами:
·
для всего кластера в целом;
·
отдельно для выбранного сервера кластера.
Для отображения списка рабочих процессов для всего кластера
в целом, следует в дереве центральных серверов выбрать нужный сервер, выбрать
нужный кластер, зарегистрированный на данном сервере, а затем выбрать и
раскрыть ветку «Процессы»:
Для отображения списка рабочих процессов только для
выбранного сервера кластера, следует в дереве центральных серверов выбрать
нужный сервер, выбрать нужный кластер, выбрать нужный сервер кластера, а затем
выбрать и раскрыть ветку «Процессы»:
Дерево центральных серверов содержит перечень рабочих
процессов. Каждый рабочий процесс идентифицируется именем сервера. В поле
свойств отображается список рабочих процессов, содержащий имя сервера, номер
порта рабочего процесса и признаки включенности и активности рабочего процесса.
Признак включенности рабочего процесса может
устанавливаться или сниматься в свойствах рабочего процесса, а признак
активности свидетельствует о том, что рабочий процесс запущен и выполняется.
Добавление рабочего процесса
Добавление рабочего процесса, в отличие от просмотра,
возможно только для конкретного сервера кластера.
Для добавления нового рабочего процесса сервера кластера
следует выбрать в дереве центральных серверов требуемый сервер, выбрать
требуемый кластер, выбрать требуемый сервер кластера, выбрать ветку «Процессы»
и выполнить команду контекстного меню «New — Процесс»
или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств рабочего процесса:
В поля диалога необходимо ввести следующие данные:
·
Компьютер – имя сервера,
на котором будет запущен рабочий процесс. Недоступно для изменения;
·
Производительность –
относительное значение производительности, Значение по умолчанию – 1000.
Подробнее можно прочитать в разделе «Анализ статистики загруженности рабочих
процессов».
·
Процесс включен – признак
включенности процесса. По умолчанию не установлен. Это означает, что при
запуске кластера данный рабочий процесс не будет запущен.
Просмотр и изменение свойств рабочего процесса
Для просмотра и изменения свойств рабочего процесса следует
выбрать требуемый рабочий процесс в списке рабочих процессов и выполнить
команду контекстного меню «Properties» или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств рабочего процесса:
Помимо свойств, которые отображаются в диалоге при создании
нового рабочего процесса, диалог свойств существующего рабочего процесса
содержит следующие поля, которые недоступны для редактирования:
·
Процесс запущен – признак
активности процесса. Если он установлен это означает, что процесс запущен и
выполняется;
·
Время запуска – время
последнего запуска рабочего процесса;
·
IP порт – адрес рабочего
процесса, который выделяется системой динамически при запуске рабочего процесса
из диапазона IP
адресов, указанного для данного сервера;
·
Служебный порт –
служебный порт рабочего процесса, назначаемый системой при запуске рабочего
процесса. Используется для взаимодействия процессов сервера;
·
Соединений – текущее
количество соединений, обслуживаемых рабочим процессом;
·
Реакция сервера – среднее
время, затраченное на обслуживание одного соединения. Равно сумме значений
следующих четырех полей: «Затрачено сервером», «Затрачено СУБД», «Затрачено клиентом» и
«Затрачено менеджером блокировок»;
·
Затрачено сервером –
среднее время, затраченное рабочим процессом на обслуживание одного соединения;
·
Затрачено СУБД – среднее
время, затраченное СУБД на обслуживание одного соединения;
·
Затрачено клиентом – среднее
время, затраченное клиентом на обслуживание одного соединения;
·
Затрачено менеджером блокировок
– среднее время, затраченное менеджером блокировок на обслуживание одного
соединения;
·
Клиентских потоков –
среднее количество клиентских потоков, обработанное рабочим процессом.
Используется системой для вычисления производительности рабочего процесса.
Подробнее о параметрах производительности рабочего процесса
можно прочитать в разделе «Анализ статистики загруженности рабочих процессов».
В свойствах существующего рабочего процесса доступны для
изменения только производительность и признак включенности рабочего процесса.
Остановка/запуск рабочего процесса
Для остановки рабочего процесса следует открыть диалог
свойств нужного рабочего процесса и снять флаг включенности рабочего процесса.
Рабочий процесс будет остановлен после того, как завершится последнее
клиентское соединение, обслуживаемое данным рабочим процессом. При повторных
запусках кластера серверов выключенные рабочие процессы запускаться не будут.
Для запуска остановленного рабочего процесса следует
открыть диалог свойств нужного рабочего процесса и установить флаг включенности
рабочего процесса. Через некоторое время рабочий процесс будет запущен
менеджером кластера.
Удаление рабочего процесса
Для удаления рабочего процесса из состава кластера следует
выбрать требуемый рабочий процесс в списке рабочих процессов и выполнить
команду контекстного меню «Delete» или аналогичную команду главного меню утилиты.
Выбранный рабочий процесс может быть удален только в том
случае, если он не обслуживает ни одного соединения.
При попытке удаления рабочего процесса, содержащего
соединения, будет выдано сообщение об ошибке:
Работа со списком информационных баз
Для отображения списка информационных баз, зарегистрированных
в кластере, следует в дереве центральных серверов выбрать нужный сервер,
выбрать нужный кластер, зарегистрированный на данном сервере, а затем выбрать и
раскрыть ветку «Информационные базы»:
Дерево центральных серверов содержит перечень
информационных баз кластера. Каждая информационная база идентифицируется
именем. В поле свойств отображается список информационных баз выбранного
кластера, содержащий имя информационной базы и ее описание.
Регистрация новой информационной базы
Регистрация новой информационной базы в кластере серверов
может быть выполнена двумя способами: из клиентского приложения и
непосредственно в кластере серверов.
При добавлении новой информационной базы в клиентском
приложении ее регистрация в кластере серверов выполняется системой автоматически.
Для регистрации новой информационной базы с помощью утилиты
администрирования кластера серверов следует выбрать в дереве центральных
серверов требуемый центральный сервер, выбрать требуемый кластер,
зарегистрированный на этом сервере, выбрать ветку «Информационные базы» и
выполнить команду контекстного меню «New — Информационная база» или аналогичную
команду главного меню утилиты.
В результате выполнения команды на экране появится диалог
свойств информационной базы:
В поля диалога необходимо ввести следующие данные:
·
Имя – имя информационной
базы в кластере серверов;
Внимание! Имена информационных
баз должны быть уникальными в пределах одного кластера.
·
Описание – произвольное
описание информационной базы;
·
Безопасное соединение –
уровень безопасности информационной базы. Выбирается из списка (возможные
значения: выключено, установка соединения, постоянно). По умолчанию –
выключено. Подробнее об использовании уровней безопасности информационной базы
можно прочитать в разделе «Безопасность данных, передаваемых между клиентом и
кластером серверов».
·
Сервер баз данных –
сетевое имя компьютера, на котором установлен сервер баз данных;
·
Тип СУБД — тип
используемого сервера баз данных. Выбирается из списка (возможные значения: MS SQL Server и Postgre SQL). Значение по умолчанию —
MS SQL Server;
·
База данных — имя базы
данных на сервере баз данных;
·
Пользователь сервера БД —
имя пользователя сервера баз данных, от лица которого будет осуществляться
доступ к базе данных. Если используется база данных MS SQL Server, то существенно, чтобы
указанный пользователь был либо администратором сервера баз данных (sa), либо собственником базы
данных (если она уже существует) для того, чтобы в дальнейшем беспрепятственно
модифицировать структуру выбранной базы данных. В последнем случае этот
пользователь должен иметь доступ на чтение к базе данных master и полный доступ к базе данных tempdb. Если используется
база данных PostgreSQL,
то указанный пользователь должен либо обладать привилегиями CREATEDB или SUPERUSER,
либо быть собственником базы данных (если она уже существует);
·
Пароль пользователя БД —
пароль пользователя сервера баз данных;
·
Язык(Страна) —
региональные настройки, которые будут использованы при работе с информационной
базой. Выбирается из списка. Значение по умолчанию — Русский (Россия). В
дальнейшем значение этого свойства можно изменить с помощью Конфигуратора;
·
Смещение дат – Выбирается
из списка. Может иметь одно из двух значений: 0 или 2000. Данный параметр
определяет число лет, которое будет прибавляться к датам при их сохранении в
базе данных MS SQL Server
и вычитаться при их извлечении. Наличие данного параметра определяется
особенностями хранения дат в MS SQL Server.
Тип DATETIME,
используемый в MS SQL Server,
позволяет хранить даты в диапазоне с 1 января 1753 года по 31 декабря 9999
года. И если при работе с информационной базой может возникнуть необходимость
хранения дат предшествующих нижней границе данного диапазона, то в качестве
значения параметра следует выбрать 2000. Если же такие даты встречаться не
будут, то в качестве смещения дат можно выбрать 0. После создания
информационной базы значение данного параметра не может быть изменено.
·
Создать базу данных в случае ее
отсутствия – признак создания базы данных с указанным именем на сервере
базы данных, если при создании информационной базы, эта база данных не была
найдена на сервере. Если при регистрации новой
информационной базы этот признак установлен не был, и система не нашла базы
данных с таким именем, то она выдаст ошибку.
В процессе регистрации новой информационной базы система
проверяет, существует ли на указанном сервере баз данных база с таким именем.
Если база существует, то будет установлено соединение с ней. Если существующая
база данных уже содержит данные информационной базы 1С:Предприятия, то будет
установлена связь с уже существующей информационной базой. А если база данных
не содержит данных информационной базы, то в ней будет проинициализирована
новая информационная база 1С:Предприятия 8.1.
Просмотр свойств информационной базы
Для просмотра и изменения свойств информационной базы
следует выбрать требуемую информационную базу в списке информационных баз и
выполнить команду контекстного меню «Properties» или аналогичную
команду главного меню утилиты:
Для редактирования будут доступны свойства, относящиеся к
блокировке установки соединений пользователей в данной базой:
Блокировка установки соединений
включена — если флаг установлен это означает, что блокировка установки
соединений пользователей с данной информационной базой включена;
Если для информационной базы установлена блокировка
соединения, то запуск регламентных заданий блокируется, а при выполнении
фоновых заданий будет выдаваться ошибка соединения с информационной базой.
Начало — дата/ время начала
актуальности блокировки. Блокировка начинает действовать, если текущее время
превышает значение данного свойства;
Конец — дата/ время конца
актуальности блокировки. Если значение данного свойства отлично от нулевой даты
и меньше или равно текущему времени, то действие блокировки заканчивается;
Сообщение — текст, который будет
частью сообщения об ошибке при попытке установки соединения с заблокированной
информационной базой;
Код разрешения — строка, которая
должна быть добавлена к параметру командной строки «/uc» или к параметру
строки соединения «uc», чтобы установить соединение с информационной
базой вопреки блокировке установки соединений;
Параметр блокировки —
произвольный текст. Может использоваться в конфигурациях для различных целей.
Блокировка регламентных заданий включена
— если флаг установлен, это означает, что блокировка регламентных заданий
данной информационной базы включена.
Удаление информационной базы
Для удаления информационной базы следует выбрать требуемую
информационную базу в списке информационных баз и выполнить команду
контекстного меню «Delete» или аналогичную команду главного меню утилиты.
В результате выполнения команды на экране появится
предупреждающий вопрос: «Удалить информационную базу?».
При положительном ответе на этот вопрос система предложит
один из трех вариантов удаления информационной базы:
Может быть выбран один из следующих вариантов:
·
Удалить базу данных — при
выборе этого варианта будет удалена регистрация информационной базы в кластере
сервера и кроме этого будет удалена соответствующая ей база данных на сервере
баз данных;
·
Очистить базу данных —
при выборе этого варианта будет удалена регистрация информационной базы в
кластере сервера и кроме этого будут удалены все данные из базы данных на
сервере баз данных. Сама база данных не будет удалена из сервера баз данных;
Оставить без изменений — при выборе этого варианта будет
удалена только регистрация информационной базы в кластере сервера. Никаких
изменений в базе данных произведено не будет.
В том случае, если выбран вариант «Удалить базу
данных», но есть соединения пользователей с этой базой данных, будет
удалена регистрация информационной базы в кластере сервера, а при попытке
удаления базы данных сервер баз данных выдаст сообщение об ошибке, например:
Работа со списком соединений
Список соединений может быть отображен несколькими
способами:
·
для всего кластера в целом;
·
для отдельного рабочего процесса кластера;
·
для отдельной информационной базы;
·
для отдельного рабочего процесса сервера
кластера;
Для отображения списка соединений для всего кластера в
целом, следует в дереве центральных серверов выбрать нужный центральный сервер,
выбрать нужный кластер, зарегистрированный на данном сервере, а затем выбрать и
раскрыть ветку «Соединения»:
Для отображения списка соединений для отдельного процесса
кластера, следует в дереве центральных серверов выбрать нужный центральный
сервер, выбрать нужный кластер, выбрать нужный рабочий процесс, а затем выбрать
и раскрыть ветку «Соединения»:
Для отображения списка соединений для отдельной
информационной базы, следует в дереве центральных серверов выбрать нужный
центральный сервер, выбрать нужный кластер, выбрать нужную информационную базу,
а затем выбрать и раскрыть ветку «Соединения»:
Для отображения списка соединений для отдельного процесса
сервера кластера, следует в дереве центральных серверов выбрать нужный
центральный сервер, выбрать нужный кластер, выбрать нужный сервер кластера,
выбрать нужный рабочий процесс, а затем выбрать и раскрыть ветку «Соединения»:
В дереве центральных серверов соединения не отображаются. В
поле свойств отображается список соединений, содержащий следующую информацию:
·
База — имя
информационной базы, с которой установлено соединение;
·
Номер — номер
соединения. Номер каждого следующего соединения с информационной базой на 1 больше,
чем номер предыдущего соединения. Новое соединение получает номер 1 только если
до него с информационной базой не было ни одного соединения. Номера 0 имеют
только служебные соединения, не связанные ни с какой информационной базой.
Таким образом, как в файловом, так и в клиент-серверном варианте нумерация
соединений начинается с 1 только после того, как от информационной базы
отсоединятся все клиенты, включая регламентные и фоновые задания;
·
Пользователь —
имя пользователя информационной базы;
·
Компьютер —
сетевое имя компьютера пользователя, установившего соединение;
·
Приложение —
режим запуска клиентского приложения (1С:Предприятие или Конфигуратор);
·
Сервер — имя
сервера кластера, с которым установлено соединение;
·
Порт — номер
порта рабочего процесса, обслуживающего это соединение;
·
Установлено в —
время в которое это соединение было установлено.
Если список соединений открыт для отдельной информационной
базы, то в поле свойств отображаются дополнительные колонки, позволяющие
оперативно анализировать блокировки базы данных:
·
Соединение с СУБД — идентификатор процесса сервера баз данных.
Отображается в том случае, если в момент открытия диалога свойств, соединение
выполняет обращение к базе данных;
·
Удерживается —
время, в течение которого удерживается соединение с СУБД;
·
Заблокировано — Имя
пользователя(Номер соединения) в том случае, если процесс ожидает освобождения
транзакционной блокировки.
·
Заблокировано СУБД —
идентификатор процесса, который заблокировал данный процесс;
А также другие колонки, назначение которых понятно из их
названия.
Виды соединений
Консоль кластера
серверов может отображать два вида соединений: соединения с информационной
базой и служебные соединения с рабочими процессами кластера.
Соединения
с информационной базой
Соединения с информационной
базой имеют следующие отличительные особенности:
·
соединение выполняется с конкретной
информационной базой кластера;
·
в таком соединении может выполняться код на
встроенном языке;
·
соединение может быть разорвано принудительно
командой консоли кластера или средствами встроенного языка;
·
наличие соединений с информационной базой у
рабочего процесса кластера препятствует остановке и запуску этого рабочего
процесса.
Возможны следующие виды соединений с
информационной базой:
·
1С:Предприятие
·
Конфигуратор
·
COM-соединение
·
Фоновое задание
·
WS-соединение
1С:Предприятие
Представляет собой
соединение клиентского приложения с информационной базой. Это соединение
предназначено для модификации данных информационной базы и выполнения другой
функциональности, предоставляемой конфигурацией информационной базы.
Соединение
1С:Предприятие создается в результате интерактивного запуска клиентского
приложения в режиме «1С:Предприятие» или в результате подключения к
информационной базе с использованием технологии Automation Client/Server,
например:
// Создать Automation
сервер 1С:Предприятия
AutomationCервер = Новый COMОбъект(“V81.Application”);
// Установить
соединение с информационной базой
// TestBase в
кластере 1541 центрального сервера TestSrv AutomationCервер.Connect(“Srvr=””TestSrv””;Ref=””TestBase”””);
Соединение
1С:Предприятие существует до тех пор, пока не будет завершен сеанс
интерактивной работы с информационной базой или пока существует объект Automation сервера 1С:Предприятия.
Конфигуратор
Представляет собой
соединение клиентского приложения с информационной базой. Это соединение
предназначено для создания и модификации конфигурации информационной базы и для
выполнения административных и регламентных действий.
Соединение
конфигуратора создается в результате интерактивного запуска клиентского
приложения в режиме «Конфигуратор» и существует до тех пор, пока не будет
завершен сеанс интерактивной работы с информационной базой.
COM-соединение
Представляет собой
соединение процесса, использующего функциональность внешнего соединения
1С:Предприятия, с информационной базой. Это соединение предназначено для
модификации данных информационной базы и выполнения другой функциональности,
предоставляемой конфигурацией информационной базы.
COM-соединение
создается в результате подключения к информационной базе с использованием
технологии COM, например:
// Создать
COMСоединитель 1С:Предприятия
COMСоединитель =
Новый COMОбъект(«V81.COMConnector»);
// Установить
соединение с информационной базой
// TestBase в кластере 1541 центрального сервера TestSrv
СоединениеСИнформационнойБазой
=
COMСоединитель.Connect(«Srvr=»»TestSrv»»;Ref=»»TestBase»»»);
COM-соединение
существует до тех пор, пока существует объект COMСоединителя 1С:Предприятия.
Фоновое задание
Представляет собой
соединение рабочего процесса кластера с информационной базой. Это соединение
предназначено для выполнения кода процедуры фонового задания.
Соединение
фонового задания создается в результате запуска фонового задания на выполнение.
Такой запуск может выполняться системой 1С:Предприятие в результате
автоматического запуска регламентного задания (регламентное задание порождает
соответствующее фоновое задание) или разработчиком, средствами встроенного
языка, например
// Выполнить фоновое
задание, описанное в процедуре
// ОбновлениеИндексаПолнотекстовогоПоиска
// общего модуля
РегламентныеПроцедуры
ФоновоеЗадание
=
ФоновыеЗадания.Выполнить(“РегламентныеПроцедуры.ОбновлениеИндексаПолнотекстовогоПоиска”);
Соединение фонового
задания существует до тех пор, пока существует контекст исполняемой процедуры
фонового задания. После того, как процедура
выполнена, соединение фонового задания закрывается.
Подробнее о фоновых
заданиях см. книгу «1С:Предприятие 8.1. Конфигурирование и администрирование»
глава 16 «Механизм заданий».
WS-соединение
Представляет собой
соединение веб-сервера с информационной базой.
Предназначено для
выполнения кода модуля Web-сервиса 1C:Предприятия.
WS–соединение
возникает в процессе обращения к Web-сервису, опубликованному на веб-сервере.
Существует до тех пор, пока соединение находится в пуле WS-соединений (пока не
закончится время жизни соединения в пуле или пока данное соединение не будет
вытеснено из пула другими соединениями).
Подробнее о
Web-сервисах см. книгу «1С:Предприятие 8.1. Конфигурирование и
администрирование» глава 15 «Механизм Web-сервисов».
Служебные
соединения
Служебные
соединения имеют следующие отличительные особенности:
·
соединение выполняется с рабочим процессом и не
ассоциируется с конкретной информационной базой;
·
в служебных соединениях код на встроенном языке
не выполняется;
·
соединение не может быть разорвано
принудительно, оно создается и завершается системой;
·
наличие служебных соединений не препятствуют остановке
и запуску рабочих процессов кластера серверов.
Возможны следующие
виды служебных соединений:
·
Планировщик заданий
·
Отладчик
·
Консоль кластера
·
COM-администратор
Планировщик заданий
Представляет собой
соединение планировщика заданий с рабочим процессом. Это соединение
предназначено для управления работой фоновых заданий, в том числе для запуска
регламентных заданий по расписанию.
Соединение
планировщика заданий создается при первом запуске фонового задания. Оно может
порождать соединение фонового задания с информационной базой в том же рабочем
процессе кластера серверов. После завершения соединения фонового задания
соединение планировщика заданий не завершается, а существует до тех пор, пока
рабочий процесс кластера не будет выключен или удален.
Подробнее о фоновых
заданиях см. книгу «1С:Предприятие 8.1. Конфигурирование и администрирование»
глава 16 «Механизм заданий».
Отладчик
Представляет собой
соединение отладчика с рабочим процессом кластера, находящимся в режиме
отладки. Это соединение предназначено для управления ходом отладки и поиском
предметов отладки, имеющихся в настоящий момент.
Соединение
отладчика создается при подключении предмета отладки или при поиске предметов
отладки. Существует до тех пор, пока предмет отладки не будет отключен или не
завершит свою работу.
Подробнее об
отладчике см. книгу «1С:Предприятие 8.1. Конфигурирование и администрирование»
глава 18 «Инструменты конфигурирования» раздел «Отладчик и замеры производительности».
Консоль кластера
Представляет собой
соединение консоли кластера серверов (mmc) с рабочим процессом. Это соединение
предназначено для администрирования информационных баз кластера серверов.
Соединение консоли
кластера создается в момент обращения к данным рабочего процесса (например, при
получении параметров информационной базы, при получении подробного списка
соединений информационной базы и пр.). Соединение завершается при закрытии
консоли кластера серверов.
COM-администратор
Представляет собой
соединение с рабочим процессом сервера с использованием технологии COM. Это
соединение предназначено для администрирования информационных баз кластера
серверов.
Соединение
COM-администратора создается при подключении к выбранному рабочему процессу с
использованием технологии COM, например:
// Создать
COMСоединитель 1С:Предприятия
COMСоединитель =
Новый COMОбъект(“V81.COMConnector”);
// Установить
соединение с рабочим процессом 1562
// в кластере 1541
центрального сервера TestSrv
СоединениеСРабочимПроцессом
= COMСоединитель.ConnectWorkingProcess(“tcp://TestSrv:1562”);
Соединение
существует до тех пор, пока существует программный объект соединения с рабочим
процессом.
Просмотр
свойств соединения
Для просмотра свойств соединения следует выбрать требуемое
соединение в списке соединений и выполнить команду контекстного меню «Properties» или аналогичную команду
главного меню утилиты:
В результате выполнения команды на экране появится диалог
свойств соединения:
Диалог свойств соединения содержит следующую информацию
(все свойства соединения недоступны для редактирования):
·
Пользователь —
имя пользователя информационной базы;
·
Компьютер —
сетевое имя компьютера пользователя, установившего соединение;
·
Приложение — режим
запуска клиентского приложения;
·
ИБ монопольно —
признак монопольной блокировки метаданных информационной базы;
·
База данных — признак разделяемой блокировки базы данных;
·
Монопольно —
признак монопольной блокировки базы данных.
Подробнее о блокировках можно прочитать в разделе «Работа
со списком блокировок».
·
Сервер — имя сервера
кластера, с которым установлено соединение;
·
Порт сервера —
номер порта рабочего процесса, обслуживающего это соединение;
·
Начало работы —
время в которое это соединение было установлено;
·
Соединение — номер
соединения. Номера соединений уникальных в пределах одной информационной базы;
Параметры соединения с СУБД:
·
Соединение с СУБД —
идентификатор процесса сервера баз данных. Отображается в том случае, если в
момент открытия диалога свойств, соединение выполняет обращение к базе данных;
Захвачено СУБД —
длительность обращения к серверу баз данных на момент открытия диалога свойств.
Отображается в том случае, если в момент открытия диалога свойств, соединение
выполняет обращение к базе данных
Время вызова СУБД(всего)
Время вызовов СУБД(5 мин
Время вызова
СУБД(текущее) — время текущего обращения СУБД с начала обращения (в
секундах):
·
Заблокировано СУБД —
идентификатор процесса, который заблокировал данный процесс;
·
Заблокировано — Имя
пользователя(Номер соединения) в том случае, если процесс ожидает освобождения
транзакционной блокировки;
·
Время вызовов (всего) —
общее время серверных вызовов в секундах с момента старта клиентской сессии (в
секундах);
·
Время вызовов (5 мин.) —
время обращения этого соединения к серверу за последние пять минут;
·
Время вызова (текущее) —
текущее время исполнения последнего незавершенного серверного вызова;
·
Количество вызовов (всего) —
количество обращений этого соединения к серверу с начала клиентской сессии (в
единицах);
·
Количество вызовов (5
мин.) — количество обращений этого соединения к серверу за
последние пять минут;
·
Объем данных(всего) — объем переданных и полученных данных с момента
начала клиентской сессии (в байтах);
·
Объем данных(5 мин.) — объем переданных и полученных данных с
момента начала клиентской сессии за последние пять минут (в байтах).
Разрыв соединения
Для разрыва соединения следует выбрать требуемое соединение
в списке соединений и выполнить команду контекстного меню «Delete» или
аналогичную команду главного меню утилиты:
Внимание!!! К использованию
данного средства надо подходить с осторожностью, так как разрыв соединения
активно работающего пользователя с информационной базой может привести к потере
данных.
Если клиент выполняет на сервере код на встроенном языке
или длительный запрос в базу данных MS SQL Server, то в консоли кластера 1С:Предприятия происходит разрыв
соединения. В таком случае пользователь получает сообщение «Сеанс работы
завершен администратором».
Работа со списком блокировок
Список блокировок
может быть отображен несколькими способами:
·
для всего кластера в целом (все блокировки или
по соединениям);
·
для отдельной информационной базы (все блокировки
или по соединениям).
Для отображения списка блокировок для всего кластера в
целом, следует в дереве центральных серверов выбрать нужный центральный сервер,
выбрать нужный кластер, зарегистрированный на данном сервере, а затем выбрать и
раскрыть ветку «Блокировки»:
Если затем выбрать ветку «Все», то
будет отображен список всех блокировок кластера:
Также можно раскрыть ветку «По соединениям»
и выбрать требуемое соединение. В этом случае будет отображен список блокировок
для выбранного соединения:
Для отображения списка блокировок отдельной информационной
базы, следует в дереве центральных серверов выбрать нужный центральный сервер,
выбрать нужный кластер, выбрать нужную информационную базу, а затем выбрать и
раскрыть ветку «Блокировки»:
Если затем выбрать ветку «Все», то
будет отображен список всех блокировок данной информационной базы:
Также можно раскрыть ветку «По соединениям»
и выбрать требуемое соединение. В этом случае будет отображен список блокировок
для выбранного соединения:
Если выбран просмотр списка блокировок для конкретного
соединения, то дерево центральных серверов содержит перечень соединений. Каждое
соединение идентифицируется номером и именем пользовательского компьютера.
В поле свойств отображается список блокировок, содержащий
следующую информацию:
·
Блокировка —
идентификатор блокировки. Существует три вида блокировок, отображаемых в этом
режиме:
o
объектная блокировка 1С:Предприятия.
Идентификатор объектной блокировки — Объект БД. Представляет собой блокировку,
накладываемую системой 1С:Предприятие 8.1 на данные какого-либо объекта
базы данных (например, при редактировании в форме объекта или при использовании
метода встроенного языка Заблокировать());
o
блокировка клиентского соединения. Идентификатор
такой блокировки содержит режим запуска клиентского приложения и, в скобках,
параметры блокировки. В описании параметров блокировки могут быть использованы
либо строчные, либо прописные буквы, что означает разделяемую или эксклюзивную
блокировку. Возможны следующие варианты:
§
конфигуратор(иб, ) —
клиентское приложение запущено в режиме конфигуратора и, например, выполняется
редактирование метаданных (разделяемая блокировка метаданных);
§
конфигуратор(<ИБ>, ) —
клиентское приложение запущено в режиме конфигуратора и, например, выполняется реструктуризация
информационной базы (эксклюзивная блокировка метаданных);
§
конфигуратор(<ИБ>,
<БД>) — клиентское приложение запущено в режиме конфигуратора
и, например, выполняется реструктуризация информационной базы, сопровождаемая
пересчетом итогов (эксклюзивная блокировка метаданных и эксклюзивная блокировка
базы данных);
§
предприятие(иб, бд) —
клиентское приложение запущено в режиме 1С:Предприятие и, например, выполняется
редактирование данных (разделяемая блокировка метаданных и разделяемая
блокировка базы данных);
§
предприятие(иб,
<БД>) — клиентское приложение запущено в режиме
1С:Предприятие и, например, выполняется пересчет итогов (разделяемая блокировка
метаданных и эксклюзивная блокировка базы данных);
·
База — имя
информационной базы, в которой наложена блокировка;
·
Номер — номер
соединения, в котором наложена блокировка;
·
Клиент — имя
клиентского компьютера;
·
Приложение — режим
запуска клиентского приложения;
·
Сервер — имя сервера
кластера, на котором исполняется рабочий процесс, обслуживающий это соединение;
·
Порт – порт рабочего
процесса, обслуживающего соединение;
·
Установлено в —
время, в которое эта блокировка была установлена.