Микропроцессор – Обзор
Микропроцессор – это управляющий блок микрокомпьютера, изготовленный на небольшом чипе, способный выполнять операции ALU (Арифметическая логическая единица) и связываться с другими подключенными к нему устройствами.
Микропроцессор состоит из ALU, массива регистров и блока управления. АЛУ выполняет арифметические и логические операции с данными, полученными из памяти или устройства ввода. Массив регистров состоит из регистров, обозначенных буквами, как B, C, D, E, H, L и аккумулятора. Блок управления контролирует поток данных и инструкций внутри компьютера.
Блок-схема базового микрокомпьютера
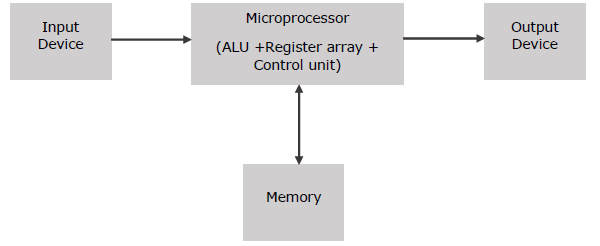
Как работает микропроцессор?
Микропроцессор следует последовательности: выборка, декодирование, а затем выполнение.
Первоначально инструкции хранятся в памяти в последовательном порядке. Микропроцессор извлекает эти инструкции из памяти, затем декодирует их и выполняет эти инструкции до тех пор, пока не будет достигнута команда STOP. Позже он отправляет результат в двоичном формате на выходной порт. Между этими процессами регистр временно хранит данные, а ALU выполняет вычислительные функции.
Список терминов, используемых в микропроцессоре
Вот список некоторых часто используемых терминов в микропроцессоре:
-
Набор инструкций – это набор инструкций, которые может понять микропроцессор.
-
Полоса пропускания – это число битов, обрабатываемых в одной инструкции.
-
Тактовая частота – определяет количество операций в секунду, которые может выполнять процессор. Он выражается в мегагерцах (МГц) или гигагерцах (ГГц). Он также известен как тактовая частота.
-
Длина слова – зависит от ширины внутренней шины данных, регистров, ALU и т. Д. 8-разрядный микропроцессор может одновременно обрабатывать 8-разрядные данные. Длина слова варьируется от 4 до 64 бит в зависимости от типа микрокомпьютера.
-
Типы данных – Микропроцессор имеет несколько форматов типов данных, таких как двоичные, BCD, ASCII, числа со знаком и без знака.
Набор инструкций – это набор инструкций, которые может понять микропроцессор.
Полоса пропускания – это число битов, обрабатываемых в одной инструкции.
Тактовая частота – определяет количество операций в секунду, которые может выполнять процессор. Он выражается в мегагерцах (МГц) или гигагерцах (ГГц). Он также известен как тактовая частота.
Длина слова – зависит от ширины внутренней шины данных, регистров, ALU и т. Д. 8-разрядный микропроцессор может одновременно обрабатывать 8-разрядные данные. Длина слова варьируется от 4 до 64 бит в зависимости от типа микрокомпьютера.
Типы данных – Микропроцессор имеет несколько форматов типов данных, таких как двоичные, BCD, ASCII, числа со знаком и без знака.
Особенности микропроцессора
Вот список некоторых из самых выдающихся особенностей любого микропроцессора –
-
Экономически эффективный – микропроцессорные чипы доступны по низким ценам и, как следствие, имеют низкую стоимость.
-
Размер – микропроцессор имеет небольшой размер чипа, поэтому является портативным.
-
Низкое энергопотребление – Микропроцессоры изготавливаются с использованием металлооксидной полупроводниковой технологии, которая имеет низкое энергопотребление.
-
Универсальность – микропроцессоры универсальны, поскольку мы можем использовать один и тот же чип в ряде приложений, конфигурируя программное обеспечение.
-
Надежность – частота отказов IC в микропроцессорах очень низка, поэтому она надежна.
Экономически эффективный – микропроцессорные чипы доступны по низким ценам и, как следствие, имеют низкую стоимость.
Размер – микропроцессор имеет небольшой размер чипа, поэтому является портативным.
Низкое энергопотребление – Микропроцессоры изготавливаются с использованием металлооксидной полупроводниковой технологии, которая имеет низкое энергопотребление.
Универсальность – микропроцессоры универсальны, поскольку мы можем использовать один и тот же чип в ряде приложений, конфигурируя программное обеспечение.
Надежность – частота отказов IC в микропроцессорах очень низка, поэтому она надежна.
Микропроцессор – Классификация
Микропроцессор можно разделить на три категории –
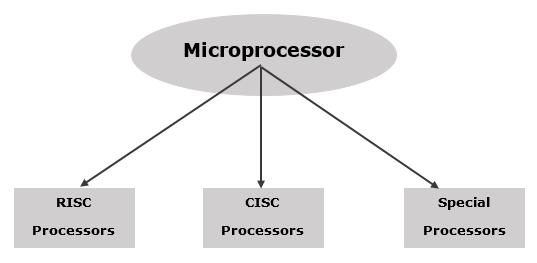
RISC-процессор
RISC расшифровывается как компьютер с сокращенным набором команд . Он предназначен для сокращения времени выполнения за счет упрощения набора команд компьютера. Используя процессоры RISC, каждая инструкция требует только одного такта для выполнения результатов в единое время выполнения. Это снижает эффективность, так как появляется больше строк кода, поэтому для хранения инструкций требуется больше оперативной памяти. Компилятор также должен работать больше, чтобы преобразовать инструкции языка высокого уровня в машинный код.
Некоторые из процессоров RISC –
- Мощность ПК: 601, 604, 615, 620
- DEC Alpha: 210642, 211066, 21068, 21164
- MIPS: TS (R10000) RISC-процессор
- PA-RISC: HP 7100LC
Архитектура РИСК
Микропроцессорная архитектура RISC использует высокооптимизированный набор инструкций. Он используется в портативных устройствах, таких как Apple iPod, благодаря своей энергоэффективности.
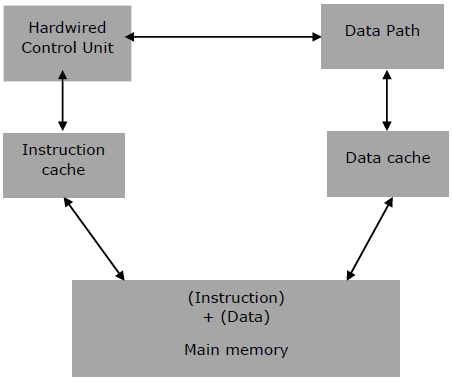
Характеристики РИСК
Основные характеристики процессора RISC следующие:
-
Он состоит из простых инструкций.
-
Он поддерживает различные форматы типов данных.
-
Он использует простые режимы адресации и инструкции фиксированной длины для конвейерной обработки.
-
Он поддерживает регистр для использования в любом контексте.
-
Время выполнения одного цикла.
-
Инструкции «LOAD» и «STORE» используются для доступа к ячейке памяти.
-
Он состоит из большего количества регистров.
-
Он состоит из меньшего количества транзисторов.
Он состоит из простых инструкций.
Он поддерживает различные форматы типов данных.
Он использует простые режимы адресации и инструкции фиксированной длины для конвейерной обработки.
Он поддерживает регистр для использования в любом контексте.
Время выполнения одного цикла.
Инструкции «LOAD» и «STORE» используются для доступа к ячейке памяти.
Он состоит из большего количества регистров.
Он состоит из меньшего количества транзисторов.
CISC Процессор
CISC расшифровывается как комплексная компьютерная инструкция . Он предназначен для минимизации количества инструкций на программу, игнорируя количество циклов на инструкцию. Акцент делается на построение сложных инструкций непосредственно в аппаратном обеспечении.
Компилятору приходится выполнять очень мало работы для перевода языка высокого уровня в язык ассемблера / машинный код, поскольку длина кода относительно мала, поэтому для хранения инструкций требуется очень мало ОЗУ.
Некоторые из процессоров CISC –
- IBM 370/168
- VAX 11/780
- Intel 80486
Архитектура CISC
Его архитектура предназначена для уменьшения стоимости памяти, поскольку в больших программах требуется больше места для хранения, что приводит к увеличению стоимости памяти. Чтобы решить эту проблему, количество команд на программу может быть уменьшено путем вложения количества операций в одну инструкцию.
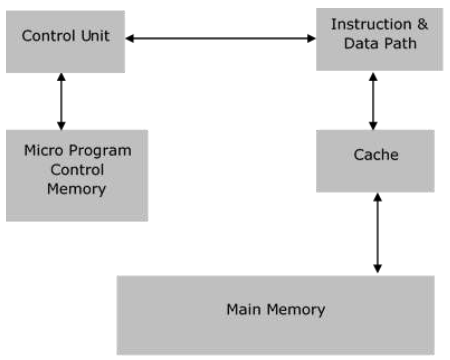
Характеристики CISC
- Разнообразие режимов адресации.
- Большое количество инструкций.
- Переменная длина форматов команд.
- Для выполнения одной инструкции может потребоваться несколько циклов.
- Логика декодирования инструкций сложна.
- Для поддержки нескольких режимов адресации требуется одна инструкция.
Специальные процессоры
Это процессоры, которые предназначены для некоторых специальных целей. Немногие из специальных процессоров кратко обсуждаются –
сопроцессор
Сопроцессор – это специально разработанный микропроцессор, который может выполнять свои функции во много раз быстрее, чем обычный микропроцессор.
Например – Математический сопроцессор.
Некоторые математические сопроцессоры Intel –
- 8087-используется с 8086
- 80287-используется с 80286
- 80387-используется с 80386
Процессор ввода / вывода
Это специально разработанный микропроцессор с собственной локальной памятью, который используется для управления устройствами ввода-вывода с минимальным участием ЦП.
Например –
- Контроллер прямого доступа к памяти
- Контроллер клавиатуры / мыши
- Контроллер графического дисплея
- Контроллер порта SCSI
Транспутер (Транзистор Компьютер)
Транспьютер – это специально разработанный микропроцессор с собственной локальной памятью и связями для соединения одного транспортера с другим транспортом для межпроцессорной связи. Впервые он был разработан в 1980 году компанией Inmos и нацелен на использование технологии СБИС.
Транспортер может использоваться как однопроцессорная система или может быть подключен к внешним каналам, что снижает стоимость строительства и повышает производительность.
Например – 16-битный T212, 32-битный T425, процессоры с плавающей запятой (T800, T805 и T9000).
DSP (цифровой сигнальный процессор)
Этот процессор специально разработан для обработки аналоговых сигналов в цифровом виде. Это делается путем выборки уровня напряжения через регулярные промежутки времени и преобразования напряжения в этот момент в цифровую форму. Этот процесс выполняется схемой, называемой аналого-цифровой преобразователь, аналого-цифровой преобразователь или АЦП.
DSP содержит следующие компоненты –
-
Память программ – хранит программы, которые DSP будет использовать для обработки данных.
-
Память данных – хранит информацию для обработки.
-
Compute Engine – выполняет математическую обработку, получая доступ к программе из памяти программ и данным из памяти данных.
-
Ввод / вывод – он подключается к внешнему миру.
Память программ – хранит программы, которые DSP будет использовать для обработки данных.
Память данных – хранит информацию для обработки.
Compute Engine – выполняет математическую обработку, получая доступ к программе из памяти программ и данным из памяти данных.
Ввод / вывод – он подключается к внешнему миру.
Его приложения –
- Синтез звука и музыки
- Аудио и видео компрессия
- Обработка видеосигнала
- 2D и 3D графическое ускорение.
Например – серия TMS 320 от Texas Instrument, например, TMS 320C40, TMS320C50.
Микропроцессор – 8085 Архитектура
8085 произносится как «восемьдесят восемьдесят пять» микропроцессор. Это 8-битный микропроцессор, разработанный Intel в 1977 году с использованием технологии NMOS.
Он имеет следующую конфигурацию –
- 8-битная шина данных
- 16-битная адресная шина, которая может адресовать до 64 КБ
- 16-битный программный счетчик
- 16-битный указатель стека
- Шесть 8-битных регистров, расположенных попарно: BC, DE, HL
- Требуется питание + 5 В для работы на однофазных тактовых частотах 3,2 МГц
Используется в стиральных машинах, микроволновых печах, мобильных телефонах и т. Д.
Микропроцессор 8085 – Функциональные блоки
8085 состоит из следующих функциональных блоков –
аккумуляторный
Это 8-битный регистр, используемый для выполнения арифметических, логических операций ввода-вывода и загрузки / сохранения. Он подключен к внутренней шине данных и ALU.
Арифметико-логическое устройство
Как следует из названия, он выполняет арифметические и логические операции, такие как сложение, вычитание, AND, OR и т. Д. Над 8-битными данными.
Регистр общего назначения
В процессоре 8085 имеется 6 регистров общего назначения, то есть B, C, D, E, H & L. Каждый регистр может содержать 8-битные данные.
Эти регистры могут работать в паре для хранения 16-битных данных, и их комбинация сочетания похожа на BC, DE & HL.
Счетчик команд
Это 16-битный регистр, используемый для хранения адреса памяти в следующей команде, которая должна быть выполнена. Микропроцессор увеличивает программу всякий раз, когда выполняется инструкция, так что счетчик программы указывает на адрес памяти следующей инструкции, которая будет выполнена.
Указатель стека
Это также 16-битный регистр, работающий как стек, который всегда увеличивается / уменьшается на 2 во время операций push & pop.
Временный регистр
Это 8-битный регистр, который содержит временные данные арифметических и логических операций.
Флаг регистр
Это 8-битный регистр, имеющий пять 1-битных триггеров, которые содержат 0 или 1 в зависимости от результата, сохраненного в аккумуляторе.
Это набор из 5 шлепанцев –
- Приметы)
- Ноль (Z)
- Вспомогательный Carry (AC)
- Паритет (P)
- Нести (С)
Его битовая позиция показана в следующей таблице –
| D7 | D6 | D5 | D4 | D3 | D2 | D1 | Д0 |
|---|---|---|---|---|---|---|---|
| S | Z | переменный ток | п | CY |
Регистр команд и декодер
Это 8-битный регистр. Когда инструкция извлекается из памяти, она сохраняется в регистре команд. Декодер команд декодирует информацию, представленную в регистре команд.
Сроки и блок управления
Он обеспечивает синхронизацию и управляющий сигнал для микропроцессора для выполнения операций. Ниже приведены сигналы синхронизации и управления, которые управляют внешними и внутренними цепями.
- Управляющие сигналы: ГОТОВ, RD ‘, WR’, ALE
- Сигналы состояния: S0, S1, IO / M ‘
- Сигналы DMA: ДЕРЖАТЬ, HLDA
- Сигналы RESET: RESET IN, RESET OUT
Управление прерываниями
Как следует из названия, он контролирует прерывания во время процесса. Когда микропроцессор выполняет основную программу и всякий раз, когда происходит прерывание, микропроцессор переносит управление из основной программы для обработки входящего запроса. После завершения запроса управление возвращается к основной программе.
В микропроцессоре 8085 имеется 5 сигналов прерывания: INTR, RST 7.5, RST 6.5, RST 5.5, TRAP.
Управление последовательным вводом / выводом
Он управляет последовательной передачей данных с помощью этих двух инструкций: SID (данные последовательного ввода) и SOD (данные последовательного ввода).
Адресный буфер и адресный буфер данных
Содержимое, хранящееся в указателе стека и программном счетчике, загружается в буфер адресов и буфер данных-адресов для связи с ЦП. Микросхемы памяти и ввода / вывода подключены к этим шинам; CPU может обмениваться нужными данными с памятью и чипами ввода / вывода.
Адресная шина и шина данных
Шина данных несет данные для хранения. Он является двунаправленным, тогда как адресная шина переносит место, где она должна храниться, и является однонаправленной. Он используется для передачи данных и адреса устройств ввода-вывода.
8085 Архитектура
Мы попытались изобразить архитектуру 8085 с помощью следующего изображения –
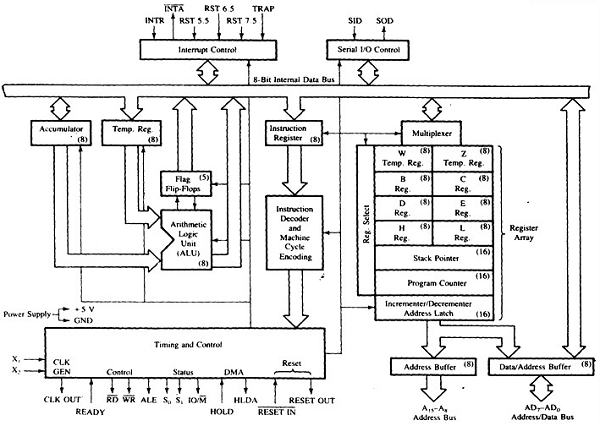
Микропроцессор – 8085 контактов
На следующем рисунке изображена схема контактов микропроцессора 8085 –

Контакты микропроцессора 8085 можно разделить на семь групп:
Адресная шина
A15-A8, он несет самый значительный 8-битный адрес памяти / ввода-вывода.
Шина данных
AD7-AD0, он несет наименее значимый 8-битный адрес и шину данных.
Сигналы управления и состояния
Эти сигналы используются для определения характера операции. Есть 3 сигнала управления и 3 сигнала состояния.
Три управляющих сигнала: RD, WR и ALE.
-
RD – этот сигнал указывает, что выбранное устройство ввода-вывода или запоминающее устройство должно быть прочитано и готово к приему данных, доступных на шине данных.
-
WR – этот сигнал указывает, что данные на шине данных должны быть записаны в выбранную память или место ввода / вывода.
-
ALE – это положительный импульс, генерируемый микропроцессором при запуске новой операции. Когда пульс становится высоким, это указывает на адрес. Когда пульс идет вниз, это указывает на данные.
RD – этот сигнал указывает, что выбранное устройство ввода-вывода или запоминающее устройство должно быть прочитано и готово к приему данных, доступных на шине данных.
WR – этот сигнал указывает, что данные на шине данных должны быть записаны в выбранную память или место ввода / вывода.
ALE – это положительный импульс, генерируемый микропроцессором при запуске новой операции. Когда пульс становится высоким, это указывает на адрес. Когда пульс идет вниз, это указывает на данные.
Три сигнала состояния: IO / M, S0 и S1.
IO / М
Этот сигнал используется для различения операций ввода-вывода и памяти, т. Е. Когда он высокий, это означает работу ввода-вывода, а когда он низкий, то он указывает на работу памяти.
S1 & S0
Эти сигналы используются для определения типа текущей операции.
Источник питания
Есть 2 источника питания – VCC и VSS. VCC указывает источник питания + 5 В, а VSS указывает сигнал заземления.
Тактовые сигналы
Есть 3 тактовых сигнала, то есть X1, X2, CLK OUT.
-
X1, X2 – Кристалл (RC, LC N / W) подключен к этим двум контактам и используется для установки частоты внутреннего тактового генератора. Эта частота внутренне делится на 2.
-
CLK OUT – этот сигнал используется в качестве системных часов для устройств, подключенных к микропроцессору.
X1, X2 – Кристалл (RC, LC N / W) подключен к этим двум контактам и используется для установки частоты внутреннего тактового генератора. Эта частота внутренне делится на 2.
CLK OUT – этот сигнал используется в качестве системных часов для устройств, подключенных к микропроцессору.
Прерывания и внешние сигналы
Прерывания – это сигналы, генерируемые внешними устройствами для запроса микропроцессора на выполнение задачи. Существует 5 сигналов прерывания, т.е. TRAP, RST 7.5, RST 6.5, RST 5.5 и INTR. Мы подробно обсудим прерывания в разделе прерываний.
-
INTA – это сигнал подтверждения прерывания.
-
RESET IN – этот сигнал используется для сброса микропроцессора путем установки счетчика программы на ноль.
-
RESET OUT – этот сигнал используется для сброса всех подключенных устройств при сбросе микропроцессора.
-
ГОТОВ – этот сигнал указывает на то, что устройство готово к отправке или получению данных. Если READY имеет низкий уровень, тогда процессор должен ждать, пока READY поднимется до высокого уровня.
-
HOLD – этот сигнал указывает, что другой мастер запрашивает использование адреса и шин данных.
-
HLDA (HOLD Acknowledge) – указывает на то, что ЦП получил запрос HOLD, и он освободит шину в следующем тактовом цикле. HLDA устанавливается на низкий уровень после снятия сигнала HOLD.
INTA – это сигнал подтверждения прерывания.
RESET IN – этот сигнал используется для сброса микропроцессора путем установки счетчика программы на ноль.
RESET OUT – этот сигнал используется для сброса всех подключенных устройств при сбросе микропроцессора.
ГОТОВ – этот сигнал указывает на то, что устройство готово к отправке или получению данных. Если READY имеет низкий уровень, тогда процессор должен ждать, пока READY поднимется до высокого уровня.
HOLD – этот сигнал указывает, что другой мастер запрашивает использование адреса и шин данных.
HLDA (HOLD Acknowledge) – указывает на то, что ЦП получил запрос HOLD, и он освободит шину в следующем тактовом цикле. HLDA устанавливается на низкий уровень после снятия сигнала HOLD.
Последовательные сигналы ввода / вывода
Есть 2 последовательных сигнала, то есть SID и SOD, и эти сигналы используются для последовательной связи.
-
SOD (строка данных последовательного выхода) – выходной SOD устанавливается / сбрасывается в соответствии с инструкцией SIM.
-
SID (строка последовательного ввода данных) – данные в этой строке загружаются в аккумулятор при каждом выполнении команды RIM.
SOD (строка данных последовательного выхода) – выходной SOD устанавливается / сбрасывается в соответствии с инструкцией SIM.
SID (строка последовательного ввода данных) – данные в этой строке загружаются в аккумулятор при каждом выполнении команды RIM.
8085 адресация режимов и прерываний
Теперь давайте обсудим режимы адресации в микропроцессоре 8085.
Режимы адресации в 8085 году
Это инструкции, используемые для передачи данных из одного регистра в другой регистр, из памяти в регистр и из регистра в память без каких-либо изменений в содержимом. Режимы адресации в 8085 году подразделяются на 5 групп –
Режим немедленной адресации
В этом режиме 8/16-битные данные указываются в самой инструкции как один из ее операндов. Например: MVI K, 20F: означает, что 20F скопирован в регистр K.
Зарегистрировать режим адресации
В этом режиме данные копируются из одного регистра в другой. Например: MOV K, B: означает, что данные в регистре B копируются в регистр K.
Режим прямой адресации
В этом режиме данные напрямую копируются с заданного адреса в регистр. Например: LDB 5000K: означает, что данные по адресу 5000K копируются в регистр B.
Режим косвенной адресации
В этом режиме данные передаются из одного регистра в другой, используя адрес, указанный регистром. Например: MOV K, B: означает, что данные передаются с адреса памяти, указанного регистром, в регистр K.
Подразумеваемый режим адресации
Этот режим не требует никакого операнда; данные определяются самим кодом операции. Например: CMP.
Прерывает в 8085
Прерывания – это сигналы, генерируемые внешними устройствами для запроса микропроцессора для выполнения задачи. Существует 5 сигналов прерывания, т.е. TRAP, RST 7.5, RST 6.5, RST 5.5 и INTR.
Прерывания классифицируются на следующие группы в зависимости от их параметра –
-
Векторное прерывание – в этом типе прерывания адрес прерывания известен процессору. Например: RST7.5, RST6.5, RST5.5, TRAP.
-
Невекторное прерывание – В этом типе прерывания адрес прерывания не известен процессору, поэтому для прерывания адрес прерывания должен отправляться внешним устройством. Например: INTR.
-
Маскируемое прерывание – в этом типе прерывания мы можем отключить прерывание, написав некоторые инструкции в программу. Например: RST7.5, RST6.5, RST5.5.
-
Немаскируемое прерывание – в этом типе прерывания мы не можем отключить прерывание, записав некоторые инструкции в программу. Например: TRAP.
-
Программное прерывание. В этом типе прерывания программист должен добавить в программу инструкции для выполнения прерывания. В 8085 есть 8 программных прерываний, то есть RST0, RST1, RST2, RST3, RST4, RST5, RST6 и RST7.
-
Аппаратное прерывание. В 8085 в качестве аппаратных прерываний используются 5 контактов прерывания, т. Е. TRAP, RST7.5, RST6.5, RST5.5, INTA.
Векторное прерывание – в этом типе прерывания адрес прерывания известен процессору. Например: RST7.5, RST6.5, RST5.5, TRAP.
Невекторное прерывание – В этом типе прерывания адрес прерывания не известен процессору, поэтому для прерывания адрес прерывания должен отправляться внешним устройством. Например: INTR.
Маскируемое прерывание – в этом типе прерывания мы можем отключить прерывание, написав некоторые инструкции в программу. Например: RST7.5, RST6.5, RST5.5.
Немаскируемое прерывание – в этом типе прерывания мы не можем отключить прерывание, записав некоторые инструкции в программу. Например: TRAP.
Программное прерывание. В этом типе прерывания программист должен добавить в программу инструкции для выполнения прерывания. В 8085 есть 8 программных прерываний, то есть RST0, RST1, RST2, RST3, RST4, RST5, RST6 и RST7.
Аппаратное прерывание. В 8085 в качестве аппаратных прерываний используются 5 контактов прерывания, т. Е. TRAP, RST7.5, RST6.5, RST5.5, INTA.
Примечание. NTA не является прерыванием, оно используется микропроцессором для отправки подтверждения. TRAP имеет самый высокий приоритет, затем RST7.5 и так далее.
Программа обработки прерываний (ISR)
Небольшая программа или подпрограмма, которая при выполнении обслуживает соответствующий источник прерывания, называется ISR.
TRAP
Это немаскируемое прерывание, имеющее самый высокий приоритет среди всех прерываний. По умолчанию он включен, пока не получит подтверждение. В случае сбоя он выполняется как ISR и отправляет данные в резервную память. Это прерывание передает управление в местоположение 0024H.
RST7.5
Это маскируемое прерывание, имеющее второй по приоритетности приоритет среди всех прерываний. Когда выполняется это прерывание, процессор сохраняет содержимое регистра ПК в стек и переходит на адрес 003CH.
RST 6.5
Это маскируемое прерывание, имеющее третий самый высокий приоритет среди всех прерываний. Когда выполняется это прерывание, процессор сохраняет содержимое регистра ПК в стек и переходит по адресу 0034H.
RST 5.5
Это маскируемое прерывание. Когда выполняется это прерывание, процессор сохраняет содержимое регистра ПК в стек и переходит по адресу 002CH.
ВВЕДЕНИ
Это маскируемое прерывание, имеющее самый низкий приоритет среди всех прерываний. Его можно отключить путем сброса микропроцессора.
Когда сигнал INTR становится высоким , могут произойти следующие события:
-
Микропроцессор проверяет состояние сигнала INTR во время выполнения каждой инструкции.
-
Когда сигнал INTR высокий, микропроцессор завершает свою текущую команду и посылает активный сигнал подтверждения прерывания низкого уровня.
-
Когда инструкции получены, микропроцессор сохраняет адрес следующей инструкции в стеке и выполняет полученную инструкцию.
Микропроцессор проверяет состояние сигнала INTR во время выполнения каждой инструкции.
Когда сигнал INTR высокий, микропроцессор завершает свою текущую команду и посылает активный сигнал подтверждения прерывания низкого уровня.
Когда инструкции получены, микропроцессор сохраняет адрес следующей инструкции в стеке и выполняет полученную инструкцию.
Микропроцессор – 8085 инструкций
Давайте посмотрим на программирование микропроцессора 8085.
Наборы инструкций – это коды команд для выполнения некоторых задач. Он классифицируется на пять категорий.
| S.No. | Инструкция и описание |
|---|---|
| 1 | Инструкция по управлению
Ниже приведена таблица со списком команд управления с их значениями. |
| 2 | Логические Инструкции
Ниже приведена таблица со списком логических инструкций с их значениями. |
| 3 | Инструкции по ветвлению
Ниже приведена таблица со списком команд ветвления с их значениями. |
| 4 | Арифметические инструкции
Ниже приведена таблица со списком арифметических инструкций с их значениями. |
| 5 | Инструкция по передаче данных
Ниже приведена таблица со списком команд передачи данных с их значениями. |
Ниже приведена таблица со списком команд управления с их значениями.
Ниже приведена таблица со списком логических инструкций с их значениями.
Ниже приведена таблица со списком команд ветвления с их значениями.
Ниже приведена таблица со списком арифметических инструкций с их значениями.
Ниже приведена таблица со списком команд передачи данных с их значениями.
8085 – Демонстрационные программы
Теперь давайте посмотрим на некоторые демонстрации программ, используя приведенные выше инструкции:
Добавление двух 8-битных чисел
Напишите программу для добавления данных в ячейку памяти 3005H и 3006H и сохраните результат в ячейке памяти 3007H.
Проблема демо –
(3005H) = 14H (3006H) = 89H
Результат –
14H + 89H = 9DH
Код программы можно записать так:
LXI H 3005H: «HL points 3005H» MOV A, M: «Получение первого операнда» INX H: «HL points 3006H» ДОБАВИТЬ М: «Добавить второй операнд» INX H: "HL points 3007H" MOV M, A: «Сохранить результат на 3007H» HLT: «Программа выхода»
Обмен местами памяти
Напишите программу для обмена данными в 5000M и 6000M памяти.
LDA 5000M : "Getting the contents at5000M location into accumulator" MOV B, A : "Save the contents into B register" LDA 6000M : "Getting the contents at 6000M location into accumulator" STA 5000M : "Store the contents of accumulator at address 5000M" MOV A, B : "Get the saved contents back into A register" STA 6000M : "Store the contents of accumulator at address 6000M"
Упорядочить числа в порядке возрастания
Напишите программу, чтобы расположить первые 10 чисел с адреса памяти 3000H в порядке возрастания.
MVI B, 09 :"Initialize counter" START :"LXI H, 3000H: Initialize memory pointer" MVI C, 09H :"Initialize counter 2" BACK: MOV A, M :"Get the number" INX H :"Increment memory pointer" CMP M :"Compare number with next number" JC SKIP :"If less, don’t interchange" JZ SKIP :"If equal, don’t interchange" MOV D, M MOV M, A DCX H MOV M, D INX H :"Interchange two numbers" SKIP:DCR C :"Decrement counter 2" JNZ BACK :"If not zero, repeat" DCR B :"Decrement counter 1" JNZ START HLT :"Terminate program execution"
Микропроцессор – 8086 Обзор
Микропроцессор 8086 – это расширенная версия микропроцессора 8085, разработанная Intel в 1976 году. Это 16-разрядный микропроцессор с 20 адресными строками и 16 строками данных, который обеспечивает хранение до 1 МБ. Он состоит из мощного набора команд, который позволяет легко выполнять такие операции, как умножение и деление.
Он поддерживает два режима работы, то есть Максимальный режим и Минимальный режим. Режим Maximum подходит для системы с несколькими процессорами, а режим Minimum подходит для системы с одним процессором.
Особенности 8086
Наиболее характерные особенности микропроцессора 8086:
-
Он имеет очередь команд, которая способна хранить шесть байтов инструкций из памяти, что приводит к более быстрой обработке.
-
Это был первый 16-битный процессор с 16-битным ALU, 16-битными регистрами, внутренней шиной данных и 16-битной внешней шиной данных, что привело к более быстрой обработке.
-
Это доступно в 3 версиях, основанных на частоте операции –
-
8086 → 5 МГц
-
8086-2 → 8 МГц
-
(c) 8086-1 → 10 МГц
-
-
Он использует два этапа конвейерной обработки: этап извлечения и этап выполнения, что повышает производительность.
-
Этап выборки может выполнять предварительную выборку до 6 байтов инструкций и сохранять их в очереди.
-
Этап выполнения выполняет эти инструкции.
-
Имеет 256 векторных прерываний.
-
Он состоит из 29 000 транзисторов.
Он имеет очередь команд, которая способна хранить шесть байтов инструкций из памяти, что приводит к более быстрой обработке.
Это был первый 16-битный процессор с 16-битным ALU, 16-битными регистрами, внутренней шиной данных и 16-битной внешней шиной данных, что привело к более быстрой обработке.
Это доступно в 3 версиях, основанных на частоте операции –
8086 → 5 МГц
8086-2 → 8 МГц
(c) 8086-1 → 10 МГц
Он использует два этапа конвейерной обработки: этап извлечения и этап выполнения, что повышает производительность.
Этап выборки может выполнять предварительную выборку до 6 байтов инструкций и сохранять их в очереди.
Этап выполнения выполняет эти инструкции.
Имеет 256 векторных прерываний.
Он состоит из 29 000 транзисторов.
Сравнение микропроцессора 8085 и 8086
-
Размер – 8085 – это 8-битный микропроцессор, тогда как 8086 – это 16-битный микропроцессор.
-
Адресная шина – 8085 имеет 16-разрядную адресную шину, а 8086 имеет 20-разрядную адресную шину.
-
Память – 8085 может получить доступ до 64 КБ, а 8086 – до 1 МБ памяти.
-
Инструкция – 8085 не имеет очереди команд, тогда как 8086 имеет очередь команд.
-
Конвейерная обработка – 8085 не поддерживает конвейерную архитектуру, в то время как 8086 поддерживает конвейерную архитектуру.
-
I / O – 8085 может адресовать 2 ^ 8 = 256 I / O, тогда как 8086 может обращаться к 2 ^ 16 = 65 536 I / O.
-
Стоимость – стоимость 8085 низкая, а 8086 высокая.
Размер – 8085 – это 8-битный микропроцессор, тогда как 8086 – это 16-битный микропроцессор.
Адресная шина – 8085 имеет 16-разрядную адресную шину, а 8086 имеет 20-разрядную адресную шину.
Память – 8085 может получить доступ до 64 КБ, а 8086 – до 1 МБ памяти.
Инструкция – 8085 не имеет очереди команд, тогда как 8086 имеет очередь команд.
Конвейерная обработка – 8085 не поддерживает конвейерную архитектуру, в то время как 8086 поддерживает конвейерную архитектуру.
I / O – 8085 может адресовать 2 ^ 8 = 256 I / O, тогда как 8086 может обращаться к 2 ^ 16 = 65 536 I / O.
Стоимость – стоимость 8085 низкая, а 8086 высокая.
Архитектура 8086 года
Следующая диаграмма изображает архитектуру микропроцессора 8086 –
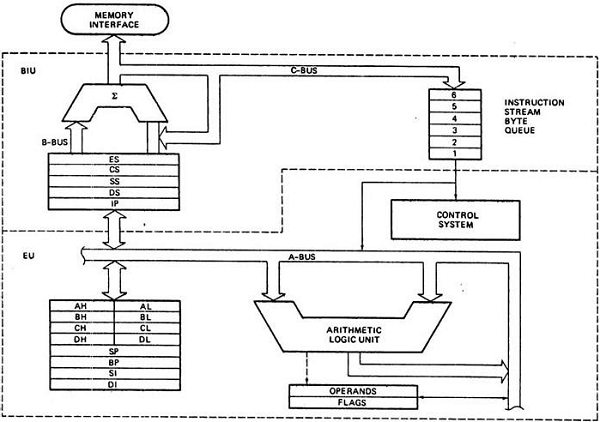
Микропроцессор – 8086 функциональных блоков
Микропроцессор 8086 разделен на два функциональных блока: EU (исполнительный модуль) и BIU (шинный интерфейсный модуль).
ЕС (исполнительный блок)
Блок выполнения дает инструкции для BIU, в которых указывается, откуда следует извлечь данные, а затем декодировать и выполнять эти инструкции. Его функция заключается в управлении операциями с данными с использованием декодера команд и ALU. EU не имеет прямого соединения с системными шинами, как показано на рисунке выше, он выполняет операции над данными через BIU.
Давайте теперь обсудим функциональные части 8086 микропроцессоров.
ALU
Он обрабатывает все арифметические и логические операции, такие как операции +, -, ×, /, OR, AND, NOT.
Флаг Регистр
Это 16-битный регистр, который ведет себя как триггер, то есть он меняет свое состояние в соответствии с результатом, сохраненным в аккумуляторе. У этого есть 9 флагов, и они разделены на 2 группы – Условные Флаги и Контрольные Флаги.
Условные флаги
Он представляет результат последней выполненной арифметической или логической инструкции. Ниже приведен список условных флагов –
-
Флаг переноса – этот флаг указывает условие переполнения для арифметических операций.
-
Вспомогательный флаг – Когда операция выполняется в ALU, это приводит к переносу / кургану от нижнего полубайта (то есть D0 – D3) к верхнему полубайту (то есть D4 – D7), тогда этот флаг устанавливается, то есть перенос, данный битом D3 для D4 – флаг AF. Процессор использует этот флаг для выполнения двоичного преобразования в BCD.
-
Флаг четности – этот флаг используется для указания четности результата, т. Е. Когда младшие 8 битов результата содержат четное число единиц, устанавливается флаг четности. Для нечетного числа 1 флаг четности сбрасывается.
-
Флаг нуля – этот флаг равен 1, если результат арифметической или логической операции равен нулю, в противном случае он равен 0.
-
Флаг знака – этот флаг содержит знак результата, т. Е. Когда результат операции отрицательный, тогда флаг знака устанавливается в 1, а в 0.
-
Флаг переполнения – этот флаг представляет результат при превышении емкости системы.
Флаг переноса – этот флаг указывает условие переполнения для арифметических операций.
Вспомогательный флаг – Когда операция выполняется в ALU, это приводит к переносу / кургану от нижнего полубайта (то есть D0 – D3) к верхнему полубайту (то есть D4 – D7), тогда этот флаг устанавливается, то есть перенос, данный битом D3 для D4 – флаг AF. Процессор использует этот флаг для выполнения двоичного преобразования в BCD.
Флаг четности – этот флаг используется для указания четности результата, т. Е. Когда младшие 8 битов результата содержат четное число единиц, устанавливается флаг четности. Для нечетного числа 1 флаг четности сбрасывается.
Флаг нуля – этот флаг равен 1, если результат арифметической или логической операции равен нулю, в противном случае он равен 0.
Флаг знака – этот флаг содержит знак результата, т. Е. Когда результат операции отрицательный, тогда флаг знака устанавливается в 1, а в 0.
Флаг переполнения – этот флаг представляет результат при превышении емкости системы.
Контрольные Флаги
Флаги управления управляют операциями исполнительного блока. Ниже приведен список контрольных флагов –
-
Флаг прерывания – используется для одноэтапного управления и позволяет пользователю выполнять одну инструкцию за один раз для отладки. Если он установлен, то программа может быть запущена в одношаговом режиме.
-
Флаг прерывания – это флаг включения / отключения прерывания, то есть используемый для разрешения / запрета прерывания программы. Он установлен в 1 для состояния разрешения прерывания и в 0 для условия отключения прерывания.
-
Флаг направления – используется в строковой операции. Как следует из названия, когда оно установлено, к строковым байтам обращаются от старшего адреса памяти к младшему адресу памяти и наоборот.
Флаг прерывания – используется для одноэтапного управления и позволяет пользователю выполнять одну инструкцию за один раз для отладки. Если он установлен, то программа может быть запущена в одношаговом режиме.
Флаг прерывания – это флаг включения / отключения прерывания, то есть используемый для разрешения / запрета прерывания программы. Он установлен в 1 для состояния разрешения прерывания и в 0 для условия отключения прерывания.
Флаг направления – используется в строковой операции. Как следует из названия, когда оно установлено, к строковым байтам обращаются от старшего адреса памяти к младшему адресу памяти и наоборот.
Регистр общего назначения
Существует 8 регистров общего назначения: AH, AL, BH, BL, CH, CL, DH и DL. Эти регистры могут использоваться отдельно для хранения 8-битных данных и могут использоваться парами для хранения 16-битных данных. Допустимые регистровые пары: AH и AL, BH и BL, CH и CL, а также DH и DL. Это относится к AX, BX, CX и DX соответственно.
-
Регистр AX – Он также известен как регистр аккумулятора. Он используется для хранения операндов для арифметических операций.
-
Регистр BX – используется в качестве базового регистра. Он используется для хранения начального базового адреса области памяти в сегменте данных.
-
Регистр CX – он называется счетчиком. Он используется в инструкции цикла для хранения счетчика цикла.
-
Регистр DX – этот регистр используется для хранения адреса порта ввода / вывода для команды ввода / вывода.
Регистр AX – Он также известен как регистр аккумулятора. Он используется для хранения операндов для арифметических операций.
Регистр BX – используется в качестве базового регистра. Он используется для хранения начального базового адреса области памяти в сегменте данных.
Регистр CX – он называется счетчиком. Он используется в инструкции цикла для хранения счетчика цикла.
Регистр DX – этот регистр используется для хранения адреса порта ввода / вывода для команды ввода / вывода.
Регистр указателя стека
Это 16-битный регистр, который содержит адрес от начала сегмента до ячейки памяти, где слово было недавно сохранено в стеке.
BIU (блок шинного интерфейса)
BIU заботится обо всех передачах данных и адресов по шинам для ЕС, таких как отправка адресов, извлечение инструкций из памяти, чтение данных из портов и памяти, а также запись данных в порты и память. ЕС не имеет направления связи с системными автобусами, так что это возможно с BIU. ЕС и BIU связаны с внутренней шиной.
Он имеет следующие функциональные части –
-
Очередь инструкций – BIU содержит очередь инструкций. BIU получает до 6 байтов следующих инструкций и сохраняет их в очереди инструкций. Когда EU выполняет инструкции и готов к их следующей инструкции, он просто читает инструкцию из этой очереди команд, что приводит к увеличению скорости выполнения.
-
Выборка следующей инструкции во время выполнения текущей инструкции называется конвейерной обработкой .
-
Сегментный регистр – BIU имеет 4 сегментных шины, то есть CS, DS, SS & ES. Он содержит адреса команд и данных в памяти, которые используются процессором для доступа к ячейкам памяти. Он также содержит 1 указатель регистра IP, который содержит адрес следующей инструкции, выполняемой ЕС.
-
CS – это означает сегмент кода. Он используется для адресации области памяти в сегменте кода памяти, где хранится исполняемая программа.
-
DS – это означает сегмент данных. Он состоит из данных, используемых программой и доступных в сегменте данных по адресу смещения или содержимому другого регистра, который содержит адрес смещения.
-
SS – это означает сегмент стека. Он обрабатывает память для хранения данных и адресов во время выполнения.
-
ES – Это означает дополнительный сегмент. ES – это дополнительный сегмент данных, который используется строкой для хранения дополнительных данных назначения.
-
-
Указатель инструкции – это 16-битный регистр, используемый для хранения адреса следующей инструкции, которая должна быть выполнена.
Очередь инструкций – BIU содержит очередь инструкций. BIU получает до 6 байтов следующих инструкций и сохраняет их в очереди инструкций. Когда EU выполняет инструкции и готов к их следующей инструкции, он просто читает инструкцию из этой очереди команд, что приводит к увеличению скорости выполнения.
Выборка следующей инструкции во время выполнения текущей инструкции называется конвейерной обработкой .
Сегментный регистр – BIU имеет 4 сегментных шины, то есть CS, DS, SS & ES. Он содержит адреса команд и данных в памяти, которые используются процессором для доступа к ячейкам памяти. Он также содержит 1 указатель регистра IP, который содержит адрес следующей инструкции, выполняемой ЕС.
CS – это означает сегмент кода. Он используется для адресации области памяти в сегменте кода памяти, где хранится исполняемая программа.
DS – это означает сегмент данных. Он состоит из данных, используемых программой и доступных в сегменте данных по адресу смещения или содержимому другого регистра, который содержит адрес смещения.
SS – это означает сегмент стека. Он обрабатывает память для хранения данных и адресов во время выполнения.
ES – Это означает дополнительный сегмент. ES – это дополнительный сегмент данных, который используется строкой для хранения дополнительных данных назначения.
Указатель инструкции – это 16-битный регистр, используемый для хранения адреса следующей инструкции, которая должна быть выполнена.
Микропроцессор – 8086 Pin Configuration
8086 был первым 16-разрядным микропроцессором, доступным в 40-контактном DIP (Dual Inline Package) чипе. Теперь давайте подробно обсудим конфигурацию контактов микропроцессора 8086.
8086 Pin Diagram
Вот схема контактов микропроцессора 8086 –

Давайте теперь обсудим сигналы в деталях –
Сигналы питания и частоты
Он использует питание 5 В постоянного тока на выводе V CC 40 и заземление на выводах 1 и 20 V SS для своей работы.
Тактовый сигнал
Тактовый сигнал подается через контакт 19. Он обеспечивает синхронизацию процессора для операций. Его частота различна для разных версий: 5 МГц, 8 МГц и 10 МГц.
Адрес / шина данных
AD0-AD15. Это 16 адрес / шина данных. AD0-AD7 переносит байтовые данные младшего разряда, а AD8AD15 переносит байтовые данные старшего порядка. В течение первого тактового цикла он переносит 16-битный адрес и после этого переносит 16-битные данные.
Адрес / статус шины
A16-A19 / S3-S6. Это 4 адреса / статус шины. В течение первого тактового цикла он несет 4-битный адрес, а затем передает сигналы состояния.
S7 / ППТ
BHE расшифровывается как Bus High Enable. Он доступен на выводе 34 и используется для индикации передачи данных с использованием шины данных D8-D15. Этот сигнал низкий в течение первого тактового цикла, после чего он активен.
Читать ( $ overline {RD} $ )
Он доступен на выводе 32 и используется для считывания сигнала для операции чтения.
готовы
Он доступен на выводе 22. Это сигнал подтверждения от устройств ввода-вывода о том, что данные передаются. Это активный высокий сигнал. Когда он высокий, это означает, что устройство готово для передачи данных. Когда оно низкое, это указывает на состояние ожидания.
СБРОС
Он доступен на выводе 21 и используется для возобновления выполнения. Это заставляет процессор немедленно прекратить свою текущую деятельность. Этот сигнал является активным высоким в течение первых 4 тактов для СБРОСА микропроцессора.
ВВЕДЕНИ
Он доступен на выводе 18. Это сигнал запроса прерывания, который дискретизируется в течение последнего тактового цикла каждой команды, чтобы определить, рассматривал ли процессор это как прерывание или нет.
NMI
Он обозначает немаскируемое прерывание и доступен на выводе 17. Это вход, инициируемый фронтом, который вызывает запрос прерывания для микропроцессора.
$ Overline {TEST} $
Этот сигнал похож на состояние ожидания и доступен на выводе 23. Когда этот сигнал высокий, то процессор должен ждать состояния IDLE, иначе выполнение продолжается.
MN / $ overline {MX} $
Он обозначает Minimum / Maximum и доступен на выводе 33. Он указывает, в каком режиме должен работать процессор; когда он высокий, он работает в минимальном режиме и наоборот.
INTA
Это сигнал подтверждения прерывания и идентификатор, доступный на выводе 24. Когда микропроцессор получает этот сигнал, он подтверждает прерывание.
ALE
Он обозначает защелку разрешения адреса и доступен на выводе 25. Положительный импульс генерируется каждый раз, когда процессор начинает какую-либо операцию. Этот сигнал указывает на наличие действительного адреса в адресной строке / строке данных.
DEN
Он обозначает Data Enable и доступен на выводе 26. Он используется для включения Transreceiver 8286. Transreceiver – это устройство, используемое для отделения данных от адреса / шины данных.
DT / R
Он обозначает сигнал передачи / приема данных и доступен на выводе 27. Он определяет направление потока данных через трансивер. Когда он высокий, данные передаются и наоборот.
М / МО
Этот сигнал используется для различения операций памяти и ввода / вывода. Когда он высокий, это указывает на операцию ввода / вывода, а когда он низкий, указывает на работу памяти. Он доступен на контакте 28.
WR
Он обозначает сигнал записи и доступен на выводе 29. Он используется для записи данных в память или устройство вывода в зависимости от состояния сигнала M / IO.
HLDA
Он обозначает сигнал подтверждения приема и доступен на выводе 30. Этот сигнал подтверждает сигнал HOLD.
ДЕРЖАТЬ
Этот сигнал указывает процессору, что внешние устройства запрашивают доступ к шинам адреса / данных. Он доступен на контакте 31.
QS 1 и QS 0
Это сигналы состояния очереди, которые доступны на контактах 24 и 25. Эти сигналы обеспечивают состояние очереди команд. Их условия показаны в следующей таблице –
| QS 0 | QS 1 | Статус |
|---|---|---|
| 0 | 0 | Нет операции |
| 0 | 1 | Первый байт кода операции из очереди |
| 1 | 0 | Очистить очередь |
| 1 | 1 | Последующий байт из очереди |
S 0 , S 1 , S 2
Это сигналы состояния, которые обеспечивают состояние работы, которое используется контроллером шины 8288 для генерации сигналов управления памятью и вводом / выводом. Они доступны на контактах 26, 27 и 28. Ниже приведена таблица, показывающая их статус –
| S 2 | S 1 | S 0 | Статус |
|---|---|---|---|
| 0 | 0 | 0 | Подтверждение прерывания |
| 0 | 0 | 1 | Чтение ввода / вывода |
| 0 | 1 | 0 | I / O Write |
| 0 | 1 | 1 | стой |
| 1 | 0 | 0 | Извлечение кода операции |
| 1 | 0 | 1 | Чтение памяти |
| 1 | 1 | 0 | Запись в память |
| 1 | 1 | 1 | пассивный |
ЗАМОК
Когда этот сигнал активен, он указывает другим процессорам не просить ЦП покинуть системную шину. Он активируется с помощью префикса LOCK любой инструкции и доступен на выводе 29.
RQ / GT 1 и RQ / GT 0
Это сигналы Запроса / Предоставления, используемые другими процессорами, запрашивающими ЦПУ освободить системную шину. Когда ЦП получает сигнал, он отправляет подтверждение. RQ / GT 0 имеет более высокий приоритет, чем RQ / GT 1 .
Микропроцессор – 8086 инструкционных наборов
Микропроцессор 8086 поддерживает 8 типов инструкций –
- Инструкция по передаче данных
- Арифметические инструкции
- Инструкции по управлению битами
- Строковые Инструкции
- Инструкции по переносу выполнения программы (инструкции по ветвлению и петле)
- Инструкция по управлению процессором
- Инструкции по контролю итерации
- Инструкции по прерыванию
Давайте теперь обсудим эти наборы команд в деталях.
Инструкция по передаче данных
Эти инструкции используются для передачи данных из исходного операнда в целевой операнд. Ниже приведен список инструкций в этой группе –
Инструкция по переводу слова
-
MOV – используется для копирования байта или слова из предоставленного источника в указанное место назначения.
-
PPUSH – используется для размещения слова в верхней части стека.
-
POP – используется для получения слова с вершины стека в указанное место.
-
PUSHA – используется для помещения всех регистров в стек.
-
POPA – используется для получения слов из стека во все регистры.
-
XCHG – используется для обмена данными из двух мест.
-
XLAT – используется для перевода байта в AL с использованием таблицы в памяти.
MOV – используется для копирования байта или слова из предоставленного источника в указанное место назначения.
PPUSH – используется для размещения слова в верхней части стека.
POP – используется для получения слова с вершины стека в указанное место.
PUSHA – используется для помещения всех регистров в стек.
POPA – используется для получения слов из стека во все регистры.
XCHG – используется для обмена данными из двух мест.
XLAT – используется для перевода байта в AL с использованием таблицы в памяти.
Инструкция по переносу портов ввода и вывода
-
IN – используется для чтения байта или слова из предоставленного порта в аккумулятор.
-
OUT – используется для отправки байта или слова из аккумулятора в указанный порт.
IN – используется для чтения байта или слова из предоставленного порта в аккумулятор.
OUT – используется для отправки байта или слова из аккумулятора в указанный порт.
Инструкция по переводу адреса
-
LEA – используется для загрузки адреса операнда в предоставленный регистр.
-
LDS – используется для загрузки регистра DS и другого предоставленного регистра из памяти
-
LES – используется для загрузки регистра ES и другого предоставленного регистра из памяти.
LEA – используется для загрузки адреса операнда в предоставленный регистр.
LDS – используется для загрузки регистра DS и другого предоставленного регистра из памяти
LES – используется для загрузки регистра ES и другого предоставленного регистра из памяти.
Инструкция по передаче флаговых регистров
-
LAHF – используется для загрузки AH младшим байтом регистра флага.
-
SAHF – используется для сохранения регистра AH в младший байт регистра флага.
-
PUSHF – используется для копирования регистра флага в верхней части стека.
-
POPF – используется для копирования слова из верхней части стека в регистр флага.
LAHF – используется для загрузки AH младшим байтом регистра флага.
SAHF – используется для сохранения регистра AH в младший байт регистра флага.
PUSHF – используется для копирования регистра флага в верхней части стека.
POPF – используется для копирования слова из верхней части стека в регистр флага.
Арифметические инструкции
Эти инструкции используются для выполнения арифметических операций, таких как сложение, вычитание, умножение, деление и т. Д.
Ниже приведен список инструкций в этой группе –
Инструкция по выполнению сложения
-
ДОБАВИТЬ – Используется для добавления предоставленного байта в байт / слово в слово.
-
ADC – используется для добавления с переносом.
-
INC – используется для увеличения предоставленного байта / слова на 1.
-
AAA – Используется для настройки ASCII после добавления.
-
DAA – используется для настройки десятичной дроби после операции сложения / вычитания.
ДОБАВИТЬ – Используется для добавления предоставленного байта в байт / слово в слово.
ADC – используется для добавления с переносом.
INC – используется для увеличения предоставленного байта / слова на 1.
AAA – Используется для настройки ASCII после добавления.
DAA – используется для настройки десятичной дроби после операции сложения / вычитания.
Инструкция по выполнению вычитания
-
SUB – Используется для вычитания байта из байта / слова из слова.
-
SBB – Используется для вычитания с заимствованием.
-
DEC – используется для уменьшения предоставленного байта / слова на 1.
-
NPG – Используется для отрицания каждого бита предоставленного байта / слова и добавления дополнения 1/2.
-
CMP – используется для сравнения 2 предоставленных байтов / слов.
-
AAS – Используется для настройки кодов ASCII после вычитания.
-
DAS – используется для настройки десятичной дроби после вычитания.
SUB – Используется для вычитания байта из байта / слова из слова.
SBB – Используется для вычитания с заимствованием.
DEC – используется для уменьшения предоставленного байта / слова на 1.
NPG – Используется для отрицания каждого бита предоставленного байта / слова и добавления дополнения 1/2.
CMP – используется для сравнения 2 предоставленных байтов / слов.
AAS – Используется для настройки кодов ASCII после вычитания.
DAS – используется для настройки десятичной дроби после вычитания.
Инструкция по выполнению умножения
-
MUL – используется для умножения байта без знака на слово / слово за словом.
-
IMUL – используется для умножения подписанного байта за байтом / слово за словом.
-
AAM – используется для настройки кодов ASCII после умножения.
MUL – используется для умножения байта без знака на слово / слово за словом.
IMUL – используется для умножения подписанного байта за байтом / слово за словом.
AAM – используется для настройки кодов ASCII после умножения.
Инструкция по выполнению деления
-
DIV – Используется для деления беззнакового слова по байту или без знака двойного слова по слову.
-
IDIV – Используется для деления подписанного слова в байтах или подписанного двойного слова в слово.
-
AAD – используется для настройки кодов ASCII после деления.
-
CBW – используется для заполнения старшего байта слова копиями знакового бита младшего байта.
-
CWD – используется для заполнения верхнего слова двойного слова знаковым битом нижнего слова.
DIV – Используется для деления беззнакового слова по байту или без знака двойного слова по слову.
IDIV – Используется для деления подписанного слова в байтах или подписанного двойного слова в слово.
AAD – используется для настройки кодов ASCII после деления.
CBW – используется для заполнения старшего байта слова копиями знакового бита младшего байта.
CWD – используется для заполнения верхнего слова двойного слова знаковым битом нижнего слова.
Инструкции по управлению битами
Эти инструкции используются для выполнения операций, в которых задействованы биты данных, например, таких как логические операции, сдвиг и т. Д.
Ниже приведен список инструкций в этой группе –
Инструкция по выполнению логической операции
-
НЕ – используется для инвертирования каждого бита или слова.
-
И – Используется для добавления каждого бита в байте / слове с соответствующим битом в другом байте / слове.
-
ИЛИ – Используется для умножения каждого бита в байте / слове на соответствующий бит в другом байте / слове.
-
XOR – используется для выполнения операции Exclusive-OR над каждым битом в байте / слове с соответствующим битом в другом байте / слове.
-
TEST – используется для добавления операндов для обновления флагов, без влияния на операнды.
НЕ – используется для инвертирования каждого бита или слова.
И – Используется для добавления каждого бита в байте / слове с соответствующим битом в другом байте / слове.
ИЛИ – Используется для умножения каждого бита в байте / слове на соответствующий бит в другом байте / слове.
XOR – используется для выполнения операции Exclusive-OR над каждым битом в байте / слове с соответствующим битом в другом байте / слове.
TEST – используется для добавления операндов для обновления флагов, без влияния на операнды.
Инструкция по выполнению сменных операций
-
SHL / SAL – используется для сдвига битов байта / слова влево и установки нуля (S) в младших битах.
-
SHR – используется для сдвига битов байта / слова вправо и установки нуля (S) в старших битах.
-
SAR – используется для сдвига битов байта / слова вправо и копирования старого MSB в новый MSB.
SHL / SAL – используется для сдвига битов байта / слова влево и установки нуля (S) в младших битах.
SHR – используется для сдвига битов байта / слова вправо и установки нуля (S) в старших битах.
SAR – используется для сдвига битов байта / слова вправо и копирования старого MSB в новый MSB.
Инструкции для выполнения операций поворота
-
ROL – Используется для поворота битов байта / слова влево, то есть от MSB к LSB и к сигналу переноса [CF].
-
ROR – используется для поворота битов байта / слова вправо, то есть от LSB к MSB и к сигналу переноса [CF].
-
RCR – используется для поворота битов байта / слова вправо, то есть от LSB к CF и CF к MSB.
-
RCL – используется для поворота битов байта / слова влево, то есть от MSB к CF и от CF к LSB.
ROL – Используется для поворота битов байта / слова влево, то есть от MSB к LSB и к сигналу переноса [CF].
ROR – используется для поворота битов байта / слова вправо, то есть от LSB к MSB и к сигналу переноса [CF].
RCR – используется для поворота битов байта / слова вправо, то есть от LSB к CF и CF к MSB.
RCL – используется для поворота битов байта / слова влево, то есть от MSB к CF и от CF к LSB.
Строковые Инструкции
Строка – это группа байтов / слов, и их память всегда выделяется в последовательном порядке.
Ниже приведен список инструкций в этой группе –
-
REP – Используется для повторения данной инструкции до CX ≠ 0.
-
REPE / REPZ – Используется для повторения данной инструкции до тех пор, пока CX = 0 или нулевой флаг ZF = 1.
-
REPNE / REPNZ – используется для повторения данной инструкции до тех пор, пока CX = 0 или нулевой флаг ZF = 1.
-
MOVS / MOVSB / MOVSW – используется для перемещения байта / слова из одной строки в другую.
-
COMS / COMPSB / COMPSW – используется для сравнения двух строковых байтов / слов.
-
INS / INSB / INSW – используется в качестве входной строки / байта / слова из порта ввода-вывода в указанное место памяти.
-
OUTS / OUTSB / OUTSW – используется в качестве выходной строки / байта / слова из предоставленной ячейки памяти в порт ввода / вывода.
-
SCAS / SCASB / SCASW – Используется для сканирования строки и сравнения ее байта с байтом в AL или слова строки со словом в AX.
-
LODS / LODSB / LODSW – используется для сохранения байта строки в AL или слова строки в AX.
REP – Используется для повторения данной инструкции до CX ≠ 0.
REPE / REPZ – Используется для повторения данной инструкции до тех пор, пока CX = 0 или нулевой флаг ZF = 1.
REPNE / REPNZ – используется для повторения данной инструкции до тех пор, пока CX = 0 или нулевой флаг ZF = 1.
MOVS / MOVSB / MOVSW – используется для перемещения байта / слова из одной строки в другую.
COMS / COMPSB / COMPSW – используется для сравнения двух строковых байтов / слов.
INS / INSB / INSW – используется в качестве входной строки / байта / слова из порта ввода-вывода в указанное место памяти.
OUTS / OUTSB / OUTSW – используется в качестве выходной строки / байта / слова из предоставленной ячейки памяти в порт ввода / вывода.
SCAS / SCASB / SCASW – Используется для сканирования строки и сравнения ее байта с байтом в AL или слова строки со словом в AX.
LODS / LODSB / LODSW – используется для сохранения байта строки в AL или слова строки в AX.
Инструкции переноса выполнения программы (инструкции ветвления и петли)
Эти инструкции используются для передачи / ветвления команд во время исполнения. Он включает в себя следующие инструкции –
Инструкция по передаче инструкции во время исполнения без каких-либо условий –
-
CALL – используется для вызова процедуры и сохранения адреса возврата в стек.
-
RET – используется для возврата из процедуры в основную программу.
-
JMP – используется для перехода к указанному адресу для перехода к следующей инструкции.
CALL – используется для вызова процедуры и сохранения адреса возврата в стек.
RET – используется для возврата из процедуры в основную программу.
JMP – используется для перехода к указанному адресу для перехода к следующей инструкции.
Инструкция для передачи инструкции во время исполнения с некоторыми условиями –
-
JA / JNBE – Используется для перехода, если выполнено указание выше / не ниже / равно.
-
JAE / JNB – используется для перехода, если инструкция выше / не ниже удовлетворяет.
-
JBE / JNA – Используется для перехода, если инструкция ниже / равно / не выше удовлетворяет.
-
JC – используется для прыжка, если флаг переноса CF = 1
-
JE / JZ – используется для перехода, если равен / ноль флаг ZF = 1
-
JG / JNLE – используется для перехода, если инструкция больше / не меньше / равна.
-
JGE / JNL – используется для перехода, если выполнено больше / равно / не меньше, чем инструкция.
-
JL / JNGE – используется для перехода, если удовлетворяется инструкция меньше / не больше / равно.
-
JLE / JNG – используется для перехода, если выполнено меньше / равно / если не больше, чем инструкция.
-
JNC – используется для прыжка, если нет флага переноса (CF = 0)
-
JNE / JNZ – используется для перехода, если не равен / нулевой флаг ZF = 0
-
JNO – используется для перехода, если нет флага переполнения OF = 0
-
JNP / JPO – используется для перехода, если не четность / четность нечетная PF = 0
-
JNS – используется для прыжка, если не знак SF = 0
-
JO – используется для перехода, если флаг переполнения OF = 1
-
JP / JPE – используется для перехода, если четность / четность даже PF = 1
-
JS – Используется для перехода, если флаг знака SF = 1
JA / JNBE – Используется для перехода, если выполнено указание выше / не ниже / равно.
JAE / JNB – используется для перехода, если инструкция выше / не ниже удовлетворяет.
JBE / JNA – Используется для перехода, если инструкция ниже / равно / не выше удовлетворяет.
JC – используется для прыжка, если флаг переноса CF = 1
JE / JZ – используется для перехода, если равен / ноль флаг ZF = 1
JG / JNLE – используется для перехода, если инструкция больше / не меньше / равна.
JGE / JNL – используется для перехода, если выполнено больше / равно / не меньше, чем инструкция.
JL / JNGE – используется для перехода, если удовлетворяется инструкция меньше / не больше / равно.
JLE / JNG – используется для перехода, если выполнено меньше / равно / если не больше, чем инструкция.
JNC – используется для прыжка, если нет флага переноса (CF = 0)
JNE / JNZ – используется для перехода, если не равен / нулевой флаг ZF = 0
JNO – используется для перехода, если нет флага переполнения OF = 0
JNP / JPO – используется для перехода, если не четность / четность нечетная PF = 0
JNS – используется для прыжка, если не знак SF = 0
JO – используется для перехода, если флаг переполнения OF = 1
JP / JPE – используется для перехода, если четность / четность даже PF = 1
JS – Используется для перехода, если флаг знака SF = 1
Инструкция по управлению процессором
Эти инструкции используются для управления действиями процессора путем установки / сброса значений флага.
Ниже приведены инструкции в этой группе:
-
STC – используется для установки флага переноса CF на 1
-
CLC – используется для сброса / сброса флага переноса CF на 0
-
CMC – используется для установки дополнения в состоянии флага переноса CF.
-
STD – используется для установки флага направления DF на 1
-
CLD – используется для сброса / сброса флага направления DF на 0
-
STI – используется для установки флага разрешения прерывания на 1, т. Е. Для включения входа INTR.
-
CLI – используется для сброса флага разрешения прерываний на 0, т. Е. Для отключения входа INTR.
STC – используется для установки флага переноса CF на 1
CLC – используется для сброса / сброса флага переноса CF на 0
CMC – используется для установки дополнения в состоянии флага переноса CF.
STD – используется для установки флага направления DF на 1
CLD – используется для сброса / сброса флага направления DF на 0
STI – используется для установки флага разрешения прерывания на 1, т. Е. Для включения входа INTR.
CLI – используется для сброса флага разрешения прерываний на 0, т. Е. Для отключения входа INTR.
Инструкции по контролю итерации
Эти инструкции используются для выполнения данных инструкций несколько раз. Ниже приведен список инструкций в этой группе –
-
LOOP – используется для зацикливания группы команд до тех пор, пока условие не будет удовлетворено, то есть CX = 0
-
LOOPE / LOOPZ – используется для зацикливания группы команд до тех пор, пока она не удовлетворит ZF = 1 и CX = 0
-
LOOPNE / LOOPNZ – используется для зацикливания группы команд до тех пор, пока она не удовлетворит ZF = 0 и CX = 0
-
JCXZ – используется для перехода к указанному адресу, если CX = 0
LOOP – используется для зацикливания группы команд до тех пор, пока условие не будет удовлетворено, то есть CX = 0
LOOPE / LOOPZ – используется для зацикливания группы команд до тех пор, пока она не удовлетворит ZF = 1 и CX = 0
LOOPNE / LOOPNZ – используется для зацикливания группы команд до тех пор, пока она не удовлетворит ZF = 0 и CX = 0
JCXZ – используется для перехода к указанному адресу, если CX = 0
Инструкции по прерыванию
Эти инструкции используются для вызова прерывания во время выполнения программы.
-
INT – Используется для прерывания программы во время выполнения и вызова указанной службы.
-
INTO – используется для прерывания программы во время выполнения, если OF = 1
-
IRET – используется для возврата из службы прерываний в основную программу
INT – Используется для прерывания программы во время выполнения и вызова указанной службы.
INTO – используется для прерывания программы во время выполнения, если OF = 1
IRET – используется для возврата из службы прерываний в основную программу
Микропроцессор – 8086 прерываний
Прерывание – это метод создания временной остановки во время выполнения программы и позволяет периферийным устройствам получать доступ к микропроцессору. Микропроцессор отвечает на это прерывание ISR (подпрограммой обработки прерываний), которая представляет собой короткую программу для инструктирования микропроцессора о том, как обрабатывать прерывание.
На следующем рисунке показаны типы прерываний, которые мы имеем в микропроцессоре 8086 –
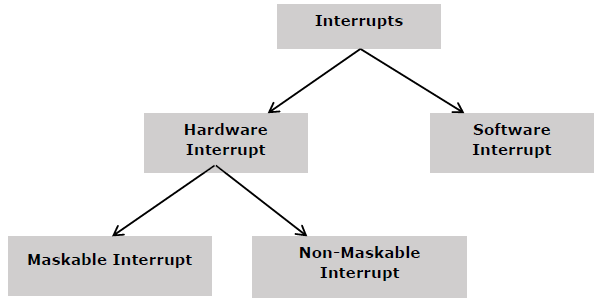
Аппаратные прерывания
Аппаратное прерывание вызывается любым периферийным устройством, посылая сигнал через указанный контакт в микропроцессор.
8086 имеет два вывода аппаратного прерывания, то есть NMI и INTR. NMI является немаскируемым прерыванием, а INTR является маскируемым прерыванием, имеющим более низкий приоритет. Еще один связанный контакт прерывания – это INTA, называемый подтверждением прерывания.
NMI
Это один немаскируемый вывод прерывания (NMI), имеющий более высокий приоритет, чем маскируемый вывод запроса прерывания (INTR), и он имеет прерывание типа 2.
Когда это прерывание активировано, происходят следующие действия:
-
Завершает текущую инструкцию, которая выполняется.
-
Помещает значения регистра флага в стек.
-
Выдвигает значение CS (сегмент кода) и значение IP (указатель инструкции) адреса возврата в стек.
-
IP загружается из содержимого слова местоположения 00008H.
-
CS загружается из содержимого следующего слова местоположения 0000AH.
-
Флаг прерывания и флаг прерывания сбрасываются в 0.
Завершает текущую инструкцию, которая выполняется.
Помещает значения регистра флага в стек.
Выдвигает значение CS (сегмент кода) и значение IP (указатель инструкции) адреса возврата в стек.
IP загружается из содержимого слова местоположения 00008H.
CS загружается из содержимого следующего слова местоположения 0000AH.
Флаг прерывания и флаг прерывания сбрасываются в 0.
ВВЕДЕНИ
INTR является маскируемым прерыванием, потому что микропроцессор будет прерываться только в том случае, если прерывания разрешены с использованием команды установки флага прерывания. Его не следует включать с помощью команды очистки флага прерывания.
Прерывание INTR активируется портом ввода / вывода. Если прерывание включено и NMI отключено, то микропроцессор сначала завершает текущее выполнение и дважды посылает «0» на вывод INTA. Первый «0» означает, что INTA информирует внешнее устройство о готовности, а во время второго «0» микропроцессор получает 8-битный, скажем, X, от программируемого контроллера прерываний.
Эти действия предпринимаются микропроцессором –
-
Сначала завершает текущую инструкцию.
-
Активирует выход INTA и получает тип прерывания, скажем, X.
-
Значение регистра флага, значение CS возвращаемого адреса и значение IP возвращаемого адреса помещаются в стек.
-
Значение IP загружается из содержимого слова местоположения X × 4
-
CS загружается из содержимого местоположения следующего слова.
-
Флаг прерывания и флаг прерывания сбрасываются на 0
Сначала завершает текущую инструкцию.
Активирует выход INTA и получает тип прерывания, скажем, X.
Значение регистра флага, значение CS возвращаемого адреса и значение IP возвращаемого адреса помещаются в стек.
Значение IP загружается из содержимого слова местоположения X × 4
CS загружается из содержимого местоположения следующего слова.
Флаг прерывания и флаг прерывания сбрасываются на 0
Программные прерывания
Некоторые инструкции вставляются в нужную позицию в программу для создания прерываний. Эти инструкции по прерыванию можно использовать для проверки работы различных обработчиков прерываний. Включает в себя –
INT- инструкция прерывания с номером типа
Это 2-байтовая инструкция. Первый байт предоставляет код операции, а второй байт – номер типа прерывания. В этой группе 256 типов прерываний.
Его выполнение включает в себя следующие этапы –
-
Значение регистра флага помещается в стек.
-
Значение CS адреса возврата и значение IP адреса возврата помещаются в стек.
-
IP загружается из содержимого слова местоположения «номер типа» × 4
-
CS загружается из содержимого местоположения следующего слова.
-
Флаг прерывания и Флаг ловушки сбрасываются на 0
Значение регистра флага помещается в стек.
Значение CS адреса возврата и значение IP адреса возврата помещаются в стек.
IP загружается из содержимого слова местоположения «номер типа» × 4
CS загружается из содержимого местоположения следующего слова.
Флаг прерывания и Флаг ловушки сбрасываются на 0
Начальный адрес для прерывания типа 0 – 000000H, для прерывания типа 1 – 00004H, аналогично для типа 2 – 00008H и так далее. Первые пять указателей являются выделенными указателями прерывания. то есть
-
Прерывание ТИПА 0 представляет деление на нулевую ситуацию.
-
Прерывание ТИПА 1 представляет одношаговое выполнение во время отладки программы.
-
Прерывание типа 2 представляет немаскируемое прерывание NMI.
-
Прерывание ТИПА 3 представляет прерывание точки останова.
-
Прерывание ТИПА 4 представляет прерывание переполнения.
Прерывание ТИПА 0 представляет деление на нулевую ситуацию.
Прерывание ТИПА 1 представляет одношаговое выполнение во время отладки программы.
Прерывание типа 2 представляет немаскируемое прерывание NMI.
Прерывание ТИПА 3 представляет прерывание точки останова.
Прерывание ТИПА 4 представляет прерывание переполнения.
Прерывания от типа 5 до типа 31 зарезервированы для других усовершенствованных микропроцессоров, а прерывания от 32 до типа 255 доступны для аппаратных и программных прерываний.
INT 3-точка прерывания Инструкция по прерыванию
Это однобайтовая инструкция с кодом операции CCH. Эти инструкции вставляются в программу таким образом, что, когда процессор достигает этого уровня, он останавливает нормальное выполнение программы и выполняет процедуру точки останова.
Его выполнение включает в себя следующие этапы –
-
Значение регистра флага помещается в стек.
-
Значение CS адреса возврата и значение IP адреса возврата помещаются в стек.
-
IP загружается из содержимого слова местоположения 3 × 4 = 0000CH
-
CS загружается из содержимого местоположения следующего слова.
-
Флаг прерывания и Флаг ловушки сбрасываются на 0
Значение регистра флага помещается в стек.
Значение CS адреса возврата и значение IP адреса возврата помещаются в стек.
IP загружается из содержимого слова местоположения 3 × 4 = 0000CH
CS загружается из содержимого местоположения следующего слова.
Флаг прерывания и Флаг ловушки сбрасываются на 0
INTO – прерывание по команде переполнения
Это однобайтовая инструкция и их мнемоническое INTO . Код операции для этой инструкции – CEH. Как следует из названия, это условная команда прерывания, то есть она активна, только когда флаг переполнения установлен в 1 и переходит к обработчику прерываний, чей номер типа прерывания равен 4. Если флаг переполнения сбрасывается, то выполнение продолжается до Следующая инструкция.
Его выполнение включает в себя следующие этапы –
-
Значения регистров флага помещаются в стек.
-
Значение CS адреса возврата и значение IP адреса возврата помещаются в стек.
-
IP загружается из содержимого слова местоположения 4 × 4 = 00010H
-
CS загружается из содержимого местоположения следующего слова.
-
Флаг прерывания и флаг Trap сбрасываются на 0
Значения регистров флага помещаются в стек.
Значение CS адреса возврата и значение IP адреса возврата помещаются в стек.
IP загружается из содержимого слова местоположения 4 × 4 = 00010H
CS загружается из содержимого местоположения следующего слова.
Флаг прерывания и флаг Trap сбрасываются на 0
Микропроцессор – 8086 режимов адресации
Различные способы обозначения исходного операнда в инструкции известны как режимы адресации . В программировании 8086 есть 8 различных режимов адресации –
Режим немедленной адресации
Режим адресации, в котором операнд данных является частью самой инструкции, называется режимом немедленной адресации.
пример
MOV CX, 4929 H, ADD AX, 2387 H, MOV AL, FFH
Зарегистрировать режим адресации
Это означает, что регистр является источником операнда для инструкции.
пример
MOV CX, AX ; copies the contents of the 16-bit AX register into
; the 16-bit CX register),
ADD BX, AX
Режим прямой адресации
Режим адресации, в котором эффективный адрес ячейки памяти записывается непосредственно в инструкции.
пример
MOV AX, [1592H], MOV AL, [0300H]
Зарегистрировать режим косвенной адресации
Этот режим адресации позволяет адресовать данные в любом месте памяти через адрес смещения, который хранится в любом из следующих регистров: BP, BX, DI & SI.
пример
MOV AX, [BX] ; Suppose the register BX contains 4895H, then the contents
; 4895H are moved to AX
ADD CX, {BX}
Основанный режим адресации
В этом режиме адресации адрес смещения операнда задается суммой содержимого регистров BX / BP и смещения 8 бит / 16 бит.
пример
MOV DX, [BX+04], ADD CL, [BX+08]
Режим индексированной адресации
В этом режиме адресации адрес смещения операндов находится путем сложения содержимого регистра SI или DI и смещения 8-бит / 16-бит.
пример
MOV BX, [SI+16], ADD AL, [DI+16]
Режим адресации на основе индекса
В этом режиме адресации адрес смещения операнда вычисляется путем суммирования базового регистра с содержимым регистра индекса.
пример
ADD CX, [AX+SI], MOV AX, [AX+DI]
На основе индексируется с режимом смещения
В этом режиме адресации смещение операндов вычисляется путем добавления содержимого базового регистра. Индекс регистрирует содержимое и смещение 8 или 16 бит.
пример
MOV AX, [BX+DI+08], ADD CX, [BX+SI+16]
Обзор многопроцессорной конфигурации
Мультипроцессор означает множественный набор процессоров, которые выполняют инструкции одновременно. Существует три основных многопроцессорных конфигурации.
- Конфигурация сопроцессора
- Тесно связанная конфигурация
- Слабосвязанная конфигурация
Конфигурация сопроцессора
Копроцессор – это специально разработанная схема на микропроцессорном чипе, которая может очень быстро выполнить ту же задачу, которую выполняет микропроцессор. Это снижает нагрузку на основной процессор. Сопроцессор использует одну и ту же память, систему ввода-вывода, шину, управляющую логику и тактовый генератор. Сопроцессор выполняет специализированные задачи, такие как математические вычисления, графическое отображение на экране и т. Д.
8086 и 8088 могут выполнять большинство операций, но их набор команд не способен выполнять сложные математические операции, поэтому в этих случаях микропроцессору требуется математический сопроцессор, такой как математический сопроцессор Intel 8087, который может легко выполнять эти операции очень быстро.
Блок-схема конфигурации сопроцессора
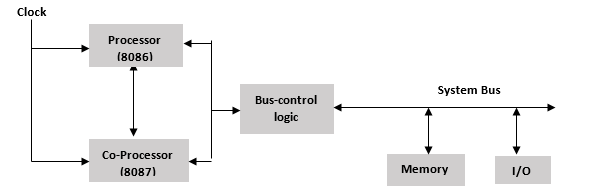
Как сопроцессор и процессор связаны?
-
Сопроцессор и процессор соединены через сигналы TEST, RQ- / GT- и QS 0 & QS 1 .
-
Сигнал TEST подключается к контакту BUSY сопроцессора, а остальные 3 контакта подключаются к 3 контактам сопроцессора с тем же именем.
-
Сигнал TEST определяет активность сопроцессора, т.е. сопроцессор занят или находится в режиме ожидания.
-
RT- / GT- используется для автобусного арбитража.
-
Сопроцессор использует QS 0 и QS 1 для отслеживания состояния очереди хост-процессора.
Сопроцессор и процессор соединены через сигналы TEST, RQ- / GT- и QS 0 & QS 1 .
Сигнал TEST подключается к контакту BUSY сопроцессора, а остальные 3 контакта подключаются к 3 контактам сопроцессора с тем же именем.
Сигнал TEST определяет активность сопроцессора, т.е. сопроцессор занят или находится в режиме ожидания.
RT- / GT- используется для автобусного арбитража.
Сопроцессор использует QS 0 и QS 1 для отслеживания состояния очереди хост-процессора.
Тесно связанная конфигурация
Тесно связанная конфигурация аналогична конфигурации сопроцессора, то есть обе они совместно используют одну и ту же память, системную шину ввода-вывода, логику управления и генератор управления с главным процессором. Однако сопроцессор и хост-процессор выбирают и выполняют свои собственные инструкции. Системная шина контролируется сопроцессором и хост-процессором независимо.
Блок-схема тесно связанной конфигурации
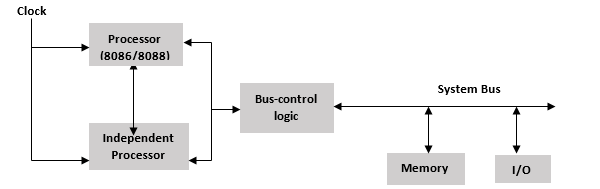
Как связаны процессор и независимый процессор?
-
Связь между хостом и независимым процессором осуществляется через пространство памяти.
-
Ни одна из инструкций не используется для связи, как WAIT, ESC и т. Д.
-
Главный процессор управляет памятью и активирует независимый процессор, посылая команды на один из его портов.
-
Затем независимый процессор обращается к памяти для выполнения задачи.
-
После завершения задачи он отправляет подтверждение хост-процессору, используя сигнал состояния или запрос прерывания.
Связь между хостом и независимым процессором осуществляется через пространство памяти.
Ни одна из инструкций не используется для связи, как WAIT, ESC и т. Д.
Главный процессор управляет памятью и активирует независимый процессор, посылая команды на один из его портов.
Затем независимый процессор обращается к памяти для выполнения задачи.
После завершения задачи он отправляет подтверждение хост-процессору, используя сигнал состояния или запрос прерывания.
Слабосвязанная конфигурация
Слабосвязанная конфигурация состоит из ряда модулей микропроцессорных систем, которые подключены через общую системную шину. Каждый модуль состоит из собственного тактового генератора, памяти, устройств ввода-вывода и подключен через локальную шину.
Блок-схема слабосвязанной конфигурации
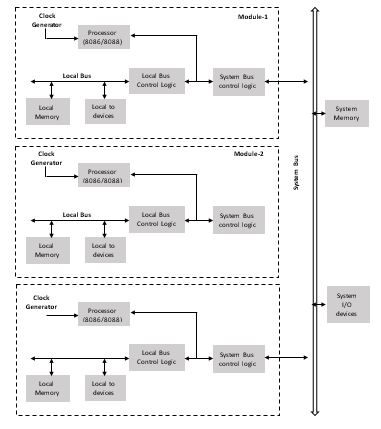
преимущества
-
Наличие более одного процессора приводит к повышению эффективности.
-
Каждый из процессоров имеет собственную локальную шину для доступа к локальным устройствам памяти / ввода-вывода. Это облегчает параллельную обработку.
-
Структура системы является гибкой, то есть отказ одного модуля не влияет на весь отказ системы; неисправный модуль может быть заменен позже.
Наличие более одного процессора приводит к повышению эффективности.
Каждый из процессоров имеет собственную локальную шину для доступа к локальным устройствам памяти / ввода-вывода. Это облегчает параллельную обработку.
Структура системы является гибкой, то есть отказ одного модуля не влияет на весь отказ системы; неисправный модуль может быть заменен позже.
8087 Числовой процессор данных
Процессор числовых данных 8087 также известен как математический сопроцессор, расширение числового процессора и модуль с плавающей запятой . Это был первый математический сопроцессор, разработанный Intel для сопряжения с 8086/8088, что привело к более простому и быстрому вычислению.
Как только инструкции идентифицированы процессором 8086/8088, они передаются сопроцессору 8087 для дальнейшего выполнения.
Типы данных, поддерживаемые 8087:
- Двоичные целые числа
- Упакованные десятичные числа
- Вещественные числа
- Временный реальный формат
Наиболее характерные особенности процессора обработки цифровых данных 8087:
-
Он поддерживает данные типа integer, float и real, размером от 2 до 10 байтов.
-
Скорость обработки настолько высока, что она может рассчитать умножение двух 64-битных действительных чисел за ~ 27 мкс, а также вычислить квадратный корень за ~ 35 мкс.
-
Это соответствует стандартам IEEE с плавающей запятой.
Он поддерживает данные типа integer, float и real, размером от 2 до 10 байтов.
Скорость обработки настолько высока, что она может рассчитать умножение двух 64-битных действительных чисел за ~ 27 мкс, а также вычислить квадратный корень за ~ 35 мкс.
Это соответствует стандартам IEEE с плавающей запятой.
8087 Архитектура
Архитектура 8087 разделена на две группы: блок управления (CU) и блок расширения чисел (NEU).
-
Блок управления обрабатывает весь обмен данными между процессором и памятью, например, получает и декодирует инструкции, считывает и записывает операнды памяти, поддерживает параллельную очередь и т. Д. Все инструкции сопроцессора являются инструкциями ESC, т. Е. Начинаются с «F», сопроцессор выполняет только команды ESC, в то время как другие инструкции выполняются микропроцессором.
-
Блок числового расширения обрабатывает все инструкции числового процессора, такие как арифметические, логические, трансцендентные и инструкции по передаче данных. Он имеет 8 регистров, которые содержат операнды для инструкций и их результатов.
Блок управления обрабатывает весь обмен данными между процессором и памятью, например, получает и декодирует инструкции, считывает и записывает операнды памяти, поддерживает параллельную очередь и т. Д. Все инструкции сопроцессора являются инструкциями ESC, т. Е. Начинаются с «F», сопроцессор выполняет только команды ESC, в то время как другие инструкции выполняются микропроцессором.
Блок числового расширения обрабатывает все инструкции числового процессора, такие как арифметические, логические, трансцендентные и инструкции по передаче данных. Он имеет 8 регистров, которые содержат операнды для инструкций и их результатов.
Архитектура сопроцессора 8087 выглядит следующим образом –
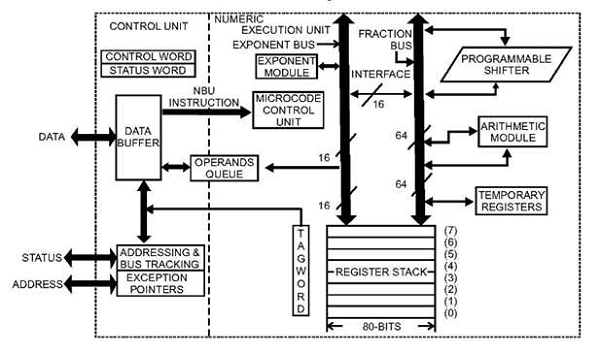
8087 Pin Описание
Давайте сначала взглянем на схему контактов 8087 –
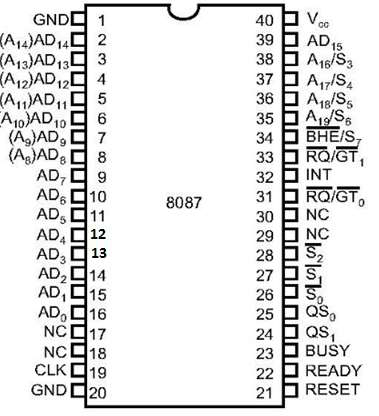
В следующем списке приведено описание Pin 8087 –
-
AD 0 – AD 15 – это линии адреса / данных с мультиплексированием по времени, которые переносят адреса в течение первого тактового цикла и данные со второго тактового цикла и далее.
-
A 19 / S 6 – A 16 / S – Эти строки являются мультиплексированными по времени адресными / статусными строками. Он функционирует аналогично соответствующим контактам 8086. S 6 , S 4 и S3 постоянно высокие, в то время как S 5 постоянно низкие.
-
$ overline {BHE} $ / S 7 – во время первого тактового цикла $ overline {BHE} $ / S 7 используется для включения данных на старший байт шины данных 8086 и после этого работает как строка состояния S 7 .
-
QS 1 , QS 0 – это входные сигналы состояния очереди, которые обеспечивают состояние очереди команд, их состояние, как показано в следующей таблице:
AD 0 – AD 15 – это линии адреса / данных с мультиплексированием по времени, которые переносят адреса в течение первого тактового цикла и данные со второго тактового цикла и далее.
A 19 / S 6 – A 16 / S – Эти строки являются мультиплексированными по времени адресными / статусными строками. Он функционирует аналогично соответствующим контактам 8086. S 6 , S 4 и S3 постоянно высокие, в то время как S 5 постоянно низкие.
$ overline {BHE} $ / S 7 – во время первого тактового цикла $ overline {BHE} $ / S 7 используется для включения данных на старший байт шины данных 8086 и после этого работает как строка состояния S 7 .
QS 1 , QS 0 – это входные сигналы состояния очереди, которые обеспечивают состояние очереди команд, их состояние, как показано в следующей таблице:
| QS 0 | QS 1 | Статус |
|---|---|---|
| 0 | 0 | Нет операции |
| 0 | 1 | Первый байт кода операции из очереди |
| 1 | 0 | Очистить очередь |
| 1 | 1 | Последующий байт из очереди |
-
INT – это сигнал прерывания, который изменяется на высокий уровень, когда во время выполнения было получено немаскированное исключение.
-
BUSY – это выходной сигнал, когда он высокий, он указывает на состояние занятости процессора.
-
READY – это входной сигнал, используемый для информирования сопроцессора о том, готова ли шина к приему данных или нет.
-
СБРОС – это входной сигнал, используемый для отклонения внутренних операций сопроцессора и подготовки его к дальнейшему выполнению, когда этого требует ЦП.
-
CLK – Вход CLK обеспечивает основные временные характеристики для работы процессора.
-
VCC – это сигнал источника питания, который требует + 5В для работы схемы.
-
S 0 , S 1 , S 2 – это сигналы состояния, которые обеспечивают состояние операции, которое используется контроллером шины 8087 для генерации сигналов памяти и управляющих сигналов ввода / вывода. Эти сигналы активны в течение четвертого тактового цикла.
INT – это сигнал прерывания, который изменяется на высокий уровень, когда во время выполнения было получено немаскированное исключение.
BUSY – это выходной сигнал, когда он высокий, он указывает на состояние занятости процессора.
READY – это входной сигнал, используемый для информирования сопроцессора о том, готова ли шина к приему данных или нет.
СБРОС – это входной сигнал, используемый для отклонения внутренних операций сопроцессора и подготовки его к дальнейшему выполнению, когда этого требует ЦП.
CLK – Вход CLK обеспечивает основные временные характеристики для работы процессора.
VCC – это сигнал источника питания, который требует + 5В для работы схемы.
S 0 , S 1 , S 2 – это сигналы состояния, которые обеспечивают состояние операции, которое используется контроллером шины 8087 для генерации сигналов памяти и управляющих сигналов ввода / вывода. Эти сигналы активны в течение четвертого тактового цикла.
| S 2 | S 1 | S 0 | Состояние очереди |
|---|---|---|---|
| 0 | Икс | Икс | неиспользуемый |
| 1 | 0 | 0 | неиспользуемый |
| 1 | 0 | 1 | Чтение памяти |
| 1 | 1 | 0 | Запись в память |
| 1 | 1 | 1 | пассивный |
-
RQ / GT 1 и RQ / GT 0 – это сигналы Запрос / Предоставление, используемые процессорами 8087 для получения контроля над шиной от хост-процессора 8086/8088 для передачи операндов.
RQ / GT 1 и RQ / GT 0 – это сигналы Запрос / Предоставление, используемые процессорами 8087 для получения контроля над шиной от хост-процессора 8086/8088 для передачи операндов.
Микропроцессор – интерфейс ввода-вывода
В этой главе мы обсудим Интерфейс памяти и Интерфейс ввода-вывода с 8085.
Интерфейс – это путь для связи между двумя компонентами. Интерфейс бывает двух типов: интерфейс памяти и интерфейс ввода / вывода.
Интерфейс памяти
Когда мы выполняем любую инструкцию, нам нужен микропроцессор для доступа к памяти для чтения кодов команд и данных, хранящихся в памяти. Для этого и память, и микропроцессор требуют некоторых сигналов для чтения и записи в регистры.
Процесс сопряжения включает в себя некоторые ключевые факторы, чтобы соответствовать требованиям к памяти и сигналам микропроцессора. Следовательно, схема сопряжения должна быть сконструирована таким образом, чтобы она соответствовала требованиям к сигналам памяти с сигналами микропроцессора.
IO Interfacing
Существуют различные устройства связи, такие как клавиатура, мышь, принтер и т. Д. Итак, нам необходимо связать клавиатуру и другие устройства с микропроцессором, используя защелки и буферы. Этот тип интерфейса известен как интерфейс ввода / вывода.
Блок-схема памяти и интерфейса ввода-вывода
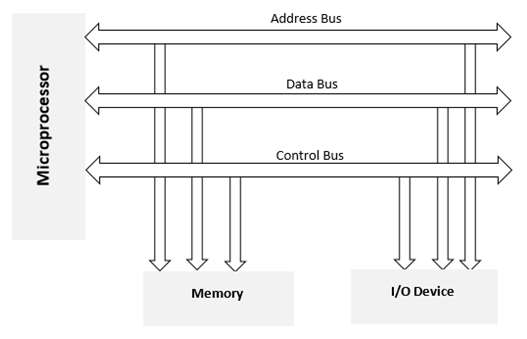
8085 Интерфейсные Пины
Ниже приведен список 8085 контактов, используемых для взаимодействия с другими устройствами.
- A 15 – A 8 (Высшая адресная шина)
- AD 7 – AD 0 (нижний адрес / шина данных)
- ALE
- RD
- WR
- ГОТОВЫ
Способы связи – микропроцессор с внешним миром?
Существует два способа связи, при которых микропроцессор может соединяться с внешним миром.
- Интерфейс последовательной связи
- Параллельный интерфейс связи
Интерфейс последовательной связи – при этом типе связи интерфейс получает один микропроцессор данных и поочередно отправляет их в другую систему, и наоборот.
Интерфейс параллельной связи – при этом типе связи интерфейс получает байт данных от микропроцессора и отправляет их по битам в другие системы одновременно (или) параллельно и наоборот.
8279 – Программируемая клавиатура
Программируемый контроллер клавиатуры / дисплея 8279 разработан компанией Intel, которая связывает клавиатуру с процессором. Сначала клавиатура сканирует клавиатуру и определяет, была ли нажата какая-либо клавиша. Затем он отправляет их относительный ответ нажатой клавиши в ЦП и наоборот.
Сколько способов клавиатура связана с процессором?
Клавиатура может быть подключена как в режиме прерывания, так и в режиме опроса. В режиме прерывания процессор запрашивает обслуживание, только если нажата какая-либо клавиша, в противном случае ЦП продолжит выполнение своей основной задачи.
В режиме опроса ЦПУ периодически считывает внутренний флаг 8279, чтобы проверить, нажата ли какая-либо клавиша или нет при нажатии клавиши.
Как работает клавиатура 8279?
Клавиатура состоит максимум из 64 клавиш, которые взаимодействуют с процессором с помощью кодов клавиш. Эти коды клавиш сбрасываются и сохраняются в 8-байтовом FIFORAM, к которому может обращаться ЦП. Если в FIFO введено более 8 символов, это означает, что одновременно нажимается более восьми клавиш. Это когда статус переполнения установлен.
Если FIFO содержит действительную ключевую запись, то ЦПУ прерывается в режиме прерывания, иначе ЦП проверяет состояние при опросе, чтобы прочитать запись. Как только процессор считывает запись ключа, FIFO обновляется, и запись ключа выталкивается из FIFO, чтобы создать пространство для новых записей.
Архитектура и описание
Контроль ввода / вывода и буфер данных
Этот блок контролирует поток данных через микропроцессор. Он включается только когда D низкий. Его буфер данных связывает внешнюю шину системы с внутренней шиной микропроцессора. Контакты A0, RD и WR используются для команд, состояний или операций чтения / записи данных.
Регистр контроля и синхронизации и контроль синхронизации
Это устройство содержит регистры для хранения клавиатуры, режимов отображения и других операций, запрограммированных ЦПУ. Блок синхронизации и управления управляет временем работы схемы.
Счетчик сканирования
Он имеет два режима: режим кодирования и режим декодирования. В кодированном режиме счетчик обеспечивает двоичный счетчик, который должен быть декодирован извне, чтобы обеспечить линии сканирования для клавиатуры и дисплея.
В режиме декодированного сканирования счетчик внутренне декодирует младшие 2 бита и обеспечивает декодированное сканирование 1 из 4 на SL 0 -SL 3 .
Буферы возврата, отладка клавиатуры и контроль
Этот блок сначала сканирует закрытие клавиш по строкам, если он найден, тогда блок отладки клавиатуры отклоняет ввод ключа. В случае, если та же клавиша обнаружена, код этой клавиши напрямую передается в ОЗУ датчика вместе со статусом клавиши SHIFT & CONTROL.
FIFO / датчик ОЗУ и логика состояния
Это устройство действует как 8-байтовая ОЗУ «первым пришел – первым обслужен» (FIFO), где код клавиши каждой нажатой клавиши вводится в ОЗУ в соответствии с их последовательностью. Логика состояния генерирует запрос прерывания после каждой операции чтения FIFO, пока FIFO не станет пустым.
В режиме отсканированной матрицы датчиков этот модуль действует как ОЗУ датчика, где каждый его ряд загружается со статусом соответствующего ряда датчиков в матрицу. Когда датчик меняет свое состояние, линия IRQ меняется на высокий и прерывает процессор.
Показать регистры адресов и показать ОЗУ
Этот блок состоит из регистров адреса дисплея, которые содержат адреса слова, в настоящее время считываемого / записываемого ЦП в / из ОЗУ дисплея.
8279 – Пин Описание
На следующем рисунке показана схема контактов 8279 –
Линии шины данных, DB 0 – DB 7
Это 8 двунаправленных линий шины данных, используемых для передачи данных в / из ЦП.
CLK
Вход синхронизации используется для генерации внутренних таймингов, требуемых микропроцессором.
СБРОС
Как следует из названия, этот вывод используется для сброса микропроцессора.
CS Chip Select
Когда этот вывод установлен на низкий уровень, он разрешает операции чтения / записи, иначе этот вывод должен быть установлен на высокий.
А 0
Этот вывод указывает передачу команды / информации о состоянии. Когда оно низкое, это указывает на передачу данных.
RD, WR
Этот контакт чтения / записи позволяет буферу данных отправлять / получать данные по шине данных.
IRQ
Эта линия вывода прерывания становится высокой, когда в ОЗУ датчика FIFO есть данные. Строка прерывания уменьшается с каждой операцией чтения ОЗУ FIFO. Однако, если ОЗУ FIFO дополнительно содержит какую-либо запись кода ключа, которая должна быть прочитана ЦП, этот вывод снова повышается, чтобы создать прерывание для ЦП.
V ss , V cc
Это линии заземления и питания микропроцессора.
SL 0 – SL 3
Это линии сканирования, используемые для сканирования матрицы клавиатуры и отображения цифр. Эти строки могут быть запрограммированы как закодированные или декодированные с использованием регистра управления режимом.
RL 0 – RL 7
Это линии возврата, которые подключены к одному терминалу ключей, в то время как другой терминал ключей подключен к декодированным линиям сканирования. Эти строки устанавливаются в 0 при нажатии любой клавиши.
СДВИГ
Статус строки ввода Shift сохраняется вместе с каждым кодом клавиши в FIFO в режиме отсканированной клавиатуры. Пока он опущен вниз с помощью ключа, он поднимается изнутри, чтобы держать его высоко
CNTL / STB – режим управления / стробирования I / P
В режиме клавиатуры эта строка используется в качестве управляющего ввода и сохраняется в FIFO при закрытии клавиши. Строка является стробирующей линией, которая вводит данные в FIFO RAM в режиме стробированного ввода. У этого есть внутренняя тяга. Линия снята с ключом закрытия.
BD
Он обозначает пустой дисплей. Он используется для очистки дисплея во время переключения цифр.
OUTA 0 – OUTA 3 и OUTB 0 – OUTB 3
Это выходные порты для двух 16×4 или одного 16×8 внутренних регистров обновления дисплея. Данные из этих строк синхронизируются со строками сканирования для сканирования дисплея и клавиатуры.
Операционные режимы 8279
В 8279 есть два режима работы – режим ввода и режим вывода .
Режим ввода
Этот режим имеет дело с вводом, данным с клавиатуры, и этот режим далее классифицирован на 3 режима.
-
Режим сканированной клавиатуры – в этом режиме матрица клавиш может быть сопряжена с использованием либо кодированного, либо декодированного сканирования. При кодированном сканировании, клавиатуре 8 × 8 или в декодированном сканировании может быть подключена клавиатура 4 × 8. Код клавиши, нажатой с состояниями SHIFT и CONTROL, сохраняется в ОЗУ FIFO.
-
Сканированная матрица датчиков – в этом режиме матрица датчиков может быть сопряжена с процессором с использованием сканирования кодером или декодером. При сканировании кодера может быть сопряжена матрица датчиков 8 × 8 или со сканированием декодера матрица датчиков 4 × 8.
-
Strobed Input – в этом режиме, когда линия управления установлена на 0, данные на обратных линиях сохраняются в байтах FIFO.
Режим сканированной клавиатуры – в этом режиме матрица клавиш может быть сопряжена с использованием либо кодированного, либо декодированного сканирования. При кодированном сканировании, клавиатуре 8 × 8 или в декодированном сканировании может быть подключена клавиатура 4 × 8. Код клавиши, нажатой с состояниями SHIFT и CONTROL, сохраняется в ОЗУ FIFO.
Сканированная матрица датчиков – в этом режиме матрица датчиков может быть сопряжена с процессором с использованием сканирования кодером или декодером. При сканировании кодера может быть сопряжена матрица датчиков 8 × 8 или со сканированием декодера матрица датчиков 4 × 8.
Strobed Input – в этом режиме, когда линия управления установлена на 0, данные на обратных линиях сохраняются в байтах FIFO.
Режим вывода
Этот режим имеет дело с операциями, связанными с отображением. Этот режим далее классифицируется на два режима вывода.
-
Сканирование дисплея – этот режим позволяет организовать мультиплексные дисплеи 8/16 символов в виде двух 4-битных / одиночных 8-битных блоков отображения.
-
Отображение ввода – этот режим позволяет вводить данные для отображения с правой или левой стороны.
Сканирование дисплея – этот режим позволяет организовать мультиплексные дисплеи 8/16 символов в виде двух 4-битных / одиночных 8-битных блоков отображения.
Отображение ввода – этот режим позволяет вводить данные для отображения с правой или левой стороны.
Микропроцессор – контроллер 8257 DMA
DMA означает прямой доступ к памяти. Он разработан Intel для быстрой передачи данных. Это позволяет устройству передавать данные непосредственно в / из памяти без какого-либо вмешательства ЦП.
Используя контроллер DMA, устройство запрашивает у ЦП свои данные, адрес и управляющую шину, поэтому устройство может передавать данные непосредственно в / из памяти. Передача данных DMA начинается только после получения сигнала HLDA от CPU.
Как выполняются операции DMA?
Ниже приведена последовательность операций, выполняемых DMA –
-
Первоначально, когда какое-либо устройство должно отправить данные между устройством и памятью, оно должно отправить запрос DMA (DRQ) на контроллер DMA.
-
Контроллер DMA отправляет запрос удержания (HRQ) в ЦП и ожидает, пока ЦП утвердит HLDA.
-
Затем микропроцессор делит три состояния на всю шину данных, адресную шину и управляющую шину. ЦП покидает контроль над шиной и подтверждает запрос HOLD через сигнал HLDA.
-
Теперь процессор находится в состоянии HOLD, и контроллер DMA должен управлять операциями по шинам между процессором, памятью и устройствами ввода-вывода.
Первоначально, когда какое-либо устройство должно отправить данные между устройством и памятью, оно должно отправить запрос DMA (DRQ) на контроллер DMA.
Контроллер DMA отправляет запрос удержания (HRQ) в ЦП и ожидает, пока ЦП утвердит HLDA.
Затем микропроцессор делит три состояния на всю шину данных, адресную шину и управляющую шину. ЦП покидает контроль над шиной и подтверждает запрос HOLD через сигнал HLDA.
Теперь процессор находится в состоянии HOLD, и контроллер DMA должен управлять операциями по шинам между процессором, памятью и устройствами ввода-вывода.
Особенности 8257
Вот список некоторых выдающихся особенностей 8257 –
-
Он имеет четыре канала, которые можно использовать на четырех устройствах ввода-вывода.
-
Каждый канал имеет 16-битный адрес и 14-битный счетчик.
-
Каждый канал может передавать данные до 64 КБ.
-
Каждый канал может быть запрограммирован независимо.
-
Каждый канал может выполнять операции чтения чтения, записи записи и проверки операций передачи.
-
Он генерирует сигнал MARK для периферийного устройства о том, что было передано 128 байтов.
-
Это требует однофазных часов.
-
Его частота колеблется от 250 Гц до 3 МГц.
-
Он работает в 2 режимах, то есть в режиме Master и Slave .
Он имеет четыре канала, которые можно использовать на четырех устройствах ввода-вывода.
Каждый канал имеет 16-битный адрес и 14-битный счетчик.
Каждый канал может передавать данные до 64 КБ.
Каждый канал может быть запрограммирован независимо.
Каждый канал может выполнять операции чтения чтения, записи записи и проверки операций передачи.
Он генерирует сигнал MARK для периферийного устройства о том, что было передано 128 байтов.
Это требует однофазных часов.
Его частота колеблется от 250 Гц до 3 МГц.
Он работает в 2 режимах, то есть в режиме Master и Slave .
8257 Архитектура
На следующем изображении показана архитектура 8257 –
8257 Pin Описание
На следующем рисунке показана схема контактов контроллера прямого доступа к памяти 8257 –
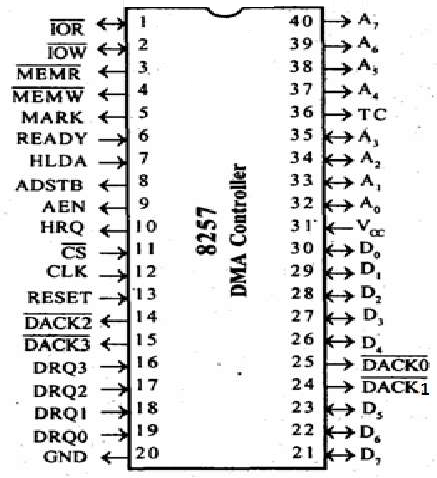
DRQ 0 −DRQ 3
Это четыре отдельных канала ввода запроса DMA, которые используются периферийными устройствами для использования услуг DMA. Когда выбран режим с фиксированным приоритетом, то DRQ 0 имеет самый высокий приоритет, а DRQ 3 имеет самый низкий приоритет среди них.
DACK o – DACK 3
Это линии подтверждения активного низкого уровня DMA, которые обновляют запрашивающее периферийное устройство о состоянии их запроса ЦПУ. Эти линии также могут выступать в качестве стробирующих линий для запрашивающих устройств.
Д о – Д 7
Это двунаправленные линии передачи данных, которые используются для сопряжения системной шины с внутренней шиной данных контроллера DMA. В подчиненном режиме он переносит командные слова в 8257 и слово состояния из 8257. В основном режиме эти строки используются для отправки старшего байта сгенерированного адреса в защелку. Этот адрес дополнительно фиксируется с помощью сигнала ADSTB.
IOR
Это двунаправленная входная линия с тремя активными состояниями, которая используется ЦП для считывания внутренних регистров 8257 в подчиненном режиме. В основном режиме он используется для чтения данных с периферийных устройств во время цикла записи в память.
IOW
Это активная линия с тремя состояниями в двух направлениях, которая используется для загрузки содержимого шины данных в регистр 8-битного режима или в верхний / нижний байт 16-битного регистра адресов DMA или регистра подсчета терминалов. В режиме мастера он используется для загрузки данных на периферийные устройства во время цикла чтения памяти DMA.
CLK
Это сигнал тактовой частоты, который требуется для внутренней работы 8257.
СБРОС
Этот сигнал используется для сброса контроллера DMA путем отключения всех каналов DMA.
A o – A 3
Это четыре наименее значимые адресные строки. В подчиненном режиме они действуют как вход, который выбирает один из регистров для чтения или записи. В режиме master они являются четырьмя наименее значимыми строками вывода адресов памяти, сгенерированными 8257.
CS
Это линия выбора активных и низких фишек. В режиме Slave он разрешает операции чтения / записи в / из 8257. В режиме мастера он отключает операции чтения / записи в / из 8257.
А 4 – А 7
Это верхний полубайт младшего байтового адреса, сгенерированного DMA в режиме мастера.
ГОТОВЫ
Это активный высокий асинхронный входной сигнал, который подготавливает DMA путем вставки состояний ожидания.
HRQ
Этот сигнал используется для приема сигнала запроса удержания от устройства вывода. В подчиненном режиме он связан с линией входа DRQ 8257. В режиме Master он связан со входом HOLD ЦПУ.
HLDA
Это сигнал подтверждения удержания, который указывает контроллеру DMA, что шина была предоставлена запрашивающему периферийному устройству центральным процессором, когда он установлен в 1.
МЭМР
Это сигнал чтения из нехватки памяти, который используется для чтения данных из адресованных областей памяти во время циклов чтения DMA.
MEMW
Это сигнал трех активных состояний, который используется для записи данных в адресную ячейку памяти во время операции записи DMA.
ADST
Этот сигнал используется для преобразования старшего байта адреса памяти, сгенерированного контроллером DMA, в защелки.
АЕН
Этот сигнал используется для отключения адресной шины / шины данных.
TC
Он обозначает «Количество терминалов», которое указывает текущий цикл DMA для существующих периферийных устройств.
ОТМЕТКА
Знак будет активироваться после каждых 128 циклов или целых кратных с самого начала. Это указывает на то, что текущий цикл DMA является 128-м циклом с момента предыдущего вывода MARK на выбранное периферийное устройство.
V cc
Это сигнал мощности, необходимый для работы схемы.
Микроконтроллеры – Обзор
Микроконтроллер – это небольшой и недорогой микрокомпьютер, который предназначен для выполнения конкретных задач встроенных систем, таких как отображение информации о микроволновом излучении, прием удаленных сигналов и т. Д.
Общий микроконтроллер состоит из процессора, памяти (RAM, ROM, EPROM), последовательных портов, периферийных устройств (таймеры, счетчики) и т. Д.
Разница между микропроцессором и микроконтроллером
В следующей таблице приведены различия между микропроцессором и микроконтроллером.
| микроконтроллер | Микропроцессор |
|---|---|
| Микроконтроллеры используются для выполнения одной задачи в приложении. | Микропроцессоры используются для больших приложений. |
| Его проектирование и стоимость оборудования низкие. | Его проектирование и стоимость оборудования высоки. |
| Легко заменить. | Не так легко заменить. |
| Он построен по технологии CMOS, которая требует меньше энергии для работы. | Потребляемая мощность высока, потому что он должен контролировать всю систему. |
| Он состоит из ЦП, ОЗУ, ПЗУ, портов ввода / вывода. | Он не состоит из ОЗУ, ПЗУ, портов ввода / вывода. Он использует свои контакты для взаимодействия с периферийными устройствами. |
Типы микроконтроллеров
Микроконтроллеры делятся на различные категории в зависимости от памяти, архитектуры, битов и наборов команд. Ниже приведен список их типов –
Немного
На основе битовой конфигурации микроконтроллер делится на три категории.
-
8-битный микроконтроллер. Этот тип микроконтроллера используется для выполнения арифметических и логических операций, таких как сложение, вычитание, умножение и т. Д. Например, Intel 8031 и 8051 представляют собой 8-битный микроконтроллер.
-
16-разрядный микроконтроллер – этот тип микроконтроллера используется для выполнения арифметических и логических операций, где требуется более высокая точность и производительность. Например, Intel 8096 представляет собой 16-разрядный микроконтроллер.
-
32-разрядный микроконтроллер. Этот тип микроконтроллера обычно используется в устройствах с автоматическим управлением, таких как автоматы, медицинские приборы и т. Д.
8-битный микроконтроллер. Этот тип микроконтроллера используется для выполнения арифметических и логических операций, таких как сложение, вычитание, умножение и т. Д. Например, Intel 8031 и 8051 представляют собой 8-битный микроконтроллер.
16-разрядный микроконтроллер – этот тип микроконтроллера используется для выполнения арифметических и логических операций, где требуется более высокая точность и производительность. Например, Intel 8096 представляет собой 16-разрядный микроконтроллер.
32-разрядный микроконтроллер. Этот тип микроконтроллера обычно используется в устройствах с автоматическим управлением, таких как автоматы, медицинские приборы и т. Д.
объем памяти
В зависимости от конфигурации памяти микроконтроллер делится на две категории.
-
Микроконтроллер с внешней памятью. Микроконтроллеры такого типа спроектированы таким образом, что на чипе отсутствует программная память. Следовательно, он называется микроконтроллером внешней памяти. Например: микроконтроллер Intel 8031.
-
Микроконтроллер со встроенной памятью. Этот тип микроконтроллера спроектирован таким образом, что микроконтроллер имеет все программы и память данных, счетчики и таймеры, прерывания, порты ввода / вывода встроены в микросхему. Например: микроконтроллер Intel 8051.
Микроконтроллер с внешней памятью. Микроконтроллеры такого типа спроектированы таким образом, что на чипе отсутствует программная память. Следовательно, он называется микроконтроллером внешней памяти. Например: микроконтроллер Intel 8031.
Микроконтроллер со встроенной памятью. Этот тип микроконтроллера спроектирован таким образом, что микроконтроллер имеет все программы и память данных, счетчики и таймеры, прерывания, порты ввода / вывода встроены в микросхему. Например: микроконтроллер Intel 8051.
Набор инструкций
На основе конфигурации набора команд микроконтроллер делится на две категории.
-
CISC – CISC расшифровывается как компьютер с комплексными инструкциями. Это позволяет пользователю вставить одну инструкцию в качестве альтернативы многим простым инструкциям.
-
RISC – RISC расшифровывается как Компьютеры с сокращенным набором команд. Это сокращает время работы за счет сокращения тактового цикла на инструкцию.
CISC – CISC расшифровывается как компьютер с комплексными инструкциями. Это позволяет пользователю вставить одну инструкцию в качестве альтернативы многим простым инструкциям.
RISC – RISC расшифровывается как Компьютеры с сокращенным набором команд. Это сокращает время работы за счет сокращения тактового цикла на инструкцию.
Применение микроконтроллеров
Микроконтроллеры широко используются в различных устройствах, таких как –
-
Светочувствительные и контролирующие устройства, такие как LED.
-
Приборы для измерения и контроля температуры, такие как микроволновая печь, дымоходы.
-
Пожарная сигнализация и устройства безопасности, такие как пожарная сигнализация.
-
Измерительные приборы, такие как вольтметр.
Светочувствительные и контролирующие устройства, такие как LED.
Приборы для измерения и контроля температуры, такие как микроволновая печь, дымоходы.
Пожарная сигнализация и устройства безопасности, такие как пожарная сигнализация.
Измерительные приборы, такие как вольтметр.
Микроконтроллеры – архитектура 8051
Микроконтроллер 8051 разработан Intel в 1981 году. Это 8-битный микроконтроллер. Он состоит из 40-контактного DIP (двойной встроенный пакет), 4 КБ памяти ROM и 128 байтов памяти RAM, 2 16-битных таймеров. Он состоит из четырех параллельных 8-битных портов, которые программируются и адресуются в соответствии с требованиями. Кристаллический генератор на кристалле встроен в микроконтроллер с частотой кристалла 12 МГц.
Давайте теперь обсудим архитектуру микроконтроллера 8051.
На следующем рисунке системная шина соединяет все вспомогательные устройства с процессором. Системная шина состоит из 8-битной шины данных, 16-битной адресной шины и сигналов управления шиной. Все другие устройства, такие как память программ, порты, память данных, последовательный интерфейс, управление прерываниями, таймеры и центральный процессор, все соединены вместе через системную шину.
Микроконтроллеры – 8051 Pin Описание
Схема выводов микроконтроллера 8051 выглядит следующим образом:
-
Контакты с 1 по 8 – Эти контакты известны как Порт 1. Этот порт не выполняет никаких других функций. Это внутренний двунаправленный порт ввода-вывода.
-
Вывод 9 – это вывод RESET, который используется для сброса микроконтроллера к его начальным значениям.
-
Контакты с 10 по 17 – эти контакты известны как порт 3. Этот порт выполняет некоторые функции, такие как прерывания, вход таймера, сигналы управления, сигналы последовательной связи RxD и TxD и т. Д.
-
Выводы 18 и 19 – эти выводы используются для сопряжения внешнего кристалла, чтобы получить системные часы.
-
Контакт 20 – Этот контакт обеспечивает питание цепи.
-
Контакты с 21 по 28 – эти контакты известны как порт 2. Он служит портом ввода / вывода. Сигналы шины адреса более высокого порядка также мультиплексируются с использованием этого порта.
-
Вывод 29 – это вывод PSEN, означающий включение хранилища программ. Используется для считывания сигнала из внешней памяти программ.
-
Вывод 30 – это вывод EA, который обозначает вход внешнего доступа. Он используется для включения / выключения интерфейса внешней памяти.
-
Вывод 31 – это вывод ALE, который обозначает включение фиксации адреса. Он используется для демультиплексирования сигнала адрес-данные порта.
-
Контакты с 32 по 39 – эти контакты известны как порт 0. Он служит портом ввода / вывода. Адрес младшего разряда и сигналы шины данных мультиплексируются через этот порт.
-
Вывод 40 – этот вывод используется для подачи питания в цепь.
Контакты с 1 по 8 – Эти контакты известны как Порт 1. Этот порт не выполняет никаких других функций. Это внутренний двунаправленный порт ввода-вывода.
Вывод 9 – это вывод RESET, который используется для сброса микроконтроллера к его начальным значениям.
Контакты с 10 по 17 – эти контакты известны как порт 3. Этот порт выполняет некоторые функции, такие как прерывания, вход таймера, сигналы управления, сигналы последовательной связи RxD и TxD и т. Д.
Выводы 18 и 19 – эти выводы используются для сопряжения внешнего кристалла, чтобы получить системные часы.
Контакт 20 – Этот контакт обеспечивает питание цепи.
Контакты с 21 по 28 – эти контакты известны как порт 2. Он служит портом ввода / вывода. Сигналы шины адреса более высокого порядка также мультиплексируются с использованием этого порта.
Вывод 29 – это вывод PSEN, означающий включение хранилища программ. Используется для считывания сигнала из внешней памяти программ.
Вывод 30 – это вывод EA, который обозначает вход внешнего доступа. Он используется для включения / выключения интерфейса внешней памяти.
Вывод 31 – это вывод ALE, который обозначает включение фиксации адреса. Он используется для демультиплексирования сигнала адрес-данные порта.
Контакты с 32 по 39 – эти контакты известны как порт 0. Он служит портом ввода / вывода. Адрес младшего разряда и сигналы шины данных мультиплексируются через этот порт.
Вывод 40 – этот вывод используется для подачи питания в цепь.
Микроконтроллеры 8051 Входные выходные порты
Микроконтроллеры 8051 имеют 4 порта ввода-вывода каждый из 8-битных, которые можно настроить как вход или выход. Следовательно, всего 32 входных / выходных контакта позволяют микроконтроллеру быть связанным с периферийными устройствами.
-
Конфигурация выводов, т.е. вывод можно настроить как 1 для входа и 0 для выхода в соответствии с логическим состоянием.
-
Вывод входа / выхода (I / O) – Все цепи в микроконтроллере должны быть подключены к одному из его выводов, кроме порта P0, поскольку в него не встроены подтягивающие резисторы.
-
Входной вывод – Логика 1 применяется к биту P-регистра. Выходной FE-транзистор выключен, а другой вывод остается подключенным к напряжению источника питания через подтягивающий резистор высокого сопротивления.
-
-
Порт 0 – Порт P0 (ноль) характеризуется двумя функциями –
-
Когда используется внешняя память, к ней применяется младший байт адреса (адреса A0A7), в противном случае все биты этого порта конфигурируются как вход / выход.
-
Когда порт P0 сконфигурирован как выход, тогда другие порты, состоящие из выводов со встроенным подтягивающим резистором, подключенным его концом к источнику питания 5 В, на выводах этого порта этот резистор не используется.
-
Конфигурация выводов, т.е. вывод можно настроить как 1 для входа и 0 для выхода в соответствии с логическим состоянием.
Вывод входа / выхода (I / O) – Все цепи в микроконтроллере должны быть подключены к одному из его выводов, кроме порта P0, поскольку в него не встроены подтягивающие резисторы.
Входной вывод – Логика 1 применяется к биту P-регистра. Выходной FE-транзистор выключен, а другой вывод остается подключенным к напряжению источника питания через подтягивающий резистор высокого сопротивления.
Порт 0 – Порт P0 (ноль) характеризуется двумя функциями –
Когда используется внешняя память, к ней применяется младший байт адреса (адреса A0A7), в противном случае все биты этого порта конфигурируются как вход / выход.
Когда порт P0 сконфигурирован как выход, тогда другие порты, состоящие из выводов со встроенным подтягивающим резистором, подключенным его концом к источнику питания 5 В, на выводах этого порта этот резистор не используется.
Конфигурация входа
Если какой-либо вывод этого порта сконфигурирован как вход, то он действует так, как будто он «плавает», т. Е. Вход имеет неограниченное входное сопротивление и неопределенный потенциал.
Конфигурация выхода
Когда вывод сконфигурирован как выход, он действует как «открытый сток». При применении логики 0 к биту порта соответствующий вывод будет подключен к заземлению (0 В), а при применении логики 1 внешний выход будет оставаться «плавающим».
Чтобы применить логику 1 (5 В) к этому выходному контакту, необходимо создать внешний подтягивающий резистор.
Порт 1
P1 является истинным портом ввода / вывода, так как у него нет альтернативных функций, как в P0, но этот порт можно настроить только как общий ввод / вывод. Он имеет встроенный подтягивающий резистор и полностью совместим с цепями TTL.
Порт 2
P2 аналогичен P0, когда используется внешняя память. Контакты этого порта занимают адреса, предназначенные для внешней микросхемы памяти. Этот порт может использоваться для старшего байта адреса с адресами A8-A15. Если память не добавлена, этот порт можно использовать как общий порт ввода-вывода, аналогичный порту 1.
Порт 3
В этом порту функции аналогичны другим портам, за исключением того, что логика 1 должна применяться к соответствующему биту регистра P3.
Ограничения тока на контактах
-
Когда выводы сконфигурированы как выход (т. Е. Логический 0), то выводы одного порта могут получать ток 10 мА.
-
Когда эти выводы настроены как входы (т. Е. Логическая 1), тогда встроенные подтягивающие резисторы обеспечивают очень слабый ток, но могут активировать до 4 входов TTL серии LS.
-
Если все 8 бит порта активны, то общий ток должен быть ограничен 15 мА (порт P0: 26 мА).
-
Если все порты (32 бита) активны, то максимальный максимальный ток должен быть ограничен 71 мА.
Когда выводы сконфигурированы как выход (т. Е. Логический 0), то выводы одного порта могут получать ток 10 мА.
Когда эти выводы настроены как входы (т. Е. Логическая 1), тогда встроенные подтягивающие резисторы обеспечивают очень слабый ток, но могут активировать до 4 входов TTL серии LS.
Если все 8 бит порта активны, то общий ток должен быть ограничен 15 мА (порт P0: 26 мА).
Если все порты (32 бита) активны, то максимальный максимальный ток должен быть ограничен 71 мА.
Микроконтроллеры – 8051 Прерывания
Прерывания – это события, которые временно приостанавливают основную программу, передают управление внешним источникам и выполняют их задачу. Затем он передает управление основной программе, где он остановился.
8051 имеет 5 сигналов прерывания, то есть INT0, TFO, INT1, TF1, RI / TI. Каждое прерывание можно включить или отключить, установив биты регистра IE, и всю систему прерываний можно отключить, очистив бит EA того же регистра.
IE (Разрешение прерывания) Регистрация
Этот регистр отвечает за включение и отключение прерывания. Для регистра EA установлено значение 1 для разрешения прерываний и значение 0 для отключения прерываний. Последовательность битов и их значения показаны на следующем рисунке.

| Е.А. | IE.7 | Это отключает все прерывания. Когда EA = 0, прерывание не будет подтверждено, а EA = 1 разрешает прерывание по отдельности. |
| – | IE.6 | Зарезервировано для будущего использования. |
| – | IE.5 | Зарезервировано для будущего использования. |
| ES | IE.4 | Включает / отключает прерывание последовательного порта. |
| ET1 | IE.3 | Включает / отключает прерывание переполнения таймера1. |
| EX1 | IE.2 | Включает / отключает внешнее прерывание1. |
| ET0 | IE.1 | Включает / отключает прерывание переполнения таймера 0. |
| EX0 | IE.0 | Включает / отключает внешнее прерывание0. |
Регистр IP (приоритет прерывания)
Мы можем изменить уровни приоритета прерываний, изменив соответствующий бит в регистре приоритетов прерываний (IP), как показано на следующем рисунке.
-
Прерывание с низким приоритетом может быть прервано только прерыванием с высоким приоритетом, но не может быть прервано другим прерыванием с низким приоритетом.
-
Если два прерывания разных уровней приоритета получены одновременно, запрос более высокого уровня приоритета обслуживается.
-
Если запросы с одинаковыми уровнями приоритета принимаются одновременно, то внутренняя последовательность опроса определяет, какой запрос должен быть обслужен.
Прерывание с низким приоритетом может быть прервано только прерыванием с высоким приоритетом, но не может быть прервано другим прерыванием с низким приоритетом.
Если два прерывания разных уровней приоритета получены одновременно, запрос более высокого уровня приоритета обслуживается.
Если запросы с одинаковыми уровнями приоритета принимаются одновременно, то внутренняя последовательность опроса определяет, какой запрос должен быть обслужен.

| – | IP.6 | Зарезервировано для будущего использования. |
| – | IP.5 | Зарезервировано для будущего использования. |
| PS | IP.4 | Он определяет уровень приоритета прерывания последовательного порта. |
| PT1 | IP.3 | Он определяет прерывание по таймеру 1 приоритета. |
| PX1 | IP.2 | Он определяет уровень приоритета внешнего прерывания. |
| PT0 | IP.1 | Он определяет уровень приоритета прерывания timer0. |
| PX0 | IP.0 | Он определяет внешнее прерывание с нулевым уровнем приоритета. |
TCON Зарегистрироваться
Регистр TCON определяет тип внешнего прерывания для микроконтроллера.
8255A – Программируемый периферийный интерфейс
8255A – это программируемое устройство ввода-вывода общего назначения, предназначенное для передачи данных из ввода-вывода для прерывания ввода-вывода при определенных условиях по мере необходимости. Может использоваться практически с любым микропроцессором.
Он состоит из трех 8-битных двунаправленных портов ввода / вывода (24I / O линий), которые могут быть настроены в соответствии с требованиями.
Порты 8255А
8255A имеет три порта: порт A, порт B и порт C.
-
Порт A содержит один 8-разрядный выходной фиксатор / буфер и один 8-разрядный входной буфер.
-
Порт B похож на Порт A.
-
Порт C может быть разделен на две части: PORT C нижний (PC0-PC3) и PORT C верхний (PC7-PC4) с помощью управляющего слова.
Порт A содержит один 8-разрядный выходной фиксатор / буфер и один 8-разрядный входной буфер.
Порт B похож на Порт A.
Порт C может быть разделен на две части: PORT C нижний (PC0-PC3) и PORT C верхний (PC7-PC4) с помощью управляющего слова.
Эти три порта дополнительно разделены на две группы, то есть группа A включает в себя PORT A и верхний PORT C. Группа B включает в себя PORT B и нижний PORT C. Эти две группы могут быть запрограммированы в трех разных режимах, т.е. первый режим называется как mode 0, второй режим называется режимом 1, а третий режим называется режимом 2.
Режимы работы
8255A имеет три различных режима работы –
-
Режим 0 – в этом режиме порт A и B используются как два 8-битных порта, а порт C – как два 4-битных порта. Каждый порт может быть запрограммирован либо в режиме ввода, либо в режиме вывода, где выходы заблокированы, а входы не заблокированы. Порты не имеют возможности прерывания.
-
Режим 1 – В этом режиме порты A и B используются как 8-битные порты ввода / вывода. Они могут быть настроены как входные или выходные порты. Каждый порт использует три линии от порта C в качестве сигналов квитирования. Входы и выходы заблокированы.
-
Режим 2 – В этом режиме порт A может быть настроен как двунаправленный порт, а порт B – в режиме 0 или режиме 1. Порт A использует пять сигналов от порта C в качестве сигналов квитирования для передачи данных. Оставшиеся три сигнала от порта C могут использоваться как простой ввод-вывод или как квитирование для порта B.
Режим 0 – в этом режиме порт A и B используются как два 8-битных порта, а порт C – как два 4-битных порта. Каждый порт может быть запрограммирован либо в режиме ввода, либо в режиме вывода, где выходы заблокированы, а входы не заблокированы. Порты не имеют возможности прерывания.
Режим 1 – В этом режиме порты A и B используются как 8-битные порты ввода / вывода. Они могут быть настроены как входные или выходные порты. Каждый порт использует три линии от порта C в качестве сигналов квитирования. Входы и выходы заблокированы.
Режим 2 – В этом режиме порт A может быть настроен как двунаправленный порт, а порт B – в режиме 0 или режиме 1. Порт A использует пять сигналов от порта C в качестве сигналов квитирования для передачи данных. Оставшиеся три сигнала от порта C могут использоваться как простой ввод-вывод или как квитирование для порта B.
Особенности 8255A
Выдающиеся особенности 8255A следующие:
-
Он состоит из 3 8-битных портов ввода-вывода, т.е. PA, PB и ПК.
-
Шина адреса / данных должна быть внешне demux’d.
-
Это TTL-совместимый.
-
Это улучшило способность вождения постоянного тока.
Он состоит из 3 8-битных портов ввода-вывода, т.е. PA, PB и ПК.
Шина адреса / данных должна быть внешне demux’d.
Это TTL-совместимый.
Это улучшило способность вождения постоянного тока.
8255 Архитектура
На следующем рисунке показана архитектура 8255A –
Intel 8255A – Описание контактов
Давайте сначала взглянем на схему контактов Intel 8255A –

Теперь давайте обсудим функциональное описание контактов в 8255A.
Буфер данных
Это 8-битный буфер с тремя состояниями, который используется для подключения микропроцессора к системной шине данных. Данные передаются или принимаются буфером в соответствии с инструкциями ЦПУ. Управляющие слова и информация о состоянии также передаются по этой шине.
Логика управления чтением / записью
Этот блок отвечает за управление внутренней / внешней передачей данных / контроля / слова состояния. Он принимает входные данные от адреса ЦП и шин управления и, в свою очередь, выдает команды обеим группам управления.
CS
Это означает Chip Select. НИЗКИЙ на этом входе выбирает микросхему и обеспечивает связь между 8255A и CPU. Он подключен к декодированному адресу, а A 0 и A 1 подключены к адресным линиям микропроцессора.
Их результат зависит от следующих условий –
| CS | А 1 | А 0 | Результат |
|---|---|---|---|
| 0 | 0 | 0 | ПОРТ А |
| 0 | 0 | 1 | ПОРТ Б |
| 0 | 1 | 0 | ПОРТ С |
| 0 | 1 | 1 | Контрольный регистр |
| 1 | Икс | Икс | Нет выбора |
WR
Стоит писать. Этот управляющий сигнал включает операцию записи. Когда этот сигнал становится низким, микропроцессор записывает данные в выбранный порт ввода-вывода или регистр управления.
СБРОС
Это активный высокий сигнал. Он очищает регистр управления и устанавливает все порты в режиме ввода.
RD
Это стоит для чтения. Этот управляющий сигнал включает операцию чтения. Когда сигнал низкий, микропроцессор считывает данные с выбранного порта ввода-вывода 8255.
А 0 и А 1
Эти входные сигналы работают с RD, WR и одним из сигналов управления. Ниже приведена таблица, показывающая их различные сигналы с их результатом.
| А 1 | А 0 | RD | WR | CS | Результат |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 0 |
Операция ввода ПОРТ А → Шина данных |
| 0 | 1 | 0 | 1 | 0 | ПОРТ B → Шина данных |
| 1 | 0 | 0 | 1 | 0 | ПОРТ C → Шина данных |
| 0 | 0 | 1 | 0 | 0 |
Операция вывода Шина данных → ПОРТ А |
| 0 | 1 | 1 | 0 | 0 | Шина данных → ПОРТ А |
| 1 | 0 | 1 | 0 | 0 | Шина данных → ПОРТ B |
| 1 | 1 | 1 | 0 | 0 | Шина данных → ПОРТ D |
Операция ввода
Операция вывода
Intel 8253 – Программируемый интервальный таймер
Intel 8253 и 8254 представляют собой программируемые интервальные таймеры (PTI), разработанные для микропроцессоров для выполнения функций синхронизации и подсчета с использованием трех 16-разрядных регистров. Каждый счетчик имеет 2 входа, то есть Clock & Gate, и 1 контакт для выхода «OUT». Для работы счетчика в его регистр загружается 16-битный счетчик. По команде он начинает уменьшать счет до тех пор, пока не достигнет 0, а затем генерирует импульс, который можно использовать для прерывания ЦП.
Разница между 8253 и 8254
В следующей таблице различаются функции 8253 и 8254 –
| 8253 | 8254 |
|---|---|
| Его рабочая частота составляет 0 – 2,6 МГц. | Его рабочая частота составляет 0 – 10 МГц. |
| Использует технологию N-MOS | Использует технологию H-MOS |
| Команда Read-Back недоступна | Доступна команда Read-Back |
| Чтение и запись одного и того же счетчика не могут чередоваться. | Чтение и запись одного и того же счетчика могут чередоваться. |
Особенности 8253/54
Наиболее характерные особенности 8253/54:
-
Он имеет три независимых 16-битных счетчика вниз.
-
Он может обрабатывать входы от постоянного тока до 10 МГц.
-
Эти три счетчика могут быть запрограммированы для двоичного или BCD-счетчика.
-
Он совместим практически со всеми микропроцессорами.
-
8254 имеет мощную команду READ BACK, которая позволяет пользователю проверять значение счетчика, запрограммированный режим, текущий режим и текущее состояние счетчика.
Он имеет три независимых 16-битных счетчика вниз.
Он может обрабатывать входы от постоянного тока до 10 МГц.
Эти три счетчика могут быть запрограммированы для двоичного или BCD-счетчика.
Он совместим практически со всеми микропроцессорами.
8254 имеет мощную команду READ BACK, которая позволяет пользователю проверять значение счетчика, запрограммированный режим, текущий режим и текущее состояние счетчика.
8254 Архитектура
Архитектура 8254 выглядит следующим образом –
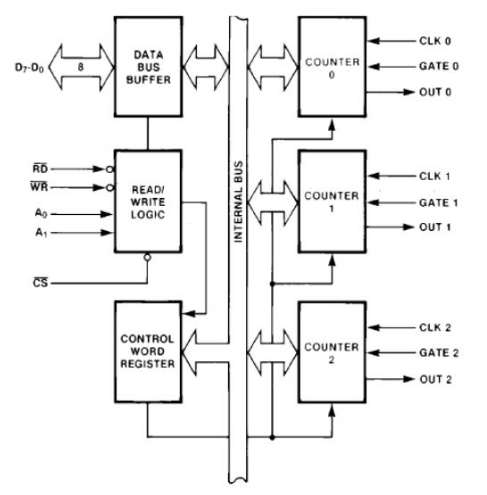
8254 Pin Описание
Вот схема контактов 8254 –
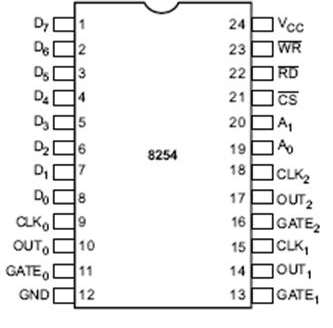
На рисунке выше показаны три счетчика, буфер шины данных, логика управления чтением / записью и регистр управления. Каждый счетчик имеет два входных сигнала – CLOCK & GATE и один выходной сигнал – OUT.
Буфер данных
Это трехсторонний, двунаправленный, 8-битный буфер, который используется для интерфейса 8253/54 с системной шиной данных. У него есть три основные функции –
- Программирование режимов 8253/54.
- Загрузка регистров счета.
- Чтение значений счетчика.
Чтение / запись логики
Он включает в себя 5 сигналов, то есть RD, WR, CS и адресные линии A 0 и A 1 . В режиме периферийного ввода / вывода сигналы RD и WR подключаются к IOR и IOW соответственно. В режиме ввода-вывода с отображением в памяти они подключены к MEMR и MEMW.
Адресные линии A 0 и A 1 ЦПУ подключены к линиям A 0 и A 1 8253/54, а CS привязан к декодированному адресу. Регистр командного слова и счетчики выбираются в соответствии с сигналами в строках A 0 и A 1 .
| А 1 | А 0 | Результат |
|---|---|---|
| 0 | 0 | Счетчик 0 |
| 0 | 1 | Счетчик 1 |
| 1 | 0 | Счетчик 2 |
| 1 | 1 | Регистр управляющих слов |
| Икс | Икс | Нет выбора |
Регистр управляющих слов
Этот регистр доступен, когда строки A 0 и A 1 находятся в логике 1. Он используется для записи командного слова, которое указывает используемый счетчик, его режим, а также операцию чтения или записи. Следующая таблица показывает результат для различных входов управления.
| А 1 | А 0 | RD | WR | CS | Результат |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | Счетчик записи 0 |
| 0 | 1 | 1 | 0 | 0 | Счетчик записи 1 |
| 1 | 0 | 1 | 0 | 0 | Счетчик записи 2 |
| 1 | 1 | 1 | 0 | 0 | Напишите контрольное слово |
| 0 | 0 | 0 | 1 | 0 | Счетчик чтения 0 |
| 0 | 1 | 0 | 1 | 0 | Считать счетчик 1 |
| 1 | 0 | 0 | 1 | 0 | Считать счетчик 2 |
| 1 | 1 | 0 | 1 | 0 | Нет операции |
| Икс | Икс | 1 | 1 | 0 | Нет операции |
| Икс | Икс | Икс | Икс | 1 | Нет операции |
Счетчики
Каждый счетчик состоит из одного 16-разрядного счетчика, который может работать как в двоичном, так и в двоичном формате. Его вход и выход настраивается путем выбора режимов, сохраненных в регистре командного слова. Программист может читать содержимое любого из трех счетчиков, не нарушая фактический счетчик в процессе.
Intel 8253/54 – рабочие режимы
8253/54 может работать в 6 различных режимах. В этой главе мы обсудим эти режимы работы.
Он используется для генерации прерывания для микропроцессора после определенного интервала.
Первоначально выходной сигнал низкий после установки режима. Выход остается НИЗКИМ после загрузки значения счетчика в счетчик.
Процесс уменьшения счетчика продолжается до тех пор, пока счетчик клемм не будет достигнут, то есть счет станет нулевым, а выходной сигнал станет ВЫСОКИМ и останется высоким до тех пор, пока не будет перезагружен новый счет.
Сигнал GATE высокий для нормального счета. Когда значение GATE становится низким, отсчет прекращается, и текущий счет фиксируется до тех пор, пока значение GATE снова не станет высоким.
Может использоваться как моностабильный мультивибратор.
В этом режиме вход затвора используется как триггерный вход.
Выход остается высоким до тех пор, пока счет не будет загружен и не будет применен триггер.
Выход обычно высокий после инициализации.
Когда счет становится равным нулю, на выходе генерируется другой низкий импульс, и счетчик будет перезагружен.
Этот режим аналогичен режиму 2, за исключением того, что выход остается низким в течение половины периода таймера и высоким для другой половины периода.
В этом режиме выходной сигнал будет оставаться высоким до тех пор, пока таймер не обратится к нулю, после чего выходной сигнал будет пульсировать низко, а затем снова повышаться.
Счет фиксируется, когда сигнал GATE становится НИЗКИМ.
При подсчете клемм выходной сигнал понижается в течение одного тактового цикла, а затем повышается. Этот низкий пульс можно использовать как стробоскоп.
Этот режим генерирует строб в ответ на внешний сигнал.
Этот режим аналогичен режиму 4, за исключением того, что отсчет инициируется сигналом на входе затвора, что означает, что он запускается аппаратно, а не программно.
После того, как он инициализирован, выходной сигнал становится высоким.
Когда счетчик контактов достигнут, выходной сигнал понижается в течение одного тактового цикла.
Центральный процессор часто называют «мозгом» компьютера, ведь он, как и человеческий мозг, состоит из нескольких частей, собранных воедино для работы над информацией. Среди них есть те, что отвечают за прием информации, ее хранение, обработку и вывод. В этой статье портал TechSpot разбирает все ключевые элементы процессора, за счет которых и работают ваши компьютеры.
Этот текст входит в серию статей, в которых тщательно разбирается работа ключевых компонентов компьютера. Кроме того, если вы заинтересовались темой, рекомендуем ознакомиться с переводами статей серии «Как разрабатываются и создаются процессоры?».

В этой статье будут затронуты как основы работы процессоров, так и более сложные понятия. К сожалению, без некоторой абстрактности не обойтись, но на это есть свои причины. К примеру, если взглянуть на блок питания, можно легко рассмотреть все его части — от конденсаторов до транзисторов, однако в случае с процессорами все не так просто, ведь мы физически не можем разглядеть все микросхемы, а Intel и AMD не спешат делиться подробностями работы своей продукции с широкой публикой. Тем не менее, информация, представленная в статье, применима к подавляющему большинству современных процессоров.
Итак, приступим. Любому вычислительному устройству нужно нечто наподобие центрального процессора. По сути, программист пишет код для выполнения собственных целей, а затем процессор выполняет его для получения необходимого результата. Процессор также подключен к другим частям системы, вроде памяти и устройств ввода/вывода, чтобы обеспечить загрузку необходимых данных, но в этой статье мы не будем акцентировать на них внимание.
Фундамент любого процессора: архитектура набора команд
Первое, на что натыкаешься при разборе любого процессора — это на архитектуру набора команд (ISA). Архитектура является чем-то вроде фундамента работы процессора и именно от нее зависит то, как он работает и как все внутренние системы взаимодействуют друг с другом. Существует огромное количество архитектур, но самыми распространенными являются x86 (преимущественно в стационарных компьютерах и ноутбуках) и ARM (в мобильных устройствах и встроенных системах).
Чуть менее распространенными и более нишевыми являются MIPS, RISC-V и PowerPC. Архитектура набора отвечает за ряд основных вещей: какие инструкции процессор может обрабатывать, как он взаимодействует с памятью и кэшем, как задача распределяется по нескольким этапам обработки и др.

Чтобы лучше понять устройство процессора, разберем его элементы в том порядке, по которому выполняются команды. Различные типы инструкций могут следовать разными путями и использовать разные компоненты ЦП, поэтому здесь они будут обобщены, чтобы охватить максимум. Начнем с базового дизайна одноядерных процессоров и постепенно будем переходить к более продвинутым и сложным экземплярам.
Блок управления и исполнительный тракт
Элементы процессора можно разделить на два основных: блок управления (он же — управляющий автомат) и исполнительный тракт (он же — операционный автомат). Говоря простым языком, процессор — это поезд, в котором машинист (управляющий автомат) управляет различными элементами двигателя (операционного автомата).
Исполнительный тракт подобен двигателю и, как следует из названия, это путь, по которому данные передаются при их обработке. Он получает входные данные, обрабатывает их и отправляет в нужное место после завершения операции. Блок управления, в свою очередь, направляет этот поток данных. В зависимости от инструкции, исполнительный тракт будет направлять сигналы к различным компонентам процессора, включать и выключать различные части пути, а также отслеживать состояние всего процессора.
Блок-схема работы базового процессора. Черными линиями отображен поток данных, а красными — поток команд.
Цикл выполнения команд — Выборка
Первое, что должен сделать процессор — определить, какие команды необходимо выполнить следующими, а затем переместить их из памяти в блок управления. Команды создаются компилятором и зависят от архитектуры набора (ISA). Наиболее распространенные типы базовых инструкций (например, «загрузка», «хранение», «сложение», «вычитание» и др.) общие для всех ISA, но существует множество дополнительных, специальных типов команд, уникальных для конкретной архитектуры набора. Блок управления знает, какие сигналы и куда нужно направить для выполнения определенного типа команды.
К примеру, при запуске .exe файла в Windows, код этой программы отправляется в память и процессор получает адрес, с которого начинается первая команда. Процессор всегда поддерживает внутренний реестр, отслеживающий откуда должна будет выполняться следующая команда. Этот реестр называется счетчиком команд.
После того, как процессор определил точку, с которой нужно начинать цикл, происходит перемещение команды из памяти в вышеупомянутый реестр — этот процесс называется выборкой команды. По-хорошему, команда, скорее всего, уже находится в кэше процессора, но этот вопрос будет рассмотрен чуть позже.
Цикл выполнения команд — Декодирование
Когда процессор получает команду, ему нужно точно определить тип этой команды. Данный процесс называется декодированием. Каждая команда обладает особым набором битов, опкодом, который дает возможность процессору распознать ее тип. Примерно по тому же принципу работает распознавание компьютером различных расширений файлов. К примеру, .jpg и .png — форматы изображений, но каждый из них обрабатывает данные по-разному, поэтому компьютеру и нужно точно распознавать их тип.
Стоит отметить, что сложность декодирования может зависеть от того, насколько продвинутой является архитектура набора команд процессора. У архитектуры RISC-V, к примеру, несколько десятков команд, а у x86 — несколько тысяч. У типичного процессора Intel x86 процесс декодирования является одним из сложнейших и занимает огромное количество памяти. Чаще всего процессоры декодируют команды, связанные с памятью, арифметическими вычислениями и переходом.
3 основных типа команд
Команда памяти может представлять собой нечто вроде «прочтите значение из адреса памяти 1234 вместо значения А» или «запишите значение Б в адрес памяти 5678». Арифметические команды имеют вид в духе «добавьте значение А к значению Б и сохраните результат в значении В». Инструкции перехода, в свою очередь, похожи на «выполните этот код, если значение В положительное, или выполните другой код, если значение В отрицательное». Зачастую в программах используется цепочка сразу из нескольких вышеупомянутых примеров, из-за чего конечный результат выглядит примерно так: «добавьте значение адреса памяти 1234 к значению адреса памяти 5678 и сохраните его в адресе памяти 4321, если результат положительный, либо в адрес 8765, если результат отрицательный».
Перед тем, как перейти к выполнению декодированной команды, давайте уделим немного внимания регистрам.
Регистрами называются немногочисленные, но крайне быстрые фрагменты памяти процессора. У 64-битных процессоров каждый из них вмещает 64 бита, а всего их может быть несколько десятков на одно ядро. Регистры используются для хранения используемых в данный момент значений и их можно считать чем-то вроде кэша нулевого уровня. В приведенных выше примерах команд значения А, Б и В будут сохранены именно в регистре.
Арифметико-логическое устройство
Вернемся к этапу выполнения команд. Сразу отметим, что он отличается для всех трех вышеупомянутых типов команд, поэтому давайте рассмотрим каждый их них.
Самыми простыми для понимания являются арифметические команды. Эти команды отправляются в арифметическо-логическое устройство (ALU) для последующей обработки. Устройство представляет собой цепь, которая чаще всего работает с двумя значениями, отмеченными сигналом, и выдает результат.
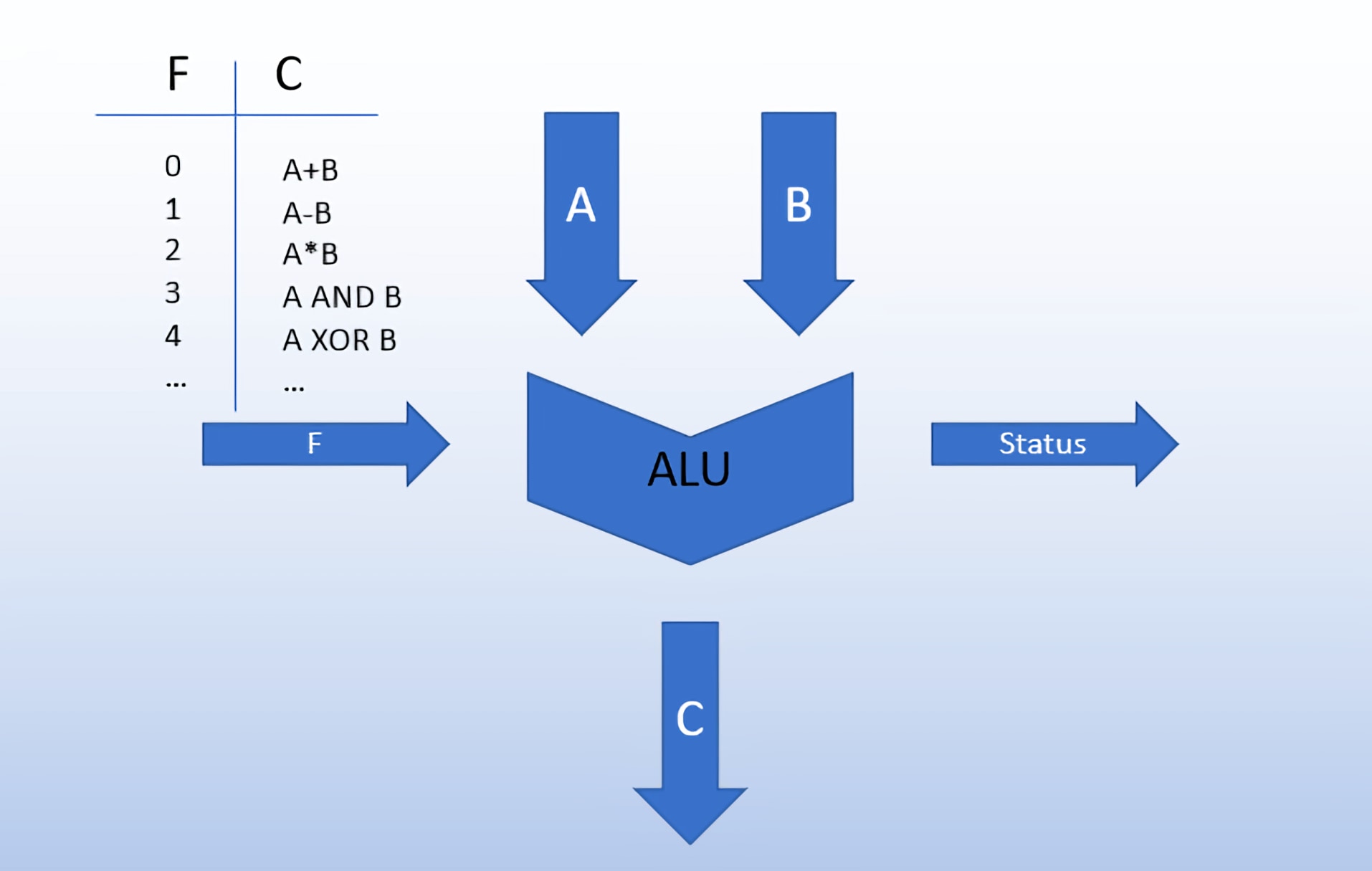
Представьте себе обычный калькулятор. Для любого вычисления вы вводите значения, выбираете необходимую арифметическую операцию и получаете результат. Арифметическо-логическое устройство (ALU) работает по похожему принципу. Тип операции зависит от опкода команды, который управляющий автомат отправляет в ALU и которое в дополнение к базовой арифметике может производить со значениями такие битовые операции, как AND, OR, NOT и XOR. Кроме того, арифметическо-логическое устройство выводит информацию о проведенном вычислении для управляющего автомата (например, оказалось ли оно положительным, отрицательным, равным нулю или вызвало переполнение).
Несмотря на то, что арифметическо-логическое устройство чаще всего связано именно с арифметическими операциями, оно находит свое применение и в инструкциях памяти или перехода. Например, если процессору нужно вычислить адрес памяти, заданный в результате прошлого вычисления, либо в случае необходимости вычислить переход для добавления в счетчик программ, если инструкция того требует (пример: «если предыдущий результат отрицателен, перейти на 20 команд вперед»).
Команды и иерархия памяти
Чтобы лучше понять принцип работы команд, связанных с памятью, стоит обратить внимание на концепцию иерархии памяти — связь между кэшем, оперативной памятью и главным запоминающим устройством. Когда процессор работает с командой памяти, данных о которой у него еще нет в регистре, он будет продвигаться по иерархии памяти, пока не найдет нужную информацию. Большинство современных процессоров имеют три уровня кэша: первый, второй и третий. Сначала процессор проверит наличие необходимых команд в кэше первого уровня — самом маленьком и быстром из всех. Зачастую этот кэш разделен на две части: первая отведена под данные, а вторая — под команды. Помните, команды извлекаются процессором из памяти так же, как и любые другие данные.
Типичный кэш первого уровня может состоять из нескольких сотен килобайт. Если процессор не найдет в нем то, что нужно, то перейдет к проверке кэша второго уровня (размером в несколько мегабайт), а затем — третьего (уже занимающего десятки мегабайт). В случае, если необходимых данных не будет и в кэше третьего уровня, то поиск будет производиться в оперативной памяти, а затем в накопителях. С каждым подобным «шагом», увеличивается не только объем доступных данных, но и задержка.
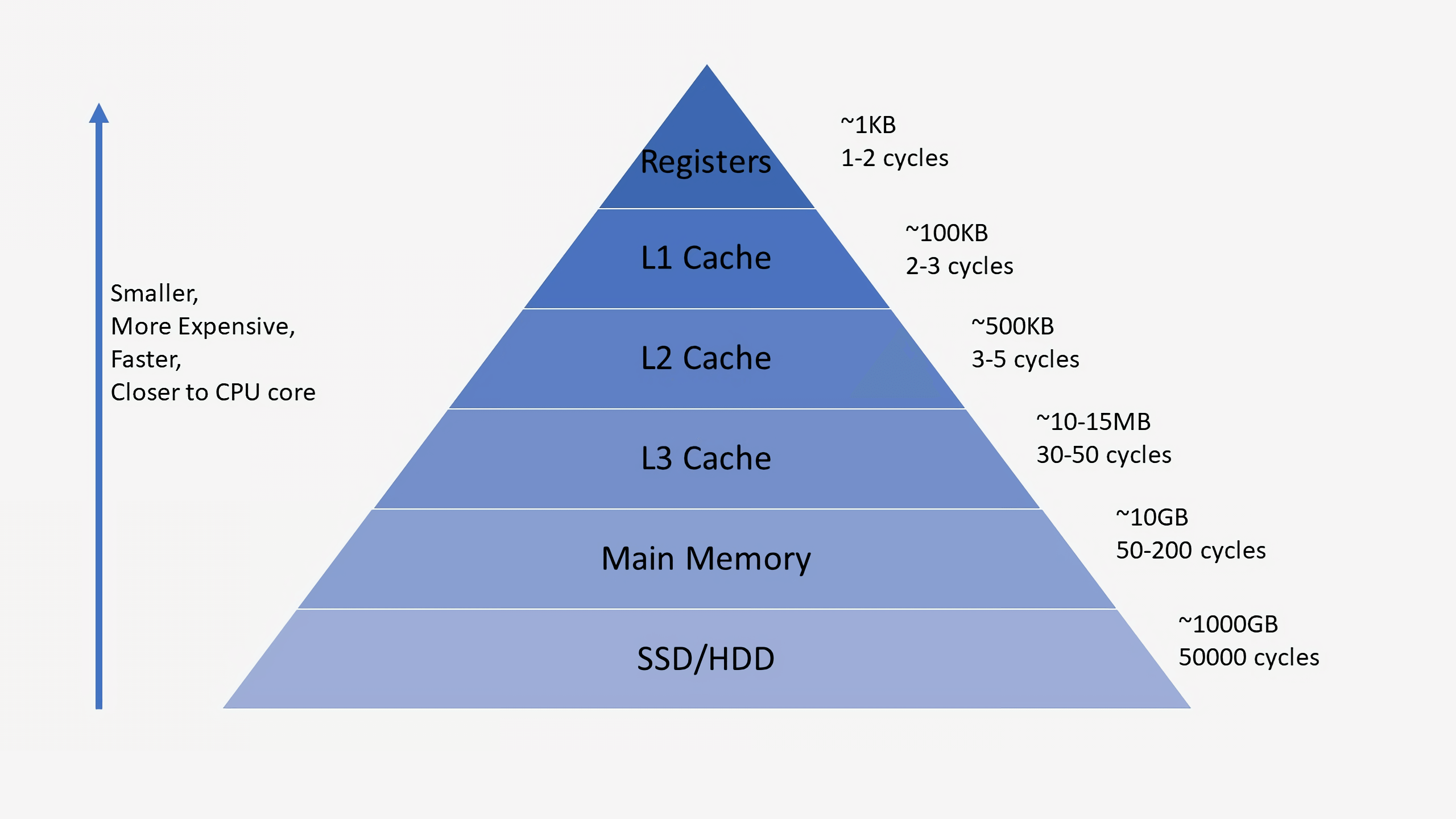
После того, как процессор нашел необходимые данные, он отправляет их вверх по иерархии памяти для сокращения время поиска, на случай, если они понадобятся в дальнейшем. Для справки: процессор может считывать данные во внутреннем регистре всего за один-два цикла, в кэше первого уровня понадобится немногим больше, в кэше второго уровня уже около десяти, а третьего — несколько десятков циклов. Если приходится задействовать память или накопители, то процессору может понадобятся десятки тысяч, а то и миллионы циклов. В зависимости от системы, у каждого ядра процессора может быть собственный кэш первого уровня, общий с другим ядром кэш второго уровня и кэш третьего уровня у группы из четырех или более ядер. Более подробно речь о многоядерных процессорах пойдет позже.
Команды перехода и ветвления
Последняя из трех основных типов команд — это команда ветвления. Команды современных программ постоянно переходят с одного потока процессов на другой, а это значит, что процессор крайне редко выполняет более дюжины смежных команд без перехода. Команды ветвления происходят от элементов программирования, таких как код IF, FOR и RETURN. Все они используются для прерывания выполнения программы или переключения на другую часть кода. Кроме команд ветвления существуют и команды перехода, которые отличаются от первых тем, что они всегда участвуют в процессе выполнения программы.
Кроме обычных команд перехода, существуют и условные переходы, с которыми процессору работать особенно сложно, поскольку он может выполнять несколько инструкций одновременно и конечный результат всей ветки может быть нельзя определить пока не начата работа над выполнением связанных команд.
Чтобы понять, почему процессору трудно работать с условными переходами, стоит обратить внимание на такое понятие, как вычислительный конвейер. Каждый шаг в выполнении какой-либо команды может занимать несколько циклов, а это значит, что арифметико-логическое устройство могло бы простаивать без дела пока происходит выборка команды. Чтобы максимизировать эффективность вычислительной мощности процессора, каждая стадия разделяется на несколько частей — в процессе, который называется вычислительным конвейером (конвейерной обработкой).
Самой простой аналогией будет процесс стирки. Предположим, что у вас достаточно вещей на две полные загрузки стиральной машины, а стирка и сушка каждой партии занимает по часу. Вы вполне можете загрузить в стиральную машину первую партию вещей, а потом переместить на сушилку, а когда они высохнут — заняться второй партией. Это займет четыре часа. Однако, если вы разделите процесс на этапы и начнете стирку второй партии вещей, пока сушится первая, вы сможете выполнить всю работу за три часа. Сокращение времени зависит от количества загружаемых вещей и количества стиральных/сушильных машин. Для выполнения отдельной загрузки в любом случае понадобится два часа, но в приведенном примере накладывание процессов увеличивает общую пропускную способность с 0,5 загрузки/час до 0,75 загрузки в час.
Графическое представление конвейера, используемого в ядрах процессоров AMD Bobcat (2011). Обратите внимание, как много в нем различных элементов и стадий.
Процессоры используют тот же принцип для повышения пропускной способности команд. Конвейеры современных процессоров на архитектуре ARM или x86 могут использовать свыше 20 стадий вычислительного конвейера, а это значит, что ядро процессора одновременно обрабатывает свыше 20 различных команд. Процессоры могут отличаться по разделению этих стадий под различные нужды, но в одном из примеров, принцип работы которого находится в открытом доступе, имеется 4 цикла для выборки, 6 циклов для декодирования, 3 цикла для выполнения команд и 7 циклов для отправки результатов в память.
Возвращаясь к теме, теперь вы можете понять в чем проблема. Если процессор не определил тип команды до десятого цикла, то он начнет работу уже над 9 новыми командами, которые могут оказаться ненужными, если ветка команд уже не работает. Чтобы этого не происходило, процессоры оборудованы сложным механизмом, который называется модулем предсказателем переходов. По принципу работы этот механизм схож с машинным обучением. Детальное описание работы модуля предсказателя переходов — это тема для отдельной статьи, поэтому придется обойтись довольно простым объяснением: данный механизм отслеживает статус предыдущих переходов, чтобы определить, будет ли задействован следующий переход или нет. Современные предсказатели переходов могут обеспечить точность в 95% и выше.
После того, как точно станет известен результат перехода (т.е. завершился конкретный этап на конвейере), счетчик команд обновится и процессор приступит к выполнению следующей операции. Если же результат не совпал с тем, который предугадал предсказатель команд, процессор сбросит все команды, которые начал выполнять по ошибке, и запустит работу с правильной точки.
Внеочередное исполнение
Теперь, когда вы знаете принцип работы трех наиболее распространенных типов команд, давайте уделим внимание более продвинутыми функциям процессоров. Практически все современные модели ЦП фактически исполняют команды не в порядке их получения. Существует такая функция, как внеочередное исполнение, призванная сократить время простоя процессора во время ожидания завершения остальных команд.
Если процессор понимает, что следующей команде необходимы данные, для поиска которых понадобится больше времени, он может изменить порядок команд, начав работу над не связанной командой, пока происходит поиск. Внеочередное исполнение команд — необычайно полезная, но далеко не единственная вспомогательная функция процессора.

Еще одной крайне полезной особенностью процессора является предвыборка. Если засечь время, необходимое для выполнения случайной инструкции от начала и до конца, то можно обнаружить, что большую часть времени занимает доступ к памяти. Блок предварительной выборки — элемент в ЦП, который рассматривает команды, находящиеся в очереди, и определяет, какие данные им потребуются. Если он замечает, что для операции нужны данные, которые еще не находятся в кэше процессора, то он извлечет их из оперативной памяти и в кэш. Отсюда и его название.
Ускорители и будущее процессоров
Еще одна важная функция, которая все чаще появляется в процессорах — ускорители для конкретных задач. Эти ускорители представляют собой небольшие схемы, главная цель которых — как можно быстрее выполнить определенную задачу. Этой задачей может быть шифрование, кодирование данных или машинное обучение.
Конечно, процессор может делать все это самостоятельно, но созданный конкретно для этой цели блок будет намного более эффективен. Наглядным показателем мощностей ускорителей будет сравнение встроенного графического процессора с дискретной видеокартой. Разумеется, процессор может выполнять вычисления, необходимые для обработки графики, но наличие отдельного блока обеспечивает намного более высокую производительность. С ростом числа ускорителей фактическое ядро центрального процессора может занимать всего лишь небольшую часть чипа.
На первом рисунке снизу изображено устройство процессора Intel, выпущенного более десяти лет назад, где большая часть занята ядрами и кешем, а на втором показан гораздо более современный чип от AMD. Как мы видим, во втором случае большая часть кристалла отведена не под ядра, а под другие компоненты.
Кристалл процессора Intel первого поколения архитектуры Nehalem. Обратите внимание: ядра и кэш занимают подавляющее часть площади.
Кристалл системы на чипе от AMD. Много места отведено под ускорители и внешние интерфейсы.
Многоядерность
Последняя особенность процессоров, которая будет рассмотрена в этой статье — то, как можно объединить несколько отдельных процессоров для получения многоядерного. Это не просто объединение нескольких копий одного ядра, ведь как нельзя просто превратить однопоточную программу в многопоточную, так нельзя и провернуть подобное с процессором. Проблема возникает из-за зависимости ядер.
В случае с четырьмя ядрами процессору необходимо отправлять команды в 4 раза быстрее. Также нужно четыре раздельных интерфейса для памяти. Именно из-за наличия нескольких ядер на одном чипе, потенциально работающих с одними и теми же частями данных, возникает проблема слаженности и согласованности их работы. Предположим, если два ядра обрабатывали команду, использующую одни и те же данные, то как процессор определяет, у которого из них правильное значение? А что, если одно ядро модифицировало данные, но они не успели вовремя дойти до второго ядра? Поскольку у них есть отдельные кэши, в которых могут храниться пересекающиеся данные, для устранения возможных конфликтов необходимо использовать сложные алгоритмы и контроллеры.
Чрезвычайно важную роль в многоядерных процессорах играет и точность прогнозирования переходов. Чем больше в процессоре ядер, тем выше вероятность того, что одной из исполняемых команд будет именно команда перехода, способная в любое время изменить общий поток задач.
Как правило, отдельные ядра обрабатывают команды из разных потоков, тем самым снижая зависимость между ядрами. Поэтому, открыв диспетчер задач, вы чаще всего видите, что загружено лишь одно ядро процессора, а другие едва работают — многие программы попросту изначально не предназначены для многопоточности. Кроме того, могут быть определенные случаи, в которых эффективнее использовать только одно ядро процессора, а не тратить ресурсы на попытки разделить команды.
Физическая оболочка процессора
Несмотря на то, что большая часть этой статьи была посвящена сложным механизмам работы архитектуры процессора, не стоит забывать и о том, что все это должно быть создано и работать в виде реального, физического объекта.
Для того, чтобы синхронизировать работу всех компонентов процессора, используется тактовый сигнал. Современные процессоры обычно работают на частотах от 3.0 ГГц до 5.0 ГГц, и за последнее десятилетие ситуация особо не изменилась. При каждом цикле внутри чипа включаются и выключаются миллиарды транзисторов.
Такты важны для того, чтобы обеспечить идеальную работу каждой стадии вычислительного конвейера. Количество команд, обрабатываемых процессором за каждую секунду, зависит именно от них. Частоту можно увеличить путем разгона, сделав чип быстрее, но это в свою очередь повысит энергопотребление и тепловыделение.

Фото: Michael Dziedzic
Тепловыделение — главный враг процессоров. Когда цифровая электроника нагревается, может начаться разрушение микроскопических транзисторов. Это в свою очередь может привести к повреждению чипа, если тепло не отвести. Чтобы этого не произошло, каждый процессор оборудован термораспределителями. Сам кристалл может занимать всего 20% площади процессора, ведь увеличение площади позволяет более равномерно распределять тепло по радиатору. Кроме того, дополнительно увеличивается количество имеющихся ножек процессора (контактов), предназначенных для взаимодействия с другими компонентами компьютера.
На современных процессорах может располагаться свыше тысячи входных и выходных контактов на задней панели. Мобильный чип может быть оснащен всего несколькими сотнями, поскольку большинство вычислительных элементов расположены уже внутри чипа. Независимо от дизайна, около половины из них предназначены для распределения питания, а остальные — для передачи данных с оперативной памяти, чипсета, накопителей, устройств PCIe и др. Высокопроизводительным процессорам, потребляющим сто и более ампер при полной нагрузке, нужны сотни ножек для равномерного распределения тока. Обычно они покрываются золотом для улучшения проводимости. Стоит отметить, что разные производители располагают ножки по-разному во всей своей многочисленной продукции.
Подытожим на примере
Чтобы подвести итоги, кратко рассмотрим архитектуру процессора Intel Core 2. Это было еще в 2006 году, поэтому некоторые детали могут быть устаревшими, но информации о новых разработках отсутствуют в публичном доступе.
На самом верху располагается кэш команд и буфер ассоциативной трансляции. Буфер помогает процессору определить, где в памяти располагаются необходимые команды. Эти инструкции хранятся в кэше команд первого уровня, а после этого отправляются в предекодер, так как из-за сложностей архитектуры x86 декодирование происходит во множество этапов. Сразу же за ними идет предсказатель переходов и предвыборщик кода, которые снижают вероятность возникновения потенциальных проблем со следующими командами.
Далее команды отправляются в очередь команд. Вспомните, как внеочередное исполнение позволяет процессору выбрать именно ту команду, которую практичнее всего выполнить в конкретный момент из очереди текущих инструкций. После того, как процессор определил нужную команду, та декодируется во множество микроопераций. В то время как команда может содержать сложную для ЦП задачу, микрооперации представляют собой детализированные задачи, которые процессору легче интерпретировать.
Затем эти инструкции попадают в таблицу псевдонимов регистров, переупорядочивающий буфер и станцию резервации. Подробно расписать их принцип работы в одном абзаце, увы, не получится, так как это — информация, которую обычно подают на последних курсах технических вузов. Если в двух словах, то все они используются в процессе внеочередного исполнения для управления зависимостями между командами.
На самом деле, у каждого ядра процессора множество арифметическо-логических устройств и портов памяти. Команды отправляются в станцию резервации, пока не освободится устройство или порт. Затем команда обрабатывается с помощью кэша данных первого уровня, а полученный результат сохраняется для дальнейшего использования, после чего процессор может приступать к следующей задаче. На этом все!
Пусть эта статья и не предназначалась для того, чтобы служить исчерпывающим руководством по тому, как работает каждый из процессоров, она должна дать вам базовое представление об их внутренней работе и сложности. К сожалению, о том, как действительно работают современные процессоры, знают лишь работники Intel и AMD, поэтому информация, описанная в этой статье — лишь вершина айсберга, ведь каждый пункт, описанный в тексте — это результат огромного количества исследований и разработок.
Другие материалы по теме
Если вам хочется узнать больше о том, как создаются различные компоненты, описанные в этом тексте, то настоятельно советуем обратить внимание на вторую часть серии статей «Как разрабатываются и создаются процессоры?». Если же вы больше заинтересованы в том, как производятся физические оболочки процессоров, то вам стоит ознакомиться с третьей статьей той же серии.
По материал: techspot.com
Обновлено: 24.09.2023
Процессор. Процессор аппаратно реализуется на большой интегральной схеме (БИС). Большая интегральная схема на самом деле не является «большой» по размеру и представляет собой, наоборот, маленькую плоскую полупроводниковую пластину размером примерно 20×20 мм, заключенную в плоский корпус с рядами металлических штырьков (контактов). БИС является «большой» по количеству элементов.
Использование современных высоких технологий позволяет разместить на БИС процессора огромное количество (42 миллиона в процессоре Pentium 4 — рис. 4.2) функциональных элементов (переключателей), размеры которых составляют всего около 0,13 микрон (1 микрон = 10 -6 метра).
Рис. 4.2. Внутренняя структура процессора Intel Pentium 4
Важнейшей характеристикой, определяющей быстродействие процессора, является тактовая частота, то есть количество тактов в секунду. Такт — это промежуток времени между началами подачи двух последовательных импульсов специальной микросхемой — генератором тактовой частоты, синхронизирующим работу узлов компьютера. На выполнение процессором каждой базовой операции (например, сложения) отводится определенное количество тактов. Ясно, что чем больше тактовая частота, тем больше операций в секунду выполняет процессор. Тактовая частота измеряется в мегагерцах (МГц) и гигагерцах (ГГц). 1 МГц = миллион тактов в секунду. За 20 с небольшим лет тактовая частота процессора увеличилась почти в 500 раз, от 5 МГц (процессор 8086, 1978 год) до 2,4 ГГц (процессор Pentium 4, 2002 год) — табл. 4.1.
Другой характеристикой процессора, влияющей на его производительность, является разрядность процессора. Разрядность процессора определяется количеством двоичных разрядов, которые могут передаваться или обрабатываться процессором одновременно. Часто уточняют разрядность процессора и пишут 64/36, что означает, что процессор имеет 64-разрядную шину данных и 36-разрядную шину адреса.
В первом отечественном школьном компьютере «Агат» (1985 год) был установлен процессор, имевший разрядность 8/16, соответственно одновременно он обрабатывал 8 битов, а его адресное пространство составляло 64 килобайта.
Современный процессор Pentium 4 имеет разрядность 64/36, то есть одновременно процессор обрабатывает 64 бита, а адресное пространство составляет 68 719 476 736 байтов — 64 гигабайта.
Производительность процессора является его интегральной характеристикой, которая зависит от частоты процессора, его разрядности, а также особенностей архитектуры (наличие кэш-памяти и др.). Производительность процессора нельзя вычислить, она определяется в процессе тестирования, по скорости выполнения процессором определенных операций в какой-либо программной среде.
Оперативная память. Оперативная память, предназначенная для хранения информации, изготавливается в виде модулей памяти. Модули памяти представляют собой пластины с рядами контактов, на которых размещаются БИС памяти. Модули памяти могут различаться между собой по размеру и количеству контактов (DIMM, RIMM, DDR — рис. 4.3), быстродействию, информационной емкости и так далее.
Рис. 4.3. Модули памяти DIMM, RIMM, DDR
Важнейшей характеристикой модулей оперативной памяти является быстродействие, которое зависит от максимально возможной частоты операций записи или считывания информации из ячеек памяти. Современные модули памяти обеспечивают частоту до 800 МГц, а их информационная емкость может достигать 512 Мбайт.
В персональных компьютерах объем адресуемой памяти и величина фактически установленной оперативной памяти практически всегда различаются. Хотя объем адресуемой памяти может достигать 64 Гбайт, величина фактически установленной оперативной памяти может быть значительно меньше, например, «всего» 64 Мбайт.
1. Какие технические характеристики и как влияют на производительность компьютера?

Приветствую. В данной статье я постараюсь рассказать как оперативная память может влиять на процессор. Постараюсь написать все простыми словами, чтобы было понятно даже начинающему пользователю.
Что делает процессор и оперативная память?
Сперва необходимо разобраться как работает процессор и оперативная память. Зачем нужны вообще эти устройства, что они делают?
- Процессор или CPU (Central Processing Unit) — устройство которое обрабатывает данные, можно сказать что занимается вычислениями (выполняет машинные инструкции).
- Оперативная память или RAM (Random Access Memory) — место, где хранятся данные, которые обрабатываются процессором. Также в этой памяти хранятся данные, которые потребуются в будущем. Неиспользуемая память может использоваться под кэш, чтобы повторный запуск приложений и работа некоторых функций — была быстрее.
Также вы еще можете встретить термин GPU — это значит видеокарта, а iGPU — встроенное графическое ядро в процессоре.
Процессор и оперативная память — два важных устройствах, от которых собственно и зависит производительность устройства, неважно, ноутбук это, компьютер или смартфон. Везде присутствует оперативка и процессор. Да, если устройство для игр — то также еще важен графический адаптер.

Информация, которая может быть полезной.

В серверах используется много оперативной памяти. Сервер — это постоянно запущенное огромное количество программ, которые в свою очередь разделены на условные группы. Сервер может иметь два процессора (возможно и больше). Чтобы огромное количество запущенных приложений корректно функционировало — нужно также огромное количество оперативной памяти.
Как оперативная память влияет на процессор?
Поэтому отвечая на вопрос как влияет оперативная память на процессор, можно сказать так: от ее количества зависит сможет ли процессор постоянно обрабатывать новые данные, а не ждать, пока появятся новые данные в памяти.
Дело в том, что процессор данные обрабатывает относительно быстро. Но если памяти не хватает — то чтобы освободить память для новой программы, нужно часть содержимого оперативки сбросить на диск. Этот процесс небыстрый и называется своппинг. Потом, когда данные, которые были сброшены на диск — опять понадобятся, они будут прочтены с диска и записаны в память. Но проблема в том, что запись на диск (write) и чтение (read) — процесс медленный относительно скорости оперативки.
Поэтому когда мало оперативки — присутствуют тормоза, которые вызывает диск, но процессор при этом может быть нагружен слабо, он просто ждет пока данные будут загружены в оперативку, чтобы он их смог обработать. А чтобы они были загружены — нужно освободить место в памяти. Когда оперативки достаточно — данные запущенных программ не сбрасываются на диск и процессор всегда имеет к ним быстрый доступ. Уже можно сделать вывод — чем больше оперативки, тем больше может быть запущенно приложений и это абсолютно верно.
Больше оперативки или мощный процессор?
Здесь тоже все спорно:
- Если процессор слабый, то сколько не добавляйте оперативки — ситуацию это не изменит. Процессор все равно медленно обрабатывает данные, поэтому вы будете ждать дольше.
- Если процессор быстрый, а оперативки не хватает — процессор обработает данные и будет ждать новых. Ждать будет потому что оперативки мало и чтобы появилось место — нужно сбросить часть данных на диск, а на это нужно время.
Вывод: мощность процессора и обьем оперативки — должно гармонично сочетаться. Чего-то одного много или мощного — будет недостаточно. Если не хватает оперативы, то какой бы вы мощный проц не поставили — это ничего не изменит.
А что может помочь? Улучшит ситуацию твердотельный диск SSD — его скорость считывания/записи намного выше, чем у обычного жесткого диска HDD.
Если вы когда-нибудь задумывались, что это за процесс, за которым следует процессор и Оперативная память что он назначил для получения данных и инструкций, которые он должен выполнить, то вам повезло, потому что в этой статье мы собираемся объяснить, что это за процесс связи между двумя наиболее важными элементами ПК, с которыми общаются разное.
В этой статье мы не будем объяснять, какой тип оперативной памяти лучше or спецификации каждого , но процессор связывается с ним, чтобы иметь возможность выполнять программы.
Причина почему мы используем внешнюю память потому, что количество транзисторов, необходимых для хранения информации, не поместится в пространстве процессора , поэтому необходимо использовать память RAM, внешнюю по отношению к процессору, для хранения инструкций и данных, которые они будут выполнять.
Зачем процессору связь с ОЗУ?
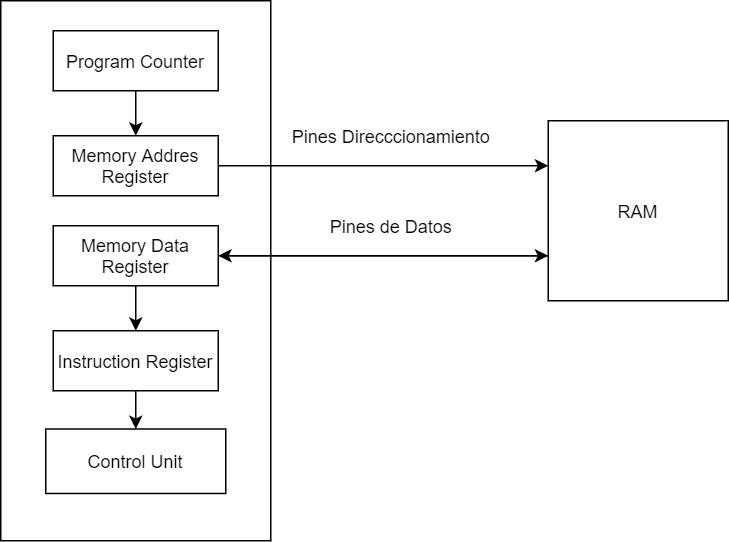
- Счетчик команд: ПК указывает на следующую строку памяти, где находится следующая инструкция процессора. Его значение увеличивается на 1 каждый раз, когда завершается полный цикл команд или когда команда перехода изменяет значение программного счетчика.
- Регистр адреса памяти: MAR копирует содержимое ПК и отправляет его в RAM через адресные контакты ЦП, которые соединены с адресными контактами RAM.
- Регистр данных памяти : Если инструкция прочитана, то ОЗУ будет передавать через свою шину данных содержимое адреса памяти, на который указывал MAR.
- Реестр инструкций: Инструкция копируется в регистр инструкций, откуда блок управления расшифровывает ее, чтобы знать, как выполнить инструкцию.
Что такое память DRAM?
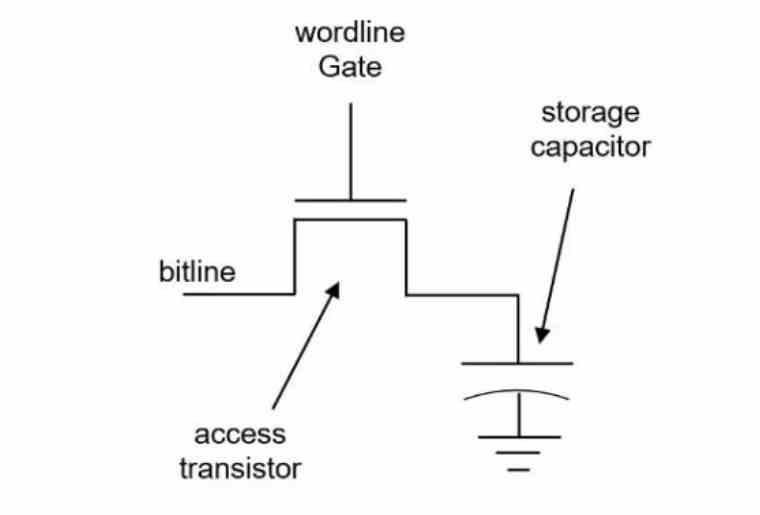
тип памяти, используемой для RAM как системное ОЗУ, так и видеопамять или видеопамять. Память DRAM или 1T-DRAM . В этом типе памяти каждый бит хранится в комбинация конденсатора и транзистора , а не в нескольких транзисторах, таких как SRAM, отсюда и название 1T-DRAM.
Вся память RAM, используемая в настоящее время в ПК: DDR4, GDDR6, HBM2e, LPDDR4 и т. Д., Является памятью типа DRAM, в то время как внутренняя память процессоров, кеши регистров и блокноты относятся к типу SRAM.
Указанная комбинация конденсатора и транзистора называется Bitcell , когда конденсатор битовой ячейки заряжен, интерпретируется, что информация, содержащаяся в этой битовой ячейке, равна 1, когда она не заряжена, она интерпретируется как 0.
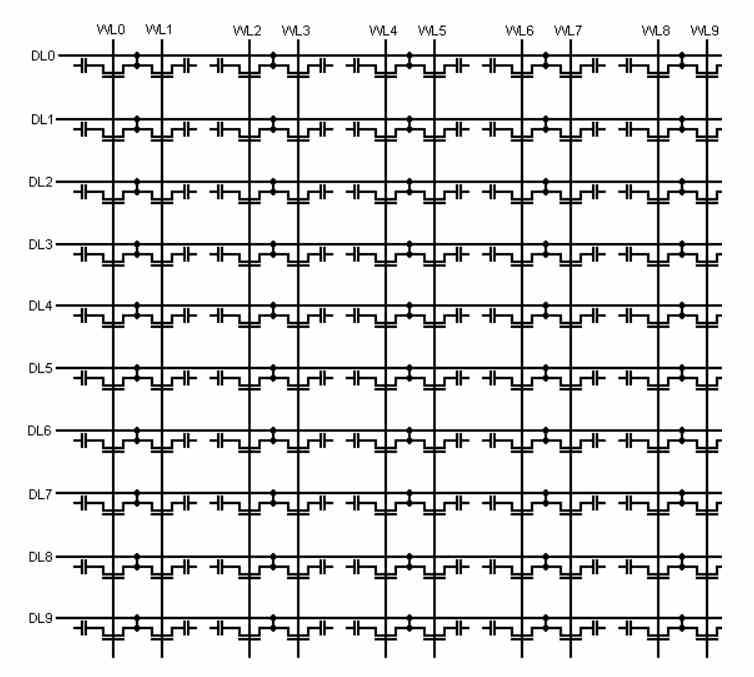
Битовые ячейки организованы в матрицу, в которой контакты адресации используются для доступа к ним следующим образом:
- Первая половина битов выбирает строку, к которой мы хотим получить доступ
- Вторая половина битов адресации содержит столбец, к которому мы хотим получить доступ,
Для этого между матрицей битовых ячеек и шиной адресации существует двоичный декодер, который позволяет выбрать соответствующую битовую ячейку.
Контакты для связи с RAM

- адресация штифты : Обычно обозначается от A0 до AN, где N — количество контактов и равно количеству бит адресации, которое всегда равно 2 ^ N.
- Контакты данных : Здесь данные передаются в оперативную память и из нее.
- Запись разрешена: Если вывод активен, передача данных осуществляется в память, запись, с другой стороны, если она не активна, то в сторону процессора, чтение.
Если наша система имеет несколько микросхем памяти RAM, то первые биты адресации используются для выбора, к какой из микросхем памяти мы хотим получить доступ в модуле памяти DIMM. Также были случаи, когда адрес и контакты данных совпадали. Это связано с тем, что адресация и доступ к данным не выполняются одновременно.
Но чтобы понять, как работает адресация, мы должны рассмотреть основную часть электроники — двоичный декодер.
Двоичный декодер и его роль в связи с RAM
В оперативной памяти адресация передается в двух циклах: сначала отправляется строка, к которой необходимо получить доступ, а затем столбец, а не одновременно.
По этой причине обращение к оперативной памяти происходит в два этапа.
Банки памяти
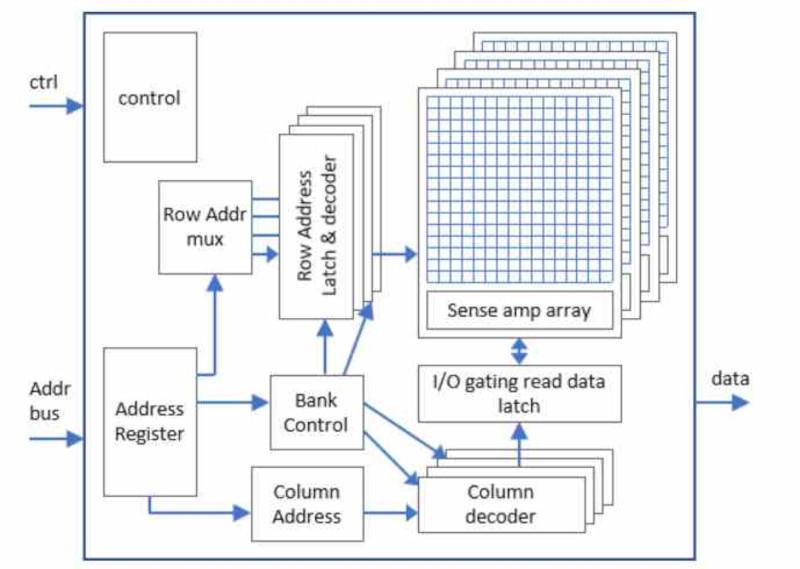
Данные в ОЗУ не хранятся последовательно , но в разных банках на одном чипе, каждый из банков содержит массив битовых ячеек , но если мы хотим передать, например, n битов данных, нам понадобится n массивов битовых ячеек, каждый из которых подключен к выводу шины данных.
Использование несколько банков , в той же микросхеме памяти, позволяет выбрать несколько бит одновременно с одним доступом к памяти , поскольку все банки разделяют адресацию . Таким образом, если у нас есть 8 банков памяти, выбор конкретной битовой ячейки приведет к одновременной передаче данных в 8 банков памяти и из них.
Стандартный размер банков в памяти RAM составляет 8 бит, поэтому максимальный объем памяти при адресации всегда считается как 2 ^ n байтов. Фактически, это 16-, 32-, 64-битные шины и т. Д. Они передают данные нескольких последовательных адресов памяти, начиная с первого.
Связь между RAM и CPU

- Выберите столбец (Адресация)
- Выберите строку (Адресация)
- Передача данных.
Для этого используется ряд специальных контактов, один из которых мы уже видели, и это запись Enable, а два других следующие:
- Строб доступа к колонке: Этот вывод активируется, когда мы указываем оперативной памяти, что указываем столбец, к которому хотим получить доступ.
- Строб доступа к строке :: Этот вывод активируется, когда мы указываем оперативной памяти, что указываем строку, к которой хотим получить доступ.
Обе операции можно резюмировать следующим образом:
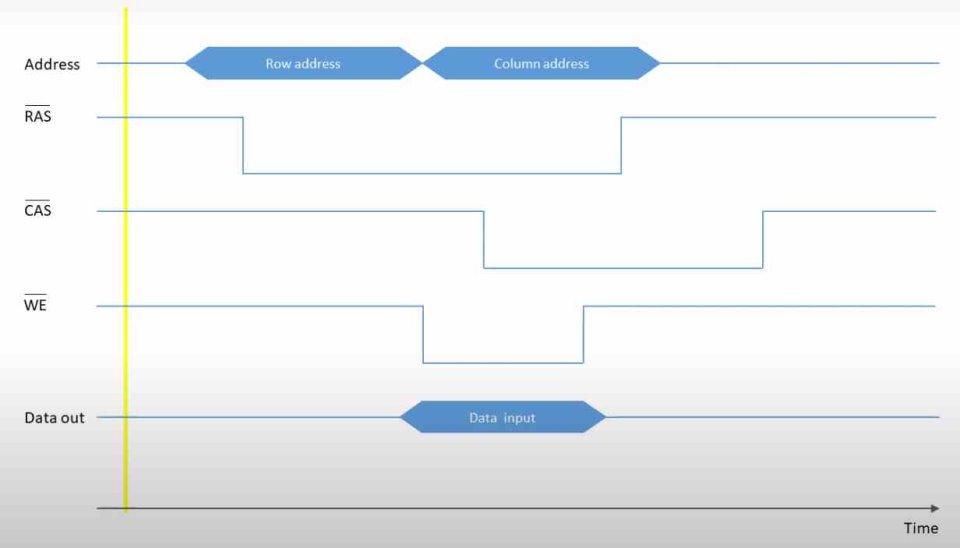
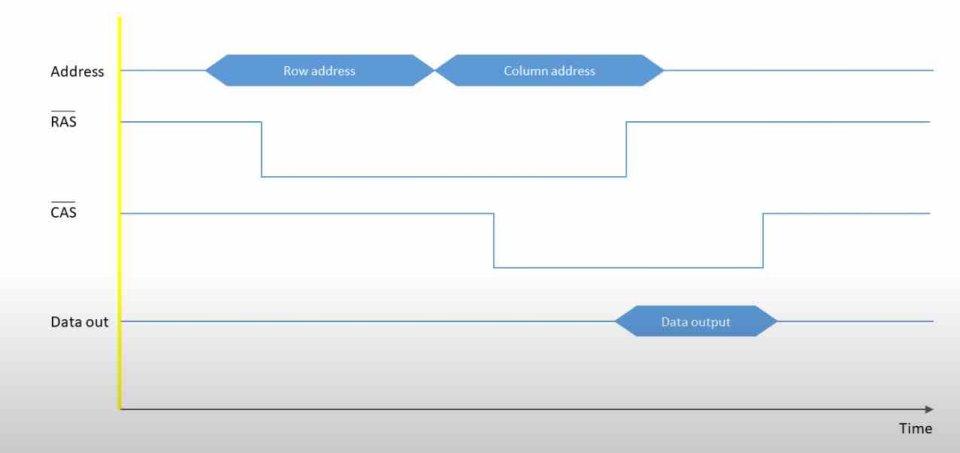
- Операция чтения очень проста, для этого у вас должен быть неактивен вывод WE, чтобы указать, что данные идут из ОЗУ в процессор, указать строку, а затем столбец, чтобы информация поступала к процессору из ОЗУ памяти. .
- Операция записи несколько отличается, для этого вывод WE должен быть активен, но данные передаются не после выбора столбца данных, а после выбора строки и одновременно с выбором столбца, в котором находятся данные.
Благодаря этому вы уже можете получить приблизительное представление о том, как работает связь между процессором и его оперативной памятью.

Егор Морозов | 16 Июня, 2018 — 14:30

Для большинства пользователей ПК критерий выбора оперативной памяти схож с выбором накопителя — чем больше, тем лучше. И с этим, конечно же, не поспоришь — как говорится, памяти много не бывает. Но почему-то многие забывают про скоростные характеристики памяти, считая, что они слабо влияют на производительность.
Однако на практике получается интересная картина — так, при разгоне памяти. растет производительность центрального процессора, причем зачастую это не какие-то доли или единицы процентов, заметные только в бенчмарках — нет, это вполне ощутимые и при обычной работе десятки процентов. Казалось бы — это какая-то магия, разгоняешь один компонент, а увеличивается производительность другого, но это перестает казаться странным, если вспомнить, что компьютер — это совокупность завязанных друг на друга компонентов, которые не могут работать по отдельности. Ведь, к примеру, уже никого не удивляет, что система на SSD грузится и работает существенно быстрее, чем на HDD, хотя все остальные компоненты при этом могут быть точно такими же.
Но если с накопителями все понятно — чем быстрее их скорости чтения и записи, тем быстрее будут читаться файлы, и тем быстрее будет происходить с ними работа, то вот в случае с ОЗУ и процессором все остается туманным, и в этой статье мы попытаемся развеять этот туман.
Как происходит обсчет данных на процессоре
Начнем с того, как именно процессор работает с данными. По сути перед ним стоит задача: у него есть неструктурированная информация, с которой он должен что-то делать. Сама информация хранится в кэше процессора — это небольшой объем быстрой памяти, которая обычно расположена на одном кристалле с CPU для быстрого доступа к ней.

Каждый процессор имеет множество вычислительных блоков — ALU или FPU — которые и предназначены для работы с арифметическими и логическими данными. И каждый такт процессор выбирает из очереди именно те микрооперации, которые могут занять как можно больше вычислительных блоков, и если так получается, что мы нагружаем все доступные блоки, то мы достигаем максимальной загрузки и, значит, и производительности процессора.
На практике же, разумеется, всегда встречаются простои. Рассмотрим это на простом примере: допустим, нам нужно сложить X и Y. Казалось бы, плевая задача — но только при условии того, что мы эти X и Y знаем. Но зачастую X — это результат сложения A и B, а Y — результат, допустим, разности C и D. Поэтому процессору сначала нужно посчитать A+B и C-D, и лишь потом он сможет вычислить X+Y. В итоге вычисление X+Y откладывается как минимум на один такт, что приводит к появлению пустого места в конвейере на текущем такте.
И тут есть два дальнейших сценария — или процессор не ошибся и все посчитал верно, тем самым ускорив вычисления, или же он ошибся, и нужно полностью перезапускать весь вычислительный конвейер, что приводит к резкому падению производительности. И, к слову, именно улучшения в предсказателе ветвлений в последнее время и дают наибольший вклад в рост производительности — его дорабатывают так, чтобы он как можно меньше ошибался.
Нужно больше золота памяти

Очевидно, что проблем с недостатком данных не было бы в принципе, если процессор хранил все нужные данные у себя. Однако на практике это слишком дорого, поэтому кэш рос медленно — в 90-ые годы это были десятки килобайт кэша первого уровня (L1). На рубеже тысячелетий этого стало катастрофически мало, и добавили кэш второго уровня, L2, объемом в сотни килобайт. В конце нулевых появился кэш L3, позволяющий хранить несколько мегабайт информации, ну и совсем недавно, в 2015 году, появились процессоры с кэшем четвертого уровня, L4, объем которого мог быть до 128 МБ.
Смысл в увеличении объема кэша был прост — обеспечить процессор как можно большим количеством данных, получить доступ к которым он может с наименьшими задержками, что, в свою очередь, уменьшает количество простоев. Но, разумеется, все данные в кэш поместить не получится, поэтому часть их хранится в ОЗУ, которая имеет задержки доступа зачастую на порядок больше, чем кэш L1, и в разы больше, чем L3. Плюс пропускная способность памяти кажется просто смешной, если сравнивать ее с теми гигантскими объемами информации, с которыми процессор может оперировать ежесекундно.
Поэтому, если нам нужно обсчитать большой объем информации, который не помещается в кэш, то задержки при работе с ОЗУ и ее относительно низкая пропускная способность прямым образом влияют на загрузку процессора — то есть на то, будут ли у него данные для вычислений, или нет — а это, в свою очередь, напрямую влияет на его производительность.
Теперь представим, что у нас есть идеальная память, частоту которой можно увеличить вдвое. Что произойдет? Во-первых, вдвое увеличится пропускная способность. Во-вторых, вдвое уменьшатся задержки — потому что они изначально измеряются не в наносекундах, а в тактах контроллера памяти, которые обратно пропорциональны частоте. Соответственно рост частоты вдвое во столько же раз уменьшает задержки.
Конечно, на практике это ни разу не так — есть еще собственная задержка контроллера памяти, да и вдвое увеличить частоту и не увеличить при этом тайминги — фантастика. Но, раз мы представили идеальную картину, то пусть будет так. В итоге мы уменьшили задержки вдвое, и теперь процессор простаивает лишь 25% времени.

Зеленое — нагрузка на процессор, красное — простой, желтое — аппроксимирующая линия, по которой явно видно, что с ростом частоты до бесконечности время простоя уменьшается до нуля.
И тут становится ясно, что ОЗУ в общем-то не увеличивает производительность процессора — она лишь уменьшает время его простоя, приближая его к той производительности, которую он мог бы выдавать в идеальном мире. Поэтому не надейтесь на то, что, купив какой-нибудь Intel Celeron и DDR4-5000, вы получите производительность Core i7 — нет, такого не будет и близко. Но все еще, имея высокопроизводительный процессор, можно заставить его выдавать больше производительности, разогнав память. А вот оптимальный уровень частоты ОЗУ и ее задержек для каждого процессора свой — но это уже практическая область, которую мы в этой статье касаться не будем.
Читайте также:
- Электромагнитный способ документирования кратко
- Легенда о реке агидель кратко башкирская
- Водные ресурсы ирландии кратко
- Природные ресурсы омана кратко
- Каково предназначение и смысл жизни человека согласно бердяеву кратко
3.1. ВВЕДЕНИЕ
Работа большинства ЭВМ сопряжена с передачей данных и управляющей информации
между процессором и памятью. Обычно программируемая управляющая
информация называется машинным языком. Для того чтобы выполнить
некоторую программу, данная программа должна быть представлена на машинном
языке используемой ЭВМ. С развитием вычислительной техники машинные языки
стали весьма сложными и трудными для освоения программистом. Вследствие этого
были созданы языки ассемблера и языки высокого уровня, которые затем транслируются
на машинный язык. Среди различных языков, поддерживаемых вычислительными
системами, наиболее близок к машинному языку язык ассемблера. Поэтому для
должного понимания языка ассемблера необходимо понимание машинного языка,
на который транслируется программа, написанная на языке ассемблера. В данной
главе описываются основы организации ЭВМ семейства VAX, процессор, память,
а также то, как осуществляется управление некоторыми основными операциями
с помощью машинного языка.
3.2. ОРГАНИЗАЦИЯ ЭВМ
На рис. 3.1 показаны
важнейшие части простой цифровой ЭВМ: устройство ввода, устройство
вывода, память и центральное устройство управления,
или процессор. Устройство ввода позволяет вводить информацию
в ЭВМ. К простым устройствам ввода относятся кнопки или клавиши электронного
калькулятора либо клавиатура, подобная клавиатуре пишущей машинки. Устройство
вывода позволяет получить обратно результаты работы ЭВМ. В число простых
устройств вывода входят цифровые индикаторы электронного калькулятора, подобные
пишущей машинке печатающие устройства, а также экран видеотерминала. Память используется
для запоминания информации. В общем случае память может быть представлена
как множество ячеек, каждая из которых содержит некоторое число.
(Кроме основной памяти большинство ЭВМ для хранения дополнительной информации
имеет внешние запоминающие устройства, такие как магнитные диски.) Устройство
ввода, устройство вывода и память соединяются электрическими проводниками
с центральным устройством управления, называемым процессором. Процессор,
посылая по этим проводникам электрические сигналы, может:
- 1) запросить устройство ввода, чтобы получить или считать информацию
и сделать её доступной для процессора или памяти; - 2) запросить устройство вывода, чтобы напечатать определённую
порцию информации; - 3) запросить память, чтобы сохранить или запомнить определённую
порцию информации в определённой ячейке памяти; - 4) запросить память, чтобы получить обратно или выбрать порцию
информации, которая до этого была запомнена в определённой ячейке памяти.
Процессор
Память
Устройство ввода
Устройство вывода
Рис. 3.1. Структура ЭВМ
В этой простой ЭВМ устройство ввода, устройство вывода и память являются
пассивными устройствами. Они не выполняют никаких действий до тех пор, пока
не получат указание процессора выполнить какую-либо операцию. Процессор представляет
собой активное устройство, управляющее обменом информацией между ним самим
и другими устройствами. Последовательность операций, выполняемых процессором,
определяется множеством инструкций, которые образуют машинную
программу. Работа программиста заключается в том, чтобы составить соответствующую
последовательность инструкций, указывающих процессору, какие операции необходимо
выполнить для решения конкретной задачи.
3.3. ОРГАНИЗАЦИЯ ПАМЯТИ ЭВМ СЕМЕЙСТВА VAX
ОСНОВНЫЕ ПОНЯТИЯ
Память ЭВМ семейства VAX можно рассматривать как набор ячеек памяти,
каждая из которых содержит 8-битовый байт. Поэтому назовём содержимое такой
ячейки байтом памяти или просто байтом. Байт в ячейке памяти
обычно можно представить двумя шестнадцатеричными цифрами (от ^X00 до ^XFF).
Каждая ячейка памяти идентифицируется числом, называемым адресом ячейки
памяти. Он позволяет однозначно идентифицировать ячейку. По аналогии адрес
ячейки памяти можно представить себе как адрес дома на улице. И так же, как
по адресу дома на улице можно найти или идентифицировать конкретное здание,
адрес памяти позволяет найти или идентифицировать определённую ячейку памяти.
В ЭВМ семейства VAX адресом является 32-битовое двоичное целое число. Обычно
32-битовые адреса представляются восемью шестнадцатеричными цифрами. Например,
предположим, что по адресу ^X00ABCDEF содержится
байт ^X35.
В шестнадцатеричном представлении это выглядит следующим образом:
| Шестнадцатеричное содержимое |
Шестнадцатеричный адрес |
|---|---|
|
35 |
00ABCDEF |
Здесь адрес показан справа, а содержимое показано слева потому,
что таким образом располагает информацию ассемблер ЭВМ VAX. Причины этого
будут выявлены позже. Обратите внимание, что с каждым байтом памяти связываются
два числа — адрес (32-битовое число) и содержимое (8-битовое число).
Поскольку в 32 двоичных разрядах могут быть образованы 232, или
4 292 967 296, двоичные комбинации, то в программе для ЭВМ семейства VAX
можно было бы адресовать до 4 294 967 296 различных байтов памяти (приблизительно
5 млрд, байтов, или 4 Гбайта). Первый байт памяти имеет адрес ^X00000000,
а последний — адрес ^XFFFFFFFF.
На рис. 3.2 показано возможное
содержимое первых 11 байтов памяти.
| Шестнадца- теричное содержимое |
Шестнадца- теричный адрес |
|---|---|
|
90 |
00000000 |
|
9F |
00000001 |
|
34 |
00000002 |
|
12 |
00000003 |
|
00 |
00000004 |
|
00 |
00000005 |
|
9F |
00000006 |
|
EF |
00000007 |
|
CD |
00000008 |
|
0В |
00000009 |
|
00 |
0000000А |
Рис. 3.2. Пример шестнадцатеричного представления содержимого
памяти
Как было показано в гл. 2,
ЭВМ семейства VAX кроме байтов работают со словами, длинными
словами и квадрасловами. В памяти ЭВМ 16-битовое слово запоминается
в двух смежных байтах. В следующем примере показано, как слово ^X1234 можно
запомнить в байтах памяти с адресами ^X00000002 и ^X00000003.
| Шестнадцатеричное содержимое | Шестнадцатеричный адрес |
|---|---|
|
34 |
00000002 |
|
12 |
00000003 |
Отметим, что здесь представлено слово ^X1234,
а не слово ^X3412.
В ЭВМ семейства VAX младшие разряды слова, в данном случае имеющие шестнадцатеричное
представление ^X34,
запоминаются в байте с младшим адресом ^X00000002,
а старшие разряды слова ^X12 —
в байте со старшим адресом ^X00000003.
При таком представлении слов байты слова нужно читать сверху вниз. Чтобы
избежать этого, распечатки данных для ЭВМ семейства VAX обычно читаются справа
налево. Поэтому слова в памяти часто представляются следующим образом:
| Шестнадцатеричное содержимое |
Шестнадцатеричный адрес |
|---|---|
|
1234 |
00000002 |
Здесь указывается только один адрес, однако при этом понимается,
что в байте памяти с адресом ^X00000002 содержится ^X34,
а в байте с адресом ^X00000003 содержится ^X12.
Для напоминания программистам о возможном расположении информации в нескольких
байтах такие программы, как ассемблер, располагают адрес справа от содержимого.
В памяти ЭВМ 32-битовые длинные слова запоминаются в четырёх смежных байтах.
В следующем примере показано, как может быть запомнено в памяти длинное слово ^X000BCDEF,
начиная с адреса ^X00000007.
| Шестнадцатеричное содержимое | Шестнадцатеричный адрес |
|---|---|
|
EF |
00000007 |
|
CD |
00000008 |
|
0В |
00000009 |
|
00 |
0000000А |
Отметим, что здесь снова необходимо читать байты длинного
слова снизу вверх. Содержимым длинного слова, начинающегося с адреса ^X00000007,
является ^X000BCDEF,
а не ^XEFCD0B00.
Чтобы устранить это неудобство, длинные слова в памяти часто представляются
в следующем виде:
| Шестнадцатеричное содержимое | Шестнадцатеричный адрес |
|---|---|
|
000BCDEF |
00000007 |
Программист должен помнить, что в данном случае длинное слово
в действительности занимает байты с адресами от ^X00000007 до ^X0000000A,
а младшие разряды длинного слова ^XEF содержатся
в байте с адресом ^X00000007.
Квадраслово (64 бита) запоминается в памяти в восьми смежных байтах. А ещё
большая единица информации — 128-битовое октаслово запоминается в памяти
в шестнадцати смежных байтах.
Предположим, что в 11 байтах, показанных на рис.
3.2, представлены три байта, два слова и одно длинное слово в следующем
порядке:
- Байты располагаются по адресам ^X00000000, ^X00000001 и ^X00000006.
- Слова начинаются с адресов ^X00000002 и ^X00000004.
- Длинное слово начинается с адреса ^X00000007.
| Шестнадцатеричное содержимое |
Шестнадцатеричный адрес |
|---|---|
|
90 |
00000000 |
|
9F |
00000001 |
|
1234 |
00000002 |
|
0000 |
00000004 |
|
9F |
00000006 |
|
000BCDEF |
00000007 |
Рис. 3.3. Компактное представление содержимого памяти
Содержимое памяти, показанное на рис.
3.2, может быть представлено и более компактно, как показано на рис.
3.3. Далее в основном будет использоваться такое представление. Однако
важно понимать, что на рис.
3.2 и 3.3 изображена
одна и та же информация, которая является просто различным представлением
одного и того же содержимого памяти. Рассматривая рис.
3.3, можно предположить, что содержимое ^X9F байта
памяти с адресом ^X00000006 будет
обрабатываться как байт. Тем не менее вполне возможно, что в один момент
времени программа будет обрабатывать содержимое данного байта памяти как
байт, в другой момент времени — как часть слова, а в последующее время
— как часть длинного слова. Не существует способа, который позволил бы,
посмотрев на байт в памяти, определить, как он будет использоваться.
АДРЕС И СОДЕРЖИМОЕ ПАМЯТИ
Очень важно не путать адрес байта, слова и длинного слова с содержимым байта,
слова и длинного слова. В частности, это может происходить при работе с длинными
словами, так как длина адреса памяти и длина длинного слова совпадают и равны
32 бита. Например, ниже показаны длинные слова, расположенные в памяти, начиная
с адреса ^X00001000.
| Шестнадцатеричное содержимое | Шестнадцатеричный адрес |
|---|---|
|
00001234 |
00001000 |
|
A3B4F303 |
00001004 |
|
00001000 |
00001008 |
|
00000000 |
0000100C |
|
…….. |
00001010 |
Во второй строке начальным адресом длинного слова является ^X00001004,
а его содержимым является ^XA3B4F303.
Возможно изменить содержимое ячейки памяти, но нельзя изменить её адрес.
Иначе говоря, если содержимое ячейки памяти представляет собой переменную
величину, то адрес ячейки памяти фиксирован.
Различие между адресом ячейки памяти и её содержимым усложняет то обстоятельство,
что содержимым одной ячейки памяти часто является адрес другой ячейки памяти.
Например, содержимое длинного слова ^X00001000,
расположенного по адресу ^X00001008,
само может быть адресом ^X00001000.
В этом случае говорят, что содержимое длинного слова с адресом ^X00001008 указывает
на длинное слово ^X00001234 с
адресом ^X00001000.
Использование таких указателей весьма распространено и крайне важно. Если
программа должна выполнять обработку объектов, расположенных в памяти, то
ей должны быть доступны адреса этих объектов и эти адреса вместе с машинной
программой должны присутствовать в памяти. Более того, указатели и адреса
составляют основу для построения многих структур данных. Путаница между адресом
ячейки памяти и содержимым ячейки памяти представляет собой одну из наиболее
общих ошибок при написании программ на языке ассемблера.
3.4. ВЗАИМОДЕЙСТВИЕ ПРОЦЕССОРА С ПАМЯТЬЮ
РАБОТА С ПАМЯТЬЮ. ОПЕРАЦИИ ВЫБОРКИ И ЗАПИСИ
Память ЭВМ работает под управлением процессора. Процессор может либо запросить
память произвести выборку байта из определённой ячейки памяти, либо осуществить
запись отдельного байта в определённую ячейку памяти. Операция выборки не
изменяет, а операция записи изменяет содержимое указываемой ячейки памяти.
Для того чтобы произвести выборку, процессор посылает устройству памяти адрес
требуемой ячейки памяти, а устройство памяти отвечает на запрос процессора,
посылая ему содержимое адресуемой ячейки. Например, воспользуемся данными,
приведёнными на рис. 3.3.
Если процессор выдал запрос устройству памяти на выборку байта из ячейки
памяти с адресом ^X00000006,
то устройство памяти отвечает на запрос, посылая процессору число ^X9F.
Содержимым ячейки памяти с адресом ^X00000006 останется
число ^X9F.
Для выполнения операции записи процессор посылает устройству памяти адрес
требуемой ячейки памяти вместе с числом, которое должно быть помещено в указываемую
ячейку. Снова воспользуемся данными, приведёнными на рис.
3.3. Предположим, что процессор запросил устройство памяти выполнить
запись байта ^X1B в
ячейку памяти с адресом ^X00000006.
Старое содержимое ячейки памяти с адресом ^X00000006 будет
потеряно или уничтожено, а её новым содержимым будет ^X1B.
При этом не останется никакой записи о том, что в ячейке памяти с адресом ^X00000006 когда-либо
содержалось ^X9F.
Если бы впоследствии процессор выдал устройству памяти запрос на выборку
байта из ячейки памяти с адресом ^X00000006,
то устройством памяти в ответ на запрос было бы передано новое содержимое
этой ячейки ^X1B.
Операции выборки и записи, производимые над более крупными порциями информации,
такими как слова и длинные слова, выполняются аналогично. Воспользуясь данными,
приведёнными на рис. 3.3,
предположим, что процессор запрашивает устройство памяти, чтобы осуществить
выборку содержимого слова, начинающегося с адреса ^X00000002.
Устройство памяти отвечает на запрос, посылая процессору содержимое байта ^X34,
расположенного по адресу ^X00000002,
а также содержимое байта ^X12 с
адресом ^X00000003.
Процессор объединяет эти два байта, чтобы образовать слово ^X1234.
Аналогично если процессор запрашивает устройство памяти для выполнения выборки
длинного слова, начинающегося с адреса ^X00000007,
то устройство памяти отвечает, посылая процессору содержимое байтов с адресами ^X00000007, ^X00000008, ^X00000009 и ^X0000000A.
Процессор из этих четырёх байтов формирует длинное слово ^X000BCDEF.
Если бы процессор выдал запрос устройству памяти на выборку длинного слова,
начинающего с адреса ^X00000004,
то устройство памяти в ответ на запрос послало бы процессору четыре байта,
расположенные в памяти по адресам с ^X00000004 до ^X00000007,
которые после этого были бы собраны процессором в длинное слово ^XEF9F0000[1].
Выборка и запись являются единственными операциями, которые может выполнять
устройство памяти. Например, устройство памяти не может выполнить сложение.
Если желательно сложить два числа, находящиеся в памяти, то оба эти числа
должны быть выбраны из памяти и переданы процессору, а после сложения полученный
результат снова должен быть записан в память.
ИНСТРУКЦИЯ СЛОЖЕНИЯ БАЙТОВ
Как уже упоминалось, процессор является активным устройством, управляющим
передачей данных между ним самим и другими устройствами, входящими в состав
ЭВМ, такими, как, например, память. В свою очередь, программист управляет
процессором с помощью написанной им последовательности инструкций, называемой
программой, которая выполняется процессором. Например, приведённая ниже инструкция
заставит процессор выполнить сложение байта, расположенного в ячейке памяти
с адресом ^X00001001,
с байтом, содержащимся в ячейке памяти с адресом ^X00001003,
а 8-битовый результат поместить в ячейку памяти с адресом ^X00001003.
ADDB2 ^X00001001,^X00001003
Отметим, что эта инструкция не заставляет процессор выполнять сложение чисел ^X00001001 и ^X00001003,
что в результате даёт число ^X00002004.
Вместо этого инструкция даёт указание процессору сложить содержимое байтов
памяти с адресами ^X00001001 и ^X00001003.
а их сумму поместить в байт памяти с адресом ^X00001003.
Эта инструкция выполняется процессором за четыре шага.
Шаг 1. Выбрать байт из ячейки памяти с адресом ^X00001001.
Шаг 2. Выбрать байт из ячейки памяти с адресом ^X00001003.
Шаг 3. Сложить байты, выбранные на шаге 1
и шаге 2.
Шаг 4. Запомнить полученную сумму в ячейке
памяти с адресом ^X00001003.
Байты с адресами ^X00001001 и ^X00001003 называются
операндами, так как они являются теми объектами, над которыми выполняется
операция сложения по инструкции ADDB2.
ИНСТРУКЦИИ ВЫЧИТАНИЯ БАЙТОВ, ПЕРЕСЫЛКИ БАЙТОВ И ВОЗВРАТА УПРАВЛЕНИЯ
Инструкции SUBB2 (SUBtract Byte — вычесть байт,
два операнда) и MOVB (MOVe Byte — переслать байт)
подобны инструкции ADDB2 (ADD Byte — сложить байты,
два операнда). Чтобы выполнить инструкцию.
SUBB2 ^X00001FFF,^X00000500
процессор совершает такую последовательность действий:
Шаг 1. Выбирает байт из ячейки памяти с адресом ^X00001FFF.
Шаг 2. Выбирает байт из ячейки памяти с адресом ^X00000500.
Шаг 3. Вычитает байт, выбранный на шаге 1,
из байта, выбранного на шаге 2.
Шаг 4. Запоминает полученную разность в ячейке
памяти с адресом ^X00000500.
Для выполнения инструкции
MOVB ^X00001000,^X00001003
процессор совершает два следующих действия:
Шаг 1. Выбирает байт из ячейки памяти с адресом ^X00001000
Шаг 2. Запоминает выбранный на шаге 1 байт
в ячейке памяти с адресом ^X00001003.
Программа представляет собой просто последовательность инструкций. Например,
в результате выполнения программы, приведённой на рис. 3.4,
содержимое байта памяти с адресом ^X00001003 станет
равным сумме байтов с адресами ^X00001000, ^X00001001 и ^X00001002.
|
ИНСТРУКЦИЯ 1 |
MOVB |
^X00001000, ^X00001003 |
|
ИНСТРУКЦИЯ 2 |
ADDB2 |
^X00001001, ^X00001003 |
|
ИНСТРУКЦИЯ 3 |
ADDB2 |
^X00001002, ^X00001003 |
|
ИНСТРУКЦИЯ 4 |
RET |
Рис. 3.4. Пример простой программы
Приведённые на рис. 3.4 инструкции
процессор выполняет последовательно одну за другой. По инструкции RET (сокращение
от RETurn — возврат) управление процессором из текущей программы возвращается
программе, инициировавшей выполнение текущей программы. Если текущая программа
является основной программой, запущенной на выполнение из операционной системы
VAX/VMS, то по инструкции RET управление процессором
будет возвращено ОС VAX/VMS.
Например, предположим, что в памяти первоначально содержится следующая информация:
| Содержимое | Адрес |
|---|---|
|
1А |
00001000 |
|
26 |
00001001 |
|
05 |
00001002 |
|
?? |
00001003 |
Два вопросительных знака означают, что не надо заботиться (или знать) о
первоначальном содержимом байта с адресом ^X00001003.
По первой инструкции программы, приведённой на рис. 3.4,
произойдёт пересылка значения ^X1A в
байт с адресом ^X00001003;
по второй инструкции выполнится сложение значения ^X26 с
содержимым байта с адресом ^X00001003,
после чего его содержимое изменится и станет равно ^X1A + ^X26,
или ^X40;
по третьей инструкции сложение со значением ^X05 изменит
содержимое байта с адресом ^X00001003,
которое станет равно ^X40 + ^X05,
или ^X45.
Когда этой программой будет возвращено управление, содержимое памяти будет
следующим:
| Содержимое | Адрес |
|---|---|
|
1А |
00001000 |
|
26 |
00001001 |
|
05 |
00001002 |
|
45 |
00001003 |
3.5. ПРОГРАММЫ В МАШИННОМ КОДЕ
КОДЫ МАШИННОГО ЯЗЫКА
Теперь вполне резонно возникает вопрос: «Где в ЭВМ хранится программа?» В
приведённом ранее описании было названо одно место, в котором может содержаться
информация, — память. Поэтому память может быть использована для хранения
программ. Однако так как в ячейках памяти информация может храниться только
в двоичном виде, то конкретные инструкции процессора должны быть закодированы
в двоичном коде. В следующей таблице приведены коды операций инструкций MOVB, ADDB2, SUBB2 и RET;
каждое двухзначное шестнадцатеричное число обозначает 8-битовый двоичный
код операции:
| Мнемоника | Код операции |
|---|---|
|
MOVB |
90 |
|
ADDB2 |
80 |
|
SUBB2 |
82 |
|
RET |
04 |
Кроме кода операции в инструкциях ЭВМ VAX присутствуют спецификаторы операндов,
которые указывают, как могут быть найдены операнды (в данном случае — пересылаемые,
складываемые или вычитаемые байты). Простейший способ обозначить операнд
— это задать его 32-битовый адрес (он уже применялся в данной главе). Такой
способ нахождения операнда называется абсолютной адресацией. Для обозначения
абсолютной адресации используется код или спецификатор операнда 9F.
В следующем примере в шестнадцатеричном представлении показано, как кодируется
инструкция MOVB:
90 9F 00001000 9F 00001003
Код операции 90 определяет инструкцию MOVB.
Спецификатор первого операнда 9F указывает, что будет задан 32-битовый адрес
операнда, а ^X00001000 является
этим адресом. Спецификатор второго операнда 9F указывает, что и второй операнд
задаётся 32-битовым адресом, затем следует адрес ^X00001003.
Если данная инструкция размещена в памяти с адреса ^X00001004,
то это выглядит следующим образом:
| Примечание | Содержимое | Адрес |
|---|---|---|
|
Код операции MOVB |
90 |
00001004 |
|
Спецификатор операнда |
9F |
00001005 |
|
Адрес, по которому выбирается байт |
00001000 |
00001006 |
|
Спецификатор операнда |
9F |
0000100А |
|
Адрес, по которому заносится байт |
00001003 |
0000100В |
Инструкции в таком полностью числовом формате называются инструкциями
на машинном языке или в машинном коде. Обратите внимание, что, когда
инструкция MOVB кодируется в машинном коде, она
занимает 11 байтов памяти. Код операции занимает 1 байт, а также требуется
по 5 байтов для определения месторасположения каждого из двух операндов
— 1 байт для спецификатора операнда и 4 байта для 32-битового адреса.
Более компактно приведённая выше инструкция MOVB может
быть записана следующим образом:
| Содержимое памяти | Адрес |
|---|---|
|
00001003 9F 00001000 9F 90 |
00001004 |
Инструкцию в таком формате следует читать справа налево. Адрес
начала инструкции ^X00001004 помещается
в конце строки. Слева от адреса расположена информация, обозначающая содержимое
памяти в диапазоне адресов от ^X00001004 до ^X0000100E.
После адреса начала инструкции в строке в последовательности справа налево
находятся: код операции ^X90,
спецификатор первого операнда байт ^X9F,
адрес ^X00001000,
по которому выбирается пересылаемый байт, спецификатор второго операнда байт ^X9F и
адрес ^X00001003,
по которому заносится в память пересылаемый байт. Далее в книге обычно будет
использоваться именно такое представление для инструкций в машинном коде.
Отметьте, что два приведённых представления инструкции MOVB содержат
одинаковую информацию о содержимом памяти. Единственным различием является
их формат.
Инструкции ADDB2 и SUBB2 имеют
одинаковый формат с инструкцией MOVB и различаются
только кодами операций. В противоположность этому инструкция RET занимает
только 1 байт памяти, так как она не имеет никаких операндов. На рис. 3.5 показано,
как будет выглядеть в машинном коде программа, приведённая на рис. 3.4.
| Примечания | Содержимое | Адрес | ||
|---|---|---|---|---|
|
БАЙТ ДАННЫХ |
1А |
00001000 |
||
|
БАЙТ ДАННЫХ |
26 |
00001001 |
||
|
БАЙТ ДАННЫХ |
05 |
00001002 |
||
|
РЕЗУЛЬТАТ (СУММА) |
?? |
00001003 |
||
|
MOVB ИНСТРУКЦИЯ |
00001003 9F |
00001000 9F |
90 |
00001004 |
|
ADDB2 ИНСТРУКЦИЯ |
00001003 9F |
00001001 9F |
80 |
0000100F |
|
ADDB2 ИНСТРУКЦИЯ |
00001003 9F |
00001002 9F |
80 |
0000101А |
|
RET ИНСТРУКЦИЯ |
04 |
00001025 |
Рис. 3.5. Стандартный формат программы в машинном коде
При выполнении инструкций с адреса ^X00001004 процессор:
- 1) выполняет инструкцию MOVB, начинающуюся
с адреса ^X00001004; - 2) выполняет инструкцию ADDB2, начинающуюся
с адреса ^X0000100F; - 3) выполняет инструкцию ADDB2, начинающуюся
с адреса ^X0000101A; - 4) выполняет инструкцию RET, расположенную
по адресу ^X00001025.
В результате этого в байт памяти с адресом ^X00001003 было
бы помещено значение ^X45.
3.6. ПРОГРАММНЫЙ СЧЁТЧИК
В предыдущем разделе было описано, как числа, включая данные и инструкции
на машинном языке, хранятся в памяти. В дополнение к основной памяти непосредственно
сам процессор ЭВМ VAX содержит небольшое количество памяти с очень быстрым
доступом. Чтобы отличить эти довольно ограниченные внутренние запоминающие
ячейки процессора от существенно большей области основной памяти, внутренние
запоминающие ячейки процессора называются регистрами процессора или
просто регистрами.
Хотя в процессоре ЭВМ VAX существуют разнообразные внутренние запоминающие
ячейки, большинство программистов в основном имеют дело с 16 регистрами,
называемыми регистрами общего назначения (сокращённо РОН). Поскольку
все 16 регистров общего назначения являются 32-разрядными, то в каждый регистр
помещается длинное слово (четыре байта). Чтобы различать между собой регистры
общего назначения, им присвоены номера от 0 до 15 (десятичные числа) или
от ^X0 до ^XF (шестнадцатеричные
числа). Обратите внимание, что эти регистры сильно отличаются от ячеек памяти.
Каждая минимальная адресуемая ячейка памяти может содержать только один байт
(восемь битов информации). Если в память помещается 32-битовое длинное слово,
то для него требуется четыре таких ячейки памяти. В противоположность этому
в каждый регистр общего назначения помещается длинное слово, так что в 16
регистрах общего назначения всего размещаются 16 длинных слов, или 64 байта.
Вопреки своему названию регистр общего назначения 15 используется для весьма
определённой цели. (Как мы увидим далее, регистры общего назначения 12, 13
и 14 также применяются для определённых целей.) При выполнении процессором
каждой инструкции на машинном языке он использует регистр 15 для адресации
следующей инструкции. Вследствие этого регистр процессора 15 называется программным
счётчиком (Program Counter) или просто PC.
Чтобы понять, как работает программный счётчик, ниже показаны первые 15 байтов
программы, приведённой на рис. 3.5.
| Память | ||
|---|---|---|
| Содержимое | Адрес | Процессор |
|
1А |
00001000 |
00001004 PC |
|
26 |
00001001 |
|
|
05 |
00001002 |
|
|
?? |
00001003 |
|
|
90 |
00001004 |
|
|
9F |
00001005 |
|
|
00 |
00001006 |
|
|
10 |
00001007 |
|
|
00 |
00001008 |
|
|
00 |
00001009 |
|
|
9F |
0000100А |
|
|
03 |
0000100В |
|
|
10 |
0000100С |
|
|
00 |
0000100D |
|
|
00 |
0000100Е |
|
|
… |
0000100F |
Для того чтобы выполнить программу, начинающуюся с адреса ^X00001004,
необходимо поместить адрес ^X00001004 в
программный счётчик PC, как показано выше. Такая
загрузка адреса производится ОС VAX/VMS при передаче ею управления программе
на машинном языке. После этого процессор выполняет инструкцию MOVB,
начинающуюся с адреса ^X00001004,
для чего он должен совершить следующие действия.
Шаг 1. Выбрать 8-битовый код операции. Так
как программный счётчик содержит значение ^X00001004,
процессор произведёт выборку байта ^X90,
расположенного по адресу ^X00001004,
считая, что данный байт является кодом операции. Кроме того, процессор увеличит
содержимое программного счётчика на 1, так что теперь программный счётчик
будет содержать значение ^X00001005 (в
этом случае говорят, что программный счётчик указывает на адрес ^X00001005).
Шаг 2. Выбрать байт спецификатора операнда.
Так как выбранный на шаге 1 код операции является кодом операции инструкции MOVB,
то вслед за этим процессор производит выборку байта ^X9F,
на который в текущий момент времени указывает регистр PC.
Процессор считает, что данный байт является спецификатором операнда. Содержимое
программного счётчика увеличивается на 1, после чего программный счётчик
указывает на адрес ^X00001006.
Шаг 3. Выбрать адрес первого операнда. Выбранный
на шаге 2 байт спецификатора операнда ^X9F показывает,
что программный счётчик указывает на адрес операнда. Иначе говоря, следующие
после байта спецификатора операнда четыре байта представляют собой адрес
операнда. Процессор производит выборку четырёх байтов с адресами от ^X00001006 до ^X00001009 и
собирает эти байты, чтобы сформировать адрес ^X00001000.
Одновременно с этим содержимое программного счётчика увеличивается на 4,
так что он указывает теперь на адрес ^X0000100A.
Шаг 4. Выбрать первый операнд. Так как на
шаге 3 был выбран адрес нахождения операнда ^X00001000,
то процессор производит выборку байта ^X1A,
расположенного по этому адресу.
Шаг 5. Выбрать байт спецификатора второго
операнда. Поскольку в инструкции MOVB требуется
два операнда, то процессор производит выборку байта ^X9F,
на который указывает регистр PC, содержащий адрес ^X0000100A,
и интерпретирует этот байт как байт спецификатора операнда. Процессор также
увеличивает на 1 содержимое регистра PC, которое
становится равным ^X0000100B.
Шаг 6. Выбрать адрес второго операнда. Так
как на шаге 5 был выбран код ^X9F,
то процессор производит выборку содержимого байтов с адресами от ^X0000100B до ^X0000100E и,
объединяя их вместе, формирует адрес ^X00001003.
Кроме того, содержимое регистра PC увеличивается
на 4. Регистр PC содержит теперь адрес ^X0000100F.
Шаг 7. Выполнить пересылку. Процессор помещает
байт ^X1A,
выбранный на шаге 4, по адресу ^X00001003,
выбранному на шаге 6. Этим завершается выполнение инструкции MOVB.
Содержимым регистра PC остаётся ^X0000100F,
так как на текущем шаге содержимое регистра не модифицировалось.
После завершения выполнения инструкции процессор производит выборку байта,
указываемого программным счётчиком, и увеличивает содержимое регистра PC,
считая, что данный байт является новым кодом операции. (После завершения
шага 7 приведённой выше последовательности действий процессор будет производить
выборку содержимого памяти с адресом ^X0000100F,
считая, что это новый код операции.) Последовательность действий, которую
затем выполняет процессор, зависит от нового кода операции. Если код операции
соответствует инструкции MOVB, то процессор выполнит
предыдущие семь шагов; если новый код операции задаёт инструкцию ADDB2 или SUBB2,
процессор выполнит последовательность действий, состоящую из девяти шагов.
Первые шесть шагов идентичны первым шести шагам выполнения инструкции MOVB,
показанным выше. Остальные три шага приводятся ниже.
Шаг 7. Выбрать второй операнд. Процессор производит
выборку байта, используя адрес, полученный на шаге 6.
Шаг 8. Выполнить сложение или вычитание. Процессор
складывает (или вычитает) байт, выбранный на шаге 4, с байтом (из байта),
выбранным на шаге 7.
Шаг 9. Запомнить результат. Процессор помещает
вычисленное на шаге 8 значение в байт памяти, расположенный по адресу, который
был выбран на шаге 6.
Выполняя программу, процессор слепо выбирает из памяти и выполняет инструкции
на машинном языке до тех пор, пока: 1) не будет встречена инструкция RET,
2) оператор сам (вручную) не остановит ЭВМ или 3) некоторое состояние ошибки
не заставит процессор завершить выполнение программы.
3.7. ОШИБКИ ВЫПОЛНЕНИЯ
Как мы только что видели, содержимое байта памяти можно интерпретировать
или использовать различными способами. Например, на рис. 3.5 некоторые
байты трактовались как коды операций, другие — как спецификаторы операндов,
третьи — как байты, составляющие 4-байтовый адрес, а прочие рассматривались
как операнды. Невозможно посмотреть содержимое байта памяти и определить,
как следует интерпретировать это содержимое. Если в каком-либо конкретном
байте памяти содержится код ^X9F,
то это содержимое может быть:
- 1) кодом операции инструкции PUSHAB (PUSH
Address of Byte — включить в стек адрес байта), она будет рассматриваться
в гл. 9, - 2) спецификатором операнда ^X9F;
- 3) одним из четырёх байтов длинного слова ^X9F9F9F9F,
являющегося адресом; - 4) байтовым операндом, интерпретируемым как целое число без знака,
эквивалентное десятичному числу 159; - 5) байтовым операндом, интерпретируемым как целое число со знаком,
эквивалентное десятичному числу -97.
Важно отличать друг от друга коды операций, спецификаторы операндов, адреса
и операнды, так как каждому из них отводится различная роль. Код операции
даёт указание процессору совершить некоторую операцию, такую как MOVB, ADDB2, SUBB2 или RET.
Поскольку каждый код операции является 8-битовым, то потенциально имеется
28, или 256, различных кодов операции[2].
В программах пользователей может использоваться большинство допустимых кодов
операций. Однако некоторые коды операций, включая инструкцию HALT (остановить)
с кодом операции ^X00,
относятся к привилегированным инструкциям и могут выполняться
только теми компонентами операционной системы, которые имеют особые привилегии.
Если в программе пользователя предпринимается попытка выполнить привилегированную
инструкцию, то возникнет ошибка, называемая прерыванием
по резервной инструкции (reserved instruction trap), и управление будет
возвращено ОС VAX/VMS.
Байт спецификатора операнда указывает способ определения местонахождения
операнда. Поскольку спецификатор операнда занимает восемь битов (один байт),
то потенциально существует 28, или 256, различных способов определения
местонахождения операнда. До сих пор рассматривался единственный спецификатор
операнда — код ^X9F.
Это значение спецификатора операнда указывает, что после байта спецификатора
операнда непосредственно следует длинное слово адреса операнда. Как было
отмечено ранее, такой способ определения местонахождения операнда называется абсолютной
адресацией. Некоторые из других 255 возможных значений байта — спецификатора
операнда являются недопустимыми. Попытка использования недопустимого значения
вызовет прерывание по резервному режиму адресации (reserved
addressing mode fault), по которому управление будет возвращено ОС VAX/VMS.
Адреса представляют собой 32-битовые длинные слова, значение адреса может
изменяться от ^X00000000 до ^XFFFFFFFF.
Однако операционная система VAX/VMS обычно ограничивает диапазон адресов,
к которым может иметь доступ программа пользователя. Попытка нарушить эти
ограничения приводит к ошибке, называемой прерыванием по
нарушению контроля доступа (access control violation fault).
Для байтового операнда допустимо любое шестнадцатеричное значение от ^X00 до ^XFF.
Как было отмечено в гл. 2,
в формате байта могут быть представлены числа со знаком и без знака. Важно
понять, что имеется только одна инструкция сложения байтов — ADDB2.
Например, при сложении байтов ^XFC и ^X02 результат
будет равен ^XFE.
Если эти значения интерпретировать как числа без знака, то их сложение будет
соответствовать сложению десятичных чисел 252 и 2, что даст в результате
254. При интерпретации этих значений как чисел со знаком их сложение соответствует
сложению чисел -4 и 2, что в сумме даст -2.
Ошибки переполнения возможны при любой интерпретации чисел. Например, сумма ^XFF и ^X03 равна ^X02.
(В обычных условиях правильной суммой является ^X102,
но это число не помещается в формате байта.) Для чисел со знаком такой результат
корректен, так как сумма чисел -1 и 3 равна 2. Однако в случае чисел без
знака результат неверен, так как сумма чисел 255 и 3, конечно, не равна 2.
Тогда говорят, что произошло переполнение числа без знака.
На ЭВМ семейства VAX переполнение числа без знака не рассматривается как
ошибка. В гл. 6 объясняется,
как проводится проверка на переполнение беззнаковых чисел.
Аналогично сумма ^X7E и ^X04 равна ^X82.
В этом случае для чисел без знака результат будет правильным (126 плюс 4
равно 130), но для чисел со знаком он неверен (126 плюс 4 не равно -126).
Тогда говорят, что произошло переполнение числа со знаком.
Если в специальный разряд процессора, называемый битом IV, занесена 1, то
при переполнении числа со знаком будет порождаться ошибка, называемая прерыванием
по арифметической операции (arithmetic trap). В противном случае ошибка
не возникает. В гл. 6 показано
также, как программист может проверить наличие ошибки переполнения числа
со знаком.
Как отмечалось ранее, помимо байтовых операндов ЭВМ семейства VAX могут
работать с операндами в формате 16-битового слова, 32-битового длинного слова
и в некоторых случаях — с операндами в формате 64-битового квадраслова. При
выполнении арифметических операций над операндами в формате слова или длинного
слова может происходить переполнение чисел со знаком и без знака, точно так
же как и при выполнении операций над байтами.
УПРАЖНЕНИЯ 3.1
- На рис. 3.3 укажите
шестнадцатеричные значения следующих элементов:- а) слова, начинающегося с адреса ^X00000000;
- б) слова, начинающегося с адреса ^X00000001;
- в) слова, начинающегося с адреса ^X00000008;
- г) длинного слова, начинающегося с адреса ^X00000000;
- д) длинного слова, начинающегося с адреса ^X00000001;
- е) длинного слова, начинающегося с адреса ^X00000005.
- Дайте определение каждому из следующих терминов:
- а) код операции;
- б) спецификатор операнда;
- в) операнд;
- г) программный счётчик;
- д) регистр процессора;
- е) регистр общего назначения;
- ж) ошибка выполнения;
- з) инструкция на машинном языке;
- и) программа в машинном коде.
- Пусть байты памяти с адресами от^X0200 до ^X0203 содержат
следующее:Содержимое Адрес 1F
00000200
05
00000201
FF
00000202
3F
00000203
Опишите, что произойдёт при выполнении нижеследующих инструкций на машинном
языке. Для каждой инструкции выпишите адрес и новое содержимое каждого
байта, если оно изменилось. (Считайте, что инструкции выполняются независимо
друг от друга. Перед выполнением каждой инструкции содержимое байтов
памяти с адресами от ^X0200 до ^X0203 имеет
начальные значения, приведённые выше) :а) 00000203
9F
00000200
9F
90;
б) 00000201
9F
00000200
9F
80;
в) 00000202
9F
00000200
9F
80;
г) 00000200
9F
00000201
9F
82;
д) 00000203
9F
00000203
9F
82.
3.8. НЕКОТОРЫЕ ДОПОЛНИТЕЛЬНЫЕ ИНСТРУКЦИИ
ОПИСАНИЕ ИНСТРУКЦИЙ
Для описания инструкций ЭВМ семейства VAX будут применяться условные обозначения,
подобные обозначениям, используемым фирмой Digital Equipment Corporation
в документации для вычислительных систем VAX. Например, описание четырёх
инструкций, с которыми читатель уже знаком, выглядит следующим образом:
| Мнемоника | Код операции | Операнды | Операция (описание) |
|---|---|---|---|
|
ADDB2 |
80 |
add, sum |
sum ← sum + add |
|
SUBB2 |
82 |
sub, dif |
dif ← dif — sub |
|
MOVB |
90 |
src, dst |
dst ← src |
|
RET |
04 |
возврат управления |
В первой строке дано описание инструкции ADDB2.
Мнемонический код операции ADDB2 обозначает инструкцию
сложения байтов (Add Byte) с двумя операндами. В графе «Код операции» указывается
код операции ^X80,
соответствующий инструкции ADDB2. Обозначения add
(слагаемое) и sum (сумма) в поле операндов могут рассматриваться как имена
переменных в языках высокого уровня, таких как Фортран и Паскаль. Данные
обозначения используются также в графе описания действия операции «Операция».
В этой графе описание sum ← sum + add показывает, что первый операнд,
обозначенный add, складывается со вторым операндом sum, а результат сложения
помещается в sum — во второй операнд.
Другие инструкции описываются аналогично. Для инструкции SUBB2 (Subtract
Byte — вычесть байт, два операнда) описанием операции является dif ← dif
— sub. Это означает, что по месту нахождения второго операнда dif (разность)
помещается разность между первоначальным значением второго операнда dif и
значением первого операнда sub (вычитаемое). В описании инструкции MOVB обозначение
src (от SouRCe — источник) относится к тому операнду, который будет выбираться
или считываться из памяти, а обозначение dst (от DeSTination — место назначения
или получатель) относится к операнду, по месту нахождения которого будет
занесён или записан в память результат.
Следует сделать два замечания относительно такого описания инструкций. Во-первых,
описания следует читать в обычном порядке — слева направо, в отличие от кодов
машинного языка, которые читаются справа налево. Во-вторых, такой формат
описания использовался при описании инструкций ЭВМ семейства VAX, приведённых
на развороте обложки и в приложении
Е.
ДОПОЛНИТЕЛЬНЫЕ ИНСТРУКЦИИ
На примере инструкции сложения будет проиллюстрировано, как из отдельных
инструкций образуется семейство инструкций. В гл.
1 рассматривалась инструкция ADDL2 (ADD Longword
— сложить длинное слово, два операнда). Семейство инструкций сложения ADD
включает инструкции сложения операндов в формате байта и слова. Описание
инструкций сложения дано ниже.
| Мнемоника | Код операции | Операнды | Операция |
|---|---|---|---|
|
ADDB2 |
80 |
add, sum |
sum ← sum + add |
|
ADDW2 |
А0 |
||
|
ADDL2 |
С0 |
Эти инструкции будут называться семейством инструкций ADD2.
В гл. 1 рассматривалась также инструкция ADDL3 (ADD
Longword — сложить длинное слово, три операнда). Семейство инструкций сложения ADD включает
также инструкции с тремя операндами, в том числе инструкции сложения операндов
в формате байта и слова. Описание семейства инструкций ADD3 приведено
ниже.
| Мнемоника | Код операции | Операнды | Операция |
|---|---|---|---|
|
ADDB3 |
81 |
add1, add2, sum |
sum ← add1 + add2 |
|
ADDW3 |
А1 |
||
|
ADDL3 |
С1 |
Например, инструкция на машинном языке
00000800 9F 00001000 9F 00001200 9F C1
вызовет сложение длинного слова, начинающегося с адреса ^X00001200,
с длинным словом, начинающимся с адреса ^X00001000,
а сумма будет помещена в длинное слово, расположенное по адресу ^X00000800.
Если бы адресам ^X0000800, ^X00001000 и ^X00001200 соответствовали
символические имена A, B и C,
то эта инструкция могла быть написана на языке ассемблера следующим образом:
ADDL3 C,B,A
Семейство инструкций вычитания SUB подобно
семейству инструкций сложения ADD. Ниже приведём
шесть из них:
| Мнемоника | Код операции | Операнды | Операция |
|---|---|---|---|
|
SUBB2 |
82 |
sub, dif |
dif ← dif — sub |
|
SUBW2 |
А2 |
||
|
SUBL2 |
С2 |
||
|
SUBB3 |
83 |
sub, min, dif |
dif ← min — sub |
|
SUBW3 |
А3 |
||
|
SUBL3 |
С3 |
Семейство инструкций пересылки MOVB включает следующие
инструкции:
| Мнемоника | Код операции | Операнды | Операция |
|---|---|---|---|
|
MOVB |
90 |
src, dst |
dst ← src |
|
MOVW |
B0 |
||
|
MOVL |
D0 |
||
|
MOVQ |
7D |
Инструкция MOVQ (MOVe Quadword) служит для пересылки
64-битового квадраслова.
3.9. ДОПОЛНИТЕЛЬНЫЕ СПЕЦИФИКАТОРЫ ОПЕРАНДОВ
НЕПОСРЕДСТВЕННАЯ АДРЕСАЦИЯ
Байт спецификатора операнда указывает способ определения местонахождения
операнда. Рассмотренный ранее спецификатор операнда ^X9F указывает,
что для нахождения операнда используется режим абсолютной адресации.
Данный режим адресации указывает, что адрес операнда содержится в длинном
слове, расположенном непосредственно после байта спецификатора операнда.
Режим непосредственной адресации подобен режиму абсолютной адресации,
за тем исключением, что после байта спецификатора операнда непосредственно
следует не адрес операнда, а сам операнд. Для указания режима непосредственной
адресации используется спецификатор операнда ^X8F.
Рассмотрим, например, следующую инструкцию на машинном языке:
| Второй операнд | Первый операнд | Код операции |
|---|---|---|
|
00000800 9F |
50 8F |
80 |
Код операции ^X80 соответствует
инструкции ADDB2 — сложение байтов. Спецификатор
первого операнда ^X8F указывает,
что используется непосредственная адресация. В следующем байте содержится
значение ^X50,
которое является значением первого операнда. В остальных пяти байтах инструкции
содержится указание, что для выборки второго операнда применяется абсолютная
адресация, а сам операнд расположен по адресу ^X00000800.
В результате по данной инструкции будет складываться значение ^X50 и
содержимое байта памяти с адресом ^X00000800.
Если перед выполнением данной инструкции значение этого содержимого равно ^X60,
то после выполнения инструкции содержимое этого байта памяти будет равно
значению ^XB0.
Подобным образом по следующей инструкции будет выполнено сложение числа ^X01234567 с
содержимым длинного слова, начинающегося с адреса ^X00000A00:
| Второй операнд | Первый операнд | Код операции |
|---|---|---|
|
00000А00 9F |
01234567 8F |
С0 |
Поскольку коду операции ^XC0 или
инструкции ADDL2 требуются операнды в формате длинного
слова, то непосредственный операнд (в данном случае 01234567) размещается
в четырёх байтах, следующих за байтом спецификатора операнда. Обратите внимание
что ячейка памяти с адресом ^X01234567 никак
не участвует в выполнении этой инструкции.
Операнды, содержащиеся в машинном коде самой инструкции, такие как 50 и
01234567 в предыдущих примерах, называются непосредственными операндами.
Поскольку операнды находятся непосредственно в машинном коде самой инструкции,
то они становятся доступными сразу же после выборки инструкции.
В языке ассемблера для указания непосредственной адресации используется
знак номера #. Например, в следующих инструкциях на языке ассемблера:
ADDB2 #80,ALPHA ADDL2 #1000,BETA
знак номера #, стоящий перед первым операндом, укажет ассемблеру
при трансляции этих инструкций на машинный язык, что используется непосредственная
адресация.
ОТНОСИТЕЛЬНАЯ АДРЕСАЦИЯ
Режим абсолютной адресации, определяемый спецификатором ^X9F,
позволяет получать доступ к любой адресуемой области памяти. Однако такой
режим является неэкономным с точки зрения распределения памяти. Например,
программа в машинном коде, приведённая на рис. 3.5,
повторно показана на рис. 3.6.
Обратите внимание, что большинство байтов этой программы отводится для хранения
адресов. Программа занимает 38 байтов памяти, из них 24 байта отведено для
указания адресов.
Более эффективен другой способ адресации, называемый относительной адресацией.
При относительной адресации местонахождение операнда задаётся разностью между
действительным адресом нахождения операнда и текущим значением программного
счётчика. Эта разность называется смещением. В сущности, смещение определяет
местонахождение операнда по отношению к текущему адресу, т.е. предшествует
ли адрес операнда текущему адресу или находится после него, а также насколько
велико удаление адреса операнда относительно текущего. Вспомним, что программный
счётчик PC содержит адрес текущей инструкции или
части этой инструкции.
Чтобы понять, как работает относительная адресация, рассмотрим рис. 3.7.
Программа, приведённая на рис. 3.7,
идентична программе, показанной на рис. 3.6,
за тем исключением, что вместо абсолютной адресации используется относительная.
На рис. 3.7 вместо спецификатора
операнда ^X9F применяется
спецификатор ^XAF.
Спецификатор ^XAF означает,
что для указания адреса используется единственный байт. Если содержимое байта
(рассматриваемое как число, представленное в дополнительном коде) является
отрицательным, это означает, что операнд расположен в памяти перед текущим
адресом и смещён относительно него на указанное число байтов. Если содержимое
байта является положительным, это означает, что операнд размещается в памяти
после текущего адреса через соответствующее число байтов.
| Примечания | Содержимое | Адрес | ||
|---|---|---|---|---|
|
БАЙТ ДАННЫХ |
1А |
00001000 |
||
|
БАЙТ ДАННЫХ |
26 |
00001001 |
||
|
БАЙТ ДАННЫХ |
05 |
00001002 |
||
|
РЕЗУЛЬТАТ (СУММА) |
?? |
00001003 |
||
|
MOVB ИНСТРУКЦИЯ |
0000100З 9F |
00001000 9F |
90 |
00001004 |
|
ADDB2 ИНСТРУКЦИЯ |
00001003 9F |
00001001 9F |
80 |
0000100F |
|
ADDB2 ИНСТРУКЦИЯ |
00001003 9F |
00001002 9F |
80 |
0000101А |
|
RET ИНСТРУКЦИЯ |
04 |
00001025 |
Рис. 3.6. Стандартный формат программы в машинном коде
Например, рассмотрим на рис. 3.7 инструкцию MOVB.
Код операции ^X90 расположен
по адресу ^X00001004.
Содержимым байта с адресом ^X00001006 является
код ^XAF,
который указывает, что местонахождение первого операнда будет определяться
с помощью относительной адресации. Следующий байт с адресом ^X00001006 содержит
смещение ^XF9.
Число ^XF9,
интерпретируемое как число со знаком, эквивалентно десятичному числу — 7.
После выборки из памяти смещения содержимое программного счётчика будет увеличено,
так что он будет содержать адрес ^X00001007.
Поэтому адресом первого операнда инструкции MOVB является
00001007
-7
00001000
Обратите внимание, что адрес операнда ^X00001000 совпадает
с адресом первого операнда инструкции MOVB, представленной
на рис. 3.6. Вычислить
адрес остальных операндов предлагается читателю в качестве упражнения (См.
п. 3 упр. 3.1).
Применение относительной адресации вместо абсолютной уменьшает объём памяти,
занимаемый программой, с 38 до 20 байтов. Программа не только получается
меньше, но и выполняется быстрее, так как при выполнении производится меньшее
число выборок из памяти. Однако относительная адресация со смещением, заданным
в формате байта, пригодна только для небольших программ, поскольку, задавая
смещение в формате байта, максимально можно адресовать 127 ячеек после или
128 ячеек перед, относительно текущего значения программного счётчика. Чтобы
избежать подобных ограничений, в ЭВМ семейства VAX для относительной адресации
позволяется использовать слова и длинные слова. Эти режимы адресации распознаются
по спецификаторам операндов ^XCF и ^XEF соответственно.
Использование смещений, задаваемых в формате слова или длинного слова, не
только увеличит объём программы, но и позволит также адресовать любое место
в программе независимо от её объёма.
Режимы относительной адресации со смещением, заданным в формате байта, слова
и длинного слова, можно найти в программах на языке ассемблера, приведённых
в следующей главе, а более подробное описание этих режимов можно найти в гл. 7.
Как мы увидим, кроме экономии времени выполнения и объёма занимаемой памяти
относительная адресация имеет и другие преимущества. В результате когда ассемблер
выполняет трансляцию операторов, таких как
MOVB A,B ADDL3 C,D,E
на машинный язык, то вместо абсолютной он использует относительную
адресацию. Отметим, что применение последней не требует какой-либо дополнительной
работы от программиста, так как смещение вычисляет сам ассемблер.
| Примечания | Содержимое | Адрес |
|---|---|---|
|
БАЙТ ДАННЫХ |
1А |
00001000 |
|
БАЙТ ДАННЫХ |
26 |
00001001 |
|
БАЙТ ДАННЫХ |
05 |
00001002 |
|
РЕЗУЛЬТАТ (СУММА) |
?? |
00001003 |
|
MOVB ИНСТРУКЦИЯ |
FA AF F9 AF 90 |
00001004 |
|
ADDB2 ИНСТРУКЦИЯ |
F5 AF F5 AF 80 |
0000100F |
|
ADDB2 ИНСТРУКЦИЯ |
F0 AF F1 AF 80 |
0000100F |
|
RET ИНСТРУКЦИЯ |
04 |
00001025 |
Рис. 3.7. Применение относительной адресации в программе
на машин ном языке
УПРАЖНЕНИЯ 3.2
- Пусть в памяти содержатся следующие длинные слова:
Содержимое Адрес 0000000F
00000200
FFFFFFFF
00000204
00000100
00000208
00000001
0000020C
Опишите, что произойдёт при выполнении каждой из нижеследующих инструкций
на машинном языке. Выпишите для каждой инструкции адрес и новое содержимое
каждого длинного слова, если оно изменилось. (Считайте, что инструкции
выполняются независимо друг от друга. Перед выполнением каждой инструкции
байты памяти с адресами от ^X0200 до ^X020F принимают
исходные значения, приведённые выше.)а) 00000208 9F
00000200 9F
D0
б) 00000208 9F
00000200 8F
D0
в) 00000204 9F
0000020С 9F
С0
г) 00000204 9F
0000020С 8F
С0
д) 0000020С 9F
00000204 9F
С2
е) 00000204 9F
00000010 8F
00000208 9F С1
ж) 00000204 9F
00000208 9F
00000020 8F С3
з) 00000208 9F
00000200 9F
7D
- Какие шестнадцатеричные числа будут содержаться в длинных словах с адресами ^X0200, ^X0204, ^X0208 и ^X020C после
того, как следующая программа вернёт управление операционной системе? Выполнение
начинается с адреса ^X0210:Инструкция Адрес 00000200 9F
00000020 8F
D0
00000210
00000204 9F
00000040 8F
D0
0000021B
00000208 9F
00000200 9F
00000204 9F
C1
00000226
0000020С 9F
00000208 9F
0000000F 8F
C3
00000236
04
00000246
- Для программы рис. 3.7 определите
адреса оставшихся пяти операндов. Сравните эти адреса с адресами операндов
программы рис. 3.6. - Напишите, начиная с адреса ^X0200,
программы в машинном коде, эквивалентные следующим программам на языках
Фортран и Паскаль:Фортран Паскаль INTEGER J, K, L
PROGRAM FOUR;
J=15
VAR
K=22
J, K, L: INTEGER;
L=J—K+9
BEGIN
STOP
J := 15;
END
K := 22;
L := J—K+9;
END.
- Выполните ассемблирование следующей программы на языке ассемблера и проанализируйте
листинг ассемблера с программой в машинном коде. Определите коды операций,
спецификаторы операндов, адреса и числа в листинге ассемблера. (Директива .ENABLE в
первой строке программы предписывает ассемблеру использование абсолютной
адресации, которая была описана в данной главе.).ENABLE
ABSOLUTE
J:
.BLKL
1
K:
.BLKL
1
DIF:
.BLKL
1
.ENTRY
ADDRESS,0
FIRST:
MOVL
#512,J
MOVL
#64,K
SUBL3
K,J,DIF
LAST:
$EXIT_S
.END
ADDRESS
- Повторите п. 5, исключив из программы первую строку (.ENABLE ABSOLUTE).
Это позволит ассемблеру использовать относительную адресацию. Объясните
формирование каждого относительного адреса и покажите, что при этом обеспечивается
правильный исполнительный адрес в процессе выполнения программы.
| < НАЗАД | ОГЛАВЛЕНИЕ | ВПЕРЁД > |
Performed by © gid, 2012-2023.
Центральный процессор (ЦП) — устройство, непосредственно предназначенное для выполнения вычислительных операций. Процессор работает под управлением программы, выполняя вычисления или принимая логические решения, необходимые для обработки информации.
Большинство современных центральных процессоров строятся на базе 32-битной архитектуры Intel-совместимых процессоров IA-32 (Intel Architecture), которая является третьим поколением базовой архитектуры x86.
Структура центрального процессора
Функционально центральный процессор можно разделить на две части:
- операционную, содержащую арифметико-логическое устройство (АЛУ) и микропроцессорную память (МПП) — регистры общего назначения;
- интерфейсную, содержащую адресные регистры, устройство управления, регистры памяти для хранения кодов команд, выполняемых в ближайшие такты; схемы управления шиной и портами.

Обе части ЦП работают параллельно, причем интерфейсная часть опережает операционную, так что выборка очередной команды из памяти (ее запись в блок регистров команд и предварительный анализ) происходит во время выполнения операционной частью предыдущей команды. Такая организация ЦП позволяет существенно повысить его эффективное быстродействие.
Устройство управления (УУ) вырабатывает управляющие сигналы, поступающие по кодовым шинам инструкций в другие блоки вычислительной машины. УУ формирует управляющие сигналы для выполнения команд центрального процессора.
Арифметико-логическое устройство (АЛУ) предназначено для выполнения арифметических и логических операций преобразования информации.
Системная шина – набор проводников, по которым передаются сигналы, соединяющая процессор с другими компонентами на системной плате. Системная шина состоит из шины данных, шины адреса, шины управления.
- Шина данных – служит для пересылки данных между процессором и оперативным запоминающим устройством (ОЗУ).
- Шина адреса – используется для передачи сигналов, с помощью которых определяется местоположение ячейки памяти для выполняемых процессором операций чтения/записи и ввода-вывода.
- Шина управления – служит для пересылки управляющих сигналов. Каждая линия этой шины имеет своё особое назначение, поэтому они могут быть как однонаправленными, так и двунаправленными.
Микропроцессорная память
Микропроцессорная память представляет собой набор регистров, которые условно можно разделить на 4 группы:
- регистры общего назначения;
- сегментные регистры;
- регистр счетчика команд;
- регистр признаков.
Регистр – устройство сверхбыстродействующей памяти в процессоре, служащее для временного хранения управляющей информации, операндов и/или результатов выполняемых операций. Совокупность регистров процессора называется набором регистров.
Набор регистров общего назначения 32-битной архитектуры центрального процессора включает в себя
- 4 универсальных регистра: EAX, EBX, ECX, EDX;
- 2 индексных регистра: ESI, EDI;
- 2 регистра для работы со стеком: ESP, EBP.

Каждый из 32-разрядных универсальных регистров представляет собой логическое объединение, позволяющее отдельно обращаться к своей младшей 16-разрядной части: AX, BX, CX, DX. Каждый 16-разрядный регистр позволяeт независимо обращаться к старшему (H) и младшему (L) байту. Соответствующие 8-разрядные регистры имеют имена AH, AL, BH, BL, CH, CL, DH, DL.

Регистр EAX (аккумулятор) – автоматически применяется при операциях умножения, деления и при работе с портами ввода-вывода. Его использование в арифметических, логических и некоторых других операциях позволяет увеличить скорость их выполнения. Используется для записи возвращаемого значения из функции.
Регистр EBX (регистр базы) – может содержать адреса элементов оперативной памяти. По умолчанию эти адреса будут представлять собой смещение в сегменте данных.
Регистр ECX (счетчик) – используется в операциях повторения, например в циклах, в строковых командах и т.д.
Регистр EDX (регистр данных) – является единственным элементом, который может хранить адреса портов ввода-вывода в командах типа IN (получить из порта) и OUT (вывести в порт). Без его помощи невозможно обратиться к портам с адресами в адресном пространстве больше 1 байта. Автоматически применяется также в операциях умножения и деления.
Индексные регистры используются для выполнения косвенной адресации, а также автоматически используются в строковых командах. Каждый 32-разрядный индексный регистр представляет собой логическое объединение, позволяющее отдельно обратиться к своей младшей 16-разрядной части.
Регистр ESI (регистр индекса источника) может содержать адреса элементов в оперативной памяти. По умолчанию эти адреса будут представлять собой смещение в сегменте данных. При выполнении операций со строками в этом регистре содержится смещение строки источника в сегменте данных.
Регистр EDI (регистр индекса приемника) может содержать адреса элементов в оперативной памяти. По умолчанию эти адреса будут представлять собой смещение в сегменте данных. При выполнении операций со строками в этом регистре содержится смещение строки приемника в сегменте данных.

Регистры для работы со стеком используются для хранения вершины стека (ESP) и текущего элемента (базы) — EBP. Каждый 32-разрядный регистр для работы со стеком представляет собой логическое объединение, позволяющее отдельно обратиться к своей младшей 16-разрядной части.
Регистр EBP (указатель базы) может содержать адреса элементов в оперативной памяти. Эти адреса будут представлять собой смещение в сегменте стека.
Регистр ESP (указатель стека) используется для записи данных в стек и чтения их из стека. Фактически он содержит смещение в сегменте стека, которое определяет нужное слово памяти. Значения этого регистра автоматически меняются командами для работы со стеком типов push, pop, pushf, popf, call, ret.

Сегментные регистры представляют собой набор 16-разрядных регистров (для 32-битной архитектуры центрального процессора).
Сегмент — это логический элемент программы, который представляет собой независимый, поддерживаемый на аппаратном уровне блок памяти.

Регистр CS (регистр сегмента кода) определяет стартовый адрес сегмента, в который помещается код выполняемой программы. Это единственный сегментный регистр, который нельзя загрузить непосредственно. Косвенно загрузить в регистр CS новое значение могут команды вида jxx, call, int, ret, iret.
Регистр DS (регистр сегмента данных) определяет стартовый адрес сегмента, в который помещаются данные для программы. По умолчанию смещения в сегменте данных задаются в регистрах EBX, ESI и EDI.
Регистр SS (регистр сегмента стека) определяет стартовый адрес сегмента, в который помещается стек для программы. По умолчанию смещения для сегмента стека задаются в регистрах ESP и EBP.
Регистры ES, FS, GS (регистры сегментов дополнительных данных) опредляют стартовый адрес сегмента, в который помещаются дополнительные данные для программы. Например, в случае строковых команд, DS определяет сегмент для строки-источника, а ES – сегмент для строки-приемника. За исключением строковых команд, доступ к данным в сегменте ES обычно менее эффективен, чем в сегменте DS.
Регистр счетчика команд
Регистр EIP (указатель команд) содержит смещение в сегменте кода следующей выполняемой команды. Как только некоторая команда начинает выполняться, значение регистра EIP увеличивается на ее длину так, что будет адресовать следующую команду. Физический адрес команды в памяти выполняемой программы определяет пара регистров CS:EIP, то есть к физическому адресу начала сегмента кода добавляется смещение следующей команды в сегменте кода, хранящееся в регистре EIP.
Обычно команды выполняются в той последовательности, в которой они расположены в программе. Нарушают эту последовательность только команды переходов (они начинаются с буквы j: jxx), команды вызова подпрограммы (call), обработчиков прерываний (int) и возврата (ret, iret). Непосредственно содержимое EIP нельзя изменить или прочитать. Косвенно загрузить в регистр EIP новое значение могут только команды jxx, call, int, ret, iret. Регистр EIP является 32-битным. Младшая 16-битная часть регистра счетчика команд имеет имя IP.
Регистр признаков
Регистр признаков EFLAGS включает биты, каждый из которых устанавливается в единичное или в нулевое состояние при определенных условиях. Регистр EFLAGS 32-битный. Младшая 16-битная часть регистра признаков имеет имя FLAGS.

Все биты регистра признаков подразделяются на
- s — биты состояния (STATUS);
- c — биты управления (CONTROL);
- x — системные биты (SYSTEM).

CF – бит переноса: устанавливается в 1, когда арифметическая операция генерирует перенос или выход за разрядную сетку результата. сбрасывается в 0 в противном случае. Этот флаг показывает состояние переполнения для беззнаковых целочисленных арифметических действий. Он также используется в арифметических действиях с повышенной точностью. Может быть установлен командой STC или сброшен командой CLC.
PF – бит четности: устанавливается в 1, если результат последней операции имеет четное число единиц.
AF – бит вспомогательного переноса: устанавливается в 1, если арифметическая операция генерирует перенос из младшей тетрады битов (из 3 бита в 4), сбрасывается в 0 в противном случае. Этот флаг используется в двоично-десятичной арифметике.
ZF – бит нулевого значения: устанавливается в 1, если результат нулевой, сбрасывается в 0 в противном случае.
SF – знаковый бит: устанавливается равным старшему биту результата, который определяет знак в знаковых целочисленных операциях (0 – положительное число, 1 – отрицательное число).
TF – бит пошаговой отладки: устанавливается в 1 для включения режима пошаговой отладки программы, сбрасывается в 0 в противном случае.
IF – бит прерываний: при значении 1 микропроцессор реагирует на внешние аппаратные прерывания по входу INTR. При значении 0 микропроцессор игнорирует внешние прерывания.
DF – бит направления: управляет строковыми командами (MOVS, CMPS, SCAS, LODS, STOS). Если DF = 1 (команда STD), то содержимое индексных регистров ESI, EDI увеличивается, если DF = 0 (команда CLD), то содержимое индексных регистров ESI, EDI уменьшается.
OF – бит переполнения: устанавливается в 1, если целочисленный результат выходит за пределы разрядной сетки. Тем самым данный бит указывает на потерю старшего бита результата.
IOPL – уровень приоритета: 2-битовое поле, которое отображает уровень приоритета ввода-вывода для выполняемой в данное время программы или задачи. Действительный приоритет задачи может быть меньше или равен IOPL.
NT – флаг вложенной задачи: управляет последовательностью вызванных и прерванных задач. Установлен в 1, если текущая задача связана с предыдущей, сброшен в 0, если текущая задача не связана с другими задачами.
RF — флаг возобновления: используется при обработке прерываний от регистров отладки.
VM — флаг виртуального 8086: признак работы процессора в режиме виртуального 8086: 1 – процессор работает в режиме виртуального 8086, 0 – процессор работает в реальном или защищенном режиме.
AC — флаг контроля выравнивания: предназначен для разрешения контроля выравнивания при обращениях к памяти. Если требуется контролировать выравнивание данных и команд по адресам, кратным 2 или 4, то установка данных битов приведет к тому, что все обращения по некратным адресам будут вызывать исключительную ситуацию.
VIF — флаг виртуального прерывания: при определенных условиях (одно из которых – работа микропроцессора в V-режиме) является аналогом флага IF. Флаг VIF используется совместно с флагом VIP.
VIP — флаг отложенного виртуального прерывания: устанавливается в 1 для индикации отложенного прерывания. Используется совместно с VIF в виртуальном режиме.
ID — флаг поддержки идентификации процессора: используется для отображения поддержки микропроцессором инструкции CPUID.
Назад
Назад: Язык ассемблера