SQL – это язык структурированных запросов. СУРБД – система управления реляционными базами данных. Существуют следующие разновидности баз данных:
- Система управления файлами
- Иерархические
- Сетевые
- Реляционные
- Объектно-ориентированные
- Гибридные
1) Иерархические – первые базы данных. Иерархическая база данных основана на древовидной структуре хранения информации и напоминает файловую систему компьютера. С точки зрения организации хранения информации, иерархическая база данных состоит из упорядоченного набора деревьев одного типа – каждая
запись в базе данных реализована в виде отношений предок-потомок. Основной недостаток иерархической структуры базы данных –невозможность реализовать отношения многие ко многим. Иерархические базы данных наиболее пригодны для моделирования структур, являющихся иерархическими по своей природе. Иерархия подразумевает только одного родителя.
2) Сетевые базы данных – являются расширением иерархических баз данных. Иерархические базы данных из-за большого количества недостатков просуществовали недолго и были заменены на сетевые базы данных.Сетевые базы данных представляют собой организацию данных в виде железнодорожных путей, где каждая крупная станция имеет связи с несколькими другими станциями. В сетевых базах данных имеется связь многие ко многим. Недостатком сетевых баз данных является сложность разработки больших приложений.
3) Реляционные базы данных – произвели настоящий прорыв в развитии теории баз данных. Основная задача реляционной модели была упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении
которых расположены данные.Особенности реляционной базы данных:
- Данные хранятся в таблицах, состоящих из столбцов и строк
- На пересечении каждого столбца и строки находится только одно значение
- У каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип.
- Столбцы располагаются в определенном порядке, который задается при создании таблицы, в отличие от строк, которые располагаются в произвольном порядке.
- В таблице может не быть ни одной строчки, но должен быть хотя бы один столбец.
- Запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов.
Первичные ключи
Строки в реляционной базе данных неупорядоченные. Для выбора в таблице конкретной строки создается один или несколько столбцов, значения которых во всех строках уникальны. Такой столбец называется первичным ключом.
Первичный ключ (primary key) – является уникальным значением в столбце. Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа.
По способу задания первичных ключей различают логические (естественные) ключи и суррогатные (искусственные).
Логический ключ – представляет собой значение, определяющее запись естественным образом.
Суррогатный ключ – представляет собой дополнительное поле в базе данных, предназначенное для обеспечения записей первичным ключом.
Нормализация базы данных
Нормализацией схемы базы данных – называется процедура, производимая над базой данных с целью удаления в ней избыточности.
Централизованная архитектура
При централизованной архитектуре и приложение, СУБД и база данных размещаются на одном центральном мэйнфрейме – базовой универсальной вычислительной машине. Пользователи подключаются к нему посредством терминалов. Терминал представлял собой клавиатуру, монитор и сетевую карту, посредством которой происходит обмен данных терминала с мэйнфреймом. Роль приложения состоит в принятии вводимых данных с пользовательского терминала по сети и передаче их на обработку СУБД с последующей передачей полученного от СУБД ответа на монитор терминала.
Архитектура клиент-сервер
В клиент-серверной архитектуре персональные компьютеры объединены в локальную сеть, в этой же сети находится и сервер баз данных, на котором содержатся общие для всех клиентом базы данные и СУБД. Вычислительные возможности сервера полностью сосредоточены на обслуживании СУБД.
Трехуровневая архитектура интернета
Трехуровневая модель позволяет отделить клиентское программное обеспечение от серверной части, а на серверной стороне отделить веб-сервер от сервера базы данных.
Несколько серверов, работающих над одной и той же задачей, функционируют надежнее и обходятся дешевле, чем один сервер высокой производительности.
Кластерная модель
Кластеры часто называют дешевыми супер ЭВМ. Ряд маломощных машин объединяют в локальную сеть. Специальное программное обеспечение распределяет вычисления между отдельными хостами сети. Выход из строя одного из хостов никак не отражается на работе все сети, а сам кластер легко расширяется за счет ввода дополнительных машин.
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
Индексы
Индексы – основной способ ускорения работы баз данных. Чтобы найти нужную запись, необходимо сканировать всю таблицу, на что уходит большое количество времени.
Идея индексов состоит в том, чтобы создать для столбца копию, которая постоянно будет поддерживаться в отсортированном состоянии. Это позволяет очень быстро осуществлять поиск по такому столбцу, так, как заранее известно, где необходимо искать значение.
Добавление или удаление записи требует дополнительного времени на сортировку столбца, кроме того, создание копии увеличивает объем памяти, необходимый для размещения таблицы на жестком диске.
Существует несколько видов индексов:
- Первичный ключ – главный индекс таблицы. В таблице может быть только один первичный ключ, и все значения такого индекса должны отличаться друг от друга, являться уникальными в пределах одного столбца.
- Обычный индекс – таких индексов может быть несколько.
- Уникальный индекс – уникальных индексов также может быть несколько, на значения индекса не должны повторяться.
- Полнотекстовый индекс – специальный вид индекса для столбцов типа TEXT, позволяющий производить полнотекстовый поиск.
Типы и структура таблиц
СУБД MySQL поддерживает несколько видов таблиц, каждая из которых имеет свои возможности и ограничения.
MyISAM
MyISAM – является родным типом таблиц для базы СУБД MySQL. База данных в MySQL организуется как каталог. Таблицы базы данных организуются как файлы данного каталога. Каждая MyISAM таблица хранится на диске в трех файлах, имена которых совпадают с названием таблицы, а расширение может принимать одно из следующих значений:
- Frm – содержит структуру таблицы, в файле данного типа хранится информация об именах и типах столбцов и индексов.
- Myd – файл, в котором содержатся данные таблицы.
- Myi – файл, котором содержатся индексы таблицы.
Особенности типа таблиц MyISAM:
- Данные хранятся в кросс-платформенном формате, это позволяет переносить базы данных с сервера непосредственным копированием файлов, минуя промежуточные форматы.
- Максимальное число индексов в таблице составляет 64. Каждый индекс может состоять максимум из 16 столбцов.
- Для каждого из текстовых столбцов может быть назначена своя кодировка.
- Допускается индексирования текстовых столбцов, в том числе и переменной длины.
- Поддерживается полнотекстовый поиск.
- Каждая таблица имеет специальный флаг, указывающий правильность закрытия таблиц. Если сервер останавливается аварийно, то при его повторном старте незакрытые флаги сигнализируют о возможных сбойных таблицах, сервер автоматически проверяет их и пытается восстановить.
MERGE
Тип таблиц MERGE позволяет сгруппировать несколько таблиц типа MyISAM в одну. Такой тип таблиц применяется для снятия ограничения на объем таблиц MyISAM. Таблицы MyISAM, которые подвергаются объединению в одну таблицу MERGE, должны иметь одинаковую структуру, то есть, одинаковые столбцы и индексы, а также порядок их следования.
При создании таблицы типа MERGE будут образованы файлы структуры таблицы с расширением frm и файлы с расширением mrg. Файл mrgсодержит список индексных файлов, работа с которыми должна осуществляться как с единым файлом.
MEMORY (HEAP)
Тип таблиц MEMORY хранится в оперативной памяти, поэтому все запросы к такой таблице выполняются очень быстро. Недостатком является полная потеря данных в случае сбоя работы сервера, поэтому в таблице данного типа хранят только временную информацию, которую можно легко восстановить заново.
При создании таблицы типа MEMORY она ассоциируется с одним-единственным файлом, имеющим расширение frm, в котором определяется структура таблицы.
При остановке или перезапуске сервера данный файл остается в текущей азе данных, но содержимое таблицы, которое хранится в оперативной памяти, теряется.
Ограничения MEMORY таблиц:
- Индексы используются только в операциях сравнения совместимо с операторами = и <=>, с другими операторами, такими как > или < индексирование столбцов не имеет смысла
- Возможно использование только неуникальных индексов.
- Можно использовать записи фиксированной длины, поэтому в них не допустимы столбцы типов TEXT и BLOD.
- В версиях, предшествующих MySQL 4.0.2, не поддерживается индексирование столбцов, содержащих NULL-значения.
EXAMPLE
Данный тип таблиц является заглушкой: можно создать таблицу данного типа, но хранить или получить из нее данные нельзя. При создании таблиц данного тип, точно также как и в случае MEMORY, создается один файл с расширением frm, в котором определяется структура таблицы.
EXAMPLE был введен для удобства сторонних разработчиков и демонстрирует, каким образом следует создавать собственные типы таблиц.
BDB (BerkeleyDB)
Таблицы типа BDB обслуживаются транзакционным обработчиком Berkeley DB, разработанным компанией Sleepycat. При создании таблиц данного типа формируются два файла: первый с расширением frm, в котором определяется структура базы данных, а второй с расширением db, в котором размещаются данные и индексы.
Особенности типа BDB:
- Для каждой таблицы ведется журнал. Это позволяет значительно повысить устойчивость базы и увеличить вероятность успешного восстановления после сбоя.
- Таблицы BDB хранятся в виде бинарных деревьев. Такое представление замедляет сканирование таблицы и увеличивает занимаемое место на жестком диске по сравнению с другими типами таблиц. С другой стороны, поиск отдельных значений в таких таблицах осуществляется быстрее.
- Каждая таблица BDB должна иметь первичный ключ, в случае его отсутствия создается скрытый первичный ключ, снабженный атрибутом AUTO_INCREMENT.
- Поддерживаются транзакции на уровне страниц.
- Подсчет числа строк в таблице при помощи встроенной функции count() осуществляется медленнее, чем для MyISAM, так как в отличие от последних, для BDB-таблиц не поддерживается подсчет количества строк в таблице, и MySQL вынужден каждый раз сканировать таблицу заново.
- Ключи не являются упакованными, и ключи занимают больше места.
- Если таблица займет все пространство на диске, то будет выведено сообщение об ошибке и выполнен откат транзакции.
- Для обеспечения блокировок таблиц на уровне операционной системы в файл db в момент создания таблицы записывается путь к файлу. Это приводит к тому, что файлы нельзя перемещать из текущего каталога в другой каталог.
- При создании резервных копий таблиц необходимо использовать утилиту mysqldump или создать резервные копии всех db файлов и файлов журналов. Обработчик таблицы хранит незавершенные транзакции в файлах журналов, их наличие требуется при запуске сервера MySQL.
InnoDB
Данный тип таблиц обеспечивает высокую производительность и устойчивое хранение данных в таблицах объемом вплоть до 1 Тбайт и нагрузкой на
сервер до 800 вставок/обновлений в секунду.Особенности таблиц типа InnoDB:
- Таблицы не создаются в базах данных, и для каждой из таблиц не выделяется отдельный файл данных. Исключение – файл определения с расширением frm, который создается по умолчанию. Все таблицы хранятся в едином табличном пространстве, поэтому имена таблиц должны быть уникальными.
- Хранение данных в едином табличном пространстве позволяет снять ограничение на объем таблиц, так как файл с таблицами может быть разбит не несколько частей и распределен по нескольким дискам или даже хостам.
- Данный тип таблиц поддерживает автоматическое восстановление после сбоев.
- Обеспечивается поддержка транзакций.
- Единственный тип таблиц, поддерживающий внешние ключи и каскадное удаление.
- Выполняется блокировка на уровне отдельных записей.
- Расширенная поддержка кодировок.
- Рушатся при достижении объема в несколько гигабайт, однако заметно уступают в скорости и не поддерживают полнотекстовый поиск.
NDB Cluster
Этот тип таблиц предназначен для организации кластеров, когда таблицы распределены между несколькими компьютерами, объединенными в локальную сеть.
ARCHIVE
Этот тип введен для хранения большого объема данных в сжатом формате. При создании данного типа MySQL, так же как и для таблиц любого другого типа, создает файл с именем, совпадающим с именем таблицы, и расширением frm. В этом файле хранится определение структуры таблицы. Помимо этого создаются два файла с расширением arz и arm, в которых хранятся данные и мета-данные.
CSV
Представляет собой обычный текстовой файл, записи в котором хранятся в строках, а поля разделены точкой с запятой. При создании таблицы в каталоге с текущей базой данных формируется два файла с именами, совпадающими с именем таблицы, и расширениями frm и csv.
FEDERATED
Позволяет хранить данные в удаленных таблицах, расположенных на другой машине сети. Во время создания таблицы в локальном каталоге создается только файл определения структуры таблицы с расширением frm, никакие другие файлы не создаются, так как все данные хранятся на удаленной машине.
BLACKHOLE
Таблица этого типа дословно переводится как черная дыра. Любые данные, помещаемые в таблицы этого типа, уничтожаются. Основное применение таблицы – это проверка синтаксиса дампов, когда необходимо проверить дамп на наличие ошибок, чтобы не производить реальное развертывание базы данных.
Транзакции
Транзакция – это последовательность операторов SQL, выполняющихся как единая операция, которая не прерывается другими клиентами. То есть пока происходит работа с записями таблицы, никто другой не может получить доступ к этим записям. Доступ к записям автоматически блокируется.
Репликация
Репликация позволяет дублировать данные основного сервера на одном или более подчиненных серверов. Репликация может осуществляться в режиме онлайн, или время от времени – подчиненный сервер может загружаться только для того, чтобы загрузить обновления.
Хранимые процедуры
Хранимые процедуры позволяют объединить последовательность запросов и сохранить их на сервере.
Преимущества хранимых процедур:
- Повторное использование кода
- Сокращение сетевого трафика.
- Безопасность.
- Простота доступа.
- Выполнение деловой логики.
Триггеры
Триггер – эта хранимая процедура, привязанная к событию на изменения содержимого таблицы: вставка, обновление, удаление.
Представления
Представление – это запрос на выборку, которому присваивается уникальное имя и который может сохранять или удалять из базы данных как обычную хранимую процедуру.
Информационная схема – это стандартный набор представлений системной таблицы.
Представление CHARACTER_SETS
Содержит список и характеристики кодировок, доступных текущему пользователю.
Представление COLLATIONS
Содержит список и характеристики сортировок, доступных текущему пользователю.
Представление COLLATION_CHARACTER_SET_APPLICABILITY
Содержит всевозможные комбинации кодировок и сортировок, доступные текущему пользователю.
Представление COLUMN_PRIVILEGES
Содержит информацию о привилегиях текущего пользователя на столбцы таблиц.
Представление COLUMNS
Содержит информацию о доступных текущему пользователю столбцах во всех таблицах всех баз данных.
Представление KEY_COLUMN_USAGE
Содержит информацию об индексированных столбцах, доступных текущему пользователю.
Представление ROUTINES
Содержит список и параметры хранимых процедур и функций, доступных текущему пользователю для выполнения.
Представление SCHEMA_PRIVILEGES
Содержит глобальные привилегии всех пользователей сервера MySQL.
Представление SCHEMATA
Содержит список и характеристики баз данных, доступных текущему пользователю.
Представление STATISTICS
Содержит разнообразную информацию об индексах.
Представление TABLE_CONSTRAINTS
Содержит информацию об ограничивающих индексах, которые имеют ограничение уникальности значения (PRIMARY KEY, UNIQUE) или ограничение внешнего ключа (FOREIGN KEY).
Представление TABLE_PRIVILEGES
Содержит информацию о табличных привилегиях.
Представление TABLES
Содержит список таблиц и их характеристики.
Представление USER_PRIVILEGES
Содержит информацию о глобальных привилегиях базы данных.
Представление VIEWS
Содержит информацию о глобальных привилегиях базы данных.
Реляционные базы данных
Реляционная модель базы данных состоит из трех частей:
Структурная часть – описывает, какие объекты рассматриваются реляционной моделью. Реляционная база данных состоит из набора отношений. Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Целостная часть – описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.
Манипуляционная часть – описывает два эквивалентных способа манипулирования реляционными данными – реляционную алгебру и реляционное исчисление.
Термины реляционных баз данных.
| Реляционный термин | Описание |
| Отношение | Таблица |
| Заголовок отношения | Заголовок таблицы |
| Тело отношения | Тело таблицы |
| Атрибут отношения | Наименование столбца (поля) таблицы |
| Кортеж отношения | Строка (запись) таблицы |
| Степень отношения | Количество столбцов таблицы |
| Мощность (кардинальность) отношения |
Количество строк таблицы |
| Домен | Базовый или пользовательский тип данных |
Атрибуты
Атрибуты сущности – это именованная характеристика, являющаяся некоторым свойством сущности.
При проектировании атрибутов полезно задавать такие вопросы:
- Какие данные о сущности мы хотим хранить?
- Какие свойства есть у экземпляра этой сущности, даже если вокруг нее больше ничего нет?
- Есть ли у экземпляра этой сущности только один экземпляр этой вещи?
- Может ли изменяться описанная атрибутом характеристика сущности с течением времени?
Бинарные связи
Бинарные связи – это связи, в которые вступают ровно две сущности. Важнейшее свойство связи – кардинальное число.
Типы бинарных связей:
- Связь типа «один-к-одному» означает, что один экземпляр первой сущности связан не более чем с одним экземпляром второй сущности и, наоборот, один экземпляр второй сущности связан не более чем с одним экземпляром первой сущности.
- Связь типа «один-ко-многим» означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности, но при этом один экземпляр второй сущности связан не более чем с один экземпляром первой сущности.
- Связь типа «много-ко-многим» означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Эта связь должна быть заменена двумя связями типа один-ко-многим путем создания промежуточной сущности.
Ролевые связи
Ролевые связи необходимы, когда:
- Экземпляры одной и той же сущности вступают в связи между собой.
- В зависимости от значения одного из атрибутов сущности по-разному определяется само множество других ее атрибутов.
- В зависимости от значения одного из атрибутов сущности она по-разному вступает в связи с другими сущностями.
Рекурсивные связи
Рекурсивная связь – это связь, в которой одни и те же сущности учувствуют несколько раз или в разных ролях. Классический пример рекурсивной связи –
это связь сущности с самой собой.
Различают три варианта рекурсивной связи:
- Рекурсивная связь «один-к-одному», моделирующая цепочку.
- Рекурсивная связь «один-ко-многим» или иерархическая рекурсивная связь.
- Рекурсивная связь «много-ко-многим» или сетевая рекурсивная связь.
Логическое проектирование и оптимизация
OLTP – обработка транзакций в режиме реального времени. Способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы минимальное время отклика. Примерами OLTP приложений могут быть системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег.
Особенности OLTP приложений:
- Транзакций очень много.
- Транзакции выполняются одновременно.
- При возникновении ошибки транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета, но не поступили на другой счет).
- Все запросы к базе данных, которые должны выполняться в реальном времени, состоят из команд вставки, обновления, удаления.
OLAP системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками.
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры очистки, связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного при выполнении предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
Уровни моделирования реляционной базы данных
Внешний уровень – уровень представления базы данных с точки зрения пользователя.
Концептуальный – описывает какие данные хранятся в базе данных, а также, какие связи имеются между этими данными.
Внутренний – описывает физическое представление базы данных в компьютере, то есть отвечает на вопрос, как информация хранится в базе данных.
Вводятся следующие понятия:
- Модель предметной области – знания о предметной области, описанные с помощью некоторого формального общепринятого способа.
- Логическая (концептуальная) модель данных – является органической составляющей модели предметной области, описывает понятия предметной области в реляционных терминах данных.
- Физическая модель данных – описывает данные средствами конкретной реляционной СУБД.
- База данных и приложение – средства, реализованные на конкретной программно-аппаратной основе.
Критерии оценки качества логической модели
Критерии важные с точки зрения получения качественной базы данных:
1. Адекватность базы данных предметной области.
2. Скорость выполнения операций обновления данных.
3. Скорость выполнения операций выборки данных.
4. Легкость разработки и сопровождения базы данных.
5. Отсутствие неоправданной избыточности данных.
Физическое представление базы данных
Проблемы, которые приходится решать при проектировании физического представления базы данных:
- Определение требований к системным ресурсам.
- Выбор файловой структуры и определение группы файлов.
- Анализ запросов и транзакций с целью корректного размещения базовых таблиц и индексов по группам файлов.
- Определение вторичных индексов и размещение их в группах файлов.
- Анализ адекватности базы данных, с точки зрения возможности выполнения всех заданных транзакций при допустимом уровне их конфликтности и приемлемом совокупном быстродействии.
- Анализ необходимости введения контролируемой избыточности данных и средств ее реализации.
- Определение необходимости применения специфических настроек сервера для конкретной системной конфигурации.
- Разработка механизмов защиты.
Самое краткое руководство по проектированию Баз Данных
Время на прочтение
4 мин
Количество просмотров 5.2K
Приключилось мне в рамках одного проекта импортировать существующую базу. База эта была создана в аксесе и собствен6но суть проекта заключалась в создании веб-приложения, предоставляющего схожую функциональность, но с учетом нынешних реалий (веб-интерфейс, разделение полномочий и т.п.). Если рассматривать в обсуждаемом ключе, разработка строилась так:
1. создаю свою систему, удовлетворяющую требованиям
2. импортирую данные из исходной базы
Эта заметка о пункте номер два.
Я впервые столкнулся с полностью ненормализованной базой. Т.е. в ней были нарушены практически все принципы построения реляционных БД. Но тем не менее эта база использовалась продолжительное время. Не стану вдаваться в подробности, отмечу лишь что вызвало первый шок — таблицы с именами «январь», «февраль» и т.д. для графика работы. Поверьте, дальше все было гораздо хуже. Я понимаю, что не мне судить человека, который это создал — система, использовалась не один год и в какой-то мере удовлетворяла потребности заказчика. Просто я не хочу больше сталкиваться с такими «базами». Надеюсь данная заметка поможет в этом.
Самое краткое руководство по проектированию Баз Данных.
В качестве примера будем проектировать базу по учету товаров. С древовидным каталогом и данными о производителях.
1. Объекты
Первое что надо сделать — выделить виды объектов предметной области. В нашем случае это «товар», «раздел каталога» и «производитель». Для каждого вида создается своя таблица. Каждая запись (строка) таблицы содержит данные об одном объекте. Порядок следования записей не определен. Если данные добавляются в алфавитном порядке — при запросе на получение записей этот порядок будет нарушен.
Необходимо избегать дублирования данных. Например недопустимо хранить в каждой записи таблицы «товар» полную информацию о производителе. Т.к. при изменении каких-то данных производителя, придется искать все упоминания о нем в таблице «товары». Назовем нашим таблицы item, node и company.
2. Первичный ключ
Что бы «обращаться» к конкретному объекту необходимо дать ему уникальный номер. Вообще говоря это может быть любое уникальное поле или группа полей (например, в случае учета сотрудников — номер паспорта или фамилия, имя, отчество), однако по многим причинам гораздо удобней сделать отдельное поле с уникальным значением. Это поле и есть первичный ключ. Обычно это поле называют «id» (идентификатор).
3. Связи, внешние ключи
Все объекты каким-то образом связаны друг с другом — производители производят товары, товары размещаются в каталоге и т.п. Отношения бывают трех видов:
один-ко-многим
один производитель может создавать много разных товаров. Реализуется просто — в таблице объектов, которых «много» создается поле с id объекта, который «один». В случае товаров и производителей нужно в таблицу item добавить поле company_id, которое будет содержать id производителя данного товара. Такое поле называют внешним ключем.
многие-ко-многим
любой товар может присутствовать сразу в нескольких разделах каталога. Такая связь хранится в отдельной таблице с полями id товара и id раздела. Таким образом каждая запись таблицы означает присутствие товара в разделе каталога.
один-к-одному
допустим наш товар это книги и диски. Их общая информация и тип товара хранятся в таблице item, а данные специфичные для книг и для дисков будем хранить в таблицах book и disk соответственно. Т.е. для каждой записи в таблице book есть ровно одна запись в item. По сути это один объект хранится в двух таблицах.
Реализуется так — первичный ключ таблицы book содержит id из таблицы item. Т.е. первичный ключ одновременно является внешним ключем.
дерево
по сути это тоже что и один-ко-многим. Один раздел каталога содержит много других. Реализация такая же — запись таблицы node содержит id родительского раздела (parent_id)
4. обеспечение целостности
Все связи и ключи должны быть описаны должным образом, что бы избежать противоречий. Тогда система управления базой не позволит удалить производителя, на которого ссылается товар или раздел каталога, содержащий подразделы. Так же возможны другие виды реакции. Главное, что база всегда будет находится в корректном состоянии, т.е. не будет внешних ключей ссылающихся на несуществующие записи.
То же самое на SQL
1. создаем таблицы
-- раздел каталога
create table node (
id numeric not null, -- первичный ключ
parent_id numeric not null, -- внешний ключ. ссылается на родительский раздел
name varchar(200)
);
-- компания-производитель
create table company (
id numeric not null, -- первичный ключ
name varchar(1000),
);
-- товар
create table item (
id numeric not null, -- первичный ключ
company_id numeric not null, -- внешний ключ. ссылается на компанию-производителя
type varchar(10) NOT NULL, -- 'book' или 'disc'
name varchar(1000), -- наименование
qty numeric, -- кол-во товара
price numeric -- цена за единицу
);
2-3-4. Создаем недостающие связи и указываем какие поля являются первичными и внешними ключами.
-- товар - книга
create table book (
id numeric not null, -- одновременно первичный и внешний ключ, ссылающийся на item
author varchar(1000)
);
-- товар - диск
create table disk (
id numeric not null, -- одновременно первичный и внешний ключ, ссылающийся на item
play_time numeric
);
create table node_item (
node_id numeric not null,
item_id numeric not null
);
-- для каждой таблицы указываем ее первичный ключ
alter table node add constraint "PK_NODE" primary key (id);
alter table item add constraint "PK_ITEM" primary key (id);
alter table company add constraint "PK_COMPANY" primary key (id);
alter table book add constraint "PK_BOOK" primary key (id);
alter table disk add constraint "PK_DISK" primary key (id);
-- у таблицы, реализующей отношение многие-ко-многим, первичный ключ составной.
alter table node_item add constraint "PK_NODE_ITEM" primary key (node_id, item_id);
-- указываем внешние ключи и на что они ссылаются
alter table node add constraint "FK_NODE_PARENT" foreign key (parent_id) references node(id);
alter table item add constraint "FK_ITEM_COMPANY" foreign key (company_id) references company(id);
alter table node_item add constraint "FK_NODEITEM_NODE" foreign key (node_id) references node(id);
alter table node_item add constraint "FK_NODEITEM_ITEM" foreign key (item_id) references item(id);
alter table book add constraint "FK_BOOK_ITEM" foreign key (id) references item(id);
alter table disk add constraint "FK_DISK_ITEM" foreign key (id) references item(id);
1. Введение в базы данных. Основные понятия и определения
2. Реляционные базы данных. Ограничения целостности
3. Принципы построения баз данных. Жизненный цикл баз данных
4. Архитектуры баз данных
5. Организация процессов обработки данных в БД. Технология создания приложения в среде Delphi
6. Технология оперативной обработки транзакции
7. Реляционный способ доступа к базе данных. Основные сведения о языке SQL
8. Построение приложений баз данных в архитектуре «клиент-сервер». SQL-сервер Interbase
9. Информационные хранилища. OLAP-технология
10. Перспективы развития БД и СУБД
1. Введение в базы данных. Основные понятия и определения
В настоящее время успешное функционирование различных фирм, организаций и предприятий просто не возможно без развитой информационной системы, которая позволяет автоматизировать сбор и обработку данных. Обычно для хранения и доступа к данным, содержащим сведения о некоторой предметной области, создается база данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Под предметной областью принято понимать некоторую область человеческой деятельности или область реального мира, подлежащих изучению для организации управления и автоматизации, например, предприятие, вуз и.т.д.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, наполнения, обновления и удаления баз данных.
Основополагающими понятиями в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы, Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями но, тем не менее, можно выделить нечто общее в этих определениях.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними. В зависимости от вида организации данных различают следующие важнейшие модели БД:
- иерархическую
- сетевую
- реляционную
- объектно-ориентированную
В иерархической БД данные представляются в виде древовидной структуры. Подобная структура БД удобна для работы с данными, упорядоченными иерархически. При оперировании данными со сложными логическими связями иерархическая модель оказывается слишком громоздкой.
В сетевой БД данные организуются в виде графа. Недостатком сетевой структуры является жесткость структуры и сложность ее организации.
Реляционная БД получила свое название от английского термина relation (отношение). Была предложена в 70-м году сотрудником фирмы IBM Эдгаром Коддом. Реляционная БД представляет собой совокупность таблиц, связанных отношениями. Достоинствами реляционной модели данных являются простота, гибкость структуры. Кроме того ее удобно реализовывать на компьютере. Большинство современных БД для персональных компьютеров являются реляционными.
Объектно-ориентированные БД объединяют сетевую и реляционную модели и используются для создания крупных БД с данными сложной структуры.
Базы данных можно разделить на базы данных первого поколения: иерархические, сетевые; второго поколения: реляционные; третьего поколения: объектно-ориентированные, обектно-реляционные.
Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистемы складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, то учитывало все изменения в базе данных, вносимые другими приложениями.
Для поиска информации в базах данных используется информационно-поисковая система. Информационно-поисковая система опирается на базу данных, в которой осуществляется поиск нужных документов по заявкам пользователей.
Различают фактографические автоматизированные информационные системы (АИС), у которых базы данных составляются из форматированных (формализованных) записей, и документальные АИС, записями которых могут служить различные неформализованные документы (статьи, письма и т.п.). В фактографических АИС примером форматированных записей могут служить, скажем, записи об операциях по приему и выдаче денег в сберкассе; запись имеет четыре основных атрибута: дата, характер операции (принято, выдано), сумма, остаток вклада.
В качестве форматированной записи может рассматриваться кадровая анкета (личный листок по учету кадров). Правда, такие ее разделы, как «прежняя работа», «поездки за границу» и др. в обычной анкете не до конца формализованы и имеют переменную длину, поэтому при автоматизации этой задачи необходимы некоторые поправки. Обычно бывает целесообразно фиксировать максимальное количество позиций в каждом разделе и тем самым выравнивать длину записей (у многих записей при этом могут возникать позиции с пустым заполнением).
Основной задачей, решаемой в документальных АИС, является поиск документов по их содержанию. Документальная система по заданию пользователя выдает необходимые ему документы (книги, статьи, законы, патенты, отчеты и т.д.). В задании могут указываться сведения об искомых документах: автор, наименование, время издания, издательство и т.д.
2. Реляционные базы данных. Ограничения целостности
Американский математик Э.Ф.Кодд (E.F.Codd) в 1970 впервые сформулировал основные понятия и ограничения реляционной модели. Цели создания реляционной модели формулировались следующим образом:
- обеспечение более высокой степени независимости от данных. Прикладные программы не должны зависеть от изменений внутреннего представления данных, в частности от изменений организации файлов, переупорядочивания записей и путей доступа;
- создание прочного фундамента для решения семантических вопросов, а также проблем непротиворечивости и избыточности данных. В частности, в статье Кодда вводится понятие нормализованных отношений, т.е. отношений без повторяющихся групп;
- расширение языков управления данными за счет включения операций над множествами.
Коммерческие системы на основе реляционной модели данных начали появляться в конце 70-х – начале 80-х годов. Благодаря популярности реляционной модели многие нереляционные системы теперь обеспечиваются реляционным пользовательским интерфейсом, независимо от используемой базовой модели.
Кроме того, позже были предложены некоторые расширения реляционной модели данных, предназначенные для наиболее полного и точного выражения смысла данных, для поддержки объектно-ориентированных, а также для поддержки дедуктивных возможностей.
Реляционная модель основана на математическом понятии отношения, физическим представлением которого является таблица. Дело в том, что Кодд, будучи опытным математиком, широко использовал математическую терминологию, особенно из теории множеств и логики предикатов.
Отношение – это плоская таблица, состоящая из столбцов и строк.
В любой реляционной СУБД предполагается, что пользователь воспринимает базу данных как набор таблиц. Однако следует подчеркнуть, что это восприятие относится только к логической структуре базы данных, т.е. ко внешнему и концептуальному уровням. Подобное восприятие не относится к физической структуре базы данных, которая может быть реализована с помощью различных структур.
Атрибут — это поименованный столбец отношения.
В реляционной модели отношения используются для хранения информации об объектах, представленных в базе данных. Отношение обычно имеет вид двумерной таблицы, в которой строки соответствуют отдельным записям, а столбцы — атрибутам. При этом атрибуты могут располагаться в любом порядке, независимо от их переупорядочивания, отношение будет оставаться одним и тем же, а потому иметь тот же смысл. Например, информация об отделениях компании может быть представлена отношением Branch, включающим столбцы с атрибутами Вno (Номер отделения), Street (Улица), City (Город), Postcode (Почтовый индекс), Tel_ No (Номер телефона) и Fax_ No (Номер факса). Аналогично, информация о работниках компании может быть представлена отношением Staff (Персонал), включающим столбцы с атрибутами Sno (Личный номер сотрудника), FName (Имя), LName (Фамилия), Address (Адрес), Tel_No (Номер телефона), Position (Должность), Sex (Пол), DOB (Дата рождения), Salary (Зарплата), INN (Личный номер социального страхования) и Вno (Номер отделения, в котором данный сотрудник работает). В табл. 1 и 2 показаны примеры отношений Branch и Staff. Каждый столбец содержит значения одного и того же атрибута, например столбец Вnо содержит только номера существующих отделений компании.
Элементами отношения являются кортежи, или строки, таблицы. Кортеж – это строка отношения. В отношении Branch каждая строка содержит 6 значений, по одному для каждого атрибута. Кортежи могут располагаться в любом порядке, при этом отношение будет оставаться тем же самым, а значит, и иметь тот же смысл.
Примеры отношений Branch и Staff.
Таблица 1. Отношение Branch
|
Bno |
City |
Postcode |
Street |
Tel_No |
Fax_No |
|
23 |
Москва |
111111 |
Победы |
1231112 |
1231113 |
|
24 |
Ростов |
3334546 |
Октябрьская |
1334456 |
1334455 |
|
25 |
Самара |
456009 |
Лесная |
1213345 |
1213346 |
Таблица 2. Отношение Staff
|
Sno |
FName |
LName |
Adress |
Tel_No |
Position |
Sex |
DOB |
Salary |
INN |
Bno |
|
234 |
Иван |
Иванов |
Москва Победы 14-24 |
121112 |
Менеджер |
м |
01.01.67 |
500$ |
441414 |
23 |
|
235 |
Марина |
Смирнова |
Москва Ленина 215-35 |
1417877 |
Менеджер |
ж |
01.01.75 |
500$ |
543243 |
25 |
Степень отношения определяется количеством атрибутов, которое оно содержит.
Отношение Branch (см. табл. 1) имеет шесть атрибутов и, следовательно, его степень равна шести. Это значит, что каждая строка таблицы является 6-арным кортежем, т.е. кортежем, содержащим шесть значений. Отношение только с одним атрибутом имеет степень 1 и называется унарным (unary) отношением (или 1-арным кортежем). Отношение с двумя атрибутами называется бинарным (binary), отношение с тремя атрибутами – тернарным (ternary), а для отношений с большим количеством атрибутов используется термин n—арный (n-ary). Определение степени отношения является частью заголовка отношения.
Количество содержащихся в отношении кортежей называется кардинальностью отношения. Эта характеристика меняется при каждом добавлении или удалении кортежей. Кардинальность является свойством тела отношения и определяется текущим состоянием отношения в произвольно взятый момент.
Альтернативная терминология. Терминология, используемая в реляционной модели, порой может привести к путанице, поскольку помимо предложенных терминов существует еще один. Отношение в нем называется таблицей , кортежи – записями (records), а атрибуты – полями (fields). Эта терминология основана на том факте, что физически СУБД может хранить каждое отношение в отдельном файле. В табл. 3 показаны соответствия, существующие между упомянутыми выше группами терминов.
Таблица 3. Альтернативные варианты терминов в реляционной модели
|
Вариант1 |
Вариант2 |
|
Отношение |
Таблица |
|
Кортеж |
Запись |
|
Атрибут |
Поле |
Далее в пособии могут использоваться термины из обоих вариантов.
Фундаментальные свойства отношений (таблиц)
Отношение обладает следующими характеристиками:
- оно имеет имя, которое отличается от имен всех других отношений;
- каждая ячейка отношения содержит только атомарное (неделимое) значение;
- каждый атрибут имеет уникальное имя;
- значения атрибута берутся из одного и того же домена;
- порядок следования атрибутов не имеет никакого значения;
- каждый кортеж является уникальным, т.е. дубликатов кортежей быть не может;
- теоретически порядок следования кортежей в отношении не имеет никакого значения. (Однако практически этот порядок может существенно повлиять на эффективность доступа к ним.)
Для иллюстрации смысла этих ограничений рассмотрим отношение Branch (см. табл. 1). Поскольку каждая ячейка должна содержать только одно значение, то не допускается хранение в одной и той же ячейке двух номеров телефона одного и того же отделения компании. Иначе говоря, отношения не могут содержать повторяющихся групп. Об отношении, которое обладает таким свойством, говорят, что оно нормализовано, или находится в первой нормальной форме. (Более подробно нормальные формы рассматриваются ниже)
Имена столбцов, указанные в их верхней строке, соответствуют именам атрибутов отношения. Значения атрибута Bno берутся из домена BRANCH_NUMBERS — не допускается размещение в этом столбце иных значений, например почтового индекса. Столбцы можно менять местами при условии, что имя атрибута перемещается вместе с его значениями. Таблица все еще будет представлять то же отношение, если атрибут Tel_No расположить в ней перед атрибутом Postcode, хотя для лучшей читабельности разумнее было бы располагать отдельные части адреса поблизости.
Отношение не может содержать кортежей-дубликатов. Например, строка ( 23, Москва, 111111, Победы, 1231112, 1231113) может быть представлена в отношении только один раз. При необходимости строки можно менять местами произвольным образом (например, переместить строку отделения ‘23’ на место строки отделения ‘24’), само отношение при этом останется прежним.
Большая часть свойств отношений происходит от свойств математических отношений реляционной алгебры.
Как уже говорилось, наиболее популярны реляционные модели данных. В соответствии с реляционной моделью данных данные представляются в виде совокупности таблиц, над которыми могут выполняться операции, формулируемые в терминах реляционной алгебры или реляционного исчисления.
В отличие от иерархических и сетевых моделей данных в реляционной модели операции над объектами имеют теоретико-множественный характер. Это дает возможность пользователям формулировать их запросы более компактно, в терминах более крупных агрегатов данных.
Рассмотрим терминологию, используемую при работе с реляционными базами данных.
Первичный ключ. Первичным ключом называется поле или набор полей, однозначно идентифицирующих запись.
Нередко возможны несколько вариантов выбора первичного ключа. Например, в небольшой организации первичными ключами сущности «сотрудник» могут быть как табельный номер, так и комбинация фамилии, имени и отчества (при уверенности, что в организации нет полных тезок), либо номер и серия паспорта (если паспорта есть у всех сотрудников). В таких случаях при выборе первичного ключа предпочтение отдается наиболее простым ключам (в данном примере — табельному номеру). Другие кандидаты на роль первичного ключа называются альтернативными ключами.
Требования, предъявляемые к первичному ключу:
- уникальность – то есть в таблице не должно существовать двух или более записей с одинаковым значением первичного ключа;
- первичный ключ не должен содержать пустых значений.
При выборе первичного ключа рекомендуется выбирать атрибут, значение которого не меняется в течение всего времени существования экземпляра (в этом случае табельный номер предпочтительнее фамилии, так как ее можно сменить, вступив в брак).
По полям, которые часто используются при поиске и сортировке данных устанавливаются вторичные ключи: они помогут системе значительно быстрее найти нужные данные. В отличие от первичных ключей поля для индексов (вторичные ключи) могут содержать неуникальные значения.
Первичные ключи используются для установления связей между таблицами в реляционной БД. В этом случае первичному ключу одной таблицы (родительской) соответствует внешний ключ другой таблицы (дочерней). Внешний ключ содержит значения связанного с ним поля, являющегося первичным ключом. Значения во внешнем ключе могут быть неуникальными, но не должны быть пустыми. Первичный и внешний ключи должны быть одинакового типа.
Связи между таблицами. Записи в таблице могут зависеть от одной или нескольких записей другой таблицы. Такие отношения между таблицами называются связями. Связь определяется следующим образом: поле или несколько полей одной таблицы, называемое внешним ключом, ссылается на первичный ключ другой таблицы. Рассмотрим пример. Так как каждый заказ должен исходить от определенного клиента, каждая запись таблицы Orders (заказы) должна ссылаться на соответствующую запись таблицы Customers (клиенты). Это и есть связь между таблицами Orders и Customers. В таблице Orders должно быть поле, где хранятся ссылки на те или иные записи таблицы Customers.
Существует три типа связей между таблицами.
Один к одному — каждая запись родительской таблицы связана только с одной записью дочерней. Такая связь встречается на практике намного реже, чем отношение один ко многим и реализуется путем определения уникального внешнего ключа. Связь один к одному используют, если не хотят, чтобы таблица «распухала» от большого числа полей. Базы данных, в состав которых входят таблицы с такой связью не могут считаться полностью нормализованными.
Один ко многим — каждая запись родительской таблицы связана с одной или несколькими записями дочерней. Например, один клиент может сделать несколько заказов, однако несколько клиентов не могут сделать один заказ. Связь один ко многим является самой распространенной для реляционных баз данных.
Многие ко многим — несколько записей одной таблицы связаны с несколькими записями другой. Например, один автор может написать несколько книг и несколько авторов — одну книгу. В случае такой связи в общем случае невозможно определить, какая запись одной таблицы соответствует выбранной записи другой таблицы, что делает неосуществимой физическую (на уровне индексов и триггеров) реализацию такой связи между соответствующими таблицами. Поэтому перед переходом к физической модели все связи «многие ко многим» должны быть переопределены (некоторые CASE-средства, если таковые используются при проектировании данных, делают это автоматически).Подобная связь между двумя таблицами реализуется путем создания третьей таблицы и реализации связи типа «один ко многим» каждой из имеющихся таблиц с промежуточной таблицей.
Для рассмотрения ссылочной целостности возьмем в качестве примера наиболее часто встречающуюся в базах данных связь один-ко-многим – см таблицы 4 и 5. Как можно заметить, дочерняя и родительская таблицы связаны между собой по общему полю «Товар». Назовем это поле полем связи.
Таблица 4. Таблица «Товары»
|
Товар |
Ед изм |
Цена |
|
Сахар |
кг |
18 |
|
Макароны |
кг |
18 |
|
Куры |
кг |
90 |
|
Фанта |
бут |
20 |
Таблица 5. Таблица «Отпуск товаров»
|
Товар |
Дата |
Количество |
|
Сахар |
10.12.07. |
100 |
|
Сахар |
12.12.07. |
200 |
|
Сахар |
14.12.07 |
50 |
|
Макароны |
10.12.07 |
1000 |
|
Макароны |
12.12.07 |
500 |
|
Фанта |
07.12.07 |
2000 |
|
Фанта |
05.12.07 |
3000 |
Возможны два вида изменений, которые приведут к утере связей между записями в родительской и дочерней таблицах:
- изменение значения поля связи в записи родительской таблицы без изменения значений полей связи в соответствующих записях дочерней таблицы;
- изменение значения поля связи в одной из записей дочерней таблицы без соответствующего изменения значения полей связи в родительской и дочерней таблицах.
Рассмотрим первый случай. Если изменить значения поля «Товар» с «Сахар» на «Рафинад» в таблице «Товары», а в таблице «Отпуск товаров» значение поля связи «Сахар» оставить прежним. В результате получим:
- в дочерней таблице «Отпуск товаров» для товара «Рафинад» (таблица «Товары») нет сведений о его отпуске со склада;
- некоторые записи таблицы «Отпуск товаров» содержат сведения об отпуске товара «Сахар», о котором нет информации в таблице «Товары».
Рассмотрим второй случай. Пусть в одной из записей таблицы «Отпуск товаров» значение поля связи «Сахар» изменилось на «Рафинад». В результате:
- в дочерней таблице «Отпуск товаров» недостоверны сведения об отпуске со склада товара «Сахар» (таблица «Товары»);
- одна из записей таблицы «Отпуск товаров» содержит данные об отпуске товара «Рафинад», сведения о котором отсутствуют в таблице «Товары».
И в первом, и втором случае мы наблюдаем нарушение целостности базы данных; это означает, что хранящаяся в ней информация становится недостоверной.
СУБД обычно блокирует действия, которые нарушают целостность связей между таблицами, т.е. нарушают ссылочную целостность. Когда говорят о ссылочной целостности, имеют в виду совокупность связей между отдельными таблицами во всей БД. Нарушение хотя бы одной такой связи делает информацию в БД недостоверной.
Чтобы предотвратить потерю ссылочной целостности, используется механизм каскадных изменений. Он состоит в обеспечении следующих действий:
- при изменении поля связи в записи родительской таблицы следует синхронно изменить значения полей связи в соответствующих записях дочерней таблицы;
- при удалении записи в родительской таблице следует удалить соответствующие записи в дочерней таблице.
Изменения или удаления в записях дочерней таблицы при одновременном изменении (удалении) записи родительской таблицы называются каскадными изменениями и каскадными удалениями.
Существует другая разновидность каскадного удаления: при удалении родительской записи в записях дочерних таблиц значения полей связи обнуляются. Эта разновидность применяется редко, т.к. дочерние таблицы в этом случае будут содержать избыточные данные, например, сведения о товаре, которого нет на складе.
Обычно для реализации ссылочной целостности в дочерней таблице создают внешний ключ, в который входят поля связи дочерней таблицы. Этот ключ для дочерней таблицы является первичным и поэтому по составу полей должен совпадать с, первичным ключом родительской таблицы или реже — с частью первичного ключа.
3. Принципы построения баз данных. Жизненный цикл баз данных
Классическая технология проектирования реляционных баз данных связана с теорией нормализации, основанной на анализе функциональных зависимостей между атрибутами отношений. Процесс нормализации имеет своей целью устранение избыточности данных. Нормализация позволяет существенно сократить объем хранимой информации и устранить аномалии в организации хранения данных. Степень нормализации данных может быть различной. Приведение модели к требуемому уровню нормальной формы является основой построения реляционной базы данных.
Нормализация достигается путем проверки соответствия таблиц ряду условий, определенных в трех уровнях нормализации: первой, второй и третьей нормальных формах (существуют также и другие уровни).
Первая нормальная форма требует, чтобы каждое поле таблицы БД было неделимым и не содержало повторяющихся групп.
Неделимость поля означает, что содержащиеся в нем значения не должны делиться на более мелкие. Например, если в поле «Подразделение» содержится название факультета и кафедры, требование неделимости не соблюдается и необходимо выделить название факультета или кафедры в отдельное поле.
Повторяющимися являются поля, содержащие одинаковые по смыслу значения. Например, если требуется получить статистику продаж четырех товаров по месяцам, можно создать поля для хранения данных о продаже по каждому товару. Однако что делать, если товаров не 4, а 104, и как быть, если количество товаров заранее не известно? Повторяющиеся группы следует устранить, сохранив в таблице единственное поле «Товар». В результате получим запись, содержащую информацию о статистике продаж по одному товару, но этот товар может быть любым.
Вторая нормальная форма требует, чтобы все поля таблицы зависели от первичного ключа, то есть, чтобы первичный ключ однозначно определял запись и не был избыточен. Если же в какой-либо таблице имеется зависимость каких-либо не ключевых полей от части первичного ключа, следует выделить их в отдельную таблицу, сделав первичным ключом новой таблицы ту часть первичного ключа, от которой зависят данные поля, и установить связь «один ко многим» от новой таблицы к старой.
Третья нормальная форма требует, чтобы в таблицах не имелось транзитивных зависимостей между не ключевыми полями, то есть чтобы значение любого поля, не входящего в первичный ключ, не зависело от значения другого поля, также не входящего в первичный ключ.
Результатом нормализации является модель данных, которую легко поддерживать, не содержащая неопределенностей в данных и повторений данных.
После формальных определений трех уровней нормализации разберем конкретный пример и опишем возможные проблемы. В качестве примера будет рассматриваться база данных, содержащая сведения о посещаемых студентами курсах.
Таблицы базы данных до нормализации
В этом примере предполагается, что:
- студент может записаться на любое число курсов;
- лекторы могут вести несколько курсов;
- каждый лектор всегда проводит занятия в одной и той же аудитории;
- в каждой аудитории читается только один курс.
Пусть для хранения этих сведений используются следующие Таблицы.
Таблица 6. Students (студенты)
|
Name (имя) |
Phoneno (телефон) |
CourseRegistrations (посещаемые курсы) |
|
Maijorie Green |
415986 |
Basic Computing, Database Administration |
|
Bun Gringelsby |
707938 |
Database Administration, Advanced Hardware Support |
|
Anico Yokamoto |
415935 |
Advanced Hardware Support |
Таблица 7. Courses (курсы)
|
Course (курс) |
Lecturer (лектор) |
Room (аудитория) |
|
Basic Computing |
Meander Smith |
542 South |
|
Database Administration |
Dean Straight |
221 East |
|
Advanced Hardware Support |
Dean Straight |
221 East |
В этом случае появляются следующие логические противоречия:
- если курсBasic Computing будет закрыт, из таблицы будет удален лектор Meander Smith и аудитория 542 South;
- число курсов, на которые может записаться студент, ограничено длиной записи которую допускает поле Course Registrations;
- трудно выполнять поиск значений в поле Course Registrations, а также использовать его в вычислениях;
- в каждой регистрационной записи повторяется полное название курса. В результате неэффективно используется пространство и растет вероятность появления несогласованных данных, если название курса введено с ошибками. Кроме того, при изменении названия курса потребуется проводить поиск и обновление всех регистрационных записей;
- таблицу Students невозможно индексировать по фамилии, так как в поле name хранятся полные имена студентов;
- если лектор сменит аудиторию, придется обновить сведения обо всех преподаваемых им курсах.
Проведем нормализацию
Таблицы базы данных после нормализации
Таблица 8. Students (студенты)
|
StudentsID(код студента) |
Firstname (имя) |
Lastname (фамилия) |
Phoneno (телефон) |
|
1001 |
Maijorie |
Green |
415986 |
|
1002 |
Bun |
Gringelsby |
707938 |
|
1003 |
Anico |
Yokamoto |
415935 |
Таблица 9. Регистрационные записи (Registrations)
|
RegID (код записи) |
StudentsID(код студента |
Courses (курсы) |
|
1 |
1001 |
1 |
|
2 |
1002 |
2 |
|
3 |
1003 |
3 |
|
4 |
1004 |
4 |
|
5 |
1005 |
5 |
Таблица 10. Courses (курсы)
|
Course ID(курс) |
Course (курс) |
LecturerID (код лектора) |
|
1 |
Basic Computing |
1 |
|
2 |
Database Administration |
2 |
|
3 |
Advanced Hardware Support |
3 |
Таблица 11. Lecturers (лектор)
|
LecturerID (код лектора) |
Firstname (имя) |
Lastname (фамилия) |
Room (аудитория) |
|
1 |
Meander |
Smith |
542 South |
|
2 |
Dean |
Straight |
221 East |
Между таблицами существуют следующие связи:
Students (студенты) — Courses (курсы): отношение «многие ко многим» через промежуточную таблицу Registrations (регистрационные записи), другими словами это отношение сведено к двум отношениям «один ко многим»;
Students (студенты) — Registrations (регистрационные записи): отношения «один ко многим»;
Courses (курсы) — Registrations (регистрационные записи): отношение «один ко многим»;
Lecturers (лекторы) — Courses (курсы): отношение «один ко многим».
Очевидные преимущества нормализации этих таблиц:
- каждая таблица содержит только один набор связанных данных. Например, в таблице Students теперь нет сведений о посещаемых курсах;
- в каждой таблице имеется первичный ключ: в таблице Students — это поле StudentID, в таблице Registrations — RegID, в таблице Courses — CourseID и в таблице Lecturers — LecturerW,
- отсутствуют составные поля. Каждое поле описывает только один атрибут. Например, поле, содержавшее имя и фамилию студента, разбито на отдельные поля, которые содержат имя и фамилию студента;
- отсутствуют повторяющиеся данные. Так, теперь имена лекторов записываются только один раз;
- отсутствуют поля, содержащие несколько значений. Например, каждая регистрационная запись курса теперь расположена в отдельной строке таблицы Registrations. Для сравнения взгляните на поле Course Registrations (посещаемые курсы) предыдущего варианта таблицы Students;
- каждое поле полностью зависит от первичного ключа. Например, в таблице Courses нет поля Room. Это связано с тем, что аудитория зависит не от кода курса (CourseID), а от кода лектора (LecturerID).
Вот основные преимущества нормализации:
- облегчается сортировка и создание индекса, поскольку таблицы стали более компактными;
- индексы становятся более компактными;
- меньшее число индексов в одной таблице позволяет быстрее выполнять обновления записей;
- в таблицах содержится меньше значений NULL и избыточных данных, что повышает компактность базы данных;
- уменьшается вероятность конфликтов блокировок таблиц, поскольку блокировать приходится ограниченные наборы данных.
Проект реляционной базы данных — это набор взаимосвязанных отношений, для которых определены все атрибуты, заданы первичные ключи отношений и заданы еще некоторые дополнительные свойства отношений, которые относятся к принципам поддержки целостности. Фактически проект базы данных — это фундамент будущего программного комплекса, который будет использоваться достаточно долго и многими пользователями. Этапы жизненного цикла базы данных (см рис 1) аналогичны, в основном, развитию любой программной системы, однако в них есть определенная специфика, касающаяся только баз данных.

Рис. 1. Этапы жизненного цикла БД
Процесс проектирования БД представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. Можно выделить следующие этапы проектирования:
- Системный анализ и словесное описание информационных объектов предметной области.
- Проектирование инфологической модели предметной области — частично формализованное описание объектов предметной области в терминах некоторой семантической модели, например, в терминах ЕR-модели.
- Даталогическое или логическое проектирование БД, то есть описание БД в терминах принятой дата логической модели данных.
- Физическое проектирование БД, то есть выбор эффективного размещения БД на внешних носителях для обеспечения наиболее эффективной работы приложения.
Если учесть, что между вторым и третьим этапами необходимо принять решение, с использованием какой стандартной СУБД будет реализовываться наш проект, то условно процесс проектирования БД можно представить последовательностью выполнения пяти соответствующих этапов (см. рис. 2.)
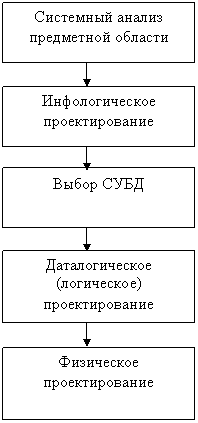
Рис. 2. Этапы проектирования БД
4. Архитектуры баз данных
По технологии обработки данных базы данных подразделяются на централизованные и распределенные. Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе данных – доступ к ней пользователей различных ЭВМ данной сети. Такой способ использования баз данных часто применяют в локальных сетях персональных ЭВМ.
Появление сетей ЭВМ позволило наряду с централизованными создавать и распределенные базы данных. Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Однако пользователь распределенной базы данных не обязан знать, каким образом ее компоненты размещены в узлах сети, и представляет себе эту базу данных как единое целое. Работа с такой базой данных осуществляется с помощью системы управления распределенной базой данных (СУРБД). Данные, содержащиеся в распределенной базе данных, их представление на всех уровнях архитектуры СУРБД и размещение в сети описываются в системном справочнике, который сам может быть декомпозирован и размещен в различных узлах сети.
Части распределенной базы данных, размещенные на отдельных ЭВМ сети, управляются собственными (локальными) СУБД и могут использоваться одновременно как самостоятельные локальные базы данных. Локальные СУБД не обязательно должны быть одинаковыми в разных узлах сети. Объединение неоднородных локальных баз данных в единую распределенную базу данных является сложной научно-технической проблемой. Ее решение потребовало проведения большого комплекса научных исследований и экспериментальных разработок.
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым) доступом.
Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры подобных систем:
- файл-сервер;
- клиент-сервер.
Файл-сервер. Данная архитектура систем БД предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Каждый пользователь может запускать приложение, расположенное на сервере, при этом на компьютере пользователя запускается копия приложения. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном производится обработка. Когда пользователь сети работает с БД, на его компьютере появляется локальная копия общей БД. Эта копия периодически обновляется данными, содержащимися в БД, расположенной на сервере. Архитектура файл-сервер обычно используется в таких сетях, где имеется немного компьютеров. Для ее реализации предназначены персональные СУБД, например Paradox и DBase. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает.
Клиент-сервер. В этой концепции подразумевается, что помимо хранения централизованной БД сервер базы данных должен обеспечивать выполнение основного объема обработки данных. Технология клиент-сервер разделяет приложение на две части: клиентскую и серверную. Клиентская обеспечивает интерактивный интерфейс, сервер обеспечивает управление данными, разделение информации, администрирование и безопасность. Для получения данных приложение-клиент формирует и отсылает запрос удаленному серверу, на котором размещена БД. Запрос формируется на языке SQL, который является стандартом доступа к серверу при использовании реляционных баз данных. После получения запроса удаленный сервер направляет его SQL-серверу (серверу баз данных). SQL-сервер – это программа, которая управляет удаленной БД и обеспечивает выполнение запроса и выдачу клиенту его результатов – требуемых данных. Вся обработка запроса выполняется на удаленном сервере. Для реализации архитектуры клиент-сервер обычно применяются многопользовательские СУБД, например Qracle, MS SQL Server, InterBase и др. Подобные СУБД называют промышленными, так как они позволяют организовать информационную систему, состоящую из большого числа пользователей.
5. Организация процессов обработки данных в БД. Технология создания приложения в среде Delphi
В качестве среды программирования для рассмотрения технологии создания приложений баз данных в данном разделе выбрана объектно-ориентированная среда программирования Delphi, которая на сегодня является одной из самых распространенных средств создания приложений баз данных для корпоративных применений. Простота и естественность языка, ориентация системы на разработку именно такого рода приложений, наконец, эффективность (большая производительность и относительно небольшие размеры) создаваемых с ее помощью программ сделали Delphi незаменимым средством разработки различного рода клиентских мест, т.е. программ для доступа к БД.
Таблицы БД располагаются на диске. Они являются физическими объектами. Для операций с данными, содержащимися в таблицах, используются наборы данных.
В терминах системы Delphi набор данных – это совокупность записей, взятых из одной или нескольких таблиц баз данных. Записи, включаемые в набор, данных отбираются по определенным правилам. Набор данных является логической таблицей, с которой можно работать при выполнении приложения. Взаимодействие таблицы и набора данных напоминает взаимодействие физического файла и файловой переменной. Для выполнения операций с наборами данных используются два способа доступа к данным: навигационный и реляционный.
Навигационный способ доступа заключается в обработке каждой отдельной записи набора данных. Этот способ обычно используется в локальных БД или в удаленных БД небольшого размера. При навигационном способе доступа каждый набор данных имеет невидимый указатель текущей записи. Указатель определяет запись, с которой могут выполняться такие операции, как редактирование или удаление. Поля текущей записи доступны для просмотра. Например, компоненты DBEdit и DBText; отображают содержимое соответствующих полей именно текущей записи. Компонент DBGrid указывает текущую запись с помощью специального маркера.
Реляционный способ доступа основан на обработке группы записей. Если требуется обработать одну запись, все равно обрабатывается группа, состоящая из одной записи. При реляционном способе доступа используются SQL-запросы, поэтому его называют также SQL-ориентированным. Реляционный способ доступа ориентирован на работу с удаленными БД и является для них предпочтительным. Однако его можно использовать и для локальных БД.
Реляционный способ доступа к данным в приложении можно реализовать с помощью компонента Query.
Средства для работы с реляционными базами данных.Хотя система Delphi не имеет своего формата таблиц БД, она тем не менее обеспечивает мощную поддержку большого количества различных СУБД — как локальных (например, dBase или Paradox), так и промышленных (например, Sybase или InterBase). Средства Delphi, предназначенные для работы с БД, можно разделить на два вида:
- инструменты
- компоненты
К инструментам относятся специальные программы и пакеты, обеспечивающие обслуживание БД вне разрабатываемых приложений. Компоненты предназначены для создания приложений, осуществляющих операции с БД.
Напомним, что в Delphi имеется окно Обозревателя дерева объектов, которое отображает иерархическую структуру объектов текущей формы. При разработке приложений баз данных это окно удобно использовать для просмотра структуры базы данных и изменения связей между компонентами. Кроме того, в окне Редактора кода имеется вкладка Diagram служащая для отображения и настройки взаимосвязей между элементами баз данных.
Технология создания информационной системы. Продемонстрируем возможности Delphi по работе с БД на примере создания простой информационной системы. Эту информационную систему можно разработать даже без написания кода: все необходимые операции выполняются с помощью программы Database Desktop, Конструктора формы и Инспектора объектов. Работа над информационной системой состоит из следующих основных этапов:
- создание БД;
- создание приложения.
Кроме приложения и БД, в информационную систему также входят вычислительная система и СУБД. Предположим, что компьютер или компьютерная сеть уже существуют, и их характеристики удовлетворяют потребностям будущей информационной системы. В качестве СУБД выберем Delphi.
В простейшем случае БД состоит из одной таблицы. Если таблицы уже имеются, то первый этап не выполняется. Отметим, что совместно с Delphi.поставляется большое количество примеров приложений, в том числе и приложений БД. Готовые таблицы также можно использовать для своих приложений.
Для работы с таблицами БД при проектировании приложения удобно использовать программу Database Desktop, которая позволяет:
- создавать таблицы;
- изменять структуры;
- редактировать записи.
Кроме того, с помощью Database Desktop можно выполнять и другие действия над БД (создание, редактирование и выполнение визуальных и SQL-запросов, операций с псевдонимами).
Для примера рассмотрим создание приложения, использующего механизм доступа ВDЕ и позволяющего перемещаться по записям таблицы БД, просматривать и редактировать поля, удалять записи из таблицы, а также вставлять новые. Файл проекта приложения обычно не требует от разработчика выполнения каких-либо действий. Поэтому при создании приложения главной задачей является конструирование форм, в простейшем случае — одной формы.
Компонент Table обеспечивает взаимодействие с таблицей БД. Для связи с требуемой таблицей нужно установить в соответствующие значения свойство DataBaseName, указывающее путь к БД, и свойство TableName, указывающее имя таблицы. После задания таблицы для открытия набора данных свойство Active должно быть установлено в значение True.
В рассматриваемом приложении использована таблица клиентов, входящая в состав поставляемых с Delphi примеров, ее главный файл – Clients.dbf Файлы этой и других таблиц примеров находятся в каталоге, путь к которому указывает псевдоним dbdemos. Настройка псевдонима может быть выполнена с помощью программы BDE Administrator.
Компонент DataSourse1 является промежуточным звеном между компонентом Table, соединенным с реальной таблицей БД, и визуальными компонентами DBGrid и DBNavigator, с помощью которых пользователь взаимодействует с этой таблицей. На компонент Table1, с которым связан компонент DataSourse1, указывает свойство DataSet последнего.
Компонент DBGrid1 отображает содержимое таблицы БД в виде сетки, в которой столбцы соответствуют полям, а строки — записям таблицы. По умолчанию пользователь может просматривать и редактировать данные. Компонент DBNavigator1позволяет пользователю перемещаться по таблице, редактировать, вставлять и удалять записи. Компоненты DBGrid1 и DBNavigator1 связываются со своим источником данных -компонентом DataSourse1 через свойства DataSourse. Взаимосвязь компонентов приложения и таблицы БД и используемые при этом свойства компонентов показаны на рис. 3.
Разрабатывая приложение, можно задавать значения всех свойств компонентов с помощью Инспектора объектов. При этом требуемые значения либо непосредственно вводятся в поле, либо выбираются в раскрывающихся списках. В последнем случае приложение создается с помощью мыши и не требует набора каких-либо символов на клавиатуре. В табл. 12 приведены компоненты, используемые для работы с таблицей БД, их основные свойства и значения этих свойств.
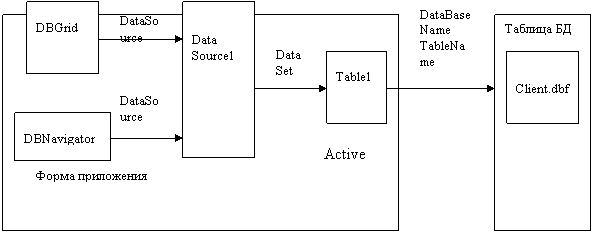
Рис. 3. Взаимосвязь компонентов приложения и таблицы БД
Таблица 12. Значения свойств компонентов
|
Компонент |
Свойства |
Значения |
|
Table1 |
DataBaseName |
dbDemos |
|
TableName |
Client.dbf |
|
|
Active |
True |
|
|
DataSource1 |
DataSet |
Table1 |
|
DBGrid1 |
DataSource |
DataSource1 |
|
DBNavigator1 |
DataSource |
DataSource1 |
В дальнейшем при организации приложений, использующих механизм доступа BDE, предполагается, что названные компоненты связаны между собой именно таким образом, и свойства, с помощью которых эта связь осуществляется, не рассматриваются.
Для автоматизации процесса создания формы, использующей компоненты для операций с БД, можно вызвать Database Form Wizard (Мастер форм баз данных). Этот Мастер расположен на странице Business Хранилища объектов.
Мастер позволяет создавать формы для работы с отдельной таблицей и со связанными таблицами, при этом можно использовать наборы данных Table или Query.
6. Технология оперативной обработки транзакции
Как уже упоминалось, транзакция – это одно действие или последовательность действий, выполняемых одним и тем же пользователем (или прикладной программой), осуществляющим доступ к базе данных или изменение ее содержимого. Транзакции представляют такие события реального мира, как, например, регистрация предлагаемого для сдачи в аренду объекта недвижимости, назначение встречи с потенциальным арендатором с целью осмотра некоторого объекта, прием на работу нового сотрудника или регистрация нового клиента. Все эти транзакции должны обращаться к базе данных с той целью, чтобы хранимые в ней данные всегда гарантированно соответствовали текущей ситуации в реальном мире, а также для удовлетворения информационных потребностей пользователей.
Транзакция может состоять из нескольких операций, подобных, например, переводу денег с одного счета на другой. Однако, с точки зрения пользователя, эти операции представляют собой единое задание. С точки зрения СУБД каждая транзакция переводит базу данных из одного непротиворечивого состояния в другое. СУБД обеспечивает непротиворечивость базы данных даже в случае возникновения сбоя. Кроме того, СУБД гарантирует, что после завершения транзакции все внесенные ею изменения будут надежно сохранены в базе данных целиком и полностью (без необходимости выполнения другой транзакции для устранения недостатков, возникших при выполнении первой транзакции). Если по какой-либо причине транзакция не будет завершена, СУБД гарантирует, что все внесенные ею изменения будут отменены. В примере с банковским переводом денег это значит, что если деньги сняты (дебетованы) с одного счета и сбой транзакции произошел во время их помещения (кредитования) на другой счет, то СУБД отменит дебет первого счета. Если операции дебета и кредита поместить в отдельные транзакции, то сразу после дебетования первого счета и завершения транзакции это изменение отменить будет нельзя, разве что только посредством запуска другой транзакции с кредитованием этого счета на снятую сумму.
Цель проектирования транзакций заключается в определении и документировании высокоуровневых характеристик всех транзакций, которые должны будут выполняться в разрабатываемой базе данных. Эту работу следует выполнить еще на начальной стадии проектирования, что позволит обеспечить поддержку всех требуемых транзакций со стороны логической модели данных. При этом очень важно, чтобы характеристики всех транзакций были зафиксированы в документации. Существует несколько методов описания высокоуровневых характеристик транзакций. Наиболее важные из них следующие:
- данные, которые используются транзакцией;
- функциональные характеристики транзакции;
- выходные данные, формируемые транзакцией;
- степень важности транзакции для пользователей;
- предполагаемая интенсивность использования.
Имеется три основных типа транзакций: транзакции извлечения, транзакции обновления и смешанные транзакции.
Транзакции извлечения используются для выборки некоторых данных с целью отображения их на экране или помещения в отчет. Примером транзакции извлечения является поиск и отображение подробных сведений об объекте недвижимости (по заданному номеру объекта).
Транзакции обновления используются для вставки новых, удаления старых или же изменения уже существующих записей базы данных. Примером транзакции обновления является внесение в базу подробных сведений о новом объекте недвижимости.
Смешанные транзакции включают в себя как операции извлечения, так и операции обновления данных. Примером смешанной транзакции является поиск и отображение подробных сведений об объекте недвижимости (по заданному номеру объекта) с последующим изменением месячной арендной платы.
Структура каждой транзакции строится на основании имеющейся спецификации требований пользователей. Подобные транзакции могут представлять собой сложные операций, которые в результате анализа раскладываются на несколько более простых операций, каждая из которых представляет собой отдельную транзакцию.
Любая транзакция всегда должна переводить базу данных из одного согласованного состояния в другое, хотя допускается, что согласованность состояния базы будет нарушаться в ходе выполнения транзакции. Любая транзакция завершается одним из двух возможных способов. В случае успешного завершения результаты транзакции фиксируются (commit) в базе данных, последняя переходит в новое согласованное состояние. Если выполнение транзакции не увенчалось успехом, она отменяется. В этом случае в базе данных должно быть восстановлено то согласованное состояние, в котором она находилась до начала данной транзакции. Этот процесс называется откатом (roll back) транзакции. Зафиксированная транзакция не может быть отменена. Если оказывается, что зафиксированная транзакция была ошибочной, потребуется выполнить другую транзакцию, отменяющую действия, выполненные первой транзакцией. Эту транзакцию называют компенсирующей. Следует отметить, что отмененная транзакция может быть еще раз запущена позже и в зависимости от причин предыдущего отказа вполне успешно завершена и зафиксирована в базе данных.
Никакая СУБД не обладает внутренней возможностью установить, какие именно изменения должны быть восприняты как единое целое, образующее одну логическую транзакцию. Следовательно, должен существовать метод, позволяющий указывать границы каждой из транзакций извне, со стороны пользователя. В большинстве языков манипулирования данными для указания границ отдельных транзакций используются операторы BEGIN TRANSACTION, COMMIT и ROLLBACK (или их эквиваленты). Если эти ограничители не были использованы, вся выполняемая программа расценивается как единая транзакция. СУБД автоматически выполнит команду COMMIT при нормальном завершении этой программы. Аналогично в случае ее аварийного завершения в базе данных автоматически будет выполнена команда ROLLBACK.
Существуют некоторые свойства, которыми должна обладать любая из транзакций. Ниже представлены четыре основных свойства (ACID – аббревиатура, составленная из первых букв их английских названий).
- Атомарность. Это свойство типа “все или ничего”. Любая транзакция представляет собой неделимую единицу работы, которая может быть либо выполнена вся целиком, либо не выполнена вовсе.
- Согласованность. Каждая транзакция должна переводить базу данных из одного согласованного состояния в другое согласованное состояние.
- Изолированность. Все транзакции выполняются независимо одна от другой. Другими словами, промежуточные результаты незавершенной транзакции не должны быть доступны другим транзакциям.
- Продолжительность. Результаты успешно завершенной (зафиксированной) транзакции должны сохраняться в базе данных постоянно и не должны быть утеряны в результате последующих сбоев.
СУБД, созданная для поддержки оперативной обработки транзакций называется OLTP-системой (Online Transaction Processing). Обычно OLTP-системы проектируются с целью обеспечения максимально интенсивной обработки транзакций. Организация обычно имеет несколько различных OLTP-систем, предназначенных для поддержки таких бизнес-процессов, как контроль товарных запасов, выписка счетов клиентам, продажа товаров. Эти системы генерируют оперативные данные, которые являются очень подробными, текущими и подверженными изменениям. OLTP-системы оптимизированы для интенсивной обработки транзакций, которые проектируются заранее, многократно повторяются и связаны преимущественно с обновлением данных. В соответствии с этими особенностями данные в OLTP-системах организованы согласно требованиям конкретных бизнес-приложений и позволяют принимать повседневные решения большому количеству параллельно работающих пользователей-исполнителей.
7. Реляционный способ доступа к базе данных. Основные сведения о языке SQL
Увеличение объема и структурной сложности хранимых данных, расширение круга пользователей информационных систем привели к широкому распространению наиболее удобных и сравнительно простых для понимания реляционных (табличных) систем управления базами данных.
Все языки манипулирования данными, созданные до появления реляционных баз данных и разработанные для многих СУБД персональных компьютеров, так называемые дореляционные языки манипулирования данными (ЯМД) – это языки, ориентированные на операции с данными, представленными в виде логических записей файлов. Их применение требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом можно получить их.
Появление теории реляционных баз данных и предложенного Коддом Э.Ф. языка запросов “alpha”, основанного на реляционном исчислении, инициировало разработку ряда языков запросов, которые можно отнести к двум классам:
- Алгебраические языки запросов – языки, позволяющие выражать запросы средствами специализированных операторов, применяемых к отношениям (JOIN – соединить, INTERSECT – пересечь, SUBTRACT – вычесть и т.д.).
- Языки исчисления предикатов – набор правил для записи выражения, определяющего новое отношение из заданной совокупности существующих отношений.
Из всех этих языков полностью сохранились и развиваются QBE (Query By Example) и SQL (Structured Query Language), а из остальных взяты в расширение внутренних языков СУБД только наиболее интересные конструкции. В начале 1980-х годов SQL “победил” другие языки запросов и стал фактическим стандартом таких языков для профессиональных реляционных СУБД
Непроцедурный, структурированный язык запросов (SQL) – язык, ориентированный на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений языка запросов SQL – ориентированность в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных.
Недавно принятый стандарт ANSI SQL-92 расширяет возможности встроенных SQL-операторов и позволяет включить динамический SQL. И в интерактивной и во встроенной формах SQL имеются многочисленные части, или субподразделения. К сожалению, эти термины не используются повсеместно во всех реализациях. Они подчеркиваются ANSI и полезны на концептуальном уровне, но большинство SQL программ практически не обрабатывают их отдельно, так что они, по существу, становятся функциональными категориями команд SQL. DDL (Data Definition Language – язык определения данных) – так называемый язык описания схемы в стандарте ANSI, состоит из команд, которые создают объекты (таблицы, индексы, просмотры и т.д.) в базе данных. DML (Data Manipulation Language – язык манипулирования данными) – это набор команд, которые определяют, какие значения представлены в таблицах в любой момент времени. DCL (Data Control Language – язык управления данными) – комплекс средств, которые определяют, разрешить ли пользователю выполнять определенные действия или нет.
Реализация в SQL концепции операций, ориентированных на табличное представление данных, позволило создать компактный язык с небольшим (менее 30) набором предложений. Как в интерактивном, так и в встроенном SQL существуют следующие предложения:
- предложения определения данных (определение баз данных, а также определение и уничтожение таблиц и индексов);
- запросы на выбор данных (предложение SELECT);
- предложения модификации данных (добавление, удаление и изменение данных);
- предложения управления данными (предоставление и отмена привилегий на доступ к данным, управление транзакциями и другие).
Кроме того, SQL предоставляет возможность выполнять в этих предложениях следующее:
- арифметические вычисления (включая разнообразные функциональные преобразования), обработку текстовых строк и выполнение операций сравнения значений арифметических выражений и текстов;
- упорядочение строк и (или) столбцов при выводе содержимого таблиц на печать или экран дисплея;
- создание представлений (виртуальных таблиц), позволяющих пользователям иметь свой взгляд на данные без увеличения их объема в базе данных;
- запоминание выводимого по запросу содержимого таблицы, нескольких таблиц или представления в другой таблице (реляционная операция присваивания).
- агрегирование данных: группирование данных и применение к этим группам таких операций, как среднее, сумма, максимум, минимум, число элементов и т.п.
Основные типы данных SQL – используемые языком SQL основные типы данных, форматы которых могут несколько различаться для разных СУБД: целое число; десятичное число; вещественное число; символьная строка фиксированной или переменной длины; дата в формате (по умолчанию mm/dd/yy); время в формате (по умолчанию hh.mm.ss); деньги в формате, определяющем символ денежной единицы и его расположение (суффикс или префикс) и др.
Таблицы создаются командой CREATE TABLE. Эта команда создает структуру таблицы. Значения вводятся с помощью DML команды INSERT (см. далее). Команда CREATE TABLE в основном определяет имя таблицы в виде описания набора имен столбцов, указанных в определенном порядке. Она также определяет типы данных и размеры столбцов. Cинтаксис команды CREATE TABLE будет следующим:
CREATE TABLE базовая_таблица (столбец тип_данных [,столбец тип_данных] …);
Индекс – это структура данных, которая помогает СУБД быстрее обнаруживать отдельные записи в таблице, а потому позволяет сократить время выполнения запросов пользователя. Таблицы могут иметь большое количество строк, а так как строки не находятся в каком-нибудь определенном порядке, на их поиск по указанному значению может потребоваться время. Индекс в базе данных аналогичен предметному указателю, приведенному в конце книги. Это структура, связанная с таблицей и предназначенная для поиска информации по тому же принципу, что и предметный указатель в книге.
Предложение для создания следующее:
CREATE INDEX ON (имя_столбца[,] …);
Таблица должна уже быть создана и должна содержать имя столбца. Однажды созданный индекс будет невидим пользователю. SQL самостоятельно решает, когда он необходим чтобы ссылаться на него, и делает это автоматически.
Представления (View) – это таблицы, чье содержание выбирается или получается из других таблиц. Они работают в запросах и операторах DML точно так же, как и базовые таблицы, но не содержат никаких собственных данных. Представление создается командой CREATE VIEW. Она состоит из слов CREATE VIEW (создать представление), имени представления, которое нужно создать, слова AS (как) и, далее, запроса.
Синтаксис предложения CREATE VIEW имеет вид:
CREATE VIEW имя_представления
[(столбец[,столбец] …)]
AS подзапрос;
Как уже говорилось, SQL представляет собой структурированный язык запросов. Запросы – наиболее часто используемый элемент SQL. Все запросы на получение практически любых данных в SQL осуществляются с помощью единственного предложения SELECT – предложения языка SQL, с помощью которого можно выполнить все запросы на получение практически любого количества данных из одной или нескольких таблиц БД, в общем случае результатом реализации предложения SELECT является другая таблица.
Предложение SELECT выглядит следующим образом:
SELECT [ DISTINCT]
<Список полей > или *
FROM < Список таблиц>
[WERE<Условие отбора>]
[ORDER BY <Список полей для сортировки >]
[GROUP BY < Список полей для группирования>]
[HAVING <Условия группирования >]
[UNION<Вложенный оператор SELECT>]
Критерий отбора строк формируется из одного или нескольких условий, соединенных логическими операторами:
- AND – когда должны удовлетворяться оба разделяемых с помощью AND условия;
- OR – когда должно удовлетворяться одно из разделяемых с помощью OR условий;
- AND NOT – когда должно удовлетворяться первое условие и не должно – второе;
- OR NOT – когда или должно удовлетворяться первое условие, или не должно удовлетворяться второе.
Операторы языка манипулирования данными DML управляют значениями, представляемыми в таблицах. Значения могут быть помещены и удалены из полей тремя операторами языка DML: INSERT (вставить), UPDATE (модифицировать), DELETE (удалить).
В языке SQL также имеется возможность изменения таблицы после того, как она была создана. Команда ALTER TABLE используется, чтобы изменить определение существующей таблицы. Обычно она добавляет столбцы к таблице. Иногда она может удалять столбцы или добавлять в (удалять из) определение таблицы новые (существующие) ограничения. Типичный синтаксис, чтобы добавить столбец к таблице:
ALTER TABLE имя_таблицы
ADD имя_столбца;
8. Построение приложений баз данных в архитектуре «клиент-сервер». SQL-сервер Interbase
Ранее были рассмотрены локальные базы данных, когда и БД, и взаимодействующее с ней приложение располагаются на одном компьютере. В данном разделе будут рассмотрены некоторые особенности работы с удаленными БД, используемыми в сети, где приложение и БД располагаются на разных компьютерах.
В принципе локальную БД тоже можно использовать для коллективного доступа т. е. в сетевом варианте. В этом случае файлы базы данных и приложение для работы с ней располагаются на сервере сети. Пользователь запускает со своего компьютера находящееся на сервере приложение, при этом у него запускается копия приложения. Можно установить приложение и непосредственно на компьютере пользователя, в этом случае приложению должно быть известно местонахождение общей БД, заданное, например, через псевдоним. Подобный сетевой вариант использования локальной БД соответствует архитектуре «файл-сервер».
Достоинствами сетевой архитектуры «файл-сервер» являются простота разработки и эксплуатации БД и приложения. Разработчик фактически создает локальную БД и приложение, которые затем просто используются в сетевом варианте. При этом не требуется дополнительное программное обеспечение для организации работы с БД. Однако архитектуре «файл-сервер» свойственны и существенные недостатки. Для работы с данными используется навигационный способ доступа, при этом по сети циркулируют большие объемы данных. В результате сеть оказывается перегруженной, что является причиной ее низкого быстродействия и плохой производительности при работе с БД. Требуется синхронизация работы отдельных пользователей, связанная с блокировкой в таблицах тех записей, которые редактирует другой пользователь. Приложения не только обрабатывают данные, но и управляют самой базой данных. В связи с тем, что управление БД осуществляется с разных компьютеров, затрудняются управление доступом, соблюдение конфиденциальности и поддержание целостности БД.
Из-за этих недостатков архитектура «файл-сервер», как правило, используется в небольших сетях. Для сетей с большим количеством пользователей предпочтительным вариантом (а порой и единственным возможным) является архитектура «клиент-сервер».В сетевой архитектуре «клиент-сервер» БД размешается на компьютере-сервере сети (сервере или удаленном сервере) и называется также удаленной БД. Приложение, осуществляющее работу с этой БД, находится на компьютере пользователя. Приложение пользователя является клиентом, его также называют приложением-клиентом. Клиент и сервер взаимодействуют следующим образом. Клиент формирует и отсылает запрос серверу, на котором размешена БД. Сервер выполняет запрос и выдает клиенту в качестве результатов требуемые данные. Таким образом, в архитектуре «клиент-сервер» клиент посылает запрос и получает только те данные, которые ему действительно нужны. Вся обработка запроса выполняется на удаленном сервере. К достоинствам такой архитектуры относятся следующие факторы. Для работы с данными используется реляционный способ доступа, что снижает нагрузку на сеть. Приложения не управляют напрямую базой, управлением занимается только сервер. В связи с этим можно обеспечить высокую степень защиты данных. В приложении отсутствует код, связанный с управлением БД, поэтому приложения упрощаются.
Отметим, что сервером называют не только компьютер, но и специальную программу, которая управляет БД. Так как в основе организации обмена данными между клиентом и сервером лежит язык SQL такую программу еще называют SQL-сервером, а базу данных — базой данных SQL. В широком смысле слова под сервером понимают компьютер, программу и саму базу данных. SQL-серверами являются промышленные СУБД, такие как InterBase, Oracle и др. Каждый из серверов имеет свои преимущества и особенности, связанные, например, со структурой БД и реализацией языка SQL, которые необходимо учитывать при разработке приложения. Далее мы будем понимать под сервером программу (т. е. SQL -сервер), а установленную на компьютере-сервере базу данных будем называть удаленной БД.
При работе в архитектуре «клиент-сервер» приложение должно:
- устанавливать соединение с сервером и завершать его;
- формировать и отсылать запрос серверу, получая от него результаты выполнения запроса;
- обрабатывать полученные данные.
При этом обработка данных не имеет принципиальных отличий по сравнению с обработкой данных в локальных БД.
Удаленная БД, как и локальная, представляет собой совокупность взаимосвязанных таблиц. Однако данные этих таблиц, как правило, содержатся в одном общем файле. Как и в случае с локальной БД, для таблиц удаленной БД могут устанавливаться связи (отношения), ограничения ссылочной целостности, ограничения на значения столбцов и т. д. Для удаленных БД поле называется столбцом. Для управления БД сервер использует:
- триггеры;
- генераторы;
- хранимые процедуры;
- функции, определяемые пользователем;
- механизм транзакций;
- механизм кэшированных изменений;
Многие из перечисленных элементов обеспечиваются возможностями языка SQL сервера, в котором, по сравнению с локальной версией, имеются существенные особенности, рассматриваемые ниже.
Система Delphi обеспечивает разработку приложений для различных серверов, предоставляя для этого соответствующие средства. Отметим, что многие описанные ранее принципы разработки приложений и средства для работы с локальными БД относятся и к работе с удаленными БД. В частности, для разработки приложений используются такие компоненты, как источник данных DataSource,_наборы данных Table, ADOTable, SQLTable, IBTable, Query, ADOQuery, SQLQuery, сетка DBGrid и др.
Для реализации реляционного способа доступа к удаленной БД с помощью BDE необходимо использовать только средства языка SQL. Поэтому в качестве компонентов должны выбираться такие как Query, StoredProc, UpdateSQL. Кроме того, для набора данных нельзя использовать методы, характерные для навигационного способа доступа.
Напомним, что если при выполнении модифицирующего БД запроса с помощью компонента Query не нужен результирующий набор данных, то этот запрос предпочтительнее выполнять с помощью метода ExecSQL. Для работы с таблицами и запросами по-прежнему можно использовать такие программы, как Database Desktop и SQL Explorer.
Средства Delphi, предназначенные для работы с удаленными БД, можно разделить на два вида: инструменты и компоненты.
К инструментам относятся специальные программы и пакеты, обеспечивающие обслуживание БД вне разрабатываемых приложений. Среди них:
- InterBase Server Manager — программа управления запуском сервера InterBase;
- IBConsole — консоль сервера InterBase;
- SQL Monitor — программа отслеживания порядка выполнения SQL-запросов к удаленным БД.
Компоненты предназначены для создания приложений, выполняющих операции с удаленной БД. Перечислим наиболее важные из них:
- Database (соединение с БД);
- Session (текущий сеанс работы с БД);
- StoredProc (вызов хранимой процедуры);
- UpdateSQL (модификация набора данных, основанного на SQL-запросе);
- DCOMConnection (DСОМ-соединение);
- компоненты страниц АDО, dbExpress, Interbase Палитры компонентов.
Отметим, что многие из названных компонентов, например, Database, Session, UpdateSQL, используются также при работе с локальными БД. Так, компонент Database позволяет, реализовать механизм транзакций при навигационном способе доступа к данным с помощью механизма ВDЕ. Однако наиболее часто эти компоненты применяются именно при работе с удаленными базами. Часть компонентов, например, клиентский набор данных ClientDataSet и соединение с сервером DCOMConnection, предназначена для работы в трехуровневой (трехзвенной) архитектуре «клиент-сервер» («тонкий» клиент) и используется для построения сервера приложений.
В основе операций, выполняемых с удаленными БД как с помощью инструментов, так и программно, лежит язык SQL. Например, при создании таблицы с помощью программы IBConsole необходимо набрать и выполнить SQL-запрос (инструкцию) Create Table. Если создание таблицы с помощью механизма ВDЕ осуществляется из приложения пользователя, то для этой цели используется набор данных Query, который выполняет такой же запрос. Основное различие заключается в том, каким образом выполняется SQL-запрос к удаленной БД.
Итак, для удаленных БД разница между средствами, используемыми в приложении, и инструментами намного меньше, чем для локальных баз данных.
Сервер InterBase.Все серверы имеют похожие принципы организации данных и управления ими. В качестве примера рассмотрим работу с сервером InterBase 6.x, который является «родным» для_Delphi. Совместно с Delphi поставляются две части сервера InterBase 6.x: серверная и клиентская. Серверная часть InterBase является локальной версией сервера InterBase и используется для отладки приложений, предназначенных для работы с удаленными БД, позволяя на одном компьютере проверить их в сетевом варианте. После отладки на локальном компьютере приложение можно перенести на сетевые компьютеры без изменений, для чего нужно:
- скопировать БД на сервер;
- установить для приложения новые параметры соединения с удаленной БД.
Скопировать БД можно с помощью программ типа Проводник Windows. Клиентская часть нужна для обеспечения доступа приложения к удаленной БД.При разработке БД и приложений с использованием локальной версии сервера InterBase нужно иметь в виду, что она имеет ряд ограничений и может не поддерживать, например, механизм событий сервера или определяемые пользователем функции. Полнофункциональная версия сервера InterBase приобретается и устанавливается отдельно от Delphi.Как упоминалось, в основе работы с удаленной БД лежат возможности языка SQL, обеспечивающие соответствующие операции. Назначение и возможности языка SQL для удаленных БД в принципе совпадают с назначением и возможностями этого языка для локальных БД.
Бизнес-правила. Как отмечалось, бизнес-правила представляют собой механизмы управления БД и предназначены для поддержания БД в целостном состоянии. Кроме того, они нужны для реализации ограничений БД, а также для выполнения ряда других действий, например, накапливания статистики работы с БД.
Бизнес-правила можно реализовывать на физическом и программном уровнях. В первом случае эти правила (например, ограничение ссылочной целостности для связанных таблиц) задаются при создании таблиц и входят в структуру БД. Для этого в синтаксис инструкции Create Table включаются соответствующие операнды, например, Default (значение по умолчанию). В дальнейшей работе нельзя нарушить или обойти ограничение, заданное на физическом уровне.
На программном уровне бизнес-правила можно реализовать в сервере и в приложении. Причем эти бизнес-правила не должны быть определены на физическом уровне. Для реализации бизнес-правил в сервере обычно используются триггеры. Достоинствами такого подхода является то, что вычислительная нагрузка по управлению БД целиком ложится на сервер, что снижает нагрузку на приложение и сеть, а также то, что действие ограничений распространяется на все приложения, осуществляющие доступ к БД. Однако одновременно снижается гибкость управления БД. Кроме того, нужно учитывать, что средства отладки триггеров и хранимых процедур сервера развиты недостаточно хорошо.
Для программирования бизнес-правил в приложении используются компоненты и их средства. Достоинство такого подхода заключается в легкости изменения бизнес-правил и возможности определить правила «своего» приложения. Недостатком является снижение безопасности БД, связанное с тем, что каждое приложение может устанавливать свои правила управления БД.
Информация всей БД сервера InterBase хранится в одном файле с расширением gdb. Размер этого файла может составлять единицы и даже десятки гигабайт. Отметим, что аналогичный размер БД имеет СУБД Microsoft SOL Server, в то время как для более мощных СУБД Oracle и SyBase размер БД достигает десятков и сотен гигабайт.
В отличие от локальной БД, структуру которой составляли таблицы (отдельные или связанные), удаленная БД имеет более сложную структуру, которая включает в свой состав следующие элементы: таблицы, триггеры ,индексы, функции пользователя. ограничения, хранимые процедуры, домены, просмотры, генераторы, исключения, привилегии.
Элементы структуры удаленной БД также называют метаданными. Слово «мета» имеет смысл «над», т. е. метаданные представляют собой данные, которые описывают структуру БД. Для InterBase максимальное число таблиц в БД равно 65 536, а максимальное число столбцов в таблице — 1000. Отметим, что таблицы InterBase имеют меньшее число допустимых типов столбцов (полей), чем таблицы локальных БД Paradox.
Домен представляет собой именованное описание столбца. После определения домена его имя можно использовать для описания других столбцов. Аналогом домена является тип данных.
Просмотр является логической (виртуальной) таблицей, записи в которую отобраны с помощью инструкции Select. Преимущество просмотра в том, что один раз отобрав записи их можно использовать в дальнейшем без повторного выполнения Select. Это выгодно при частом выполнении одинаковых запросов.
Хранимая процедура представляет собой подпрограмму, расположенную на сервере и вызываемую из приложения клиента. Использование этих объектов увеличивает скорость доступа к БД по следующим причинам:
- вместо текста запроса серверу передается по сети короткое обращение к хранимой процедуре;
- хранимая процедура не требует предварительной синтаксической проверки.
Триггер представляет собой процедуру, которая находится на сервере БД и вызывается автоматически при модификации записей БД, т.е. при изменении столбцов или при их удалении и добавлении. В отличие от хранимых процедур триггеры нельзя вызвать из приложения клиента, а также передавать им параметры и получать от них результаты.
Функция, определяемая пользователем, представляет собой обычную функцию, написанную на алгоритмическом языке, например, Pascal. Созданная функция оформляется в виде динамической библиотеки DLL, откуда может быть вызвана обычным способом. Для обеспечения вызова функции системе Windows должен быть известен путь к соответствующей библиотеке. Использование таких функций расширяет состав функций языка SQL.
Механизм кэшированных изменений заключается в том, что на компьютере клиента в кэше (буфере) создается локальная копия данных, и все изменения в данных выполняются в этой копии. Для хранения локальной копии используется специальный буфер (кэш). Сделанные изменения можно подтвердить, перенеся их в основную БД, хранящуюся на сервере, или отказаться от них. Этот механизм напоминает механизм транзакций, но, в отличие от него, снижает нагрузку на сеть, т. к. все изменения передаются в основную БД одним пакетом. Следует иметь к виду, что для всех записей локальной копии отсутствуют блокировки на изменение их значений. Блокировки могут быть установлены другими приложениями для основной БД, находящейся на сервере. Механизм кэшированных изменений реализуется в приложении, для чего компоненты, в первую очередь Database, Table и Query (используемые при доступе с помощью BDE), имеют соответствующие средства. Кроме того, механизм кэшированных изменений поддерживается предназначенным для этого компонентом UpdateSQL.Основные достоинства рассматриваемого механизма проявляются для удаленных БД, но его можно использовать и при работе с локальными БД.
Привилегии представляют собой права доступа к БД. Управление привилегиями заключается в их установке и удалении. После создания объекта БД (например, таблицы) доступ к ней разрешен только создателю и системному администратору, имеющему имя SYSDBA. Для доступа к БД остальных пользователей им нужно назначить соответствующие привилегии. Сразу после появления нового пользователя, созданного например, с помощью программы InterBase Manager Server , этот пользователь имеет минимальные права доступа: ему разрешено только войти в БД (соединиться с ней), указав свое имя и пароль, однако ни один объект этой БД ему не доступен. Чтобы обеспечить возможность активной работы с БД, нужно определить (переопределить) привилегии.
Установку привилегий выполняет инструкция Grant. Привилегии позволяют разграничить доступ к таблицам и просмотрам со стороны пользователей. При этом под «пользователем» понимается любой объект, обращающийся к данным. Кроме собственно пользователя (приложения), такими объектами могут быть таблицы, просмотры, хранимые процедуры и триггеры. Если привилегия предоставляется одновременно нескольким пользователям, то их имена перечисляются через запятую.
9. Информационные хранилища. OLAP-технология
В настоящее время в связи с широким распространением систем поддержки принятия решений организации стремятся сконцентрировать основное внимание на способах использования накопленных оперативных данных в этих системах, имея целью получить за счет этого дополнительный рост своей конкурентоспособности. Прежние системы оперативной обработки проектировались без учета какой-либо поддержки подобных бизнес-требований, а потому преобразование обычных OLTP-систем в системы поддержки принятия решений оказалось чрезвычайно сложной задачей. Как правило, типичная организация имеет множество различных систем операционной обработки с перекрывающимися, а иногда и противоречивыми определениями, например, с разными типами, выбранными для представления одних и тех же данных. Основной задачей организации является преобразование накопленных архивов данных в источник новых знаний, причем таким образом, чтобы пользователю было предоставлено единое интегрированное и консолидированное представление о данных организации. Концепция хранилища данных была задумана как технология, способная удовлетворить требования систем поддержки принятия решений и базирующаяся на информации, поступающей из нескольких различных источников оперативных данных.
Наиболее упорным и удачливым сторонником технологии хранилищ данных оказался Билл Инмон (Bill Inmon), который за активное продвижение этой концепции был удостоен почетного титула “отца – основателя хранилищ данных”. Хранилище данных – предметно-ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных, предназначенный для поддержки принятия решений.
В определении Инмона указанные характеристики данных понимаются следующим образом.
Предметная ориентированность. Хранилище данных организовано вокруг основных предметов (или субъектов) организации (например, клиенты, товары и продажи), а не вокруг прикладных областей деятельности (выписка счета клиенту, контроль товарных запасов и продажа товаров). Это свойство отражает необходимость хранения данных, предназначенных для поддержки принятия решений, а не обычных оперативно-прикладных данных.
Интегрированность. Смысл этой характеристики состоит в том, что оперативно-прикладные данные обычно поступают из разных источников, которые часто имеют несогласованное представление одних и тех же данных, например, используют разный формат. Для предоставления пользователю единого обобщенного представления данных необходимо создать интегрированный источник, обеспечивающий согласованность хранимой информации.
Привязка ко времени. Данные в хранилище точны и корректны только в том случае, когда “они привязаны к некоторому моменту или промежутку времени. Привязанность хранилища данных ко времени следует из большой длительности того периода, за который была накоплена сохраняемая в нем информация, из явной или неявной связи временных отметок со всеми сохраняемыми данными, а также из того факта, что хранимая информация фактически представляет собой набор моментальных снимков состояния данных.
Неизменяемость. Это означает, что данные не обновляются в оперативном режиме, а лишь регулярно пополняются за счет информации из оперативных систем обработки. При этом новые данные никогда не заменяют прежние, а лишь дополняют их. Таким образом, база данных хранилища постоянно пополняется новыми данными, последовательно интегрируемыми с уже накопленной информацией.
Каким бы ни было определение, конечной целью создания хранилища данных является интеграция корпоративных данных в едином репозитории, обращаясь к которому пользователи смогут составлять запросы, генерировать отчеты и выполнять анализ данных. Хранилище данных является рабочей средой для систем поддержки принятия решений, которая извлекает данные, хранимые в различных оперативных источниках, организует их и передает лицам, ответственным за принятие решений в данной организации. Подводя итог, можно сказать, что технология хранилищ данных – это технология управления данными и их анализа.
Технология OLAP. Основной вопрос при обработке информации заключается в том, как обрабатывать все более и более крупные базы данных, содержащие данные с постоянно усложняющейся структурой, сохранив при этом приемлемое время реакции системы на запрос. Архитектура “клиент/сервер” позволяет организациям устанавливать специализированные серверы, оптимизированные для решения задач специфического управления данными. Для таких бизнес-приложений, как анализ рынка и финансовое прогнозирование, требуется использовать запросо-центрированные схемы баз данных, которые, по сути, имеют вид многомерных массивов. Эти приложения характеризуются необходимостью извлекать большое количество записей из очень больших наборов данных и мгновенно вычислять на их основе итоговые значения. Предоставление поддержки для таких приложений является основным назначением всех OLAP-инструментов. Оперативная аналитическая обработка (OLAP) – это динамический синтез, анализ и консолидация больших объемов многомерных данных.
Термин “OLAP” был предложен Коддом в 1993 году и определяет архитектуру, которая поддерживает сложные аналитические приложения. Большинство OLAP- приложений создается на основе специализированных многомерных СУБД или ММ СУБД (multi-dimensional DBMS) с ограниченным набором данных и настраиваемым пользовательским интерфейсом приложений. OLAP-архитектура предусматривает определенные уровни с четким разделением функций между приложением и СУБД. На основе этого разделения появилось новое поколение OLAP-инструментов, предоставляющих такие возможности, которые позволяют обычным СУБД конкурировать со специализированными технологиями ММ СУБД.
Отметим, что таблица в реляционной СУБД может представлять многомерные данные только в двух измерениях. В OLAP-технологии серверы баз данных для хранения данных и связей между ними используют многомерные структуры. Многомерные структуры лучше всего представлять как кубы данных, которые, в свою очередь, могут состоять из других кубов данных. Каждая сторона куба является размерностью.
Многомерные базы данных очень компактны и обеспечивают простые средства просмотра и манипулирования элементами данных, обладающих многими взаимосвязями. Подобный куб легко может быть расширен с целью включения новой размерности, например, содержащей количество сотрудников компании в каждом городе. Над данными в кубе могут выполняться операции матричной арифметики, что позволяет легко вычислить значение среднего дохода на одного сотрудника компании посредством применения простой матричной операции ко всем ячейкам куба:
средний_доход_на_сотрудника = общий_доход / количество_сотрудников.
Рассмотрим проблемы обеспечения OLAP-системы данными, что напрямую связано со складами данных (Datawarehouse). Любая крупная и давно существующая корпорация обладает несколькими базами данных, относящимися к разным видам деятельности. Данные могут иметь разные представления, а иногда могут быть даже несогласованными (например, из-за ошибки ввода в одну из баз данных). Это нехорошо даже для OLTP-систем (выше уже говорилось о все более часто возникающих потребностях в интеграции корпоративных информационных OLTP-систем) и в принципе непригодно для OLAP-систем, которые должны обрабатывать общие исторические согласованные корпоративные данные. Более того, для оперативной аналитической обработки требуется привлечение внешних источников данных, которые тем более могут обладать разными форматами и требовать согласования. Видимо, на подобных рассуждениях и возникла концепция склада данных как предметно-ориентированного, интегрированного, неизменчивого, поддерживающего хронологию набора данных, организованного для целей поддержки управления.
В основе концепции склада данных лежат две основные идеи:
1. Интеграция разъединенных детализированных данных (детализированных в том смысле, что они описывают некоторые конкретные факты, свойства, события и т.д.) в едином хранилище. В процессе интеграции должно выполняться согласование рассогласованных детализированных данных и, возможно, их агрегация. Данные могут поступать из исторических архивов корпорации, оперативных баз данных, внешних источников.
2. Разделение наборов данных, используемых для оперативной обработки, и наборов данных, применяемых для решения задач анализа.
Последнее, на что обращается внимание в этом разделе, — это рынки данных (Data Mart). Рынок данных по своему исходному определению — это набор тематически связанных баз данных, которые содержат информацию, относящуюся к отдельным аспектам деятельности корпорации. По сути дела, рынок данных — это облегченный вариант склада данных, содержащий только тематически объединенные данные. В последнее время все более популярной становится идея совместить концепции склада и рынка данных в одной реализации и использовать склад данных в качестве единственного источника интегрированных данных для всех рынков данных.
Как было сказано выше, проблемой больших информационных хранилищ является то, что накладные расходы на внешнюю память возрастают нелинейно при возрастании объема хранилища. Следовательно, встает проблема архивации данных. Одним из современных направлений и разработок в этой области является применение фрактальных методов в архивации. Понятия фрактал и фрактальная геометрия, появившиеся в конце 70-х, с середины 80-х прочно вошли в обиход математиков и программистов. Слово фрактал образовано от латинского fractus и в переводе означает состоящий из фрагментов. Оно было предложено Бенуа Мандельбротом в 1975 году для обозначения нерегулярных, но самоподобных структур, которыми он занимался.
Как уже говорилось, одним из основных свойств фракталов является самоподобие. В самом простом случае небольшая часть фрактала содержит информацию о всем фрактале. Определение фрактала, данное Мандельбротом, звучит так: «Фракталом называется структура, состоящая из частей, которые в каком-то смысле подобны целому». Фракталы с большой точностью описывают многие физические явления и образования реального мира: горы, облака, турбулентные (вихревые) течения, корни, ветви и листья деревьев, кровеносные сосуды, что далеко не соответствует простым геометрическим фигурам.
Для того, чтобы представить все многообразие фракталов удобно прибегнуть к их общепринятой классификации. Существует три класса фракталов.
1. Геометрические фракталы. Фракталы этого класса самые наглядные. В двухмерном случае их получают с помощью ломаной (или поверхности в трехмерном случае), называемой генератором. За один шаг алгоритма каждый из отрезков, составляющих ломаную, заменяется на ломаную-генератор в соответствующем масштабе. В результате бесконечного повторения этой процедуры получается геометрический фрактал.
2. Алгебраические фракталы. Это самая крупная группа фракталов. Получают их с помощью нелинейных процессов в n-мерных пространствах. Наиболее изучены двухмерные процессы. Интерпретируя нелинейный итерационный процесс, как дискретную динамическую систему, можно пользоваться терминологией теории этих систем: фазовый портрет, установившийся процесс, аттрактор и т.д.
3. Стохастические фракталы. Еще одним известным классом фракталов являются стохастические фракталы, которые получаются в том случае, если в итерационном процессе хаотически менять какие-либо его параметры. При этом получаются объекты очень похожие на природные — несимметричные деревья, изрезанные береговые линии и т.д. Двумерные стохастические фракталы используются при моделировании рельефа местности и поверхности моря .
Одни из наиболее мощных приложений фракталов лежат в компьютерной графике. Во-первых, это фрактальное сжатие изображений, и, во-вторых, построение ландшафтов, деревьев, растений и генерирование фрактальных текстур. Достоинства алгоритмов фрактального сжатия изображений — очень маленький размер упакованного файла и малое время восстановления картинки. Фрактально упакованные картинки можно масштабировать без появления пикселизации. Но процесс сжатия занимает продолжительное время и иногда длится часами. Алгоритм фрактальной упаковки с потерей качества позволяет задать степень сжатия, аналогично формату jpeg. В основе алгоритма лежит поиск больших кусков изображения подобных некоторым маленьким кусочкам. И в выходной файл записывается только какой кусочек какому подобен. При сжатии обычно используют квадратную сетку (кусочки — квадраты), что приводит к небольшой угловатости при восстановлении картинки, шестиугольная сетка лишена такого недостатка.
Применение фрактальных методов в архивации помогает решать проблемы сжатия больших объемов информационных массивов.
10. Перспективы развития БД и СУБД
Объектно-ориентированные СУБД. Объектно-ориентированный подход является одним из новых подходов к созданию программного обеспечения, который считается очень перспективным для решения некоторых классических проблем разработки программного обеспечения. Базовым понятием объектно-ориентированной технологии является то, что все программное обеспечение должно всегда, когда это возможно, создаваться на основе стандартных и повторно используемых компонентов. Традиционно создание программного обеспечения и управление базами данных представляли собой совершенно разные дисциплины. Технология баз данных была сконцентрирована в основном на статических концепциях хранения информации, тогда как технология создания программного обеспечения моделировала динамические аспекты программного обеспечения. С появлением следующего (третьего) поколения систем управления базами данных, а именно объектно-ориентированных СУБД (ООСУБД) и объектно-реляционных СУБД (ОРСУБД), эти две дисциплины слились воедино, что позволило параллельно моделировать данные и процессы, действующие на эти данные.
Очевидный успех реляционных систем в течение двух последних десятилетий позволяет сторонникам традиционных подходов считать, что реляционную модель достаточно расширить дополнительными (объектно-ориентированными) возможностями. Другие специалисты считают, что базовая реляционная модель неспособна адекватно обслуживать такие сложные приложения, как системы автоматизированного проектирования и автоматизированной разработки программного обеспечения, а также геоинформационные системы.
Приведем некоторые преимущества, которые часто цитируются в поддержку объектно-ориентированного подхода.
Определение системы на основе объектов упрощает создание программных компонентов, которые очень близко имитируют область их применения, облегчая таким образом понимание особенностей системы и ее проектирование.
Благодаря инкапсуляции и сокрытию информации использование объектов и сообщений способствует модульному проектированию, поскольку реализация одного объекта зависит не от внутренних особенностей других объектов, а только от типа их реакции на те или иные сообщения. Кроме того, условие модульности накладывается принудительно, а потому позволяет создавать более надежное программное обеспечение.
Использование классов и механизма наследования способствует разработке повторно используемых и расширяемых компонентов при создании новых или модернизации существующих систем.
ООСУБД появились сначала в инженерно-конструкторских приложениях и только недавно получили признание у разработчиков финансовых и телекоммуникационных приложений. Хотя доля рынка ООСУБД все еще остается очень маленькой , тем не менее ООСУБД продолжают находить все новые области применения, например в World Wide Web. Действительно, по оценкам некоторых аналитиков, рынок ООСУБД ежегодно будет возрастать на 50%, что выше темпов роста всего рынка баз данных в целом.
Распределенные СУБД. Основной причиной разработки систем, использующих базы данных, является стремление интегрировать все обрабатываемые в организации данные в единое целое и обеспечить к ним контролируемый доступ. Хотя интеграция и предоставление контролируемого доступа могут способствовать централизации, последняя не является самоцелью. На практике создание компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный подход, по сути, отражает организационную структуру компании, логически состоящую из отдельных подразделений, отделов, проектных групп и тому подобного, которые физически распределены по разным офисам, отделениям, предприятиям или филиалам, причем каждая отдельная единица имеет дело с собственным набором обрабатываемых данных. Разработка распределенных баз данных, отражающих организационные структуры предприятий, позволяет сделать данные, поддерживаемые каждым из существующих подразделений, общедоступными, обеспечив при этом их сохранение именно в тех местах, где они чаще всего используются. Подобный подход расширяет возможности совместного использования информации, одновременно повышая эффективность доступа к ней.
Распределенные системы призваны разрешить проблему островов информации. Базы данных иногда рассматривают как некие электронные острова, представляющие собой отдельные и, в общем случае, труднодоступные места, подобные удаленным друг от друга островам. Данное положение может являться следствием географической разобщенности, несовместимости используемой компьютерной архитектуры, несовместимости используемых коммутационных протоколов и т.д. Интеграция отдельных баз данных в одно логическое целое способна изменить подобное положение дел.
Распределенная база данных – это набор логически связанных между собой разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети. Тогда распределенная СУБД – это программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распределенность информации прозрачной для конечного пользователя.
Система управления распределенными базами данных (СУРБД) состоит из единой логической базы данных, разделенной на некоторое количество фрагментов. Каждый фрагмент базы данных сохраняется на одном или нескольких компьютерах, которые соединены между собой линиями связи и каждый из которых работает под управлением отдельной СУБД. Любой из сайтов способен независимо обрабатывать запросы пользователей, требующие доступа к локально сохраняемым данным (что создает определенную степень локальной автономии), а также способен обрабатывать данные, сохраняемые на других компьютерах сети.
Мультимедийные информационные системы. В следующем поколении компьютеризованных приложений немногое вызывает столь большой интерес, как мультимедиа. Дополнение аудио, видео, текста и изображений к традиционным типам приложений стало еще одним шагом в продвижении к более тесному сближению компьютерных систем с теми сущностями реального мира, для представления которых они создаются. В простейшем случае мультимедийная информационная система концептуально подобна любой другой информационной системе. Ее среда подразделяется на систему доставки (пользовательский интерфейс), некоторую разновидность базовых возможностей управления информацией, а также коммуникационную инфраструктуру. В мультимедийных системах все эти три уровня имеют свойства, отличные от свойств их аналогов в более традиционных компьютерных средах. Это касается, в том числе, и методов разработки приложений.
Рассмотрим сначала систему доставки, средствами которой пользователь вводит запросы и получает возвращаемую системой информацию. Гипермедийные интерфейсы будут главными системами доставки для следующего поколения мультимедийных приложений. Такие интерфейсы позволяют пользователю просматривать информационную базу, состоящую из многих различных типов данных, регламентированными, непредсказуемыми способами, которые являются существенными для получения сведений из информационной базы.
Саму информационную базу мультимедийной информационной системы можно было бы рассматривать как конгломерат многих типов данных, обсуждаемых в этой и в других главах книги. Типичная мультимедийная информационная система обычно оперирует следующими типами данных:
- «нормальные» типы данных в базе данных (которые можно встретить в реляционной или сетевой базе данных или даже в поддерживаемых самим приложением плоских файлах);
- данные неподвижных изображений, как в фотографиях;
- другие типы графики;
- данные движущихся изображений (видео);
- аудио (т.е. голос, музыкальные звуки, звуки, издаваемые животными);
- текстовые данные, например такие, которые можно найти в документах текстовых процессоров или файлах электронных таблиц.
Итак, мы обсудили систему доставки и информационную базу. Рассмотрим теперь коммуникационную инфраструктуру. Общее правило большого пальца относительно поддержки требований мультимедийных информационных систем заключается в следующем: «Чем больше используется «оживших» данных, тем более широкая необходима полоса пропускания». Под «ожившими» мы понимаем здесь такие данные, как видео- или высококачественные (например, стерео) аудиоданные. Такие данные действительно не только занимают огромные объемы пространства памяти, если не используется техника сжатия данных (на одну минуту не слишком качественного видео при передаче 15 кадров в секунду, что составляет лишь половину телевизионной скорости, потребовалось бы 117 Мбайт памяти15), но требуют также для своей поддержки сетей с высокой пропускной способностью. Это справедливо и для локальных сетей ЭВМ, и для глобальных распределенных сред. Потребности адекватной поддержки крупномасштабной передачи полного спектра мультимедийных типов данных привели к появлению глобальных сетевых технологий (Wide Area Networking, WAN), например таких, как асинхронный режим передачи данных или переключаемый мулътимегабитовый сервис данных.
Один из простых мнемонических способов выражения требований, удовлетворение которых обеспечивает полноценное использование мультимедийной среды на настольном компьютере, состоит в принципе «4-х Г»: гигабайт основной памяти, как минимум, гигабайт внешней памяти, гига операций в секунду и гигабит в секунду — скорость передачи данных. При столь быстрых темпах прогресса в области технологий технических средств, к которым мы стали привыкать, такая базовая технология, без сомнения, появится.
В управлении мультимедийной информацией принципы временных и пространственных данных часто оказываются весьма важными при формировании мультимедийных документов. Например, создание электронного видео требует, чтобы кадры были правильно упорядочены. Для достижения этой цели, особенно когда исходные данные для видео объединяются из ряда различных источников, необходимо дополнить такую информацию временными свойствами. Подобным же образом составление мультимедийного документа, например, электронного журнала, означает, что должны поддерживаться пространственные отношения между данными, когда документ компонуется не только из различных типов сред (например, видео показывается слева от текста и до вывода аудио), но также и внутри среды заданного типа.
Традиционные методологии разработки приложений не удается достаточно хорошо перенести на мультимедийные системы. Действительно, в разработках мультимедийных приложений не применяется «программирование». Более подходящий здесь термин «создание» (authoring). Вместо языков программирования и компиляторов доминирующей парадигмой разработки, возникшей мультимедиа, являются системы скриптов (например, Microsoft Viewer). В силу того, что мультимедийных приложений разрабатывается очень много, возможности скриптов должны быть достаточными дли создания логики таких приложений, которая бы позволяла пользователям выполнить необходимые им функции в гипермедийной среде (например, перемещение произвольным образом между различными темами).
Гипертекстовые БД. Публикация баз данных в Интернете — это размещение информации из баз данных на Web-страницах сети. Отметим, что такая публикация связана с решением следующих типичных задач, встающих перед разработчиками современного программного обеспечения:
- организация взаимосвязи СУБД, работающих на различных платформах;
- построение информационных систем в Интернете на основе многоуровневой архитектуры БД (архитектура таких систем включает дополнительный уровень — Web-сервер с модулями расширения серверной части, который и реализует возможность информационного обмена и публикации БД в глобальной сети);
- построение локальных интранет-сетей на основе технологии публикации БД в Интернете (локальные сети строятся на принципах Интернета с выходом при необходимости в глобальную сеть);
- использование в Интернете информации из существующих локальных сетевых баз данных (при необходимости опубликования в глобальной сети информации из локальных сетей);
- применение БД для упорядочивания (каталогизирования) информации (огромный объем данных, представленных в Интернете, не обладает требуемой степенью структурированности, что делает процесс поиска необходимой информации весьма сложным и долгим);
- применение языка SQL для поиска необходимой информации в БД;
- использование средств СУБД для обеспечения безопасности данных, разграничения доступа и управления транзакциями при создании Интернет-магазинов, защищенных информационных систем и т. д.;
- стандартизация пользовательского интерфейса на основе применения Web-обозревателей с типовым внешним видом пользовательского интерфейса и его типовой реакцией на действия пользователя;
- использование Web-обозревателя в качестве дешевой клиентской программы для доступа к БД.
Размещение информации из БД в Интернете представляет собой новую информационную технологию, получившую широкое распространение в последнее время в связи с ростом популярности и доступности «всемирной паутины». Рассмотрим базовые элементы Интернет-технологий, являющиеся основой для разработки Web-приложений.
В Интернете вся информация размещается на Web-страницах, для написания которых используются язык HTML (Hyper Text Markup Language — язык разметки гипертекста) или его расширения, такие как DHTML (Dynamic – динамический HTML) и XML ( eXtensible Markup Language — расширяемый язык разметки). В состав Web-страницы могут входить текстовая информация, ссылки на другие Web-страницы, графические изображения, аудио- и видеоинформация и другие данные. Web-страницы хранятся на Web-сервере.
Для доступа к Web-страницам используются специальные клиентские программы – Web-обозреватели (программы просмотра, называемые также Web -браузерами или Web -броузерами — от англ. browser), находящиеся на компьютерах пользователей. Обозреватель формирует запрос на получение требуемой страницы или другого ресурса с помощью специального адреса URL (Uniform Recourse Locator — универсальный указатель ресурса). Этот адрес определяет тип протокола для передачи ресурса, имя домена, используемое для доступа к Web-узлу, номер порта, локальный путь к файлу и дополнительные аргументы. Соединение с Web-узлом устанавливается с помощью протокола передачи данных HTTP (Hyper Text Transfer Protocol — протокол передачи гипертекста).
Как отмечалось, расширяемый язык разметки XML представляет собой развитие языка HTML и по сравнению с ним обеспечивает ряд дополнительных возможностей. Главное отличие XML от HTML заключается в том, что он позволяет определить структуру документа и типы хранимых в нем данных. Напомним, что одно из достоинств XML состоит в том, что в разрабатываемых с его помощью документах описание структуры хранимых данных отделено от собственно данных. В связи с этим XML представляет собой удобное средство обмена данными между отдельными приложениями, т. к. позволяет обеспечить согласованный обмен данными в случаях, когда структуры данных (например, имена и типы полей) в приложениях различаются.
Кроме того, с помощью XML можно упростить доступ к данным, хранимым в базах данных. Например, для доступа к данным персональных БД или табличного процессора Excel пользователю требуется установить соответствующие программные инструменты. Вместо этого можно создать активные серверные или сценарии на языке JScript или VBScript, которые будут извлекать данные из БД и помещать их в документ XML. В дальнейшем информацию из полученного таким образом документа XML можно использовать в других приложениях или отображать на Web-страницах. Т. е. полученные данные становятся доступными для всех пользователей, имеющих обозреватель, независимо от наличия СУБД или табличного процессора. Документы XML могут использоваться как на стороне клиента, так и на стороне сервера.
База данных с правильной структурой обеспечит вам доступ к актуальным и точным сведениям. Поскольку правильная структура важна для выполнения поставленных задач при работе с базой данных, имеет смысл изучить принципы создания баз данных. Это поможет вам создать базу данных, отвечающую вашим потребностям и позволяющую быстро вносить в нее изменения.
В этой статье приведены рекомендации по планированию базы данных для настольного компьютера. Вы узнаете, как выбирать необходимые сведения, как распределять данные по таблицам и столбцам и как таблицы связаны друг с другом. Прежде чем создавать свою первую базу данных, прочитайте эту статью.
Важно:
Access возможности разработки, которые можно создавать приложения баз данных для Интернета. Многие аспекты проектирования отличаются при проектировании веб-страниц. В этой статье не обсуждается проектирование веб-баз данных. Дополнительные сведения см. в статье Создание базы данных Access для публикации в Интернете.
В этой статье
-
Некоторые термины, связанные с базами данных
-
Что такое правильная структура базы данных?
-
Процесс проектирования
-
Определение назначения базы данных
-
Поиск и упорядочение необходимых сведений
-
Распределение данных по таблицам
-
Преобразование элементов данных в столбцы
-
Задание первичных ключей
-
Создание связей между таблицами
-
Усовершенствование структуры
-
Применение правил нормализации
Некоторые термины, связанные с базами данных
В Access данные упорядочиваются в таблицах, которые представляют собой списки строк и столбцов, напоминающие бухгалтерский блокнот или электронную таблицу. В простой базе данных может быть всего одна таблица. Для большинства баз данных их потребуется несколько. Например, в одной таблице можно хранить сведения о товарах, в другой — о заказах, а в третьей — о клиентах.
Каждую строку правильнее называть записью, а каждый столбец — полем. Запись — это эффективный и согласованный способ объединения сведений о чем-либо. Поле — это отдельный элемент сведений (элементы такого типа есть в каждой записи). Например, в таблице «Товары» каждая строка или запись может содержать сведения об одном товаре. Каждые столбец или поле содержат сведения определенного типа об этом товаре, например название или цену.
К началу страницы
Что такое правильная структура базы данных?
В основе процесса создания базы данных лежат определенные принципы. Первый принцип состоит в том, чтобы избегать повторяющихся сведений (также называемых избыточными данными), поскольку они занимают много места и повышают вероятность появления ошибок и несоответствий. Второй принцип провозглашает важность правильности и полноты сведений. Если база данных содержит неправильные сведения, то все отчеты, созданные на основе сведений из этой базы данных, будут содержать неправильные сведения. В итоге решения, которые принимаются на основе этих отчетов, могут оказаться неверными.
Правильная структура базы данных подразумевает:
-
распределение сведений по тематическим таблицам для уменьшения количества повторяющихся данных;
-
предоставление приложению Access данных, необходимых для объединения сведений в таблицах при необходимости;
-
обеспечение точности и целостности сведений;
-
соответствие требованиям к обработке данных и созданию отчетов.
К началу страницы
Процесс проектирования
Процесс проектирования включает следующие этапы:
-
Определение назначения базы данных
Помогает подготовиться к остальным этапам.
-
Поиск и упорядочение необходимых сведений
Соберите сведения всех типов, которые потребуется внести в базу данных, например названия товаров и номера заказов.
-
Разделение данных по таблицам
Разделите элементы данных по основным темам или группам, например «Товары» и «Заказы». Затем для каждой темы создается таблица.
-
Преобразование элементов данных в столбцы
Решите, какие сведения будут храниться в каждой таблице. Каждый элемент становится полем и отображается в виде столбца в таблице. Например, таблица «Сотрудники» может содержать такие поля, как «Фамилия» и «Дата найма».
-
Задание первичных ключей
Выберите первичный ключ для каждой таблицы. Первичный ключ — это столбец, однозначно определяющий каждую строку. Примеры: «Код товара» и «Код заказа».
-
Настройка связей между таблицами
Проанализируйте все таблицы и определите, как данные одной таблицы связаны с данными других таблиц. Добавьте в таблицы поля или создайте новые таблицы для формирования необходимых связей.
-
Усовершенствование структуры
Проверьте структуру базы данных на наличие ошибок. Создайте таблицы и добавьте несколько записей с образцами данных. Посмотрите, можно ли получить нужные результаты из таблиц. При необходимости внесите изменения в структуру.
-
Применение правил нормализации
Примените правила нормализации, чтобы проверить правильность структуры таблиц. При необходимости внесите изменения в таблицы.
К началу страницы
Определение назначения базы данных
Рекомендуется записать на бумаге назначение базы данных: ее цель, предполагаемое применение и список пользователей, которые будут с ней работать. Небольшой базе данных для домашнего бизнеса можно дать простое определение, например: «База данных содержит сведения о клиентах и используется для почтовой рассылки и создания отчетов». Для более сложной базы данных, с которой будет работать множество людей, как это часто бывает в больших организациях, определение может состоять из нескольких абзацев, включая время и способы использования ее разными людьми. Идея состоит в том, чтобы детально сформулировать определение, к которому затем можно обращаться в процессе проектирования. Такое определение поможет сосредоточиться на целях и задачах при принятии решений.
К началу страницы
Поиск и упорядочение необходимых сведений
Чтобы найти и упорядоступить необходимую информацию, начните с имеющихся сведений. Например, вы можете записать заказы на покупку в записи книги или сохранить сведения о клиентах в бумажных формах в картотеке. Соберите эти документы и соберите в списке каждый тип показанной информации (например, каждое поле, заполненное в форме). Если у вас еще нет форм, представьте, что вам нужно создать форму для записи сведений о клиенте. Какие сведения нужно поместить в форму? Какие поля заливки нужно создать? Определите и перечислить каждый из этих элементов. Предположим, что в настоящее время список клиентов находится на индексных карточках. Изучив эти карточки, вы можете показать, что каждая карточка содержит имя клиента, адрес, город, штат, почтовый индекс и номер телефона. Каждый из этих элементов представляет потенциальный столбец в таблице.
При подготовке списка не старайтесь придать ему законченный вид с первого раза. Записывайте все элементы, которые приходят в голову. Если с базой данных будет работать кто-то еще, попросите их внести свои предложения. Позднее вы сможете скорректировать список.
Теперь подумайте, какие типы отчетов или почтовых рассылок будут выполняться на основе сведений из базы данных. Например, это может быть отчет о продажах товаров по регионам или сводный отчет о складских запасах товаров. Возможно, вы также будете отправлять клиентам стандартные письма, содержащие сведения о продажах или специальных предложениях. Продумайте структуру отчета и представьте себе его внешний вид. Какие сведения нужно включить в отчет? Составьте список. То же сделайте для писем и других отчетов, которые предполагается создавать.

Продумывая структуру предполагаемых отчетов и почтовых рассылок, вы определите те элементы, которые нужно включить в базу данных. Предположим, вы даете клиентам возможность подписаться на периодическую рассылку обновлений (или отказаться от нее) и хотите распечатать список тех, кто подписался. Для записи этих сведений вы добавляете в таблицу клиентов столбец «Отправка почты». В этом поле для каждого клиента можно выбрать значение «Да» или «Нет».
Для отправки клиентам почтовых сообщений требуется записать еще один элемент данных. Если клиент захочет получать почтовые сообщения, вам потребуется его адрес электронной почты. Следовательно, для каждого клиента нужно записать этот адрес.
Имеет смысл создать прототип каждого отчета или выходного списка и продумайте, какие элементы потребуется создать для этого отчета. Например, при проверке письма на бланке могут возникнуть некоторые моменты. Если вы хотите включить правильное приветствие, например строку «Г-н», «Г-жа» или «Ms», которая начинает приветствие, необходимо создать элемент приветствия. Кроме того, письма обычно начинаются с буквы «Уважаемый г-н Климов», а не «Уважаемый. Г-н Сильвстер Климов». Это позволяет сохранить фамилию отдельно от имени.
Важно помнить, что каждый фрагмент сведений целесообразно разделить на минимальные элементы. Например, лучше разделить имя и фамилию, чтобы их удобнее было использовать. В частности, чтобы отсортировать отчет по фамилиям, фамилия должна храниться отдельно. Вообще, если вы хотите выполнять сортировку, поиск, вычисления или отчет на основе элемента данных, следует поместить этот элемент в отдельное поле.
Подумайте о тех вопросах, ответы на которые вам поможет получать база данных. Например, каков объем продаж отдельного товара за последний месяц? Где находятся самые перспективные клиенты? Кто поставляет самый продаваемый товар? Список возможных вопросов поможет вам определить дополнительные элементы данных для записи.
Собрав все нужные сведения, вы можете переходить к следующему этапу.
К началу страницы
Распределение данных по таблицам
Чтобы распределить данные по таблицам, выделите основные группы или темы. Например, после поиска и упорядочения сведений для базы данных продаж товаров вы можете получить предварительный список такого вида:

Основные группы здесь — товары, поставщики, клиенты и заказы. Поэтому имеет смысл использовать четыре таблицы: по одной для сведений о товарах, поставщиках, клиентах и заказах. Это не окончательный список, но неплохое начало. Вы можете уточнять список, пока не получите наиболее эффективную структуру.
При первом просмотре предварительной таблицы вам может показаться, что удобнее было бы поместить все сведения в одну таблицу, а не в четыре, как показано на предыдущей иллюстрации. Сейчас вы поймете, почему это плохая идея. Посмотрите на эту таблицу:
В этом случае каждая строка содержит сведения о товаре и его поставщике. Так как у одного поставщика может быть несколько товаров, имя и адрес поставщика должны повторяться несколько раз. Это пустая трата места на диске. Гораздо лучше записать сведения о поставщике только один раз в отдельной таблице «Поставщики» и связать ее с таблицей «Товары».
Вторая проблема с этой структурой возникает тогда, когда нужно изменить сведения о поставщике. Предположим, вам нужно изменить адрес поставщика. Но поскольку адрес указан во многих полях, можно случайно изменить его только в одном поле, забыв о других. Эту проблему можно решить, записав адрес поставщика только в одном поле.
При проектировании базы данных всегда старайтесь записать каждый факт только один раз. Если вы обнаружите, что сведения повторяются (например, адрес конкретного поставщика), поместите их в отдельную таблицу.
Наконец, предположим, что у вас есть только один товар, поставляемый компанией Coho Winery, и вы хотите удалить этот товар, но сохранить имя и адрес поставщика. Как удалить запись о товаре, не потеряв сведений о поставщике? Это невозможно. Поскольку каждая запись содержит сведения и о товаре, и о поставщике, вы не можете удалить их по отдельности. Чтобы разделить эти сведения, необходимо сделать из одной таблицы две: одну — для сведений о товаре, другую —для сведений о поставщике. Тогда удаление записи о товаре не приведет к удалению записи о поставщике.
Выбрав тему для таблицы, проследите, чтобы столбцы в ней содержали сведения только по этой теме. Например, в таблице товаров должны храниться сведения только о товарах. Поскольку адрес поставщика относится к сведениям о поставщиках, а не о товарах, он должен храниться в таблице поставщиков.
К началу страницы
Преобразование элементов данных в столбцы
Чтобы определить столбцы таблицы, решите, какие сведения по теме таблицы вам нужно отслеживать. Например, в таблицу клиентов можно включить столбцы «Имя», «Адрес», «Город, область, почтовый индекс», «Отправка почты», «Обращение» и «Адрес электронной почты». Набор столбцов одинаков для всех записей в таблице, поэтому для каждой записи можно хранить одни и те же сведения. Например, столбец «Адрес» содержит адреса клиентов. Каждая запись содержит сведения только об одном клиенте, а поле адреса — его адрес.
После определения первоначального набора столбцов для каждой таблицы вы можете затем уточнять и дополнять их. Например, удобно хранить имя и фамилию клиента в разных столбцах, чтобы проще было выполнять сортировку, поиск и индексирование только по этим столбцам. Адрес также состоит из нескольких компонентов (собственно адреса, города, области, почтового индекса и страны), которые лучше хранить в отдельных столбцах. Например, если вы захотите выполнить поиск, фильтрацию или сортировку по областям, вам потребуется, чтобы сведения об областях хранились в отдельном столбце.
Вам также нужно определить, какого рода данные будут храниться в базе данных: отечественные или международные. Например, если вы планируете хранить в базе данных международные адреса, лучше использовать столбец «Регион», а не «Страна», потому что в таком столбце можно указывать области внутри своей страны и регионы других стран. Точно так же в поле «Почтовый индекс» можно будет хранить почтовые индексы разных стран.
В списке ниже приведены некоторые советы по определению столбцов.
-
Не включайте вычисляемые данные
Не следует хранить в таблицах результаты вычислений. Лучше пусть Access выполняет вычисления всякий раз, как вы захотите увидеть результат. Предположим, что в отчете о заказанных товарах отображаются промежуточные итоги для заказанных товаров каждой категории. Но в таблице нет столбца для промежуточных итогов. Вместо этого в таблице есть столбец для заказанных товаров, в котором хранится количество единиц каждого товара. Используя эти данные, Access вычисляет промежуточные итоги каждый раз при печати отчета. Сами промежуточные итоги не требуется хранить в таблице.
-
Разбивайте информацию на минимальные логические компоненты
Может возникнуть желание использовать одно поле для полных имен или названий продуктов вместе с описаниями продуктов. Если в поле объединится несколько разных сведений, позднее будет сложно получить отдельные факты. Попробуйте разбить данные на логические части; Например, можно создать отдельные поля для имени и фамилии или для названия продукта, категории и описания.

Доработав столбцы с данными во всех таблицах, вы можете перейти к выбору первичного ключа для каждой из них.
К началу страницы
Задание первичных ключей
Каждая таблица должна содержать столбец или набор столбцов для однозначного определения каждой строки таблицы. Часто для этого используется уникальный идентификационный номер, например код сотрудника или серийный номер. В базах данных эти сведения называются первичным ключом таблицы. Используя поля первичных ключей, Access быстро связывает данные из нескольких таблиц и сводит их для вас воедино.
Если у вас уже есть уникальный идентификатор для таблицы, например код товара, однозначно определяющий товар в каталоге, вы можете использовать его в качестве первичного ключа таблицы, но только при условии, что значения в этом столбце будут разными для всех записей. В первичном ключе не должно быть повторяющихся значений. Например, не следует использовать в качестве первичного ключа имена людей, поскольку они не уникальны. С большой долей вероятности в одной таблице могут оказаться двое людей с одинаковыми именами.
У первичного ключа всегда должно быть значение. Если в какой-то момент столбец может содержать неназначенное или неизвестное (отсутствующее) значение, его нельзя использовать в качестве компонента первичного ключа.
Всегда выбирайте первичный ключ, значение которого не изменится. В базе данных с несколькими таблицами первичный ключ одной таблицы может использоваться в качестве ссылки в других таблицах. Если первичный ключ изменяется, это изменение необходимо применить ко всем ссылкам на этот ключ. Используя неизменяемый первичный ключ, вы снижаете вероятность нарушения синхронизации с другими таблицами.
Часто в качестве первичного ключа используется произвольное уникальное число. Например, каждому заказу можно назначить уникальный номер. Целью номера заказа является определение заказа. После того как оно будет назначено, оно никогда не изменится.
Если вы не имеете в виду столбец или набор столбцов, которые могут стать хорошим первичным ключом, рассмотрите возможность использования столбца с типом данных «Автономер». При использовании типа данных «Тип данных», Access автоматически назначает значение. Такой идентификатор не имеет смысла; Оно не содержит фактических сведений, описывающих строку, которую она представляет. Идентификаторы factless идеально подходят для использования в качестве первичного ключа, так как они не изменяются. Первичный ключ, содержащий сведения о строке (например, номер телефона или имя клиента), может измениться, так как сами фактуальные данные могут измениться.
1. Столбец с типом данных «Счетчик» — отличный первичный ключ. Коды товаров никогда не совпадают.
В некоторых случаях первичный ключ таблицы составляется из несколько полей. Например, в таблице «Сведения о заказах», которая содержит элементы строк заказов, первичный ключ может включать два столбца: «Код заказа» и «Код товара». Первичный ключ из нескольких столбцов называется составным.
В базе данных продаж вы можете создать столбец типа «Счетчик» для первичного ключа каждой из таблиц: «Код товара» для таблицы товаров, «Код заказа» для таблицы заказов, «Код клиента» для таблицы клиентов и «Код поставщика» для таблицы поставщиков.

К началу страницы
Создание связей между таблицами
Теперь, когда вы распределили сведения по таблицам, вам нужен способ их осмысленного объединения. Например, показанная ниже форма содержит сведения из нескольких таблиц.
1. Эта форма содержит данные из таблиц клиентов,
2. сотрудников,
3. заказов,
4. товаров
5. и сведений о заказах.
Access — это система управления реляционными базами данных. В реляционной базе данных сведения распределяются по отдельным тематическим таблицам. Для последующего объединения данных используются связи между таблицами.
К началу страницы
Создание связи «один ко многим»
Рассмотрим пример таблиц «Поставщики» и «Товары» в базе данных «Заказы на товары». Поставщик может поставлять любое количество товаров. Следуют, что у любого поставщика, представленного в таблице «Поставщики», может быть много товаров, представленных в таблице «Товары». Поэтому связь между таблицами «Поставщики» и «Товары» является связью «один-к-многим».
Чтобы создать связь «один ко многим» в структуре базы данных, добавьте первичный ключ на стороне «один» в таблицу на стороне «многие» в виде дополнительного столбца или столбцов. Например, в данном случае вы добавляете столбец «Код поставщика» из таблицы «Поставщики» в таблицу «Товары». Затем Access сможет с помощью кода поставщика в таблице «Товары» найти поставщика для каждого товара.
Столбец «Код поставщика» в таблице «Товары» называется внешним ключом. Внешний ключ — это первичный ключ другой таблицы. Столбец «Код поставщика» в таблице «Товары» является внешним ключом, потому что он также является первичным ключом в таблице «Поставщики».

Создавая пары первичных и внешних ключей, вы создаете основу для объединения сведений из связанных таблиц. Если вы не знаете точно, в каких таблицах должен быть общий столбец, определение связи «один ко многим» обеспечивает необходимость общего столбца для двух таблиц.
К началу страницы
Создание связи «многие ко многим»
Рассмотрим связь между таблицами «Товары» и «Заказы».
Отдельный заказ может включать несколько товаров. С другой стороны, один товар может входить в несколько заказов. Таким образом, для каждой записи в таблице «Заказы» может существовать несколько записей в таблицы «Товары». Для каждой записи в таблице «Товары» может быть несколько записей в таблице «Заказы». Этот тип связи называется отношением «многие-к-многим», так как для любого товара может быть множество заказов. и для любого заказа может быть множество продуктов. Обратите внимание на то, что для обнаружения связей «многие-к-многим» между таблицами важно учитывать обе стороны связи.
Связь между темами двух таблиц (заказов и товаров) относится к типу «многие ко многим». Это проблема. Представьте, что произойдет, если для создания связи между двумя таблицами вы попытаетесь добавить поле «Код товара» в таблицу «Заказы». Чтобы заказ мог включать несколько товаров, вам потребуется несколько записей для каждого заказа в таблице «Заказы». В этом случае сведения о заказе придется повторять в каждой строке заказа, что может привести к неэффективности структуры таблицы и потере точности данных. Та же проблема возникает при создании поля «Код заказа» в таблице «Товары» — для каждого товара в таблице потребуется несколько записей. Как решить эту проблему?
Ответ на этот вопрос заключается в том, чтобы создать третью (связуемую) таблицу, которая разбивает связь «многие-к-многим» на две связи «один-к-многим». Первичные ключи двух таблиц вставляются в третью таблицу. В результате в третьей таблице записывают все экземпляры связи.
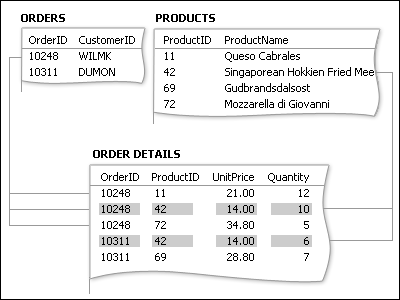
Каждая запись в таблице «Сведения о заказах» представляет собой отдельный элемент строки заказа. Первичный ключ этой таблицы состоит из двух полей — внешних ключей таблиц «Заказы» и «Товары». Использовать только поле «Код заказа» в качестве первичного ключа для этой таблицы нельзя, поскольку в одном заказе может быть несколько элементов строки. Код заказа повторяется для каждого элемента строки, так что это поле не содержит уникальные значения. Использовать только поле «Код товара» также нельзя, поскольку один товар может входить в разные заказы. Но вместе эти два поля всегда обеспечивают уникальное значение для каждой записи.
В базе данных продаж товаров между таблицами «Заказы» и «Товары» нет прямой связи. Но они связаны опосредованно через таблицу «Сведения о заказах». Связь «многие ко многим» между заказами и товарами представлена в базе данных двумя связями «один ко многим».
-
Связь «один ко многим» между таблицами «Заказы» и «Сведения о заказах». В каждом заказе может быть несколько элементов строк, но каждый элемент строки связан только с одним заказом.
-
Связь «один ко многим» между таблицами «Товары» и «Сведения о заказах». Каждый товар может быть связан с несколькими элементами строк, но каждый элемент строки связан только с одним товаром.
В таблице «Сведения о заказах» можно определить все продукты по определенному заказу. Вы также можете определить все заказы для определенного товара.
После создания таблицы «Сведения о заказах» список таблиц и полей может выглядеть так:

К началу страницы
Создание связи «один к одному»
Еще бывает связь «один к одному». Предположим, вам нужно записать дополнительные сведения о товаре, которые редко используются или применяются к небольшому количеству товаров. Поскольку эти сведения используются редко и в результате их хранения в таблице «Товары» образуются пустые поля для всех товаров, к которым они неприменимы, вам лучше поместить эти сведения в отдельную таблицу. Как и в таблице товаров, в качестве первичного ключа используется код товара. Связь между этой дополнительной таблицей и таблицей «Товары» относится к типу «один к одному». Каждой записи таблицы товаров соответствует одна запись в дополнительной таблице. При определении такой связи у обеих таблиц должно быть общее поле.
Если оказывается, что в базе данных нужно создать связь «один к одному», подумайте, можно ли поместить сведения из двух таблиц в одну таблицу. Если вы этого не хотите по какой-либо причине, например из-за возникновения пустых полей, посмотрите в приведенном ниже списке, как представлять связь в структуре базы данных.
-
Если две таблицы объединены одной тематикой, для создания связи можно использовать один и тот же первичный ключ в обеих.
-
Если тематика и первичные ключи таблиц различаются, выберите любую из таблиц и вставьте ее первичный ключ в другую таблицу в качестве внешнего ключа.
Определяя связи между таблицами, вы обеспечиваете правильность таблиц и столбцов. При наличии связи «один к одному» или «один ко многим» в таблицах необходимы общие столбцы. При наличии связи «многие ко многим» необходима третья таблица, представляющая связь.
К началу страницы
Усовершенствование структуры
После создания необходимых таблиц, полей и связей следует создать и заполнить таблицы образцами данных и поработайте с ними: создание запросов, добавление новых записей и так далее. Это поможет выделить потенциальные проблемы. Например, может потребоваться добавить столбец, который вы забыли вставить на этапе разработки, или разделить таблицу на две таблицы, чтобы удалить дублирование.
Проверьте, можно ли использовать базу данных для получения ответов на ваши вопросы. Создайте черновые формы и отчеты и посмотрите, отображаются ли в них нужные данные. Проверьте, нет ли в базе данных повторяющихся данных и при необходимости измените ее структуру.
При внимательном изучении первоначальной базы данных вы наверняка увидите, где ее можно улучшить. Вот некоторые моменты, которые нужно проверить:
-
Не забыли ли вы какие-то столбцы? Если да, относятся ли эти сведения к имеющимся таблицам? Если это сведения по другой теме, возможно, потребуется создать еще одну таблицу. Создайте столбец для каждого элемента данных, который нужно отслеживать. Если данные невозможно получить из других столбцов путем вычислений, скорее всего, для них нужен новый столбец.
-
Есть ли ненужные столбцы, значения которых получаются из других полей с помощью вычислений? Если элемент данных можно получить из других столбцов с помощью вычислений (например, цену со скидкой можно вычислять на основе розничной цены), лучше не создавать для него новый столбец.
-
Приходится ли вам неоднократно вводить одни и те же сведения в одной из таблиц? Если да, вам нужно разделить одну таблицу на две и установить между ними связь «один ко многим».
-
У вас есть таблицы с большим количеством полей, ограниченным количеством записей и множеством пустых полей в отдельных записях? Если да, подумайте о том, как изменить структуру таблицы, чтобы в ней было меньше полей и больше записей.
-
Каждый элемент данных разделен на минимальные полезные фрагменты? Поместите в отдельный столбец каждый элемент данных, который необходимо использовать для отчетов, сортировки, поиска или вычислений.
-
Данные в каждом столбце соответствуют теме таблицы? Если столбец содержит данные, которые не относятся к теме таблицы, их нужно поместить в другую таблицу.
-
Все связи между таблицами представлены общими полями или третьей таблицей? Для отношений «один к одному» и «один-к-многим» требуются общие столбцы. Для связей «многие-к-многим» требуется третья таблица.
Усовершенствование таблицы «Товары»
Допустим, все товары в базе данных продаж можно отнести к общим категориям: напитки, приправы и морепродукты. В таблице «Товары» может быть поле, в котором показана категория каждого товара.
Предположим, что после проверки и уточнения дизайна базы данных вы решили сохранить вместе с ее именем описание категории. При добавлении поля «Описание категории» в таблицу «Товары» необходимо повторить описание каждой категории для каждого товара, попадаемного в эту категорию, — это не лучшее решение.
Лучше выделить категории в качестве отдельной темы для отслеживания в базе данных и создать для них отдельную таблицу с собственным первичным ключом. Затем первичный ключ таблицы «Категории» можно добавить в таблицу «Товары» в качестве внешнего ключа.
Связь между таблицами «Категории» и «Товары» относится к типу «один ко многим»: категория может включать несколько товаров, но при этом каждый товар может входить лишь в одну категорию.
Анализируя структуры таблиц, обращайте внимание на повторяющиеся группы. Рассмотрим таблицу со следующими столбцами:
-
Код товара
-
Название
-
Код товара1
-
Название1
-
Код товара2
-
Название2
-
Код товара3
-
Название3
Здесь каждый товар представлен повторяющейся группой столбцов, которые различаются только номерами в конце имени столбца. Если столбцы пронумерованы таким образом, вам следует пересмотреть структуру таблицы.
У такой структуры есть несколько недостатков. Во-первых, вам придется установить ограничение на количество товаров. После превышения этого ограничения вам потребуется добавить в структуру таблицы новую группу столбцов, а это задача не на пять минут.
Еще одна проблема состоит в том, что для поставщиков, у которых количество товаров меньше максимального, дополнительные столбцы будут оставаться пустыми, занимая лишнее место. Но самый серьезный недостаток такой структуры — усложнение многих задач, таких как сортировка или индексирование таблицы по кодам или названиям товаров.
Если вы видите повторяющиеся группы, посмотрите внимательно, можно ли разделить одну таблицу на две. В приведенном выше примере лучше использовать две таблицы (одну для поставщиков, другую для товаров), связанные с помощью кода поставщика.
К началу страницы
Применение правил нормализации
Теперь вы можете применить к структуре своей базы данных правила нормализации данных (иногда их называют просто правила нормализации). Эти правила позволяют проверить правильность структуры таблиц. Процесс применения этих правил к структуре базы данных называется нормализацией базы данных или просто нормализацией.
Нормализацию лучше всего выполнять после внесения в базу данных всех элементов данных и получения предварительной структуры. Цель этого процесса — убедиться в том, что элементы данных распределены по соответствующим таблицам. Правильность самих элементов данных при нормализации не проверяется.
Правила нормализации нужно применять последовательно, проверяя на каждом этапе соответствие структуры базы данных одной из так называемых «нормальных форм». Обычно применяются пять нормальных форм — с первой по пятую. В этой статье рассматриваются первые три формы, поскольку их достаточно для большинства структур баз данных.
Первая нормальная форма
Согласно первой нормальной форме на пересечении строки и столбца в таблице должно находиться одно значение, а не список значений. Например, у вас не может быть поля «Цена» с несколькими ценами. Если представить каждое пересечение строки и столбца как ячейку, эта ячейка должна содержать лишь одно значение.
Вторая нормальная форма
Согласно второй нормальной форме каждый столбец, не являющийся ключевым, должен зависеть от всего ключевого столбца, а не от его части. Это правило применяется, если первичный ключ состоит из нескольких столбцов. Допустим, ваша таблица содержит следующие столбцы, причем столбцы «Код заказа» и «Код товара» образуют первичный ключ:
-
Код заказа (первичный ключ)
-
Код товара (первичный ключ)
-
Название товара
Эта структура не соответствует второй нормальной форме, поскольку название товара зависит от кода товара, но не зависит от кода заказа, то есть этот столбец зависит не от всего первичного ключа. Из этой таблицы нужно удалить столбец «Название товара». Он относится к другой таблице («Товары»).
Третья нормальная форма
Согласно третьей нормальной форме столбцы, не являющиеся ключевыми, должны не только зависеть от всего первичного ключа, но и быть независимыми друг от друга.
Иначе говоря, каждый столбец, не являющийся ключевым, должен зависеть только от первичного ключа. Допустим, у вас есть таблица со следующими столбцами:
-
Код товара (первичный ключ)
-
Название
-
Рекомендуемая розничная цена
-
Скидка
Предположим, что скидка зависит от рекомендуемой розничной цены. В этом случае таблица не соответствует третьей нормальной форме, поскольку столбец «Скидка», не являющийся ключевым, зависит от столбца «Рекомендуемая розничная цена», который тоже не является ключевым. Независимость столбцов друг от друга означает, что изменение любого неключевого столбца не должно влиять на другие столбцы. Если вы измените значение в поле «Рекомендуемая розничная цена», соответствующим образом изменится и значение скидки, тем самым нарушая правило. В данном случае столбец «Скидка» следует перенести в другую таблицу, в которой столбец «Рекомендуемая розничная цена» является ключевым.
К началу страницы
![]()
Загрузить PDF
![]()
Загрузить PDF
Microsoft Access — это программа для создания баз данных, которая позволяет с легкостью управлять и редактировать базы данных. Она подходит буквально для всего, начиная от небольших проектов и заканчивая крупным бизнесом, она очень наглядна. Это делает ее прекрасным помощником для ввода и хранения данных, поскольку пользователю не нужно иметь дело с таблицами и графиками. Приступайте к чтению, чтобы научиться использовать Microsoft Access максимально эффективно.
-

1
Во вкладке «Файл» выберите «Новая». В базах данных можно хранить информацию различных форм. Вы можете создать пустую базу данных, пустую веб-базу данных, или выбрать любую из широкого ассортимента шаблонов.
- Пустая база данных — это стандартная база данных программы Access, отлично подходит для локального использования. Создание пустой базы данных также приводит к созданию одной таблицы.
- Веб-базы данных разработаны для применения вместе со встроенными инструментами Access для публикации в интернете. Создание пустой базы данных также приводит к созданию одной таблицы.
- Шаблоны — это заранее построенные базы данных широкого спектра применения. Выбирайте шаблоны, если вы не хотите тратить слишком много времени, сводя структуру баз данных в единое целое.
-
2
Назовите свою базу данных. Выбрав тип базы данных, назовите ее согласно предназначению. Это будет особенно полезно, если вы работаете одновременно с несколькими разными базами данных. Введите название в поле «Имя файла». Нажмите «Создать», чтобы сгенерировать новую базу данных.
Реклама


-
1
Определите лучшую структуру для хранения вашей информации. Если создаете пустую базу данных, вам стоит заранее подумать, как организовать хранение своей информации и заранее добавить необходимую структуру. Существует несколько вариантов, как вы можете изменять и взаимодействовать со своими данными в Access:
- Таблицы — основной вид хранения информации. Таблицы можно сравнить с таблицами Excel: все данные распределяются по строкам и столбцам. Именно поэтому импортировать информацию из Excel или других табличных редакторов относительно просто.
- Формы — это способ внесения информации в базу данных. Используя таблицы, информацию в базу данных можно вносить напрямую, однако формы позволяют делать это более быстро и наглядно.
- Отчеты позволяют подсчитывать и выводить информацию из базы данных. Отчеты нужны для анализа информации и для получения ответов на необходимые вопросы, например сколько прибыли было получено, или где находятся клиенты. Как правило, их используют для распечатки в бумажном виде.
- Запросы необходимы для получения и сортировки информации. Запросами можно пользоваться для поиска определенных записей из нескольких таблиц. Их также можно использовать для создания и обновления информации.
-
2
Создайте свою первую таблицу. Если речь идет о создании пустой базы данных, автоматически будет создана пустая таблица. Вводить туда данные можно вручную или копируя и вставляя из другого источника.
- Каждую часть данных нужно вставлять в отдельную колонку (поле), в то время как каждую запись нужно начинать с новой строки. Например, каждая строка — это клиент, а каждая колонка — это отдельная информация об этом клиенте (имя, фамилия, электронная почта, телефон и прочее).
- Вы можете переименовывать названия колонок, чтобы было понятнее, какое поле для чего предназначено. Дважды щелкните по заголовку колонки, чтобы изменить его название.
-
3
Импортируйте информацию из другого источника. Если вы хотите импортировать информацию из файла поддерживаемого формата или определенного места, вы можете настроить Access на импорт информации и добавление в вашу базу данных. Это полезно для импорта информации с веб-сервера или из другого открытого источника.
- Перейдите на вкладку «Внешние данные».
- Выберите тип файла, который собираетесь импортировать. В разделе «Импорт и объединение» вы найдете несколько вариантов для выбора. Нажмите кнопку «больше», чтобы открыть еще больше вариантов выбора. ODBC — это протокол для подключения баз данных, например таких как SQL.
- Укажите место расположения файла. Если файл расположен на сервере, вам нужно будет ввести адрес сервера.
- В следующем окне выберите «Указать, как и где вы хотите сохранять данные в текущей базе данных». Нажмите «ОК». Следуйте инструкциям для импорта необходимой информации.
-
4
Добавьте еще таблицу. Разные записи следует хранить в разных базах данных. Так базы данных будут работать безошибочно. Например, в одной таблице будет содержаться информация о клиентах, в другой — о заказах. Затем вы сможете связать таблицу о клиентах с информацией в таблице о заказах.
- В разделе «Создание» вкладки «Домой» нажмите кнопку создания таблицы. Новая таблица появится в вашей базе данных. Внесите нужную информацию так же, как делали это в первой таблице.
Реклама




-
1
Узнайте, как работают ключи. В каждой таблице есть уникальный ключ для каждой записи. По умолчанию Access создает колонку имен, которая растет с каждым вводом. Это и есть первичный ключ. Таблицы также могут иметь внешние ключи. Это поля, связанные с другой таблицей в базе данных. Связанные поля содержат одну и ту же информацию.
- Например, в таблице заказов у вас может быть поле «Имя клиента» для отслеживания, кто именно заказал определенный продукт. Вы можете создать связь этого поля с полем «Имя» в вашей таблице клиентов.
- Создание связей позволяет улучшить целостность, эффективность и удобство чтения информации.
-
2
Нажмите на вкладку «Работа с базами данных». Выберите «Схема данных». Откроется окно с обзором всех таблиц в базе данных. Каждое поле будет указано под названием его таблицы.
- Прежде чем создавать связь, необходимо создать поле для внешних ключей. Например, если вы хотите использовать «Идентификатор клиента» в таблице заказов, создайте поле под именем «Клиент» и оставьте его пустым. Оно должно быть такого же формата, как и то, с которым вы устанавливаете связь (в этом случае числа).
-
3
Перетащите поле, которое вы хотите использовать как внешний ключ. Переместите его в заранее приготовленное поле для внешнего ключа. Нажмите «Создание» в появившемся окне, чтобы создать связь между полями. Появится линия между двух таблиц, связав тем самым поля.
- При создании связей установите флажок в графе «Обеспечить целостность данных». Данная функция позволяет вносить изменения во второе поле при изменении первого, что исключает неточность данных.
Реклама



-
1
Поймите роль запросов. Запрос — это действие, которое позволяет быстро посмотреть, добавить или изменить информацию в базе данных. Существует большой выбор запросов, начиная от простого поиска и заканчивая созданием новых таблиц, основанных на имеющейся информации. Запросы — это необходимый инструмент для подготовки отчетов.[1]
- Запросы разделяются на два главных вида: «Выбор» или «Действие». Запросы на выборку позволяют извлекать информацию из таблиц и делать вычисления. Запросы действия позволяют добавлять, изменять и удалять данные из таблиц.
-
2
Воспользуйтесь мастером запросов, чтобы создать запрос на выборку. Если вы хотите создать базовый запрос на выборку, воспользуйтесь мастером запросов, чтобы он шаг за шагом помог вам в этом. Вы можете найти мастер запросов во вкладке «Создание». Он позволяет находить нужные поля в таблице.
Реклама


Создание запроса на выборку по критериям
-
1
Откройте инструмент «Конструктор запросов». Вы можете использовать критерии поиска, чтобы сузить выбор и выводить только нужную информацию. Для начала нажмите на вкладку «Создание» и выберите инструмент «Конструктор запросов».
-
2
Выберите таблицу. Откроется окно выбора таблиц. Дважды щелкните по нужной таблице для запроса, а затем нажмите «Закрыть».
-
3
Добавляйте поля, из которых нужно получить данные. Дважды щелкните по каждому полю, чтобы добавить их в запрос. Эти поля будут добавляться в сетку конструктора.
-
4
Добавьте собственные критерии. Вы можете использовать разные виды критериев, такие как текст или функции. Например, если вы хотите отобразить цены выше, чем 5000 рублей в поле «Цены», введите
>=5000, чтобы добавить этот критерий. Если вы хотите найти клиентов только из России, введитеРоссияв поле критериев.- В одном запросе можно использовать несколько критериев.
-
5
Нажмите «Выполнить», чтобы увидеть результаты. Кнопка «Выполнить» в виде восклицательного знака находится во вкладке «Конструктор». Результаты запроса будут выведены в отдельное окно. Нажмите Ctrl + S, чтобы сохранить результаты запроса.
Реклама





Создание выборного запроса по параметрам
-
1
Откройте инструмент «Конструктор запросов». Запрос по параметрам позволит вам установить, какие именно результаты вы хотите видеть каждый раз, когда делаете запрос. Например, если в вашей базе данных есть клиенты из разных городов, вы можете настроить запрос по параметрам, чтобы выводить результаты для определенного города.
-
2
Создайте запрос на выборку и выберите таблицу(-ы). Добавляйте поля для отбора путем двойного клика в общем обзоре таблицы.
-
3
Добавляйте параметр в раздел критериев. Параметры разделены между собой скобками «[]». Текст внутри скобок будет выведен в строку, которая появится во время проведения запроса. Например, для запроса города кликните по ячейке критериев в поле города и введите
[Какой город?].- Параметр может заканчиваться на «?» или «:», но не «!» или «.»
-
4
Сделайте запрос по множеству параметров. Вы можете использовать несколько параметров , чтобы создать поисковый запрос. Например, в поле «Дата» можно ввести диапазон дат, введя
Между [Введите начальную дату:] И [Введите дату окончания:]. В результате запроса вы получите две строки. [2]
Реклама




Создание запроса на создание таблицы
-
1
Во вкладке «Создание» нажмите «Конструктор запросов». Вы можете использовать запросы для получения выбранной информации из уже существующих таблиц или можете создавать новые таблицы с этой информацией. Это будет особенно полезно, если вы хотите поделиться какой-либо частью базы данных или создать особые формы для подразделов вашей базы данных. Для начала вам нужно создать обычный запрос на выборку.
-
2
Выберите таблицу(-ы) из которых вы хотите извлечь данные. Дважды щелкните по таблице, из которой необходимо извлечь информацию. Вы можете использовать сразу несколько таблиц, если требуется.
-
3
Выберите поля, из которых нужно извлечь данные. Дважды щелкните по каждому полю для добавления. Оно будет добавлено в сетку запросов.
-
4
Выставьте необходимые критерии. Если вам нужна определенная информация из полей, установите фильтр по критериям. Перейдите в раздел «Создание запроса на выборку по критериям» выше за более подробной информацией.
-
5
Протестируйте запрос, чтобы убедиться, что он выводит нужные результаты. Прежде чем создать таблицу, выполните запрос, чтобы убедиться, что он извлекает необходимую вам информацию. Настраивайте критерии и поля, пока не получите нужный вам результат.
-
6
Сохраните запрос. Нажмите Ctrl + S, чтобы сохранить запрос для дальнейшего использования. Он появится в колонке навигации в левой части экрана. Если вы нажмете на этот запрос, вы сможете использовать его снова, затем перейдите на вкладку «Конструктор».
-
7
Нажмите на кнопку «Создать таблицу» в группе выбора типа запроса. Появится окно, запрашивающее имя новой таблицы. Введите имя таблицы и нажмите «ОК».
-
8
Нажмите кнопку «Выполнить». Согласно установленным запросам будет создана новая таблица. Таблица появится в колонке навигации слева.
Реклама








Создание запроса на добавление
-
1
Откройте ранее созданный запрос. Вы можете использовать запрос на добавление, чтобы добавить информацию в таблицу, которая уже создана в другой таблице. Это полезно, когда необходимо добавить больше данных в готовую таблицу, созданную по запросу создания таблицы.
-
2
Нажмите кнопку «Добавление» во вкладке «Конструктор». Откроется диалоговое окно. Выберите в нем таблицу, которую нужно дополнить.
-
3
Измените критерии запроса, чтобы они соответствовали добавляемой информации. Например, если вы создали таблицу с критерием «2010» в поле «Год», измените это значение согласно добавляемой информации, например «2011».
-
4
Выберите, куда именно вы хотите добавить информацию. Убедитесь, что добавляете данные в подходящие поля для каждой добавляемой колонки. Например, если вы вносите изменения, приведенные выше, информацию следует добавить в поле «Год» на каждой строчке.
-
5
Выполните запрос. Нажмите кнопку «Выполнить» на вкладке «Конструктор». Запрос будет проведен и информация будет добавлена в таблицу. Вы можете открыть таблицу, чтобы убедиться в правильности введенных данных.
Реклама





-
1
Выберите таблицу, для которой вы хотите создать форму. Формы отображают данные по каждому полю и позволяют с легкостью переключаться между записями или создавать новые. Формы — необходимый инструмент при длительных периодах ввода информации; большинство пользователей считают, что пользоваться формами гораздо проще, чем таблицами.
-
2
Нажмите кнопку «Форма» во вкладке «Создание». Будет автоматически создана форма, основанная на данных из таблице. Программа Access автоматически создает поля с нужным размером, но по желанию их всегда можно изменить или сдвинуть.
- Если вы не хотите отображать определенное поле в форме, вызовите контекстное меню правой кнопкой мыши и нажмите «Удалить».
- Если таблицы связаны между собой, над каждой записью появится описание, отображающее объединенные данные. Так редактировать эти данные гораздо проще. Например, каждому торговому представителю можно приписать базу клиентов.
-
3
Перемещайтесь по новой форме. Указатели в форме стрелок позволяют перемещаться от одной записи к другой. Поля будут заполнены вашими данными в момент переключения между ними. Вы можете воспользоваться кнопками по краям, чтобы сразу перейти к первой или последней записи.
-
4
Нажмите кнопку описания, чтобы воспользоваться таблицей. Она находится в верхнем левом углу и позволяет изменять значения выбранной таблицы с помощью форм.
-
5
Внесите изменения в существующие записи. Вы можете изменять текст в любом поле каждой записи, чтобы изменить информацию в таблице. Все изменения автоматически отобразятся в таблице, то же произойдет и во всех связанных таблицах.
-
6
Вносите новые записи. Нажмите «Добавить запись» возле кнопок навигации, чтобы добавить новую запись в конце списка. Затем вы сможете использовать поля для внесения данных в пустые записи внутри таблицы. Это гораздо проще, чем добавлять новые данные через табличный вид.
-
7
Сохраните форму, когда закончите работу с ней. Убедитесь, что сохранили форму, нажав Ctrl + S; вы сможете с легкостью войти в нее снова позже. Она появится в колонке навигации в левой части экрана.[3]
Реклама







-
1
Выберите таблицу или запрос. Отчеты позволяют быстро отобразить сводку по нужным данным. Их часто используют для создания отчетов по выручке или для отчетов по доставке, но их можно настроить почти для любой области использования. Отчеты используют данные из таблиц или запросов, созданных вами ранее.
-
2
Нажмите вкладку «Создание». Выберите тип необходимого отчета. Существует несколько разных путей создания отчетов. Access может сделать отчет для вас автоматически, либо создайте его самостоятельно.
- Отчет — будет создан автоотчет, использующий всю доступную информацию из вашего источника. Ничего не будет сгруппировано, но для небольших баз данных вполне подойдет.
- Пустой отчет — будет создан пустой отчет, который вы сами сможете заполнить нужными данными. Вы сможете выбирать информацию из любого доступного поля, чтобы создать необходимый отчет.
- Мастер отчетов поможет вам пройти через процесс создания отчета, позволяя выбирать и группировать данные, а затем редактировать подходящим образом.
-
3
Выберите источник для пустого отчета. Если вы выбрали создание пустого отчета, вам нужно указать для него источник. Сначала нажмите вкладку «Упорядочить», а затем перейдите в «Свойства». Для этого также можно нажать Alt + Enter.
- Нажмите на стрелочку рядом с полем «Источник записей». Появится список всех доступных таблиц и запросов. Выберите один, и он будет отнесен к отчету.
-
4
Добавьте поля в отчет. Указав источник, добавьте поля из него в свой отчет. Нажмите вкладку «Формат», затем нажмите «Добавить существующие поля». Список полей доступен в правой части.
- Нажмите и переместите поля, которые необходимо добавить в раздел «Конструктор». Запись появится в отчете. При добавлении дополнительных полей они будут добавляться автоматически к уже существующим.
- Вы можете изменять размер полей путем нажатия на грани и перемещения указателя.
- Удаляйте поля из отчета, выделив заголовок и нажав кнопку «Удалить».
-
5
Добавляйте группы в свой отчет. Группы позволяют быстро разбираться в информации из отчета, поскольку все подается в организованном виде. К примеру, если вам необходимо создать группы для продаж по региону или с привязкой к продавцу, все это можно сделать с помощью группировки.
- На вкладке «Конструктор», выберите «Группировка».
- Правой кнопкой мыши щелкните по части поля, которое вы хотите добавить в группу. Выберите «Сгруппировать» из меню.
- Появится заголовок для группы. Вы можете изменять заголовок на любой желаемый.
-
6
Сохраните и поделитесь своим отчетом. Как только отчет будет готов, вы можете сохранить его и распечатать как любой документ. Используйте его, чтобы рассказать об эффективности компании инвесторам, поделиться контактной информацией с работниками и для других целей.
Реклама






Советы
- Microsoft Access открывается в режиме скрытой информации, в котором находятся опции, позволяющие вам открывать существующие базы данных, создавать новые и получать доступ к командам для редактирования любых ваших баз.
Реклама
Предупреждения
- Некоторые возможности Access не всегда доступны — все зависит от типа созданной вами базы данных. Например, нельзя предоставить доступ к базе данных, созданной для использования оффлайн, а некоторые возможности оффлайн баз, например, суммарное число запросов, не будут работать в веб-базе данных.
Реклама
Источники
Об этой статье
Эту страницу просматривали 299 340 раз.