Contents
- 1 Введение в Apache NiFi
- 1.1 Apache NiFi Introduction
- 1.2 Что такое Apache NiFi?
- 1.2.1 Apache Nifi Crash Course
- 1.2.2 Почему мы используем Apache NiFi?
- 1.2.3 Особенности Apache NiFi
- 1.2.4 Архитектура Apache NiFi
- 1.2.5 Ключевые концепции Apache NiFi
- 1.2.6 Пользовательский интерфейс Apache NiFi
- 1.2.7 Компоненты Apache NiFi
- 1.2.8 Классификация процессоров в Apache NiFi
- 1.2.9 Как установить Apache NiFi?
- 1.2.10 Как построить поток?
- 1.2.10.1 Добавить и настроить процессоры
- 1.2.11 Преимущества Apache NiFi
- 1.2.12 Недостатки Apache NiFi
В этом руководстве вы познакомитесь с Apache NiFi и подробно ознакомитесь с его концепциями и архитектурой. Вы обнаружите, насколько просто и адаптируемо создавать конвейеры данных в режиме реального времени и управлять ими.
Apache NiFi — это система потоков данных, основанная на концепциях программирования на основе потоков. Он разработан Агентством национальной безопасности (АНБ), а затем в 2015 году стал официальной частью Apache Project Suite.
Каждые 6-8 недель Apache NiFi выпускает новое обновление для удовлетворения требований пользователей.
Это руководство по Apache NiFi предназначено для начинающих и профессионалов, которые хотят изучить основы Apache NiFi. Он включает в себя несколько разделов, которые предоставляют основные знания о том, как работать с NiFi.
Что такое Apache NiFi?
Apache NiFi — это надежная, масштабируемая и надежная система, которая используется для обработки и распространения данных. Он создан для автоматизации передачи данных между системами.
- NiFi предлагает пользовательский веб-интерфейс для создания, мониторинга и управления потоками данных. NiFi расшифровывается как Niagara Files, который был разработан Агентством национальной безопасности (АНБ), но теперь поддерживается фондом Apache.
- Apache NiFi — это веб-платформа пользовательского интерфейса, в которой нам необходимо определить источник, место назначения и процессор для сбора, хранения и передачи данных соответственно.
- У каждого процессора в NiFi есть отношения, которые используются при соединении одного процессора с другим.
NiFi построен на ряде основных концепций, включая процессоры, соединения и flowfiles. Процессоры — это модули, которые выполняют конкретные действия с данными, такие как фильтрация, трансформация или маршрутизация. Соединения используются для связи процессоров между собой, позволяя данным перемещаться от одного процессора к другому. Flowfiles — это пакеты данных, которые передаются между процессорами через соединения.


Apache Nifi Crash Course
This workshop will provide a hands on introduction to simple event data processing and data flow processing using a Sandbox on students’ personal machines.
Почему мы используем Apache NiFi?
Apache NiFi имеет открытый исходный код; поэтому он находится в свободном доступе на рынке. Он поддерживает несколько форматов данных, таких как социальные сети, географическое положение, журналы и т.д.
Apache NiFi поддерживает широкий спектр протоколов, таких как SFTP, KAFKA, HDFS и т.д., что делает эту платформу более популярной в ИТ-индустрии. Есть так много причин, чтобы выбрать Apache NiFi. Они следующие.
- Apache NiFi помогает организациям интегрировать NiFi в существующую инфраструктуру.
- Это позволяет пользователям использовать функции экосистемы Java и существующие библиотеки.
- Он обеспечивает управление в режиме реального времени, что позволяет пользователю управлять потоком данных между любым источником, процессором и пунктом назначения.
- Это помогает визуализировать DataFlow на уровне предприятия.
- Это помогает агрегировать, преобразовывать, маршрутизировать, извлекать, прослушивать, разделять и перетаскивать поток данных.
- Это позволяет пользователям запускать и останавливать компоненты на индивидуальном и групповом уровнях.
- NiFi позволяет пользователям извлекать данные из различных источников в NiFi и позволяет им создавать потоковые файлы.
- Он предназначен для масштабирования в кластерах, которые обеспечивают гарантированную доставку данных.
- Визуализируйте и отслеживайте производительность и поведение в бюллетене потока, который предлагает встроенную и информативную документацию.
Особенности Apache NiFi
Особенности Apache NiFi заключаются в следующем:
- Apache NiFi — это пользовательский веб-интерфейс, который предлагает беспрепятственный опыт проектирования, мониторинга, управления и обратной связи.
- Он даже предоставляет модуль происхождения данных, который помогает отслеживать и контролировать данные от источника до места назначения потока данных.
- Разработчики могут создавать свои настраиваемые процессоры и задачи отчетности в соответствии с требованиями.
- Он поддерживает устранение неполадок и оптимизацию потока.
- Он обеспечивает быструю разработку и эффективное тестирование.
- Он обеспечивает шифрование контента и связь по защищенному протоколу.
- Он поддерживает буферизацию всех данных в очереди и обеспечивает возможность обратного давления, поскольку очереди могут достигать заданных пределов.
- Apache NiFi предоставляет систему пользователю, пользователя системе и функции безопасности мультитенантной аутентификации.
Архитектура Apache NiFi
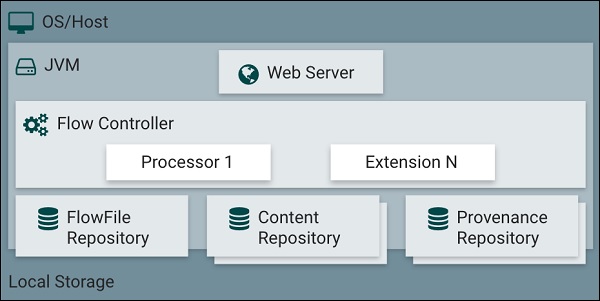
Архитектура Apache NiFi включает веб-сервер, контроллер потока и процессор, работающий на виртуальной машине Java (JVM).
Он имеет три репозитория, такие как репозиторий FlowFile, репозиторий контента и репозиторий происхождения.
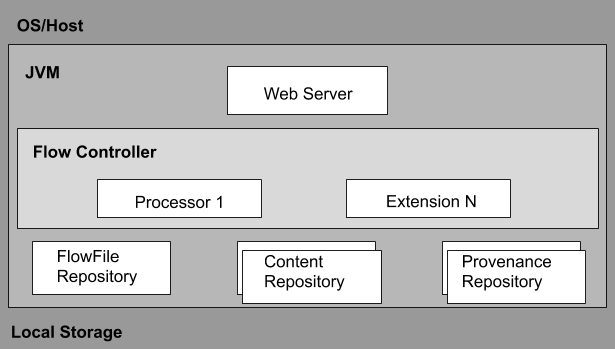
- Веб сервер
Веб-сервер используется для размещения API управления и контроля на основе HTTP.
- Контроллер потока
Контроллер потока — это мозг операции. Он предлагает потоки для запуска расширений и управляет расписанием, когда расширения получают ресурсы для запуска.
- Расширения
Несколько типов расширений NiFi определены в других документах. Расширения используются для работы и выполнения в JVM.
- Репозиторий FlowFile
Репозиторий FlowFile включает текущее состояние и атрибут каждого FlowFile, который проходит через поток данных NiFi.
Он отслеживает состояние, которое активно в потоке в данный момент. Стандартным подходом является непрерывный журнал упреждающей записи, который находится в описанном разделе диска.
- Репозиторий контента
Репозиторий контента используется для хранения всех данных, присутствующих в файлах потока. Подход по умолчанию — довольно простой механизм, который хранит блоки данных в файловой системе.
Чтобы уменьшить конкуренцию за любой отдельный том, укажите более одного места хранения файловой системы, чтобы получить разные разделы.
- Репозиторий происхождения
В репозитории происхождения хранятся все данные о событиях происхождения. Конструкцию репозитория можно подключить к реализации по умолчанию, использующей один или несколько томов физических дисков.
Данные о событиях индексируются и доступны для поиска в каждом месте.
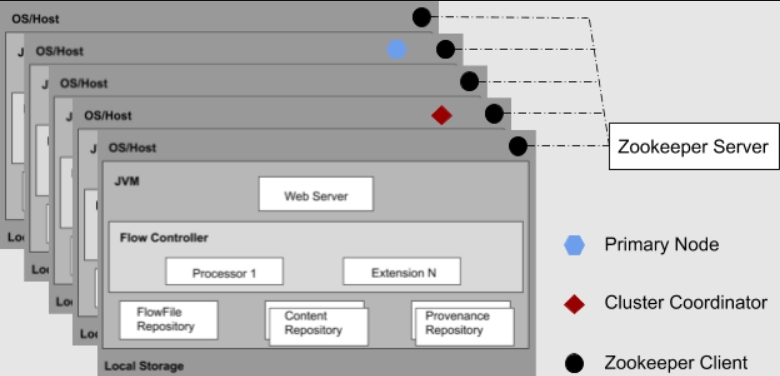
Начиная с версии NiFi 1.0, включен шаблон кластеризации с нулевым лидером. Каждый узел в кластере выполняет аналогичные задачи с данными, но работает с другим набором данных.
Apache Zookeeper выбирает один узел в качестве координатора кластера. Координатор кластера используется для подключения и отключения узлов. Кроме того, в каждом кластере есть один основной узел.
Ключевые концепции Apache NiFi
Ключевые концепции Apache NiFi заключаются в следующем:
- Поток : Поток создается для подключения различных процессоров для совместного использования и изменения данных, которые требуются от одного источника данных к другому месту назначения.
- Соединение : Соединение используется для соединения процессоров, которые действуют как очередь для хранения данных в очереди, когда это необходимо. Он также известен как ограниченный буфер в терминах программирования на основе потоков (FBP). Это позволяет нескольким процессам взаимодействовать с разной скоростью.
- Процессоры . Процессор — это модуль Java, который используется либо для извлечения данных из исходной системы, либо для их сохранения в целевой системе. Для добавления атрибута или изменения содержимого в FlowFile можно использовать несколько процессоров. Он отвечает за отправку, слияние, маршрутизацию, преобразование, обработку, создание, разделение и получение потоковых файлов.
- FlowFile : FlowFile — это базовая концепция NiFi, которая представляет собой единый объект данных, выбранных из исходной системы в NiFi. Это позволяет пользователям вносить изменения в Flowfile, когда он перемещается из исходного процессора в место назначения. Различные события, такие как создание, получение, клонирование и т. д., которые выполняются в Flowfile с использованием разных процессоров в потоке.
- Событие : событие представляет собой изменение в Flowfile при обходе потоком NiFi. Такие события отслеживаются в источнике данных.
- Происхождение данных : Происхождение данных — это репозиторий, который позволяет пользователям проверять данные, касающиеся файла Flow, и помогает в устранении неполадок, если возникают какие-либо проблемы при обработке файла Flow.
- Группа процессов : группа процессов представляет собой набор процессов и их соответствующих соединений, которые могут получать данные от входного порта и отправлять их через выходные порты.
Пользовательский интерфейс Apache NiFi
Apache NiFi — это веб-платформа, к которой пользователь может получить доступ через веб-интерфейс. Пользовательский интерфейс NiFi позволяет создавать, визуализировать, отслеживать и редактировать автоматизированные потоки данных.
Пользовательский интерфейс разделен на несколько сегментов, и каждый сегмент отвечает за разные функции приложения. Эти сегменты включают в себя различные типы команд, которые обсуждаются следующим образом:
Когда диспетчер потока данных (DFM) переходит к пользовательскому интерфейсу (UI), на экране появляется пустой холст, на котором можно построить поток данных.
На рисунке панель инструментов компонентов располагается в верхней левой части экрана. Он включает компоненты, которые позволяют перетаскивать элементы на холст для создания потока данных.
Строка состояния предоставляет информацию о количестве активных потоков, объеме существующих данных, количестве существующих групп удаленных процессов, количестве существующих процессоров, количестве существующих групп процессов с управлением версиями и отметке времени последнего обновления всей информации.
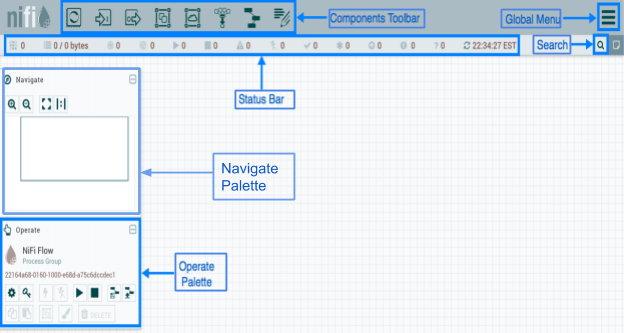
Глобальное меню находится в правой части пользовательского интерфейса и содержит параметры, используемые для управления существующими компонентами на холсте.
Строка поиска используется для поиска информации о компонентах в DataFlow. Палитра навигации используется для панорамирования холста, а также для увеличения и уменьшения масштаба.
Вид с высоты птичьего полета в палитре навигации предлагает высокоуровневое представление потока данных и позволяет охватить большие части потока данных.
Палитра Operate в левой части экрана содержит различные кнопки, которые используются DFM для управления потоком, а также для доступа и настройки свойств системы.
Компоненты Apache NiFi
Ниже перечислены компоненты Apache NiFi:
Процессор
![]()
Пользователи могут перетащить значок процессора на холст и добавить необходимый процессор для потока данных в NiFi.
Входной порт
![]()
Входной порт используется для получения данных от процессора, который недоступен в группе процессов. Когда значок ввода перетаскивается на холст, это позволяет добавить порт ввода в поток данных.
Выходной порт
Выходной порт используется для передачи данных процессору, которого нет в группе процессов. Когда значок выходного порта перетаскивается на холст, он позволяет добавить выходной порт.
Группа процессов
Группа процессов помогает добавлять группы процессов в холст NiFi. Когда значок группы процессов перетаскивается на холст, он позволяет ввести имя группы процессов, а затем он добавляется на холст.
Группа удаленных процессов
Воронка
Воронка используется для отправки вывода процессора на различные процессоры. Пользователи могут перетащить значок воронки на холст, чтобы добавить воронку в поток данных.
Это позволяет добавить группу удаленных процессов на холст NiFi.
Шаблон
Значок шаблона используется для добавления шаблона потока данных на холст NiFi. Это помогает повторно использовать поток данных в одном или разных экземплярах.
После перетаскивания он позволяет пользователям выбирать существующий шаблон для потока данных.
Этикетка
Они используются для добавления текста на холст NiFi относительно любого компонента, доступного в NiFi. Он предоставляет цвета, используемые пользователем для добавления эстетического ощущения.
Классификация процессоров в Apache NiFi
Ниже приводится классификация процессов Apache NiFi.
- Процессоры AWS
Процессоры AWS отвечают за связь с системой веб-сервисов Amazon. Такими обработчиками категорий являются PutSNS, FetchS3Object, GetSQS, PutS3Object и т. д.
- Процессоры извлечения атрибутов
Процессоры извлечения атрибутов отвечают за извлечение, изменение и анализ обработки атрибутов FlowFile в потоке данных NiFi.
Примерами являются ExtractText, EvaluateJSONPath, AttributeToJSON, UpdateAttribute и т. д.
- Процессоры доступа к базе данных
Процессоры доступа к базе данных используются для выбора или вставки данных, а также для выполнения и подготовки других операторов SQL из базы данных.
Такие процессоры используют настройки контроллера подключения к данным Apache NiFi. Примерами являются PutSQL, ListDatabaseTables, ExecuteSQL, PutDatabaseRecord и т. д.
- Процессоры приема данных
Процессоры приема данных используются для приема данных в поток данных, таких как начальная точка любого потока данных в Apache NiFi. Примеры: GetFile, GetFTP, GetKAFKA, GetHTTP и т. д.
- Процессоры преобразования данных
Процессоры преобразования данных используются для изменения содержимого FlowFiles.
Их можно использовать для замены данных FlowFile, когда пользователю необходимо отправить FlowFile в формате HTTP для вызова процессора HTTP. Примеры: JoltTransformJSON ReplaceText и т. д.
- HTTP-процессоры
Процессоры HTTP работают с вызовами HTTP и HTTPS. Примеры: InvokeHTTP, ListenHTTP, PostHTTP и т. д.
- Процессоры маршрутизации и посредничества
Процессоры маршрутизации и посредничества используются для маршрутизации FlowFiles к разным процессорам в зависимости от информации в атрибутах FlowFiles.
Он отвечает за управление потоками данных NiFi. Примерами являются RouteOnContent, RouteText, RouteOnAttribute и т. д.
- Отправка процессоров данных
Отправляющие процессоры данных — это конечные процессоры в потоке данных. Он отвечает за хранение или отправку данных в пункт назначения.
После отправки данных процессор DROP FlowFile с успешным отношением. Примеры: PutKAFKA, PutFTP, PutSFTP, PutEmail и т. д.
- Процессоры разделения и агрегации
Процессоры разделения и агрегации используются для разделения и объединения контента, доступного в потоке данных. Примеры: SplitXML, SplitJSON, SplitContent, MergeContent и т. д.
- Процессоры системного взаимодействия
Процессоры системного взаимодействия используются для запуска процесса в любой операционной системе. Он также запускает сценарии на разных языках с разными системами.
Примерами являются ExecuteScript, ExecuteStreamCommand, ExecuteGroovyScript, ExecuteProcess и т. д.
Как установить Apache NiFi?
Чтобы установить Apache NiFi, выполните следующие действия.
1. Нажмите на ссылку и загрузите последнюю версию Apache NiFi.
2. В разделе «Двоичные файлы» щелкните zip-файл установки приложения NiFi для ОС Windows.
3. Приведенная выше ссылка перенаправляет вас на новую страницу. Здесь вы получите ссылку для загрузки Apache NiFi.
4. После загрузки файла распакуйте его.
5. Откройте папку bin (т.е. nifi-1.12.1 > bin) и нажмите run-nifi и запустите для запуска.
6. Панель инструментов NiFi запустится в браузере после успешной установки. Панель инструментов Apache известна как холст, где мы создаем потоки данных.
Как построить поток?
Чтобы построить поток, нам нужно добавить два процессора на холст и настроить их. Давайте посмотрим, как добавить и настроить процессоры.
Добавить и настроить процессоры
Чтобы добавить и настроить процессоры, выполните следующие действия.
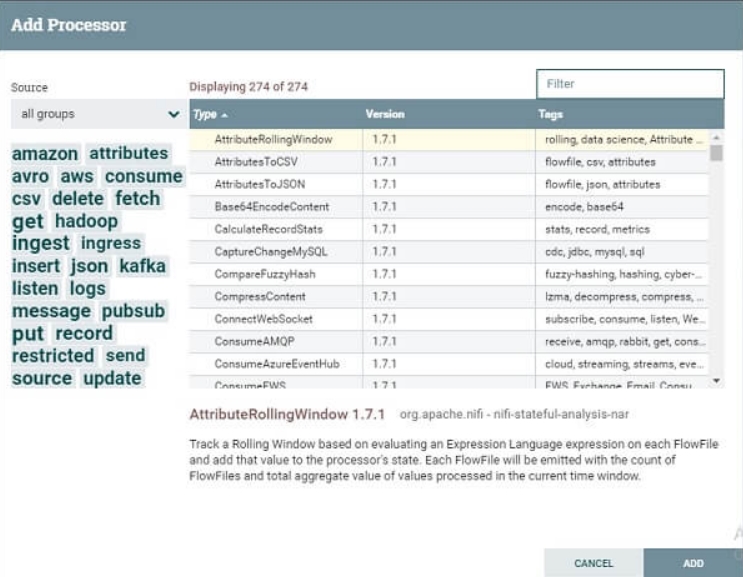
- Перейдите в раздел компонентов на панели инструментов и перетащите процессор. Откроется окно Добавить процессор со списком процессоров.
- Найдите нужный процессор или сократите список процессоров в зависимости от категории и функциональности.
- Нажмите на процессор, который вы хотите выбрать, и добавьте его на холст, дважды щелкнув процессор или нажав «Добавить».
- Если вы знаете имя процессора, вы можете ввести его в строке фильтра. Добавьте еще один процессор на холст.
- Вы увидите, что оба процессора недействительны, потому что они имеют предупреждающее сообщение, указывающее, что требования должны быть настроены, чтобы сделать процессоры действительными и выполняться.
- Чтобы удовлетворить требования предупреждения, нам нужно настроить и запустить процессоры.
Преимущества Apache NiFi
Преимущества Apache NiFi заключаются в следующем:
- Apache NiFi предлагает пользовательский веб-интерфейс (UI). Чтобы он мог работать в веб-браузере, используя порт и локальный хост.
- В веб-браузере Apache NiFi использует протокол HTTPS для обеспечения безопасного взаимодействия с пользователем.
- Он поддерживает протокол SFTP, который позволяет получать данные с удаленных компьютеров.
- Он также предоставляет политики безопасности на уровне группы процессов, уровне пользователя и других модулях.
- NiFi поддерживает все устройства, на которых работает Java.
- Он обеспечивает управление в режиме реального времени, что упрощает перемещение данных между источником и получателем.
- Apache NiFi поддерживает кластеризацию, поэтому он может работать на нескольких узлах с одним и тем же потоком, обрабатывая разные данные, что повышает производительность обработки данных.
- NiFi поддерживает более 188 процессоров, и пользователь может создавать собственные плагины для поддержки различных типов систем данных.
Недостатки Apache NiFi
Ниже приведены недостатки Apache NiFi.
- У Apache NiFi есть проблема с сохранением состояния в случае переключения основного узла, из-за которого процессоры не могут получать данные из исходных систем.
- При внесении пользователем каких-либо изменений узел отключается от кластера, а затем файл flow.xml становится недействительным. Узел не может подключиться к кластеру, пока администратор не скопирует XML-файл вручную с узла.
- Чтобы работать с Apache NiFi, вы должны хорошо разбираться в базовой системе.
- Он предлагает уровень темы, и авторизации SSL может быть недостаточно.
- Требуется поддерживать цепочку хранения данных.
Вывод
И наконец, Apache NiFi используется для автоматизации и управления потоками данных между системами. Как только данные извлекаются из внешнего источника, они представляются как FlowFile в архитектуре Apache NiFi.
Я надеюсь, что это руководство поможет вам разработать и настроить потоки данных в Apache NiFi. Теперь ваша очередь исследовать NiFi. Если возникнут какие-либо запросы, не стесняйтесь оставлять свой запрос в сеансе комментариев.
Apache NiFi – Введение
Apache NiFi – это мощная, простая в использовании и надежная система для обработки и распределения данных между различными системами. Он основан на технологии Niagara Files, разработанной NSA, а затем, через 8 лет, передан в фонд Apache Software. Он распространяется под лицензией Apache License Version 2.0, январь 2004 года. Последняя версия для Apache NiFi – 1.7.1.
Apache NiFi – платформа приема данных в режиме реального времени, которая может передавать и управлять передачей данных между различными источниками и системами назначения. Он поддерживает широкий спектр форматов данных, таких как журналы, данные о географическом местоположении, социальные сети и т. Д. Он также поддерживает множество протоколов, таких как SFTP, HDFS и KAFKA, и т. Д. Эта поддержка широкого спектра источников данных и протоколов делает эту платформу популярной в многие ИТ-организации.
Apache NiFi – общие характеристики
Основные характеристики Apache NiFi следующие:
-
Apache NiFi предоставляет веб-интерфейс пользователя, который обеспечивает плавное взаимодействие между дизайном, управлением, обратной связью и мониторингом.
-
Это очень настраиваемый. Это помогает пользователям с гарантированной доставкой, низкой задержкой, высокой пропускной способностью, динамическим назначением приоритетов, обратным давлением и изменением потоков во время выполнения.
-
Он также предоставляет модуль происхождения данных для отслеживания и мониторинга данных от начала до конца потока.
-
Разработчики могут создавать свои собственные процессоры и задачи отчетности в соответствии со своими потребностями.
-
NiFi также обеспечивает поддержку безопасных протоколов, таких как SSL, HTTPS, SSH и других шифрований.
-
Он также поддерживает управление пользователями и ролями, а также может быть настроен с LDAP для авторизации.
Apache NiFi предоставляет веб-интерфейс пользователя, который обеспечивает плавное взаимодействие между дизайном, управлением, обратной связью и мониторингом.
Это очень настраиваемый. Это помогает пользователям с гарантированной доставкой, низкой задержкой, высокой пропускной способностью, динамическим назначением приоритетов, обратным давлением и изменением потоков во время выполнения.
Он также предоставляет модуль происхождения данных для отслеживания и мониторинга данных от начала до конца потока.
Разработчики могут создавать свои собственные процессоры и задачи отчетности в соответствии со своими потребностями.
NiFi также обеспечивает поддержку безопасных протоколов, таких как SSL, HTTPS, SSH и других шифрований.
Он также поддерживает управление пользователями и ролями, а также может быть настроен с LDAP для авторизации.
Apache NiFi – основные понятия
Основные понятия Apache NiFi следующие:
-
Группа процессов – это группа потоков NiFi, которая помогает пользователю управлять и поддерживать потоки в иерархическом порядке.
-
Поток – создается для соединения разных процессоров для передачи и изменения данных, если это необходимо, из одного источника данных или источников в другие источники данных назначения.
-
Процессор . Процессор – это Java-модуль, отвечающий за выборку данных из системы источников или сохранение их в системе назначения. Другие процессоры также используются для добавления атрибутов или изменения содержимого в потоковом файле.
-
Flowfile – это основное использование NiFi, которое представляет собой единый объект данных, выбранных из исходной системы в NiFi. NiFiprocessor делает изменения в потоковый файл, в то время как он перемещается от исходного процессора к месту назначения. Различные процессы, такие как CREATE, CLONE, RECEIVE и т. Д., Выполняются в поточном файле различными процессорами в потоке.
-
Событие – события представляют изменение потока файла при прохождении потока NiFi. Эти события отслеживаются в происхождении данных.
-
Происхождение данных – это хранилище. Он также имеет пользовательский интерфейс, который позволяет пользователям проверять информацию о потоковом файле и помогает в устранении неполадок, возникающих при обработке потокового файла.
Группа процессов – это группа потоков NiFi, которая помогает пользователю управлять и поддерживать потоки в иерархическом порядке.
Поток – создается для соединения разных процессоров для передачи и изменения данных, если это необходимо, из одного источника данных или источников в другие источники данных назначения.
Процессор . Процессор – это Java-модуль, отвечающий за выборку данных из системы источников или сохранение их в системе назначения. Другие процессоры также используются для добавления атрибутов или изменения содержимого в потоковом файле.
Flowfile – это основное использование NiFi, которое представляет собой единый объект данных, выбранных из исходной системы в NiFi. NiFiprocessor делает изменения в потоковый файл, в то время как он перемещается от исходного процессора к месту назначения. Различные процессы, такие как CREATE, CLONE, RECEIVE и т. Д., Выполняются в поточном файле различными процессорами в потоке.
Событие – события представляют изменение потока файла при прохождении потока NiFi. Эти события отслеживаются в происхождении данных.
Происхождение данных – это хранилище. Он также имеет пользовательский интерфейс, который позволяет пользователям проверять информацию о потоковом файле и помогает в устранении неполадок, возникающих при обработке потокового файла.
Преимущества Apache NiFi
-
Apache NiFi позволяет получать данные с удаленных компьютеров с помощью SFTP и гарантирует передачу данных.
-
Apache NiFi поддерживает кластеризацию, поэтому он может работать на нескольких узлах с одинаковым потоком, обрабатывая разные данные, что повышает производительность обработки данных.
-
Он также предоставляет политики безопасности на уровне пользователя, группы процессов и других модулей.
-
Его пользовательский интерфейс также может работать по протоколу HTTPS, что делает взаимодействие пользователей с NiFi безопасным.
-
NiFi поддерживает около 188 процессоров, и пользователь также может создавать собственные плагины для поддержки широкого спектра систем данных.
Apache NiFi позволяет получать данные с удаленных компьютеров с помощью SFTP и гарантирует передачу данных.
Apache NiFi поддерживает кластеризацию, поэтому он может работать на нескольких узлах с одинаковым потоком, обрабатывая разные данные, что повышает производительность обработки данных.
Он также предоставляет политики безопасности на уровне пользователя, группы процессов и других модулей.
Его пользовательский интерфейс также может работать по протоколу HTTPS, что делает взаимодействие пользователей с NiFi безопасным.
NiFi поддерживает около 188 процессоров, и пользователь также может создавать собственные плагины для поддержки широкого спектра систем данных.
Недостатки Apache NiFi
-
Когда узел отключается от кластера NiFi, когда пользователь вносит в него какие-либо изменения, то flow.xml становится недействительным. Узел не может подключиться обратно к кластеру, если администратор не скопирует вручную файл flow.xml с подключенного узла.
-
Apache NiFi имеет проблему с сохранением состояния в случае переключения основного узла, что иногда делает процессоры неспособными получать данные из систем источников.
Когда узел отключается от кластера NiFi, когда пользователь вносит в него какие-либо изменения, то flow.xml становится недействительным. Узел не может подключиться обратно к кластеру, если администратор не скопирует вручную файл flow.xml с подключенного узла.
Apache NiFi имеет проблему с сохранением состояния в случае переключения основного узла, что иногда делает процессоры неспособными получать данные из систем источников.
Apache NiFi – Основные понятия
Apache NiFi состоит из веб-сервера, контроллера потока и процессора, который работает на виртуальной машине Java. Он также имеет 3 репозитория Flowfile Repository, Content Repository и Provenance Repository, как показано на рисунке ниже.
Flowfile Repository
Этот репозиторий хранит текущее состояние и атрибуты каждого потокового файла, который проходит через потоки данных Apache NiFi. Расположение этого хранилища по умолчанию находится в корневом каталоге apache NiFi. Расположение этого репозитория можно изменить, изменив свойство с именем «nifi.flowfile.repository.directory».
Репозиторий контента
Этот репозиторий содержит все содержимое всех потоковых файлов NiFi. Его каталог по умолчанию также находится в корневом каталоге NiFi, и его можно изменить с помощью свойства «org.apache.nifi.controller.repository.FileSystemRepository». Этот каталог занимает много места на диске, поэтому желательно иметь достаточно места на установочном диске.
Хранилище прованс
Репозиторий отслеживает и хранит все события всех потоковых файлов, которые поступают в NiFi. Существует два репозитория провенанса – изменчивое хранилище провенанса (в этом репозитории все данные провенанса теряются после перезапуска) и постоянное хранилище провенанса . Его каталог по умолчанию также находится в корневом каталоге NiFi, и его можно изменить с помощью свойств «org.apache.nifi.provenance.PersistentProvenanceRepository» и «org.apache.nifi.provenance.VolatileProvenanceRepositor» для соответствующих репозиториев.
Apache NiFi – настройка среды
В этой главе мы узнаем о настройке среды Apache NiFi. Шаги для установки Apache NiFi следующие:
Шаг 1 – Установите текущую версию Java на свой компьютер. Пожалуйста, установите JAVA_HOME на вашем компьютере. Вы можете проверить версию, как показано ниже:
В операционной системе Windows (ОС) (с использованием командной строки) –
> java -version
В ОС UNIX (с использованием терминала):
$ echo $JAVA_HOME
Шаг 2 – Загрузите Apache NiFi с https://nifi.apache.org/download.html
-
Для Windows OS скачать ZIP файл.
-
Для ОС UNIX скачать файл TAR.
-
Для изображений докера перейдите по следующей ссылке https://hub.docker.com/r/apache/nifi/.
Для Windows OS скачать ZIP файл.
Для ОС UNIX скачать файл TAR.
Для изображений докера перейдите по следующей ссылке https://hub.docker.com/r/apache/nifi/.
Шаг 3 – Процесс установки Apache NiFi очень прост. Процесс отличается с ОС –
-
ОС Windows – разархивируйте zip-пакет и установите Apache NiFi.
-
ОС UNIX – Извлеките tar-файл в любом месте, и Logstash будет установлен.
ОС Windows – разархивируйте zip-пакет и установите Apache NiFi.
ОС UNIX – Извлеките tar-файл в любом месте, и Logstash будет установлен.
$tar -xvf nifi-1.6.0-bin.tar.gz
Шаг 4 – Откройте командную строку, перейдите в каталог bin NiFi. Например, C: \ nifi-1.7.1 \ bin и выполните файл run-nifi.bat.
C:\nifi-1.7.1\bin>run-nifi.bat
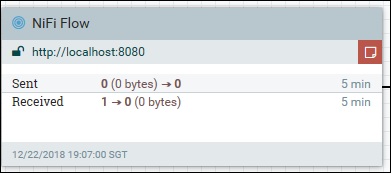
Шаг 5 – Потребуется несколько минут, чтобы запустить интерфейс NiFi. Пользователь может проверить nifi-app.log, как только пользовательский интерфейс NiFi будет запущен, пользователь может ввести http: // localhost: 8080 / nifi / для доступа к пользовательскому интерфейсу.
Apache NiFi – пользовательский интерфейс
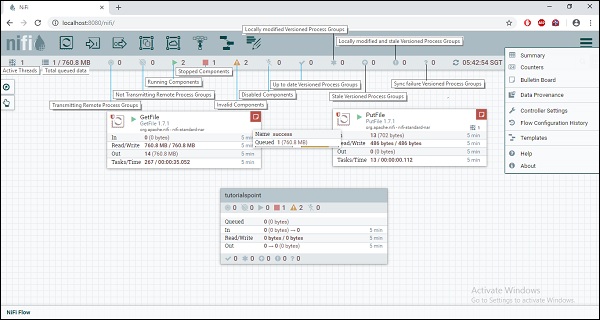
Apache – это веб-платформа, доступ к которой может получить пользователь с помощью веб-интерфейса. Пользовательский интерфейс NiFi очень интерактивен и предоставляет широкий спектр информации о NiFi. Как показано на рисунке ниже, пользователь может получить доступ к информации о следующих атрибутах:
- Активные темы
- Всего данных в очереди
- Передача удаленных групп процессов
- Не передавать удаленные группы процессов
- Запущенные компоненты
- Остановленные компоненты
- Неверные компоненты
- Отключенные компоненты
- Последние версии групп процессов
- Локально модифицированные версионные группы процессов
- Устаревшие версионные группы процессов
- Локально модифицированные и устаревшие группы процессов
- Ошибка синхронизации версий групп процессов
Компоненты Apache NiFi
Apache NiFi UI имеет следующие компоненты –
процессоры
Пользователь может перетащить значок процесса на холст и выбрать нужный процессор для потока данных в NiFi.
![]()
Входной порт
Значок ниже перетаскивается на холст, чтобы добавить входной порт в любой поток данных.
Входной порт используется для получения данных от процессора, которого нет в этой группе процессов.

После перетаскивания этого значка NiFi просит ввести имя порта ввода, а затем оно добавляется на холст NiFi.
Выходной порт
Значок ниже перетаскивается на холст, чтобы добавить выходной порт в любой поток данных.
Выходной порт используется для передачи данных процессору, которого нет в этой группе процессов.

После перетаскивания этого значка NiFi просит ввести имя выходного порта, а затем он добавляется на холст NiFi.
Группа процессов
Пользователь использует значок ниже, чтобы добавить группу процессов на холсте NiFi.
![]()
После перетаскивания этого значка NiFi просит ввести имя группы процессов, а затем оно добавляется на холст NiFi.
Удаленная группа процессов
Это используется для добавления удаленной группы процессов в холст NiFi.

раструб
Воронка используется для передачи выходных данных процессора нескольким процессорам. Пользователь может использовать значок ниже, чтобы добавить воронку в поток данных NiFi.
![]()
шаблон
Этот значок используется для добавления шаблона потока данных на холст NiFi. Это помогает повторно использовать поток данных в одном и том же или разных экземплярах NiFi.
![]()
После перетаскивания пользователь может выбрать шаблоны, уже добавленные в NiFi.
этикетка
Они используются для добавления текста на холсте NiFi о любом компоненте, присутствующем в NiFi. Он предлагает диапазон цветов, используемых пользователем, чтобы добавить эстетический смысл.
![]()
Apache NiFi – Процессоры
Процессоры Apache NiFi являются основными блоками создания потока данных. Каждый процессор имеет разные функциональные возможности, что способствует созданию выходного потокового файла. Поток данных, показанный на изображении ниже, извлекает файл из одного каталога с использованием процессора GetFile и сохраняет его в другом каталоге с помощью процессора PutFile.
Получить файл
Процесс GetFile используется для извлечения файлов определенного формата из определенного каталога. Он также предоставляет пользователю другие возможности для большего контроля при извлечении. Мы обсудим это в разделе свойств ниже.
Настройки GetFile
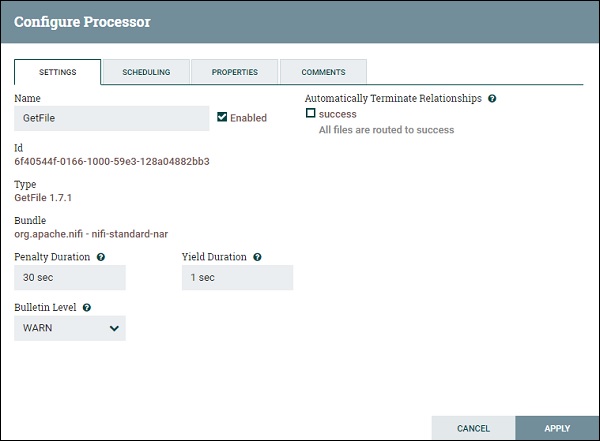
Ниже приведены различные настройки процессора GetFile –
название
В настройке «Имя» пользователь может определить любое имя для процессоров в соответствии с проектом или тем, что делает имя более значимым.
включить
Пользователь может включить или отключить процессор, используя этот параметр.
Длительность штрафа
Этот параметр позволяет пользователю добавить длительность штрафного времени в случае сбоя потока файла.
Продолжительность урожая
Этот параметр используется для указания времени выхода для процессора. В этот период процесс не запланирован снова.
Уровень бюллетеня
Этот параметр используется для указания уровня журнала этого процессора.
Автоматически разорвать отношения
Здесь есть список проверок всех доступных отношений этого конкретного процесса. Установив флажки, пользователь может запрограммировать процессор на прекращение потока файла для этого события и не отправлять его дальше в потоке.
Планирование GetFile
Это следующие параметры планирования, предлагаемые процессором GetFile:
График стратегии
Вы можете либо запланировать процесс на основе времени, выбрав время или указанную строку CRON, выбрав опцию драйвера CRON.
Параллельные задачи
Эта опция используется для определения расписания одновременных задач для этого процессора.
выполнение
Пользователь может определить, запускать ли процессор во всех узлах или только в основном узле, используя эту опцию.
Расписание запуска
Он используется для определения стратегии, основанной на времени, или выражения CRON для стратегии, управляемой CRON.
Свойства GetFile
GetFile предлагает несколько свойств, как показано на рисунке ниже, а также обязательные свойства, такие как Входной каталог и фильтр файлов, для дополнительных свойств, таких как Path Filter и Maximum File Size. Пользователь может управлять процессом извлечения файлов, используя эти свойства.
GetFile Комментарии
Этот раздел используется для указания любой информации о процессоре.
PutFile
Процессор PutFile используется для хранения файла из потока данных в определенном месте.
Настройки PutFile
Процессор PutFile имеет следующие настройки –
название
В настройке «Имя» пользователь может определить любое имя для процессоров в соответствии с проектом или тем, что делает имя более значимым.
включить
Пользователь может включить или отключить процессор, используя этот параметр.
Длительность штрафа
Этот параметр позволяет пользователю добавить длительность штрафного времени в случае сбоя потока файла.
Продолжительность урожая
Этот параметр используется для указания времени выхода для процессора. За это время процесс не запланирован снова.
Уровень бюллетеня
Этот параметр используется для указания уровня журнала этого процессора.
Автоматически разорвать отношения
В этих настройках есть список проверок всех доступных взаимосвязей этого конкретного процесса. Установив флажки, пользователь может запрограммировать процессор на прекращение потока файла для этого события и не отправлять его дальше в потоке.
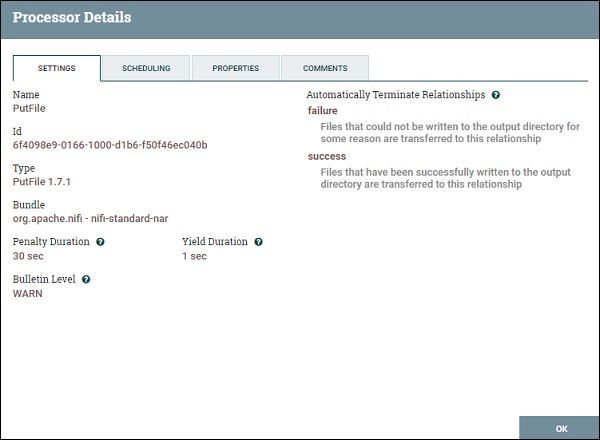
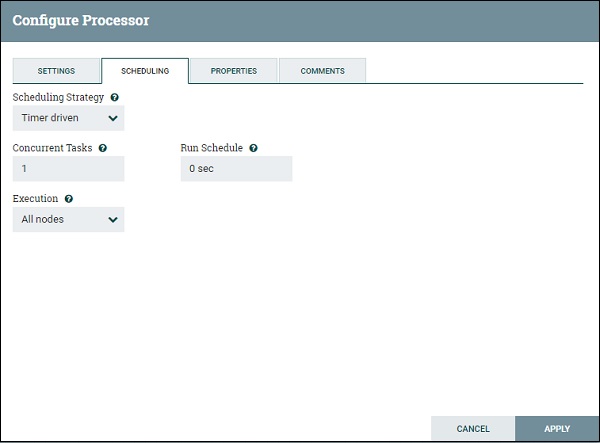
Планирование PutFile
Это следующие параметры планирования, предлагаемые процессором PutFile:
График стратегии
Вы можете запланировать процесс на основе времени, либо выбрав управляемый таймером, либо указав строку CRON, выбрав опцию драйвера CRON. Существует также экспериментальная стратегия Event Driven, которая запускает процессор при конкретном событии.
Параллельные задачи
Эта опция используется для определения расписания одновременных задач для этого процессора.
выполнение
Пользователь может определить, следует ли запускать процессор во всех узлах или только в основном узле, используя эту опцию.
Расписание запуска
Он используется для определения времени для стратегии, управляемой таймером, или выражения CRON для стратегии, управляемой CRON.
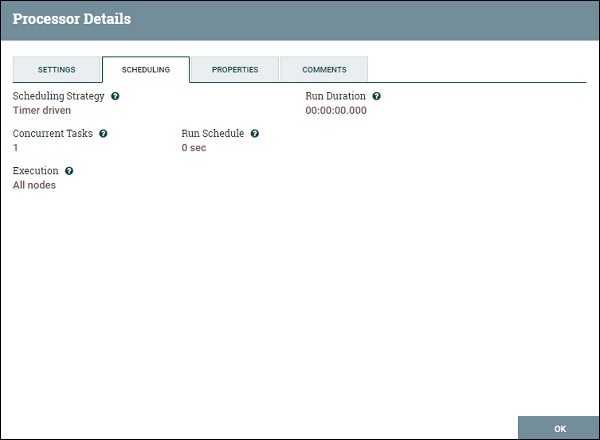
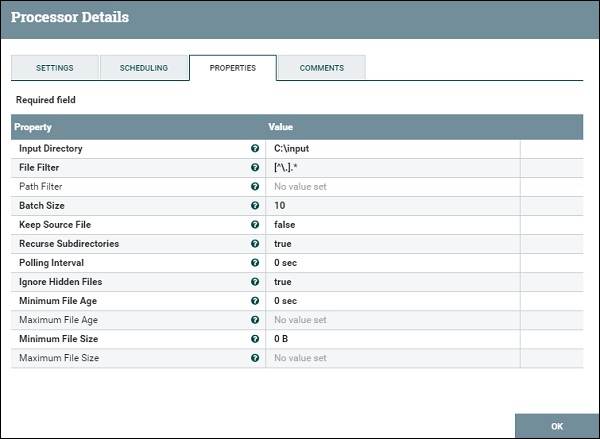
PutFile Properties
Процессор PutFile предоставляет такие свойства, как Directory, чтобы указать выходной каталог для передачи файлов, а другие – для управления передачей, как показано на рисунке ниже.
PutFile Комментарии
Этот раздел используется для указания любой информации о процессоре.
Apache NiFi – классификация процессоров
В этой главе мы обсудим категоризацию процессов в Apache NiFi.
Процессоры загрузки данных
Процессоры в категории Data Ingestion используются для ввода данных в поток данных NiFi. Это в основном отправная точка любого потока данных в Apache NiFi. Некоторые из процессоров, которые принадлежат к этим категориям: GetFile, GetHTTP, GetFTP, GetKAFKA и т. Д.
Процессоры маршрутизации и посредничества
Процессоры маршрутизации и посредничества используются для маршрутизации потоковых файлов к различным процессорам или потокам данных в соответствии с информацией в атрибутах или содержимом этих потоковых файлов. Эти процессоры также отвечают за управление потоками данных NiFi. Некоторые из процессоров, которые принадлежат к этой категории, являются RouteOnAttribute, RouteOnContent, ControlRate, RouteText и т. Д.
Процессоры доступа к базам данных
Процессоры этой категории доступа к базе данных способны выбирать или вставлять данные или выполнять и подготавливать другие операторы SQL из базы данных. Эти процессоры в основном используют настройки контроллера пула соединений данных Apache NiFi. Некоторые из процессоров, которые относятся к этой категории, – это ExecuteSQL, PutSQL, PutDatabaseRecord, ListDatabaseTables и т. Д.
Процессоры извлечения атрибутов
Процессоры извлечения атрибутов отвечают за извлечение, анализ, изменение обработки атрибутов потокового файла в потоке данных NiFi. Некоторые из процессоров, которые принадлежат к этой категории, являются UpdateAttribute, EvaluateJSONPath, ExtractText, AttributesToJSON и т. Д.
Процессоры системного взаимодействия
Процессоры System Interaction используются для запуска процессов или команд в любой операционной системе. Эти процессоры также запускают сценарии на многих языках для взаимодействия с различными системами. Некоторые из процессоров, которые принадлежат к этой категории: ExecuteScript, ExecuteProcess, ExecuteGroovyScript, ExecuteStreamCommand и т. Д.
Процессоры преобразования данных
Процессоры, принадлежащие Data Transformation, способны изменять содержимое потоковых файлов. Они могут использоваться для полной замены данных потокового файла, обычно используемого, когда пользователь должен отправить потоковый файл как тело HTTP для вызова процессора HTP. Некоторые из процессоров, которые принадлежат к этой категории, являются ReplaceText, JoltTransformJSON и т. Д.
Отправка процессоров данных
Отправляющие процессоры данных обычно являются конечным процессором в потоке данных. Эти процессоры отвечают за хранение или отправку данных на целевой сервер. После успешного сохранения или отправки данных эти процессоры сбрасывают потоковый файл с успешным отношением. Некоторые из процессоров, которые относятся к этой категории: PutEmail, PutKafka, PutSFTP, PutFile, PutFTP и т. Д.
Процессоры расщепления и агрегации
Эти процессоры используются для разделения и объединения содержимого, присутствующего в потоковом файле. Некоторые из процессоров, которые относятся к этой категории: SplitText, SplitJson, SplitXml, MergeContent, SplitContent и т. Д.
HTTP-процессоры
Эти процессоры работают с вызовами HTTP и HTTPS. Некоторые из процессоров, которые относятся к этой категории: InvokeHTTP, PostHTTP, ListenHTTP и т. Д.
Процессоры AWS
Процессоры AWS отвечают за взаимодействие с системой веб-сервисов Amazon. Некоторые из процессоров, которые относятся к этой категории, – это GetSQS, PutSNS, PutS3Object, FetchS3Object и т. Д.
Apache NiFi – Процессоры Взаимоотношения
В потоке данных Apache NiFi потоковые файлы перемещаются от одного процессора к другому через соединение, которое проверяется с помощью взаимосвязи между процессорами. Каждый раз, когда создается соединение, разработчик выбирает одно или несколько отношений между этими процессорами.
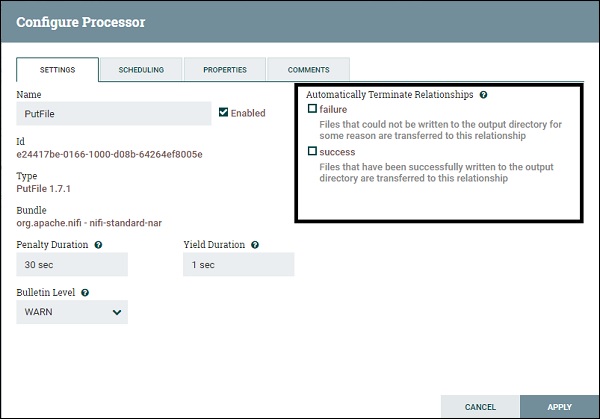
Как вы можете видеть на изображении выше, флажки в черном прямоугольнике являются отношениями. Если разработчик выберет эти флажки, потоковый файл прекратит работу в этом конкретном процессоре, когда связь будет успешной или неудачной, или и тем, и другим.
успех
Когда процессор успешно обрабатывает потоковый файл, например, сохраняет или извлекает данные из любого источника данных без получения какого-либо соединения, аутентификации или какой-либо другой ошибки, тогда потоковый файл переходит в отношение успеха.
недостаточность
Когда процессор не может обработать файл потока без ошибок, таких как ошибка аутентификации или проблема с подключением и т. Д., Тогда файл потока переходит в отношение сбоя.
Разработчик также может передавать потоковые файлы другим процессорам, используя соединения. Разработчик может выбрать, а также распределить нагрузку, но балансировка нагрузки только что выпущена в версии 1.8, которая не будет рассмотрена в этом руководстве.
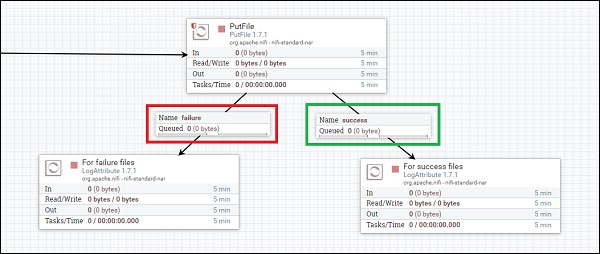
Как вы можете видеть на изображении выше, соединение, отмеченное красным, имеет отношение сбоя, что означает, что все потоковые файлы с ошибками будут отправлены в процессор слева, и, соответственно, все потоковые файлы без ошибок будут перенесены в соединение, отмеченное зеленым.
Давайте теперь перейдем к другим отношениям.
comms.failure
Эта связь встречается, когда не удается получить потоковый файл с удаленного сервера из-за сбоя связи.
не найдено
Любой Flowfile, для которого мы получаем сообщение «Not Found» с удаленного сервера, переходит в отношение not.found .
доступ запрещен
Когда NiFi не может получить потоковый файл с удаленного сервера из-за недостаточного разрешения, он будет проходить через это отношение.
Apache NiFi – FlowFile
Поточный файл является основным объектом обработки в Apache NiFi. Он содержит содержимое и атрибуты данных, которые используются процессорами NiFi для обработки данных. Содержимое файла обычно содержит данные, полученные из исходных систем. Наиболее распространенные атрибуты Apache NiFi FlowFile –
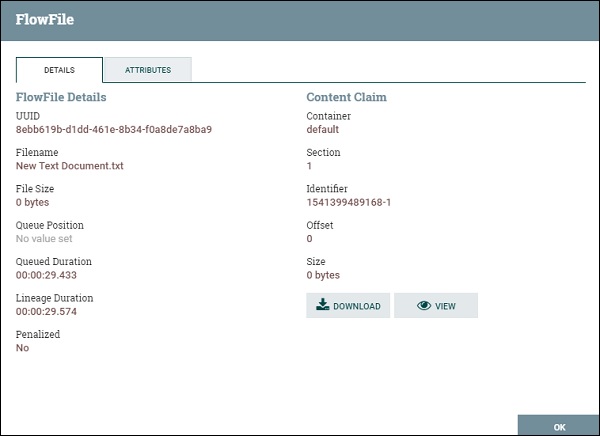
UUID
Это означает универсальный уникальный идентификатор, который является уникальным идентификатором потокового файла, сгенерированного NiFi.
Имя файла
Этот атрибут содержит имя файла этого потокового файла, и он не должен содержать структуру каталогов.
Размер файла
Он содержит размер Apache NiFi FlowFile.
mime.type
Он определяет MIME-тип этого FlowFile.
дорожка
Этот атрибут содержит относительный путь к файлу, к которому принадлежит потоковый файл, и не содержит имя файла.
Apache NiFi – очереди
Подключение потока данных Apache NiFi имеет систему очередей для обработки большого объема данных. Эти очереди могут обрабатывать очень большое количество FlowFiles, чтобы процессор мог обрабатывать их последовательно.
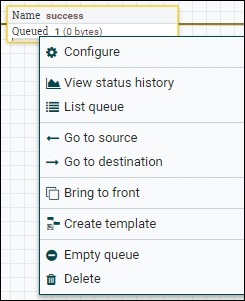
В очереди на изображении выше есть 1 потоковый файл, переданный через отношения успеха. Пользователь может проверить файл потока, выбрав опцию Список очереди в раскрывающемся списке. В случае любой перегрузки или ошибки пользователь также может очистить очередь, выбрав опцию пустой очереди, а затем пользователь может перезапустить поток, чтобы снова получить эти файлы в потоке данных.

Список потоковых файлов в очереди состоит из позиции, UUID, имени файла, размера файла, длительности очереди и длительности линии. Пользователь может просмотреть все атрибуты и содержимое потокового файла, щелкнув значок информации, присутствующий в первом столбце списка потокового файла.
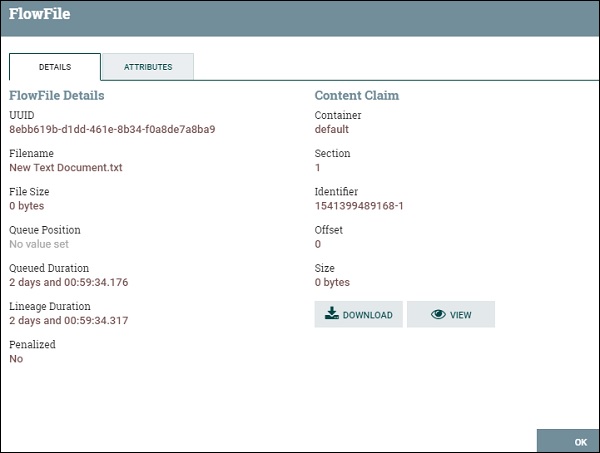
Apache NiFi – Технологические группы
В Apache NiFi пользователь может поддерживать разные потоки данных в разных группах процессов. Эти группы могут основываться на разных проектах или организациях, которые поддерживает экземпляр Apache NiFi.
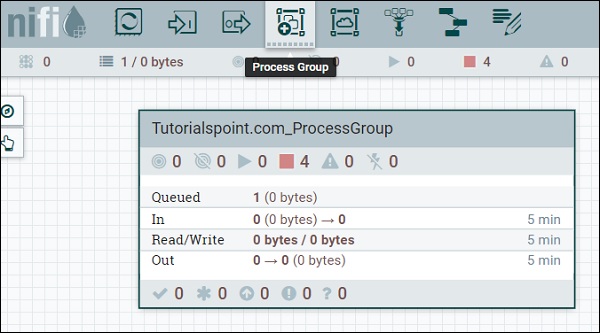
Четвертый символ в меню в верхней части интерфейса NiFi, как показано на рисунке выше, используется для добавления группы процессов в холст NiFi. Группа процессов с именем «Tutorialspoint.com_ProcessGroup» содержит поток данных с четырьмя процессорами, которые в данный момент находятся в стадии остановки, как вы можете видеть на рисунке выше. Группы процессов могут быть созданы иерархически, чтобы управлять потоками данных в лучшей структуре, что легко понять.

В нижнем колонтитуле пользовательского интерфейса NiFi вы можете увидеть группы процессов и вернуться к началу группы процессов, в которой в настоящее время находится пользователь.
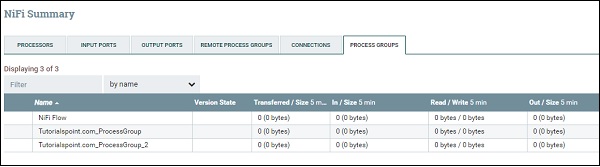
Чтобы увидеть полный список групп процессов, представленных в NiFi, пользователь может перейти к сводке, используя меню, представленное в левой верхней части интерфейса NiFi. Таким образом, есть вкладка групп процессов, в которой перечислены все группы процессов с такими параметрами, как состояние версии, перенесено / размер, в / размер, чтение / запись, выход / размер и т. Д., Как показано на рисунке ниже.
Apache NiFi – этикетки
Apache NiFi предлагает ярлыки, позволяющие разработчику писать информацию о компонентах, представленных на холсте NiFI. Крайний левый значок в верхнем меню NiFi UI используется для добавления метки на холсте NiFi.

Разработчик может изменить цвет метки и размер текста, щелкнув правой кнопкой мыши по метке и выбрав соответствующую опцию в меню.
Apache NiFi – Конфигурация
Apache NiFi – настраиваемая платформа. Файл nifi.properties в каталоге conf
содержит большую часть конфигурации.
Обычно используемые свойства Apache NiFi следующие:
Основные свойства
Этот раздел содержит свойства, которые являются обязательными для запуска экземпляра NiFi.
| S.No. | Имя свойства | Значение по умолчанию | описание |
|---|---|---|---|
| 1 | nifi.flow.configuration.file | ./conf/flow.xml.gz | Это свойство содержит путь к файлу flow.xml. Этот файл содержит все потоки данных, созданные в NiFi. |
| 2 | nifi.flow.configuration.archive.enabled | правда | Это свойство используется для включения или отключения архивирования в NiFi. |
| 3 | nifi.flow.configuration.archive.dir | ./conf/archive/ | Это свойство используется для указания каталога архива. |
| 4 | nifi.flow.configuration.archive.max.time | 30 дней | Это используется для указания времени хранения для архивирования контента. |
| 5 | nifi.flow.configuration.archive.max.storage | 500 МБ | он содержит максимальный размер архива, каталог может расти. |
| 6 | nifi.authorizer.configuration.file | ./conf/authorizers.xml | Указать файл конфигурации авторизатора, который используется для авторизации пользователя. |
| 7 | nifi.login.identity.provider.configuration.file | ./conf/login-identity-providers.xml | Это свойство содержит конфигурацию провайдеров идентификации для входа, |
| 8 | nifi.templates.directory | ./conf/templates | Это свойство используется для указания каталога, в котором будут храниться шаблоны NiFi. |
| 9 | nifi.nar.library.directory | ./lib | Это свойство содержит путь к библиотеке, которую NiFi будет использовать для загрузки всех компонентов, использующих файлы NAR, присутствующие в этой папке lib. |
| 10 | nifi.nar.working.directory | ./work/nar/ | В этом каталоге будут храниться распакованные файлы nar после их обработки NiFi. |
| 11 | nifi.documentation.working.directory | ./work/docs/components | Этот каталог содержит документацию всех компонентов. |
Государственное управление
Эти свойства используются для хранения состояния компонентов, полезных для начала обработки, где компоненты оставлены после перезапуска и при следующем запуске расписания.
| S.No. | Имя свойства | Значение по умолчанию | описание |
|---|---|---|---|
| 1 | nifi.state.management.configuration.file | ./conf/state-management.xml | Это свойство содержит путь к файлу state-management.xml. Этот файл содержит все состояние компонента, присутствующее в потоках данных этого экземпляра NiFi. |
| 2 | nifi.state.management.provider.local | местный провайдер | Он содержит идентификатор местного государственного провайдера. |
| 3 | nifi.state.management.provider.cluster | гк-провайдер | Это свойство содержит идентификатор поставщика состояния кластера. Это будет игнорироваться, если NiFi не кластеризован, но должен быть заполнен, если работает в кластере. |
| 4 | nifi.state.management. встроенный. работник зоопарка. Начните | ложный | Это свойство указывает, должен ли этот экземпляр NiFi запускать встроенный сервер ZooKeeper. |
| 5 | nifi.state.management. встроенный. zookeeper.properties | ./conf/zookeeper.properties | Это свойство содержит путь к файлу свойств, который предоставляет свойства ZooKeeper, чтобы использовать if <nifi.state.management. встроенный. работник зоопарка. начало> имеет значение true. |
FlowFile Repository
Давайте теперь посмотрим на важные детали репозитория FlowFile –
| S.No. | Имя свойства | Значение по умолчанию | описание |
|---|---|---|---|
| 1 | nifi.flowfile.repository. реализация | org.apache.nifi. контроллер. репозиторий. WriteAhead FlowFileRepository | Это свойство используется для указания либо сохранения потоковых файлов в памяти или на диске. Если пользователь хочет сохранить потоковые файлы в памяти, измените его на «org.apache.nifi.controller. Repository.VolatileFlowFileRepository». |
| 2 | nifi.flowfile.repository.directory | ./flowfile_repository | Указать каталог для репозитория flowfile. |
Apache NiFi – Администрация
Apache NiFi предлагает поддержку нескольких инструментов, таких как ambari, zookeeper для целей администрирования. NiFi также предоставляет конфигурацию в файле nifi.properties для настройки HTTPS и других вещей для администраторов.
работник зоопарка
Сам NiFi не управляет процессом голосования в кластере. Это означает, что при создании кластера все узлы являются основными и координирующими. Итак, zookeeper настроен для управления голосованием основного узла и координатора. Файл nifi.properties содержит некоторые свойства для настройки zookeeper.
| S.No. | Имя свойства | Значение по умолчанию | описание |
|---|---|---|---|
| 1 | nifi.state.management.embedded.zookeeper. свойства | ./conf/zookeeper.properties | Чтобы указать путь и имя файла свойств zookeeper. |
| 2 | nifi.zookeeper.connect.string | пустой | Чтобы указать строку подключения zookeeper. |
| 3 | nifi.zookeeper.connect.timeout | 3 сек | Чтобы указать время ожидания соединения зоопарка с NiFi. |
| 4 | nifi.zookeeper.session.timeout | 3 сек | Чтобы указать время ожидания сессии Zookeeper с NiFi. |
| 5 | nifi.zookeeper.root.node | / Nifi | Чтобы указать корневой узел для zookeeper. |
| 6 | nifi.zookeeper.auth.type | пустой | Чтобы указать тип аутентификации для zookeeper. |
Включить HTTPS
Чтобы использовать NiFi поверх HTTPS, администраторы должны сгенерировать хранилище ключей и доверенных сертификатов и установить некоторые свойства в файле nifi.properties. Инструментарий TLS можно использовать для генерации всех необходимых ключей для включения HTTPS в apache NiFi.
| S.No. | Имя свойства | Значение по умолчанию | описание |
|---|---|---|---|
| 1 | nifi.web.https.port | пустой | Чтобы указать номер порта https. |
| 2 | nifi.web.https.network.interface.default | пустой | Стандартный интерфейс для https в NiFi. |
| 3 | nifi.security.keystore | пустой | Указать путь и имя файла хранилища ключей. |
| 4 | nifi.security.keystoreType | пустой | Чтобы указать тип хранилища ключей типа JKS. |
| 5 | nifi.security.keystorePasswd | пустой | Чтобы указать пароль хранилища ключей. |
| 6 | nifi.security.truststore | пустой | Чтобы указать путь и имя файла склада доверенных сертификатов. |
| 7 | nifi.security.truststoreType | пустой | Чтобы указать тип хранилища доверенных сертификатов, например, JKS. |
| 8 | nifi.security.truststorePasswd | пустой | Чтобы указать пароль склада доверенных сертификатов. |
Другие свойства для администрации
Существуют и другие свойства, которые используются администраторами для управления NiFi и обеспечения непрерывности его обслуживания.
| S.No. | Имя свойства | Значение по умолчанию | описание |
|---|---|---|---|
| 1 | nifi.flowcontroller.graceful.shutdown.period | 10 сек | Чтобы указать время для постепенного отключения контроллера потока NiFi. |
| 2 | nifi.administrative.yield.duration | 30 сек | Указать длительность административной доходности для NiFi. |
| 3 | nifi.authorizer.configuration.file | ./conf/authorizers.xml | Указать путь и имя файла конфигурации авторизатора. |
| 4 | nifi.login.identity.provider.configuration.file | ./conf/login-identity-providers.xml | Чтобы указать путь и имя файла конфигурации провайдера идентификации. |
Apache NiFi – Создание потоков
Apache NiFi предлагает большое количество компонентов, которые помогают разработчикам создавать потоки данных для любых типов протоколов или источников данных. Чтобы создать поток, разработчик перетаскивает компоненты из строки меню на холст и соединяет их, щелкая и перетаскивая мышь из одного компонента в другой.
Как правило, NiFi имеет компонент слушателя в начале потока, такой как getfile, который получает данные из исходной системы. На другом конце находится компонент-передатчик, такой как putfile, и между ними есть компоненты, которые обрабатывают данные.
Например, давайте создадим поток, который берет пустой файл из одного каталога, добавляет некоторый текст в этот файл и помещает его в другой каталог.

-
Для начала перетащите значок процессора на холст NiFi и выберите процессор GetFile из списка.
-
Создайте входной каталог, например, c: \ inputdir.
-
Щелкните правой кнопкой мыши по процессору и выберите «Настроить», на вкладке свойств добавьте « Входной каталог» (c: \ inputdir), нажмите «Применить» и вернитесь на холст.
-
Перетащите значок процессора на холст и выберите процессор ReplaceText из списка.
-
Щелкните правой кнопкой мыши по процессору и выберите «Настроить». На вкладке свойств добавьте текст типа «Hello tutorialspoint.com» в текстовое поле «Значение замены» и нажмите «Применить».
-
Перейдите на вкладку «Настройки», установите флажок «Ошибка» справа и вернитесь на холст.
-
Подключите процессор GetFIle к ReplaceText в случае успеха.
-
Перетащите значок процессора на холст и выберите процессор PutFile из списка.
-
Создайте выходной каталог, например, c: \ outputdir .
-
Щелкните правой кнопкой мыши по процессору и выберите «Настроить». На вкладке свойств добавьте каталог (c: \ outputdir), нажмите «Применить» и вернитесь на холст.
-
Перейдите на вкладку «Настройки» и установите флажок «Ошибка и успех» справа, а затем вернитесь на холст.
-
Подключите процессор ReplaceText к PutFile в случае успеха.
-
Теперь запустите поток и добавьте пустой файл во входной каталог, и вы увидите, что он переместится в выходной каталог, и текст будет добавлен в файл.
Для начала перетащите значок процессора на холст NiFi и выберите процессор GetFile из списка.
Создайте входной каталог, например, c: \ inputdir.
Щелкните правой кнопкой мыши по процессору и выберите «Настроить», на вкладке свойств добавьте « Входной каталог» (c: \ inputdir), нажмите «Применить» и вернитесь на холст.
Перетащите значок процессора на холст и выберите процессор ReplaceText из списка.
Щелкните правой кнопкой мыши по процессору и выберите «Настроить». На вкладке свойств добавьте текст типа «Hello tutorialspoint.com» в текстовое поле «Значение замены» и нажмите «Применить».
Перейдите на вкладку «Настройки», установите флажок «Ошибка» справа и вернитесь на холст.
Подключите процессор GetFIle к ReplaceText в случае успеха.
Перетащите значок процессора на холст и выберите процессор PutFile из списка.
Создайте выходной каталог, например, c: \ outputdir .
Щелкните правой кнопкой мыши по процессору и выберите «Настроить». На вкладке свойств добавьте каталог (c: \ outputdir), нажмите «Применить» и вернитесь на холст.
Перейдите на вкладку «Настройки» и установите флажок «Ошибка и успех» справа, а затем вернитесь на холст.
Подключите процессор ReplaceText к PutFile в случае успеха.
Теперь запустите поток и добавьте пустой файл во входной каталог, и вы увидите, что он переместится в выходной каталог, и текст будет добавлен в файл.
Выполнив вышеуказанные шаги, разработчики могут выбрать любой процессор и другой компонент NiFi, чтобы создать подходящий поток для своей организации или клиента.
Apache NiFi – шаблоны
Apache NiFi предлагает концепцию шаблонов, которая упрощает повторное использование и распределение потоков NiFi. Потоки могут быть использованы другими разработчиками или в других кластерах NiFi. Это также помогает разработчикам NiFi делиться своей работой в таких репозиториях, как GitHub.
Создать шаблон
Давайте создадим шаблон для потока, который мы создали в главе № 15 «Apache NiFi – Создание потоков».
Выделите все компоненты потока с помощью клавиши Shift, а затем щелкните значок создания шаблона в левой части холста NiFi. Вы также можете увидеть ящик для инструментов, как показано на рисунке выше. Нажмите на иконку создания шаблона, отмеченную синим, как на картинке выше. Введите имя для шаблона. Разработчик также может добавить описание, которое не является обязательным.
Скачать шаблон
Затем перейдите к пункту «Шаблоны NiFi» в меню в верхнем правом углу пользовательского интерфейса NiFi, как показано на рисунке ниже.
Теперь щелкните значок загрузки (присутствует справа в списке) шаблона, который вы хотите загрузить. Файл XML с именем шаблона будет загружен.
Загрузить шаблон
Чтобы использовать шаблон в NiFi, разработчик должен загрузить свой XML-файл в NiFi с помощью пользовательского интерфейса. Рядом со значком «Создать шаблон» есть значок «Загрузить шаблон» (помечен синим цветом на изображении ниже) и просмотрите XML.
Добавить шаблон
На верхней панели инструментов NiFi UI значок шаблона находится перед значком метки. Значок помечен синим цветом, как показано на рисунке ниже.

Перетащите значок шаблона, выберите шаблон из выпадающего списка и нажмите «Добавить». Это добавит шаблон к холсту NiFi.
Apache NiFi – API
NiFi предлагает большое количество API, который помогает разработчикам вносить изменения и получать информацию о NiFi из любого другого инструмента или пользовательских приложений. В этом уроке мы будем использовать приложение почтальона в Google Chrome, чтобы объяснить некоторые примеры.
Чтобы добавить ваш Google Chrome, перейдите по указанному ниже URL-адресу и нажмите кнопку «Добавить в Chrome». Теперь вы увидите новое приложение, добавленное в Google Chrome.
Интернет-магазин Chrome
Текущая версия NiFi rest API – 1.8.0, а документация представлена в указанном ниже URL.
https://nifi.apache.org/docs/nifi-docs/rest-api/index.html
Ниже приведены наиболее часто используемые модули API отдыха NiFi –
-
http: // <URL-адрес nifi>: <порт nifi> / nifi-api / < путь-api >
-
Если HTTPS включен, https: // <URL-адрес nifi>: <порт nifi> / nifi-api / < путь-api >
http: // <URL-адрес nifi>: <порт nifi> / nifi-api / < путь-api >
Если HTTPS включен, https: // <URL-адрес nifi>: <порт nifi> / nifi-api / < путь-api >
| S.No. | Имя модуля API | апи-путь | Описание |
|---|---|---|---|
| 1 | Доступ | /доступ | Для аутентификации пользователя и получения токена доступа от NiFi. |
| 2 | контроллер | / контроллер | Управлять кластером и создавать отчетные задачи. |
| 3 | Услуги Контроллера | / контроллер-услуги | Он используется для управления службами контроллера и обновления ссылок на службы контроллера. |
| 4 | Задачи отчетности | / отчетно-задачи | Управлять отчетными задачами. |
| 5 | поток | /течь | Чтобы получить метаданные потока данных, статус компонента и историю запросов |
| 6 | Группы процессов | / Процесс-групп | Для загрузки и создания шаблона и создания компонентов. |
| 7 | процессоры | / процессоры | Создать и запланировать процессор и установить его свойства. |
| 8 | связи | / соединения | Чтобы создать соединение, установите приоритет очереди и обновите место назначения соединения |
| 9 | FlowFile Queues | / flowfile-очереди | Для просмотра содержимого очереди, загрузки содержимого потокового файла и пустой очереди. |
| 10 | Удаленные группы процессов | / дистанционный процесс-групп | Создать удаленную группу и включить передачу. |
| 11 | происхождение | / источник | Чтобы запросить происхождение и поиск происхождений событий. |
Давайте теперь рассмотрим пример и запустим почтальона, чтобы получить подробную информацию о работающем экземпляре NiFi.
Запрос
GET http://localhost:8080/nifi-api/flow/about
отклик
{
"about": {
"title": "NiFi",
"version": "1.7.1",
"uri": "http://localhost:8080/nifi-api/",
"contentViewerUrl": "../nifi-content-viewer/",
"timezone": "SGT",
"buildTag": "nifi-1.7.1-RC1",
"buildTimestamp": "07/12/2018 12:54:43 SGT"
}
}
Apache NiFi – провенанс данных
Apache NiFi регистрирует и хранит каждую информацию о событиях, произошедших в загруженных данных в потоке. Хранилище данных о происхождении хранит эту информацию и предоставляет пользовательский интерфейс для поиска информации об этом событии. Доступ к данным можно получить как на уровне NiFi, так и на уровне процессора.
В следующей таблице перечислены различные поля в списке событий NiFi Data Provenance, имеющие следующие поля:
| S.No. | Имя поля | Описание |
|---|---|---|
| 1 | Дата / время | Дата и время события. |
| 2 | Тип | Тип события, как «CREATE». |
| 3 | FlowFileUuid | UUID файла потока, для которого выполняется событие. |
| 4 | Размер | Размер потока файла. |
| 5 | Имя компонента | Имя компонента, который выполнил событие. |
| 6 | Тип компонента | Тип компонента. |
| 7 | Показать родословную | В последнем столбце есть значок show lineage, который используется для просмотра линии потока файла, как показано на рисунке ниже. |
![]()
Чтобы получить больше информации о событии, пользователь может щелкнуть значок информации в первом столбце интерфейса пользователя NiFi Data Provenance.
В файле nifi.properties есть некоторые свойства, которые используются для управления хранилищем данных NiFi Data Provenance.
| S.No. | Имя свойства | Значение по умолчанию | Описание |
|---|---|---|---|
| 1 | nifi.provenance.repository.directory.default | ./provenance_repository | Чтобы указать путь по умолчанию для данных о происхождении NiFi. |
| 2 | nifi.provenance.repository.max.storage.time | 24 часа | Указать максимальное время хранения данных о происхождении NiFi. |
| 3 | nifi.provenance.repository.max.storage.size | 1 ГБ | Указать максимальное хранилище данных о происхождении NiFi. |
| 4 | nifi.provenance.repository.rollover.time | 30 секунд | Указать время пролонгации данных происхождения NiFi. |
| 5 | nifi.provenance.repository.rollover.size | 100 МБ | Указать размер ролловера для данных о происхождении NiFi. |
| 6 | nifi.provenance.repository.indexed.fields | EventType, FlowFileUUID, имя файла, ProcessorID, отношение | Чтобы указать поля, используемые для поиска и индексации данных происхождения NiFi. |
Apache NiFi – мониторинг
В Apache NiFi есть несколько способов отслеживать различные статистические данные системы, такие как ошибки, использование памяти, использование процессора, статистика потоков данных и т. Д. В этом руководстве мы обсудим наиболее популярные из них.
Встроенный мониторинг
В этом разделе мы узнаем больше о встроенном мониторинге в Apache NiFi.
Доска объявлений
На доске объявлений показаны последние ошибки и предупреждения, генерируемые процессорами NiFi, в режиме реального времени. Чтобы получить доступ к доске объявлений, пользователь должен перейти в выпадающее меню справа и выбрать опцию доски объявлений. Он обновляется автоматически, и пользователь также может отключить его. Пользователь также может перейти к фактическому процессору, дважды щелкнув по ошибке. Пользователь также может отфильтровать бюллетени, выполнив следующие действия:
- по сообщению
- по имени
- по идентификатору
- по идентификатору группы
Пользовательский интерфейс данных
Для отслеживания событий, происходящих на любом конкретном процессоре или во всем NiFi, пользователь может получить доступ к данным происхождения из того же меню, что и доска объявлений. Пользователь также может фильтровать события в хранилище данных происхождения, работая со следующими полями:
- по названию компонента
- по типу компонента
- по типу
Обзор интерфейса NiFi
Доступ к сводке Apache NiFi также можно получить из того же меню, что и доска объявлений. Этот интерфейс содержит информацию обо всех компонентах этого конкретного экземпляра или кластера NiFi. Они могут быть отфильтрованы по имени, по типу или по URI. Существуют разные вкладки для разных типов компонентов. Ниже приведены компоненты, которые можно отслеживать в итоговом пользовательском интерфейсе NiFi.
- процессоры
- Входные порты
- Выходные порты
- Удаленные группы процессов
- связи
- Группы процессов
В этом пользовательском интерфейсе внизу справа есть ссылка с названием «Диагностика системы» для проверки статистики JVM.
Задачи отчетности
Apache NiFi предоставляет несколько задач отчетности для поддержки внешних систем мониторинга, таких как Ambari, Grafana и т. Д. Разработчик может создать настраиваемую задачу отчетности или настроить встроенные задачи для отправки метрик NiFi в системы внешнего мониторинга. В следующей таблице перечислены задачи отчетности, предлагаемые NiFi 1.7.1.
| S.No. | Название задачи отчетности | Описание |
|---|---|---|
| 1 | AmbariReportingTask | Чтобы настроить Ambari Metrics Service для NiFi. |
| 2 | ControllerStatusReportingTask | Чтобы сообщить информацию из сводного интерфейса NiFi за последние 5 минут. |
| 3 | MonitorDiskUsage | Чтобы сообщить и предупредить об использовании диска определенного каталога. |
| 4 | MonitorMemory | Для наблюдения за количеством кучи Java, используемой в пуле памяти Java JVM. |
| 5 | SiteToSiteBulletinReportingTask | Сообщать об ошибках и предупреждениях в бюллетенях с использованием протокола Site to Site. |
| 6 | SiteToSiteProvenanceReportingTask | Чтобы сообщить о событиях NiFi Data Provenance с использованием протокола Site to Site. |
NiFi API
Существует API, называемый системной диагностикой, который можно использовать для мониторинга статистики NiFI в любом специально разработанном приложении. Давайте проверим API в почтальоне.
Запрос
http://localhost:8080/nifi-api/system-diagnostics
отклик
{
"systemDiagnostics": {
"aggregateSnapshot": {
"totalNonHeap": "183.89 MB",
"totalNonHeapBytes": 192819200,
"usedNonHeap": "173.47 MB",
"usedNonHeapBytes": 181894560,
"freeNonHeap": "10.42 MB",
"freeNonHeapBytes": 10924640,
"maxNonHeap": "-1 bytes",
"maxNonHeapBytes": -1,
"totalHeap": "512 MB",
"totalHeapBytes": 536870912,
"usedHeap": "273.37 MB",
"usedHeapBytes": 286652264,
"freeHeap": "238.63 MB",
"freeHeapBytes": 250218648,
"maxHeap": "512 MB",
"maxHeapBytes": 536870912,
"heapUtilization": "53.0%",
"availableProcessors": 4,
"processorLoadAverage": -1,
"totalThreads": 71,
"daemonThreads": 31,
"uptime": "17:30:35.277",
"flowFileRepositoryStorageUsage": {
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
},
"contentRepositoryStorageUsage": [
{
"identifier": "default",
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
}
],
"provenanceRepositoryStorageUsage": [
{
"identifier": "default",
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
}
],
"garbageCollection": [
{
"name": "G1 Young Generation",
"collectionCount": 344,
"collectionTime": "00:00:06.239",
"collectionMillis": 6239
},
{
"name": "G1 Old Generation",
"collectionCount": 0,
"collectionTime": "00:00:00.000",
"collectionMillis": 0
}
],
"statsLastRefreshed": "09:30:20 SGT",
"versionInfo": {
"niFiVersion": "1.7.1",
"javaVendor": "Oracle Corporation",
"javaVersion": "1.8.0_151",
"osName": "Windows 7",
"osVersion": "6.1",
"osArchitecture": "amd64",
"buildTag": "nifi-1.7.1-RC1",
"buildTimestamp": "07/12/2018 12:54:43 SGT"
}
}
}
}
Apache NiFi – Обновление
Перед началом обновления Apache NiFi ознакомьтесь с заметками о выпуске, чтобы узнать об изменениях и дополнениях. Пользователь должен оценить влияние этих дополнений и изменений в его / ее текущей установке NiFi. Ниже приведена ссылка для получения заметок о выпуске новых выпусков Apache NiFi.
https://cwiki.apache.org/confluence/display/NIFI/Release+Notes
В настройке кластера пользователь должен обновить установку NiFi каждого узла в кластере. Следуйте приведенным ниже инструкциям для обновления Apache NiFi.
-
Сделайте резервную копию всех пользовательских NAR-файлов, имеющихся в вашем текущем NiFi или lib или любой другой папке.
-
Загрузите новую версию Apache NiFi. Ниже приведена ссылка для загрузки исходного кода и бинарных файлов последней версии NiFi.
https://nifi.apache.org/download.html
-
Создайте новый каталог в том же каталоге установки текущего NiFi и распакуйте новую версию Apache NiFi.
-
Останови Нифи изящно. Сначала остановите все процессоры и дайте обработать все потоковые файлы, присутствующие в потоке. Как только поток больше не будет, остановите NiFi.
-
Скопируйте конфигурацию authorizers.xml из текущей установки NiFi в новую версию.
-
Обновите значения в bootstrap-messages-services.xml и bootstrap.conf новой версии NiFi из текущей.
-
Добавьте пользовательский журнал из logback.xml в новую установку NiFi.
-
Сконфигурируйте провайдера идентификационных данных для входа в login-identity-provider.xml из текущей версии.
-
Обновите все свойства в nifi.properties новой установки NiFi с текущей версии.
-
Убедитесь, что группа и пользователь новой версии совпадают с текущей версией, чтобы избежать ошибок, связанных с отказом в разрешении.
-
Скопируйте конфигурацию из state-management.xml текущей версии в новую версию.
-
Скопируйте содержимое следующих каталогов из текущей версии установки NiFi в те же каталоги в новой версии.
-
./conf/flow.xml.gz
-
Также flow.xml.gz из каталога архива.
-
Для провенанса и содержимого репозиториев измените значения в nifi. файл свойств для текущих репозиториев.
-
скопируйте состояние из ./state/local или измените nifi.properties, если указан любой другой внешний каталог.
-
-
Перепроверьте все выполненные изменения и проверьте, влияют ли они на какие-либо новые изменения, добавленные в новой версии NiFi. Если есть какое-либо влияние, проверьте решения.
-
Запустите все узлы NiFi и убедитесь, что все потоки работают правильно, а хранилища данных хранят данные, а пользовательский интерфейс извлекает их с любыми ошибками.
-
Следите за сообщениями в течение некоторого времени, чтобы проверить наличие новых ошибок.
-
Если новая версия работает правильно, то текущая версия может быть заархивирована и удалена из каталогов.
Сделайте резервную копию всех пользовательских NAR-файлов, имеющихся в вашем текущем NiFi или lib или любой другой папке.
Загрузите новую версию Apache NiFi. Ниже приведена ссылка для загрузки исходного кода и бинарных файлов последней версии NiFi.
https://nifi.apache.org/download.html
Создайте новый каталог в том же каталоге установки текущего NiFi и распакуйте новую версию Apache NiFi.
Останови Нифи изящно. Сначала остановите все процессоры и дайте обработать все потоковые файлы, присутствующие в потоке. Как только поток больше не будет, остановите NiFi.
Скопируйте конфигурацию authorizers.xml из текущей установки NiFi в новую версию.
Обновите значения в bootstrap-messages-services.xml и bootstrap.conf новой версии NiFi из текущей.
Добавьте пользовательский журнал из logback.xml в новую установку NiFi.
Сконфигурируйте провайдера идентификационных данных для входа в login-identity-provider.xml из текущей версии.
Обновите все свойства в nifi.properties новой установки NiFi с текущей версии.
Убедитесь, что группа и пользователь новой версии совпадают с текущей версией, чтобы избежать ошибок, связанных с отказом в разрешении.
Скопируйте конфигурацию из state-management.xml текущей версии в новую версию.
Скопируйте содержимое следующих каталогов из текущей версии установки NiFi в те же каталоги в новой версии.
./conf/flow.xml.gz
Также flow.xml.gz из каталога архива.
Для провенанса и содержимого репозиториев измените значения в nifi. файл свойств для текущих репозиториев.
скопируйте состояние из ./state/local или измените nifi.properties, если указан любой другой внешний каталог.
Перепроверьте все выполненные изменения и проверьте, влияют ли они на какие-либо новые изменения, добавленные в новой версии NiFi. Если есть какое-либо влияние, проверьте решения.
Запустите все узлы NiFi и убедитесь, что все потоки работают правильно, а хранилища данных хранят данные, а пользовательский интерфейс извлекает их с любыми ошибками.
Следите за сообщениями в течение некоторого времени, чтобы проверить наличие новых ошибок.
Если новая версия работает правильно, то текущая версия может быть заархивирована и удалена из каталогов.
Apache NiFi – группа удаленных процессов
Apache NiFi Remote Process Group или RPG позволяет потоку направлять потоки файлов в поток к различным экземплярам NiFi с использованием протокола Site-to-Site. Начиная с версии 1.7.1, NiFi не предлагает сбалансированных отношений, поэтому RPG используется для балансировки нагрузки в потоке данных NiFi.

Разработчик может добавить RPG с верхней панели инструментов пользовательского интерфейса NiFi, перетащив значок, как показано на рисунке выше, на холст. Чтобы настроить RPG, Разработчик должен добавить следующие поля:
| S.No. | Имя поля | Описание |
|---|---|---|
| 1 | URL-адрес | Чтобы указать разделенные запятыми URL-адреса удаленных целевых NiFi. |
| 2 | Транспортный протокол | Чтобы указать транспортный протокол для удаленных экземпляров NiFi. Это либо RAW, либо HTTP. |
| 3 | Интерфейс локальной сети | Чтобы указать локальный сетевой интерфейс для отправки / получения данных. |
| 4 | HTTP прокси-сервер имя хоста | Чтобы указать имя хоста прокси-сервера для транспортировки в RPG. |
| 5 | Порт прокси-сервера HTTP | Указать порт прокси-сервера для транспортной цели в RPG. |
| 6 | Пользователь HTTP-прокси | Это необязательное поле для указания имени пользователя для HTTP-прокси. |
| 7 | Пароль прокси HTTP | Это необязательное поле для указания пароля для указанного выше имени пользователя. |
Разработчик должен включить его, прежде чем использовать его, как мы запускаем процессоры, прежде чем их использовать.
Apache NiFi – Настройки контроллера
Apache NiFi предлагает общие сервисы, которые могут совместно использоваться процессорами, а задача создания отчетов называется настройкой контроллера. Это как пул соединений с базой данных, который может использоваться процессорами, обращающимися к одной и той же базе данных.
Чтобы получить доступ к настройкам контроллера, используйте раскрывающееся меню в правом верхнем углу интерфейса NiFi, как показано на рисунке ниже.
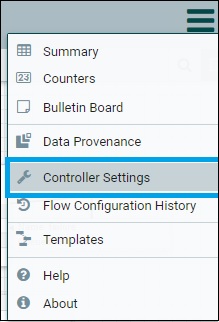
Apache NiFi предлагает множество настроек контроллера, мы обсудим наиболее часто используемые и их настройку в NiFi.
DBCPConnectionPool
Добавьте знак «плюс» на странице «Настройки Nifi» после выбора параметра «Настройки контроллера». Затем выберите DBCPConnectionPool из списка настроек контроллера. DBCPConnectionPool будет добавлен на главной странице настроек NiFi, как показано на рисунке ниже.

Он содержит следующую информацию о настройке контроллера : Имя
- Тип
- сверток
- государственный
- Объем
- Настроить и удалить значок
Нажмите на иконку конфигурации и заполните необходимые поля. Поля перечислены в таблице ниже –
| S.No. | Имя поля | Значение по умолчанию | описание |
|---|---|---|---|
| 1 | URL соединения с базой данных | пустой | Чтобы указать URL-адрес подключения к базе данных. |
| 2 | Имя класса драйвера базы данных | пустой | Чтобы указать имя класса драйвера для базы данных, например com.mysql.jdbc.Driver для mysql. |
| 3 | Максимальное время ожидания | 500 миллис | Указать время ожидания данных от соединения с базой данных. |
| 4 | Макс. Всего подключений | 8 | Указать максимальное количество выделенного соединения в пуле соединений с базой данных. |
Чтобы остановить или настроить параметры контроллера, сначала необходимо остановить все подключенные компоненты NiFi. NiFi также добавляет область действия в настройках контроллера для управления его конфигурацией. Следовательно, не будут затронуты только те, которые имеют одни и те же настройки и будут использовать те же настройки контроллера.
Apache NiFi – задача отчетности
Задачи отчетов Apache NiFi аналогичны службам контроллера, которые работают в фоновом режиме и отправляют или регистрируют статистику экземпляра NiFi. Доступ к задаче создания отчетов NiFi также можно получить на той же странице, что и настройки контроллера, но на другой вкладке.

Чтобы добавить задачу отчетности, разработчику необходимо нажать на кнопку «плюс», расположенную в правой верхней части страницы задач отчетности. Эти задачи отчетности в основном используются для мониторинга деятельности экземпляра NiFi, в бюллетенях или происхождении. Главным образом в этих задачах по отчетности используется передача данных с сайта на сайт для передачи статистических данных NiFi на другой узел или внешнюю систему.
Давайте теперь добавим настроенную задачу отчетности для большего понимания.
MonitorMemory
Эта задача создания отчетов используется для создания бюллетеней, когда пул памяти пересекает указанный процент. Выполните следующие действия, чтобы настроить задачу создания отчетов MonitorMemory.
-
Добавьте знак «плюс» и найдите MonitorMemory в списке.
-
Выберите MonitorMemory и нажмите ДОБАВИТЬ.
-
Как только он будет добавлен на главную страницу главной задачи отчетов, нажмите на значок настройки.
-
На вкладке свойств выберите пул памяти, который вы хотите отслеживать.
-
Выберите процент, после которого вы хотите, чтобы бюллетени оповещали пользователей.
-
Запустите задачу отчетности.
Добавьте знак «плюс» и найдите MonitorMemory в списке.
Выберите MonitorMemory и нажмите ДОБАВИТЬ.
Как только он будет добавлен на главную страницу главной задачи отчетов, нажмите на значок настройки.
На вкладке свойств выберите пул памяти, который вы хотите отслеживать.
Выберите процент, после которого вы хотите, чтобы бюллетени оповещали пользователей.
Запустите задачу отчетности.
Apache NiFi – пользовательский процессор
Apache NiFi является платформой с открытым исходным кодом и дает разработчикам возможность добавить свой собственный процессор в библиотеку NiFi. Выполните следующие действия, чтобы создать собственный процессор.
-
Загрузите последнюю версию Maven по ссылке, приведенной ниже.
https://maven.apache.org/download.cgi
-
Добавьте переменную среды с именем M2_HOME и задайте значение в качестве установочного каталога maven.
-
Загрузите Eclipse IDE по ссылке ниже.
https://www.eclipse.org/downloads/download.php
-
Откройте командную строку и выполните команду Maven Archetype.
Загрузите последнюю версию Maven по ссылке, приведенной ниже.
https://maven.apache.org/download.cgi
Добавьте переменную среды с именем M2_HOME и задайте значение в качестве установочного каталога maven.
Загрузите Eclipse IDE по ссылке ниже.
https://www.eclipse.org/downloads/download.php
Откройте командную строку и выполните команду Maven Archetype.
> mvn archetype:generate
-
Ищите тип nifi в проектах архетипов.
-
Выберите org.apache.nifi: проект nifi-процессор-пакет-архетип.
-
Затем из списка версий выберите последнюю версию, т. Е. 1.7.1, для этого урока.
-
Введите groupId, artifactId, версию, пакет, artifactBaseName и т. Д.
-
Тогда будет создан maven проект с каталогами.
-
nifi- <artifactBaseName> -processors
-
nifi- <artifactBaseName> -nar
-
-
Запустите приведенную ниже команду в каталоге nifi- <artifactBaseName> -processors, чтобы добавить проект в eclipse.
Ищите тип nifi в проектах архетипов.
Выберите org.apache.nifi: проект nifi-процессор-пакет-архетип.
Затем из списка версий выберите последнюю версию, т. Е. 1.7.1, для этого урока.
Введите groupId, artifactId, версию, пакет, artifactBaseName и т. Д.
Тогда будет создан maven проект с каталогами.
nifi- <artifactBaseName> -processors
nifi- <artifactBaseName> -nar
Запустите приведенную ниже команду в каталоге nifi- <artifactBaseName> -processors, чтобы добавить проект в eclipse.
mvn install eclipse:eclipse
-
Откройте затмение и выберите импорт из меню файла.
-
Затем выберите «Существующие проекты в рабочую область» и добавьте проект из каталога nifi- <artifactBaseName> -processors в eclipse.
-
Добавьте свой код в публичную функцию void onTrigger (контекст ProcessContext, сеанс ProcessSession), которая запускается, когда запланирован запуск процессора.
-
Затем упакуйте код в файл NAR, выполнив указанную ниже команду.
Откройте затмение и выберите импорт из меню файла.
Затем выберите «Существующие проекты в рабочую область» и добавьте проект из каталога nifi- <artifactBaseName> -processors в eclipse.
Добавьте свой код в публичную функцию void onTrigger (контекст ProcessContext, сеанс ProcessSession), которая запускается, когда запланирован запуск процессора.
Затем упакуйте код в файл NAR, выполнив указанную ниже команду.
mvn clean install
-
Файл NAR будет создан в nifi -nar / целевой каталог.
-
Скопируйте файл NAR в папку lib Apache NiFi и перезапустите NiFi.
-
После успешного перезапуска NiFi проверьте список процессоров для нового пользовательского процессора.
-
На наличие ошибок проверьте файл ./logs/nifi.log.
Файл NAR будет создан в nifi -nar / целевой каталог.
Скопируйте файл NAR в папку lib Apache NiFi и перезапустите NiFi.
После успешного перезапуска NiFi проверьте список процессоров для нового пользовательского процессора.
На наличие ошибок проверьте файл ./logs/nifi.log.
Apache NiFi – Сервис пользовательских контроллеров
Apache NiFi является платформой с открытым исходным кодом и предоставляет разработчикам возможность добавить свои собственные сервисы контроллеров в Apache NiFi. Шаги и инструменты почти такие же, как и для создания собственного процессора.
-
Откройте командную строку и выполните команду Maven Archetype.
Откройте командную строку и выполните команду Maven Archetype.
> mvn archetype:generate
-
Ищите тип nifi в проектах архетипов.
-
Выберите org.apache.nifi: проект nifi-service-bundle-archetype .
-
Затем из списка версий выберите самую последнюю версию – 1.7.1 для этого урока.
-
Введите groupId, artifactId, версию, пакет, artifactBaseName и т. Д.
-
Будет создан Maven проект с каталогами.
-
nifi- <artifactBaseName>
-
nifi- <artifactBaseName> -nar
-
nifi- <artifactBaseName> -api
-
nifi- <artifactBaseName> -api-Нар
-
-
Запустите приведенную ниже команду в каталогах nifi- <artifactBaseName> и nifi- <artifactBaseName> -api, чтобы добавить эти два проекта в затмение.
-
mvn установить затмение: затмение
-
-
Откройте затмение и выберите импорт из меню файла.
-
Затем выберите «Существующие проекты в рабочую область» и добавьте проект из каталогов nifi- <artifactBaseName> и nifi- <artifactBaseName> -api в eclipse.
-
Добавьте свой код в исходные файлы.
-
Затем упакуйте код в файл NAR, выполнив указанную ниже команду.
-
mvn clean install
-
-
Два файла NAR будут созданы в каждом каталоге nifi- <artifactBaseName> / target и nifi- <artifactBaseName> -api / target.
-
Скопируйте эти файлы NAR в папку lib Apache NiFi и перезапустите NiFi.
-
После успешного перезапуска NiFi проверьте список процессоров для нового пользовательского процессора.
-
На наличие ошибок проверьте файл ./logs/nifi.log .
Ищите тип nifi в проектах архетипов.
Выберите org.apache.nifi: проект nifi-service-bundle-archetype .
Затем из списка версий выберите самую последнюю версию – 1.7.1 для этого урока.
Введите groupId, artifactId, версию, пакет, artifactBaseName и т. Д.
Будет создан Maven проект с каталогами.
nifi- <artifactBaseName>
nifi- <artifactBaseName> -nar
nifi- <artifactBaseName> -api
nifi- <artifactBaseName> -api-Нар
Запустите приведенную ниже команду в каталогах nifi- <artifactBaseName> и nifi- <artifactBaseName> -api, чтобы добавить эти два проекта в затмение.
mvn установить затмение: затмение
Откройте затмение и выберите импорт из меню файла.
Затем выберите «Существующие проекты в рабочую область» и добавьте проект из каталогов nifi- <artifactBaseName> и nifi- <artifactBaseName> -api в eclipse.
Добавьте свой код в исходные файлы.
Затем упакуйте код в файл NAR, выполнив указанную ниже команду.
mvn clean install
Два файла NAR будут созданы в каждом каталоге nifi- <artifactBaseName> / target и nifi- <artifactBaseName> -api / target.
Скопируйте эти файлы NAR в папку lib Apache NiFi и перезапустите NiFi.
После успешного перезапуска NiFi проверьте список процессоров для нового пользовательского процессора.
На наличие ошибок проверьте файл ./logs/nifi.log .
Apache NiFi – логирование
Apache NiFi использует библиотеку logback для обработки своей регистрации. В каталоге conf NiFi есть файл logback.xml, который используется для настройки регистрации в NiFi. Журналы создаются в папке журналов NiFi, а файлы журналов описаны ниже.
Nifi-app.log
Это основной файл журнала nifi, в котором регистрируются все действия приложения apache NiFi, начиная с загрузки файлов NAR и заканчивая ошибками во время выполнения или сообщениями, встречающимися компонентами NiFi. Ниже приведен стандартный appender в файле logback.xml для файла nifi-app.log .
<appender name="APP_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-app.log</file> <rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"> <fileNamePattern> ${org.apache.nifi.bootstrap.config.log.dir}/ nifi-app_%d{yyyy-MM-dd_HH}.%i.log </fileNamePattern> <maxFileSize>100MB</maxFileSize> <maxHistory>30</maxHistory> </rollingPolicy> <immediateFlush>true</immediateFlush> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <pattern>%date %level [%thread] %logger{40} %msg%n</pattern> </encoder> </appender>
Имя приложения – APP_FILE, а класс – RollingFileAppender, что означает, что регистратор использует политику отката. По умолчанию максимальный размер файла составляет 100 МБ и может быть изменен до необходимого размера. Максимальное время хранения APP_FILE составляет 30 файлов журнала и может быть изменено в соответствии с требованиями пользователя.
Nifi-user.log
Этот журнал содержит пользовательские события, такие как веб-безопасность, конфигурация веб-API, авторизация пользователя и т. Д. Ниже приведен пример добавления файла nifi-user.log в файл logback.xml.
<appender name="USER_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-user.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/
nifi-user_%d.log
</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
Имя приложения – USER_FILE. Это следует политике ролловера. Максимальный срок хранения для USER_FILE – 30 файлов журнала. Ниже приведены стандартные регистраторы для приложения USER_FILE, присутствующего в nifi-user.log.
<logger name="org.apache.nifi.web.security" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.web.api.config" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.authorization" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.cluster.authorization" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.web.filter.RequestLogger" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger>
Nifi-bootstrap.log
Этот журнал содержит журналы начальной загрузки, стандартный вывод apache NiFi (все system.out написаны в коде в основном для отладки) и стандартную ошибку (все system.err написаны в коде). Ниже по умолчанию добавлен nifi-bootstrap.log в logback.log.
<appender name="BOOTSTRAP_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-bootstrap.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/nifi-bootstrap_%d.log
</fileNamePattern>
<maxHistory>5</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
Файл nifi-bootstrap.log, имя аппендера – BOOTSTRAP_FILE, что также соответствует политике отката. Максимальное время хранения для приложения BOOTSTRAP_FILE составляет 5 файлов журнала. Ниже приведены стандартные логгеры для файла nifi-bootstrap.log.
Время на прочтение
6 мин
Количество просмотров 17K
Введение
Так получилось, что на моем текущем месте работы мне пришлось познакомиться с данной технологией. Начну с небольшой предыстории. На очередном митинге, нашей команде сказали, что нужно создать интеграцию с известной системой. Под интеграцией подразумевалось, что эта известная система будет нам слать запросы через HTTP на определенный ендпоинт, а мы, как это ни странно, слать обратно ответы в виде SOAP сообщения. Вроде все просто и тривиально. Из этого следует что нужно…
Задача
Создать 3 сервиса. Первый из них — Сервис обновления БД. Этот сервис, при поступлении новых данных из сторонней системы, обновляет данные в базе данных и генерирует некий файл в формате CSV, для передачи его в следующую систему. Вызывается ендпоинт второго сервиса — Сервиса транспортировки через FTP, который получает переданный файл, валидирует его, и кладет в файловое хранилище через FTP. Третий сервис — Сервис передачи данных потребителю, работает асинхронно с первыми двумя. Он принимает запрос от сторонней внешней системы, на получение файла о котором шла речь выше, берет готовый файл ответа, модифицирует его (обновляет поля id, description, linkToFile) и посылает ответ в виде SOAP сообщения. Т е в целом картина следующая: первые два сервиса начинают свою работу только тогда, когда пришли данные для обновления. Третий сервис работает постоянно поскольку потребителей информации много, порядка 1000 запросов на получение данных в минуту. Сервисы доступны постоянно и их инстанцы располагаются на разных окружениях, таких как тест, демо, препрод и прод. Ниже представлена схема работы этих сервисов. Сразу поясню, что некоторые детали упрощены для избежания лишней сложности.
Техническое углубление
При планировании решения задачи, сначала решили сделать приложения на java с использованием Spring framework, балансировщиком Nginx, базой данных Postgres и прочими техническими и не очень штуками. Поскольку время на проработку технического решения позволяло рассмотреть другие подходы решения этой задачи, взгляд упал на модную в определенных кругах технологию Apache NIFI. Сразу скажу, что эта технология позволила заметить нам эти 3 сервиса. В этой статье будет описана разработка сервиса транспортировки файла и сервиса передачи данных потребителю, однако если статья зайдет, напишу про сервис обновления данных в БД.
Что это такое
NIFI представляет собой распределенную архитектуру для быстрой параллельной загрузки и обработки данных, большое количество плагинов для источников и преобразований, версионирование конфигураций и многое другое. Приятным бонусом является то, что он очень прост в использовании. Тривиальные процессы, такие как getFile, sendHttpRequest и другие — можно представить в виде квадратов. Каждый квадрат представляет некий процесс, взаимодействие которого можно увидеть на рисунке ниже. Более подробная документация по взаимодействию настройке процессов написана здесь , для тех кому на русском — здесь. В документации отлично расписано как распаковать и запустить NIFI, а так же, как создать процессы, они же квадраты
Идея написать статью родилась после продолжительных поисков и структурирования полученной информации в что-то осознанное, а так же желание немного облегчить жизнь будущим разработчиками..
Пример
Рассмотрен пример того как взаимодействуют квадраты между собой. Общая схема довольно простая: Получаем HTTP запрос (В теории с файлом в теле запроса. Для демонстрации возможностей NIFI, в данном примере запрос стартует процесс получения файла из локального ФХ), далее отсылаем обратно ответ, что запрос получен, параллельно запускается процесс получения файла из ФХ и далее процесс перемещение его через FTP в ФХ. Стоит пояснить, что процессы взаимодействуют между собой посредством так называемого flowFile. Это базовая сущность в NIFI, которая хранит в себе атрибуты и содержимое. Содержимое — данные которые представлены файлом потока. Т е грубо говоря, если вы получили файл из одного квадрата и передаете его в другой, контентом будет ваш файл.
Как вы можете заметить — на этом рисунке изображен общий процесс. HandleHttpRequest — принимает запросы, ReplaceText — генерирует тело ответа, HandleHttpResponse — отдает ответ. FetchFile — получает файл из файлового хранилища передает его квадрату PutSftp — кладет этот файл на FTP, по указанному адресу. Теперь подробнее об этом процессе.
В данном случае — request всему начало. Посмотрим его параметры конфигурации.

Здесь все довольно тривиально за исключением StandartHttpContextMap — это некий сервис который который позволяет посылать и принимать запросы. Более подробно и даже с примерами можно посмотреть — здесь
Далее посмотрим параметры конфигурации ReplaceText квадрата. В ней стоит обратить внимание на ReplacementValue — это то, что вернется пользователю в виде ответа. В settings можно регулировать уровень логгирования, логи можно посмотреть {куда распаковали nifi}/nifi-1.9.2/logs там же есть параметры failure/success — основываясь на эти параметры можно регулировать процесс в целом. Т е в случае успешной обработки текста — вызовется процесс отправки ответа пользователю, а в другом случае мы просто залогируем неуспешный процесс.

В свойствах HandleHttpResponse особо ничего интересного нет кроме статуса при успешном создании ответа.
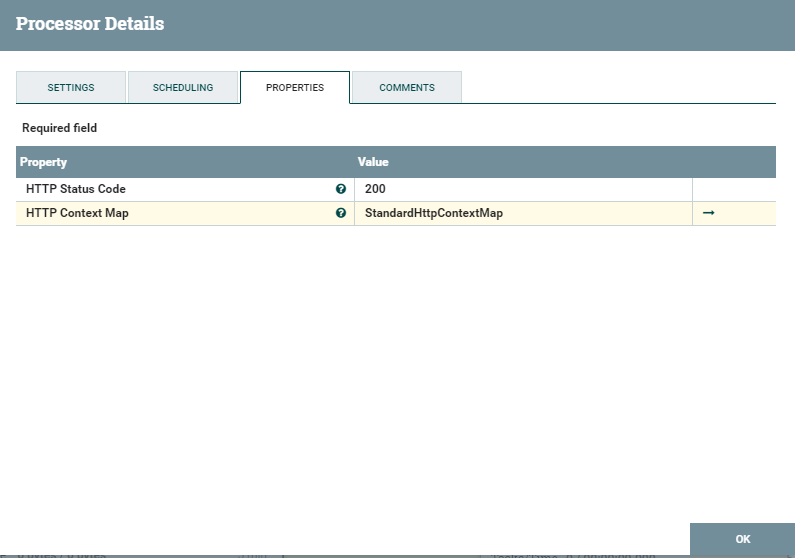
С запросом ответом разобрались — перейдем дальше к получению файла и помещением его на FTP сервер. FetchFile — получает файл по указанному в настройках пути и передает его в следующий процесс.

И далее квадрат PutSftp — помещает файл в файловое хранилище. Параметры конфигурации можем увидеть ниже.
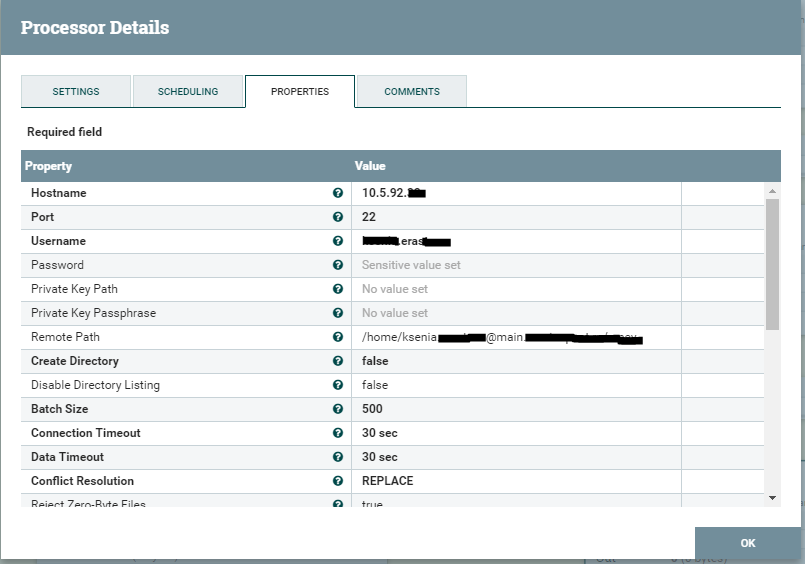
Стоит обратить внимание на то, что каждый квадрат — это отдельный процесс, который должен быть запущен. Мы рассмотрели самый простой пример который не требует какой либо сложной кастомизиции. Далее рассмотрим процесс немного сложнее, где немного попишем на грувях.
Более сложный пример
Сервис передачи данных потребителю получился немного сложнее за счет процесса модификации SOAP сообщения. Общий процесс представлен на рисунке ниже.
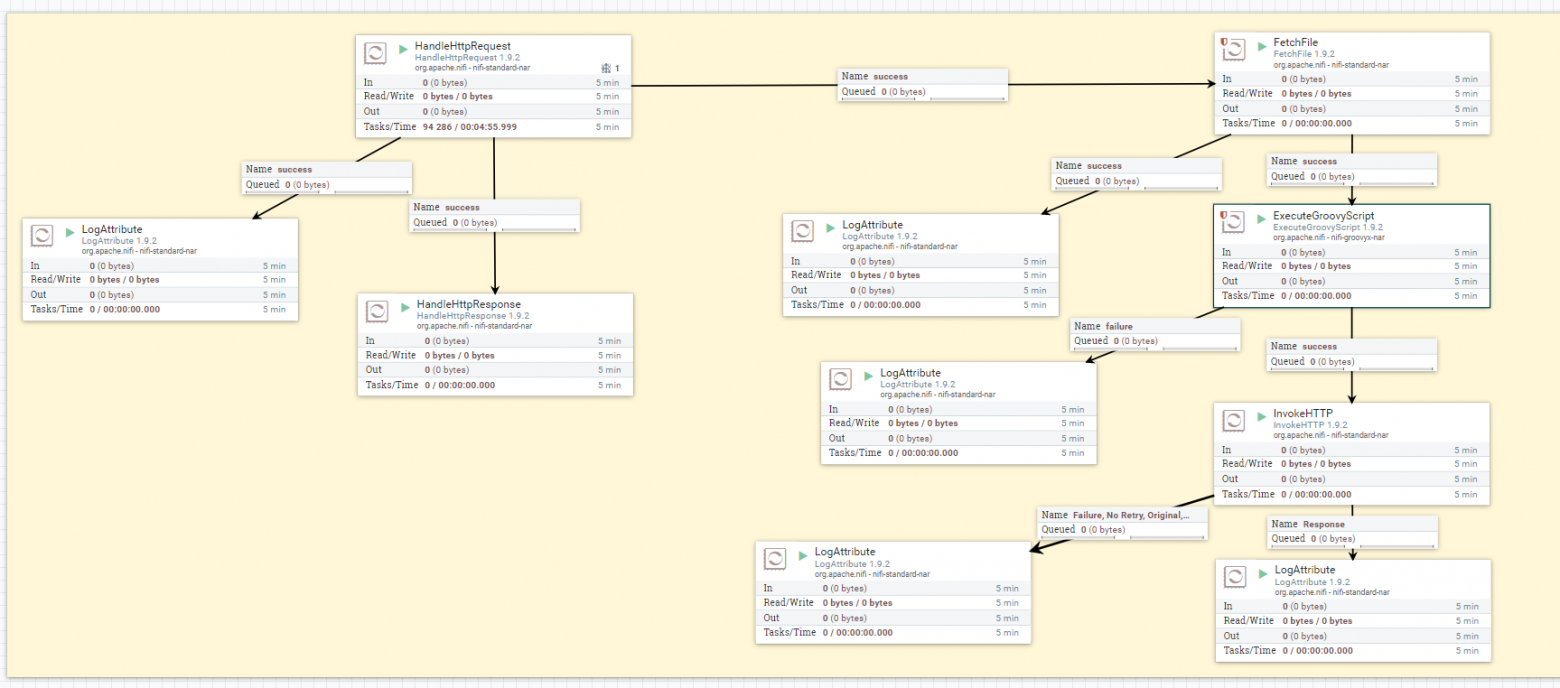
Здесь идея тоже не особо сложная: получили запрос от потребителя, что ему нужны данные, отправили ответ, что получили сообщение, запустили процесс получения файла ответа, далее отредактировали его с определенной логикой, после чего передали файл потребителю в виде SOAP сообщения на сервер.
Думаю не стоит описывать заново те квадраты, которые мы видели выше — перейдем сразу к новым. Если вам необходимо редактировать какой либо файл и обычные квадраты типа ReplaceText не подходят, вам придется писать свой скрипт. Сделать это можно с помощью квадрата ExecuteGroogyScript. Настройки его представлены ниже.

Есть два варианта загрузки скрипта в этот квадрат. Первый — это путем загрузки файла со скриптом. Второй — вставкой скрипта в scriptBody. На сколько я знаю, квадрат executeScript поддерживает несколько ЯП — один из них groovy. Разочарую java разработчиков — на java нельзя писать скрипты в таких квадратах. Для тех кому очень хочется — нужно создать свой кастомный квадрат и подкинуть его в систему NIFI. Вся эта операция сопровождается довольно продолжительными танцами с бубном, которыми мы не будем в рамках этой статьи заниматься. Я выбрала язык groovy. Ниже представлен тестовый скрипт который просто инкрементно обновляет id в SOAP сообщении. Важно отметить. Вы берете файл из flowFile обновляете его, не стоит забывать, что его нужно, обновленный, обратно туда положить. Так же стоит отметить, что не все библиотеки подключены. Может получиться так, что вам все-таки придется импортировать одну из либ. Минусом еще является то, что скрипт в данном квадрате довольно трудно дебажить. Есть способ подключиться к JVM NIFI и начать процесс отладки. Лично я запускала у себя локальное приложение и имитировала получение файла из сессии. Отладкой тоже занималась локально. Ошибки, которые вылезают при загрузке скрипта довольно легко гугляться и пишутся самим NIFI в лог.
import org.apache.commons.io.IOUtils
import groovy.xml.XmlUtil
import java.nio.charset.*
import groovy.xml.StreamingMarkupBuilder
def flowFile = session.get()
if (!flowFile) return
try {
flowFile = session.write(flowFile, { inputStream, outputStream ->
String result = IOUtils.toString(inputStream, "UTF-8");
def recordIn = new XmlSlurper().parseText(result)
def element = recordIn.depthFirst().find {
it.name() == 'id'
}
def newId = Integer.parseInt(element.toString()) + 1
def recordOut = new XmlSlurper().parseText(result)
recordOut.Body.ClientMessage.RequestMessage.RequestContent.content.MessagePrimaryContent.ResponseBody.id = newId
def res = new StreamingMarkupBuilder().bind { mkp.yield recordOut }.toString()
outputStream.write(res.getBytes(StandardCharsets.UTF_8))
} as StreamCallback)
session.transfer(flowFile, REL_SUCCESS)
}
catch(Exception e) {
log.error("Error during processing of validate.groovy", e)
session.transfer(flowFile, REL_FAILURE)
}Собственно на этом кастомизация квадрата заканчивается. Далее обновленный файл передается в квадрат который занимается посылкой файла на сервер. Ниже представлены настройки этого квадрата.
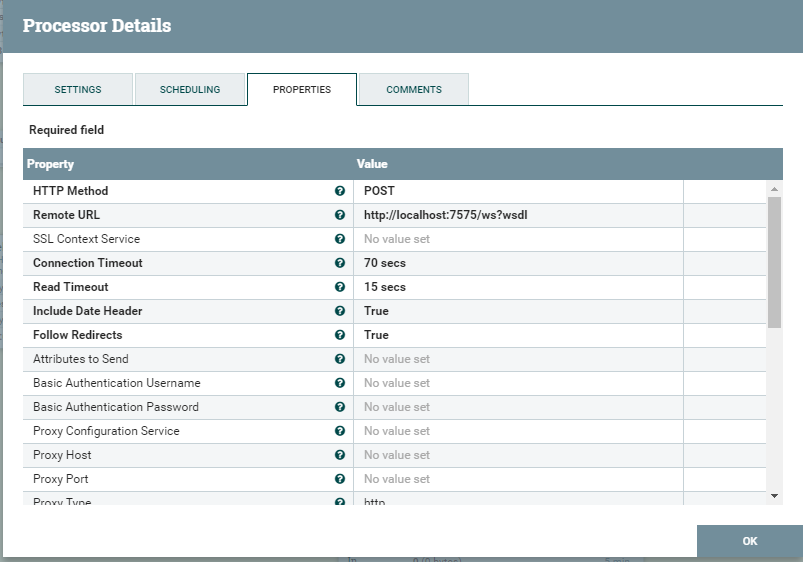
Описываем метод, которым будет передаваться SOAP сообщение. Пишем куда. Далее нужно указать, что это именно SOAP.
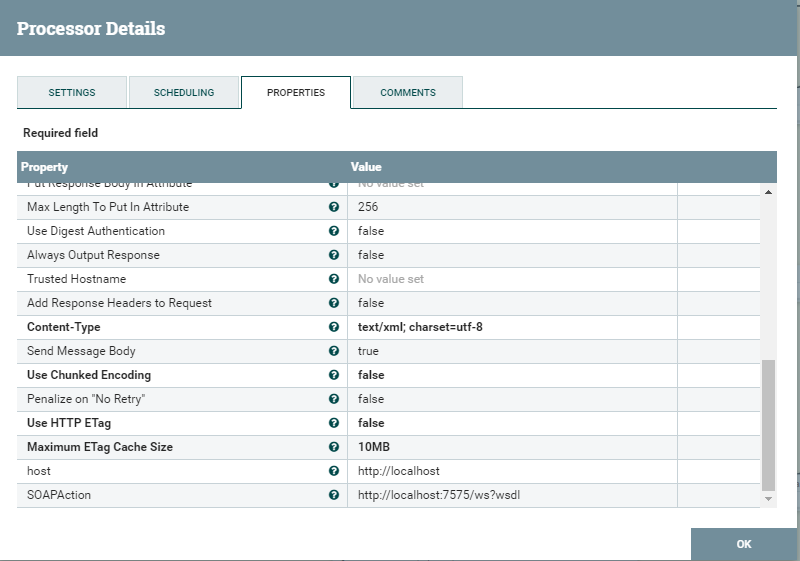
Добавляем несколько свойств таких как хост и действие(soapAction). Сохраняем, проверяем. Более подробно как посылать SOAP запросы можно посмотреть тут
Мы рассмотрели несколько вариантов использования процессов NIFI. Как они взаимодействуют и какая от них реальная польза. Рассмотренные примеры являются тестовыми и немного отличаются от того, что реально на бою. Надеюсь, эта статья будет немного полезной для разработчиков. Спасибо за внимание. Если есть какие-либо вопросы — пишите. Постараюсь ответить.
Apache NiFi — Introduction
Apache NiFi is a powerful, easy to use and reliable system to process and distribute data between disparate systems. It is based on Niagara Files technology developed by NSA and then after 8 years donated to Apache Software foundation. It is distributed under Apache License Version 2.0, January 2004. The latest version for Apache NiFi is 1.7.1.
Apache NiFi is a real time data ingestion platform, which can transfer and manage data transfer between different sources and destination systems. It supports a wide variety of data formats like logs, geo location data, social feeds, etc. It also supports many protocols like SFTP, HDFS, and KAFKA, etc. This support to wide variety of data sources and protocols making this platform popular in many IT organizations.
Apache NiFi- General Features
The general features of Apache NiFi are as follows −
-
Apache NiFi provides a web-based user interface, which provides seamless experience between design, control, feedback, and monitoring.
-
It is highly configurable. This helps users with guaranteed delivery, low latency, high throughput, dynamic prioritization, back pressure and modify flows on runtime.
-
It also provides data provenance module to track and monitor data from the start to the end of the flow.
-
Developers can create their own custom processors and reporting tasks according to their needs.
-
NiFi also provides support to secure protocols like SSL, HTTPS, SSH and other encryptions.
-
It also supports user and role management and also can be configured with LDAP for authorization.
Apache NiFi -Key Concepts
The key concepts of Apache NiFi are as follows −
-
Process Group − It is a group of NiFi flows, which helps a userto manage and keep flows in hierarchical manner.
-
Flow − It is created connecting different processors to transfer and modify data if required from one data source or sources to another destination data sources.
-
Processor − A processor is a java module responsible for either fetching data from sourcing system or storing it in destination system. Other processors are also used to add attributes or change content in flowfile.
-
Flowfile − It is the basic usage of NiFi, which represents the single object of the data picked from source system in NiFi. NiFiprocessormakes changes to flowfile while it moves from the source processor to the destination. Different events like CREATE, CLONE, RECEIVE, etc. are performed on flowfile by different processors in a flow.
-
Event − Events represent the change in flowfile while traversing through a NiFi Flow. These events are tracked in data provenance.
-
Data provenance − It is a repository.It also has a UI, which enables users to check the information about a flowfile and helps in troubleshooting if any issues that arise during the processing of a flowfile.
Apache NiFi Advantages
-
Apache NiFi enables data fetching from remote machines by using SFTP and guarantees data lineage.
-
Apache NiFi supports clustering, so it can work on multiple nodes with same flow processing different data, which increase the performance of data processing.
-
It also provides security policies on user level, process group level and other modules too.
-
Its UI can also run on HTTPS, which makes the interaction of users with NiFi secure.
-
NiFi supports around 188 processors and a user can also create custom plugins to support a wide variety of data systems.
Apache NiFi Disadvantages
-
When node gets disconnected from NiFi cluster while a user is making any changes in it, then the flow.xml becomes invalid.Anode cannot connect back to the cluster unless admin manually copies flow.xml from the connected node.
-
Apache NiFi have state persistence issue in case of primary node switch, which sometimes makes processors not able to fetch data from sourcing systems.
Apache NiFi — Basic Concepts
Apache NiFi consist of a web server, flow controller and a processor, which runs on Java Virtual Machine. It also has 3 repositories Flowfile Repository, Content Repository, and Provenance Repository as shown in the figure below.
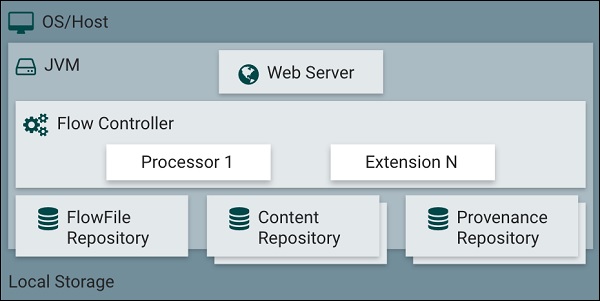
Flowfile Repository
This repository stores the current state and attributes of every flowfile that goes through the data flows of apache NiFi. The default location of this repository is in the root directory of apache NiFi. The location of this repository can be changed by changing the property named «nifi.flowfile.repository.directory».
Content Repository
This repository contains all the content present in all the flowfiles of NiFi. Its default directory is also in the root directory of NiFi and it can be changed using «org.apache.nifi.controller.repository.FileSystemRepository» property. This directory uses large space in disk so it is advisable to have enough space in the installation disk.
Provenance Repository
The repository tracks and stores all the events of all the flowfiles that flow in NiFi. There are two provenance repositories — volatile provenance repository (in this repository all the provenance data get lost after restart) and persistent provenance repository. Its default directory is also in the root directory of NiFi and it can be changed using «org.apache.nifi.provenance.PersistentProvenanceRepository» and «org.apache.nifi.provenance.VolatileProvenanceRepositor» property for the respective repositories.
Apache NiFi — Environment Setup
In this chapter, we will learn about the environment setup ofApache NiFi. The steps for installation of Apache NiFi are as follows −
Step 1 − Install the current version of Java in your computer. Please set theJAVA_HOME in your machine. You can check the version as shown below:
In Windows Operating System (OS) (using command prompt) −
> java -version
In UNIX OS (Using Terminal):
$ echo $JAVA_HOME
Step 2 − DownloadApache NiFi from https://nifi.apache.org/download.html
-
For windows OSdownload ZIP file.
-
For UNIX OSdownload TAR file.
-
For docker images,go to the following link https://hub.docker.com/r/apache/nifi/.
Step 3 − The installation process for Apache NiFi is very easy. The process differs with the OS −
-
Windows OS − Unzip the zip package and the Apache NiFi is installed.
-
UNIX OS − Extract tar file in any location and the Logstash is installed.
$tar -xvf nifi-1.6.0-bin.tar.gz
Step 4 − Open command prompt, go to the bin directory of NiFi. For example, C:\nifi-1.7.1\bin, and execute run-nifi.bat file.
C:\nifi-1.7.1\bin>run-nifi.bat
Step 5 − It will take a few minutes to get the NiFi UI up. A user cancheck nifi-app.log, once NiFi UI is up then, a user can enter http://localhost:8080/nifi/ to access UI.
Apache NiFi — User Interface
Apache is a web-based platform that can be accessed by a user using web UI. The NiFi UI is very interactive and provides a wide variety of information about NiFi. As shown in the image below, a user can access information about the following attributes −
- Active Threads
- Total queued data
- Transmitting Remote Process Groups
- Not Transmitting Remote Process Groups
- Running Components
- Stopped Components
- Invalid Components
- Disabled Components
- Up to date Versioned Process Groups
- Locally modified Versioned Process Groups
- Stale Versioned Process Groups
- Locally modified and Stale Versioned Process Groups
- Sync failure Versioned Process Groups
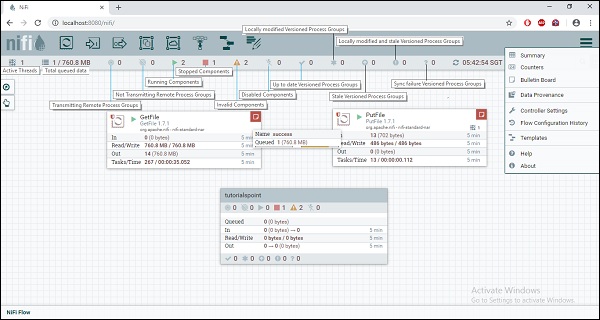
Components of Apache NiFi
Apache NiFi UI has the following components −
Processors
User can drag the process icon on the canvas and select the desired processor for the data flow in NiFi.
![]()
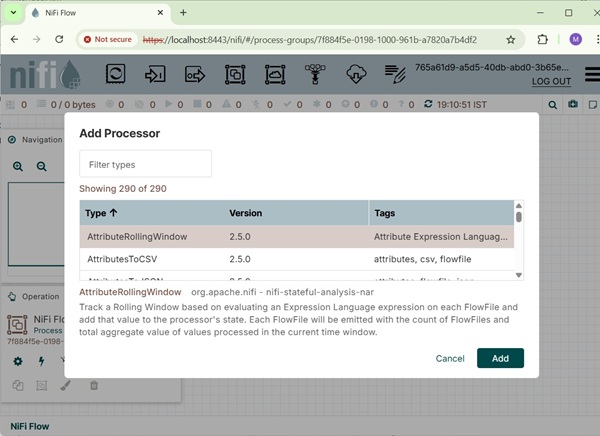
Input port
Below icon is dragged to canvas to add the input port into any data flow.
Input port is used to get data from the processor, which is not present in that process group.

After dragging this icon, NiFi asks to enter the name of the Input port and then it is added to the NiFi canvas.
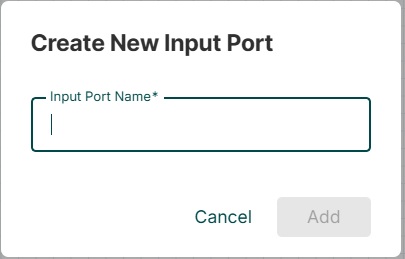
Output port
The below icon is dragged to canvas to add the output port into any data flow.
The output port is used to transfer data to the processor, which is not present in that process group.

After dragging this icon, NiFi asks to enter the name of the Output port and then it is added to the NiFi canvas.
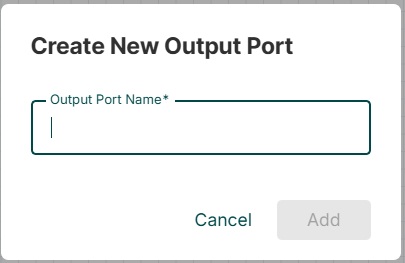
Process Group
A user uses below icon to add process group in the NiFi canvas.
![]()
After dragging this icon, NiFi asks to enter the name of the Process Group and then it is added to the NiFi canvas.
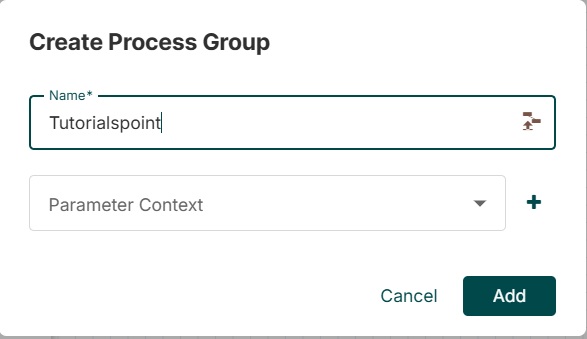
Remote Process Group
This is used to add Remote process group in NiFi canvas.

Funnel
Funnel is used to transfer the output of a processor to multiple processors. User can use the below icon to add the funnel in a NiFi data flow.
![]()
Template
This icon is used to add a data flow template to NiFi canvas. This helps to reuse the data flow in the same or different NiFi instances.
![]()
After dragging, a user can select the templates already added in the NiFi.
Label
These are used to add text on NiFi canvas about any component present in NiFi. It offers a range of colors used by a user to add aesthetic sense.
![]()
Apache NiFi — Processors
Apache NiFi processors are the basic blocks of creating a data flow. Every processor has different functionality, which contributes to the creation of output flowfile. Dataflow shown in the image below is fetching file from one directory using GetFile processor and storing it in another directory using PutFile processor.

GetFile
GetFile process is used to fetch files of a specific format from a specific directory. It also provides other options to user for more control on fetching. We will discuss it in properties section below.
GetFile Settings
Following are the different settings of GetFile processor −
Name
In the Name setting, a user can define any name for the processors either according to the project or by that, which makes the name more meaningful.
Enable
A user can enable or disable the processor using this setting.
Penalty Duration
This setting lets a user to add the penalty time duration, in the event of flowfile failure.
Yield Duration
This setting is used to specify the yield time for processor. In this duration, the process is not scheduled again.
Bulletin Level
This setting is used to specify the log level of that processor.
Automatically Terminate Relationships
This has a list of check of all the available relationship of that particular process. By checking the boxes, a user can program processor to terminate the flowfile on that event and do not send it further in the flow.
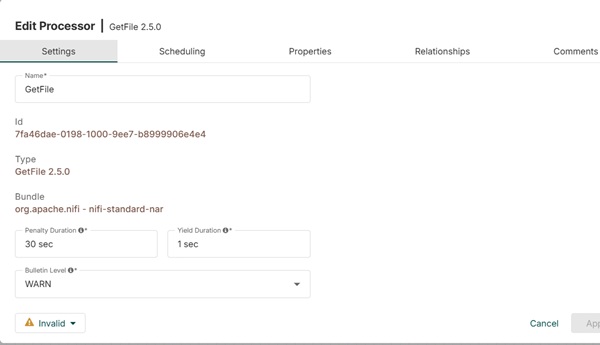
GetFile Scheduling
These are the following scheduling options offered by the GetFile processor −
Schedule Strategy
You can either schedule the process on time basis by selecting time driven or a specified CRON string by selecting a CRON driver option.
Concurrent Tasks
This option is used to define the concurrent task schedule for this processor.
Execution
A user can define whether to run the processor in all nodes or only in Primary node by using this option.
Run Schedule
It is used to define the time for time driven strategy or CRON expression for CRON driven strategy.
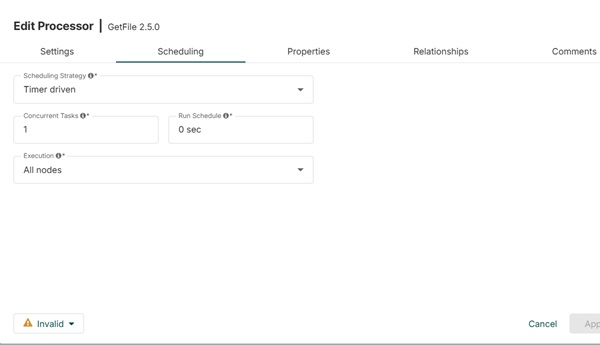
GetFile Properties
GetFile offers multiple properties as shown in the image below raging compulsory
properties like Input directory and file filter to optional properties like Path Filter and Maximum file Size. A user can manage file fetching process using these properties.
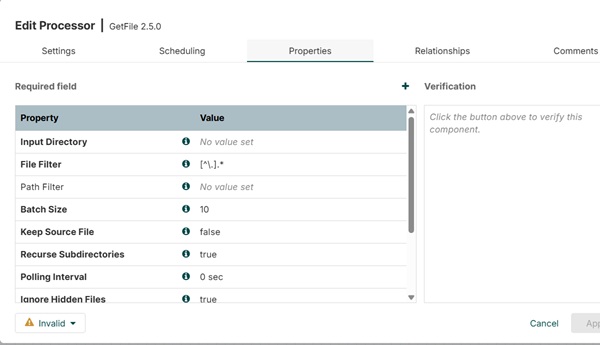
GetFile Comments
This Section is used to specify any information about processor.
PutFile
The PutFile processor is used to store the file from the data flow to a specific location.
PutFile Settings
The PutFile processor has the following settings −
Name
In the Name setting, a user can define any name for the processors either according to the project or by that which makes the name more meaningful.
Enable
A user can enable or disable the processor using this setting.
Penalty Duration
This setting lets a user add the penalty time duration, in the event of flowfile failure.
Yield Duration
This setting is used to specify the yield time for processor. In this duration, the process does not get scheduled again.
Bulletin Level
This setting is used to specify the log level of that processor.
Automatically Terminate Relationships
This settings has a list of check of all the available relationship of that particular process. By checking the boxes, user can program processor to terminate the flowfile on that event and do not send it further in the flow.
PutFile Scheduling
These are the following scheduling options offered by the PutFile processor −
Schedule Strategy
You can schedule the process on time basis either by selecting timer driven or a specified CRON string by selecting CRON driver option. There is also an Experimental strategy Event Driven, which will trigger the processor on a specific event.
Concurrent Tasks
This option is used to define the concurrent task schedule for this processor.
Execution
A user can define whether to run the processor in all nodes or only in primary node by using this option.
Run Schedule
It is used to define the time for timer driven strategy or CRON expression for CRON driven strategy.
PutFile Properties
The PutFile processor provides properties like Directory to specify the output directory for the purpose of file transfer and others to manage the transfer as shown in the image below.
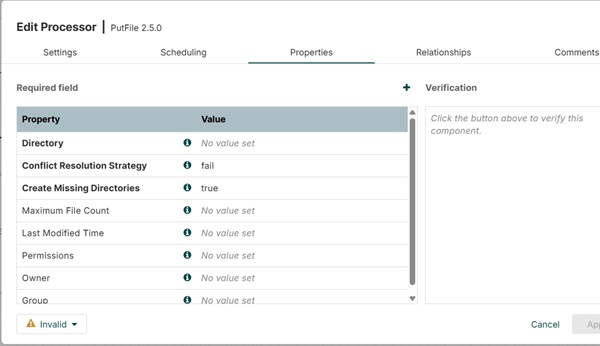
PutFile Comments
This Section is used to specify any information about processor.
Apache NiFi — Processors Categorization
In this chapter, we will discuss process categorization in Apache NiFi.
Data Ingestion Processors
The processors under Data Ingestion category are used to ingest data into the NiFi data flow. These are mainly the starting point of any data flow in apache NiFi. Some of the processors that belong to these categories are GetFile, GetHTTP, GetFTP, GetKAFKA, etc.
Routing and Mediation Processors
Routing and Mediation processors are used to route the flowfiles to different processors or data flows according to the information in attributes or content of those flowfiles. These processors are also responsible to control the NiFi data flows. Some of the processors that belong to this category are RouteOnAttribute, RouteOnContent, ControlRate, RouteText, etc.
Database Access Processors
The processors of this Database Access category are capable of selecting or inserting data or executing and preparing other SQL statements from database. These processors mainly use data connection pool controller setting of Apache NiFi. Some of the processors that belong to this category are ExecuteSQL, PutSQL, PutDatabaseRecord, ListDatabaseTables, etc.
Attribute Extraction Processors
Attribute Extraction Processors are responsible to extract, analyze, change flowfile attributes processing in the NiFi data flow. Some of the processors that belong to this category are UpdateAttribute, EvaluateJSONPath, ExtractText, AttributesToJSON, etc.
System Interaction Processors
System Interaction processors are used to run processes or commands in any operating system. These processors also run scripts in many languages to interact with a variety of systems. Some of the processors that belong to this category are ExecuteScript, ExecuteProcess, ExecuteGroovyScript, ExecuteStreamCommand, etc.
Data Transformation Processors
Processors that belong to Data Transformation are capable of altering content of the flowfiles. These can be used to fully replace the data of a flowfile normally used when a user has to send flowfile as an HTTP body to invokeHTTP processor. Some of the processors that belong to this category are ReplaceText, JoltTransformJSON, etc.
Sending Data Processors
Sending Data Processors are generally the end processor in a data flow. These processors are responsible to store or send data to the destination server. After successful storing or sending the data, these processors DROP the flowfile with success relationship. Some of the processors that belong to this category are PutEmail, PutKafka, PutSFTP, PutFile, PutFTP, etc.
Splitting and Aggregation Processors
These processors are used to split and merge the content present in a flowfile. Some of the processors that belong to this category are SplitText, SplitJson, SplitXml, MergeContent, SplitContent, etc.
HTTP Processors
These processors deal with the HTTP and HTTPS calls. Some of the processors that belong to this category are InvokeHTTP, PostHTTP, ListenHTTP, etc.
AWS Processors
AWS processors are responsible to interaction with Amazon web services system. Some of the processors that belong to this category are GetSQS, PutSNS, PutS3Object, FetchS3Object, etc.
Apache NiFi — Processors Relationship
In an Apache NiFi data flow, flowfiles move from one to another processor through connection that gets validated using a relationship between processors. Whenever a connection is created, a developer selects one or more relationships between those processors.
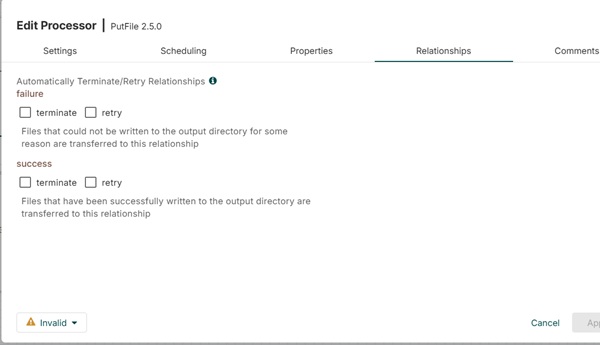
As you can see in the above image, the check boxes in black rectangle are relationships. If a developer selects these check boxes then, the flowfile will terminate in that particular processor, when the relationship is success or failure or both.
Success
When a processor successfully processes a flowfile like store or fetch data from any datasource without getting any connection, authentication or any other error, then the flowfile goes to success relationship.
Failure
When a processor is not able to process a flowfile without errors like authentication error or connection problem, etc. then the flowfile goes to a failure relationship.
A developer can also transfer the flowfiles to other processors using connections. The developer can select and also load balance it, but load balancing is just released in version 1.8, which will not be covered in this tutorial.
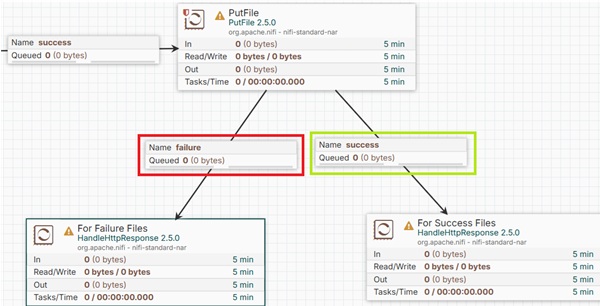
As you can see in the above image the connection marked in red have failure relationship, which means all flowfiles with errors will go to the processor in left and respectively all the flowfiles without errors will be transferred to the connection marked in green.
Let us now proceed with the other relationships.
comms.failure
This relationship is met, when a Flowfile could not be fetched from the remote server due to a communications failure.
not.found
Any Flowfile for which we receive a ‘Not Found’ message from the remote server will move to not.found relationship.
permission.denied
When NiFi unable to fetch a flowfile from the remote server due to insufficient permission, it will move through this relationship.
Apache NiFi — FlowFile
A flowfile is a basic processing entity in Apache NiFi. It contains data contents and attributes, which are used by NiFi processors to process data. The file content normally contains the data fetched from source systems. The most common attributes of an Apache NiFi FlowFile are −
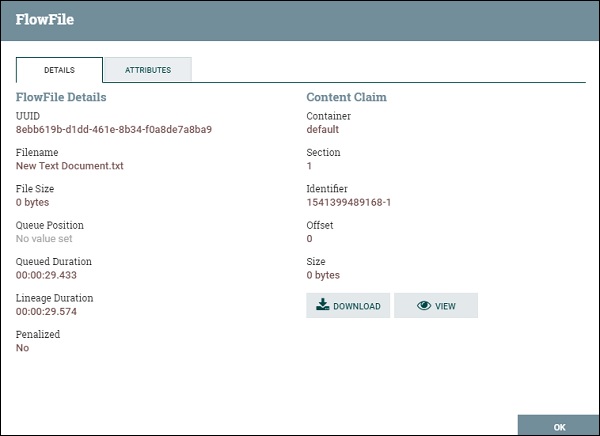
UUID
This stands for Universally Unique Identifier, which is a unique identity of a flowfile generated by NiFi.
Filename
This attribute contains the filename of that flowfile and it should not contain any directory structure.
File Size
It contains the size of an Apache NiFi FlowFile.
mime.type
It specifies the MIME Type of this FlowFile.
path
This attribute contains the relative path of a file to which a flowfile belongs and does not contain the file name.
Apache NiFi — Queues
The Apache NiFi data flow connection has a queuing system to handle the large amount of data inflow. These queues can handle very large amount of FlowFiles to let the processor process them serially.
The queue in the above image has 1 flowfile transferred through success relationship. A user can check the flowfile by selecting the List queue option in the drop down list. In case of any overload or error, a user can also clear the queue by selecting the empty queue option and then the user can restart the flow to get those files again in the data flow.

The list of flowfiles in a queue, consist of position, UUID, Filename, File size, Queue Duration, and Lineage Duration. A user can see all the attributes and content of a flowfile by clicking the info icon present at the first column of the flowfile list.
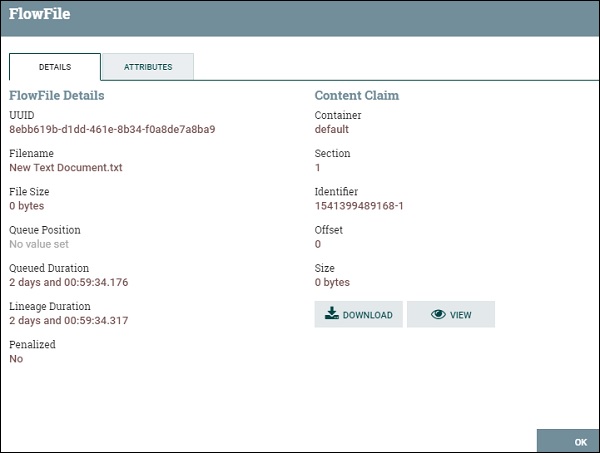
Apache NiFi — Process Groups
In Apache NiFi, a user can maintain different data flows in different process groups. These groups can be based on different projects or the organizations, which Apache NiFi instance supports.
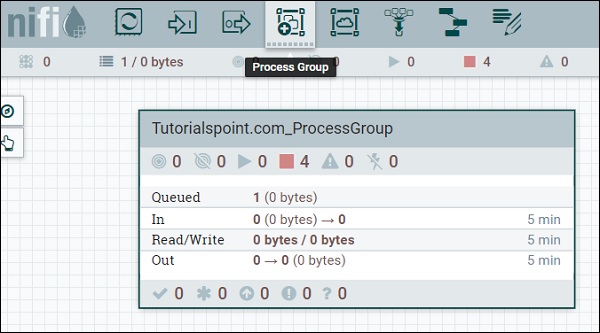
The fourth symbol in the menu at the top of the NiFi UI as shown in the above picture is used to add a process group in the NiFi canvas. The process group named
“Tutorialspoint.com_ProcessGroup” contains a data flow with four processors currently in stop stage as you can see in the above picture. Process groups can be created in hierarchical manner to manage the data flows in better structure, which is easy to understand.

In the footer of NiFi UI, you can see the process groups and can go back to the top of the process group a user is currently present in.
To see the full list of process groups present in NiFi, a user can go to the summary by using the menu present in the left top side of the NiFi UI. In summary, there is process groups tab where all the process groups are listed with parameters like Version State, Transferred/Size, In/Size, Read/Write, Out/Size, etc. as shown in the below picture.
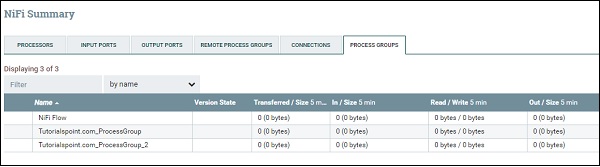
Apache NiFi — Labels
Apache NiFi offers labels to enable a developer to write information about the components present in the NiFI canvas. The leftmost icon in the top menu of NiFi UI is used to add the label in NiFi canvas.

A developer can change the color of the label and the size of the text with a right-click on the label and choose the appropriate option from the menu.
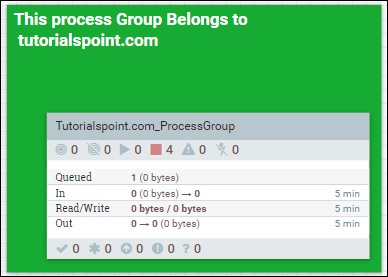
Apache NiFi — Configuration
Apache NiFi is highly configurable platform. The nifi.properties file in conf directory
contains most of the configuration.
The commonly used properties of Apache NiFi are as follows −
Core properties
This section contains the properties, which are compulsory to run a NiFi instance.
| S.No. | Property name | Default Value | description |
|---|---|---|---|
| 1 | nifi.flow.configuration.file | ./conf/flow.xml.gz | This property contains the path to flow.xml file. This file contains all the data flows created in NiFi. |
| 2 | nifi.flow.configuration.archive.enabled | true | This property is used to enable or disable archiving in NiFi. |
| 3 | nifi.flow.configuration.archive.dir | ./conf/archive/ | This property is used to specify the archive directory. |
| 4 | nifi.flow.configuration.archive.max.time | 30 days | This is used to specify the retention time for archiving content. |
| 5 | nifi.flow.configuration.archive.max.storage | 500 MB | it contains the maximum size of archiving directory can grow. |
| 6 | nifi.authorizer.configuration.file | ./conf/authorizers.xml | To specify the authorizer configuration file, which is used for user authorization. |
| 7 | nifi.login.identity.provider.configuration.file | ./conf/login-identity-providers.xml | This property contains the configuration of login identity providers, |
| 8 | nifi.templates.directory | ./conf/templates | This property is used to specify the directory, where NiFi templates will be stored. |
| 9 | nifi.nar.library.directory | ./lib | This property contains the path to library, which NiFi will use to load all the components using NAR files present in this lib folder. |
| 10 | nifi.nar.working.directory | ./work/nar/ | This directory will be storing the unpacked nar files, once NiFi processes them. |
| 11 | nifi.documentation.working.directory | ./work/docs/components | This directory contains the documentation of all components. |
State Management
These properties are used to store the state of the components helpful to start the processing, where components left after a restart and in the next schedule running.
| S.No. | Property name | Default Value | description |
|---|---|---|---|
| 1 | nifi.state.management.configuration.file | ./conf/state-management.xml | This property contains the path to state-management.xml file. This file contains all component state present in the data flows of that NiFi instance. |
| 2 | nifi.state.management.provider.local | local-provider | It contains the ID of the local state provider. |
| 3 | nifi.state.management.provider.cluster | zk-provider | This property contains the ID of the cluster-wide state provider. This will be ignored if NiFi is not clustered but must be populated if running in a cluster. |
| 4 | nifi.state.management. embedded. zookeeper. start |
false | This property specifies whether or not this instance of NiFi should run an embedded ZooKeeper server. |
| 5 | nifi.state.management. embedded. zookeeper.properties |
./conf/zookeeper.properties | This property contains the path of the properties file that provides the ZooKeeper properties to use if <nifi.state.management. embedded. zookeeper. start> is set to true. |
FlowFile Repository
Let us now look into the important details of the FlowFile repository −
| S.No. | Property name | Default Value | description |
|---|---|---|---|
| 1 | nifi.flowfile.repository. implementation |
org.apache.nifi. controller. repository. WriteAhead FlowFileRepository |
This property is used to specify either to store the flowfiles in memory or disk. If a user want to stores the flowfiles in memory then change to «org.apache.nifi.controller. repository.VolatileFlowFileRepository». |
| 2 | nifi.flowfile.repository.directory | ./flowfile_repository | To specify the directory for flowfile repository. |
Apache NiFi — Administration
Apache NiFi offers support to multiple tools like ambari, zookeeper for administration purposes. NiFi also provides configuration in nifi.properties file to set up HTTPS and other things for administrators.
zookeeper
NiFi itself does not handle voting process in cluster. This means when a cluster is created, all the nodes are primary and coordinator. So, zookeeper is configured to manage the voting of primary node and coordinator. The nifi.properties file contains some properties to setup zookeeper.
| S.No. | Property name | Default Value | description |
|---|---|---|---|
| 1 | nifi.state.management.embedded.zookeeper. properties |
./conf/zookeeper.properties | To specify the path and name of zookeeper property file. |
| 2 | nifi.zookeeper.connect.string | empty | To specify the connection string of zookeeper. |
| 3 | nifi.zookeeper.connect.timeout | 3 secs | To specify the connection timeout of zookeeper with NiFi. |
| 4 | nifi.zookeeper.session.timeout | 3 secs | To specify the session timeout of zookeeper with NiFi. |
| 5 | nifi.zookeeper.root.node | /nifi | To specify root node for zookeeper. |
| 6 | nifi.zookeeper.auth.type | empty | To specify authentication type for zookeeper. |
Enable HTTPS
To use NiFi over HTTPS, administrators have to generate keystore and truststore and set some properties in the nifi.properties file. The TLS toolkit can be used to generate all the necessary keys to enable HTTPS in apache NiFi.
| S.No. | Property name | Default Value | description |
|---|---|---|---|
| 1 | nifi.web.https.port | empty | To specify https port number. |
| 2 | nifi.web.https.network.interface.default | empty | Default interface for https in NiFi. |
| 3 | nifi.security.keystore | empty | To specify the path and file name of keystore. |
| 4 | nifi.security.keystoreType | empty | To specify the type of keystore type like JKS. |
| 5 | nifi.security.keystorePasswd | empty | To specify keystore password. |
| 6 | nifi.security.truststore | empty | To specify the path and file name of truststore. |
| 7 | nifi.security.truststoreType | empty | To specify the type of truststore type like JKS. |
| 8 | nifi.security.truststorePasswd | empty | To specify truststore password. |
Other properties for administration
There are some other properties, which are used by administrators to manage the NiFi and for its service continuity.
| S.No. | Property name | Default Value | description |
|---|---|---|---|
| 1 | nifi.flowcontroller.graceful.shutdown.period | 10 sec | To specify the time to gracefully shutdown the NiFi flowcontroller. |
| 2 | nifi.administrative.yield.duration | 30 sec | To specify the administrative yield duration for NiFi. |
| 3 | nifi.authorizer.configuration.file | ./conf/authorizers.xml | To specify the path and file name of authorizer configuration file. |
| 4 | nifi.login.identity.provider.configuration.file | ./conf/login-identity-providers.xml | To specify the path and file name of login identity provider configuration file. |
Apache NiFi — Creating Flows
Apache NiFi offers a large number of components to help developers to create data flows for any type of protocols or data sources. To create a flow, a developer drags the components from menu bar to canvas and connects them by clicking and dragging the mouse from one component to other.
Generally, a NiFi has a listener component at the starting of the flow like getfile, which gets the data from source system. On the other end of there is a transmitter component like putfile and there are components in between, which process the data.
For example, let create a flow, which takes an empty file from one directory and add some text in that file and put it in another directory.

-
To begin with, drag the processor icon to the NiFi canvas and select GetFile processor from the list.
-
Create an input directory like c:\inputdir.
-
Right-click on the processor and select configure and in properties tab add Input Directory (c:\inputdir) and click apply and go back to canvas.
-
Drag the processor icon to the canvas and select the ReplaceText processor from the list.
-
Right-click on the processor and select configure. In the properties tab, add some text like “Hello tutorialspoint.com” in the textbox of Replacement Value and click apply.
-
Go to settings tab, check the failure checkbox at right hand side, and then go back to the canvas.
-
Connect GetFIle processor to ReplaceText on success relationship.
-
Drag the processor icon to the canvas and select the PutFile processor from the list.
-
Create an output directory like c:\outputdir.
-
Right-click on the processor and select configure. In the properties tab, add Directory (c:\outputdir) and click apply and go back to canvas.
-
Go to settings tab and check the failure and success checkbox at right hand side and then go back to the canvas.
-
Connect the ReplaceText processor to PutFile on success relationship.
-
Now start the flow and add an empty file in input directory and you will see that, it will move to output directory and the text will be added to the file.
By following the above steps, developers can choose any processor and other NiFi component to create suitable flow for their organisation or client.
Apache NiFi — Templates
Apache NiFi offers the concept of Templates, which makes it easier to reuse and distribute the NiFi flows. The flows can be used by other developers or in other NiFi clusters. It also helps NiFi developers to share their work in repositories like GitHub.
Create Template
Let us create a template for the flow, which we created in chapter no 15 “Apache NiFi — Creating Flows”.
Select all the components of the flow using shift key and then click on the create template icon at the left hand side of the NiFi canvas. You can also see a tool box as shown in the above image. Click on the icon create template marked in blue as in the above picture. Enter the name for the template. A developer can also add description, which is optional.
Download Template
Then go to the NiFi templates option in the menu present at the top right hand corner of NiFi UI as show in the picture below.
Now click the download icon (present at the right hand side in the list) of the template, you want to download. An XML file with the template name will get downloaded.
Upload Template
To use a template in NiFi, a developer will have to upload its xml file to NiFi using UI. There is an Upload Template icon (marked with blue in below image) beside Create Template icon click on that and browse the xml.
Add Template
In the top toolbar of NiFi UI, the template icon is before the label icon. The icon is marked in blue as shown in the picture below.

Drag the template icon and choose the template from the drop down list and click add. It will add the template to NiFi canvas.
Apache NiFi — API
NiFi offers a large number of API, which helps developers to make changes and get information of NiFi from any other tool or custom developed applications. In this tutorial, we will use postman app in google chrome to explain some examples.
To add postmantoyour Google Chrome, go to the below mentioned URL and click add to chrome button. You will now see a new app added toyour Google Chrome.
chrome web store
The current version of NiFi rest API is 1.8.0 and the documentation is present in the below mentioned URL.
https://nifi.apache.org/docs/nifi-docs/rest-api/index.html
Following are the most used NiFi rest API Modules −
-
http://<nifi url>:<nifi port>/nifi-api/<api-path>
-
In case HTTPS is enabled
https://<nifi url>:<nifi port>/nifi-api/<api-path>
| S.No. | API module Name | api-path | Description |
|---|---|---|---|
| 1 | Access | /access | To authenticate user and get access token from NiFi. |
| 2 | Controller | /controller | To manage the cluster and create reporting task. |
| 3 | Controller Services | /controller-services | It is used to manage controller services and update controller service references. |
| 4 | Reporting Tasks | /reporting-tasks | To manage reporting tasks. |
| 5 | Flow | /flow | To get the data flow metadata and component status and query history |
| 6 | Process Groups | /process-groups | To upload and instantiate a template and create components. |
| 7 | Processors | /processors | To create and schedule a processor and set its properties. |
| 8 | Connections | /connections | To create a connection, set queue priority and update connection destination |
| 9 | FlowFile Queues | /flowfile-queues | To view queue contents, download flowfile content, and empty queue. |
| 10 | Remote Process Groups | /remote-process-groups | To create a remote group and enable transmission. |
| 11 | Provenance | /provenance | To query provenance, and search event lineage. |
Let us now consider an example and run on postman to get the details about the running NiFi instance.
Request
GET http://localhost:8080/nifi-api/flow/about
Response
{
"about": {
"title": "NiFi",
"version": "1.7.1",
"uri": "http://localhost:8080/nifi-api/",
"contentViewerUrl": "../nifi-content-viewer/",
"timezone": "SGT",
"buildTag": "nifi-1.7.1-RC1",
"buildTimestamp": "07/12/2018 12:54:43 SGT"
}
}
Apache NiFi — Data Provenance
Apache NiFi logs and store every information about the events occur on the ingested data in the flow. Data provenance repository stores this information and provides UI to search this event information. Data provenance can be accessed for full NiFi level and processor level also.
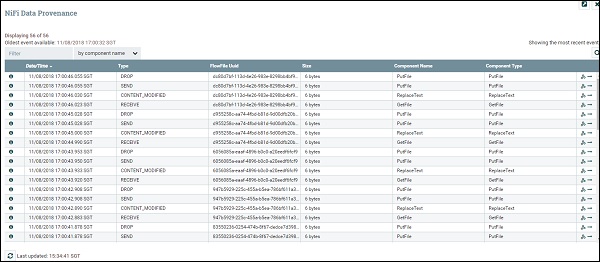
The following table lists down the different fields in the NiFi Data Provenance event list have following fields −
| S.No. | Field Name | Description |
|---|---|---|
| 1 | Date/Time | Date and time of event. |
| 2 | Type | Type of Event like ‘CREATE’. |
| 3 | FlowFileUuid | UUID of the flowfile on which the event is performed. |
| 4 | Size | Size of the flowfile. |
| 5 | Component Name | Name of the component which performed the event. |
| 6 | Component Type | Type of the component. |
| 7 | Show lineage | Last column has the show lineage icon, which is used to see the flowfile lineage as shown in the below image. |
![]()
To get more information about the event, a user can click on the information icon present in the first column of the NiFi Data Provenance UI.
There are some properties in nifi.properties file, which are used to manage NiFi Data Provenance repository.
| S.No. | Property Name | Default Value | Description |
|---|---|---|---|
| 1 | nifi.provenance.repository.directory.default | ./provenance_repository | To specify the default path of NiFi data provenance . |
| 2 | nifi.provenance.repository.max.storage.time | 24 hours | To specify the maximum retention time of NiFi data provenance. |
| 3 | nifi.provenance.repository.max.storage.size | 1 GB | To specify the maximum storage of NiFi data provenance. |
| 4 | nifi.provenance.repository.rollover.time | 30 secs | To specify the rollover time of NiFi data provenance. |
| 5 | nifi.provenance.repository.rollover.size | 100 MB | To specify the rollover size of NiFi data provenance. |
| 6 | nifi.provenance.repository.indexed.fields | EventType, FlowFileUUID, Filename, ProcessorID, Relationship | To specify the fields used to search and index NiFi data provenance. |
Apache NiFi — Monitoring
In Apache NiFi, there are multiple ways to monitor the different statistics of the system like errors, memory usage, CPU usage, Data Flow statistics, etc. We will discuss the most popular ones in this tutorial.
In built Monitoring
In this section, we will learn more about in built monitoring in Apache NiFi.
Bulletin Board
The bulletin board shows the latest ERROR and WARNING getting generated by NiFi processors in real time. To access the bulletin board, a user will have to go the right hand drop down menu and select the Bulletin Board option. It refreshes automatically and a user can disable it also. A user can also navigate to the actual processor by double-clicking the error. A user can also filter the bulletins by working out with the following −
- by message
- by name
- by id
- by group id
Data provenance UI
To monitor the Events occurring on any specific processor or throughout NiFi, a user can access the Data provenance from the same menu as the bulletin board. A user can also filter the events in data provenance repository by working out with the following fields −
- by component name
- by component type
- by type
NiFi Summary UI
Apache NiFi summary also can be accessed from the same menu as the bulletin board. This UI contains information about all the components of that particular NiFi instance or cluster. They can be filtered by name, by type or by URI. There are different tabs for different component types. Following are the components, which can be monitored in the NiFi summary UI −
- Processors
- Input ports
- Output ports
- Remote process groups
- Connections
- Process groups
In this UI, there is a link at the bottom right hand side named system diagnostics to check the JVM statistics.
Reporting Tasks
Apache NiFi provides multiple reporting tasks to support external monitoring systems like Ambari, Grafana, etc. A developer can create a custom reporting task or can configure the inbuilt ones to send the metrics of NiFi to the externals monitoring systems. The following table lists down the reporting tasks offered by NiFi 1.7.1.
| S.No. | Reporting Task Name | Description |
|---|---|---|
| 1 | AmbariReportingTask | To setup Ambari Metrics Service for NiFi. |
| 2 | ControllerStatusReportingTask | To report the information from the NiFi summary UI for the last 5 minute. |
| 3 | MonitorDiskUsage | To report and warn about the disk usage of a specific directory. |
| 4 | MonitorMemory | To monitor the amount of Java Heap used in a Java Memory pool of JVM. |
| 5 | SiteToSiteBulletinReportingTask | To report the errors and warning in bulletins using Site to Site protocol. |
| 6 | SiteToSiteProvenanceReportingTask | To report the NiFi Data Provenance events using Site to Site protocol. |
NiFi API
There is an API named system diagnostics, which can be used to monitor the NiFI stats in any custom developed application. Let us check the API in postman.
Request
http://localhost:8080/nifi-api/system-diagnostics
Response
{
"systemDiagnostics": {
"aggregateSnapshot": {
"totalNonHeap": "183.89 MB",
"totalNonHeapBytes": 192819200,
"usedNonHeap": "173.47 MB",
"usedNonHeapBytes": 181894560,
"freeNonHeap": "10.42 MB",
"freeNonHeapBytes": 10924640,
"maxNonHeap": "-1 bytes",
"maxNonHeapBytes": -1,
"totalHeap": "512 MB",
"totalHeapBytes": 536870912,
"usedHeap": "273.37 MB",
"usedHeapBytes": 286652264,
"freeHeap": "238.63 MB",
"freeHeapBytes": 250218648,
"maxHeap": "512 MB",
"maxHeapBytes": 536870912,
"heapUtilization": "53.0%",
"availableProcessors": 4,
"processorLoadAverage": -1,
"totalThreads": 71,
"daemonThreads": 31,
"uptime": "17:30:35.277",
"flowFileRepositoryStorageUsage": {
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
},
"contentRepositoryStorageUsage": [
{
"identifier": "default",
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
}
],
"provenanceRepositoryStorageUsage": [
{
"identifier": "default",
"freeSpace": "286.93 GB",
"totalSpace": "464.78 GB",
"usedSpace": "177.85 GB",
"freeSpaceBytes": 308090789888,
"totalSpaceBytes": 499057160192,
"usedSpaceBytes": 190966370304,
"utilization": "38.0%"
}
],
"garbageCollection": [
{
"name": "G1 Young Generation",
"collectionCount": 344,
"collectionTime": "00:00:06.239",
"collectionMillis": 6239
},
{
"name": "G1 Old Generation",
"collectionCount": 0,
"collectionTime": "00:00:00.000",
"collectionMillis": 0
}
],
"statsLastRefreshed": "09:30:20 SGT",
"versionInfo": {
"niFiVersion": "1.7.1",
"javaVendor": "Oracle Corporation",
"javaVersion": "1.8.0_151",
"osName": "Windows 7",
"osVersion": "6.1",
"osArchitecture": "amd64",
"buildTag": "nifi-1.7.1-RC1",
"buildTimestamp": "07/12/2018 12:54:43 SGT"
}
}
}
}
Apache NiFi — Upgrade
Before starting the upgrade of Apache NiFi, read the release notes to know about the changes and additions. A user needs to evaluate the impact of these additions and changes in his/her current NiFi installation. Below is the link to get the release notes for the new releases of Apache NiFi.
https://cwiki.apache.org/confluence/display/NIFI/Release+Notes
In a cluster setup, a user needs to upgrade NiFi installation of every Node in a cluster. Follow the steps given below to upgrade the Apache NiFi.
-
Backup all the custom NARs present in your current NiFi or lib or any other folder.
-
Download the new version of Apache NiFi. Below is the link to download the source and binaries of latest NiFi version.
https://nifi.apache.org/download.html
-
Create a new directory in the same installation directory of current NiFi and extract the new version of Apache NiFi.
-
Stop the NiFi gracefully. First stop all the processors and let all the flowfiles present in the flow get processed. Once, no more flowfile is there, stop the NiFi.
-
Copy the configuration of authorizers.xml from current NiFi installation to the new version.
-
Update the values in bootstrap-notification-services.xml, and bootstrap.conf of new NiFi version from the current one.
-
Add the custom logging from logback.xml to the new NiFi installation.
-
Configure the login identity provider in login-identity-providers.xml from the current version.
-
Update all the properties in nifi.properties of the new NiFi installation from current version.
-
Please make sure that the group and user of new version is same as the current version, to avoid any permission denied errors.
-
Copy the configuration from state-management.xml of current version to the new version.
-
Copy the contents of the following directories from current version of NiFi installation to the same directories in the new version.
-
./conf/flow.xml.gz
-
Also flow.xml.gz from the archive directory.
-
For provenance and content repositories change the values in nifi. properties file to the current repositories.
-
copy state from ./state/local or change in nifi.properties if any other external directory is specified.
-
-
Recheck all the changes performed and check if they have an impact on any new changes added in the new NiFi version. If there is any impact, check for the solutions.
-
Start all the NiFi nodes and verify if all the flows are working correctly and repositories are storing data and Ui is retrieving it with any errors.
-
Monitor bulletins for some time to check for any new errors.
-
If the new version is working correctly, then the current version can be archived and deleted from the directories.
Apache NiFi — Remote Process Group
Apache NiFi Remote Process Group or RPG enables flow to direct the FlowFiles in a flow to different NiFi instances using Site-to-Site protocol. As of version 1.7.1, NiFi does not offer balanced relationships, so RPG is used for load balancing in a NiFi data flow.

A developer can add the RPG from the top toolbar of NiFi UI by dragging the icon as shown in the above picture to canvas. To configure an RPG, a Developer has to add the following fields −
| S.No. | Field Name | Description |
|---|---|---|
| 1 | URLs | To specify comma separated remote target NiFi URLs. |
| 2 | Transport Protocol | To specify the transport protocol for remote NiFi instances. It’s either RAW or HTTP. |
| 3 | Local Network Interface | To specify the local network interface to send/receive data. |
| 4 | HTTP Proxy Server Hostname | To specify the proxy server’s hostname for the purpose of transport in RPG. |
| 5 | HTTP Proxy Server Port | To specify the proxy server’s port for the purpose of transport in RPG. |
| 6 | HTTP Proxy User | It is an optional field to specify the username for HTTP proxy. |
| 7 | HTTP Proxy Password | It is an optional field to specify the password for above username. |
A developer needs to enable it, before using it like we start processors before using them.
Apache NiFi — Controller Settings
Apache NiFi offers shared services, which can be shared by processors and reporting task is called controller settings. These are like Database connection pool, which can be used by processors accessing same database.
To access the controller settings, use the drop down menu at the right top corner of NiFi UI as shown in the below image.
There are many controller settings offered by Apache NiFi, we will discuss a commonly used one and how we set it up in NiFi.
DBCPConnectionPool
Add the plus sign in the Nifi Settings page after clicking the Controller settings option. Then select the DBCPConnectionPool from the list of controller settings. DBCPConnectionPool will be added in the main NiFi settings page as shown in the below image.

It contains the following information about the controller setting:Name
- Type
- Bundle
- State
- Scope
- Configure and delete icon
Click on the configure icon and fill the required fields. The fields are listed down in the table below −
| S.No. | Field Name | Default value | description |
|---|---|---|---|
| 1 | Database Connection URL | empty | To specify the connection URL to database. |
| 2 | Database Driver Class Name | empty | To specify the driver class name for database like com.mysql.jdbc.Driver for mysql. |
| 3 | Max Wait Time | 500 millis | To specify time to wait for the data from a connection to database. |
| 4 | Max Total Connections | 8 | To specify the maximum number of allocated connection in database connection pool. |
To stop or configure a controller setting, first all the attached NiFi components should be stopped. NiFi also adds scope in controller settings to manage the configuration of it. Therefore, only the ones which shared the same settings will not get impacted and will use the same controller settings.
Apache NiFi — Reporting Task
Apache NiFi reporting tasks are similar to the controller services, which run in the background and send or log the statistics of NiFi instance. NiFi reporting task can also be accessed from the same page as controller settings, but in a different tab.

To add a reporting task, a developer needs to click on the plus button present at the top right hand side of the reporting tasks page. These reporting tasks are mainly used for monitoring the activities of a NiFi instance, in either the bulletins or the provenance. Mainly these reporting tasks uses Site-to-Site to transport the NiFi statistics data to other node or external system.
Let us now add a configured reporting task for more understanding.
MonitorMemory
This reporting task is used to generate bulletins, when a memory pool crosses specified percentage. Follow these steps to configure the MonitorMemory reporting task −
-
Add in the plus sign and search for MonitorMemory in the list.
-
Select MonitorMemory and click on ADD.
-
Once it is added in the main page of reporting tasks main page, click on the configure icon.
-
In the properties tab, select the memory pool, which you want to monitor.
-
Select the percentage after which you want bulletins to alert the users.
-
Start the reporting task.
Apache NiFi — Custom Processor
Apache NiFi is an open source platform and gives developers the options to add their custom processor in the NiFi library. Follow these steps to create a custom processor.
-
Download Maven latest version from the link given below.
https://maven.apache.org/download.cgi
-
Add an environment variable named M2_HOME and set value as the installation directory of maven.
-
Download Eclipse IDE from the below link.
https://www.eclipse.org/downloads/download.php
-
Open command prompt and execute Maven Archetype command.
> mvn archetype:generate
-
Search for the nifi type in the archetype projects.
-
Select org.apache.nifi:nifi-processor-bundle-archetype project.
-
Then from the list of versions select the latest version i.e. 1.7.1 for this tutorial.
-
Enter the groupId, artifactId, version, package, and artifactBaseName etc.
-
Then a maven project will be created having to directories.
-
nifi-<artifactBaseName>-processors
-
nifi-<artifactBaseName>-nar
-
-
Run the below command in nifi-<artifactBaseName>-processors directory to add the project in the eclipse.
mvn install eclipse:eclipse
-
Open eclipse and select import from the file menu.
-
Then select “Existing Projects into workspace” and add the project from nifi-<artifactBaseName>-processors directory in eclipse.
-
Add your code in public void onTrigger(ProcessContext context, ProcessSession session) function, which runs when ever a processor is scheduled to run.
-
Then package the code to a NAR file by running the below mentioned command.
mvn clean install
-
A NAR file will be created at nifi—nar/target directory.
-
Copy the NAR file to the lib folder of Apache NiFi and restart the NiFi.
-
After successful restart of NiFi, check the processor list for the new custom processor.
-
For any errors, check ./logs/nifi.log file.
Apache NiFi — Custom Controllers Service
Apache NiFi is an open source platform and gives developers the options to add their custom controllers service in Apache NiFi. The steps and tools are almost the same as used to create a custom processor.
-
Open command prompt and execute Maven Archetype command.
> mvn archetype:generate
-
Search for the nifi type in the archetype projects.
-
Select org.apache.nifi:nifi-service-bundle-archetype project.
-
Then from the list of versions, select the latest version – 1.7.1 for this tutorial.
-
Enter the groupId, artifactId, version, package, and artifactBaseName, etc.
-
A maven project will be created having directories.
-
nifi-<artifactBaseName>
-
nifi-<artifactBaseName>-nar
-
nifi-<artifactBaseName>-api
-
nifi-<artifactBaseName>-api-nar
-
-
Run the below command in nifi-<artifactBaseName> and nifi-<artifactBaseName>-api directories to add these two projects in the eclipse.
-
mvn install eclipse:eclipse
-
-
Open eclipse and select import from the file menu.
-
Then select “Existing Projects into workspace” and add the project from nifi-<artifactBaseName> and nifi-<artifactBaseName>-api directories in eclipse.
-
Add your code in the source files.
-
Then package the code to a NAR file by running the below mentioned command.
-
mvn clean install
-
-
Two NAR files will be created in each nifi-<artifactBaseName>/target and nifi-<artifactBaseName>-api/target directory.
-
Copy these NAR files to the lib folder of Apache NiFi and restart the NiFi.
-
After successful restart of NiFi, check the processor list for the new custom processor.
-
For any errors, check ./logs/nifi.log file.
Apache NiFi — Logging
Apache NiFi uses logback library to handle its logging. There is a file logback.xml present in the conf directory of NiFi, which is used to configure the logging in NiFi. The logs are generated in logs folder of NiFi and the log files are as described below.
nifi-app.log
This is the main log file of nifi, which logs all the activities of apache NiFi application ranging from NAR files loading to the run time errors or bulletins encountered by NiFi components. Below is the default appender in logback.xml file for nifi-app.log file.
<appender name="APP_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-app.log</file>
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/
nifi-app_%d{yyyy-MM-dd_HH}.%i.log
</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
<immediateFlush>true</immediateFlush>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
The appender name is APP_FILE, and the class is RollingFileAppender, which means logger is using rollback policy. By default, the max file size is 100 MB and can be changed to the required size. The maximum retention for APP_FILE is 30 log files and can be changed as per the user requirement.
nifi-user.log
This log contains the user events like web security, web api config, user authorization, etc. Below is the appender for nifi-user.log in logback.xml file.
<appender name="USER_FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-user.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/
nifi-user_%d.log
</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
The appender name is USER_FILE. It follows the rollover policy. The maximum retention period for USER_FILE is 30 log files. Below is the default loggers for USER_FILE appender present in nifi-user.log.
<logger name="org.apache.nifi.web.security" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.web.api.config" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.authorization" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.cluster.authorization" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger> <logger name="org.apache.nifi.web.filter.RequestLogger" level="INFO" additivity="false"> <appender-ref ref="USER_FILE"/> </logger>
nifi-bootstrap.log
This log contains the bootstrap logs, apache NiFi’s standard output (all system.out written in the code mainly for debugging), and standard error (all system.err written in the code). Below is the default appender for the nifi-bootstrap.log in logback.log.
<appender name="BOOTSTRAP_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${org.apache.nifi.bootstrap.config.log.dir}/nifi-bootstrap.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>
${org.apache.nifi.bootstrap.config.log.dir}/nifi-bootstrap_%d.log
</fileNamePattern>
<maxHistory>5</maxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%date %level [%thread] %logger{40} %msg%n</pattern>
</encoder>
</appender>
nifi-bootstrap.log file,s appender name is BOOTSTRAP_FILE, which also follows rollback policy. The maximum retention for BOOTSTRAP_FILE appender is 5 log files. Below is the default loggers for nifi-bootstrap.log file.
<logger name="org.apache.nifi.bootstrap" level="INFO" additivity="false"> <appender-ref ref="BOOTSTRAP_FILE" /> </logger> <logger name="org.apache.nifi.bootstrap.Command" level="INFO" additivity="false"> <appender-ref ref="CONSOLE" /> <appender-ref ref="BOOTSTRAP_FILE" /> </logger> <logger name="org.apache.nifi.StdOut" level="INFO" additivity="false"> <appender-ref ref="BOOTSTRAP_FILE" /> </logger> <logger name="org.apache.nifi.StdErr" level="ERROR" additivity="false"> <appender-ref ref="BOOTSTRAP_FILE" /> </logger>
Kickstart Your Career
Get certified by completing the course
Get Started

Вступление
Компоненты nifi
Processor API
Поддержка API.
AbstractProcessor API
Срок службы компонента
Уведомление компонентов
Предел
Менеджер штата
Отчет о деятельности процессора
Запись компонентов
Атрибут записи
Рекордные отношения
Возможности и ключевые слова записи
Запишите взаимодействие атрибута FlowFile
Передовая документация
Исходное событие
Универсальный процессор
Ввод данных
Выход данных
Контент-маршрут (один к одному)
Маршрутизация на основе контента (один для более)
Поток маршрутизации на основе содержимого (один для более)
Маршрут на основе атрибута
Разделение контента (один ко многим)
Согласно атрибуту обновления контента
Богатый / модифицированный контент
Обработка ошибок
Исключения в процессоре
Ненормальность в обратном вызове: IOException, Runtimeexception
Наказание и урожайность
Откат в работе
Общее рассмотрение дизайна
Подумайте о пользователях
Сплоченность и повторное использование
Соглашение об именах
Процессор поведения комментария
Буфер данных
Услуги контроля
Разработать контроллерное обслуживание
Взаимодействие с контролем
Задача отчета
Доклад о разработке Задача
Расширение пользовательского интерфейса
Пользовательский процессор UI.
Содержание Viewer
Инструмент командной строки
TLS-Toolkit.
контрольная работа
Инструментарированный Testrunner
Добавить контрольные сервисы
Установите значение атрибута
Ожидание FlowFiles.
Пробежать процессор
Проверьте вывод
Имитация внешних ресурсов
Дополнительная функция теста
Архивы NIFI (NAR)
Каждый класс экземпляра загружен
Отказ от компонента
Как внести свой вклад в Apache NiFi
технология
Где ты начал?
Обеспечить пожертвования
свяжитесь с нами
Вступление
Руководство разработчика предназначено для предоставления читателям предоставить информацию о том, как разработать информацию, необходимую для расширений Apache NiFi, и помочь объяснить процесс мышления за компонентом развития. Он обеспечивает введение и описание API для расширения развития. Однако он не детализирует каждый способ в API, потому что это руководство предназначено для дополнения API Javadoc вместо того, чтобы заменить их. Это руководство также предполагает, что читатель знаком с Java 7 и Apache Maven.
Это руководство написано разработчиками. Перед чтением этого руководства вам нужно базовое понимание концепций NIFI и потока данных. Если нет, пожалуйста, обратитесь кОбзор Nifi с участиемРуководство пользователя NIFI,Ознакомиться с концепцией NIFI.
Компоненты nifi
NIFI предоставляет несколько расширений, чтобы позволить разработчикам добавлять функции на приложение для удовлетворения их потребностей. Следующий список предоставляет расширенные описания наиболее распространенных точек расширения:
-
процессор (Processor)
-
Интерфейс процессора является общедоступной парой NIFIFlowFile, Его свойства и механизм доступа к их содержанию. Процессор является базовым блоком сборки для составляющей потока данных NIFI. Этот интерфейс используется для выполнения всех задач:
-
Создать flowfiles.
-
Прочитайте содержание FlowFile
-
Пишите содержание FlowFile
-
Читать свойства FlowFile
-
Обновите свойство FlowFile
-
Впускные данные
-
Экспорт данных
-
Данные маршрута
-
Извлечь данные
-
Изменить данные
-
-
-
ReportingTask
-
Интерфейс ReportingTask является механизмом раскрытия NiFi, позволяя метрикам, информацию мониторинга и внутреннего состояния NiFi к внешним конечным точкам, таким как файлы журнала, электронная почта и удаленные веб-сервисы.
-
-
ControllerService
-
ControlLerervice предоставляет общий статус и функции в одном JVM, других контроллерах, а также ReportingTasks. Примеры могут включать загрузку очень больших данных, установленных в память. При выполнении этого в контроллерах данных данные могут быть загружены один раз и открыты для всех процессоров через эту услугу, а не требуют многих разных процессоров для загрузки набора данных.
-
-
FlowFilePrioritizer
-
Интерфейс FlowfilePrioritizer обеспечивает механизм, который может быть в очереди через этот механизм.FlowFileВыполните приоритетную сортировку или сортировку, так что FlowFiles может быть обработан в наиболее эффективном порядке для конкретного случая использования.
-
-
AuthorityProvider
-
PerformentProvide отвечает за определение привилегий и ролей данного пользователя (если таковой имеется).
-
Processor API
Процессор является наиболее широко используемым компонентом в NiFi. Процессор является единственным компонентом, который можно получить для создания, удаления, изменений или проверки FlowFiles (данные и атрибуты).
Загрузите и создавайте все процессоры, используя механизм сервизника Java. Это означает, что все процессоры должны соблюдать следующие правила:
-
Процессор должен иметь конструктор по умолчанию.
-
JAR-файл процессора должен содержать записи по имени META-INF / SERVICE
org.apache.nifi.processor.ProcessorОтказ Это текстовый файл, где каждая строка содержит полностью квалифицированное имя класса процессора.
хотяProcessorЭто интерфейс, который может быть реализован напрямую, но это очень редко, потому что этоorg.apache.nifi.processor.AbstractProcessorЭто базовый класс, который практически все процессоры реализованы.AbstractProcessorФункциональность, предоставленная классом, которая делает процессор разработки проще и более удобными задачами. Для объема этого документа мы сосредоточним основное вниманиеAbstractProcessorКлассы при обработке процессора API.
Параллельность
NIFI — это очень параллельные рамки. Это означает, что все расширения должны быть резьбами. Если вы не знакомы с Java, чтобы написать параллельное программное обеспечение, вы настоятельно рекомендуете вам знакомы с принципами параллелизма Java.
Поддержка API
Чтобы понять процессор API, мы должны сначала понять — по крайней мере, на высоком уровне — несколько классов поддержки и интерфейсы, которые будут обсуждаться ниже.
FlowFile
FlowFile — это логическая концепция, которая связывает данные с набором свойств о данных. Эти атрибуты включают уникальный идентификатор flowfile, а также их имя, размер и любое количество других конкретных потоковых значений. Хотя содержимое и атрибуты FlowFile можно изменить, объект FlowFile не является переменным. Процессонность может изменить FlowFile.
Основные свойства Flowfilesorg.apache.nifi.flowfile.attributes.CoreAttributesОпределение в перечислении. Наиболее распространенный атрибут, который вы увидите, это имя файла, путь и UUID. Строка в кавычкахCoreAttributesПеречислять значение свойств.
-
Имя файла («имя файла»): имя файла flowfile. Имя файла не должно содержать никакой структуры каталогов.
-
UUID («UUID»): Назначьте универсальный уникальный идентификатор для этого FlowFile для различения FlowFile и других расходов в системе.
-
Путь («PATH»): путь потока указывает, что относительный каталог FlowFile принадлежит, не содержит имя файла.
-
Absolute Path («Absolute.Path»): абсолютный путь flowfile указывает на абсолютный каталог, к которому принадлежит FlowFile, не содержит имя файла.
-
Priority(«Приоритет»): указывает значение приоритета FlowFile.
-
MIME Type(«MIME.TYPE»): тип MIME FLOWFILE.
-
Откажитесь от причины («Discard.reason»: указывает причину отказа от расщепления.
-
Альтернативный идентификатор («Alternate.identifier»: указывает идентификатор, отличный от UUID, который, как известно, ссылается на этот FlowFile.
ProcessSession
Процедность часто называют «сеансом», что обеспечивает механизм, который может быть создан, уничтожен, проверен, Clone FlowFiles и передается другим процессорам. Кроме того, процепция также обеспечивает механизм изменения расходов, добавляя или удаление атрибутов или модификации содержимого FLECFILE. Процедность также раскрывает выпускСобытие исходного кодаМеханизм, механизм обеспечивает возможность отслеживать последователей и истории FlowFile. После выполнения операций на одном или нескольких расходомерах вы можете отправить или откатывать процессинговую контролю.
ProcessContext
ProcessContext предоставляет мост между процессором и рамкой. Он предоставляет информацию о том, как в настоящее время процессор настроен и позволяет процессору выполнять рамочные задачи, такие как генерация его ресурсов, так что структура будет организовывать другие процессоры, чтобы работать без излишнего использования ресурса.
PropertyDescriptor
PropertyDescriptor определяет свойства, которые будут использоваться процессором, ReportingTask или Controllervice. Определение свойства включает его имя, описание атрибута, дополнительную логику по умолчанию, логику проверки и индикатор атрибута, необходимого для обработки, если процессор действителен. PropertyDescriptors создаетсяPropertyDescriptor.BuilderЭкземпляр класса, вызовите соответствующего метода для заполнения деталей соответствующего атрибута и, наконец, позвонитеbuildМетод создан.
Валидатор (Validator)
PropertyDescriptor должен указывать один или несколько валидаторов, который можно использовать для обеспечения того, чтобы значение атрибута, введенного пользователем, является действительным. Если валидатор указывает, что значение свойства недействительна, вы не сможете запустить или использовать компонент до того, как свойство вступает в силу. Если валидатор не указан, предполагается, что компонент недействителен, и NIFI сообщит о том, что свойство не поддерживается.
ValidationContext
При проверке значений атрибутов ValidationContext можно использовать для получения контроллеров, создание объекта PropertyValue и компиляционные и оценки значений атрибутов с использованием языков экспрессии.
PropertyValue
Все значения атрибутов, возвращаемые в процессор, возвращаются в виде объекта PropertyValue. Этот объект обладает удобным способом преобразования значений из строки в другие формы (например, цифры и периоды времени), и обеспечивает API для оценки языков экспрессии.
Отношение (Relationship)
Определения отношения FLOWFILE могут быть переданы из процессора на. ИнстанцияRelationship.BuilderЭкземпляр класса, позвоните соответствующим методу, чтобы заполнить детали отношений, наконец, звонитьbuildМетод создания отношений.
StateManager
Statemanager предоставляет механизм деживания и извлечения статуса процессоров, задач отчетности и службы контроллеров. API аналогичен CONCURRENTHASHMAP, но каждая операция требует объема. Индикация диапазона заключается в том, чтобы сохранить статус в кластере или в диапазоне кластера. Для получения дополнительной информации см.Менеджер состоянияраздел.
ProcessorInitializationContext
После создания процессора,initializeИспользоватьInitializationContextОбъект вызывает его метод. Этот объект раскрыт процессору, который не изменяется во всем жизненном цикле процессора, такого как уникальный идентификатор процессора.
ComponentLog
Поощрять процессор черезComponentLogИнтерфейс выполняет регистрацию вместо того, чтобы получить прямой экземпляр третьего регистратора. Это связано с тем, что запись включена с помощью ComponentLogLog, позвольте кадрам проводить журнальное сообщение, которое может быть настраиваемым уровнем серьезности к пользовательскому интерфейсу, позволяя мониторингу человека, который наблюдает за поток данных, когда происходит важное событие. Кроме того, он предоставляет постоянный формат записи журнала для всех процессоров, записывая отслеживание стека в режиме отладки и предоставление процессора в журнале.
AbstractProcessor API
Поскольку большинство процессоров создаются путем расширения абстрактногопроцессора, мы обсудим его класс абстракции в этом разделе. АбстрактПроцессор обеспечивает несколько способов разработчиков процессоров.
Инициализация процессора (Processor Initialization)
Когда вы создаете процессор, перед вызовом любых других методов,initСпособ абстрактногопроцессора будет вызван. Этот метод использует один параметр, то есть тип типаProcessorInitializationContextОтказ Объект контекста предоставляет компонент-компонент, уникальный идентификатор процессора и контроллер данных для процессора, который может использоваться для взаимодействия с настроенными контроллерами. Каждый такой объект хранится абстрактнымПроцессором и может быть получен подклассамиgetLogger,getIdentifierс участием getControllerServiceLookupМетод соответственно.
Раскрывая отношения между процессором (Exposing Processor’s Relationships)
Чтобы перенести процессор в новый пункт назначения для последующей обработки, процессор должен сначала иметь возможность раскрывать все отношения в настоящее время поддерживаемым кадром. Это позволяет приложениям подключить процессор друг другу, создавая соединение между процессором и присваивает соответствующие отношения с этими соединениями.
Процессор охватываетgetRelationshipsМетод открыт для эффективных отношений. Этот метод не имеет параметра и возвращает его.SetизRelationshipОбъект. Для большинства процессоров этот набор будет статичным, но другие процессоры будут динамически генерировать набор в соответствии с конфигурацией пользователя. Для тех процессоров для настроек рекомендуется создать иммобилизованный набор в методе конструктора процессора или INIT, и возвращается к этому значение, а не динамически генерировать набор. Эта модель помогает достичь более четкого кода и лучшей производительности.
Общественные свойства процессора (Exposing Processor Properties)
Большинство процессоров нуждаются в некоторой конфигурации пользователя перед доступным. Свойства, поддерживаемые процессором, передаютсяgetSupportedPropertyDescriptorsСпособ раскрывается в рамках. Этот метод не имеет параметра и возвращает его.Listиз PropertyDescriptorОбъект. Порядок объектов в списке важен, потому что он определяет порядок, в котором свойства отображаются в пользовательском интерфейсе.
PropertyDescriptorЦель состоит в том, чтобы создать новый конструктор экземпляра, создавая новый экземплярPropertyDescriptor.BuilderОбъект, вызовите соответствующий метод строителя и, наконец, позвонитеbuildметод.
Хотя этот метод охватывает большую часть случаев, иногда есть другие свойства, которые пользователю разрешено настроить имя неизвестен. Это может быть перезаписаноgetSupportedDynamicPropertyDescriptorМетод реализован. Этот способStringУникальный параметр используется в качестве параметра, который указывает имя атрибута. Этот метод возвращает одинPropertyDescriptorОбъект, объект можно использовать для проверки имени и значения атрибута. Любой свойственный объект, возвращаемый из этого метода, должен быть построен, должен быть построен,isDynamicвPropertyDescriptor.BuilderЗначение установлено значение true в классе. Поведение по умолчанию абстрактногопроцессора является свойство, которое не разрешено создавать.
Проверьте свойства процессора (Validating Processor Properties )
Если процессор настроен, недействителен, процессор не может быть запущен. Вы можете установить Validator на PropertyDescriptor или через PropertyDescriptor.builderallowableValuesМетод илиidentifiesControllerServiceМетод ограничивает допустимое значение атрибута для проверки свойства процессора.
Однако иногда атрибуты процессора могут быть проверены отдельно. С этой целью абстрактныйПроцессор опубликовал одинcustomValidateметод. Этот метод использует один тип параметраValidationContextОтказ Возвращаемое значение этого метода — любая проблема, обнаруженная в течение периода проверки.Collectionиз ValidationResultОбъект. Следует только вернуть егоisValidМетод возвратил объект ValidationResultfalseОтказ Этот метод называется только тогда, когда все атрибуты действительны в соответствии со своими соответствующими валидаторами и допустимыми значениями. То есть этот метод вызывается только тогда, когда все сам атрибуты действительны, и этот метод позволяет общую конфигурацию процессора проверки.
Изменение конфигурации ответа (Responding to Changes in Configuration)
Иногда желательно реагировать стремиться реагировать своими атрибутами. ДолженonPropertyModifiedМетод позволяет процессору сделать это. Когда пользователь меняет свойства процессора,onPropertyModifiedЭтот метод будет призван для каждого модифицированного атрибута. Этот метод имеет три параметра: PropertyDescriptor, который указывает, какие свойства, старые значения и новые значения были изменены. Если атрибут не имеет предыдущего значения, второй параметр будетnullОтказ Если свойство удалена, третий параметр будетnullОтказ Важно отметить, что этот метод будет вызываться независимо от того, действует ли значение. Этот метод называется только тогда, когда значение на самом деле модифицируется, не этот метод называется, когда пользователь обновляет процессор без изменения его значения. При вызове этого метода нить не используется для вызова этого метода, является уникальным потоком, который в настоящее время выполняет код в процессоре, если только тот процессор не создает свой собственный поток.
Исполнительная работа (Performing the Work)
Планирует, когда у процессора есть работа, чтобы сделатьonTriggerЗавершено структурой, чтобы вызвать его метод. Этот метод имеет два параметра:ProcessContextИ аProcessSessionОтказ ДолженonTriggerПервый шаг метода обычно вызываетgetСпособ по процессам должен быть, чтобы получить FlowFile, который вы хотите сделать. Этот шаг будет пропущен для процессора, извлеченного из внешнего источника к NiFi. Затем процессор может свободно проверять свойство FlowFile; добавить, удалить или изменить свойство; прочитайте или измените содержимое FlowFile; и перенесите FlowFiles в соответствующие отношения.
Когда процессор срабатывает (When Processors are Triggered)
onTriggerПроцессор называется только тогда, когда процессор планируется, и процессор работает. Если выполняется какое-либо из следующих условий, считается процессор:
-
Целью для подключения процессора по крайней мере один FlowFile в очередь
-
Процессор не имеет входящего соединения
-
Процессор использует @triggerWhempty Annotation для аннотирования
Есть несколько факторов, чтобы вызватьonTriggerПозвоните в метод процессора. Во-первых, процессор не будет запущен, если пользователь не настроил процессор для запуска. Если вы планируете запустить процессор, периодически (этот период настроен пользовательский интерфейс в пользовательском интерфейсе), проверяет, имеет ли процессор работы, как описано выше. Если это так, каркас будет проверять текущий пункт назначения обработки. Если какое-либо исходящее подключение процессора заполнено, процессор не будет запланирован по умолчанию.
но,@TriggerWhenAnyDestinationAvailableПримечание. Вы можете добавить его в класс процессора. В этом случае спрос изменен так, что только одна цель ниже по течению должна быть «доступна» (если подключенная очередь не заполнена, цель считается «доступной»), а не требует всех целей ниже по течению.
Там также связан с дискатом процессора@TriggerSeriallyКомментарий. Процессор, использующий эту аннотацию, никогда не будет иметь несколько потоков.onTriggerЗапустите метод одновременно. Однако вы должны обратить внимание на нить кода выполнения, может измениться с вызова. Следовательно, вы также должны обратить внимание на то, что процессор является нитью!
Срок службы компонента (Component Lifecycle)
API NIFI обеспечивает поддержку жизненного цикла с помощью аннотаций Java. Долженorg.apache.nifi.annotations.lifecycleПакет содержит несколько комментариев управления жизненным циклом. Следующие комментарии могут быть применены к методу Java в компоненте NiFi, чтобы указать, когда этот метод должен быть вызван. Для обсуждения жизненного цикла компонента мы определяем компоненты NIFI в качестве процессора, контроллеров или отчетных элементов.
@OnAdded
Должен@OnAddedПримечание приводит к тому, что позвоните как можно скорее. После построения компонентов компоненты будут называтьсяinitializeМетод (илиinitМетод, если это подклассAbstractProcessor), Метод пост-комментария@OnAddedОтказ Если кто-то@OnAddedАномальный метод бросает исключение, затем возвращает ошибку к пользователю, и компонент не будет добавлен в поток. Кроме того, другие методы с этой аннотацией не вызываются. Этот метод вызывается только один раз в жизненном цикле компонента. Способ использования этой аннотации должен использовать нулевые параметры.
@OnEnabled
Сказал@OnEnabledОбратите внимание, что вы можете быть использованы для указания того, что метод всякий раз, когда должна быть вызвана служба контроллера. Любой способ с этой аннотацией вызывается каждый раз, когда пользователь позволяет услугу. Кроме того, каждый раз, когда NiFi перезагружен, метод будет вызываться, если NIFI настроен на «Состояние автоматического восстановления», и служба включена.
Если метод с этой аннотацией бросает мошенники, сообщения журнала и объявления будут выпущены для компонента. В этом случае сервис сохранит состояние «включенного», недоступен. Затем все методы, имеющие эту аннотацию, будут вызваны снова после задержки. Сервис не будет доступен до всех методов с этим комментарием без отказа от любого содержимого.
Используйте этот метод аннотации должен использовать 0 параметров или один тип параметраorg.apache.nifi.controller.ConfigurationContext。
Обратите внимание, что эта аннотация будет игнорироваться, если она применяется к ReportingSactask или процессору. Для службы контроллера включена и отключено, считается событием жизненного цикла, поскольку он позволяет ему доступен или недоступен для других компонентов. Однако для процессоров и отчетных задач они не являются событиями жизненного цикла, но позволяют механизму исключить компоненты при запуске или остановке набора компонентов.
@OnRemoved
Должен@OnRemovedКомментарий заставит предыдущий компонент удалить метод, который будет называться из потока. Это очистит ресурс до удаления компонента. Способ использования этой аннотации должен использовать нулевые параметры. Этот компонент все еще будет удален, если аномалия брошена с этим одобрением.
@OnScheduled
Эта аннотация указывает на то, что метод следует вызывать каждый раз, когда компонент планирования работает. Поскольку контроллеры не запланированы, оно не значимо при использовании этой аннотации на контроллерное обслуживание и не будет соблюдаться. Это следует использовать только для процессоров и отчетных задач. Если какой-либо способ с этой аннотацией бросает исключение, другие методы с этой аннотацией не вызываются, и уведомление будет отображаться пользователю. При этих обстоятельствах,@OnUnscheduledЗатем вызвать ленту@OnStoppedСпособ аннотации является затем аннотированный метод (в ходе этого состояния, если какая-либо из этих методов брошено, эти исключения). Затем компонент будет выполнен в течение определенного периода времени, называемого «продолжительностью дохода управления».nifi.propertiesфайл. Наконец, процесс снова начнется до всех комментариев@OnScheduledВернуться без броска любых исключений. Способ с этой аннотацией может использовать нулевой параметр или один параметр можно использовать. Если вы используете один вариант параметра,ProcessContextЕсли компонент является процессором илиConfigurationContextКомпонент представляет собой ReportingTask, а параметр должен быть типа.
@OnUnscheduled
До тех пор, пока вы больше не планируете запустить процессор или ReportingTask, вы позвоните методу с этой аннотацией. В то время многие потоки могут быть все еще могут быть в процессореonTriggerМетод активен в способе. Если такие методы бросают исключение, будет сгенерировано сообщение журнала, в противном случае исключение будет игнорироваться, и другие методы с этой аннотацией все равно будут вызваны. Способ с этой аннотацией может использовать нулевой параметр или один параметр можно использовать. Если вы используете один вариант параметра,ProcessContextЕсли компонент является процессором илиConfigurationContextКомпонент представляет собой ReportingTask, а параметр должен быть типа.
@OnStopped
Когда вы больше не планируете запустить процессор или ReportingTask иonTriggerМетод при возврате всех потоков способа будет вызван метод этой аннотацией. Если этот метод бросает исключение, будет сгенерировано сообщение журнала, в противном случае исключение будет игнорироваться; другие методы с этой аннотацией все равно будут вызваны. Позволяет использовать эту аннотацию с использованием 0 или 1 параметров. Если вы используете параметры, если компонент представляет собой ReportingTask, он должен быть тип ConfigurationContext; если компонент является процессором, он должен быть типом ProcessContext.
@OnShutdown
@OnShutdownКогда NiFi успешно закрыт, любой способ использовать комментарии аннотации. Если такие методы бросают исключение, будет сгенерировано сообщение журнала, в противном случае исключение будет игнорироваться, и другие методы с этой аннотацией все равно будут вызваны. Способ использования этой аннотации должен использовать нулевые параметры. Примечание. Хотя NiFi попытается настроить метод этой аннотацией во всех компонентах этого, это не всегда возможно. Например, процесс может быть неожиданно прекращен, и в этом случае у него нет возможности вызывать эти методы. Следовательно, хотя метод использования этого комментария может быть использован для очистки ресурсов, он не должен полагаться на них для обработки критической бизнес-логики.
Уведомление компонентов (Component Notification )
API NIFI обеспечивает поддержку уведомления с помощью Java Annotations. Долженorg.apache.nifi.annotations.notificationПакет содержит несколько комментариев для управления уведомлением. Следующие комментарии могут быть применены к методу Java в компоненте NIFI, чтобы указать, когда структура должна вызывать метод. Для обсуждения уведомлений компонентов мы определяем компоненты NIFI какпроцессор,Услуги контроляили жеЗадача отчета。
@OnPrimaryNodeStateChange
@OnPrimaryNodeStateChangeКак только состояние первичного узла в кластере изменяется, подход позвонит методу. Методы с этим примечанием не должны приносить параметр для параметров или типовPrimaryNodeStateОтказ ДолженPrimaryNodeStateКакие изменения предоставляются, чтобы компоненты могли предпринять соответствующие контент действия. ДолженPrimaryNodeStateСуществует два возможных значения для перечисления:ELECTED_PRIMARY_NODE(Узел получает это состояние, был избран первичным узлом кластера NIFI) илиPRIMARY_NODE_REVOKED(Узел, который получен этим состоянием, является основным узлом, но теперь уже есть его основной роль роль узла).
Ограничено (Restricted )
Ограниченные компоненты являются компонентами, которые могут быть использованы для выполнения операторов любого необоснованного кода, предоставленного NIFI REST API / ui / ui или могут использоваться для получения или изменения данных о системах NIFI Host с использованием учетных данных NIFI OS. Эти компоненты могут использоваться другими уполномоченными пользователями NIFI, превысив ожидаемое использование приложения, обновления привилегии или могут выставлять данные о процессах NIFI или принимающих систем. Все эти функции должны считаться привилегиями, а администраторы должны понимать эти функции и явно включить их для доверительных подмножеств пользователей.
Вы можете использовать процессор тегов Annotation Annotation, сервис контроллера или задачу отчета. Это приведет к тому, что компоненты будут рассмотрены ограничения и должны быть явно добавлены в список пользователей, которые могут получить доступ к ограниченным компонентам. Как только пользователю разрешено получить доступ к компонентам ограничения, они могут позволить им создавать и изменять эти компоненты, предпосылка состоит в том, чтобы позволить всем другим разрешениям. Если вы не доступаете в ограничениях, пользователи все равно будут знать, что есть такие типы компонентов, но даже если есть достаточно разрешений, они не могут быть созданы или изменены.
Государственное управление (Государственный менеджер)
Из ProcessContext, ReportingContext и ControlLerServiceInitializationContext, компоненты могут называть этоgetStateManager()метод. Этот менеджер состояния отвечает за предоставление простых API для хранения и извлечения статуса. Этот механизм предназначен для того, чтобы разработчики могли легко хранить группу пар клавиш / значение, извлеките эти значения и обновляйте их атомным способом. Состояние может быть сохранено локально в узле, или его можно хранить на всех узлах в кластере. Однако важно отметить, что этот механизм используется только для обеспечения механизма для хранения очень «простого» состояния. Следовательно, API позволяет толькоMap<String, String>Хранить и извлекать и атримально замените всю карту. Кроме того, Zookeeper поддерживает единственную реализацию, которая в настоящее время поддерживает статус диапазона кластера хранения. Следовательно, после сериализации все карта состояния должно быть менее 1 МБ. Пытаясь хранить больше, чем этот номер приведет к исключительному. Если взаимодействие, требуемое статусом управления процессорами, является более сложным (например, большая сумма данных должна храниться и извлекать, вы должны хранить и извлекать одну клавишу), вы должны использовать другой механизм (например, связь) внешний база данных).
диапазон(Scope)
При связи с менеджером состояния все вызовы методов требуются для обеспечения диапазона. Этот диапазон будетScope.LOCALили жеScope.CLUSTERОтказ Если NIFI работает в кластере, этот объем предоставляет важное сообщение о том, как сделать операцию.
Если вы используете состояние храненияScope.CLUSTERЗатем все узлы в кластере будут связываться с тем же механизмом хранения состояния. Если вы используете состояние хранения и поискаScope.LOCALЗатем каждый узел увидит разное представление состояния.
Также стоит отметить, что если NIFI настроен как независимый экземпляр, он не работает в кластере.Scope.LOCALДиапазон всегда используется. Это состоит в том, чтобы позволить разработчикам компонентов NiFi записывать код последовательным образом, не беспокоясь о том, является ли экземпляр NIFI кластером. Разработчики должны предполагать, что этот пример — кластер и соответственно записывает код соответственно.
Хранение и статус поискаStoring and Retrieving State)
Состояние использует StatManager StoragegetState,setState,replace,с участиемclearметод. Все эти методы требуют диапазона. Следует отметить, что состояние, хранящееся с локальным объемом, полностью отличается от состояния, хранящегося с использованием кластера. Если процессор использует объемMy KeyКлючевое хранимое значениеScope.CLUSTERЗатем попробуйте использоватьScope.LOCALРоль домена извлекает это значение, значение извлечения будетnull(Если только используетсяScope.CLUSTERЦенность одновременно хранится одновременно). Состояние каждого процессора выделяют из состояния других процессоров.
Следовательно, два процессора не могут разделять одно и то же состояние. Однако в некоторых случаях необходимо поделиться статусом между двумя различными типами процессоров или двумя идентичными типами процессоров. Это можно сделать с помощью службы контроллера. Сохраняя и извлечение состояния от службы контроллера, несколько процессоров могут использовать один и тот же сервис контроллера, а также можно объяснить через API управления контроллером.
модульный тест(Unit Tests)
Mock Framework NIFI обеспечивает большое количество инструментов для выполнения модульных испытаний процессора. Тест процессорного блока обычноTestRunnerКурс начинается. следовательно,TestRunnerЭтот класс содержитgetStateManagerМетод стада. Тем не менее, возвращенный статумагер имеет определенный тип:MockStateManagerОтказ КромеStateManagerВ дополнение к способу определения интерфейса, эта реализация также дает несколько способов помочь разработчикам легко разрабатывать модульные тесты.
прежде всего,MockStateManagerдостигатьStateManagerИнтерфейс, так что вы можете проверить все статус в модульных тестах. Кроме того,MockStateManagerРаскрытыйassert*Способ выполнения состояния как утверждение, установленное ожидаемым.MockStateManagerЕсли вы обновите статус для определенного случая, возможность указывать тест на единицу немедленно выполнить неудачу.Scope。
Отчет о деятельности процессора (Reporting Processor Activity)
Процессор отвечает за отчетность о его деятельности, чтобы пользователи могли понять, какие их данные произошли. Процессор должен записывать события через компонентLog, а компонентныйLog может через инициализациюContext или по вызовамgetLoggerМетод доступаAbstractProcessor。
Кроме того, процессор должен использоватьProvenanceReporterИнтерфейс, полученный по процессамgetProvenanceReporterметод. ProvenancePorter применяется в любое время, указывающее на то, что содержимое или отправляет внешнее местоположение от внешнего источника. Provenancreporter также имеет отчет, который сообщается, бифурцированный или модифицированный FlowFile, и включает в себя несколько расходов, и включает в себя несколько расходов в один расход, а также отчет о расходе, когда FlowFile связан с другими идентификаторами. Однако эти функции менее важны для отчетов, поскольку структура может обнаружить эти функции и представлять соответствующие события от имени процессора. Тем не менее, разработчики процессора выпустили эти события как лучшую практику, потому что она явно выдает эти события в коде, и разработчики могут предоставлять другие детали, например, действие предпринимает действие, предпринятое связанную информацию. Если процессор выдает событие, структура не выдает событие повторения. Вместо этого всегда предполагает, что разработчики процессора лучше понять, что произошло в контексте процессора, чем рамки. Однако этот кадр может выдавать разные события. Например, если процессор изменяет содержимое flowfile и его свойств, то только атрибуты_модифицированные события, структура выдаст событие Content_Modified. Если какие-либо другие события выдаются для FlowFile (по процессору или кадру), структура не будет выдавать атрибуты_модифицированные события. Это связано с тем, что все факты всегда предполагают, что разработчики процессора могут лучше понять, что произошло в контексте процессора, чем в рамках. Однако этот кадр может выдавать разные события. Например, если процессор изменяет содержимое flowfile и его свойств, то только атрибуты_модифицированные события, структура выдаст событие Content_Modified. Если какие-либо другие события выдаются для FlowFile (по процессору или кадру), структура не будет выдавать атрибуты_модифицированные события. Это связано с тем, что все факты всегда предполагают, что разработчики процессора могут лучше понять, что произошло в контексте процессора, чем в рамках. Однако этот кадр может выдавать разные события. Например, если процессор изменяет содержимое flowfile и его свойств, то только атрибуты_модифицированные события, структура выдаст событие Content_Modified. Если какие-либо другие события выдаются для FlowFile (по процессору или кадру), структура не будет выдавать атрибуты_модифицированные события. Это связано с тем, что все факты будут выдавать атрибуты_модифицированные события, если какие-либо события выдаются для FlowFile (процессором или кадром). Это связано с тем, что все факты будут выдавать атрибуты_модифицированные события, если какие-либо события выдаются для FlowFile (процессором или кадром). Это потому, что все фактыProvenance EventsПонимание свойств FlowFile перед событием и свойствами, возникающими из-за процесса FlowFile, а также атрибуты_модифицированные часто считаются избыточным и приведут к очень длинному родословному расходу. Однако, если мероприятие считается связанным с точки зрения процессора, процессор может выдать это событие с другими событиями.
Запись компонентов
NIFI обеспечивает большое количество документов из самого приложения NIFI через самого пользовательского интерфейса, пытаясь сделать пользовательский опыт максимально простым. Конечно, для достижения этого разработчики процессора должны предоставить этот документ кадра. NIFI предоставляет ряд различных механизмов для предоставления документации для рамки.
Атрибут записи
Можно назватьdescriptionСпособ построителя PropertyDescriptor записывает одно свойство:
public static final PropertyDescriptor MY_PROPERTY = new PropertyDescriptor.Builder()
.name("My Property")
.description("Description of the Property")
...
.build();Если свойство состоит в том, чтобы обеспечить набор допустимых значений, эти значения будут отображаться пользователю в выпадающем поле UI. Каждое из этих значений также может быть дано:
public static final AllowableValue EXTENSIVE = new AllowableValue("Extensive", "Extensive",
"Everything will be logged - use with caution!");
public static final AllowableValue VERBOSE = new AllowableValue("Verbose", "Verbose",
"Quite a bit of logging will occur");
public static final AllowableValue REGULAR = new AllowableValue("Regular", "Regular",
"Typical logging will occur");
public static final PropertyDescriptor LOG_LEVEL = new PropertyDescriptor.Builder()
.name("Amount to Log")
.description("How much the Processor should log")
.allowableValues(REGULAR, VERBOSE, EXTENSIVE)
.defaultValue(REGULAR.getValue())
...
.build();Запись отношенийDocumenting Relationships)
Режим записи отношений процессора по существу одинаково — по вызовуdescriptionСпособ строителя отношения:
public static final Relationship MY_RELATIONSHIP = new Relationship.Builder()
.name("My Relationship")
.description("This relationship is used only if the Processor fails to process the data.")
.build();Возможности и ключевые слова записи (Documenting Capability and Keywords)
Долженorg.apache.nifi.annotations.documentationПакет предоставляет Java Annotations, которые могут быть использованы для записи компонентов. Annotation Anotation CoStability может быть добавлен в процессор, отчет о задачах или службах контроллера, чтобы обеспечить краткое описание функций, предоставляемых компонентом. Комментарий к меткам имеетvalueПеременная определяется как строковый массив. Следовательно, он используется путем предоставления нескольких значений в качестве списка String Comma, разделенных запятыми. Эти значения затем объединяются в интерфейс UI, позволяя пользователю фильтровать компоненты на основе тега (т. Е. Ключевое слово). Кроме того, UI обеспечивает облако тегов, которое позволяет пользователю выбрать метку, которую они хотят фильтровать. Наибольшая этикетка в облаке является наиболее ярлыком на компонентах в экземпляре NiFi. Примеры использования этих комментариев приведены ниже:
@Tags({"example", "documentation", "developer guide", "processor", "tags"})
@CapabilityDescription("Example Processor that provides no real functionality but is provided" +
" for an example in the Developer Guide")
public static final ExampleProcessor extends Processor {
...
}Запишите взаимодействие атрибута FlowFile
Много раз процессор ожидает, чтобы установить некоторые свойства FlowFile в входящих потоках, чтобы запускать процессор нормально. В других случаях процессор может обновлять или создать свойство FlowFile на исходящем FlowFile. Разработчики процессора могут использоватьReadsAttributeс участиемWritesAttributeДокумент Комментарий записывает эти два поведения. Эти свойства используются для генерации документа, и пользователь может лучше понять, как процессор взаимодействует с потоком.
Примечание: поскольку Java 7 не поддерживает тип повторения, вам может потребоваться использоватьReadsAttributesс участиемWritesAttributesУказывает, что процессор читает или записывает несколько свойств FlowFile. Эта аннотация может быть применена только к процессору. Один пример указан ниже:
@WritesAttributes({ @WritesAttribute(attribute = "invokehttp.status.code", description = "The status code that is returned"),
@WritesAttribute(attribute = "invokehttp.status.message", description = "The status message that is returned"),
@WritesAttribute(attribute = "invokehttp.response.body", description = "The response body"),
@WritesAttribute(attribute = "invokehttp.request.url", description = "The request URL"),
@WritesAttribute(attribute = "invokehttp.tx.id", description = "The transaction ID that is returned after reading the response"),
@WritesAttribute(attribute = "invokehttp.remote.dn", description = "The DN of the remote server") })
public final class InvokeHTTP extends AbstractProcessor {Как правило, процессоры и контрольные услуги связаны друг с другом. Иногда этоPutFileПоставить / получить отношения с //GetFileОтказ Иногда процессор использует подобноеInvokeHTTPКонтрольервисStandardSSLContextServiceОтказ Иногда контроллерное обслуживание использует другойDistributedMapCacheClientServiceс участиемDistributedMapCacheServerОтказ Разработчики этих расширений могут быть использованыSeeAlsoТеги связаны с этими разными компонентами. Этот комментарий связывает эти компоненты в документе.SeeAlsoМожет применяться к процессорам, контрольным сервисам и репортажамтаскам. Ниже перечислены следующий список: Примеры этой операции:
@SeeAlso(GetFile.class)
public class PutFile extends AbstractProcessor {Передовая документация
Когда вышеуказанный метод документа недостаточно, NIFI может раскрыть более продвинутые документы для пользователя через документ «Использование». Когда пользователь щелкните правой кнопкой мыши процессор, NIFI предоставляет пункт меню «Использовать» в контекстном меню. Кроме того, интернет-интерфейс отображает ссылку «Справка» в правом верхнем углу, который можно найти в той же информации об использовании.
Усовершенствованный документ процессора предоставляется в форме с именем HTML-файл.additionalDetails.htmlОтказ Этот файл должен существовать в каталоге полностью квалифицированного имени имени в качестве процессора, и родитель этого каталога должен быть названdocsИ существуют в корневой каталог банке процессора. Этот файл будет связан с генерируемым HTML-файлом, который будет содержать все возможности, ключевое слово, PropertyDescription и информацию об отношениях, поэтому нет необходимости копировать файл. Это место может обеспечить богатое описание операции, ожидаемых и сгенерированных типов данных в этом процессоре и ожидаемых и сгенерированных свойств FlowFile. Поскольку этот документ использует HTML-формат, вы можете включить изображения и таблицы, чтобы наилучшим образом описать этот компонент. Усовершенствованные документы могут быть предоставлены с использованием того же метода для процессоров, контрольных веществ и отчетных данных.
Исходное событие
Различные типы событий исходного отчета:
| Исходное событие | описание |
|---|---|
|
ADDINFO |
Представляет события происхождения для добавления дополнительной информации (например, новые ссылки на новый URI или UUID) |
|
ATTRIBUTES_MODIFIED |
Указывает, что свойства FlowFile в некотором роде модифицированы. Это событие не требуется при сообщении другого события одновременно, потому что другое событие уже содержит все свойства FlowFile |
| CLONE |
Указывает, что FlowFile точно такой же, как и его отец FlowFile |
|
CONTENT_MODIFIED |
Указывает, что содержимое FlowFile изменится каким-либо образом. При использовании этого типа события рекомендуется предоставить подробную информацию о том, как изменить содержимое. |
| CREATE |
Указывает, что FlowFile генерируется от данных, полученных из удаленной системы или внешнего процесса. |
| DOWNLOAD |
Указывает, что пользователь или внешнее сущность загружает содержимое flowfile |
| DROP |
Указывает событие происхождения конца объекта жизни из-за некоторых причин истечения срока действия объекта |
| EXPIRE |
Указывает событие происхождения конца объекта из-за конца объекта |
| FETCH | |
| FORK |
Указывает, что один или несколько расходомеров получают из родительского потока |
| JOIN |
Указывает, что один расходомерник получен путем соединения нескольких родительских потоков. |
| RECEIVE |
Представляет исходное событие от внешнего процесса для получения данных. Этот тип события должен быть первым событием FlowFile. Следовательно, процессор, который получает данные от внешнего источника и заменяет существующий контент FlowFile с использованием данных вместо типа получения событий. |
| REPLAY |
Указывает, что произошедшее воспроизведение события FlowFile. Ууид мероприятия указывает на UUID оригинального потока, который воспроизводится. Мероприятие содержит родительский UUID, который также является UUID, который воспроизводится назад, а подсуид, это вновь созданный FlowFile UUID, который будет перенесен, чтобы ждать |
| ROUTE |
Указывает, что FlowFile был направлен в указанные отношения и предоставляет информацию о причине расщепления маршрутизации к этому отношениям. |
| SEND |
Указывает события оригинала, отправленные на внешние процессы |
| UNKNOWN |
Указывает, что тип события происхождения неизвестен, потому что пользователи пытаются получить доступ к событию, не зная этого типа |
Режим общего процессора (Common Processor Patterns )
Хотя пользователи NIFI могут использовать много разных процессоров, большинство процессоров относятся к одному из нескольких общих режимов дизайна. Ниже мы обсудим эти режимы, режим подходит, мы следуем этим режимам, и что вам нужно обратить внимание в этот режим. Обратите внимание, что узоры и рекомендации, обсуждаемые ниже, являются общими руководящими принципами, а не укрепления правил.
Ввод данных (Data Ingress )
Процессор, извлеченный в NiFi, имеет отношения.successОтказ Этот процессор проходит процесс процессаcreateМетод генерирует новые расходы и не извлекает расходы от входящих соединений. Имя процессора начинается с «Get» или «прослушивания», в зависимости от того, является ли это опрос внешним источником или интерфейсом, который может быть подключен к некоторым внешним источникам. Имя заканчивается протоколом, используемым для связи. Следуйте процессорам этого режима включаютGetFile,GetSFTP, ListenHTTP,с участиемGetHTTP。
Этот процессор можно использовать@OnScheduledСоздайте или инициализируйте пул соединения в методе комментариев. Однако, поскольку проблемы связи могут заблокировать создание или привести к прекращению подключения, сама связь не будет создана. НоonTriggerСпособ создается из бассейна или арендованного.
onTriggerСпособ этого процессора сначала использует соединение из пула соединения (если это возможно) или иначе создает соединение с внешней службой. Когда нет данных из внешнего источника,yieldСпособ ProcessContext называется процессором, а метод возвращается таким образом, чтобы процессор избегал непрерывной работы и истощения ресурсов без каких-либо преимуществ. В противном случае этот процессор проходит через процессорную контролюcreateМетод Создайте FlowFile и назначает соответствующее имя файла и путь к FlowFile (путем добавленияfilenameс участиемpathАтрибуты) и любые другие свойства, которые могут быть подходящими. Получить выходной потерю потока содержимого через процессиюwriteМетоды, передайте новый выпускной списокCallback (обычно анонимный внутренний класс). В этом обратном обратном вызове процессор способен писать потоковую и проточный контент от внешнего ресурса в выходной потерю FlowFile. Если вы хотите написать все содержимое ввода в FlowFile,importFromМетод процесса может соотношениеwriteМетод удобнее.
Когда этот процессор хочет получить множество небольших файлов, рекомендуется создавать несколько расходов из одного сеанса перед отправкой сеанса. Как правило, это позволяет кадра более эффективно обрабатывать содержание вновь созданных FlowFiles.
Этот процессор генерирует мероприятие для проведения, указанное в том, где он получил данные и определяет, где приходит данные. Этот процессор должен записывать создание FlowFile, чтобы вы могли определить источник FlowFile, анализируя журналы (при необходимости).
Этот процессор подтверждает, что данные получены и / или удаляют данные от внешнего источника для предотвращения приема повторяющихся файлов.Это доступно только после того, как вы создадите представление процесса потока!Если этот принцип не может привести к потере данных, NiFi приведет к удалению временного файла перед отправкой сеанса. Тем не менее, обратите внимание, что вы можете получать дублирующие данные, используя этот метод, поскольку приложение может перезапустить перед отправкой сеанса и перед подтверждением или удалением данных из внешнего источника. Однако в целом потенциальные данные являются более чем потенциальными потери данных. В конце концов возвращаются в соединение или добавьте соединение в пул соединения, в зависимости от того, аренду ли соединение из пула соединения илиonTriggerСоздать в способе.
Если есть проблема связи, соединение обычно прекращается, и соединение не возвращается (или добавлено) в пул соединения. Удалите соединение с удаленной системой в методе, используя комментарий Комментарий и выключите пул соединения.@OnStoppedДля того, чтобы переработать ресурсы.
Выход данных (Data Egress)
Существует два отношения с процессорами, которые публикуют данные для внешних источников:successс участиемfailureОтказ Имя процессора начинается с «PUT», а затем протоколы для передачи данных. Следуйте процессорам этого режима включаютPutEmail,, PutSFTPс участием PostHTTP(Обратите внимание, что это имя не начинается с «Подача», потому что это может вызвать путаницу, потому что поставленные и пост имеют особое значение при обработке HTTP).
Этот процессор можно использовать@OnScheduledСоздайте или инициализируйте пул соединения в методе комментариев. Однако, поскольку проблемы связи могут заблокировать создание или привести к прекращению подключения, сама связь не будет создана. НоonTriggerСпособ создается из бассейна или арендованного.
ДолженonTriggerМетод сначала прошелgetМетод получает Flusfile от процесса процесса. Если нет доступного потока, метод возвращается без подключения к удаленному ресурсу.
Если имеется по меньшей мере один FlowFile, процессор получает соединение из пула соединения (если это возможно) или иначе создает новое соединение. Если процессор не может создать новое соединение из соединения соединения бассейна соединения, FlowFile будет направлятьсяfailure, Запись события и вернуться к способу.
Если соединение получается, процессор передает вызов.readМетод процесса процесса и передает входную систему. Запишите время и скорость передачи файлов передачи и файлы передачи. отgetProvenanceReporterМетод Получить репортер от процесса процесса и звонки на репортерsendМетод, сообщите о событии Отправления до проверенного проведения. Соединение вернется или добавится в пул соединения, в зависимости от того, аренду ли соединение из бассейна илиonTriggerМетод вновь создан.
Если есть проблема связи, соединение обычно прекращается, и соединение не возвращается (или добавлено) в пул соединения. Если есть проблема, когда данные отправляются на удаленный ресурс, желаемый способ обработки ошибки зависит от некоторых мер предосторожности. Если проблема связана с условием сети, FlowFile обычно маршрутируетfailureОтказ FlowFile не будет наказан, потому что данные не нужно иметь проблемы. противВвод данныхСлучай процессора отличается, мы обычно не звонимyieldProcessContext. Это связано с тем, что FlowFile не существует до того, как процессор может выполнять свою функцию в случае проглатывания. Однако для PUT Processor Manager DataFlow может выбрать маршрутизациюfailureК разным процессорам. Это позволяет использовать систему «резервного копирования» в случае системы или может использоваться для назначения нагрузки в нескольких системах.
Если есть проблема с данными, следует предпринять один метод. Во-первых, если проблема может быть разрешена, FlowFile будет наказан, то маршрут кfailureОтказ Например, при использовании PutFTP FlowFile не может быть передан из-за конфликтов именования файлов. Предположим, что это в конечном итоге удалит файл из каталога, чтобы новые файлы могли быть переданы. Поэтому мы будем наказать flowfile и маршрутfailureМы попробуем еще раз позже. В другом случае, если есть практическая задача (например, данные не соответствуют определенным требованиям), могут быть использованы разные методы. В этом случае будетfailureРазложение отношений являетсяfailureИ может быть благоприятнымcommunications failureотношение. Это позволяет менеджеру DataFlow определить, как эти ситуации обрабатываются отдельно. В этих случаях разница между двумя отношениями хорошо записана, разъясняя его в «описании», когда отношения созданы.
Подключение к удаленной системе удалена, а соединительный пул закрыт в методе комментария,@OnStoppedДля того, чтобы переработать ресурсы.
Контент-маршрут (один к одному)Route Based on Content (One-to-One)
Процессор данных маршрутизации контента будет одним из следующих двух форм: маршрут входящего потока — это просто цель, либо направляет входящие данные на 0 или более. Здесь мы обсудим первый случай.
Этот процессор имеет два отношения:matchedс участиемunmatchedОтказ Если требуется определенный формат данных, процессор также будет иметьfailureОтношения, используемые, когда вход не ожидается. Процессор раскрывает атрибут, указывающий стандарт маршрутизации.
Если атрибут указанной маршрутизации требует обработки (например, составление регулярного выражения), этот процесс будет завершен в методе подхода.@OnScheduled,если возможно. Затем результат сохраняется в отмеченной переменной элементаvolatile。
ДолженonTriggerМетоды получают один расценок. Этот метод считывает содержание Flusfile через метод процесса процесса.readОцените условия совпадения во время передачи потока передачи данных. Затем процессор определяет, что FlowFile должен быть направлен.matchedвсе ещеunmatchedНа основании того, соответствуют ли условия и направляют FlowFile в соответствующие отношения.
Затем процессор выдает событийное событие, указывающее, какие отношения направляются процессором.
Этот процессор использует комментарий в пакете@SideEffectFreeс участием @SupportsBatchingКомментарийorg.apache.nifi.annotations.behavior。
Маршрутизация на основе контента (один для более)Route Based on Content (One-to-Many)
Если процессор маршрутирует один разъем для возможного количества взаимоотношений, этот процессор будет немного отличаться от процессора данных на основе содержимого маршрутизации. Этот процессор обычно динамически определяется пользователемunmatchedОтношения и отношения.
Для того, чтобы использовать домохозяйство для определения свойств,getSupportedDynamicPropertyDescriptorЭтот метод должен быть переписан. Этот метод возвращает PropertyDescriptor с прилагаемым именем и применимым валидатором, чтобы убедиться, что пользователь, указанный пользователем, является действительным.
В этом процессоре,getRelationshipsМетод Возвращает набор отношений — это изменяемая переменная участникаvolatileОтказ Этот набор был первоначально построен как именованная связьunmatched。onPropertyModifiedПеремотание этого метода для создания новых отношений с тем же именем при добавлении или удалении атрибутов. Если процессор имеет не пользовательский атрибут, проверьте, является ли указанный атрибут очень важен для определенного пользователем. Это может быть реализовано по вызовуisDynamicPropertyDescriptor для передачи в этот метод. Если это свойство динамично, набор новых отношений создан и скопирован на него предыдущий набор отношений. Этот новый набор либо добавляет вновь созданные отношения, либо удаляйте его, в зависимости от того, добавляется ли новый атрибут в процессор или удалить свойство (проверяя третий параметр этой функции), чтобы обнаружить удаление атрибутаnull). Затем обновите переменные элемента, которые содержат «отношения», чтобы указать на этот новый набор.
Если свойство указанного маршрутизации требует обработки (например, составление регулярного выражения), этот процесс будет завершен в методе использования комментариев.@OnScheduled(если возможно). Затем результат сохраняется в отмеченной переменной элементаvolatileОтказ Эта переменная участника обычноMapТип ключа ТипRelationshipТип значения определяется результатом значения атрибута обработки.
ДолженonTriggerПодходgetМетод процесса получает flowfile. Если нет в наличии потока, верните его сейчас. В противном случае будет создан набор типов отношений. Этот метод считывает содержание Flusfile через метод процесса процесса.readКаждое состояние матча оценивается в передаче потока данных. Для любого состояния, которое соответствует, отношения, связанные с условием сопоставления, будут добавлены к «реляционному набору».
После прочтения содержимого FlowFile метод проверяет, если «набор отношений» пуст. Если это так, оригинальный FlowFile добавляет атрибут, чтобы указать, что он направляется в отношения и направляется.unmatchedОтказ Запишите эту информацию, выпустите мероприятие продвиганности, которое возвращается. Если размер набора равен 1, оригинальный FlowFile добавит атрибут, чтобы указать, как он направляется, и направляйте отношения, указанные в записи в наборе. Запишите эту информацию, выпустите событие продвиганности для FlowFile, который возвращается.
Если набор содержит несколько отношений, процессор создает копию FlowFile для каждого отношения, кроме. Это черезcloneМетод процесса выполняется. Нет необходимости сообщать о событии о происхождении клона, потому что структура будет справиться с этим вопросом. Оригинальный FlowFile и каждый клон направляются в соответствующие отношения, где атрибут указывает на имя отношений. Отправьте событие пропускания для каждого FlowFile. Запишите эту информацию, метод возвращается.
Этот процессор использует комментарий в пакете@SideEffectFreeс участием @SupportsBatchingКомментарийorg.apache.nifi.annotations.behavior。
Поток маршрутизации на основе содержимого (один для более)
Предыдущая предыдущая маршрутизация (однозначное) описания обеспечивают абстракцию очень мощных процессоров. Однако предполагает, что каждый FlowFile полностью напрашится к нулю или более отношениям. Если входящий формат данных является «поток» из множества различной информации, мы хотим отправлять разные части этого потока в разные отношения, что мне делать? Например, предположим, что мы хотим, чтобы процессор RouteCsv настроить несколько регулярных выражений. Если ряд в файле CSV совпадает с регулярным выражением, линия должна быть включена в расцепке выхода и отношения ассоциации. Если регулярное выражение связано с отношениями «HAP-ALLECS», соответствует 1000 строке в FlowFile, должен быть исходящий расцепщик для отношений «у« яблок », который содержит 1000 строк. Если различные регулярные выражения связаны с отношениями «у апельсинов», и регулярное выражение совпадает с 50 строками в расходе, должен быть исходящий расценок для отношений «у апельсинов», который содержит 50 строк. То есть расход приходит, два расходомерения вышли. Два расхода могут содержать некоторые из тех же текстовых линий в исходном расходе, или они могут быть совершенно разными. Это тип процессора, который мы обсудим в этом разделе.
Название этого процессора начинается с «маршрута» и заканчивается именем типа данных его маршрута. В нашем примере мы маршрутируем данные CSV, поэтому процессор называется RouteCsv. Этот процессор поддерживает динамические свойства. Каждый пользовательский атрибут имеет имя, которое отображает имя отношений. Значение свойства использует формат, необходимый для «критериев матча». В нашем примере значение атрибута должно быть действительным регулярным выражением.
Этот процессор поддерживает интерьерConcurrentMapГде ключ являетсяRelationshipТип значения зависит от формата согласования состояния. В нашем примере мы будем держать одинConcurrentMap<Relationship, Pattern>Отказ Этот процессор перезаписиonPropertyModifiedметод. Если новое значение (третий параметр), предоставленный для этого метода, является NULL, отношения, определенные именем (первым параметром), определяемым именем имени свойства (первым параметром), будут удалены из CONDURLENTMAP. В противном случае обрабатывайте новое значение (в нашем примере, позвонивPattern.compile(newValue)) Добавьте это значение в CONDURRENTMAP, где ключ снова указан именем атрибута по имени имени.
Этот процессор перезаписиcustomValidateметод. В этом методе он извлекает все свойстваValidationContextИ рассчитать количество динамических свойствDescriptors (по вызовамisDynamic()PropertyDescriptor). Если количество динамических свойствDescriptors равно 0, пользователь не добавил никаких отношений, поэтому процессор возвращаетValidationResultУказывает, что процессор недействителен, потому что он не добавляет отношения.
ПроцессорgetRelationshipsВозвращает все отношения, указанные пользователем при вызове его метода и вернутсяunmatchedотношение. Поскольку этот процессор должен прочитать и писать репозитории контента (это может быть относительно дорогим), если ожидается, что этот процессор будет использоваться для очень высокого объема данных, добавить позволяет пользователю указывать, полезны ли свойства. Свойства могут быть выгодными Отказ Они заботятся о данных, которые не соответствуют никаких сопоставленных стандартов.
onTriggerКогда вы называете этот метод, процессор получает FlowFile Via.ProcessSession.getОтказ Если нет доступных данных, возвращается процессор. В противном случае процессор создает одинMap<Relationship, FlowFile>Отказ Мы называем эту картуflowFileMapОтказ Процессор читает входящий FlowFile, вызываяProcessSession.readи предоставитьInputStreamCallbackОтказ В обратном вызове процессор читает первые данные от FlowFile. Затем процессор оценивает каждое условие матча в соответствии с этими данными. Если определенное условие (в нашем примере, регулярное выражение) соответствует, процессор получает от него.flowFileMapFlowFile, принадлежащий соответствующим отношениям. Если карта в этих отношениях не имеет flowfile, процессор создает новый FlowFile, вызывая.session.create(incomingFlowFile)Затем добавьте новый FlowFile наflowFileMapОтказ Затем процессор пишет этот блок, позвонив в FlowFilesession.append использоватьOutputStreamCallbackОтказ Из этого вывоза вы можете получить доступ к новому потоку PLACEFILE, поэтому мы можем записать данные на новый FlowFile. Тогда мы вернулись из OutdileamCallback. После пересечения каждого состояния матча, если они не совпадают, мыunmatchedОтношения выполняются с одинаковыми процедурами, как описано выше (если пользователь не настраивается настраиваемым, чтобы не соответствовать несоответствующим данным). Теперь мы позвонилиsession.appendУ нас есть новая версия FlowFile. Поэтому нам нужно обновить насflowFileMapСвязать отношения с новым потоком.
Если вы бросаете исключение в любое время, нам нужно будет направить входящий FlowFile.failureОтказ Нам также необходимо удалить каждый вновь созданный FlowFiles, потому что мы не будем передавать их в любом месте. Мы можем сделать это, позвонивsession.remove(flowFileMap.values())Отказ На данный момент мы будем записывать ошибки и возвращение.
В противном случае, если все успешно, мы теперь можем повторитьflowFileMapИ перенести каждый FlowFile в соответствующие отношения. Затем удалите оригинальный FlowFile или маршрут егоoriginalотношение. Для каждого вновь созданных FlowFiles мы также выпустим событие провидец маршрута, указывающее, какие отношения направлены. Также полезно включать, сколько информации содержится в этом FlowFile в деталях события маршрута. Это делает Manager DataFlow легко просматривать каждую связь для каждой связи с FlowFile при просмотре представления Lineage Flanege.
Кроме того, некоторые процессоры могут потребовать «пакет» для отправки данных для каждой связи для передачи на каждый FlowFile отношений имеет одинаковое значение. В нашем примере мы можем пожелать разрешить регулярные выражения иметь захватывающие группы, и если две разные линии в CSV соответствуют регулярному выражению, но группа Capture имеет разные значения, мы хотим добавить их в два разных FlowFiles. Затем вы можете добавить значение соответствия в качестве атрибута каждому FlowFile. Это может быть реализовано путем модификацииflowFileMapСделать его определенным какMap<Relationship, Map<T, FlowFile>>среди нихTТип группировки функция (в нашем примере, группа будет однаStringПотому что это результат оценки группы захвата регулярного выражения).
Основные свойства маршрута (Route Based on Attributes)
Процессор почти такой же, как вышеописанные данные маршрутизации на основе процессора контента. Он использует две разные формы: один-к одному и однозначному, то же самое верно для процессоров маршрутизации. Тем не менее, этот процессор не вызывает процессаreadМетод, потому что он не читает содержимое FlowFile. Этот процессор обычно очень быстро, так@SupportsBatchingЭто очень важно в этом случае.
Разделение контента (один ко многим)
Этот процессор обычно не требует конфигурации пользователя, кроме каждого разделения для создания. ДолженonTriggerМетоды получают FlowFile от его входной очереди. Создайте список типа FlowFile. С процессорамиreadСпособ считывает оригинальный FlowFile и использует InputStreamCallback. В InputstreamCallback прочитайте контент до тех пор, пока поток FlowFile должен быть разделен. Если вам не нужно разделять, вернуть обратный вызов и направить оригинальный FlowFile наsuccessОтказ В этом случае будет выпущено событие провидец. Обычно событие маршрута не будет выдано, когда маршрут FlowFilesuccessПоскольку это будет производить очень длинную кровь, становится трудно перемещаться. Однако в этом случае событие полезно, потому что иначе мы ожидаем, что событие Fork, и никаких событий не может вызвать путаницу. Тот факт, что FlowFile не разделен, но передаетсяsuccessИ вернуть этот метод.
Если вы достигнете точны, вам нужно разделить FlowFile, пропустите процессинговую контролюcreate(FlowFile)Метод илиclone(FlowFile, long, long)Метод создает новый FlowFile. Следующая часть кода зависит отcreateИспользовать этоcloneМетод все еще используется. Два метода следующие. Необходимо определить, какой раствор уместен в зависимости от конкретной ситуации.
Создание метода является наиболее подходящим, когда данные не могут быть скопированы непосредственно из исходного FlowFile на новый FlowFile. Например, этот метод требуется, если вы только изменяете данные каким-то образом, прежде чем копировать некоторые данные или перед копированием на новый FlowFile. Однако, если содержание нового FlowFile будет точной копией исходного расходомера, метод клонирования является более предпочтительным.
Метод созданияЕсли вы используете егоcreateМетод, метод называется используя оригинальный FlowFile в качестве параметра, так что вновь созданный FlowFile наследует оригинальные свойства FlowFile, а каркас создаст событие Forks Fork.
Тогда код входит в одинtry/finallyКусок. вfinallyВ блоке вновь созданный FlowFile будет добавлен в список созданных FlowFile. Это в одномfinallyБлок завершен, поэтому, если вы бросаете исключение, вы правильно очистите вновь созданный FlowFile. вtryВ блоке, пропуск обратного вызоваwriteИспользуйте OutdureStreamcallback, чтобы вызвать метод процесса, чтобы начать новый обратный вызов. Затем соответствующие данные скопированы с исходного потока ввода потока к новому потоковому потоку.
Метод клонированияЕсли вновь созданный FlowFile является просто непрерывным подмножеством исходных байтов FlowFile, лучше всего использовать его.clone(FlowFile, long, long)Способ, а неcreate(FlowFile)Метод процесса. В этом случае смещение исходного FLWOFILE, чье новое содержимое FlowFile должно начинаться, будет передаваться в качестве второго параметра метода.cloneОтказ Длина нового FlowFile передается в качестве третьего параметра методаcloneОтказ Например, если оригинальный FlowFile составляет 10 000 байтов, и мы называемclone(flowFile, 500, 100)Тогда вернуться к нашему потоку будетflowFileО его свойствах. Тем не менее, содержание вновь созданного FlowFile составляет 100 байтов, и начнется с компенсации 500 оригинального FlowFile. То есть содержание вновь созданного FlowFile является таким же, как содержимое байтов от 500 до 599, вы копируете оригинальный FlowFile.
После создания клона он будет добавлен в список FlowFiles.
В применимо, этот метод более популярен, чем метод создания, потому что ни один диск ввода / вывода. Эта структура может просто создать новый FlowFile, который ссылается на подмножество исходного содержания FLECFILE, на самом деле не реплицирующих данные. Однако, это не всегда возможно. Например, этот метод недоступен, если вы должны скопировать информацию о заголовке с самого начала исходного потока и добавить его в начало каждого разделения.
Два методаБудь то использование метода клонирования или метода создания, применим следующий контент:
Если какой-либо точка в Inpossstreamcallback, условие, которое не может продолжать обработку (например, ошибка формата ввода).ProcessExceptionЗатем бросьте. ПроцедностьreadВызов метода включен в один захваченный.try/catchБлокироватьProcessExceptionОтказ Если вы захватите исключение, создается сообщение журнала для объяснения. Принимать процессоруremoveМетод удаляет вновь созданные списку FlowFiles. Оригинальный FlowFile направляетсяfailure。
Если нет проблем, по маршруту оригинальный FlowFile,originalИ обновите все вновь созданные FlowFiles, чтобы включить следующие свойства:
| Имя атрибута | описание |
|---|---|
|
|
Оригинальный FlowFile UUID |
|
|
Одно число, что означает, какой FlowFile в списке (первый созданный FlowFile будет стоить |
|
|
Общее количество разделенных разделенных расходов |
Вновь созданные FlowFiles распадаютсяsuccessЗапишите это событие; и метод возвращается.
Согласно атрибуту обновления контента
Этот процессор очень похож на обсуждаемый выше процессор Content Processor. Вместо расщепления расходованияmatchedили жеunmatchedFlowFile обычно маршрутsuccessили жеfailureДобавьте атрибут в FlowFile. Конфигурация добавления свойств аналогична маршрутизации на основе содержимого (однозначное), и пользователь может определить его собственные свойства. Имя атрибута указывает на имя добавления атрибута. Значение свойства указывает на некоторые условия сопоставления, которые будут применяться к данным. Если условие соответствия совпадает с данными, добавьте имя, которое совпадает с свойством свойств. Значение собственности — это условие соответствия контента.
Например, процессор для оценки выражений XPath может разрешить пользовательское XPath. Если XPath соответствует содержанию FlowFile, FlowFile добавит атрибут, что имя равно имени имени имени свойства, и это значение равно текстовому содержанию элемента XML или атрибута, который соответствует XPath.failureЭти отношения будут использоваться, если входящий в этот пример FlowFile в этом примере не является действительным XML.successЭти отношения будут использоваться независимо от того, найден ли какой-либо матч. Затем вы можете использовать его для маршрута FlowFile в подходящее время.
Этот процессор выдает исходное событие для атрибутов_Модифицированных.
Богатый / модифицированный контент
Обогащенная / изменить режим контента очень распространен и очень распространен. Этот режим отвечает за любой общий модификацию контента. Для большинства случаев этот процессор помечен@SideEffectFreeс участием@SupportsBatchingКомментарий. Процессор имеет любое количество основных свойств и необязательных свойств, в зависимости от функциональности процессора. Процессор обычно имеетsuccessс участиемfailureотношение.failureЭти отношения обычно используются, когда входной файл не ожидается.
Этот процессор получает flowfile и использует процессируюwrite(StreamCallback)Метод обновляет его, чтобы он мог прочитать и написать следующую версию содержимого FlowFile из содержимого FlowFile. Если вы столкнулись с ошибкой во время обратного вызова, обратный вызов броситProcessExceptionОтказ ПроцедностьwriteВызов включен в одинtry/catchВ блоке, запечатлевает блокProcessExceptionИ направить FlowFile, чтобы провалиться.
Если обратный вызов успешным, будет выдан событие «Content_Modified».
Обработка ошибок
Несколько различных аварий могут возникнуть при написании процессоров. Если сам процессор не обрабатывает ошибку, разработчик процессора должен понимать, как работает структура NiFi, и важно понимать ожидаемую ошибку обработки процессора. Здесь мы обсудим, как процессор обрабатывает неожиданные ошибки во время работы.
Исключения в процессоре
ИсполнительныйonTriggerМногие вещи могут быть неправы во время метода процессора. Общие неисправности включают в себя:
-
Входящие данные не ожидаются.
-
Сетевое соединение с внешними службами не удалось.
-
Чтение или запись данных диска не удалась.
-
В процессоре или ведомой библиотеке происходит ошибка.
Любое из этих условий может привести к исключению из процессора. С точки зрения рамки, есть два типа исключений для бегающих процессоров:ProcessExceptionИ все остальные типы исключений.
Если вы бросаете ProcessException от процессора, структура предполагает, что это известный отказ результата. Кроме того, условие, которое пытается снова обработать данные позже, может быть успешным. Следовательно, кадр откатится обратно к обработке сеанса, и наказуемое обрабатывается FlowFiles.
Однако, если какое-либо другое исключение необходимо, структура предполагает, что это неудача, что разработчик не рассмотрел. В этом случае кадр также откатится за сеансом и наказывает расходы. Однако в этом случае мы можем ввести некоторые очень проблемные случаи. Например, процессор может находиться в плохом состоянии и может продолжать работать, истощение системных ресурсов, без какой-либо полезной работы. Это довольно распространено, например, при броске NullPointerException непрерывно. Чтобы избежать этого, если исключение, отличное от ProcessException, может избежать процессораonTriggerМетоды, структура также генерирует процессор. Это означает, что процессор не будет запущен, а затем выполняется некоторое время. Количество времениnifi.propertiesКонфигурация в файле, но по умолчанию 10 секунд.
Ненормальность в обратном вызове: IOException, Runtimeexception
В целом, когда происходит исключение в процессоре, это происходит из обратного вызова (IE,InputStreamCallback,OutputStreamCallback,или жеStreamCallback). То есть при обработке содержания потока. Обратный вызов разрешено броситьRuntimeExceptionили жеIOExceptionОтказ В случае runtimeexception это исключение будет распространять обратноonTriggerметод. В случаеIOExceptionИсключение будет упаковано в ProcessException, а затем бросила этот процесс процесс из карки.
По этой причине рекомендуется использовать процессор обратного вызова в одном.try/catchВыполните в блоке и зафиксируйте обратный вызов к ожидаемому обратным вызовамProcessExceptionЛюбой другой процессорRuntimeExceptionОтказ но,НеРекомендуется, чтобы процессор собирал общийExceptionили жеThrowableДело. Это не поощряется из-за двух причин.
Во-первых, если вы бросили неожиданное runtimeexception, это может быть ошибкой и позволить контрремую задницу убедиться, что нет потери данных и убедиться, что менеджер данных Dataflow может обрабатывать данные о данных, которые они думают, сохраняя данные о очереди.
Во-вторых, когда ioException брошен из обратного вызова, есть два типа IOExceptions: те, которые выброшены из кода процессора (например, данные не ожидаются отказа от формата или сетевого соединения), а также оттуда. Репозиторий (где Расположение содержимого FlowFile) хранится. Если это последний случай, рамка будет захватывать эту IOException и упаковывать его в одинFlowFileAccessExceptionРасширениеRuntimeExceptionОтказ Это сделано четко, поэтому исключение будет сбежатьonTriggerМетоды, структура может правильно обрабатывать это условие. Захват рутинных исключений предотвращает это.
Penalization vs. Yielding
Когда во время обработки возникает проблема, структура раскрывает два метода, позволяя разработчикам процессора избежать ненужных работ: «Наказание» и «Урожай». Эти две концепции могут быть запутаны для разработчиков, которые только что связались с apis nifi. Разработчики могут наказать flowfile, позвонивpenalize(FlowFile)Метод процесса. Это приводит к тому, что сам FlowFile не может получить доступ к процессору вниз по течению в течение определенного периода времени. FlowFile недоступен Manager DataFlow, устанавливая настройку длительности пенальти в диалоговом окне «Конфигурация процессора». По умолчанию 30 секунд. Как правило, это делается, когда процессор определяет из-за ожидаемых экологических причин для сортировки и не может обработать данные. Хорошим примером является процессор PuTSFTP. Если есть файл с тем же именем файла на сервере SFTP, он накажет FlowFile. В этом случае процессор накажет FlowFile и маршрут его, чтобы провалиться. Затем Manager Dataflow может поставить путь неисправностей обратно в тот же процессор PutSFTP. Таким образом, если файл имеет одно и то же имя файла, процессор снова не пытается отправить файл в течение 30 секунд (или любой период времени, используемый процессором конфигурации DFM). В то же время он может продолжать устранять другие FlowFiles.
С другой стороны, разработчики процессора разрешаются указывать на то, что он не будет выполнять никаких полезных функций в течение определенного периода времени. Это обычно происходит на процессоре, сообщающемся с удаленным ресурсом. Если процессор не может подключиться к удаленному ресурсу, или если удаленный ресурс должен предоставить данные, но отчет о нем, процессор должен вызыватьyieldДолженProcessContextТогда объекты возвращаются. При этом процессор говорит о структуре, что она не должна тратить ресурсы для запуска этого процессора для запуска, потому что он ничего не может сделать — лучше всего использовать эти ресурсы, чтобы другие процессоры могли работать.
Откат сессии (Session Rollback )
До сих пор, когда мы обсудимProcessSessionВне время мы обычно называем механизм доступа к расходу. Однако он обеспечивает еще одну очень важный характер, а именно транзакцию. Все методы, вызванные процессами, принимаются в качестве транзакций. Когда мы решили завершить транзакцию, мы можем позвонитьcommit()Или по телефонуrollback()Отказ Обычно этоAbstractProcessorОбработка класса: еслиonTriggerМетод бросает исключение, абстрактныйПроцессор будет захватывать аномальность, звонитьsession.rollback()Затем разрешите аномалии. В противном случае абстрактныйПроцессор позвонитcommit()ProcessSession。
Однако иногда разработчики захотят явные откаты. Это можно назватьrollback()или жеrollback(boolean)Способ выполняется в любое время. Если вы используете последнее, логическое значение представляет эти расходы, извлеченные из очереди (через процессиюgetМетоды должны быть наказаны перед добавлением обратных очередей.
когдаrollbackПри вызове, любые модификации, которые происходят на этом сеансе, будут отброшены, чтобы включить как модификации содержимого, так и модификации атрибутов. Кроме того, все виды событий возвращаются обратно (снаружи любые события отправки, передаваемые, создавая значения)trueизforceпараметр). FlowFile, извлеченный из очереди ввода, затем передается обратно к входной очереди (и, необязательно, наказывается), чтобы они могли быть обработаны снова.
С другой стороны, когдаcommitПри вызове этого метода новое состояние FlowFile останется в репозитории FlowFile и любая пройден в репозитории FLAVENTS. Предыдущее содержимое уничтожено (если иные не ссылаются на то же содержание), и FlowFiles передается в выходную очередь, чтобы следующий процессор мог работать.
Обращать вниманиеorg.apache.nifi.annotations.behavior.SupportsBatchingОбратите внимание, как повлиять на это поведение также важно. Если процессор использует этот комментарий, позвонитеProcessSession.commitМожет не вступить в силу немедленно. Вместо этого эти представления могут быть партии вместе, чтобы обеспечить более высокую пропускную способность. Однако, если процессор спирает обратно к процессам в любое время, все изменения с момента последнего вызоваcommitВсе будут выброшены, все «пакетные» представление вступит в силу. Эти «объемные» представление не откатится.
Общие соображения дизайна ( General Design Considerations )
Некоторые важные конструкции требуются при проектировании процессоров. Этот раздел руководства разработчика поставит некоторые идеи, что разработчики должны рассмотреть при создании процессора.
Подумайте о пользователях (Consider the User)
Одной из самых важных концепций, которые необходимо помнить при разработке процессора (или любого другого компонента), является опытом пользователя, который вы создаете. Важно помнить, что как разработчик такого компонента, у вас может быть важное понимание контекста, которое у других нет. Документ всегда должен быть предоставлен так, чтобы люди, которые не знакомы с процессом, могут легко использовать его.
При рассмотрении пользовательского опыта важно обратить внимание на последовательность. Лучше всего придерживаться стандартаСоглашение об именахОтказ Это относится к именам процессоров, имена атрибутов и значений, имена отношений, и любой другой аспект пользователю будет испытывать.
Просто критично! Избегайте добавления свойств, которые вы не хотите, чтобы пользователи понять или изменились. Как разработчик, нам сказали, что жесткое закодированное значение было очень плохим. Но это иногда приводит к воздействию разработчика, а когда требуется уточнить, сообщить пользователю только зарезервировать значение по умолчанию. Это приводит к путанице и сложности.
Сплоченность и повторное использованиеCohesion and Reusability)
Чтобы сделать один, сплоченный блок, разработчик иногда пытается объединить несколько функций в один процессор. Корпус корпуса процессора может быть преобразован в формат y и отправлять данные в формат y и отправлять новые отформатированные данные в определенные внешние службы, случай верно.
Этот метод форматирует данные определенных конечных точек, а затем отправляет данные в конечную точку в том же процессоре.
-
Процессор становится очень сложным, поскольку он должен выполнять задачи преобразования данных и отправлять данные на удаленный сервис.
-
Если процессор не может взаимодействовать с удаленным обслуживанием, он будет направлять данные в
failureотношение. В этом случае процессор будет отвечать за выполнение конвертации данных снова. Если он снова потерпит неудачу, перевод снова завершен. -
Если у нас есть пять разных процессоров для преобразования входящих данных в этот новый формат перед передачей данных, то у нас будет большое количество дубликата кода. Например, если схема меняется, вы должны обновить много процессоров.
-
Эти промежуточные данные будут отброшены, когда процессор отправляется на удаленный сервис. Формат промежуточного данных может быть полезен для других процессоров.
Чтобы избежать этих проблем, и сделать процессор более многоразовой, процессор должен всегда придерживаться принципа «сделать одно, делать хорошо». Такой процессор должен быть разделен на два отдельных процессора: процессор преобразуется из формата X в формат y, а другой процессор используется для отправки данных на удаленный ресурс.
Соглашение об именованииNaming Conventions)
Для того, чтобы обеспечить последовательный внешний вид, рекомендуется соблюдать стандартную конвенцию именования. Ниже приведен стандартный список конвенций:
-
Процессор извлечения данных из удаленной системы является GET <SERVICE> или GET <Protocol>, в зависимости от того, могут ли они опросить данные из любого источника через известного протокола (например, gethttp или getftp), или они извлечены из известных услуг Данные (такие как getkafka)
-
Нажмите данные на процессор удаленной системы, называется PUT <SERVICE> или поставить <протокол>.
-
Название отношений низкое и использует пробелы для описания слов.
-
Имена атрибутов заглавные важные слова, как имена книги.
Процессор по поведению процессора (Processor Behavior Annotations)
При создании процессора разработчик может обеспечить приглашение кадра с тем, как использовать процессор. Это делается путем применения комментариев к классу процессора. Аннотация, которую можно применять к процессору, существует в трех подскакающих.org.apache.nifi.annotationsОтказ Те, кто вdocumentationПодклюки используются для предоставления документации пользователю.lifecycleРамы у индикации в субкалях должны вызывать, какие методы должны быть вызваны процессором для реагирования на соответствующее событие жизненного цикла.behaviorСредства справки в пакете понимают, как взаимодействовать с процессорами с точки зрения планирования и общего поведения.
org.apache.nifi.annotations.behaviorСледующие комментарии в пакете могут быть использованы для изменения способа обработки рамок:
-
EventDriven: Указывает на каркас планировщика политики планирования, который может использовать график, ориентированный на событие. Эта стратегия все еще находится в тестовой фазе, но может привести к снижению использования ресурсов потоков данных, и эти потоки данных не могут обрабатывать чрезвычайно высокие скорости передачи данных. -
SideEffectFree: Указывает, что процессор не имеет никаких побочных эффектов за пределами NiFi. Следовательно, кадр может использовать один и тот же вход несколько раз, чтобы вызвать процессор, не вызывая никаких неожиданных результатов. Это означает, что власть и другие действия. Рамка может использовать его для повышения эффективности, выполняя такие операции, как передача процессингов от одного процессора в другую, если есть проблема, операция многих процессоров может быть возвращена и выполнена снова. -
SupportsBatching: Этот комментарий указывает, что структура может представить несколько процессингов, представленных в единое представление. Если этот комментарий существует, пользователь сможет выбрать, предпочитает ли высокую пропускную способность или более низкую задержку в вкладке «Планирование процессора». Этот комментарий должен применяться для большинства процессоров, но он имеет предупреждение: если процессор вызываетProcessSession.commitТем не менее, невозможно обеспечить, чтобы данные надежно хранятся в содержании NiFi, FlowFile и Flowsence. Следовательно, он не подходит для приема данных, отправки сеанса, а затем удаляя процессор с использованием удаленного ресурса, подтверждающей транзакцию из внешнего источника. -
TriggerSerially: Когда этот комментарий, кадр не позволит пользователю запланировать несколько одновременных потоков один раз для его выполнения.onTriggerметод. Вместо этого количество потоков («одновременная задача») всегда будет установлено значение1Отказ ЭтотНетТем не менее, это означает, что процессор не должен быть нитью, потому что это нить, которая выполняется.onTriggerТам могут измениться между звонками. -
PrimaryNodeOnly: Apache NiFi предоставляет два режима исполнения для процессора в кластере: «Основной узел» и «все узлы». Хотя лучшие параллелизм могут быть предоставлены во всех узлах, некоторые процессоры, как известно, запускают неожиданное поведение при работе в нескольких узлах. Например, некоторые процессоры в списке или чтение файлов в удаленных файловых системах. Если вы планируете запустить этот тип процессора на всех узлах, он приведет к ненужным повторению или даже ошибкам. Этот тип процессора должен использовать этот комментарий. Применение этой аннотации ограничит процессор ограничения только на «главный узел». -
TriggerWhenAnyDestinationAvailable: По умолчанию, если какая-либо выходная очередь заполнена, NIFI не будет организовать процессор для запуска. Это позволяет наносить давление на обратную связь с процессорной цепью. Однако даже один из исходящих очередей заполнен, некоторые процессоры также могут потребоваться выполнить. Эта примечание указывает на то, что процессор должен быть запущен, если любые отношения будут «доступны». Если соединение не используется, отношения «доступны». Например, процессор распределения использует эту аннотацию. Если вы используете политику планирования «петлей», если какая-либо выходная очередь заполнена, процессор не будет запущен. Однако, если вы используете «следующую доступную» политику планирования, -
TriggerWhenEmpty: Поведение по умолчанию предназначено для запуска процессора, когда есть как минимум один столблок или процессор без входной очереди (это типичный «исходный» процессор). Применение этой аннотации приведет к тому, что структура игнорирует размер входной очереди и вызвать процессор независимо от того, есть ли какие-либо данные в очереди ввода. Это полезно, если вам нужно запускать процессор для периодической работы к сетевым соединениям времени. -
InputRequirement: По умолчанию все процессоры позволят пользователям создавать входящие соединения для процессора, но если пользователь не создает входящее соединение, процессор все еще действует и может быть запланирован. Однако для ожидаемого процессора, используемого в качестве «исходного процессора», это может заставить пользователю чувствовать себя смущенным, и пользователь может попытаться отправить FlowFiles к процессору, только для очередей FlowFiles без обработки. И наоборот, если ожидается, что процессор будет входящим расходомерам, но не входит в очередь, процессор будет запланирован запущен, но не выполняется никакой задания, поскольку он не будет получать Flusfile, который также приведет к путанице. Итак, мы можем использовать@InputRequirementПримечание и дайте значение для негоINPUT_REQUIRED,INPUT_ALLOWEDили жеINPUT_FORBIDDENОтказ Это содержит информацию о том, когда структура недействительна, или должен ли пользователь даже нарисовать подключение к процессору. Например, если используется комментарий процессорInputRequirement(Requirement.INPUT_FORBIDDEN)Пользователь может даже создать соединение с процессором в качестве цели.
Буфер данных (Data Buffering)
Необходимо помнить, что NiFi обеспечивает общую обработку данных. Данные могут быть любым форматом. Процессор обычно имеет несколько потоков. Распространенная ошибка, сделанная разработчиками к NiFi, заключается в буфере все содержимое flowfile в память. Хотя некоторые случаи должны делать это, следует избегать как можно больше, если формат известных данных не является. Например, процессор, ответственный за выполнение XPath на XML-документе, требует загрузки всего содержимого данных в память. Обычно это приемлемо, потому что XML, как ожидается, будет очень большим. Однако процессор, поиск определенной байтовой последовательности, может использоваться для поиска сотен гигабайт или более файлов.
Он не встроен в память, но рекомендуется оценить данные (т. Е. Сканирование) при передаче потоковых от хранения контента.InputStreamОбеспечить контент обратного вызоваProcessSession.read). Конечно, в этом случае мы не хотим читать каждый байт из репозитория контента, поэтому мы будем использовать буферинпуфнуть по течению или буферизировать несколько небольших данных в зависимости от ситуации.
Услуги контроллера (Controller Services)
ДолженControllerServiceИнтерфейс позволяет разработчикам обмениваться функциями и статусом на JVM чистым, последовательным образом. Этот интерфейс похож наProcessorИнтерфейсный интерфейс, но нетonTriggerМетоды, поскольку службы контроллера не запланированы на регулярные работы, а сервисы контроллера не имеют значения, потому что они не интегрированы в поток. Вместо этого они используются процессорами, отчетными задачами и другими службами контроллера.
Разработать контроллерное обслуживание
Как и интерфейс процессора, интерфейс контроллеров, развернут метод настройки, проверки и инициализации. Эти методы взаимосвязаны с процессоромinitializeМетод такой же, но метод должен пройтиControllerServiceInitializationContextНеProcessorInitializationContext。
Услуга контроллера поставляется с дополнительным ограничением, которое не имеет ничего общего. Услуги контроллера должны включать расширенные интерфейсыControllerServiceОтказ Затем реализация может взаимодействовать только через его интерфейс. Например, процессор никогда не будет настроен с помощью контроллеров, поэтому вы должны ссылаться только только путем расширенного интерфейса.ControllerService。
Это ограничение в основном потому, что процессор может существовать в архиве NiFi (Nar), а также реализация службы контроллера, в которой находится процессор, может существовать в разных нарах. Это достигается с помощью интерфейса динамической реализации Framework, каркас может переключаться на соответствующий классный загрузчик, а требуемый метод измеряется по конкретной реализации. Однако для того, чтобы сделать его работы, реализация обслуживания процессоров и контроллеров должна делиться одно и то же определение интерфейса службы контроллера. Следовательно, эти два нара должны полагаться на NARS, содержащие интерфейс службы контроллера. Для получения дополнительной информации см.NiFi Archives(NAR)。
Взаимодействие с контролем
Контрольные сервисы могут с помощью контроллеровidentifiesControllerServiceСпособ класса Builder для PropertyDescriptor получается процессором, другим контроллером или репортажем. ControlerReviceLookup может быть передан от процессора к этомуinitializeПроцессоринициализацияContext получен. Аналогичным образом, он получается из контроллерногоерсерВице от контроллерногенерациониализацииContext, но также передается от ReportingTaskinitializeПолучается метод объекта ReportingConfiguration.
Однако для большинства случаев используйтеidentifiesControllerServiceСпособ построителя PropertyDescriptor является первым выбором и является наименее сложным методом. Чтобы использовать этот метод, мы создали свой собственный объект, который ссылается на службу контроллера:
public static final PropertyDescriptor SSL_CONTEXT_SERVICE = new PropertyDescriptor.Builder()
.name("SSL Context Service")
.description("Specified the SSL Context Service that can be used to create secure connections")
.required(true)
.identifiesControllerService(SSLContextService.class)
.build();Используя этот метод, вы предложите пользователю предоставить службу контекста SSL, которая должна использоваться. Это делается, предоставляя пользователя раскрывающемуся меню, они могут выбрать любую конфигурированную конфигурацию SSLContExtservice, независимо от того, как она реализована.
Чтобы использовать эту услугу, процессор может использовать следующий код:
final SSLContextService sslContextService = context.getProperty(SSL_CONTEXT_SERVICE)
.asControllerService(SSLContextService.class);
Обратите внимание, что этоSSLContextServiceЭто интерфейс для расширения контроллера. Единственная реализация в настоящее времяStandardSSLContextServiceОтказ Тем не менее, разработчики процессора не должны беспокоиться об этой детализации.
Задача отчета
До сих пор мы мало упоминали о том, как общаться NiFi и его компоненты во внешнем мире. Может ли система продолжать входящую скорость передачи данных? Сколько может работать система еще? Сколько данных касается наименее напряженного времени в течение дня?
Для того, чтобы ответить на эти вопросы и больше, NIFI обеспечиваетReportingTaskИнтерфейс — это функция состояния отчетности, статистики, показателям и мониторинге информации для внешнего сервиса. ReportingTasks может получить доступ к большому количеству информации, чтобы определить, как работает система.
Доклад о разработке Задача
Как и интерфейс процессора и контроллеров, интерфейс ReportingTask раскрывает способ настройки, проверки и инициализации. Эти методы взаимосвязаны с процессором и контролем.initializeМетод такой же, за исключением того, что метод передаетсяReportingConfigurationОбъекты, а не объекты инициализации, полученные другими компонентами. ReportingTask имеет одинonTriggerСпособ вызова кадра используется для запуска задачи для выполнения своих задач.
В этомonTriggerВ способе ReportingTask уполномочен доступ к ReportingContext, который может получить конфигурацию и информацию о экземплярах NIFI. BullEtineRepositor позволяет объявлениям запроса и позволяет ReportingTask отправлять свои собственные объявления для представления пользователей. Доступ к контроллерному обслуживанию ControllerserVicelookup может получить доступ к контрольному контексту. Доступ к контексту. Доступ к настроенным контроллерам. Однако этот метод получения сервисов контроллера не является предпочтительным методом. И наоборот, предпочтительный способ получения службы контроллера — ссылаться на службу контроллера в PropertyDescriptor, напримерВзаимодействие с контролемЧасть описана в разделе.
EventAccessДоступ к этому объекту через объект, раскрытый ReportingContextProcessGroupStatusЭтот объект раскрывает статистику на объем данных, обработанных в течение последних пяти минут. Кроме того, объекты EventAccess предоставляют доступ к пронзенсу данных, хранящихся там.ProvenanceEventRepositoryОтказ Когда данные получают от внешнего источника, процессор выдает эти события исходных событий из системы от внешнего сервиса. Удалить, изменять или в соответствии с определенным маршрутом.
Каждый пронситель имеет идентификатор FlowFile, тип события, время создания события, и все свойства FlowFile, связанные с Flusfile, когда компонент доступа к Flusfile и свойство FlowFile, связанное с ним. FlowFile является результатом описанного процесса. Это обеспечивает много информации для ReportingTasks, что позволяет создавать отчеты в различных способах раскрытия показателей и функций мониторинга, необходимых для любой операции.
Расширение пользовательского интерфейса
В NiFi есть два расширения UI:
-
Пользовательский процессор UI.
-
Содержание Viewer
Пользовательские UIS могут быть созданы для предоставления параметров конфигурации, которые превышают стандартные таблицы свойств / стоимости, доступные в большинстве настроек процессора. Пример процессора с пользовательским интерфейсомUpdateAttributeс участиемJoltTransformJSON。
Вы можете создать просмотрщик содержимого для расширения типа данных, которые можно просмотреть в NIFI. NiFi поставляется с NAR в каталоге lib, который содержит Content Viewers типов данных, таких как CSV, XML, AVRO, JSON (Standard-Nar) и типы изображений, таких как PNG, JPEG и GIF (Media-Nar).
Пользовательский процессор UI.
Чтобы добавить пользовательский интерфейс до процессора:
-
Создайте свой интерфейс.
-
Создайте и связывайте войну в процессоре NAR.
-
Военная потребность
nifi-processor-configurationФайл включен в META-Reginity, который связывает пользовательский интерфейс с процессором. -
Поместите NAR в каталог lib, который будет обнаружен, когда начинается NIFI.
-
В окне «Процессор конфигурации» процессора вкладка «Свойства» теперь должна иметь один
AdvancedКнопка, кнопка будет доступ к пользовательскому интерфейсу.
Например, следующее является Nar Playout of UpdateAttribute:
Обновить атрибут NAR макет
nifi-update-attribute-bundle │ ├── nifi-update-attribute-model │ ├── nifi-update-attribute-nar │ ├── nifi-update-attribute-processor │ ├── nifi-update-attribute-ui │ ├── pom.xml │ └── src │ └── main │ ├── java │ ├── resources │ └── webapp │ └── css │ └── images │ └── js │ └── META-INF │ │ └── nifi-processor-configuration │ └── WEB-INF │ └── pom.xml
содержаниеnifi-processor-configurationследующим образом:
org.apache.nifi.processors.attributes.UpdateAttribute:${project.groupId}:nifi-update-attribute-nar:${project.version}
| Вы также можете настроить службы контроллера и задачи отчетности. |
Содержание Viewer
Чтобы добавить просмотрщик содержимого:
-
Создайте и связывайте войну в процессоре NAR.
-
Военная потребность
nifi-content-viewerФайл включен в каталог META-INF, который перечисляет поддерживаемые типы содержимого. -
Поместите NAR в каталог lib, который будет обнаружен, когда начинается NIFI.
-
Когда вы столкнулись с соответствующим типом содержимого, Viewer содержимого будет генерировать соответствующий вид.
Хорошим примером является NAR-макет стандартного просмотра контента:
Стандартный Content Viewer Nar Layout
nifi-standard-bundle │ ├── nifi-jolt-transform-json-ui │ ├── nifi-standard-content-viewer │ ├── pom.xml │ └── src │ └── main │ ├── java │ ├── resources │ └── webapp │ └── css │ └── META-INF │ │ └── nifi-content-viewer │ └── WEB-INF │ ├── nifi-standard-nar │ ├── nifi-standard-prioritizers │ ├── nifi-standard-processors │ ├── nifi-standard-reporting-tasks │ ├── nifi-standard-utils │ └── pom.xml
содержаниеnifi-content-viewerследующим образом:
application/xml application/json text/plain text/csv avro/binary application/avro-binary application/avro+binary
TLS-Toolkit.
Режим работы Client / Server поставляется из желаемой заготовки конфигурации TLS без необходимости выполнения генерируемых в централизованном месте. Это упрощает конфигурацию в кластерной среде. Поскольку мы не обязательно имеем центральное расположение логики генерации запуска или доверенного органа сертификата, используйте общий ключ для проверки клиента и сервера.
TLS-Toolkit использует HMAC для проверки открытого ключа сервера CA и CSR, отправленного клиентом для предотвращения промежуточных атак. Общий ключ (токен) используется в качестве ключа HMAC.
Основной процесс выглядит следующим образом:
-
Клиент генерирует keypair.
-
Клиент генерирует запрос на полезную нагрузку JSON, содержащую CSR и HMAC, где токен используется в качестве клавиша, отпечаток клавиши CSR в качестве данных.
-
Клиент подключен к файлу Hostname CA в указанном порте HTTPS и проверяет совпадение CA CN и CN и имя хоста CA (Примечание: потому что мы не доверяем CA, это увеличивает небезопасно, это просто способ, если возможно, ранняя ошибка).
-
Сервер использует токен в качестве ключа и использует отпечаток открытого ключа CSR в качестве данных и проверяет от клиента Payloads HMAC. Это доказывает, что клиент знает общий ключ и хочет подписать CSR с открытым ключом. (Примечание: средний человек может переслать эту функцию, но не может изменить CSR, не делая HMACS, чтобы цель невозможна).
-
Сервер подписывает CSR и отправляет ответную полезную нагрузку от ответа JSON, содержащую сертификат и отпечаток руки HMAC в качестве ключа в качестве ключа и его открытого ключа.
-
Клиент использует токен в качестве ключа и отпечаток открытого ключа сертификата, предоставленный сеансом TLS, проверяет ответ HMAC. Это подтверждает, что CA знает, что общий ключ — это ок от нашего разговора через TLS.
-
Клиент проверяет, подписан ли сертификат CA от сеанса TLS в полезной нагрузке.
-
Клиент добавляет сгенерированную клавиатуру к клавишему магазину с цепочкой сертификата и добавляет сертификат CA из соединения TLS с его доверительной библиотекой.
-
Клиент записывает конфигурацию JSON, которая включает в себя клавише, доверительный пароль и другие детали, связанные с Exchange.
контрольная работа
Компоненты, которые будут использоваться в более крупных каркасах, обычно очень хлопотно и хитрым. С NiFi мы стремимся сделать тестовые компоненты максимально простыми. С этой целью мы создали одинnifi-mockМодуль, который можно использовать в сочетании с JUNIT, чтобы обеспечить широкий тест компонентов.
Структура моделирования в основном используется для тестирования процессоров, поскольку они наиболее часто развиваемые точки расширения до сих пор. Однако структура обеспечивает возможность протестировать службу контроллера.
Поведение компонента обычно проверяется путем создания теста на функцию для проверки компонента. Это связано с тем, что процессор обычно состоит из нескольких вспомогательных методов, но логика в основном включена в основном.onTriggerМетод. ДолженTestRunnerИнтерфейс позволяет нам тестировать услуги процессора и контроллера, используя больше «необработанных» объектов, таких как файловые и байтовые массивы для FlowFiles, и обрабатывать процессорные процессы процессы для создания процессов и требуемого процессора процессора, и вызывают необходимый метод жизненного цикла, чтобы убедиться, что поведение процессора в модульном тесте одинаково в производстве.
Инструментарированный Testrunner
Большинство из модульных испытаний процессоров или служб контроллера создаютсяTestRunnerЭкземпляр начинается класс. Чтобы добавить необходимые классы в процессор, вы можете использовать зависимости Maven:
<dependency>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-mock</artifactId>
<version>${nifi version}</version>
</dependency>мыTestRunnerПозвонив статическимnewTestRunnerметодTestRunners(родыorg.apache.nifi.utilВ пакете) для создания нового. Эти методы обеспечивают параметр для измеряемого процессора (может быть классом процессора, который будет протестирован или пример процессора) и позволяет назвать процессору.
Добавить контрольные сервисы
После создания нового тестового бегуна мы можем добавить любые услуги контроллера нашему процессору для проверки времени выполнения для выполнения его работы. Мы называем этоaddControllerServiceСпособ также доступен для идентификатора службы контроллера и экземпляра службы контроллера для завершения этого.
Если служба контроллера должна быть настроена, его природа может быть установлена путем вызоваsetProperty(ControllerService, PropertyDescriptor, String),setProperty(ControllerService, String, String)или жеsetProperty(ControllerService, PropertyDescriptor, AllowableValue)метод. Каждый метод возвращает одинValidationResultОтказ Затем вы можете проверить этот объект, чтобы убедиться, что он действителен, вызывая это свойство.isValidОтказ Можно назватьsetAnnotationData(ControllerService, String)Способ установить данные аннотации.
Теперь мы можем убедиться, что служба контроллера действительна.assertValid(ControllerService)— Или, если вы используете тест сама служба контроля управления, убедитесь, что значение конфигурации недействительна.assertNotValid(ControllerService)。
После добавления службы контроллера на тестовый бегун и настройте его, теперь вы можете назвать этоenableControllerService(ControllerService)Способ включен. Если служба контроллера недействительна, этот метод бросит неtalucalStateException. В противном случае сервис теперь может быть использован.
Установите значение атрибута
После настройки любых необходимых служб контроллера нам нужно настроить наш процессор. Мы можем сделать это, позвонив так же, как услуги контроллера без необходимости указать любой сервис контроллера. То есть мы можем позвонитьsetProperty(PropertyDescriptor, String)и многое другое. КаждыйsetPropertyСпособ вернулся сноваValidationResultАтрибуты могут быть использованы для обеспечения действий действий значений атрибутов.
Точно так же, по нашим ожиданиям, мы также можем позвонитьassertValid()а такжеassertNotValid()Убедитесь, что конфигурация процессора действительна.
Ожидание FlowFiles.
Перед подпуском запуска процессора вам обычно нужно выпускать расходы в очередь для обработки процессора. Это может быть использовано в этом классеenqueueМетод реализацииTestRunnerОтказ ДолженenqueueСпособ имеет несколько различных покрытий, а добавленные данные в форме добавляются.byte[],InputStreamили жеPathОтказ Каждый из этих методов также поддерживаетсяMap<String, String>Добавьте варианты, которые поддерживают свойства FlowFile.
Кроме того, есть еще один видenqueueМетоды Var-args для объекта FlowFile можно получить. Например, это может быть использовано для получения выхода процессора, а затем предоставить ему ввод процессора.
Пробежать процессор
Настройте службы контроллера и выполните необходимый FlowFile в очередь, вы можете позвонитьrunСпособ для запуска процессора для запускаTestRunnerОтказ Если этот метод вызывается без каких-либо параметров, он будет использовать@OnScheduledОбратите внимание на любой метод в процессоре, вызывающий процессорonTriggerМетод один раз, затем запустить@OnUnscheduledfinally @OnStoppedметод.
Если вы хотите вызватьonTriggerДругие мероприятия@OnUnscheduledс участием @OnStoppedЕсли событие Life Cycle проводится несколько итераций, тоrun(int)Способ можно использовать для обозначения сейчасonTriggerМногие итерации должны быть вызваны.
Кроме того, когда мы хотим вызвать процессор, он не запускает время@OnUnscheduledс участием@OnStoppedСобытие жизненного цикла. Например, это помогает проверить состояние обработчика до того, как произойдут эти события. Это можно использоватьrun(int, boolean)Пройти и передаватьfalseКак второй параметр. Однако после этого позвоните@OnScheduledМетоды жизненного цикла могут вызвать проблемы. Итак, мы можем сейчасonTriggerБеги снова, не используя методыrun(int,boolean,boolean)версияrunа такжеfalseЭти события происходят как третья передача параметров.
Если поведение, которое тестирует несколько потоков, полезно, это также можно назватьsetThreadCountМетод реализацииTestRunnerОтказ По умолчанию 1 нить. Если вы используете несколько потоков, обязательно запомните.runпереводTestRunnerОпределяет количество раз, когда процессор должен быть вызван, не количество процессоров не должно вызывать каждую нить. Следовательно, если количество потоков установлено на 2, ноrun(1)Вызов, используется только один поток.
Проверьте вывод
После того, как процессор работает, тестирование устройства обычно необходимо проверить, что FlowFiles соответствует ожидаемым требованиям. Это можно использоватьTestRunnersassertAllFlowFilesTransferredс участием assertTransferCountМетод реализован. Предыдущий метод будет использовать отношения и целое число в качестве параметра для указания того, сколько расходомеров следует передавать в отношения. Если это количество FlowFiles не передается в заданные отношенияили жеЛюбой расход передается в любые другие отношения, в противном случае метод не пройдет через модульное тестирование. ДолженassertTransferCountМетоды только в том, что значение FlowFile — ожидаемое количество заданных отношений.
После подсчета проверки мы можем передать егоgetFlowFilesForRelationshipМетоды практические выходные потоки. Этот метод возвращает одинList<MockFlowFile>Отказ Важно обратить внимание на тип списка.MockFlowFileВместоFlowFileинтерфейс. Это потому чтоMockFlowFileЕсть много способов проверки контента.
Например,MockFlowFileСуществует утверждение свойств FlowFile.assertAttributeExists) Метод, заявляйте, что другие свойства не существуют (assertAttributeNotExists) Или атрибуты имеют правильное значение (assertAttributeEquals,assertAttributeNotEquals). Существует аналогичный подход к содержимому, использующему для проверки потока. Может поставить содержимое flowfile иbyte[],с участиемInputStreamДокумент или строка сравнивается. Если ожидаемые данные текста, версия строки предпочтительна, потому что если вывод не ожидается, он обеспечивает более интуитивное сообщение об ошибке.
Имитация внешних ресурсов
Одной из самых больших проблем при тестировании процессора NIFI, подключенного к удаленному ресурсу, заключается в том, что мы не хотим на самом деле подключаться к некоторым удаленным ресурсам из модульного теста. Мы можем настроить простой сервер в тестировании подразделения и настроить процессор и связь, но мы должны понимать и реализовать спецификацию специфики серверов и не могу правильно отправлять сообщение об ошибке. Мы хотим проверить.
Как правило, используемый здесь способ — это способ подключения к соединению или клиенту, ответственным за получение удаленного ресурса в процессоре. Мы обычно отмечаем этот метод как защищенные. В тесте подразделения мы неTestRunnerВызовTestRunners.newTestRunner(Class)И укажите класс процессора для создания, но создайте подкласс процессора в тесте устройства и использовать его:
@Test
public void testConnectionFailure() {
final TestRunner runner = TestRunners.newTestRunner(new MyProcessor() {
protected Client getClient() {
// Return a mocked out client here.
return new Client() {
public void connect() throws IOException {
throw new IOException();
}
// ...
// other client methods
// ...
};
}
});
// rest of unit test.
}Это позволяет нам реализовать клиент, клиент имитирует все сетевые связи и возвращает различные ошибки, которые мы хотим проверить, и убедиться, что наша логика правильная для клиента, чтобы клиент был успешно звонить клиенту.
Дополнительная функция теста
В дополнение к вышеуказанным функциям, предусмотренным тестовой структурой, TestRunner также предоставляет несколько удобных методов для проверки поведения процессора. Способ обеспечения входной очереди, который был опустошен. Установки тесты могут получить процессContext, ProcesssessionSactory, PromansSessionSessionalfactory, ProvenancerePorter, а также другие специфические организации Festrunner, которые будут использоваться. ДолженshutdownСпособ обеспечивает возможность протестировать возможность выполнения метода процессора, работающего только при выключении NiFi. Вы можете установить данные аннотации для процессора с использованием пользовательского интерфейса пользователя. Наконец, это может бытьsetThreadCount(int)Настройка метода должна использоваться для запуска количества потоков процессора.
Архивы NIFI (NAR)
Когда программное обеспечение со стороны многих различных организаций размещено в той же среде, Java Classloaders в ближайшее время станет проблемой. Если несколько компонентов зависит от одной и той же библиотеки, но каждый компонент опирается на разные версии, будет много проблем, которые обычно приводят к неожиданному поведению илиNoClassDefFoundErrorошибка. Чтобы предотвратить эти проблемы, NiFi представляет архив NAR или концепцию NAR.
NAR позволяет нескольким компонентам и их зависимостям упаковать их в один пакет. Затем пакет NAR обеспечивает изоляцию классов с другими пакетами NAR. Разработчики всегда должны развертывать свои компоненты NiFi в качестве пакетов NAR.
С этой целью разработчики создали новую заготовку Maven, которую мы ссылаемся на него в качестве Nar Artifact. Настройки упаковкиnar。dependenciesЗатем создайте часть POM, так что NAR зависит от всех компонентов NiFi, которые будут включены в NAR.
Для того, чтобы использовать упаковкуnarМы должны использовать этоnifi-nar-maven-pluginМодуль. Это достигается путем добавления следующего сегмента кода в POM.XML NAR:
<build>
<plugins>
<plugin>
<groupId>org.apache.nifi</groupId>
<artifactId>nifi-nar-maven-plugin</artifactId>
<version>1.1.0</version>
<extensions>true</extensions>
</plugin>
</plugins>
</build>
В библиотеке кода Apache NiFi, это существует в корневом POM NIFI, где все другие заготовки NIFI унаследованы, поэтому нам не нужно его включать в наши другие инструменты POM файлы.,
Нар может иметь тип зависимостиnarОтказ Если вы укажете несколько типов зависимостейnarЗатем нифи-нар-Maven-плагин будет неправ. Если NAR A добавляет зависимость от NAR B, это будетне будуВ результате всех компонентов пакета NAR B NAR A. Вместо этого это пойдет на NAR ANar-Dependency-IdизMANIFEST.MFДокумент добавляет элемент. Это приведет к установке NAR B ClassLoader в качестве родительского класса NAR A. В этом случае мы называем NAR B как NAR AParent。
Эта ссылка родительских классов является механизм, используемый NIFI для совместных услуг контроллера между всеми NARS. Такой как» РазвиватьВ разделе «Услуги контроллера» Служба контроллера должна быть разделена на расширенный интерфейс.ControllerServiceИ внедрить реализацию интерфейса. До тех пор, пока служба контроллера и процессор разделяет одно и то же определение интерфейса службы контроллера, сервисы контроллера могут ссылаться от любого процессора, независимо от того, какой NAR есть.
Чтобы поделиться тем же определением, NAR NAR и контролерной реализации процессора и контроллера должен быть NAR, определяемый службой родительских серверов. Примерные иерархии могут быть следующими:
Услуги контроллера NAR макет
root
├── my-controller-service-api
│ ├── pom.xml
│ └── src
│ └── main
│ └── java
│ └── org
│ └── my
│ └── services
│ └── MyService.java
│
├── my-controller-service-api-nar
│ └── POM.XML // Тип этого файла POM является NAR. Он зависит от NiFi-Standard-Services-API-NAR.
│
│
│
├── my-controller-service-impl
│ ├── POM.XML // Этот файл POM имеет тип JAR. Он опирается на My-Controller-Service-API. У него нет заготовки, которая опирается на NAR
│ └── src
│ ├── main
│ │ ├── java
│ │ │ └── org
│ │ │ └── my
│ │ │ └── services
│ │ │ └── MyServiceImpl.java
│ │ └── resources
│ │ └── META-INF
│ │ └── services
│ │ └── org.apache.nifi.controller.ControllerService
│ └── test
│ └── java
│ └── org
│ └── my
│ └── services
│ └── TestMyServiceImpl.java
│
│
├── my-controller-service-nar
│ └── POM.XML // Тип этого файла POM является NAR. Он зависит от My-Controller-Service-API-NAR.
│
│
└── other-processor-nar
└── POM.XML // Тип этого файла POM является NAR. Он зависит от My-Controller-Service-API-NAR.Хотя это, кажется, очень сложно, оно становится все сложнее после создания иерархии или дважды. Обратите внимание, что этоmy-controller-service-api-narЗависит отnifi-standard-services-api-narОтказ Это должно сделать какой-либо зависимый нарmy-controller-service-api-narТакже может получить доступnifi-standard-services-api-narВсе услуги контроллера, предоставляемые SSLContextService. В том же клинке нет необходимости создавать различные «сервисные API» NARS для каждой службы. Вместо этого обычно есть «Service-API» NAR упакованная множество различных устройств API контроллера, который обычно имеет смысл.nifi-standard-services-api-narОтказ Как правило, API не содержит широкого спектра зависимостей, поэтому изоляция CloseLoader может быть не так важна, поэтому многие заготовки API обычно приемлемы в том же NAR.
Per-Instance ClassLoading
Разработчики компонентов могут пожелать добавлять дополнительные ресурсы на путь класса к компоненту во время выполнения. Например, вы можете предоставить процессору драйвером JDBC для взаимодействия с реляционной базой данных, позволяя процессору использовать любые драйверы вместо того, чтобы пытаться свернуть драйвер в NAR.
Это может объявить один или несколько экземпляров свойствdynamicallyModifiesClasspathОсознать правдивость. Например:
PropertyDescriptor EXTRA_RESOURCE = new PropertyDescriptor.Builder()
.name("Extra Resources")
.description("The path to one or more resources to add to the classpath.")
.addValidator(StandardValidators.NON_EMPTY_VALIDATOR)
.expressionLanguageSupported(true)
.dynamicallyModifiesClasspath(true)
.build();
После установки этих свойств на компоненте рама будет идентифицировать всеdynamicallyModifiesClasspathУстановить на истинные свойства. Для каждого свойства структура пытается разбирать ресурсы файловых систем из значения свойства. Это значение может быть разделенным запятыми списком одного или нескольких каталогов или файлов, где любые пути не существуют. Если ресурс представляет каталог, каталог перечислен, и все файлы в этом каталоге будут добавлены в классные пути отдельно.
Каждый атрибут может быть применен верификатором в формат значения. Например, используя стандартныеVALIDATAMS.File_Exists_Validator, чтобы ограничить атрибут, чтобы принять один файл. Используйте StandardValidators.non_empty_Validator, чтобы позволить запятыми разделить файлы или каталоги.
Добавьте ресурс в классификатор экземпляра, добавив ресурсы на внутренний класс, который всегда впервые проверен. Пока значение этих атрибутов изменяется, внутренний классный загрузчик выключен и воссоздан с использованием нового ресурса.
NIFI доступен@RequiresInstanceClassLoadingПримечание, чтобы дополнительно расширить и изолировать библиотеки, доступные на пути класса компонентов. Вы можете прокомментировать компонент,@RequiresInstanceClassLoadingКопия NAR ClassLoader в Nar CloseLoader компонента должна указывать компоненты. в случае@RequiresInstanceClassLoadingНе существует, экземпляр CloseLoader просто устанавливает свой родительскую классную нагрузку на Nar CloseLoader вместо копирования ресурсов.
Должен@RequiresInstanceClassLoadingКомментарий также предоставляет необязательный флаг «клоненцесторресурсы». Если установлено значение TRUE, экземпляр ClassLoader будет содержать ресурсы предка до тех пор, пока первый классной загрузчик сервисной API контроллера не содержит ссылку на компонент, либо до приема NAR. Если установлено значение false или не указано, включены только ресурсы в компоненте NAR.
Эта функция мудро использует эту функцию, поскольку @requiresInstanceClassloading реплицируется из Nar ClassLoader из Nar CloseLoader из каждого экземпляра компонента. Если вы создадите десять экземпляров компонента, все классы в NAR CloseLoader в компоненте будут загружены в памяти 10 раз. Это в конечном итоге увеличит занятость памяти при создании достаточного экземпляра компонентов.
Кроме того, есть некоторые ограничения при использовании @requiresInstanceClassloading при использовании служб контроллера. Процессоры, задачи отчетов и службы контроллера могут ссылаться на API службы контроллера в одном из его свойств дескрипторов. Возможно, могут возникнуть проблемы, когда API Controller Service подключается к компоненту или осуществлению службы контроллера ссылки на него. Если вы столкнулись с одним из этих ситуаций, и расширение требует загрузки классов экземпляра, расширение будет пропущена и правильная ошибка. Чтобы решить эту проблему, API контроллера API должен быть включен в родительский NAR. Реализация услуг и расширение сервиса должно зависеть от API Controller Service API. Смотрите сервис контроллера NAR макет в контролереАрхивы Nifi (NARS)раздел. Пока служба AP контроллера в комплекте с расширением, которое должно быть, даже если @requiresInstanceClassloading не используется, будет записано предупреждение, чтобы помочь избежать этой плохой практики.
Отказ от компонента
Иногда вам может потребоваться отбросить компоненты. Всякий раз, когда это происходит, разработчик может использовать аннотацию @deprecationnotice, чтобы указать, что компонент был отброшен, позволяя разработчикам описывать причину устаревших и предлагать альтернативный компонент. Ниже приведен пример того, как это сделать:
@DeprecationNotice(alternatives = {ListenSyslog.class}, classNames = {"org.apache.nifi.processors.standard.ListenRELP"}, reason = "Technology has been superseded", )
public class ListenOldProtocol extends AbstractProcessor {Как видите, альтернатива может быть использована для определения альтернативного компонента и массива, в то время как имена могут использоваться для представления аналогичного контента с помощью строкового массива.
Как внести свой вклад в Apache NiFi
Мы всегда рады внести свой вклад из сообщества — особенно из вклада новых участников! Мы заинтересованы в принятии взносов кода, а также произведения искусства, которые могут быть применены к приложениям в качестве значков или стилей.
технология
Бэкэнда Apache NiFi написана в Java. Веб-слой широко используется с JAX-RS и JavaScript для предоставления пользовательских интерфейсов. Мы полагаемся на несколько сторонних библиотек JavaScript, включая D3 и jQuery и т. Д. Мы используем Apache Maven для использования нашей версии системы управления для нашей версии системы управления.
ДокументацияAsciidoc.Создайте.
Где ты начал?
Страница Jira NifiМожно использовать для нахождения билетов на маркировку «новичков», или вы можете пойти в глубине любого билета, чтобы создать процессор. Процессор должен быть независимым, не зависящим от других внешних компонентов (кроме услуг контроллера), поэтому они обеспечивают хорошую отправную точку для новых разработчиков NIFI. Это позволяет разработчикам NIFI API и является самой масштабируемой частью в системе потока данных.
Документы на уровне системы и обзоры расположены в <Код Checkout Location> / NiFi / NiFi-Docs / SRC / Main / Asciidoc. можетИспользуйте предварительный просмотр в реальном времени для редактирования Acciidoc,Генерировать документ.
Обеспечить пожертвования
Вы можете предоставить вклад, создавая патч:
git format-patch
И прикрепите этот патч к билетам или генерируйте запрос на тягу.
Для более подробной информации о взносах см.Руководство по авторуРодственные части.
свяжитесь с нами
Список рассылки разработчика ([email protected]) Закрыть мониторинг, мы склонны быстро реагировать. Если у вас есть какие-либо вопросы, пожалуйста, не стесняйтесь отправить нам электронное письмо — мы всегда можем предоставить помощь! К сожалению, электронные письма могут быть потеряны в произвольной пьесе, поэтому, если вы отправите электронные письма и не получаете ответ в течение одного или двух дней, это наша вина — не беспокойтесь о том, чтобы беспокоить нас. Просто напишите список рассылки снова.